1. Introduction
Benefiting from the rapid developments of hyperspectral imaging technology, hyperspectral sensors acquire a wide range of different bands from the electromagnetic spectrum. The resultant hyperspectral image (HSI) contains an enormous amount of spectral and spatial information representing texture, border, and shape of ground objects. Owing to the specific characteristics of ground objects, HSI can identify each individual pixel accurately. So far, a variety of applications have been developed based on HSI, such as agricultural applications [
1], anomaly detection [
2] and marine monitoring [
3].
As a popular direction of research, DL performs excellently in feature extraction and learning ability [
4,
5,
6], and this has caught the attention of experts in the HSI classification field. There are many famous DL models for HSI classification, such as stacked autoencoder (SAE) [
7], convolutional neural network (CNN) [
8], recurrent neural network (RNN) [
9], deep belief network (DBN) [
10], long short-term memory (LSTM) [
11], and generative adversarial networks (GAN) [
12]. In these frameworks, CNN has dominated the main structure of DL in HSI classification. The architecture of CNN evolved from 1-D CNN to 3-D CNN. One-dimensional CNN was used in the early stage of HSI classification to extract spectral features [
13]. However, 1-D CNN neglected the spatial dimension characteristics of ground objects. To make full use of spatial information, 2-D CNN was developed to acquire HSI information from the spatial domain [
14,
15]. Later, combined with three-dimensional features of HSI, 3-D CNN was proposed to simultaneously extract spatial and spectral information, further deepening the application of CNN in HSI classification [
16,
17].
However, traditional CNN still has shortcomings, such as the limitation of the local receptive field. The attention mechanism has been intensively studied in recent years to learn sufficient and detailed spectral–spatial features in the field of DL. Zhou et al. [
18] proposed a spectral–spatial self–mutual attention network, which aimed to construct the correlation between spectral domain and spatial domain through self-attention and mutual attention. Dong et al. [
19] used a superpixel-based graph attention network and pixel-based CNN to construct deep features. Through the weighted fusion of each specific feature and the cross information between different features, the recognition ability of the model was improved.
Despite acquiring success in HSI classification, DL models primarily depend on massively labeled samples. Meanwhile, the labeling process is laborious. Thus, making DL models perform well in small labeled sample environments is a hotspot in the field of HSI classification [
20]. Many studies have focused on building DL paradigms with few labeled samples, such as transfer learning [
21], active learning [
22], and few-shot learning [
23] to solve this problem.
Specifically, transfer learning aims to identify the labels in the target domain based on information from the source domain. The primary operating paradigm of transfer learning is deep feature distribution adaptation. Yang et al. [
21] first combined transfer learning with DL for HSI classification. The model pre-trains with training samples of source domain and then transfers to the target domain by fine-tuning the parameters of the network, accommodating the new feature distribution. Subsequent transfer learning models basically abide by the above technical lines [
24,
25,
26].
Active learning aims to assess and sort the candidate instances by designing metrics and querying labels for the representative samples. After iterations of purposeful query, valuable samples are chosen and labeled again for the model to fine-tune. A few advanced active learning strategies are designed for HSI, such as Bayesian CNN [
27] and super-pixel and neighborhood assumption-based semi-supervised active learning (SSAL-SN) [
28]. By means of active learning, a reduction in labeling expenses can be achieved. In fact, many active learning strategies combine with posterior probability, which rely on another classifier to query valuable samples [
29,
30,
31]. Tuia et al. [
29] used the distance of feature to the hyperplane as the posterior probability to exclude samples with similar information. Li et al. [
30] first used autoencoder to extract deep features and measured uncertainty of a given sample through category probability output by neural network. Hu et al. [
31] used posterior probability distribution to evaluate the interior indeterminacy of multi-view and to learn the exterior indeterminacy of samples.
Few-shot learning focuses on fully exploring the deep relationship between samples to build a discriminatory decision boundary [
20]. Many DL networks that combine with few-shot learning have been studied in HSI classification, such as the siamese network [
32], the prototype network [
33] and the relation network [
34]. Zhao et al. [
32] designed a two-branch siamese network with shared parameters to learn the differences between features. In [
33], a prototype network combining residual network and prototype learning mechanism was constructed for enhancing homogeneity in the same class and separation in different classes. To model the complex relationship among samples, Deng et al. [
34] introduced relation network to replace feature extractor and metric module with deep learning.
Furthermore, the above DL paradigms can be combined to learn more useful knowledge from a small sample pool. Deng et al. [
35] used active learning to find more generic samples to fine-tune the network in transfer learning. Li et al. [
36] combined a prototypical network with active learning to request labels from valuable examples to enhance the network’s ability in extracting features.
The essential reason for the limited labeled sample problem is the unreliable minimization of empirical risk. It is difficult for the model to learn the complete data distribution from limited training samples, resulting in prediction bias. Although effective model architectures and learning paradigms can be used to deal with this problem, they ignore the influence of the quality of training samples on the classification ability of the model in the limited labeled samples problem. We believe that if representative samples can be obtained, the model can learn more deep features and fit a more complete feature distribution with a limited labeling cost. Therefore, in this paper, we focused on the quality of the original input. Siamese network and active learning were used to evaluate and find samples with feature uncertainty. By training a small number of representative samples to help the model learn a complete data distribution, we corrected a large number of testing sample misclassifications.
In this paper, an active learning-driven siamese network (ALSN) is proposed. First, a dual learning-based siamese network (DLSN) was designed for the limited labeled samples problem. The DLSN used multiple sets of convolution kernels to extract sample features. Then, the contrastive learning module learnt to distinguish the intra-class and inter-class relationships, and the classification module learnt the characteristics of these samples from another perspective. Second, an adversarial uncertainty-based active learning method (AUAL) was proposed for the minimal labeling cost requirement. This method aimed to use posteriori probability of classification to query samples that had a conflicting probability of being classified into different categories, providing the DLSN with a few high-value samples on which to focus for more indistinguishable feature relationships. In addition, regarding the problem that traditional active learning only considers the value of a sample on one side of the decision boundary, an active learning architecture, based on inter-class uncertainty (ICUAL), was designed. By feeding original samples of different categories into the DLSN, deep features were extracted and fused. After multiple nonlinear projections, the inter-class uncertainty was evaluated by using the output of the negative sample pairs. Those with high inter-class uncertainty were queried, and combined with all positive sample pairs to construct lightweight training sample pair sets. Finally, the network was fine-tuned to improve the classification accuracy.
To sum up, the main innovations of this study can be generalized as follows:
A DLSN is designed to extract features of HSI. The network consists of a contrastive learning module and a classification module. The former contrastively learns deep relationships between sample pairs, and the latter learns the features of samples and guides classification.
We propose an adversarial uncertainty-based active learning method (AUAL) which is able to query class-adversarial samples at the edge of the decision boundary for fine-tuning the network.
We propose an active learning architecture based on inter-class uncertainty (ICUAL). By measuring the uncertainty of sample pairs, the instances located on both sides of the inter-class decision boundary are queried and sent to the training set. The classification ability of the model can be optimized by strengthening the inter-class feature comparison.
3. Proposed Framework
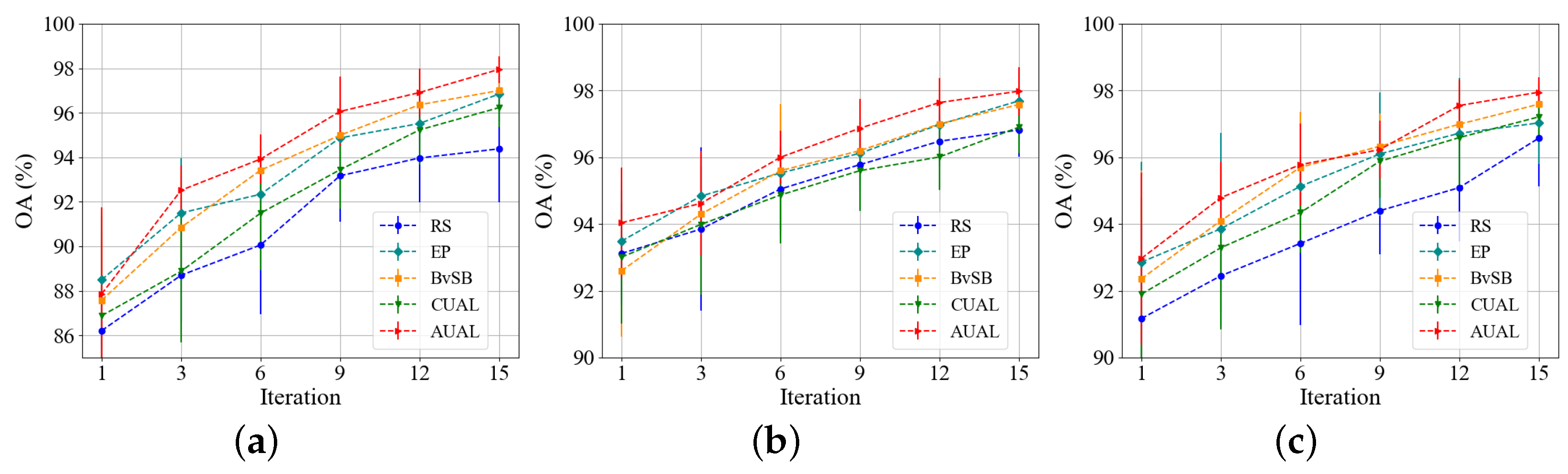
In this section, we first explain the operation of ALSN and then explain the various parts of the framework. As shown in
Figure 1, ALSN consists of the DLSN, AUAL and ICUAL. Firstly, the DLSN, which consists of a contrastive learning module and a classification module, is pre-trained by a few samples and sample pairs. The remaining samples and negative sample pairs together form the candidate pool. Then, the pre-trained DLSN uses the classification module to extract deep features of the candidate samples and output the probabilities that the candidate samples belong to each class. According to the class probability provided by the DLSN, AUAL actively queries the class-adversarial samples from the candidate pool into the training data set, which are used with pre-training samples to fine-tune the network. After AUAL, the newly labeled and previous training samples form the sample pairs. Positive sample pairs are directly sent to the training set, and negative sample pairs are sent to the candidate pool. The contrastive learning module fuses features of the negative sample pair and outputs the probability that the candidate sample pair belongs to a negative class. Next, ICUAL queries the negative sample pairs with inter-class uncertainty from the candidate pool, constructs the lightweight sample pair training set, and optimizes the model from both ends of the decision boundary through fine-tuning, which further enhances the classification ability of the DLSN.
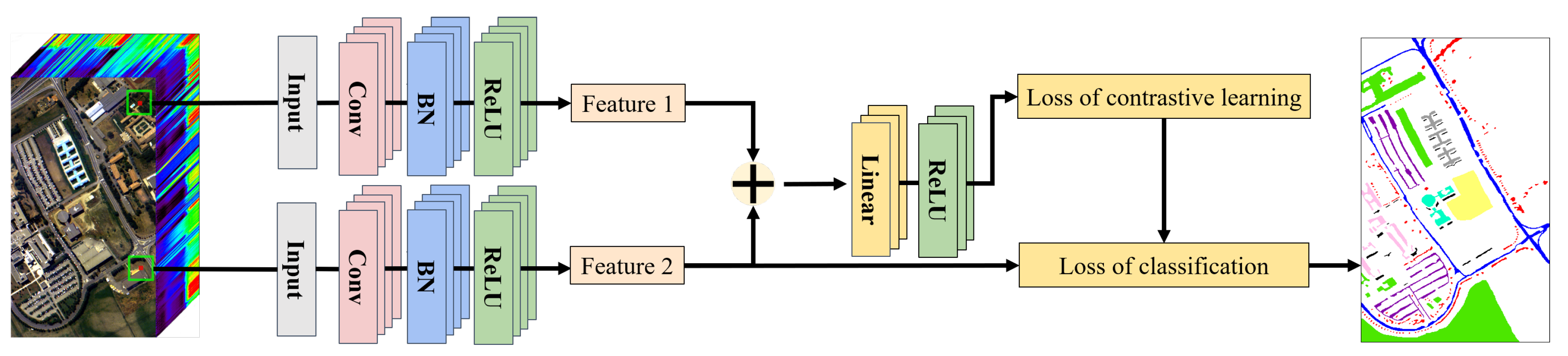
3.1. Dual Learning-Based Siamese Network
As shown in
Figure 2, our proposed dual learning-based siamese network (DLSN) includes a contrastive learning module and a classification module. To facilitate the introduction of these two modules, we first introduce two training data formats of the model. The HSI dataset includes
categories of ground objects. We set
samples in each class as the training datasets. The training dataset of the
th class could be represented as
. The label of training samples could be denoted by
and
. Thus, the training data set of the classification module was
. For any two samples
and
,
, a sample pair
was constructed, which was the data set of the contrastive learning module. The label was formulated as below:
In the contrastive learning module, we first used a two-branch DLSN with shared weight parameters to extract the features of sample
and
in the sample pair
. Then, two sets of features h(
) and h(
) were fused as
and fed into the nonlinear projection layer [
45] to obtain refined features of the sample pair. Finally, we used the binary classifier to match the probability of sample pairs. We used a binary cross-entropy loss function to partly adjust the network in this module, which is described as:
where
and
denote class probability and the label of a sample pair
. During training, the module constantly contrasts the feature similarity of
to learn the ability of distinguishing the relationship feature between positive and negative sample pairs.
For the classification module, we used the DLSN trained by the contrastive learning module to extract the deep features from labeled training samples and we used multi-category cross-entropy loss for supervisory learning, represented as:
where
represents the number of the category,
is the
th label, and
is the probability of the
th label the model predicts.
The detailed structure of DLSN is shown in
Table 1. The encoder includes a 3D convolution layer, 2D convolution layer, batch normalization layer and ReLU layer. The adaptive global pooling layer was adopted to further down sample the features. Then, in the contrastive learning module, the nonlinear projection head is composed of a fully connected layer and ReLU layer, designed to learn fused sample pair feature representation. Finally, the two modules all use the fully connected layer for classification.
Since each sample forms multiple pairs with other samples, abundant sample pairs heavily increase the training cost of the DLSN. Further, negative sample pairs outnumbered the positive. If there are no constraints on the model, DLSN pays serious attention to inter-class distance, while ignoring the convergence of intra-class distance. So we adopted a random selection strategy [
38] to choose a few equal proportions of positive and negative sample pairs for training during each epoch. The random selection strategy was proved to ensure a balance of positive and negative sample pairs and accelerated the training speed.
3.2. Adversarial Uncertainty-Based Active Learning (AUAL)
The common goal of the siamese network and of active learning is to acquire stronger classification ability with the least labeling cost. Therefore, we believe that the combination of these two methods is meaningful for dealing with limited labeled samples problem. However, if the siamese network, with high classification ability, is taken as the backbone network of active learning, it is a problem as to whether the active learning method, based on posterior probability, can query the really valuable samples under the requirement of minimal labeling cost.
Based on this problem, we propose a method called adversarial uncertainty-based active learning (AUAL) to accurately query valuable samples under small sample problems. First, the posterior probability-based active learning method measures the uncertainty of samples through the backbone network, aiming at the confusion degree of samples in the feature space. We believe that a sample set queried in this way can still be subdivided into class-adversarial samples and class-chaotic samples. Class-adversarial samples are those that have conflicting probability of being classified into a limited number of categories during the classification process. These samples are usually located close to the decision boundaries of specific groups of categories. The class-chaotic samples refer to the instances with relatively balanced and generally low probability of being classified into various categories in the classification process. These samples are located at multiple sets of the edge of decision boundaries. Class-adversarial samples and class-chaotic samples can be queried as Equations (
5) and (
6):
where
stands for the best posterior probability of category and
denotes the second-largest posterior probability of category.
is a constant used to prevent invalid calculation due to the same
and
.
We believe that in the limited labeled samples problem, it is more valuable to provide class-adversarial samples for the backbone network with high classification ability. Training these samples can precisely fine-tune some missing decision boundaries and help the model learn a more complete data distribution. Class-chaotic samples are more suitable for the backbone network with low classification ability. By training these samples, multiple decision boundaries can be optimized simultaneously with less labeling costs.
Therefore, in our framework, DLSN is set as the backbone network, and Formula (
5) is iteratively used to query class-adversarial samples for labeling. After these samples are sent to the data set, the classification ability of the DLSN can be improved by fine-tuning at minimal labeling cost.
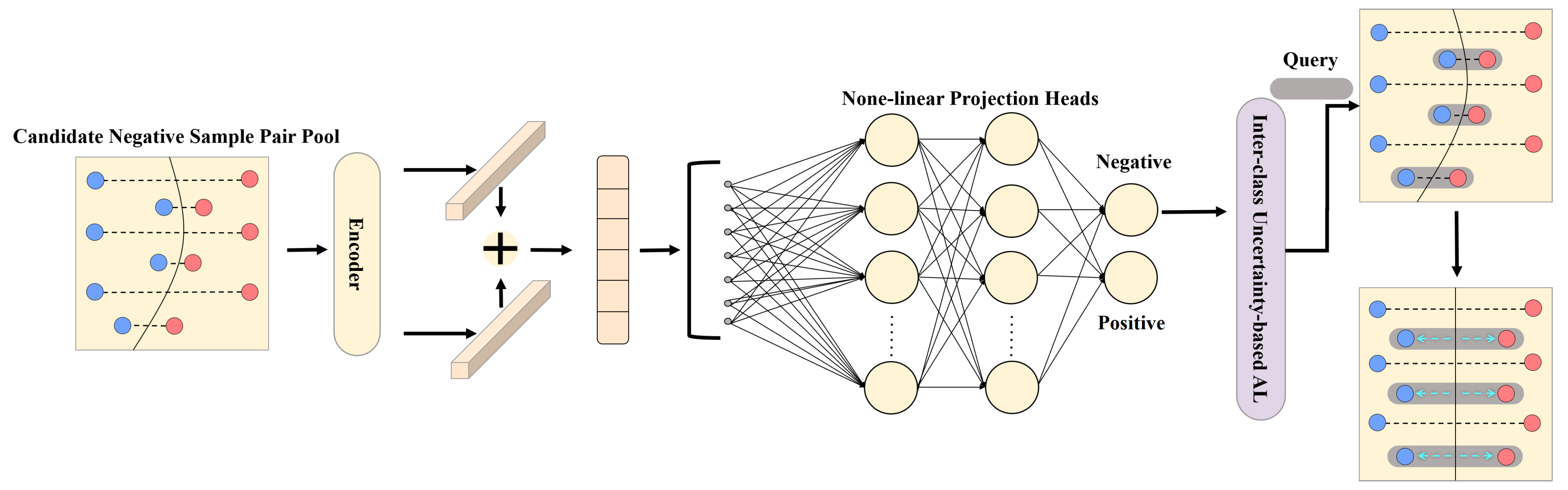
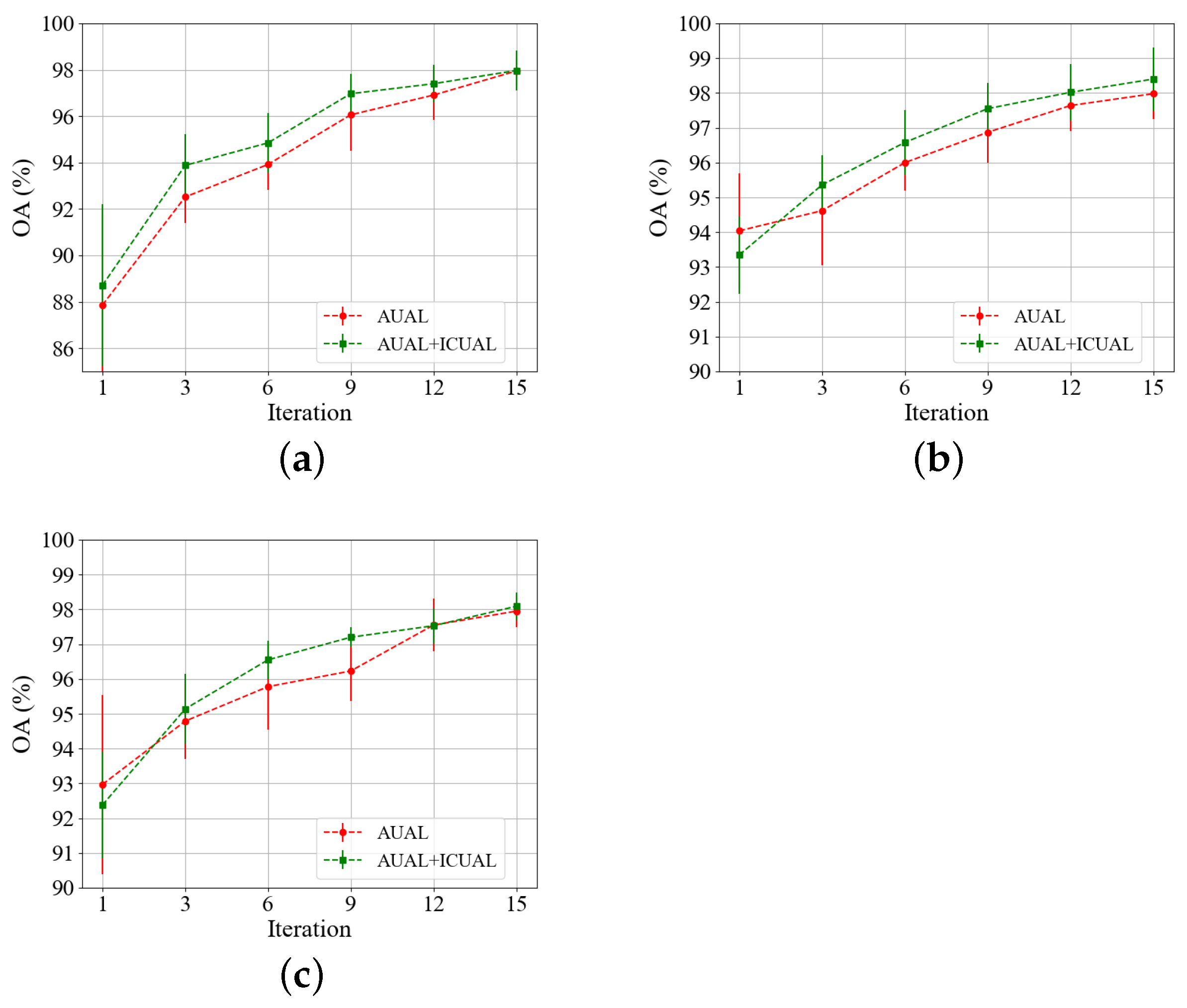
3.3. Inter-Class Uncertainty-Based Active Learning (ICUAL)
In our framework, as the iteration progresses, new instances and previous samples form many negative sample pairs. There are many redundant instances that cannot provide effective features in these negative sample pairs. Therefore, we believe that by eliminating abundant invalid negative sample pairs and mining valuable instances, the model can accurately learn and distinguish the characteristics of inter-class relationship, and avoid underfitting. However, traditional active learning, based on posteriori probability, queries individual samples at the decision boundary. This method essentially queries the samples that unilaterally change the decision boundary by fine-tuning the feature encoder, which is not suitable to measure inter-class relationships. Inspired by the siamese network, we propose an active learning architecture based on inter-class uncertainty (ICUAL). By actively querying inter-class instances located at both ends of the decision boundary, we constructed a lightweight sample pair data set. The decision boundary could be purposely optimized by simultaneously strengthening the inter-class feature contrast on both sides of the decision boundary.
Specifically, in the pre-training process of the model, we only used all the positive sample pairs and the same number of negative sample pairs as the positive sample pairs to construct a pre-training data set, and the rest were sent to the candidate pool. Meanwhile, we paired the samples queried in each iteration with the training samples. The positive sample pairs were added to the training data set, and the negative sample pairs were added to the candidate pool. After each iteration of AUAL, the ICUAL started in time. Through purposeful iterative screening, we formed a small and precise sample pair training set, providing more valuable inter-class features for the model. It is worth mentioning that, at the end of contrastive learning module we designed there is a binary classifier, which provides a metric method of inter-class uncertainty. As shown in the
Figure 3, we input the entire sample pair candidate pool, and the features of each unit in the sample pair fused after being extracted by the encoder. After multiple layers of nonlinear projection, the classifier output the classification probability of negative instances. We used the following formula to query instances that lay on the binary classification boundary:
where
indicates the probability of negative class. In this way, all positive sample pairs and selected negative sample pairs could be regarded as a small and refined training set. Under the premise of using positive sample pairs to ensure intra-class aggregation, the samples on both sides of the decision boundary were fully mined. The decision boundary was jointly optimized through precise fine-tuning of negative sample pairs composed of bilateral samples. At the same time, in order to achieve the coordination of training cost and classification accuracy, we conducted multiple rounds of ICUAL after each iteration of AUAL. By means of dynamic supplementation, DLSN could be prevented from losing valuable features. Therefore, by training these valuable negative sample pairs, the ability of the contrastive learning module to distinguish inter-class or intra-class features could be greatly improved, thereby enhancing the ability of the DLSN to capture the global feature distribution and make classification decisions.
Synthesizing the above methods, the pseudo code of the ALSN algorithm can be seen in Algorithm 1.
| Algorithm 1 Active Learning-driven Siamese Network (ALSN) for Hyperspectral Image Classification. |
- 1:
Input: - D_1
training sample set - D_2
training sample pair set - U_1
candidate unlabeled sample set - U_2
candidate labeled sample pair set - N_1
the number of samples to query - N_2
the number of negative sample pairs to query - R_1
max iteration to query samples - R_2
max round to query sample pairs
- 2:
Initialization: k = 0, i = 0 - 3:
for k = 0 to R1-1 do - 4:
calculate class probability of candidate sample in - 5:
select instances from by AUAL - 6:
update =⋃ and = - 7:
fine-tune the DLSN - 8:
for i = 0 to R2-1 do - 9:
calculate class probability of candidate sample pair in - 10:
select instances from by ICUAL - 11:
update =⋃ and = - 12:
fine-tune the DLSN - 13:
end for - 14:
end for - 15:
Output: Make predictions for the testing data with the trained DLSN.
|



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



































































