

3D LiDAR Multi-Object Tracking with Short-Term and Long-Term Multi-Level Associations



Abstract
:1. Introduction
- A novel Multi-Object Tracking framework that incorporates a multi-level association approach is proposed. Specifically, it combines short-term relations, which consider the geometrical information between detections and predictions, with long-term relations, which consider the historical trajectory of tracks.
- A long-term association method using Graph Convolutional Networks (GCNs) to link the historical trajectories of targets with challenging detections is introduced.
- The proposed method relies solely on the current LiDAR frame data and past detection results, making it well-suited for real-time and online applications. By eliminating the requirement for supplementary data such as a map, the proposed approach becomes more practical and offers improved efficiency in real-world scenarios.
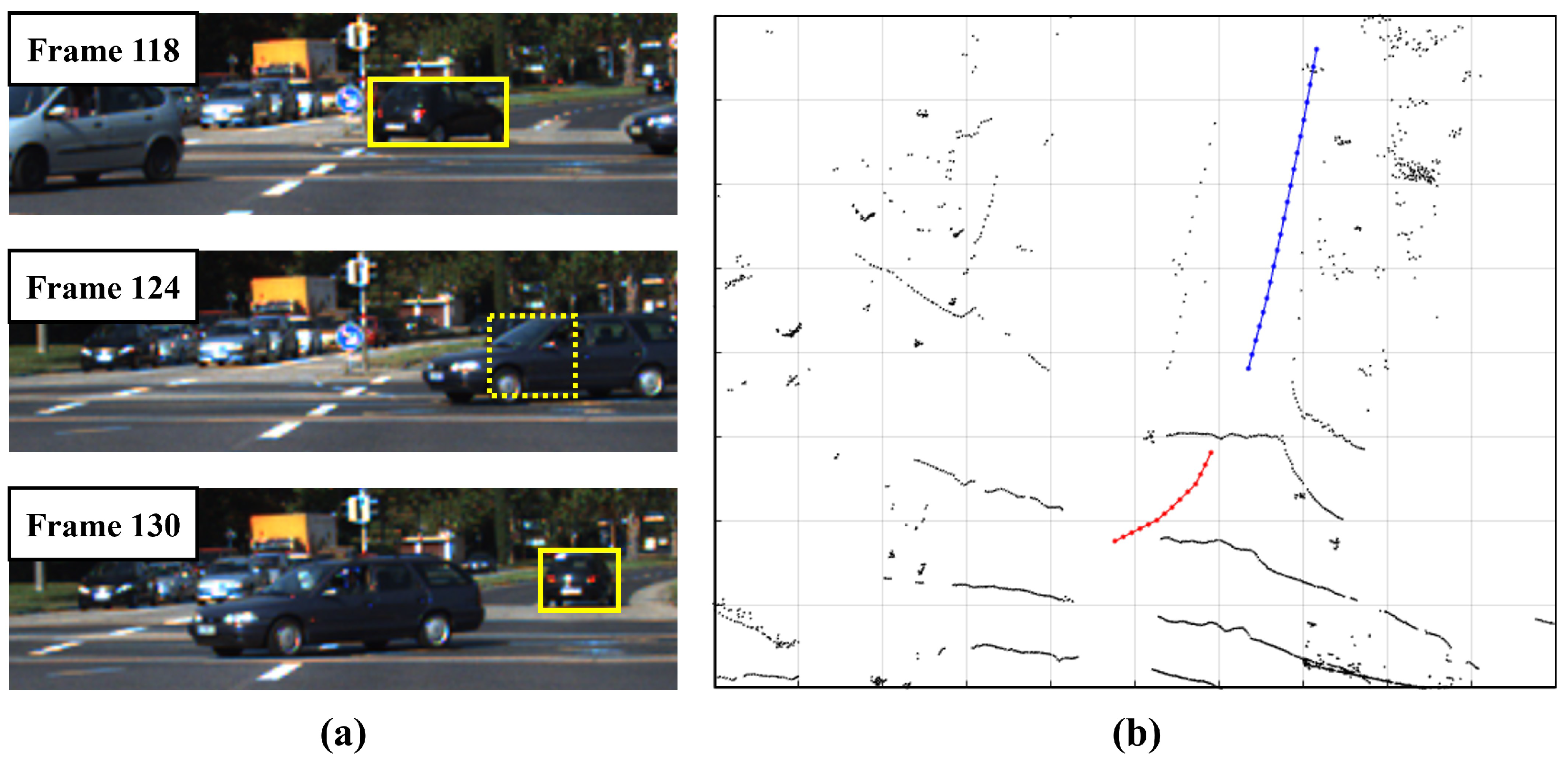
- An effective approach to manage unmatched targets is suggested, addressing issues related to short-term and long-term association. This strategy effectively manages occluded targets, ensuring more-reliable and -accurate tracking results.
2. Related Works
2.1. Three-Dimensional-Point-Cloud-Based Deep Learning Applications for Detection and Robotics
2.2. Tracking-by-Detection in 3D LiDAR Point Clouds
2.3. Graph-Based MOT
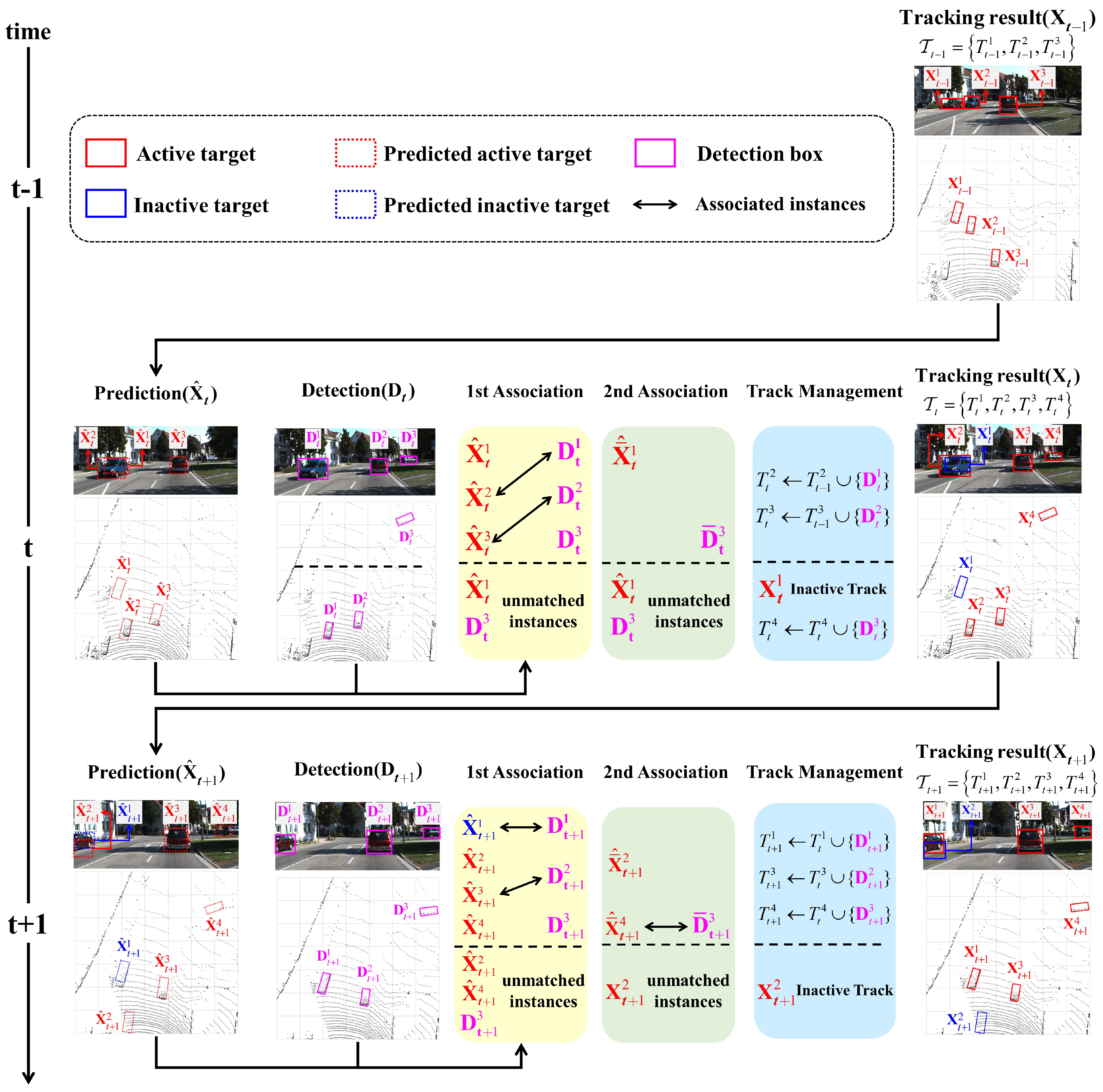
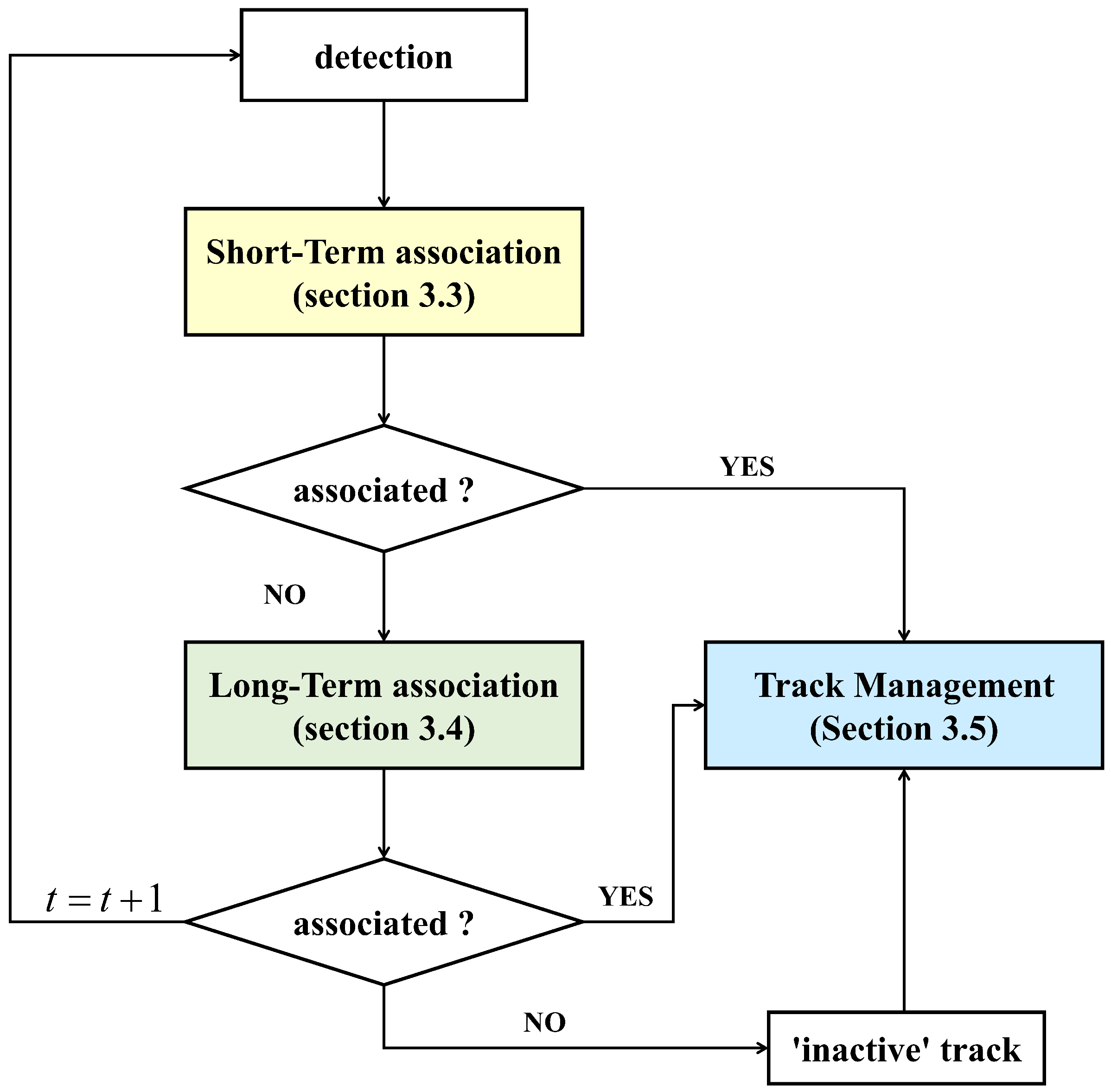
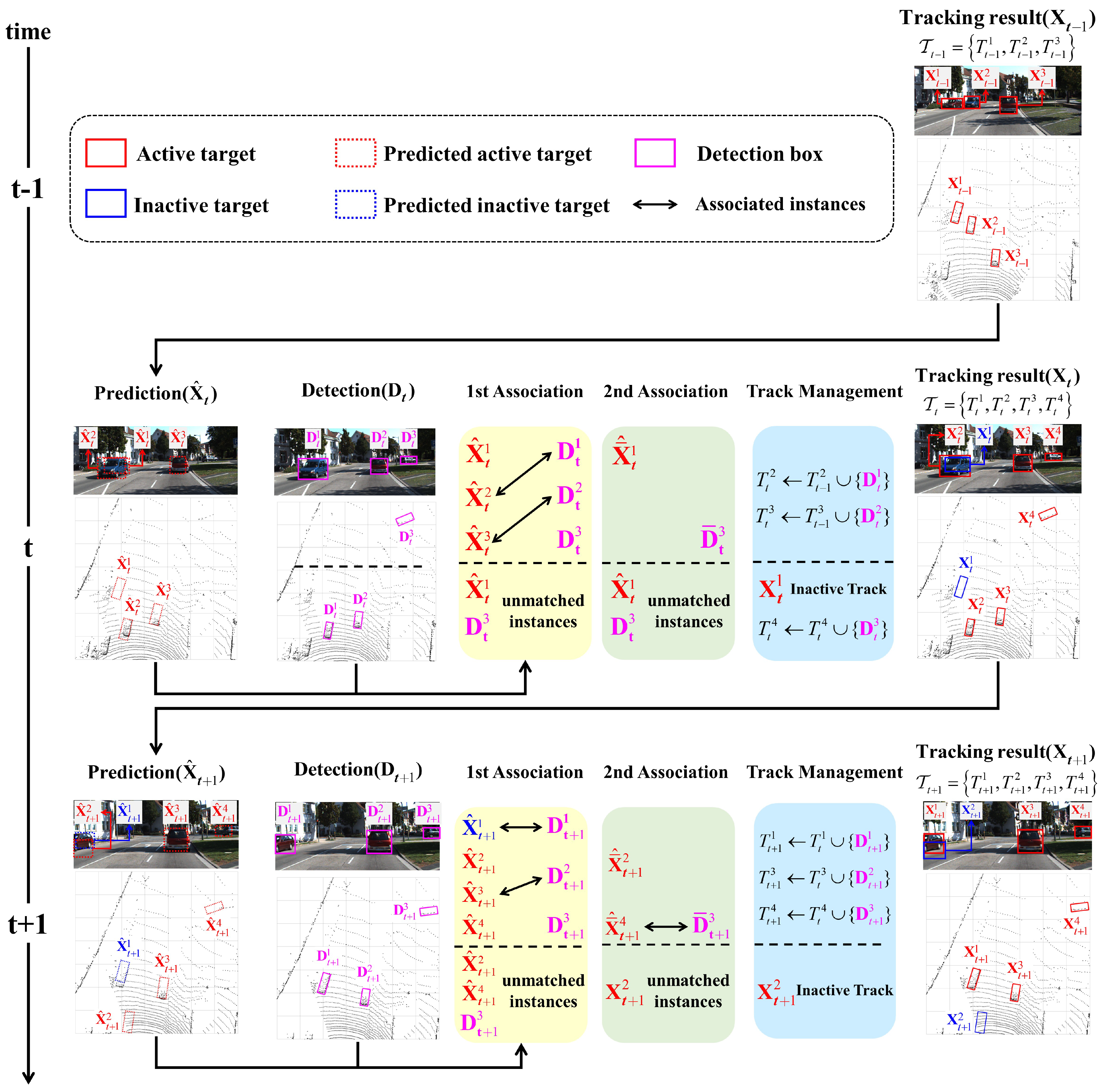
3. Proposed Method
3.1. State Definition
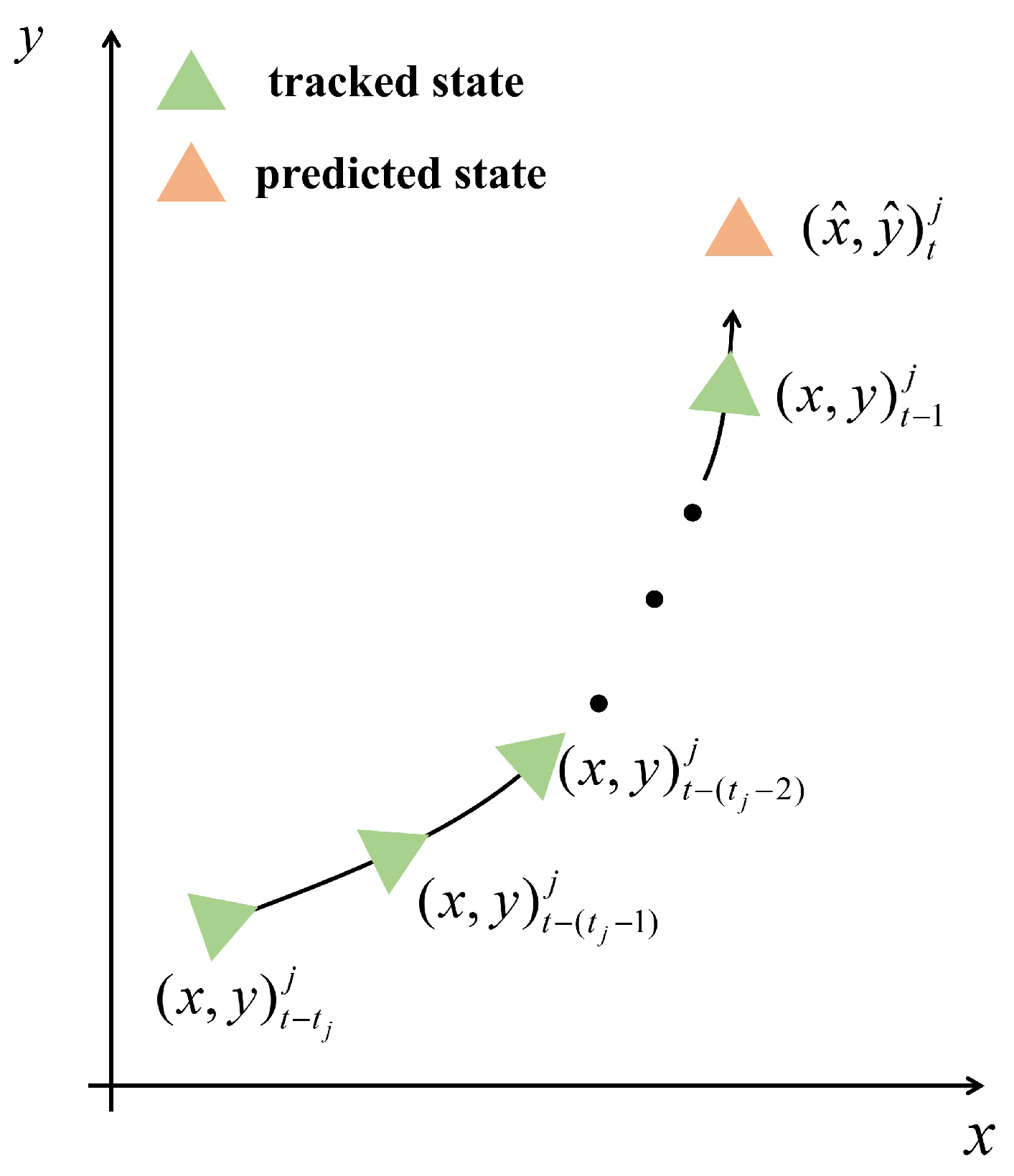
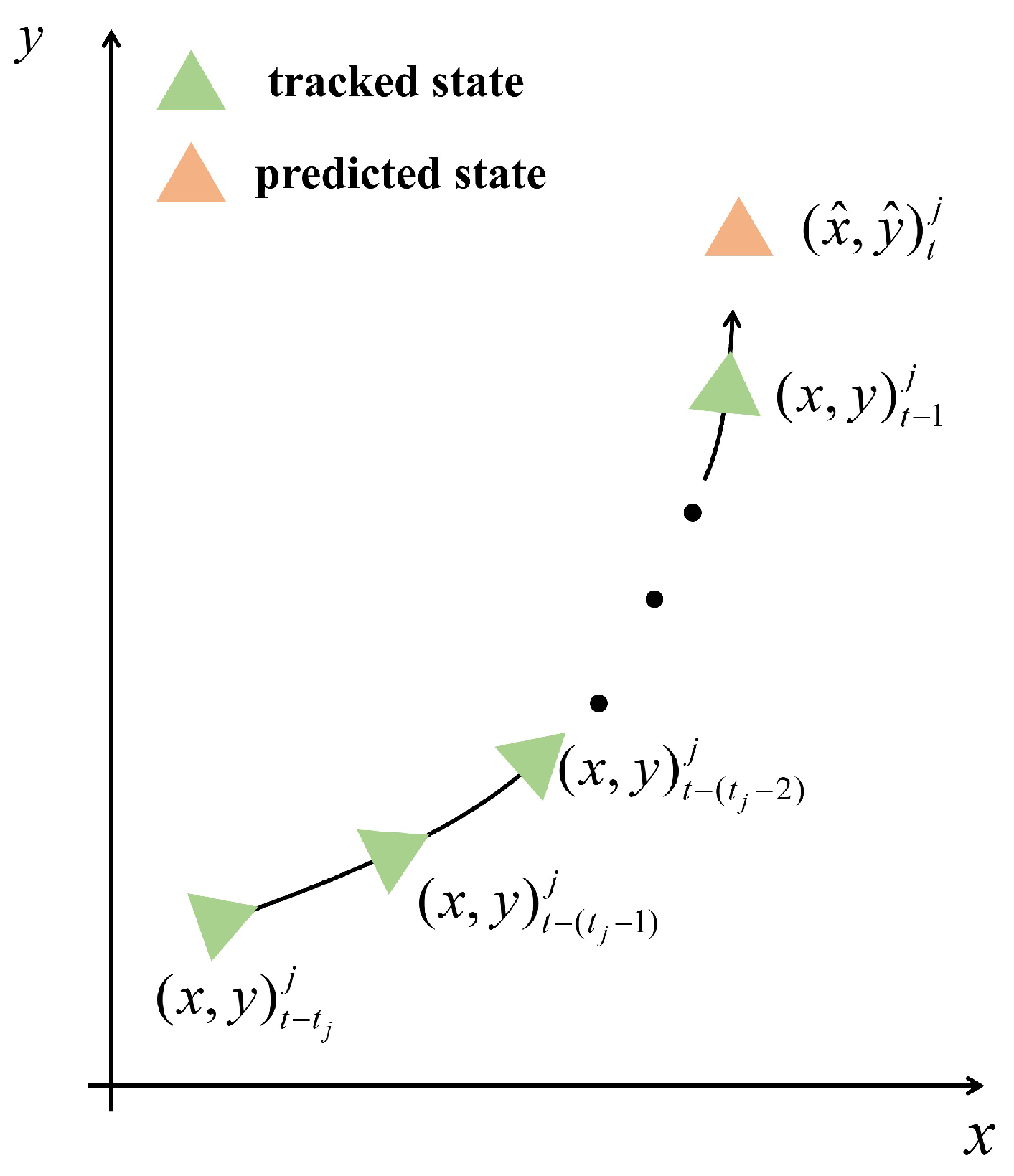
3.2. State Prediction
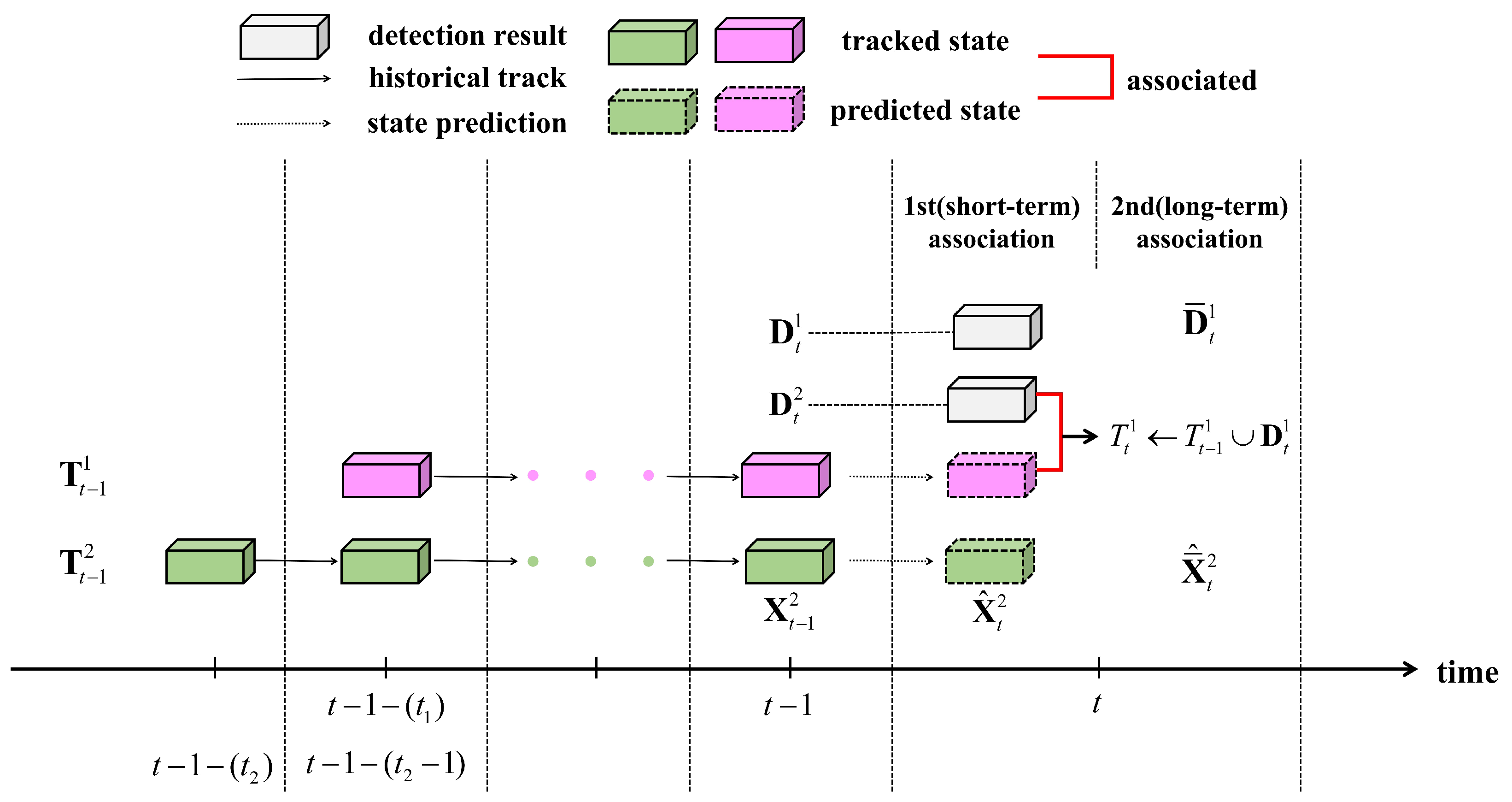
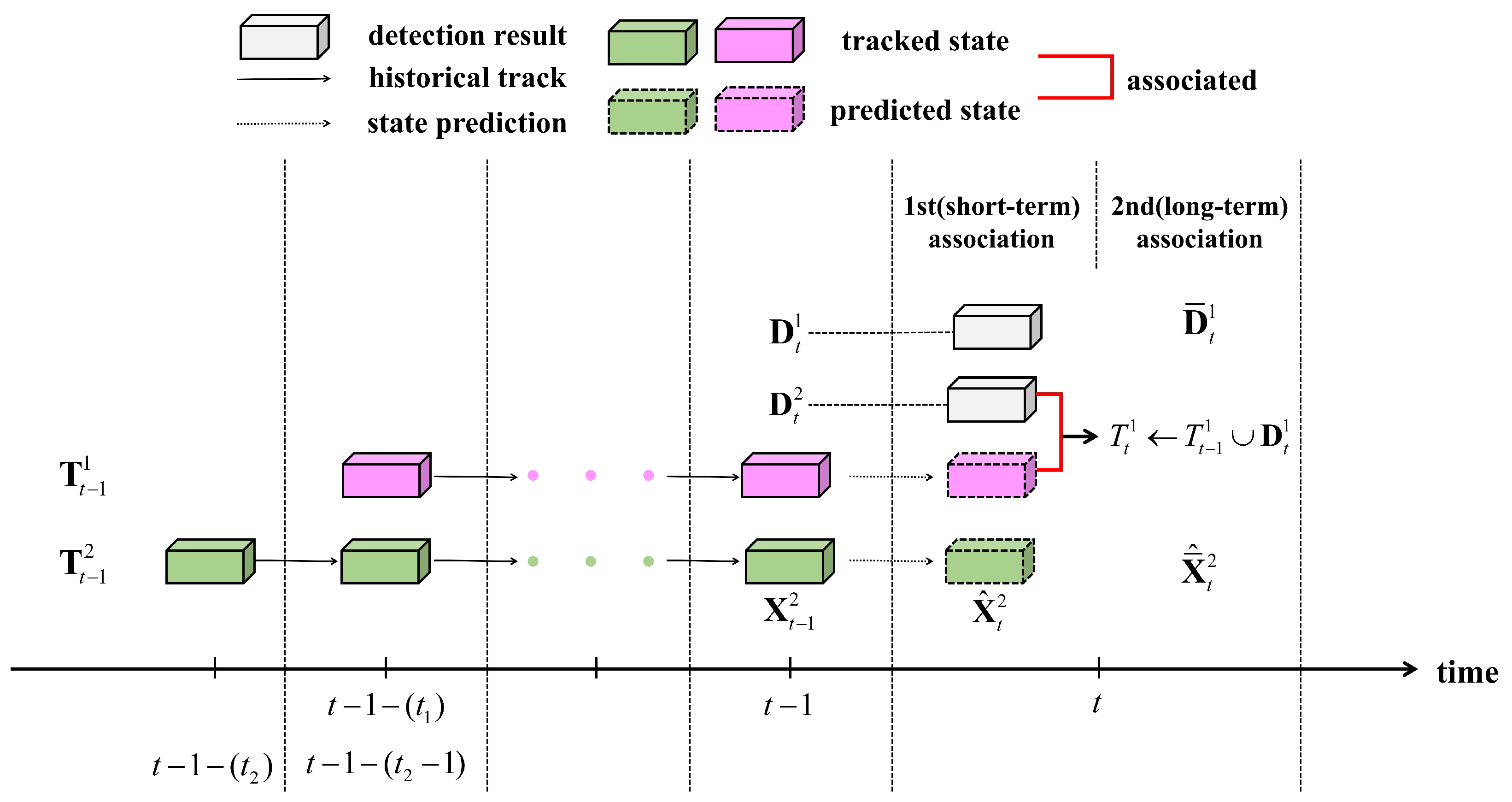
3.3. First Association Based on Short-Term Relation
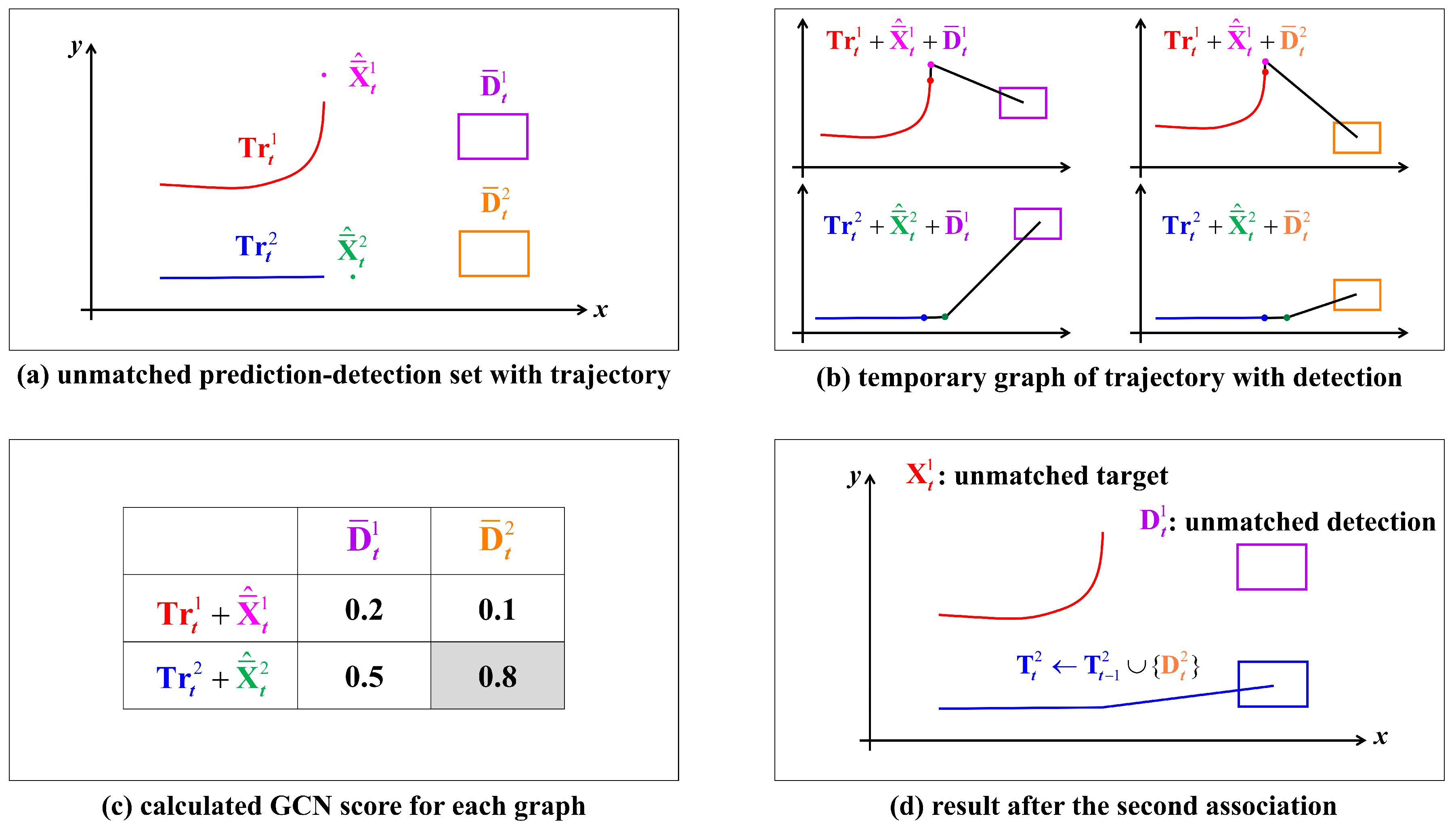
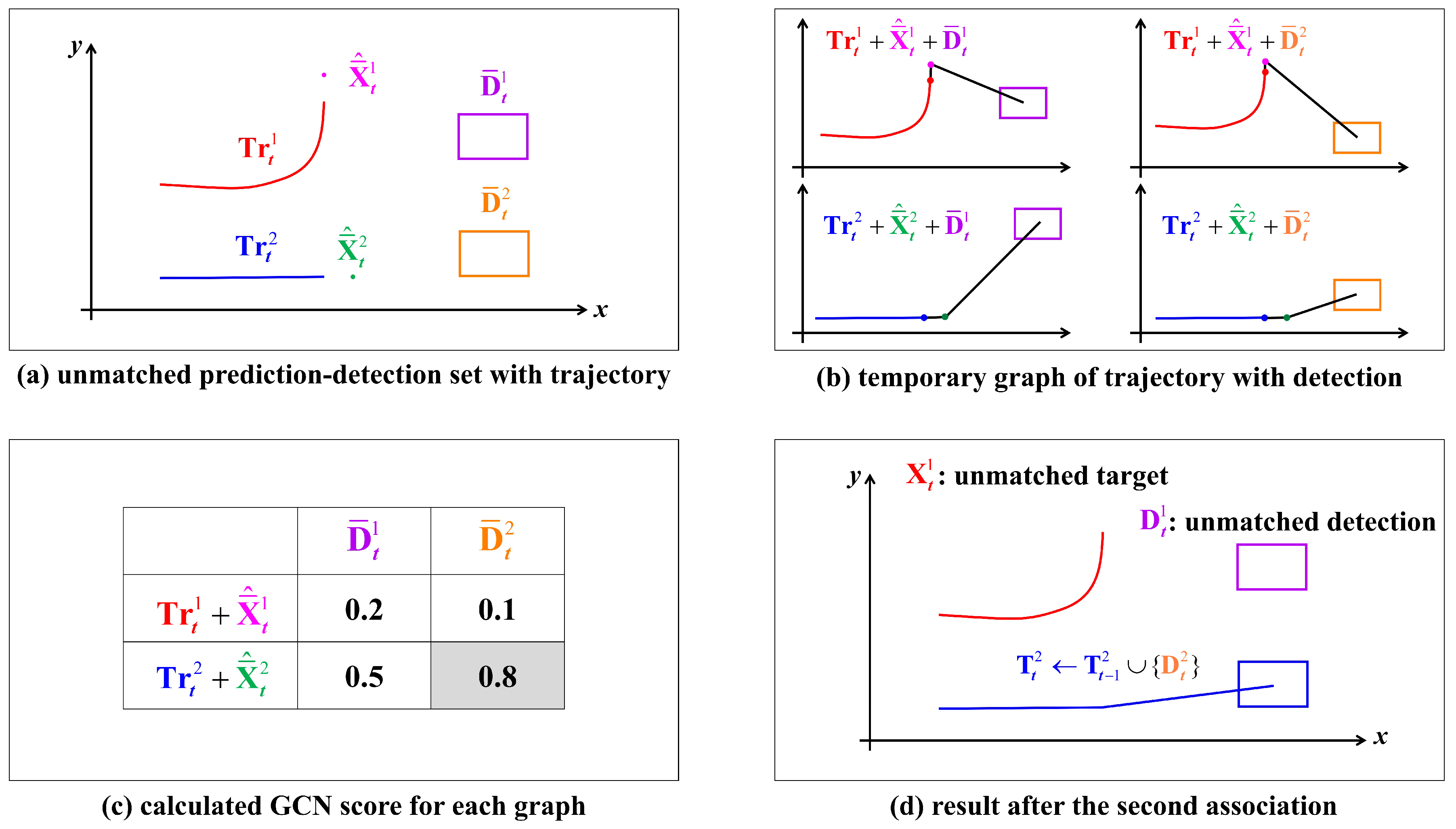
3.4. Second Association Based on Long-Term Relation
3.5. Track Management
4. Experiment
4.1. Dataset and Experiment Settings
4.2. Evaluation Metrics
4.3. Quantitative Result
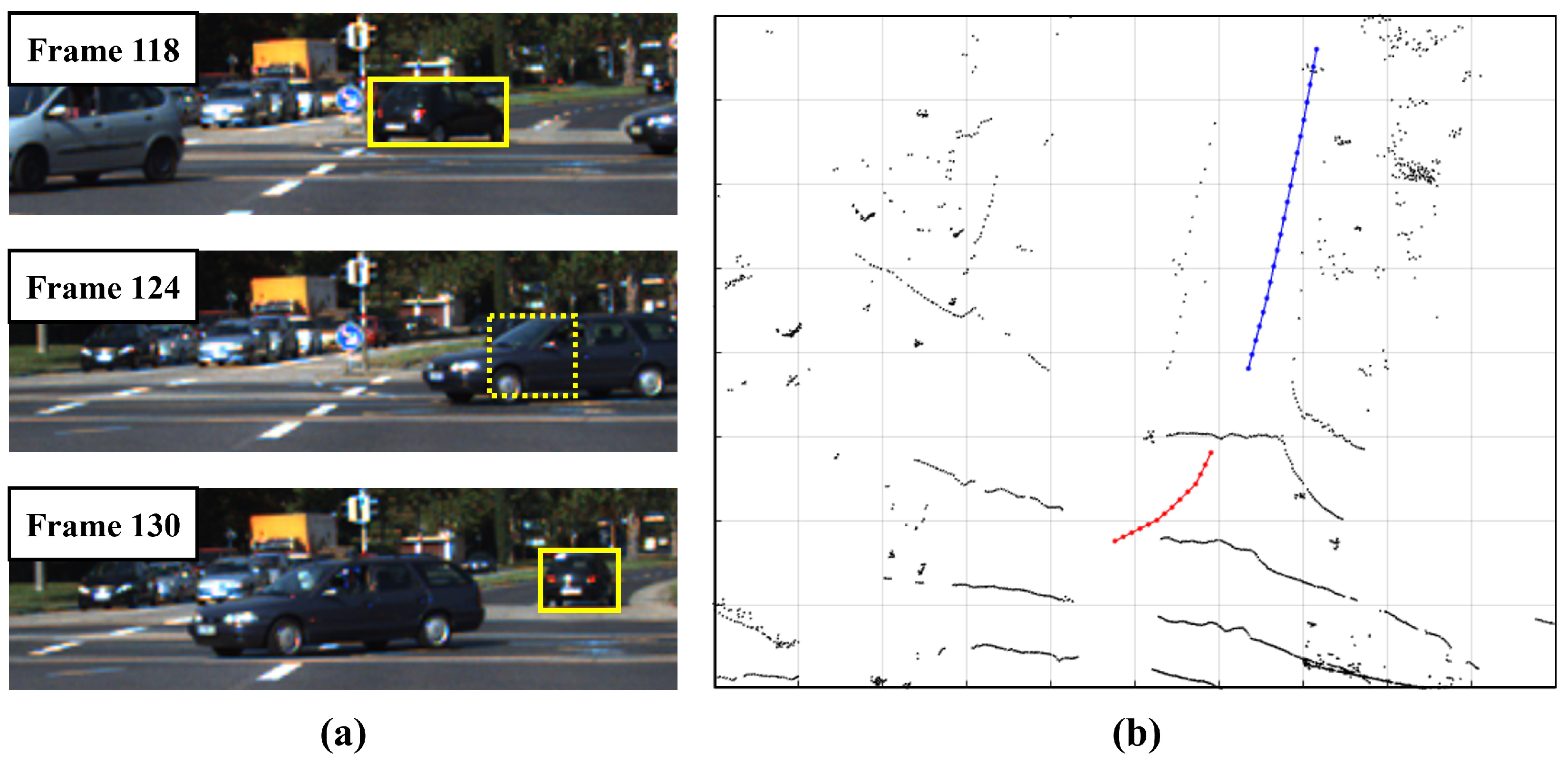
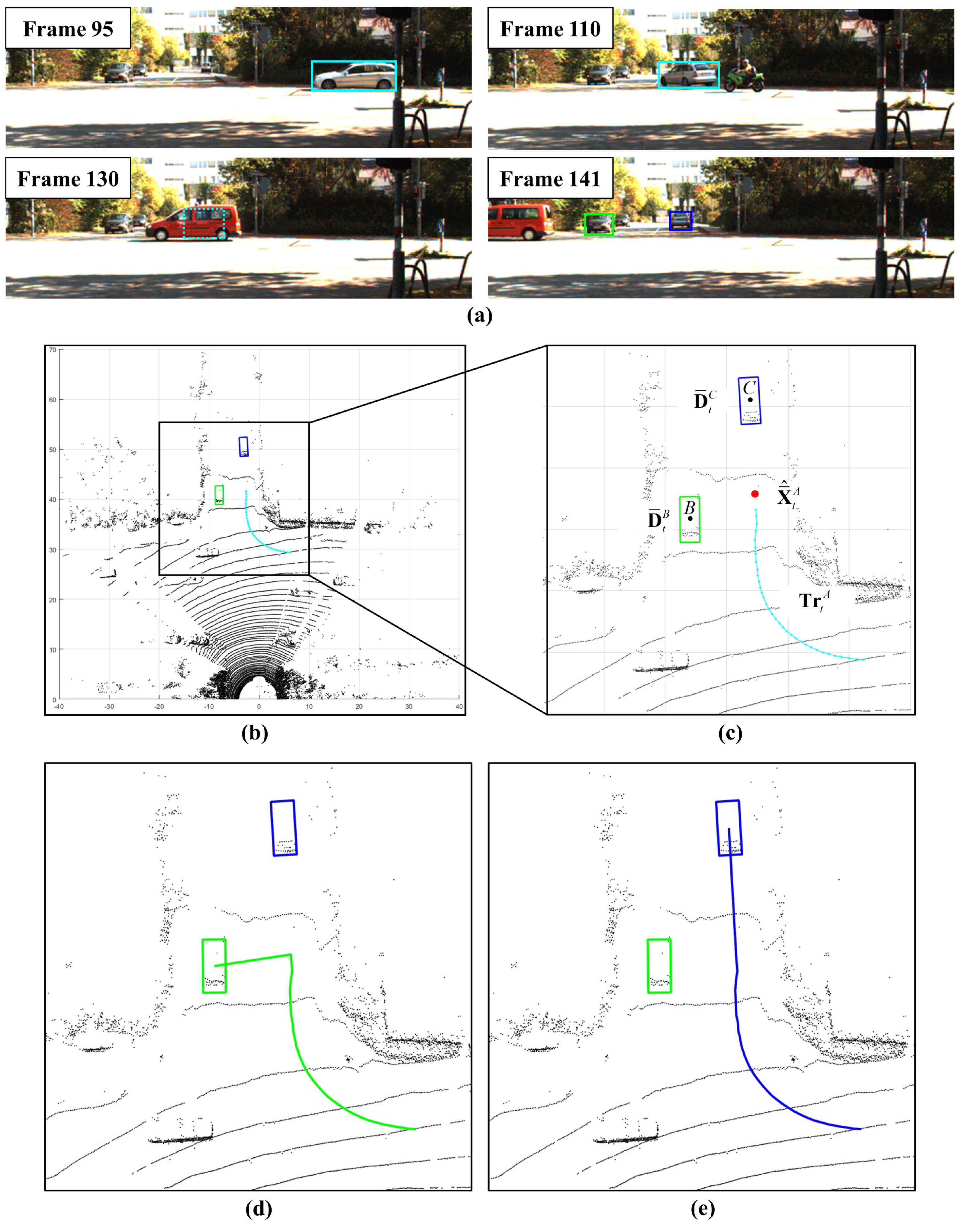
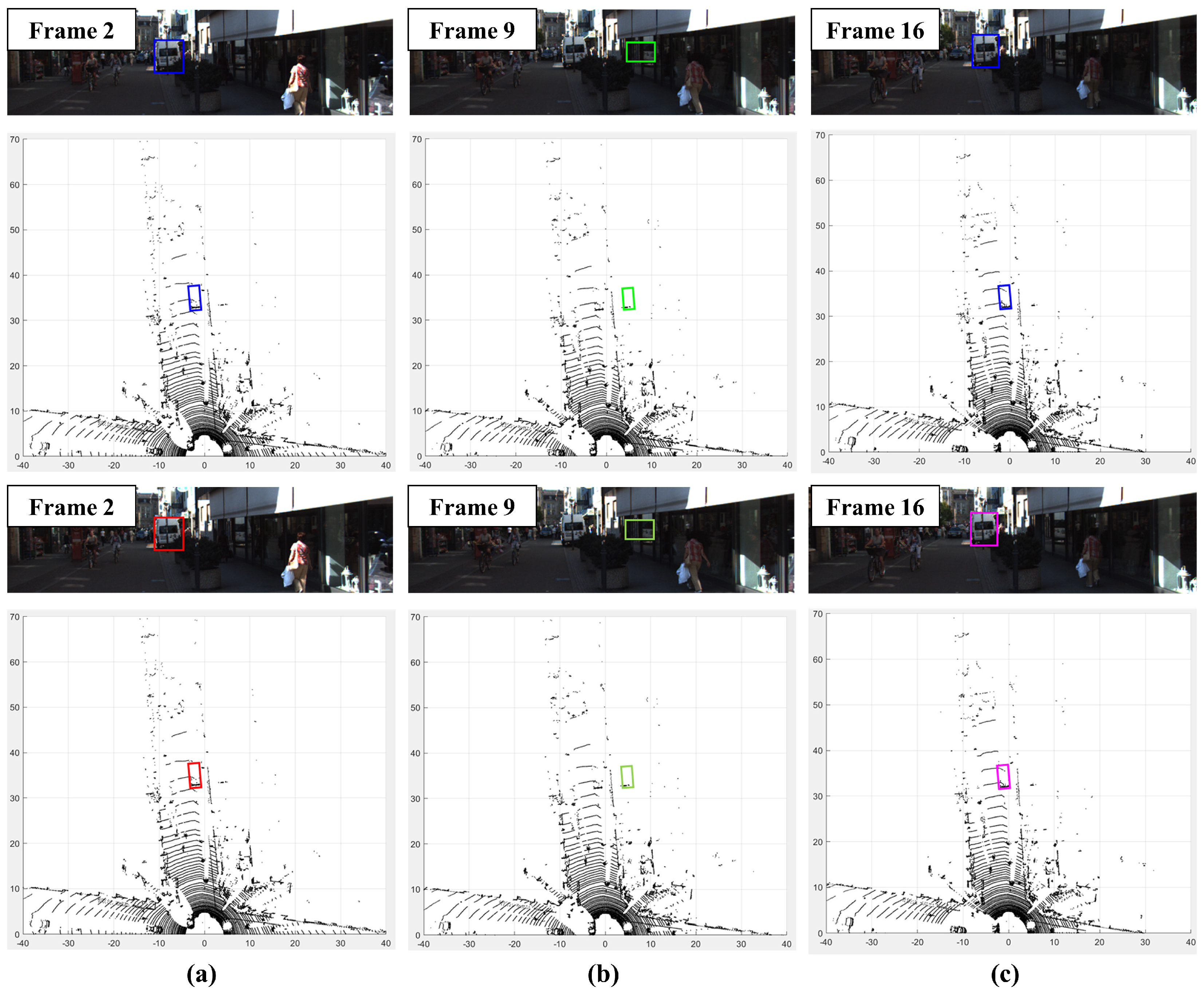
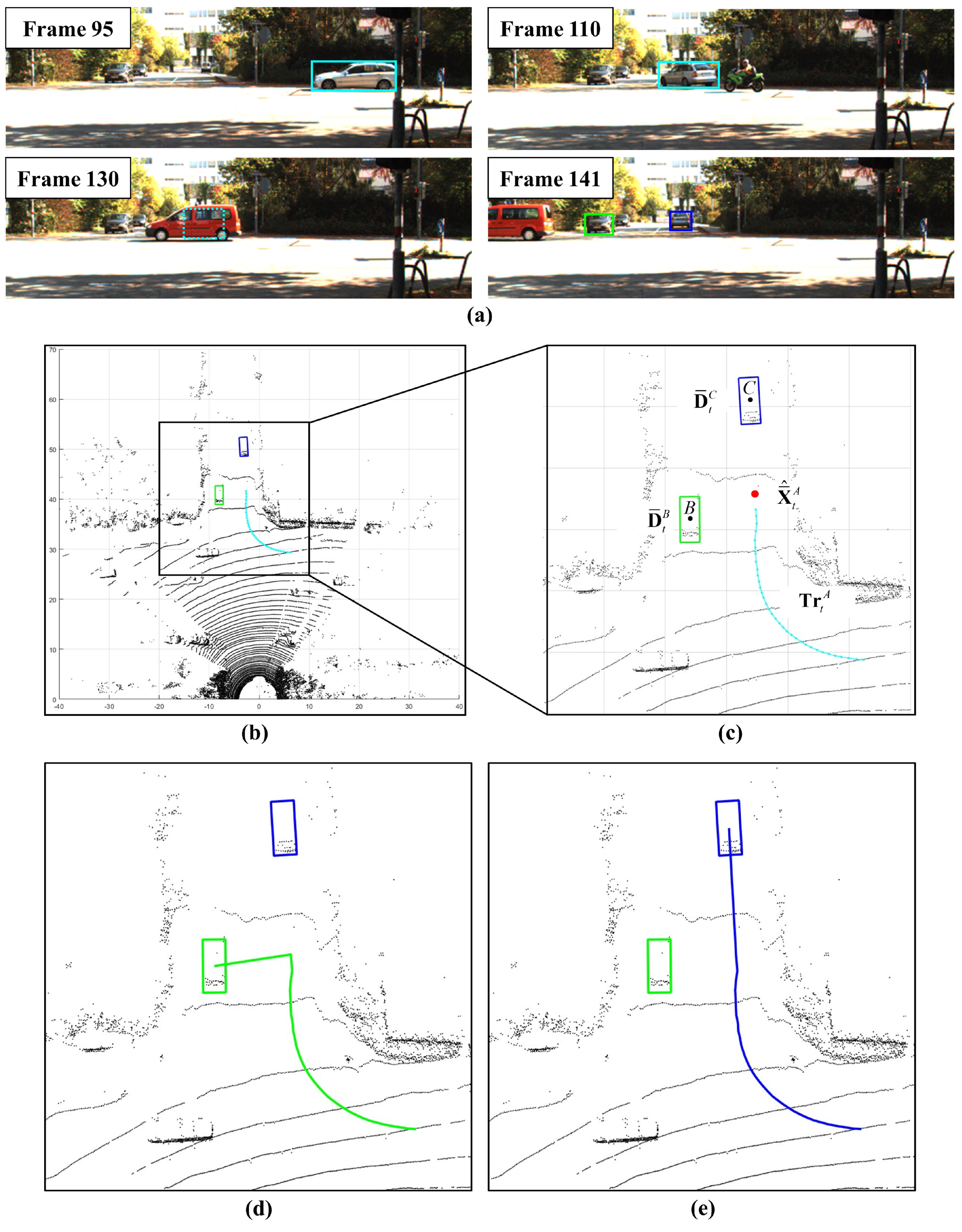
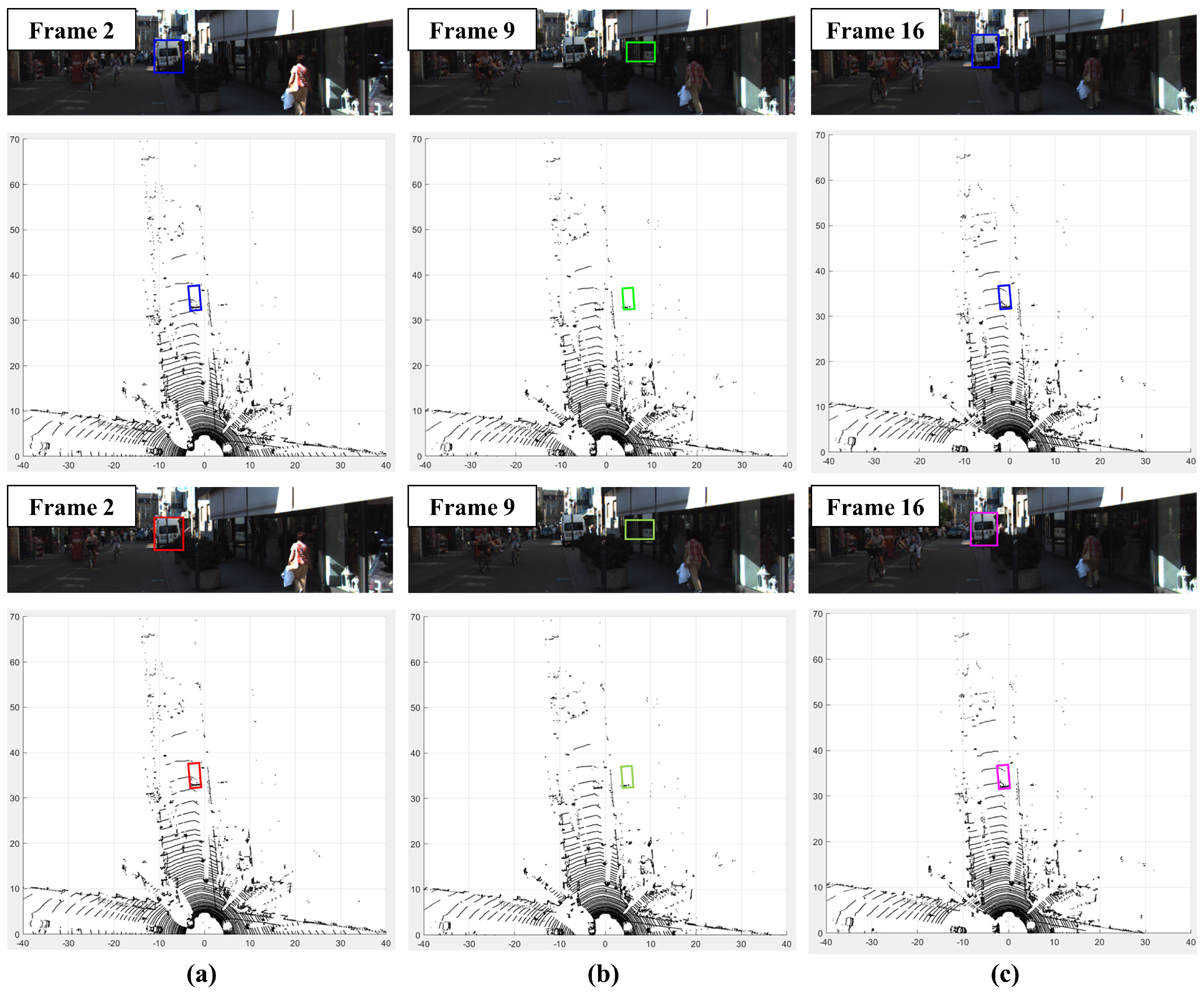
4.4. Qualitative Result
4.5. Ablation Study
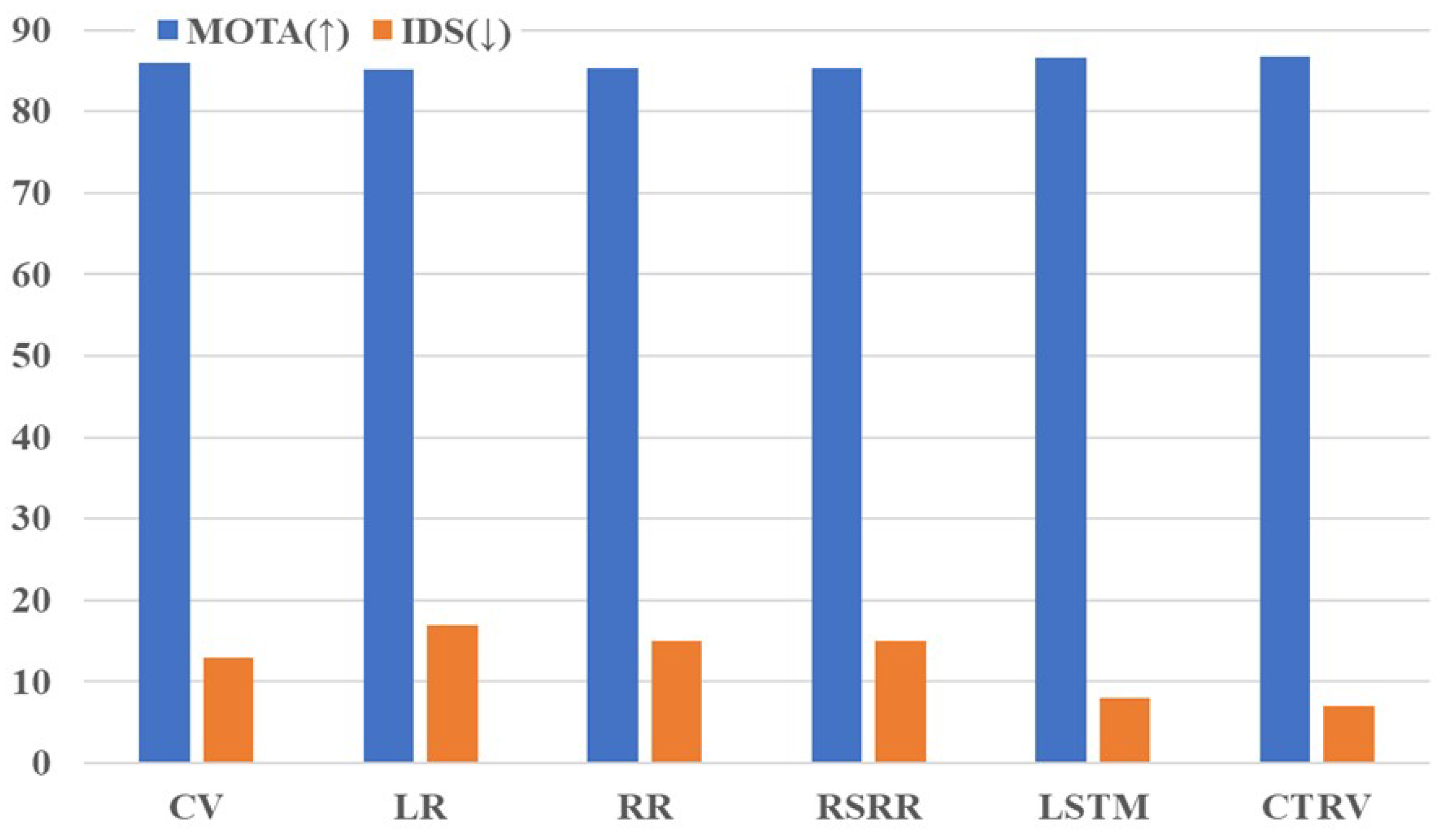
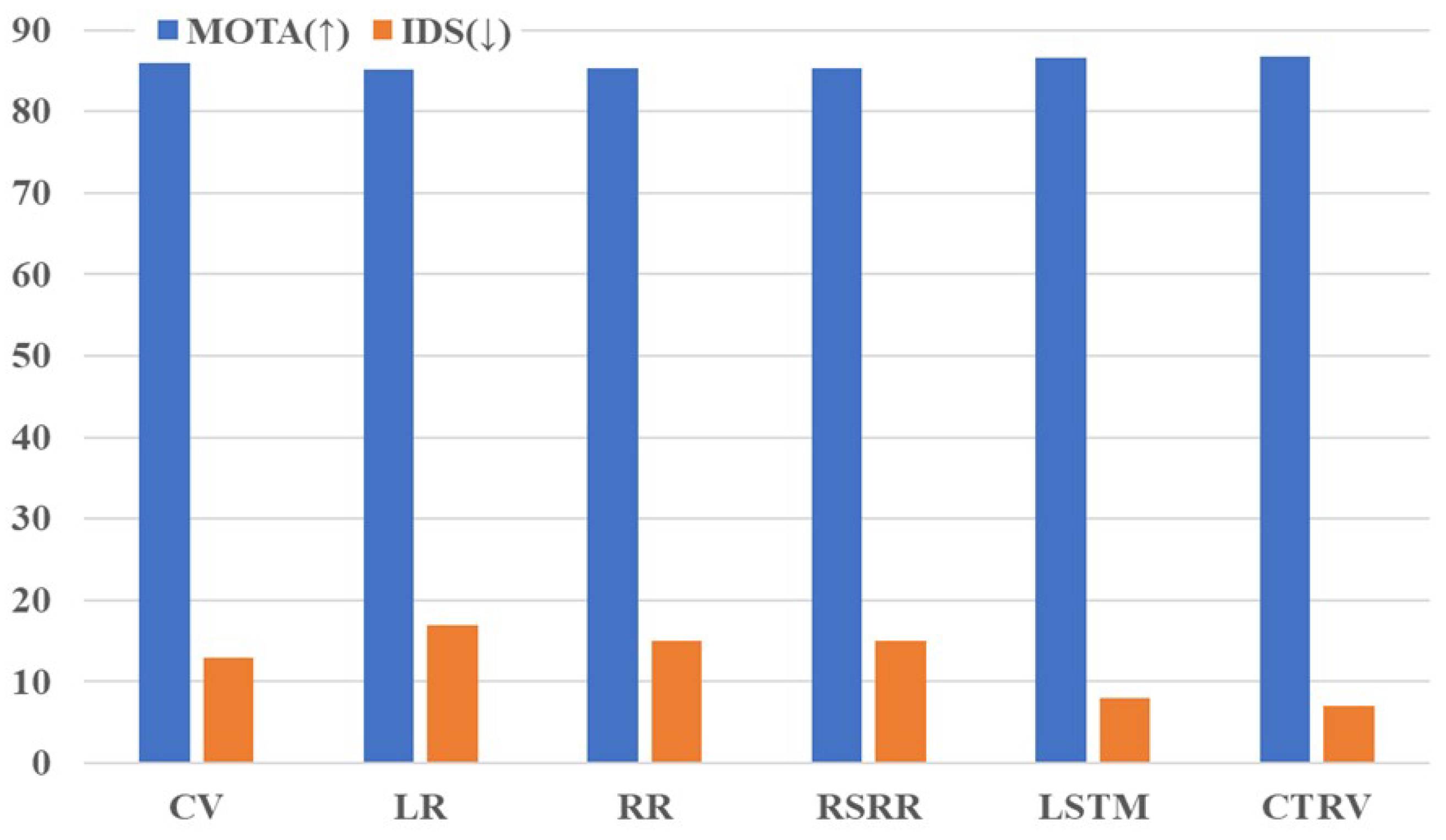
4.5.1. Effectiveness of the Predictor
4.5.2. Effectiveness of Proposed Multi-Level Association
4.5.3. Tracking Performance with Respect to Target Distance
4.5.4. Tracking Performance with False Detection
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Weng, X.; Wang, J.; Held, D.; Kitani, K. 3D Multi-Object Tracking: A baseline and new evaluation metrics. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 10359–10366. [Google Scholar]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3D object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11784–11793. [Google Scholar]
- Chiu, H.; Prioletti, A.; Li, J.; Bohg, J. Probabilistic 3D Multi-Object Tracking for autonomous driving. arXiv 2020, arXiv:2001.05673. [Google Scholar]
- Liu, H.; Ma, Y.; Hu, Q.; Guo, Y. CenterTube: Tracking Multiple 3D Objects with 4D Tubelets in Dynamic Point Clouds. IEEE Trans. Multimed. 2023; early access. [Google Scholar]
- Du, Y.; Zhao, Z.; Song, Y.; Zhao, Y.; Su, F.; Gong, T.; Meng, H. Strongsort: Make deepsort great again. IEEE Trans. Multimed. 2023; early access. [Google Scholar]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-object tracking by associating every detection box. In Proceedings of the Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXII. Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–21. [Google Scholar]
- Cao, J.; Pang, J.; Weng, X.; Khirodkar, R.; Kitani, K. Observation-centric sort: Rethinking sort for robust Multi-Object Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 9686–9696. [Google Scholar]
- Kim, A.; Ošep, A.; Leal-Taixé, L. Eagermot: 3D Multi-Object Tracking via sensor fusion. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 11315–11321. [Google Scholar]
- Huang, K.; Hao, Q. Joint multi-object detection and tracking with camera-LiDAR fusion for autonomous driving. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 6983–6989. [Google Scholar]
- Wang, X.; Fu, C.; Li, Z.; Lai, Y.; He, J. DeepFusionMOT: A 3D Multi-Object Tracking Framework Based on Camera-LiDAR Fusion with Deep Association. IEEE Robot. Autom. Lett. 2022, 7, 8260–8267. [Google Scholar] [CrossRef]
- Cheng, X.; Zhou, J.; Liu, P.; Zhao, X.; Wang, H. 3D Vehicle Object Tracking Algorithm Based on Bounding Box Similarity Measurement. IEEE Trans. Intell. Transp. Syst. 2023; early access. [Google Scholar]
- Kim, A.; Brasó, G.; Ošep, A.; Leal-Taixé, L. PolarMOT: How far can geometric relations take us in 3D Multi-Object Tracking? In Proceedings of the Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXII. Springer: Berlin/Heidelberg, Germany, 2022; pp. 41–58. [Google Scholar]
- Wu, H.; Li, Q.; Wen, C.; Li, X.; Fan, X.; Wang, C. Tracklet Proposal Network for Multi-Object Tracking on Point Clouds. In Proceedings of the International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; pp. 1165–1171. [Google Scholar]
- Luo, W.; Yang, B.; Urtasun, R. Fast and furious: Real-time end-to-end 3D detection, tracking and motion forecasting with a single convolutional net. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3569–3577. [Google Scholar]
- Chang, M.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3D tracking and forecasting with rich maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8748–8757. [Google Scholar]
- Dai, P.; Weng, R.; Choi, W.; Zhang, C.; He, Z.; Ding, W. Learning a proposal classifier for multiple object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2443–2452. [Google Scholar]
- Gharineiat, Z.; Tarsha Kurdi, F.; Campbell, G. Review of automatic processing of topography and surface feature identification LiDAR data using machine learning techniques. Remote Sens. 2022, 14, 4685. [Google Scholar] [CrossRef]
- Solares-Canal, A.; Alonso, L.; Picos, J.; Armesto, J. Automatic tree detection and attribute characterization using portable terrestrial lidar. Trees 2023, 37, 963–979. [Google Scholar] [CrossRef]
- Kim, B.; Choi, B.; Park, S.; Kim, H.; Kim, E. Pedestrian/vehicle detection using a 2.5-D multi-layer laser scanner. IEEE Sens. J. 2015, 16, 400–408. [Google Scholar] [CrossRef]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3D object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]
- Zhou, C.; Zhang, Y.; Chen, J.; Huang, D. OcTr: Octree-based Transformer for 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5166–5175. [Google Scholar]
- Wu, H.; Wen, C.; Shi, S.; Li, X.; Wang, C. Virtual Sparse Convolution for Multimodal 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 21653–21662. [Google Scholar]
- Chen, X.; Li, S.; Mersch, B.; Wiesmann, L.; Gall, J.; Behley, J.; Stachniss, C. Moving object segmentation in 3D LiDAR data: A learning-based approach exploiting sequential data. IEEE Robot. Autom. Lett. 2021, 6, 6529–6536. [Google Scholar] [CrossRef]
- Wang, S.; Zhu, J.; Zhang, R. Meta-rangeseg: Lidar sequence semantic segmentation using multiple feature aggregation. IEEE Robot. Autom. Lett. 2022, 7, 9739–9746. [Google Scholar] [CrossRef]
- Marcuzzi, R.; Nunes, L.; Wiesmann, L.; Behley, J.; Stachniss, C. Mask-based panoptic lidar segmentation for autonomous driving. IEEE Robot. Autom. Lett. 2023, 8, 1141–1148. [Google Scholar] [CrossRef]
- Xia, Y.; Xu, Y.; Wang, C.; Stilla, U. VPC-Net: Completion of 3D vehicles from MLS point clouds. ISPRS J. Photogramm. Remote Sens. 2021, 174, 166–181. [Google Scholar] [CrossRef]
- Zheng, C.; Yan, X.; Zhang, H.; Wang, B.; Cheng, S.; Cui, S.; Li, Z. Beyond 3D siamese tracking: A motion-centric paradigm for 3D single object tracking in point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8111–8120. [Google Scholar]
- Wang, P.; Ren, L.; Wu, S.; Yang, J.; Yu, E.; Yu, H.; Li, X. Implicit and Efficient Point Cloud Completion for 3D Single Object Tracking. IEEE Robot. Autom. Lett. 2023, 8, 1935–1942. [Google Scholar] [CrossRef]
- Cui, Y.; Xu, H.; Wu, J.; Sun, Y.; Zhao, J. Automatic vehicle tracking with roadside LiDAR data for the connected-vehicles system. IEEE Intell. Syst. 2019, 34, 44–51. [Google Scholar] [CrossRef]
- Meng, Z.; Xia, X.; Xu, R.; Liu, W.; Ma, J. HYDRO-3D: Hybrid Object Detection and Tracking for Cooperative Perception Using 3D LiDAR. IEEE Trans. Intell. Transp. Syst. 2023; early access. [Google Scholar]
- Yu, H.; Luo, Y.; Shu, M.; Huo, Y.; Yang, Z.; Shi, Y.; Guo, Z.; Li, H.; Hu, X.; Yuan, J.; et al. Dair-v2x: A large-scale dataset for vehicle-infrastructure cooperative 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21361–21370. [Google Scholar]
- Xu, R.; Xia, X.; Li, J.; Li, H.; Zhang, S.; Tu, Z.; Meng, Z.; Xiang, H.; Dong, X.; Song, R.; et al. V2v4real: A real-world large-scale dataset for vehicle-to-vehicle cooperative perception. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 13712–13722. [Google Scholar]
- Guo, G.; Zhao, S. 3D Multi-Object Tracking with adaptive cubature Kalman filter for autonomous driving. IEEE Trans. Intell. Veh. 2022, 8, 512–519. [Google Scholar] [CrossRef]
- Wu, H.; Han, W.; Wen, C.; Li, X.; Wang, C. 3D Multi-Object Tracking in point clouds based on prediction confidence-guided data association. IEEE Trans. Intell. Transp. Syst. 2021, 23, 5668–5677. [Google Scholar] [CrossRef]
- Shenoi, A.; Patel, M.; Gwak, J.; Goebel, P.; Sadeghian, A.; Rezatofighi, H.; Martin-Martin, R.; Savarese, S. Jrmot: A real-time 3D multi-object tracker and a new large-scale dataset. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 10335–10342. [Google Scholar]
- Brasó, G.; Leal-Taixé, L. Learning a neural solver for multiple object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6247–6257. [Google Scholar]
- Li, J.; Gao, X.; Jiang, T. Graph networks for multiple object tracking. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 719–728. [Google Scholar]
- Weng, X.; Wang, Y.; Man, Y.; Kitani, K. Gnn3dmot: Graph neural network for 3D Multi-Object Tracking with 2D-3D multi-feature learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6499–6508. [Google Scholar]
- He, J.; Huang, Z.; Wang, N.; Zhang, Z. Learnable graph matching: Incorporating graph partitioning with deep feature learning for multiple object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5299–5309. [Google Scholar]
- Zhai, G.; Meng, H.; Wang, X. A constant speed changing rate and constant turn rate model for maneuvering target tracking. Sensors 2014, 14, 5239–5253. [Google Scholar] [CrossRef] [PubMed]
- Ondruska, P.; Posner, I. Deep tracking: Seeing beyond seeing using recurrent neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Milan, A.; Rezatofighi, S.; Dick, A.; Reid, I.; Schindler, K. Online multi-target tracking using recurrent neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Xiang, J.; Zhang, G.; Hou, J. Online Multi-Object Tracking based on feature representation and Bayesian filtering within a deep learning architecture. IEEE Access 2019, 7, 27923–27935. [Google Scholar] [CrossRef]
- Hu, H.; Cai, Q.; Wang, D.; Lin, J.; Sun, M.; Krahenbuhl, P.; Darrell, T.; Yu, F. Joint monocular 3D vehicle detection and tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5390–5399. [Google Scholar]
- Kuhn, H. The Hungarian method for the assignment problem. Nav. Res. Logist. (NRL) 2005, 52, 7–21. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The clear mot metrics. EURASIP J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef]
- Luiten, J.; Osep, A.; Dendorfer, P.; Torr, P.; Geiger, A.; Leal-Taixé, L.; Leibe, B. Hota: A higher order metric for evaluating Multi-Object Tracking. Int. J. Comput. Vis. 2021, 129, 548–578. [Google Scholar] [CrossRef]
- Wang, S.; Sun, Y.; Liu, C.; Liu, M. Pointtracknet: An end-to-end network for 3-d object detection and tracking from point clouds. IEEE Robot. Autom. Lett. 2020, 5, 3206–3212. [Google Scholar] [CrossRef]
- Wang, S.; Cai, P.; Wang, L.; Liu, M. Ditnet: End-to-end 3D object detection and track id assignment in spatio-temporal world. IEEE Robot. Autom. Lett. 2021, 6, 3397–3404. [Google Scholar] [CrossRef]
- Luiten, J.; Fischer, T.; Leibe, B. Track to reconstruct and reconstruct to track. IEEE Robot. Autom. Lett. 2020, 5, 1803–1810. [Google Scholar] [CrossRef]
- Jiang, C.; Wang, Z.; Liang, H.; Tan, S. A fast and high-performance object proposal method for vision sensors: Application to object detection. IEEE Sens. J. 2022, 22, 9543–9557. [Google Scholar] [CrossRef]
- Zhang, K.; Liu, Y.; Mei, F.; Jin, J.; Wang, Y. Boost Correlation Features with 3D-MiIoU-Based Camera-LiDAR Fusion for MODT in Autonomous Driving. Remote Sens. 2023, 15, 874. [Google Scholar] [CrossRef]
- Wang, X.; Fu, C.; He, J.; Wang, S.; Wang, J. StrongFusionMOT: A Multi-Object Tracking Method Based on LiDAR-Camera Fusion. IEEE Sens. J. 2022, 23, 11241–11252. [Google Scholar] [CrossRef]
- Xia, Y.; Wu, Q.; Li, W.; Chan, A.; Stilla, U. A Lightweight and Detector-Free 3D Single Object Tracker on Point Clouds. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5543–5554. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method (Abbreviation) | HOTA (↑) | MOTA (↑) | MOTP (↑) | AssA (↑) | IDS (↓) | FRAG (↓) |
|---|---|---|---|---|---|---|
| Point3DT [50] | 57.20% | 67.56% | 76.83% | 59.15% | 294 | 756 |
| AB3DMOT [1] # | 69.99% | 83.61% | 85.23% | 69.33% | 113 | 206 |
| DiTNet [51] | 72.21% | 84.53% | 84.36% | 74.04% | 101 | 210 |
| PolarMOT [12] # | 75.16% | 85.08% | 85.63% | 76.95% | 462 | 599 |
| CenterTube [4] | 71.25% | 86.97% | 85.19% | 69.24% | 191 | 344 |
| Proposed method # | 75.65% | 85.03% | 84.93% | 80.02% | 39 | 367 |
| Method (Abbreviated) | HOTA (↑) | MOTA (↑) | MOTP (↑) | AssA (↑) | IDS (↓) | FRAG (↓) |
|---|---|---|---|---|---|---|
| MOTSFusion [52] # | 68.74% | 84.24% | 85.03% | 66.16% | 415 | 569 |
| JRMOT [36] | 69.61% | 85.10% | 85.28% | 66.89% | 271 | 273 |
| JMODT [9] | 70.73% | 85.35% | 85.37% | 68.76% | 350 | 693 |
| EagerMOT [8] # | 74.39% | 87.82% | 85.69% | 74.16% | 239 | 390 |
| Opm-NC2 [53] # | 73.19% | 84.21% | 85.86% | 73.77% | 195 | 301 |
| DeepFusionMOT [10] # | 75.46% | 84.63% | 85.02% | 80.05% | 84 | 472 |
| BcMOT [54] | 71.00% | 85.48% | 85.31% | 69.14% | 381 | 732 |
| StrongFusion-MOT [55] | 75.65% | 85.53% | 85.07% | 79.84% | 58 | 416 |
| Proposed method # | 75.65% | 85.03% | 84.93% | 80.02% | 39 | 367 |
| Application | MOTA (↑) | IDS (↓) | FRAG (↓) | ||
|---|---|---|---|---|---|
| Short-Term | Long-Term | Track Management | |||
| ✓ | - | - | 85.28% | 23 | 219 |
| ✓ | ✓ | - | 86.01% | 15 | 142 |
| ✓ | - | ✓ | 85.84% | 18 | 184 |
| ✓ | ✓ | ✓ | 86.79% | 7 | 83 |
| Method | Distance < 30 m | 30 m ≤ Distance ≤ 50 m | Distance > 50 m | |||
|---|---|---|---|---|---|---|
| MOTA (↑) | IDS (↓) | MOTA (↑) | IDS (↓) | MOTA (↑) | IDS (↓) | |
| AB3DMOT [1] | 86.85% | 6 | 85.27% | 9 | 83.73% | 8 |
| Proposed method | 88.89% | 0 | 86.35% | 5 | 85.13% | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cho, M.; Kim, E. 3D LiDAR Multi-Object Tracking with Short-Term and Long-Term Multi-Level Associations. Remote Sens. 2023, 15, 5486. https://doi.org/10.3390/rs15235486
Cho M, Kim E. 3D LiDAR Multi-Object Tracking with Short-Term and Long-Term Multi-Level Associations. Remote Sensing. 2023; 15(23):5486. https://doi.org/10.3390/rs15235486
Chicago/Turabian StyleCho, Minho, and Euntai Kim. 2023. "3D LiDAR Multi-Object Tracking with Short-Term and Long-Term Multi-Level Associations" Remote Sensing 15, no. 23: 5486. https://doi.org/10.3390/rs15235486
APA StyleCho, M., & Kim, E. (2023). 3D LiDAR Multi-Object Tracking with Short-Term and Long-Term Multi-Level Associations. Remote Sensing, 15(23), 5486. https://doi.org/10.3390/rs15235486