

A Novel Real-Time Edge-Guided LiDAR Semantic Segmentation Network for Unstructured Environments

Abstract
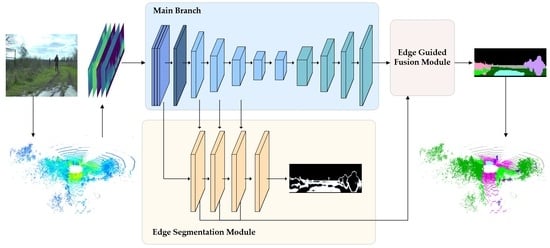
1. Introduction
- We propose a novel edge-guided network for real-time LiDAR semantic segmentation in unstructured environments. The network fully exploits edge cues and deeply integrates them with semantic features to solve the problem of inaccurate segmentation results in unstructured environments due to blurred class edges. Compared with state-of-the-art point clouds segmentation networks, the proposed network performs better in the segmentation of unstructured environments, especially in drivable areas and static obstacles with large areas;
- We design an edge segmentation module which contains three edge attention blocks. Different from the published point clouds semantic segmentation methods, this module adaptively extracts high-resolution edge semantic features accurately from the feature maps of the main branch in a supervised manner, which improves the accuracy of edge segmentation on the one hand, and provides edge guidance for semantic segmentation of the main branch on the other hand, thus helping to capture edge features of classes in unstructured environments more effectively;
- We design an edge guided fusion module to better fuse edge features and semantic features, and improve the discrimination of pixels around edges between classes. Different from the traditional feature fusion methods, this module fully exploits the multi-scale information and recalibrates the importance of different scale features through a channel-dependent method, effectively utilizing the complementary information of edge features and semantic features to further improve the segmentation accuracy of the model.
2. Related Work
2.1. Semantic Segmentation of Large-Scale Point Clouds
2.2. Semantic Segmentation of Unstructured Environments
2.3. Edge Improved Semantic Segmentation
3. Methods
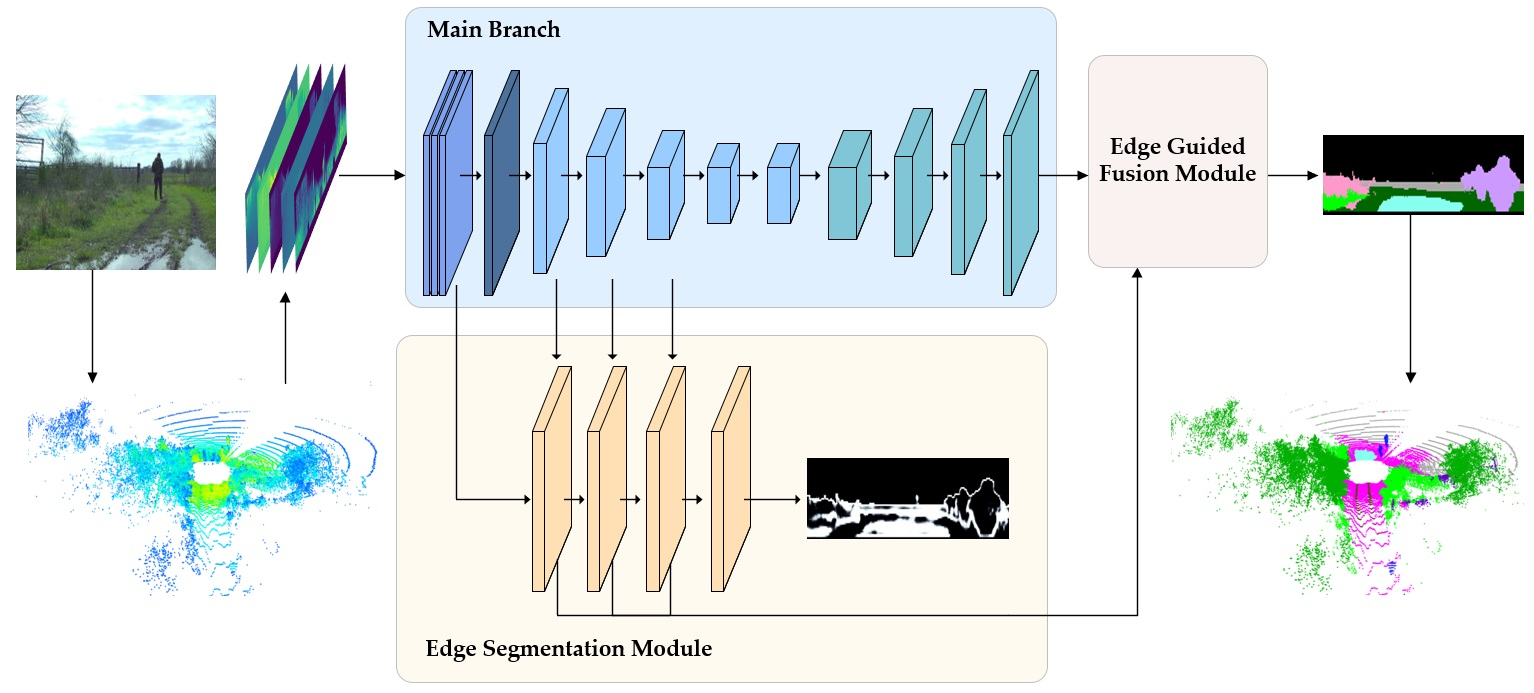
3.1. Network Overview
3.2. Data Pre-Processing
3.2.1. Pre-Processing of Input Data
3.2.2. Pre-Processing of Labels
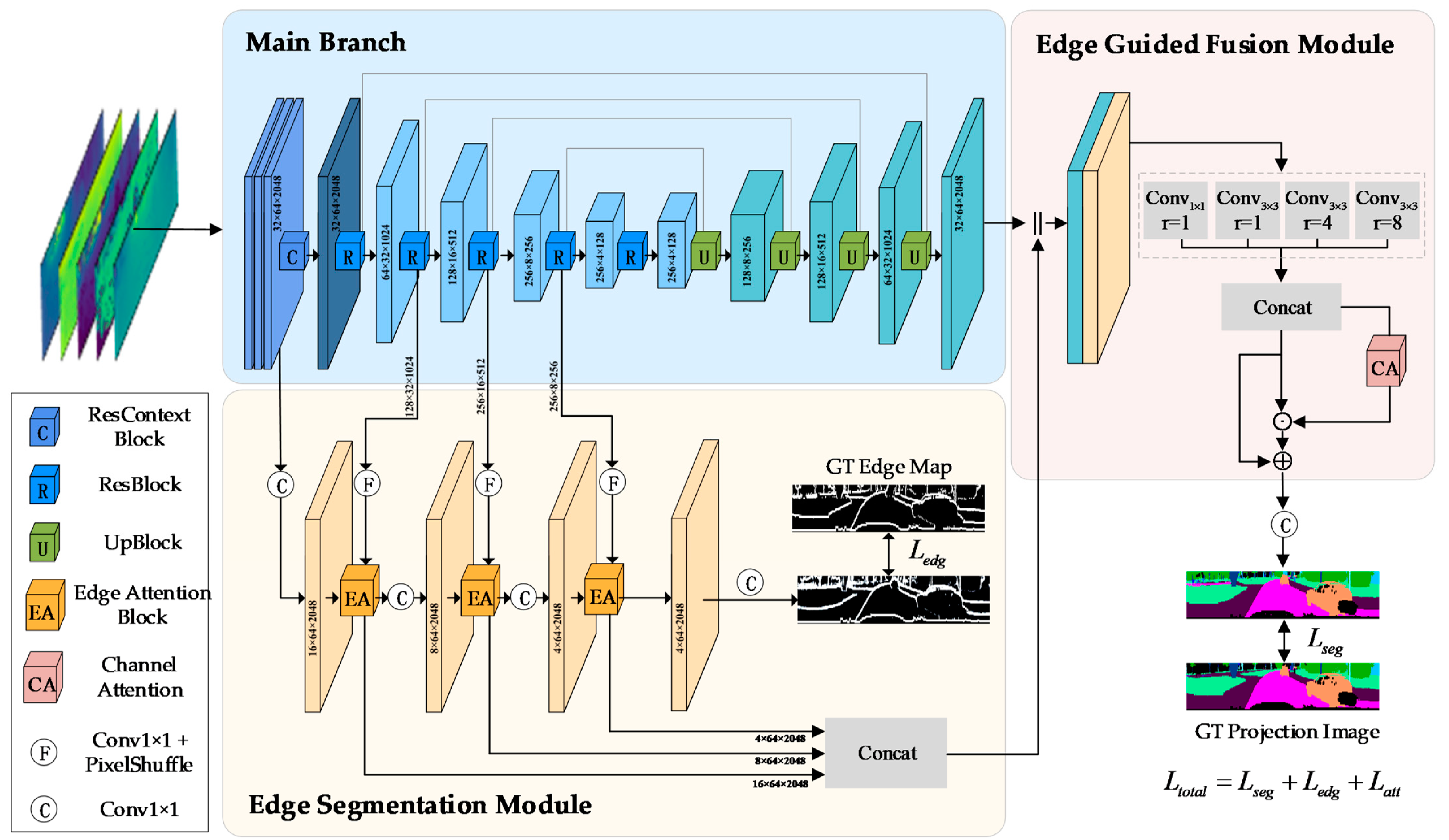
3.3. Main Branch
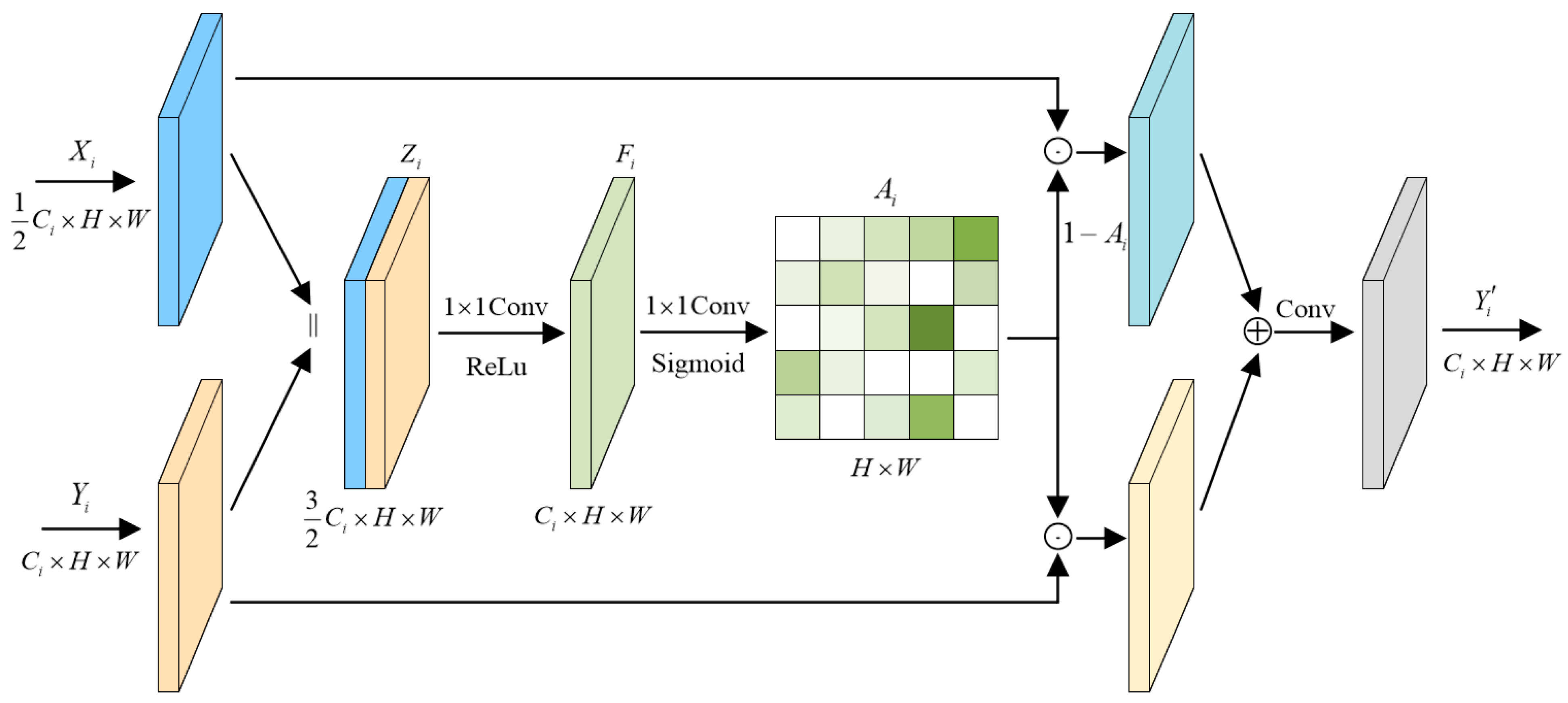
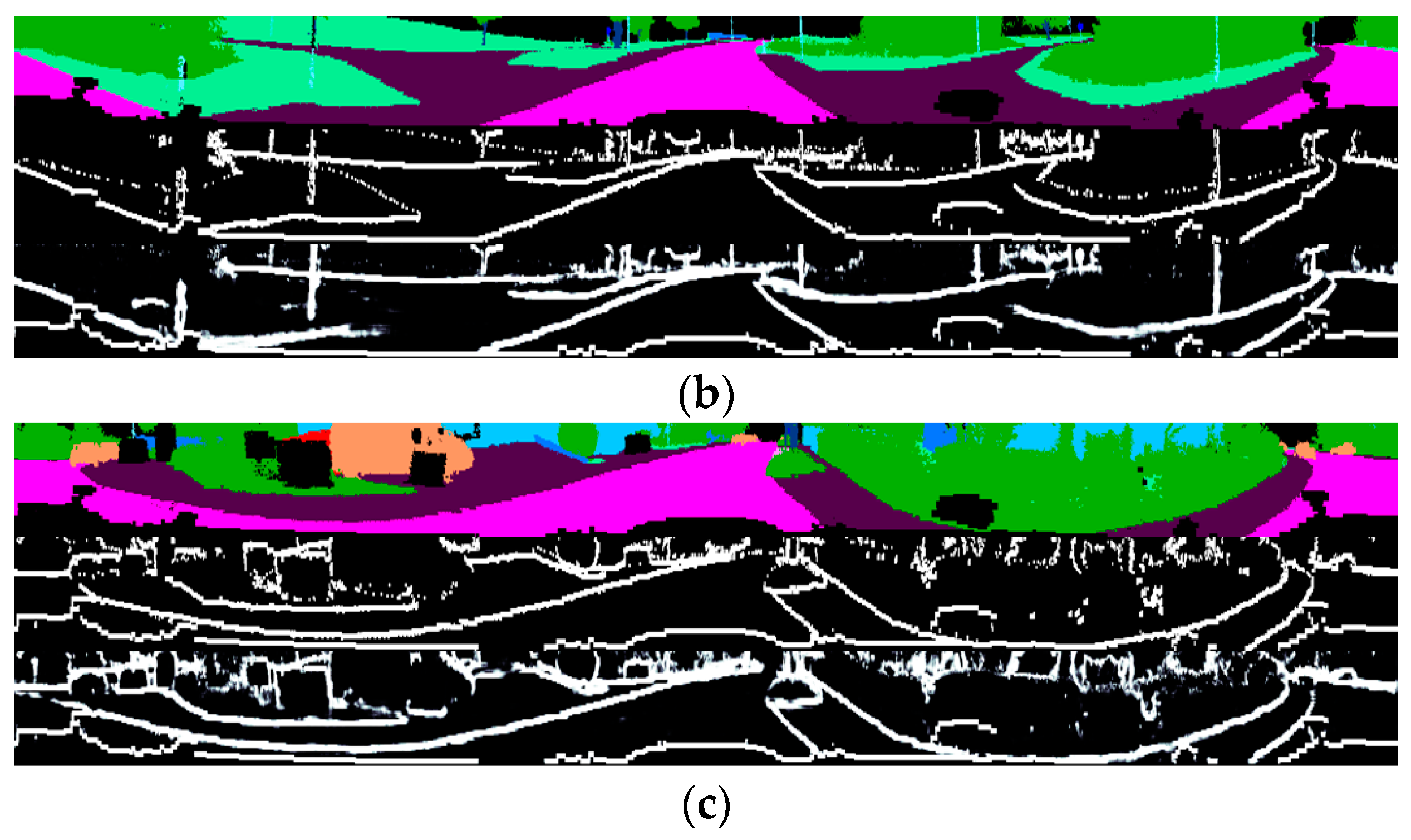
3.4. Edge Segmentation Module
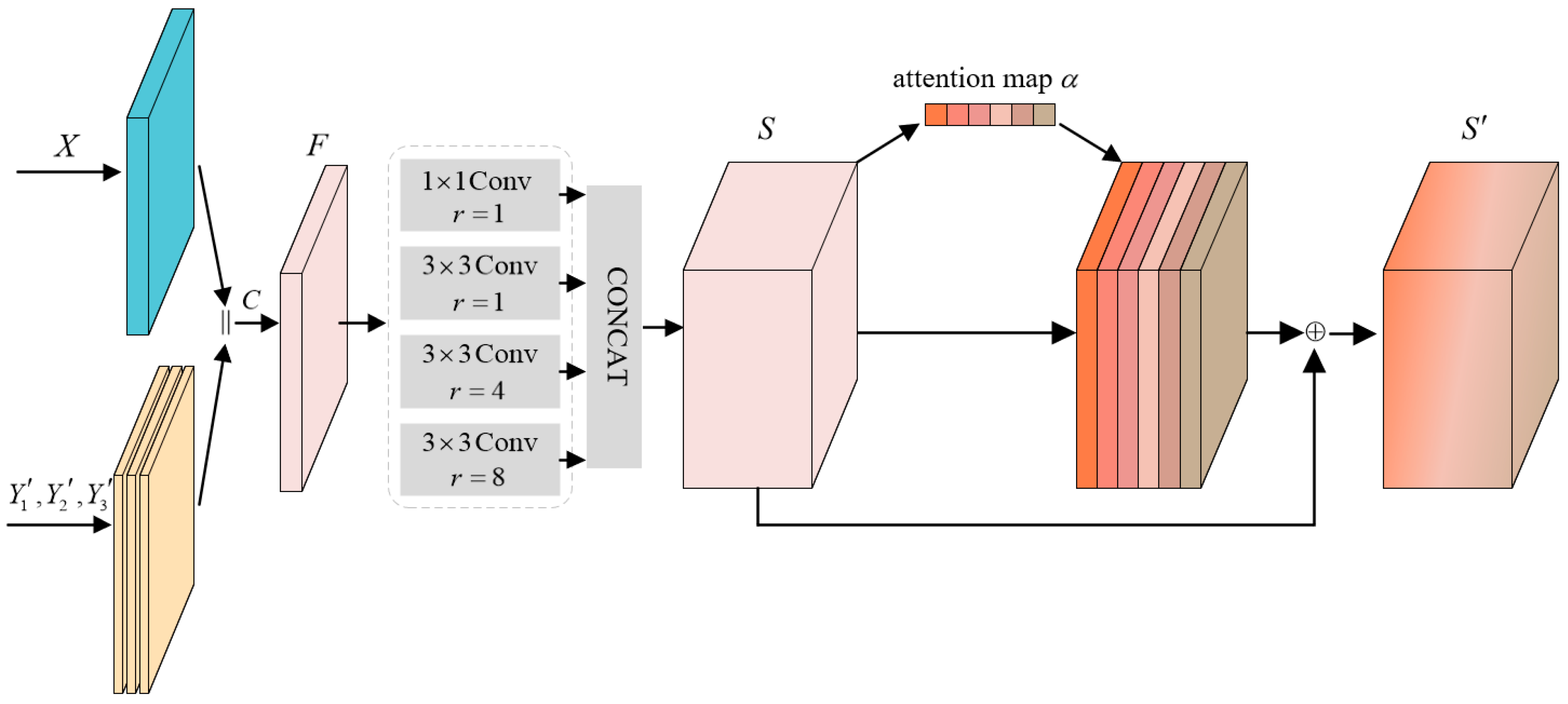
3.5. Edge Guided Fusion Module
3.6. Loss Function
4. Experiments and Results
4.1. Dataset and Metric
4.1.1. Dataset
4.1.2. Metric
4.2. Implementation Details
4.3. Experimental Results
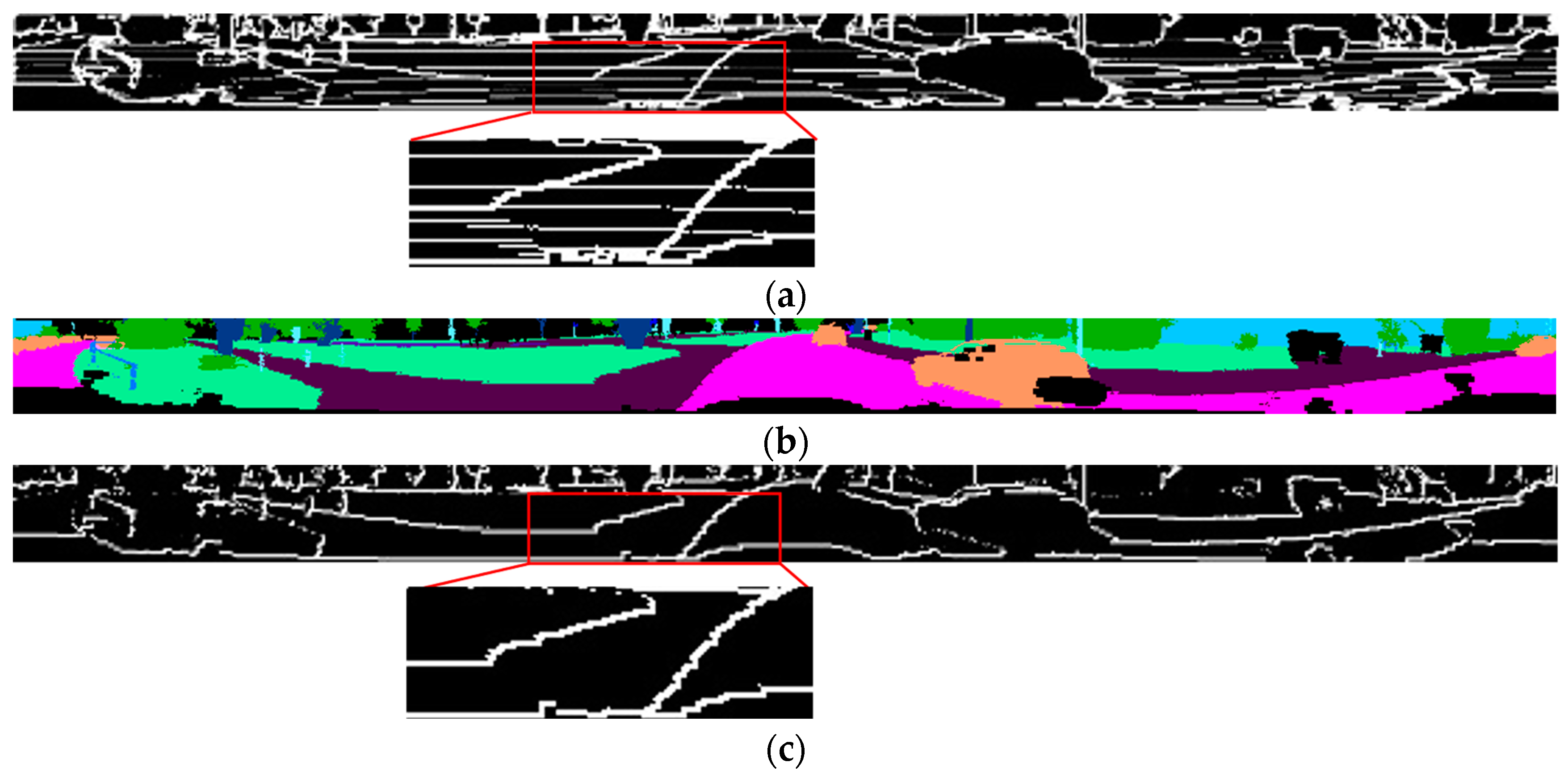
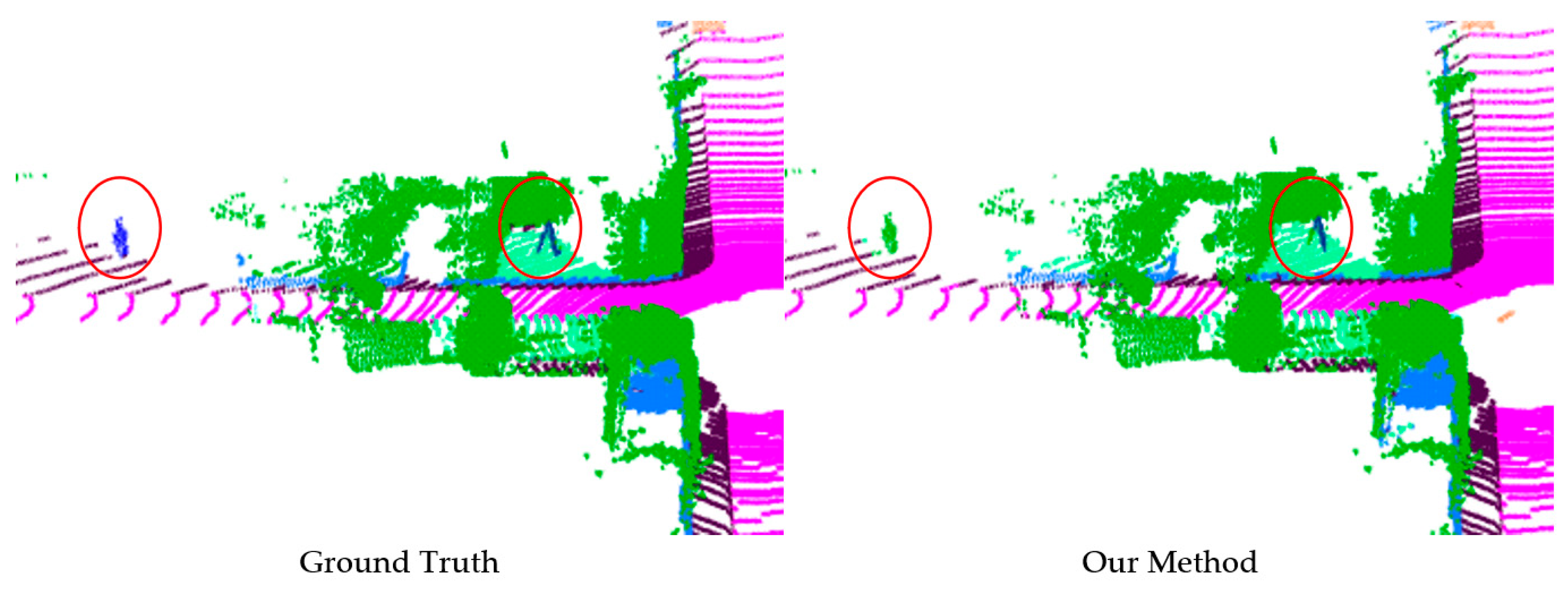
4.3.1. Experiment on SemanticKITTI Dataset
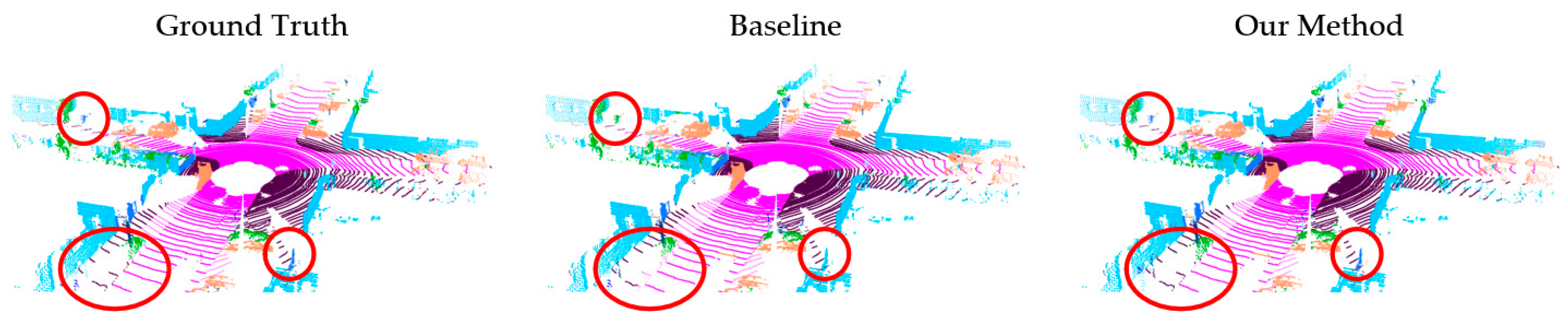
4.3.2. Experiment on RELLIS-3D Dataset
4.3.3. Experiment on Our Real Vehicle Test Dataset
4.4. Ablation Study
- Using only ESM improves mIoU by 0.76% with 11.15 GFLOPs and 0.05 M parameters increasement compared to baseline;
- Using only EGFM improves mIoU by 0.21% with 17.75 GFLOPs and 0.07 M parameters increasement compared to baseline. Compared with only using the ESM, the performance improvement is not obvious. This is because the EGFM is based on the ESM and after the ESM is removed, the EGFM cannot fuse the edge features well;
- When combing the ESM and EGFM (our method), the mIoU is improved by 1.36% with 24.90 GFLOPs and 0.10 M parameters, an increase compared to the baseline, and performs much better than adding just one module alone as described above;
- When removing the three 1 × 1 convolutions from our method, the mIoU drop by 0.07%, but the FLOPs and parameters show only a minor decrease;
- The ablation experiments demonstrate the effectiveness of our designed modules and the effectiveness of using edge features to enhance semantic segmentation accuracy.
- With the removal of EAB and CA, the mIoU of our model decreased by 0.62% but is still 0.74% higher than the baseline, which proves the effectiveness of our overall edge-guided framework;
- By deleting only EAB, the mIoU of our model decreased by 0.45%, and after deleting only CA, the mIoU decreased by 0.21%, which indicates that EAB has a greater impact on the overall model than CA. We argue that the reason for this phenomenon lies in that, the absence of three cascading EABs can make the fused features contain too much unnecessary information, thus negatively affecting the response of CA, while CA does not affect the preceding EABs as it calibrates the fused features.
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Time (ms) | mIoU (%) | Road | Parking | Sidewalk | Vegetation | Terrain | Truck | Car | Bike | Motor | Other-vehicle | Person | Building | Fence | Trunk | Pole | Traffic-sign |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | 25 | 66.09 | 94.58 | 54.05 | 81.68 | 81.90 | 66.80 | 81.26 | 83.46 | 65.38 | 46.25 | 49.71 | 62.31 | 78.55 | 57.50 | 54.71 | 46.92 | 52.31 |
| ours | 35 | 68.59 | 95.20 | 58.51 | 82.14 | 82.31 | 66.83 | 87.26 | 84.54 | 70.14 | 48.68 | 47.20 | 61.49 | 82.15 | 60.37 | 59.72 | 59.44 | 51.49 |

Appendix B



References
- He, Y.; Yu, H.; Liu, X.; Yang, Z.; Sun, W.; Wang, Y.; Fu, Q.; Zou, Y.; Mian, A. Deep learning based 3D segmentation: A survey. arXiv 2021, arXiv:2103.05423. [Google Scholar]
- Wang, W.; You, X.; Yang, J.; Su, M.; Zhang, L.; Yang, Z.; Kuang, Y. LiDAR-Based Real-Time Panoptic Segmentation via Spatiotemporal Sequential Data Fusion. Remote Sens. 2022, 14, 1775. [Google Scholar] [CrossRef]
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Glaeser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1341–1360. [Google Scholar] [CrossRef]
- Zhao, L.; Xu, S.; Liu, L.; Ming, D.; Tao, W. SVASeg: Sparse Voxel-Based Attention for 3D LiDAR Point Cloud Semantic Segmentation. Remote Sens. 2022, 14, 4471. [Google Scholar] [CrossRef]
- Asgari Taghanaki, S.; Abhishek, K.; Cohen, J.P.; Cohen-Adad, J.; Hamarneh, G. Deep semantic segmentation of natural and medical images: A review. Artif. Intell. Rev. 2021, 54, 137–178. [Google Scholar] [CrossRef]
- Yang, R.; Yu, Y. Artificial convolutional neural network in object detection and semantic segmentation for medical imaging analysis. Front. Oncol. 2021, 11, 638182. [Google Scholar] [CrossRef]
- Li, Y.; Ma, L.; Zhong, Z.; Liu, F.; Chapman, M.A.; Cao, D.; Li, J. Deep learning for lidar point clouds in autonomous driving: A review. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3412–3432. [Google Scholar] [CrossRef]
- Guo, Z.; Huang, Y.; Hu, X.; Wei, H.; Zhao, B. A survey on deep learning based approaches for scene understanding in autonomous driving. Electronics 2021, 10, 471. [Google Scholar] [CrossRef]
- Baheti, B.; Innani, S.; Gajre, S.; Talbar, S. Semantic scene segmentation in unstructured environment with modified DeepLabV3+. Pattern Recognit. Lett. 2020, 138, 223–229. [Google Scholar] [CrossRef]
- Liu, H.; Yao, M.; Xiao, X.; Cui, H. A hybrid attention semantic segmentation network for unstructured terrain on Mars. Acta Astronaut. 2022, in press. [Google Scholar] [CrossRef]
- Gao, B.; Xu, A.; Pan, Y.; Zhao, X.; Yao, W.; Zhao, H. Off-road drivable area extraction using 3D LiDAR data. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1505–1511. [Google Scholar]
- Zhu, Z.; Li, X.; Xu, J.; Yuan, J.; Tao, J. Unstructured road segmentation based on road boundary enhancement point-cylinder network using LiDAR sensor. Remote Sens. 2021, 13, 495. [Google Scholar] [CrossRef]
- Chen, Y.; Xiong, Y.; Zhang, B.; Zhou, J.; Zhang, Q. 3D point cloud semantic segmentation toward large-scale unstructured agricultural scene classification. Comput. Electron. Agric. 2021, 190, 106445. [Google Scholar] [CrossRef]
- Wei, H.; Xu, E.; Zhang, J.; Meng, Y.; Wei, J.; Dong, Z.; Li, Z. BushNet: Effective semantic segmentation of bush in large-scale point clouds. Comput. Electron. Agric. 2022, 193, 106653. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Thomas, H.; Qi, C.R.; Deschaud, J.-E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117. [Google Scholar]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 922–928. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Tang, H.; Liu, Z.; Zhao, S.; Lin, Y.; Lin, J.; Wang, H.; Han, S. Searching efficient 3d architectures with sparse point-voxel convolution. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 685–702. [Google Scholar]
- Zhou, H.; Zhu, X.; Song, X.; Ma, Y.; Wang, Z.; Li, H.; Lin, D. Cylinder3d: An effective 3d framework for driving-scene lidar semantic segmentation. arXiv 2020, arXiv:2008.01550. [Google Scholar]
- Vosselman, G.; Gorte, B.G.; Sithole, G.; Rabbani, T. Recognising structure in laser scanner point clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2004, 46, 33–38. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. Squeezeseg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3d lidar point cloud. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1887–1893. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. Squeezesegv2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a lidar point cloud. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. Rangenet++: Fast and accurate lidar semantic segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 4213–4220. [Google Scholar]
- Kochanov, D.; Nejadasl, F.K.; Booij, O. Kprnet: Improving projection-based lidar semantic segmentation. arXiv 2020, arXiv:2007.12668. [Google Scholar]
- Cortinhal, T.; Tzelepis, G.; Erdal Aksoy, E. SalsaNext: Fast, uncertainty-aware semantic segmentation of LiDAR point clouds. In Proceedings of the International Symposium on Visual Computing, San Diego, CA, USA, 5–7 October 2020; pp. 207–222. [Google Scholar]
- Liu, T.; Liu, D.; Yang, Y.; Chen, Z. Lidar-based traversable region detection in off-road environment. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 4548–4553. [Google Scholar]
- Chen, L.; Yang, J.; Kong, H. Lidar-histogram for fast road and obstacle detection. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1343–1348. [Google Scholar]
- Bertasius, G.; Shi, J.; Torresani, L. Semantic segmentation with boundary neural fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3602–3610. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters--improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Learning a discriminative feature network for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1857–1866. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-scnn: Gated shape cnns for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5229–5238. [Google Scholar]
- Ma, H.; Yang, H.; Huang, D. Boundary Guided Context Aggregation for Semantic Segmentation. arXiv 2021, arXiv:2110.14587. [Google Scholar]
- Gong, J.; Xu, J.; Tan, X.; Zhou, J.; Qu, Y.; Xie, Y.; Ma, L. Boundary-aware geometric encoding for semantic segmentation of point clouds. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; pp. 1424–1432. [Google Scholar]
- Hu, Z.; Zhen, M.; Bai, X.; Fu, H.; Tai, C.-L. Jsenet: Joint semantic segmentation and edge detection network for 3d point clouds. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XX 16. pp. 222–239. [Google Scholar]
- Hao, F.; Li, J.; Song, R.; Li, Y.; Cao, K. Mixed Feature Prediction on Boundary Learning for Point Cloud Semantic Segmentation. Remote Sens. 2022, 14, 4757. [Google Scholar] [CrossRef]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3d semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 2016; pp. 1534–1543. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Haralick, R.M.; Sternberg, S.R.; Zhuang, X. Image analysis using mathematical morphology. IEEE Trans. Pattern Anal. Mach. Intell. 1987, PAMI-9, 532–550. [Google Scholar] [CrossRef] [PubMed]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9297–9307. [Google Scholar]
- Jiang, P.; Osteen, P.; Wigness, M.; Saripalli, S. Rellis-3d dataset: Data, benchmarks and analysis. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 1110–1116. [Google Scholar]










| Methods | Time (ms) | mIoU (%) | Road | Parking | Sidewalk | Vegetation | Terrain | Truck | Car | Bike | Motor | Other-vehicle | Person | Building | Fence | Trunk | Pole | Traffic-sign |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RandLANet | 639 | 60.99 | 91.44 | 42.21 | 76.50 | 84.19 | 73.63 | 67.74 | 93.07 | 65.74 | 20.64 | 41.46 | 48.79 | 85.55 | 38.86 | 58.49 | 51.63 | 36.05 |
| Cylinder3D | 157 | 69.57 | 93.21 | 41.38 | 79.63 | 83.92 | 63.09 | 75.44 | 95.46 | 75.29 | 53.01 | 44.96 | 73.35 | 90.68 | 60.96 | 67.57 | 65.43 | 49.71 |
| SPVNAS | 173 | 69.05 | 91.77 | 43.52 | 74.95 | 85.61 | 63.75 | 82.42 | 96.09 | 81.69 | 40.31 | 62.87 | 65.29 | 88.91 | 56.76 | 61.54 | 60.87 | 48.46 |
| SalsaNext | 25 | 65.67 | 93.28 | 38.93 | 79.22 | 83.85 | 69.67 | 66.61 | 91.92 | 79.67 | 37.49 | 45.57 | 66.73 | 85.2 | 48.43 | 60.31 | 56.62 | 47.24 |
| ours | 35 | 68.02 | 94.41 | 44.96 | 80.97 | 85.67 | 70.04 | 88.67 | 92.12 | 80.44 | 44.53 | 39.5 | 60.74 | 86.12 | 51.36 | 63.29 | 60.78 | 44.72 |
| Methods | Time (ms) | mIoU | Grass | Tree | Bush | Mud | Rubble | Concrete | Log | Pole | Water | Vehicle | Person | Fence | Barrier | Puddle |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RandLANet | 633 | 38.61 | 62.11 | 76.72 | 69.82 | 8.46 | 1.72 | 72.83 | 6.29 | 42.78 | 0 | 34.75 | 82.89 | 10.23 | 54.25 | 17.63 |
| Cylinder3D | 149 | 45.61 | 64.92 | 76.51 | 71.77 | 10.62 | 2.28 | 80.42 | 5.49 | 63.78 | 0 | 50.31 | 87.03 | 11.81 | 80.53 | 33.04 |
| SPVNAS | 168 | 42.68 | 64.12 | 76.06 | 71.51 | 8.54 | 5.23 | 70.01 | 15.05 | 54.43 | 0 | 48.57 | 85.79 | 10.99 | 64.81 | 22.44 |
| SalsaNext | 25 | 42.52 | 65.34 | 79.64 | 73.59 | 11.58 | 6.61 | 77.87 | 22.17 | 44.26 | 0 | 26.62 | 84.41 | 13.53 | 63.69 | 26.02 |
| ours | 35 | 43.88 | 66.14 | 79.73 | 73.93 | 12.92 | 6.78 | 77.15 | 22.42 | 48.9 | 0 | 27.9 | 84.32 | 13.27 | 77.23 | 23.67 |
| Module | Time (ms) | mIoU (%) | FLOPs (G) | Parameters (M) | ||
|---|---|---|---|---|---|---|
| Baseline | ESM | EGFM | ||||
| ✓ | 25 | 42.52 | 121.01 | 6.69 | ||
| ✓ | ✓ | 29 | 43.28 | 132.16 | 6.74 | |
| ✓ | ✓ | 33 | 42.73 | 138.75 | 6.76 | |
| ✓ | ✓ | ✓ | 35 | 43.88 | 145.91 | 6.79 |
| ✓ * | ✓ | ✓ | 34 | 43.81 | 145.26 | 6.78 |
| Baseline | ESM Type | EGFM Type | mIoU (%) |
|---|---|---|---|
| ✓ | w/o EAB | w/o CA | 43.26 |
| ✓ | w/o EAB | w/CA | 43.43 |
| ✓ | w/EAB | w/o CA | 43.67 |
| ✓ | w/EAB | w/CA | 43.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, X.; Li, X.; Ni, P.; Xu, Q.; Kong, D. A Novel Real-Time Edge-Guided LiDAR Semantic Segmentation Network for Unstructured Environments. Remote Sens. 2023, 15, 1093. https://doi.org/10.3390/rs15041093
Yin X, Li X, Ni P, Xu Q, Kong D. A Novel Real-Time Edge-Guided LiDAR Semantic Segmentation Network for Unstructured Environments. Remote Sensing. 2023; 15(4):1093. https://doi.org/10.3390/rs15041093
Chicago/Turabian StyleYin, Xiaoqing, Xu Li, Peizhou Ni, Qimin Xu, and Dong Kong. 2023. "A Novel Real-Time Edge-Guided LiDAR Semantic Segmentation Network for Unstructured Environments" Remote Sensing 15, no. 4: 1093. https://doi.org/10.3390/rs15041093
APA StyleYin, X., Li, X., Ni, P., Xu, Q., & Kong, D. (2023). A Novel Real-Time Edge-Guided LiDAR Semantic Segmentation Network for Unstructured Environments. Remote Sensing, 15(4), 1093. https://doi.org/10.3390/rs15041093