
Aircraft Detection from Low SCNR SAR Imagery Using Coherent Scattering Enhancement and Fused Attention Pyramid



Abstract
:1. Introduction
- (1)
- For aircraft detection in low SCNR SAR images, the CSE is introduced and integrated to construct the Faster R-CNN-based detector. The CSE preprocessing can apparently enhance the scattering information of the aircraft and reduce the background clutter and speckle noise.
- (2)
- We propose a novel FLCAPN attention pyramid that aggregates the features with local information and contextual information. In FLCAPN, the local attention can learn target local features adaptively, and the contextual attention facilitates the network in extracting significant context information from the whole image, reducing false alarms in an efficient and effective way.
- (3)
- We construct a low SCNR SAR image dataset for aircraft detection and conduct extensive experiments via benchmark comparison. The results demonstrate the effectiveness and superiority of the proposed approach.
2. Related Work
2.1. CNN-Based Object Detection Methods
2.2. Feature Pyramid Networks in Object Detection
2.3. CNN-Based Object Detection in SAR Images
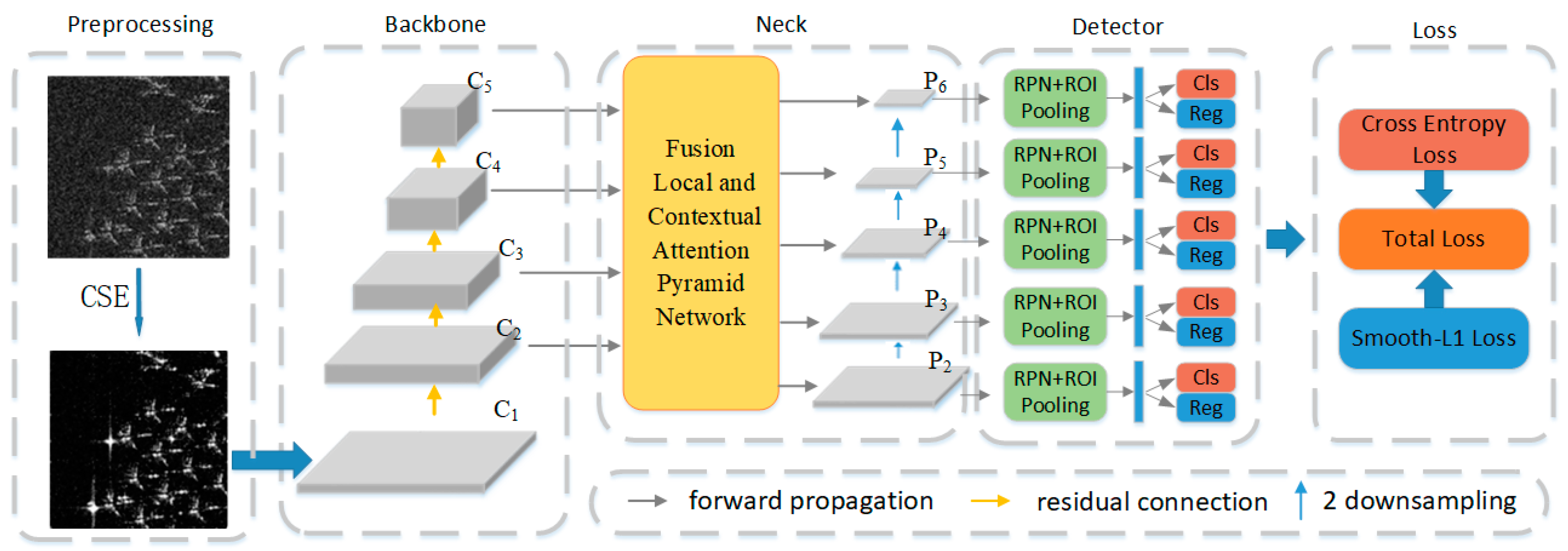
3. Methodology
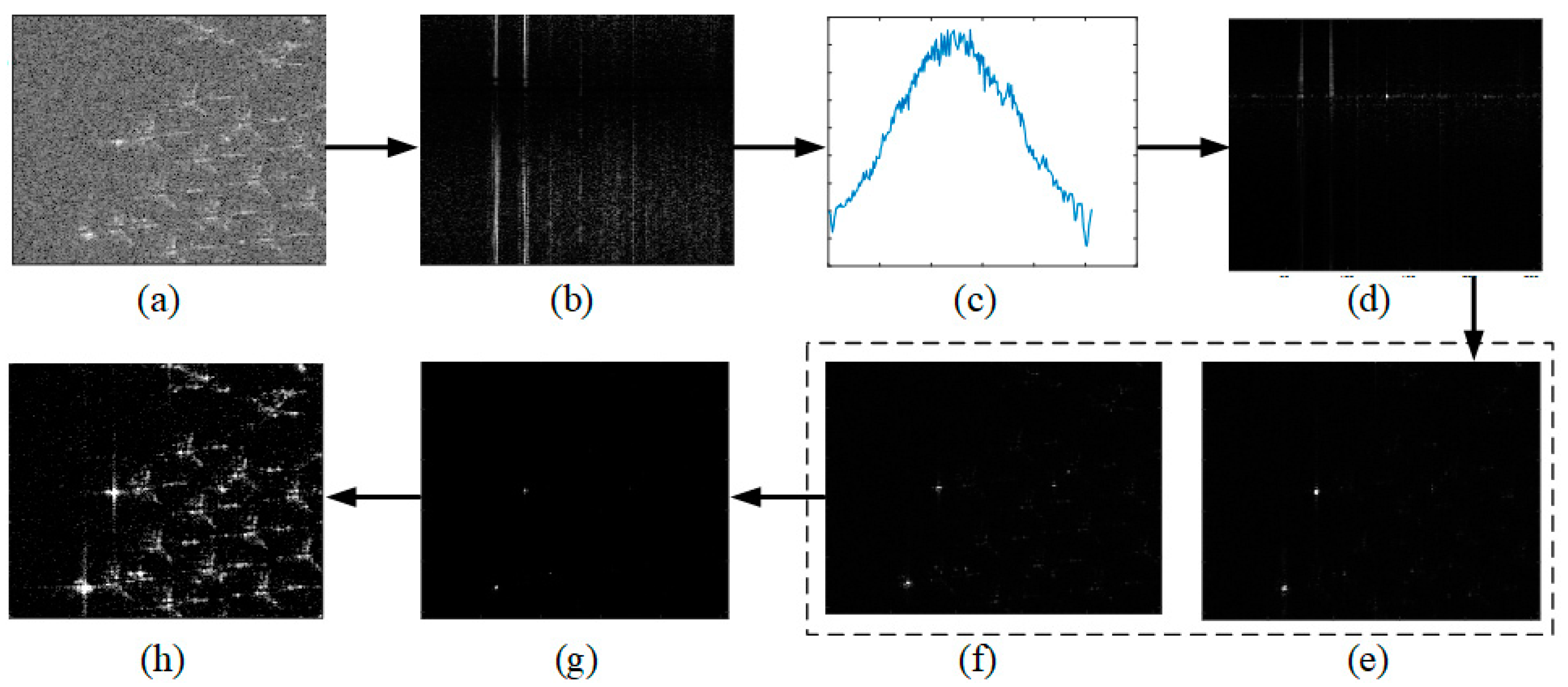
3.1. CSE Preprocessing
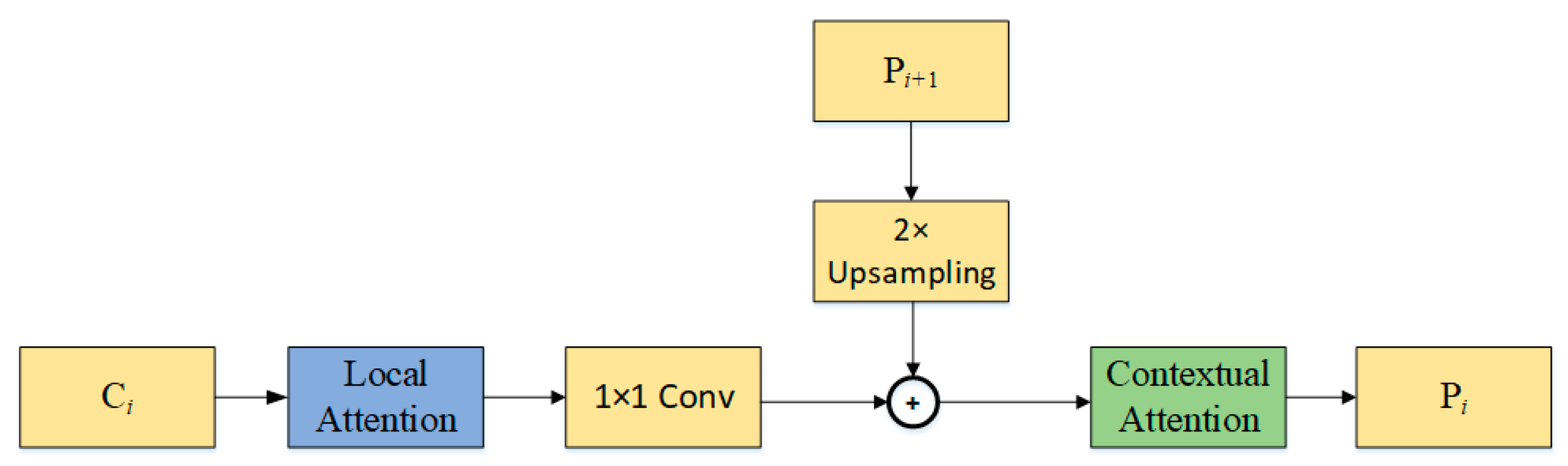
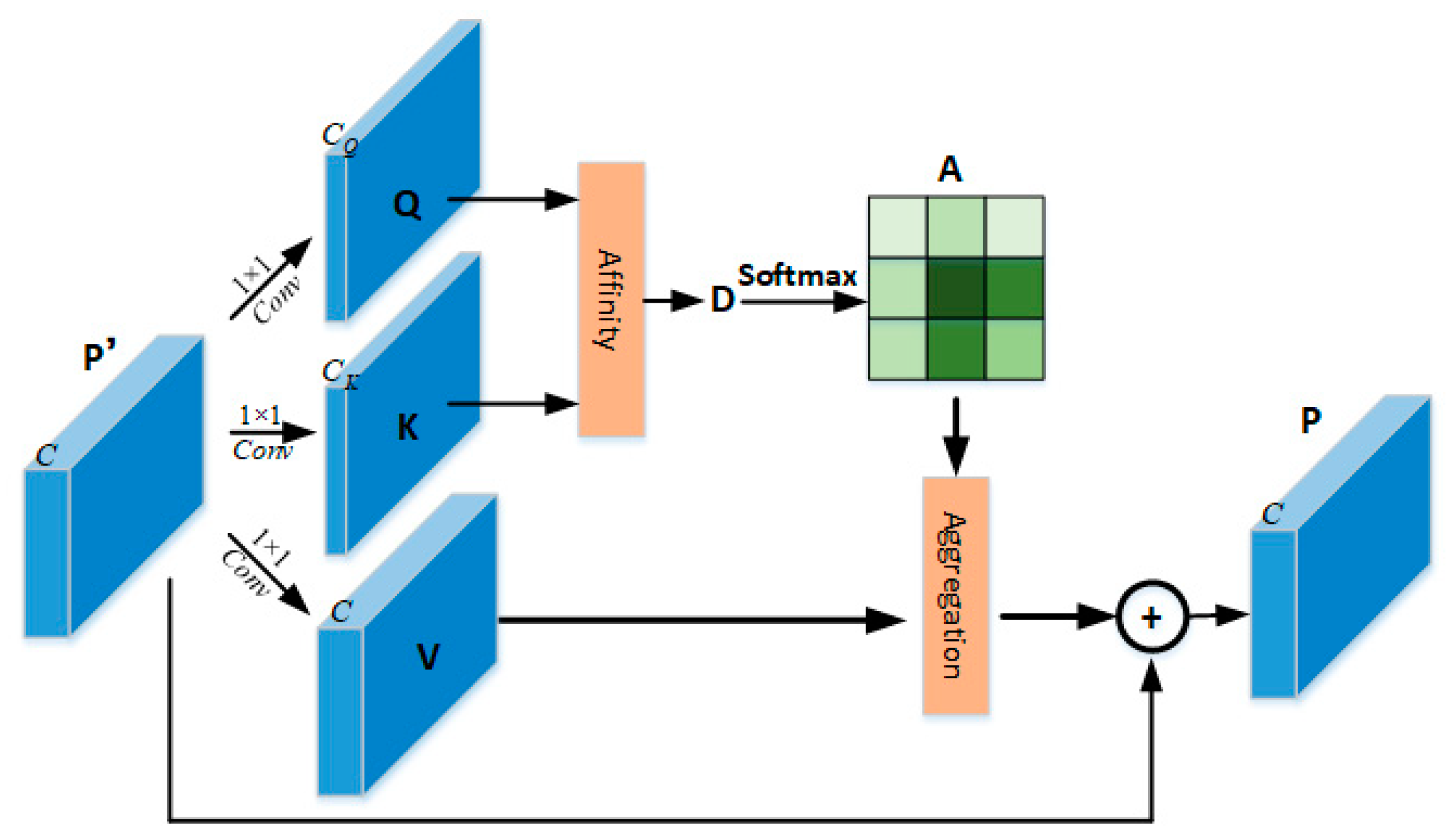
3.2. Fusion Local and Contextual Attention Pyramid Network
- (1)
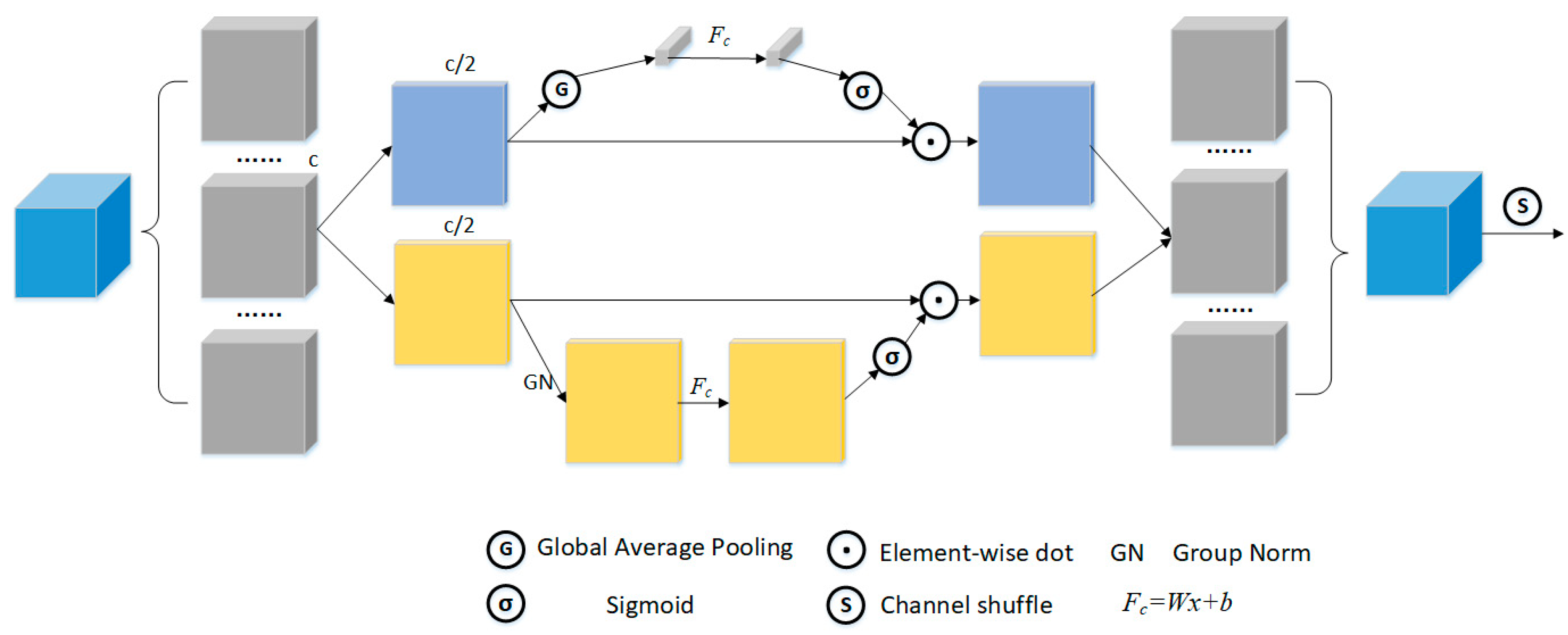
- Local attention: Considering the SAR imaging principle, the target image can be seen as a series of scattering centers that are difficult to detect due to the influence of speckle noise and clutter. LA is excavated to reduce the negative impact of noise and clutter so that the network can adaptively focus on aircraft targets. The overall architecture of the LA module is illustrated in Figure 6.
- (2)
- Contextual attention: In order to make the network capture the information around the target, the CA is designed to obtain the difference between the target and the surrounding background. It is implemented by adding upper-level features and local features obtained through LA. The process is shown in Figure 7.
3.3. Loss Function
4. Experiments and Analysis
4.1. Dataset and Setting
4.2. Evaluation Metric
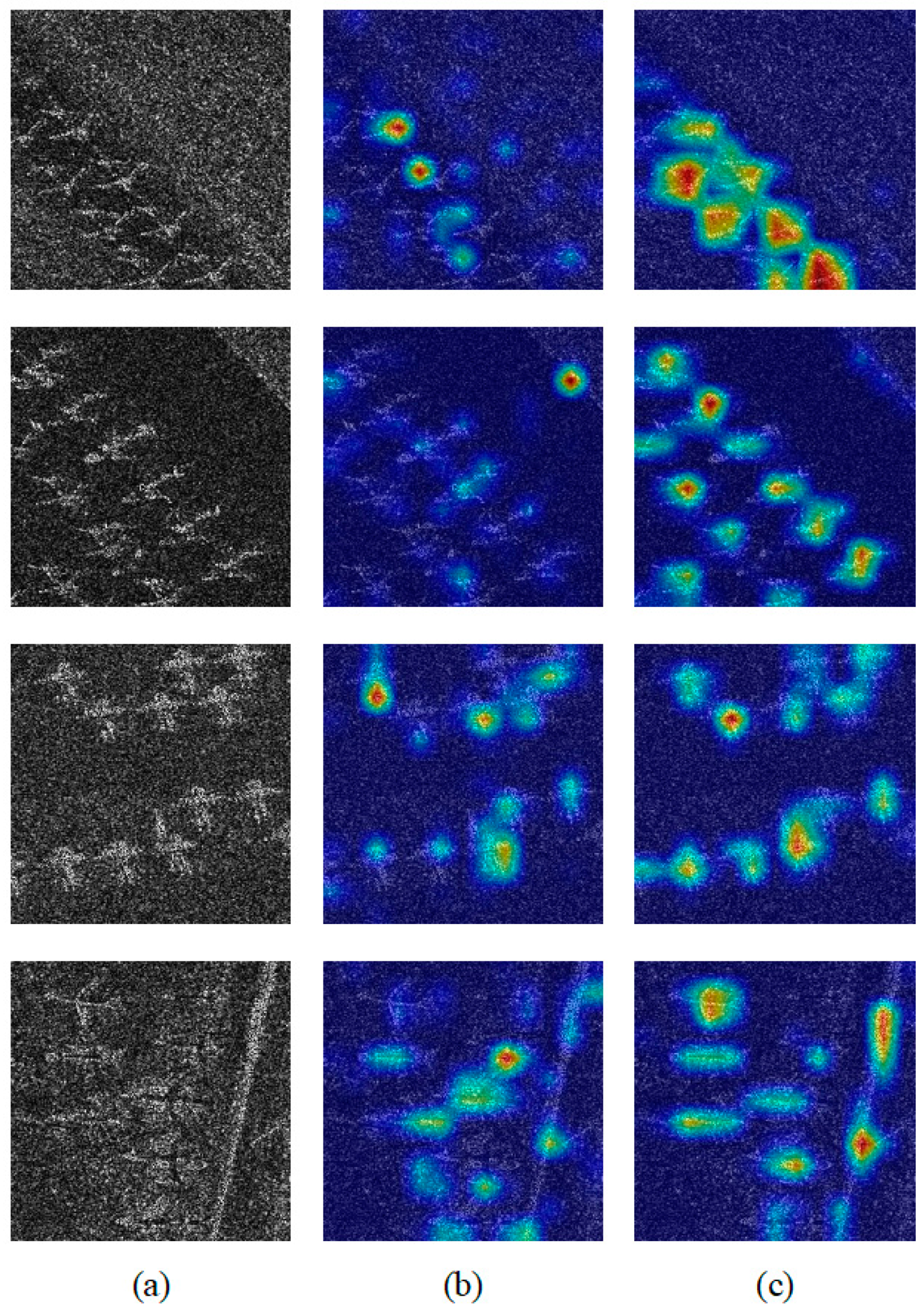
4.3. Effect of CSE
4.4. Effect of FLCAPN
4.5. Ablation Studies
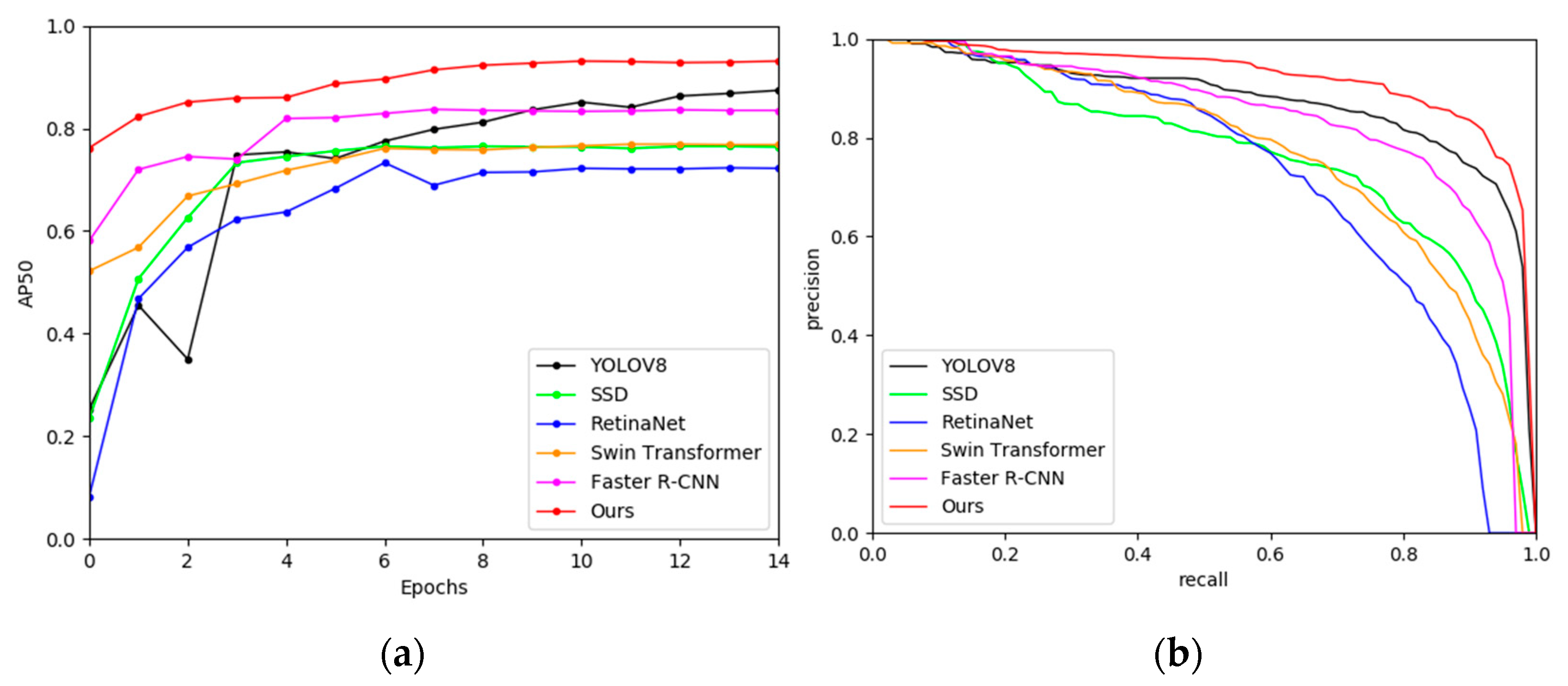
4.6. Comparison with Other CNN-Based Methods
4.7. Parameter Quantity and FPS
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, R.; Wang, Z.; Xia, K.; Zou, H.; Li, J. Target recognition in single-channel SAR images based on the complex-valued convolutional neural network with data augmentation. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 796–804. [Google Scholar] [CrossRef]
- Ai, J.; Pei, Z.; Yao, B.; Wang, Z.; Xing, M. AIS data aided rayleigh cfar ship detection algorithm of multiple target environment in sar images. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 1266–1282. [Google Scholar] [CrossRef]
- Ge, B.; An, D.; Chen, L.; Wang, W.; Feng, D.; Zhou, Z. Ground moving target detection and trajectory reconstruction methods for multichannel airborne circular SAR. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 2900–2915. [Google Scholar] [CrossRef]
- Gao, J.; Gao, X.; Sun, X. Geometrical features-based method for aircraft target interpretation in high-resolution SAR images. Foreign Electron. Meas. Technol. 2022, 34, 21–28. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, H.; Xu, F. Aircraft target detection from spaceborne synthetic aperture radar image. Aerosp. Shanghai 2018, 35, 57–64. [Google Scholar]
- Guo, Q.; Wang, H.; Xu, F. Research progress on aircraft detection and recognition in SAR imagery. J. Radars 2020, 9, 497–513. [Google Scholar] [CrossRef]
- Tan, Y.; Li, Q.; Li, Y.; Tian, J. Aircraft detection in high-resolution SAR images based on a gradient textural saliency map. Sensors 2015, 15, 23071–23094. [Google Scholar] [CrossRef]
- Li, L.; Du, L.; Wang, Z. Target detection based on dual-domain sparse reconstruction saliency in SAR images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2018, 11, 4230–4243. [Google Scholar] [CrossRef]
- He, C.; Tu, M.; Liu, X.; Xiong, D.; Liao, M. Mixture statistical distribution based multiple component model for target detection in high resolution SAR imagery. ISPRS Int. J. Geo-Inf. 2017, 6, 336. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A.; Liu, W.; et al. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster r-cnn. In Proceedings of the SAR Big Data Era Models Methods Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Jiao, J.; Zhang, Y.; Sun, H.; Yang, X.; Gao, X.; Hong, W.; Fu, K.; Sun, X. A densely connected end-to-end neural network for multiscale and multiscene SAR ship detection. IEEE Access 2018, 6, 20881–20892. [Google Scholar] [CrossRef]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense attention pyramid networks for multi-scale ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Li, D.; Liang, Q.; Liu, H.; Liu, Q.; Liu, H.; Liao, G. A novel multidimensional domain deep learning network for SAR ship detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Yang, R. A novel cnn-based detector for ship detection based on rotatable bounding box in SAR images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 1938–1958. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 10–16 October 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]
- Ultralytics YOLOv8. Available online: https://github.com/ultralytics/ultralytics (accessed on 17 August 2023).
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 765–781. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, DC, USA, 14–19 June 2020; pp. 10778–10787. [Google Scholar] [CrossRef]
- Qiao, S.; Chen, L.C.; Yuille, A. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 10208–10219. [Google Scholar] [CrossRef]
- Ghiasi, G.; Lin, T.-Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7029–7038. [Google Scholar] [CrossRef]
- Xu, H.; Yao, L.; Li, Z.; Liang, X.; Zhang, W. Auto-fpn: Automatic network architecture adaptation for object detection beyond classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6648–6657. [Google Scholar] [CrossRef]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and excitation rank faster r-cnn for ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 751–755. [Google Scholar] [CrossRef]
- Cui, Z.; Wang, X.; Liu, N.; Cao, Z.; Yang, J. Ship detection in large-scale SAR images via spatial shuffle-group enhance attention. IEEE Trans. Geosci. Remote Sens. 2021, 59, 379–391. [Google Scholar] [CrossRef]
- Fu, J.; Sun, X.; Wang, Z.; Fu, K. An anchor-free method based on feature balancing and refinement network for multiscale ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1331–1344. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Li, C.; Kuang, G. Pyramid attention dilated network for aircraft detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 662–666. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, H.; Xu, F. Scattering enhanced attention pyramid network for aircraft detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7570–7587. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Kang, Y. Sfr-net: Scattering feature relation network for aircraft detection in complex SAR images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Liu, Z.; Hu, D.; Kuang, G.; Liu, L. Attentional feature refinement and alignment network for aircraft detection in SAR imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Chen, L.; Luo, R.; Xing, J.; Li, Z.; Yuan, Z.; Cai, X. Geospatial transformer is what you need for aircraft detection in SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, N.; Guo, J.; Zhang, C.; Wang, B. SCFNet: Semantic Condition Constraint Guided Feature Aware Network for Aircraft Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–20. [Google Scholar] [CrossRef]
- Zhao, D.; Chen, Z.; Gao, Y.; Shi, Z. Classification Matters More: Global Instance Contrast for Fine-Grained SAR Aircraft Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Souyris, J.-C.; Henry, C.; Adragna, F. On the use of complex SAR image spectral analysis for target detection: Assessment of polarimetry. IEEE Trans. Geosci. Remote Sens. 2003, 41, 2725–2734. [Google Scholar] [CrossRef]
- Suess, M.; Grafmueller, B.; Zahn, R. Target detection and analysis based on spectral analysis of a SAR image:a simulation approach. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Toulouse, France, 21–25 July 2003; pp. 2005–2007. [Google Scholar] [CrossRef]
- Ferro-Famil, L.; Reigber, A.; Pottier, E.; Boerner, W.-M. Scene characterization using subaperture polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 2003, 41, 2264–2276. [Google Scholar] [CrossRef]
- Park, J.; Woo, S.; Lee, J.-Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, X.; Wei, Y.; Huang, L.; Shi, H.; Liu, W.; Huang, T.S. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradientbased localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Scene 1 | Scene 2 |
|---|---|---|
| Resolution | 1 m | 1 m |
| Polarization | HH | HH |
| Size | 11,132 6251 | 11,166 6082 |
| Methods | AP | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|
| FPN | 0.503 | 0.891 | 0.519 | 0.426 | 0.567 | 0.723 |
| FPN + LA | 0.505 | 0.897 | 0.524 | 0.436 | 0.575 | 0.707 |
| FPN + CA | 0.507 | 0.896 | 0.525 | 0.425 | 0.556 | 0.721 |
| FLCAPN | 0.514 | 0.901 | 0.531 | 0.406 | 0.585 | 0.711 |
| CSE | FLCAPN | AP | AP50(mAP) | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|---|
| - | - | 0.503 | 0.891 | 0.519 | 0.426 | 0.567 | 0.723 |
| ✓ | - | 0.519 | 0.907 | 0.528 | 0.406 | 0.570 | 0.677 |
| - | ✓ | 0.514 | 0.901 | 0.531 | 0.406 | 0.585 | 0.711 |
| ✓ | ✓ | 0.534 | 0.917 | 0.561 | 0.418 | 0.590 | 0.714 |
| Method | AP | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|
| Faster R-CNN | 0.503 | 0.835 | 0.519 | 0.426 | 0.567 | 0.723 |
| RetinaNet | 0.480 | 0.723 | 0.449 | 0.388 | 0.517 | 0.717 |
| YOLOv8 | 0.388 | 0.874 | 0.320 | 0.301 | 0.450 | 0.460 |
| SSD-300 | 0.465 | 0.764 | 0.453 | 0.367 | 0.503 | 0.643 |
| Swin Transformer | 0.378 | 0.768 | 0.315 | 0.332 | 0.417 | 0.367 |
| Ours | 0.534 | 0.917 | 0.561 | 0.418 | 0.590 | 0.714 |
| Method | Faster R-CNN | RetinaNet | YOLOv8 | SSD-300 | Swin Transformer | Ours |
|---|---|---|---|---|---|---|
| PQ | 41.348 M | 36.33 M | 3.2 M | 23.746 M | 44.75 M | 46.272 M |
| FPS | 396 | 452 | 1010 | 243 | 137 | 310 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Hu, D.; Li, S.; Luo, Y.; Li, J.; Zhang, C. Aircraft Detection from Low SCNR SAR Imagery Using Coherent Scattering Enhancement and Fused Attention Pyramid. Remote Sens. 2023, 15, 4480. https://doi.org/10.3390/rs15184480
Zhang X, Hu D, Li S, Luo Y, Li J, Zhang C. Aircraft Detection from Low SCNR SAR Imagery Using Coherent Scattering Enhancement and Fused Attention Pyramid. Remote Sensing. 2023; 15(18):4480. https://doi.org/10.3390/rs15184480
Chicago/Turabian StyleZhang, Xinzheng, Dong Hu, Sheng Li, Yuqing Luo, Jinlin Li, and Ce Zhang. 2023. "Aircraft Detection from Low SCNR SAR Imagery Using Coherent Scattering Enhancement and Fused Attention Pyramid" Remote Sensing 15, no. 18: 4480. https://doi.org/10.3390/rs15184480
APA StyleZhang, X., Hu, D., Li, S., Luo, Y., Li, J., & Zhang, C. (2023). Aircraft Detection from Low SCNR SAR Imagery Using Coherent Scattering Enhancement and Fused Attention Pyramid. Remote Sensing, 15(18), 4480. https://doi.org/10.3390/rs15184480