


Development and Application of Predictive Models to Distinguish Seepage Slicks from Oil Spills on Sea Surfaces Employing SAR Sensors and Artificial Intelligence: Geometric Patterns Recognition under a Transfer Learning Approach


 ,
,
Abstract
1. Introduction
1.1. Oil Slick Source Identification under a Transfer Learning Approach
1.2. Technical and Ethical Framework for Building and Operating Predictive Models Using AI

2. Database Description and Methodology
2.1. Oil Slick Database
- Study case 1 (GoM ⇥ GoM): GoM models applied to predict the OSS of 698 new samples of seepage slicks and oil spills detected in the GoM (Figure 2b,c). This scenario has similar domains (DS = DT) in terms of geographic regions (DS ⇥ GoM; DT ⇥ GoM) and satellites employed for detection (DS ⇥ [RDS1, RDS2]; DT ⇥ [RDS1, RDS2]);
- Study case 2 (GMex ⇥ GAm): GMex models applied to predict the OSS of 1738 new samples of seepage slicks detected in the GAm (Figure 2d,e). This scenario has different domains (DS ≠ DT) in terms of geographic regions (DS ⇥ GMex; DT ⇥ GAm) and satellites employed for detection (DS ⇥ RDS2; DT ⇥ RDS1);
- Study case 3 (GoM ⇥ BR): GoM models applied to predict the OSS of 421 new samples of seepage slicks and oil spills detected in the BR (Figure 2f,g). This is the most challenging scenario, comprising different domains (DS ≠ DT) in terms of geographic regions (DS ⇥ GoM; DT ⇥ BR), satellites employed for detection (DS ⇥ [RDS1, RDS2]; DT ⇥ [RDS1, RDS2, SNT1]), and meteo-oceanographic conditions.
2.2. Methodology for Predictive Models Development, Application and Deployment
2.2.1. Measures of Effectiveness
3. Results
3.1. Predictive Models Development
3.2. Predictive Models Application: Recognition of Geometric Patterns under a Transfer Learning Approach
3.2.1. Study Case 1: GoM ⇥ GoM
3.2.2. Study Case 2: GMex ⇥ GAm
3.2.3. Study Case 3: GoM ⇥ BR
3.3. Moving Transfer Learning into the Real World

3.4. Operationalizing Predictive Models for OSS Identification: Real-World Case Integrating TL and Inverse Oil Drifting Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Committee on Oil in the Sea; Divisions of Earth and Life Studies and Transportation Research Board, National Research Council. Oil in the Sea III: Inputs, Fates, and Effects; National Academies Press: Washington, DC, USA, 2003; ISBN 978-0-309-08438-3. [Google Scholar] [CrossRef]
- MacDonald, I.R.; Garcia-Pineda, O.; Beet, A.; Asl, S.D.; Feng, L.; Graettinger, G.; French-McCay, D.; Holmes, J.; Hu, C.; Huffer, F.; et al. Natural and unnatural oil slicks in the Gulf of Mexico. J. Geophys. Res. Oceans 2015, 120, 8364–8380. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Pineda, O.; MacDonald, I.; Silva, M.; Shedd, W.; Asl, S.D.; Schumaker, B. Transience and persistence of natural hydrocarbon seepage in Mississippi Canyon, Gulf of Mexico. Deep-Sea Res. Part II: Topical Stud. In Oceanogaphyr. 2016, 129, 119–129. [Google Scholar] [CrossRef]
- Dembicki, H., Jr. Reducing the risk of finding a working petroleum system using SAR imaging, sea surface slick sampling, and geophysical seafloor characterization: An example from the eastern Black Sea basin, offshore Georgia. Mar. Pet. Geol. 2020, 115, 104276. [Google Scholar] [CrossRef]
- O’Reilly, C.; Silva, M.; Daneshgar, A.S.; Meurer, W.P.; MacDonald, I.R. Distribution, Magnitude, and Variability of Natural Oil Seeps in the Gulf of Mexico. Remote Sens. 2022, 14, 3150. [Google Scholar] [CrossRef]
- Alpers, W.; Espedal, H.A. Chapter 11: Oils and surfactants. In Synthetic Aperture Radar Marine User’s Manual; Jackson, C.R., Apel, J.R., Eds.; U.S. Department of Commerce, National Oceanic and Atmospheric Administration: Washington, DC, USA, 2004; pp. 263–275. [Google Scholar]
- Leifer, I.; Lehr, B.; Simecek-Beatty, D.; Bradley, E.; Clark, R.; Dennison, P.; Hu, Y.; Matheson, S.; Jones, C.; Holt, B.; et al. State of the art satellite and airborne marine oil spill remote sensing: Application to the BP Deepwater Horizon oil spill. Remote Sens. Environ. 2012, 124, 185–209. [Google Scholar] [CrossRef]
- Dong, Y.; Liu, Y.; Hu, C.; MacDonald, I.R.; Lu, Y. Chronic oiling in global oceans. Science 2022, 376, 1300–1304. [Google Scholar] [CrossRef]
- International Tanker Owners Pollution Federation Limited (ITOPF). Handbook: Promoting Effective Spill Response. 2022; pp. 1–60. Available online: https://www.itopf.org/fileadmin/uploads/itopf/data/Documents/Company_Lit/ITOPF_Handbook22_web.pdf (accessed on 5 December 2022).
- ESA Publication: Earth Observation for Sustainable Development Goals—Compendium of Guidance on Earth Observation to Support the Targets and Indicators of the SDG. ESA Contract No. 4000123494/18/I-NB. 2020. Available online: https://eo4society.esa.int/wp-content/uploads/2021/01/EO_Compendium-for-SDGs.pdf (accessed on 10 November 2022).
- Persello, C.; Wegner, J.D.; Hansch, R.; Tuia, D.; Ghamisi, P.; Koeva, M.; Camps-Valls, G. Deep Learning and Earth Observation to Support the Sustainable Development Goals: Current approaches, open challenges, and future opportunities. IEEE Geosci. Remote Sens. Mag. 2022, 10, 172–200. [Google Scholar] [CrossRef]
- Johnson, C.D.; Ruiter, J.M. Publication developed by International Space University and University of South Australia. In Final Report Southern Hemisphere Space Studies Program: Space 2030: Space for the Future, Space for All; International Space University: Illkirch-Graffenstaden, France, 2019. [Google Scholar]
- API (American Petroleum Institute). Remote Sensing in Support of Oil Spill Response: Planning Guidance; Technical Report No. 1144; American Petroleum Institute: Washington, DC, USA, 2013. [Google Scholar]
- IPIECA (International Petroleum Industry Environmental Conservation Association). An Assessment of Surface Surveillance Capabilities for Oil Spill Response Using Satellite Remote Sensing; Technical Report PIL-4000–35-TR-1.0; International Petroleum Industry Environmental Conservation Association: London, UK, 2014. [Google Scholar]
- Fingas, M.; Brown, C.E. A Review of Oil Spill Remote Sensing. Sensors 2018, 18, 91. [Google Scholar] [CrossRef]
- Alpers, W.; Hühnerfuss, H. The damping of ocean waves by surface films: A new look at an old problem. J. Geophys. Res. Space Phys. 1989, 94, 6251–6265. [Google Scholar] [CrossRef]
- Holt, B. Chapter 02: SAR Imaging of the Ocean Surface. In Synthetic Aperture Radar Marine User’s Manual; Jackson, C.R., Appl, J.R., Eds.; U.S. Department of Commerce, National Oceanic and Atmospheric Administration: Washington DC, USA, 2004; pp. 263–275. [Google Scholar]
- Brekke, C.; Solberg, A.H.S. Oil spill detection by satellite remote sensing. Remote Sens. Environ. 2005, 95, 1–13. [Google Scholar] [CrossRef]
- Richards, J.A. Remote Sensing with Imaging Radar. In Aperture Antennas for Millimeter and Sub-Millimeter Wave Applications; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Caruso, M.J.; Migliaccio, M.; Hargrove, J.T.; Garcia-Pineda, O.; Graber, H.C. Oil spills and slicks imaged by synthetic aperture radar. Oceanography 2013, 26, 112–123. [Google Scholar] [CrossRef]
- Alpers, W.; Holt, B.; Zeng, K. Oil spill detection by imaging radars: Challenges and pitfalls. Remote Sens. Environ. 2017, 201, 133–147. [Google Scholar] [CrossRef]
- Matias, I.O.; Genovez, P.C.; Torres, S.B.; Araújo, F.F.P.; Oliveira, A.J.S.; Miranda, F.P.; Silva, G.M.S. Improved Classification Models to Distinguish Natural from Anthropic Oil Slicks in the Gulf of Mexico: Seasonality and Radarsat-2 Beam Mode Effects under a Machine Learning Approach. Remote Sens. 2021, 13, 4568. [Google Scholar] [CrossRef]
- Mano, M.; Beisl, C.H.; Soares, C. Oil Seeps on the Seafloor of Perdido, Mexico. In Proceedings of the AAPG 2016 International Convention and Exhibition, Cancun, Mexico, 6–9 September 2016. [Google Scholar]
- Mano, M.; Beisl, C.H.; Landau, L. Identifying Oil Seep Areas at Seafloor Using Oil Inverse Modeling. In Proceedings of the Article #90135©2011 AAPG International Conference and Exhibition, Milan, Italy, 23–26 October 2011. [Google Scholar]
- Bjerde, K.; Solberg, A.; Solberg, R. Oil spill detection in SAR imagery. Int. Geosci. Remote Sens. Symp. 2002, 3, 943–945. [Google Scholar] [CrossRef]
- Solberg, A.H.; Storvik, G.; Solberg, R.; Volden, E. Automatic Detection of Oil Spills in ERS SAR Images. IEEE Trans. Geosci. Remote Sens. 1999, 37, 1916–1924, Publisher Item Identifier S 0196-2892(99)03483-X. [Google Scholar] [CrossRef]
- Solberg, R.; Theophilopoulos, N.A. Envisys—A solution for automatic oil spill detection in the Mediterranean. In Proceedings of the 4th Thematic Conference on Remote Sensing for Marine and Coastal, Ann Arbor, MI, USA, 1 June 1997; Environmental Research Institute of Michigan: Ann Arbor, MI, USA, 1997; pp. 3–12. [Google Scholar]
- Solberg, A.H.S.; Dokken, S.T.; Solberg, R. Automatic detection of oil spills in Envisat, Radarsat and ERS SAR images. In Proceedings of the International Geoscience and Remote Sensing Symposium, Toulouse, France, 21–25 July 2003; Volume 4. [Google Scholar] [CrossRef]
- Solberg, A.; Clayton, P.; Indregard, M. D2–Report on Benchmarking Oil Spill Recognition Approaches and Best Practice. Kongsberg Satellite Services–Norway Archive No.: 04-10225-A-Doc, Issue/Revision, 2.1. 2005. Available online: www.ksat.no (accessed on 29 November 2006).
- Kubat, M.; Holte, C.; Matwin, S. Machine learning for detection of oil spills in satellite Radar images. Mach. Learn. 1998, 30, 195–215. [Google Scholar] [CrossRef]
- Fiscella, B.; Giancaspro, A.; Nirchio, F.; Pavese, P.; Trivero, P. Oil spill detection using marine SAR images. Int. J. Remote. Sens. 2000, 21, 3561–3566. [Google Scholar] [CrossRef]
- Mera, D.; Cotos, J.M.; Varela-Pet, J.; Rodríguez, P.G.; Caro, A. Automatic decision support system based on SAR data for oil spill detection. Comput. Geosci. 2014, 72, 184–191. [Google Scholar] [CrossRef]
- Al-Ruzouq, R.; Gibril, M.B.A.; Shanableh, A.; Kais, A.; Hamed, O.; Al-Mansoori, S.; Khalil, M.A. Sensors, Features, and Machine Learning for Oil Spill Detection and Monitoring: A Review. Remote Sens. 2020, 12, 3338. [Google Scholar] [CrossRef]
- Topouzelis, K.; Psyllos, A. Oil spill feature selection and classification using decision tree forest on SAR image data. J. Photogramm. Remote Sens. 2012, 68, 135–143. [Google Scholar] [CrossRef]
- Genovez, P.C.; Ebecken, N.F.F.; Freitas, C.C.; Bentz, C.M.; Freitas, R.M. Intelligent hybrid system for dark spot detection using SAR data. Expert Syst. Appl. 2017, 81, 384–397. [Google Scholar] [CrossRef]
- Mera, D.; Bolon-Canedo, V.; Cotos, J.M.; Alonso-Betanzos, A. On the use of feature selection to improve the detection of sea oil spills in SAR images. Comput. Geosci. 2017, 100, 166–178. [Google Scholar] [CrossRef]
- Keramitsoglou, I.; Cartalis, C.; Kiranoudis, C. Automatic identification of oil spills on satellite images. Environ. Model. Softw. 2006, 21, 640–652. [Google Scholar] [CrossRef]
- Karathanassi, V.; Topouzelis, K.; Pavlakis, P.; Rokos, D. An object-oriented methodology to detect oil spills. Int. J. Remote Sens. 2006, 27, 5235–5251. [Google Scholar] [CrossRef]
- Topouzelis, K.N. Oil spill detection by SAR images: Dark formation detection, feature extraction and classification algorithms. Sensors 2008, 8, 6642–6659. [Google Scholar] [CrossRef] [PubMed]
- Migliaccio, M.; Nunziata, F.; Buono, A. SAR polarimetry for sea oil slick observation. Int. J. Remote Sens. 2015, 36, 3243–3273. [Google Scholar] [CrossRef]
- Miranda, F.P.; Marmol, A.M.Q.; Pedroso, E.C.; Beisl, C.H.; Welgan, P.; Morales, L.M. Analysis of RADARSAT-1 data for offshore monitoring activities in the Cantarell Complex, Gulf of Mexico, using the unsupervised semivariogram textural classifier (USTC). Can. J. Remote Sens. 2004, 30, 424. [Google Scholar] [CrossRef]
- Carvalho, G.D.A.; Minnett, P.J.; Paes, E.T.; Miranda, F.P.; Landau, L. Oil-Slick Category Discrimination (Seeps vs. Spills): A Linear Discriminant Analysis Using RADARSAT-2 Backscatter Coefficients (σ°, β°, and γ°) in Campeche Bay (Gulf of Mexico). Remote Sens. 2019, 11, 1652. [Google Scholar] [CrossRef]
- Miranda, F.P.; Silva, G.M.A.; Matias, I.O.; Genovez, P.C.; Torres, S.B.; Ponte, F.F.A.; Oliveira, A.J.S.; Nasser, R.B.; Robichez, G. Machine learning to distinguish natural and anthropic oil slicks: Classification model and the Radarsat-2 beam mode effects. In Proceedings of the Rio Oil & Gas Expo and Conference, Rio de Janeiro, Brazil, 21–24 September 2020. [Google Scholar] [CrossRef]
- Miranda, F.P.; Silva, G.M.A.; Matias, I.O.; Genovez, P.C.; Torres, S.B.; Ponte, F.F.A.; Oliveira, A.J.S.; Beisl, C.H. Geometric Pattern Recognition Using Machine Learning: Predictive Models to Distinguish Natural from Anthropic Oil Slicks in The Gulf of Mexico. In Proceedings of the Rio Oil & Gas Expo and Conference, Rio de Janeiro, Brazil, 26–29 September 2022. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Kouw, W.M.; Loog, M. Technical Report: An Introduction to Domain Adaptation and Transfer Learning; Cornell University: Ithaca, NY, USA, 2019; pp. 1–41. [Google Scholar] [CrossRef]
- Daume, H., III; Marcu, D. Domain Adaptation for Statistical Classifiers. J. Artif. Intell. Res. 2006, 26, 101–126. [Google Scholar] [CrossRef]
- Uguroglu, S.; Carbonell, J. Feature Selection for Transfer Learning. In Lecture Notes in Computer Science, Proceedings of the ECML PKDD: Joint European Conference on Machine Learning and Knowledge Discovery in Databases, V III, Athens, Greece, 5–9 September 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 430–442. [Google Scholar]
- Crosby, C. Operationalizing Artificial Intelligence for Algorithmic Warfare. Military Reiew. 2020, 42–51. [Google Scholar]
- Pan, S.J.; Kwok, J.T.; Yang, Q. Transfer Learning via Dimensionality Reduction. In Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence, Chicago, IL, USA, 13–17 July 2008; pp. 677–682. Available online: https://www.aaai.org/Papers/AAAI/2008/AAAI08-108.pdf (accessed on 1 March 2022).
- Ando, R.K.; Zhang, T. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data. J. Mach. Learn. Res. 2005, 6, 1817–1853. [Google Scholar]
- Arnold, A.; Nallapati, R.; Cohen, W.W. A Comparative Study of Methods for Transductive Transfer Learning. In Proceedings of the Seventh IEEE International Conference on Data Mining Workshops, Omaha, NE, USA, 28–31 October 2007; pp. 77–82. Available online: https://ieeexplore.ieee.org/document/4476649 (accessed on 1 March 2022). [CrossRef]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Pereira, F. Analysis of representations for domain adaptation. Conference: Advances in Neural Information Processing Systems 19. In Proceedings of the Twentieth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006. [Google Scholar]
- Raina, R.; Ng, A.Y.; Koller, D. Constructing Informative Priors using Transfer Learning. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 713–720. [Google Scholar]
- Quinonero-Candela, J.; Sugiyama, M.; Schwaighofer, A.; Lawrence, N. Dataset Shift in Machine Learning; Massachusetts Institute of Technology Press: Cambridge, MA, USA, 2009; ISBN 978-0-262-17005-5. [Google Scholar]
- Barnett, M.R. Tools for Multivariate Geostatistical Modeling. In Guidebook Series; Published by the Center for Computational Geostatistics; University of Alberta: Edmonton, AB, Canada, 2021; Volume 13, pp. 1–107. Available online: http://www.uofaweb.ualberta.ca/ccg/ (accessed on 1 May 2022).
- European Commission Publication Developed by the High-Level Expert Group on Artificial Intelligence. Ethics Guidelines for Trustworthy AI. 2019; pp. 1–41. Available online: https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai (accessed on 10 November 2022).
- European Commission Publication Developed by the High-Level Expert Group on Artificial Intelligence. The Assessment List for Trustworthy Artificial Intelligence (ALTAI) for Self-Assessment. 2020; pp. 1–34. ISBN 978-92-76-20008-6. Available online: https://digital-strategy.ec.europa.eu/en/library/assessment-list-trustworthy-artificial-intelligence-altai-self-assessment (accessed on 10 November 2022). [CrossRef]
- European Commission Publication: DG Research & Innovation RTD.03.001-Research Ethics and Integrity Sector. Ethics by Design and Ethics of Use Approaches for Artificial Intelligence. 2021; pp. 1–28. Available online: https://ec.europa.eu/info/funding-tenders/opportunities/docs/2021-2027/horizon/guidance/ethics-by-design-and-ethics-of-use-approaches-for-artificial-intelligence_he_en.pdf (accessed on 10 November 2022).
- Baatz, M.; Benz, U.; Dehghani, S. User Guide 3: ECognition Object-Oriented Image Analysis; Definiens Imaging: München, Germany, 2003. [Google Scholar]
- Barnes, R.; Solomon, J. Gerrymandering and compactness: Implementation flexibility and abuse. Political Anal. 2021, 29, 448–466. [Google Scholar] [CrossRef]
- Topouzelis, K.; Stathakis, D.; Karathanassi, V. Investigation of genetic algorithms contribution to feature selection for oil spill detection. Int. J. Remote Sens. 2009, 30, 611–625. [Google Scholar] [CrossRef]
- Stathakis, D.; Topouzelis, K.; Karathanassi, V. Large-scale feature selection using evolved neural networks. In Proceedings of the SPIE the International Society for Optical Engineering, Image and Signal Processing for Remote Sensing XII, Stockholm, Sweden, 11–14 September 2006; Volume 6365, pp. 1–9. [Google Scholar] [CrossRef]
- Bentz, C.; Ebecken, N.F.; Politano, A.T. Automatic recognition of coastal and oceanic environmental events with orbital radars. IEEE Int. Geosci. Remote Sens. Symp. 2007, 1, 914–916. [Google Scholar] [CrossRef]
- Abiodun, O.I.; Kiru, M.U.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Umar, A.M.; Gana, U. Comprehensive Review of Artificial Neural Network Applications to Pattern Recognition. IEEE Access 2019, 7, 158820–158846. [Google Scholar] [CrossRef]
- Belgiu, M.; Dragut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Hemachandran, K.; Tayal, S.; George, P.M.; Singla, P.; Kose, U. Bayesian Reasoning and Gaussian Processes for Machine Learning Applications; Imprint Chapman and Hall/CRC: New York, NY, USA, 2022; ISBN 9781003164265. [Google Scholar] [CrossRef]
- Mai, Q. A review of discriminant analysis. in high dimensions. Wiley Periodicals, Inc. WIREs Comput. Stat. 2013. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Marsland, S. Machine Learning an Algorithmic Perspective. In Chapman & Hall/CRC Machine Learning & Pattern Recognition Series, 2nd ed.; CRC Press: Boca Raton, FL, USA; Taylor & Francis Group: Abingdon, UK, 2015; ISBN 13 978-1-4665-8333. [Google Scholar]
- Dhanabal, S.; Chandramathi, S. A Review of various k-Nearest Neighbor Query Processing Techniques. Int. J. Comput. Appl. 2011, 31, 14–22. [Google Scholar]
- Lampropoulos, A.S.; Tsihrintzis, G.A. Machine Learning Paradigms: Applications in Recommender Systems; Springer International Publishing: Cham, Switzerland, 2015; p. 92. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; Massachusetts Institute of Technology MIT Press: Cambridge, MA, USA; London, UK, 2012; ISBN 978-0-262-01802-9. [Google Scholar]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Del Frate, F.; Petrocchi, A.; Lichtenegger, J.; Calabresi, G. Neural networks for oil spill detection using ERS-SAR Data. IEEE Trans. Geosci. Remote Sens. 2000, 38, 2282–2287, Publisher Item Identifier S 0196-2892(00)08910-5. [Google Scholar] [CrossRef]
- Topouzelis, K.; Karathanassi, V.; Pavlakis, P.; Rokos, D. Detection and discrimination between oil spills and look-alike phenomena through neural networks. ISPRS J. Photogramm. Remote Sens. 2007, 62, 264–270. [Google Scholar] [CrossRef]
- Xu, L.; Li, J.; Brenning, A. A comparative study of different classification techniques for marine oil spill identification using RADARSAT-1 imagery. Remote Sens. Environ. 2014, 141, 14–23. [Google Scholar] [CrossRef]
- Cao, Y.; Linlin Xu, L.; Clausi, D. Exploring the Potential of Active Learning for Automatic Identification of Marine Oil Spills Using 10-Year (2004–2013) RADARSAT Data. Remote Sens. 2017, 9, 1041. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Y.; Liang, X.S.; Tsou, J. Comparison of Oil Spill Classifications Using Fully and Compact Polarimetric SAR Images. Appl. Sci. 2017, 7, 193. [Google Scholar] [CrossRef]
- Liu, P.; Li, Y.; Liu, B.; Chen, P.; Xu, J. Semi-Automatic Oil Spill Detection on X-Band Marine Radar Images Using Texture Analysis, Machine Learning, and Adaptive Thresholding. Remote Sens. 2019, 11, 756. [Google Scholar] [CrossRef]
- Mercier, G. Partially Supervised Oil-Slick Detection by SAR Imagery Using Kernel Expansion. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2839–2846. [Google Scholar] [CrossRef]
- Azamathulla, H.M.; Wu, F.C. Support Vector Machine approach for longitudinal dispersion coefficients in natural streams. Appl. Soft Comput. 2011, 11, 2902–2905. [Google Scholar] [CrossRef]
- Azamathulla, H.M.; Ghani, A.A.; Chang, C.K.; Hasan, Z.A.; Zakaria, N.A. Machine learning approach to predict sediment load–a case study. Clean–Soil Air Water 2010, 38, 969–976. [Google Scholar] [CrossRef]
- Mather, P.M.; Koch, M. Chapter 8 in the Book Computer Processing of Remotely-Sensed Images: An Introduction, 4th ed.; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2011; ISBN 978-0-470-74239-6. [Google Scholar]
- Barsi, A.; Kugler, Z.; Lászlo, I.; Szabó, G.Y.; Abdulmutalib, H.M. Accuracy Dimensions in Remote Sensing. Proc. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, XLII-3, 61–67. [Google Scholar] [CrossRef]
- Carvalho, G.D.A.; Minnett, P.J.; Paes, E.; De Miranda, F.P.; Landau, L. Refined Analysis of RADARSAT-2 Measurements to Discriminate Two Petrogenic Oil-Slick Categories: Seeps versus Spills. J. Mar. Sci. Eng. 2018, 6, 153. [Google Scholar] [CrossRef]
- Carvalho, G.D.A.; Minnett, P.J.; De Miranda, F.P.; Landau, L.; Paes, E. Exploratory Data Analysis of Synthetic Aperture Radar (SAR) Measurements to Distinguish the Sea Surface Expressions of Naturally-Occurring Oil Seeps from Human-Related Oil Spills in Campeche Bay (Gulf of Mexico). ISPRS Int. J. Geo-Inf. 2017, 6, 379. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code | Acronym | Description |
|---|---|---|
| 1 | Area: A (km2) | Area of Oil Slick (A) |
| 2 | Perimeter: P (km) | Perimeter of Oil Slick (P) |
| 3 | Area/Perimeter: AtoP | A/P |
| 4 | Perimeter/Area: PtoA | P/A |
| 5 | MBG_Width_RA (km) | Width of Bounding Rectangle (RA—Figure 1a) |
| 6 | MBG_Length_RA (km) | Length of Bounding Rectangle (RA—Figure 1a) |
| 7 | MBG_Orient_RA | Orientation of the Longer Side of the MBG_Length_RA (RA—Figure 1a) |
| 8 | MBG_Width_CH (km) | Width of Convex Hull (CH—Figure 1c) |
| 9 | MBG_Length_CH (km) | Length of Convex Hull (CH—Figure 1c) |
| 10 | MBG_Orient_CH | Orientation of the Line Connecting Antipodal Pairs (CH—Figure 1c) |
| 11 | Shape | Shape Index = (0.25 * P)/(A)1/2 |
| 12 | Compact | C = (4 * 3.1419 * A)/P2 |
| 13 | Compac Reock | CR = A/Area of the Bounding Circle (CIR—Figure 1b) |
| 14 | Compac Hull | CH = A/Area of the Convex Hull (ACH) (CH—Figure 1c) |
| 15 | Compac RA | CRA = A/Area of the Bounding Rectangle (ARA) (RA–Figure 1a) |
| 16 | Complex | Complex = P2/A |
| 17 | Fractal Index | FracRanding = 2 * ln(0.25 * P)/ln(A) ln = logarithm |
| 18 | Smoothness RA | S = P/MBG_Length_RA (RA—Figure 1a) |
| 19 | Lenght_CH/Width_CH | MBG_Length_CH/MBG_Width_CH (CH—Figure 1c) |
| 20 | ACH-A | Area of the Convex Hull (ACH)—Area of Oil Slick (A) |
| 21 | PtoA_PtoARA | PtoA of Slick/PtoA of Bounding Rectangle (RA—Figure 1a) |
| 22 | PtoA_PtoACIR | PtoA of Slick/PtoA of Bounding Circle (CIR—Figure 1b) |
| 23 | PtoA_PtoACH | PtoA of Slick/PtoA of Convex Hull (CH—Figure 1c) |
| 24 | AtoP_AtoPRA | AtoP of Slick/AtoP of Bounding Rectangle (RA—Figure 1a) |
| 25 | AtoP_AtoPCIR | AtoP of Slick/AtoP of Bounding Circle (CIR) (CH—Figure 1b) |
| 26 | AtoP_AtoPCH | AtoP of Slick/AtoP of Convex Hull (CH) (CH—Figure 1c) |
| (a) GMex Geometric Feature Space (XSGMex) | (b) GoM Geometric Feature Space (XSGoM) | ||||||
|---|---|---|---|---|---|---|---|
| No | Code | Acronym | Importance Order | N o | Code | Acronym | Importance Order |
| 1 | 2 | Perimeter | 11.90 | 1 | 6 | MBG_Length_RA | 11.62 |
| 2 | 20 | ACH-A | 9.27 | 2 | 1 | Area | 10.24 |
| 3 | 16 | Complex | 8.47 | 3 | 20 | ACH-A | 8.30 |
| 4 | 1 | Area | 8.27 | 4 | 17 | Fractal Index | 7.21 |
| 5 | 18 | Smoothness RA | 6.54 | 5 | 5 | MBG_Width_RA (km) | 6.77 |
| 6 | 25 | AtoP_AtoPCIR | 6.31 | 6 | 2 | Perimeter | 6.64 |
| 7 | 7 | MBG_Orient_RA | 5.93 | 7 | 18 | Smoothness RA | 6.17 |
| 8 | 22 | PtoA_PtoACIR | 5.63 | 8 | 19 | Lenght_CH/Width_CH | 6.04 |
| 9 | 17 | Fractal Index | 5.39 | 9 | 3 | AtoP | 6.00 |
| 10 | 10 | MBG_Orient_CH | 5.16 | 10 | 12 | Compact | 5.53 |
| 11 | 5 | MBG_Width_RA | 5.13 | 11 | 10 | MBG_Orient_CH | 5.37 |
| 12 | 26 | AtoP_AtoPCH | 4.49 | 12 | 14 | Compac Hull | 5.12 |
| 13 | 3 | AtoP | 4.46 | 13 | 7 | MBG_Orient_RA | 5.09 |
| 14 | 13 | Compac Reock | 4.43 | 14 | 13 | Compac Reock | 4.96 |
| 15 | 19 | Lenght_CH/Width_CH | 4.35 | 15 | 25 | AtoP_AtoPCIR | 4.94 |
| 16 | 14 | Compac Hull | 4.26 | ||||
| ML Algori-thms | (a) Test Accuracies: Confusion Matrix | (b) Cross Validation: K-Fold = 5 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Global Accuracy | Cohen Kappa | Precision | Sensitivity | F-Score | Accuracy Interval (AIn) | AIn Median | AIn Std | AUC | |
| LR | 77.12 | 54.24 | 77.16 | 75.06 | 77.11 | 71.03~81.70% | 76.36 | 2.67 | 83.67 |
| ANN | 76.51 | 53.02 | 76.88 | 70.70 | 76.43 | 68.80~77.87% | 73.33 | 2.27 | 79.40 |
| SVM | 76.39 | 52.78 | 77.39 | 66.83 | 76.17 | 68.85~83.88% | 76.36 | 3.76 | 82.41 |
| LDA | 76.15 | 52.30 | 76.32 | 72.15 | 76.11 | 66.05~86.68% | 76.36 | 5.16 | 83.25 |
| RF | 75.18 | 50.36 | 75.43 | 70.22 | 75.12 | 67.90~79.98% | 73.94 | 3.02 | 82.38 |
| GNB | 74.46 | 48.91 | 74.46 | 73.61 | 74.45 | 70.01~77.87% | 73.94 | 1.96 | 83.36 |
| KNN | 72.03 | 44.07 | 72.25 | 67.07 | 71.96 | 65.95~79.51% | 72.72 | 3.39 | 79.90 |
| ML Algori-thms | (a) Test Accuracies: Confusion Matrix | (b) Cross Validation: K-Fold = 5 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Global Accuracy | Cohen Kappa | Precision | Sensitivity | F-Score | Accuracy Interval (AIn) | AIn Median | AIn Std | AUC | |
| SVM | 75.24 | 49.95 | 75.20 | 78.39 | 75.21 | 71.75~77.25% | 74.50 | 1.37 | 81.53 |
| RF | 74.68 | 48.72 | 74.63 | 78.98 | 74.61 | 71.95~78.64% | 75.30 | 1.67 | 80.94 |
| ANN | 74.20 | 47.84 | 74.16 | 77.66 | 74.16 | 65.72~77.93% | 71.83 | 3.05 | 81.43 |
| LDA | 73.89 | 47.01 | 73.83 | 79.12 | 73.78 | 70.10~78.11% | 74.10 | 2.00 | 80.49 |
| LR | 73.89 | 47.07 | 73.83 | 78.54 | 73.80 | 66.28~77.94% | 72.11 | 2.92 | 80.77 |
| KNN | 73.09 | 45.70 | 73.07 | 75.62 | 73.08 | 70.41~75.40% | 72.91 | 1.25 | 77.93 |
| GNB | 72.69 | 45.30 | 73.00 | 71.53 | 72.75 | 70.88~74.94% | 72.91 | 1.02 | 79.69 |
| Applied Prediction Models | GoM Models (DS) Applied to GoM Samples (DT) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| (a) Traditional Machine Learning | (b) Transfer Learning: Common Data Shift | (c) Transfer Learning: Data Interpolation | |||||||
| GA | Sensitivity | F-Score | GA | Sensitivity | F-Score | GA | Sensitivity | F-Score | |
| SVM | 75.93 | 80.79 | 78.52 | 75.93 | 81.84 | 78.73 | 75.93 | 81.84 | 78.73 |
| ANN | 75.07 | 77.89 | 77.28 | 75.79 | 79.74 | 78.19 | 75.93 | 79.74 | 78.29 |
| RF | 75.07 | 80.00 | 77.75 | 75.21 | 80.53 | 77.96 | 74.93 | 80.00 | 77.65 |
| LDA | 74.07 | 81.05 | 77.29 | 74.21 | 81.58 | 77.50 | 74.21 | 81.84 | 77.56 |
| LR | 74.21 | 80.79 | 77.33 | 73.64 | 80.53 | 76.88 | 73.35 | 80.53 | 76.69 |
| Maximum | 75.93 | 81.05 | 78.52 | 75.93 | 81.84 | 78.73 | 75.93 | 81.84 | 78.73 |
| Minimum | 74.07 | 77.89 | 77.28 | 73.64 | 79.74 | 76.88 | 73.35 | 79.74 | 76.69 |
| Median | 75.07 | 80.79 | 77.33 | 75.21 | 80.53 | 77.96 | 74.93 | 80.53 | 77.65 |
| Std | 0.75 | 1.30 | 0.53 | 1.00 | 0.86 | 0.70 | 1.12 | 1.00 | 0.78 |
| Applied Prediction Models | GMex (DS) Models Applied to GAm Samples (DT) | |||||
|---|---|---|---|---|---|---|
| (a) Traditional Machine Learning | (b) Transfer Learning: Common Data Shift | (c) Transfer Learning: Data Interpolation | ||||
| GA | F-Score | GA | F-Score | GA | F-Score | |
| LR | 52.13 | 68.53 | 70.25 | 83.86 | 79.80 | 88.77 |
| LDA | 50.63 | 67.23 | 68.81 | 82.33 | 78.19 | 87.76 |
| RF | 49.08 | 65.84 | 68.76 | 82.57 | 76.81 | 86.89 |
| ANN | 51.73 | 68.18 | 67.78 | 79.56 | 76.47 | 86.66 |
| SVM | 51.27 | 67.78 | 70.71 | 83.24 | 74.86 | 85.62 |
| Maximum | 52.13 | 68.53 | 70.71 | 83.86 | 79.80 | 88.77 |
| Minimum | 49.08 | 65.84 | 67.78 | 79.56 | 74.86 | 85.62 |
| Median | 51.27 | 67.78 | 68.76 | 82.57 | 76.81 | 86.89 |
| StD | 1.19 | 1.05 | 2.28 | 1.65 | 1.86 | 1.19 |
| Applied Prediction Models | GoM Models (DS) Applied to BR Samples (DT): All Satellites | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| (a) Traditional Machine Learning | (b) Transfer Learning: Common Data Shift | (c) Transfer Learning: Data Interpolation | |||||||
| GA | Sensitivity | F-Score | GA | Sensitivity | F-Score | GA | Sensitivity | F-Score | |
| LR | 56.06 | 56.94 | 68.05 | 65.08 | 73.41 | 77.56 | 66.51 | 75.14 | 78.67 |
| LDA | 57.48 | 58.96 | 69.51 | 64.85 | 73.12 | 77.37 | 66.03 | 74.57 | 78.30 |
| ANN | 54.63 | 56.65 | 67.24 | 64.37 | 71.97 | 76.85 | 64.61 | 72.25 | 77.04 |
| SVM | 58.91 | 63.58 | 71.78 | 63.42 | 71.39 | 76.23 | 63.90 | 71.97 | 76.62 |
| RF | 55.82 | 58.67 | 68.58 | 64.61 | 71.68 | 76.90 | 63.66 | 71.39 | 76.35 |
| Maximum | 58.91 | 63.58 | 71.78 | 65.08 | 73.41 | 77.56 | 66.51 | 75.14 | 78.67 |
| Minimum | 54.63 | 56.65 | 67.24 | 63.42 | 71.39 | 76.23 | 63.66 | 71.39 | 76.35 |
| Median | 56.06 | 58.67 | 68.58 | 64.61 | 71.97 | 76.90 | 64.61 | 72.25 | 77.04 |
| Std | 1.65 | 2.78 | 1.74 | 0.64 | 0.90 | 0.52 | 1.27 | 1.68 | 1.03 |
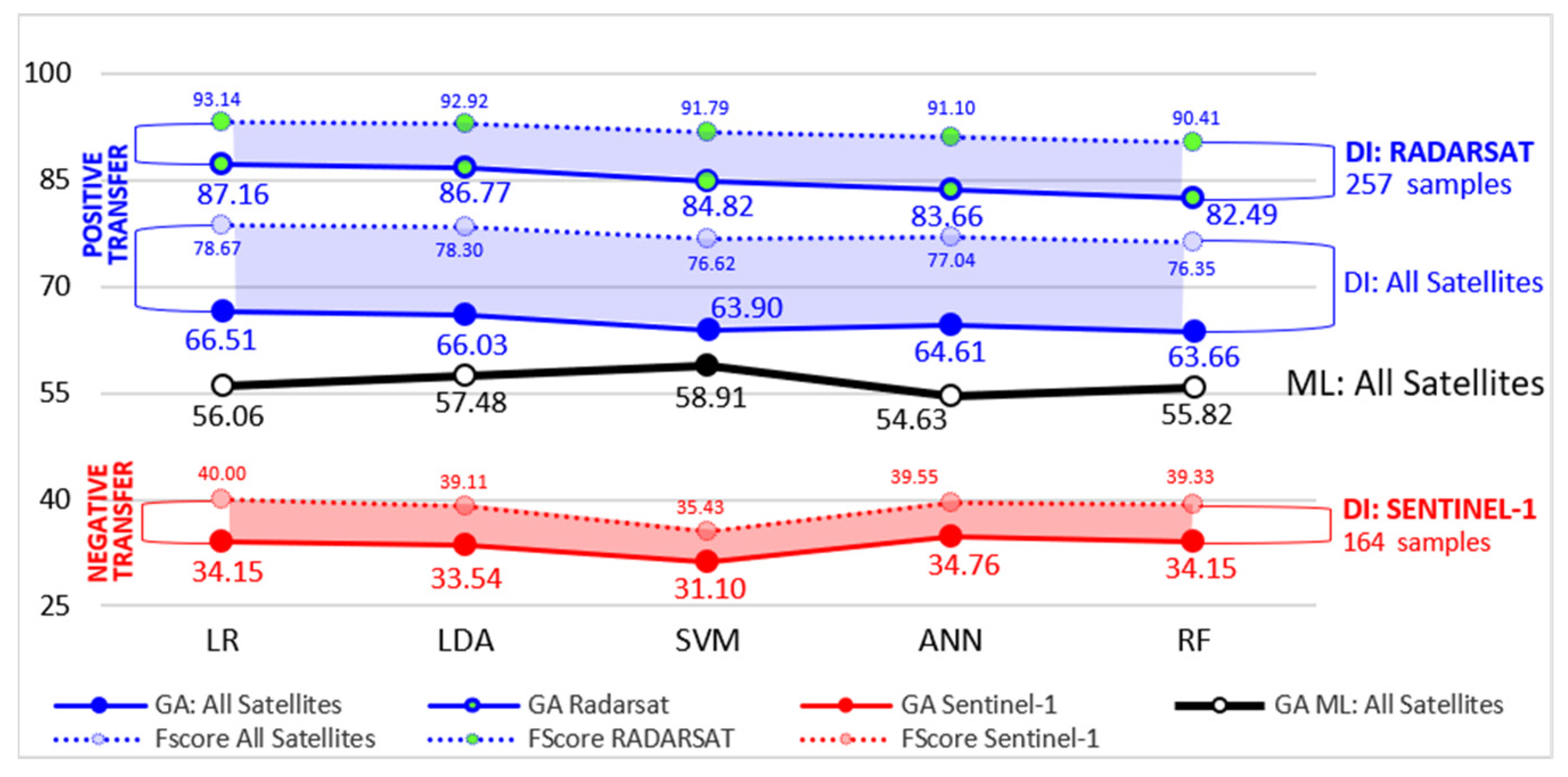
| Applied Prediction Models | Traditional ML | Transductive Transfer learning: Data Interpolation (DI) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (a) All Satellites | (b) All Satellites | (c) RADARSAT | (d) SENTINEL-1 | |||||||||||
| GA | F- Score | GA | F-Score | DifGA | DifFSc | GA | F-Score | DifGA | DifFSc | GA | F-Score | DifGA | DifFSc | |
| LR | 56.06 | 68.05 | 66.51 | 78.67 | 10.45 | 10.62 | 87.16 | 93.14 | 31.10 | 25.09 | 34.15 | 40.00 | −21.91 | −28.05 |
| LDA | 57.48 | 69.51 | 66.03 | 78.30 | 8.55 | 8.79 | 86.77 | 92.92 | 29.29 | 23.41 | 33.54 | 39.11 | −23.94 | −30.40 |
| ANN | 54.63 | 67.24 | 64.61 | 77.04 | 9.98 | 9.80 | 83.66 | 91.10 | 29.03 | 23.86 | 34.76 | 39.55 | −19.87 | −27.69 |
| SVM | 58.91 | 71.78 | 63.90 | 76.62 | 4.99 | 4.84 | 84.82 | 91.79 | 25.91 | 20.01 | 31.10 | 35.43 | −27.81 | −36.35 |
| RF | 55.82 | 68.58 | 63.66 | 76.35 | 7.84 | 7.77 | 82.49 | 90.41 | 26.67 | 21.82 | 34.15 | 39.33 | −21.67 | −29.26 |
| Maximum | 58.91 | 71.78 | 66.51 | 78.67 | 10.45 | 10.62 | 87.16 | 93.14 | 31.10 | 25.09 | 34.76 | 40.00 | −19.87 | −27.69 |
| Minimum | 54.63 | 67.24 | 63.66 | 76.35 | 4.99 | 4.84 | 82.49 | 90.41 | 25.91 | 20.01 | 31.10 | 35.43 | −27.81 | −36.35 |
| Median | 56.06 | 68.58 | 64.61 | 77.04 | 8.55 | 8.79 | 84.82 | 91.79 | 29.03 | 23.41 | 34.15 | 39.33 | −21.91 | −29.26 |
| Std | 1.65 | 1.74 | 1.27 | 1.03 | 2.16 | 2.24 | 2.00 | 1.17 | 2.10 | 1.97 | 1.43 | 1.85 | 3.03 | 3.52 |
| ML | (a) GoM ⇥ GoM | (b) GMex ⇥ GAm | (c) GoM ⇥ BR: RDS | (d) GoM ⇥ BR: SNT1 | ||||
|---|---|---|---|---|---|---|---|---|
| GICDS | GIDI | GICDS | GIDI | GICDS | GIDI | GICDS | GIDI | |
| LR | 0.07 | 0.07 | 0.63 | 0.87 | 0.87 | 1.00 | −0.79 | −0.72 |
| ANN | 0.12 | 0.12 | 0.53 | 0.79 | 0.94 | 0.95 | −0.68 | −0.68 |
| LDA | 0.10 | 0.10 | 0.63 | 0.87 | 0.91 | 0.94 | −0.84 | −0.79 |
| RF | 0.10 | 0.09 | 0.68 | 0.88 | 0.90 | 0.88 | −0.72 | −0.74 |
| SVM | 0.09 | 0.09 | 0.66 | 0.76 | 0.83 | 0.83 | −1.00 | −0.95 |
| Minimum | 0.07 | 0.07 | 0.53 | 0.76 | 0.83 | 0.83 | −1.00 | −0.95 |
| Maximum | 0.12 | 0.12 | 0.68 | 0.88 | 0.94 | 1.00 | −0.68 | −0.68 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Genovez, P.C.; Ponte, F.F.d.A.; Matias, Í.d.O.; Torres, S.B.; Beisl, C.H.; Mano, M.F.; Silva, G.M.A.; Miranda, F.P.d. Development and Application of Predictive Models to Distinguish Seepage Slicks from Oil Spills on Sea Surfaces Employing SAR Sensors and Artificial Intelligence: Geometric Patterns Recognition under a Transfer Learning Approach. Remote Sens. 2023, 15, 1496. https://doi.org/10.3390/rs15061496
Genovez PC, Ponte FFdA, Matias ÍdO, Torres SB, Beisl CH, Mano MF, Silva GMA, Miranda FPd. Development and Application of Predictive Models to Distinguish Seepage Slicks from Oil Spills on Sea Surfaces Employing SAR Sensors and Artificial Intelligence: Geometric Patterns Recognition under a Transfer Learning Approach. Remote Sensing. 2023; 15(6):1496. https://doi.org/10.3390/rs15061496
Chicago/Turabian StyleGenovez, Patrícia Carneiro, Francisco Fábio de Araújo Ponte, Ítalo de Oliveira Matias, Sarah Barrón Torres, Carlos Henrique Beisl, Manlio Fernandes Mano, Gil Márcio Avelino Silva, and Fernando Pellon de Miranda. 2023. "Development and Application of Predictive Models to Distinguish Seepage Slicks from Oil Spills on Sea Surfaces Employing SAR Sensors and Artificial Intelligence: Geometric Patterns Recognition under a Transfer Learning Approach" Remote Sensing 15, no. 6: 1496. https://doi.org/10.3390/rs15061496
APA StyleGenovez, P. C., Ponte, F. F. d. A., Matias, Í. d. O., Torres, S. B., Beisl, C. H., Mano, M. F., Silva, G. M. A., & Miranda, F. P. d. (2023). Development and Application of Predictive Models to Distinguish Seepage Slicks from Oil Spills on Sea Surfaces Employing SAR Sensors and Artificial Intelligence: Geometric Patterns Recognition under a Transfer Learning Approach. Remote Sensing, 15(6), 1496. https://doi.org/10.3390/rs15061496