1. Introduction
Synthetic aperture radar (SAR) is a kind of microwave remote sensor for vast, extensive, and long-term monitoring due to its certain penetration capability and powerful anti-interference ability [
1,
2]. Ship detection in SAR images plays a significant role in military and civil scenarios, such as military reconnaissance, maritime traffic control, and sea rescue [
3,
4]. Traditional ship-detection methods usually distinguish ships by modeling the statistical distribution of a cluttered background, which is typically represented by the constant false alarm rate (CFAR) method [
5]. The use of CFAR has led to great achievements in simple background detection; however, it does lose detection accuracy and generalization in complex background scenarios, such as in small ship detection or bad sea conditions.
Recently, deep learning methods have emerged as the mainstream in many applications for their high accuracy and strong flexibility, such as human detection [
6], urban road transport detection [
7], 3D point cloud [
8,
9] and trajectory prediction [
10]. In ship-related research, ship trajectory prediction algorithms can provide early warnings to avoid collisions [
11,
12] and ship-detection algorithms can effectively improve marine transport management. Especially, convolutional neural networks (CNNs) play an important role in ship detection for their high-feature proposal capability and compatibility with parallel computing in GPUs. Detection algorithms are usually divided into two categories: two-stage detection and one-stage detection. Two-stage detection algorithms, represented by Faster R-CNN [
13], Mask R-CNN [
14], etc., use a region proposal network (RPN) at the first stage to generate numerous regions of interest (RoI) with different scales and shapes. At the second stage, these regions are processed and refined to locate and classify objects. Generally, two-stage algorithms can achieve superior detection accuracy but have huge computational costs and model sizes, thus rendering them challenging to train and deploy on edge devices. To address this problem, one-stage algorithms that are utilized without generating regions have been proposed, such as You Only Look Once (YOLO) [
15], RetinaNet [
16], Fully Convolutional One-Stage Object Detection (FCOS) [
17], and YOLOX [
18]. For instance, the YOLO series preset anchor boxes in feature maps and perform regression to refine anchor boxes, while YOLOX believes objects locates in the center of anchor boxes and predicts bounding boxes for detection. One-stage algorithms have attracted more attention because they can reduce both computational costs and model size with minimal accuracy loss. In optical ship detection, YOLO-based detectors have demonstrated that the detection paradigm of “backbone-neck-head” in YOLO has a powerful ability in feature extraction [
19,
20]. The YOLO series also show its great generality and flexibility in other scenarios, like ship depth estimation [
21] and ship instance segmentation [
22]. In SAR ship detection, where imagery is generally simpler than optical imagery, researchers have been wrestling with redundant computations in YOLO to make detectors lighter and faster [
23,
24].
In real-world object detection, there exist objects with variant scales. While large objects are easier to detect due to their distinct low-level features like edge information, the detection accuracy of small objects is insufficient because of their lack of high-level features [
25]. In general object detectors, multi-scale feature fusion modules are commonly used to improve the detection accuracy of small objects. For example, AugFPN [
26] implements consistent supervision and residual feature augmentation to narrow the semantic gaps and reduce the information loss of the highest pyramid level in feature pyramid networks (FPNs). DenserNet [
27] aggregates feature maps at different semantic levels to produce more keypoint features. Through weakly supervised triplet ranking loss, DenserNet succeeds in large-scale localization and image retrieval with efficient computation. These feature fusion modules make full use of the complementarity between different levels of features, as well as the correlation between multi-scale features [
28]. In SAR imagery, small ships are also widely present, and they are difficult to locate and classify due to their missing color information and vague edges. Therefore, proposing an efficient multi-scale feature fusion method that is suitable for real-time SAR ship detection is necessary.
In the past few years, transformers [
29] have been increasingly adopted in various natural language processing (NLP) models. Transformers’ strong generalization ability and impressive performance make them capable of being gradually deployed in diverse scenarios. In computer vision tasks, vision transformer (ViT) [
30] is the first classification model incorporating transformer blocks, thereby achieving perfect performance. However, ViT models usually have substantial computational costs, thus limiting their feasibility for deployment on resource-constrained devices. To alleviate this problem, there has been a growing focus on developing lightweight ViT models. In particular, EfficientViT [
31] has emerged as a solution that attains higher accuracy, faster inference speeds, and lower computational complexity. Although certain researchers are exploring the integration of ViT into real-time SAR ship detectors, there are few works using lightweight ViT.
This paper implements a real-time SAR ship detector LRTransDet based on lightweight ViT, Faster-WF2 modules, and the coordinate attention (CA) mechanism. We also propose a corresponding solution to small ship detection in SAR images. Our model achieves superior performance on four challenging multi-scale SAR ship datasets. The contribution points of this work are as follows:
This paper constructs a novel real-time SAR Ship-Detection Network with lightweight ViT, a faster weighted feature fusion neck, and an optimized loss function, which is named LRTransDet. Compared with the SOTA detector, our model obtains higher detection accuracy with lower time and space complexity while also having a real-time inference speed;
In terms of feature extraction, we innovatively embed the latest lightweight ViT detection network into the backbone. Our backbone combines the globality of transformers and the locality of CNN, all while reducing computational complexity and still ensuring high-quality multi-scale feature extraction;
We reconstruct the detector’s neck based on Faster-WF2 modules and the CA mechanism, thereby enhancing and boosting the feature fusion across multi-scale feature maps with complex backgrounds. We also conduct ablation experiments to prove the effectiveness of these components in the neck;
For the situations where numerous small targets exist in SAR images, we propose a loss function that combines the Complete Intersection over Union (CIoU) measurement scheme and the Wasserstein distance. This optimization approach empowers the detector to excel in capturing small ship targets;
To evidence the performance of our proposed model, we conduct tests on four real-world challenging SAR datasets: the SSDD, the SAR-Ship Dataset, the HRSID, and the LS-SSDDv1.0. Compared with general object detectors and state-of-the-art SAR ship detectors, our model demonstrates superior performance by achieving a mean average precision (mAP) of 97.8%, 95.1%, 93.9%, and 76.2% on the four datasets (all while demanding lower computational resources with GFLOPs measuring at 3.85, 0.96, 9.4, and 9.4 on the four datasets), respectively.
In the rest of the article, we detail some of the related works in
Section 2, introduce the architecture and module details of our proposed LRTransDet in
Section 3, analyze the experimental results for our detector in
Section 4, show the limitations of our model and future work in
Section 5, and draw our conclusions in
Section 6.
3. Methodology
This section mainly introduces the details of our proposed LRTransDet. The overall architecture of the model will be introduced in
Section 3.1. Lightweight ViT, Faster-WF2, coordinate attention, and our optimized loss function in the model will be introduced in
Section 3.2,
Section 3.3 and
Section 3.4. Finally, the metric for evaluating the performance of our model will be introduced in
Section 3.5.
3.1. Model Architecture
Our proposed model is a faster and superior SAR ship-detection model named LRTransDet. Its overall architecture is shown in
Figure 2, and its features are as follows: LRTransDet is a one-stage SAR ship-detection model. Its design refers to YOLOv5, and it includes a backbone based on lightweight ViT, a faster weighted feature fusing neck, and a detection head. In addition, considering the problem of there being too many small ships to detect in certain SAR images, we optimized the loss function to improve the detection ability of the model.
YOLOv5, the fifth version of the YOLO series, has been used in many object detection tasks [
49]. There are three parts of YOLOv5: the backbone, the neck, and the head. The backbone extracts features from input images and has three basic units: the CBS (which contains the convolution, batch norm and SiLU) module, the cross stage partial (CSP) module, and the spatial pyramid pooling-fast (SPPF) module. In the neck, YOLOv5 uses a Feature Pyramid Network (FPN) and a Path Aggregation Network (PANet) for the top-down and bottom-up fusion on feature maps. The major units in the neck are also the CBS and CSP modules. However, different from the CSP unit in the backbone, the CSP in the neck does not contain a residual structure. The output in the three different scales of the neck, which correspond to small targets, medium targets, and large targets in the feature maps, are sent to the head for further detection and positioning.
Compared with some of the latest YOLO series models, such as YOLOv7 [
50], despite the fact that they demonstrate better performance on the general COCO dataset, YOLOv5 is still a more stable and mature choice for industrial applications, including remote sensing. Secondly, the later models come with larger parameters when compared with their equivalent in the YOLOv5 model. As a result, our model uses YOLOv5-small (YOLOv5s) as the baseline to optimize the real-time SAR ship-detection task. First of all, we innovatively embedded the latest lightweight ViT feature extraction framework in the backbone, which ensures the model can extract rich information from the multi-scale input images but can still maintain low computational costs.
Secondly, we propose a faster weighted feature fusion neck that is based on weighted feature fusion. We designed a set of faster and better feature fusion modules with an attention mechanism, which can improve the performance of feature fusion on the basis by reducing the calculation amount of the original neck in YOLOv5s.
Finally, we optimized the loss function for the small ships in the SAR images. In our loss function, we used the measurement scheme based on combining the Wasserstein distance with the original CIoU measurement scheme. The aforementioned details of our model will be explained in the following parts.
3.2. Embedding the Lighter ViT into the Backbone
As mentioned in
Section 2, the transformers achieved great success in computer vision. Based on the multi-head self-attention mechanism, transformers can calculate the attention weights of the input sequence in different subspaces so as to obtain more information. To a certain extent, transformers can reduce the degree of calculation while still maintaining the performance of the model. However, there is still a computing bottleneck in the ViT. For example, in original transformer structures, the computation of attention is a softmax attention, which requires a large amount of time to complete its computations; in addition, it has a large space complexity and takes up a great deal of computing resources. There are also certain studies that have shown that not all attention heads have significant contribution in terms of results [
51].
In one-object detectors, the task of the backbone is to extract more effective information from the image and to then pass it to subsequent parts of the model in order to complete further classification and positioning. As we all know, in SAR ship datasets, there are many small ships, and the image size in certain datasets is also large. As such, it is easy to lose information when using a simple deep convolutional network for feature extraction. On the other hand, transformers have the capacity to extract a wide range of features. But the classical transformer has limitations on speed and in extracting local features. In order to ensure both the quality and speed in feature extraction, we embedded EfficientViT into the backbone of the LRTransDet.
As shown in
Figure 3a, the core part of our backbone is composed of six stages, and it contains EfficientViT blocks as its core part stem. In addition, stage 0 and stage 1 only contain the CBH (convolution, batch norm, and hardswish) module, the depthwise separable convolution (DSConv), and the mobile inverted bottleneck convolution (MBConv) from MobileNet-V2 [
52]. DSConv is composed of the depth-wise convolution (DWConv) and point-wise convolution (PWConv). The former operation is calculated once in each input channel of the feature maps, and the latter uses a
kernel to perform a convolution in the depth direction of each feature map. As such, by comparing with ordinary convolution, DSConv can decrease the complexity with the same depth of the network. This structure has been widely used in the MobileNet series. Since the transformation of the number of feature map channels in the MBConv structure is opposite to that in the ordinary ResNet structure, the residual structure in MBConv is called the inverted residual structure. The MBConv in our backbone first uses a
Conv to expand the number of channels of the feature map; then, it uses a
DWConv and a
PWConv to extract features from the feature map. Finally, it uses the residual structure to enhance information fusion. In a MBConv, the gradient propagation can be enhanced and the memory consumption during inference can be reduced. Stage 3 and stage 4 include EfficientViT modules, which are the core part of the backbone. Different from the softmax attention mechanism, which is mentioned in
Section 2, the linear attention calculation of the similarity function in EfficientViT block is shown as follows:
In this equation, we assume that the input is x, , and , where N is the number of samples in x, and are the three learnable matrices. is the linear similarity function, where is the kernel function. In our work, we chose . The reason for this is because we used this function so that we can employ the associative law in matrix multiplication, which can reduce the calculation complexity and improve the calculation speed.
The detail of the EfficientViT module is shown in
Figure 4. We used the lightweight multi-scale attention (Lightweight MSA) mechanism and the main block in the EfficientViT module to generate the attention results. Specifically, we used the
convolution to obtain the
tokens, in which the image blocks were similar to the processing units in NLP tasks. Considering that the ReLU-based attention mechanism has certain performance limitations, the aggregation process was set for generating multi-scale tokens in the lightweight MSA mechanism. After obtaining these tokens, the ReLU-based attention mechanism was still used to calculate the attention weights for each
. Then, the output was concatenated and sent to a
convolution for the next feature fusion.
This design combines the advantages of CNNs and transformers, which can extract the local features of SAR images by downsampling the convolution operations step by step. With the use of transformers, global features are not lost. Next, we sent the outputs from S2, S3, and SPPF to the neck for feature fusion and detection.
3.3. A Faster Weighted Feature Fusion Neck
The main difficulty of SAR ship detection is that input images have complex backgrounds and various ship scales. Meanwhile, real-time implementation also requires speed and quality from the detector. Therefore, determining how to extract valid information from multi-scale feature maps at a high speed remains a key problem to be solved in neck part design. The FPN-PANet-based neck in YOLOv5 has a large number of calculations and low speed. And the simple channel-wise feature map connection renders it easy to lose information in the multi-level feature pyramid, thus affecting the accuracy of the SAR ship detector. In order to solve this problem, we propose a faster weighted feature fusion neck that is based on the Faster-WF2 module, whose overall architecture is shown in
Figure 5. It mainly includes several main modules of the Faster-WF2 and CA mechanism, which can ensure the performance of feature fusion while reducing the calculation of the neck.
Recently, in many lightweight convolution networks, DSConv has often been used to reduce computation. Having said that, since DSConv greatly affects the accuracy of the network and needs a high amount of memory space to access the temporary variables, this convolution operation is difficult to deploy in every network. Inspired by the latest model FasterNet [
53], we utilized two convolution methods, partial convolution (PConv) and PWConv, in the neck, and optimized the existing CSP to reduce calculation complexity.
Due to there being little differences between channels in SAR ship images, we considered the fact that there are some redundant operations during the process of certain general CNN structures. In fact, in convolution layers, some weights produce a small contribution to outputs. Therefore, we attempted to implement the FasterBlock method with a partial convolution in the detector to reduce the calculation in the SAR ship detection, specifically with little performance loss or even improvements.
The details of FasterBlock and PConv are shown in the
Figure 6 below. In FasterBlock, we used PConv to reduce the computational redundancy and memory usage. By setting the segmentation coefficient as
, the input feature map
was divided into two parts, whose shape were
and
. We only conducted the standard convolution calculation on
, and then directly concatenated
to the convolution results. Next, to make full use of the information of each channel, we added two PWConv layers after PConv to process the feature maps. The overall structure of the convolution in the FasterBlock looked like a “T-shape” convolution, which could direct more attention to the center of each feature map. In fact, there were more meaningful weights at the center than at the edges in a convolution operation. This “T-shape” convolution could also improve the efficiency of the convolution layers by reducing the FLOPs [
53].
Furthermore, instead of simple channel concatenation in YOLOv5, we used the weighted feature fusion operation from Bi-FPN [
54] to set a group of learnable parameters for each of the feature maps that were of different scales. Through this operation, we could distinguish the importance of the different feature maps in the training process so that our model could retain more important information of the small ship targets. The calculation of the weighted fusion in
Figure 5 is shown in Equation (
3) as follows:
where
and
are the two learnable parameters, and
and
are the corresponding feature maps to be fused.
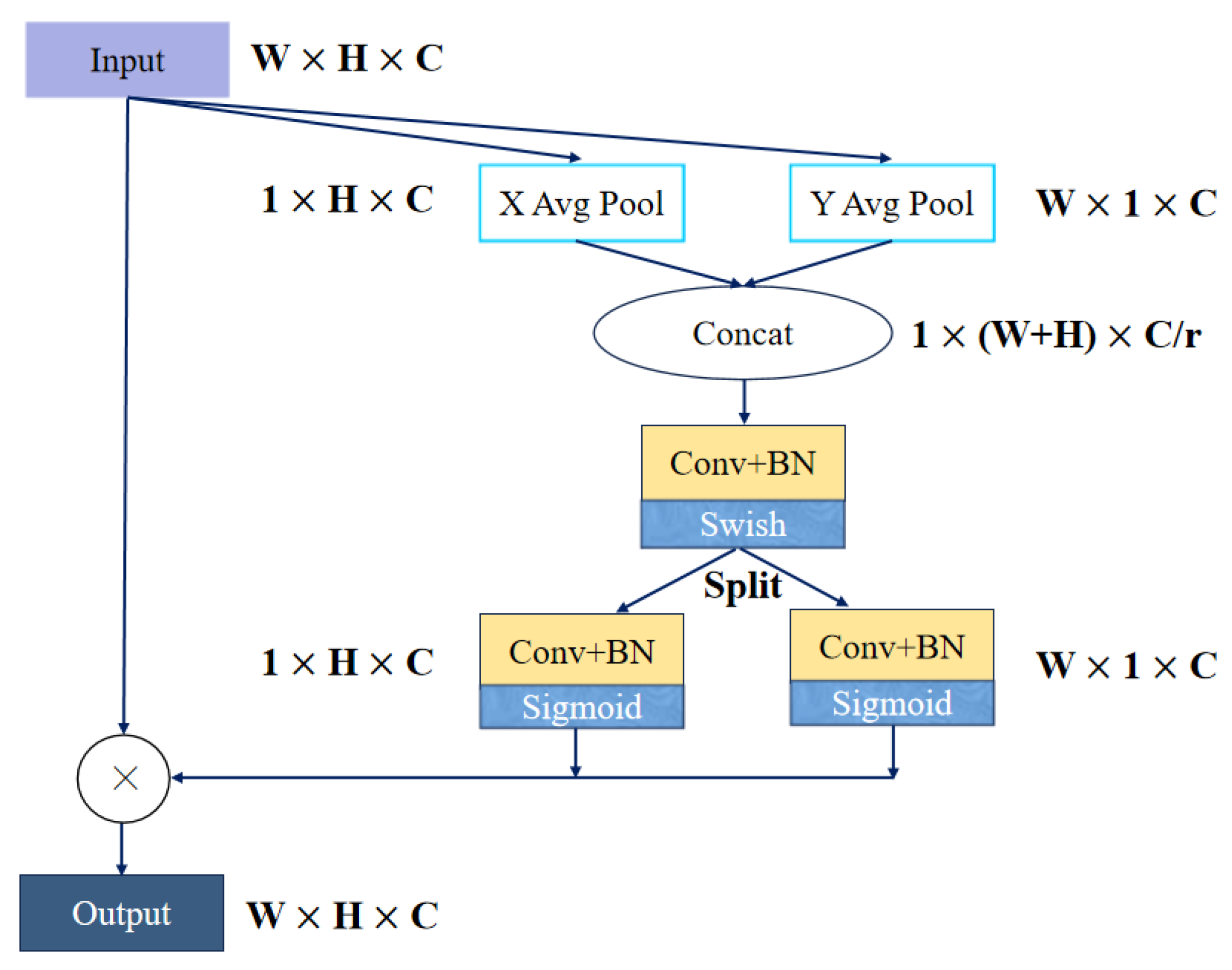
For the purpose of compensating for the possible information loss caused by reducing the parameters and FLOPs, we used the coordinate attention mechanism [
55] to enhance the model’s attention to the position information during the feature fusion process. Compared with other commonly used attention mechanisms, the CA mechanism has a smaller scale of calculation, and it enables the network to have the ability to focus on a wider range of targets, which is helpful for ship detection in some large-scale SAR images. Its calculation process is shown in
Figure 7 below.
Specifically, the CA module contains two parts, which are named coordinate information embedding and coordinate attention generation. These are used to encode each channel of the feature map and to generate attention toward the different coordinates of vertical and horizontal direction. The process of coordinate embedding is shown in Formula (4) as follows:
In Equation (
4), the input image
with the size of
is split into two parts,
and
, with the size of
and
after average pooling. Then, these two parts of the feature maps were concatenated to generate temporary feature maps, which were used to compute the attention weights in the height and width direction. Finally, the output
Y of the CA module could be described as follows:
where
is the sigmoid function,
is the swish function, and the
is the convolutional operation.
Finally, we combined the Faster-WF2 module and CA to allow our neck to have a better feature fusion quality with a faster inference. We assumed the input image size was
, and the details structure of our network is shown in
Table 1. Each Faster-WF2 module includes one or more convolution operations, i.e., FasterBlock and/or the weighted fusion unit. The number of them used can be dynamically adjusted according to the complexity and accuracy requirements of the task. In our experiment, the number of these components was set to 1.
3.4. Loss Function
Intersection over Union (IoU) calculates the degree of coincidence between the predicted bounding box of the detector and the ground truth bounding box of the target, which is an important metric through which to measure the accuracy of detector positioning in object detection tasks. At present, the threshold of IoU is usually used to determine whether the current anchor matches the target in YOLOv5s, which is effective for most object detection tasks. However, in certain SAR images, there are many small ships that are represented by only a few pixels, which makes the IoU-based indicators particularly sensitive to the movement of the small targets. Although simply reducing the threshold of IoU can allow them to match more anchors, it will also greatly affect the overall training quality. To solve this problem, we use the normalized Wasserstein distance (NWD)-based method of measuring IoU [
56] to optimize the loss function. First, we reconstructed all the bounding boxes from the head into a two-dimensional Gaussian distribution. Second, we used NWD to calculate the similarity between these bounding boxes, and then we decided which bounding box would be assigned to each small ship target.
Specifically, the calculation method of the Wasserstein distance between the
and
distributions was as follows:
In this formula, is the joint distribution of and , and can be any distance. Compared with the other commonly used calculation method such as KL divergence distance or JS divergence distance, Wasserstein distance has the advantage of measuring the distance between two completely non-overlapping distributions. In this extreme case, JS divergence is constant, and KL divergence is meaningless.
For those small ship targets in SAR images, there may be certain background pixels in the boundary of their bounding boxes. In order to distinguish between the ship and the background, we used a two-dimensional Gaussian distribution to assign weights for the pixels in the bounding box:
where the
and
denote the coordinate (
), the mean vector, and the co-variance matrix of the Gaussian distribution. With respect to the two bounding boxes
and
, we converted them into a 2D Gaussian distribution of
and
. The Wasserstein distance between them can be described as follows:
where
means the Frobenius norm.
Finally, due to the value of the IoU being between [0, 1], we needed to transform
to its normalized exponential form:
where
is a constant determined by the different datasets.
The loss function for our proposed method is shown in Formula (11), where
N is the number of heads. It is divided into three parts:
,
, and
, which measure the loss of the detector on the bounding box regression, object confidence, and classification, respectively.
In YOLOv5, the calculation of
is based CIoU as follows:
where
is the number of anchors set to the target,
is the output by the detector, and
is the ground truth. Furthermore,
can be described as follows:
where
In Equation (
14),
is the weight function and
v is used to measure the similarity between the aspect ratio of the ground truth and the prediction box.
and
are the width and height of the ground truth, respectively, and
and
are the width and height of the prediction box, respectively.
CIoU has the ability to improve the convergence speed and stability during network training. In order to leverage the advantages of CIoU and the NWD, we designed a ratio
to balance the NWD metric and the CIoU scheme. Our bounding box regression loss can be calculated as follows:
Overall, in our optimized loss function
, we used the normalized Wasserstein distance to improve our model’s performance on those small targets detection. First, considering that most small objects are not strict rectangles, we reconstruct the bounding boxes as a two-dimensional Gaussian distribution. This distribution has the ability to distinguish the importance of the pixels in the center and those at the edge, which describes the differences between foreground and background better. Secondly, as IoU calculates the Jaccard similarity coefficient of two limited sample sets [
57], we use the Wasserstein distance to measure the distance between these two-dimensional Gaussian distributions. The reason we use Wasserstein distance is that it has the ability to calculate the distance between two completely non-overlapping distribution. This method also has the advantages for detecting small objects in its scale invariance and smoothness to location deviation [
56]. Finally, in order for this indicator to be calculated in the loss function of our model, Wasserstein distance needs to be normalized to [0, 1].
In addition, for
and
, we used BCEWithLogitsLoss in YOLOv5 [
49]:
3.5. Evaluating Metrics
In object detection tasks, mAP is often used as one of the most important indicators through which to evaluate the performance of a model. To calculate the mAP, we first need to determine the precision and recall. The definitions of precision (
P) and recall (
R) were understood as follows:
In the formula, true positive () is the number of instances whose labels are predicted by the model and corresponding ground truth as both being positive. False positive () is the number of instances whose labels are predicted by the model as being positive but where the corresponding ground truth is negative. False negative () is the number of instances whose labels are predicted by the model as being negative but where the corresponding ground truth is positive. A detection result is identified as only when its IoU with the ground truth is greater than a given IoU threshold (0.5 is the threshold most commonly used).
By setting different thresholds for IoU, we can draw a PR curve. The mAP can be obtained by calculating the area surrounded by the PR curve and the axis:
The
-score is also a comprehensive indicator through which to analyze the performance of the model, which is defined as follows:
In addition to these indicators, we also used floating point operations (FLOPs) and parameters to evaluate the time complexity and space complexity of our model. The time complexity of the convolution operation can be calculated by the following:
where
M is the size of the output feature map calculated by the convolution operation,
K is the kernel size of the convolution operation, and
and
are the number of input channels and output channels, respectively. Therefore, the overall time complexity of the model is as follows:
In Equation (
22),
is the number of all convolutional layers in the model. The space complexity of the model can be measured by the following parameters:
Furthermore, we used the frames per second (FPS) of the model to judge the real-time performance of the detector. Specifically, the FPS was tested with a batch size of 1 and 32 in our experiments.
4. Experiment
In this section, we verify the performance of our proposed model. First, we introduce the four datasets and the environment settings we used in the experiments. Second, we compare the detection result of our model with some popular general object detection models and the latest state-of-the-art (SOTA) SAR ship-detection models to show the advantages of our proposed method. Finally, we designed a series of ablation experiments to show the function and contribution of our proposed lightweight ViT-based backbone, Faster-WF2 module, CA mechanism, and optimized loss function.
4.1. Datasets
We used four sizable, real-world datasets from public repositories: the SAR Ship-Detection Dataset (SSDD) [
58], the SAR-Ship Dataset [
59], the High-Resolution SAR Image Dataset (HRSID) [
60], and the Large-Scale SAR Ship-Detection Dataset-v1.0 (LS-SSDD-v1.0) [
61]. These datasets were used to verify the effectiveness and generalization of our proposed method. The distribution of ships in the four datasets is shown in
Figure 8. In addition, the statistics of these real-world public datasets are shown in
Table 2.
The SSDD dataset was released in 2017; it contains 1160 images of complex scenes, and 2456 ships of different sizes. The images in the SSDD have sizes that vary from to , and resolutions that vary from 1 m to 15 m. In our experiments, we resized all of the images to , and divided the dataset into a training set and a test set with the proportion of 8:2.
The SAR-Ship Dataset was released in 2019 for complex backgrounds; it contains 43,819 images and includes 59,535 ships. The images in the SAR-Ship Dataset have sizes of pixels, and resolutions from m to m. We also used the SAR-Ship Dataset for the ablation experiment. The whole dataset was divided into a training set and a test set with the proportion of 8:2.
The HRSID dataset was released in 2020. It contains 5604 images with pixels, and 16,951 ships. The resolution of the images are 0.5 m, 1 m, and 3 m. Moreover, 98% of ships are small and medium ships, which is appropriate for high resolution detection tasks. We divided the dataset into a training set with 65% of the images and a test set with 35% of the images.
The LS-SSDD-v1.0 Dataset was released in 2020 for large-scale scene tasks, and it contains 15 images with 24,000 × 16,000 pixels, 6003 small ships, and 12 medium ships. The images were cut into 9000 sub-images with pixels, which were divided into a training set with 6000 images and a test set with 3000 images in our experiment. The resolution of the images in LS-SSDD-v1.0 was m.
4.2. Experiment Settings and Hyperparameters
Our experimental environment configuration is shown in
Table 3. All of the experiments used the same environment.
In our experiment, we compared the performance of our detector with both the general object detection models and the state-of-the-art SAR ship detectors. We set the initial learning rate as 0.01, the momentum as 0.937, and the weight decay as 0.0005; in addition, we used an SGD optimizer during the training stage. For general object detection models other than YOLOv5s, we used the MMdetection framework provided by OpenMMLab to implement them [
62]. MMdetection is a toolbox that supports various mainstream object detection frameworks. Finally, for SSDD, we checked the image size in this dataset, and the average image size on SSDD was
; as such, we set the input size to
, which would not cause a large loss of image information. For the SAR-Ship Dataset, we set the inputs at its standard image resolution of
, whereas HRSID and LS-SSDD-v1.0 were used in their standard image resolution of
to prove that LRTransDet has the ability to process multiple scale inputs.
4.3. Results from the SSDD
The SSDD is the most commonly used dataset in SAR ship-detection tasks thus far [
63]. We compared LRTransDet with general object detectors such as Faster-RCNN, RetinaNet, FCOS, YOLOX, and our baseline YOLOv5s. The results of this is shown in
Table 4. It can be seen that, although the FCOS and YOLOX obtained higher indicators in precision and recall (97.0% and 95.6%), our model had advantages in
-score, mAP, FLOPs, parameters, and FPS (95.0%, 97.8%, 3.07M, 3.85G, 74.6, and 964, respectively). The results from the SSDD showed that our model is lighter and faster than the general detectors, and the results were also obtained in real-time.
As shown in
Table 5, compared with the latest SOTA SAR ship detectors, our model also obtained a superiority in mAP, in parameters, and in FLOPs. The experiment results show that our model exceeded ATSD and MHASD by 1% in mAP (whose FLOPs and parameters were the lowest, respectively, in this table). Compared with LPEDet, which has the best performance in this table, our model not only has a slight advantage in mAP, but it also achieves lower FLOPs and parameters. The experiments on the SSDD show that our model can obtain a higher accuracy and speed with lower memory usage.
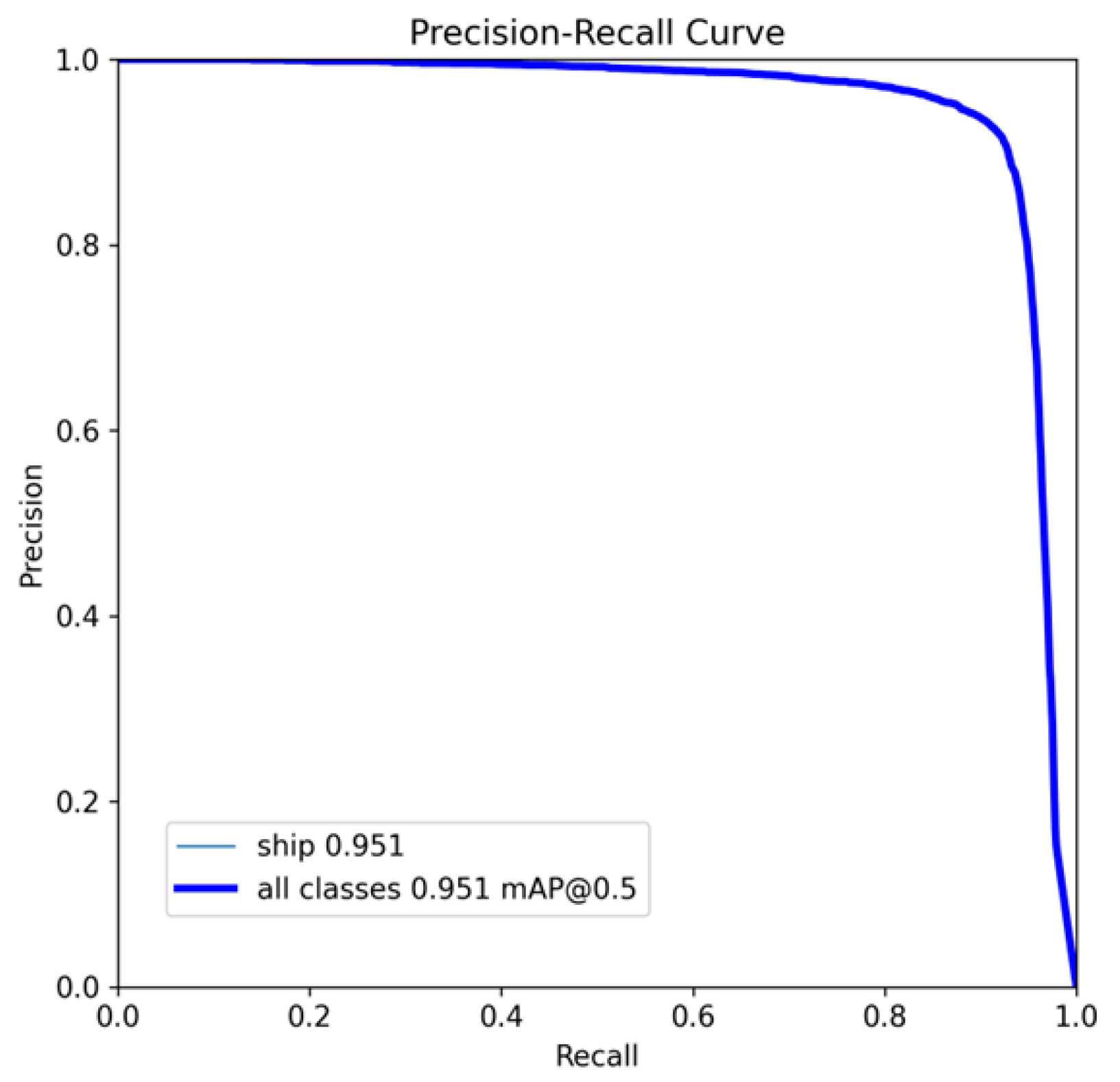
The precision–recall curve (PR-Curve) for our proposed model is shown in
Figure 9. Additionally, the visualization results from the SSDD are shown in
Figure 10. It shows that our proposed model has the ability to detect multiple small ships in the SSDD that are offshore, and large ships that are inshore particularly well. In addition, it also has a high confidence for these targets.
4.4. Results from the SAR-Ship Dataset
There was a great deal of noise and variations in the complex backgrounds represented in the images of the SAR-Ship Dataset; as such, we chose this dataset to verify the noise resistance and robustness of LRTransDet. The specific results are shown in
Table 6 and
Table 7. The PR-Curve is shown in the
Figure 11, and it evidently shows that the PR-Curve of our proposed model is smooth. Compared with the general detectors, it demonstrated that our model is still able to keep a high precision, recall, and
-score in the detection tasks in complex background scenarios. In addition, LRTransDet showed clear superiority over all of the general benchmarks, i.e., the mAP, parameters, FLOPs, and FPS. The comprehensive results showed that our model has a higher detection accuracy (95.1%), faster detection speed (76.4 FPS with a batch of 1, and 1619 FPS with a batch of 32), and lower conputational complexity (0.96 GFLOPs and 3.07 M params.).
Table 7 shows the results of LRTransDet and other SOTA models on the SAR-Ship Dataset. It is not easy to collect all of their indicators from all the SOTA detectors at the same time because some of the methods do not provide accurate parameters and FLOPs. Compared with others of the latest detectors, our model has the best mAP, parameters, and FLOPs, which thus verifies that LRTransDet has a better and more comprehensive ability than SOTA models. The results also prove that our model can deal with complex scenes and the impact of noise well, and that it has the power to obtain more information by lower computation and memory costs.
The visualization results on the SAR-Ship Dataset are shown in
Figure 12. It can be clearly observed that our model can handle noisy images and keep a high detection confidence.
4.5. Results on Large-Scale Datasets
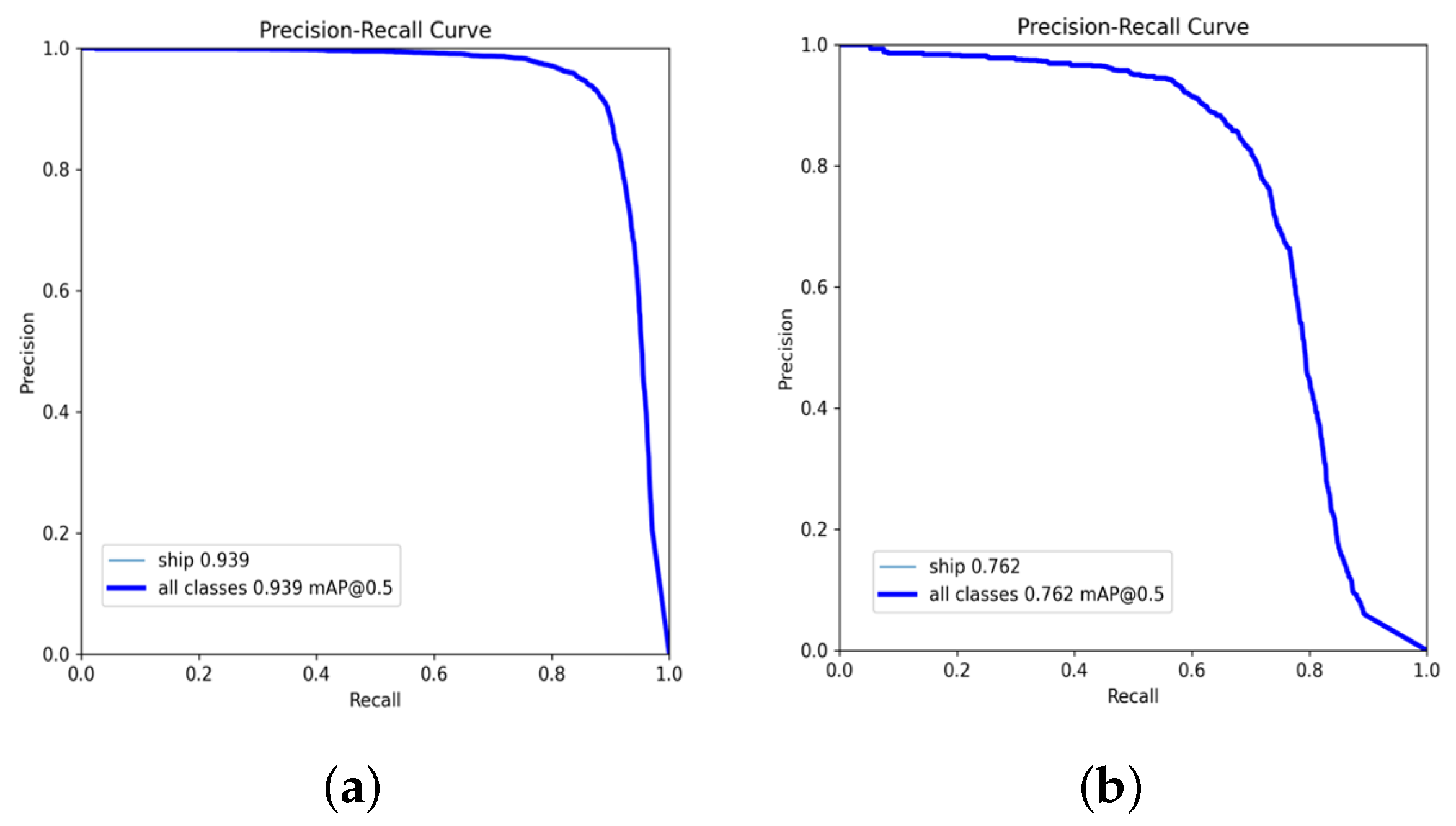
When certificating our model, it was found that it can also handle the large-scale SAR ship scenes. As such, we conducted relevant experimental verification on two representative large-scale SAR ship datasets—HRSID and LS-SSDD-v1.0. The PR-Curve of LRTransDet on these two large-scale datasets is shown in
Figure 13. In
Table 8 and
Table 9, we compare LRTransDet with some of the popular general object detectors. Our model achieved large benefits on these two datasets, reaching 93.9% and 76.2% mAP on HRSID and LS-SSDD-v1.0, respectively, and these values exceeded the best general detector by 1.2% and 1.1%. In addition, compared with these general object detectors, our model can maintain high precision, recall, and an
-score at the same time, such that LRTransDet has a better and more stable performance. In terms of computational complexity, our model had lower time duration and space complexity (9.4 GFLOPs and 3.07 M params.) than the general detector. For FPS, our model has a faster speed during inference (75.8 FPS with a batch of 1, and 578 FPS with a batch of 32); as such, our model functions better in real-time.
In addition, we also compared our model with the latest SOTA SAR ship detectors on the HRSID and LS-SSDD-v1.0, and the results are shown in
Table 10 and
Table 11, respectively. It can be found that LRTransDet has a better ability on large-scale image detection tasks than the latest SAR ship detectors. This is particularly the case on the HRSID as LRTransDet obtains clear advantages in the mAP and in parameters. It has a 3.6% higher mAP than the best SOTA detector, FBUA-Net, as shown in
Table 10. In addition, it has fewer 2 M parameters than LPEDet (3.07 M with 5.68 M). Although ATSD has 2 fewer GFLOPs, our model achieved 5.8% more mAP (93.9% with 88.1%) than it. Meanwhile, the FPS in the two large-scale datasets proves that our model is suitable for real-time scenarios.
In the LS-SSDD-v1.0, compared with the lightest SOTA model Lite-YOLOv5 (as shown in
Table 11), our detector had more than 3% greater mAP while using more 2 M parameters and 5 GFLOPs. Considering the three indicators comprehensively, these results prove that our proposed model has the capacity to keep operating with a relatively lower requirement of calculation time while also delivering a better accuracy.
The visualization results on the two large-scale datasets are shown in
Figure 14 and
Figure 15.
Figure 14 shows the detection results and ground truth in the HRSID. Compared with the SSDD, there are many complex scenes and small targets in the inshore images of the HRSID, and the results show that our model can capture these ships well. In addition,
Figure 15 shows the results and corresponding ground truth in the LS-SSDD-v1.0. We can see that the targets are smaller than those in other datasets, such that ships in this dataset are more difficult to detect.
4.6. Ablation Experiment
To prove the role of our proposed lightweight ViT-based backbone, we conduct a series of ablation experiments on the Faster-WF2 module, CA mechanism, and an optimized loss function designed for small ships in our model. In
Table 12, we compare the experimental results when using two different backbones on the SAR-Ship Dataset. In our designed ablation, we compare our EfficientViT backbone with CSPDarkNet53, thereby revealing that our chosen backbone significantly reduces both GFLOPs (2.35 G compared to 0.96 G) and parameters (6.40 M compared to 3.07 M) by more than two-fold. Although our mAP lags behind the CSPDarkNet53 by 0.4%, our backbone still produces a comprehensive performance. Moreover, fewer calculations and a higher inference speed also make our model suitable for deployment on hardware platforms. This comparative experimental result also proves that the MBConv operation in our backbone has obviously reduced computational complexity. Meanwhile, the power of transformers to capture global information also makes up for the performance loss caused by reducing computational complexity to a certain extent.
Second, we compare the results by using different numbers of Faster-WF2 modules in
Table 13. Through adding a greater number of Faster-WF2 modules, we can see that the mAP and calculation costs were both optimized. Compared with the model without Faster-WF2 modules, the detector using four Faster-WF2 modules had a 0.8% higher precision, a 0.4% higher recall, a 0.7% higher
-score, and a 0.6% higher mAP, reducing 0.55 M parameters and 0.13 GFLOPs. These results show that our Faster-WF2 module can improve the performance of the detector by using the FasterBlock to remove the computation redundancy in SAR images and setting the weighted fusion unit to aggregate more information from the different scales of the feature maps.
To further verify the effectiveness of CA mechanism in our neck structure, as shown in
Table 14, we compare the performance of our detector in terms of whether the CA mechanism is used or not. It was found that, after applying the coordinate attention mechanism, the mAP improved by 1.2% (from 93.9% to 95.1%), but the parameters and FLOPs only saw a small increase. As a result, this ablation result shows that the CA mechanism is able to capture the location information in the feature maps well, and its ability also has a certain impact on feature fusion in the neck.
Finally, we evaluate the effectiveness of the NWD optimized loss function in
Table 15. The experimental results show that our optimization for the loss function is effective, and that the model with an NWD metric improves the mAP by 1.6% when compared with the traditional CIoU-based loss function. Considering that the bounding boxes in the SAR-Ship Dataset are small [
59], this result proves that the NWD metric effectively captures the information of small ships in SAR images. Moreover, the backgrounds in this dataset are more complex, our ablation results also verify that the NWD optimized loss function enables the model to better handle complex scenes.
5. Discussion and Future Works
LRTransDet consists of a lightweight ViT-based backbone and a faster weighted feature fusion neck. The lightweight ViT structure can capture more SAR image information while demanding minimal computational resources. The Faster-WF2 module in our neck reduces redundant calculations in SAR images, thereby enhancing the processing speed of our model during the multi-scale feature fusion. The loss function combined with the NWD metric optimizes the performance of our model in terms of ship detection. The experimental results on the four challenging SAR datasets have demonstrated the advantages of our proposed detector in this paper.
However, there are still some limitations. As shown in
Figure 16a,d, when the image is an inshore image with a complex background and includes many ships, our detector may experience occasional missed detections. For instance, in the lower left corner of
Figure 16a, a ship marked by the red rectangle eluded detection. As shown in
Figure 16d, only five ships were detected in the region marked by the red rectangle, and the detector missed most of the ships in the corresponding ground truth. Moreover, in
Figure 13f, when the ground truth bounding boxes overlapped, our model may deliver a false detection for detecting multiple overlapping ships as one ship. (The error example case is shown in the part marked by the yellow rectangle in
Figure 16e). Finally, in
Figure 16g, LRTransDet had difficulty in distinguishing objects that closely resembled ships. These bottlenecks that affect the model’s performance are also the directions we need to improve next.
In the future, we will continue to mitigate the problem of our detector and improve the performance of our model. Our focus will be on enhancing the overall performance of our model while also exploring the integration of quantization and compression technologies, as well as streamlining the deployment of our detector on hardware platforms. In addition, we will further explore and optimize the detection algorithm on datasets with more complex information.
6. Conclusions
In this paper, we introduced LRTransDet, an efficient, multi-scale, and noise-resistant SAR ship-detection model. To extract rich features from SAR images, we integrated EfficientViT into the backbone, which has the power to combine the ability of CNNs to extract local features, and uses transformers to extract global features. In addition, to reduce the redundant calculation of the neck and improve the fusion efficiency of the feature pyramid, we designed a faster weighted feature fusion neck that is based on the Faster-WF2 module and coordinate attention mechanism. Meanwhile, when aiming at detecting small ships, we combined the NWD metric with the CIoU metric, optimized the loss function, and ensured a strong performance in small ship detection. According to the experimental results on the SSDD, the SAR-Ship Dataset, the HRSID, and the LS-SSDD-v1.0, our detector achieved a superior performance when compared against certain general object detection models and some of the latest SOTA ship-detection models. Through a series of ablation experiments, we proved that our proposed backbone, neck, and optimized loss function can improve the performance of the network in detection tasks without consuming too many computing and storage resources.
In summary, LRTransDet delivers a superior performance while maintaining lower resource consumption and higher processing speeds. It was demonstrated that it is suitable for ship-detection tasks on edge devices, which has great significance to the application of lightweight SAR ship-detection models in the industry. In the future, we will try to deploy our model on a hardware platform, and continue to design a detector that is more compatible with SAR ship detection.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}