
Rice Yield Prediction in Hubei Province Based on Deep Learning and the Effect of Spatial Heterogeneity


Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data
2.2.1. Hubei Province Yield Data
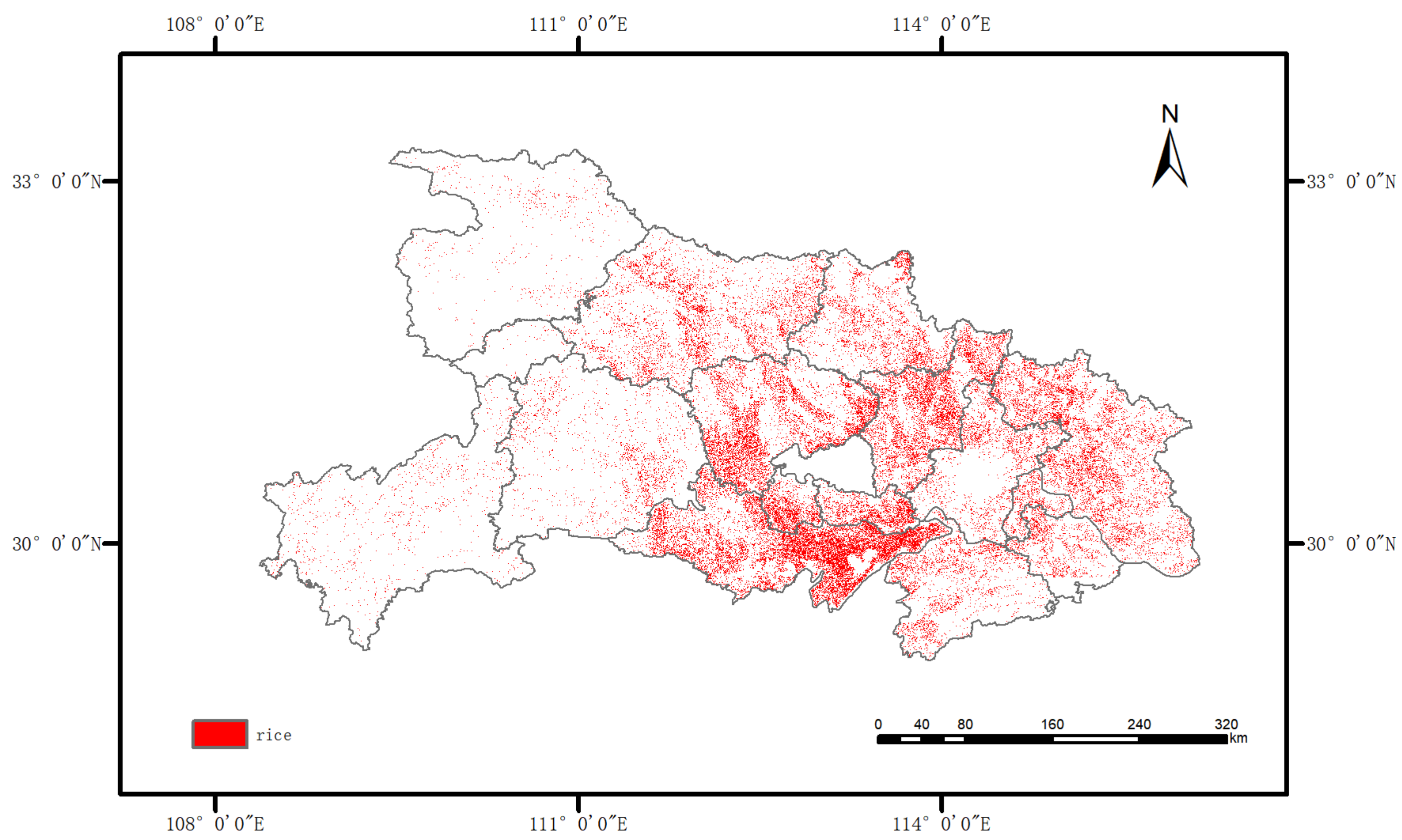
2.2.2. Rice Mask Layer
2.2.3. County Boundary Data
2.2.4. MODIS Data
2.2.5. Weather Data
2.2.6. Spatial Heterogeneity Variables
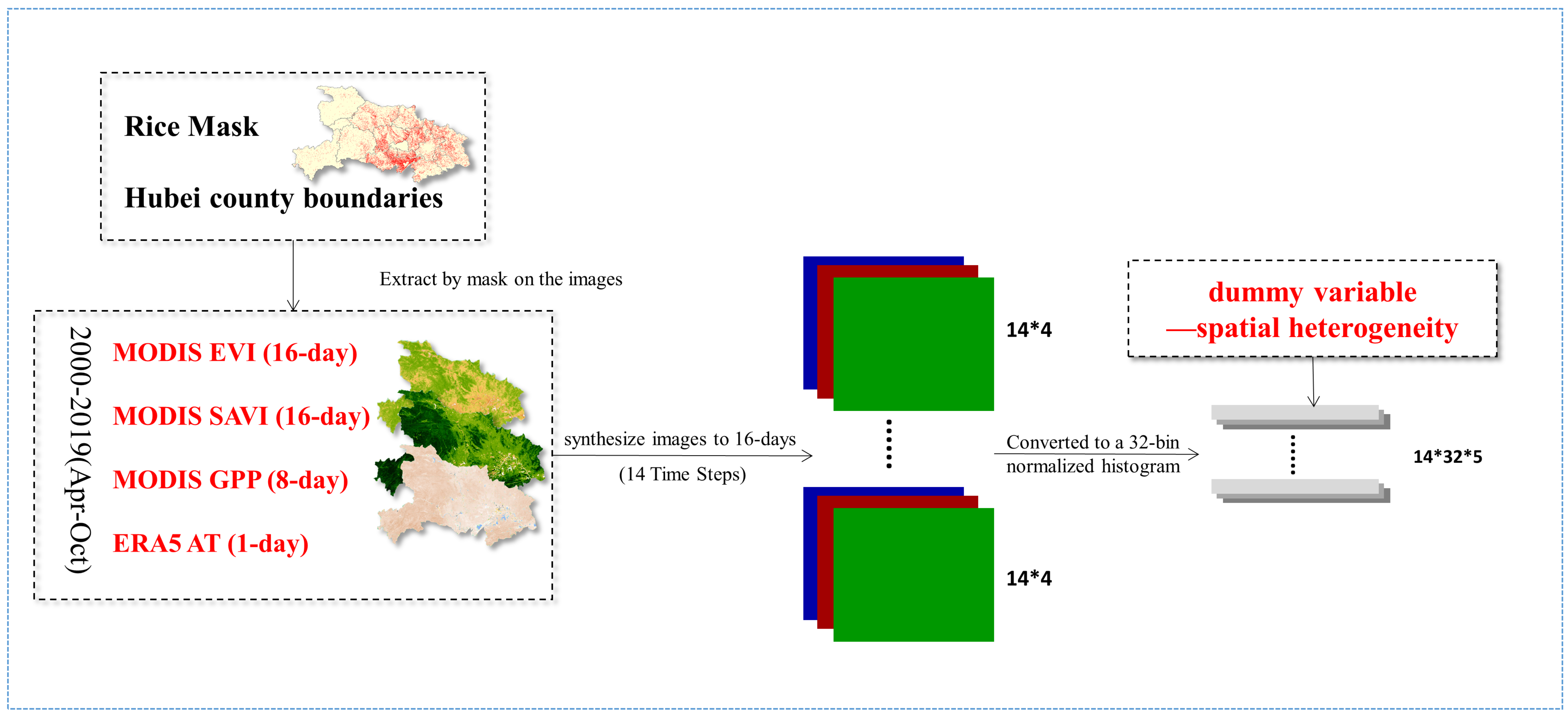
2.3. Preprocessing in GEE
- Download data. Download remote sensing data from 2000 to 2019, April to October. A 16-day synthesis of 8 days of MODIS GPP data and daily air temperature data from ERA5 was performed. Alignment with MODIS EVI and MODIS SAVI;
- Rice masks and county boundary layers. The rice mask layer is used to process the remote sensing data and eliminate the interference from other vegetation on the ground. The county boundary data of Hubei province are imported into GEE to extract remote sensing data of each county;
- Convert the histogram. GEE provides a convenient and fast API to convert image collections into county-level 32-bin normalized histograms;
- A dummy variable. After numbering each county in Hubei Province, the output is a 32-bin histogram in a uniform format, which is added as a factor to the feature;
- In this study, annual time steps of 14, with 5 bands per time step, were converted to histograms and then input into the model. The format of the input variables is 32 × 5 × 14. The corresponding county-level yield was assigned to each input variable based on the obtained rice yield statistics in Hubei Province.
Model Architecture
- CNN. Convolutional neural network (CNN) is a neural network with convolutional structure. The basic components are input layer, convolutional layer, pooling layer, fully connected layer and output layer. Convolutional layers are linked to the input layer using local weighting and weight sharing. The features of the input data are extracted by convolutional kernels. The pooling layer reduces the amount of data for convolution operations. After the convolution and pooling layers, one or more fully connected layers are usually connected. Fully connected layers can integrate local information with category differentiation in the convolutional or pooling layers [41]. The output value of the last fully connected layer is passed to the output layer. The main component of the CNN model is the convolutional operation. CNN uses a convolutional kernel applied to the input variables to produce a set of spatial features of the input data by convolutional operations. In this paper, we set up two convolutional layers, Conv2D. The first layer was set up with 32 filters and the convolutional kernel size was 3 × 3. The second layer was set up with 64 filters and the convolutional kernel size was 3 × 3. The pooling layer used the maximum pooling method.
- ConvLSTM. The long short-term memory network (LSTM) is a modified version of the recurrent neural network (RNN). Unlike CNNs, the neurons in RNNs have a feedback structure. This feedback structure enables the previous data to receive the influence of the later data. Therefore, recurrent neural networks have better performance when dealing with temporally correlated sequential data. LSTM effectively improves the problem of gradient explosion, which exists in recurrent neural networks and makes it difficult to learn the relationship between long interval data, by filtering the information obtained through the gate function. Convolutional LSTM (ConvLSTM) [42] is a model that combines features of convolutional and sequential models into a single architecture. Use the convolutional layer as the gate function of the LSTM [26]. ConvLSTM uses the three-gate control structure of LSTM [43] and uses convolutional operations to extract spatial features. The ConvLSTM model used in this paper was set up with 3 ConvLSTM2D layers and a convolutional kernel size of 1 × 2.
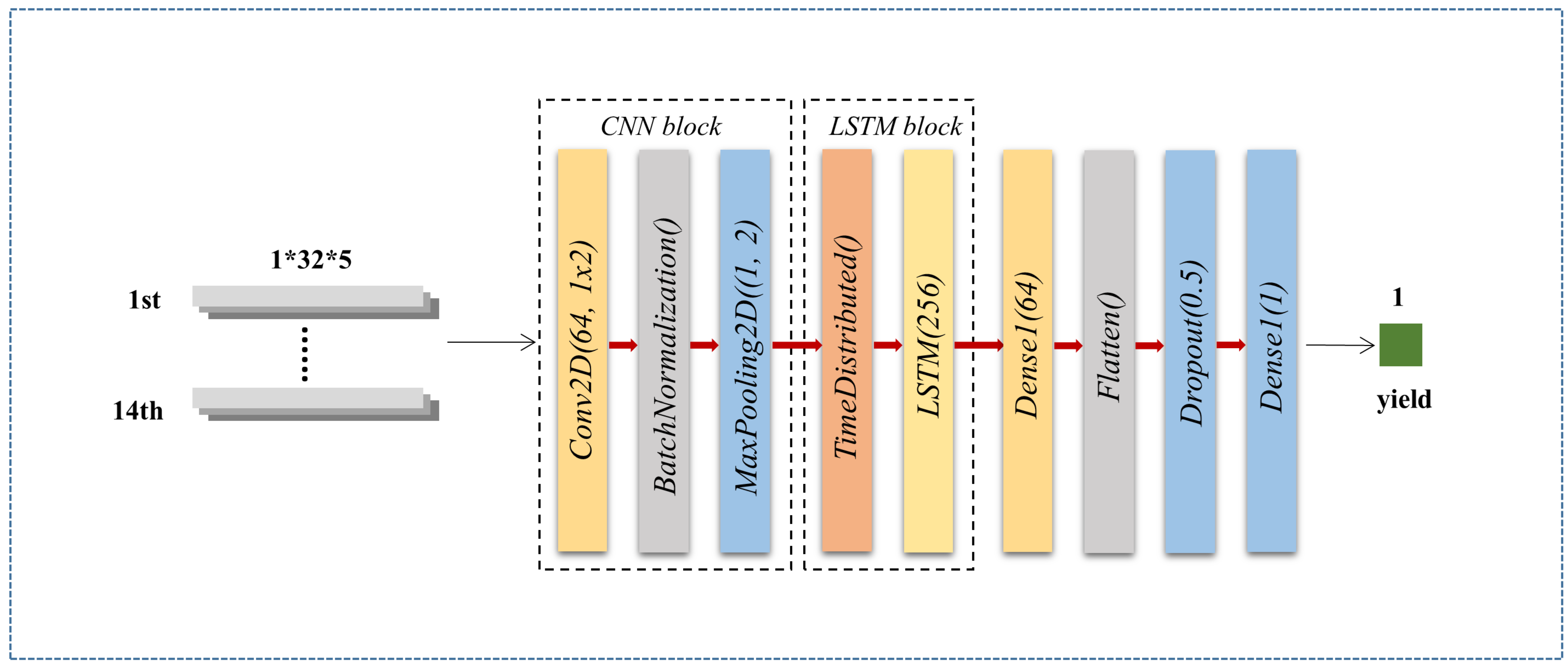
- CNN-LSTM. CNN can learn relevant features from images. The LSTM network performs well on data processing of long time sequences. The CNN-LSTM model used in this study consists mainly of a two-dimensional convolutional neural network and an LSTM network. The CNN first extracts spatial features and then passes the extracted spatial features to the LSTM network. The input to the model is based on the 32 × 5 × 14 feature variables generated by GEE preprocessing. Figure 3 shows the CNN-LSTM model architecture we used.
2.4. Evaluation
3. Results
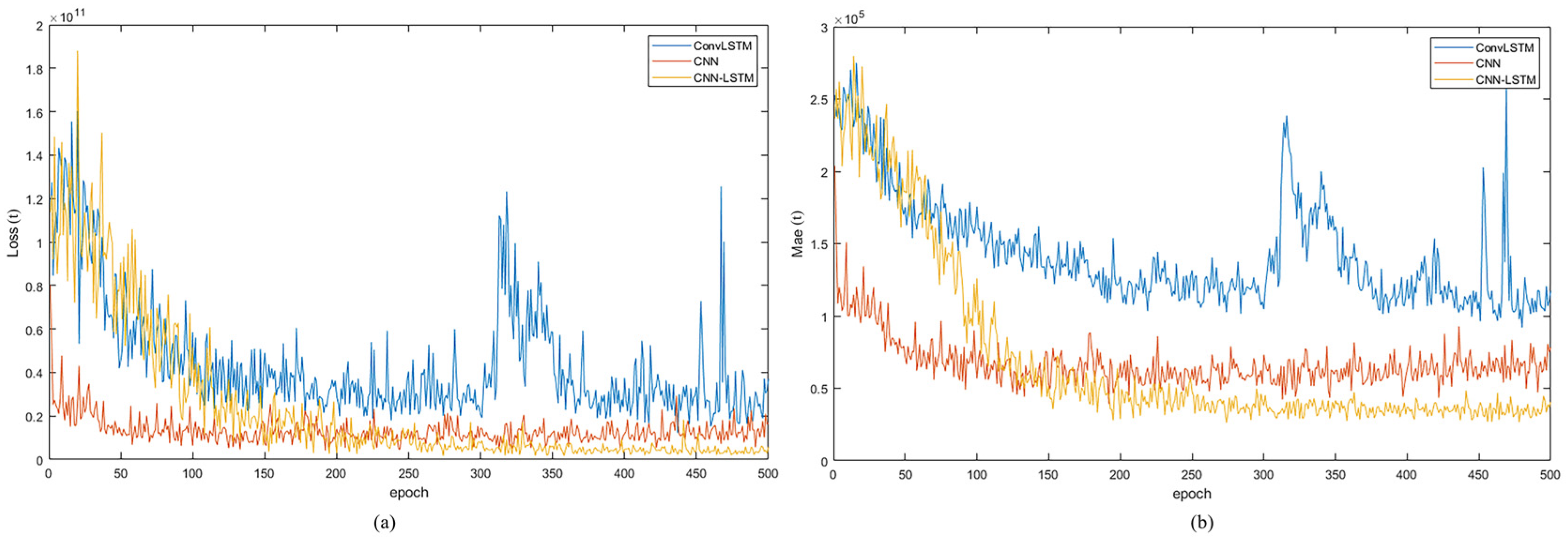
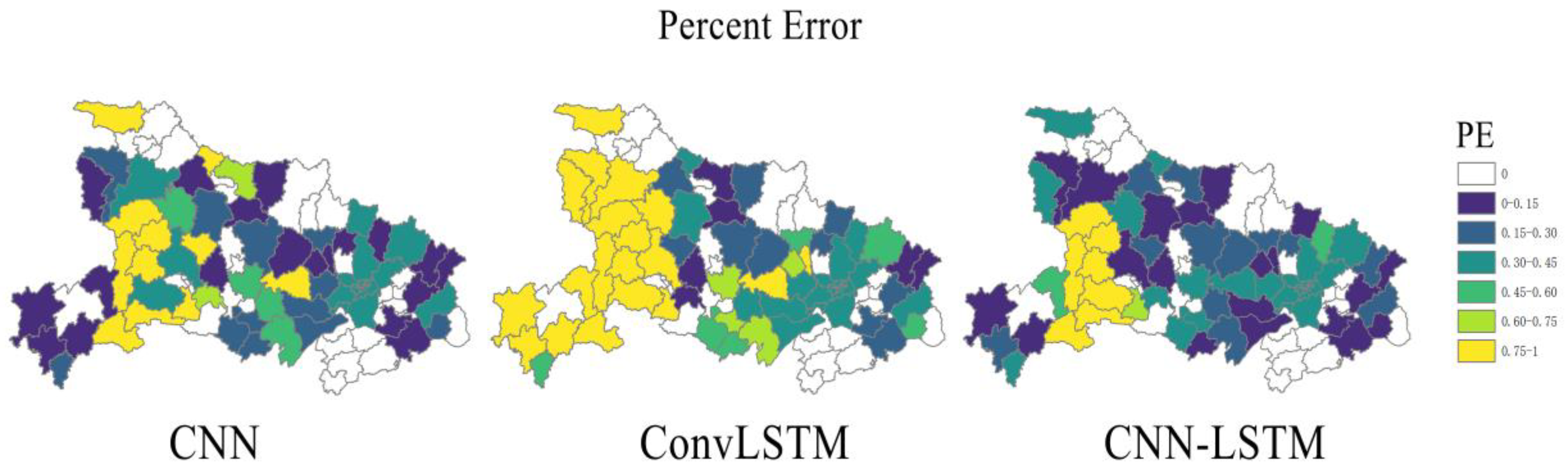
3.1. Comparison of the Three Models
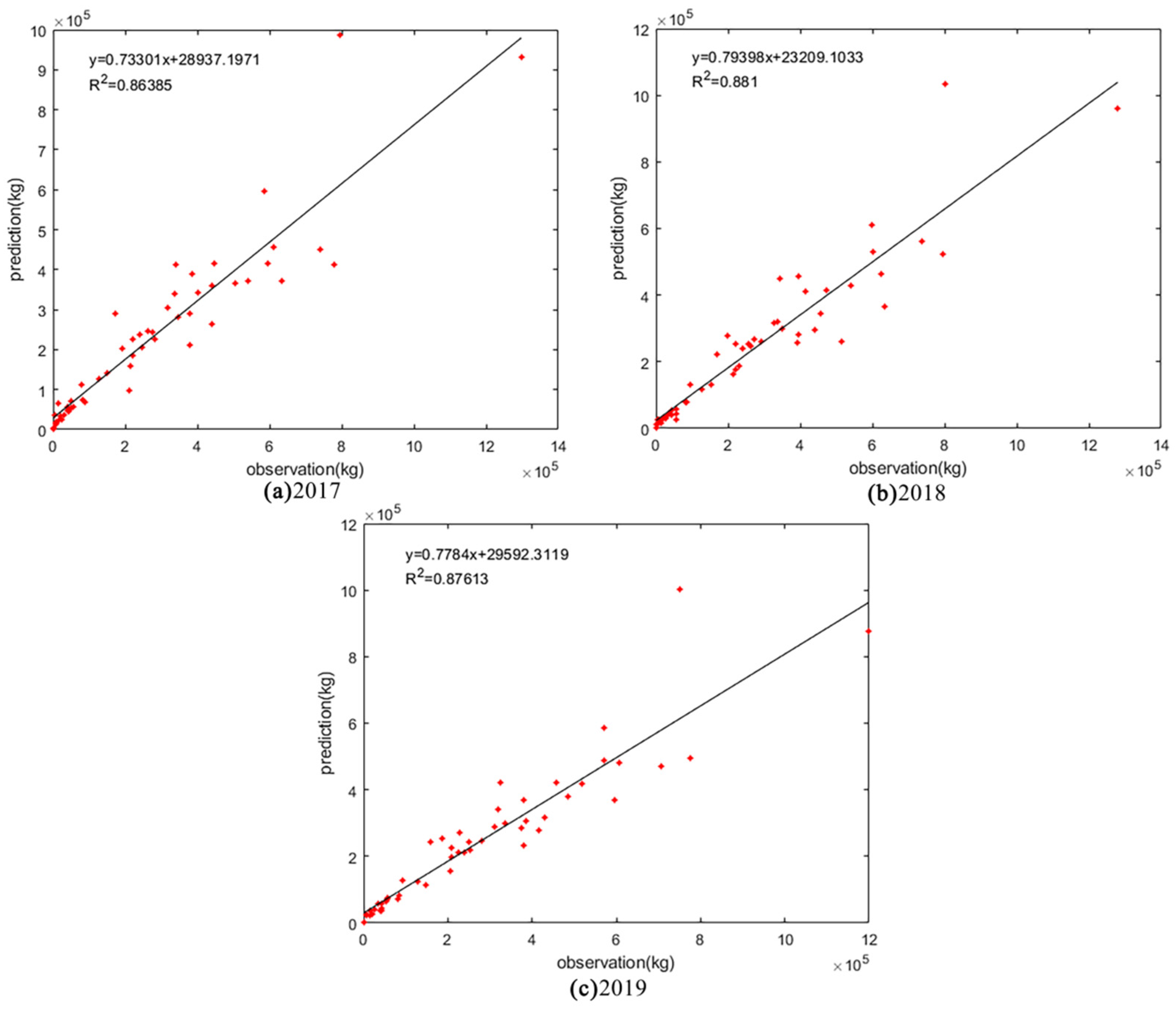
3.2. Accuracy of CNN-LSTM Hybrid Model
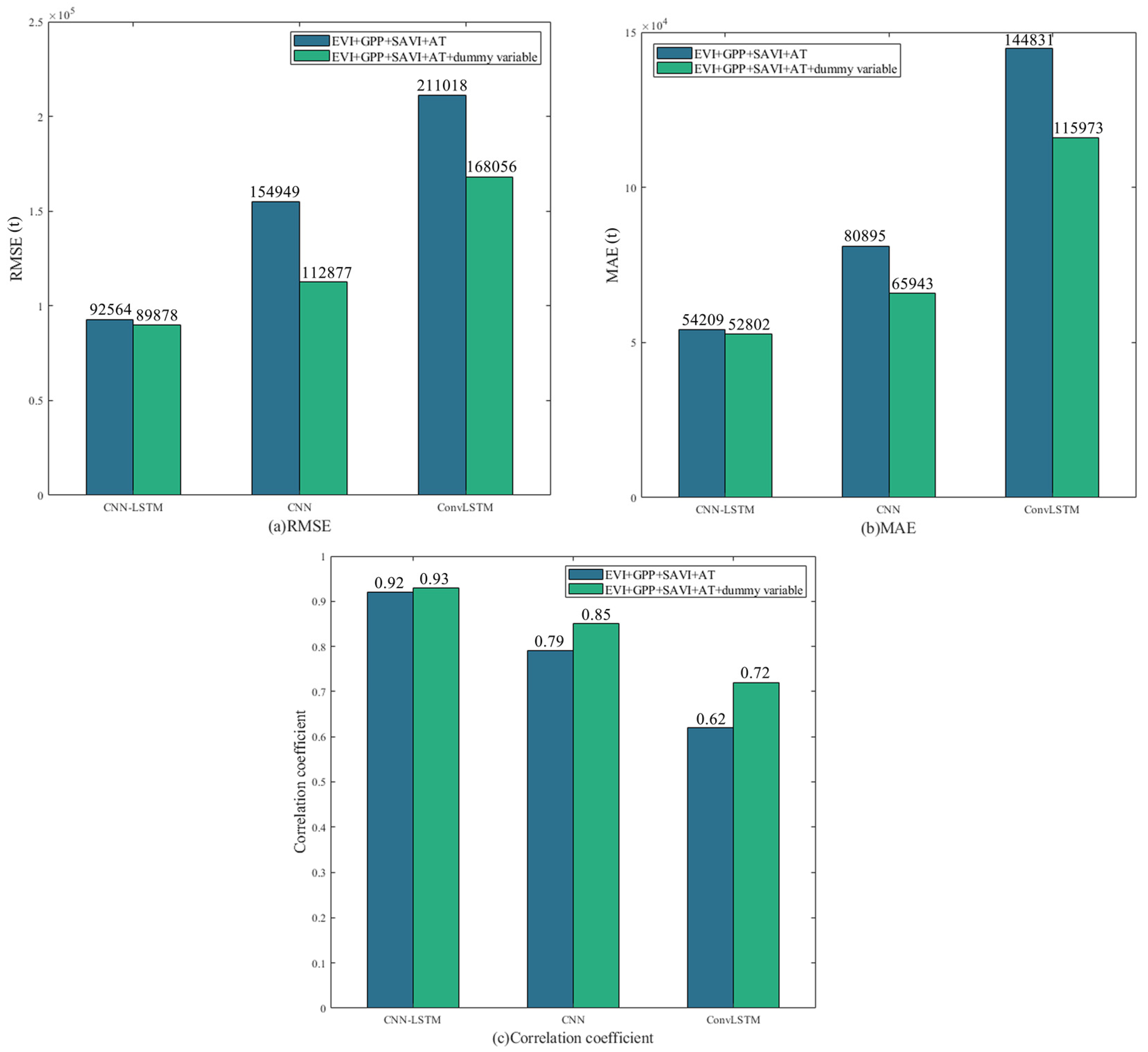
3.3. Impact of the Dummy Variable on Prediction Accuracy
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Shrestha, R.; Di, L.; Yu, E.G.; Kang, L.; Shao, Y.; Bai, Y. Regression model to estimate flood impact on corn yield using MODIS NDVI and USDA cropland data layer. J. Integr. Agric. 2017, 16, 398–407. [Google Scholar] [CrossRef]
- Zhou, Q.; Ismaeel, A. Integration of maximum crop response with machine learning regression model to timely estimate crop yield. Geo-Spat. Inf. Sci. 2021, 24, 474–483. [Google Scholar] [CrossRef]
- He, X.; Yang, L.; Li, A.; Zhang, L.; Shen, F.; Cai, Y.; Zhou, C. Soil organic carbon prediction using phenological parameters and remote sensing variables generated from Sentinel-2 images. Catena 2021, 205, 105442. [Google Scholar] [CrossRef]
- Duchemin, B.; Maisongrande, P.; Boulet, G.; Benhadj, I. A simple algorithm for yield estimates: Evaluation for semi-arid irrigated winter wheat monitored with green leaf area index. Environ. Modell. Softw. 2008, 23, 876–892. [Google Scholar] [CrossRef]
- Peng, L. Wheat and Maize Yield Model Estimation Based on Modis and Meteorological Data in Shaanxi Province. Master’s Thesis, Zhejiang University, Hangzhou, China, 2014. Volume 67. [Google Scholar]
- Bolton, D.K.; Friedl, M.A. Forecasting crop yield using remotely sensed vegetation indices and crop phenology metrics. Agric. For. Meteorol. 2013, 173, 74–84. [Google Scholar] [CrossRef]
- Liu, M.; Feng, R.; Ji, R.; Wu, J.; Wang, H.; Yu, W. Estimation of Leaf Area Index and Aboveground Biomass of Spring Maize by MODIS-NDVI. Chin. Agric. Sci. Bull. 2015, 31, 80–87. [Google Scholar]
- Rahman, M.M.; Robson, A. Integrating Landsat-8 and Sentinel-2 Time Series Data for Yield Prediction of Sugarcane Crops at the Block Level. Remote Sens. 2020, 12, 1313. [Google Scholar] [CrossRef]
- Gavahi, K.; Abbaszadeh, P.; Moradkhani, H. DeepYield: A combined convolutional neural network with long short-term memory for crop yield forecasting. Expert Syst. Appl. 2021, 184, 115511. [Google Scholar] [CrossRef]
- Xu, L.; Abbaszadeh, P.; Moradkhani, H.; Chen, N.; Zhang, X. Continental drought monitoring using satellite soil moisture, data assimilation and an integrated drought index. Remote Sens. Environ. 2020, 250, 112028. [Google Scholar] [CrossRef]
- Xu, L.; Chen, N.; Zhang, X.; Moradkhani, H.; Zhang, C.; Hu, C. In-situ and triple-collocation based evaluations of eight global root zone soil moisture products. Remote Sens. Environ. 2021, 254, 112248. [Google Scholar] [CrossRef]
- Agarwal, S.; Tarar, S. A Hybrid Approach for Crop Yield Prediction Using Machine Learning and Deep Learning Algorithms. J. Phys. Conf. Ser. 2021, 1714, 012012. [Google Scholar] [CrossRef]
- Bocca, F.F.; Rodrigues, L.H.A. The effect of tuning, feature engineering, and feature selection in data mining applied to rainfed sugarcane yield modelling. Comput. Electron. Agric. 2016, 128, 67–76. [Google Scholar] [CrossRef]
- Kim, N.; Lee, Y. Machine Learning Approaches to Corn Yield Estimation Using Satellite Images and Climate Data: A Case of Iowa State. J. Korean Soc. Surv. Geod. Photogramm. Cartogr. 2016, 34, 383–390. [Google Scholar] [CrossRef]
- Nevavuori, P.; Narra, N.; Lipping, T. Crop yield prediction with deep convolutional neural networks. Comput. Electron. Agric. 2019, 163, 104859. [Google Scholar] [CrossRef]
- Xu, L.; Chen, N.; Chen, Z.; Zhang, C.; Yu, H. Spatiotemporal forecasting in earth system science: Methods, uncertainties, predictability and future directions. Earth-Sci. Rev. 2021, 222, 103828. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Z.; Tao, F.; Zhang, L.; Luo, Y.; Zhang, J.; Han, J.; Xie, J. Integrating Multi-Source Data for Rice Yield Prediction across China using Machine Learning and Deep Learning Approaches. Agric. For. Meteorol. 2021, 297, 108275. [Google Scholar] [CrossRef]
- Chergui, N. Durum wheat yield forecasting using machine learning. Artif. Intell. Agric. 2022, 6, 156–166. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Z.; Luo, Y.; Zhang, L.; Zhang, J.; Li, Z.; Tao, F. Wheat yield predictions at a county and field scale with deep learning, machine learning, and google earth engine. Eur. J. Agron. 2021, 123, 126204. [Google Scholar] [CrossRef]
- Xu, L.; Chen, N.; Zhang, X.; Chen, Z. A data-driven multi-model ensemble for deterministic and probabilistic precipitation forecasting at seasonal scale. Clim. Dyn. 2020, 54, 3355–3374. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, X.; Wang, C.; Chen, N. Temporal continuous monitoring of cyanobacterial blooms in Lake Taihu at an hourly scale using machine learning. Sci. Total Environ. 2023, 857, 159480. [Google Scholar] [CrossRef]
- Xiang, J. Research on Grain Yield Forecasting Based on Satellite Remote Sensing Images. Master’s Thesis, Xidian University, Xi’an, China, 2020. [Google Scholar]
- Ji, Z.; Pan, Y.; Zhu, X.; Wang, J.; Li, Q. Prediction of Crop Yield Using Phenological Information Extracted from Remote Sensing Vegetation Index. Sensors 2021, 21, 1406. [Google Scholar] [CrossRef] [PubMed]
- Nevavuori, P.; Narra, N.; Linna, P.; Lipping, T. Crop Yield Prediction Using Multitemporal UAV Data and Spatio-Temporal Deep Learning Models. Remote Sens. 2020, 12, 4000. [Google Scholar] [CrossRef]
- Wang, X.; Huang, J.; Feng, Q.; Yin, D. Winter Wheat Yield Prediction at County Level and Uncertainty Analysis in Main Wheat-Producing Regions of China with Deep Learning Approaches. Remote Sens. 2020, 12, 1744. [Google Scholar] [CrossRef]
- Fernandez-Beltran, R.; Baidar, T.; Kang, J.; Pla, F. Rice-Yield Prediction with Multi-Temporal Sentinel-2 Data and 3D CNN: A Case Study in Nepal. Remote Sens. 2021, 13, 1391. [Google Scholar] [CrossRef]
- Yang, Q.; Shi, L.; Han, J.; Zha, Y.; Zhu, P. Deep convolutional neural networks for rice grain yield estimation at the ripening stage using UAV-based remotely sensed images. Field Crop. Res. 2019, 235, 142–153. [Google Scholar] [CrossRef]
- Yaramasu, R.; Bandaru, V.; Pnvr, K. Pre-season crop type mapping using deep neural networks. Comput. Electron. Agric. 2020, 176, 105664. [Google Scholar] [CrossRef]
- Sun, J.; Di, L.; Sun, Z.; Shen, Y.; Lai, Z. County-Level Soybean Yield Prediction Using Deep CNN-LSTM Model. Sensors 2019, 19, 4363. [Google Scholar] [CrossRef]
- Shelestov, A.; Lavreniuk, M.; Kussul, N.; Novikov, A.; Skakun, S. Exploring Google Earth Engine Platform for Big Data Processing: Classification of Multi-Temporal Satellite Imagery for Crop Mapping. Front. Earth Sci. 2017, 5, 17. [Google Scholar] [CrossRef]
- Han, J.; Zhang, Z.; Cao, J.; Luo, Y.; Zhang, L.; Li, Z.; Zhang, J. Prediction of Winter Wheat Yield Based on Multi-Source Data and Machine Learning in China. Remote Sens. 2020, 12, 236. [Google Scholar] [CrossRef]
- Clinton, N.; Stuhlmacher, M.; Miles, A.; Uludere Aragon, N.; Wagner, M.; Georgescu, M.; Herwig, C.; Gong, P. A Global Geospatial Ecosystem Services Estimate of Urban Agriculture. Earth’s Future 2018, 6, 40–60. [Google Scholar] [CrossRef]
- Zhang, G.; Wie, J.; Ding, Z. Spatial pattern and its influencing factors of industrialization-urbanization comprehensive level in China at town level. Geogr. Res. 2020, 39, 627–650. [Google Scholar]
- Shen, Y.; Jiang, C.; Chan, K.L.; Hu, C.; Yao, L. Estimation of Field-Level NOx Emissions from Crop Residue Burning Using Remote Sensing Data: A Case Study in Hubei, China. Remote Sens. 2021, 13, 404. [Google Scholar] [CrossRef]
- Gu, Z.; Zhang, Z.; Yang, J.; Wang, L. Quantifying the Influences of Driving Factors on Vegetation EVI Changes Using Structural Equation Model: A Case Study in Anhui Province, China. Remote Sens. 2022, 14, 4203. [Google Scholar] [CrossRef]
- Li, M.; Wu, T.; Wang, S.; Sang, S.; Zhao, Y. Phenology–Gross Primary Productivity (GPP) Method for Crop Information Extraction in Areas Sensitive to Non-Point Source Pollution and Its Influence on Pollution Intensity. Remote Sens. 2022, 14, 2833. [Google Scholar] [CrossRef]
- Zhen, Z.; Chen, S.; Yin, T.; Chavanon, E.; Lauret, N.; Guilleux, J.; Henke, M.; Qin, W.; Cao, L.; Li, J.; et al. Using the Negative Soil Adjustment Factor of Soil Adjusted Vegetation Index (SAVI) to Resist Saturation Effects and Estimate Leaf Area Index (LAI) in Dense Vegetation Areas. Sensors 2021, 21, 2115. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, X.; Yang, L.; Chen, N.; Nam, W.; Niyogi, D. Urbanization-induced drought modification: Example over the Yangtze River Basin, China. Urban Clim. 2022, 44, 101231. [Google Scholar] [CrossRef]
- Zhou, F.-Y.; Jin, L.-P.; Dong, J. Review of Convolutional Neural Networks. Chin. J. Comput. 2017, 40, 1229–1251. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar]
- Li, C.; Feng, Y.; Sun, T.; Zhang, X. Long Term Indian Ocean Dipole (IOD) Index Prediction Used Deep Learning by convLSTM. Remote Sens. 2022, 14, 523. [Google Scholar] [CrossRef]
- Sergey, I.; Christian, S. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Sun, Y. Study of Production Potential and Zoning Plant of Rice in Hubei Province Uing GIS. Master’s Thesis, Huazhong Agricultural University, Wuhan, China, 2010. [Google Scholar]
- Gao, X. Effects of Climate Change and Farmers’ Adaptation on Rice Irrigation Efficiency: A Case Study of Rice Growers in Hubei Province. Water Sav. Irrig. 2020, 46–50, 56. [Google Scholar]
- Liu, X.; Zhang, W. Research progress on the effects of high temperature and heat damage on rice and defensive measures in Hubei Province. Seed Technol. 2018, 36, 108, 114. [Google Scholar]
- Ghazaryan, G.; Skakun, S.; König, S.; Rezaei, E.E.; Siebert, S.; Dubovyk, O. Crop Yield Estimation Using Multi-Source Satellite Image Series and Deep Learning. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 16–26 July 2020; pp. 5163–5166. [Google Scholar]
- Gastli, M.S.; Nassar, L.; Karray, F. Satellite Images and Deep Learning Tools for Crop Yield Prediction and Price Forecasting. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Liu, X.; Zhang, Z.; Liu, B.; Wang, Y.; Luo, L.; Qiu, W. Assessment and Spatial Heterogeneity of Ecological Resilience in the Yangtze River Basin. Res. Environ. Sci. 2022, 35, 2758–2767. [Google Scholar]
- Han, G.-X.; Zhou, G.-S.; Xu, Z.-Z. Research and Prospects for Soil Respiration of Farmland Ecosystems in China. Chin. J. Plant Ecol. 2008, 32, 719–733. [Google Scholar]
- Ma, C.; Johansen, K.; McCabe, M.F. Combining Sentinel-2 data with an optical-trapezoid approach to infer within-field soil moisture variability and monitor agricultural production stages. Agric. Water Manag. 2022, 274, 107942. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Test RMSE (t) | Test MAE (t) | Test R - |
|---|---|---|---|
| CNN | 112,877 | 65,943 | 0.850 |
| ConvLSTM | 168,056 | 115,973 | 0.721 |
| CNN-LSTM | 89,878 | 52,802 | 0.934 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, S.; Xu, L.; Chen, N. Rice Yield Prediction in Hubei Province Based on Deep Learning and the Effect of Spatial Heterogeneity. Remote Sens. 2023, 15, 1361. https://doi.org/10.3390/rs15051361
Zhou S, Xu L, Chen N. Rice Yield Prediction in Hubei Province Based on Deep Learning and the Effect of Spatial Heterogeneity. Remote Sensing. 2023; 15(5):1361. https://doi.org/10.3390/rs15051361
Chicago/Turabian StyleZhou, Shitong, Lei Xu, and Nengcheng Chen. 2023. "Rice Yield Prediction in Hubei Province Based on Deep Learning and the Effect of Spatial Heterogeneity" Remote Sensing 15, no. 5: 1361. https://doi.org/10.3390/rs15051361
APA StyleZhou, S., Xu, L., & Chen, N. (2023). Rice Yield Prediction in Hubei Province Based on Deep Learning and the Effect of Spatial Heterogeneity. Remote Sensing, 15(5), 1361. https://doi.org/10.3390/rs15051361