


Rust-Style Patch: A Physical and Naturalistic Camouflage Attacks on Object Detector for Remote Sensing Images


Abstract
1. Introduction
- We propose a method to generate natural, rust-like adversarial patches generation method based on style transfer, which makes the adversarial patches as natural as possible while making the object detector fail for target objects detection.
- We utilize attention techniques to obtain the most aggressive regions, effectively reducing the size of the adversarial patch, and balancing the attack effect and naturalness by a preset size threshold.
- Experiments on the coco dataset in both digital and physical domains show the effectiveness and attack performance of the method. Experiments on the NWPU VHR-10 dataset also prove the effectiveness of our method on remote sensing images.
2. Related Work and Background
2.1. Naturalistic Adversarial Patch
2.2. Explainable Adversarial Attack
2.3. Background
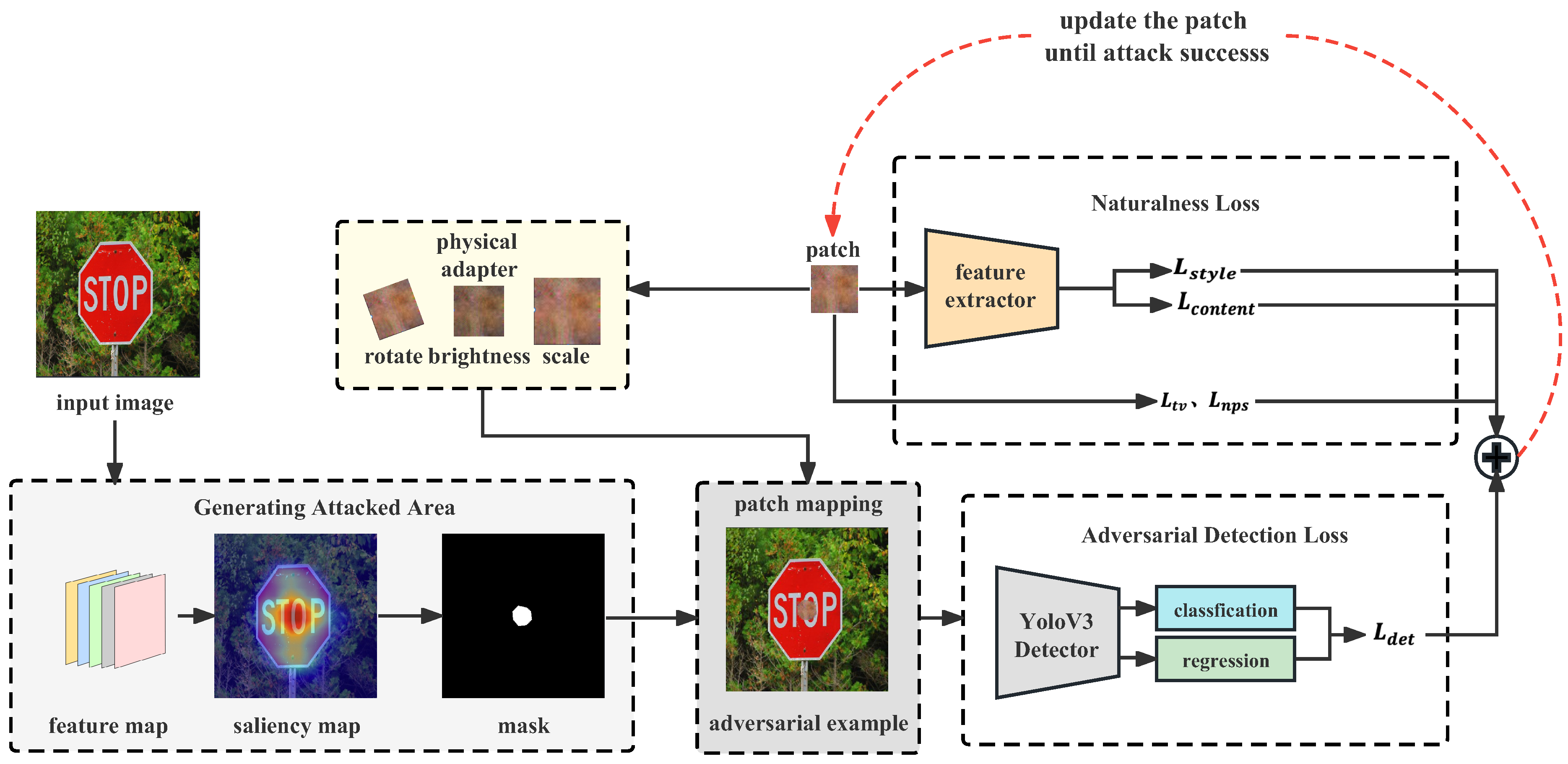
3. Methods
3.1. Overview
3.2. Generating Attacked Area
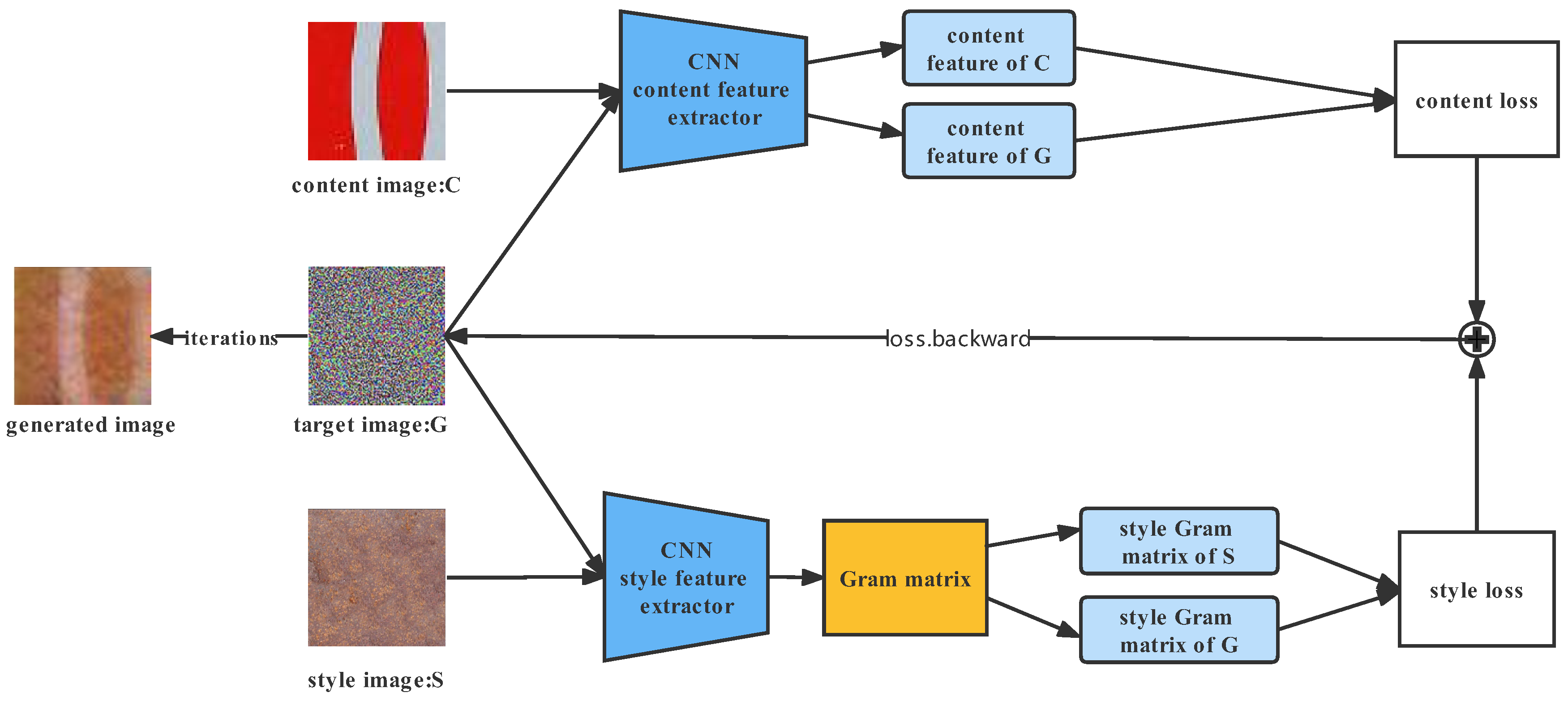
3.3. Generating Naturalistic Adversarial Patches
3.3.1. Naturalness Loss
3.3.2. Adversarial Detection Loss
3.4. Adaptation for Physical-World Conditions
3.5. Overall Optimization Process
| Algorithm 1: Generate rust-style adversarial patch |
 |
4. Experimentation and Results Discussion
4.1. Experiment Settings
4.2. Digital Attack
4.3. Physical Attack
4.4. Ablation Experimental
4.4.1. The Balance between Attack Performance and Naturalness
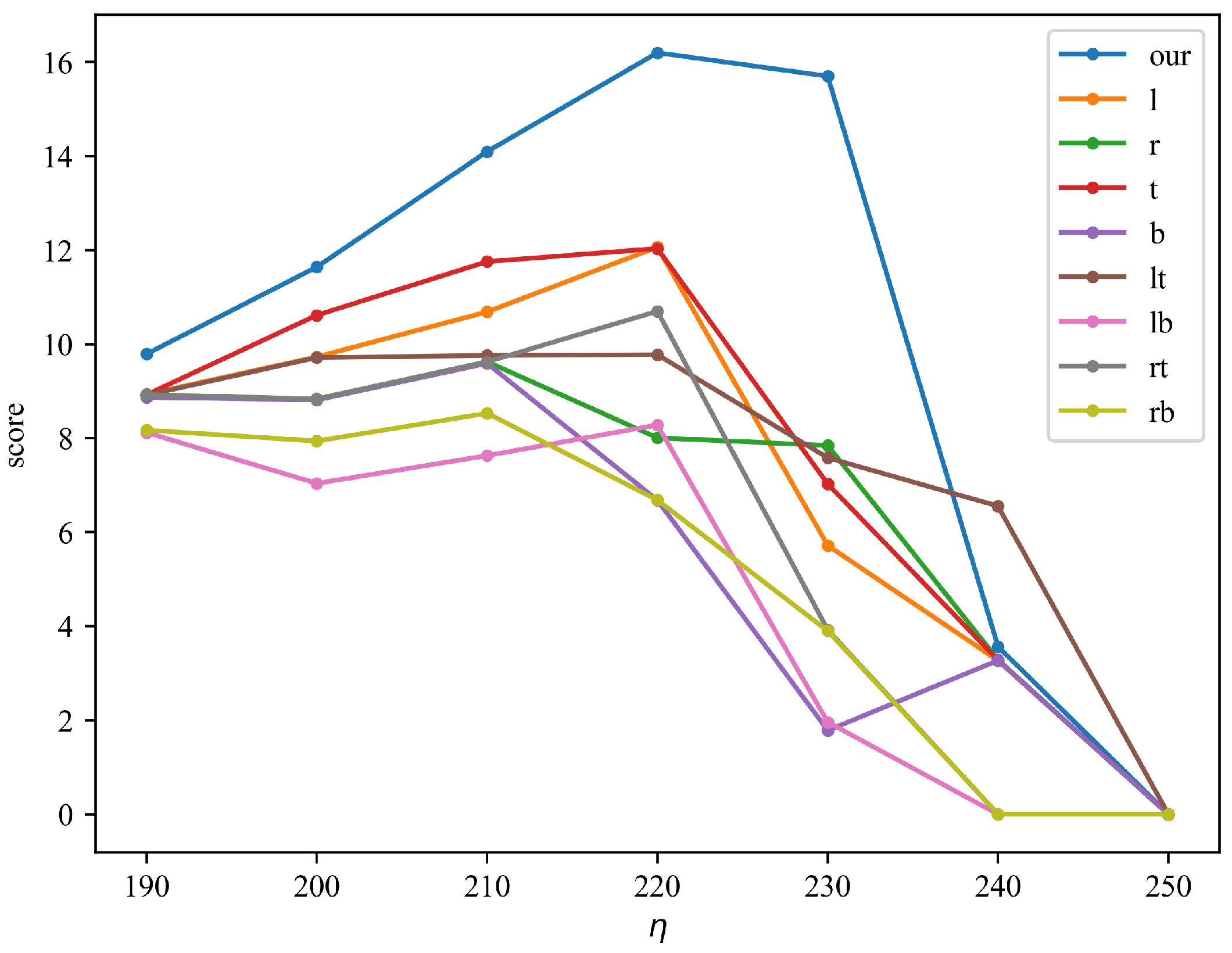
4.4.2. The Influence of the Location of Patch and the Threshold
4.4.3. The Performance of Camouflage Losses
4.4.4. The Effectiveness of Physical Adaption
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qian, R.; Lai, X.; Li, X. 3D Object Detection for Autonomous Driving: A Survey. Pattern Recognit. 2022, 130, 108796. [Google Scholar] [CrossRef]
- Fang, W.; Shen, L.; Chen, Y. Survey on Image Object Detection Algorithms Based on Deep Learning. In Artificial Intelligence and Security; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2021; pp. 468–480. [Google Scholar]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Yasir, M.; Jianhua, W.; Mingming, X.; Hui, S.; Zhe, Z.; Shanwei, L.; Colak, A.T.I.; Hossain, M.S. Ship Detection Based on Deep Learning Using SAR Imagery: A Systematic Literature Review. Soft Comput. 2022, 27, 63–84. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing Properties of Neural Networks. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gu, Z.; Li, H.; Khan, S.; Deng, L.; Du, X.; Guizani, M.; Tian, Z. IEPSBP: A Cost-Efficient Image Encryption Algorithm Based on Parallel Chaotic System for Green IoT. IEEE Trans. Green Commun. Netw. 2021, 6, 89–106. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2015, arXiv:1412.6572. [Google Scholar]
- Van Etten, A. The Weaknesses of Adversarial Camouflage in Overhead Imagery. arXiv 2022, arXiv:2207.02963. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial Examples in the Physical World. arXiv 2017, arXiv:1607.02533. [Google Scholar]
- Brown, T.B.; Mané, D.; Roy, A.; Abadi, M.; Gilmer, J. Adversarial Patch. arXiv 2018, arXiv:1712.09665. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting Adversarial Attacks with Momentum. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 9185–9193. [Google Scholar]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Zhu, B.; Gu, Z.; Qian, Y.; Lau, F.; Tian, Z. Leveraging transferability and improved beam search in textual adversarial attacks. Neurocomputing 2022, 500, 135–142. [Google Scholar] [CrossRef]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal Adversarial Perturbations. arXiv 2017, arXiv:1610.08401. [Google Scholar]
- Athalye, A.; Engstrom, L.; Ilyas, A.; Kwok, K. Synthesizing Robust Adversarial Examples. In Proceedings of the 35th International Conference on Machine Learning (PMLR), Stockholm, Sweden, 10–15 July 2018; pp. 284–293. [Google Scholar]
- Liu, X.; Yang, H.; Liu, Z.; Song, L.; Li, H.; Chen, Y. DPatch: An Adversarial Patch Attack on Object Detectors. arXiv 2019, arXiv:1806.02299. [Google Scholar]
- Chow, K.H.; Liu, L.; Loper, M.; Bae, J.; Gursoy, M.E.; Truex, S.; Wei, W.; Wu, Y. Adversarial Objectness Gradient Attacks in Real-time Object Detection Systems. In Proceedings of the 2020 Second IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), Atlanta, GA, USA, 28–31 October 2020; pp. 263–272. [Google Scholar]
- Le, T.T.H.; Kang, H.; Kim, H. Robust Adversarial Attack Against Explainable Deep Classification Models Based on Adversarial Images with Different Patch Sizes and Perturbation Ratios. IEEE Access 2021, 9, 133049–133061. [Google Scholar] [CrossRef]
- Adhikari, A.; Hollander, R.D.; Tolios, I.; Bekkum, M.V.; Raaijmakers, S. Adversarial Patch Camouflage against Aerial Detection. arXiv 2020, arXiv:2008.13671. [Google Scholar]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust Physical-World Attacks on Deep Learning Visual Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1625–1634. [Google Scholar]
- Zhang, H.; Zhou, W.; Li, H. Contextual Adversarial Attacks For Object Detection. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Chen, S.T.; Cornelius, C.; Martin, J.; Chau, D.H. ShapeShifter: Robust Physical Adversarial Attack on Faster R-CNN Object Detector. In Machine Learning and Knowledge Discovery in Databases; Springer International Publishing: Cham, Switzerland, 2019; Volume 11051, pp. 52–68. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar]
- Sitawarin, C.; Bhagoji, A.N.; Mosenia, A.; Chiang, M.; Mittal, P. DARTS: Deceiving Autonomous Cars with Toxic Signs. arXiv 2018, arXiv:1802.06430. [Google Scholar]
- Duan, R.; Mao, X.; Qin, A.K.; Chen, Y.; Ye, S.; He, Y.; Yang, Y. Adversarial Laser Beam: Effective Physical-World Attack to DNNs in a Blink. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16062–16071. [Google Scholar]
- Gnanasambandam, A.; Sherman, A.M.; Chan, S.H. Optical Adversarial Attack. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 92–101. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28. [Google Scholar]
- Thys, S.; Van Ranst, W.; Goedeme, T. Fooling Automated Surveillance Cameras: Adversarial Patches to Attack Person Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Wang, Y.; Lv, H.; Kuang, X.; Zhao, G.; Tan, Y.A.; Zhang, Q.; Hu, J. Towards a Physical-World Adversarial Patch for Blinding Object Detection Models. Inf. Sci. 2021, 556, 459–471. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1802.06430. [Google Scholar]
- Hu, Y.C.T.; Kung, B.H.; Tan, D.S.; Chen, J.C.; Hua, K.L.; Cheng, W.H. Naturalistic Physical Adversarial Patch for Object Detectors. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 10–17 October 2021; pp. 7848–7857. [Google Scholar]
- Du, A.; Chen, B.; Chin, T.J.; Law, Y.W.; Sasdelli, M.; Rajasegaran, R.; Campbell, D. Physical Adversarial Attacks on an Aerial Imagery Object Detector. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2022; pp. 3798–3808. [Google Scholar]
- Xue, M.; Yuan, C.; He, C.; Wang, J.; Liu, W. NaturalAE: Natural and Robust Physical Adversarial Examples for Object Detectors. J. Inf. Secur. Appl. 2021, 57, 102694. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Gu, Z.; Hu, W.; Zhang, C.; Lu, H.; Yin, L.; Wang, L. Gradient Shielding: Towards Understanding Vulnerability of Deep Neural Networks. IEEE Trans. Netw. Sci. Eng. 2021, 8, 921–932. [Google Scholar] [CrossRef]
- Liu, A.; Liu, X.; Fan, J.; Ma, Y.; Zhang, A.; Xie, H.; Tao, D. Perceptual-Sensitive GAN for Generating Adversarial Patches. Proc. AAAI Conf. Artif. Intell. 2019, 33, 1028–1035. [Google Scholar] [CrossRef]
- Subramanya, A.; Pillai, V.; Pirsiavash, H. Fooling Network Interpretation in Image Classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, South Korea, 27 October–2 November 2019; pp. 2020–2029. [Google Scholar]
- Wang, J.; Liu, A.; Yin, Z.; Liu, S.; Tang, S.; Liu, X. Dual Attention Suppression Attack: Generate Adversarial Camouflage in Physical World. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8565–8574. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A Neural Algorithm of Artistic Style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Sharif, M.; Bhagavatula, S.; Bauer, L.; Reiter, M.K. Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition. In CCS ’16: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1528–1540. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Song, D.; Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Tramer, F.; Prakash, A.; Kohno, T. Physical Adversarial Examples for Object Detectors. In Proceedings of the 12th USENIX Workshop on Offensive Technologies, Baltimore, MD, USA, 13–14 August 2018. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | ASR (%) | SSIM |
|---|---|---|
| Disappearance Attack | 95.7 | 0.913 |
| NWPU VHR-10 | 78.2 | 0.926 |
| Method | ASR (%) | Patch Size Ratio (%) | SSIM | Score | |
|---|---|---|---|---|---|
| Indoor | Outdoor | ||||
| our | 70.6 | 65.3 | 13.5 | 0.861 | 25.0 |
| [47] | 72.7 | 56.7 | 24.0 | 0.558 | 8.7 |
| NaturalAE | 62.0 | 72.0 | 100.0 | 0.642 | 2.5 |
| Clean image | 0.0 | 0.0 | 0.0 | 1.000 | - |
| Patch Size Ratio (%) | 6.0 | 10.2 | 13.5 | 20.4 | 33.6 | 40.0 |
| SSIM | 0.985 | 0.917 | 0.913 | 0.897 | 0.854 | 0.812 |
| ASR (%) | 7.7 | 61.5 | 95.7 | 96.2 | 96.6 | 97.1 |
| Physiccal Adaption | Success Rate (%) | SSIM |
|---|---|---|
| No | 22.0 | 0.889 |
| Yes | 70.6 | 0.858 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, B.; Zhang, D.; Dong, F.; Zhang, J.; Shafiq, M.; Gu, Z. Rust-Style Patch: A Physical and Naturalistic Camouflage Attacks on Object Detector for Remote Sensing Images. Remote Sens. 2023, 15, 885. https://doi.org/10.3390/rs15040885
Deng B, Zhang D, Dong F, Zhang J, Shafiq M, Gu Z. Rust-Style Patch: A Physical and Naturalistic Camouflage Attacks on Object Detector for Remote Sensing Images. Remote Sensing. 2023; 15(4):885. https://doi.org/10.3390/rs15040885
Chicago/Turabian StyleDeng, Binyue, Denghui Zhang, Fashan Dong, Junjian Zhang, Muhammad Shafiq, and Zhaoquan Gu. 2023. "Rust-Style Patch: A Physical and Naturalistic Camouflage Attacks on Object Detector for Remote Sensing Images" Remote Sensing 15, no. 4: 885. https://doi.org/10.3390/rs15040885
APA StyleDeng, B., Zhang, D., Dong, F., Zhang, J., Shafiq, M., & Gu, Z. (2023). Rust-Style Patch: A Physical and Naturalistic Camouflage Attacks on Object Detector for Remote Sensing Images. Remote Sensing, 15(4), 885. https://doi.org/10.3390/rs15040885