
A Geoscience-Aware Network (GASlumNet) Combining UNet and ConvNeXt for Slum Mapping



Abstract

1. Introduction
2. Study Area
3. Methods
3.1. Preparing Slum Dataset
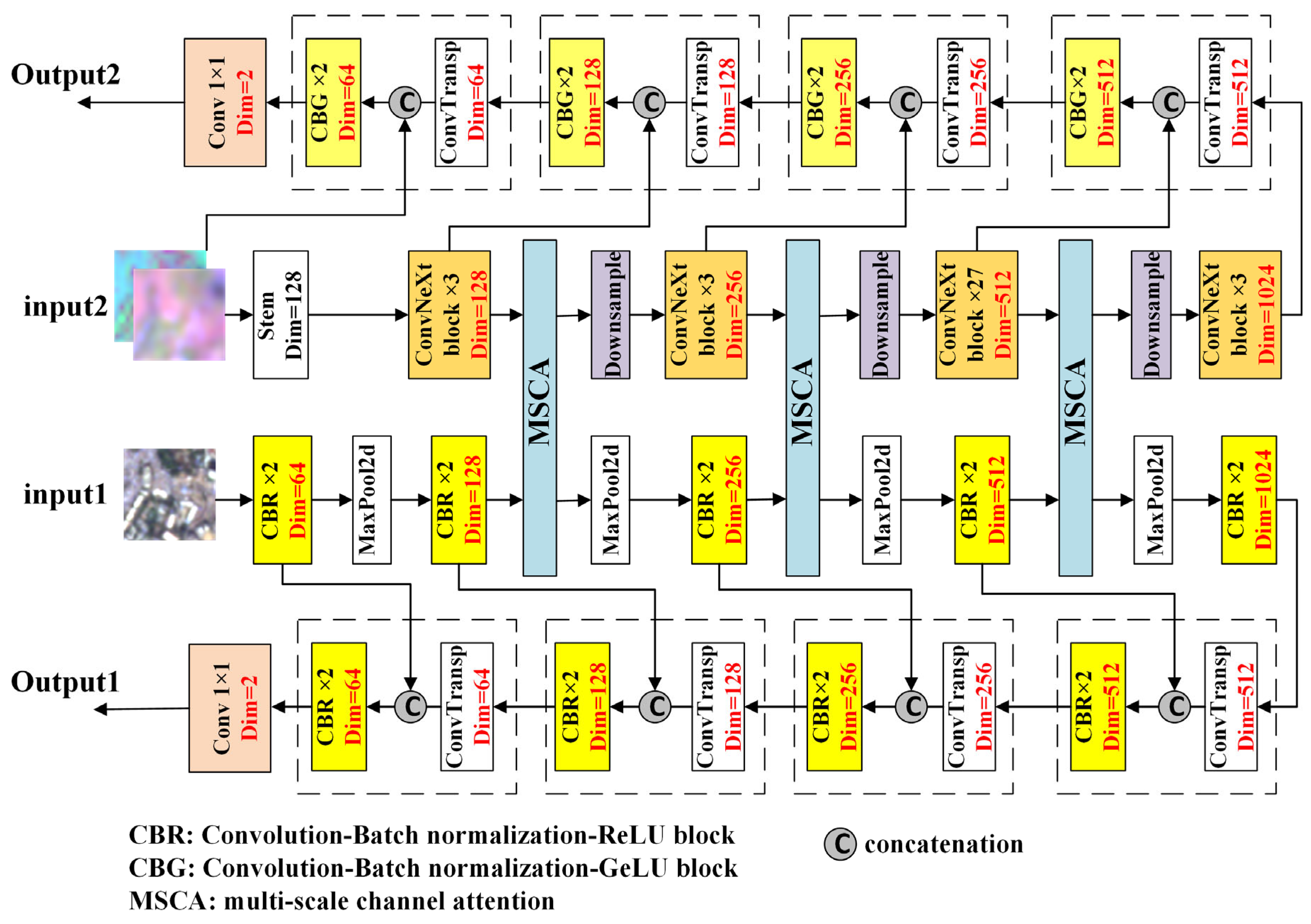
3.2. Architecture of GASlumNet
3.2.1. UNet Stream
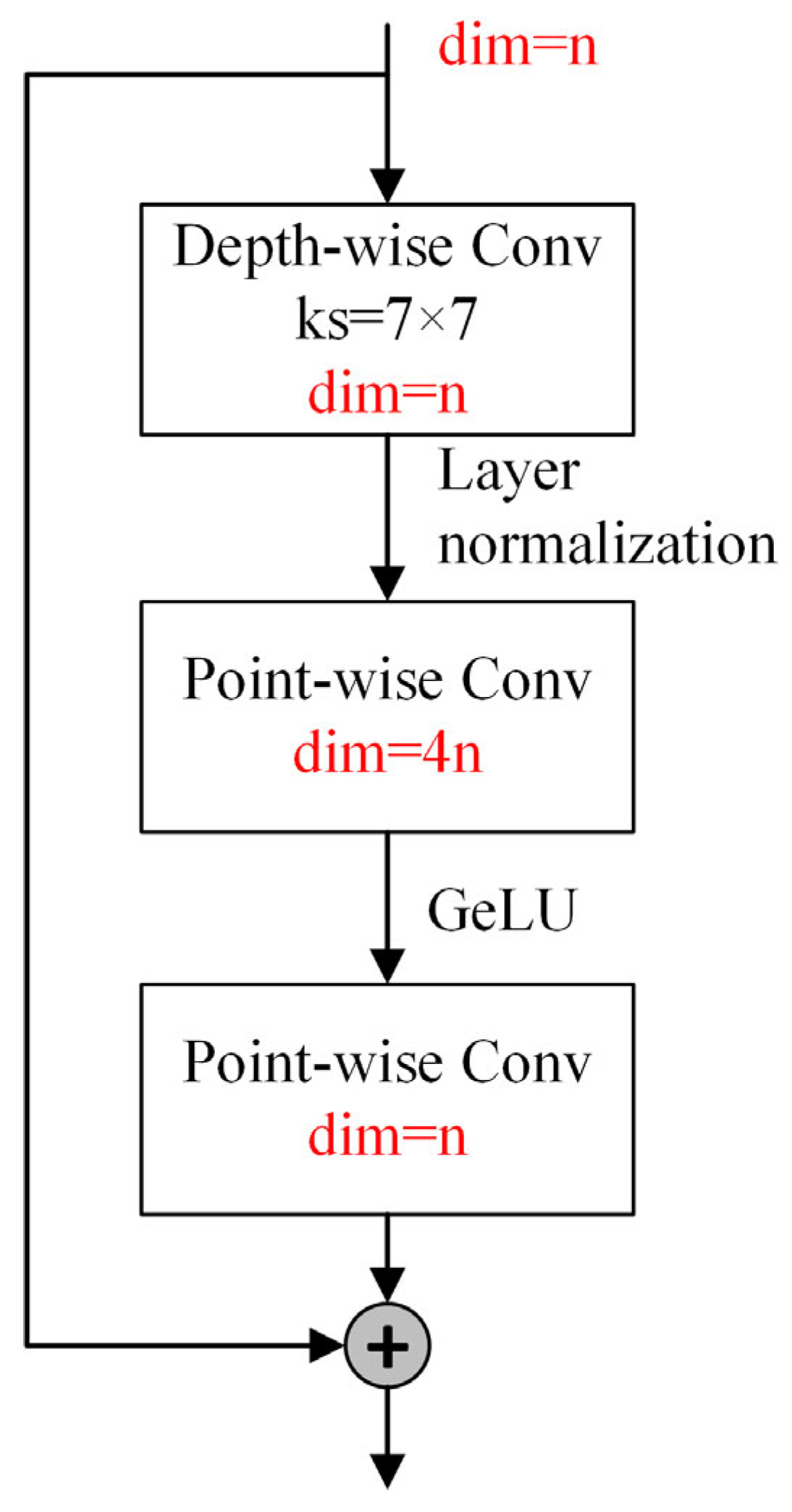
3.2.2. ConvNeXt Stream
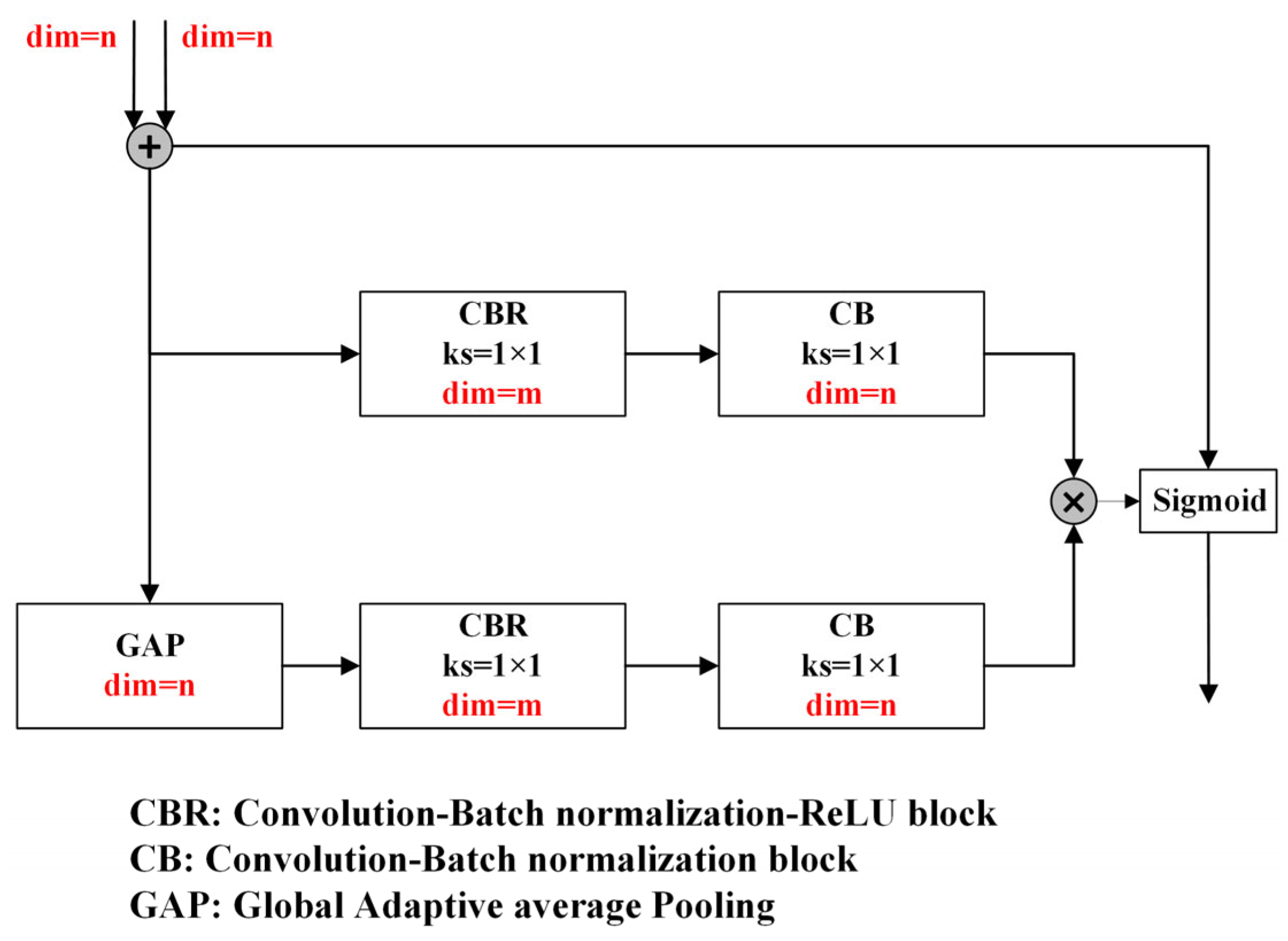
3.2.3. Feature-Level Fusion with Multi-Scale Attention
3.2.4. Decision-Level Fusion and Joint Loss Function
3.3. Evaluation Metrics
4. Experiment and Results
4.1. Experimental Settings
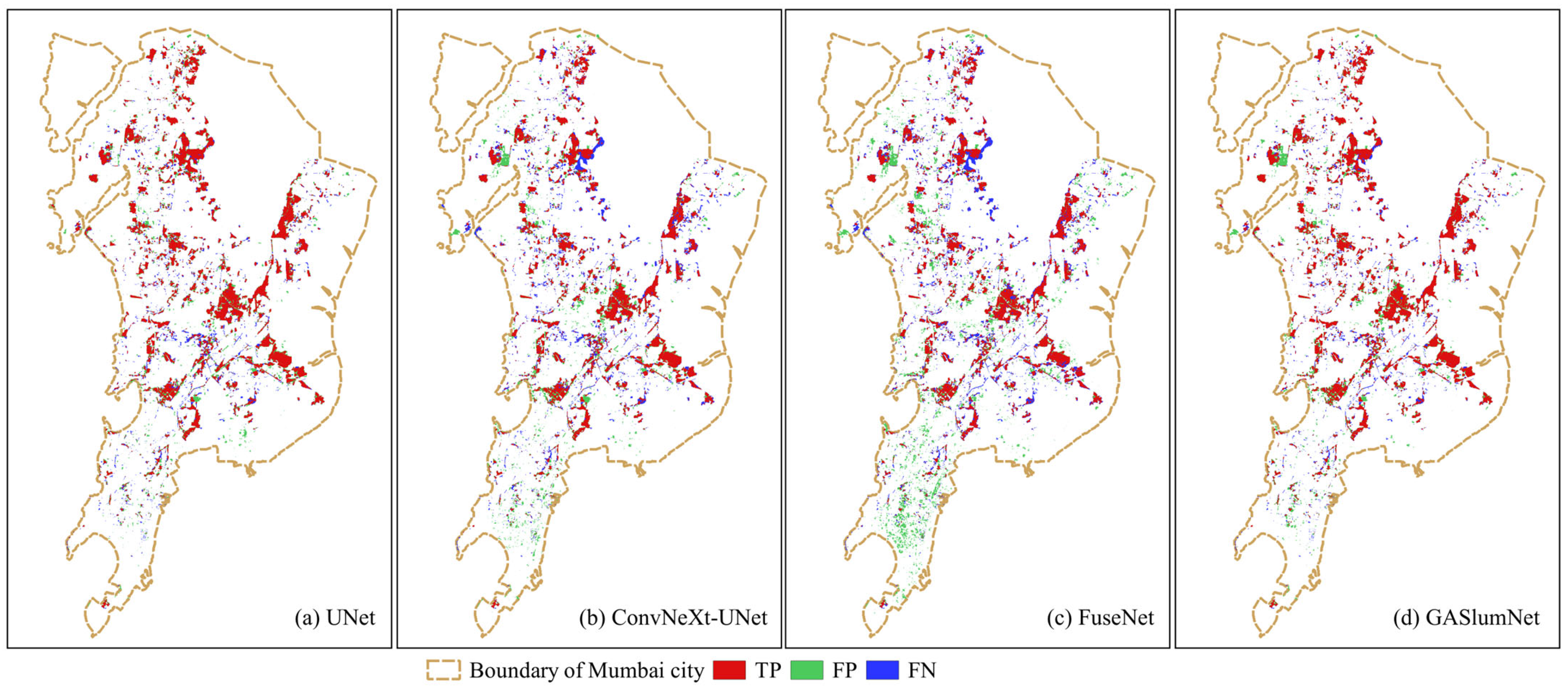
4.2. Comparisons of Slum Mapping among Different Methods
4.3. Patch-Based Accuracy Assessment among Different Methods
4.4. Land Cover Types of False Positives and False Negatives Generated by Different Methods
4.5. Results under Different Ancillary Geo-Scientific Features
- (1)
- Overall, GASlumNet consistently achieved the highest slum mapping accuracies across different input features. Specifically, GASlumNet demonstrated improvements in IoU values of 2.52%, 3.09% and 10.97%, and increases in OA values of 0.35%, 0.29% and 2.25% compared to UNet, ConvNeXt-UNet, and FuseNet when utilizing RGB, spectral and textural features. GASlumNet also attained the highest IoU values among all the models.
- (2)
- The incorporation of ancillary geographic features into the models positively impacted the performance. With the exception of FuseNet, models in Table 8 that simultaneously used multiple input features outperformed those using only RGB bands, spectral features or textural features. For instance, when the RGB bands were concatenated with ancillary geographic features (spectral or textural) and fed into the model, UNet and ConvNeXt-UNet achieved higher accuracies than when using only RGB bands.
- (3)
- In comparison to FuseNet, which also employed a dual-stream architecture and multiple input features, GASlumNet consistently exhibited significantly higher precision, recall, OA and IoU values, underscoring the superior effectiveness of GASlumNet over FuseNet.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Input Features | Precision | Recall | OA | IoU | |
|---|---|---|---|---|---|---|
| UNet | RGB | 68.54 | 71.47 | 91.99 | 53.81 | |
| Spectral | 70.84 | 62.21 | 91.72 | 49.53 | ||
| Textural | 69.36 | 60.74 | 91.37 | 47.89 | ||
| RGB, spectral | 76.87 | 67.29 | 93.08 | 55.96 | ||
| RGB, textural | 71.49 | 72.02 | 92.59 | 55.95 | ||
| RGB, spectral, textural | 72.61 | 70.82 | 92.70 | 55.89 | ||
| ConvNeXt-UNet | RGB | 67.59 | 70.05 | 91.70 | 52.44 | |
| Spectral | 68.12 | 63.52 | 91.35 | 48.96 | ||
| Textural | 66.53 | 62.27 | 90.98 | 47.42 | ||
| RGB, spectral | 66.80 | 75.76 | 91.92 | 55.04 | ||
| RGB, textural | 73.10 | 69.79 | 92.70 | 55.53 | ||
| RGB, spectral, textural | 74.03 | 68.64 | 92.76 | 55.32 | ||
| FuseNet | RGB, spectral | 64.14 | 58.76 | 90.32 | 44.23 | |
| RGB, textural | 65.02 | 67.80 | 91.03 | 49.68 | ||
| RGB, spectral, textural | 65.12 | 63.61 | 90.80 | 47.44 | ||
| Input Features of UNet (RGB-Stream) | Input Features of ConvNeXt (Auxiliary Stream) | |||||
| GASlumNet | RGB | Spectral | 69.81 | 77.55 | 92.69 | 58.07 |
| RGB | Textural | 74.05 | 71.98 | 93.05 | 57.48 | |
| RGB, spectral | Textural | 75.02 | 70.04 | 93.10 | 57.25 | |
| RGB, textural | Spectral | 73.83 | 71.68 | 92.98 | 57.16 | |
| RGB | Spectral, textural | 72.82 | 74.69 | 93.05 | 58.41 | |
4.6. Results under Different Balance Parameters
5. Discussion
5.1. Differences from Existing Related Studies
5.2. Performance of GASlumNet
5.3. Applicability and Limitations of GASlumNet
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- UN-Habitat. World Cities Report 2020: The Value of Sustainable Urbanization; United Nations Human Settlements Programme: Nairobi, Kenya, 2020. [Google Scholar]
- Wirastri, M.V.; Morrison, N.; Paine, G. The Connection between Slums and COVID-19 Cases in Jakarta, Indonesia: A Case Study of Kapuk Urban Village. Habitat Int. 2023, 134, 102765. [Google Scholar] [CrossRef]
- Thomson, D.R.; Stevens, F.R.; Chen, R.; Yetman, G.; Sorichetta, A.; Gaughan, A.E. Improving the Accuracy of Gridded Population Estimates in Cities and Slums to Monitor SDG 11: Evidence from a Simulation Study in Namibia. Land Use Policy 2022, 123, 106392. [Google Scholar] [CrossRef]
- Maung, N.L.; Kawasaki, A.; Amrith, S. Spatial and Temporal Impacts on Socio-Economic Conditions in the Yangon Slums. Habitat Int. 2023, 134, 102768. [Google Scholar] [CrossRef]
- UN-Habitat. The Challenge of Slums: Global Report on Human Settlements, 2003; Routledge: London, UK, 2003. [Google Scholar]
- UN-Habitat. Slum Almanac 2015–2016: Tracking Improvement in the Lives of Slum Dwellers. Participatory Slum Upgrading Programme. 2016. Available online: https://unhabitat.org/sites/default/files/documents/2019-05/slum_almanac_2015-2016_psup.pdf. (accessed on 27 November 2023).
- United Nations. Transforming Our World: The 2030 Agenda for Sustainable Development; United Nations: New York, NY, USA, 2015. [Google Scholar]
- MacTavish, R.; Bixby, H.; Cavanaugh, A.; Agyei-Mensah, S.; Bawah, A.; Owusu, G.; Ezzati, M.; Arku, R.; Robinson, B.; Schmidt, A.M. Identifying Deprived “Slum” Neighbourhoods in the Greater Accra Metropolitan Area of Ghana Using Census and Remote Sensing Data. World Dev. 2023, 167, 106253. [Google Scholar] [CrossRef] [PubMed]
- Kuffer, M.; Abascal, A.; Vanhuysse, S.; Georganos, S.; Wang, J.; Thomson, D.R.; Boanada, A.; Roca, P. Data and Urban Poverty: Detecting and Characterising Slums and Deprived Urban Areas in Low-and Middle-Income Countries. In Advanced Remote Sensing for Urban and Landscape Ecology; Springer: Cham, Switzerland, 2023; pp. 1–22. [Google Scholar]
- UN-Habitat. Metadata on SDGs Indicator 11.1. 1 Indicator Category: Tier I. UN Human Settlements Program, Nairobi. 2018. Available online: http://unhabitat.org/sites/default/files/2020/06/metadata_on_sdg_indicator_11.1.1.pdf (accessed on 27 November 2023).
- Kohli, D.; Sliuzas, R.; Kerle, N.; Stein, A. An Ontology of Slums for Image-Based Classification. Comput. Environ. Urban Syst. 2012, 36, 154–163. [Google Scholar] [CrossRef]
- Kohli, D.; Kerle, N.; Sliuzas, R. Local Ontologies for Object-Based Slum Identification and Classification. Environs 2012, 3, 3. [Google Scholar]
- Kohli, D.; Sliuzas, R.; Stein, A. Urban Slum Detection Using Texture and Spatial Metrics Derived from Satellite Imagery. J. Spat. Sci. 2016, 61, 405–426. [Google Scholar] [CrossRef]
- Badmos, O.S.; Rienow, A.; Callo-Concha, D.; Greve, K.; Jürgens, C. Urban Development in West Africa—Monitoring and Intensity Analysis of Slum Growth in Lagos: Linking Pattern and Process. Remote Sens. 2018, 10, 1044. [Google Scholar] [CrossRef]
- Kuffer, M.; Pfeffer, K.; Sliuzas, R.; Baud, I. Extraction of Slum Areas from VHR Imagery Using GLCM Variance. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1830–1840. [Google Scholar] [CrossRef]
- Mudau, N.; Mhangara, P. Mapping and Assessment of Housing Informality Using Object-Based Image Analysis: A Review. Urban Sci. 2023, 7, 98. [Google Scholar] [CrossRef]
- Abed, A.D. Urban Upgrading of Slums: Baghdad and London Slums as Study Models for Urban Rehabilitation. Comput. Urban Sci. 2023, 3, 31. [Google Scholar] [CrossRef]
- Mahabir, R.; Croitoru, A.; Crooks, A.T.; Agouris, P.; Stefanidis, A. A Critical Review of High and Very High-Resolution Remote Sensing Approaches for Detecting and Mapping Slums: Trends, Challenges and Emerging Opportunities. Urban Sci. 2018, 2, 8. [Google Scholar] [CrossRef]
- Kuffer, M.; Wang, J.; Nagenborg, M.; Pfeffer, K.; Kohli, D.; Sliuzas, R.; Persello, C. The Scope of Earth-Observation to Improve the Consistency of the SDG Slum Indicator. ISPRS Int. J. Geo-Inf. 2018, 7, 428. [Google Scholar] [CrossRef]
- Trento Oliveira, L.; Kuffer, M.; Schwarz, N.; Pedrassoli, J.C. Capturing Deprived Areas Using Unsupervised Machine Learning and Open Data: A Case Study in São Paulo, Brazil. Eur. J. Remote Sens. 2023, 56, 2214690. [Google Scholar] [CrossRef]
- Dewan, A.; Alrasheedi, K.; El-Mowafy, A. Mapping Informal Settings Using Machine Learning Techniques, Object-Based Image Analysis and Local Knowledge. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Pasadena, CA, USA, 16–21 July 2023; pp. 7249–7252. [Google Scholar]
- Duque, J.C.; Patino, J.E.; Betancourt, A. Exploring the Potential of Machine Learning for Automatic Slum Identification from VHR Imagery. Remote Sens. 2017, 9, 895. [Google Scholar] [CrossRef]
- Prabhu, R.; Parvathavarthini, B.; Alagu Raja, R.A. Slum Extraction from High Resolution Satellite Data Using Mathematical Morphology Based Approach. Int. J. Remote Sens. 2021, 42, 172–190. [Google Scholar] [CrossRef]
- Brenning, A. Interpreting Machine-Learning Models in Transformed Feature Space with an Application to Remote-Sensing Classification. Mach. Learn. 2023, 112, 3455–3471. [Google Scholar] [CrossRef]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J. Deep Learning in Environmental Remote Sensing: Achievements and Challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q.; Zhang, B. More Diverse Means Better: Multimodal Deep Learning Meets Remote-Sensing Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4340–4354. [Google Scholar] [CrossRef]
- Li, J.; Hong, D.; Gao, L.; Yao, J.; Zheng, K.; Zhang, B.; Chanussot, J. Deep Learning in Multimodal Remote Sensing Data Fusion: A Comprehensive Review. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102926. [Google Scholar] [CrossRef]
- Bergamasco, L.; Bovolo, F.; Bruzzone, L. A Dual-Branch Deep Learning Architecture for Multisensor and Multitemporal Remote Sensing Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 2147–2162. [Google Scholar] [CrossRef]
- Wurm, M.; Stark, T.; Zhu, X.X.; Weigand, M.; Taubenböck, H. Semantic Segmentation of Slums in Satellite Images Using Transfer Learning on Fully Convolutional Neural Networks. ISPRS J. Photogramm. Remote Sens. 2019, 150, 59–69. [Google Scholar] [CrossRef]
- Verma, D.; Jana, A.; Ramamritham, K. Transfer Learning Approach to Map Urban Slums Using High and Medium Resolution Satellite Imagery. Habitat Int. 2019, 88, 101981. [Google Scholar] [CrossRef]
- Stark, T.; Wurm, M.; Zhu, X.X.; Taubenböck, H. Satellite-Based Mapping of Urban Poverty with Transfer-Learned Slum Morphologies. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5251–5263. [Google Scholar] [CrossRef]
- Rehman, M.F.U.; Aftab, I.; Sultani, W.; Ali, M. Mapping Temporary Slums from Satellite Imagery Using a Semi-Supervised Approach. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3512805. [Google Scholar] [CrossRef]
- El Moudden, T.; Dahmani, R.; Amnai, M.; Fora, A.A. Slum Image Detection and Localization Using Transfer Learning: A Case Study in Northern Morocco. Int. J. Electr. Comput. Eng. 2023, 13, 3299–3310. [Google Scholar] [CrossRef]
- Ge, Y.; Zhang, X.; Atkinson, P.M.; Stein, A.; Li, L. Geoscience-Aware Deep Learning: A New Paradigm for Remote Sensing. Sci. Remote Sens. 2022, 5, 100047. [Google Scholar] [CrossRef]
- Lu, W.; Hu, Y.; Zhang, Z.; Cao, W. A Dual-Encoder U-Net for Landslide Detection Using Sentinel-2 and DEM Data. Landslides 2023, 20, 1975–1987. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very High Resolution Urban Remote Sensing with Multimodal Deep Networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. Fusenet: Incorporating Depth into Semantic Segmentation via Fusion-Based Cnn Architecture. In Part I 13, Proceedings of the Computer Vision–ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Revised Selected Papers; Springer: Berlin/Heidelberg, Germany, 2017; pp. 213–228. [Google Scholar]
- He, Q.; Sun, X.; Diao, W.; Yan, Z.; Yao, F.; Fu, K. Multimodal Remote Sensing Image Segmentation with Intuition-Inspired Hypergraph Modeling. IEEE Trans. Image Process. 2023, 32, 1474–1487. [Google Scholar] [CrossRef]
- Xiong, Z.; Chen, S.; Wang, Y.; Mou, L.; Zhu, X.X. GAMUS: A Geometry-Aware Multi-Modal Semantic Segmentation Benchmark for Remote Sensing Data. arXiv 2023, arXiv:2305.14914. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Part III 18, Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A Convnet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Philpot, W.; Jacquemoud, S.; Tian, J. ND-Space: Normalized Difference Spectral Mapping. Remote Sens. Environ. 2021, 264, 112622. [Google Scholar] [CrossRef]
- Zha, Y.; Gao, J.; Ni, S. Use of Normalized Difference Built-up Index in Automatically Mapping Urban Areas from TM Imagery. Int. J. Remote Sens. 2003, 24, 583–594. [Google Scholar] [CrossRef]
- Peng, F.; Lu, W.; Hu, Y.; Jiang, L. Mapping Slums in Mumbai, India, Using Sentinel-2 Imagery: Evaluating Composite Slum Spectral Indices (CSSIs). Remote Sens. 2023, 15, 4671. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, 6, 610–621. [Google Scholar] [CrossRef]
- Wurm, M.; Weigand, M.; Schmitt, A.; Geiß, C.; Taubenböck, H. Exploitation of Textural and Morphological Image Features in Sentinel-2A Data for Slum Mapping. In Proceedings of the 2017 Joint Urban Remote Sensing Event (JURSE), Dubai, United Arab Emirates, 6–8 March 2017; pp. 1–4. [Google Scholar]
- Kotthaus, S.; Smith, T.E.; Wooster, M.J.; Grimmond, C.S.B. Derivation of an Urban Materials Spectral Library through Emittance and Reflectance Spectroscopy. ISPRS J. Photogramm. Remote Sens. 2014, 94, 194–212. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional Feature Fusion. In Proceedings of the 2021 IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3560–3569. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Phan, T.H.; Yamamoto, K. Resolving Class Imbalance in Object Detection with Weighted Cross Entropy Losses. arXiv 2020, arXiv:2006.01413. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Gram-Hansen, B.J.; Helber, P.; Varatharajan, I.; Azam, F.; Coca-Castro, A.; Kopackova, V.; Bilinski, P. Mapping Informal Settlements in Developing Countries Using Machine Learning and Low Resolution Multi-Spectral Data. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019; pp. 361–368. [Google Scholar]
- Song, X.; Hua, Z.; Li, J. GMTS: GNN-Based Multi-Scale Transformer Siamese Network for Remote Sensing Building Change Detection. Int. J. Digit. Earth 2023, 16, 1685–1706. [Google Scholar] [CrossRef]


| Level | Indicators | Observation in Slums | Features |
|---|---|---|---|
| Environment | Location | Hazardous and flood-prone areas; close to railways, highways and major roads; close to water areas; some on steep slopes | Association-distance to river, roads |
| Neighborhood characteristics | Close to CBD, middle/high socioeconomic status areas and industrial areas | Association-distance to socioeconomic-status areas | |
| Settlement | Shape | Generally irregular; elongated formation following the river or railway | Geometry |
| Density | Highly compact; high roof coverage; low vegetation/open space coverage | Texture | |
| Object | Access network | Generally unpaved, narrow, irregular roads and footpaths | Geometry/spectral features |
| Building characteristics | Roof: iron sheet, asbestos, plastic, fiber, clay tiles; less bright than formal settlements building size: small | Spectral/morphological features |
| UNet Stream | ConvNeXt Stream | ||||||
|---|---|---|---|---|---|---|---|
| Stage | ks | s, p | h, w, c | Stage | ks | s, p | h, w, c |
| DS1 | 1, 1 | H, W, 64 | Stem | 2, 0 | H/2, W/2, 128 | ||
| Maxp | 2, 0 | H/2, W/2, 64 | |||||
| DS2 | 1, 1 | H/2, W/2, 128 | DS1 | [1, 3] [1, 0] [1, 0] | H/2, W/2, 128 | ||
| Maxp | 2, 0 | H/4, W/4, 128 | Dlayer1 | 2, 0 | H/4, W/4, 256 | ||
| DS3 | 1, 1 | H/4, W/4, 256 | DS2 | [1, 3] [1, 0] [1, 0] | H/4, W/4, 256 | ||
| Maxp | 2, 0 | H/8, W/8, 256 | Dlayer2 | 2, 0 | H/8, W/8, 512 | ||
| DS4 | 1, 1 | H/8, W/8, 512 | DS3 | [1, 3] [1, 0] [1, 0] | H/8, W/8, 512 | ||
| Maxp | 2, 0 | H/16, W/16, 512 | Dlayer3 | 2, 0 | H/16, W/16, 1024 | ||
| DS5 | 1, 1 | H/16, W/16, 1024 | DS4 | [1, 3] [1, 0] [1, 0] | H/16, W/16, 1024 | ||
| Stage | ks | s, p | h, w, c | |
|---|---|---|---|---|
| US1 | ConvT1 | 2, 0 | H/8, W/8, 512 | |
| CBR/CBG | 1, 1 | H/8, W/8, 512 | ||
| US2 | ConvT2 | 2, 0 | H/4, W/4, 256 | |
| CBR/CBG | 1, 1 | H/4, W/4, 256 | ||
| US3 | ConvT3 | 2, 0 | H/2, W/2, 128 | |
| CBR/CBG | 1, 1 | H/2, W/2, 128 | ||
| US4 | ConvT4 | 2, 0 | H, W, 64 | |
| CBR/CBG | 1, 1 | H, W, 64 | ||
| Conv | 1, 1 | H, W, 2 | ||
| Items | Settings | |
|---|---|---|
| Super parameters | No. of categories | 2 |
| Balance parameter | 0.7 | |
| Settings for model training | Batch size | 64 |
| Epochs | 100 | |
| Optimizer | Adam | |
| Learning rate | 1 × 10−3 | |
| Weight decay | 5 × 10−4 | |
| Experimental environment | System | Windows 10 |
| Language | Python | |
| Framework | Pytorch 1.11.0 | |
| CPU | CPUs (Intel(R) Xeon(R) Silver 4210R) with 64 GB memory | |
| GPU | NAVIDIA GeForce RTX 3090 with 24 GB memory |
| Models | Precision (%) | Recall (%) | OA (%) | IoU (%) |
|---|---|---|---|---|
| UNet | 68.54 | 71.47 | 91.99 | 53.81 |
| ConvNeXt-UNet | 67.59 | 70.05 | 91.70 | 52.44 |
| FuseNet | 65.12 | 63.61 | 90.80 | 47.44 |
| GASlumNet | 72.82 | 74.69 | 93.05 | 58.41 |
| Models | Small Slum Pockets (<5 ha) | Medium Slum Patches (5~25 ha) | Large Slum Patches (≥25 ha) |
|---|---|---|---|
| UNet | 47.88 | 79.99 | 82.47 |
| ConvNeXt-UNet | 46.01 | 79.10 | 80.75 |
| FuseNet | 41.61 | 69.63 | 76.39 |
| GASlumNet | 50.79 | 83.36 | 85.81 |
| Models | ESA Land Cover Types | |||||
|---|---|---|---|---|---|---|
| Built-Up (ha) | Bare/Sparse Vegetation (ha) | Tree Cover (ha) | Water (ha) | Others (ha) | ||
| FP | UNet | 216.34 | 81.39 | 15.41 | 1.87 | 4.40 |
| ConvNeXt-UNet | 232.68 | 75.90 | 11.76 | 1.75 | 4.74 | |
| FuseNet | 223.48 | 88.02 | 12.85 | 0.27 | 7.18 | |
| GASlumNet | 183.92 | 73.07 | 10.04 | 0.63 | 3.27 | |
| FN | UNet | 145.42 | 99.83 | 27.08 | 1.63 | 5.51 |
| ConvNeXt-UNet | 154.59 | 102.95 | 28.88 | 1.51 | 3.83 | |
| FuseNet | 193.57 | 122.59 | 32.18 | 1.87 | 4.18 | |
| GASlumNet | 119.92 | 92.58 | 28.60 | 1.63 | 3.69 | |
| Precision | Recall | OA | IoU | |
|---|---|---|---|---|
| 0 | 67.59 | 70.05 | 91.70 | 52.44 |
| 0.1 | 75.03 | 70.67 | 93.10 | 57.21 |
| 0.3 | 75.80 | 70.30 | 93.19 | 57.41 |
| 0.5 | 76.28 | 70.49 | 93.28 | 57.81 |
| 0.7 | 72.82 | 74.69 | 93.05 | 58.41 |
| 0.9 | 73.00 | 73.98 | 93.03 | 58.09 |
| 1 | 68.54 | 71.47 | 91.99 | 53.81 |
| Methods | RS Imagery (Spatial Resolution—m) | Precision | Recall | OA | IoU |
|---|---|---|---|---|---|
| CSSIs (threshold-based) [44] | Sentinel-2 (10 m) | 63.86 | 58.38 | - | 43.89 |
| CSSIs (ML-based) [44] | Sentinel-2 (10 m) | 61.56 | 82.50 | - | 54.45 |
| CCF [55] | Sentinel-2 (10 m) | - | - | - | 40.30 |
| CNN transfer learning [30] | Pleiades (0.5 m), Sentinel-2 (10 m) | - | - | 92.00 | 43.20 |
| CNN [30] | Pleiades (0.5 m) | - | - | 94.30 | 58.30 |
| GASlumNet | Jilin-1 (5 m), Sentinel-2 (10 m) | 76.13 | 79.85 | 94.89 | 63.86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, W.; Hu, Y.; Peng, F.; Feng, Z.; Yang, Y. A Geoscience-Aware Network (GASlumNet) Combining UNet and ConvNeXt for Slum Mapping. Remote Sens. 2024, 16, 260. https://doi.org/10.3390/rs16020260
Lu W, Hu Y, Peng F, Feng Z, Yang Y. A Geoscience-Aware Network (GASlumNet) Combining UNet and ConvNeXt for Slum Mapping. Remote Sensing. 2024; 16(2):260. https://doi.org/10.3390/rs16020260
Chicago/Turabian StyleLu, Wei, Yunfeng Hu, Feifei Peng, Zhiming Feng, and Yanzhao Yang. 2024. "A Geoscience-Aware Network (GASlumNet) Combining UNet and ConvNeXt for Slum Mapping" Remote Sensing 16, no. 2: 260. https://doi.org/10.3390/rs16020260
APA StyleLu, W., Hu, Y., Peng, F., Feng, Z., & Yang, Y. (2024). A Geoscience-Aware Network (GASlumNet) Combining UNet and ConvNeXt for Slum Mapping. Remote Sensing, 16(2), 260. https://doi.org/10.3390/rs16020260