


MSFANet: Multiscale Fusion Attention Network for Road Segmentation of Multispectral Remote Sensing Data



Abstract
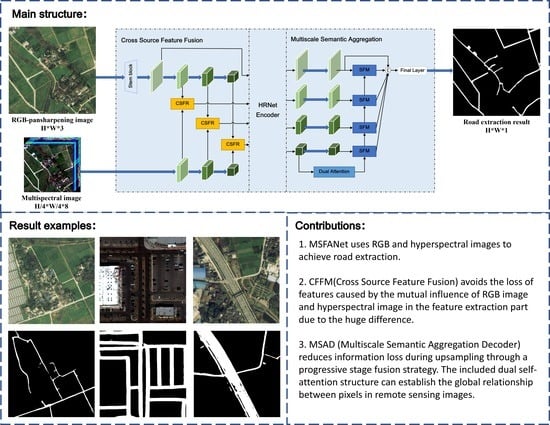
1. Introduction
- (1)
- Firstly, we designed the cross-source feature fusion module to generate feature maps at different scales to exploit the semantic representation at different scales and calibrate RGB and multispectral features at different scales by a lightweight attention mechanism to avoid the multiple noises generated by different data;
- (2)
- After the HRNet multiscale encoder, we construct a multiscale semantic aggregation decoder to obtain global contextual information in spatial and spectral dimensions using a self-attentive mechanism and fuse and decode feature maps and contextual information at different scales layer by layer to optimize road segmentation results;
- (3)
- By combining CFFM and MSAD, MSFANet’s performance evaluation implementation on our self-built Chongzhou road dataset and SpaceNet road dataset can show that our proposed model can improve the performance of road extraction and outperform the state-of-the-art models while being competitive in terms of the number of parameters and computational efficiency.
2. Related Research
2.1. Development of Semantic Segmentation Backbone
2.2. Segmentation in Remote Sensing Road Extraction
2.3. Attention Mechanisms
2.4. Multi-Source Data in Remote Sensing Segmentation
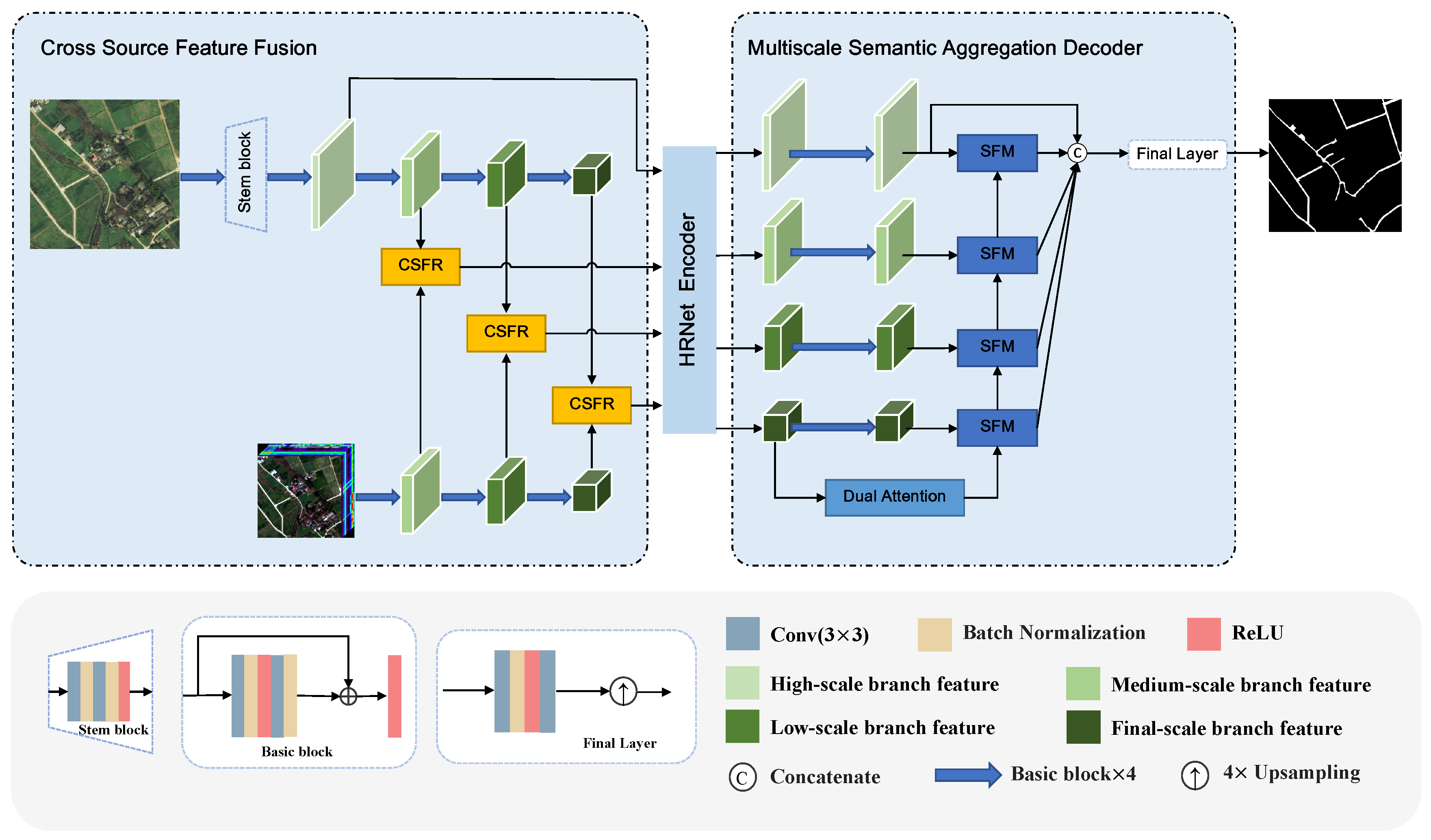
3. Methodology
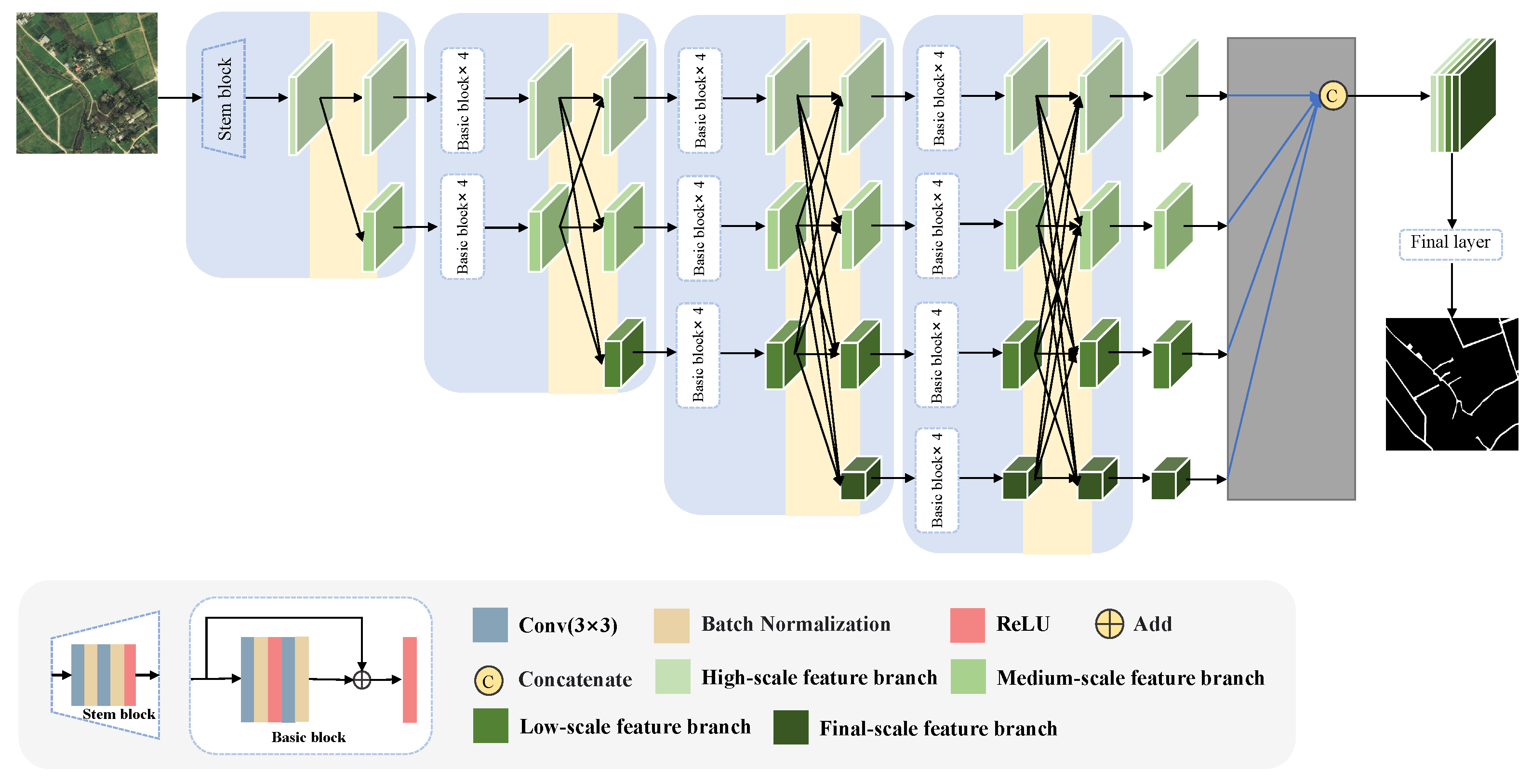
3.1. The Structure of HRNet
3.2. Architecture of MSFANet
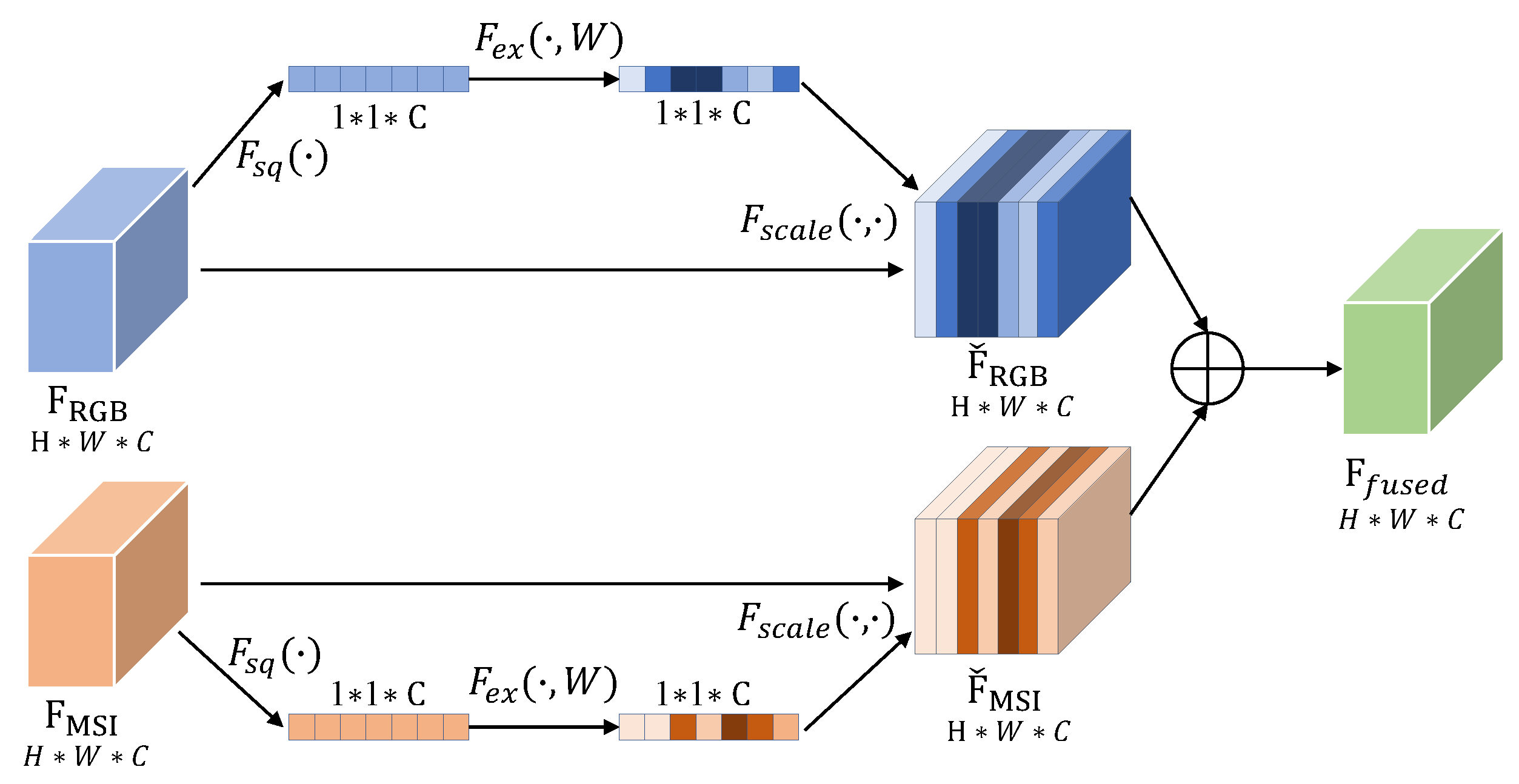
3.3. Cross-Source Feature Fusion Module
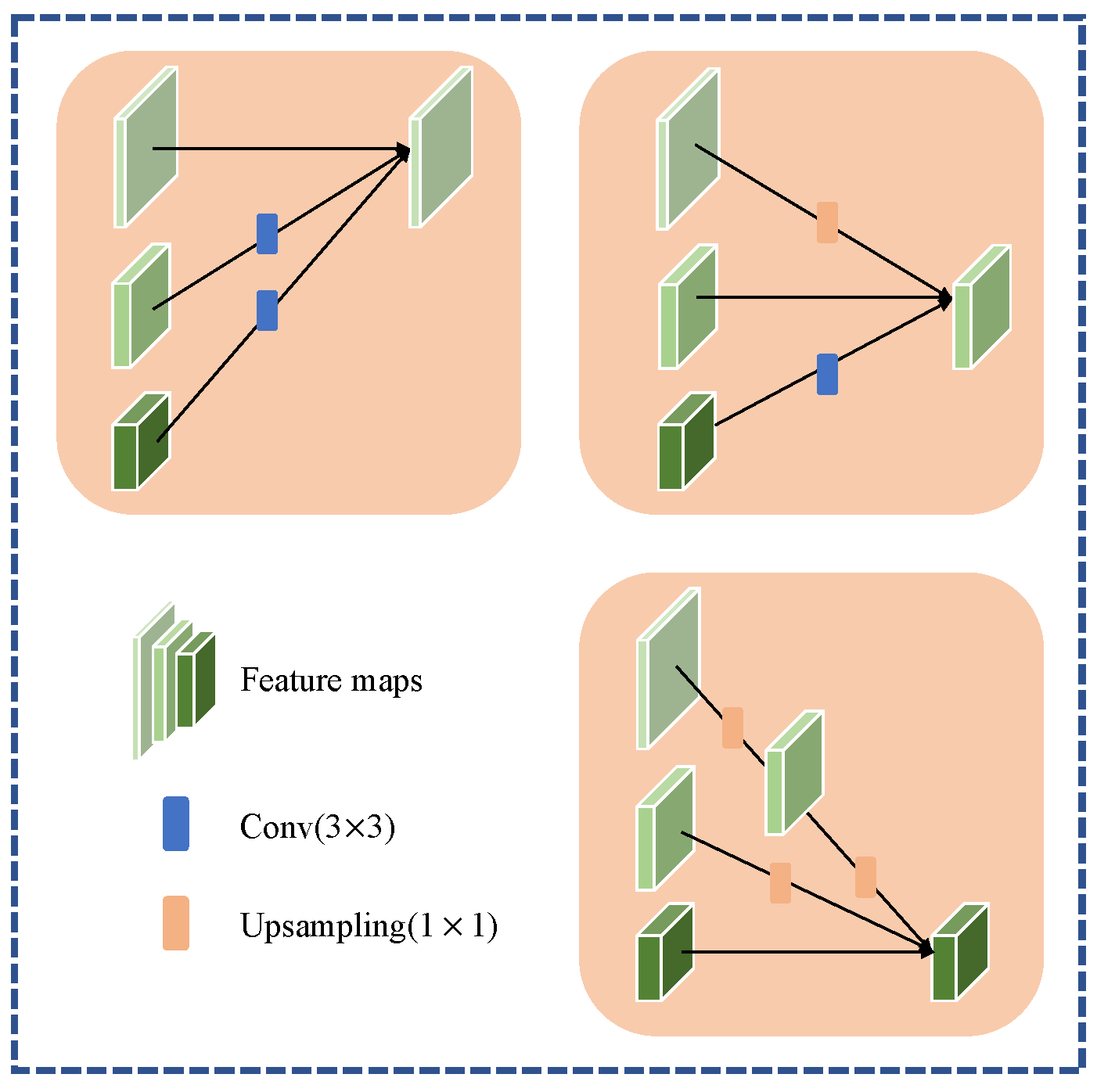
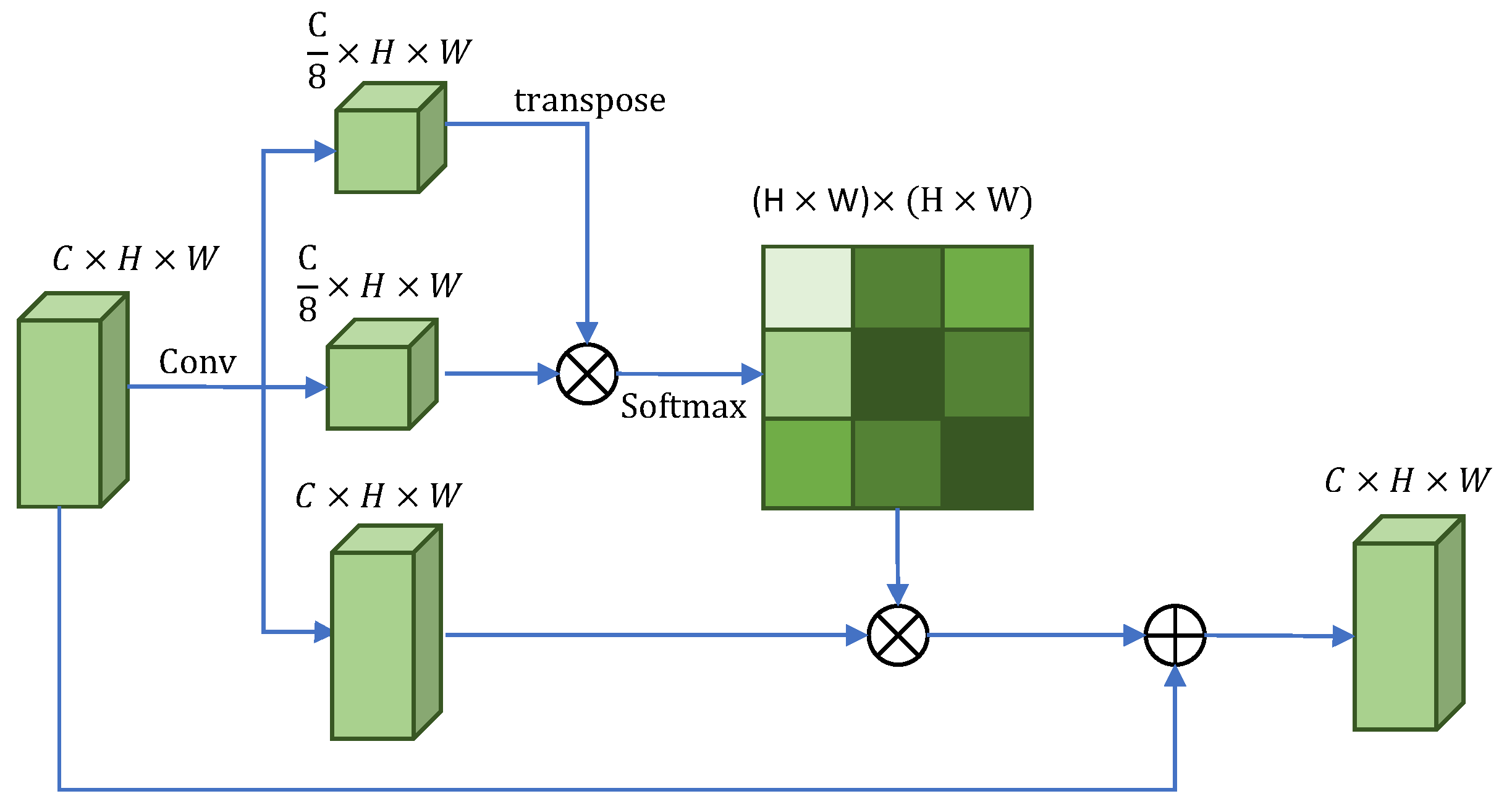
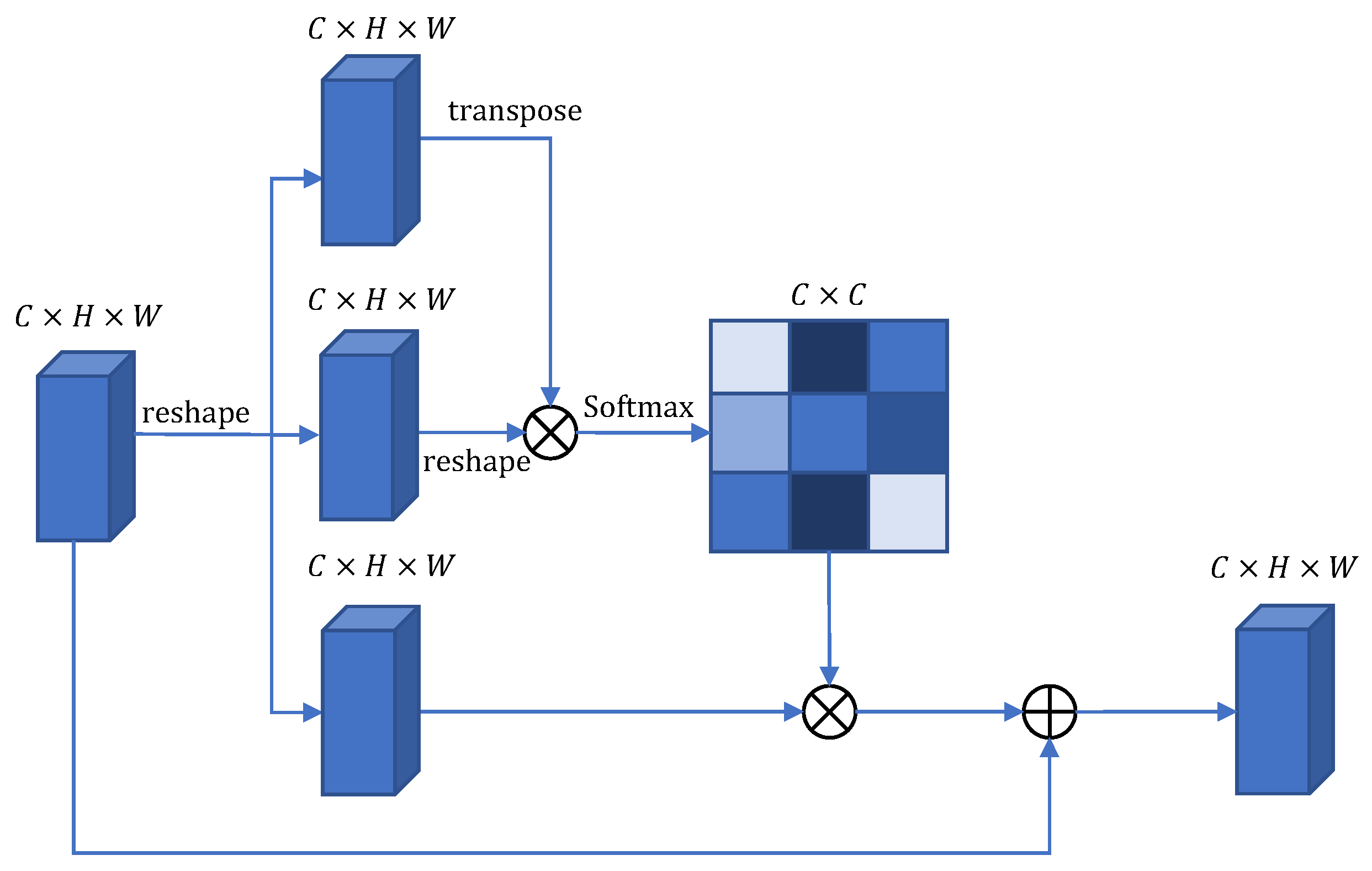
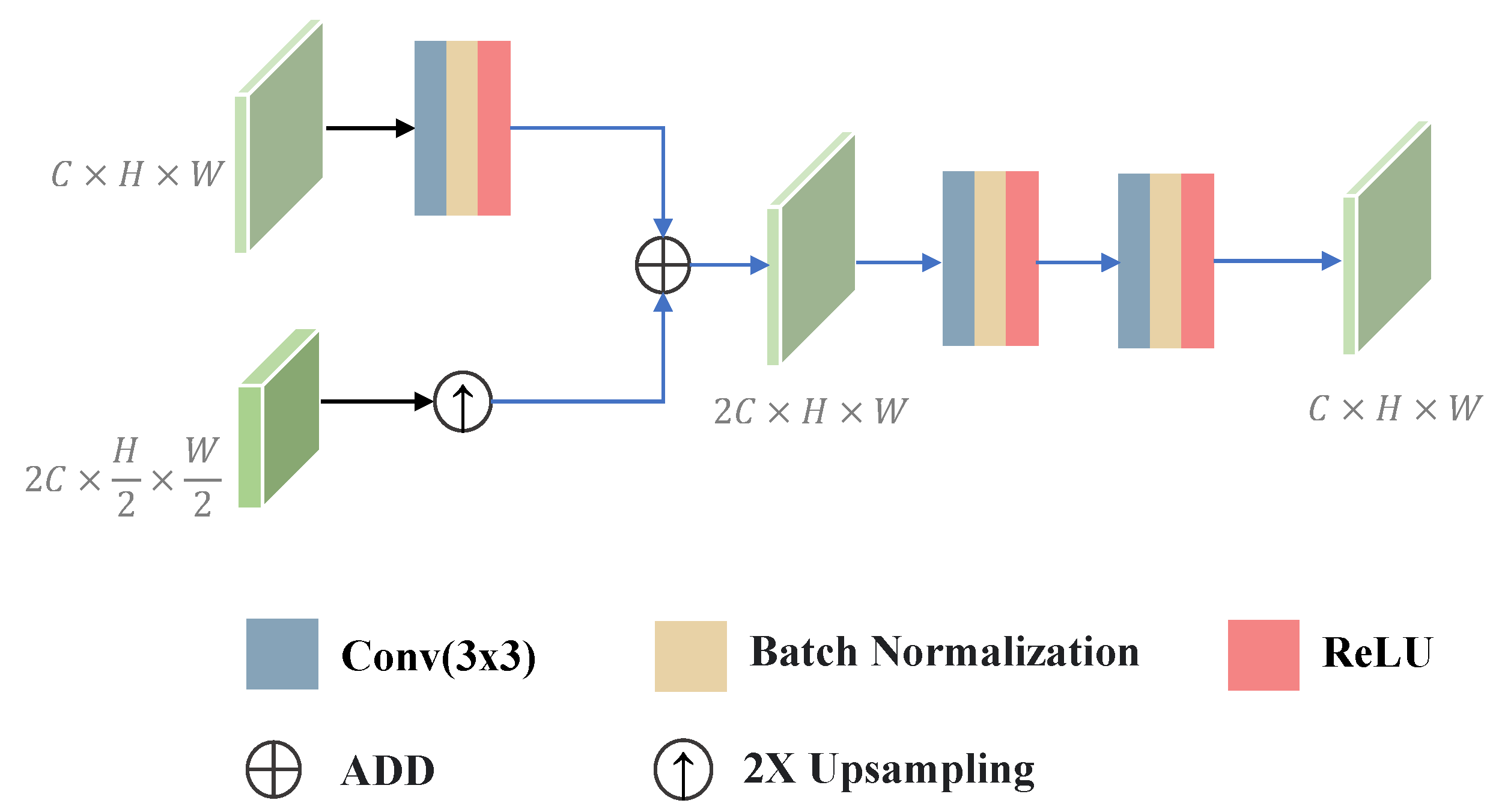
3.4. Multiscale Semantic Aggregation Decoder
4. Experiments
4.1. Dataset Descriptions
4.1.1. Chongzhou Road Dataset
4.1.2. Spacenet Road Dataset
4.2. Implementation Details and Metrics
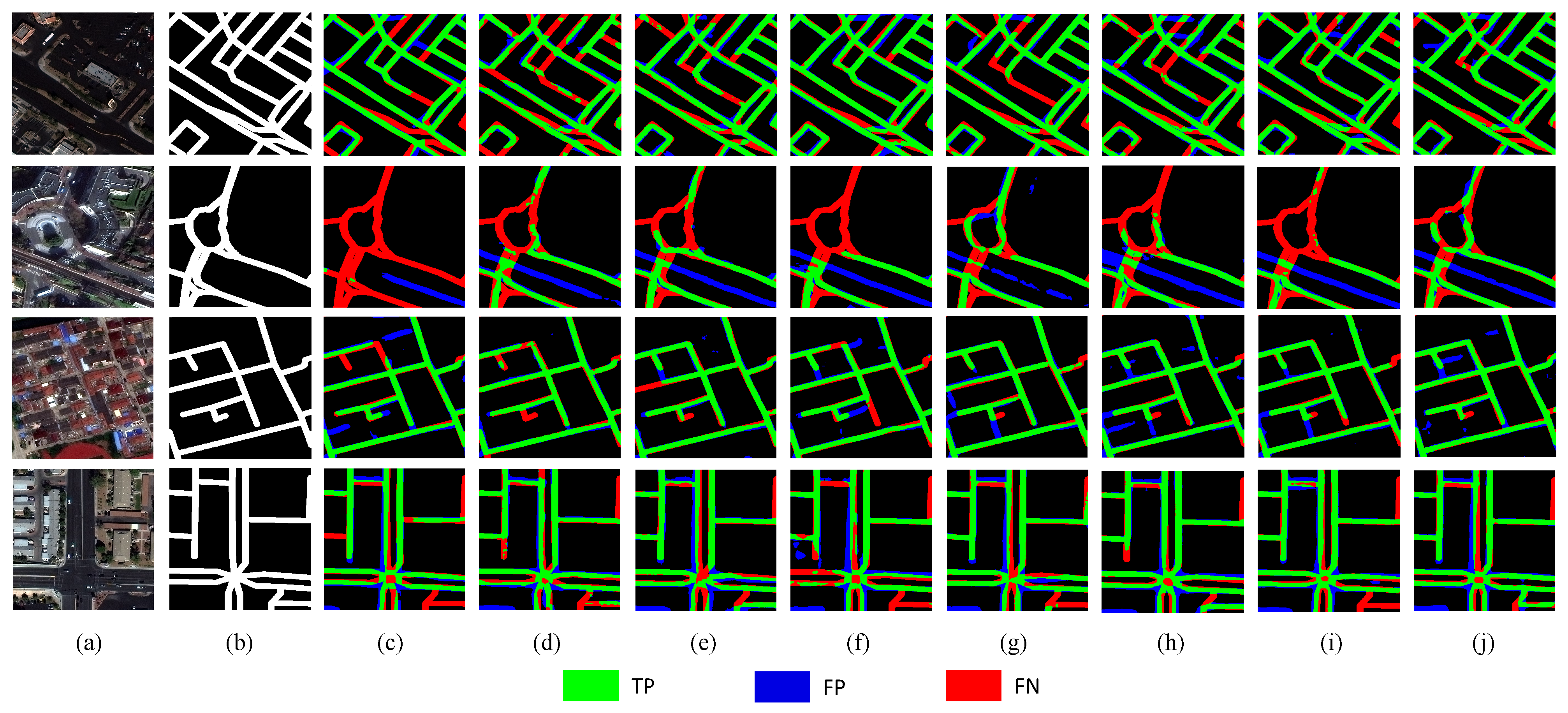
4.3. Results and Analysis
- (1)
- TP is the result of correct segmentation, colored green.
- (2)
- FP is the result of labeled background but identified as a road during segmentation, colored blue.
- (3)
- FN is the result of the road not being identified during segmentation, colored red.
4.4. Ablation Study
5. Discussion
5.1. Visualization Analysis
- (1)
- The comparison of activation maps in columns (b) and (c) shows that our proposed method can learn richer road features, including more detailed semantic representation information. Compare the activation map with the RGB images and labels in columns (a) and (d). It can be found that our model can extract more road features when the road is occluded, which improves the continuity of road extraction. Specific examples include the road in the upper left corner of the first row that is shaded by trees, and the road on the right in the second row that is shaded by building shadows.
- (2)
- For other features similar to roads, in our proposed method, the network has better road extract capability and will not misclassify similar features as roads. This can be demonstrated from the activation map in the third row. For the land area similar to the road in the upper left corner of the image, the activation map of MSFANet has a lower weight in this area, and no misidentification occurs, which improves the accuracy of the road extraction result.
- (3)
- At the position where the roads are connected, such as the lower right corner of the first row, the weight of the activation graph at the connection node is lower in the proposed method. This problem will affect the accuracy of road extraction, and it will also be solved in our follow-up research.
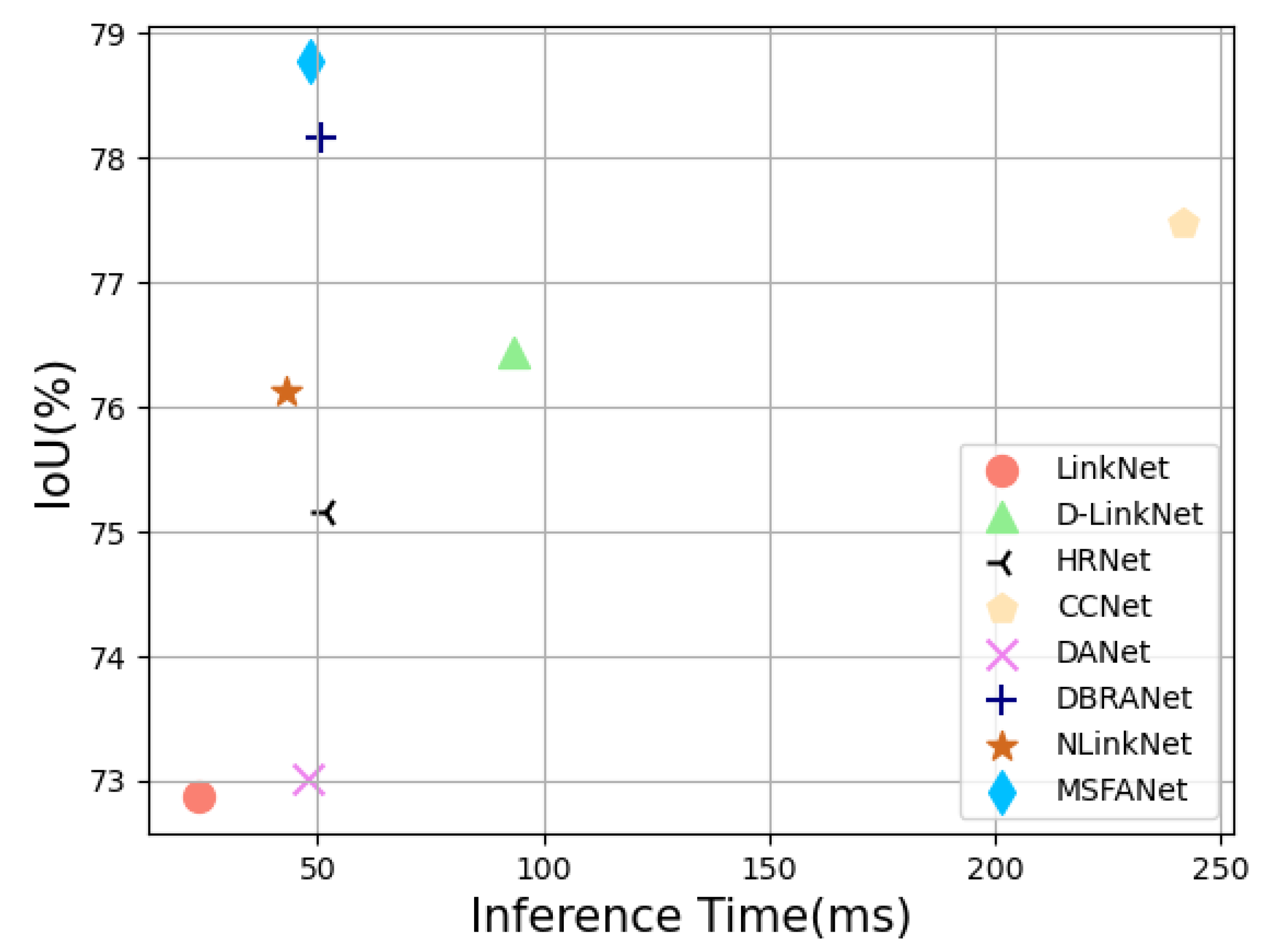
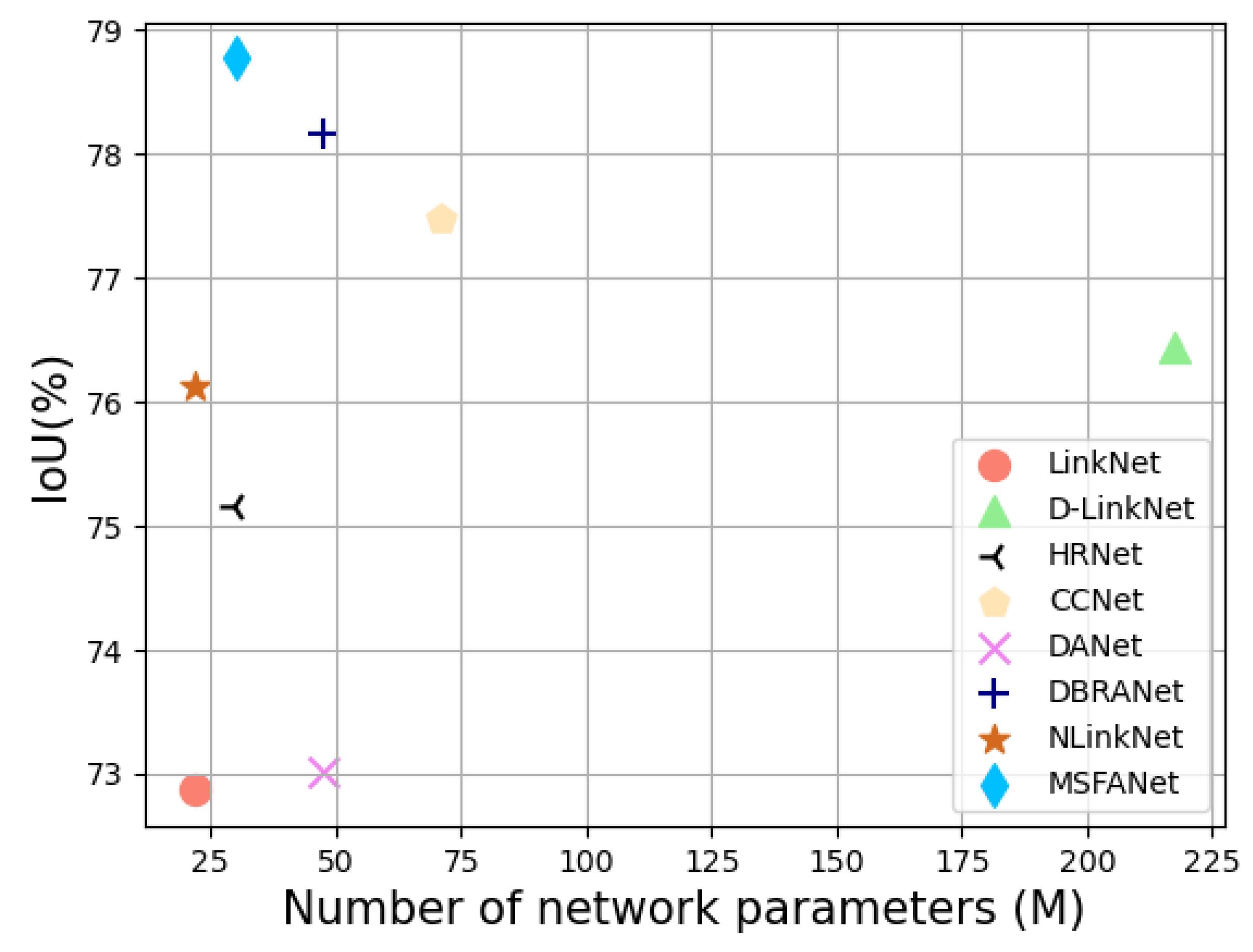
5.2. Computational Efficiency
5.3. Summary of MSFANet
- (1)
- Use RGB and hyperspectral images as the input of the road extraction network, use CFFM to calibrate RGB and hyperspectral multi-scale features, and fuse the same scale features. It avoids the loss of features caused by the mutual influence of RGB image and hyperspectral image in the feature extraction part due to the huge difference.
- (2)
- MSAD is designed in the decoding stage after the HRNet encoder. The information loss during upsampling is reduced by a progressive stage fusion strategy. The included dual self-attention structure can establish the global relationship between pixels in remote sensing images.
- (3)
- From the analysis of our experimental results, our method can extract the road features blocked by obstacles, and the ground objects that can be transplanted and similar to the road features are misclassified, which improved the extraction capabilities of the entire road extraction model.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, M.; Sui, H.; Chen, S.; Wang, J.; Chen, X. BT-RoadNet: A boundary and topologically-aware neural network for road extraction from high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2020, 168, 288–306. [Google Scholar] [CrossRef]
- Bachagha, N.; Wang, X.; Luo, L.; Li, L.; Khatteli, H.; Lasaponara, R. Remote sensing and GIS techniques for reconstructing the military fort system on the Roman boundary (Tunisian section) and identifying archaeological sites. Remote Sens. Environ. 2020, 236, 111418. [Google Scholar] [CrossRef]
- Jia, J.; Sun, H.; Jiang, C.; Karila, K.; Karjalainen, M.; Ahokas, E.; Khoramshahi, E.; Hu, P.; Chen, C.; Xue, T.; et al. Review on active and passive remote sensing techniques for road extraction. Remote Sens. 2021, 13, 4235. [Google Scholar] [CrossRef]
- Xu, Z.; Liu, Y.; Gan, L.; Hu, X.; Sun, Y.; Liu, M.; Wang, L. csBoundary: City-Scale Road-Boundary Detection in Aerial Images for High-Definition Maps. IEEE Robot. Autom. Lett. 2022, 7, 5063–5070. [Google Scholar] [CrossRef]
- Li, Q.; Chen, L.; Li, M.; Shaw, S.L.; Nüchter, A. A sensor-fusion drivable-region and lane-detection system for autonomous vehicle navigation in challenging road scenarios. IEEE Trans. Veh. Technol. 2013, 63, 540–555. [Google Scholar] [CrossRef]
- Aboah, A. A Vision-Based System for Traffic Anomaly Detection Using Deep Learning and Decision Trees. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Nashville, TN, USA, 19–25 June 2021; pp. 4207–4212. [Google Scholar]
- Bonnefon, R.; Dhérété, P.; Desachy, J. Geographic information system updating using remote sensing images. Pattern Recognit. Lett. 2002, 23, 1073–1083. [Google Scholar] [CrossRef]
- Lian, R.; Wang, W.; Mustafa, N.; Huang, L. Road extraction methods in high-resolution remote sensing images: A comprehensive review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5489–5507. [Google Scholar] [CrossRef]
- Stoica, R.; Descombes, X.; Zerubia, J. A Gibbs point process for road extraction from remotely sensed images. Int. J. Comput. Vis. 2004, 57, 121–136. [Google Scholar] [CrossRef]
- Bacher, U.; Mayer, H. Automatic road extraction from multispectral high resolution satellite images. In Proceedings of the CMRT05, Vienna, Austria, 29–30 August 2005; Volume 36. [Google Scholar]
- Mohammadzadeh, A.; Tavakoli, A.; Valadan Zoej, M.J. Road extraction based on fuzzy logic and mathematical morphology from pan-sharpened Ikonos images. Photogramm. Rec. 2006, 21, 44–60. [Google Scholar] [CrossRef]
- Maurya, R.; Gupta, P.; Shukla, A.S. Road extraction using k-means clustering and morphological operations. In Proceedings of the 2011 International Conference on Image Information Processing, Shimla, Himachal Pradesh, India, 3–5 November 2011; pp. 1–6. [Google Scholar]
- Song, M.; Civco, D. Road extraction using SVM and image segmentation. Photogramm. Eng. Remote Sens. 2004, 70, 1365–1371. [Google Scholar] [CrossRef]
- Amo, M.; Martínez, F.; Torre, M. Road extraction from aerial images using a region competition algorithm. IEEE Trans. Image Process. 2006, 15, 1192–1201. [Google Scholar] [CrossRef]
- Yager, N.; Sowmya, A. Support vector machines for road extraction from remotely sensed images. In Proceedings of the Computer Analysis of Images and Patterns: 10th International Conference, CAIP 2003, Groningen, The Netherlands, 25–27 August 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 285–292. [Google Scholar]
- Storvik, G.; Fjortoft, R.; Solberg, A.H.S. A Bayesian approach to classification of multiresolution remote sensing data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 539–547. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Ke, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Yadong, M.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Wang, Y.; Peng, Y.; Li, W.; Alexandropoulos, G.C.; Yu, J.; Ge, D.; Xiang, W. DDU-Net: Dual-decoder-U-Net for road extraction using high-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Yang, M.; Yuan, Y.; Liu, G. SDUNet: Road extraction via spatial enhanced and densely connected UNet. Pattern Recognit. 2022, 126, 108549. [Google Scholar] [CrossRef]
- Yang, X.; Li, X.; Ye, Y.; Lau, R.Y.; Zhang, X.; Huang, X. Road detection and centerline extraction via deep recurrent convolutional neural network U-Net. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7209–7220. [Google Scholar] [CrossRef]
- Wan, J.; Xie, Z.; Xu, Y.; Chen, S.; Qiu, Q. DA-RoadNet: A dual-attention network for road extraction from high resolution satellite imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6302–6315. [Google Scholar] [CrossRef]
- Huan, H.; Sheng, Y.; Zhang, Y.; Liu, Y. Strip Attention Networks for Road Extraction. Remote Sens. 2022, 14, 4516. [Google Scholar] [CrossRef]
- Ma, W.; Karakuş, O.; Rosin, P.L. AMM-FuseNet: Attention-based multi-modal image fusion network for land cover mapping. Remote Sens. 2022, 14, 4458. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhou, L.; Zhang, C. Linknet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 192–1924. [Google Scholar]
- He, S.; Bastani, F.; Jagwani, S.; Alizadeh, M.; Balakrishnan, H.; Chawla, S.; Elshrif, M.M.; Madden, S.; Sadeghi, M.A. Sat2graph: Road graph extraction through graph-tensor encoding. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 51–67. [Google Scholar]
- Xie, Y.; Miao, F.; Zhou, K.; Peng, J. HsgNet: A road extraction network based on global perception of high-order spatial information. ISPRS Int. J. Geo Inf. 2019, 8, 571. [Google Scholar] [CrossRef]
- Chen, S.B.; Ji, Y.X.; Tang, J.; Luo, B.; Wang, W.Q.; Lv, K. DBRANet: Road extraction by dual-branch encoder and regional attention decoder. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Wang, Y.; Seo, J.; Jeon, T. NL-LinkNet: Toward lighter but more accurate road extraction with nonlocal operations. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. In Proceedings of the British Machine Vision Conference, Newcastle, UK, 3–6 September 2018; p. 285. [Google Scholar]
- Rudner, T.G.; Rußwurm, M.; Fil, J.; Pelich, R.; Bischke, B.; Kopačková, V.; Biliński, P. Multi3net: Segmenting flooded buildings via fusion of multiresolution, multisensor, and multitemporal satellite imagery. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 702–709. [Google Scholar]
- Ma, X.; Zhang, X.; Pun, M.O. A crossmodal multiscale fusion network for semantic segmentation of remote sensing data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3463–3474. [Google Scholar] [CrossRef]
- Lei, T.; Li, L.; Lv, Z.; Zhu, M.; Du, X.; Nandi, A.K. Multi-modality and multi-scale attention fusion network for land cover classification from VHR remote sensing images. Remote Sens. 2021, 13, 3771. [Google Scholar] [CrossRef]
- Sun, Y.; Fu, Z.; Sun, C.; Hu, Y.; Zhang, S. Deep multimodal fusion network for semantic segmentation using remote sensing image and LiDAR data. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–18. [Google Scholar] [CrossRef]
- Cao, Z.; Diao, W.; Sun, X.; Lyu, X.; Yan, M.; Fu, K. C3net: Cross-modal feature recalibrated, cross-scale semantic aggregated and compact network for semantic segmentation of multi-modal high-resolution aerial images. Remote Sens. 2021, 13, 528. [Google Scholar] [CrossRef]
- De Carvalho, O.L.F.; de Carvalho Júnior, O.A.; De Albuquerque, A.O.; Santana, N.C.; Borges, D.L.; Luiz, A.S.; Gomes, R.A.T.; Guimarães, R.F. Multispectral panoptic segmentation: Exploring the beach setting with worldview-3 imagery. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102910. [Google Scholar] [CrossRef]
- Van Etten, A.; Lindenbaum, D.; Bacastow, T.M. Spacenet: A remote sensing dataset and challenge series. arXiv 2018, arXiv:1807.01232. [Google Scholar]
- Batra, A.; Singh, S.; Pang, G.; Basu, S.; Jawahar, C.; Paluri, M. Improved road connectivity by joint learning of orientation and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10385–10393. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations From Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2921–2929. [Google Scholar]
- Chu, X.; Chen, L.; Yu, W. NAFSSR: Stereo Image Super-Resolution Using NAFNet. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1239–1248. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Band Name | Spectral Band |
|---|---|
| Panchromatic Band | 450–800 nm |
| Coastal Blue | 400–450 nm |
| Blue | 450–510 nm |
| Green | 510–580 nm |
| Yellow | 585–625 nm |
| Red | 630–690 nm |
| Red edge | 705–745 nm |
| Near-IR1 | 770–895 nm |
| Near-IR2 | 860–1040 nm |
| System | Ubuntu 18.04.6 |
|---|---|
| HPC Resource | NVIDIA GeForce RTX 3090 Ti |
| DL Framework | Pytorch V1.11.0 |
| Compiler | Python V3.9.12 |
| Optimizer | AdamW |
| Loss Function | CEloss |
| Learning Rate | 0.001 |
| LR Policy | PolyLR |
| Batch Size | 4 (ChongZhou), 8 (SpaceNet) |
| Method | IoU | mIoU | Recall | Precision | F1 |
|---|---|---|---|---|---|
| ChongZhou Dataset | |||||
| LinkNet [18] | 72.87 | 85.99 | 85.60 | 83.00 | 84.28 |
| DLinkNet [29] | 76.44 | 87.85 | 89.30 | 84.20 | 86.68 |
| HRNet [20] | 75.16 | 87.19 | 89.10 | 82.80 | 85.84 |
| CCNet [36] | 77.48 | 88.39 | 90.50 | 84.40 | 87.34 |
| DANet [37] | 73.02 | 86.07 | 85.60 | 83.30 | 84.43 |
| DBRANet [32] | 78.17 | 88.74 | 90.50 | 85.20 | 87.77 |
| NLLinkNet [33] | 76.12 | 87.68 | 89.30 | 83.80 | 86.46 |
| Ours | 78.77 | 89.05 | 90.20 | 86.20 | 88.16 |
| SpaceNet Dataset | |||||
| LinkNet | 58.13 | 76.55 | 69.70 | 77.70 | 73.48 |
| DLinkNet | 59.79 | 77.44 | 72.80 | 77.00 | 74.84 |
| HRNet | 55.07 | 74.88 | 65.30 | 77.80 | 71.00 |
| CCNet | 59.27 | 77.18 | 71.40 | 77.80 | 74.46 |
| DANet | 60.16 | 77.66 | 72.90 | 77.50 | 75.13 |
| DBRANet | 59.66 | 76.83 | 88.20 | 71.00 | 73.97 |
| NLLinkNet | 58.77 | 76.87 | 76.70 | 71.50 | 74.01 |
| Ours | 61.45 | 78.38 | 74.50 | 77.80 | 76.11 |
| Methods | Multi Spectral | CFFM | MSAD | IoU | mIoU | F1 | Precision | Recall |
|---|---|---|---|---|---|---|---|---|
| Chongzhou dataset | ||||||||
| HRNet | 75.16 | 87.19 | 85.84 | 82.80 | 89.10 | |||
| HRNet | ✓ | 77.69 | 88.50 | 87.47 | 84.90 | 90.20 | ||
| MSFANet | ✓ | 77.03 | 88.16 | 89.90 | 84.30 | 87.01 | ||
| MSFANet | ✓ | ✓ | 75.87 | 87.55 | 86.29 | 84.00 | 88.70 | |
| MSFANet | ✓ | ✓ | 77.90 | 88.60 | 87.60 | 85.60 | 89.70 | |
| MSFANet | ✓ | ✓ | ✓ | 78.77 | 89.05 | 88.16 | 86.20 | 90.20 |
| SpaceNet dataset | ||||||||
| HRNet | 55.07 | 74.88 | 71.00 | 65.30 | 77.80 | |||
| HRNet | ✓ | 55.81 | 75.23 | 71.66 | 67.70 | 76.10 | ||
| MSFANet | ✓ | 60.52 | 77.88 | 75.41 | 72.90 | 78.10 | ||
| MSFANet | ✓ | ✓ | 57.74 | 76.25 | 73.21 | 71.60 | 74.90 | |
| MSFANet | ✓ | ✓ | 59.84 | 77.40 | 74.90 | 74.80 | 75.00 | |
| MSFANet | ✓ | ✓ | ✓ | 61.45 | 78.38 | 76.11 | 74.50 | 77.80 |
| Methods | Inference Time (ms/per Image) | Parameters (M) | IoU (%) |
|---|---|---|---|
| LinkNet | 23.4 | 21.643 | 72.87 |
| D-LinkNet | 93.6 | 217.65 | 76.44 |
| HRNet | 51.8 | 29.538 | 75.16 |
| CCNet | 241.8 | 70.942 | 77.48 |
| DANet | 47.7 | 47.436 | 73.02 |
| DBRANet | 51.2 | 47.68 | 78.17 |
| NLinkNet | 42.8 | 21.82 | 76.12 |
| MSFANet | 48.4 | 30.25 | 78.77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tong, Z.; Li, Y.; Zhang, J.; He, L.; Gong, Y. MSFANet: Multiscale Fusion Attention Network for Road Segmentation of Multispectral Remote Sensing Data. Remote Sens. 2023, 15, 1978. https://doi.org/10.3390/rs15081978
Tong Z, Li Y, Zhang J, He L, Gong Y. MSFANet: Multiscale Fusion Attention Network for Road Segmentation of Multispectral Remote Sensing Data. Remote Sensing. 2023; 15(8):1978. https://doi.org/10.3390/rs15081978
Chicago/Turabian StyleTong, Zhonggui, Yuxia Li, Jinglin Zhang, Lei He, and Yushu Gong. 2023. "MSFANet: Multiscale Fusion Attention Network for Road Segmentation of Multispectral Remote Sensing Data" Remote Sensing 15, no. 8: 1978. https://doi.org/10.3390/rs15081978
APA StyleTong, Z., Li, Y., Zhang, J., He, L., & Gong, Y. (2023). MSFANet: Multiscale Fusion Attention Network for Road Segmentation of Multispectral Remote Sensing Data. Remote Sensing, 15(8), 1978. https://doi.org/10.3390/rs15081978