
AD-SiamRPN: Anti-Deformation Object Tracking via an Improved Siamese Region Proposal Network on Hyperspectral Videos


Abstract
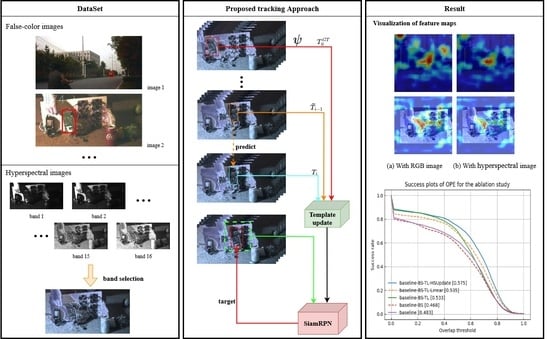
1. Introduction
- •
- The SiamRPN model is applied into the field of HOT, which verifies its applicability in processing HSVs.
- •
- To reduce redundancy in HSVs, bands are determined by an intelligent optimization algorithm based on maximum joint entropy.
- •
- TL has been effectively applied into the domain of HOT, which effectively solves the limitation of lacking labeled data in hyperspectral datasets referring to learning deep models.
- •
- The proposed HSUpdateNet with an effective template update strategy, which exploits rich spectral information, helps to obtain a more accurate cumulative template, and deals with the problem of deformation.
2. Materials and Methods
2.1. SiamRPN
2.2. Hyperspectral Band Selection
2.3. Transfer Learning
2.4. Hyperspectral Update Learning
3. Results
3.1. Experiment Setup
3.2. Ablation Study
3.3. Qualitative Comparison
3.4. Quantitative Comparison of Adversarial Deformation
3.5. Quantitative Comparison
4. Discussion
- •
- The dearth of high-quality datasets with annotations is a major drawback of hyperspectral target tracking, potentially hindering the learning of valuable information and resulting in overfitting. To address this limitation, our future efforts will focus on enhancing the feature extraction capabilities of the tracker, perhaps by employing self-supervised approaches, such as contrast learning.
- •
- The band selection module eliminates the information redundancy of HSVs and retaines the physical information. It obtains high tracking speed, but the improvement in performance was not quantified. In the future, we will compare this with other feature reduction approaches to validate the effectiveness of our band selection module.
- •
- Experiments have demonstrated that the spectral information helps to distinguish the target from the background information, and from this, future work can proceed to design a rational network that uses the raw 16-dimensional data as input to the network to extract valid hyperspectral features.
5. Conclusions
- •
- Hyperspectral information helps trackers detect an object with similar color attributes from its neighborhood.
- •
- The high quality of the training set in the GOT database provides the basis for the generalizability of our tracking algorithm (AD-SiamPRN).
- •
- The band selection module retains the spectral significance of the spectral channel, and the intelligent optimization algorithm speeds up the tracking task.
- •
- The transfer model aids in the extraction of semantic information from HSV, hence enhancing the tracker’s performance. The template update module (HSUpdateNet) performs well with respect to issues such as deformation.
- •
- Future work proceeds to design a rational network that uses the raw 16-dimensional data as input to the network to extract valid hyperspectral features. Besides, the effective attention mechanism should be applied into the field of HOT.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, S.; Zhang, T.; Cao, X.; Xu, C. Structural correlation filter for robust visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4312–4320. [Google Scholar]
- Lukezic, A.; Vojir, T.; Cehovin Zajc, L.; Matas, J.; Kristan, M. Discriminative correlation filter with channel and spatial reliability. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6309–6318. [Google Scholar]
- Xiong, F.; Zhou, J.; Qian, Y. Material based object tracking in hyperspectral videos. IEEE Trans. Image Process. 2020, 29, 3719–3733. [Google Scholar] [CrossRef] [PubMed]
- Qian, K.; Zhou, J.; Xiong, F.; Zhou, H.; Du, J. Object tracking in hyperspectral videos with convolutional features and kernelized correlation filter. In Proceedings of the International Conference on Smart Multimedia, Toulon, France, 24–26 August 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 308–319. [Google Scholar]
- Wang, N.; Yeung, D.Y. Learning a deep compact image representation for visual tracking. Adv. Neural Inf. Process. Syst. 2013, 26, 1–9. [Google Scholar]
- Wang, L.; Ouyang, W.; Wang, X.; Lu, H. Visual tracking with fully convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 11–18 December 2015; pp. 3119–3127. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 850–865. [Google Scholar]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Li, X.; Liu, Q.; Fan, N.; He, Z.; Wang, H. Hierarchical spatial-aware siamese network for thermal infrared object tracking. Knowl.-Based Syst. 2019, 166, 71–81. [Google Scholar] [CrossRef]
- Li, P.; Chen, B.; Ouyang, W.; Wang, D.; Yang, X.; Lu, H. Gradnet: Gradient-guided network for visual object tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6162–6171. [Google Scholar]
- Xiu, C.; Chai, Z. Target tracking based on the cognitive associative network. IET Image Process. 2019, 13, 498–505. [Google Scholar] [CrossRef]
- Zhang, T.; Quan, S.; Yang, Z.; Guo, W.; Zhang, Z.; Gan, H. A two-stage method for ship detection using PolSAR image. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5236918. [Google Scholar] [CrossRef]
- Shen, M.; Gan, H.; Ning, C.; Hua, Y.; Zhang, T. TransCS: A Transformer-Based Hybrid Architecture for Image Compressed Sensing. IEEE Trans. Image Process. 2022, 31, 6991–7005. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, L.; Liu, Q.; Zhang, D.; Yang, M.H. Fast visual tracking via dense spatio-temporal context learning. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 127–141. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning spatially regularized correlation filters for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- Zhang, L.; Suganthan, P.N. Robust visual tracking via co-trained kernelized correlation filters. Pattern Recognit. 2017, 69, 82–93. [Google Scholar] [CrossRef]
- Kiani Galoogahi, H.; Fagg, A.; Lucey, S. Learning background-aware correlation filters for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1135–1143. [Google Scholar]
- Liu, H.; Li, B. Target tracker with masked discriminative correlation filter. IET Image Process. 2020, 14, 2227–2234. [Google Scholar] [CrossRef]
- Lan, X.; Yang, Z.; Zhang, W.; Yuen, P.C. Spatial-temporal Regularized Multi-modality Correlation Filters for Tracking with Re-detection. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–16. [Google Scholar] [CrossRef]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware siamese networks for visual object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 17–24 May 2018; pp. 101–117. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4282–4291. [Google Scholar]
- Lu, X.; Li, J.; He, Z.; Wang, W.; Wang, H. Distracter-aware tracking via correlation filter. Neurocomputing 2019, 348, 134–144. [Google Scholar] [CrossRef]
- Moorthy, S.; Choi, J.Y.; Joo, Y.H. Gaussian-response correlation filter for robust visual object tracking. Neurocomputing 2020, 411, 78–90. [Google Scholar] [CrossRef]
- Danelljan, M.; Shahbaz Khan, F.; Felsberg, M.; Van de Weijer, J. Adaptive color attributes for real-time visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1090–1097. [Google Scholar]
- Wang, N.; Zhou, W.; Tian, Q.; Hong, R.; Wang, M.; Li, H. Multi-cue correlation filters for robust visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4844–4853. [Google Scholar]
- Kong, J.; Ding, Y.; Jiang, M.; Li, S. Collaborative model tracking with robust occlusion handling. IET Image Process. 2020, 14, 1701–1709. [Google Scholar] [CrossRef]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese fully convolutional classification and regression for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6269–6277. [Google Scholar]
- Zhang, Z.; Peng, H.; Fu, J.; Li, B.; Hu, W. Ocean: Object-aware anchor-free tracking. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 771–787. [Google Scholar]
- Ding, Y.; Zhang, Z.; Zhao, X.; Hong, D.; Cai, W.; Yu, C.; Yang, N.; Cai, W. Multi-feature fusion: Graph neural network and CNN combining for hyperspectral image classification. Neurocomputing 2022, 501, 246–257. [Google Scholar] [CrossRef]
- Zhang, Z.; Ding, Y.; Zhao, X.; Siye, L.; Yang, N.; Cai, Y.; Zhan, Y. Multireceptive field: An adaptive path aggregation graph neural framework for hyperspectral image classification. Expert Syst. Appl. 2023, 217, 119508. [Google Scholar] [CrossRef]
- Li, Z.; Xiong, F.; Zhou, J.; Wang, J.; Lu, J.; Qian, Y. BAE-Net: A band attention aware ensemble network for hyperspectral object tracking. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Online, 6–8 March 2020; pp. 2106–2110. [Google Scholar]
- Van Nguyen, H.; Banerjee, A.; Chellappa, R. Tracking via object reflectance using a hyperspectral video camera. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 44–51. [Google Scholar]
- Wang, S.; Qian, K.; Chen, P. BS-SiamRPN: Hyperspectral Video Tracking based on Band Selection and the Siamese Region Proposal Network. In Proceedings of the 2022 12th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Rome, Italy, 13–16 September 2022; pp. 1–8. [Google Scholar]
- Zhang, Z.; Zhu, X.; Zhao, D.; Arun, P.V.; Zhou, H.; Qian, K.; Hu, J. Hyperspectral Video Target Tracking Based on Deep Features with Spectral Matching Reduction and Adaptive Scale 3D Hog Features. Remote Sens. 2022, 14, 5958. [Google Scholar] [CrossRef]
- Uzkent, B.; Rangnekar, A.; Hoffman, M.J. Tracking in aerial hyperspectral videos using deep kernelized correlation filters. IEEE Trans. Geosci. Remote Sens. 2018, 57, 449–461. [Google Scholar] [CrossRef]
- Zhang, Z.; Qian, K.; Juan, D.; Zhou, H. Multi-Features Integration Based Hyperspectral Videos Tracker. In Proceedings of the 2021 11th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Amsterdam, The Netherlands, 24–26 March 2021. [Google Scholar]
- Song, Y.; Ma, C.; Wu, X.; Gong, L.; Bao, L.; Zuo, W.; Shen, C.; Lau, R.W.; Yang, M.H. Vital: Visual tracking via adversarial learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8990–8999. [Google Scholar]
- Liu, Z.; Wang, X.; Shu, M.; Li, G.; Sun, C.; Liu, Z.; Zhong, Y. An anchor-free Siamese target tracking network for hyperspectral video. In Proceedings of the 2021 11th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Amsterdam, The Netherlands, 24–26 March 2021; pp. 1–5. [Google Scholar]
- Sun, W.; Du, Q. Hyperspectral band selection: A review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 118–139. [Google Scholar] [CrossRef]
- Qian, K.; Chen, P.; Zhao, D. GOMT: Multispectral video tracking based on genetic optimization and multi-features integration. In Proceedings of the IET Image Processing; John Wiley & Sons Inc.: Hoboken, NJ, USA; 2023. [Google Scholar] [CrossRef]
- Huang, L.; Zhao, X.; Huang, K. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1562–1577. [Google Scholar] [CrossRef]
- Luo, W.; Li, X.; Li, W.; Hu, W. Robust visual tracking via transfer learning. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 485–488. [Google Scholar]
- Zhang, L.; Gonzalez-Garcia, A.; Joost, V.; Danelljan, M.; Khan, F.S. Learning the Model Update for Siamese Trackers. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H. End-to-end representation learning for correlation filter based tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2805–2813. [Google Scholar]
- Guo, Q.; Feng, W.; Zhou, C.; Huang, R.; Wan, L.; Wang, S. Learning dynamic siamese network for visual object tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1763–1771. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Xijun, L.; Jun, L. An adaptive band selection algorithm for dimension reduction of hyperspectral images. In Proceedings of the 2009 International Conference on Image Analysis and Signal Processing, Wuhan, China, 21–23 October 2009; pp. 114–118. [Google Scholar]
- Zhao, H.; Bruzzone, L.; Guan, R.; Zhou, F.; Yang, C. Spectral-Spatial Genetic Algorithm-Based Unsupervised Band Selection for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9616–9632. [Google Scholar] [CrossRef]
- Akbari, D. Improved neural network classification of hyperspectral imagery using weighted genetic algorithm and hierarchical segmentation. IET Image Process. 2019, 13, 2169–2175. [Google Scholar] [CrossRef]
- Angeline, P.J.; Saunders, G.M.; Pollack, J.B. An evolutionary algorithm that constructs recurrent neural networks. IEEE Trans. Neural Netw. 1994, 5, 54–65. [Google Scholar] [CrossRef]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Transfer learning for time series classification. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 1367–1376. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2010, 22, 199–210. [Google Scholar] [CrossRef] [PubMed]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 97–105. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Pitié, F.; Kokaram, A. The linear Monge-Kantorovitch linear colour mapping for example-based colour transfer. In Proceedings of the 4th European Conference on Visual Media Production, London, UK, 27–28 November 2007. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Online object tracking: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video | Car3 | Fruit | Hand | Kangaroo | Pedestrian2 | Player |
|---|---|---|---|---|---|---|
| Frame | 331 | 552 | 184 | 117 | 363 | 901 |
| Resolution | 512 × 256 | 493 × 232 | 341 × 186 | 385 × 206 | 512 × 256 | 463 × 256 |
| Initial Size | 188 × 84 | 32 × 37 | 103 × 108 | 22 × 41 | 13 × 44 | 23 × 69 |
| Challenge | LR, OCC | BC, OCC | BC, DFM | OPR, SV | DFM, OCC | IPR, SV |
| Method | Video Type | AUC | DP@20P |
|---|---|---|---|
| baseline | false-color | 0.482 | 0.763 |
| baseline-BS | HSV | 0.468 | 0.771 |
| baseline-BS-TL | HSV | 0.533 | 0.845 |
| baseline-BS-TL-L | HSV | 0.535 | 0.820 |
| baseline-BS-TL-H | HSV | 0.575 | 0.861 |
| Algorithm | Video type | AUC | DP@20P |
|---|---|---|---|
| DaSiamRPN | false-color | 0.670 | 0.920 |
| SiamRPN++ | false-color | 0.669 | 0.971 |
| DeepHKCF | HSV | 0.433 | 0.774 |
| BS-SiamRPN | HSV | 0.641 | 0.970 |
| MHT | HSV | 0.708 | 0.930 |
| MFIHVT | HSV | 0.655 | 0.946 |
| BAENet | HSV | 0.51 | 0.920 |
| Ours | HSV | 0.708 | 0.971 |
| Algorithm | Video Type | AUC | DP@20P | FPS |
|---|---|---|---|---|
| DaSiamRPN | false-color | 0.558 | 0.831 | 48 |
| SiamRPN++ | false-color | 0.529 | 0.834 | 41 |
| DeepHKCF | HSV | 0.385 | 0.737 | 2 |
| BS-SiamRPN | HSV | 0.533 | 0.845 | 55 |
| MHT | HSV | 0.584 | 0.876 | 2 |
| MFIHVT | HSV | 0.601 | 0.891 | 2 |
| BAENet | HSV | 0.616 | 0.876 | - |
| Ours | HSV | 0.575 | 0.861 | 35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Qian, K.; Shen, J.; Ma, H.; Chen, P. AD-SiamRPN: Anti-Deformation Object Tracking via an Improved Siamese Region Proposal Network on Hyperspectral Videos. Remote Sens. 2023, 15, 1731. https://doi.org/10.3390/rs15071731
Wang S, Qian K, Shen J, Ma H, Chen P. AD-SiamRPN: Anti-Deformation Object Tracking via an Improved Siamese Region Proposal Network on Hyperspectral Videos. Remote Sensing. 2023; 15(7):1731. https://doi.org/10.3390/rs15071731
Chicago/Turabian StyleWang, Shiqing, Kun Qian, Jianlu Shen, Hongyu Ma, and Peng Chen. 2023. "AD-SiamRPN: Anti-Deformation Object Tracking via an Improved Siamese Region Proposal Network on Hyperspectral Videos" Remote Sensing 15, no. 7: 1731. https://doi.org/10.3390/rs15071731
APA StyleWang, S., Qian, K., Shen, J., Ma, H., & Chen, P. (2023). AD-SiamRPN: Anti-Deformation Object Tracking via an Improved Siamese Region Proposal Network on Hyperspectral Videos. Remote Sensing, 15(7), 1731. https://doi.org/10.3390/rs15071731