3.1. Overall Structure
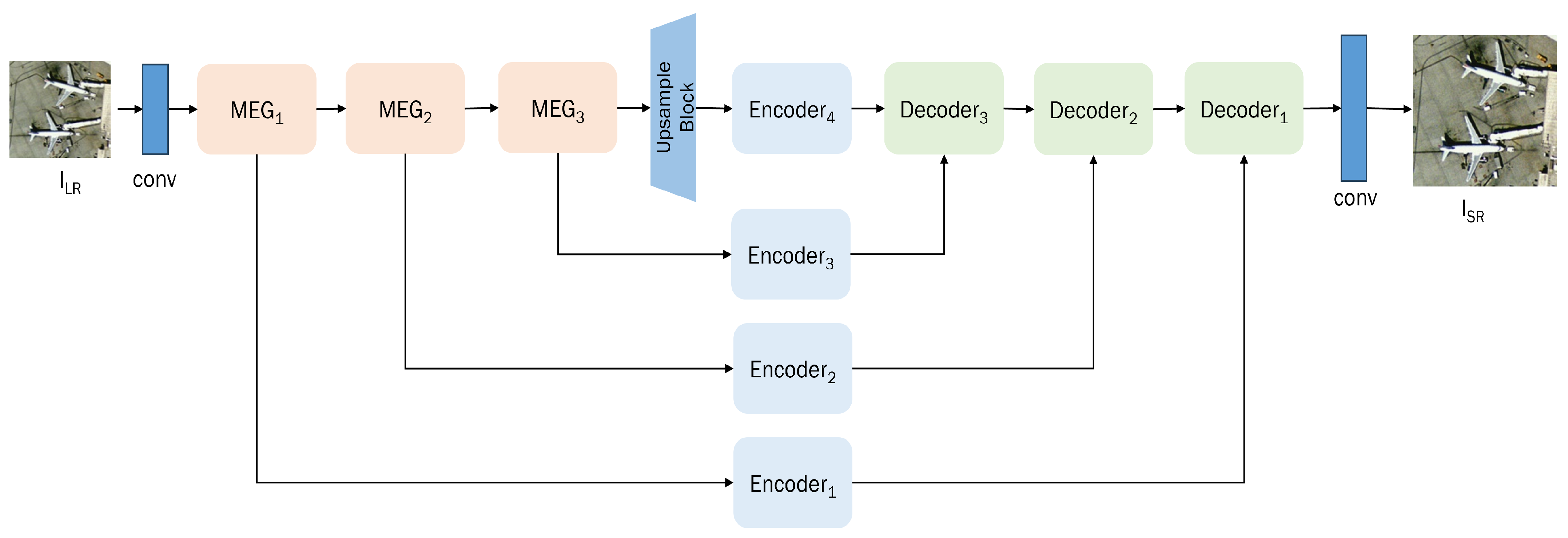
Figure 2 illustrates the overall architecture of the proposed network. Initially, the input data, which is of low resolution in the context of remote sensing, undergoes a transformation using convolutional layers to convert it into feature space.
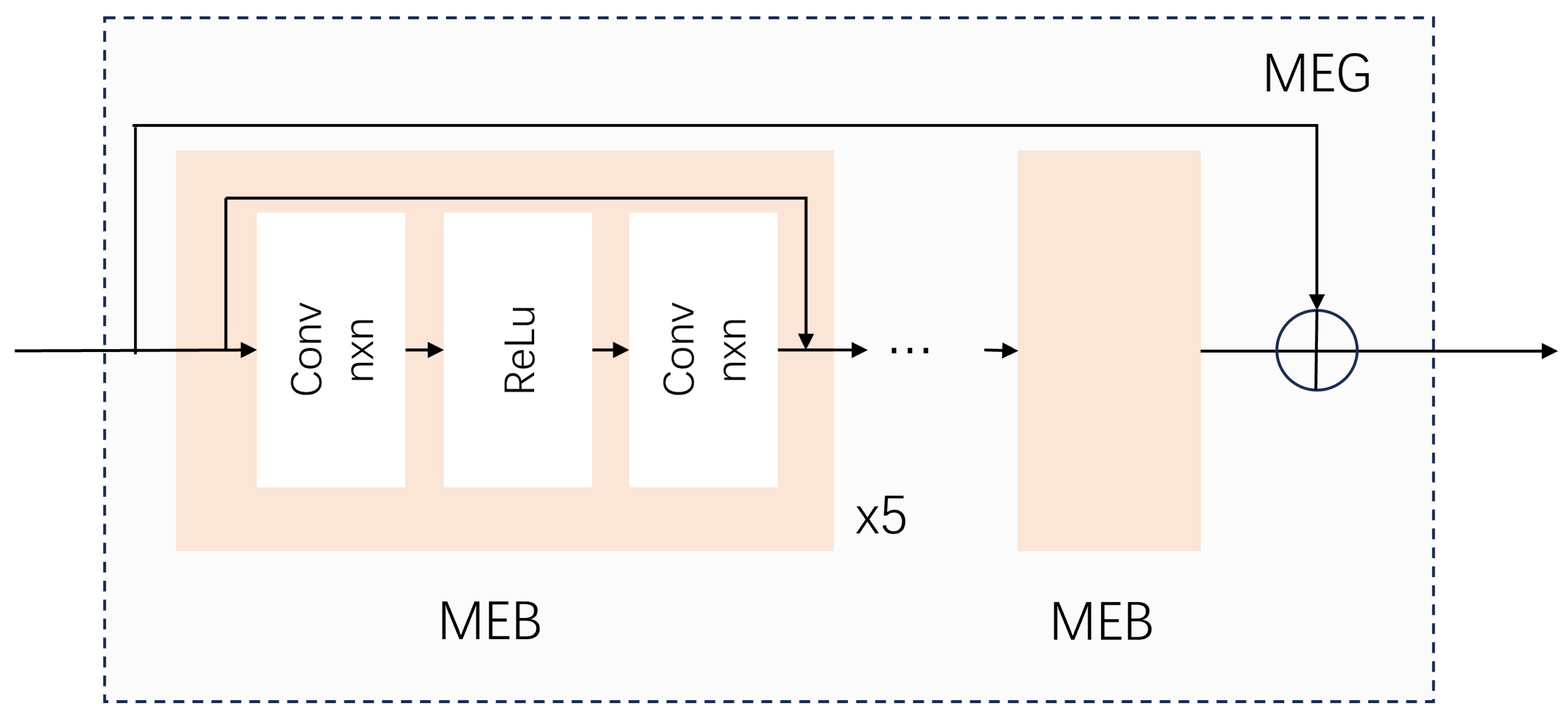
In the shallow feature extraction module, the multi-scale feature extraction group (MEG) is proposed to extract shallow feature information with various convolution kernel sizes.
In the initial phase of feature extraction, the block of this module makes use of convolution kernels with dimensions of 3 × 3, 5 × 5, and 3 × 3, respectively. The design of the feature extraction module is shown in
Figure 3 and the shallow feature extraction process can be represented as follows:
where
stands for the low-resolution image,
stands for convolution,
represents the initial feature, and
represents the
nth MEG module. This utilization of multi-scale convolution enhances feature extraction, enabling the capture of richer information and the improvement in feature representation. Addressing the intricate nature of multi-scale feature processing, the deep feature extraction module involves a design that branches into multiple levels for fusion. This module utilizes transformer-based self-attention calculations to facilitate deep feature extraction, and the obtained features are expanded through subpixel space to perform the necessary multi-level fusion and reconstruction operations. Subpixel convolution is applied in the reconstruction module to effectively utilize subpixel space for generating results, leading to a significant reduction in parameter scale. Considering the well-established advantages of multi-level fusion in processing remote sensing data across diverse scales, our network architecture incorporates four branches to facilitate more effective interaction with multi-scale information. Thus, the process can be represented as
where
represents the
nth encoding module,
represents the output of the
nth encoder module,
represents the
nth decoding module,
represents the output of the
nth decoder module,
represents convolution, and
refers to the final super-resolution image. The encoders excel in the multi-level extraction of high/low-dimensional features across various stages. Following this, the decoder systematically fuses these features in a staged manner within the sub-pixel space, resulting in a progressive enhancement of features. The design of the overall structure of the network mainly consists of the module of the encoder–decoder computation part with a sparsely activated self-attention encoder and subpixel multi-level fusion decoder, and these will be further elaborated in the following two subsections.
3.2. Transformer Encoder for Sparse Representation
We apply the self-attention mechanism of the transformer after extracting features through multi-scale convolution. The self-attention mechanism has consistently demonstrated its ability to capture global similarity information and optimize feature weighting. Through the utilization of a combination of multi-head self-attention blocks and multi-layer perception blocks, the encoder structure effectively enhances and consolidates features extracted from the shallow layers of multi-scale convolution. We suggest that the generation guidance can be further augmented by incorporating a penalty term into the self-attention encoder architecture, thereby prompting the model to generate more explicit details in a constructive manner. Sparse coding will serve as the technique employed for super-resolution tasks in remote sensing images.
In encoder, the extracted shallow features are further divided into tokens for the self-attention computation. The feature
is split into patches and flattened to obtain the
. The number of patches
, and it is also the length of the input sequence. Use linear projection to map
to
D-dimensions for vector computation in the module. Thus, the encoder is an input that can be expressed as follows:
where
W is the linear layer of
.
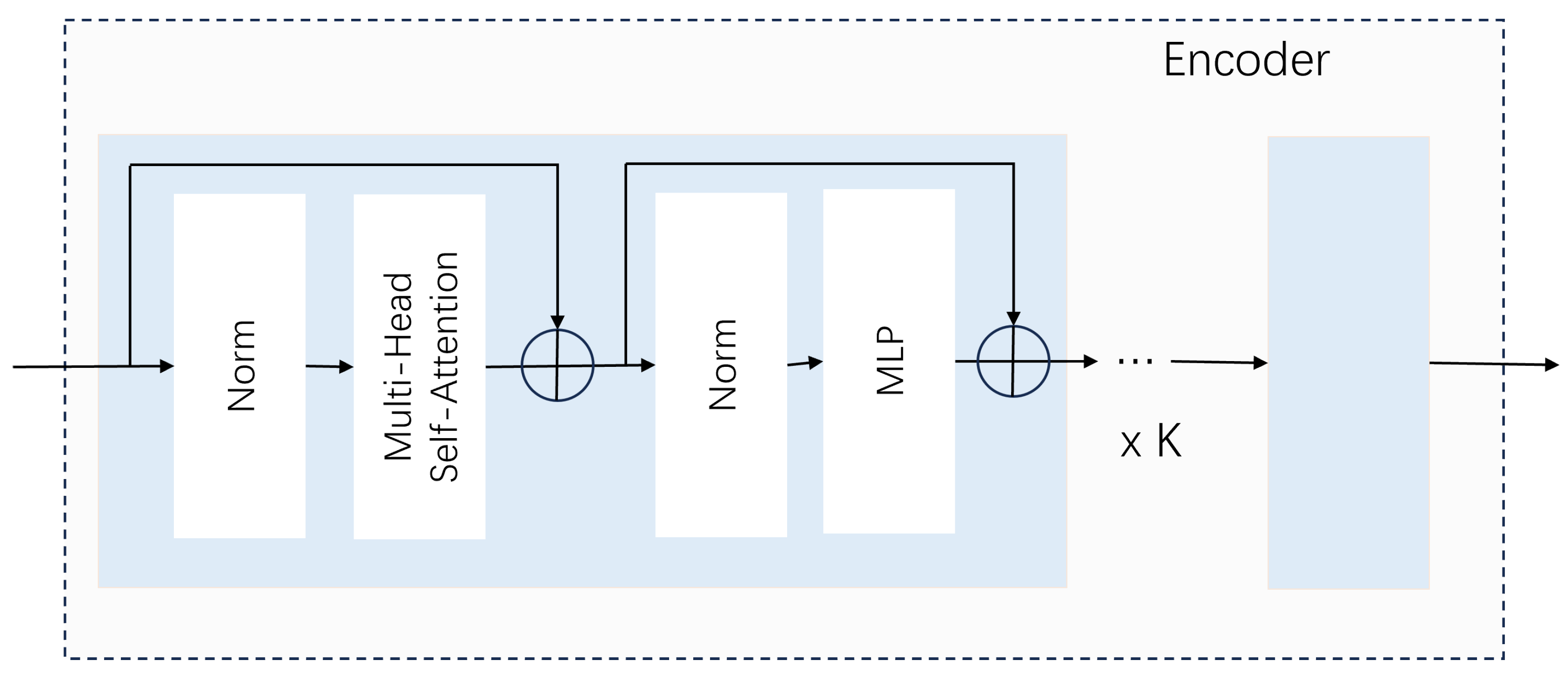
The encoder is following the original structure of [
17,
21]. It mainly contains a multi-head attention module and a multilayer perceptron structure and uses layer normalization and residual structure before each module. The encoder structure used is shown in
Figure 4. The calculations within the encoder can be expressed as follows:
where
and
denote the intermediate features.
Y represents the output of encoder block. Self-attention helps learn more similarity from the data. The variables
Q,
K, and
V for attention calculation are obtained from three linear layers, and the self-attention calculation is performed according to Equation (
5).
where
denotes the dimensions of features in these encoders,
h is the heads of the encoder module, and
,
,
, and
are all projection matrices.
The inherent uncertainty of current super-resolution generation often leads to blurred outputs when implemented in deep neural networks, thereby undermining the clarity of intricate lines. This problem is particularly pronounced in object super-resolution for remote sensing images due to scale complexity. To address this, we propose the incorporation of supplementary bias generation guidance, leveraging self-attention mechanisms, to enhance image quality. Dictionary learning has demonstrated substantial theoretical potential in both machine learning and deep neural networks. By integrating sparse coding with self-attention encoders, we can optimize the deep feature extraction module to accommodate the sparsity of remote sensing image data. The self-attention calculation mimics human attention patterns by adopting a weighted approach to determine the final attention value for the original data. For the attention values K, Q, V, a sparse penalty term is introduced for V, ensuring that the overall self-attention outcome aligns more closely with a sparse structure. This method not only enhances attention quality but also accentuates key landmark features within the image, thereby providing superior generation guidance. Furthermore, sparse self-attention enables the network to filter out interference pixels from low-resolution inputs, resulting in more robust global feature modeling. Considering the information redundancy inherent in remote sensing images, the strategic incorporation of sparse representation introduces a computational bias that promotes sparsity, thereby amplifying the network’s capacity for feature learning.
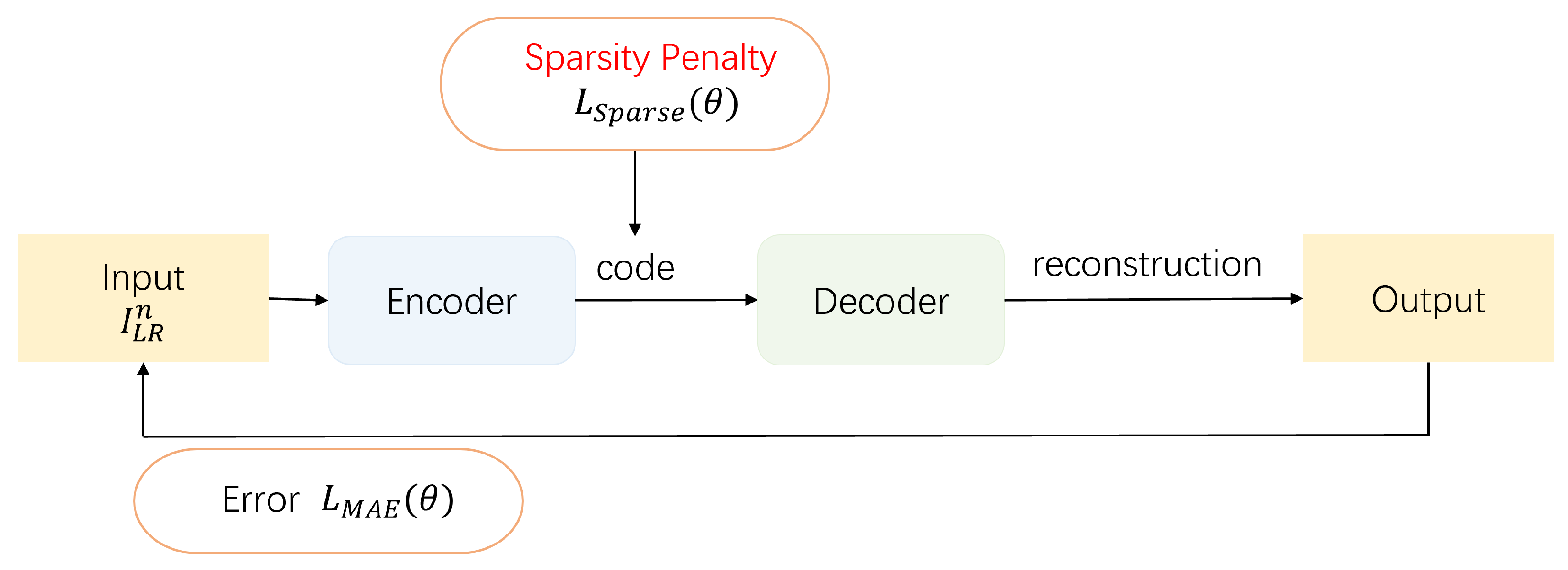
The sparse encoder introduces the loss term of the sparsity penalty by calculating the sparsity degree for the output results of the encoder, which finally guides the encoder–decoder to learn more sparse features and obtain stronger learning ability. The sparse encoder [
47,
48] has proven that sparse coding can help with data feature learning in neural networks, assisting in learning task characteristics. The original sparse encoder–decoder principle is shown in
Figure 5, and the sparsity of the encoding results of the encoder output is usually selected to calculate the sparsity, perform sparse penalty, and thus constrain the overall sparse direction of the encoder–decoder. Given the inherent similarities and complementarities between sparse coding and the self-attention mechanism, employing sparse coding to guide the attention of self-attention can be beneficial. This approach has the potential to enhance the capabilities of the Transformer structure, thereby yielding more robust and globally effective feature learning outcomes.
Imparting sparse loss to the encoding information shared between the encoder and decoder compels self-attention to prioritize key details during the learning process. This imposition not only enhances stability but also intensifies the focus on critical information in the self-encoding/decoding feature learning outcomes. The
regular value of
V in the self-attention module is selected as its activation degree, and this value is used as the penalty term for sparse coding in the generation process, so as to better guide the self-attention. Equation (
6) provides a representation of the sparse loss.
where
N denotes the number of images in a training batch,
denotes the parameter set of our network, and
K signifies the quantity of self-attention computations in the encoding module.
To quantify the accuracy of image reconstruction, we compute the mean absolute error (MAE) between the reconstructed images and their respective ground truth, represented as
where
and
denote the
nth reconstructed high-resolution image and the corresponding ground truth image, respectively.
N represents the number of images in a training batch, and
signifies the parameter set of our network. In summary, the ultimate target loss of the proposed model is the weighted sum of the two losses as Equation (
8) shows.
The parameter is employed as a weight to harmonize the balance between the two losses. By implementing sparse characterization in self-attention computations, we can attain feature extraction capabilities that are both stable and reliable.
3.3. Subpixel Multi-Level Decoder
Within the module corresponding to the decoder structure, features are subjected to further multi-level fusion and reconstruction within the subpixel space. The decoding structure of the basic Transformer [
17,
21,
22] is frequently associated with the self-attention computation module. Nevertheless, the computational burden associated with this module frequently poses substantial challenges to the overall framework. Our research indicates that sub-pixel space can serve as a potential solution to mitigate these issues. Furthermore, given the theoretical benefits of sub-pixel space, its integration with the decoding structure could substantially improve the network’s comprehension and generation capabilities in relation to the physical world. Sub-pixel space for the imaging process of pictures has had more physical analysis and attention to the discretization processing of the physical world continuous image in the imaging. One pixel point on the result of the imaged picture contains its nearby color information. By calculating for the sub-pixels that are substantially present in the imaging process, it can better use the information obtained in the imaging, so as to generate a super-resolution result that is more consistent with the actual results of the physical world. Subpixel convolution [
25] is recognized as an efficacious method for sub-pixel spatial utilization.
Figure 6 exemplifies this process in the context of sub-image space. The procedure of subpixel convolution operates under the assumption that corresponding sub-pixel values exhibit a strong correlation with their original imaging pixels. By calculating the results of subdivision between two pixels, a more robust upsampling generation capability is achieved.
It has been observed that the self-attention encoder of the Transformer model can effectively transfer more global modeling information. The application of subpixel space theory can enhance the overall network’s self-attention, enabling it to learn super-resolution generation results that align more closely with physical reality. Furthermore, concentrating on the decoder with the assistance of subpixel space can facilitate superior multilevel fusion and upsampling generation for the extracted features. Utilizing subpixel convolution in lieu of self-attention computation during the decoding stage can significantly reduce computational cost pressure. Subpixel convolution is used to generate features within a low-dimensional space, and convolution effectively fuses multi-scale features from different branches. These successive convolution processes promote collaborative feature interaction across different stages, ultimately resulting in the production of high-resolution image outcomes. The decoder structure of the original Transformer primarily functions as a decoding step, involving a self-attention calculation. This design mirrors that of the decoder structure, incorporating a self-attention module, normalization, and a multilayer perceptron module. However, employing self-attention in both the encoder and decoder can lead to increased computational costs compared to convolution operations. Moreover, if each decoder adopts a self-attention design for multilevel fusion, it imposes significant computational strain on the structural foundation of multilevel fusion, resulting in an increase in cost that does not align with the intended lifting effect. The principle of subpixel space has been demonstrated to be an effective computing strategy in both physical imaging and neural network domains. In the interaction between the Transformer and convolution, this approach can further leverage the theoretical foundation of subpixel space. By focusing on embedding the calculation of subpixel convolution and convolution within the decoder module, it is possible to complete the reconstruction of deep features extracted by the Transformer and assess the impact of convolution calculation in multilevel fusion.
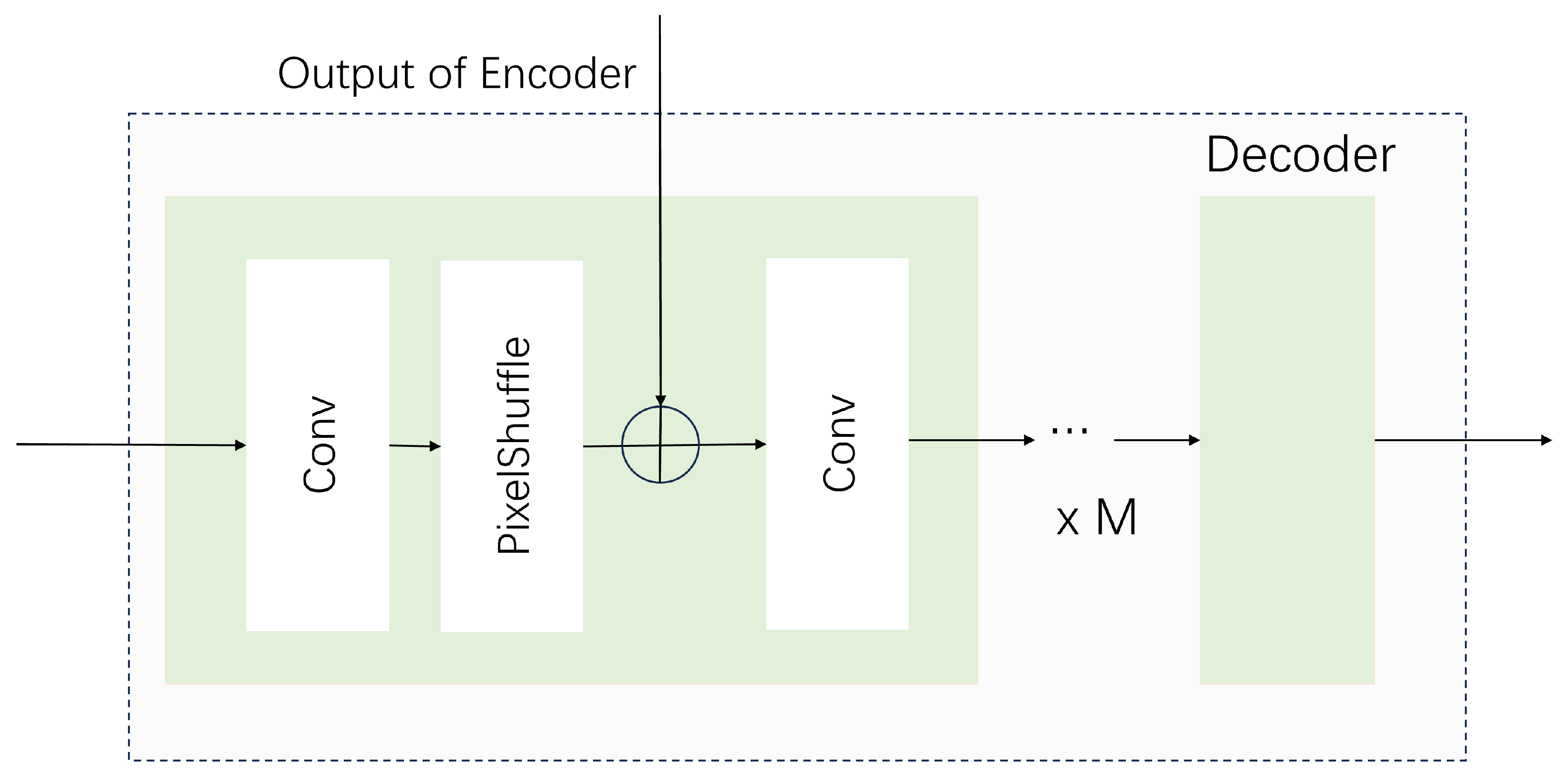
In the case of the upsampled encoder output, a decoder will be utilized to systematically combine and regenerate it with the output of the non-upsampled encoder branch. Specifically, the encoder processing results after upsampling are gradually added to the sub-pixel upsampling results for the output results of the encoders at each level of upsampling, and the convolution operation is fused step by step. The structure of the subpixel decoder of multi-level fusion is shown in
Figure 7. Through multi-level feature fusion within the subpixel space, enhanced generation is attainable. The incorporation of subpixel convolution in synergy with conventional convolution in the decoder extends the advantages of both convolution and transformer, leading to a better utilization of local correlations on the basis of long-range modeling.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}