1. Introduction
Remote-sensing images (RSIs) have become significant carriers of geospatial information. Their military and economic value are important and serve a crucial role in various domains, such as reconnaissance, surveying and mapping, monitoring and navigation [
1]. Though the open network environment and digital storage technique help in realizing rapid communication and effective sharing of RSIs, it brings new difficulties in terms of security for the image datasets. Recently, ownership violations, data leakage and illegal tampering against RSIs have been repetitively prohibited [
2,
3]. Cloud storage is a cost-effective service that provides huge storage space and provides a lot of new opportunities for huge RSIs. Owing to the openness of Cloud technology, the information that is stored in the Cloud is at risk of malicious damage or deletion by the Cloud service providers [
4]. In this background, ensuring the safety of RSIs saved in Cloud storage has been a hot research topic in recent years.
RSIs capture sensitive data, such as military places, oilfields and airports, which are at the risk of being misused and stolen. Further, when such images are processed without safety precautions, it eases the extraction process and provides seamless access to sensitive data that in turn may be exploited for illegal activities. This scenario suggests the requirement for developing a reliable privacy approach that ensures the encryption of large-scale RSIs on the Cloud server without being compromised. Privacy preservation in RSIs is essential as they frequently contain sensitive data of the individuals and their properties. This data may be exploited for unauthorized surveillance, theft of identity and other malicious actions. Moreover, the release of such sensitive data is unethical and illegal and violates an individual’s right to privacy. Thus, it is essential to protect the individual’s privacy and their properties in RSIs by executing a few methods such as access control, data masking and data encryption.
Encryption acts as a potential means of security. If the encoded data are stored in Clouds, it is simple to tamper with the cipher text, and the encrypted outcomes may not be restorable [
5,
6]. To avoid this situation, many backups of secret information are needed. In [
7], the author presented an overview of the privacy-preservation deep learning (PPDL) method that was implemented to protect the privacy of businesses or individual users. This work deceptively argues that the PPDL approaches benefitted from public data analytics. Further, the approaches also thwarted data leakage and maintained the privacy of delicate data from illegal use and unauthorized access [
8,
9]. DL is typically utilized to build prediction methods for speech and text recognition applications and image processing. Such methods are highly accurate and particularly trained on large datasets [
10]. Prediction techniques learn from the existing available datasets and utilize the knowledge to generate novel data that were once inaccessible. In several cases, such information even comprises delicate data that require preservation. Thus, there is a significant challenge existing here, i.e., to protect the privacy of the data if it is transferred to the public Cloud for analysis and processing [
11,
12]. In most cases, personal computers are not capable of processing huge satellite images. Thus, to extract the insights and valuable knowledge from such huge RS datasets, there comes a higher demand for the execution of big data analytics utilizing public Cloud servers [
13]. As mentioned earlier, the satellite images may contain delicate and confidential data, such as military locations, oilfields and airports that can be misused and stolen. Similarly, if these images are processed without protection, it becomes easy to derive the delicate data and exploit it for illegal purposes [
14,
15]. Hence, it is both a challenging and a rewarding task to explore the possible PPDL approaches to implement them in the satellite images.
Al-Khasawneh et al. [
16] described a novel chaos-related encryption method that utilizes Gauss-iterated maps, an external secret key, Henon and Logistic. The presented encryption technique was able to effectively encode a large number of images. If the number of images increases, though the images are smaller in size, the technology becomes impractical or inefficient. This study also analyzed the parallel image encryption technique on a huge number of RSIs in Hadoop. Zhang et al. [
17] devised a QAPP method, i.e., quality-aware and privacy-preserving medical image release technique, which efficiently compiled DCT with differential privacy (DP). To be specific, QAPP had three stages. Initially, DCT was implemented in all the medical images to gain its cosine coefficients matrix. Secondly, the original cosine coefficients matrixes were compressed into k*k cosine coefficients matrixes which retained the core features of all the images. Thirdly, a suitable Laplace noise was injected into the formed k*k matrixes to attain differential privacy. Then, the noise-added coefficients were utilized for building the noise-added healthcare images using inverse DCT.
In [
18], a new biometric-related authentication mechanism was modelled utilizing two servers, such as the untrusted storage server and a crypto-match server. This mechanism used the Paillier cryptosystem, the biometric image cryptosystem and cryptographic hashing. In the presented cryptosystem, the keystreams were generated from both logistic maps and Henon. It is possible to compute the control variables of such chaotic maps from the input biometric images. Abd EL-Latif et al. [
19] presented a new encryption system for a privacy-preserving IoT-related healthcare mechanism in order to protect the privacy of the patients. Decryption or encryption processes depend on controlled alternate quantum walks. The presented cryptosystem method had two stages, such as permutation and substitution, and both were related to independently computed quantum walks. In the study conducted earlier [
20], the authors used the BC to build a new privacy-preserving remote data integrity checking technique for IoT information management mechanism without the inclusion of trusted third parties. This technique used BC, a lifted EC-ElGamal cryptosystem and bilinear pairing to protect the security and data privacy of the IoT mechanisms and also to support an effective public batch signature verification.
Qin et al. [
21] devised a privacy-preserving image retrieval technique related to adaptive weighted fusion and DL. At first, the authors derived the high-level semantic features of the images, low-level feature edge histogram descriptors and the BOW (bag of words). Then, a pre-filter table was built for the fusion features in order to enhance the search efficiency by the locality-sensitive hashing (LSH) technique. Both the logistic encryption method and the KNN technique were utilized in this study to protect the privacy of the fused images and features, correspondingly. In [
22], a privacy-preserving effective and secure remote user authentication method was proposed to be applied in agricultural WSN. The presented technique was formally assessed through a probabilistic random-oracle-model (ROR) to emphasize the robustness of the method. In addition, the technique was also simulated through the AVISPA tool to exhibit its effectiveness in terms of security.
Yang and Newsam [
23] examined the bag-of-visual-words (BOVW) systems for land-use classifiers from high-resolution overhead images. The authors assumed a typical non-spatial representation in which the frequency can be utilized for segregation amongst the analogous classes’ and not the places of quantized image features. The proposed feature was used to determine how words can be exploited in the text document classifier without considering their order of presentation. In [
24], the authors concentrated entirely on the existing approaches that manage the RSI scene classifier on restricted labelled instances. The authors classified literary works under three broad categories, such as algorithm-level, data-level and model-level. Zhou et al. [
25] conducted a systematic review of the presently established RSIR approaches and benchmarks using over 200 papers. In particular, the authors grouped the RSIR approaches under different hierarchical models based on label, modality and image source. Zhu et al. [
26] aimed at assisting this work by systematically examining the DL approaches and their applications across different sensor schemes. The authors also offered a detailed summary of the DL execution tips and connection to tutorials, open-source codes and pre-trained approaches that act as great self-contained reference materials for DL practitioners and individuals who are looking forward to being introduced to DL.
Numerous automated tools are available in the literature for effective detection and classification of RSIs. Despite the presence of ML and DL models in the earlier studies, there is still a need to enhance the classification performance along with security. Due to the continuous deepening of the models, the number of parameters in DL models increases too quickly, which results in a model overfitting issue. At the same time, different hyperparameters exert significant impact on the efficiency of the CNN model. Particularly, a few hyperparameters, such as epoch count, batch size and learning rate selection are essential to attain effective outcomes. Since the trial-and-error method for hyperparameter tuning is a tedious and erroneous process, the metaheuristic algorithms are applied. Therefore, in this work, the artificial gorilla troops optimizer (AGTO) algorithm is employed for parameter selection of the DenseNet model. The inclusion of the automated hyperparameter tuning techniques helps reduce the computation time and improve RSI classification performance. In addition, the inclusion of the encryption technique results in enhanced security of the RSIs.
The current research article develops a block-scrambling-based encryption with privacy preserving optimal deep-learning-driven classification (BSBE-PPODLC) technique for the classification of RSIs. The presented BSBE-PPODLC technique initially encrypts the RSI using the BSBE technique, which enables the secure communication of the images in a wireless medium. During the reception process, both decryption and image classification processes occur. In the presented BSBE-PPODLC technique, the image classification process encompasses three sub-processes, namely, densely connected network (DenseNet) feature extraction, extreme gradient boosting (XGBoost) classifier and AGTO-based hyperparameter tuning. The proposed BSBE-PPODLC technique was simulated using the RSI dataset, and the results were assessed under several aspects.
2. The Proposed Model
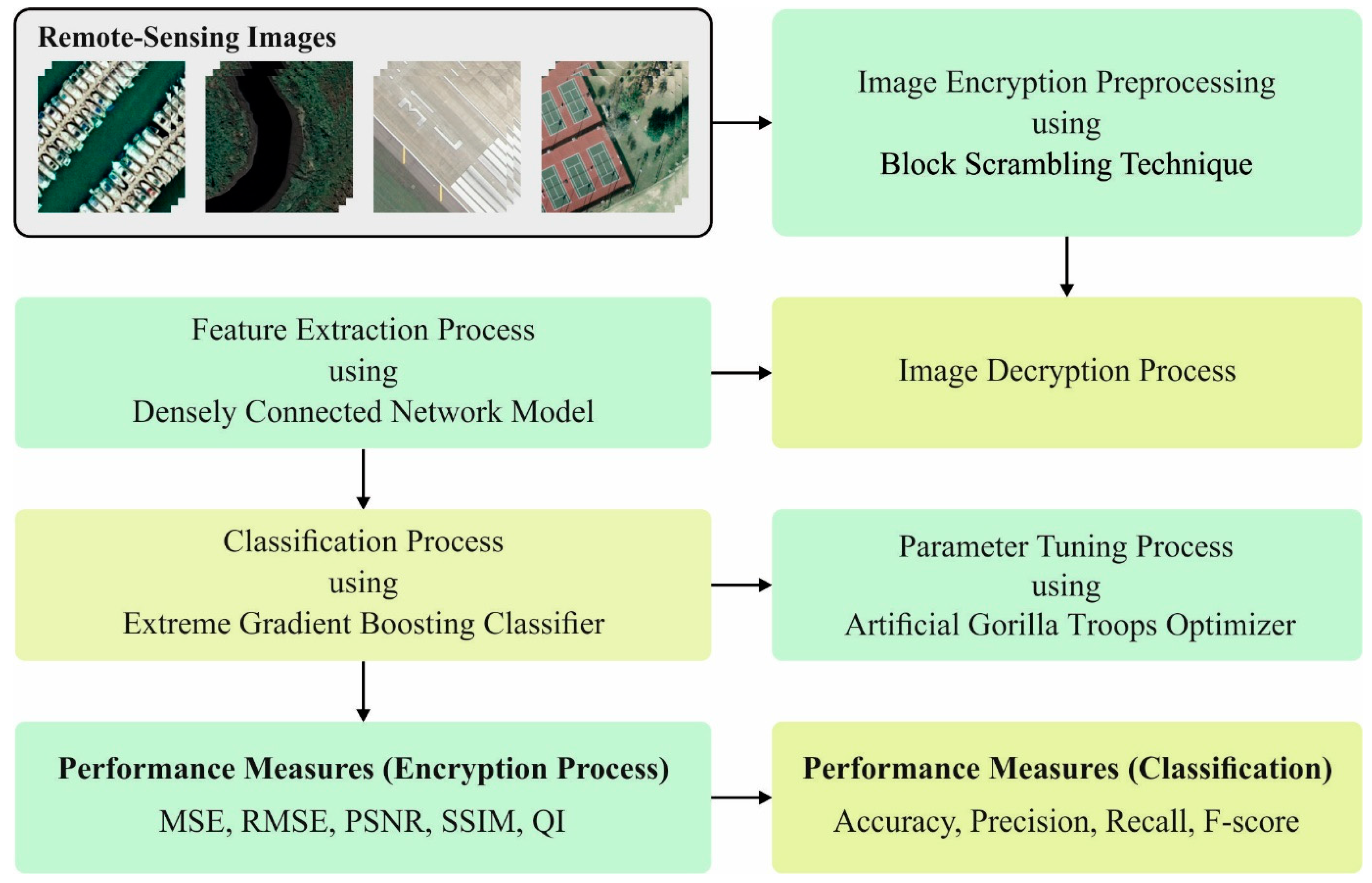
The current research paper introduces an effective BSBE-PPODLC approach for encryption and classification of the RSIs. The presented BSBE-PPODLC technique initially encrypts the RSIs using the BSBE technique, which enables the secure communication of the images in a wireless medium. During the reception process, both decryption and image classification processes occur. In the presented BSBE-PPODLC technique, the image classification process encompasses three sub-processes, namely DenseNet feature extraction, XGBoost classifier and AGTO-based hyperparameter tuning.
Figure 1 represents the block diagram of the proposed BSBE-PPODLC approach.
2.1. Encryption Using the BSBE Technique
The BSBE technique is employed in this study for secure encryption of the RSIs. In the BSBE technique, a user may want to securely transmit image
to viewers using social networking service (SNS) providers [
27]. While the consumer does not provide the confidential key
to the SNS provider, the privacy of the image that was shared under the control of the users is secured, even if the SNS provider recompresses image
. Thus, the consumer is assured of the privacy by him/herself. In case of
methods, the consumer is bound to disclose the unencrypted images to recompress them.
In this method, an image with pixels is primarily separated into non-overlapped blocks with ; afterwards, four block-scrambling-based processing stages are executed to separate the images. The process to execute the image encryption to generate the encryption image is provided as follows:
Step 1: Separate the image into pixels as blocks and each block with pixels. Then, permute the separated blocks arbitrarily with the help of an arbitrary integer created by a confidential key bit per pixel. During this work, the occurrence value has generally been utilized for every color element.
Step 2: Rotate and invert all the blocks arbitrarily by utilizing an arbitrary integer created by the key whereas has generally been utilized for every colour element as well.
Step 3: Execute negative–positive alteration for all the blocks by whereas is generally utilized for every colour element.
During this stage, the transformed pixel value from
block
, is calculated as given below.
Here, implies an arbitrary binary integer created by signifies the pixel value of a novel image with bit per pixel. During this work, the value of the occurrence probability is utilized for inverting the bits arbitrarily.
Step 4: Shuffle three color elements from all the blocks by utilizing an integer that is arbitrarily chosen amongst six integers by key
An instance of the encryption image is . During this case, it is concentrated on the block-scrambling-based image encrypt for subsequent reasons.
- (a)
The encrypted image is well-suited for JPEG standards.
- (b)
The compression efficacy to encrypt the images is almost similar to the original ones in the JPEG standard.
- (c)
Robustness against several attacks is established.
2.2. Image Classification Module
During the classification process, the BSBE-PPODLC technique encompasses three sub-processes, namely DenseNet feature extraction, XGBoost classifier and AGTO-based hyperparameter tuning. XGBoost is chosen due to the following advantages: high accuracy, fast training speed, scalability, robustness and flexibility.
2.2.1. Feature Extraction
For the feature extraction process, the DenseNet model is exploited in the current study [
28]. DenseNet was chosen due to its efficiency on a combination of features from many layers. Further, it also enables better feature representation and reduces the risk of overfitting. The DenseNet model links every layer with another one in a feedforward manner, thus generating a dense block of layers. It enables the free movement of the data and their gradients via the network and enables robust learning of the features. It requires fewer parameters than the classical CNN, which in turn minimizes the risk of overfitting and makes it computationally efficient.
DenseNet differs from ResNet in the way how the data are passed. In DenseNet, the feature map of the output layer is concatenated with the incoming feature maps instead of adding them. Therefore, the equation is transformed as follows.
The same problem has been confronted in the studies conducted on ResNet in which it is not possible to combine or concatenate the activities of feature maps since they are of distinct sizes despite. So, it is not practical to either concatenate or add the feature maps in ResNet. DenseNet is separated into dense blocks. In this regard, the dimension of the feature map remains unchanged, whereas the number of filters changes between them. The layer that exists between the dense blocks is termed a transition layer. It can be utilized for downsampling through pooling, batch normalization and convolutional layers. The channel dimension increases at all the layers due to the concatenation of the feature map; ‘’ represents the growth rate hyperparameter which maintains the quantity of the data that is saved in all the layers of the network. When produces feature maps, the generalized formula to determine the number of feature maps using the - layer is demonstrated in the above formula.
A feature map acts as the data or learning data of the network. All the layers have access to the feature map of the preceding layers due to which it possesses collective knowledge. All the layers add feature maps or new data to this collective knowledge in a concrete feature map of the data. Consequently, DenseNet saves and utilizes the data from the preceding layers which is not so in the case of conventional ConvNet and ResNet models.
2.2.2. Hyperparameter Tuning
To adjust the hyperparameter values of the DenseNet method, the AGTO algorithm is used in this study. The knowledge of the group performances in wild gorillas inspires the AGTO technique [
29]. Initializing, global exploration and local exploitation are three stages which make up the AGTO, similar to other intelligent approaches.
Assume that a
-dimensional space has
gorillas. To identify the position of the
gorilla in the universe, it is expressed as
, in which
and is determined as follows:
where
lies between 0 and 1. The searching range is defined based on the upper as well as lower limits,
and
respectively. The matrix
has
arbitrary value in the range of 0 and 1, and it is assigned to every element of
rows and
columns from the matrix signified as
.
At this point,
implies the iteration time,
signifies the gorilla’s predefined position vector, and
refers to the position of the potential searching agent during the subsequent iteration. Additionally, the arbitrary numbers
and
imply the number value between 0 and 1. Two places between the predefined gorillas’ population,
and
are chosen arbitrarily;
stands for a fixed value. With the employment of the problem dimensional as an index,
indicates the row vector, whereas the element value is developed arbitrarily in
. In addition,
is expressed as follows
At this point,
implies the cosine function,
stands for positive real numbers between zero and one, and
implies the highest iteration number. The following equation is used to determine L.
At this point, represents an arbitrary value in the range of −1 and 1. Then, all the probable solutions are created because of the exploration, and the fitness value is related to them. If demonstrates , then it is retained and employed in the place of . It can be demonstrated as a condition. Here, refers to the fitness function for the problem in question . Furthermore, an optimum option that exists at the time is assumed to be the silverback.
If a novel gorilla troop is generated, the silverback is the leading male which is at its peak health and strength. It is followed by blackback gorillas as they forage for food. Certainly, silverbacks tend to age and die, and younger blackbacks from the troops fight other males and occupy and control the troops. The exploitation step in this AGTO model follows the silverback gorillas and plays for adult female gorillas.
is projected to control these moves. Once
in Equation (6) is superior to
, then the silverback primary method is followed.
In this case, a better solution initiated is represented by the X silverback, the predefined position vector is demonstrated as
and
is evaluated using Equation (7). The values of
are determined as follows.
where
signifies the entire individual number, and
refers to the vector that illustrates the position of the gorilla.
It can be a pre-determined place as signified by and the influence force, which is estimated by Equations (9) and (10). An arbitrary value within 0 and 1 is employed for in Equation (6).
2.2.3. Image Classification
For image classification, the XGBoost model is used. Due to its accurate and fast performance, XGBoost is regarded as a robust ensemble-learning-based classifier [
30]. The ensemble architecture is designed based on various decision tree algorithms. In this model, the trees are added to the parent model by training to fit into accurate prediction and to remove the error that results from the preceding trees. In order to overcome the loss function, the gradient descent optimization technique is utilized. The loss gradient diminishes as the model becomes trained accurately, and the process is called gradient boosting. The XGBoost classifier from the Python repository was utilized in this study, in its initial condition, to check for efficiency. The efficiency of the built-in mechanism is estimated concerning cross-entropy loss, called log loss. The more accurate the classification, the lesser the log loss values are.
where
indicates the actual label within {0, 1} and
represents the probability score.
The system efficiency of the inbuilt XGBoost classifiers are examined, and the variation in the inherent parameter can be performed to minimize the loss as defined earlier.
3. Results and Discussion
In this section, the proposed BSBE-PPODLC method was experimentally validated using the UCM dataset (
http://weegee.vision.ucmerced.edu/datasets/landuse.html), Accessed on 14 September 2022. The UCM dataset comprises a set of aerial images of land use in the UC Merced area. It was developed by researchers at the University of California, Merced and is frequently utilized as a benchmark dataset to evaluate the performance of land-use classification tasks. The UCM dataset includes 21 classes of land use, including agriculture, bare land, buildings, forests, grassland, highways and water bodies. It includes 2100 images, each with a size of 256 × 256 pixels and is divided into training and test datasets. The images in the dataset were collected using aerial imagery from the National Agricultural Imagery Program (NAIP).
Figure 2 illustrates some of the sample images.
Figure 3 demonstrates the original and the encrypted images.
Table 1 represents the overall encryption results achieved by the proposed BSBE-PPODLC model. The experimental outcomes show that the proposed BSBE-PPODLC method achieved effectual performance under all the images. For example, with the harbor test image, the BSBE-PPODLC technique gained an MSE of 0.1956, RMSE of 0.4423, PSNR of 55.22 dB, SSIM of 99.83% and a QI of 99.97%. Meanwhile, with the river test image, the BSBE-PPODLC technique obtained an MSE of 0.2794, RMSE of 0.5286, PSNR of 53.67 dB, SSIM of 99.80% and a QI of 99.90%. Eventually, with the runway test image, the BSBE-PPODLC method reached an MSE of 0.3465, RMSE of 0.5886, PSNR of 52.73 dB, SSIM of 99.80% and a QI of 99.97%.
In
Table 2 and
Figure 4, the overall MSE analysis outcomes achieved by the proposed BSBE-PPODLC model and other existing models are given. The outcomes display that the HBMO-LBG and the QPSO-LBG methods attained a poor performance with maximum MSE values. Next, the FF-LBG model and the CS-LBG methods reached moderately low MSE values. Although the SSA-LBG model tried to attain a reasonable MSE value, the BSBE-PPODLC model exhibited the maximum performance with a minimal MSE of 0.1956 for the Harbor image, 0.2794 for the River image, 0.3465 for the runway image and 0.2909 for the tennis court image.
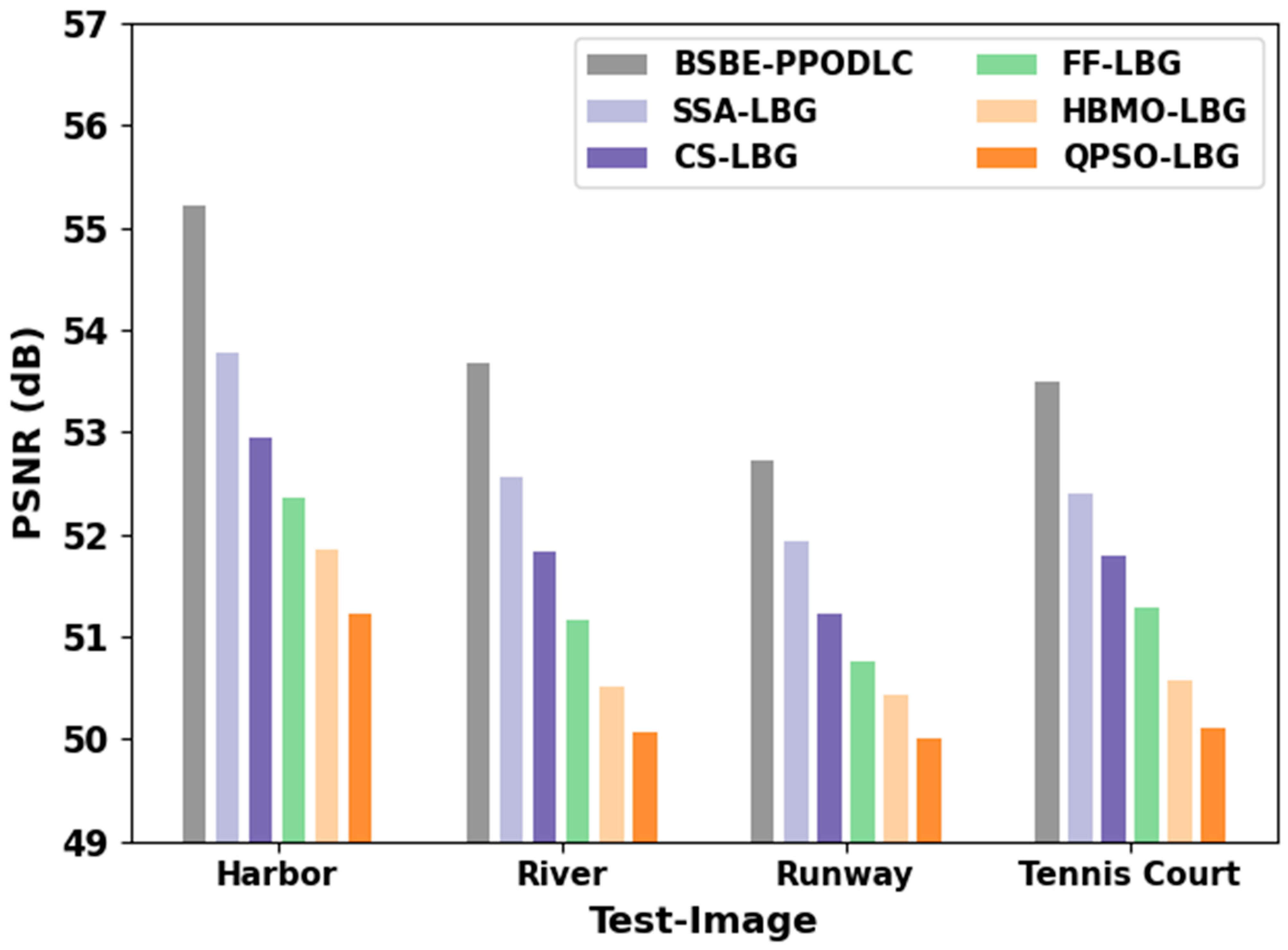
In
Table 3 and
Figure 5, the overall PSNR study outcomes accomplished by the proposed BSBE-PPODLC approach and other existing methods are portrayed. The outcomes show that the HBMO-LBG and the QPSO-LBG algorithms achieved a poor performance with minimal PSNR values. Then, the FF-LBG model and the CS-LBG approaches reached moderately increased PSNR values. Although the SSA-LBG technique attempted to achieve a reasonable PSNR value, the proposed BSBE-PPODLC algorithm exhibited improved results with a maximum PSNR of 55.22 dB in the case of the harbor image, 53.67 dB for the river image, 0.3465 for the runway image and 0.2909 for the tennis court image.
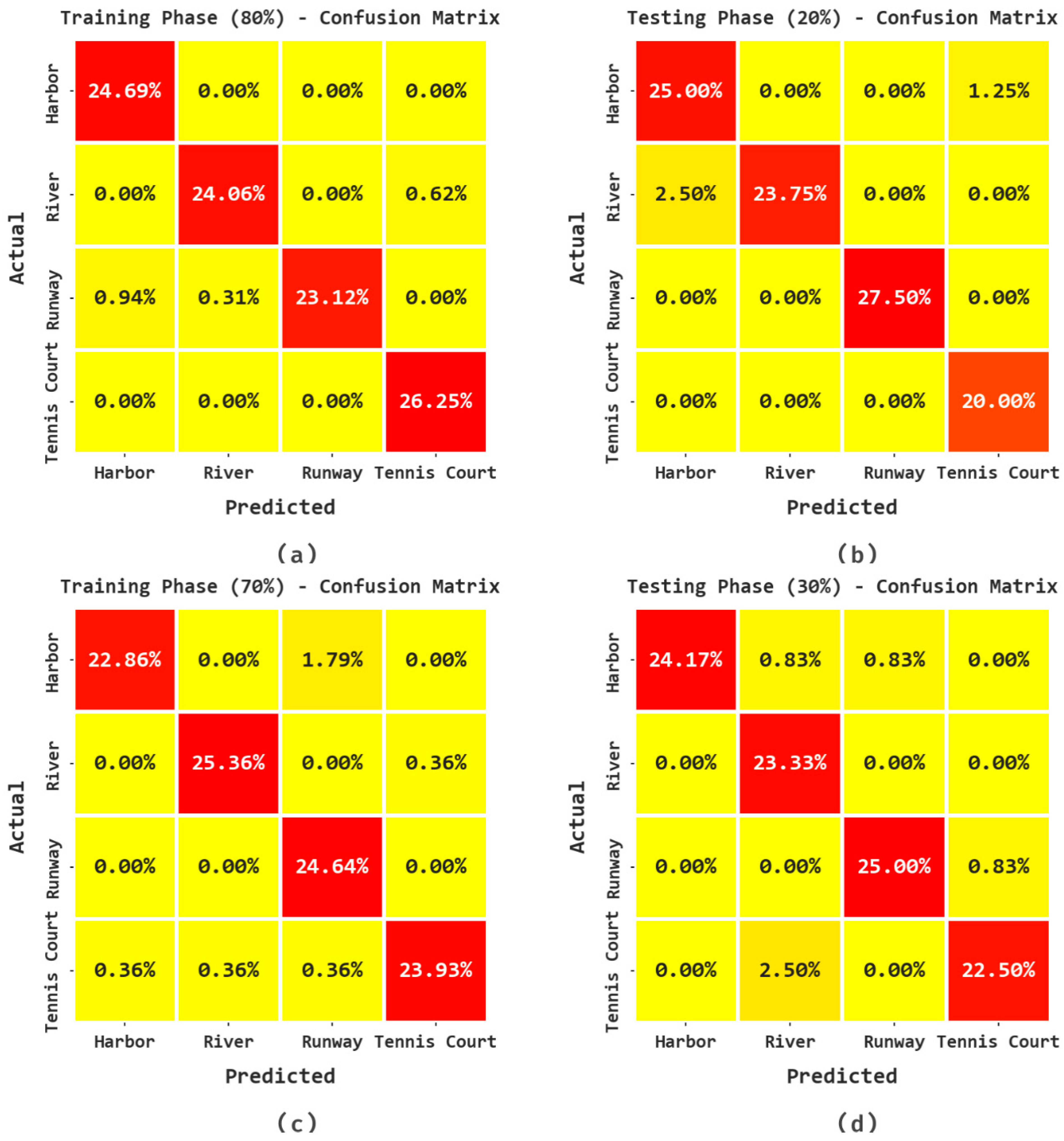
In
Figure 6, the RSI classification results attained by the proposed BSBE-PPODLC model are presented in the form of a confusion matrix. The results specify that the proposed BSBE-PPODLC method effectively identified four classes.
Table 4 and
Figure 7 represent the classification performance of the BSBE-PPODLC model on 80:20 of TR/TS data. The obtained values show that the BSBE-PPODLC algorithm identified all the class labels on the RSIs. For example, with 80% of the TR database, the BSBE-PPODLC technique accomplished an average
of 99.06%,
of 98.18%,
of 98.09% and an
of 98.10%. Moreover, with 20% of the TS database, the BSBE-PPODLC method attained an average
of 98.12%,
of 96.26%,
of 96.43 % and an
of 96.25%.
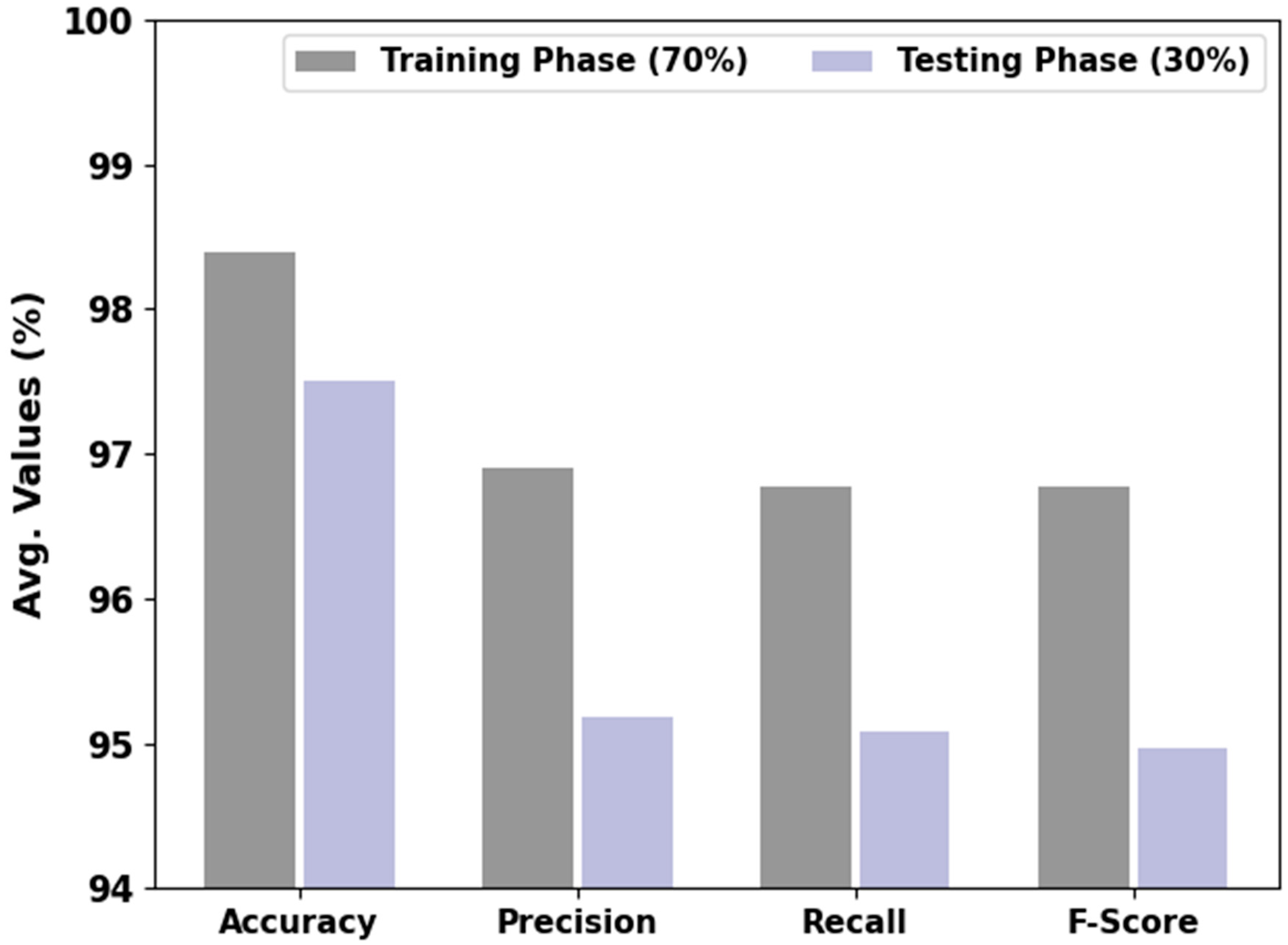
Table 5 and
Figure 8 show the classification performance accomplished by the proposed BSBE-PPODLC method on 70:30 of TR/TS data. The gained values show that the BSBE-PPODLC technique identified all the class labels on the RSIs. For example, with 70% of the TR database, the BSBE-PPODLC method established an average
of 98.39%,
of 96.90%,
of 96.77% and an
of 96.77%. Furthermore, with 30% of the TS database, the BSBE-PPODLC method accomplished an average
of 97.50%,
of 95.18%,
of 95.08 % and an
of 94.97%.
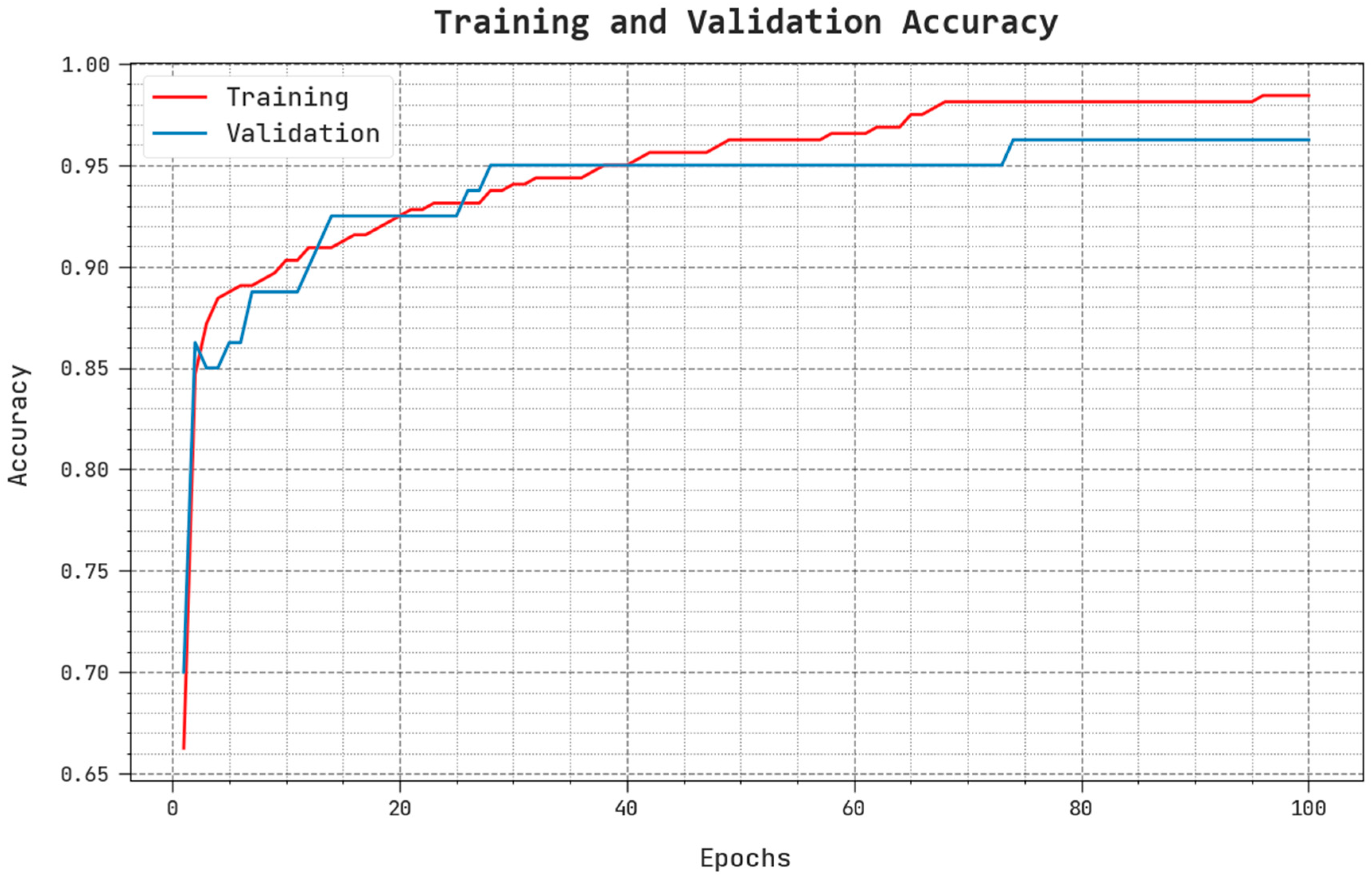
The TACC and VACC performance outcomes of the BSBE-PPODLC methodology, are shown in
Figure 9. The figure implies that the BSBE-PPODLC technique achieved improved performance with increased TACC and VACC values. Notably, the BSBE-PPODLC method reached the maximum TACC outcomes.
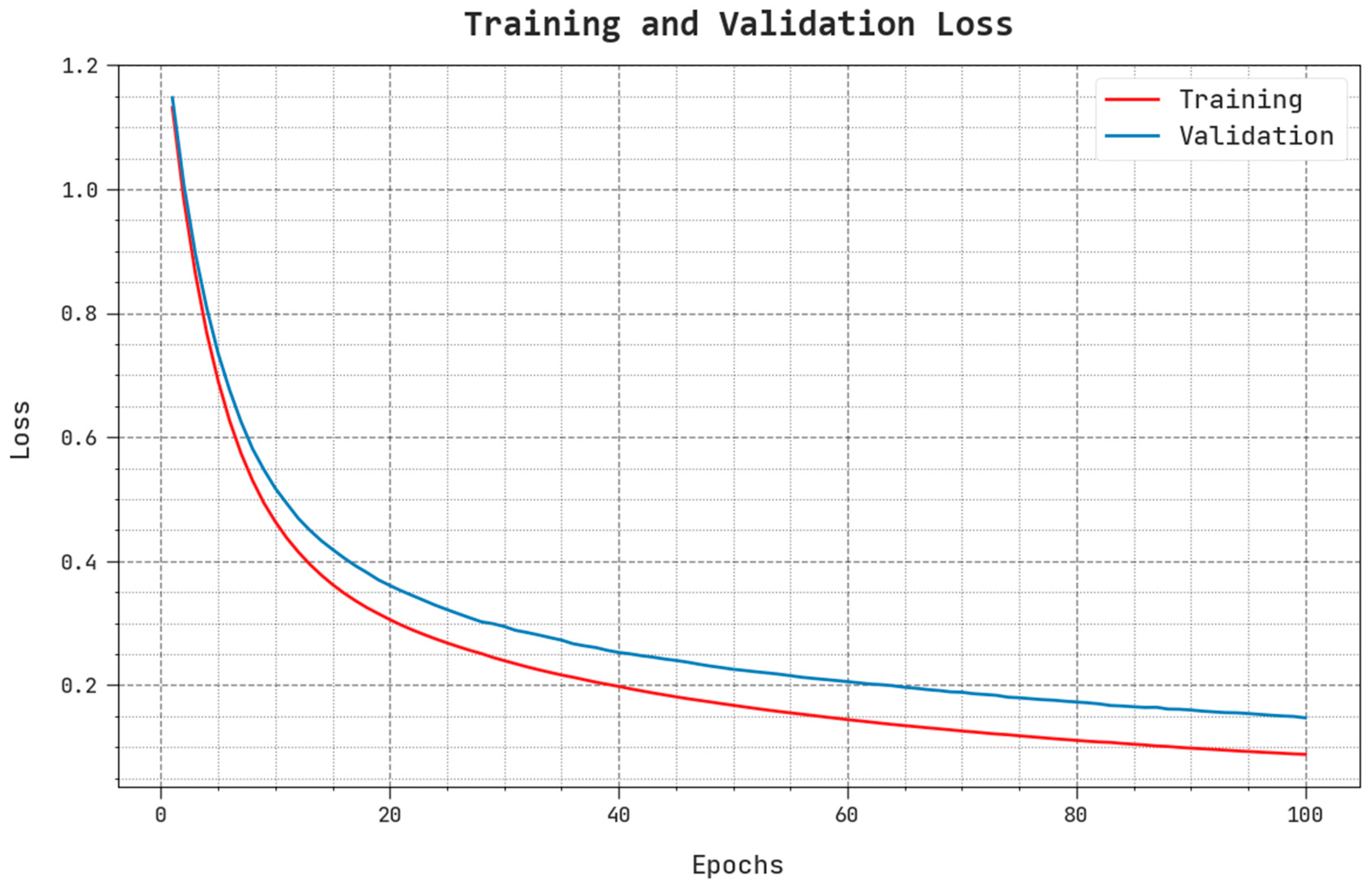
The TLS and VLS performance results of the BSBE-PPODLC techniques are portrayed in
Figure 10. The figure shows that the BSBE-PPODLC method had a better performance with the least TLS and VLS values. Seemingly, the proposed BSBE-PPODLC method achieved low VLS outcomes.
A clear precision–recall study was conducted upon the proposed BSBE-PPODLC method under the test database and the results are shown in
Figure 11. The figure shows that the proposed BSBE-PPODLC technique achieved enhanced precision–recall values under several classes.
A comprehensive ROC study was conducted upon the BSBE-PPODLC technique with the test database and the results are detailed in
Figure 12. The fallouts exhibited from the BSBE-PPODLC method established its ability in categorizing the test database into different classes.
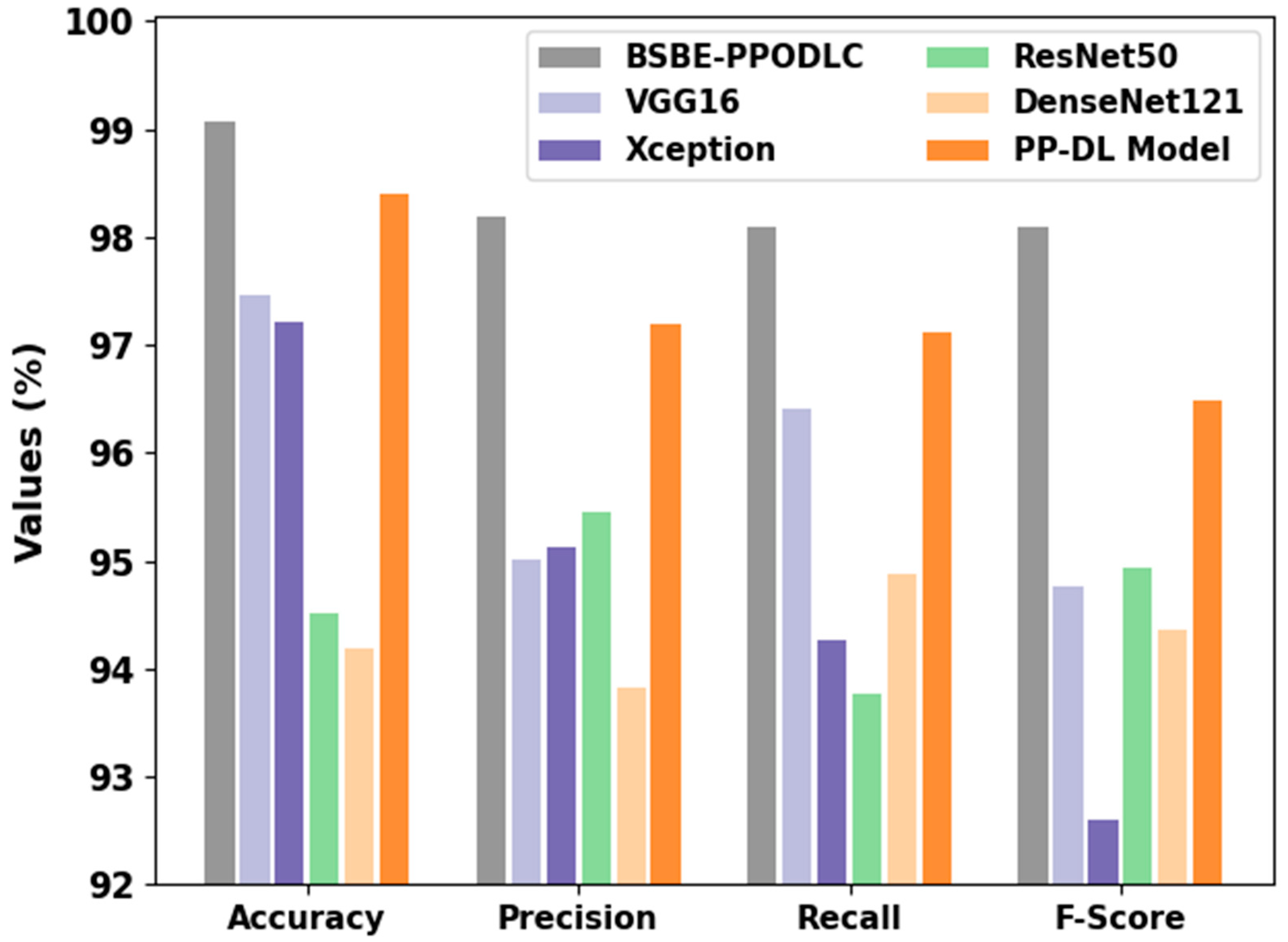
In
Table 6 and
Figure 13, the RSI classification performance of the BSBE-PPODLC model and other DL models are portrayed [
31,
32]. The outcomes show that the ResNet50 and the DenseNet models offered the least classification performance. Next, the VGG16 and the Xception models reached moderately closer performance.
In contrast, the PP-DL method achieved a reasonable performance with an of 98.40%, of 97.20%, of 97.11% and an of 96.48%. However, the proposed BSBE-PPODLC model exhibited its supremacy with an of 99.06%, of 98.18%, of 98.09% and an of 98.10%. These results confirmed the better performance of the proposed BSBE-PPODLC method over other DL approaches











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}