
CSAN-UNet: Channel Spatial Attention Nested UNet for Infrared Small Target Detection

Abstract

1. Introduction
- (1)
- We propose CSAN-UNet, an innovative architecture tailored for precise segmentation of small infrared targets, optimizing computational efficiency.
- (2)
- We introduce a Cascaded Channel and Spatial Convolutional Attention Module (CSCAM) for improved feature enhancement during downsampling, preserving crucial target details.
- (3)
- We develop a lightweight Channel-Priority and Spatial Attention Cascade Module (CPSAM) for efficient extraction of target semantic information with minimal computational demand.
- (4)
- We demonstrate CSAN-UNet’s superior performance and efficiency through rigorous testing on two public datasets, surpassing existing state-of-the-art solutions.
2. Related Work
2.1. Single-Frame Infrared Small Target Detection
2.2. Attention Mechanisms and Feature Fusion
3. Proposed Method
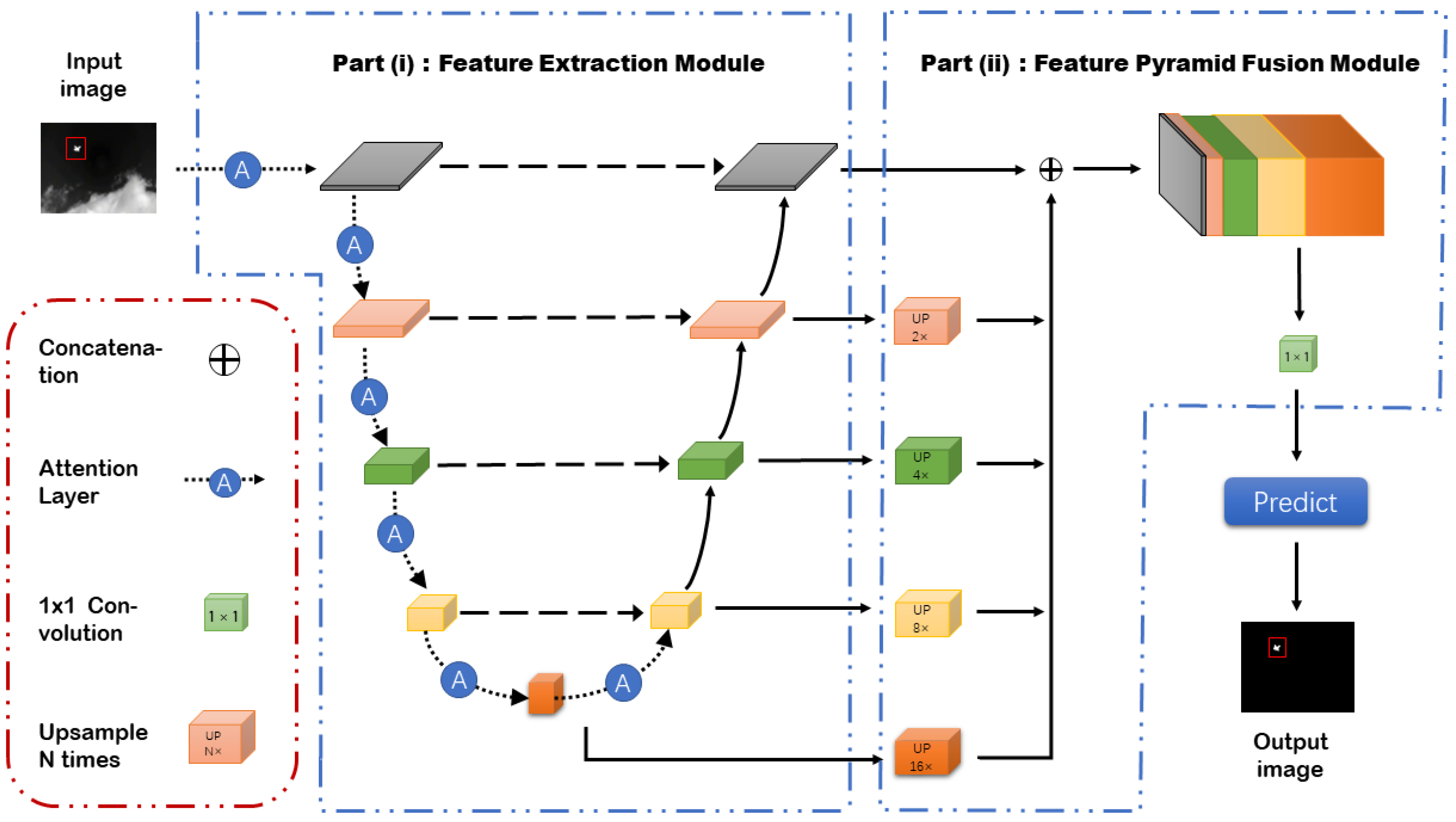
3.1. Network Architecture
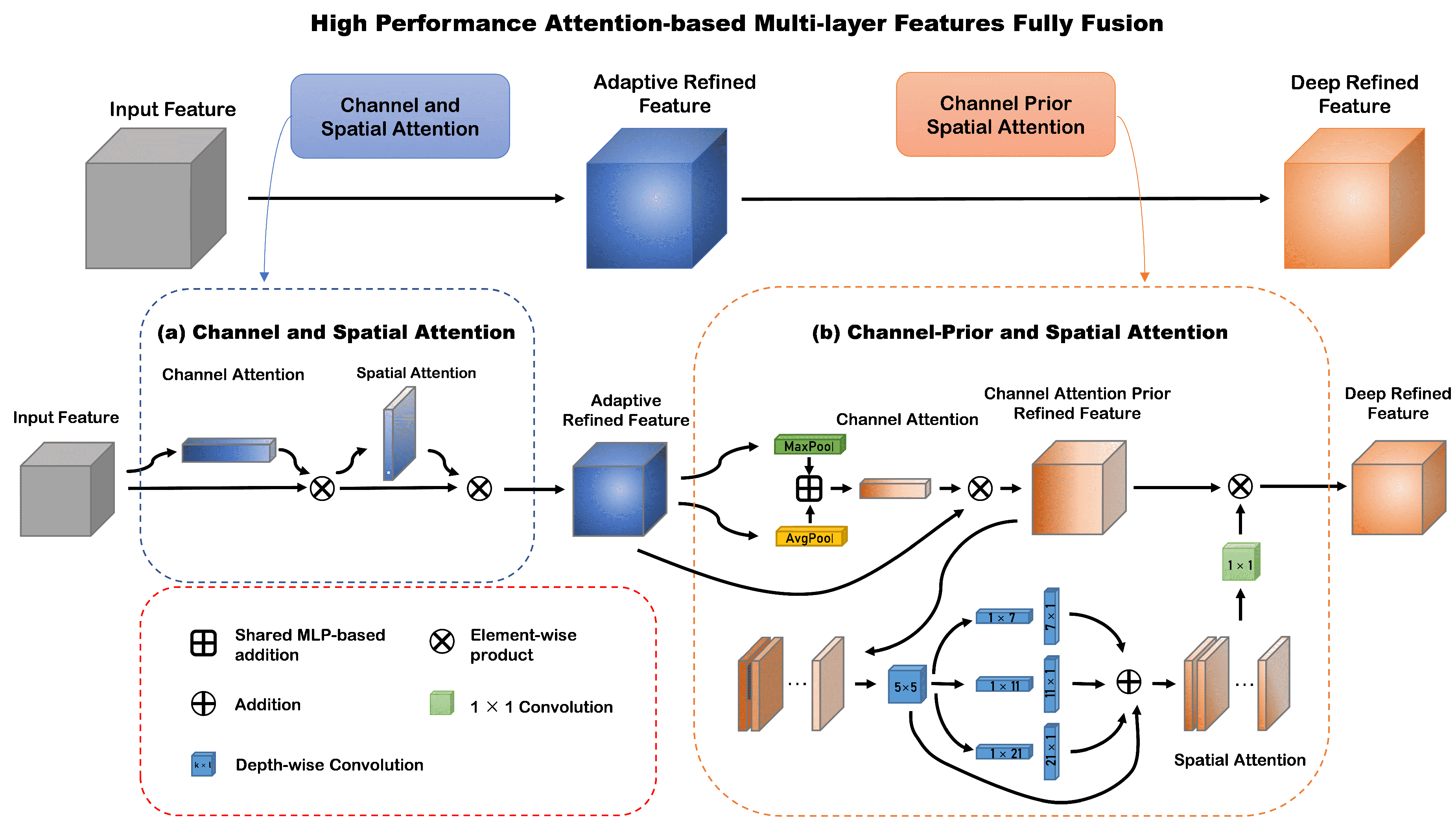
3.2. The Attention-Based Feature Enhancement Layer
3.2.1. CPSAM
3.2.2. CSCAM
3.3. The Feature Fusion Module
4. Result of Evaluational Experiment
4.1. Evaluation Metrics
- (1)
- Intersection over union (): The Intersection over Union () metric is a fundamental tool used to evaluate the effectiveness of algorithms in semantic segmentation, focusing particularly on how accurately these algorithms can delineate object contours within an image. is calculated by determining the ratio of the intersection area between the predicted labels from the segmentation algorithm and the ground truth labels, which represent the actual labels, to the union of these two areas. This calculation provides crucial insights into the precision with which a segmentation algorithm can outline and overlap with the actual boundaries of objects in an image. As such, serves as an essential measure for assessing the accuracy of segmentation models, indicating the degree to which the predicted segmentation corresponds to the ground truth. is defined as follows:where represents the True Positives, represents the False Negatives, and represents the False Positives.
- (2)
- Probability of Detection: The Probability of Detection () is a metric used to evaluate the effectiveness of detection algorithms by measuring their ability to accurately identify target instances within a dataset. It is calculated as the ratio of the number of correctly predicted target instances to the total number of actual target instances , assessing the algorithm’s accuracy in detecting present targets. This metric is crucial for gauging the reliability and effectiveness of detection systems in real-world applications, highlighting their practical utility in operational settings. is calculated as follows:In this paper, we determine whether a target is correctly predicted by comparing its centroid deviation to a predefined deviation threshold, Dthresh. If the centroid deviation of the target is lower than , we classify it as a correctly predicted target. For this study, we have set the predefined deviation threshold to be 3.
- (3)
- False-Alarm Rate: The False-Alarm Rate () is a critical metric used to measure the precision of a detection algorithm, quantifying how often the algorithm incorrectly identifies targets within an image. It focuses on the error aspect of detection by calculating the ratio of the number of falsely predicted pixels () to the total number of pixels in the image (). This calculation helps assess the proportion of pixels incorrectly marked as targets, providing insights into the algorithm’s precision and its ability to minimize false positives. The False-Alarm Rate is essential for evaluating the robustness and reliability of detection systems, emphasizing their effectiveness in avoiding incorrect target identifications. The definition of is as follows:
- (4)
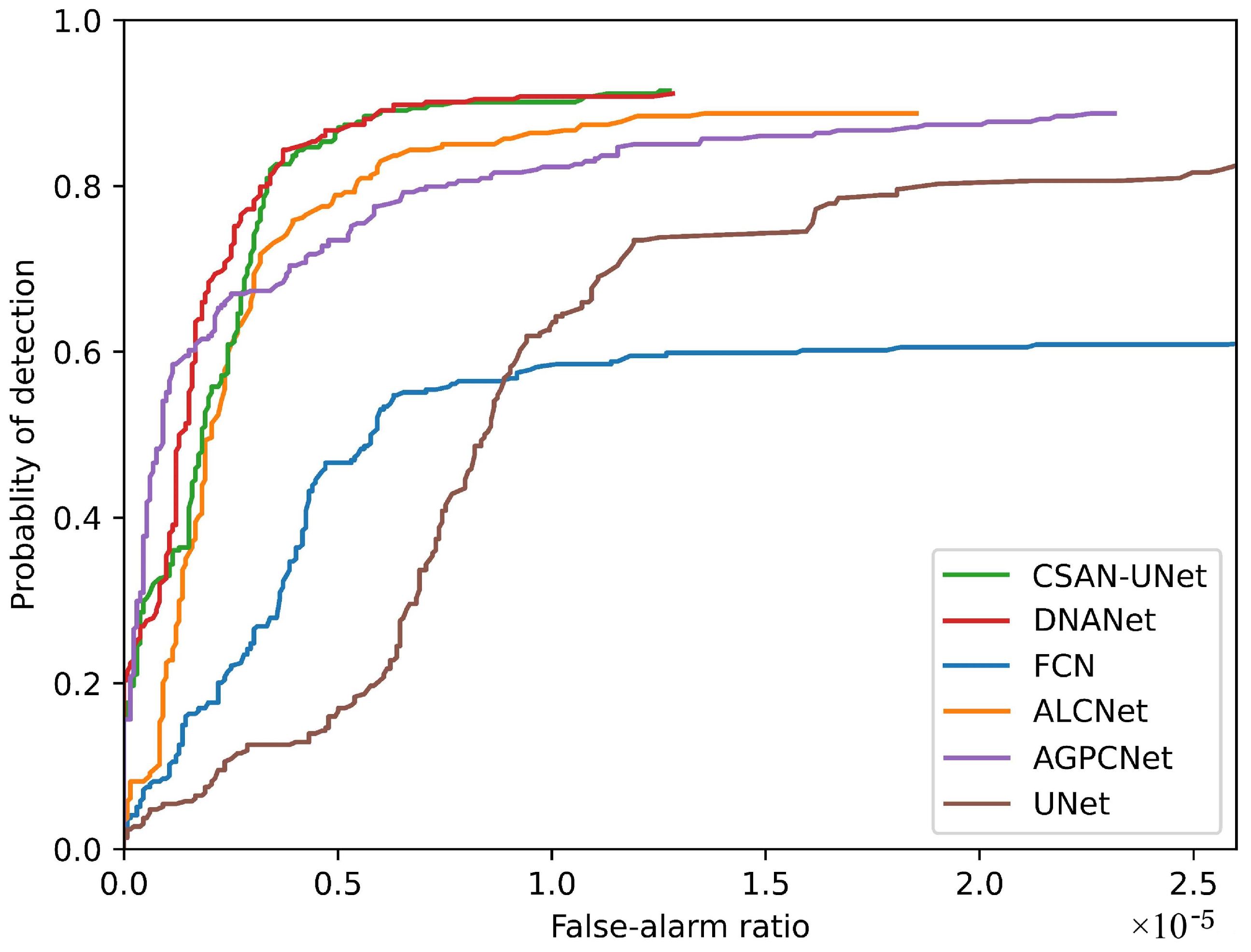
- Receiver Operation Characteristics: The Receiver Operating Characteristics () curve is a crucial tool that graphically illustrates the trade-offs between the Probability of Detection () and the False Alarm Rate () for detection algorithms. By plotting against , the ROC curve helps assess how effectively a detection system can identify true positives while minimizing false alarms. This visualization is critical for assessing how effectively a detection system performs in challenging environments, where small infrared targets need to be identified against complex backgrounds.
- (5)
- Floating Point Operations: Floating Point Operations () represent the number of floating-point arithmetic operations performed by a model during its execution. In our work, are used to assess the efficiency and computational requirements of different models.
- (6)
- Parameters: Parameters represent the learnable variables that enable the model to capture and represent patterns in the data. By analyzing the number of parameters in a model, we can gain insights into its size, memory requirements, and computational efficiency. The parameter count provides a quick and simple way to compare different models and understand their relative complexities.
- (7)
- Frames Per Second: In our study, Frames Per Second () is utilized as an evaluation indicator to measure the speed of model inference. quantifies the number of images processed by the model within a single second (). It provides a valuable metric to assess the efficiency and real-time performance of a model during inference. The definition of is as follows:
4.2. Implementation Details
4.3. Comparison with State-of-the-Art Methods
4.3.1. Comparison with Traditional Model-Driven Methods
- (1)
- Quantitative Results. For the traditional algorithms we compared, we followed a consistent procedure. First, we generated predictions using each method, and then we applied noise suppression by setting a threshold to eliminate low-response areas. In particular, We calculated the adaptive threshold () using the following formula:where refers to the maximum output value generated by the methods, often representing the most intense prediction, such as the highest probability or the strongest activation within the output layer, represents an adaptive threshold that is dynamically determined by the outputs to optimize binary classifications, represents the standard deviation, which measures how spread out the values are from the mean, and calculates the average value of the output.
- (2)
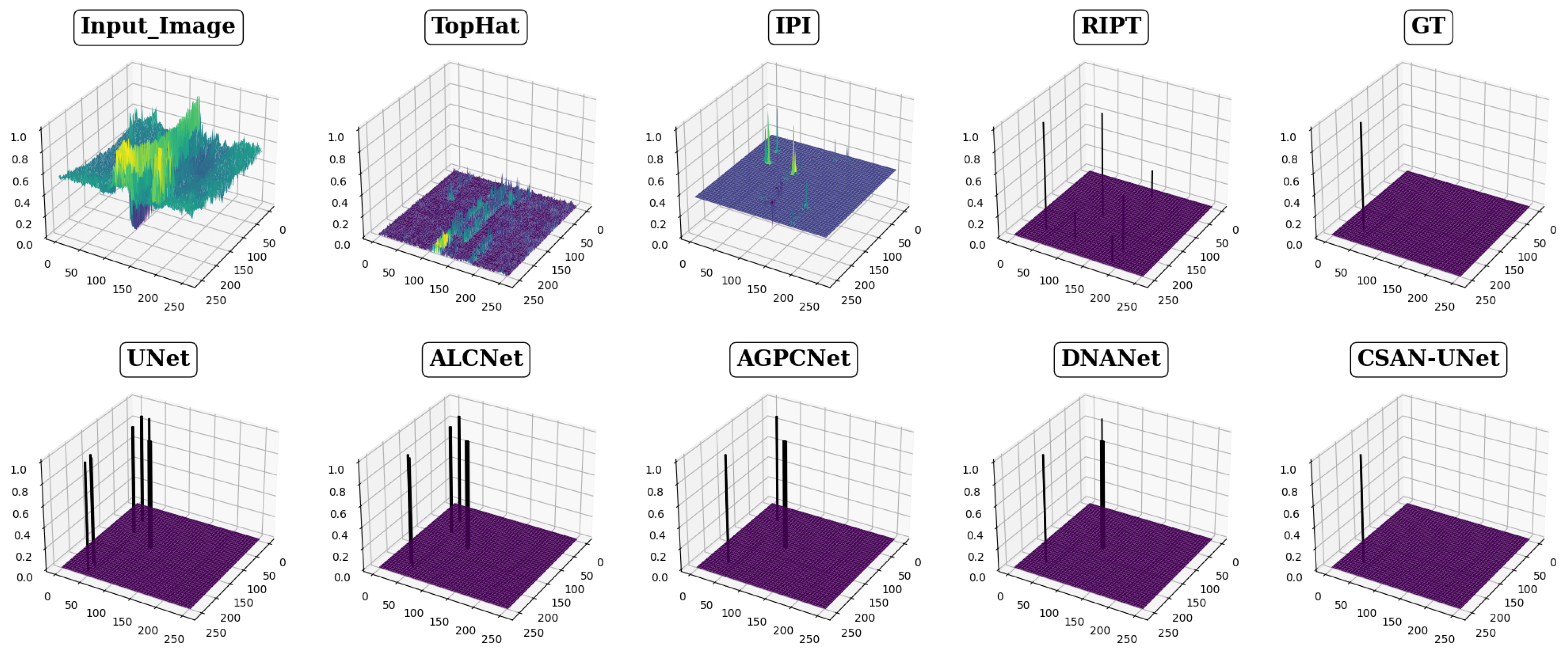
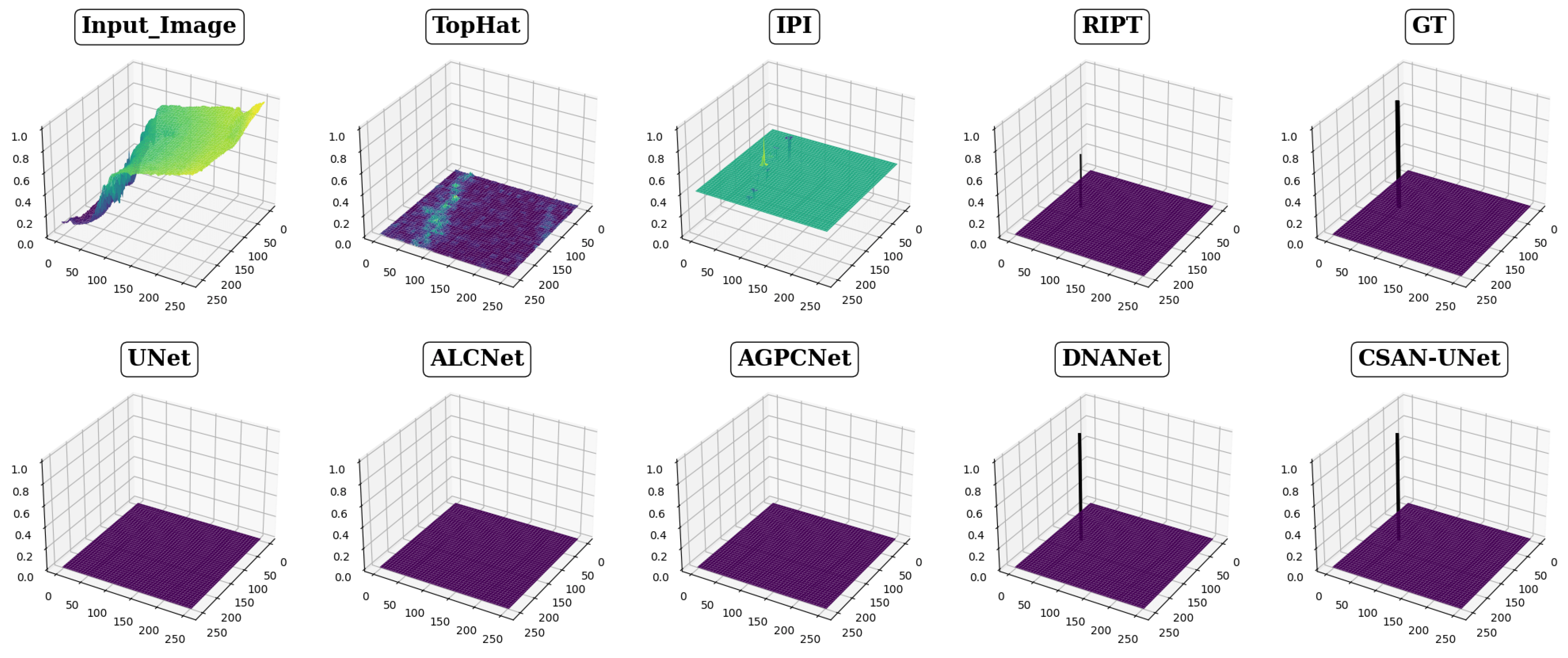
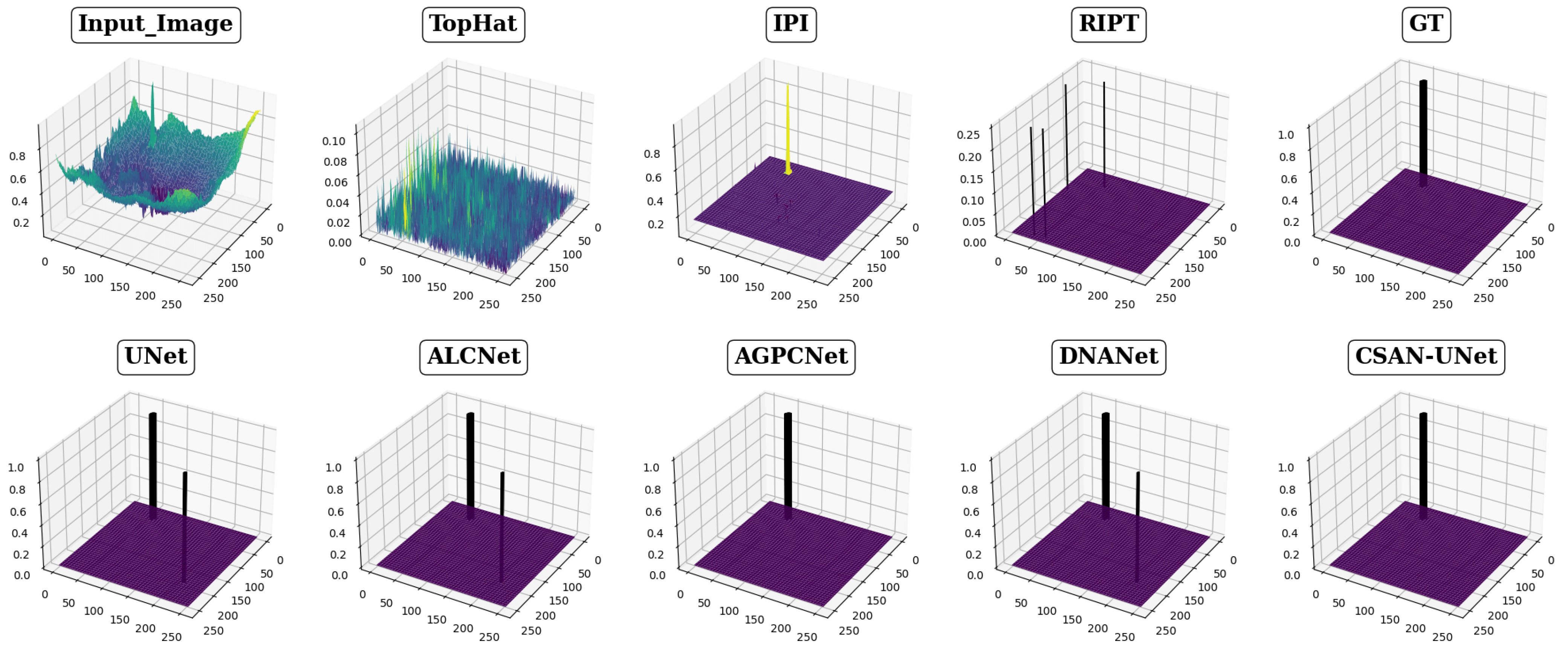
- Qualitative comparison (Figure 3). The comparison involves eight different detection methods, including CSAN-UNet and three traditional methods, focusing on three typical scenes of infrared small targets. Each method’s results are distinctly labeled in the upper center corner of each image to facilitate identification. To improve visibility and allow for detailed examination of segmentation capabilities, the target areas within each scene are enlarged and positioned in the lower right corner of the image display. Results are color-coded for clarity: red circles indicate correctly detected targets, highlighting successful identifications, while yellow circles denote false positives, showing where methods incorrectly identified targets. The absence of red circles signifies a missed detection, indicating the method’s failure to recognize an actual target present in the scene. This visualization strategy is designed to clearly demonstrate the effectiveness of each detection method, enabling a direct visual comparison that showcases their precision and accuracy in detecting and segmenting small infrared targets, thereby highlighting the strengths and weaknesses of each method.
4.3.2. Comparison with Data-Driven Methods
- (1)
- Quantitative Results. To ensure a fair comparison, we retrained all data-driven methods using the same training datasets as our CSAN-UNet. We followed the original papers of these methods and used their specified fixed thresholds. All other parameters were kept consistent with the values stated in their original papers. It is important to highlight that we implemented these methods ourselves to ensure fairness in the comparison.
- (2)
- Qualitative comparison. In this part we use the same settings as the corresponding part in Section 4.3.1 and show the results in Figure 3.
4.4. Ablation Study
- (1)
- Ablation study for the CSCAM: CSCAM is used to adaptively enhance small infrared targets after downsampling, making up for the information loss after downsampling and maintaining deep target features, and enhancing the network’s ability to extract contextual information. We compared CSAN-UNet with four variants to verify the benefits brought by this module.
- CSAN-UNet w/o attention: We use the classic residual connection layer instead of the attention-based feature enhancement layer
- CSAN-UNet-CSCAM-ResNet: We use the classic residual connection instead of CPSAM to fully evaluate the effectiveness of CSCAM in maintaining deep target features.
- CSAN-UNet-ResNet-CPSAM: We use the classic residual connection instead of CSCAM to evaluate the contribution of CBCAM to network performance.
- CSAN-UNet with CPSAM: We use CPSAM to replace the feature-enhanced CSCAM to explore the limitations of CPSAM in compensating for the information loss caused by downsampling.
- (2)
- Ablation study for the CPSAM: CPSAM is used to efficiently extract deep semantic features of small targets and fully combine contextual information to improve the modeling capabilities of the network. It serves as a lightweight, high-performance attention module that reduces the computational burden. In addition, CPSAM overcomes the limitation of uniform distribution of spatial attention weights between channels, reduces noise and improves the accuracy of infrared small target detection. We compared CSCAN-UNet with four variants to demonstrate the effectiveness of this module.
- CSAN-UNet w/o attention: In this variant, we excluded both the channel attention and spatial attention modules from the network architecture, in order to specifically study the individual contributions of these modules to the overall network performance.
- CSAN-UNet w/o CA: In this variant, we removed the Spatial attention (SA) module and retained only the Channel attention (CA) module to examine the contribution of SA to the network performance.
- CSAN-UNet w/o SA: In this variant, we removed the Channel attention (CA) module and retained only the Spatial attention (SA) module to examine the contribution of CA to the network performance.
- CSAN-UNet with CSCAM: In this variant, we utilized the CSCAM instead of the CPSAM to comprehensively evaluate the contribution of CPSAM to both reducing network computational complexity and improving network performance.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Teutsch, M.; Krüger, W. Classification of small boats in infrared images for maritime surveillance. In Proceedings of the 2010 International WaterSide Security Conference, Carrara, Italy, 3–5 November 2010; pp. 1–7. [Google Scholar]
- Kou, R.; Wang, H.; Zhao, Z.; Wang, F. Optimum selection of detection point and threshold noise ratio of airborne infrared search and track systems. Appl. Opt. 2017, 56, 5268–5273. [Google Scholar] [CrossRef]
- Rawat, S.S.; Verma, S.K.; Kumar, Y. Review on recent development in infrared small target detection algorithms. Procedia Comput. Sci. 2020, 167, 2496–2505. [Google Scholar] [CrossRef]
- Huang, S.; Liu, Y.; He, Y.; Zhang, T.; Peng, Z. Structure-adaptive clutter suppression for infrared small target detection: Chain-growth filtering. Remote Sens. 2019, 12, 47. [Google Scholar] [CrossRef]
- Zhao, M.; Li, W.; Li, L.; Hu, J.; Ma, P.; Tao, R. Single-frame infrared small-target detection: A survey. IEEE Geosci. Remote Sens. Mag. 2022, 10, 87–119. [Google Scholar] [CrossRef]
- Azimi-Sadjadi, M.R.; Pan, H. Two-dimensional block diagonal LMS adaptive filtering. IEEE Trans. Signal Process. 1994, 42, 2420–2429. [Google Scholar] [CrossRef]
- Rivest, J.F.; Fortin, R. Detection of dim targets in digital infrared imagery by morphological image processing. Opt. Eng. 1996, 35, 1886–1893. [Google Scholar] [CrossRef]
- Deshpande, S.D.; Er, M.H.; Venkateswarlu, R.; Chan, P. Max-Mean and Max-Median Filters for Detection of Small-Targets. In Proceedings of the Signal and Data Processing of Small Targets 1999, Denver, CO, USA, 19–23 July 1999. [Google Scholar]
- Wei, Y.; You, X.; Li, H. Multiscale patch-based contrast measure for small infrared target detection. Pattern Recognit. 2016, 58, 216–226. [Google Scholar] [CrossRef]
- Shi, Y.; Wei, Y.; Yao, H.; Pan, D.; Xiao, G. High-boost-based multiscale local contrast measure for infrared small target detection. IEEE Geosci. Remote Sens. Lett. 2017, 15, 33–37. [Google Scholar] [CrossRef]
- Han, J.; Liang, K.; Zhou, B.; Zhu, X.; Zhao, J.; Zhao, L. Infrared small target detection utilizing the multiscale relative local contrast measure. IEEE Geosci. Remote Sens. Lett. 2018, 15, 612–616. [Google Scholar] [CrossRef]
- Chen, Y.; Song, B.; Wang, D.; Guo, L. An effective infrared small target detection method based on the human visual attention. Infrared Phys. Technol. 2018, 95, 128–135. [Google Scholar] [CrossRef]
- Kou, R.; Wang, C.; Fu, Q.; Yu, Y.; Zhang, D. Infrared small target detection based on the improved density peak global search and human visual local contrast mechanism. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 6144–6157. [Google Scholar] [CrossRef]
- Han, J.; Moradi, S.; Faramarzi, I.; Zhang, H.; Zhao, Q.; Zhang, X.; Li, N. Infrared small target detection based on the weighted strengthened local contrast measure. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1670–1674. [Google Scholar] [CrossRef]
- Chen, C.P.; Li, H.; Wei, Y.; Xia, T.; Tang, Y.Y. A Local Contrast Method for Small Infrared Target Detection. IEEE Trans. Geosci. Remote Sens. 2013, 52, 574–581. [Google Scholar] [CrossRef]
- Recht, B.; Fazel, M.; Parrilo, P.A. Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization. SIAM Rev. 2010, 52, 471–501. [Google Scholar] [CrossRef]
- Wang, X.; Peng, Z.; Kong, D.; Zhang, P.; He, Y. Infrared dim target detection based on total variation regularization and principal component pursuit. Image Vis. Comput. 2017, 63, 1–9. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, Z. Infrared small target detection based on partial sum of the tensor nuclear norm. Remote Sens. 2019, 11, 382. [Google Scholar] [CrossRef]
- Zhou, F.; Wu, Y.; Dai, Y.; Wang, P. Detection of small target using schatten 1/2 quasi-norm regularization with reweighted sparse enhancement in complex infrared scenes. Remote Sens. 2019, 11, 2058. [Google Scholar] [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared patch-image model for small target detection in a single image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y. Reweighted infrared patch-tensor model with both nonlocal and local priors for single-frame small target detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3752–3767. [Google Scholar] [CrossRef]
- Wang, H.; Zhou, L.; Wang, L. Miss detection vs. false alarm: Adversarial learning for small object segmentation in infrared images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8509–8518. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric contextual modulation for infrared small target detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 950–959. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Attentional local contrast networks for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9813–9824. [Google Scholar] [CrossRef]
- Zhang, T.; Li, L.; Cao, S.; Pu, T.; Peng, Z. Attention-Guided Pyramid Context Networks for Detecting Infrared Small Target Under Complex Background. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 4250–4261. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, R.; Yang, Y.; Bai, H.; Zhang, J.; Guo, J. ISNet: Shape matters for infrared small target detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18 June–24 June 2022; pp. 877–886. [Google Scholar]
- Li, B.; Xiao, C.; Wang, L.; Wang, Y.; Lin, Z.; Li, M.; An, W.; Guo, Y. Dense nested attention network for infrared small target detection. IEEE Trans. Image Process. 2022, 32, 1745–1758. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Proceedings 4. Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 205–218. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Huang, H.; Chen, Z.; Zou, Y.; Lu, M.; Chen, C. Channel prior convolutional attention for medical image segmentation. arXiv 2023, arXiv:2306.05196. [Google Scholar]
- Zuo, Z.; Tong, X.; Wei, J.; Su, S.; Wu, P.; Guo, R.; Sun, B. AFFPN: Attention fusion feature pyramid network for small infrared target detection. Remote Sens. 2022, 14, 3412. [Google Scholar] [CrossRef]
- Zhao, B.; Wang, C.; Fu, Q.; Han, Z. A novel pattern for infrared small target detection with generative adversarial network. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4481–4492. [Google Scholar] [CrossRef]
- Hou, Q.; Wang, Z.; Tan, F.; Zhao, Y.; Zheng, H.; Zhang, W. RISTDnet: Robust infrared small target detection network. IEEE Geosci. Remote Sens. Lett. 2021, 19, 7000805. [Google Scholar] [CrossRef]
- Wu, T.; Li, B.; Luo, Y.; Wang, Y.; Xiao, C.; Liu, T.; Yang, J.; An, W.; Guo, Y. MTU-Net: Multilevel TransUNet for Space-Based Infrared Tiny Ship Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5601015. [Google Scholar] [CrossRef]
- Ying, X.; Liu, L.; Wang, Y.; Li, R.; Chen, N.; Lin, Z.; Sheng, W.; Zhou, S. Mapping degeneration meets label evolution: Learning infrared small target detection with single point supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 15528–15538. [Google Scholar]
- Wu, X.; Hong, D.; Chanussot, J. UIU-Net: U-Net in U-Net for Infrared Small Object Detection. IEEE Trans. Image Process. 2023, 32, 364–376. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Li, Q.; Gong, M.; Yuan, Y.; Wang, Q. Symmetrical Feature Propagation Network for Hyperspectral Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5536912. [Google Scholar] [CrossRef]
- Guo, C.; Szemenyei, M.; Yi, Y.; Wang, W.; Chen, B.; Fan, C. Sa-unet: Spatial attention u-net for retinal vessel segmentation. In Proceedings of the 2020 25th international conference on pattern recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 1236–1242. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Li, Q.; Yuan, Y.; Wang, Q. Multiscale Factor Joint Learning for Hyperspectral Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5523110. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters–improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Zhang, Z.; Zhang, X.; Peng, C.; Xue, X.; Sun, J. Exfuse: Enhancing feature fusion for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 269–284. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | NUAA-SIRST | IRSTD-1K | ||||
|---|---|---|---|---|---|---|
| IoU (×10−2) | Pd (×10−2) | Fa (×10−6) | IoU (×10−2) | Pd (×10−2) | Fa (×10−6) | |
| Top-Hat [7] | 7.143 | 79.84 | 1012 | 10.06 | 75.11 | 1432 |
| Max-Median [8] | 4.172 | 69.20 | 55.33 | 6.998 | 65.21 | 59.73 |
| IPI [20] | 25.67 | 85.55 | 11.47 | 27.92 | 81.37 | 16.18 |
| RIPI [21] | 11.05 | 79.08 | 22.61 | 14.11 | 77.55 | 28.31 |
| WSLCM [14] | 1.158 | 77.95 | 5446 | 3.452 | 72.44 | 6619 |
| TLLCM [15] | 1.029 | 79.09 | 5899 | 3.311 | 77.39 | 6738 |
| CSAN | 75.89 | 97.72 | 8.1285 | 69.28 | 91.50 | 7.2877 |
| Method | FLOPs (G) | Params (M) | FPS | NUAA-SIRST | IRSTD-1K | ||||
|---|---|---|---|---|---|---|---|---|---|
| IoU (×10−2) | Pd (×10−2) | Fa (×10−6) | IoU (×10−2) | Pd (×10−2) | Fa (×10−6) | ||||
| FCN [45] | 21.6534 | 20.8615 | 68.99 | 60.80 | 90.11 | 50.69 | 49.15 | 61.22 | 80.46 |
| UNet [28] | 47.2597 | 30.6029 | 74.9 | 70.00 | 95.81 | 63.45 | 55.35 | 90.51 | 42.96 |
| GCN [46] | 14.1150 | 55.4502 | 15.7 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Exfuse [47] | 50.7750 | 120.5935 | 20.8 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| MDvsFA [22] | 230.1406 | 3.5937 | 5.9 | 60.30 | 89.35 | 56.35 | 49.50 | 82.11 | 80.33 |
| ALC [24] | 3.4458 | 0.3553 | 59.10 | 71.17 | 96.57 | 35.79 | 61.82 | 88.77 | 18.5231 |
| AGPC [25] | 40.2152 | 11.7878 | 15.6 | 72.01 | 95.81 | 35.29 | 62.30 | 89.45 | 19.58 |
| DNA [27] | 13.3013 | 4.4793 | 31.9 | 75.38 | 96.19 | 14.26 | 68.34 | 91.15 | 9.10 |
| CSAN | 5.4723 | 2.2795 | 52.6 | 75.89 | 97.72 | 8.12 | 69.28 | 91.50 | 7.28 |
| Model | NUAA-SIRST | IRSTD-1K | ||||
|---|---|---|---|---|---|---|
| IoU (×10−2) | Pd (×10−2) | Fa (×10−6) | IoU (×10−2) | Pd (×10−2) | Fa (×10−6) | |
| CSAN-UNet w/o attention | 73.50 | 95.43 | 47.48 | 65.84 | 88.09 | 40.84 |
| CSAN-UNet-CSCAM-ResNet | 73.75 | 95.81 | 16.11 | 66.10 | 89.45 | 38.83 |
| CSAN-UNet-ResNet-CPSAM | 74.25 | 96.57 | 21.46 | 66.94 | 89.79 | 40.46 |
| CSAN-UNet with CPSAM | 72.05 | 93.53 | 31.01 | 63.92 | 87.75 | 56.78 |
| CSAN-UNet (our) | 75.89 | 97.72 | 8.12 | 69.28 | 91.50 | 7.28 |
| NUAA-SIRST | IRSTD-1K | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | FLOPs (M) | Params (M) | IoU (×10−2) | Pd (×10−2) | Fa (×10−6) | IoU (×10−2) | Pd (×10−2) | Fa (×10−6) |
| CSAN-UNet w/o attention | 6.5424 | 3.8696 | 73.50 | 95.43 | 47.48 | 65.84 | 88.09 | 40.84 |
| CSAN-UNet w/o CA | 6.5487 | 3.8952 | 74.09 | 95.81 | 20.46 | 66.78 | 90.13 | 35.90 |
| CSAN-UNet w/o SA | 6.5487 | 3.8952 | 74.40 | 96.57 | 9.91 | 67.26 | 90.81 | 10.40 |
| CSAN-UNet with CSCAM | 6.5487 | 3.8952 | 75.26 | 96.95 | 19.18 | 67.60 | 91.15 | 10.05 |
| CSAN-UNet (our) | 5.4723 | 2.2795 | 75.89 | 97.72 | 8.12 | 69.28 | 91.50 | 7.28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, Y.; Shi, Z.; Zhang, Y.; Zhang, Y.; Li, H. CSAN-UNet: Channel Spatial Attention Nested UNet for Infrared Small Target Detection. Remote Sens. 2024, 16, 1894. https://doi.org/10.3390/rs16111894
Zhong Y, Shi Z, Zhang Y, Zhang Y, Li H. CSAN-UNet: Channel Spatial Attention Nested UNet for Infrared Small Target Detection. Remote Sensing. 2024; 16(11):1894. https://doi.org/10.3390/rs16111894
Chicago/Turabian StyleZhong, Yuhan, Zhiguang Shi, Yan Zhang, Yong Zhang, and Hanyu Li. 2024. "CSAN-UNet: Channel Spatial Attention Nested UNet for Infrared Small Target Detection" Remote Sensing 16, no. 11: 1894. https://doi.org/10.3390/rs16111894
APA StyleZhong, Y., Shi, Z., Zhang, Y., Zhang, Y., & Li, H. (2024). CSAN-UNet: Channel Spatial Attention Nested UNet for Infrared Small Target Detection. Remote Sensing, 16(11), 1894. https://doi.org/10.3390/rs16111894