


Hybrid Task Cascade-Based Building Extraction Method in Remote Sensing Imagery


Abstract
:1. Introduction
- This study introduces the hybrid task cascade network for building detection from remote sensing imagery based on the inherent characteristics of building targets. We also investigate the impact of global semantic features on the performance of building object detection.
- We compare the influence of the integrated architecture in HTC, which makes the bounding box prediction and mask prediction intertwined, and the mask information flow architecture, which combines mask information at different stages of the cascade structure to improve the accuracy of mask detection.
- Extensive experiments are conducted on three diverse remote sensing imagery building datasets, including CrowdAI mapping challenge dataset [19], WHU aerial image dataset [20]) and Chinese Typical City Buildings Dataset [21]. The results demonstrate the superiority of the HTC network over the swin-transformer-based method and other existing state-of-the-art (SOTA) segmentation methods.
2. Related Works
2.1. Encoder–Decoder Structure-Based Semantic Segmentation
2.2. Mask R-CNN Structure-Based Instance Segmentation
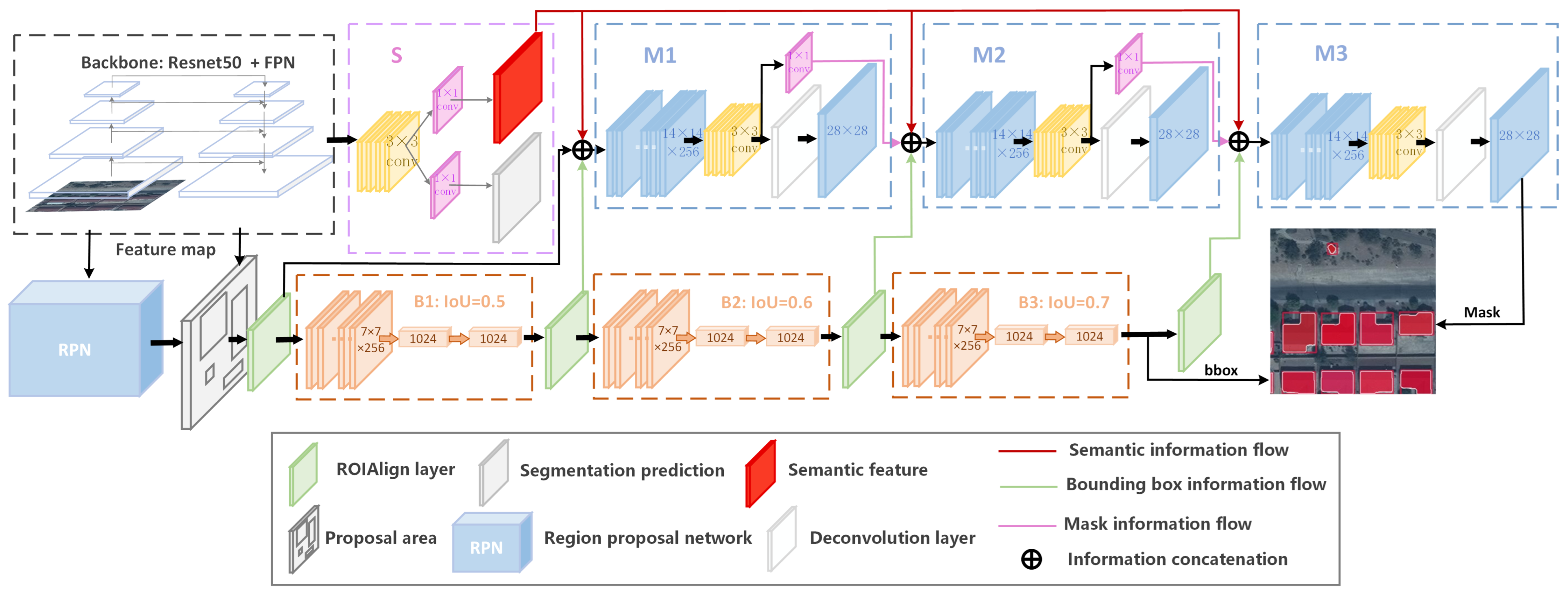
3. Methodology
3.1. Network Stucture of HTC
3.2. Loss Function
4. Experiments
4.1. Implementation Details
4.2. Datasets
4.2.1. CrowdAI Mapping Challenge Dataset
4.2.2. WHU Aerial Image Dataset
4.2.3. Chinese Typical City Buildings Dataset
4.3. Evaluation Metrics
4.4. Baseline Methods
5. Experimental Results
5.1. Results on the CrowdAI Mapping Challenge Dataset
5.2. Results on the WHU Aerial Image Dataset
5.3. Results on the Chinese Typical City Buildings Dataset
5.4. Ablation Experiments
5.5. Effects of Different IoU Threshold
5.6. Efficiency and Generalizability Tests
6. Discussion
6.1. Summary of Results
6.2. Future Work
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? the inria aerial image labeling benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Chen, J.; Wang, G.; Luo, L.; Gong, W.; Cheng, Z. Building Area Estimation in Drone Aerial Images Based on Mask R-CNN. IEEE Geosci. Remote Sens. Lett. 2021, 18, 891–894. [Google Scholar] [CrossRef]
- Chen, D.; Tu, W.; Cao, R.; Zhang, Y.; He, B.; Wang, C.; Shi, T.; Li, Q. A hierarchical approach for fine-grained urban villages recognition fusing remote and social sensing data. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102661. [Google Scholar] [CrossRef]
- Amo-Boateng, M.; Sey, N.E.N.; Amproche, A.A.; Domfeh, M.K. Instance segmentation scheme for roofs in rural areas based on Mask R-CNN. Egypt. J. Remote Sens. Space Sci. 2022, 25, 569–577. [Google Scholar] [CrossRef]
- Han, Q.; Yin, Q.; Zheng, X.; Chen, Z. Remote sensing image building detection method based on Mask R-CNN. Complex Intell. Syst. 2021, 8, 1847–1855. [Google Scholar] [CrossRef]
- Wang, Y.; Li, S.; Teng, F.; Lin, Y.; Wang, M.; Cai, H. Improved mask R-CNN for rural building roof type recognition from uav high-resolution images: A case study in hunan province, China. Remote Sens. 2022, 14, 265. [Google Scholar] [CrossRef]
- Powers, R.P.; Hay, G.J.; Chen, G. How wetland type and area differ through scale: A GEOBIA case study in Alberta’s Boreal Plains. Remote Sens. Environ. 2012, 117, 135–145. [Google Scholar] [CrossRef]
- Hu, L.; Zheng, J.; Gao, F. A building extraction method using shadow in high resolution multispectral images. In Proceedings of the 2011 IEEE International Geoscience and Remote Sensing Symposium, Vancouver, BC, Canada, 24–29 July 2011; pp. 1862–1865. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, X.; Xin, Q.; Sun, Y.; Zhang, P. Automatic building extraction from high-resolution aerial images and LiDAR data using gated residual refinement network. ISPRS J. Photogramm. Remote Sens. 2019, 151, 91–105. [Google Scholar] [CrossRef]
- Yuan, J.; Cheriyadat, A.M. Learning to count buildings in diverse aerial scenes. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Fort Worth, TX, USA, 4–7 November 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 271–280. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Feitosa, R.Q.; van der Meer, F.; van der Werff, H.; van Coillie, F.; et al. Geographic Object-Based Image Analysis—Towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4974–4983. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Mohanty, S.P. Crowdai Mapping Challenge 2018: Baseline with Mask RCNN. GitHub Repository. 2018. Available online: https://github.com/crowdai/crowdai-mapping-challenge-mask-rcnn (accessed on 6 October 2023).
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Fang, F.; Wu, K.; Zheng, D. A dataset of building instances of typical cities in China [DB/OL]. Sci. Data Bank 2021. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Shrestha, S.; Vanneschi, L. Improved fully convolutional network with conditional random fields for building extraction. Remote Sens. 2018, 10, 1135. [Google Scholar] [CrossRef]
- Yang, G.; Zhang, Q.; Zhang, G. EANet: Edge-aware network for the extraction of buildings from aerial images. Remote Sens. 2020, 12, 2161. [Google Scholar] [CrossRef]
- Tang, Z.; Chen, C.Y.C.; Jiang, C.; Zhang, D.; Luo, W.; Hong, Z.; Sun, H. Capsule–Encoder–Decoder: A Method for Generalizable Building Extraction from Remote Sensing Images. Remote Sens. 2022, 14, 1235. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, D.; Ma, A.; Zhong, Y.; Fang, F.; Xu, K. Multiscale U-Shaped CNN Building Instance Extraction Framework with Edge Constraint for High-Spatial-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6106–6120. [Google Scholar] [CrossRef]
- Ma, J.; Wu, L.; Tang, X.; Liu, F.; Zhang, X.; Jiao, L. Building extraction of aerial images by a global and multi-scale encoder-decoder network. Remote Sens. 2020, 12, 2350. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Yuan, W.; Xu, W. Msst-net: A multi-scale adaptive network for building extraction from remote sensing images based on swin transformer. Remote Sens. 2021, 13, 4743. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–16 October 2021; pp. 10012–10022. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Girard, N.; Smirnov, D.; Solomon, J.; Tarabalka, Y. Polygonal building extraction by frame field learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 5891–5900. [Google Scholar]
- Zhao, K.; Kang, J.; Jung, J.; Sohn, G. Building extraction from satellite images using mask R-CNN with building boundary regularization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 247–251. [Google Scholar]
- Douglas, D.H.; Peucker, T.K. Algorithms for the reduction of the number of points required to represent a digitized line or its caricature. Cartogr. Int. J. Geogr. Inf. Geovis. 1973, 10, 112–122. [Google Scholar] [CrossRef]
- Sohn, G.; Jwa, Y.; Jung, J.; Kim, H. An implicit regularization for 3D building rooftop modeling using airborne lidar data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 1, 305–310. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, J.; Fan, Y.; Gao, H.; Shao, Y. An efficient building extraction method from high spatial resolution remote sensing images based on improved mask R-CNN. Sensors 2020, 20, 1465. [Google Scholar] [CrossRef] [PubMed]
- Fang, F.; Wu, K.; Liu, Y.; Li, S.; Wan, B.; Chen, Y.; Zheng, D. A coarse-to-fine contour optimization network for extracting building instances from high-resolution remote sensing imagery. Remote Sens. 2021, 13, 3814. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhao, W.; Persello, C.; Stein, A. Building outline delineation: From aerial images to polygons with an improved end-to-end learning framework. ISPRS J. Photogramm. Remote Sens. 2021, 175, 119–131. [Google Scholar] [CrossRef]
- Zhu, Q.; Liao, C.; Hu, H.; Mei, X.; Li, H. MAP-Net: Multi Attending Path Neural Network for Building Footprint Extraction from Remote Sensed Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6169–6181. [Google Scholar] [CrossRef]
- Liu, X.; Chen, Y.; Wei, M.; Wang, C.; Goncalves, W.N.; Marcato, J.; Li, J. Building Instance Extraction Method Based on Improved Hybrid Task Cascade. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3002005. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1483–1498. [Google Scholar] [CrossRef]
- Caesar, H.; Uijlings, J.; Ferrari, V. Coco-stuff: Thing and stuff classes in context. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1209–1218. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Vu, T.; Kang, H.; Yoo, C.D. Scnet: Training inference sample consistency for instance segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 2701–2709. [Google Scholar]
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. Solov2: Dynamic and fast instance segmentation. Adv. Neural Inf. Process. Syst. 2020, 33, 17721–17732. [Google Scholar]
- Fu, R.; He, J.; Liu, G.; Li, W.; Mao, J.; He, M.; Lin, Y. Fast seismic landslide detection based on improved mask R-CNN. Remote Sens. 2022, 14, 3928. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef]
- Xu, C.; Wang, G.; Yan, S.; Yu, J.; Zhang, B.; Dai, S.; Li, Y.; Xu, L. Fast vehicle and pedestrian detection using improved Mask R-CNN. Math. Probl. Eng. 2020, 2020, 5761414. [Google Scholar] [CrossRef]
- Wu, B.; Shen, Y.; Guo, S.; Chen, J.; Sun, L.; Li, H.; Ao, Y. High Quality Object Detection for Multiresolution Remote Sensing Imagery Using Cascaded Multi-Stage Detectors. Remote Sens. 2022, 14, 2091. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Q.; Tu, W.; Mai, K.; Yao, Y.; Chen, Y. Functional urban land use recognition integrating multi-source geospatial data and cross-correlations. Comput. Environ. Urban Syst. 2019, 78, 101374. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Bounding Box (%) | Mask (%) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mask R-CNN | 55.7 | 82.4 | 64.6 | 27.1 | 71.4 | 69.8 | 61.1 | 54.3 | 82.6 | 64.4 | 26.4 | 69.2 | 68.5 | 59.6 |
| Swin Mask R-CNN | 56.0 | 82.5 | 65.5 | 28.4 | 71.4 | 72.0 | 61.0 | 54.9 | 83.4 | 64.9 | 27.7 | 69.4 | 71.6 | 59.8 |
| SOLOv2 | — | — | — | — | — | — | — | 53.7 | 82.4 | 63.0 | 25.3 | 69.4 | 72.0 | 60.2 |
| Cascade Mask R-CNN | 58.1 | 83.5 | 66.1 | 29.4 | 73.9 | 71.0 | 63.5 | 55.2 | 83.5 | 65.0 | 27.8 | 69.7 | 70.1 | 60.5 |
| SCNet | 58.1 | 83.8 | 66.1 | 29.2 | 74.2 | 72.3 | 63.9 | 55.6 | 83.7 | 65.3 | 27.5 | 70.3 | 72.2 | 61.7 |
| Proposed Method | 58.7 | 84.1 | 66.6 | 29.7 | 74.5 | 74.0 | 64.9 | 55.9 | 84.2 | 66.1 | 28.2 | 70.4 | 72.5 | 62.5 |
| Methods | Bounding Box (%) | Mask (%) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mask R-CNN | 63.7 | 83.9 | 73.3 | 49.3 | 79.8 | 73.6 | 68.0 | 60.4 | 84.8 | 71.4 | 44.5 | 77.3 | 75.2 | 64.2 |
| Swin Mask R-CNN | 63.9 | 84.8 | 74.2 | 50.0 | 79.5 | 74.2 | 68.2 | 62.7 | 84.9 | 73.5 | 47.2 | 79.1 | 78.1 | 66.5 |
| SOLOv2 | — | — | — | — | — | — | — | 55.1 | 83.3 | 64.3 | 37.2 | 74.3 | 76.8 | 59.4 |
| Cascade Mask R-CNN | 65.9 | 84.7 | 74.7 | 51.2 | 82.3 | 76.6 | 69.9 | 60.5 | 84.8 | 71.5 | 44.5 | 77.5 | 76.7 | 64.1 |
| SCNet | 64.9 | 85.2 | 74.3 | 50.2 | 81.5 | 74.7 | 69.2 | 60.3 | 84.8 | 71.1 | 44.2 | 77.4 | 76.8 | 64.1 |
| Proposed Method | 66.5 | 85.5 | 75.8 | 52.1 | 82.7 | 76.5 | 70.7 | 61.7 | 85.5 | 73.1 | 46.1 | 78.3 | 77.9 | 65.4 |
| Methods | Bounding Box (%) | Mask (%) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mask R-CNN | 47.8 | 72.1 | 52.7 | 23.2 | 54.7 | 58.9 | 61.7 | 45.3 | 71.5 | 49.7 | 17.7 | 51.0 | 58.3 | 58.8 |
| Swin Mask R-CNN | 46.9 | 72.1 | 52.4 | 22.4 | 53.9 | 57.3 | 59.4 | 45.1 | 71.4 | 49.8 | 17.3 | 51.1 | 57.5 | 57.3 |
| SOLOv2 | — | — | — | — | — | — | — | 43.0 | 69.9 | 46.9 | 13.6 | 49.4 | 58.7 | 56.3 |
| Cascade Mask R-CNN | 50.0 | 71.7 | 55.4 | 24.0 | 57.0 | 61.4 | 64.3 | 46.1 | 71.6 | 50.9 | 18.1 | 51.9 | 59.2 | 59.4 |
| SCNet | 49.9 | 72.9 | 54.6 | 24.4 | 56.8 | 60.7 | 65.0 | 46.7 | 72.7 | 51.5 | 18.5 | 52.5 | 60.7 | 61.5 |
| Proposed Method | 50.8 | 73.2 | 56.0 | 24.9 | 57.7 | 62.0 | 66.9 | 47.0 | 72.8 | 52.1 | 18.7 | 53.0 | 60.6 | 62.5 |
| Cascade | Integrated | Mask Info | Semantic | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ✓ | 58.1 | 83.5 | 66.1 | 29.4 | 73.9 | 71.0 | 63.5 | |||
| ✓ | ✓ | ✓ | 58.6 | 84.0 | 66.9 | 29.8 | 74.3 | 72.0 | 64.9 | |
| ✓ | ✓ | ✓ | 58.7 | 84.1 | 66.6 | 29.8 | 74.4 | 71.7 | 64.9 | |
| ✓ | ✓ | ✓ | 58.9 | 84.1 | 66.7 | 30.0 | 74.7 | 72.7 | 65.0 | |
| ✓ | ✓ | 61.4 | 87.4 | 69.3 | 34.6 | 75.6 | 73.1 | 67.9 | ||
| ✓ | ✓ | ✓ | ✓ | 58.7 | 84.1 | 66.6 | 29.7 | 74.5 | 74.0 | 64.9 |
| Cascade | Integrated | Mask Info | Semantic | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ✓ | 55.2 | 83.5 | 65.0 | 27.8 | 69.7 | 70.1 | 60.5 | |||
| ✓ | ✓ | ✓ | 55.9 | 84.1 | 65.9 | 28.3 | 70.4 | 71.1 | 62.5 | |
| ✓ | ✓ | ✓ | 55.8 | 84.2 | 65.7 | 28.3 | 70.3 | 71.0 | 62.5 | |
| ✓ | ✓ | ✓ | 55.8 | 84.1 | 65.7 | 28.3 | 70.3 | 72.0 | 62.3 | |
| ✓ | ✓ | 58.3 | 87.5 | 68.4 | 32.9 | 71.3 | 71.4 | 65.2 | ||
| ✓ | ✓ | ✓ | ✓ | 55.9 | 84.2 | 66.1 | 28.2 | 70.4 | 72.5 | 62.5 |
| Methods | IoU | Bounding Box (%) | Mask (%) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mask R-CNN | 0.5 | 55.7 | 82.4 | 64.6 | 27.1 | 71.4 | 69.8 | 61.1 | 54.3 | 82.6 | 64.4 | 26.4 | 69.2 | 68.5 | 59.6 |
| Mask R-CNN | 0.6 | 56.1 | 82.1 | 64.8 | 27.7 | 72.0 | 68.3 | 61.5 | 54.4 | 82.9 | 64.3 | 26.7 | 69.3 | 68.9 | 59.9 |
| HTC | (0.5, 0.6, 0.7) | 58.7 | 84.1 | 66.6 | 29.7 | 74.5 | 74.0 | 64.9 | 55.9 | 84.2 | 66.1 | 28.2 | 70.4 | 72.5 | 62.5 |
| HTC | (0.6, 0.7, 0.8) | 59.1 | 83.9 | 66.9 | 29.8 | 75.1 | 72.7 | 65.1 | 56.2 | 84.1 | 66.1 | 28.3 | 70.9 | 72.5 | 62.6 |
| Methods | IoU | Bounding Box (%) | Mask (%) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mask R-CNN | 0.5 | 63.7 | 83.9 | 73.3 | 49.3 | 79.8 | 73.6 | 68.0 | 60.4 | 84.8 | 71.4 | 44.5 | 77.3 | 75.2 | 64.2 |
| Mask R-CNN | 0.6 | 64.6 | 83.8 | 74.6 | 50.0 | 81.4 | 72.9 | 68.6 | 60.9 | 83.9 | 72.4 | 44.7 | 78.1 | 75.1 | 64.3 |
| HTC | (0.5, 0.6, 0.7) | 66.5 | 85.5 | 75.8 | 52.1 | 82.7 | 76.5 | 70.7 | 61.7 | 85.5 | 73.1 | 46.1 | 78.3 | 77.9 | 65.4 |
| HTC | (0.55, 0.65, 0.75) | 66.9 | 85.3 | 75.6 | 52.3 | 83.4 | 77.0 | 71.1 | 62.0 | 85.5 | 73.1 | 46.0 | 78.9 | 78.9 | 65.7 |
| HTC | (0.6, 0.7, 0.8) | 67.2 | 85.1 | 76.2 | 52.6 | 83.9 | 77.0 | 71.2 | 62.4 | 85.2 | 73.6 | 46.5 | 79.2 | 78.8 | 66.0 |
| Methods | Parameters (M) | fps () |
|---|---|---|
| Mask R-CNN | 335 | 20.64 |
| Cascade Mask R-CNN | 587 | 14.12 |
| Swin Mask R-CNN | 542 | 18.58 |
| SOLOv2 | 352 | 15.19 |
| SCNet | 720 | 8.42 |
| HTC | 609 | 8.92 |
| HTC (without semantic branch) | 588 | 12.39 |
| Backbone | Mask (%) | Parameters (M) | fps () | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Resnet-18 | 59.9 | 84.5 | 70.6 | 43.5 | 77.0 | 76.4 | 64.0 | 509 | 9.47 |
| Resnet-50 | 61.7 | 85.5 | 73.1 | 46.1 | 78.3 | 77.9 | 65.4 | 609 | 8.92 |
| Resnet-101 | 60.3 | 84.7 | 71.2 | 44.2 | 76.8 | 77.9 | 64.2 | 754 | 8.16 |
| Resnext-101 | 61.3 | 85.0 | 72.4 | 45.5 | 78.2 | 77.7 | 64.8 | 751 | 8.10 |
| HRNetV2p | 62.3 | 85.9 | 73.6 | 46.6 | 79.3 | 77.7 | 65.9 | 980 | 7.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, R.; Zhou, M.; Huang, Y.; Tu, W. Hybrid Task Cascade-Based Building Extraction Method in Remote Sensing Imagery. Remote Sens. 2023, 15, 4907. https://doi.org/10.3390/rs15204907
Deng R, Zhou M, Huang Y, Tu W. Hybrid Task Cascade-Based Building Extraction Method in Remote Sensing Imagery. Remote Sensing. 2023; 15(20):4907. https://doi.org/10.3390/rs15204907
Chicago/Turabian StyleDeng, Runqin, Meng Zhou, Yinni Huang, and Wei Tu. 2023. "Hybrid Task Cascade-Based Building Extraction Method in Remote Sensing Imagery" Remote Sensing 15, no. 20: 4907. https://doi.org/10.3390/rs15204907
APA StyleDeng, R., Zhou, M., Huang, Y., & Tu, W. (2023). Hybrid Task Cascade-Based Building Extraction Method in Remote Sensing Imagery. Remote Sensing, 15(20), 4907. https://doi.org/10.3390/rs15204907