1. Introduction
Due to its broad coverage and unique high-altitude view, object detection in RS (remote sensing) datasets has received widespread focus with practical applications in various fields, such as military surveillance, environmental analysis, and precision agriculture. Traditional object detection methods typically involve extracting image features by manual design. These features are then combined to classify objects. However, generating the candidate regions is time-consuming. Designing features manually is also unreliable, complex, and poorly generalized. These traditional methods have limited practical application. Therefore, the focus of research on object detection methods has gradually shifted to the application of deep learning methods.
Generally, object detection approaches that employ CNNs fall into two major types: two-stage and one-stage approaches, depending on different pipelines [
1]. Specifically, the two-stage approaches, such as Faster R-CNN [
2], conduct classification and regression following the generation of region proposals. The end-to-end pipeline of the one-stage approaches, such as YOLO [
3], directly executes the classification and localization task on the output of the model’s backbone. To sustain detection speed advantages while increasing accuracy, several attempts have been made with these approaches [
4,
5,
6,
7,
8]. In addition to the above classification, mainstream object detection approaches are also categorized as anchor-based or anchor-free methods, according to whether the priori bounding boxes are explicitly defined. Two-stage methods, like the proposals generated by RPN in Faster R-CNN [
2], are generally anchor-based as they use candidate prior bounding boxes. One-stage methods used to be mainly anchor-based, but many anchor-free methods have been developed with satisfactory accuracy in recent years.
Anchor-based methods predict the location of objects of interest by matching the anchors with ground truth boxes. Representative methods, such as Mask R-CNN [
9] and YOLOv2 [
4], are employed. The R-CNN [
10] implements a strategy of sliding windows to produce fixed anchors with predefined scales. However, utilizing the same group of anchors for instances of various sizes can reduce the effectiveness of object recognition. Therefore, it is necessary to set the corresponding hyperparameters of the anchors when applying anchor-based methods to different datasets for object detection. Achieving high detection accuracy is dependent on the proper hyperparameter settings. YOLOv2 [
4] uses the K-means clustering method to obtain the size of the anchor box. In addition, the issue of imbalanced positive and negative samples impacts detection accuracy. This is because only a tiny proportion of the predefined anchors become positive samples. RetinaNet [
11] provides a focal loss function that modifies positive/negative and hard/simple sample weights in the loss function using hyperparameters. YOLOv3 [
5] sets nine distinct anchor boxes to predict multi-scale objects. Nevertheless, multi-scale objects with different orientations significantly increase the challenge of setting appropriate hyperparameters for anchors in high-altitude RS datasets.
Anchor-free methods predict objects by matching pixel points. The main advantages of anchor-free methods are their flexibility, generality, and low computational complexity. They avoid the massive computational resources typically required for anchors. Among them, the model’s ability to capture small objects is enhanced by key-point-based regression methods. CornerNet [
12], a pioneer in anchor-free methods, uses the upper-left and upper-right corners of the object bounding box as prediction key points. However, the key points used by CornerNet may fall outside the objects, causing the model to fail to capture internal information. This can lead to CornerNet missing instances when detecting small objects. Based on this, ExtremeNet [
13] predicts four extreme points and one central point of the target. Another improvement of CornerNet, CenterNet [
14], detects the central point of objects to predict the scales of bounding boxes. Unlike keypoint-based methods that rely solely on key points for detection, FCOS [
15] uses a per-pixel approach. All anchors falling within the ground truth box are considered positive samples. The center-ness branch assigns a low score to the predicted boxes that deviate from the center of objects. YOLOX [
16] adopts the center sampling strategy of FCOS. In addition, YOLOX improves detection accuracy by introducing a decoupling head, robust data augmentation, and a novel label assignment strategy. Based on YOLOX, RTMDet [
17] achieves a further breakthrough in accuracy. It uses strategies such as deep convolution with a large kernel and dynamic soft label assignment. Therefore, we choose RTMDet as a robust baseline for the proposed method.
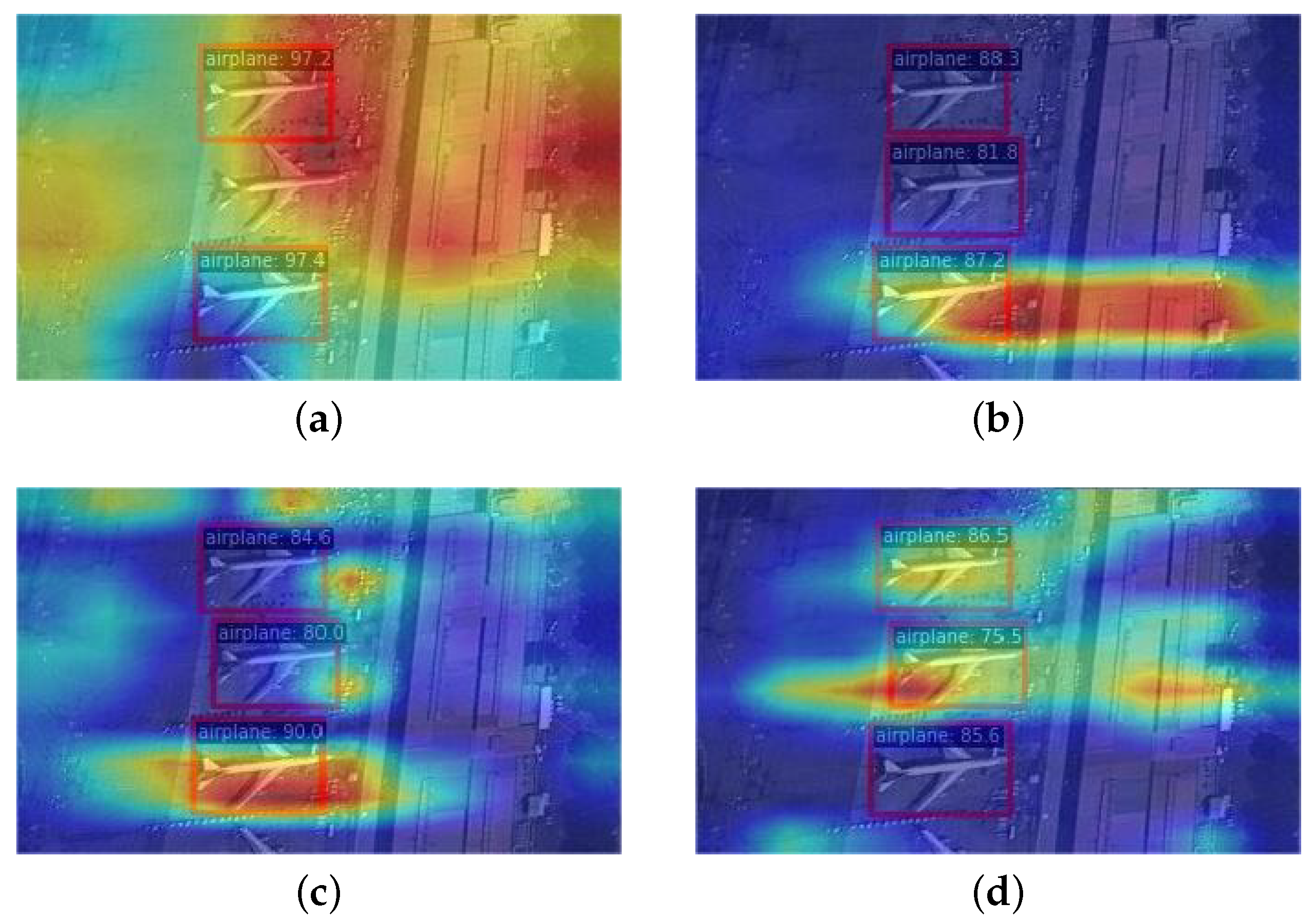
Current generic object detection approaches have developed various variants, such as increasing model width and depth and adding multi-scale fusion networks [
18]. These methods are usually applied to natural images. The accuracy of these detection methods in RS images is not very satisfactory. This is because RS images have different characteristics from natural images. To illustrate this, some examples were selected from the MAR20 dataset. As seen in
Figure 1a, RS images have a high density of small objects, which makes detection much more difficult. Second, objects in RS images vary significantly in scales and orientations, as illustrated in
Figure 1b. This makes the detection task more challenging. Additionally, existing detection methods are prone to losing small objects’ weak features in RS images. The complex scenes can interfere with detection, as
Figure 1c shows. The overhead view of RS images reduces the available feature information for object detection. Small objects occupy a small resolution and are susceptible to interference from background information [
19]. Consequently, the feature and contextual information of small objects extracted by the model is limited [
20]. Therefore, developing a method to enhance the effect of detecting small objects in RS datasets is urgently needed.
Due to scale differences, the detection accuracy of medium and large objects is significantly better in comparison with small ones. Therefore, many feature fusion architectures have been developed to reduce small object feature loss and improve overall object detection accuracy. To enhance shallow feature maps’ semantic and depth information, the Feature Pyramid Network (FPN) [
18] was developed for object detection. Building on the top-down path of FPN, a bottom-up path is added to complement the localization information of deep feature maps in the Path Aggregation Network (PANet) [
21]. The feature fusion of deep and shallow layers in FPN and PANet can provide more feature information for object detection. However, these FPN variants have limitations. For example, simply concatenating deep and shallow feature maps does not adequately fuse multi-scale features and may introduce irrelevant information interference. To obtain better results in small object detection, FE-YOLOv5 [
19] employs the feature enhancement strategy to enhance the model’s spatial perception capability and feature enhancement. QueryDet [
20] develops a novel coarse-to-fine cascaded sparse query mechanism. Cao et al. [
22] added the mixed attention and the dilated convolution modules in the YOLOv4 network. LMSN [
23] proposed multi-scale feature fusion and receptive field enhancement modules to achieve lightweight multi-scale object detection. EFPN [
24] developed a feature texture transfer module and a new foreground–background balance loss function. The is-YOLOv5 [
25] modified the information path of feature fusion and improved the SPP module. AFPN [
26] designed three new attention modules to enhance the model’s perception capabilities of foreground and contextual information. Methods to boost the accuracy of small object detection in RS images are still relatively rare. CotYOLOv3 [
27] redesigned the residual blocks in the backbone Darknet-53 as Contextual Transformer blocks. FE-CenterNet [
28] employs feature aggregation and attention generation structures to detect vehicle objects in RS images.
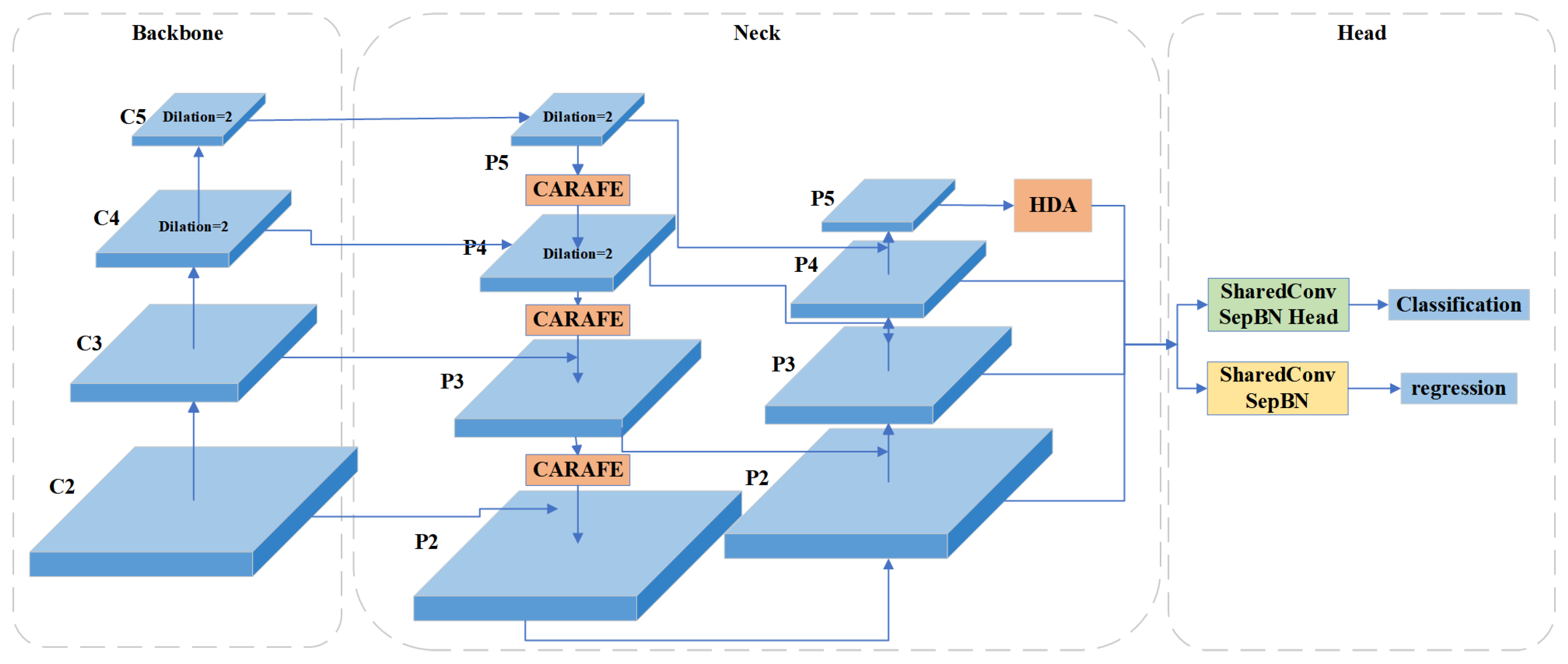
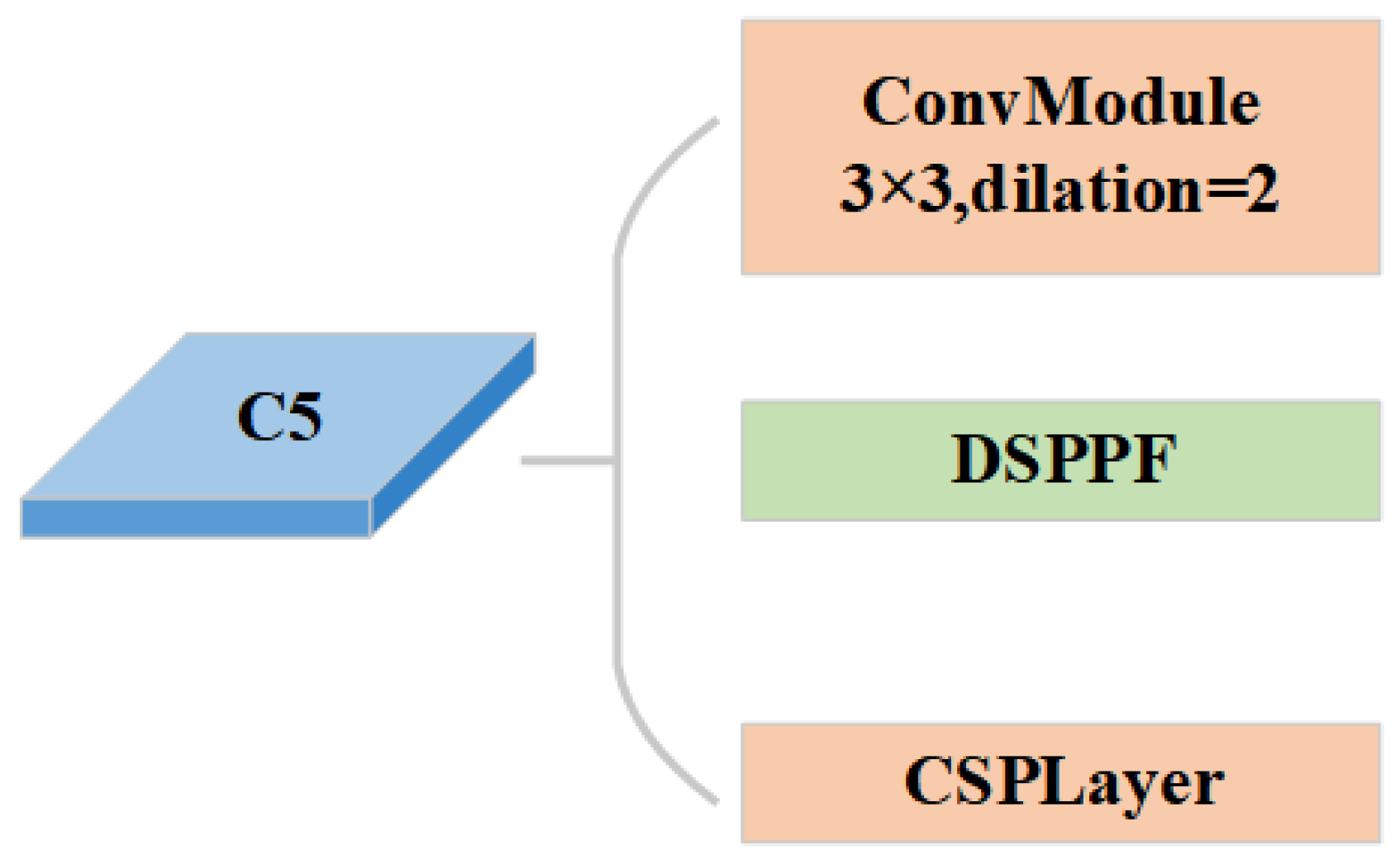
The baseline RTMDet [
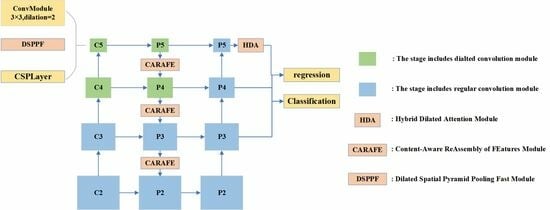
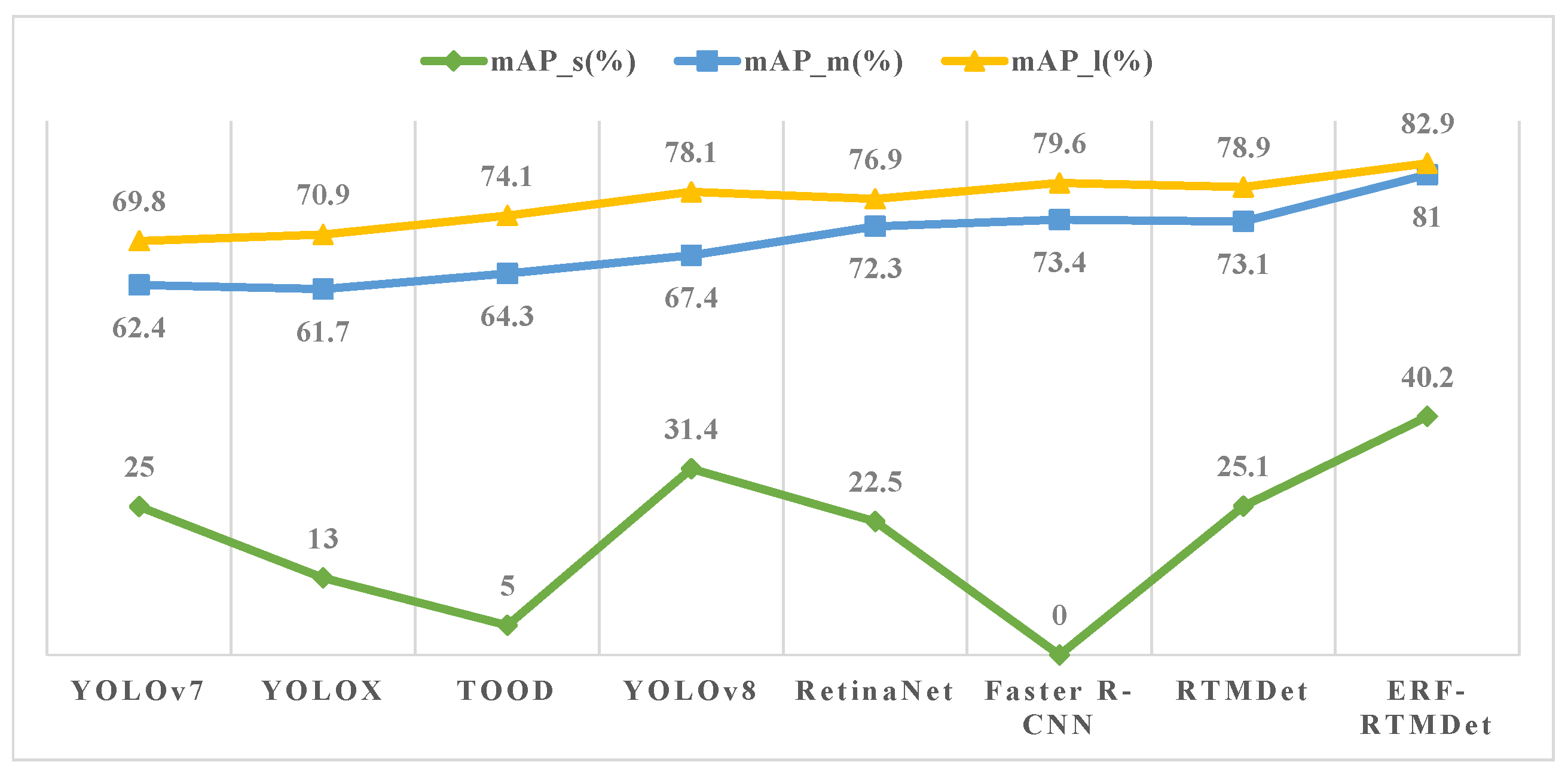
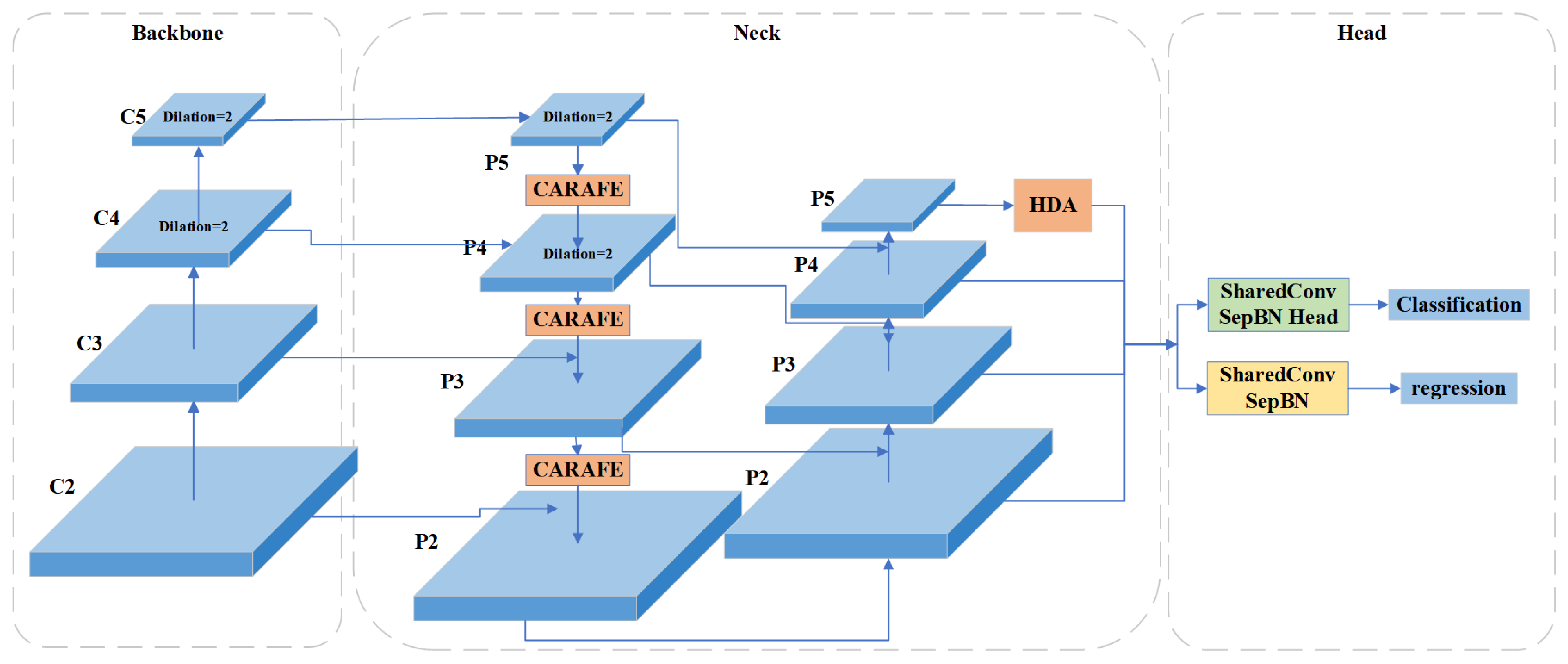
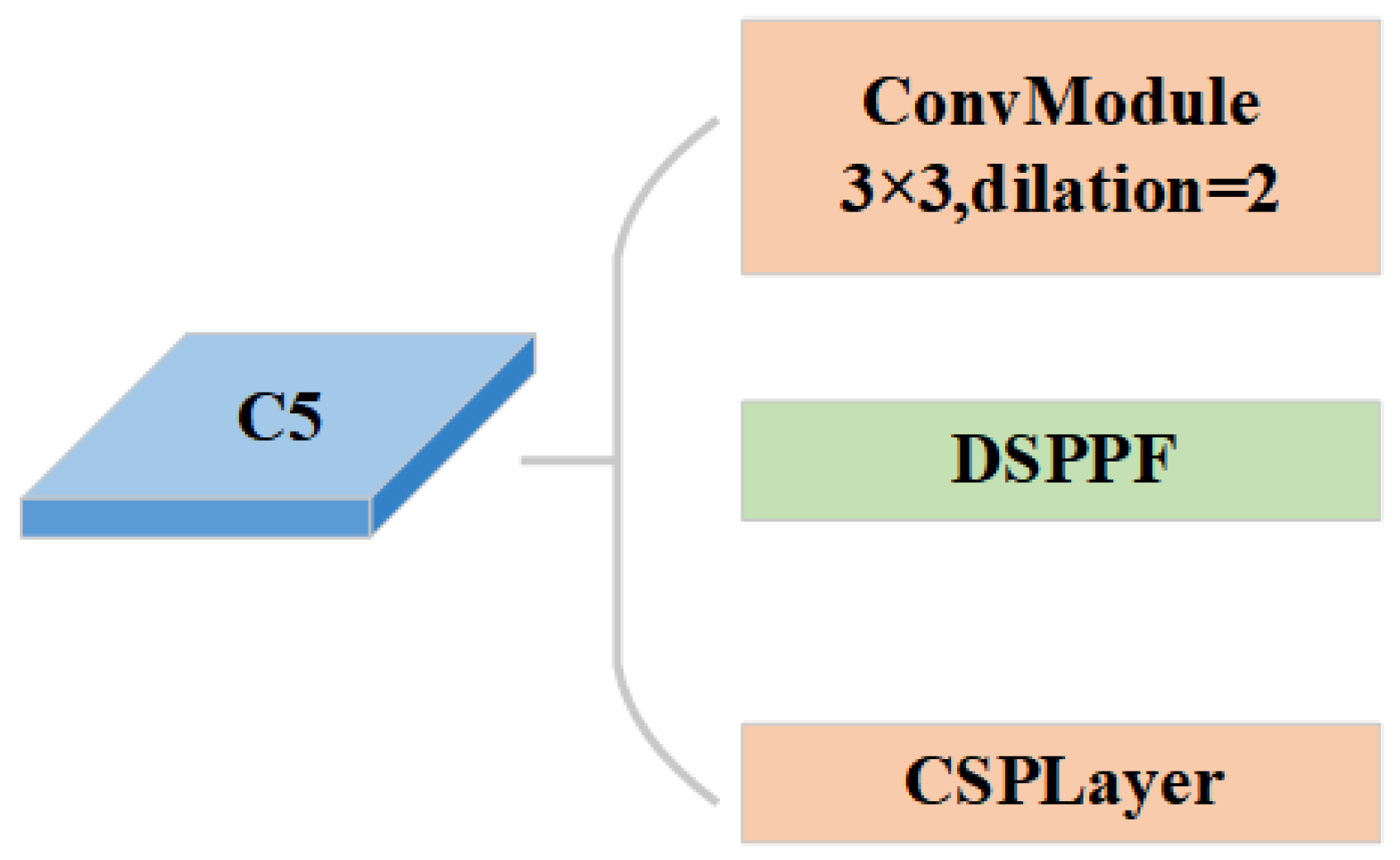
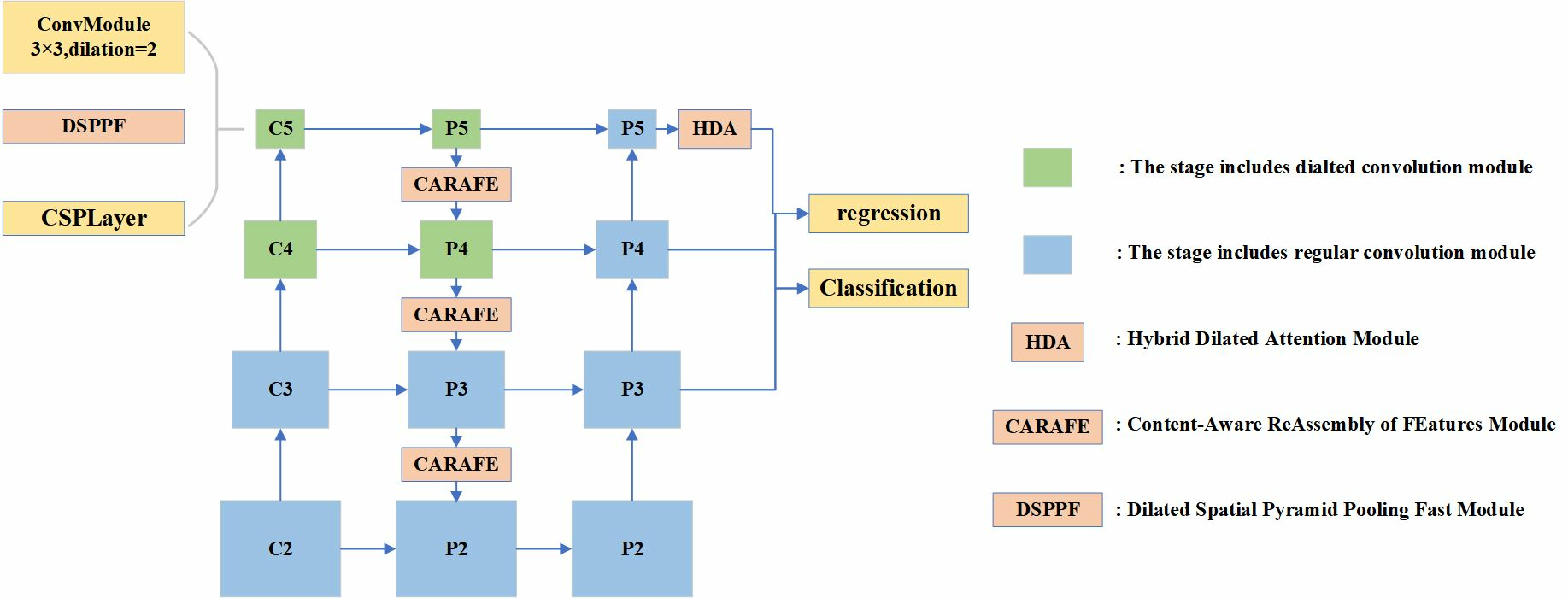
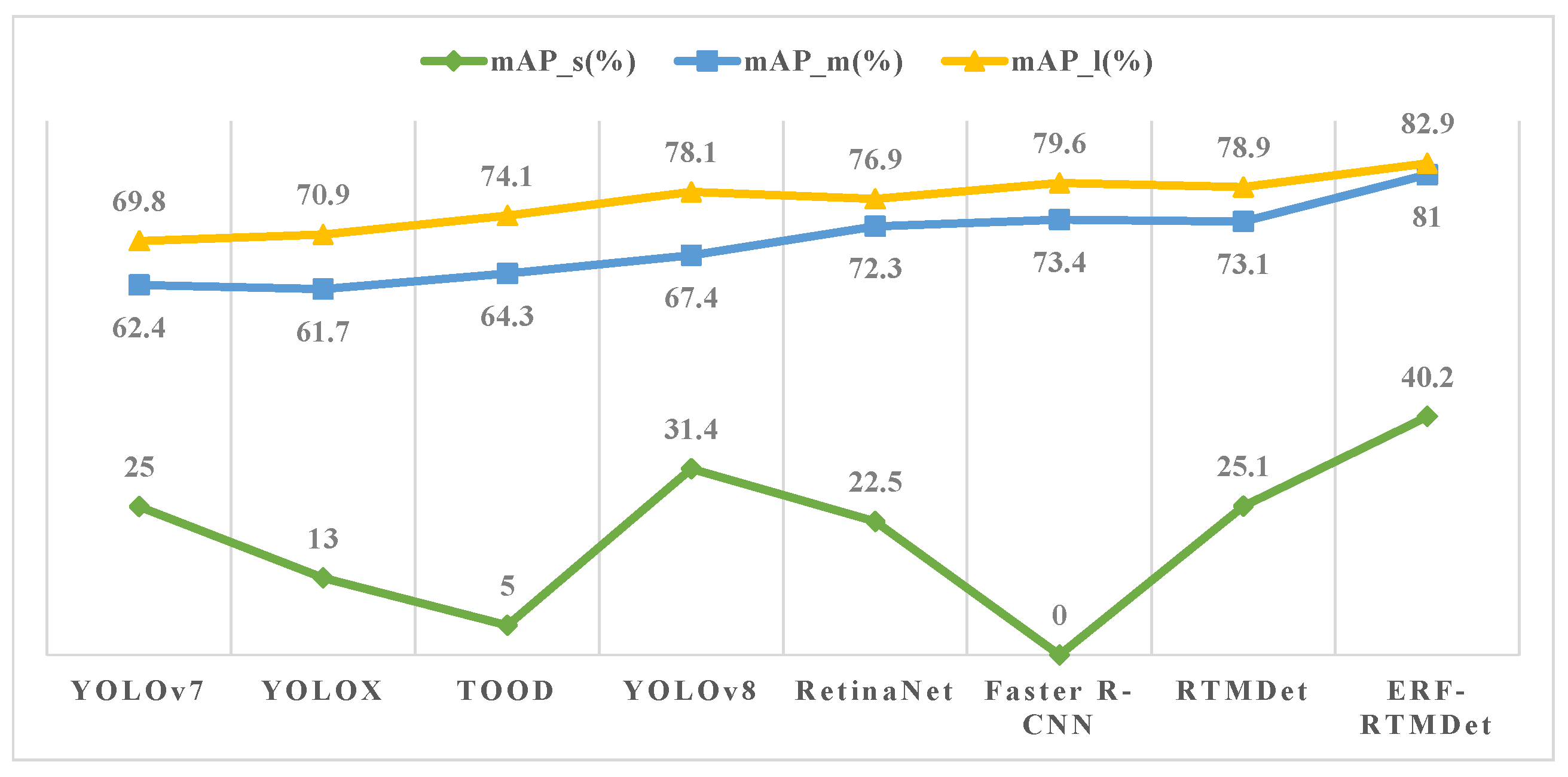
17] achieves high accuracy by implementing deep convolution with large convolution kernels and a dynamic soft label assignment strategy. However, the small object detection accuracy improvement of the RTMDet method is not satisfactory. First, multiple convolutional layers in the backbone continuously perform downsampling operations while extracting feature maps. The discriminative features of small objects decrease with decreasing resolution. Second, the deep feature maps extracted by the backbone have low resolution and large receptive fields. These are not appropriate when detecting small objects. Furthermore, small objects may be more negatively affected by the small bounding box perturbations. Inspired by the above small object detection methods, our ERF-RTMDet model introduces two novel modules: the dilated spatial pyramid pooling fast (DSPPF) module and the hybrid dilated attention (HDA) module. Additionally, we adopt the Content-Aware Reassembly of Features (CARAFE) upsampling operator further to boost the small object detection accuracy in RS images. Specifically, we first introduce high-resolution shallow feature maps. Then, the CARAFE upsampling operator replaces the nearest-neighbor upsampling operator in feature fusion. Finally, we developed the DSPPF and HDA modules to extend the receptive field of small objects. Thus, an improved small object detection approach with the enhanced receptive field, ERF-RTMDet, is proposed to achieve more robust detection capability in RS images. The quantitive detection results of various representative methods on objects of three scale types are compared in
Figure 2. Following the definition of the generic MsCOCO dataset [
29], in this paper, small objects are defined as objects smaller than
pixels, medium objects are defined as ones larger than
pixels smaller than
pixels, and large objects are defined as ones larger than
pixels. The results show that the accuracy of detecting small objects (mAP_s) is significantly worse in comparison with medium (mAP_m) and large ones (mAP_l). The precision in detecting small objects with ERF-RTMDet is 8.8% higher than the most effective comparative method. ERF-RTMDet not only shrinks the distance between the accuracy of detecting small objects and medium and large objects; it can also maintain or even slightly boost the detection effect on medium and large objects.
The major contributions of our study are briefly outlined below:
- 1.
To address the small object detection challenges faced by existing detection methods, the ERF-RTMDet method is proposed to enhance the receptive field and enrich the feature information of small objects.
- 2.
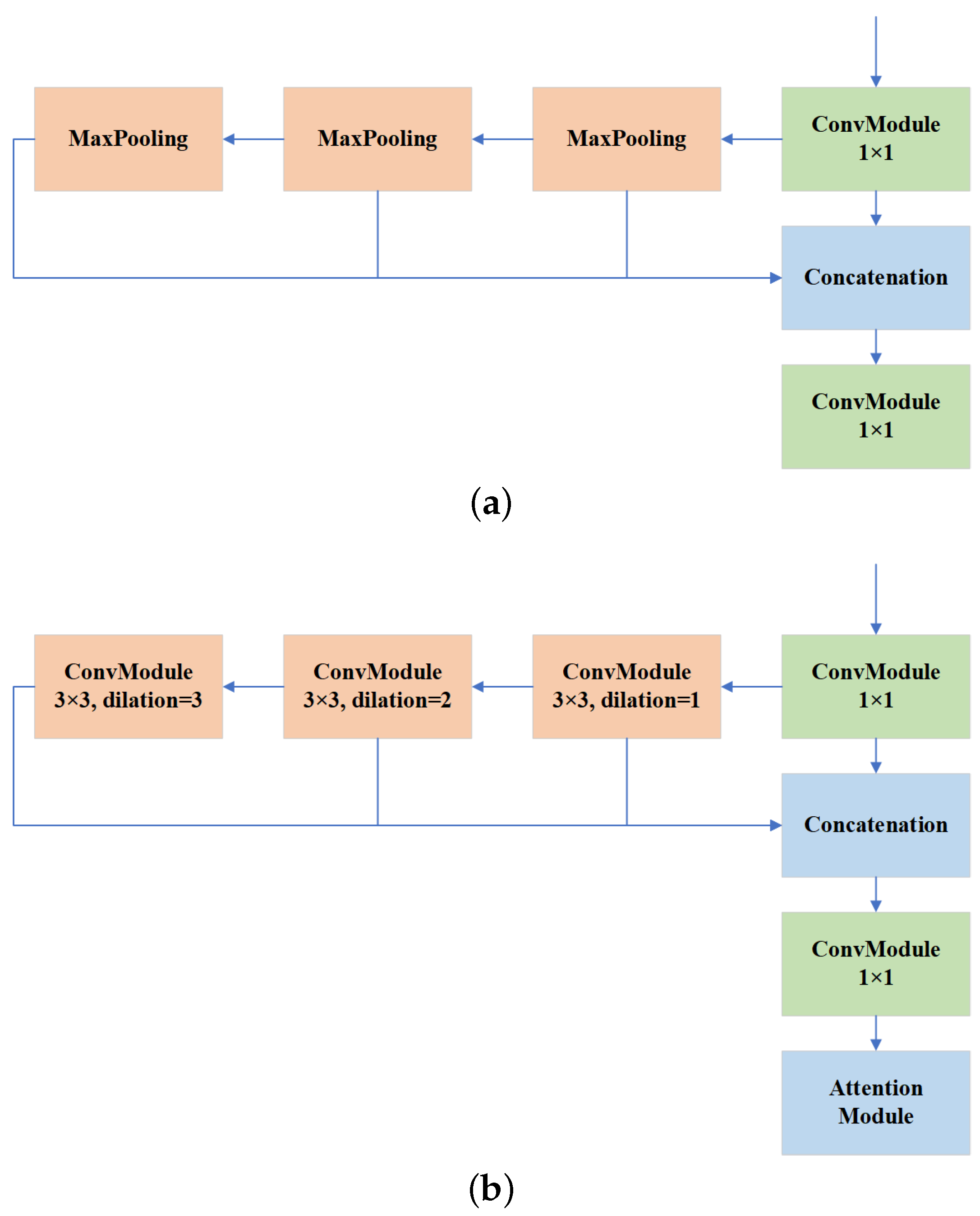
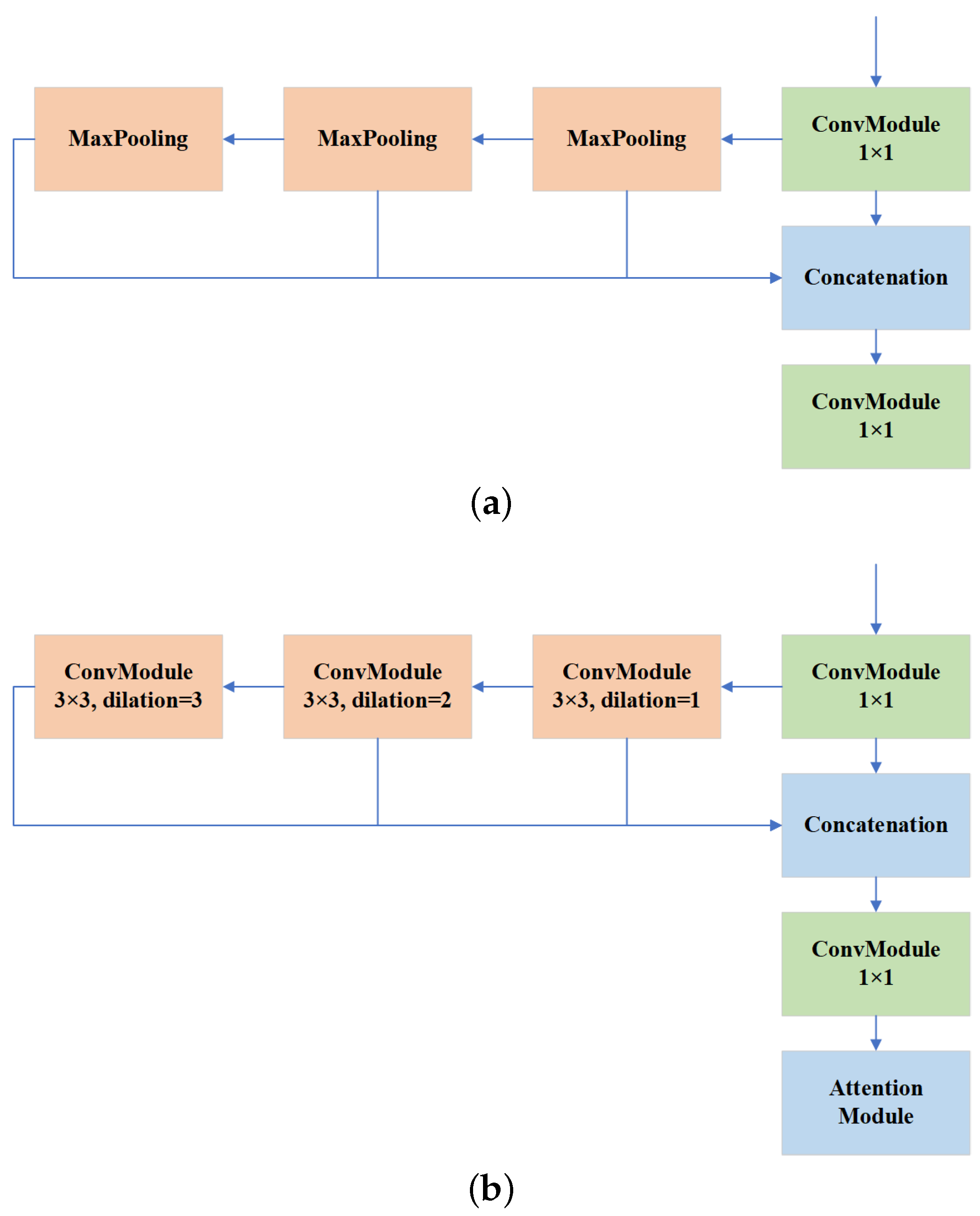
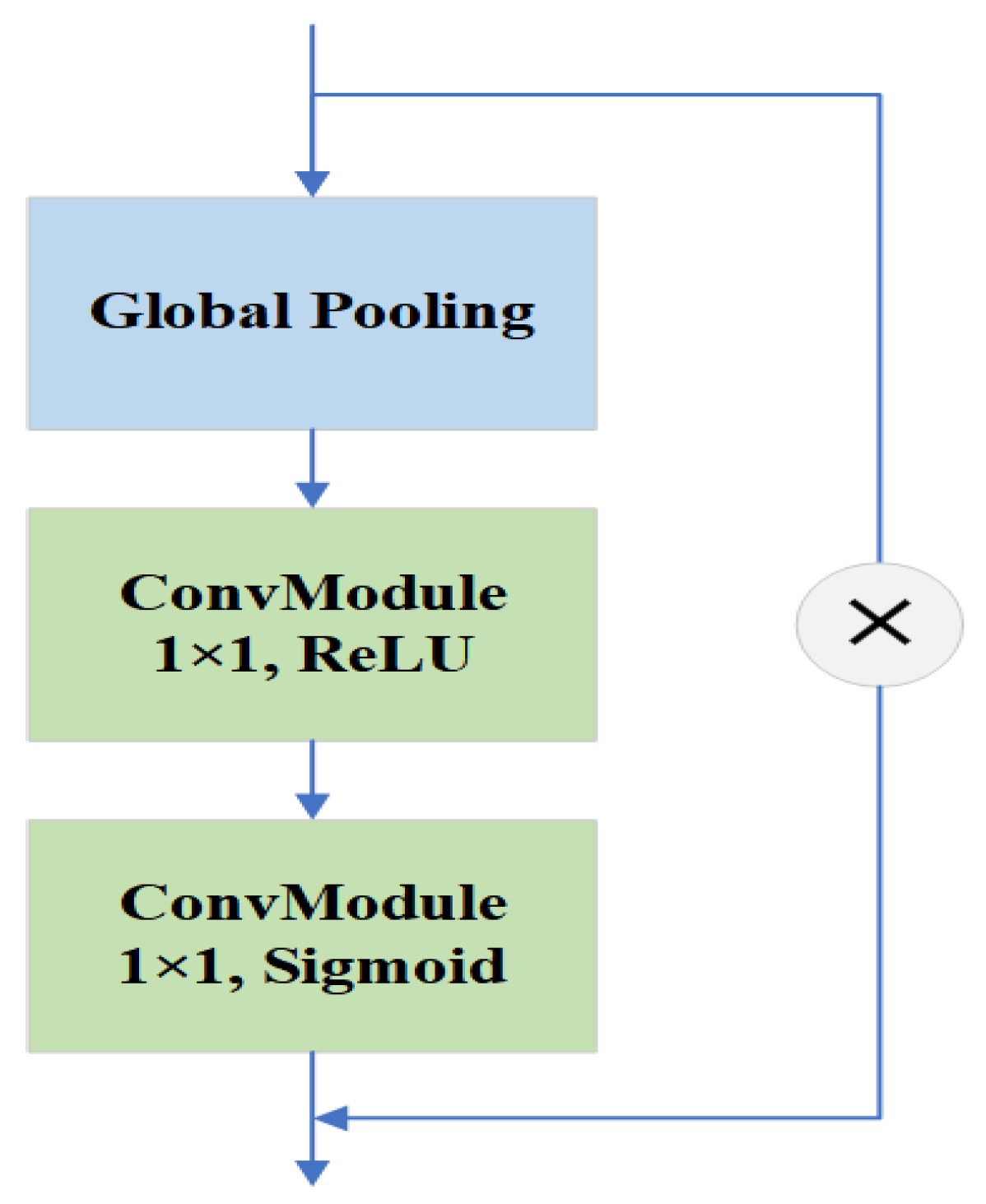
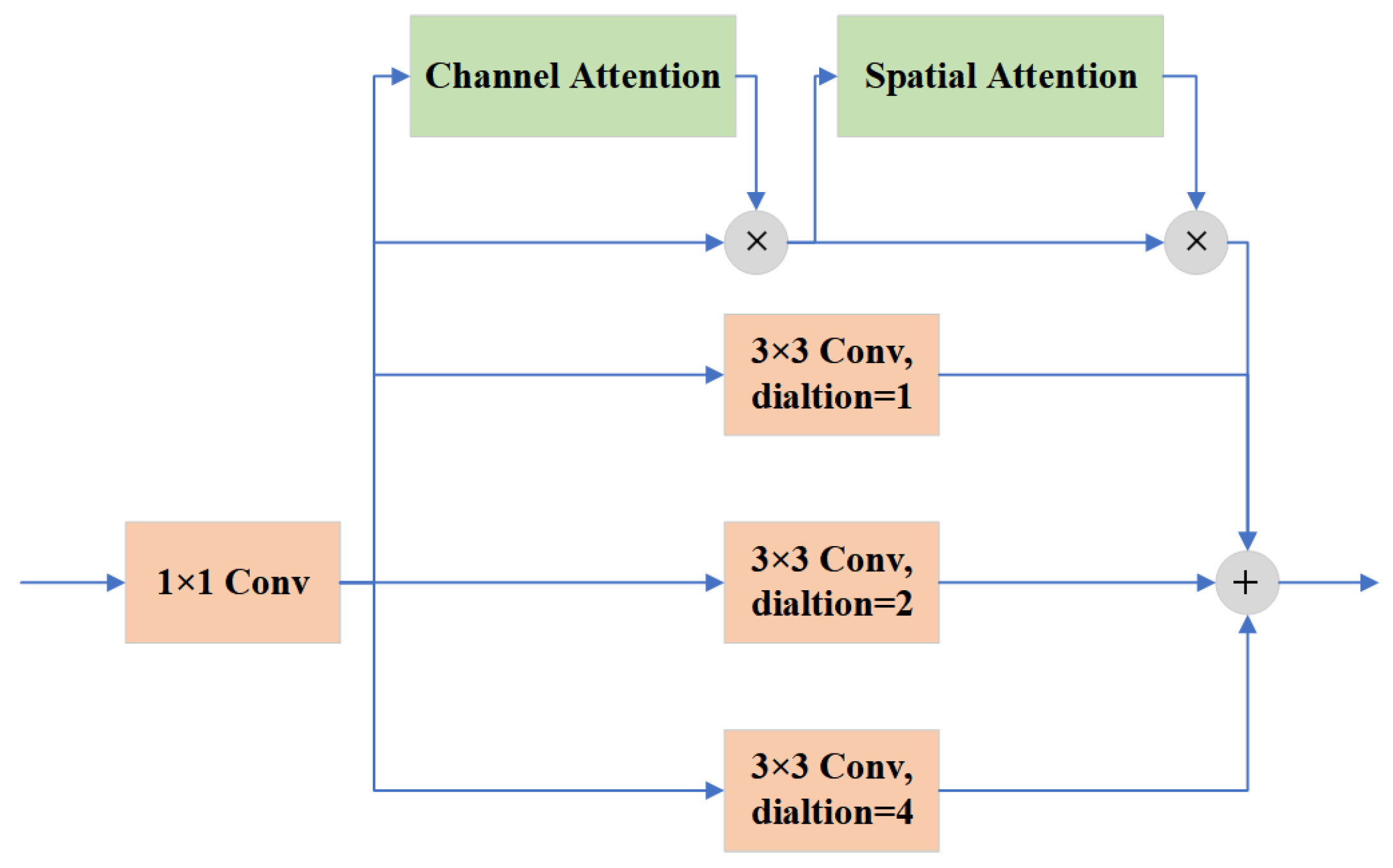
A dilated spatial pyramid pooling fast module is proposed. The DSPPF module achieves a larger multi-scale receptive field while maintaining resolution. The successive dilated convolutions are employed to extract more contextual information about small objects. The DSPPF module further improves the accuracy through the channel attention module to avoid the interference of background information.
- 3.
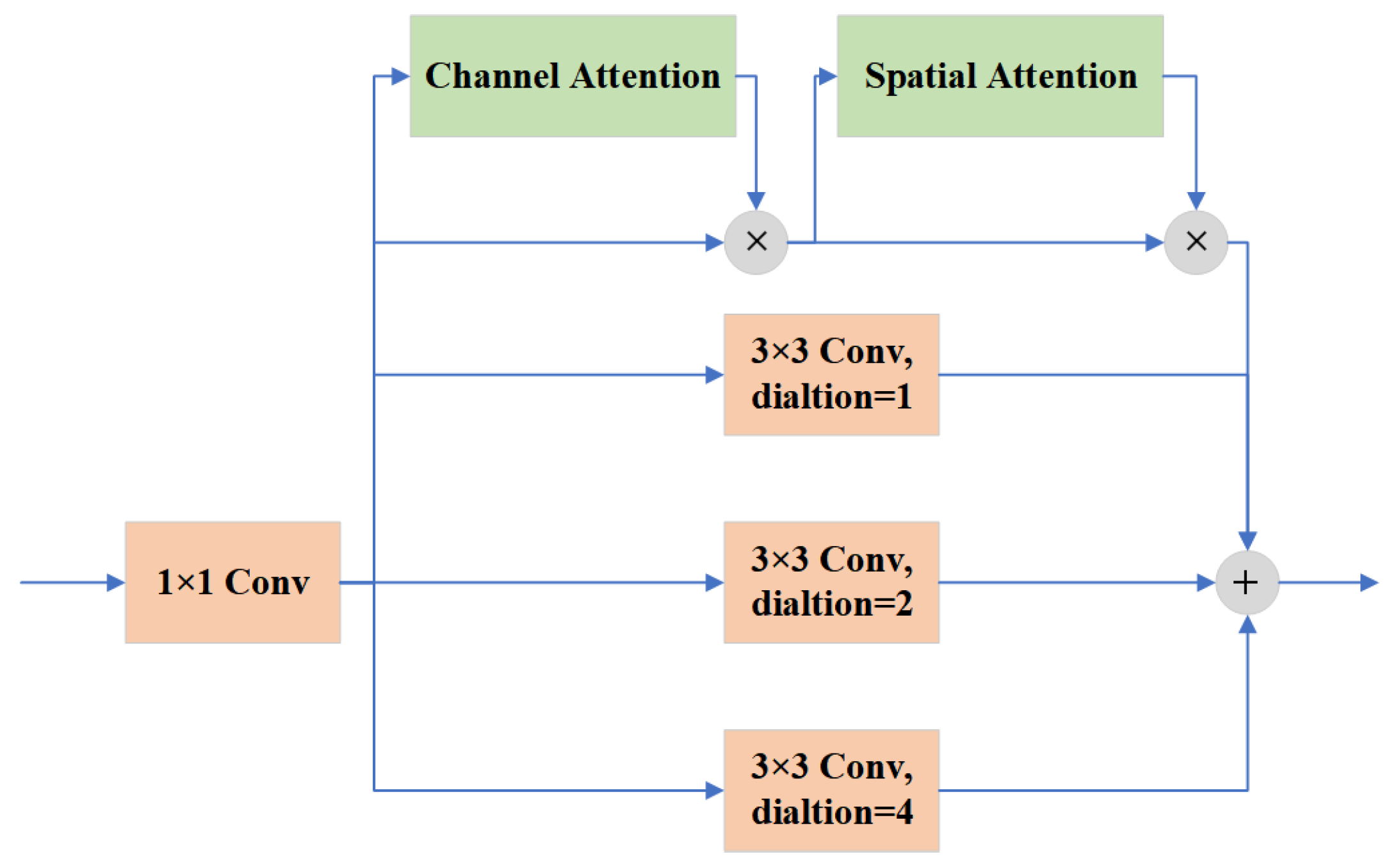
A hybrid dilated attention module is proposed. To obtain more detailed information of small objects, the HDA module uses parallel convolutional layers with different dilation rates to fuse different receptive fields. It is followed by spatial and channel attention modules to extract meaningful information from the fused features.
- 4.
The CARAFE Module [
30] is used in the feature fusion as the upsampling operator rather than the nearest neighbor sampling operator. This allows the upsampled feature maps to contain more information about small objects, leading to the more efficient extraction of object feature information.
- 5.
The experimental results show that ERF-RTMDet achieves higher detection accuracy on small objects while sustaining or slightly boosting the detection precision on mid-scale and large-scale objects.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}