


A Heterogeneity-Enhancement and Homogeneity-Restraint Network (HEHRNet) for Change Detection from Very High-Resolution Remote Sensing Imagery

Abstract
:
1. Introduction
2. Materials and Methods
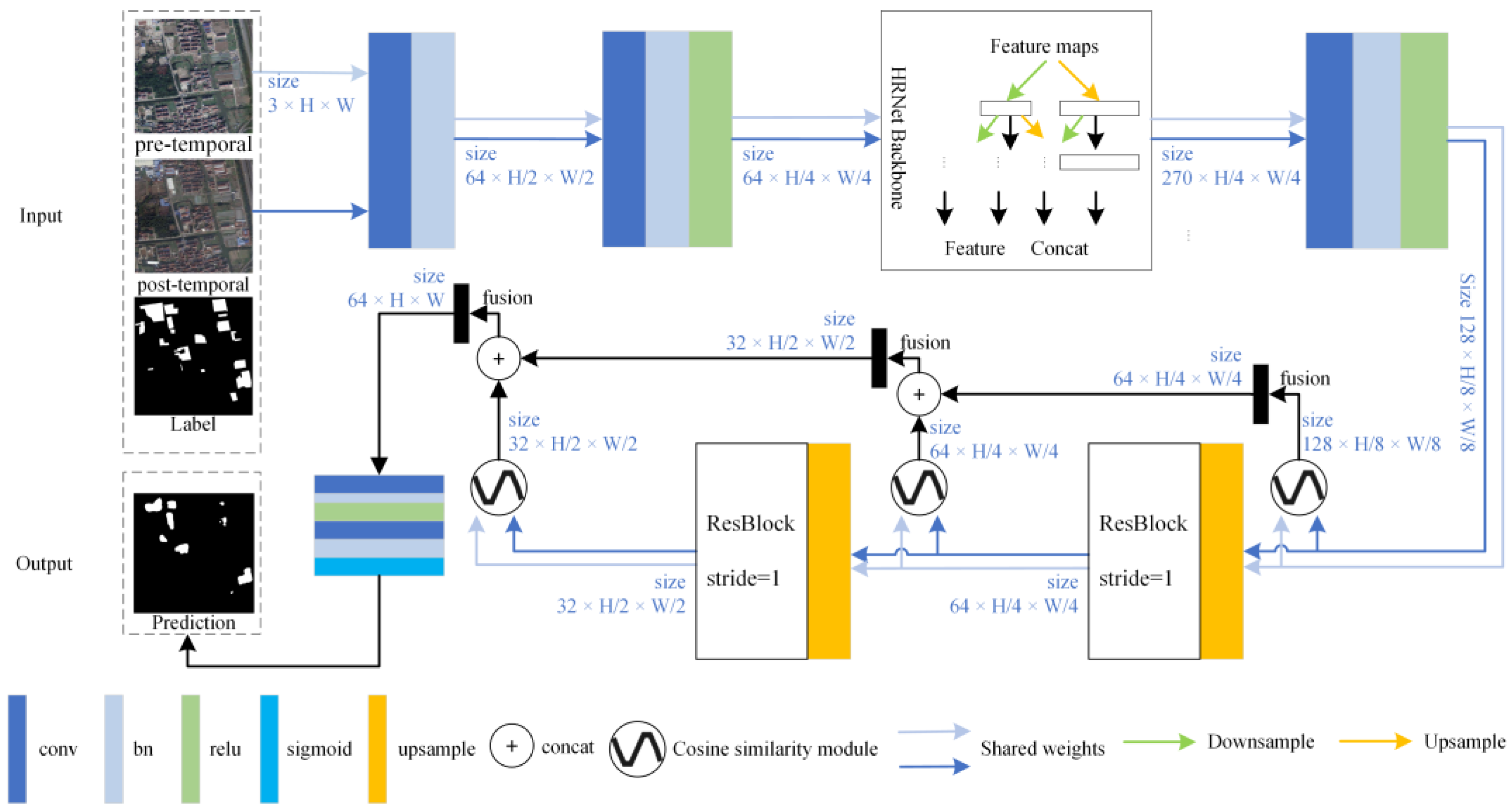
2.1. Framework
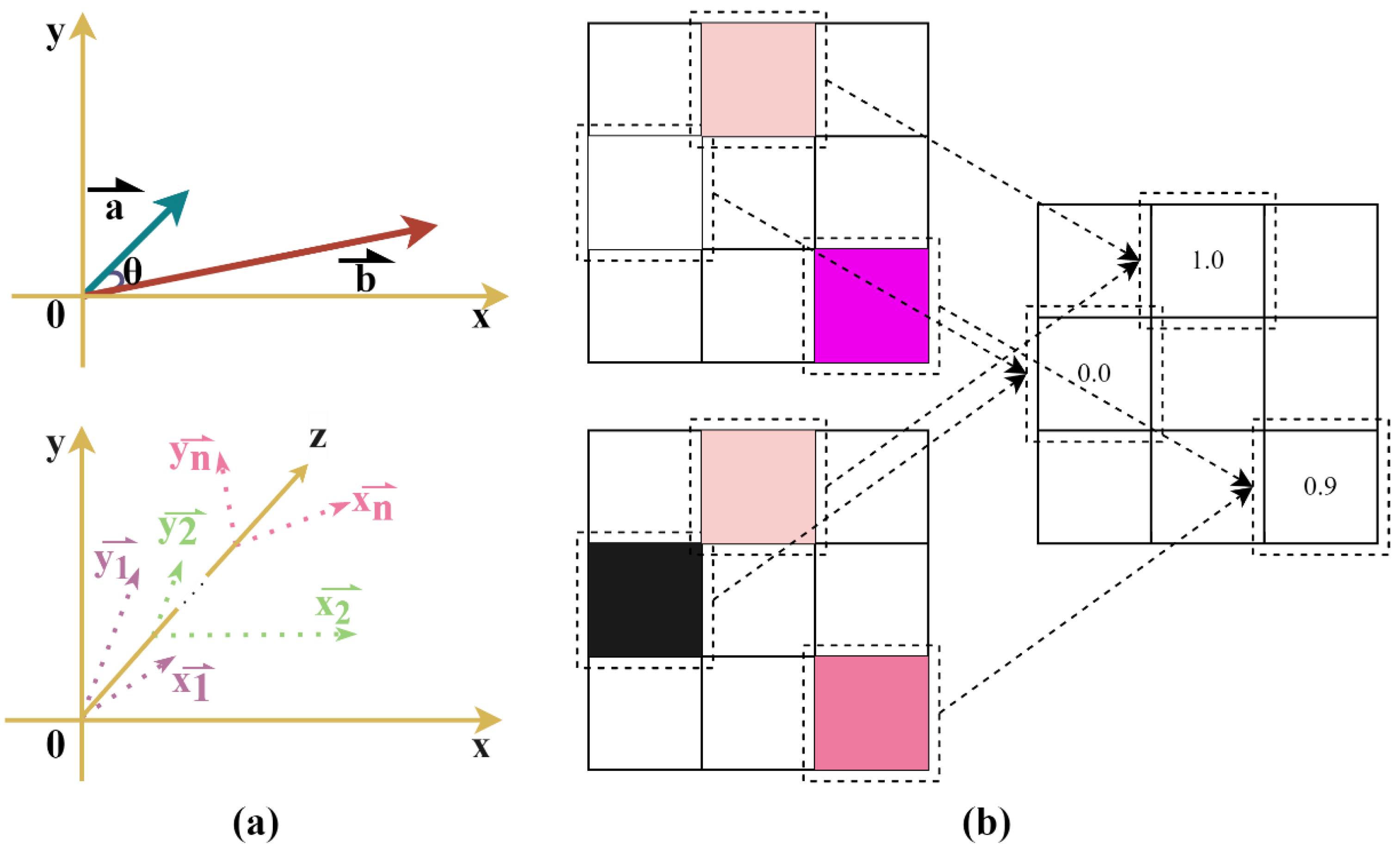
2.2. Cosine Similarity Module
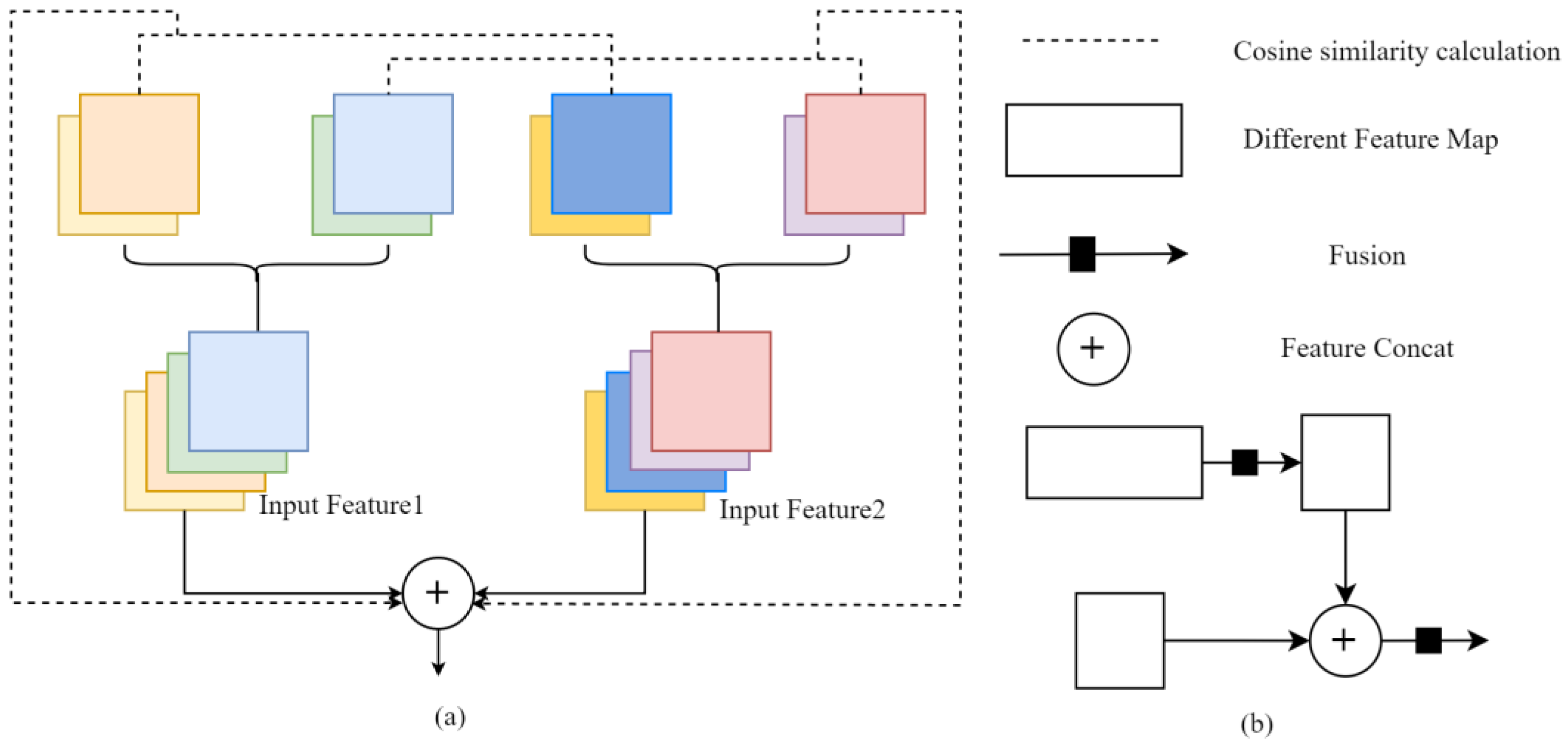
2.3. Multilayer Feature Progressive Fusion Enhancement Module
3. Experiments and Results
3.1. Dataset
3.2. Experimental Settings
3.3. Evaluation Measures
3.4. Experimental Results
4. Discussion and Analysis
4.1. Comparative Experimental Results Analysis
4.2. Ablation Study and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Paul, S.; Saxena, K.G.; Nagendra, H.; Lele, N. Tracing land use and land cover change in peri-urban Delhi, India, over 1973-2017 period. Environ. Monit. Assess. 2021, 193, 52. [Google Scholar] [CrossRef]
- Zhang, Y.J.; Wang, L.; Zhou, Q.; Tang, F.; Zhang, B.; Huang, N.; Nath, B. Continuous Change Detection and Classification-Spectral Trajectory Breakpoint Recognition for Forest Monitoring. Land 2022, 11, 504. [Google Scholar] [CrossRef]
- Yokoya, N.; Yamanoi, K.; He, W.; Baier, G.; Adriano, B.; Miura, H.; Oishi, S. Breaking Limits of Remote Sensing by Deep Learning from Simulated Data for Flood and Debris-Flow Mapping. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4400115. [Google Scholar] [CrossRef]
- Velumani, K.; Lopez-Lozano, R.; Madec, S.; Guo, W.; Gillet, J.; Comar, A.; Baret, F. Estimates of Maize Plant Density from UAV RGB Images Using Faster-RCNN Detection Model: Impact of the Spatial Resolution. Plant Phenomics 2021, 2021, 9824843. [Google Scholar] [CrossRef]
- Xiao, P.F.; Zhang, X.L.; Wang, D.G.; Yuan, M.; Feng, X.Z.; Kelly, M. Change detection of built-up land: A framework of combining pixel-based detection and object-based recognition. Isprs J. Photogramm. Remote Sens. 2016, 119, 402–414. [Google Scholar] [CrossRef]
- Xu, L.; Jing, W.P.; Song, H.B.; Chen, G.S. High-Resolution Remote Sensing Image Change Detection Combined with Pixel-Level and Object-Level. IEEE Access 2019, 7, 78909–78918. [Google Scholar] [CrossRef]
- Zhang, L.; Hu, X.Y.; Zhang, M.; Shu, Z.; Zhou, H. Object-level change detection with a dual correlation attention-guided detector. ISPRS J. Photogramm. Remote Sens. 2021, 177, 147–160. [Google Scholar] [CrossRef]
- Wang, Z.H.; Liu, Y.L.; Ren, Y.H.; Ma, H.J. Object-Level Double Constrained Method for Land Cover Change Detection. Sensors 2019, 19, 79. [Google Scholar] [CrossRef]
- Bansal, P.; Vaid, M.; Gupta, S. OBCD-HH: An object-based change detection approach using multi-feature non-seed-based region growing segmentation. Multimed. Tools Appl. 2022, 81, 8059–8091. [Google Scholar] [CrossRef]
- Bai, T.; Sun, K.M.; Li, W.Z.; Li, D.R.; Chen, Y.P.; Sui, H.G. A Novel Class-Specific Object-Based Method for Urban Change Detection Using High-Resolution Remote Sensing Imagery. Photogramm. Eng. Remote Sens. 2021, 87, 249–262. [Google Scholar] [CrossRef]
- Zhang, X.Z.; Liu, G.; Zhang, C.; Atkinson, P.M.; Tan, X.H.; Jian, X.; Zhou, X.C.; Li, Y.M. Two-Phase Object-Based Deep Learning for Multi-Temporal SAR Image Change Detection. Remote Sens. 2020, 12, 548. [Google Scholar] [CrossRef]
- Oh, J.H.; Kim, H.G.; Lee, K.M. Developing and Evaluating Deep Learning Algorithms for Object Detection: Key Points for Achieving Superior Model Performance. Korean J. Radiol. 2023, 24, 698–714. [Google Scholar] [CrossRef]
- Wu, M.F.; Li, C.; Yao, Z.H. Deep Active Learning for Computer Vision Tasks: Methodologies, Applications, and Challenges. Appl. Sci. 2022, 12, 8103. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2014; pp. 3431–3440. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2016; pp. 6230–6239. [Google Scholar] [CrossRef]
- Brown, C.F.; Brumby, S.P.; Guzder-Williams, B.; Birch, T.; Hyde, S.B.; Mazzariello, J.; Czerwinski, W.; Pasquarella, V.J.; Haertel, R.; Ilyushchenko, S.; et al. Dynamic World, Near real-time global 10 m land use land cover mapping. Sci. Data 2022, 9, 251. [Google Scholar] [CrossRef]
- Berwo, M.A.; Khan, A.; Fang, Y.; Fahim, H.; Javaid, S.; Mahmood, J.; Abideen, Z.U.; Syam, M.S. Deep Learning Techniques for Vehicle Detection and Classification from Images/Videos: A Survey. Sensors 2023, 23, 4832. [Google Scholar] [CrossRef]
- Wang, L.B.; Li, R.; Zhang, C.; Fang, S.H.; Duan, C.X.; Meng, X.L.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Ding, L.; Guo, H.T.; Liu, S.C.; Mou, L.C.; Zhang, J.; Bruzzone, L. Bi-Temporal Semantic Reasoning for the Semantic Change Detection in HR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5620014. [Google Scholar] [CrossRef]
- Peng, D.; Zhang, Y.; Guan, H. End-to-End Change Detection for High Resolution Satellite Images Using Improved UNet plus. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef]
- Zheng, Z.; Wan, Y.; Zhang, Y.; Xiang, S.; Peng, D.; Zhang, B. CLNet: Cross-layer convolutional neural network for change detection in optical remote sensing imagery. Isprs J. Photogramm. Remote Sens. 2021, 175, 247–267. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, Z.Y.; Peng, J.; Chen, L.; Huang, H.Z.; Zhu, J.W.; Liu, Y.; Li, H.F. DASNet: Dual Attentive Fully Convolutional Siamese Networks for Change Detection in High-Resolution Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1194–1206. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A.; IEEE. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar] [CrossRef]
- Li, Q.; Zhong, R.; Du, X.; Du, Y. TransUNetCD: A Hybrid Transformer Network for Change Detection in Optical Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5622519. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.P.; Shi, Z.W. Remote Sensing Image Change Detection with Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5607514. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, L.; Cheng, S.L.; Li, Y.M. SwinSUNet: Pure Transformer Network for Remote Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5224713. [Google Scholar] [CrossRef]
- Song, L.; Xia, M.; Weng, L.; Lin, H.; Qian, M.; Chen, B. Axial Cross Attention Meets CNN: Bibranch Fusion Network for Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 32–43. [Google Scholar] [CrossRef]
- Dong, J.; Zhao, W.F.; Wang, S. Multiscale Context Aggregation Network for Building Change Detection Using High Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8022605. [Google Scholar] [CrossRef]
- Sun, Y.; Tian, Y.; Xu, Y.P. Problems of encoder-decoder frameworks for high-resolution remote sensing image segmentation: Structural stereotype and insufficient learning. Neurocomputing 2019, 330, 297–304. [Google Scholar] [CrossRef]
- Li, L.L.; Ma, H.B.; Jia, Z.H. Multiscale Geometric Analysis Fusion-Based Unsupervised Change Detection in Remote Sensing Images via FLICM Model. Entropy 2022, 24, 291. [Google Scholar] [CrossRef] [PubMed]
- Shi, H.; Cao, G.; Ge, Z.X.; Zhang, Y.Q.; Fu, P. Double-Branch Network with Pyramidal Convolution and Iterative Attention for Hyperspectral Image Classification. Remote Sens. 2021, 13, 1403. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Mohamed, E.H.; Shokry, E.M. QSST: A Quranic Semantic Search Tool based on word embedding. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 934–945. [Google Scholar] [CrossRef]
- Souza, P.V.D.; Nunes, C.F.G.; Guimares, A.J.; Rezende, T.S.; Araujo, V.S.; Arajuo, V.J.S. Self-organized direction aware for regularized fuzzy neural networks. Evol. Syst. 2021, 12, 303–317. [Google Scholar] [CrossRef]
- Zhu, Q.Q.; Guo, X.; Deng, W.H.; Shi, S.N.; Guan, Q.F.; Zhong, Y.F.; Zhang, L.P.; Li, D.R. Land-Use/Land-Cover change detection based on a Siamese global learning framework for high spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2022, 184, 63–78. [Google Scholar] [CrossRef]
- Wang, X.; Kan, M.; Shan, S.; Chen, X. Fully Learnable Group Convolution for Acceleration of Deep Neural Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9041–9050. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Yang, K.; Xia, G.S.; Liu, Z.; Du, B.; Yang, W.; Pelillo, M.; Zhang, L. Asymmetric Siamese Networks for Semantic Change Detection in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5609818. [Google Scholar] [CrossRef]
- Caye Daudt, R.; Le Saux, B.; Boulch, A.; Gousseau, Y. Multitask learning for large-scale semantic change detection. Comput. Vis. Image Underst. 2019, 187, 102783. [Google Scholar] [CrossRef]
- Bandara, W.G.C.; Patel, V.M.; IEEE. A transformer-based siamese network for change detection. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 207–210. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Precision | Recall | F1 Score | MIoU |
|---|---|---|---|---|
| SECOND | 0.7050 | 0.6868 | 0.6958 | 0.7013 |
| HRSCD | 0.7570 | 0.6756 | 0.7140 | 0.7000 |
| Dataset | Models | Precision | Recall | F1 Score | MIoU |
|---|---|---|---|---|---|
| SECOND | FC-LF-CONC | 0.6867 | 0.6398 | 0.6624 | 0.6713 |
| FC-LF-DIFF | 0.6505 | 0.6841 | 0.6669 | 0.6757 | |
| UNET | 0.6260 | 0.5702 | 0.5968 | 0.6308 | |
| SSCDL | 0.6663 | 0.6780 | 0.6721 | 0.6811 | |
| BIT-CD | 0.6999 | 0.6090 | 0.6513 | 0.6716 | |
| ChangeFormer | 0.6690 | 0.6030 | 0.6343 | 0.6578 | |
| HEHRNet | 0.7050 | 0.6868 | 0.6958 | 0.7013 | |
| HRSCD | FC-LF-CONC | 0.7448 | 0.6544 | 0.6967 | 0.6861 |
| FC-LF-DIFF | 0.6752 | 0.6885 | 0.6818 | 0.6662 | |
| UNET | 0.6961 | 0.6919 | 0.6940 | 0.6778 | |
| SSCDL | 0.7092 | 0.6862 | 0.6975 | 0.6822 | |
| BIT-CD | 0.7777 | 0.6545 | 0.7108 | 0.6998 | |
| ChangeFormer | 0.7945 | 0.6170 | 0.6946 | 0.6896 | |
| HEHRNet | 0.7570 | 0.6756 | 0.7140 | 0.7000 |
| Models | UNet | FC-LF-DIFF | FC-LF-CONC | SSCDL | BIT-CD | ChangeFormer | Ours |
|---|---|---|---|---|---|---|---|
| Parameters (M) | 1.239 | 1.350 | 1.546 | 2.535 | 5.106 | 5.727 | 11.000 |
| Time (s/epoch) | 111 | 121 | 140 | 228 | 460 | 516 | 991 |
| Models | CS | MFPFE | Precision | Recall | F1 Score | MIoU |
|---|---|---|---|---|---|---|
| Base | × | × | 0.6936 | 0.6665 | 0.6798 | 0.6759 |
| Base + CS | √ | × | 0.6748 | 0.6852 | 0.6800 | 0.6926 |
| Base + MFPFE | × | √ | 0.6817 | 0.6785 | 0.6801 | 0.6866 |
| HEHRNet | √ | √ | 0.6780 | 0.6958 | 0.6868 | 0.7013 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, B.; He, A.; Wang, C.; Xu, X.; Yang, H.; Wu, Y. A Heterogeneity-Enhancement and Homogeneity-Restraint Network (HEHRNet) for Change Detection from Very High-Resolution Remote Sensing Imagery. Remote Sens. 2023, 15, 5425. https://doi.org/10.3390/rs15225425
Wang B, He A, Wang C, Xu X, Yang H, Wu Y. A Heterogeneity-Enhancement and Homogeneity-Restraint Network (HEHRNet) for Change Detection from Very High-Resolution Remote Sensing Imagery. Remote Sensing. 2023; 15(22):5425. https://doi.org/10.3390/rs15225425
Chicago/Turabian StyleWang, Biao, Ao He, Chunlin Wang, Xiao Xu, Hui Yang, and Yanlan Wu. 2023. "A Heterogeneity-Enhancement and Homogeneity-Restraint Network (HEHRNet) for Change Detection from Very High-Resolution Remote Sensing Imagery" Remote Sensing 15, no. 22: 5425. https://doi.org/10.3390/rs15225425
APA StyleWang, B., He, A., Wang, C., Xu, X., Yang, H., & Wu, Y. (2023). A Heterogeneity-Enhancement and Homogeneity-Restraint Network (HEHRNet) for Change Detection from Very High-Resolution Remote Sensing Imagery. Remote Sensing, 15(22), 5425. https://doi.org/10.3390/rs15225425