
Cross-Modal Segmentation Network for Winter Wheat Mapping in Complex Terrain Using Remote-Sensing Multi-Temporal Images and DEM Data


Abstract

1. Introduction
- (1)
- In complex terrains, both plains and hilly areas are suitable for the cultivation of winter wheat. Current cross-modal algorithms typically employ a fixed receptive field across two modal branches to extract features. These approaches overlook the fact that different modal data types offer varying perspectives on wheat features. For instance, optical remote sensing images provide insights into the growth status and require a flexible receptive field due to the varying scales of planting sizes. On the other hand, Digital Elevation Models (DEM) present terrain information, including slope details and so on, necessitating a stable receptive field for accurate computation. Consequently, the unified receptive field utilized in the present model fails to accommodate the characteristics of the dual-modal data, thereby posing challenges to its effective application in extracting the distribution of winter wheat in areas with complex terrain.
- (2)
- In hilly regions, the small-scale planting areas, which occupy fewer pixels in the images and carry limited information, pose a significant challenge. During the downsampling and upsampling processes of the encoder–decoder convolutional neural network, the resolution of these small targets is further diminished and their feature information progressively weakens. This makes it difficult to effectively recover the information of these small targets, leading to a higher rate of omission in the mapping of winter wheat in hilly regions.
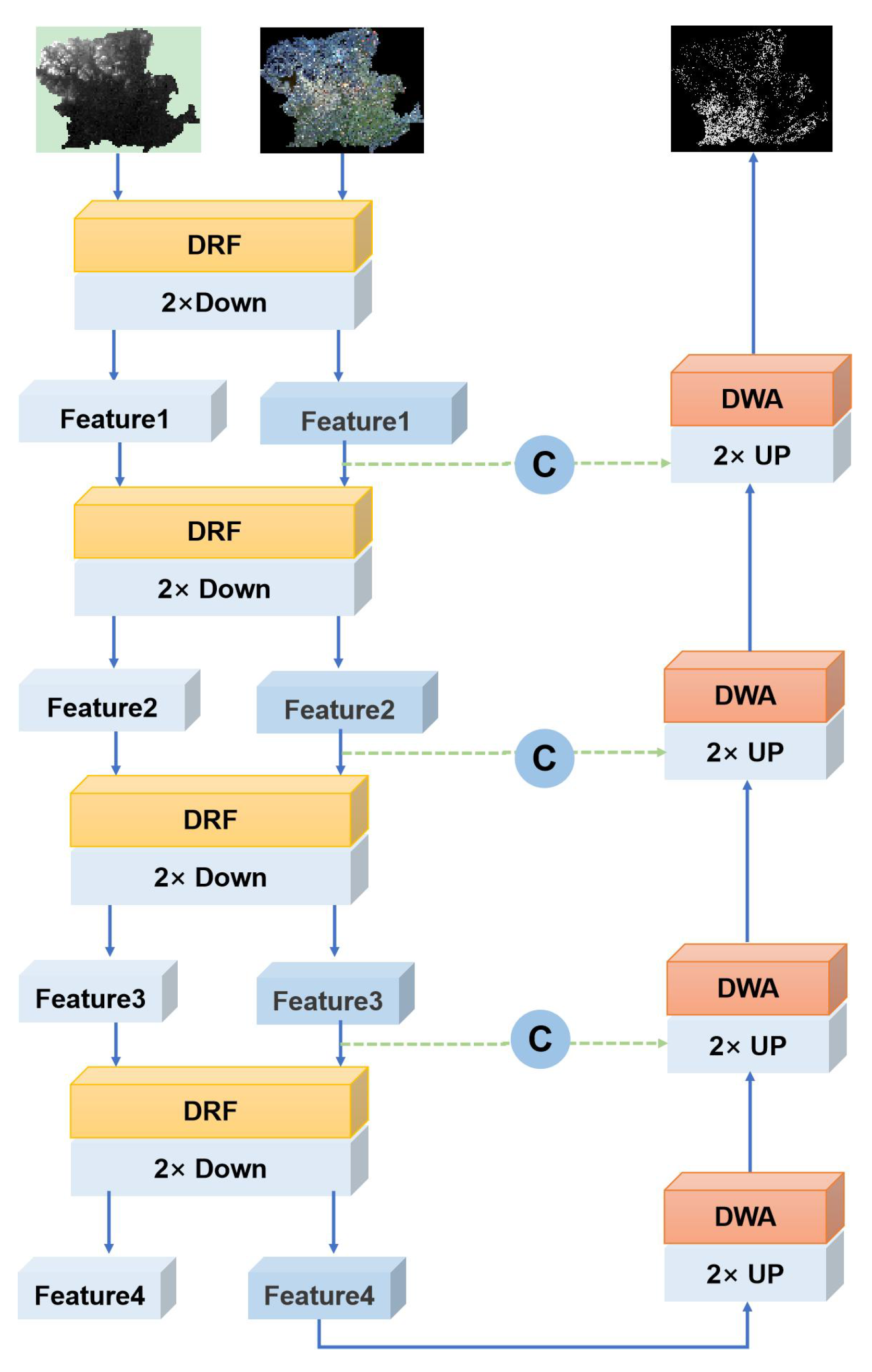
- We propose a novel network named a Cross-Modal Segmentation Network (CM-Net), which has the capability to integrate temporal, spatial, and terrain features for enhanced image segmentation.
- A Diverse Receptive Fusion (DRF) module is proposed. This module applies a deformable receptive field to optical images during the feature-fusion process, allowing it to match winter wheat plots of varying scales and a fixed receptive field to the DEM to extract evaluation features at a consistent scale.
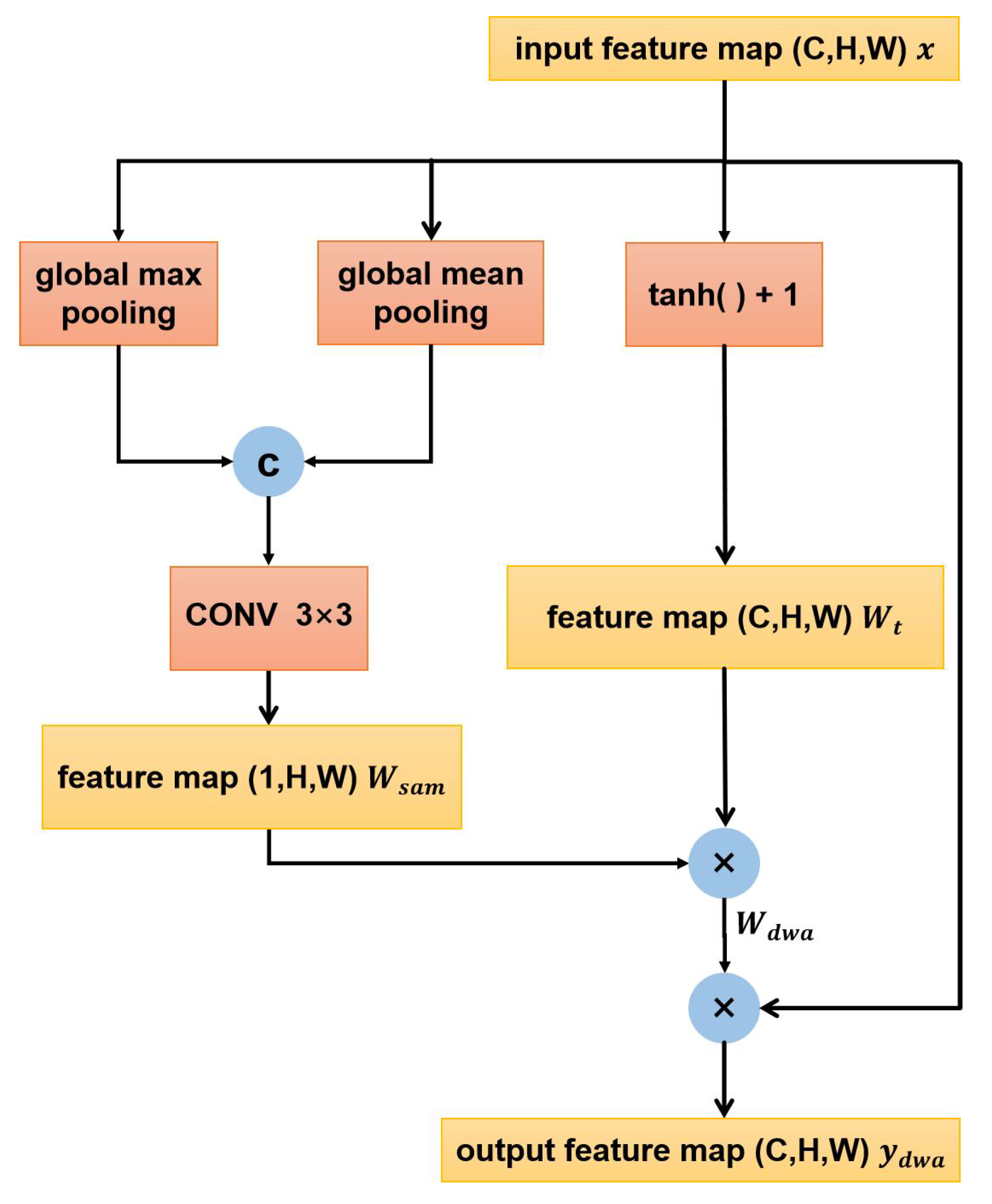
- We developed a novel spatial attention module, the Distributed Weight Attention (DWA) module. This module is specifically designed to enhance the feature intensity of our objects, thereby reducing the omission rate of planting areas, especially for the small-sized regions.
2. Methodology
2.1. Diverse Receptive Fusion Module
2.2. Distributed Weight Attention Module
3. Experimental Data and Setup
3.1. Introduction of the Wheat Dataset
3.2. Settings of Experiments
3.3. Evaluation Metrics
4. Experiment and Analysis
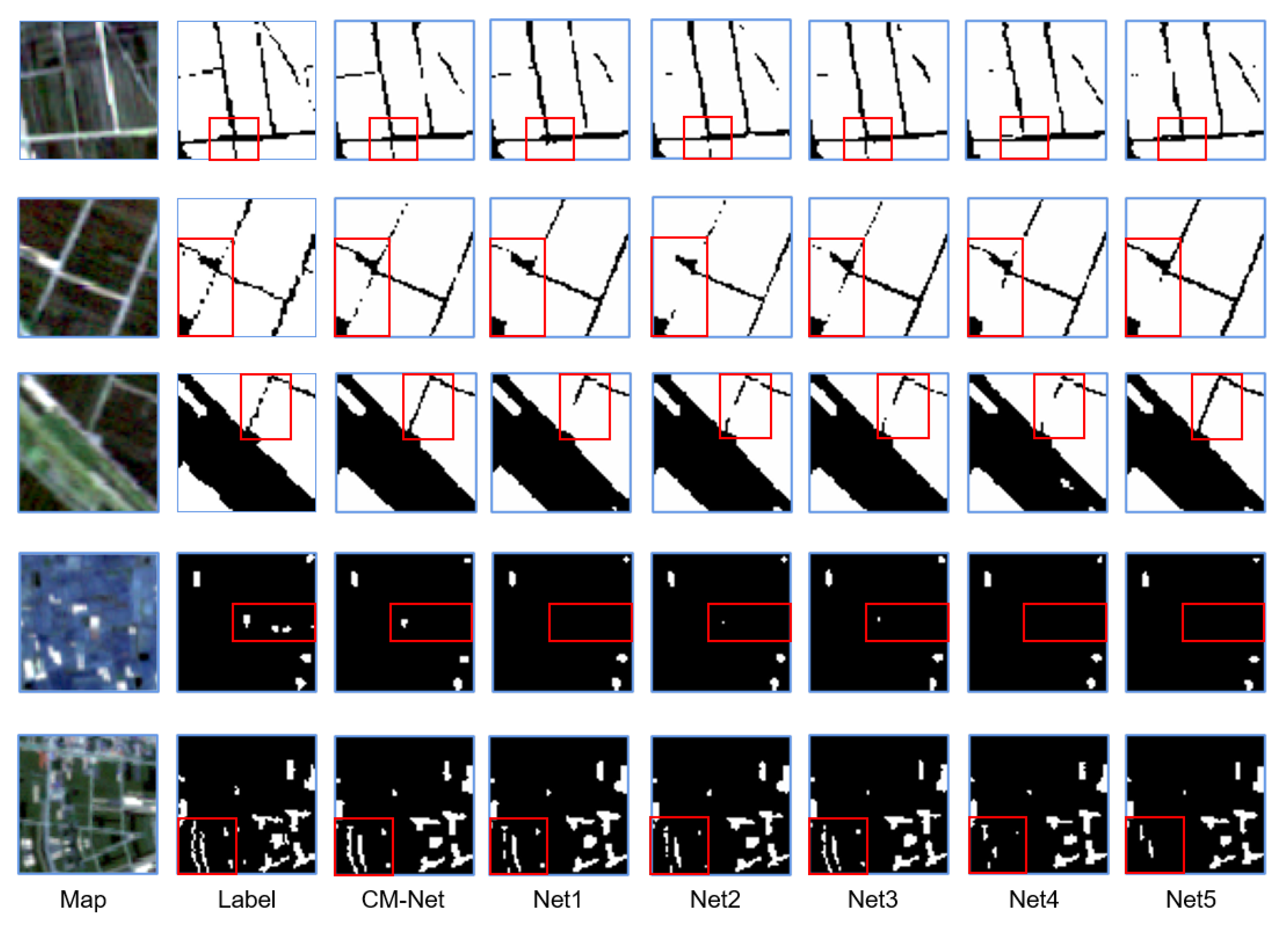
4.1. Comparative Tests
4.2. Ablation Experiments
4.2.1. Ablation for the DRF
4.2.2. Ablation for the DWA
4.2.3. Ablation for the Data Source
5. Conclusions
- (1)
- The Diverse Receptive Fusion (DRF) module is proposed. This module applies a deformable receptive field to optical images during the feature fusion process. It allows the network to match winter wheat plots of varying scales by adapting to their characteristics using a fixed receptive field for DEM images. This enables the extraction of evaluation features at a consistent scale, accommodating the dual-modal data.
- (2)
- The distributed weighted attention module (DWA) has been meticulously engineered to optimize feature intensity during the crucial decoding phase of winter wheat segmentation. By integrating sophisticated global pooling techniques with a broadened scope of activation functions, the DWA adeptly enhances the salience of essential features specific to winter wheat. Concurrently, it effectively diminishes the presence of irrelevant features. This dual capability of selective enhancement and suppression is vital for accurately extracting minute yet significant details from small planting areas.
Author Contributions
Funding
Conflicts of Interest
References
- Van Tricht, K.; Gobin, A.; Gilliams, S.; Piccard, I. Synergistic use of radar Sentinel-1 and optical Sentinel-2 imagery for crop mapping: A case study for Belgium. Remote. Sens. 2018, 10, 1642. [Google Scholar] [CrossRef]
- Guo, Y.; Jia, X.; Paull, D.; Benediktsson, J.A. Nomination-favoured opinion pool for optical-SAR-synergistic rice mapping in face of weakened flooding signals. ISPRS J. Photogramm. Remote. Sens. 2019, 155, 187–205. [Google Scholar] [CrossRef]
- Wu, M.; Huang, W.; Niu, Z.; Wang, Y.; Wang, C.; Li, W.; Hao, P.; Yu, B. Fine crop mapping by combining high spectral and high spatial resolution remote sensing data in complex heterogeneous areas. Comput. Electron. Agric. 2017, 139, 1–9. [Google Scholar] [CrossRef]
- Hao, P.; Zhan, Y.; Wang, L.; Niu, Z.; Shakir, M. Feature selection of time series MODIS data for early crop classification using random forest: A case study in Kansas, USA. Remote. Sens. 2015, 7, 5347–5369. [Google Scholar] [CrossRef]
- Zheng, B.; Myint, S.W.; Thenkabail, P.S.; Aggarwal, R.M. A support vector machine to identify irrigated crop types using time-series Landsat NDVI data. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 103–112. [Google Scholar] [CrossRef]
- Yang, G.; Li, X.; Liu, P.; Yao, X.; Zhu, Y.; Cao, W.; Cheng, T. Automated in-season mapping of winter wheat in China with training data generation and model transfer. ISPRS J. Photogramm. Remote. Sens. 2023, 202, 422–438. [Google Scholar] [CrossRef]
- Zhong, L.; Gong, P.; Biging, G.S. Efficient corn and soybean mapping with temporal extendability: A multi-year experiment using Landsat imagery. Remote. Sens. Environ. 2014, 140, 1–13. [Google Scholar] [CrossRef]
- Tian, H.; Zhou, B.; Chen, Y.; Wu, M.; Niu, Z. Extraction of winter wheat acreage based on GF-1 PMS remote sensing image on county scale. J. China Agric. Univ. 2017. [Google Scholar] [CrossRef]
- Tian, H.; Huang, N.; Niu, Z.; Qin, Y.; Pei, J.; Wang, J. Mapping winter crops in China with multi-source satellite imagery and phenology-based algorithm. Remote. Sens. 2019, 11, 820. [Google Scholar] [CrossRef]
- Li, S.; Huo, L. Remote sensing image change detection based on fully convolutional network with pyramid attention. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 4352–4355. [Google Scholar]
- Guo, J.; Ren, H.; Zheng, Y.; Nie, J.; Chen, S.; Sun, Y.; Qin, Q. Identify urban area from remote sensing image using deep learning method. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 7407–7410. [Google Scholar]
- Alp, G.; Sertel, E. Deep learning based patch-wise land cover land use classification: A new small benchmark sentinel-2 image dataset. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 3179–3182. [Google Scholar]
- Garnot, V.S.F.; Landrieu, L.; Giordano, S.; Chehata, N. Satellite image time series classification with pixel-set encoders and temporal self-attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12325–12334. [Google Scholar]
- Conrad, C.; Dech, S.; Dubovyk, O.; Klein, S.F.D.; Löw, F.; Schorcht, G.; Zeidler, J. Derivation of temporal windows for accurate crop discrimination in heterogeneous croplands of Uzbekistan using multitemporal RapidEye images. Comput. Electron. Agric. 2014, 103, 63–74. [Google Scholar] [CrossRef]
- Rußwurm, M.; Korner, M. Temporal vegetation modelling using long short-term memory networks for crop identification from medium-resolution multi-spectral satellite images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 11–19. [Google Scholar]
- Tarasiou, M.; Güler, R.A.; Zafeiriou, S. Context-self contrastive pretraining for crop type semantic segmentation. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Zhang, D.; Pan, Y.; Zhang, J.; Hu, T.; Zhao, J.; Li, N.; Chen, Q. A generalized approach based on convolutional neural networks for large area cropland mapping at very high resolution. Remote. Sens. Environ. 2020, 247, 111912. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Wei, P.; Chai, D.; Lin, T.; Tang, C.; Du, M.; Huang, J. Large-scale rice mapping under different years based on time-series Sentinel-1 images using deep semantic segmentation model. ISPRS J. Photogramm. Remote. Sens. 2021, 174, 198–214. [Google Scholar] [CrossRef]
- Ma, X.; Huang, Z.; Zhu, S.; Fang, W.; Wu, Y. Rice Planting Area Identification Based on Multi-Temporal Sentinel-1 SAR Images and an Attention U-Net Model. Remote. Sens. 2022, 14, 4573. [Google Scholar] [CrossRef]
- Sai, G.U.; Tejasri, N.; Kumar, A.; Rajalakshmi, P. Deep learning based overcomplete representations for paddy rice crop and weed segmentation. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 6077–6080. [Google Scholar]
- Garnot, V.S.F.; Landrieu, L.; Chehata, N. Multi-modal temporal attention models for crop mapping from satellite time series. ISPRS J. Photogramm. Remote. Sens. 2022, 187, 294–305. [Google Scholar] [CrossRef]
- Li, X.; Zhang, G.; Cui, H.; Hou, S.; Wang, S.; Li, X.; Chen, Y.; Li, Z.; Zhang, L. MCANet: A joint semantic segmentation framework of optical and SAR images for land use classification. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102638. [Google Scholar] [CrossRef]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. Fusenet: Incorporating depth into semantic segmentation via fusion-based cnn architecture. In Proceedings of the Computer Vision—ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Revised Selected Papers, Part I 13. Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 213–228. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder–decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhang, P.; Du, P.; Lin, C.; Wang, X.; Li, E.; Xue, Z.; Bai, X. A hybrid attention-aware fusion network (HAFNet) for building extraction from high-resolution imagery and LiDAR data. Remote. Sens. 2020, 12, 3764. [Google Scholar] [CrossRef]
- Vos, J.; Heuvelink, E. Concepts to model growth and development of plants. In Proceedings of the 2006 Second International Symposium on Plant Growth Modeling and Applications, Beijing, China, 13–17 November 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 3–10. [Google Scholar]
- Tian, Z.; Gao, Z.; Xu, Y.; Chen, H. Impacts of climate change on winter wheat production in China. In Proceedings of the 2005 IEEE International Geoscience and Remote Sensing Symposium, Seoul, Republic of Korea, 29 July 2005; IGARSS’05. IEEE: Piscataway, NJ, USA, 2005; Volume 1, p. 4. [Google Scholar]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote. Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- Zhao, J.; Zhou, Y.; Shi, B.; Yang, J.; Zhang, D.; Yao, R. Multi-stage fusion and multi-source attention network for multi-modal remote sensing image segmentation. ACM Trans. Intell. Syst. Technol. (TIST) 2021, 12, 1–20. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Overall | Winter Wheat | |||
|---|---|---|---|---|---|
| OA | AA | MIoU | IoU | F1 | |
| Ours | 94.67 | 94.52 | 89.60 | 87.88 | 93.55 |
| (MS)2-Net [32] | 93.66 | 93.47 | 87.76 | 85.77 | 92.34 |
| unetFormer [29] | 92.04 | 91.77 | 84.87 | 82.47 | 90.39 |
| UperNet [31] | 91.98 | 91.73 | 84.75 | 82.31 | 90.3 |
| DeepLabv3p [30] | 91.57 | 91.31 | 84.04 | 81.50 | 89.8 |
| SegNet [25] | 88.73 | 88.34 | 79.27 | 76.13 | 86.45 |
| PSPNet [18] | 88.67 | 88.21 | 79.22 | 76.27 | 86.54 |
| Data | Model | Overall | Winter Wheat | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Single-Temporal + Dem | Bi-Temporal | Bi-Temporal + Dem | DRF | DWA | OA | mIOU | AA | IoU | F1 | |
| CM-Net | o | o | o | 94.67 | 89.60 | 94.52 | 87.88 | 93.55 | ||
| Net1 | o | 94.52 | 89.31 | 94.35 | 87.56 | 93.37 | ||||
| Net2 | o | o | 94.56 | 89.39 | 94.40 | 87.65 | 93.42 | |||
| Net3 | o | o | 94.58 | 89.44 | 94.43 | 87.70 | 93.45 | |||
| Net4 | o | o | o | 93.93 | 88.25 | 93.72 | 86.35 | 92.68 | ||
| Net5 | o | o | o | 93.93 | 88.24 | 93.75 | 86.33 | 92.66 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, N.; Wu, Q.; Gui, Y.; Hu, Q.; Li, W. Cross-Modal Segmentation Network for Winter Wheat Mapping in Complex Terrain Using Remote-Sensing Multi-Temporal Images and DEM Data. Remote Sens. 2024, 16, 1775. https://doi.org/10.3390/rs16101775
Wang N, Wu Q, Gui Y, Hu Q, Li W. Cross-Modal Segmentation Network for Winter Wheat Mapping in Complex Terrain Using Remote-Sensing Multi-Temporal Images and DEM Data. Remote Sensing. 2024; 16(10):1775. https://doi.org/10.3390/rs16101775
Chicago/Turabian StyleWang, Nan, Qingxi Wu, Yuanyuan Gui, Qiao Hu, and Wei Li. 2024. "Cross-Modal Segmentation Network for Winter Wheat Mapping in Complex Terrain Using Remote-Sensing Multi-Temporal Images and DEM Data" Remote Sensing 16, no. 10: 1775. https://doi.org/10.3390/rs16101775
APA StyleWang, N., Wu, Q., Gui, Y., Hu, Q., & Li, W. (2024). Cross-Modal Segmentation Network for Winter Wheat Mapping in Complex Terrain Using Remote-Sensing Multi-Temporal Images and DEM Data. Remote Sensing, 16(10), 1775. https://doi.org/10.3390/rs16101775