1. Introduction
Micro-satellites are rapidly advancing and finding applications across various domains, including wildfire detection, technology demonstrations, scientific research, communication, and Earth observation [
1,
2,
3,
4]. These micro-satellites have gained popularity over traditional devices due to their reduced costs and development cycles, smaller sizes, lower power consumption, and adaptability for networking and constellation [
1]. However, their extensive use has resulted in a substantial surge in the volume of raw image data [
5]. Conventional data processing involves transmitting images to ground stations before further utilization, leading to significant delays caused by limited downlinking bandwidth. This places enormous strain on ground data processing systems [
6]. The delay between data generation and information extraction not only impacts time efficiency and ground station maintenance but also diminishes the value of the data [
7]. This delay can result in missed opportunities, such as overlooking a low-cloud-coverage observation window during ground analysis [
1]. Consequently, satellites often generate a considerable amount of redundant data, squandering resources and hardware while failing to address emergencies [
8]. This scenario has prompted researchers to consider shifting some of the processing flow onto satellites themselves.
On-board processing is gaining significant traction due to its ability to reduce the volume of data transmitted between satellites and ground stations, allowing for nearly real-time responses [
8]. Newly launched micro-satellites now come equipped with on-board intelligent processing modules, enabling the automatic generation of standardized image products and real-time object detection [
7]. Instead of transmitting raw data, these satellites send targeted patches and their positional information to ground receivers for further analysis. This reduction in on-board processed data for downlink transmission significantly alleviates the strain on communication bandwidth [
7]. Ground stations no longer have to contend with waiting for transmissions or handling vast amounts of raw data, thereby bypassing time delays, system intricacies, and maintenance costs [
8]. On-board processing empowers satellites to swiftly respond to emergencies and seamlessly integrate information from multiple sources for continuous wide-area observation [
9].
However, on-board processing encounters several new challenges. Reports indicate that micro-satellites exhibit lower geometric accuracy compared to traditional satellites [
10,
11], potentially limiting the reliability and effectiveness of subsequent applications. Achieving precise geometric accuracy is crucial before proceeding to object detection. This necessitates accurate calibration or geometric rectification. Calibration often demands prolonged time for repeated observations in calibration fields to update positioning parameters, proving time-consuming and labor-intensive for micro-satellites. Alternatively, on-board geometric rectification presents a rapid and cost-effective solution. However, the constraints of weight, volume, and power consumption in micro-satellites impose limitations on computational and storage resources [
1,
12]. Furthermore, the thermal conditions in space preclude the continuous operation of processing systems. Algorithms requiring extensive storage make traditional ground control point (GCP) databases unfeasible, while those with high computational complexity may not deliver practical real-time performance [
6,
7,
9,
12]. In essence, on-board rectification necessitates a lightweight database and improved computational efficiency.
On-board processing algorithms primarily focus on two aspects: simplifying models and reducing algorithmic complexity while maintaining accuracy. This is exemplified by the utilization of lightweight neural networks. Techniques such as Principal Component Analysis (PCA) [
13] and Linear Discriminant Analysis (LDA) [
14] aim to represent keypoint descriptors with fewer dimensions, reducing both storage consumption and computational complexity. Another method, quantization, transforms 32-bit floating-point data into 8-bit integers for the same purpose [
15,
16,
17]. Complex computations can be replaced by less intensive approximations that maintain similar precision [
18,
19]. The trend of incorporating deep learning into on-board processing is growing, introducing lightweight network models [
7,
9,
20]. These models enhance efficiency while preserving accuracy.
The other emphasis lies in shifting processing procedures onto specialized hardware resources. Embedded on-board processing systems generally fall into three categories: Digital Signal Processors (DSPs), Field-Programmable Gate Arrays (FPGA), and Graphics Processing Units (GPUs). Traditional on-board processing methods primarily revolve around FPGA utilization, involving the adaptation of algorithms to suit hardware characteristics [
8,
12,
21] and designing specific FPGA implementations tailored to particular algorithms [
22,
23,
24,
25]. However, DSP and FPGA platforms have their drawbacks, including obsolescence, rigidity, and high costs [
5]. These devices often lack sufficient computing capacity and struggle to handle diverse tasks [
9].
Traditional embedded on-board processing systems such as DSPs and FPGAs are optimized for executing specific commands to enhance efficiency. However, these typical on-board processing platforms exhibit limitations such as inflexibility and high implementation costs with the exponential growth in data volume [
5]. With recent advancements in software and hardware, there is a growing preference for employing embedded ARM and GPU architectures in on-board processing systems due to their enhanced portability and developmental flexibility [
20]. The ability of GPUs to process data in parallel has proven successful in various on-board processing tasks, including sensor correction [
5], ship detection [
7], and image registration [
20,
26]. Notably, the NVIDIA Jetson Series exhibits characteristics such as low power consumption, high performance, and compact integration, rendering it suitable for real-time on-board processing systems. Given the constraints and costs associated with DSP and FPGA platforms, it is advisable to consider embedded GPUs for on-board processing systems. Products including TX1, TX2, and Nano are designed for edge computing, offering high performance with low power consumption, a compact size, and a lower cost, making them suitable candidates for on-board processing systems.
In response to these developments, we propose an on-board rectification method that leverages a lightweight feature database to achieve precise and rapid geometric rectification based on embedded GPU technology. Initially, we construct a lightweight reference database using edge features and compression techniques. Subsequently, fast template matching is employed to mitigate significant initial geometric offsets. Finally, a refined local matching process is implemented to enhance the accuracy of the sensed image relocation. Both quantitative and practical on-board experiments confirm the viability of the proposed method. The major contributions of this paper are listed as follows:
A robust and easy-to-implement feature establishment method for a lightweight reference database, which focuses on distinctive runways and coastlines;
A feature-compressing strategy based on Run-Length Encoding is applied to the aforementioned reference database, significantly reducing the storage space while maintaining sufficient structural features;
Adaptation for on-board implementation, including a two-step matching framework that overcomes large and unknown positioning errors of micro-satellites, along with a GPU migration to fulfill the computation demand of on-board processing.
2. Method
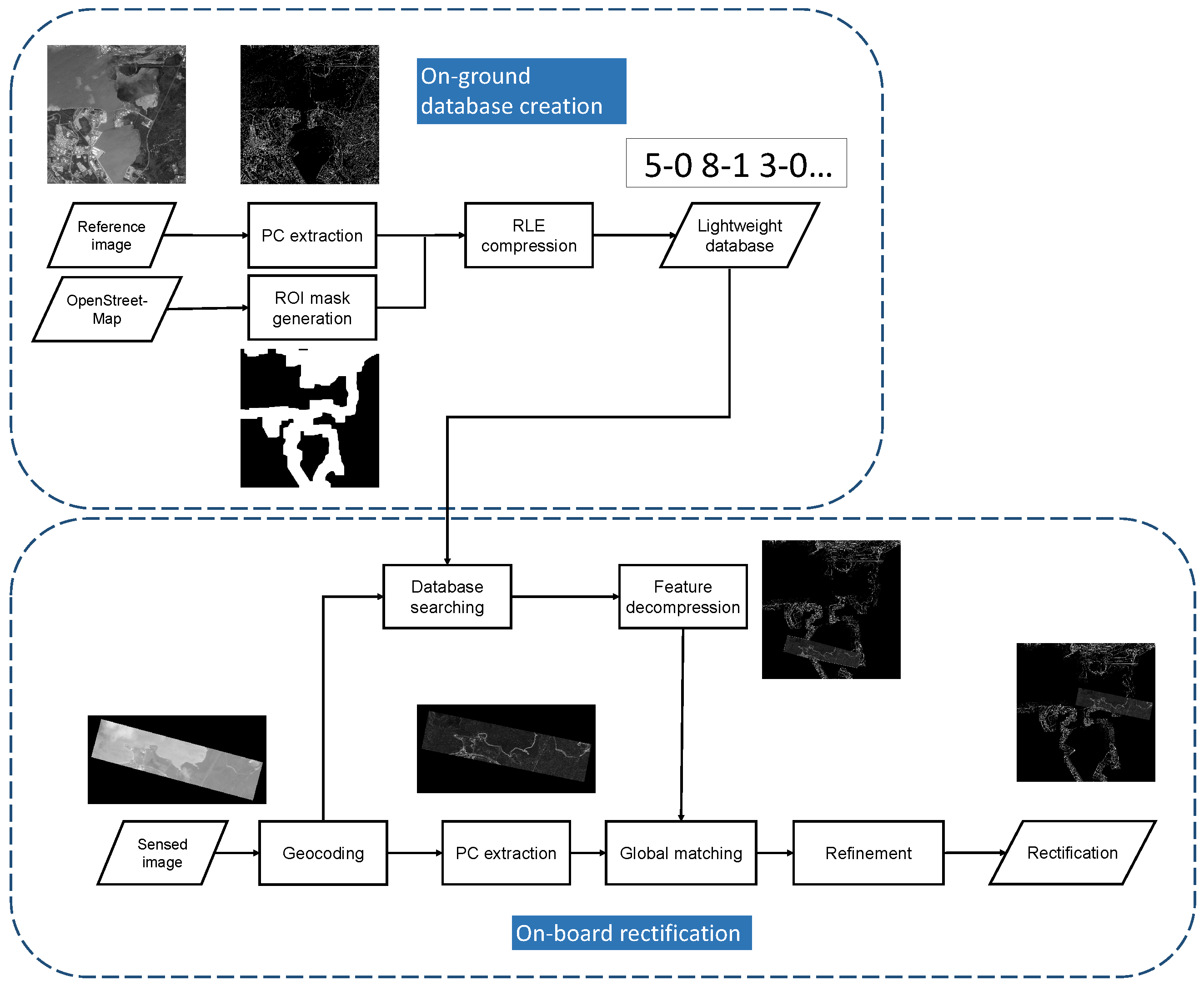
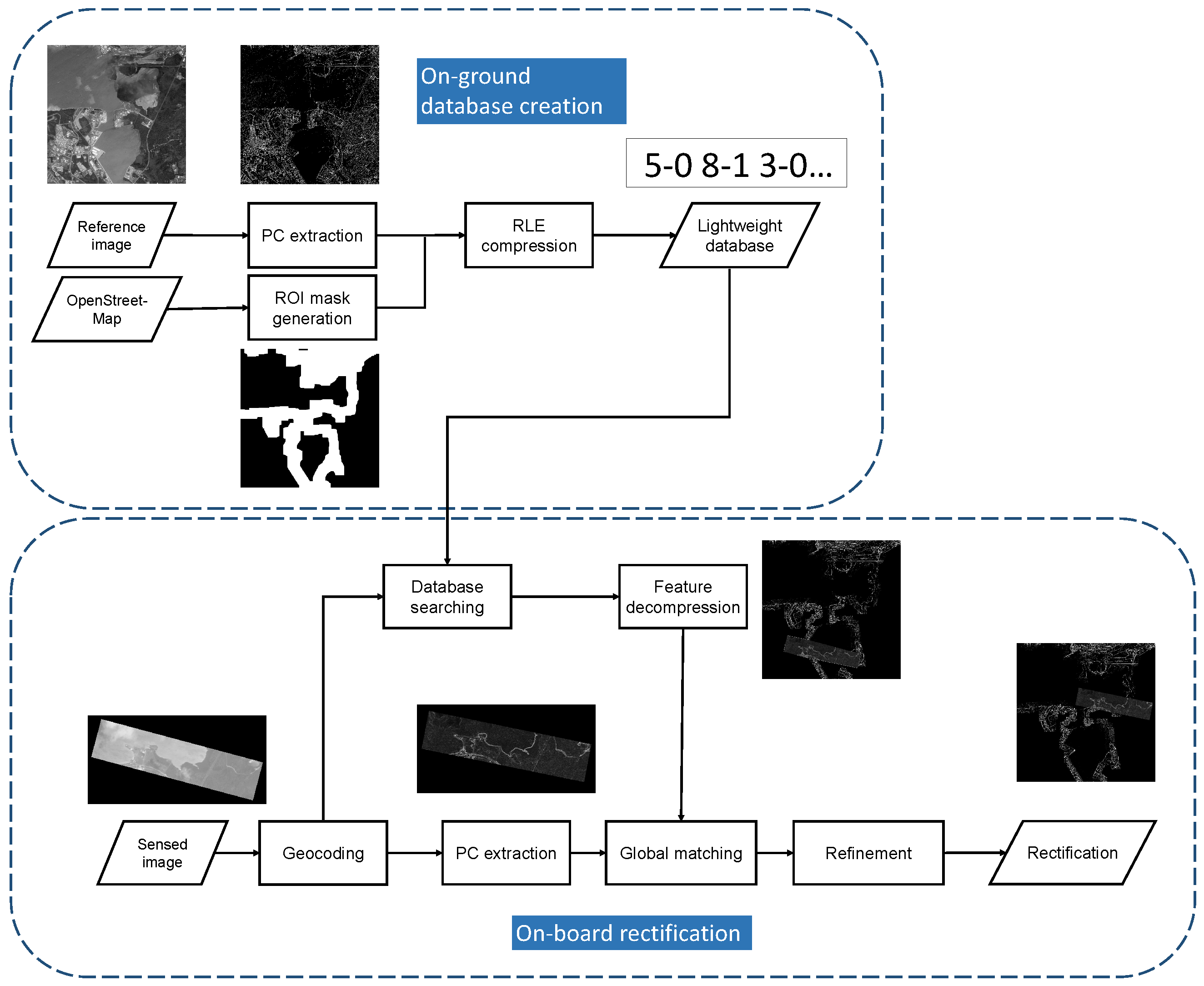
The overall flow is depicted in
Figure 1. Initially, we elaborate on constructing a lightweight feature database, which is created on the ground and then transferred and stored on the micro-satellites. During on-board processing, the sensed images are geocoded using initially inaccurate positioning parameters. Subsequently, the corresponding feature is searched for and decompressed from the database. Extracting the feature response of the sensed image, a coarse matching process is conducted to mitigate large initial offsets. Finally, a refined matching process is executed to precisely identify correspondences and correct the sensed images.
2.1. Lightweight Feature Database Construction
Conventional geometric rectification methods relying on reference images demand substantial storage space. For instance, a 16-bit reference image, fixed at 5000 × 5000 resolution with a 1 m scale, consumes over 20 MB of storage, rendering it impractical for on-board devices. We aim to establish a universal lightweight reference database for on-board rectification, independent of micro-satellite payloads or imaging modes. We consider micro-optical satellites like the Jilin-1 series; Qilu-3; and micro-SAR satellites including Qilu-1, Hisea-1, and the Nuwa constellation. This database must be intrinsic and invariant across various imaging mechanisms and conditions.
To begin, we select 1-meter-resolution Google Earth images as reference images and employ the phase congruency method [
27] to detect robust binary edge features. Subsequently, we generate a Region of Interest (ROI) mask using OpenStreetMap, preserving vital information on runways and coastlines for template matching. Additionally, the ROI mask helps eliminate redundant areas and reduces storage requirements using the Run-Length Encoding (RLE) compression technique [
28]. Finally, this lightweight database is stored in satellite hardware before launching.
2.1.1. Feature Extraction
Image matching technology can be broadly classified into two primary frameworks: template matching and feature matching. Template matching identifies correspondences using phase correlation or cross-correlation, while feature matching seeks correspondences based on differences measured by feature descriptors from two sets of keypoints. Since our focus is on constructing a universal lightweight reference database, we must account for significant differences in radiometric and geometric characteristics across diverse image modalities. Real-world optical and SAR images, illustrated in
Figure 2, vary considerably. For instance, what appears as flatland in optical images may show fluctuations in SAR images. These differences, due to imaging mechanisms, can lead to low keypoint repeatability in feature matching methods [
29]. In such cases, the feature database may store numerous redundant keypoints to facilitate reliable feature matching, although only a fraction of them are eventually matched. This demands delicately designed feature descriptors, resulting in impractical storage requirements. Hence, we opt for template matching as the basis for our rectification process.
When performing image matching using powerful on-ground servers, it is logical to extract features comprehensively for better accuracy. However, on-board devices face constraints in storage space and computing power. Therefore, we must meticulously design the reference database to cover distinct regions and extract consistent features within limited memory. First, the features should be intrinsic and easily detectable regardless of imaging conditions such as angle, timing, weather, noise, or minor ground changes. Second, the features must exhibit invariance across diverse image modalities. Lastly, the features should possess enough uniqueness to preserve only a select few without the risk of mismatches.
Most micro-satellites are primarily dedicated to observing activities in major cities worldwide. Hence, for a preliminary on-board experiment, we select airports and harbors as the primary targets. Both airports, with their artificial runways, and harbors, characterized by coastlines, exhibit strong regularity; unique characteristics; and, crucially, consistency and robustness across different image modalities and conditions. Artificial runways at airports display a distinct, regular pattern, while harbors feature distinctive coastlines. Given the substantial radiometric and geometric differences among multi-modal images, edges serve as simple and robust features invariant across various image modalities. Hence, in this study, we choose edge features from these significant structures—runways and coastlines in the reference images—as the basis for the on-board rectification feature database. We use phase congruency [
27] to extract edge features, considering its robustness against intensity variations and noise. Notably, for SAR images, we employ the enhanced version of phase congruency, SAR phase congruency [
30], to extract edges. By applying thresholding, the binary edge occupies considerably less space than the original image while retaining high distinctiveness for template matching. Additionally, our proposed method can be extended to establish a reference database for various scenes. For instance, we might focus on road networks derived from OpenStreetMap in urban scenarios.
2.1.2. Feature Compression
To reduce redundant storage capacity, we employ ROI through Run-Length Encoding (RLE). RLE is a well-established coding technique that compresses continuous regions of the same value. Following edge extraction and thresholding, the binary edge features and the masking of uninteresting areas generate extensive continuous zero-value regions, making them highly amenable to RLE for redundancy removal. The exact location of runways and coastlines can be pre-determined. By implementing the masking strategy, the reference database size is reduced to between half and one-third of its original size, effectively alleviating storage space constraints.
As depicted in
Figure 3, the edge features of coastlines and runways in the airport and harbor images exhibit remarkable similarity, regardless of the imaging modality. However, other areas display inconsistency across multi-modal images, increasing the risk of mismatching. Thus, storing only certain regions of interest in the database maintains performance while consuming less space. For instance, taking Honolulu harbor as an example, the storage space of the reference image amounts to 14.63 MB, approximately 32.4 times larger than that of the proposed feature database (463 KB). Comparatively, our feature database occupies significantly less storage space than the reference images.
2.2. Two-Step Matching Framework
The current template matching algorithm is unsuitable for on-board geometric rectification due to significant geometric errors that demand an expanded searching window. However, this approach breaches the constraints of timely processing. To overcome this, we propose a two-step matching framework to address the substantial offsets between micro-satellite images and the feature database.
First, we extract binary edge features from the micro-satellite images and identify corresponding features in the database based on geographical scope, defining them as reference and sensed features. Both reference and sensed features are downsampled by a factor of k. This allows the template, at the same size, to manage an initial offset k times larger than the original size. This downsampling process captures additional structural and contextual information from a broader geographic region, enhancing the chance of accurate matching. This initial phase, known as coarse matching, aims to achieve a rough alignment between reference and sensed images. If coarse matching fails, we perform the process once more on roughly matched features and use the result to validate the accuracy of the initial matching. As coarse matching may not guarantee matching accuracy, the subsequent step, termed refined matching, focuses on improving precision based on the roughly matched image pairs. In this phase, we divide the sensed feature into smaller patches and match each patch with the corresponding reference feature. To ensure evenly distributed matching points, we detect Harris corner points on the sensed image to define the center of these small patches and then crop the reference patches based on the coarse matching results. The Random Sample Consensus (RANSAC) method is subsequently employed to eliminate outliers in the matching process.
2.3. On-Board Implementation
Given the conditions on-board satellites, it is advisable to consider embedded GPUs for processing systems, as mentioned in
Section 1. In on-board applications that demand real-time processing, we accelerate the proposed matching method using CUDA. Feature detection using phase congruency involves convolving image intensities with a LogGabor kernel in the spatial domain. NCC primarily involves simple summation and multiplication, which are suitable for multi-thread processing using CUDA, providing better efficiency than phase correlation on this platform. The definition of template matching using NCC is as follows:
where
I represents feature intensity, and subscripts
R and
S represent reference and sensed features, respectively. In the reference image, several corner points
are selected to calculate the NCC coefficient.
denotes pixels in template
W, and the size of
W is denoted as
.
and
represent the mean and variance of pixels in
W, respectively.
The translation
shifts the template
W in the sensed image. For a fixed
, we change
to find the maximum NCC as an accurate translation, denoted as
To calculate the NCC value for each
,
summations,
submissions, and
multiplications are required. To reduce computational complexity, the calculation can be rewritten as
The calculation, which only requires
summations and
multiplications, can be further optimized using the Kogge–Stone Adder method to compute all summations in Equation (
4). By executing on distinct threads in parallel, the Kogge–Stone Adder can determine the summation of
N elements within
periods.
2.4. Complexity Analysis
In this section, we provide a complexity analysis of the proposed method. Compared to the two-step matching process, the complexity of feature decompression can be disregarded. Assuming the fixed sizes of the reference and sensed images are , and the template W is , the coarse matching step involves the initial and check matching of downsampled images of size . One matching process, implemented by phase correlation, consists of two Fast Fourier Transforms (FFTs), one matrix multiplication, and one inverse FFT. Consequently, the time complexity of the coarse matching step is , where k is the downsampled factor.
The primary time complexity lies in the refined matching step. We select K evenly distributed keypoints and compute the correspondences using NCC. Each NCC of
requires
summations and
multiplications, as previously explained. The shifting range
is set as
. Therefore, the overall complexity of the proposed method is
which can be simplified as
In practice, we allocate one thread on the GPU for each translation , each pixel in template W, and each feature point to perform the overall calculation in parallel, enhancing efficiency. Parallel computation minimizes the continuous working period, and the Jetson GPU’s advantage of low power consumption contributes to on-board energy efficiency and thermodynamic conditions. Importantly, the GPU optimization does not compromise the accuracy of the proposed method, maintaining identical algorithmic logic to CPU processing. In summary, on-board rectification demands low storage consumption, reduced complexity, and enhanced efficiency while addressing substantial initial offsets. To adapt our method for on-board processing, we undertake the following steps:
We develop a lightweight database that concentrates on the most representative area and employs RLE encoding to significantly reduce on-board storage requirements.
We introduce a two-step matching framework, which effectively addresses large positioning errors and rectifies the sensed images. Our implementation of the NCC matching method using CUDA for parallel computation aligns with on-board efficiency needs.
4. Discussion
Since the on-board rectification on the Qilu-3 micro-satellite was a preliminary experiment, we constructed a feature database for only nine target regions. For other regions, we present a discussion on the selection of appropriate features and ROI masks, along with an analysis of the boundary conditions of the proposed method.
The Qilu-3 micro-satellite is primarily intended for observing activities in major cities worldwide. Hence, for this on-board experiment, we selected runways and coastlines as primary features for our reference database. The proposed feature detection and compression method can be applied to establish a reference database for various scenes. For instance, in urban scenarios, focusing on the road network obtained from OpenStreetMap or using irrigation canals to build reference features for farmland could be viable options. The criteria for selecting features, outlined in
Section 2.1, encompass attributes such as intrinsicality, invariance, robustness, and uniqueness. However, regions like mountains or deserts, which possess intricate textures and lack artificial facilities, might pose challenges in extracting suitable features to meet these requirements, potentially causing rectification failure. Further analysis for these areas is on our agenda.
The database size is also related to the limits of our approach. Complete runway structures at airports typically cover a range of 3 to 4 km. Therefore, the proposed database size of
pixels suffices for airport scenarios. Notably, airport structures, apart from minor changes, remain relatively constant for prolonged periods. Hence, under typical circumstances, on-board airport databases do not require frequent updates. On the other hand, the applicability of coastlines is more complex. The database size hinges on coastline shapes and the geographical scope of sensed images to ensure adequate information for rectification. In our experiment, the
pixels encompassed distinct coastline structures (depicted in
Figure 5b) to support the proposed method. However, if the coastlines are excessively simple, such as featuring nearly linear structures (as shown in
Figure 5a), the proposed method may not accurately rectify the sensed images.
When coastlines change, the necessity for updates depends on the scale of the changes. The rectification method primarily emphasizes unchanged regions. Therefore, if only a small part of the coastline is changed or the general structure remains only slightly altered, the existing information in the database remains valid. However, in the event of a significant change due to a natural disaster or a complete alteration in the coastline’s structure, we recommend re-uploading the database. Similar advice applies to particularly uninteresting terrains that may have valuable new information. In our future research, we will explore an on-board database updating mode to address changes and new targets.
The effectiveness of the proposed feature database also relies on the ROI mask to reduce storage and maintenance. Choosing an appropriate ROI is a critical aspect of the proposed method. The accurate location of airport runways and coastlines can be acquired in advance from OpenStreetMap. As discussed in
Section 3, the vicinity of runways and coastlines should be partially covered by ROI masks to ensure reliability for template matching. However, this balance is crucial. Preserving too little surrounding information might result in severe mismatching while retaining too much redundant information consumes unnecessary storage. For airports, dilating the runway regions a few times ensures sufficient structural information. Regarding coastlines, precise land coverage maps offer a one-pixel coastline for extraction using edge detection methods. Dilating the one-pixel coastline a few times (ideally between 10 to 20 pixels) provides a reliable mask. For intricate or fragmented coastlines, an increased dilation count accommodates more information for template matching, while simpler coastlines may reduce dilation counts to save storage.
For the on-board platform of Qilu-3, we stored feature databases of nine test areas, as this was merely a preliminary on-board experiment. However, for a worldwide database, which is crucial for practical applications, the expected size corresponds to the number of target regions and coverage.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}