
GFCNet: Contrastive Learning Network with Geography Feature Space Joint Negative Sample Correction for Land Cover Classification




Abstract
:1. Introduction
- (1)
- We proposed a Geography Feature space joint negative sample Correction Strategy (GFCS), which comprehensively considers the geography space relationship and feature space relationship of the image to construct negative samples, effectively alleviating the class confusion of the self-supervised contrastive learning model for land cover classification.
- (2)
- We utilized the Multi-scale Feature joint Fine-tuning Strategy (MFFS) to integrate the features of different scales obtained by the self-supervised contrastive learning model, which enhances the ability of the model to capture objects of different scales.
- (3)
- Experimental results on three public land cover classification datasets indicated that the proposed GFCNet achieves the best results in all three metrics, OA, Kappa, and mIoU, compared to the baseline of seven self-supervised contrastive learning methods. In addition, GFCNet achieves a maximum improvement of 5.7% in Kappa and a maximum improvement of 4.85% in mIoU compared to the self-supervised contrastive learning methods with the original positive negative sample construction strategy.
2. Materials and Methods
2.1. Related Work
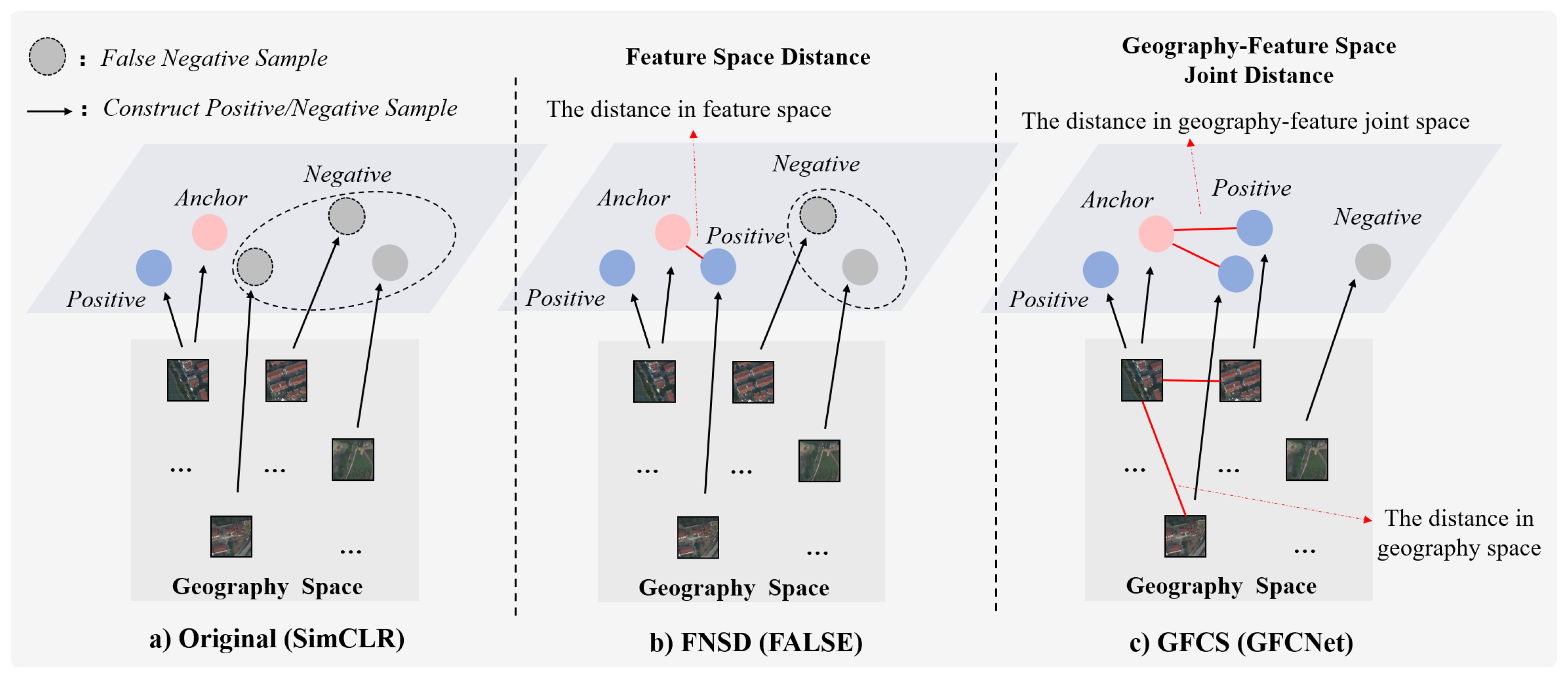
2.1.1. Negative Sample Construction Strategy for Self-Supervised Contrastive Learning
2.1.2. Self-Supervised Contrastive Learning for Land Cover Classification
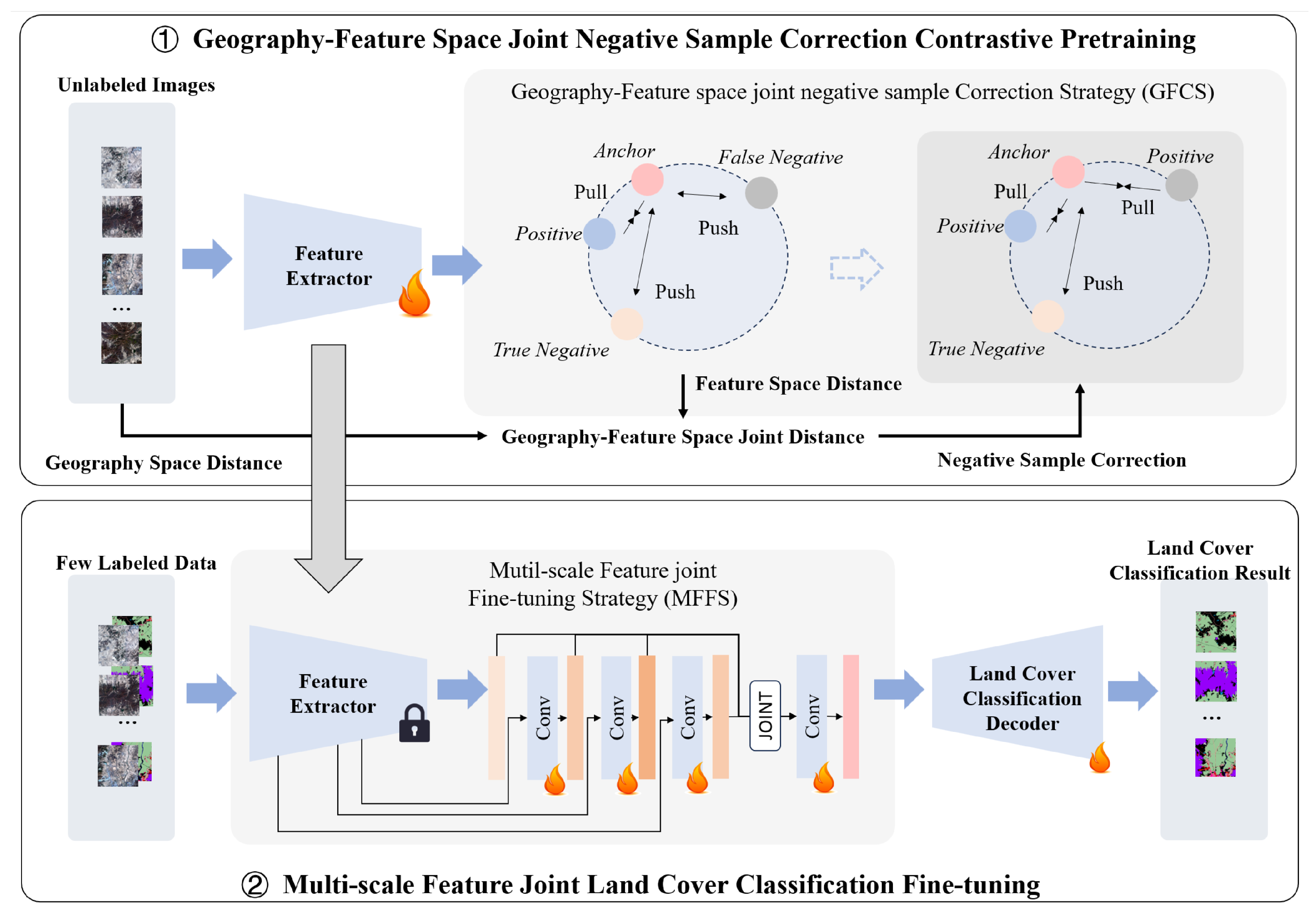
2.2. Method
2.2.1. Overview
2.2.2. Geography Feature Space Joint Negative Sample Correction Contrastive Pretraining
- (1)
- Geography Feature Space Joint Distance Computation
- (2)
- Negative Sample Correction
- (3)
- Feature Extraction and Contrastive Loss Calculation
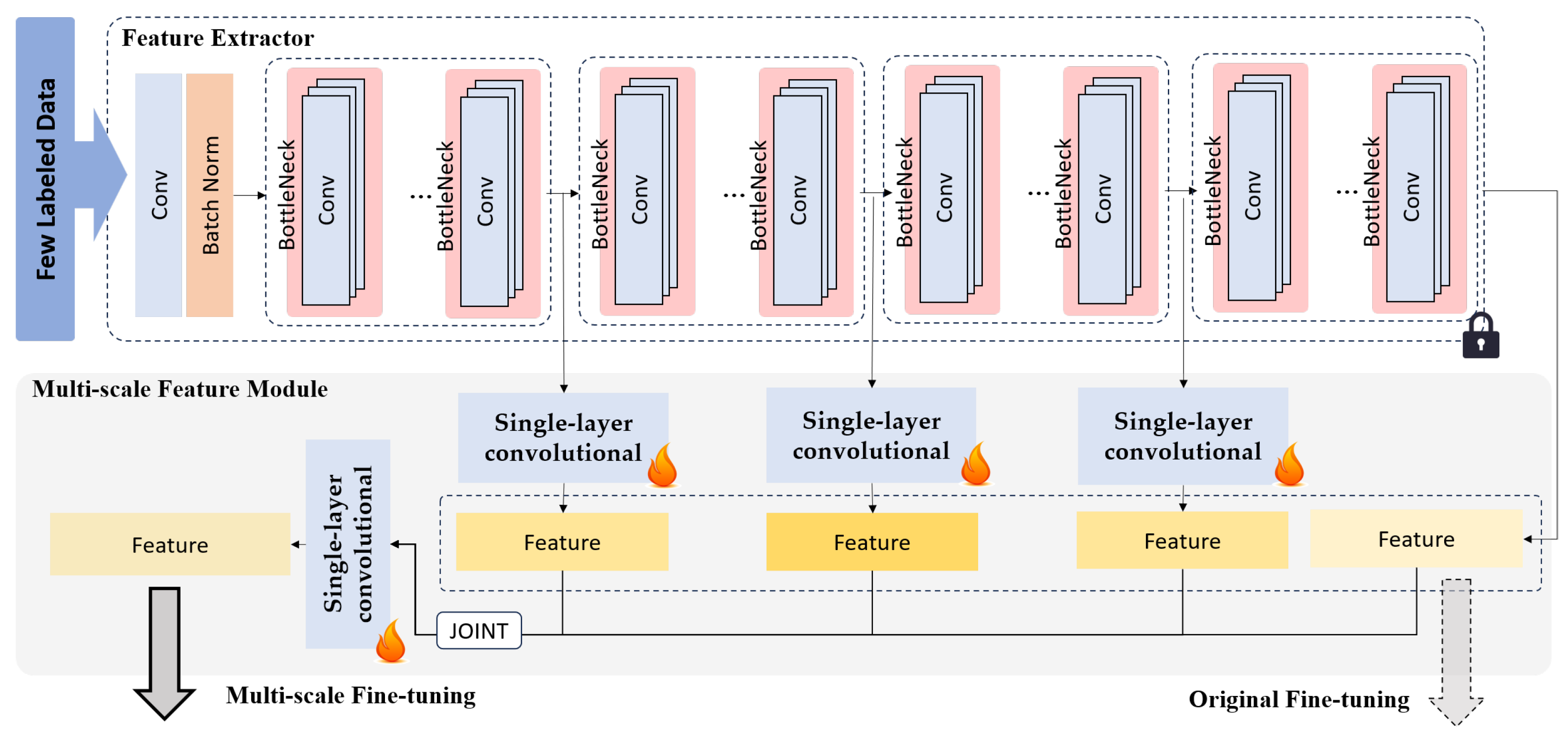
2.2.3. Multi-Scale Feature Joint Land Cover Classification Fine-Tuning
3. Experiments
3.1. Dataset Description
3.2. Baselines and Metric
3.3. Implementation Details
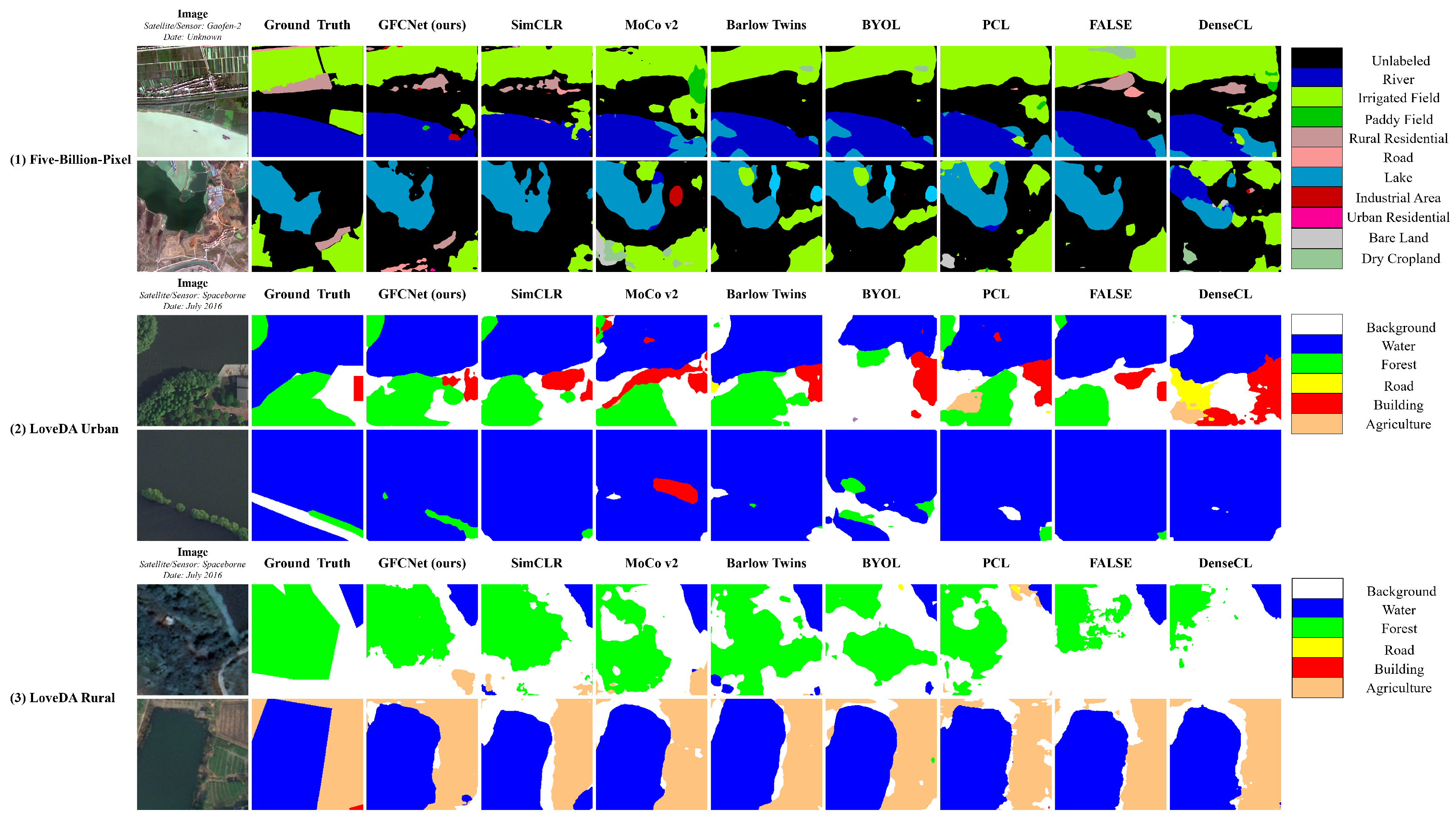
3.4. Experiment Results
3.4.1. Performance Analysis
3.4.2. Ablation Study
3.4.3. Domain Adaptation Analysis
3.4.4. Visualization of Negative Sample Correction
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hermosilla, T.; Wulder, M.A.; White, J.C.; Coops, N.C. Land cover classification in an era of big and open data: Optimizing localized implementation and training data selection to improve mapping outcomes. Remote Sens. Environ. 2022, 268, 112780. [Google Scholar]
- Talukdar, S.; Singha, P.; Mahato, S.; Pal, S.; Liou, Y.A.; Rahman, A. Land-use land-cover classification by machine learning classifiers for satellite observations—A review. Remote Sens. 2020, 12, 1135. [Google Scholar]
- Qin, R.; Liu, T. A review of landcover classification with very-high resolution remotely sensed optical images—Analysis unit, model scalability and transferability. Remote Sens. 2022, 14, 646. [Google Scholar]
- Huang, C.; Davis, L.; Townshend, J. An assessment of support vector machines for land cover classification. Int. J. Remote Sens. 2002, 23, 725–749. [Google Scholar]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar]
- Adam, E.; Mutanga, O.; Odindi, J.; Abdel-Rahman, E.M. Land-use/cover classification in a heterogeneous coastal landscape using RapidEye imagery: Evaluating the performance of random forest and support vector machines classifiers. Int. J. Remote Sens. 2014, 35, 3440–3458. [Google Scholar]
- Vali, A.; Comai, S.; Matteucci, M. Deep learning for land use and land cover classification based on hyperspectral and multispectral earth observation data: A review. Remote Sens. 2020, 12, 2495. [Google Scholar]
- Xu, R.; Wang, C.; Zhang, J.; Xu, S.; Meng, W.; Zhang, X. Rssformer: Foreground saliency enhancement for remote sensing land-cover segmentation. IEEE Trans. Image Process. 2023, 32, 1052–1064. [Google Scholar]
- Luo, M.; Ji, S. Cross-spatiotemporal land-cover classification from VHR remote sensing images with deep learning based domain adaptation. ISPRS J. Photogramm. Remote Sens. 2022, 191, 105–128. [Google Scholar]
- Tong, X.Y.; Xia, G.S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar]
- Tong, X.Y.; Xia, G.S.; Zhu, X.X. Enabling country-scale land cover mapping with meter-resolution satellite imagery. ISPRS J. Photogramm. Remote Sens. 2023, 196, 178–196. [Google Scholar] [PubMed]
- Peng, J.; Ye, D.; Tang, B.; Lei, Y.; Liu, Y.; Li, H. Lifelong Learning With Cycle Memory Networks. IEEE Trans. Neural Netw. Learn. Syst. 2023. [Google Scholar] [CrossRef]
- Peng, J.; Tang, B.; Jiang, H.; Li, Z.; Lei, Y.; Lin, T.; Li, H. Overcoming long-term catastrophic forgetting through adversarial neural pruning and synaptic consolidation. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 4243–4256. [Google Scholar]
- Li, H.; Cao, J.; Zhu, J.; Liu, Y.; Zhu, Q.; Wu, G. Curvature graph neural network. Inf. Sci. 2022, 592, 50–66. [Google Scholar]
- Zhang, L.; Zhang, L. Artificial intelligence for remote sensing data analysis: A review of challenges and opportunities. IEEE Geosci. Remote Sens. Mag. 2022, 10, 270–294. [Google Scholar]
- Tarasiou, M.; Zafeiriou, S. Embedding Earth: Self-supervised contrastive pre-training for dense land cover classification. arXiv 2022, arXiv:2203.06041. [Google Scholar]
- Scheibenreif, L.; Hanna, J.; Mommert, M.; Borth, D. Self-supervised vision transformers for land-cover segmentation and classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1422–1431. [Google Scholar]
- Yang, M.; Jiao, L.; Liu, F.; Hou, B.; Yang, S.; Zhang, Y.; Wang, J. Coarse-to-Fine contrastive self-supervised feature learning for land-cover classification in SAR images with limited labeled data. IEEE Trans. Image Process. 2022, 31, 6502–6516. [Google Scholar]
- Xue, Z.; Liu, B.; Yu, A.; Yu, X.; Zhang, P.; Tan, X. Self-supervised feature representation and few-shot land cover classification of multimodal remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5541618. [Google Scholar]
- Tao, C.; Qi, J.; Zhang, G.; Zhu, Q.; Lu, W.; Li, H. TOV: The original vision model for optical remote sensing image understanding via self-supervised learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4916–4930. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Tao, C.; Qi, J.; Lu, W.; Wang, H.; Li, H. Remote sensing image scene classification with self-supervised paradigm under limited labeled samples. IEEE Geosci. Remote Sens. Lett. 2020, 19, 8004005. [Google Scholar] [CrossRef]
- Tao, C.; Qi, J.; Guo, M.; Zhu, Q.; Li, H. Self-supervised remote sensing feature learning: Learning paradigms, challenges, and future works. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5610426. [Google Scholar] [CrossRef]
- Huang, H.; Mou, Z.; Li, Y.; Li, Q.; Chen, J.; Li, H. Spatial-Temporal Invariant Contrastive Learning for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6509805. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, X.; Mei, X.; Tao, C.; Li, H. FALSE: False Negative Samples Aware Contrastive Learning for Semantic Segmentation of High-Resolution Remote Sensing Image. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6518505. [Google Scholar] [CrossRef]
- Li, H.; Cao, J.; Zhu, J.; Luo, Q.; He, S.; Wang, X. Augmentation-Free Graph Contrastive Learning of Invariant-Discriminative Representations. IEEE Trans. Neural Netw. Learn. Syst. 2023. [Google Scholar] [CrossRef]
- Wang, X.; Zhu, J.; Yan, Z.; Zhang, Z.; Zhang, Y.; Chen, Y.; Li, H. LaST: Label-free self-distillation contrastive learning with transformer architecture for remote sensing image scene classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6512205. [Google Scholar] [CrossRef]
- Li, H.; Li, Y.; Zhang, G.; Liu, R.; Huang, H.; Zhu, Q.; Tao, C. Global and local contrastive self-supervised learning for semantic segmentation of HR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5618014. [Google Scholar] [CrossRef]
- Muhtar, D.; Zhang, X.; Xiao, P. Index your position: A novel self-supervised learning method for remote sensing images semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4411511. [Google Scholar] [CrossRef]
- Zhang, T.; Zhuang, Y.; Chen, H.; Chen, L.; Wang, G.; Gao, P.; Dong, H. Object-Centric Masked Image Modeling Based Self-Supervised Pretraining for Remote Sensing Object Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 5013–5025. [Google Scholar] [CrossRef]
- Jian, L.; Pu, Z.; Zhu, L.; Yao, T.; Liang, X. SS R-CNN: Self-Supervised learning improving mask R-CNN for ship detection in remote sensing images. Remote Sens. 2022, 14, 4383. [Google Scholar] [CrossRef]
- O Pinheiro, P.O.; Almahairi, A.; Benmalek, R.; Golemo, F.; Courville, A.C. Unsupervised learning of dense visual representations. Adv. Neural Inf. Process. Syst. 2020, 33, 4489–4500. [Google Scholar]
- Huynh, T.; Kornblith, S.; Walter, M.R.; Maire, M.; Khademi, M. Boosting contrastive self-supervised learning with false negative cancellation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 2785–2795. [Google Scholar]
- Chen, T.; Kornblith, S.; Swersky, K.; Norouzi, M.; Hinton, G.E. Big self-supervised models are strong semi-supervised learners. Adv. Neural Inf. Process. Syst. 2020, 33, 22243–22255. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Chen, T.S.; Hung, W.C.; Tseng, H.Y.; Chien, S.Y.; Yang, M.H. Incremental False Negative Detection for Contrastive Learning. In Proceedings of the International Conference on Learning Representations, Online, 25–29 April 2022. [Google Scholar]
- Li, J.; Zhou, P.; Xiong, C.; Hoi, S.C. Prototypical contrastive learning of unsupervised representations. arXiv 2020, arXiv:2005.04966. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- Caron, M.; Bojanowski, P.; Joulin, A.; Douze, M. Deep clustering for unsupervised learning of visual features. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 132–149. [Google Scholar]
- Xia, W.; Ma, C.; Liu, J.; Liu, S.; Chen, F.; Yang, Z.; Duan, J. High-resolution remote sensing imagery classification of imbalanced data using multistage sampling method and deep neural networks. Remote Sens. 2019, 11, 2523. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, R.; Shen, C.; Kong, T.; Li, L. Dense contrastive learning for self-supervised visual pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3024–3033. [Google Scholar]
- Hafidi, H.; Ghogho, M.; Ciblat, P.; Swami, A. Negative sampling strategies for contrastive self-supervised learning of graph representations. Signal Process. 2022, 190, 108310. [Google Scholar]
- Zhang, C.; Zhang, K.; Zhang, C.; Pham, T.X.; Yoo, C.D.; Kweon, I.S. How Does SimSiam Avoid Collapse Without Negative Samples? A Unified Understanding with Self-supervised Contrastive Learning. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Zhu, W.; Liu, J.; Huang, Y. Hnssl: Hard negative-based self-supervised learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 4777–4786. [Google Scholar]
- Robinson, J.D.; Chuang, C.Y.; Sra, S.; Jegelka, S. Contrastive Learning with Hard Negative Samples. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Manas, O.; Lacoste, A.; Giró-i Nieto, X.; Vazquez, D.; Rodriguez, P. Seasonal contrast: Unsupervised pre-training from uncurated remote sensing data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 9414–9423. [Google Scholar]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow twins: Self-supervised learning via redundancy reduction. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 12310–12320. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Henaff, O. Data-efficient image recognition with contrastive predictive coding. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 4182–4192. [Google Scholar]
- Jing, L.; Vincent, P.; LeCun, Y.; Tian, Y. Understanding Dimensional Collapse in Contrastive Self-supervised Learning. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar]
- Vasconcelos, C.N.; Oztireli, C.; Matthews, M.; Hashemi, M.; Swersky, K.; Tagliasacchi, A. Cuf: Continuous upsampling filters. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 9999–10008. [Google Scholar]
- Phiri, D.; Morgenroth, J. Developments in Landsat land cover classification methods: A review. Remote Sens. 2017, 9, 967. [Google Scholar] [CrossRef]
- Cihlar, J. Land cover mapping of large areas from satellites: Status and research priorities. Int. J. Remote Sens. 2000, 21, 1093–1114. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Introducing eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: New York, NY, USA, 2018; pp. 204–207. [Google Scholar]
- Pan, S.; Guan, H.; Chen, Y.; Yu, Y.; Gonçalves, W.N.; Junior, J.M.; Li, J. Land-cover classification of multispectral LiDAR data using CNN with optimized hyper-parameters. ISPRS J. Photogramm. Remote Sens. 2020, 166, 241–254. [Google Scholar]
- Gaetano, R.; Ienco, D.; Ose, K.; Cresson, R. A two-branch CNN architecture for land cover classification of PAN and MS imagery. Remote Sens. 2018, 10, 1746. [Google Scholar]
- Zhu, Q.; Guo, X.; Deng, W.; Shi, S.; Guan, Q.; Zhong, Y.; Zhang, L.; Li, D. Land-use/land-cover change detection based on a Siamese global learning framework for high spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2022, 184, 63–78. [Google Scholar] [CrossRef]
- Martini, M.; Mazzia, V.; Khaliq, A.; Chiaberge, M. Domain-adversarial training of self-attention-based networks for land cover classification using multi-temporal Sentinel-2 satellite imagery. Remote Sens. 2021, 13, 2564. [Google Scholar]
- Tzepkenlis, A.; Marthoglou, K.; Grammalidis, N. Efficient Deep Semantic Segmentation for Land Cover Classification Using Sentinel Imagery. Remote Sens. 2023, 15, 2027. [Google Scholar]
- Yuan, Y.; Lin, L. Self-supervised pretraining of transformers for satellite image time series classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 474–487. [Google Scholar]
- Wang, T.; Isola, P. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 July 2020; pp. 9929–9939. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Wang, J.; Zheng, Z.; Lu, X.; Zhong, Y. LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, Virtual Event, 13–14 December 2021; pp. 1–16. [Google Scholar]
- Wei, F.; Gao, Y.; Wu, Z.; Hu, H.; Lin, S. Aligning pretraining for detection via object-level contrastive learning. Adv. Neural Inf. Process. Syst. 2021, 34, 22682–22694. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Five-Billion-Pixel | LoveDA Urban | LoveDA Rural |
|---|---|---|---|
| Year | 2023 | 2021 | 2021 |
| Resolution | 4 m | 0.3 m | 0.3 m |
| Area | >50,000 km | 245.75 km | 289.41 km |
| Class Number | 24 | 7 | 7 |
| Crop Size | 512 × 512 | 256 × 256 | 256 × 256 |
| Amount of Data for SSL Pretraining (with no label) | 25,200 | 18,496 | 21,856 |
| Amount of Data for Fine-tuning (1% of the pretraining data) | 252 | 184 | 218 |
| Amount of Data for Testing | 6300 | 10,832 | 15,872 |
| Method | Five Billion Pixel | LoveDA Urban | LoveDA Rural | ||||||
|---|---|---|---|---|---|---|---|---|---|
| OA | Kappa | mIoU | OA | Kappa | mIoU | OA | Kappa | mIoU | |
| SimCLR | 64.31 | 55.80 | 21.34 | 40.92 | 27.51 | 32.10 | 61.32 | 45.65 | 37.83 |
| MoCo v2 | 53.03 | 40.89 | 14.13 | 40.30 | 27.32 | 32.72 | 60.66 | 45.25 | 38.54 |
| Barlow Twins | 58.66 | 48.01 | 17.90 | 41.19 | 29.36 | 32.96 | 57.10 | 41.61 | 37.01 |
| BYOL | 64.10 | 55.47 | 21.17 | 32.67 | 15.71 | 24.14 | 59.86 | 42.70 | 37.42 |
| PCL | 57.98 | 47.58 | 17.29 | 40.05 | 27.12 | 33.08 | 62.98 | 47.26 | 40.24 |
| FALSE | 64.88 | 56.69 | 21.41 | 41.22 | 27.85 | 32.67 | 62.41 | 46.43 | 40.96 |
| DenseCL | 51.35 | 39.03 | 13.43 | 36.62 | 23.34 | 30.21 | 63.04 | 47.48 | 41.14 |
| GFCNet(Ours) | 65.44 | 57.30 | 21.84 | 42.36 | 29.48 | 34.06 | 65.61 | 51.35 | 42.68 |
| Method | FNSD | GFCS | MFFS | Five-Billion-Pixel | LoveDA Urban | LoveDA Rural | |||
|---|---|---|---|---|---|---|---|---|---|
| OA | Kappa | OA | Kappa | OA | Kappa | ||||
| SimCLR | 64.31 | 55.80 | 40.92 | 27.51 | 61.32 | 45.65 | |||
| SimCLR + FNSD | ✔ | 64.88 | 56.69 | 41.22 | 27.85 | 62.41 | 46.43 | ||
| SimCLR + GFCS | ✔ | 65.20 | 57.08 | 41.91 | 29.65 | 65.27 | 51.02 | ||
| GFCNet | ✔ | ✔ | 65.44 | 57.30 | 42.36 | 29.48 | 65.61 | 51.35 | |
| Method | Original Fine-Tuning | MFFS | LoveDA Urban | LoveDA Rural | LoveDA (Urban + Rural) | |||
|---|---|---|---|---|---|---|---|---|
| OA | Kappa | OA | Kappa | OA | Kappa | |||
| GFCNet | ✔ | 41.91 | 29.65 | 65.27 | 51.02 | 56.16 | 41.81 | |
| ✔ | 42.36 | 29.48 | 65.61 | 51.35 | 57.16 | 43.95 | ||
| Fine-Tuning and Validation Dataset | Pretraining Dataset | SimCLR | FALSE | GFCNet | |||
|---|---|---|---|---|---|---|---|
| OA | Kappa | OA | Kappa | OA | Kappa | ||
| LoveDA Urban | LoveDA Urban | 40.92 | 27.51 | 41.22 | 27.85 | 42.36 | 29.48 |
| LoveDA Rural | 40.26 | 27.41 | 41.20 | 27.64 | 42.09 | 29.56 | |
| LoveDA Rural | LoveDA Rural | 61.32 | 45.65 | 62.41 | 46.43 | 65.61 | 51.35 |
| LoveDA Urban | 58.33 | 41.40 | 60.92 | 45.29 | 61.00 | 45.34 | |
| Fine-Tuning and Validation Dataset | Pretraining Dataset | SimCLR | FALSE | GFCNet | |||
|---|---|---|---|---|---|---|---|
| OA | Kappa | OA | Kappa | OA | Kappa | ||
| LoveDA (Urban + Rural) | LoveDA (Urban + Rural) | 55.47 | 41.21 | 55.65 | 41.63 | 57.16 | 43.95 |
| Five-Billion-Pixel | 54.70 | 40.28 | 55.36 | 41.36 | 56.52 | 43.48 | |
| Five Billion Pixel | Five Billion Pixel | 64.31 | 55.80 | 64.88 | 56.69 | 65.44 | 57.30 |
| LoveDA (Urban + Rural) | 64.19 | 55.77 | 64.71 | 56.32 | 65.40 | 57.37 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Jing, W.; Li, H.; Tao, C.; Zhang, Y. GFCNet: Contrastive Learning Network with Geography Feature Space Joint Negative Sample Correction for Land Cover Classification. Remote Sens. 2023, 15, 5056. https://doi.org/10.3390/rs15205056
Zhang Z, Jing W, Li H, Tao C, Zhang Y. GFCNet: Contrastive Learning Network with Geography Feature Space Joint Negative Sample Correction for Land Cover Classification. Remote Sensing. 2023; 15(20):5056. https://doi.org/10.3390/rs15205056
Chicago/Turabian StyleZhang, Zhaoyang, Wenxuan Jing, Haifeng Li, Chao Tao, and Yunsheng Zhang. 2023. "GFCNet: Contrastive Learning Network with Geography Feature Space Joint Negative Sample Correction for Land Cover Classification" Remote Sensing 15, no. 20: 5056. https://doi.org/10.3390/rs15205056
APA StyleZhang, Z., Jing, W., Li, H., Tao, C., & Zhang, Y. (2023). GFCNet: Contrastive Learning Network with Geography Feature Space Joint Negative Sample Correction for Land Cover Classification. Remote Sensing, 15(20), 5056. https://doi.org/10.3390/rs15205056