
Multi-Source Interactive Stair Attention for Remote Sensing Image Captioning


Abstract
1. Introduction
1.1. Motivation and Overview
1.2. Contributions
1.3. Organization
2. Related Work
2.1. Natural Image Captioning
2.2. Remote Sensing Image Captioning
3. Materials and Methods
3.1. Local Image Feature Processing
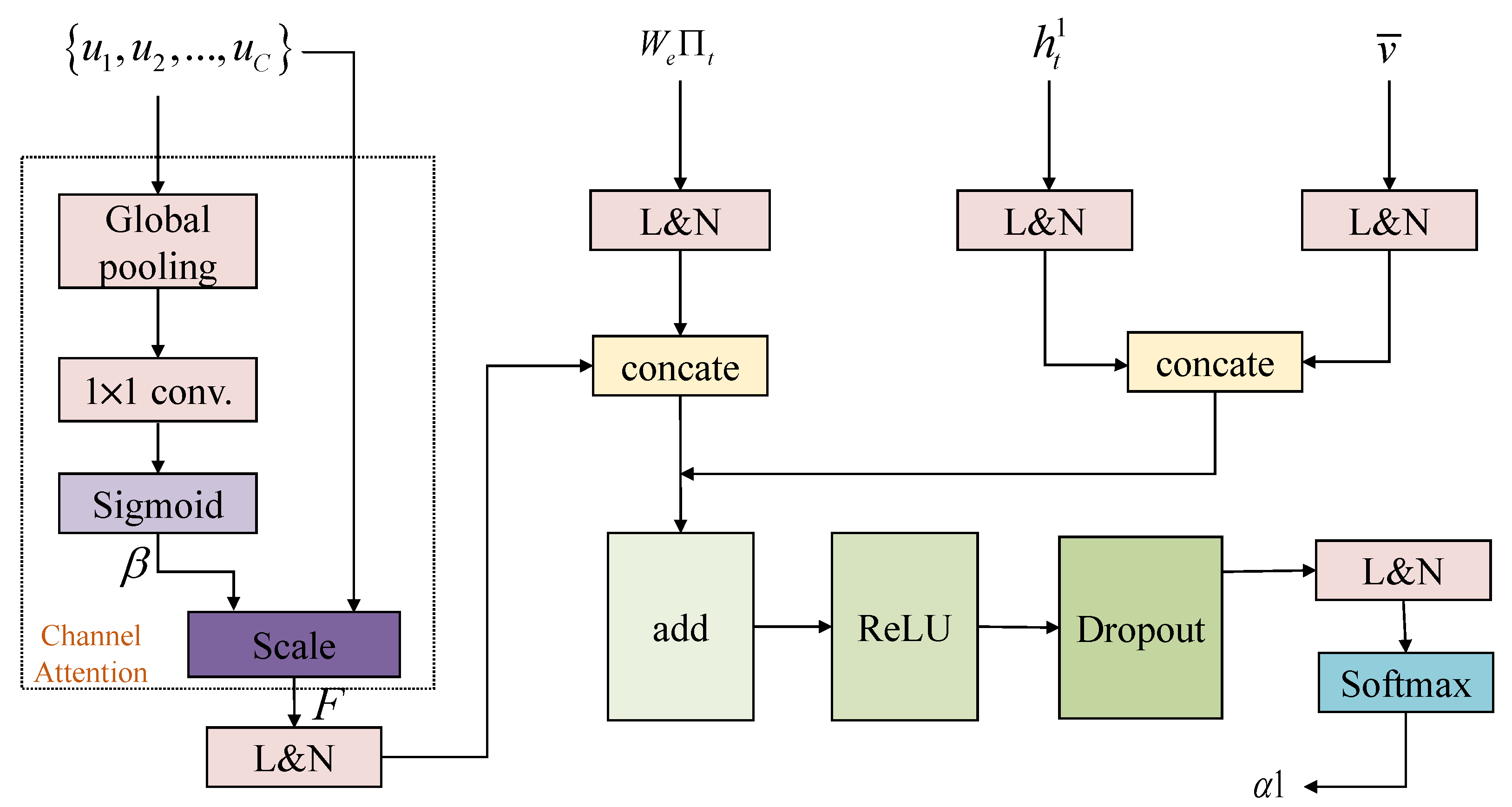
3.2. Multi-Source Interactive Attention
3.3. Stair Attention
3.4. Captioning Model
3.5. Training Strategy
4. Experiments and Analysis
4.1. Data Set and Setting
4.1.1. Data Set
- (1)
- RSICD [3]: All the images in RSICD data set are from Google Earth, and the size of each image is pixels. This data set contains 10,921 images, each of which is manually labeled with five description statements. The RSICD data set is the largest data set in the field of RSIC. There are 30 kinds of scenes in RSICD.
- (2)
- UCM-Captions [33]: The UCM-Captions data set is based on the UC Merced (UCM) land-use data set [46], which provides five description statements for each image. This data set contains 2100 images of 21 types of features, including runways, farms, and dense residential areas. There are 100 pictures in each class, and the size of each picture is pixels. All the images in this data set were captured from the large image of the city area image from the national map of the U.S. Geological Survey.
- (3)
4.1.2. Evaluation Metrics
4.1.3. Training Details and Experimental Setup
4.1.4. Compared Models
- (1)
- SAT [3]: A architecture that adopts spatial attention to encode an RSI by capturing reliable regional features.
- (2)
- FC-Att/SM-Att [4]: In order to utilize the semantic information in the RSIs, this method updates the attentive regions directly, as related to attribute features.
- (3)
- Up-Down [21]: A captioning method that considers both visual perception and linguistic knowledge learning to generate accurate descriptions.
- (4)
- LAM [39]: A RSIC algorithm based on the scene classification task, which can generate scene labels to better guide sentence generation.
- (5)
- MLA [34]: This method utilizes a multi-level attention-based RSIC network, which can capture the correspondence between each candidate word and image.
- (6)
- Sound-a-a [40]: A novel attention mechanism, which uses the interaction of the knowledge distillation from sound information to better understand the RSI scene.
- (7)
- Struc-Att [37]: In order to better integrate irregular region information, a novel framework with structured attention was proposed.
- (8)
- Meta-ML [38]: This model is a multi-stage model for the RSIC task. The representation for a given image is obtained using a pre-trained autoencoder module.
4.2. Evaluation Results and Analysis
4.3. Ablation Experiments
- (1)
- Baseline (A1): The baseline [21] was formed by VGG16 combined with two LSTMs.
- (2)
- MSIAM (A2): A2 denotes the enhanced model based on the Baseline, which utilizes the RSI semantics from sentence fragments and visual features.
- (3)
- MSISAM (A3): Integrating multi-source interaction with stair attention, A3 can highlight the most concerned image areas.
- (4)
- With SCST (A4): We trained the A3 model using the SCST and compared it with the performance obtained by the CE.
4.4. Parameter Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Faster R-CNN | Faster region convolutional neural networks. |
| VGG | Visual geometry group. |
| ResNet | Residual network. |
| BLEU | Bilingual evaluation understudy. |
| Rouge-L | Recall-oriented understudy for gisting evaluation—Longest. |
| Meteor | Metric for Evaluation of translation with explicit ordering. |
| CIDEr | Consensus-based image description evaluation. |
| SCA | Spatial channel attention. |
| I | Input remote sensing image. |
| Counts of image location features. | |
| C | Channel of feature map V. |
| K | Counts of image location features. |
| Global spatial feature computed from V. | |
| Channel attention weight. | |
| F | Channel-level features. |
| Multi-source attention weight. | |
| Stair attention weight. | |
| Final feature output after attention weight. | |
| Generated word at time t. | |
| Preceding words. | |
| Probability of generating a specific word. | |
| Probability of a random sampled sentence. | |
| L | Maximum length of ground-truth sentence. |
| Input for the Multi-source LSTM at time t. | |
| Hidden state of the Multi-source LSTM at time t. | |
| Hidden state of the Multi-source LSTM at time . | |
| Input for the Language LSTM at time t. | |
| Hidden state of the Language LSTM at time t. | |
| Hidden state of the Language LSTM at time t. | |
| Learnable weights and biases. |
References
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Lu, X.; Wang, B.; Zheng, X.; Li, X. Exploring models and data for remote sensing image caption generation. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2183–2195. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, X.; Tang, X.; Zhou, H.; Li, C. Description generation for remote sensing images using attribute attention mechanism. Remote Sens. 2019, 11, 612. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2016, 55, 645–657. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Lu, X.; Zheng, X.; Yuan, Y. Remote sensing scene classification by unsupervised representation learning. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5148–5157. [Google Scholar] [CrossRef]
- Han, X.; Zhong, Y.; Zhang, L. An efficient and robust integrated geospatial object detection framework for high spatial resolution remote sensing imagery. Remote Sens. 2017, 9, 666. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Y. Airport detection and aircraft recognition based on two-layer saliency model in high spatial resolution remote-sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 1511–1524. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhong, Y.; Wang, J.; Ma, A. Foreground-aware relation network for geospatial object segmentation in high spatial resolution remote sensing imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4096–4105. [Google Scholar]
- Li, X.; He, H.; Li, X.; Li, D.; Cheng, G.; Shi, J.; Weng, L.; Tong, Y.; Lin, Z. PointFlow: Flowing semantics through points for aerial image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4217–4226. [Google Scholar]
- Ren, Z.; Gou, S.; Guo, Z.; Mao, S.; Li, R. A mask-guided transformer network with topic token for remote sensing image captioning. Remote Sens. 2022, 14, 2939. [Google Scholar] [CrossRef]
- Fu, K.; Li, Y.; Zhang, W.; Yu, H.; Sun, X. Boosting memory with a persistent memory mechanism for remote sensing image captioning. Remote Sens. 2020, 12, 1874. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is all you need. Proc. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Yohanandan, S.; Song, A.; Dyer, A.G.; Tao, D. Saliency preservation in low-resolution grayscale images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 235–251. [Google Scholar]
- Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Mao, J.; Xu, W.; Yang, Y.; Wang, J.; Huang, Z.; Yuille, A. Deep captioning with multimodal recurrent neural networks (m-rnn). arXiv 2014, arXiv:1412.6632. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 375–383. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2017; pp. 5659–5667. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Wu, Q.; Shen, C.; Liu, L.; Dick, A.; Van Den Hengel, A. What value do explicit high level concepts have in vision to language problems? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 203–212. [Google Scholar]
- You, Q.; Jin, H.; Wang, Z.; Fang, C.; Luo, J. Image captioning with semantic attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4651–4659. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Qiu, Z.; Mei, T. Boosting image captioning with attributes. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4894–4902. [Google Scholar]
- Wu, Q.; Shen, C.; Wang, P.; Dick, A.; Van Den Hengel, A. Image captioning and visual question answering based on attributes and external knowledge. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1367–1381. [Google Scholar] [CrossRef]
- Zhou, Y.; Long, J.; Xu, S.; Shang, L. Attribute-driven image captioning via soft-switch pointer. Pattern Recognit. Lett. 2021, 152, 34–41. [Google Scholar] [CrossRef]
- Tian, C.; Tian, M.; Jiang, M.; Liu, H.; Deng, D. How much do cross-modal related semantics benefit image captioning by weighting attributes and re-ranking sentences? Pattern Recognit. Lett. 2019, 125, 639–645. [Google Scholar] [CrossRef]
- Zhang, Y.; Shi, X.; Mi, S.; Yang, X. Image captioning with transformer and knowledge graph. Pattern Recognit. Lett. 2021, 143, 43–49. [Google Scholar] [CrossRef]
- Rennie, S.J.; Marcheret, E.; Mroueh, Y.; Ross, J.; Goel, V. Self-critical sequence training for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7008–7024. [Google Scholar]
- Shi, Z.; Zou, Z. Can a machine generate humanlike language descriptions for a remote sensing image? IEEE Trans. Geosci. Remote Sens. 2017, 55, 3623–3634. [Google Scholar] [CrossRef]
- Wang, B.; Lu, X.; Zheng, X.; Li, X. Semantic descriptions of high-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1274–1278. [Google Scholar] [CrossRef]
- Qu, B.; Li, X.; Tao, D.; Lu, X. Deep semantic understanding of high resolution remote sensing image. In Proceedings of the 2016 International Conference on Computer, Information and Telecommunication Systems (CITS), Kunming, China, 6–8 July 2016. [Google Scholar]
- Li, Y.; Fang, S.; Jiao, L.; Liu, R.; Shang, R. A multi-level attention model for remote sensing image captions. Remote Sens. 2020, 12, 939. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, W.; Zhang, Z.; Gao, X.; Sun, X. Multiscale Multiinteraction Network for Remote Sensing Image Captioning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 2154–2165. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Gu, J.; Li, C.; Wang, X.; Tang, X.; Jiao, L. Recurrent attention and semantic gate for remote sensing image captioning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Zhao, R.; Shi, Z.; Zou, Z. High-resolution remote sensing image captioning based on structured attention. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Yang, Q.; Ni, Z.; Ren, P. Meta captioning: A meta learning based remote sensing image captioning framework. ISPRS J. Photogram. Remote Sens. 2022, 186, 190–200. [Google Scholar] [CrossRef]
- Zhang, Z.; Diao, W.; Zhang, W.; Yan, M.; Gao, X.; Sun, X. LAM: Remote sensing image captioning with Label-Attention Mechanism. Remote Sens. 2019, 11, 2349. [Google Scholar] [CrossRef]
- Lu, X.; Wang, B.; Zheng, X. Sound active attention framework for remote sensing image captioning. IEEE Trans. Geosci. Remote Sens. 2019, 58, 1985–2000. [Google Scholar] [CrossRef]
- Li, X.; Zhang, X.; Huang, W.; Wang, Q. Truncation cross entropy loss for remote sensing image captioning. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5246–5257. [Google Scholar] [CrossRef]
- Chavhan, R.; Banerjee, B.; Zhu, X.; Chaudhuri, S. A novel actor dual-critic model for remote sensing image captioning. arXiv 2021, arXiv:2010.01999v1. [Google Scholar]
- Shen, X.; Liu, B.; Zhou, Y.; Zhao, J.; Liu, M. Remote sensing image captioning via Variational Autoencoder and Reinforcement Learning. Knowl.-Based Syst. 2020, 203, 105920. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Zhang, F.; Du, B.; Zhang, L. Saliency-guided unsupervised feature learning for scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2175–2184. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, Michigan, 25 June 2005; pp. 65–72. [Google Scholar]
- Lin, C. ROUGE: A Package for Automatic Evaluation of Summaries; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004. [Google Scholar]
- Vedantam, R.; Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. arXiv 2015, arXiv:1411.5726. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef]
- Mindspore. 2020. Available online: https://www.mindspore.cn/ (accessed on 11 November 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Bleu1 | Bleu2 | Bleu3 | Bleu4 | Meteor | Rouge | Cider |
|---|---|---|---|---|---|---|---|
| SAT [3] | 0.7905 | 0.7020 | 0.6232 | 0.5477 | 0.3925 | 0.7206 | 2.2013 |
| FC-Att [4] | 0.8076 | 0.7160 | 0.6276 | 0.5544 | 0.4099 | 0.7114 | 2.2033 |
| SM-Att [4] | 0.8143 | 0.7351 | 0.6586 | 0.5806 | 0.4111 | 0.7195 | 2.3021 |
| Up-Down [21] | 0.8180 | 0.7484 | 0.6879 | 0.6305 | 0.3972 | 0.7270 | 2.6766 |
| LAM [39] | 0.7405 | 0.6550 | 0.5904 | 0.5304 | 0.3689 | 0.6814 | 2.3519 |
| MLA [34] | 0.8152 | 0.7444 | 0.6755 | 0.6139 | 0.4560 | 0.7062 | 1.9924 |
| sound-a-a [40] | 0.7484 | 0.6837 | 0.6310 | 0.5896 | 0.3623 | 0.6579 | 2.7281 |
| Struc-Att [37] | 0.7795 | 0.7019 | 0.6392 | 0.5861 | 0.3954 | 0.7299 | 2.3791 |
| Meta-ML [38] | 0.7958 | 0.7274 | 0.6638 | 0.6068 | 0.4247 | 0.7300 | 2.3987 |
| Ours(SCST) | 0.7643 | 0.6919 | 0.6283 | 0.5725 | 0.3946 | 0.7172 | 2.8122 |
| Methods | Bleu1 | Bleu2 | Bleu3 | Bleu4 | Meteor | Rouge | Cider |
|---|---|---|---|---|---|---|---|
| SAT [3] | 0.7993 | 0.7355 | 0.6790 | 0.6244 | 0.4174 | 0.7441 | 3.0038 |
| FC-Att [4] | 0.8135 | 0.7502 | 0.6849 | 0.6352 | 0.4173 | 0.7504 | 2.9958 |
| SM-Att [4] | 0.8154 | 0.7575 | 0.6936 | 0.6458 | 0.4240 | 0.7632 | 3.1864 |
| Up-Down [21] | 0.8356 | 0.7748 | 0.7264 | 0.6833 | 0.4447 | 0.7967 | 3.3626 |
| LAM [39] | 0.8195 | 0.7764 | 0.7485 | 0.7161 | 0.4837 | 0.7908 | 3.6171 |
| MLA [34] | 0.8406 | 0.7803 | 0.7333 | 0.6916 | 0.5330 | 0.8196 | 3.1193 |
| sound-a-a [40] | 0.7093 | 0.6228 | 0.5393 | 0.4602 | 0.3121 | 0.5974 | 1.7477 |
| Struc-Att [37] | 0.8538 | 0.8035 | 0.7572 | 0.7149 | 0.4632 | 0.8141 | 3.3489 |
| Meta-ML [38] | 0.8714 | 0.8199 | 0.7769 | 0.7390 | 0.4956 | 0.8344 | 3.7823 |
| Ours(SCST) | 0.8727 | 0.8096 | 0.7551 | 0.7039 | 0.4652 | 0.8258 | 3.7129 |
| Methods | Bleu1 | Bleu2 | Bleu3 | Bleu4 | Meteor | Rouge | Cider |
|---|---|---|---|---|---|---|---|
| SAT [3] | 0.7336 | 0.6129 | 0.5190 | 0.4402 | 0.3549 | 0.6419 | 2.2486 |
| FC-Att [4] | 0.7459 | 0.6250 | 0.5338 | 0.4574 | 0.3395 | 0.6333 | 2.3664 |
| SM-Att [4] | 0.7571 | 0.6336 | 0.5385 | 0.4612 | 0.3513 | 0.6458 | 2.3563 |
| Up-Down [21] | 0.7679 | 0.6579 | 0.5699 | 0.4962 | 0.3534 | 0.6590 | 2.6022 |
| LAM [39] | 0.6753 | 0.5537 | 0.4686 | 0.4026 | 0.3254 | 0.5823 | 2.5850 |
| MLA [34] | 0.7725 | 0.6290 | 0.5328 | 0.4608 | 0.4471 | 0.6910 | 2.3637 |
| sound-a-a [40] | 0.6196 | 0.4819 | 0.3902 | 0.3195 | 0.2733 | 0.5143 | 1.6386 |
| Struc-Att [37] | 0.7016 | 0.5614 | 0.4648 | 0.3934 | 0.3291 | 0.5706 | 1.7031 |
| Meta-ML [38] | 0.6866 | 0.5679 | 0.4839 | 0.4196 | 0.3249 | 0.5882 | 2.5244 |
| Ours(SCST) | 0.7836 | 0.6679 | 0.5774 | 0.5042 | 0.3672 | 0.6730 | 2.8436 |
| Methods | Bleu1 | Bleu2 | Bleu3 | Bleu4 | Meteor | Rouge | Cider |
|---|---|---|---|---|---|---|---|
| A1 | 0.8180 | 0.7484 | 0.6879 | 0.6305 | 0.3972 | 0.7270 | 2.6766 |
| A2 | 0.7995 | 0.7309 | 0.6697 | 0.6108 | 0.3983 | 0.7303 | 2.7167 |
| A3 | 0.7918 | 0.7314 | 0.6838 | 0.6412 | 0.4079 | 0.7281 | 2.7485 |
| A4 | 0.7643 | 0.6919 | 0.6283 | 0.5725 | 0.3946 | 0.7172 | 2.8122 |
| Methods | Bleu1 | Bleu2 | Bleu3 | Bleu4 | Meteor | Rouge | Cider |
|---|---|---|---|---|---|---|---|
| A1 | 0.8356 | 0.7748 | 0.7264 | 0.6833 | 0.4447 | 0.7967 | 3.3626 |
| A2 | 0.8347 | 0.7773 | 0.7337 | 0.6937 | 0.4495 | 0.7918 | 3.4341 |
| A3 | 0.8500 | 0.7923 | 0.7438 | 0.6993 | 0.4573 | 0.8126 | 3.4698 |
| A4 | 0.8727 | 0.8096 | 0.7551 | 0.7039 | 0.4652 | 0.8258 | 3.7129 |
| Methods | Bleu1 | Bleu2 | Bleu3 | Bleu4 | Meteor | Rouge | Cider |
|---|---|---|---|---|---|---|---|
| A1 | 0.7679 | 0.6579 | 0.5699 | 0.4962 | 0.3534 | 0.6590 | 2.6022 |
| A2 | 0.7711 | 0.6645 | 0.5777 | 0.5048 | 0.3574 | 0.6674 | 2.7288 |
| A3 | 0.7712 | 0.6636 | 0.5762 | 0.5020 | 0.3577 | 0.6664 | 2.6860 |
| A4 | 0.7836 | 0.6679 | 0.5774 | 0.5042 | 0.3672 | 0.6730 | 2.8436 |
| Methods | Encoder | Bleu1 | Bleu2 | Bleu3 | Bleu4 | Meteor | Rouge | Cider |
|---|---|---|---|---|---|---|---|---|
| VGG16 | Up-Down | 0.8180 | 0.7484 | 0.6879 | 0.6305 | 0.3972 | 0.7270 | 2.6766 |
| MSISAM | 0.7918 | 0.7314 | 0.6838 | 0.6412 | 0.4079 | 0.7281 | 2.7485 | |
| VGG19 | Up-Down | 0.7945 | 0.7231 | 0.6673 | 0.6188 | 0.4109 | 0.7360 | 2.7449 |
| MSISAM | 0.8251 | 0.7629 | 0.7078 | 0.6569 | 0.4185 | 0.7567 | 2.8334 | |
| ResNet50 | Up-Down | 0.7568 | 0.6745 | 0.6130 | 0.5602 | 0.3763 | 0.6929 | 2.4212 |
| MSISAM | 0.7921 | 0.7236 | 0.6647 | 0.6111 | 0.3914 | 0.7113 | 2.4501 | |
| ResNet101 | Up-Down | 0.7712 | 0.6990 | 0.6479 | 0.6043 | 0.4078 | 0.6950 | 2.4777 |
| MSISAM | 0.7821 | 0.7078 | 0.6528 | 0.6059 | 0.4078 | 0.7215 | 2.5882 |
| Methods | Encoder | Bleu1 | Bleu2 | Bleu3 | Bleu4 | Meteor | Rouge | Cider |
|---|---|---|---|---|---|---|---|---|
| VGG16 | Up-Down | 0.8356 | 0.7748 | 0.7264 | 0.6833 | 0.4447 | 0.7967 | 3.3626 |
| MSISAM | 0.8500 | 0.7923 | 0.7438 | 0.6993 | 0.4573 | 0.8126 | 3.4698 | |
| VGG19 | Up-Down | 0.8317 | 0.7683 | 0.7205 | 0.6779 | 0.4457 | 0.7837 | 3.3408 |
| MSISAM | 0.8469 | 0.7873 | 0.7373 | 0.6908 | 0.4530 | 0.8006 | 3.4375 | |
| ResNet50 | Up-Down | 0.8536 | 0.7968 | 0.7518 | 0.7122 | 0.4643 | 0.8111 | 3.5591 |
| MSISAM | 0.8621 | 0.8088 | 0.7640 | 0.7231 | 0.4684 | 0.8126 | 3.5774 | |
| ResNet101 | Up-Down | 0.8545 | 0.8001 | 0.7516 | 0.7067 | 0.4635 | 0.8147 | 3.4683 |
| MSISAM | 0.8562 | 0.8011 | 0.7531 | 0.7086 | 0.4652 | 0.8134 | 3.4686 |
| Methods | Encoder | Bleu1 | Bleu2 | Bleu3 | Bleu4 | Meteor | Rouge | Cider |
|---|---|---|---|---|---|---|---|---|
| VGG16 | Up-Down | 0.7679 | 0.6579 | 0.5699 | 0.4962 | 0.3534 | 0.6590 | 2.6022 |
| MSISAM | 0.7712 | 0.6636 | 0.5762 | 0.5020 | 0.3577 | 0.6664 | 2.6860 | |
| VGG19 | Up-Down | 0.7550 | 0.6383 | 0.5466 | 0.4697 | 0.3556 | 0.6533 | 2.5350 |
| MSISAM | 0.7694 | 0.6587 | 0.5715 | 0.4986 | 0.3613 | 0.6629 | 2.6631 | |
| ResNet50 | Up-Down | 0.7687 | 0.6505 | 0.5577 | 0.4818 | 0.3565 | 0.6607 | 2.5924 |
| MSISAM | 0.7785 | 0.6631 | 0.5704 | 0.4929 | 0.3648 | 0.6665 | 2.6422 | |
| ResNet101 | Up-Down | 0.7685 | 0.6555 | 0.5667 | 0.4920 | 0.3561 | 0.6574 | 2.5601 |
| MSISAM | 0.7785 | 0.6694 | 0.5809 | 0.5072 | 0.3603 | 0.6692 | 2.7027 |
| Methods | Training Time | Inference Speed (Images per Second) |
|---|---|---|
| Up-Down | 253 min | 16.66 |
| MSISAM | 217 min | 16.78 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Li, Y.; Wang, X.; Liu, F.; Wu, Z.; Cheng, X.; Jiao, L. Multi-Source Interactive Stair Attention for Remote Sensing Image Captioning. Remote Sens. 2023, 15, 579. https://doi.org/10.3390/rs15030579
Zhang X, Li Y, Wang X, Liu F, Wu Z, Cheng X, Jiao L. Multi-Source Interactive Stair Attention for Remote Sensing Image Captioning. Remote Sensing. 2023; 15(3):579. https://doi.org/10.3390/rs15030579
Chicago/Turabian StyleZhang, Xiangrong, Yunpeng Li, Xin Wang, Feixiang Liu, Zhaoji Wu, Xina Cheng, and Licheng Jiao. 2023. "Multi-Source Interactive Stair Attention for Remote Sensing Image Captioning" Remote Sensing 15, no. 3: 579. https://doi.org/10.3390/rs15030579
APA StyleZhang, X., Li, Y., Wang, X., Liu, F., Wu, Z., Cheng, X., & Jiao, L. (2023). Multi-Source Interactive Stair Attention for Remote Sensing Image Captioning. Remote Sensing, 15(3), 579. https://doi.org/10.3390/rs15030579