







SDAT-Former++: A Foggy Scene Semantic Segmentation Method with Stronger Domain Adaption Teacher for Remote Sensing Images


Abstract
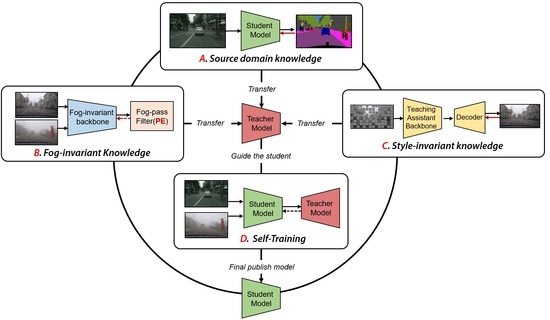
:
1. Introduction
- To the best of our knowledge, this work is the first to propose an end-to-end cyclical training domain adaptation semantic segmentation method that considers both style-invariant and fog-invariant features.
- Our method proves the importance of masked learning and feature enhancement in foggy road scene segmentation and demonstrates their mechanisms through visualizations.
- Our method significantly outperforms SDAT-Former on mainstream benchmark datasets for foggy road scene segmentation and exhibits strong generalization in rainy and snowy scenes. Compared to the original method, SDAT-Former++ pays more attention to the more important categories in road scenes and is more suitable for applications in intelligent vehicles. We test our SDAT-Former++ method on mainstream benchmarks for semantic segmentation in foggy scenes and demonstrate improvements of 3.3%, 4.8%, and 1.1% (as measured by the mIoU) on the ACDC, Foggy Zurich, and Foggy Driving datasets, respectively, compared to the original method.
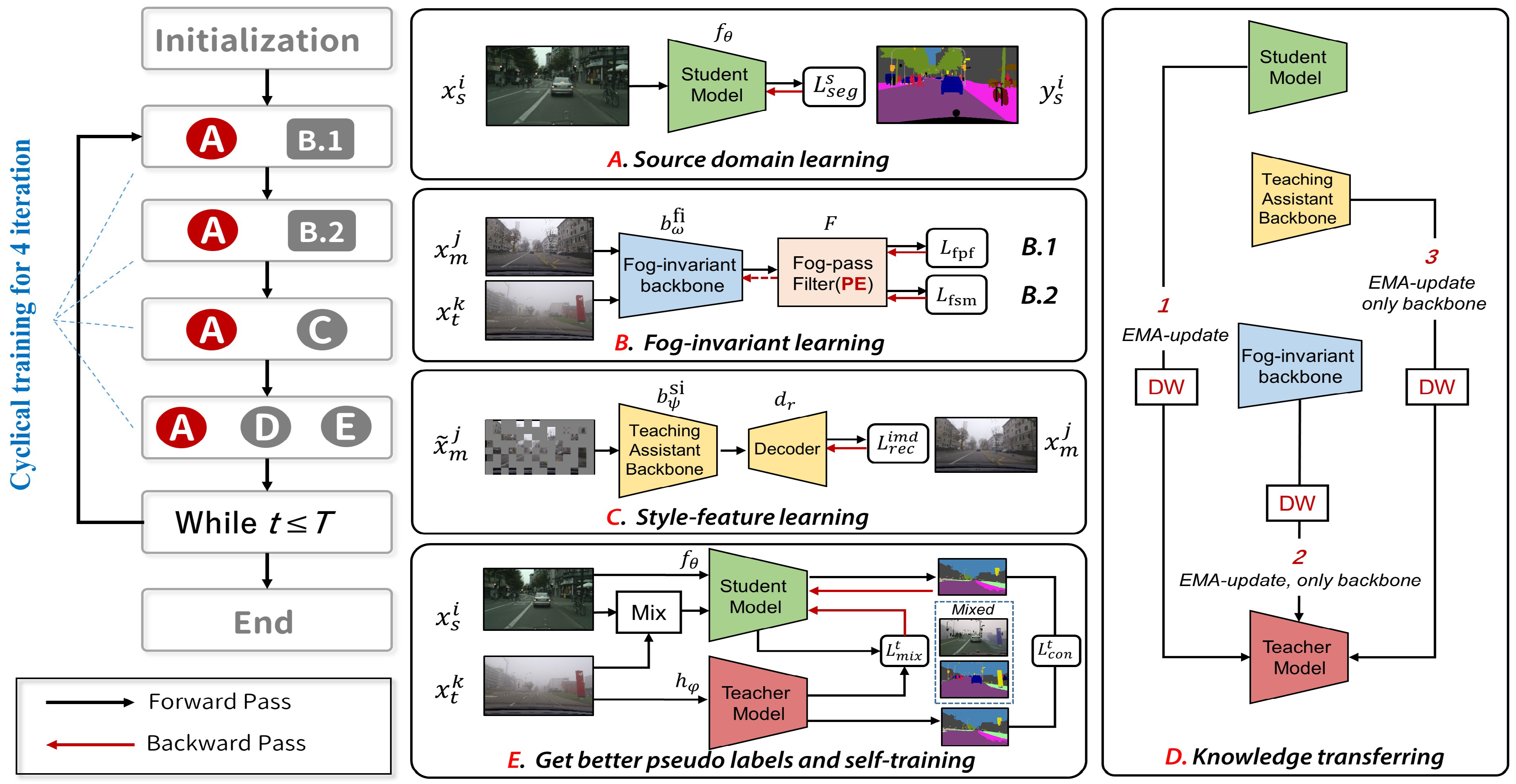
2. Method
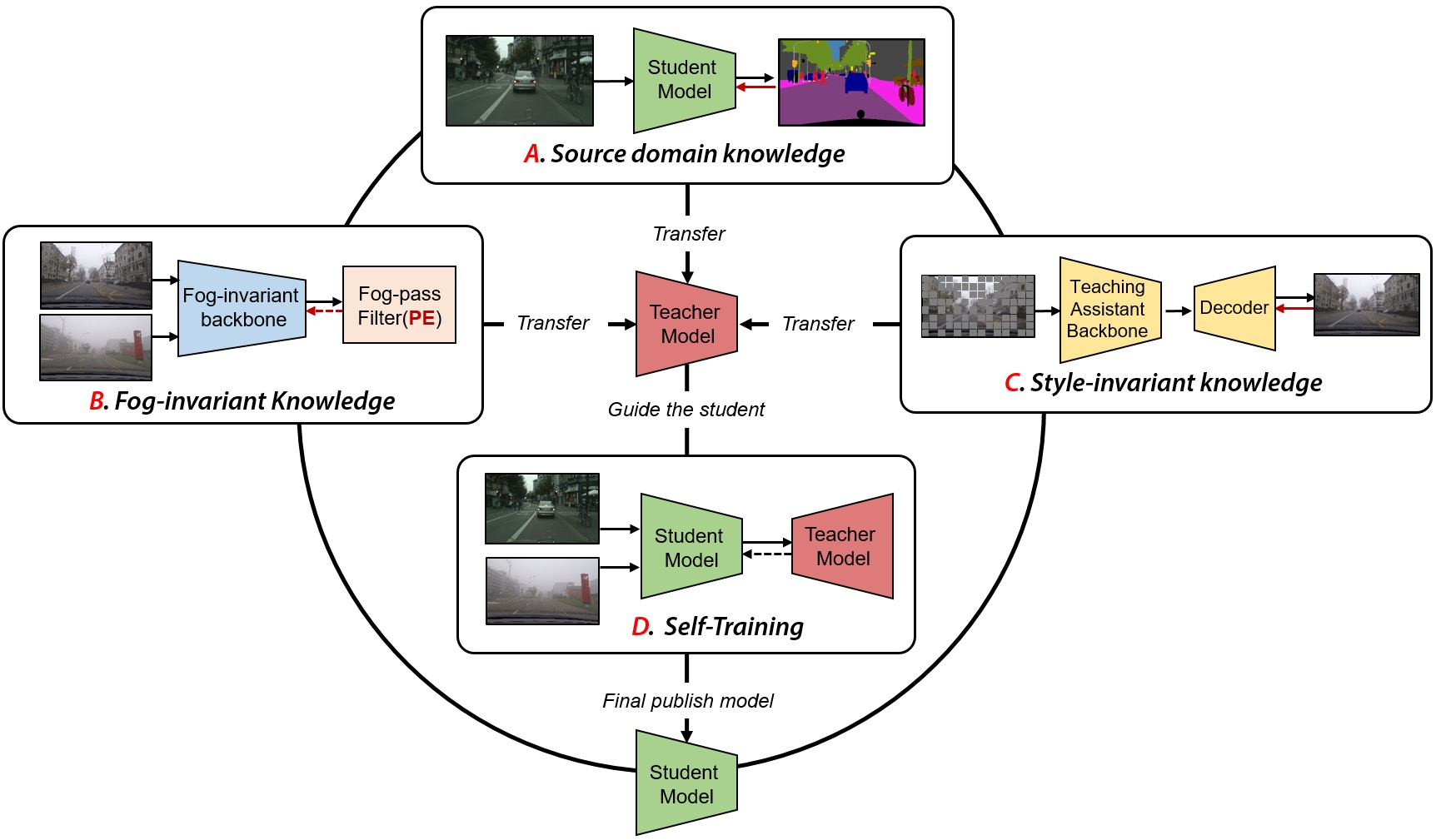
2.1. Overview
2.2. Sub-Modules
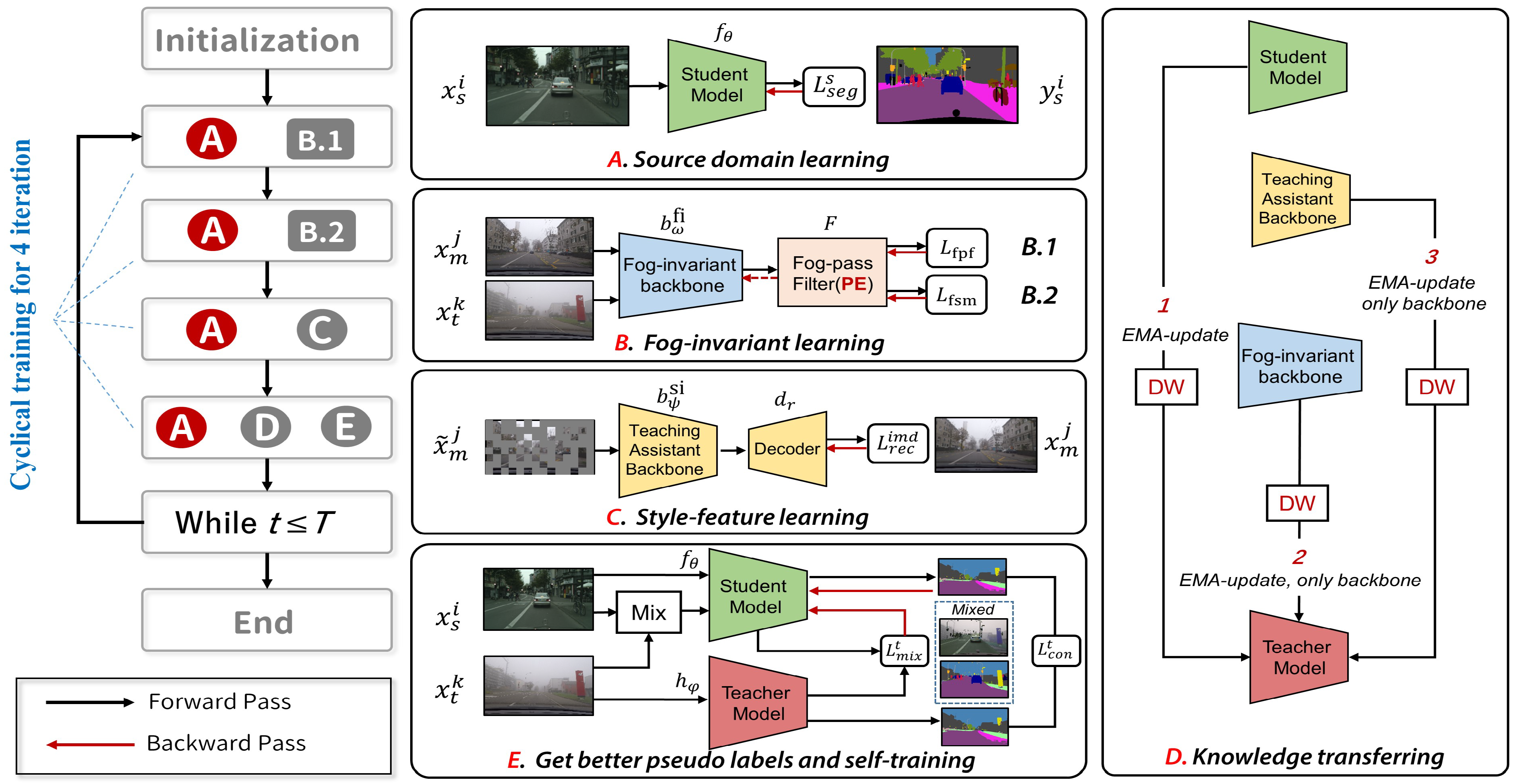
2.3. Supervised Training on Source Domain
2.4. Masked Learning on the Intermediate Domain
2.5. Fog-Invariant Feature Learning
2.5.1. Training the Fog-Pass Filter
2.5.2. Fog Factor Matching Loss
2.6. Self-Training on the Target Domain and Consistency Learning
2.7. Cyclical Training with Knowledge Transferring
3. Results
3.1. The Network Parameters
3.2. Implementation Details
3.3. Datasets
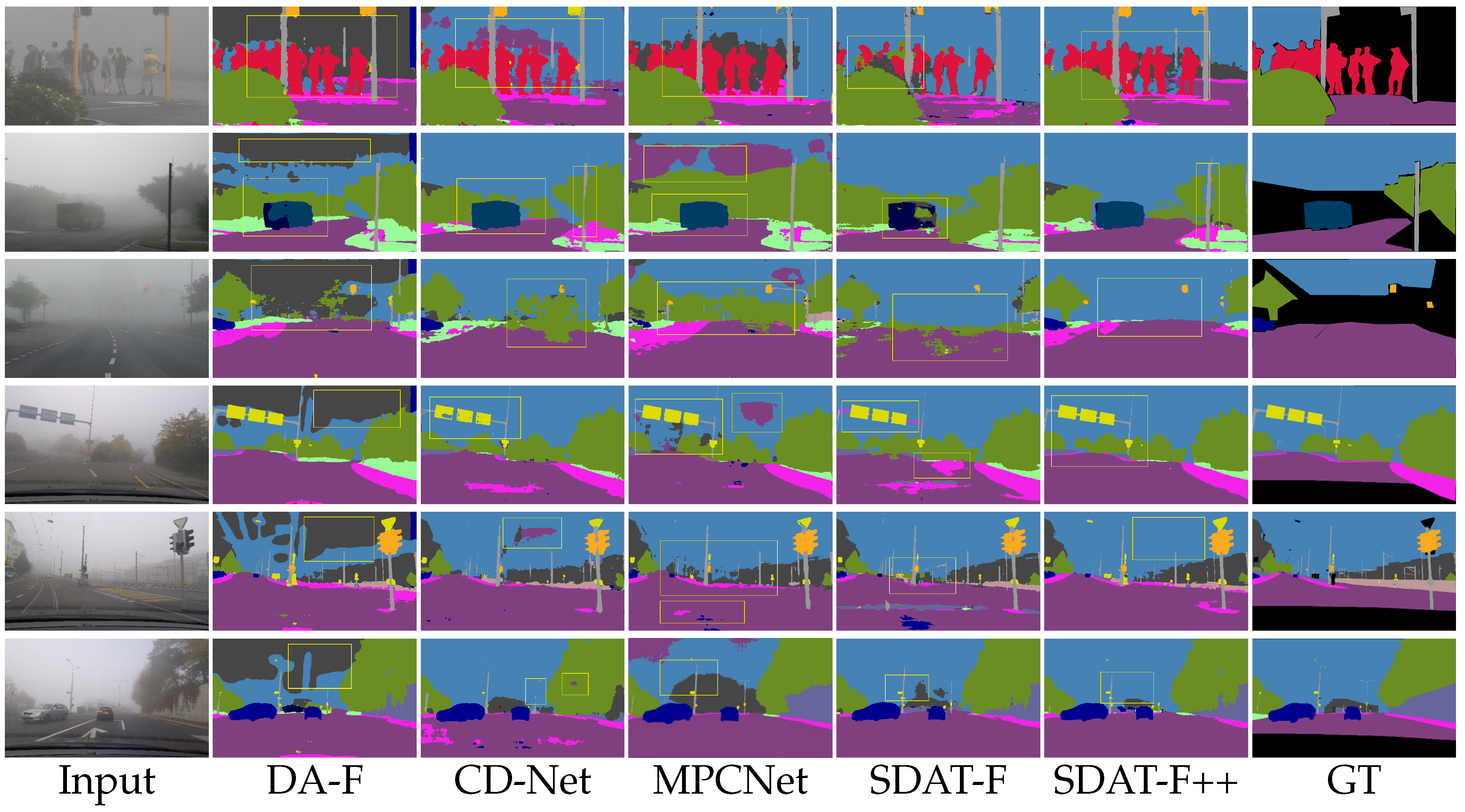
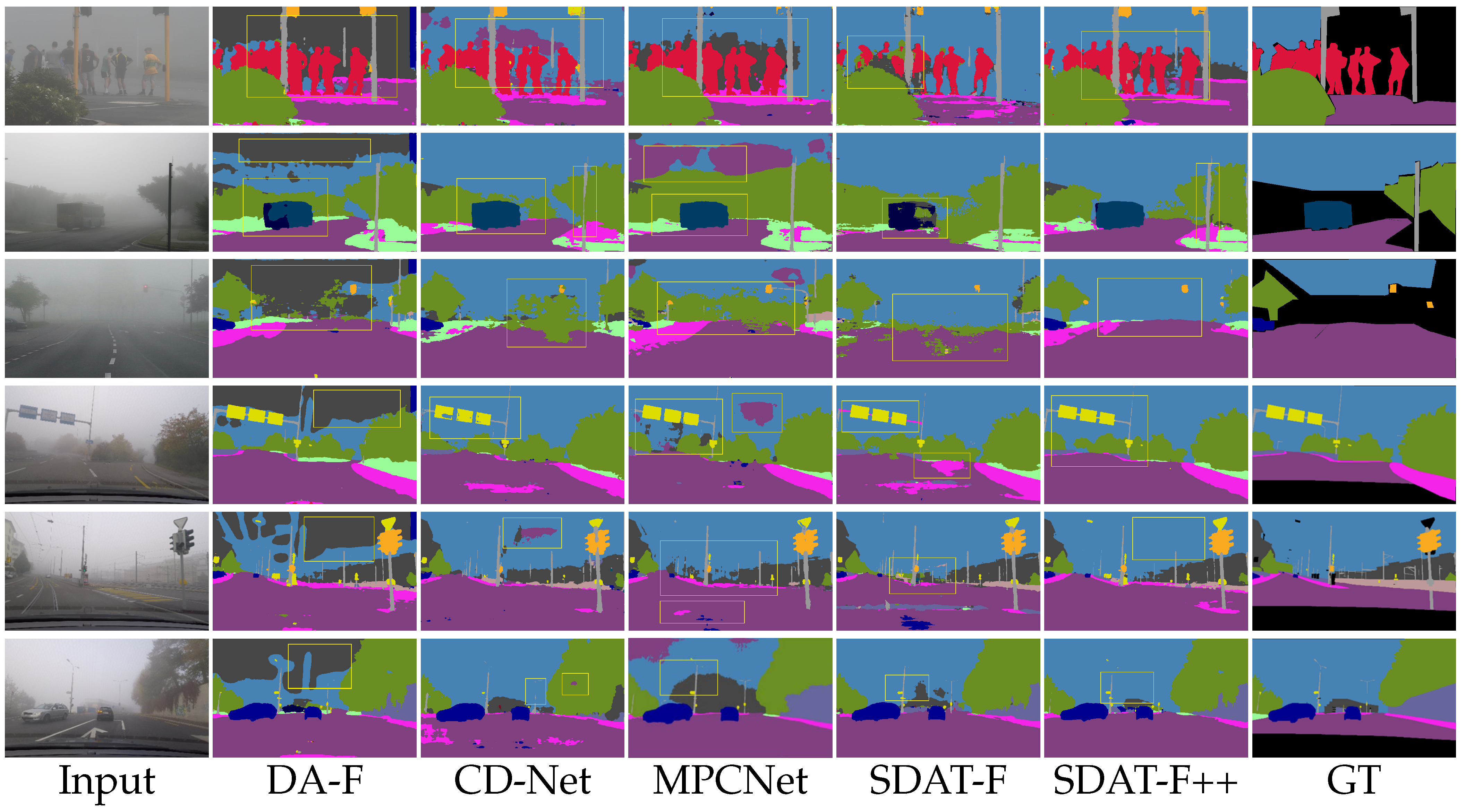
3.4. Performance Comparison
4. Discussion
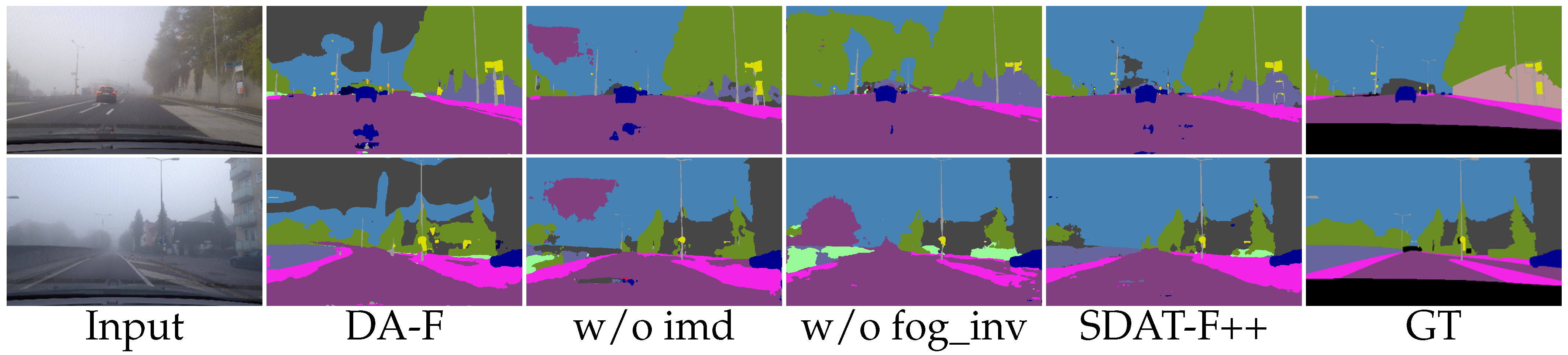
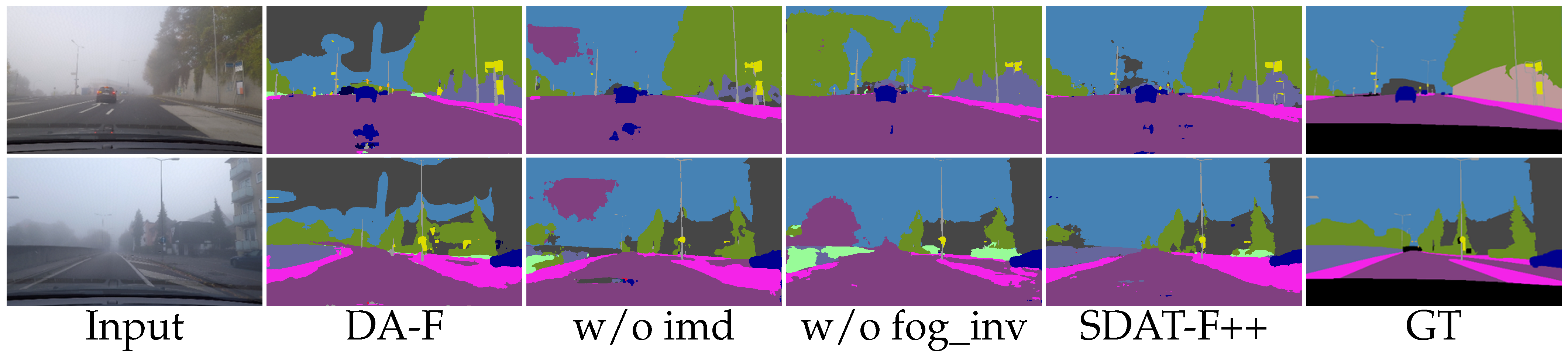
4.1. Effectiveness of Fog-Invariant Feature Learning
4.2. Effectiveness of Style-Invariant Features Learning
4.3. Effectiveness of Cyclical Training
4.4. What Does SDAT-Former++ Learn?
4.5. Sensitivity Analysis/Adaptability to Fog
4.6. Number of Images from the Intermediate Domain
4.7. Generalization to Rainy and Snowy Scenes
4.8. Order of EMA Updating
4.9. Memory Consumption Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Z.; Zhang, Y.; Yu, Y.; Jiang, Z. SDAT-Former: Foggy Scene Semantic Segmentation Via A Strong Domain Adaptation Teacher. In Proceedings of the 2023 IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023; pp. 1760–1764. [Google Scholar] [CrossRef]
- Ranft, B.; Stiller, C. The Role of Machine Vision for Intelligent Vehicles. IEEE Trans. Intell. Veh. 2016, 1, 8–19. [Google Scholar] [CrossRef]
- Dai, Y.; Li, C.; Su, X.; Liu, H.; Li, J. Multi-Scale Depthwise Separable Convolution for Semantic Segmentation in Street–Road Scenes. Remote Sens. 2023, 15, 2649. [Google Scholar] [CrossRef]
- Liu, Q.; Dong, Y.; Jiang, Z.; Pei, Y.; Zheng, B.; Zheng, L.; Fu, Z. Multi-Pooling Context Network for Image Semantic Segmentation. Remote Sens. 2023, 15, 2800. [Google Scholar] [CrossRef]
- Šarić, J.; Oršić, M.; Šegvić, S. Panoptic SwiftNet: Pyramidal Fusion for Real-Time Panoptic Segmentation. Remote Sens. 2023, 15, 1968. [Google Scholar] [CrossRef]
- Lv, K.; Zhang, Y.; Yu, Y.; Zhang, Z.; Li, L. Visual Localization and Target Perception Based on Panoptic Segmentation. Remote Sens. 2022, 14, 3983. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Lyu, X.; Gao, H.; Tong, Y.; Cai, S.; Li, S.; Liu, D. Dual attention deep fusion semantic segmentation networks of large-scale satellite remote-sensing images. Int. J. Remote Sens. 2021, 42, 3583–3610. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Xia, R.; Li, T.; Chen, Z.; Wang, X.; Xu, Z.; Lyu, X. Encoding contextual information by interlacing transformer and convolution for remote sensing imagery semantic segmentation. Remote Sens. 2022, 14, 4065. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Liu, F.; Xia, R.; Tong, Y.; Li, L.; Xu, Z.; Lyu, X. Hybridizing Euclidean and Hyperbolic Similarities for Attentively Refining Representations in Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Liu, F.; Lyu, X.; Tong, Y.; Xu, Z.; Zhou, J. A Synergistical Attention Model for Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Sakaridis, C.; Dai, D.; Van Gool, L. Semantic foggy scene understanding with synthetic data. Int. J. Comput. Vis. 2018, 126, 973–992. [Google Scholar] [CrossRef]
- Narasimhan, S.G.; Nayar, S.K. Contrast restoration of weather degraded images. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 713–724. [Google Scholar] [CrossRef]
- Michieli, U.; Biasetton, M.; Agresti, G.; Zanuttigh, P. Adversarial Learning and Self-Teaching Techniques for Domain Adaptation in Semantic Segmentation. IEEE Trans. Intell. Veh. 2020, 5, 508–518. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Proceedings of the Workshop on Challenges in Representation Learning, ICML, Atlanta, GA, USA, 16–21 June 2013; Volume 3, p. 896. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.K.; Wang, Z.; Smolley, S.P. Least Squares Generative Adversarial Networks. arXiv 2016, arXiv:1611.04076. [Google Scholar]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.Y.; Isola, P.; Saenko, K.; Efros, A.A.; Darrell, T. CyCADA: Cycle-Consistent Adversarial Domain Adaptation. Computer Vision and Pattern Recognition arXiv 2017, arXiv:1711.03213v3. [Google Scholar]
- Chang, W.L.; Wang, H.P.; Peng, W.H.; Chiu, W.C. All about structure: Adapting structural information across domains for boosting semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1900–1909. [Google Scholar]
- Tsai, Y.H.; Hung, W.C.; Schulter, S.; Sohn, K.; Yang, M.H.; Chandraker, M. Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7472–7481. [Google Scholar]
- Vu, T.H.; Jain, H.; Bucher, M.; Cord, M.; Pérez, P. Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2517–2526. [Google Scholar]
- Zou, Y.; Yu, Z.; Liu, X.; Kumar, B.V.; Wang, J. Confidence Regularized Self-Training. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Tranheden, W.; Olsson, V.; Pinto, J.; Svensson, L. Dacs: Domain adaptation via cross-domain mixed sampling. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 1379–1389. [Google Scholar]
- Zhang, P.; Zhang, B.; Zhang, T.; Chen, D.; Wang, Y.; Wen, F. Prototypical pseudo label denoising and target structure learning for domain adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12414–12424. [Google Scholar]
- Hoyer, L.; Dai, D.; Van Gool, L. Daformer: Improving network architectures and training strategies for domain-adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9924–9935. [Google Scholar]
- Ma, X.; Wang, Z.; Zhan, Y.; Zheng, Y.; Wang, Z.; Dai, D.; Lin, C.W. Both style and fog matter: Cumulative domain adaptation for semantic foggy scene understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18922–18931. [Google Scholar]
- Dai, D.; Sakaridis, C.; Hecker, S.; Van Gool, L. Curriculum model adaptation with synthetic and real data for semantic foggy scene understanding. Int. J. Comput. Vis. 2020, 128, 1182–1204. [Google Scholar] [CrossRef]
- Dai, D.; Gool, L.V. Dark Model Adaptation: Semantic Image Segmentation from Daytime to Nighttime. Computer Vision and Pattern Recognition. arXiv 2018, arXiv:1810.02575. [Google Scholar]
- Bruggemann, D.; Sakaridis, C.; Truong, P.; Gool, L.V. Refign: Align and Refine for Adaptation of Semantic Segmentation to Adverse Conditions. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 3174–3184. [Google Scholar]
- Li, Y.; Yuan, L.; Vasconcelos, N. Bidirectional learning for domain adaptation of semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 6936–6945. [Google Scholar]
- Laine, S.; Aila, T. Temporal ensembling for semi-supervised learning. arXiv 2016, arXiv:1610.02242. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Hoyer, L.; Dai, D.; Wang, H.; Van Gool, L. MIC: Masked image consistency for context-enhanced domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 11721–11732. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, Z.; Wu, S.; Xie, W.; Chen, M.; Prisacariu, V.A. NeRF–: Neural radiance fields without known camera parameters. arXiv 2021, arXiv:2102.07064. [Google Scholar]
- Christos, S.; Dengxin, D.; Luc, V.G. ACDC: The adverse conditions dataset with correspondences for semantic driving scene understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10765–10775. [Google Scholar]
- Sakaridis, C.; Dai, D.; Hecker, S.; Van Gool, L. Model adaptation with synthetic and real data for semantic dense foggy scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 687–704. [Google Scholar]
- Lee, S.; Son, T.; Kwak, S. Fifo: Learning fog-invariant features for foggy scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18911–18921. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Gong, R.; Wang, Q.; Danelljan, M.; Dai, D.; Van Gool, L. Continuous Pseudo-Label Rectified Domain Adaptive Semantic Segmentation With Implicit Neural Representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7225–7235. [Google Scholar]
- French, G.; Laine, S.; Aila, T.; Mackiewicz, M.; Finlayson, G. Semi-supervised semantic segmentation needs strong, varied perturbations. arXiv 2019, arXiv:1906.01916. [Google Scholar]
- Olsson, V.; Tranheden, W.; Pinto, J.; Svensson, L. Classmix: Segmentation-based data augmentation for semi-supervised learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 1369–1378. [Google Scholar]
- Jin, Y.; Wang, J.; Lin, D. Semi-supervised semantic segmentation via gentle teaching assistant. Adv. Neural Inf. Process. Syst. 2022, 35, 2803–2816. [Google Scholar]
- Contributors, M. MMSegmentation: Openmmlab Semantic Segmentation Toolbox and Benchmark, 2020. Available online: https://gitee.com/open-mmlab/mmsegmentation (accessed on 9 December 2023).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Manhattan, NY, USA, 2009; pp. 248–255. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Kerim, A.; Chamone, F.; Ramos, W.; Marcolino, L.S.; Nascimento, E.R.; Jiang, R. Semantic Segmentation under Adverse Conditions: A Weather and Nighttime-aware Synthetic Data-based Approach. arXiv 2022, arXiv:2210.05626. [Google Scholar]
- Zhang, H.; Patel, V.M. Densely Connected Pyramid Dehazing Network. arXiv 2018, arXiv:1803.08396. [Google Scholar]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.H. Single image dehazing via multi-scale convolutional neural networks. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 154–169. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Yang, Y.; Soatto, S. Fda: Fourier domain adaptation for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4085–4095. [Google Scholar]
- Berman, D.; Avidan, S. Non-local image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1674–1682. [Google Scholar]
- Benjdira, B.; Ali, A.M.; Koubaa, A. Streamlined Global and Local Features Combinator (SGLC) for High Resolution Image Dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1854–1863. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment | Method | Backbone | ACDC | FZ | Experiment | Method | Backbone | ACDC | FZ |
|---|---|---|---|---|---|---|---|---|---|
| Backbone | - | DeepLabv2 [49] | 33.5 | 25.9 | DA-based | LSGAN [17] | DeepLabv2 | 29.3 | 24.4 |
| - | RefineNet [50] | 46.4 | 34.6 | Multi-task [51] | DeepLabv2 | 35.4 | 28.2 | ||
| - | MPCNet [4] | 45.9 | 39.4 | AdaptSegNet [20] | DeepLabv2 | 31.8 | 26.1 | ||
| - | SegFormer [39] | 47.3 | 37.7 | ADVENT [21] | DeepLabv2 | 32.9 | 24.5 | ||
| Dehazing | DCPDN [52] | DeepLabv2 | 33.4 | 28.7 | CLAN [22] | DeepLabv2 | 38.9 | 28.3 | |
| MSCNN [53] | RefineNet | 38.5 | 34.4 | BDL [30] | DeepLabv2 | 37.7 | 30.2 | ||
| DCP [54] | RefineNet | 34.7 | 31.2 | FDA [55] | DeepLabv2 | 39.5 | 22.2 | ||
| Non-local [56] | RefineNet | 31.9 | 27.6 | DISE [19] | DeepLabv2 | 42.3 | 40.7 | ||
| SGLC [57] | RefineNet | 39.2 | 34.5 | ProDA [24] | DeepLabv2 | 38.4 | 37.8 | ||
| Synthetic | SFSU [11] | RefineNet | 45.6 | 35.7 | DACS [23] | DeepLabv2 | 41.3 | 28.7 | |
| CMAda [27] | RefineNet | 51.1 | 46.8 | DAFormer [25] | SegFormer | 48.9 | 44.4 | ||
| FIFO [38] | RefineNet | 54.1 | 48.4 | CuDA-Net [26] | DeepLabv2 | 55.6 | 49.1 | ||
| SDAT | SDAT-Former [1] | SegFormer | 56.0 | 49.0 | Ours | SDAT-Former++ | SegFormer | 59.3 | 53.8 |
| Experiment | Method | Backbone | FD | FDD |
|---|---|---|---|---|
| Backbone | - | DeepLabv2 [49] | 26.3 | 17.6 |
| - | RefineNet [50] | 34.6 | 35.8 | |
| - | SegFormer [39] | 36.2 | 37.4 | |
| Synthetic | CMAda3 [27] | RefineNet | 49.8 | 43.0 |
| FIFO [38] | RefineNet | 50.7 | 48.9 | |
| DA-based | AdaptSegNet [20] | DeepLabv2 | 29.7 | 15.8 |
| ADVENT [21] | DeepLabv2 | 46.9 | 41.7 | |
| FDA [55] | DeepLabv2 | 21.8 | 29.8 | |
| DAFormer [25] | SegFormer | 47.3 | 39.6 | |
| CuDA-Net [26] | DeepLabv2 | 53.5 | 48.2 | |
| Ours | SDAT-Former [1] | SegFormer | 54.3 | 50.8 |
| SDAT-Former++ | SegFormer | 55.4 | 51.2 |
| Experiment | mIoU | Gain | ||||
|---|---|---|---|---|---|---|
| Initialization | DAFormer | 48.92 | +0.00 | |||
| Cyclical(w/o DW ) | imd(ls+da) | fog_inv (w/o PE ) | mIoU | Gain | ||
| SDAT-F [1] | 10.23 | −38.69 | ||||
| ✓ | 49.88 | +0.96 | ||||
| ✓ | 50.52 | +1.60 | ||||
| ✓ | ✓ | 51.61 | +2.69 | |||
| ✓ | ✓ | 53.84 | +4.92 | |||
| ✓ | ✓ | ✓ | 55.98 | +7.06 | ||
| Cyclical(w/ DW) | imd(masked) | con_learn | fog_inv(w/ PE) | mIoU | Gain | |
| SDAT-F++ | ✓ | 50.34 | +1.42 | |||
| ✓ | 52.63 | +3.71 | ||||
| ✓ | 51.33 | +2.41 | ||||
| ✓ | ✓ | 56.19 | +7.27 | |||
| ✓ | ✓ | ✓ | 58.42 | +9.50 | ||
| ✓ | ✓ | ✓ | ✓ | 59.28 | +10.36 | |
| Discussion of Numbers | mIoU | |||||
|---|---|---|---|---|---|---|
| Number of images from intermediate domain | 400 | 600 | 1000 | 1600 | ACDC | FZ |
| ✓ | 56.19 | 47.42 | ||||
| ✓ | 54.17 | 51.61 | ||||
| ✓ | 59.28 | 53.82 | ||||
| ✓ | 58.34 | 53.97 | ||||
| Generalization on ACDC Validation Subsets | Rain | Snow | |
|---|---|---|---|
| Method | SegFormer(no UDA) [39] | 40.62 | 42.03 |
| DAFormer(baseline) [25] | 48.27 | 49.19 | |
| SDAT-Former [1] | 53.99 | 58.04 | |
| SDAT-Former++ | 56.83 | 60.14 | |
| Order of EMA Updating | mIoU | Gain | |||
|---|---|---|---|---|---|
| Configuration | Fi →T | S →T | TA →T | ACDC | FZ |
| 1 | 2 | 3 | 58.14 | 52.78 | |
| 2 | 1 | 3 | 59.24 | 53.80 | |
| 1 | 3 | 2 | 59.17 | 53.68 | |
| 1 | 2 | 3 | 59.28 | 53.82 | |
| Memory Consumption Comparison (GB) | |||||
|---|---|---|---|---|---|
| Train | Test | ||||
| Mini-epoch | Iter 4n | Iter 4n + 1 | Iter 4n + 2 | Iter 4n + 3 | |
| SegFormer [39] | 5.7 | ||||
| DAFormer [25] | 11.3 | 5.7 | |||
| SDAT-Former [1] | 5.9 | 7.7 | 8.3 | 11.9 | |
| SDAT-Former++ | 6.4 | 8.5 | 9.4 | 13.3 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Zhang, Y.; Zhang, Z.; Jiang, Z.; Yu, Y.; Li, L.; Zhang, L. SDAT-Former++: A Foggy Scene Semantic Segmentation Method with Stronger Domain Adaption Teacher for Remote Sensing Images. Remote Sens. 2023, 15, 5704. https://doi.org/10.3390/rs15245704
Wang Z, Zhang Y, Zhang Z, Jiang Z, Yu Y, Li L, Zhang L. SDAT-Former++: A Foggy Scene Semantic Segmentation Method with Stronger Domain Adaption Teacher for Remote Sensing Images. Remote Sensing. 2023; 15(24):5704. https://doi.org/10.3390/rs15245704
Chicago/Turabian StyleWang, Ziquan, Yongsheng Zhang, Zhenchao Zhang, Zhipeng Jiang, Ying Yu, Li Li, and Lei Zhang. 2023. "SDAT-Former++: A Foggy Scene Semantic Segmentation Method with Stronger Domain Adaption Teacher for Remote Sensing Images" Remote Sensing 15, no. 24: 5704. https://doi.org/10.3390/rs15245704
APA StyleWang, Z., Zhang, Y., Zhang, Z., Jiang, Z., Yu, Y., Li, L., & Zhang, L. (2023). SDAT-Former++: A Foggy Scene Semantic Segmentation Method with Stronger Domain Adaption Teacher for Remote Sensing Images. Remote Sensing, 15(24), 5704. https://doi.org/10.3390/rs15245704