
Improving the Accuracy of Soil Organic Carbon Estimation: CWT-Random Frog-XGBoost as a Prerequisite Technique for In Situ Hyperspectral Analysis



Abstract
:1. Introduction
2. Materials and Methods
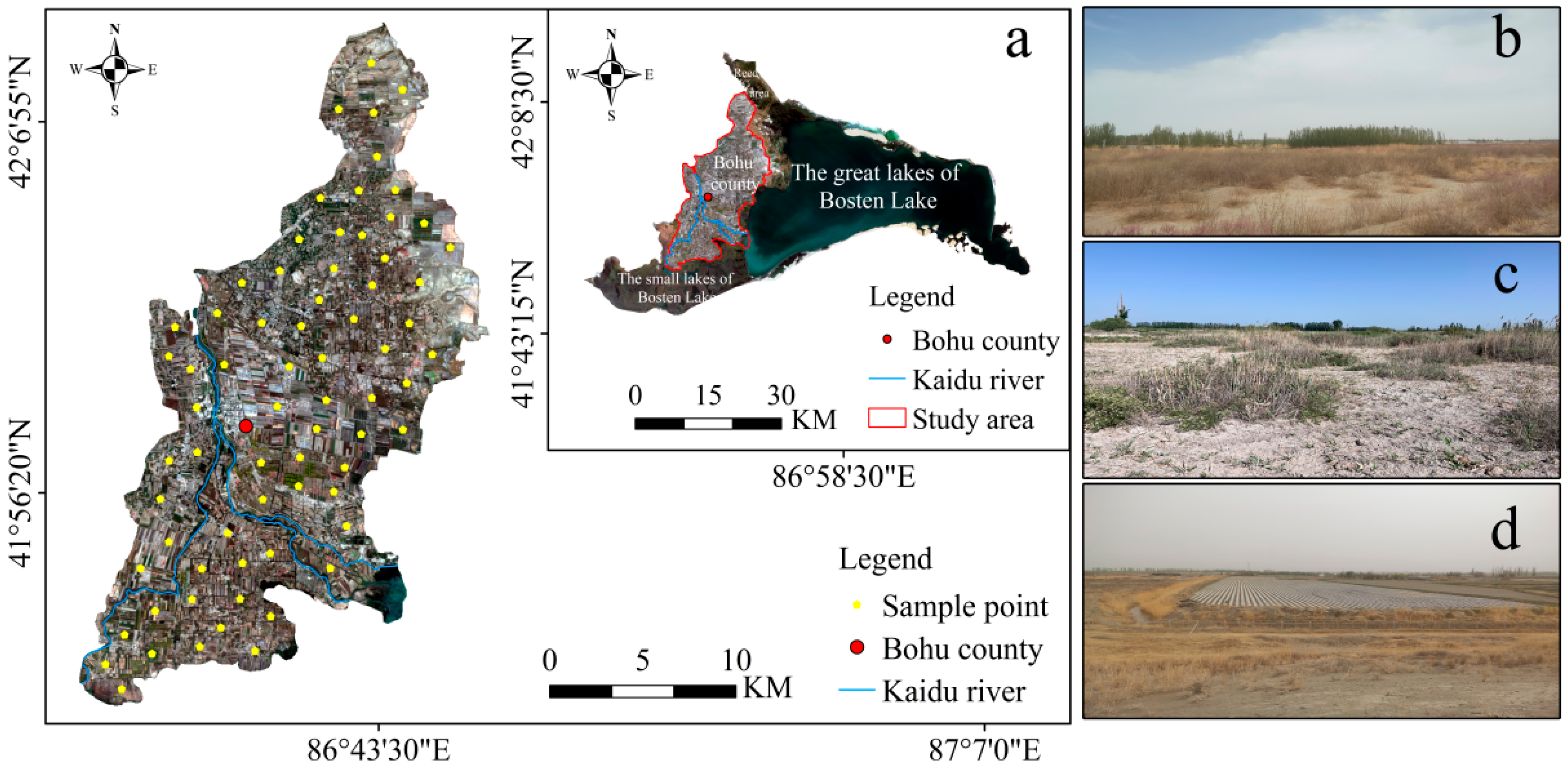
2.1. Study Area
2.2. Soil Sampling and Laboratory SOC Measurement
2.3. In Situ Spectral Measurement and Pre-Processing
2.4. Feature Variable Selection Algorithms
2.5. Model Strategies
2.6. Model Accuracy Evaluation
3. Results and Analysis
3.1. Descriptive Statistics of Soil Organic Carbon Content
3.2. Feature Variable Selected Using SPA, PSO, SA, ACO, Boruta and Random Frog Algorithms
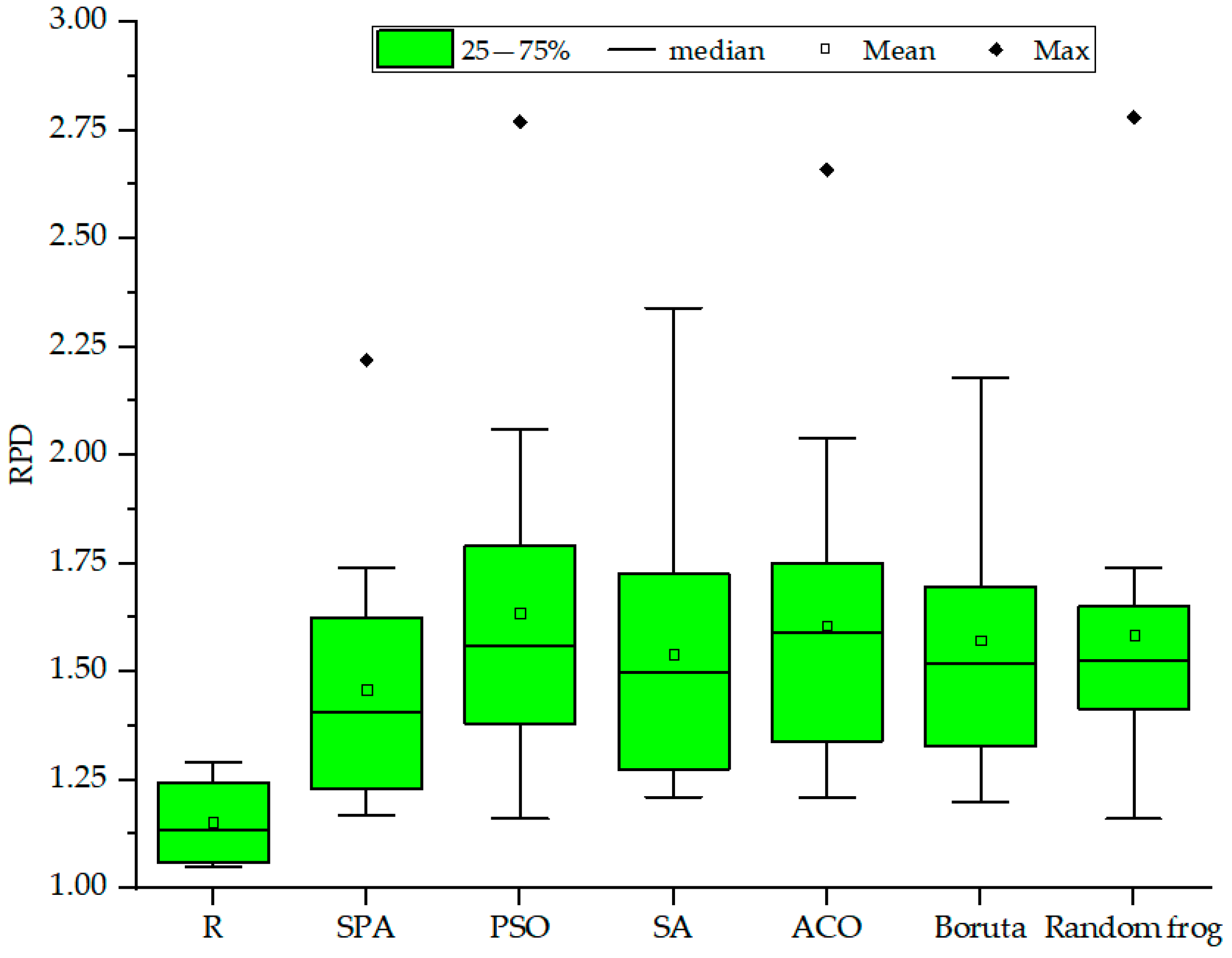
3.3. Model Validation
4. Discussion
4.1. Effects of Different Spectral Pre−Processing and Feature Variable Algorithms on Estimation Accuracy
4.2. Effects of Modeling Strategies on Estimation Accuracy
4.3. Uncertainty Analysis and Perspectives
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhou, T.; Geng, Y.; Ji, C.; Xu, X.; Wang, H.; Pan, J.; Bumberger, J.; Haase, D.; Lausch, A. Prediction of soil organic carbon and the CN ratio on a national scale using machine learning and satellite data: A comparison between Sentinel-2, Sentinel-3 andLandsat-8 images. Sci. Total Environ. 2021, 755, 142661. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Wang, X.; Baishan, K.; An, B. Hyperspectral Estimation of Soil Organic Carbon Content Based on Continuous Wavelet Transform and Successive Projection Algorithm in Arid Area of Xinjiang, China. Sustainability 2023, 15, 2587. [Google Scholar] [CrossRef]
- Guo, L.; Sun, X.; Fu, P.; Shi, T.; Dang, L.; Chen, Y.; Linderman, M.; Zhang, G.; Zhang, Y.; Jiang, Q.; et al. Mapping soil organic carbon stock by hyperspectral and time-series multispectral remote sensing images in low-relief agricultural areas. Geoderma 2021, 398, 115118. [Google Scholar] [CrossRef]
- Kuang, B.; Mouazen, A.M. Influence of the number of samples on prediction error of visible and near infrared spectroscopy of selected soil properties at the farm scale. Eur. J. Soil Sci. 2012, 63, 421–429. [Google Scholar] [CrossRef]
- Qi, H.; Paz-Kagan, T.; Karnieli, A.; Jin, X.; Li, S. Evaluating calibration methods for predicting soil available nutrients using hyperspectral VNIR data. Soil Till. Res. 2018, 175, 267–275. [Google Scholar] [CrossRef]
- Demattȇ, J.A.M.; Andre, C.D.; Luis, G.B.; Veridiana, M.S.; Arnaldo, B.S. Soil analytical quality control by traditional and spectroscopy techniques: Constructing the future of a hybrid laboratory for low environmental impact. Geoderma 2019, 337, 111–121. [Google Scholar] [CrossRef]
- Biney, J.K.M.; Blöcher, J.R.; Bell, S.M.; Borůvka, M.; Vašát, R. Can in situ spectral measurements under disturbance-reduced environmental conditions help improve soil organic carbon estimation? Sci. Total Environ. 2022, 838, 156304. [Google Scholar] [CrossRef]
- James, K.M.B.; Luboš, B.; Prince, C.A.; Karel, N.; Aleš, K. Comparison of field and laboratory wet soil spectra in the Vis-NIR range for soil organic carbon prediction in the absence of laboratory dry measurements. Remote Sens. 2020, 12, 3082. [Google Scholar]
- Ismayilov, A.; Feyziyev, F.; Elton, M.; Maharram, B. Soil Organic Carbon Prediction by Vis-NIR Spectroscopy: Case Study the Kur-Aras Plain, Azerbaijan. Commun. Soil Sci. Plant Anal. 2020, 51, 726–734. [Google Scholar]
- Shi, T.; Chen, Y.; Liu, Y.; Wu, G. Visible and near-infrared reflectance spectroscopy-An alternative formonitoring soil contamination by heavy metals. J. Hazard. Mater. 2014, 265, 166–176. [Google Scholar] [CrossRef]
- Gholizadeh, A.; Borivka, L.; Saberioon, M.M.; Kozak, J.; Vasat, R.; Nemecek, K. Comparing different datapreprocessing methods for monitoring soil heavy metals based on soil spectral features. Soil Water Res. 2015, 10, 218–227. [Google Scholar] [CrossRef]
- Zhang, S.; Shen, Q.; Nie, C.; Huang, Y.; Wang, J.; Hu, Q.; Ding, X.; Zhou, Y.; Chen, Y. Hyperspectral inversion of heavy metal content in reclaimed soil from a mining wasteland based on different spectral transformation and modeling methods. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 211, 393–400. [Google Scholar] [CrossRef] [PubMed]
- Gu, X.; Wang, Y.; Sun, Q.; Yang, G.; Zhang, C. Hyperspectral inversion of soil organic matter content in cultivated land based on wavelet transform. Comput. Electron. Agric. 2019, 167, 105053. [Google Scholar] [CrossRef]
- Nocita, M.; Kooistra, L.; Bachmann, M.; Müller, A.; Powell, M.; Weel, S. Predictions of soil surface and topsoil organic carbon content through the use of laboratory and field spectroscopy in the Albany Thicket Biome of Eastern Cape Province of South Africa. Geoderma 2011, 167, 295–302. [Google Scholar] [CrossRef]
- Hong, Y.; Guo, L.; Chen, S.; Linderman, M.; Mouazen, A.M.; Yu, L.; Chen, Y.; Liu, Y.; Liu, Y.; Cheng, H.; et al. Exploring the potential of airborne hyperspectral image for estimating opsoil organic carbon: Effects of fractional-order derivative and optimal band com-bination algorithm. Geoderma 2020, 365, 114228. [Google Scholar] [CrossRef]
- Yang, P.; Hu, J.; Hu, B.; Luo, D.; Peng, J. Estimating Soil Organic Matter Content in Desert Areas Using In Situ Hyperspectral Data and Feature Variable Selection Algorithms in Southern Xinjiang, China. Remote Sens. 2022, 14, 5221. [Google Scholar] [CrossRef]
- Guo, B.; Zhang, B.; Su, Y.; Zhang, D.; Wang, Y.; Bian, Y.; Suo, L.; Guo, X.; Bai, H. Retrieving zinc concentrations in topsoil with reflectance spectroscopy at Opencast Coal Mine sites. Sci. Rep. 2021, 11, 19909. [Google Scholar] [CrossRef]
- Chen, X.; Li, F.; Chang, Q. Combination of Continuous Wavelet Transform and Successive Projection Algorithm for the Estimation of Winter Wheat Plant Nitrogen Concentration. Remote Sens. 2023, 15, 997. [Google Scholar] [CrossRef]
- Yang, C.; Feng, M.; Song, L.; Wang, C.; Yang, W.; Xie, Y.; Ji, B.; Xiao, L.; Zhang, M.; Song, X.; et al. Study on hyperspectral estimation model of soil organic carbon content in the wheat field under different water treatments. Sci. Rep. 2021, 11, 18582. [Google Scholar] [CrossRef]
- Jobaggy, E.G.; Jackson, R.B. The vertical distribution of soil organic carbon and its relation to climate and vegetation. Ecol. Appl. 2000, 10, 423–436. [Google Scholar] [CrossRef]
- Jin, X.; Du, J.; Liu, H.; Wang, Z.; Song, K. Remote estimation of soil organic matter content in the Sanjiang Plain, Northest China: The optimal band algorithm versus the GRA-ANN model. Agric. For. Meteorol. 2016, 218–219, 250–260. [Google Scholar] [CrossRef]
- Galvao, R.K.; Araujo, M.C.; Fragoso, W.D.; Silva, E.C.; Jose, G.E.; Soares, S.F.; Paiva, H.M. A variable elimination method to improve the parsimony of MLR models using the successive projections algorithm. Chemom. Intell. Lab. Syst. 2008, 92, 83–91. [Google Scholar] [CrossRef]
- Araújo, M.C.U.; Saldanha, T.C.B.; Galvão, R.k.h.; Yoneyama, T.; Chame, H.c.; Visani, V. The successive projections algorithm for variable selection in spectroscopic multicomponent analysis. Chemom. Intell. Lab. Syst. 2001, 57, 65–73. [Google Scholar] [CrossRef]
- Chatterjeea, A.; Siarry, P. Nonlinear inertia weight variation for dynamic adaptation in particle swarm optimization. Comput. Oper. Res. 2006, 33, 859–871. [Google Scholar] [CrossRef]
- Ong, P.; Tung, I.; Chiu, C.; Tsai, I.; Shi, H.; Chen, S.; Chuang, Y. Determination of aflatoxin B1 level in rice (Oryza sativa L.) through near-infrared spectroscopy and an improved simulated annealing variable selection method. Food Control 2022, 136, 108886. [Google Scholar] [CrossRef]
- Liu, Z.; Lu, Y.; Peng, Y.; Zhao, L.; Wang, G.; Hu, Y. Estimation of Soil Heavy Metal Content Using Hyperspectral Data. Remote Sens. 2019, 11, 1464. [Google Scholar] [CrossRef]
- Zhang, C.; Ye, H.; Liu, F.; He, Y.; Kong, W.; Sheng, K. Determination and Visualization of pH Values in Anaerobic Digestion of Water Hyacinth and Rice Straw Mixtures Using Hyperspectral Imaging with Wavelet Transform Denoising and Variable Selection. Sensors 2016, 16, 244. [Google Scholar] [CrossRef]
- Hu, M.; Dong, Q.; Liu, B.; Umezuruike, L.O.; Chen, L. Estimating blueberry mechanical properties based on random frog selected hyperspectral data. Postharvest Biol. Technol. 2015, 106, 1–10. [Google Scholar] [CrossRef]
- Anronios, M.; Xanthoula-Eirini, P.; Dimitrios, M.; Thomas, A.; Rebecca, W.; Georgios, T.; Jens, W.; Ralf, B.; Abdul, M. Mouazen Machine learning based prediction of soil total nitrogen, organic carbon and moisture content by using VIS-NIR spectroscopy. Biosyst. Eng. 2016, 152, 104–116. [Google Scholar]
- Meng, X.; Bao, Y.; Wang, Y.; Zhang, X.; Liu, H. An advanced soil organic carbon content prediction model via fused temporal-spatial-spectral (TSS) information based on machine learning and deep learning algorithms. Remote Sens. Environ. 2022, 280, 113166. [Google Scholar] [CrossRef]
- Wang, S.; Guan, K.; Zhang, C.; Lee, D.; Margenot, A.J.; Ge, Y.; Peng, J.; Zhou, W.; Zhou, Q.; Huang, Y. Using soil library hyperspectral reflectance and machine learning to predict soil organic carbon: Assessing potential of airborne and spaceborne optical soil sensing. Remote Sens. Environ. 2022, 271, 112914. [Google Scholar] [CrossRef]
- Hong, Y.; Chen, S.; Chen, Y.; Marc, L.; Abdul, M.M.; Liu, Y.; Guo, L.; Yu, L.; Chen, H.; Liu, Y. Comparing laboratory and airborne hyperspectral data for the estimation andmapping of topsoil organic carbon: Feature selection coupled with random forest. Soil Till. Res. 2020, 199, 104589. [Google Scholar] [CrossRef]
- Liu, S.; Chen, J.; Guo, L.; Wang, J.; Zhou, Z.; Luo, J.; Yang, R. Prediction of soil organic carbon in soil profiles based on visible-near-infrared hyperspectral imaging spectroscopy. Soil Till. Res. 2023, 232, 105736. [Google Scholar] [CrossRef]
- Meng, X.; Bao, Y.; Liu, J.; Liu, H.; Zhang, X.; Zhang, Y.; Wang, P.; Tang, H.; Kong, F. Regional soil organic carbon prediction model based on a discrete wavelet analysis of hyperspectral satellite data. Int. J. Appl. Earth Obs. Geoinf. 2020, 89, 102111. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, T.; Yang, Z.; Bo, H.; Lin, Y.; Yang, Q.; Liu, X.; Zhang, Q.; Zhuo, X.; Wu, T. Zinc concentration prediction in rice grain using back-propagation neural network based on soil properties and safe utilization of paddy soil: A large-scale field study in Guangxi, China. Sci. Total Environ. 2021, 798, 149270. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, T.T.; Pham, T.D.; Nguyen, C.T.; Delfos, J.; Archibald, R.; Dang, K.B.; Hoang, N.B.; Guo, W.; Ngo, H.H. A novel intelligence approach based active and ensemble learning for agricultural soil organic carbon prediction using multispectral and SAR data fusion. Sci. Total Environ. 2022, 804, 150187. [Google Scholar] [CrossRef]
- Zhao, D.; Wang, J.; Jiang, X.; Zhen, J.; Miao, J.; Wang, J.; Wu, G. Reflectance spectroscopy for assessing heavy metal pollution indices in mangrove sediments using XGBoost method and physicochemical properties. Catena 2022, 211, 105967. [Google Scholar] [CrossRef]
- Hong, Y.; Chen, S.; Liu, Y.; Zhang, Y.; Yu, L.; Chen, Y.; Liu, Y.; Chen, H.; Liu, Y. Combination of fractional order derivative and memory-based learning algorithm to improve the estimation accuracy of soil organic matter by visible and near-infrared spectroscopy. Catena 2019, 174, 104–116. [Google Scholar] [CrossRef]
- Wang, L.; Wang, R.; Lu, C.; Wang, J.; Huang, W. Rapid determination of moisture content in compound fertilizer using visible and near infrared spectroscopy combined with chemometrics. Infrared Phys. Technol. 2019, 102, 103045. [Google Scholar] [CrossRef]
- Fu, C.; Gan, S.; Xiong, H.; Tian, A. A new method to estimate soil organic matter using the combination model basedon short memory fractional order derivativeand machine learning model. Infrared Phys. Technol. 2019, 134, 104922. [Google Scholar] [CrossRef]
- Rossel, R.V.; Behrens, T.; Ben-Dor, E.; Brown, D.J.; Demattê, J.A.M.; Shepherd, K.D.; Shi, Z.; Stenberg, B.; Stevens, A.; Adamchuk, V.; et al. A global spectral library to characterize the world’s soil. Earth-Sci. Rev. 2016, 155, 198–230. [Google Scholar] [CrossRef]
- Yang, H.; Qian, Y.; Yang, F.; Li, J.; Ju, W. Using wavelet transform of hyperspectral reflectance data for extracting spectral features of soil organic carbon and nitrogen. Soil Sci. 2012, 177, 674–681. [Google Scholar] [CrossRef]
- Rinnan, A.; Frans, B.; Engelsen, S.B. Review of the most common pre-processing techniques for near-infrared spectra. Trac-Trends Anal. Chem. 2009, 28, 1201–1222. [Google Scholar] [CrossRef]
- Zhang, Z.; Ding, J.; Zhu, C.; Wang, J. Combination of efficient signal pre-processing and optimal band combination algorithm to predict soil organic matter through visible and near-infrared spectra. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2020, 240, 118553. [Google Scholar] [CrossRef]
- Zhang, Z.; Ding, J.; Wang, J.; Ge, X. Prediction of soil organic matter in northwestern China using fractional order derivative spectroscopy and modified normalized difference indices. Catena 2020, 185, 104257. [Google Scholar] [CrossRef]
- Bai, Z.; Xie, M.; Hu, B.; Luo, D.; Wan, C.; Peng, J.; Shi, Z. Estimation of Soil Organic Carbon Using Vis-NIR Spectral Data and Spectral Feature Bands Selection in Southern Xinjiang, China. Sensors 2022, 22, 6124. [Google Scholar] [CrossRef]
- Wang, Y.; Xie, M.; Hu, B.; Jiang, Q.; Shi, Z.; He, Y.; Peng, J. Desert Soil Salinity Inversion Models Based on Field In Situ Spectroscopy in Southern Xinjiang, China. Remote Sens. 2022, 14, 4962. [Google Scholar] [CrossRef]
- Wu, Y.; Chen, J.; Ji, J.; Gong, P.; Liao, Q.; Tian, Q.; Ma, H. A mechanism study of reflectance spectroscopy for investigating heavy metals in soils. Soil Sci. Soc. Am. J. 2007, 71, 918–926. [Google Scholar] [CrossRef]
- Fei, S.; Li, L.; Han, Z.; Chen, Z.; Xiao, Y. Combining novel feature selection strategy and hyperspectral vegetation indices to predict crop yield. Plant Methods 2022, 18, 119. [Google Scholar] [CrossRef]
- Xu, M.; Chu, X.; Fu, Y.; Wang, C.; Wu, S. Improving the accuracy of soil organic carbon content prediction based on visible and near-infrared spectroscopy and machine learning. Environ. Earth Sci. 2021, 80, 326. [Google Scholar] [CrossRef]
- Xie, B.; Ding, J.; Ge, X.; Li, X.; Han, L.; Wang, Z. Estimation of Soil Organic Carbon Content in the Ebinur Lake Wetland, Xinjiang, China, Based on Multisource Remote Sensing Data and Ensemble Learning Algorithms. Sensors 2022, 22, 2685. [Google Scholar] [CrossRef]
- Seema; Ghosh, A.K.; Das, B.S.; Reddy, N. Application of VIS-NIR spectroscopy for estimation of soil organic carbon using different spectral preprocessing techniques and multivariate methods in the middle Indo-Gangetic plains of India. Geoderma Reg. 2020, 23, e00349. [Google Scholar] [CrossRef]
- Liu, S.; Shen, H.; Chen, S.; Zhao, X.; Biswas, A.; Jia, X. Estimating frog soil organic carbon content using vis-NIR spectroscopy: Implications for large-scale soil carbon spectroscopic assessment. Geoderma 2019, 348, 37–44. [Google Scholar] [CrossRef]
- Stevens, A.; van Wesemael, B.; Bartholomeus, H.; Rosillon, D.; Tychon, B.; Ben-Dor, E. Laboratory, field and airborne spectroscopy for monitoring organic carbon content in agricultural soils. Geoderma 2008, 144, 395–404. [Google Scholar] [CrossRef]
- Bogrekci, I.; Lee, W. Effects of soil moisture content on absorbance spectra of sandy soils in sensing phosphorus concentrations using UV-Vis-NIR spectroscopy. Trans. ASABE 2006, 49, 1175–1180. [Google Scholar] [CrossRef]
- Mouazen, A.M.; Karoui, R.; De, B.J.; Ramon, H. Characterization of soil water content using measured visible and near infrared spectra. Soil Sci. Soc. Am. J. 2006, 70, 1295–1302. [Google Scholar] [CrossRef]
- Tekin, Y.; Tumsavas, Z.; Mouazen, A.M. Effect of moisture content on prediction of organic carbon and pH using visible and near-infrared spectroscopy. Soil Sci. Soc. Am. J. 2012, 76, 188–198. [Google Scholar] [CrossRef]
- Wu, C.Y.; Jacobson, A.R.; Laba, M.; Baveye, P.C. Accounting for surface roughness effects in the near-infrared reflectance sensing of soils. Geoderma 2009, 152, 171–180. [Google Scholar] [CrossRef]
- Wang, Z.; Coburn, C.A.; Ren, X.; Teillet, M. Effect of soil surface roughness and scene components on soil surface bidirectional reflectance factor. Can. J. Soil Sci. 2012, 92, 297–313. [Google Scholar] [CrossRef]
- Summers, D.; Lewis, M.; Ostendorsf, B.; Chittleborough, D. Visible near-infrared reflectance spectroscopy as apredictive indicator of soil properties. Ecol. Indic. 2011, 11, 123–131. [Google Scholar] [CrossRef]
- Hong, Y.; Shen, R.; Chen, H.; Chen, S.; Chen, Y.; Guo, L.; He, J.; Liu, Y.; Yu, L.; Yi, L. Cadmium concentration estimation in peri-urban agricultural soils: Using reflectance spectroscopy, soil auxiliary information, or a combination of both? Geoderma 2019, 354, 113875. [Google Scholar] [CrossRef]
- Dharumarajan, S.; Gomez, C.; Lalitha, M.; Kalaiselvi, B.; Hegde, R. Soil order knowledge as a driver in soil properties estimation from Vis-NIR spectral data—Case study from northern Karnataka (India). Geoderma Reg. 2023, 32, e00596. [Google Scholar] [CrossRef]
- Horta, A.; Malone, B.; Stockmann, U.; Minasny, B.; Bishop, T.F.A.; McBratney, A.B.; Pallasser, R.; Pozza, L. Potential of integrated field spectroscopy and spatial analysis for enhanced assessment of soil contamination: A prospective review. Geoderma 2015, 241–242, 180–209. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Type | Samples Number | Statistical Index | ||||
|---|---|---|---|---|---|---|
| Max (g/kg) | Min (g/kg) | Mean (g/kg) | SD (g/kg) | CV (%) | ||
| Total sample | 70 | 40.92 | 0.91 | 12.76 | 7.50 | 58.80 |
| Calibration set | 53 | 40.92 | 1.40 | 13.02 | 7.59 | 58.33 |
| Validation set | 17 | 23.29 | 0.91 | 11.93 | 7.35 | 61.67 |
| Models | Spectral Pre-Processing | Calibration Set | Validation Set | |||
|---|---|---|---|---|---|---|
| R2 | RMSE | R2 | RMSE | RPD | ||
| PLSR | R | 0.32 | 6.84 | 0.31 | 6.38 | 1.07 |
| R-SPA | 0.47 | 5.71 | 0.40 | 5.57 | 1.22 | |
| MSC-SPA | 0.41 | 5.88 | 0.56 | 4.94 | 1.17 | |
| SNV-SPA | 0.46 | 5.63 | 0.46 | 4.91 | 1.38 | |
| CWT-3-SPA | 0.57 | 5.02 | 0.65 | 4.60 | 1.47 | |
| R-PSO | 0.38 | 6.06 | 0.43 | 5.29 | 1.28 | |
| MSC-PSO | 0.32 | 6.38 | 0.67 | 5.02 | 1.35 | |
| SNV-PSO | 0.48 | 5.53 | 0.67 | 4.80 | 1.41 | |
| CWT-9-PSO | 0.51 | 5.38 | 0.64 | 4.06 | 1.67 | |
| R-SA | 0.39 | 5.98 | 0.37 | 5.61 | 1.21 | |
| MSC-SA | 0.28 | 6.50 | 0.38 | 5.58 | 1.21 | |
| SNV-SA | 0.33 | 6.27 | 0.31 | 5.56 | 1.22 | |
| CWT-7-SA | 0.50 | 5.44 | 0.66 | 4.35 | 1.56 | |
| R-ACO | 0.31 | 6.38 | 0.38 | 5.53 | 1.22 | |
| MSC-ACO | 0.36 | 6.14 | 0.44 | 5.64 | 1.21 | |
| SNV-ACO | 0.36 | 6.14 | 0.50 | 5.07 | 1.34 | |
| CWT-7-ACO | 0.52 | 5.31 | 0.65 | 4.12 | 1.65 | |
| R-Boruta | 0.42 | 5.83 | 0.44 | 5.36 | 1.26 | |
| MSC-Boruta | 0.28 | 6.49 | 0.33 | 5.64 | 1.20 | |
| SNV-Boruta | 0.27 | 6.55 | 0.27 | 5.64 | 1.20 | |
| CWT-1-Boruta | 0.48 | 5.51 | 0.55 | 4.45 | 1.52 | |
| R-Random frog | 0.32 | 6.35 | 0.30 | 5.82 | 1.16 | |
| MSC-Random frog | 0.44 | 5.71 | 0.52 | 4.75 | 1.43 | |
| SNV-Random frog | 0.56 | 5.07 | 0.63 | 4.49 | 1.51 | |
| CWT-6-Random frog | 0.61 | 4.76 | 0.65 | 4.05 | 1.67 | |
| RF | R | 0.32 | 6.41 | 0.27 | 5.65 | 1.20 |
| R-SPA | 0.47 | 5.58 | 0.37 | 5.47 | 1.24 | |
| MSC-SPA | 0.54 | 5.40 | 0.53 | 4.76 | 1.43 | |
| SNV-SPA | 0.45 | 5.79 | 0.39 | 5.29 | 1.28 | |
| CWT-3-SPA | 0.67 | 4.54 | 0.63 | 4.15 | 1.63 | |
| R-PSO | 0.55 | 5.22 | 0.39 | 5.41 | 1.25 | |
| MSC-PSO | 0.71 | 4.39 | 0.63 | 4.13 | 1.64 | |
| SNV-PSO | 0.77 | 4.07 | 0.57 | 4.80 | 1.41 | |
| CWT-1-PSO | 0.83 | 3.95 | 0.76 | 3.91 | 1.73 | |
| R-SA | 0.41 | 5.97 | 0.41 | 4.74 | 1.33 | |
| MSC-SA | 0.55 | 5.58 | 0.54 | 4.82 | 1.41 | |
| SNV-SA | 0.72 | 4.50 | 0.54 | 4.77 | 1.42 | |
| CWT-4-SA | 0.76 | 4.24 | 0.73 | 4.16 | 1.63 | |
| R-ACO | 0.50 | 5.46 | 0.36 | 5.49 | 1.23 | |
| MSC-ACO | 0.51 | 5.45 | 0.45 | 5.05 | 1.34 | |
| SNV-ACO | 0.75 | 4.27 | 0.64 | 4.63 | 1.46 | |
| CWT-4-ACO | 0.75 | 4.49 | 0.77 | 3.94 | 1.72 | |
| R-Boruta | 0.42 | 5.87 | 0.41 | 5.24 | 1.29 | |
| MSC-Boruta | 0.65 | 4.67 | 0.65 | 4.09 | 1.66 | |
| SNV-Boruta | 0.59 | 5.12 | 0.57 | 4.46 | 1.52 | |
| CWT-1-Boruta | 0.76 | 3.98 | 0.68 | 3.92 | 1.73 | |
| R-Random frog | 0.43 | 5.88 | 0.42 | 5.27 | 1.29 | |
| MSC-Random frog | 0.59 | 4.89 | 0.56 | 4.46 | 1.52 | |
| SNV-Random frog | 0.68 | 4.64 | 0.67 | 4.44 | 1.53 | |
| CWT-1-Random frog | 0.77 | 4.20 | 0.77 | 3.90 | 1.74 | |
| BPNN | R | 0.46 | 6.42 | 0.33 | 4.91 | 1.05 |
| R-SPA | 0.47 | 5.87 | 0.33 | 5.65 | 1.22 | |
| MSC-SPA | 0.46 | 6.05 | 0.40 | 5.36 | 1.22 | |
| SNV-SPA | 0.41 | 5.87 | 0.38 | 5.38 | 1.25 | |
| CWT-5-SPA | 0.76 | 3.88 | 0.72 | 4.27 | 1.70 | |
| R-PSO | 0.54 | 5.38 | 0.28 | 5.81 | 1.16 | |
| MSC-PSO | 0.51 | 5.60 | 0.57 | 3.40 | 1.55 | |
| SNV-PSO | 0.55 | 5.37 | 0.55 | 4.50 | 1.48 | |
| CWT-5-PSO | 0.76 | 3.17 | 0.79 | 5.21 | 1.85 | |
| R-SA | 0.39 | 5.66 | 0.29 | 6.67 | 1.22 | |
| MSC-SA | 0.60 | 4.68 | 0.50 | 5.46 | 1.44 | |
| SNV-SA | 0.54 | 5.29 | 0.65 | 3.91 | 1.56 | |
| CWT-6-SA | 0.75 | 3.92 | 0.73 | 3.75 | 1.86 | |
| R-ACO | 0.51 | 4.89 | 0.50 | 6.02 | 1.40 | |
| MSC-ACO | 0.55 | 5.12 | 0.62 | 4.58 | 1.57 | |
| SNV-ACO | 0.63 | 4.84 | 0.61 | 3.17 | 1.61 | |
| CWT-8-ACO | 0.66 | 4.68 | 0.72 | 3.46 | 1.79 | |
| R-Boruta | 0.44 | 5.11 | 0.43 | 6.89 | 1.37 | |
| MSC-Boruta | 0.52 | 5.32 | 0.52 | 4.68 | 1.47 | |
| SNV-Boruta | 0.57 | 5.03 | 0.49 | 4.87 | 1.44 | |
| CWT-3-Boruta | 0.77 | 3.64 | 0.78 | 3.13 | 2.18 | |
| R-Random frog | 0.40 | 5.69 | 0.43 | 5.88 | 1.37 | |
| MSC-Random frog | 0.43 | 5.89 | 0.50 | 6.26 | 1.40 | |
| SNV-Random frog | 0.55 | 4.93 | 0.63 | 4.81 | 1.63 | |
| CWT-3-Random frog | 0.73 | 3.45 | 0.66 | 5.46 | 1.73 | |
| XGBoost | R | 0.43 | 5.98 | 0.42 | 4.70 | 1.29 |
| R-SPA | 0.67 | 4.58 | 0.66 | 4.35 | 1.56 | |
| MSC-SPA | 0.68 | 4.02 | 0.75 | 3.90 | 1.74 | |
| SNV-SPA | 0.69 | 4.56 | 0.68 | 4.19 | 1.62 | |
| CWT-5-SPA | 0.81 | 3.37 | 0.78 | 3.06 | 2.22 | |
| R-PSO | 0.53 | 5.37 | 0.60 | 4.31 | 1.57 | |
| MSC-PSO | 0.77 | 3.69 | 0.75 | 3.30 | 2.06 | |
| SNV-PSO | 0.69 | 4.83 | 0.78 | 3.41 | 1.99 | |
| CWT-7-PSO | 0.85 | 3.08 | 0.86 | 2.45 | 2.77 | |
| R-SA | 0.55 | 5.29 | 0.60 | 4.34 | 1.56 | |
| MSC-SA | 0.75 | 4.10 | 0.73 | 3.63 | 1.87 | |
| SNV-SA | 0.67 | 4.64 | 0.70 | 3.73 | 1.82 | |
| CWT-5-SA | 0.81 | 3.51 | 0.81 | 2.90 | 2.34 | |
| R-ACO | 0.68 | 4.50 | 0.63 | 4.02 | 1.69 | |
| MSC-ACO | 0.70 | 4.34 | 0.73 | 3.80 | 1.78 | |
| SNV-ACO | 0.74 | 3.86 | 0.77 | 3.32 | 2.04 | |
| CWT-5-ACO | 0.87 | 2.84 | 0.85 | 2.55 | 2.66 | |
| R-Boruta | 0.59 | 4.95 | 0.58 | 4.47 | 1.52 | |
| MSC-Boruta | 0.77 | 3.76 | 0.89 | 3.22 | 2.10 | |
| SNV-Boruta | 0.77 | 3.74 | 0.68 | 4.28 | 1.58 | |
| CWT-2-Boruta | 0.78 | 3.62 | 0.81 | 3.17 | 2.14 | |
| R-Random frog | 0.54 | 5.37 | 0.52 | 4.61 | 1.47 | |
| MSC-Random frog | 0.56 | 5.15 | 0.58 | 4.41 | 1.54 | |
| SNV-Random frog | 0.50 | 5.41 | 0.52 | 4.25 | 1.59 | |
| CWT-2-Random frog | 0.86 | 3.29 | 0.86 | 2.44 | 2.78 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Li, X.; Ma, X. Improving the Accuracy of Soil Organic Carbon Estimation: CWT-Random Frog-XGBoost as a Prerequisite Technique for In Situ Hyperspectral Analysis. Remote Sens. 2023, 15, 5294. https://doi.org/10.3390/rs15225294
Yang J, Li X, Ma X. Improving the Accuracy of Soil Organic Carbon Estimation: CWT-Random Frog-XGBoost as a Prerequisite Technique for In Situ Hyperspectral Analysis. Remote Sensing. 2023; 15(22):5294. https://doi.org/10.3390/rs15225294
Chicago/Turabian StyleYang, Jixiang, Xinguo Li, and Xiaofei Ma. 2023. "Improving the Accuracy of Soil Organic Carbon Estimation: CWT-Random Frog-XGBoost as a Prerequisite Technique for In Situ Hyperspectral Analysis" Remote Sensing 15, no. 22: 5294. https://doi.org/10.3390/rs15225294
APA StyleYang, J., Li, X., & Ma, X. (2023). Improving the Accuracy of Soil Organic Carbon Estimation: CWT-Random Frog-XGBoost as a Prerequisite Technique for In Situ Hyperspectral Analysis. Remote Sensing, 15(22), 5294. https://doi.org/10.3390/rs15225294