


Embedded Yolo-Fastest V2-Based 3D Reconstruction and Size Prediction of Grain Silo-Bag

Abstract
:1. Introduction
2. Materials and Methods
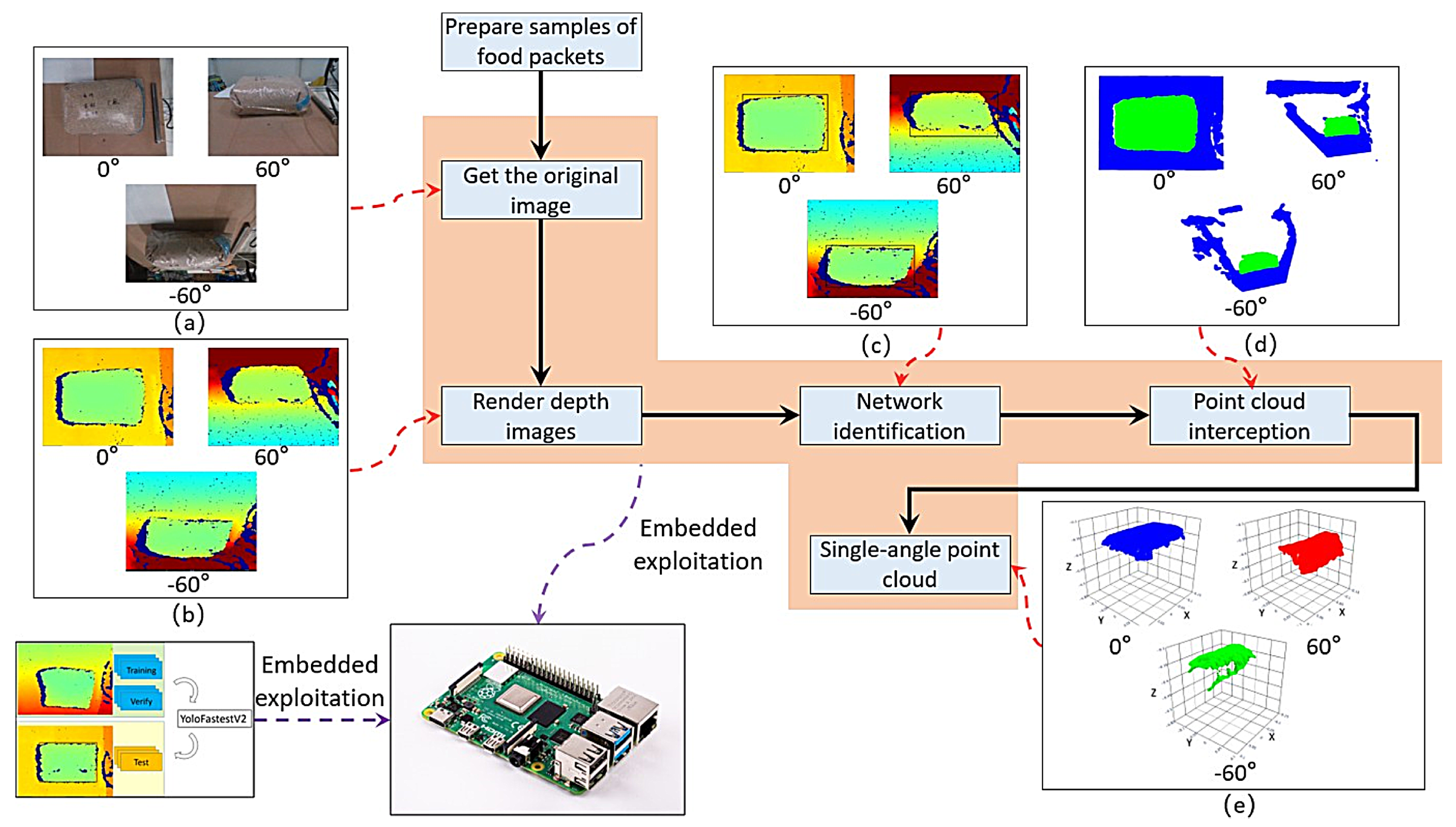
2.1. Image Acquisition System and Dataset Construction
2.2. Bagged-Grain Identification Model Selection
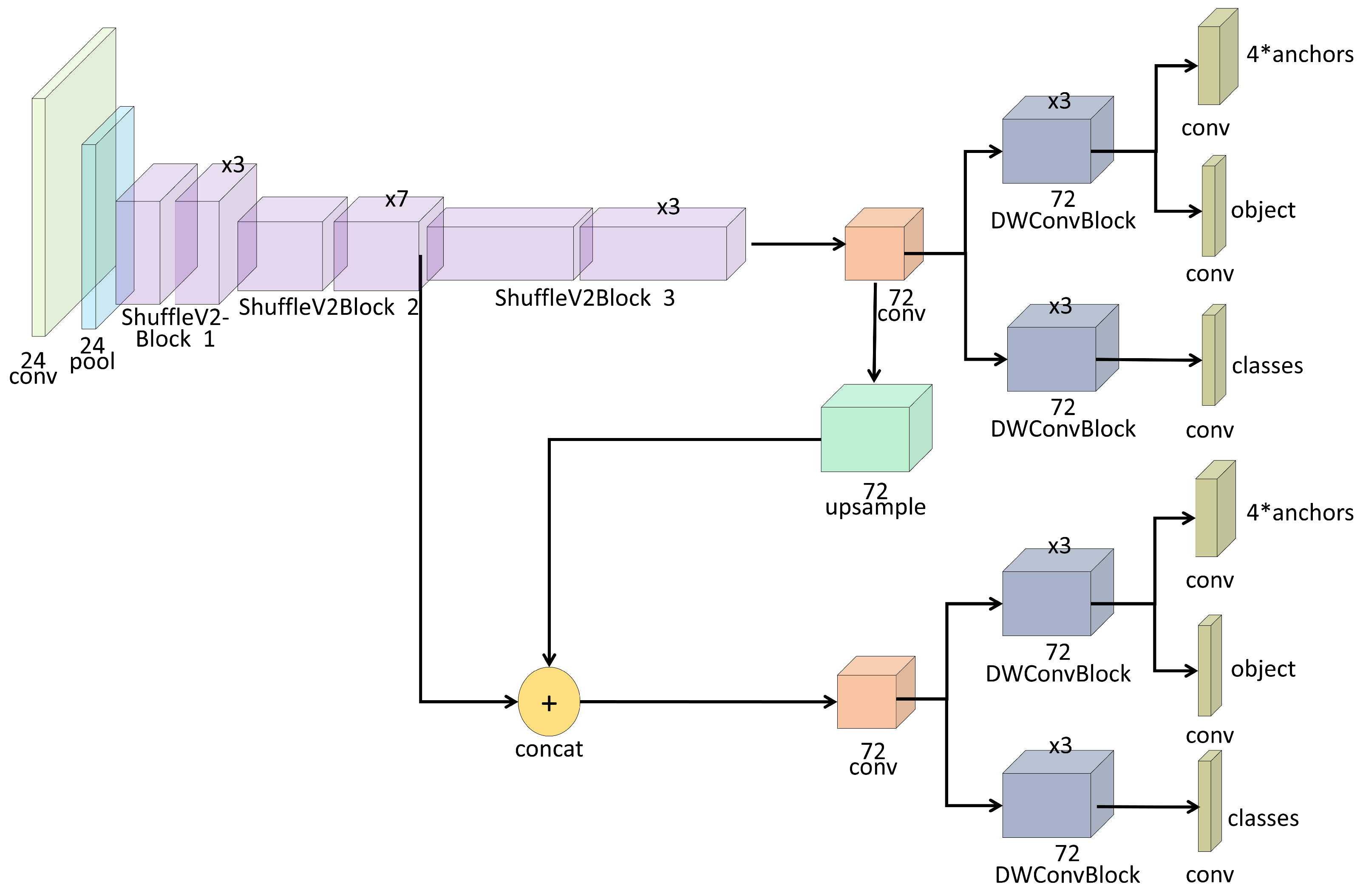
2.2.1. Yolo-Series Neural Networks Training and Model Selection
2.2.2. Yolo-Series Neural Networks Training
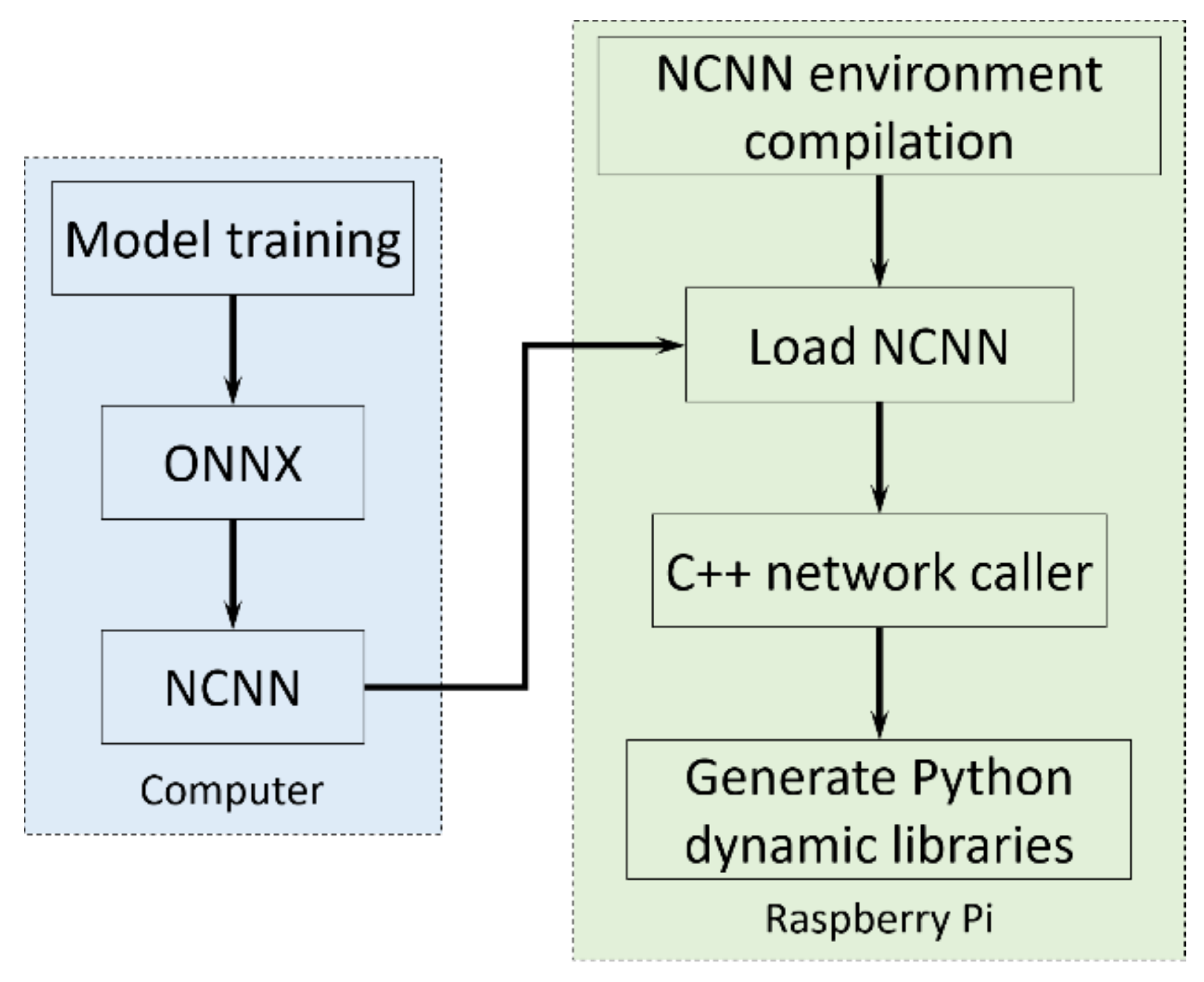
2.2.3. Yolo-Fastest V2 Acceleration on Embedded System
2.3. Three-Dimensional Reconstruction of Grain Bags
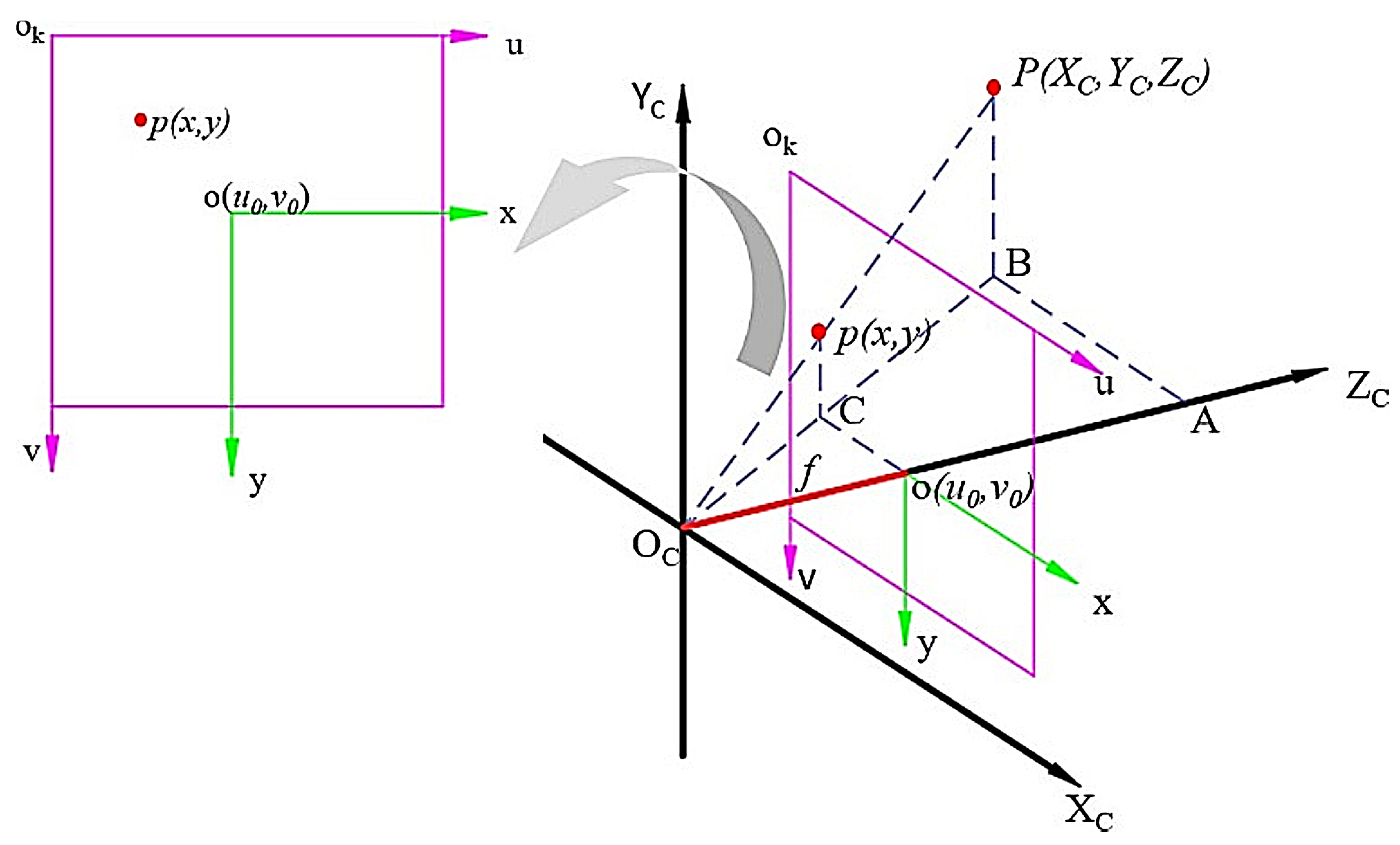
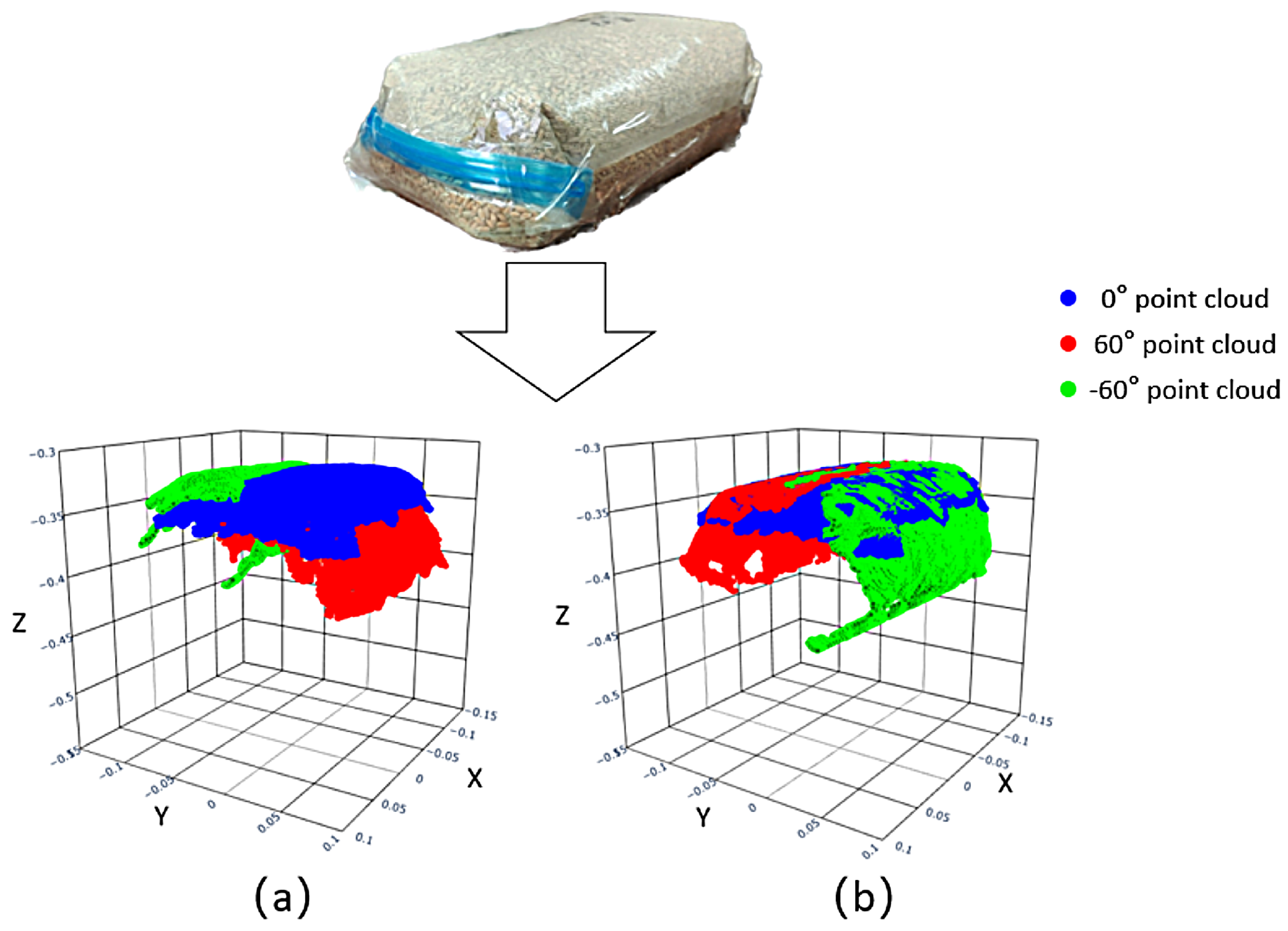
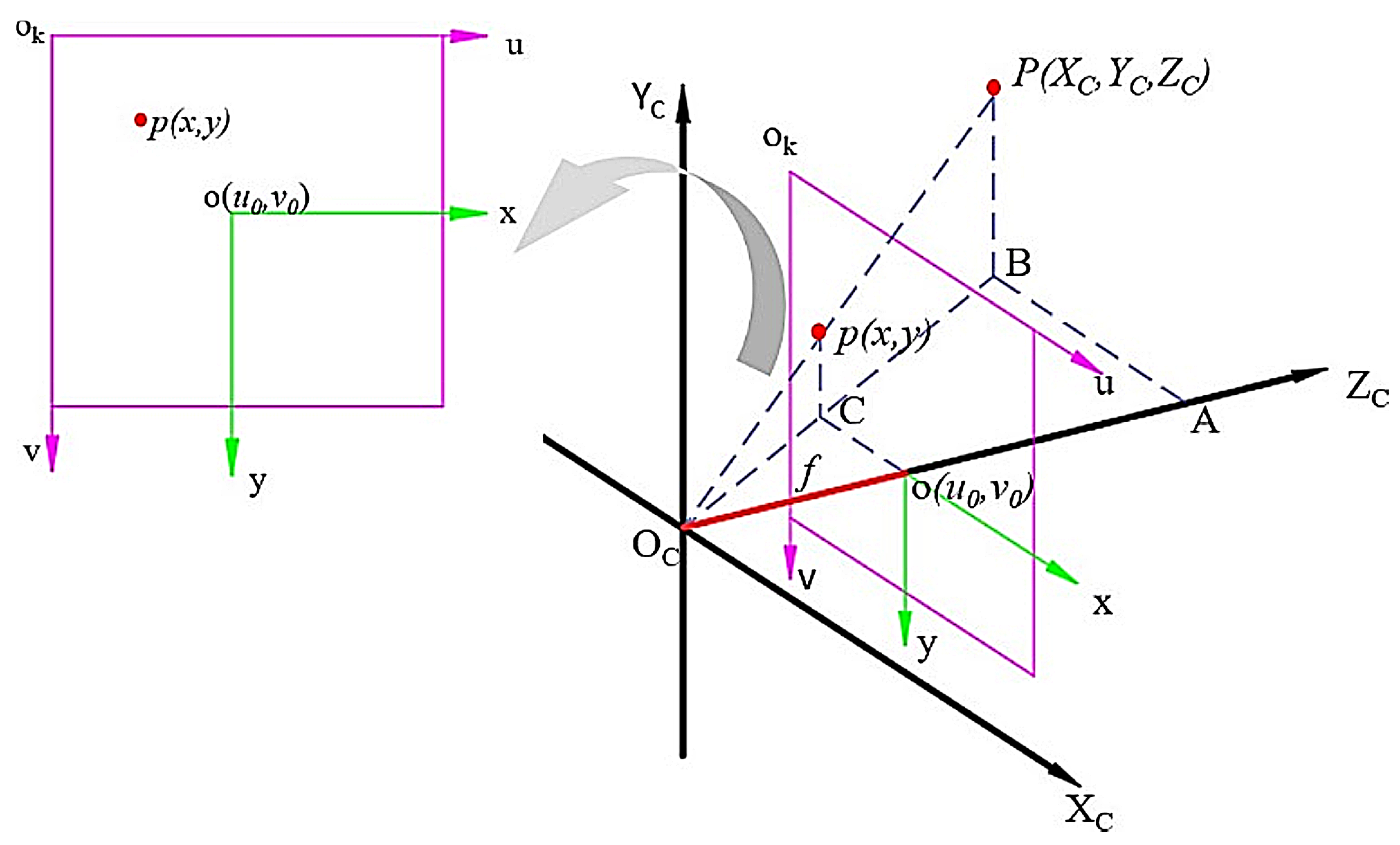
2.3.1. Single-Angle Point-Cloud Extraction Method
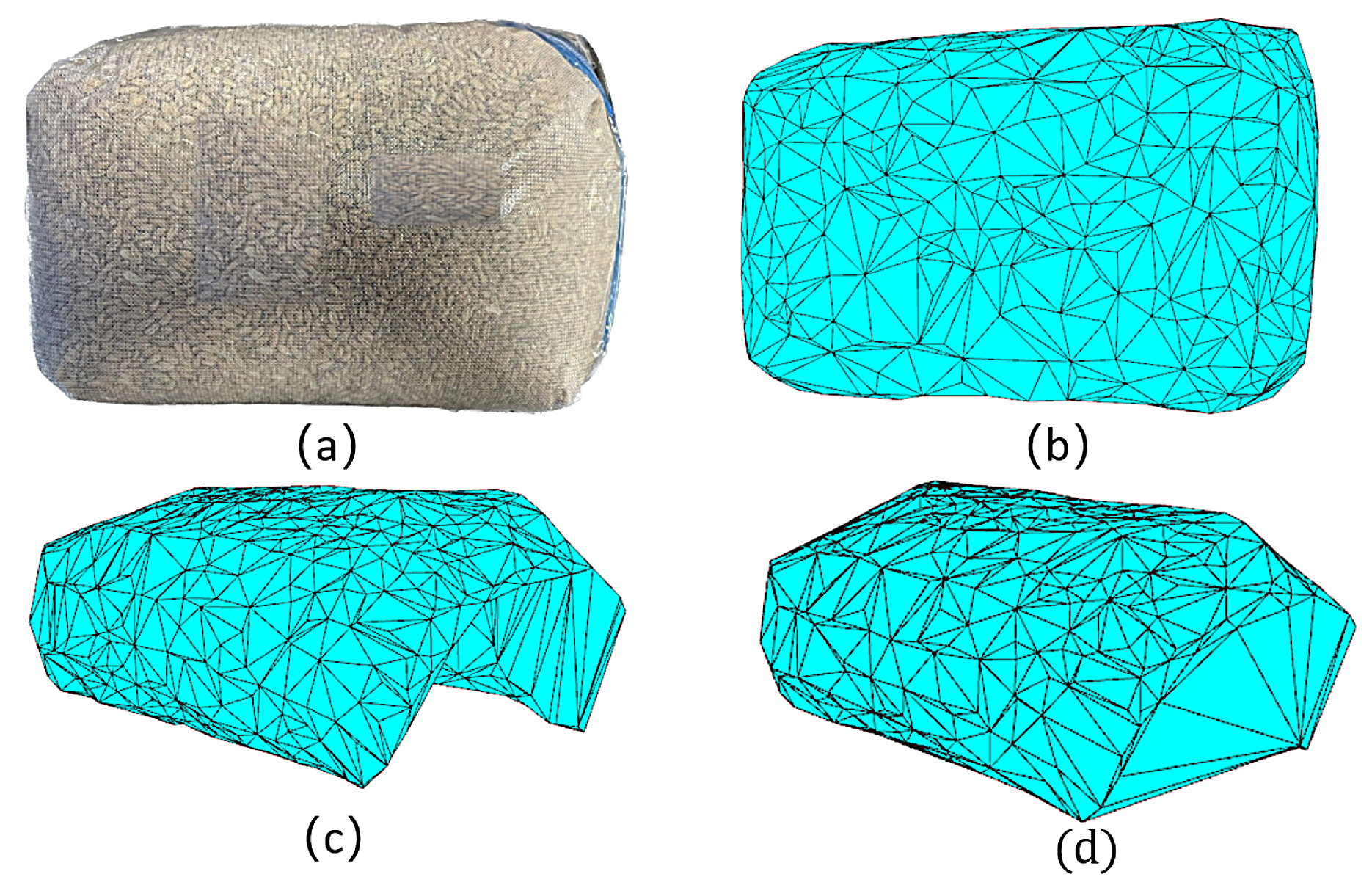
2.3.2. Multi-Angle Point-Cloud Fusion and Surface Reconstruction
3. Results and Discussion
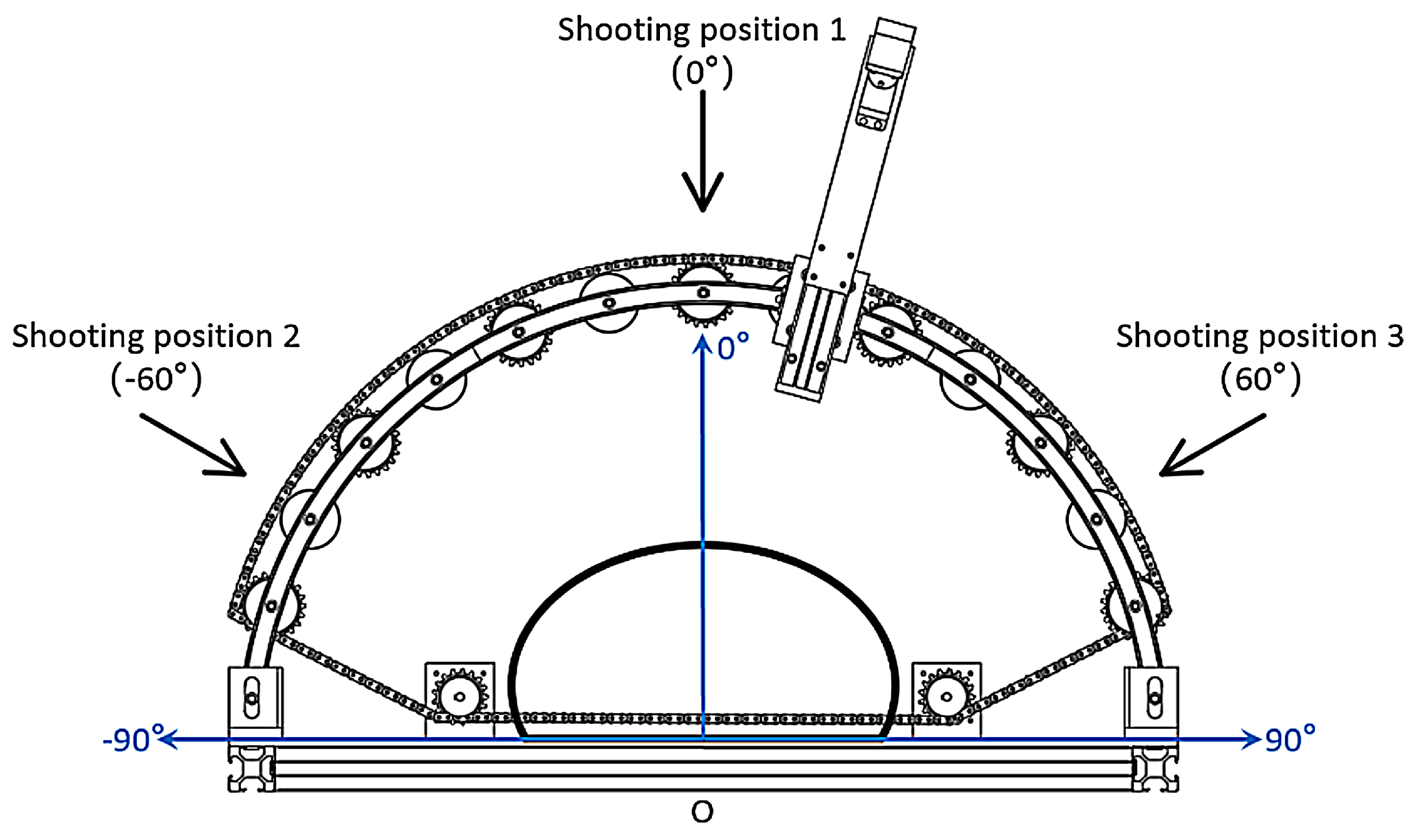
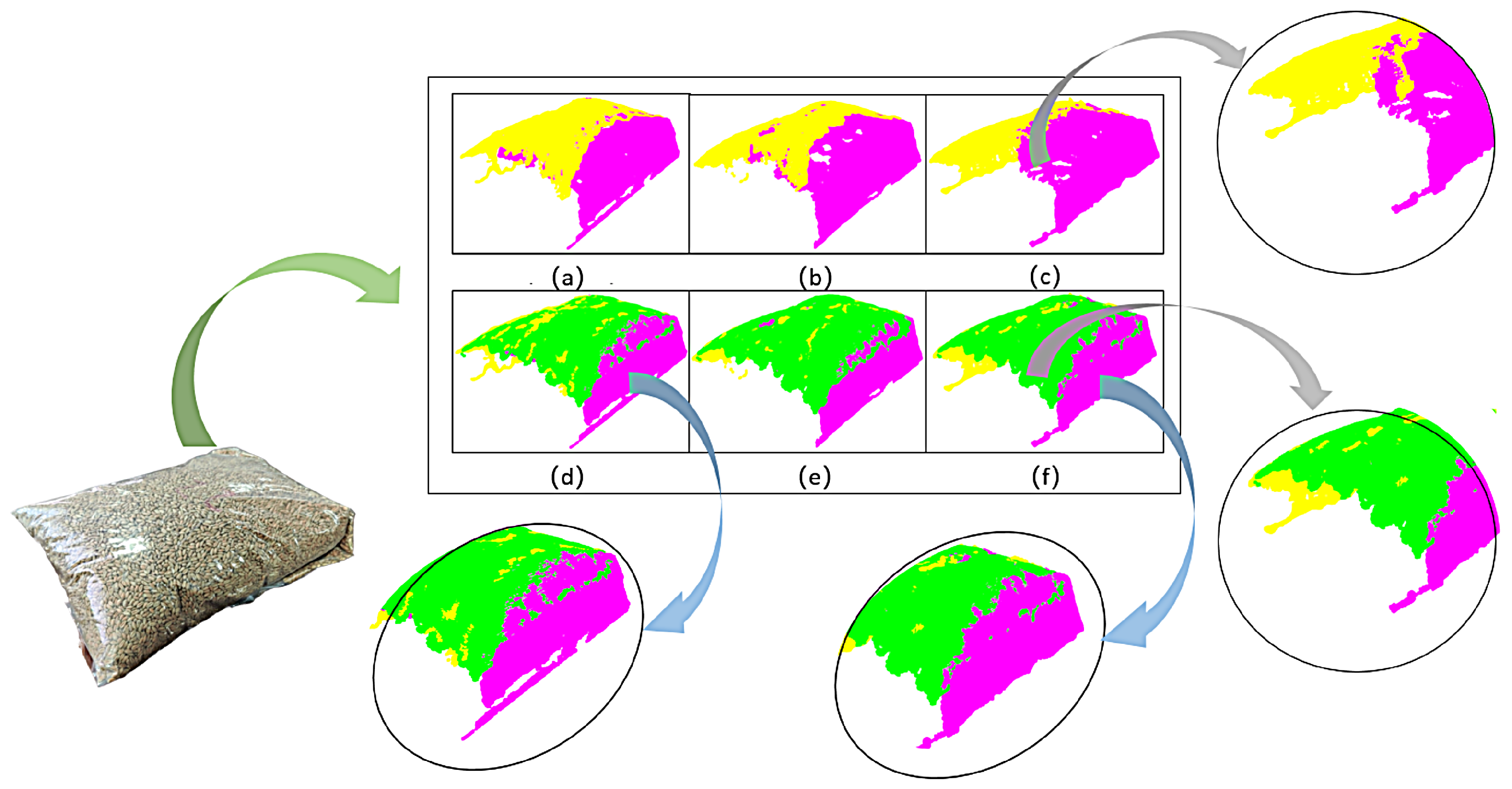
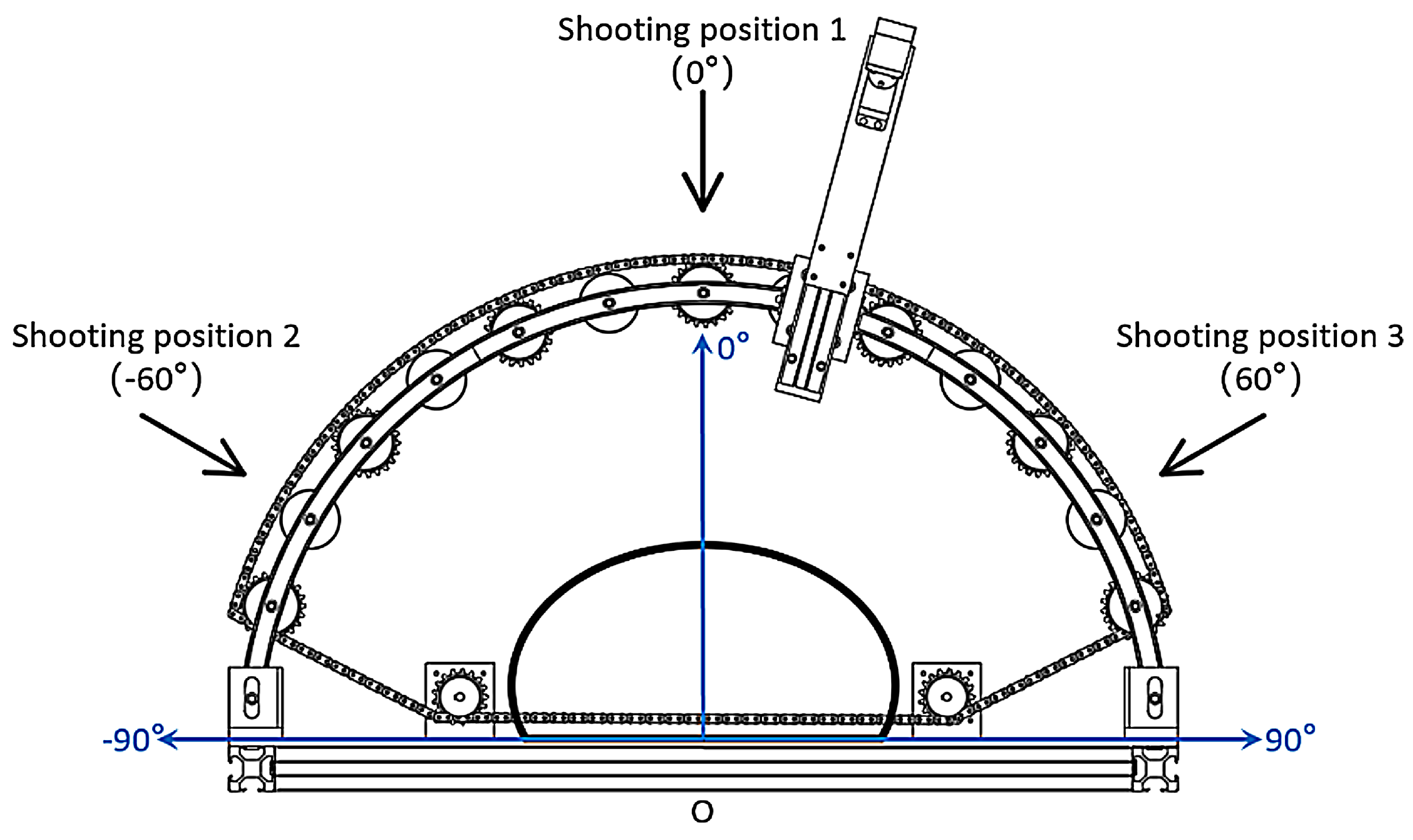
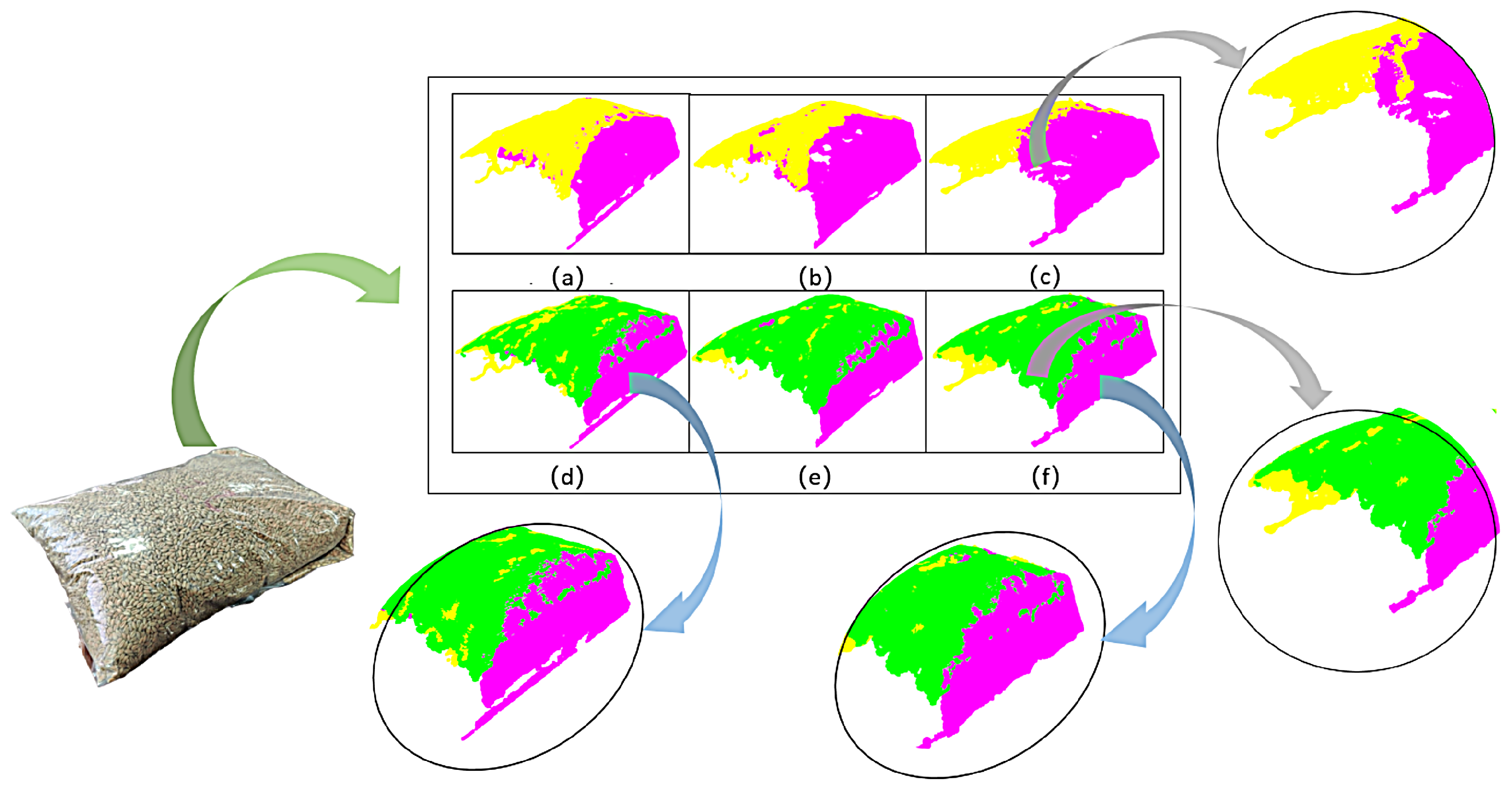
3.1. Optimal Camera Shooting Layout
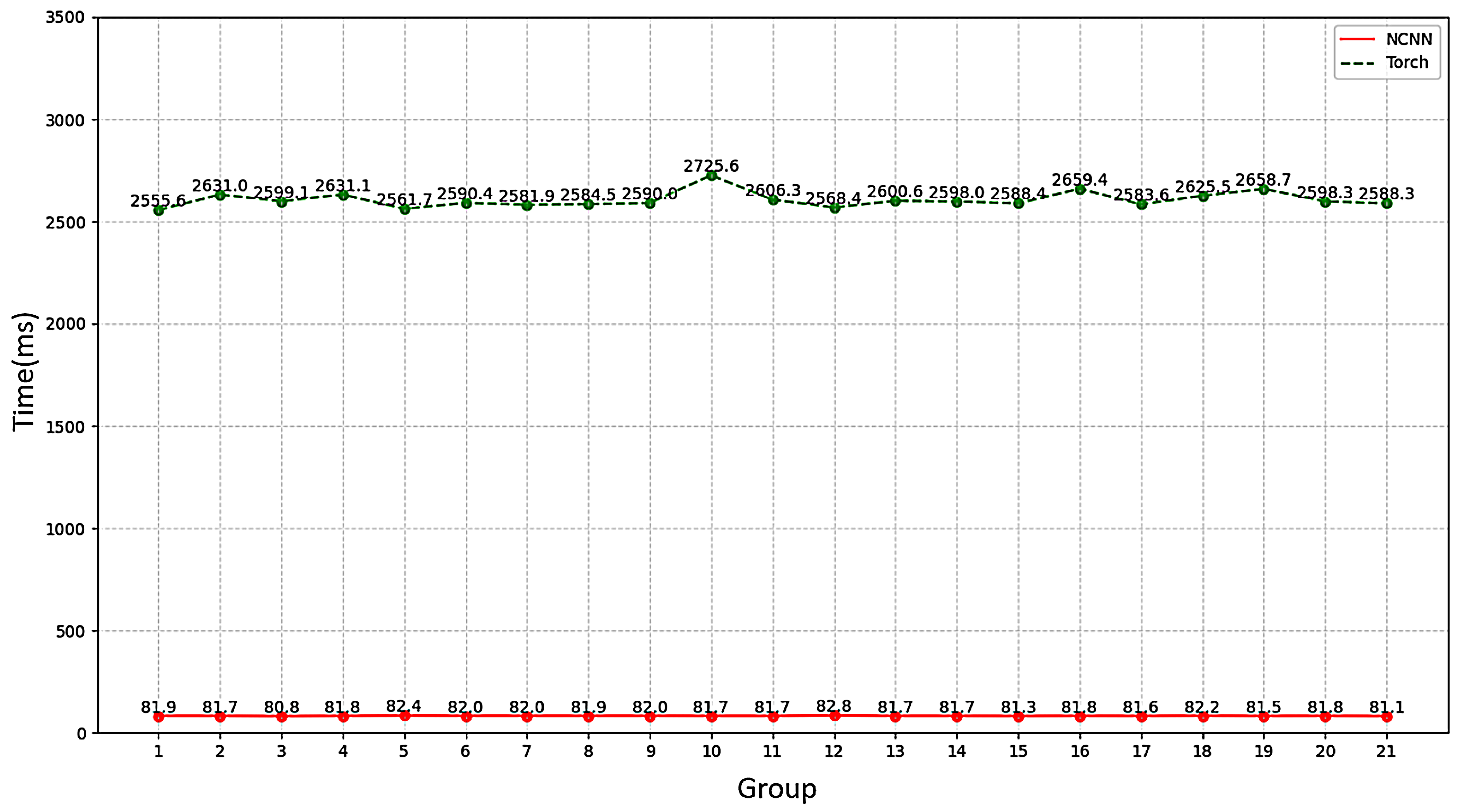
3.2. Yolo-Fastest V2 Recognition Speed and Recognition Effect
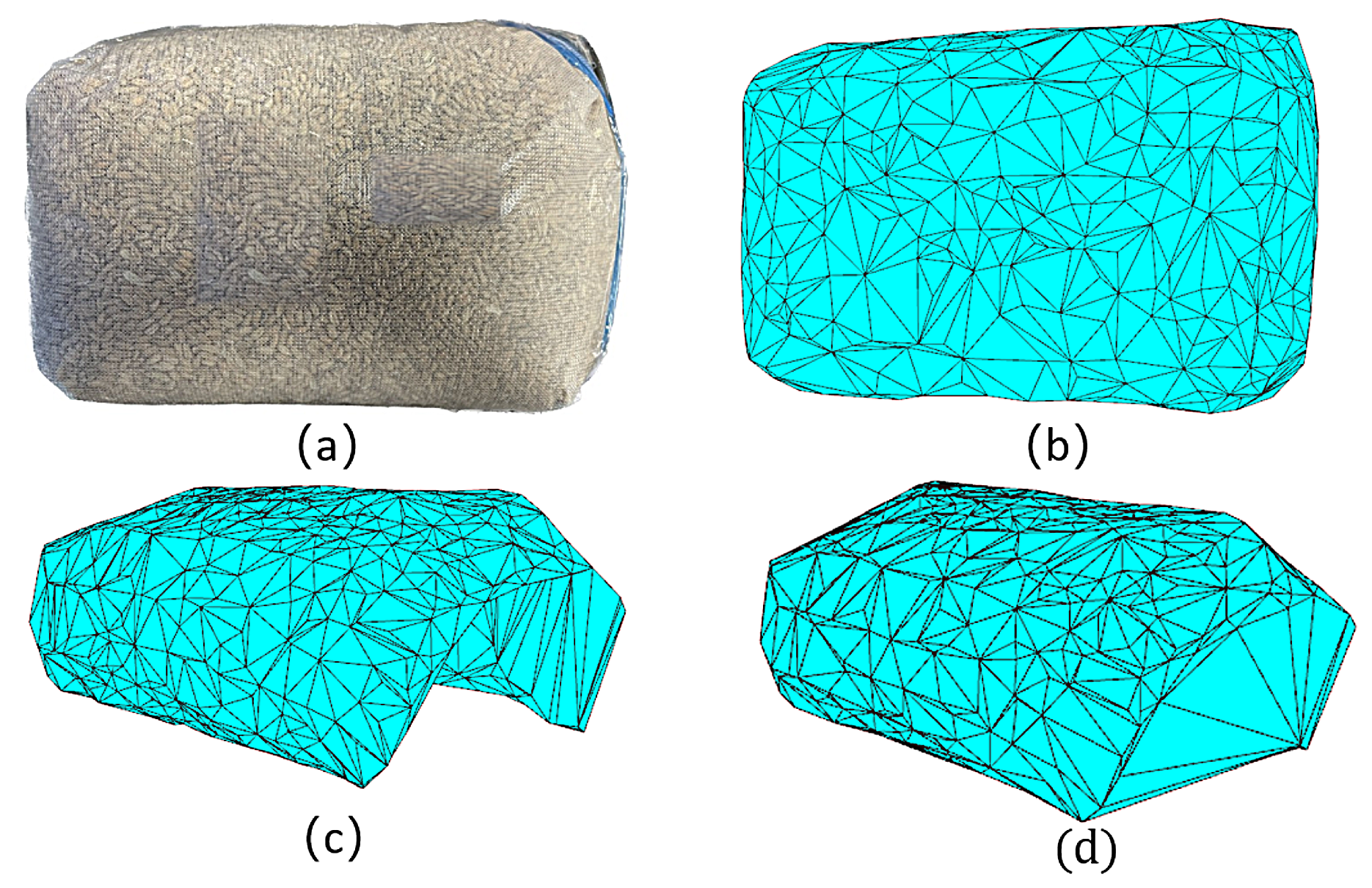
3.3. Point Cloud Extraction and 3D Reconstruction Results
4. Conclusions
- (1)
- This study trained six Yolo-series neural networks and comprehensively determined the most appropriate one for the system, known as the Yolo-Fastest V2 model. This study deployed the Yolo model on a Raspberry Pi board and introduced the NCNN model to accelerate the embedded system. Tests verified that the NCNN model-based embedded system spent 82 ms on average for processing each single frame image, which was nearly 30 times faster than the original embedded system. From this, this paper developed a novel point-cloud extraction method using the Yolo-Fastest V2 model. This study performed experiments and verified the method’s efficacy in removing interference and obtaining the grain bag point cloud at each shooting angle.
- (2)
- This work investigated the camera shooting layout by conducting 30 angle-combination layouts to reconstruct five different grain bags and determined the optimal one (−60°, 0°, 60°). Hence, this study constructed the rotation matrix to fuse multi-angle point clouds and merged the -shape three-dimensional surface reconstruction algorithm into the embedded system to derive a complete 3D model of the target under test. This work further achieved size prediction by obtaining the length, width, and height from the 3D model. The experimental results verified the proposed size prediction method that the averaged accuracies were greater than 96%; moreover, the root mean square error RMSE was less than 7 mm, the maximum residual value was less than 9 mm, and the coefficient of determination was greater than 0.92.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Promote the saving and loss reduction of grain transportation. China Finance 2022, 1, 28–29.
- Song, C. Analysis of Grain Storage Loss Causes and Loss Reduction Measures. Modern Food 2023, 29, 1–3. [Google Scholar]
- Han, W. Cause analysis of grain storage loss and countermeasures to reduce consumption and loss. Grain Food Ind. 2022, 29, 61–64. [Google Scholar]
- Liu, J.; Qiu, S. Development and application of portable detection device for grain moisture content based on microstrip microwave sensor. J. Food Saf. Qual. Insp. 2022, 13, 5485–5494. [Google Scholar]
- Liu, J.; Qiu, S.; Wei, Z. Real-time measurement of moisture content of paddy rice based on microstrip microwave sensor assisted by machine learning strategies. Chemosensors 2022, 10, 376. [Google Scholar] [CrossRef]
- Andujar, D.; Ribeiro, A. Using depth cameras to extract structural parameters to assess the growth state and yield of cauliflower crops. Comput. Electron. Agric. 2016, 122, 67–73. [Google Scholar] [CrossRef]
- Yin, Y.; Liu, G.; Li, S.; Zheng, Z.; Si, Y.; Wang, Y. A Method for Predicting Canopy Light Distribution in Cherry Trees Based on Fused Point Cloud Data. Remote Sens. 2023, 15, 2516. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, C.; Paterson, A. Quantitative analysis of cotton canopy size in field conditions using a consumer-grade RGB-D camera. Front. Plant Sci. 2018, 8, 2233. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Chen, Y. Fruit morphological measurement based on three-dimensional reconstruction. Agronomy 2020, 10, 455. [Google Scholar] [CrossRef]
- Xie, W.; Wei, S. Morphological measurement for carrot based on three-dimensional reconstruction with a ToF sensor. Postharvest. Biol. Technol. 2023, 197, 112216. [Google Scholar] [CrossRef]
- Zhang, L.; Xia, H.; Qiao, Y. Texture Synthesis Repair of RealSense D435i Depth Images with Object-Oriented RGB Image Segmentation. Sensors 2020, 20, 6725. [Google Scholar] [CrossRef] [PubMed]
- Jiang, P.; Ergu, D. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Lu, W.; Zou, M. Visual Recognition-Measurement-Location Technology for Brown Mushroom Picking Based on YOLO v5-TL. J. Agric. Mach. 2022, 53, 341–348. [Google Scholar]
- Jing, L.; Wang, R. Detection and positioning of pedestrians in orchard based on binocular camera and improved YOLOv3 algorithm. J. Agric. Mach. 2020, 51, 34–39+25. [Google Scholar]
- Elhassouny, A. Trends in deep convolutional neural Networks architectures: A review. In Proceedings of the 2019 International Conference of Computer Science and Renewable Energies, Agadir, Morocco, 22–24 July 2019; pp. 1–8. [Google Scholar]
- Wang, D.; Cao, W.; Zhang, F. A review of deep learning in multiscale agricultural sensing. Remote Sens. 2022, 14, 559. [Google Scholar] [CrossRef]
- Gonzalez-Huitron, V.; León-Borges, J. Disease detection in tomato leaves via CNN with lightweight architectures implemented in Raspberry Pi 4. Comput. Electron. Agric. 2021, 181, 105951. [Google Scholar] [CrossRef]
- Fan, W.; Hu, J.; Wang, Q. Research on mobile defective egg detection system based on deep learning. J. Agric. Mach. 2023, 54, 411–420. [Google Scholar]
- Zeng, T.; Li, S. Lightweight tomato real-time detection method based on improved YOLO and mobile deployment. Comput. Electron. Agric. 2023, 205, 107625. [Google Scholar] [CrossRef]
- Zhao, L.; Li, S. Object detection algorithm based on improved YOLOv3. Electronics 2020, 9, 537. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, X. A wheat spike detection method in UAV images based on improved YOLOv5. Remote Sens. 2021, 13, 3095. [Google Scholar] [CrossRef]
- Yung, N.; Wong, W. Safety helmet detection using deep learning: Implementation and comparative study using YOLOv5, YOLOv6, and YOLOv7. In Proceedings of the 2022 International Conference on Green Energy, Computing and Sustainable Technology, Miri Sarawak, Malaysia, 26–28 October 2022; pp. 164–170. [Google Scholar]
- Ji, W.; Pan, Y. A real-time apple targets detection method for picking robot based on ShufflenetV2-YOLOX. Agriculture 2022, 12, 856. [Google Scholar] [CrossRef]
- Wang, C.; Bochkovskiy, A. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Dog-qiuqiu/Yolo-FastestV2: Based on Yolo’s Low-Power, Ultra-Lightweight Universal Target Detection Algorithm, the Parameter is only 250k, and the Speed of the Smart Phone Mobile Terminal Can Reach 300fps+. Available online: https://github.com/dog-qiuqiu/Yolo-FastestV2github.com (accessed on 3 July 2022).
- Zhang, H.; Xu, D.; Cheng, D. An Improved Lightweight Yolo-Fastest V2 for Engineering Vehicle Recognition Fusing Location Enhancement and Adaptive Label Assignment. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 2450–2461. [Google Scholar] [CrossRef]
- Cao, C.; Wan, S.; Peng, G.; He, D.; Zhong, S. Research on the detection method of alignment beacon based on the spatial structure feature of train bogies. In Proceedings of the 2022 China Automation Congress, Chongqing, China, 2–4 December 2022; pp. 4612–4617. [Google Scholar]
- Wang, Y.; Bu, H.; Zhang, X. YPD-SLAM: A Real-Time VSLAM System for Handling Dynamic Indoor Environments. Sensors 2022, 22, 8561. [Google Scholar] [CrossRef]
- Chen, Z.; Yang, J.; Jiao, H. Garbage classification system based on improved ShuffleNet v2. Resour. Conserv. Recycl. 2022, 178, 106090. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, R.; Chen, Y.; Ding, S. A Fast bearing Fault diagnosis method based on lightweight Neural Network RepVGG. In Proceedings of the 4th International Conference on Advanced Information Science and System, Sanya, China, 25–27 November 2022; pp. 1–6. [Google Scholar]
- Li, J.; Li, Y.; Zhang, X.; Zhan, R. Application of mobile injection molding pump defect detection system based on deep learning. In Proceedings of the 2022 2nd International Conference on Consumer Electronics and Computer Engineering, Guangzhou, China, 14–16 January 2022; pp. 470–475. [Google Scholar]
- Yang, D.; Yang, L. Research and Implementation of Embedded Real-time Target Detection Algorithm Based on Deep Learning. J. Phys. Conf. Ser. 2022, 2216, 012103. [Google Scholar] [CrossRef]
- Lin, W.F.; Tsai, D.Y. Onnc: A compilation framework connecting onnx to proprietary deep learning accelerators. In Proceedings of the 2019 IEEE International Conference on Artificial Intelligence Circuits and Systems, Hsinchu, Taiwan, 18–20 March 2019; pp. 214–218. [Google Scholar]
- Peng, S.; Jiang, C. Shape as points: A differentiable poisson solver. Adv. Neural Inf. Process. Syst. 2021, 34, 13032–13044. [Google Scholar]
- Fu, Y.; Li, C.; Zhu, J. Alpha-shape Algorithm Constructs 3D Model of Jujube Tree Point Cloud. J. Agric. Eng. 2020, 36, 214–221. [Google Scholar]
- Huang, X.; Zheng, S.; Zhu, N. High-Throughput Legume Seed Phenotyping Using a Handheld 3D Laser Scanner. Remote Sens. 2022, 14, 431. [Google Scholar] [CrossRef]
- Cai, Z.; Jin, C.; Xu, J. Measurement of potato volume with laser triangulation and three-dimensional reconstruction. IEEE Access 2020, 8, 176565–176574. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Internet | mAP 1 (%) | Single Frame Detection Time (s) | Model Size (M) |
|---|---|---|---|
| Yolo v3 | 99.50 | 0.31 | 58.65 |
| Yolo v5 | 99.65 | 0.06 | 6.72 |
| Yolo v6 | 99.12 | 0.06 | 4.63 |
| YoloX | 95.45 | 0.16 | 8.94 |
| Yolo v7 | 99.56 | 0.18 | 8.71 |
| Yolo-Fastest V2 | 99.45 | 0.02 | 0.91 |
| Angle Combination | The Average Accuracy of the Model Size Reconstruction for Each Grain Package (%) | Average Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | ||
| (−10°, 10°) | 80.45 | 82.23 | 82.39 | 85.98 | 83.43 | 82.90 |
| (−20°, 20°) | 84.21 | 87.37 | 91.99 | 87.42 | 90.49 | 88.30 |
| (−30°, 30°) | 93.93 | 94.82 | 95.73 | 96.45 | 91.95 | 94.58 |
| (−40°, 40°) | 95.31 | 97.45 | 98.11 | 97.65 | 96.97 | 97.10 |
| (−50°, 50°) | 94.56 | 97.49 | 97.30 | 97.61 | 98.42 | 97.08 |
| (−60°, 60°) | 96.62 | 98.93 | 97.60 | 97.09 | 97.24 | 97.50 |
| (−10°, 0°, 10°) | 80.94 | 82.46 | 81.26 | 87.72 | 83.43 | 83.16 |
| (−20°, 0°, 20°) | 84.14 | 87.37 | 93.15 | 88.04 | 90.49 | 88.64 |
| (−30°, 0°, 30°) | 93.68 | 95.09 | 95.73 | 97.02 | 92.22 | 94.75 |
| (−40°, 0°, 40°) | 95.25 | 97.96 | 97.13 | 96.82 | 96.83 | 96.80 |
| (−50°, 0°, 50°) | 96.02 | 97.50 | 97.69 | 97.05 | 98.70 | 97.39 |
| (−60°, 0°, 60°) | 96.36 | 98.93 | 97.24 | 97.09 | 98.09 | 97.54 |
| (−40°, −10°, 10°, 40°) | 95.22 | 98.67 | 96.94 | 96.71 | 97.38 | 96.98 |
| (−50°, −10°, 10°, 50°) | 97.74 | 98.13 | 97.50 | 96.94 | 99.16 | 97.89 |
| (−60°, −10°, 10°, 60°) | 97.83 | 98.93 | 97.05 | 97.09 | 98.62 | 97.90 |
| (−40°, −20°, 20°, 40°) | 94.84 | 98.96 | 97.37 | 96.60 | 98.03 | 97.16 |
| (−50°, −20°, 20°, 50°) | 97.23 | 98.61 | 97.93 | 96.83 | 99.18 | 97.95 |
| (−60°, −20°, 20°, 60°) | 98.20 | 98.93 | 97.41 | 97.09 | 98.74 | 98.08 |
| (−40°, −30°, 30°, 40°) | 93.98 | 99.07 | 97.01 | 97.27 | 97.20 | 96.91 |
| (−50°, −30°, 30°, 50°) | 96.68 | 99.07 | 97.57 | 97.01 | 98.71 | 97.81 |
| (−60°, −30°, 30°, 60°) | 97.84 | 98.66 | 97.01 | 97.09 | 98.10 | 97.74 |
| (−40°, −10°, 0°, 10°, 40°) | 95.22 | 98.67 | 97.05 | 96.71 | 97.38 | 97.01 |
| (−50°, −10°, 0°, 10°, 50°) | 97.74 | 98.14 | 97.37 | 96.94 | 99.16 | 97.87 |
| (−60°, −10°, 0°, 10°, 60°) | 97.83 | 98.93 | 97.93 | 97.09 | 98.62 | 98.08 |
| (−40°, −20°, 0°, 20°, 40°) | 94.84 | 98.96 | 97.41 | 96.60 | 98.03 | 97.17 |
| (−50°, −20°, 0°, 20°, 50°) | 97.23 | 98.61 | 97.01 | 96.83 | 99.18 | 97.77 |
| (−60°, −20°, 0°.20°, 60°) | 98.20 | 98.93 | 97.57 | 97.09 | 98.74 | 98.11 |
| (−40°, −30°, 0°, 30°, 40°) | 94.11 | 99.34 | 97.01 | 97.20 | 97.47 | 97.03 |
| (−50°, −30°, 0°, 30°, 50°) | 96.68 | 99.07 | 97.57 | 97.01 | 98.98 | 97.86 |
| (−60°, −30°, 0°, 30°, 60°) | 97.72 | 98.66 | 96.94 | 97.09 | 98.37 | 97.75 |
| Place | Model | Recognition Time (ms) | ||||||
| Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | Group 6 | Group 7 | ||
| 0° | NCNN | 81.56 | 81.95 | 81.40 | 81.35 | 82.12 | 82.40 | 82.19 |
| Torch | 2550.13 | 2528.78 | 2639.19 | 2550.34 | 2550.49 | 2618.77 | 2626.05 | |
| 60° | NCNN | 80.46 | 80.85 | 80.34 | 81.51 | 83.33 | 80.71 | 81.80 |
| Torch | 2542.58 | 2659.31 | 2607.07 | 2727.88 | 2509.18 | 2563.88 | 2591.62 | |
| −60° | NCNN | 83.60 | 82.42 | 80.78 | 82.40 | 81.77 | 82.93 | 81.99 |
| Torch | 2567.95 | 2704.99 | 2551.16 | 2615.12 | 2625.32 | 2588.57 | 2528.04 | |
| Average time | NCNN | 81.87 | 81.74 | 80.84 | 81.75 | 82.41 | 82.01 | 81.99 |
| Torch | 2553.55 | 2631.02 | 2599.14 | 2631.11 | 2661.66 | 2590.41 | 2591.90 | |
| Place | Model | Recognition Time (ms) | ||||||
| Group 8 | Group 9 | Group 10 | Group 11 | Group 12 | Group 13 | Group 14 | ||
| 0° | NCNN | 81.82 | 82.68 | 81.89 | 81.86 | 81.76 | 81.25 | 82.40 |
| Torch | 2551.68 | 2618.47 | 2701.53 | 2529.37 | 2537.95 | 2532.29 | 2671.35 | |
| 60° | NCNN | 82.46 | 81.79 | 82.69 | 80.75 | 83.91 | 80.76 | 80.98 |
| Torch | 2623.25 | 2589.18 | 2759.84 | 2694.28 | 2598.16 | 2591.17 | 2526.22 | |
| −60° | NCNN | 81.35 | 81.46 | 80.39 | 82.35 | 82.86 | 83.10 | 81.58 |
| Torch | 2578.59 | 2562.29 | 2715.37 | 2595.19 | 2569.14 | 2678.23 | 2596.31 | |
| Average time | NCNN | 81.87 | 81.97 | 81.65 | 81.65 | 82.84 | 81.70 | 81.65 |
| Torch | 2584.50 | 2589.98 | 2725.58 | 2606.28 | 2568.42 | 2600.56 | 2597.96 | |
| Place | Model | Recognition Time (ms) | ||||||
| Group 15 | Group 16 | Group 17 | Group 18 | Group 19 | Group 20 | Group 21 | ||
| 0° | NCNN | 80.82 | 81.82 | 81.28 | 82.25 | 81.38 | 80.89 | 81.29 |
| Torch | 2592.25 | 2691.15 | 2567.79 | 2612.39 | 2701.42 | 2641.28 | 2554.71 | |
| 60° | NCNN | 80.47 | 80.41 | 80.57 | 81.59 | 81.36 | 81.86 | 80.70 |
| Torch | 2631.59 | 2612.34 | 2554.71 | 2618.23 | 2658.91 | 2596.32 | 2658.82 | |
| −60° | NCNN | 82.56 | 83.17 | 82.83 | 82.68 | 81.84 | 82.59 | 81.18 |
| Torch | 2541.24 | 2674.75 | 2628.38 | 2645.82 | 2615.76 | 2557.35 | 2551.26 | |
| Average time | NCNN | 81.28 | 81.80 | 81.56 | 82.17 | 81.53 | 81.78 | 81.06 |
| Torch | 2588.36 | 2659.41 | 2583.63 | 2625.48 | 2658.70 | 2598.32 | 2588.26 | |
| Group | Length (mm) | Precision (%) | Width (mm) | Precision (%) | Height (mm) | Precision (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Measured Value | Predicted Value | Error | Measured Value | Predicted Value | Error | Measured Value | Predicted Value | Error | ||||
| 1 | 153 | 151.94 | 1.06 | 99.42 | 155 | 158.31 | 3.31 | 97.86 | 85 | 87.82 | 2.82 | 96.68 |
| 2 | 225 | 233.06 | 8.06 | 96.42 | 190 | 187.93 | 2.07 | 98.91 | 90 | 94.64 | 4.64 | 94.84 |
| 3 | 240 | 248.53 | 8.53 | 96.45 | 180 | 187.31 | 7.31 | 95.94 | 90 | 88.43 | 1.57 | 98.26 |
| 4 | 235 | 243.12 | 8.12 | 96.54 | 160 | 167.32 | 7.32 | 95.43 | 105 | 107.13 | 2.13 | 97.97 |
| 5 | 240 | 234.71 | 5.29 | 97.80 | 170 | 177.11 | 7.11 | 95.82 | 104 | 110.94 | 6.94 | 93.33 |
| 6 | 205 | 210.43 | 5.43 | 97.35 | 175 | 180.12 | 5.12 | 97.07 | 118 | 120.32 | 2.32 | 98.03 |
| 7 | 240 | 235.65 | 4.35 | 98.19 | 226 | 232.64 | 6.64 | 97.06 | 127 | 130.96 | 3.96 | 96.88 |
| 8 | 235 | 239.42 | 4.42 | 98.11 | 175 | 168.72 | 6.28 | 96.41 | 105 | 100.28 | 4.72 | 95.51 |
| 9 | 283 | 277.32 | 5.68 | 97.99 | 225 | 228.83 | 3.83 | 98.30 | 98 | 96.42 | 1.58 | 98.39 |
| 10 | 235 | 241.21 | 6.21 | 97.36 | 195 | 203.78 | 8.78 | 95.50 | 85 | 86.91 | 1.91 | 97.75 |
| 11 | 220 | 226.34 | 6.34 | 97.12 | 185 | 189.96 | 4.96 | 97.32 | 89 | 92.97 | 3.97 | 95.54 |
| 12 | 210 | 206.33 | 3.67 | 98.25 | 185 | 190.62 | 5.62 | 96.96 | 95 | 93.29 | 1.71 | 98.2 |
| 13 | 174 | 170.61 | 3.39 | 98.05 | 167 | 163.79 | 3.21 | 98.07 | 78 | 75.46 | 2.54 | 96.74 |
| 14 | 165 | 169.45 | 4.45 | 97.30 | 150 | 155.32 | 5.32 | 96.45 | 83 | 85.38 | 2.38 | 97.13 |
| 15 | 186 | 183.78 | 2.22 | 98.81 | 177 | 171.58 | 5.42 | 96.94 | 109 | 102.69 | 6.31 | 94.21 |
| 16 | 250 | 256.21 | 6.21 | 96.75 | 212 | 215.46 | 3.46 | 98.11 | 102 | 99.89 | 2.11 | 97.93 |
| 17 | 248 | 244.56 | 3.44 | 98.61 | 192 | 196.34 | 4.34 | 97.74 | 121 | 117.36 | 3.64 | 96.99 |
| 18 | 251 | 255.56 | 4.56 | 98.18 | 215 | 209.47 | 5.53 | 97.07 | 94 | 96.73 | 2.73 | 97.09 |
| 19 | 256 | 251.12 | 4.88 | 98.09 | 197 | 190.14 | 6.86 | 96.52 | 86 | 88.06 | 2.06 | 97.60 |
| 20 | 263 | 267.45 | 4.45 | 98.31 | 230 | 221.76 | 8.24 | 96.42 | 81 | 84.38 | 3.38 | 95.83 |
| 21 | 272 | 277.71 | 5.71 | 97.90 | 220 | 225.47 | 5.47 | 97.51 | 112 | 106.84 | 2.16 | 98.07 |
| Average accuracy | 97.76 | 97.02 | 96.81 | |||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, S.; Mao, X.; Dai, D.; Wang, Z.; Chen, D.; Wang, S. Embedded Yolo-Fastest V2-Based 3D Reconstruction and Size Prediction of Grain Silo-Bag. Remote Sens. 2023, 15, 4846. https://doi.org/10.3390/rs15194846
Guo S, Mao X, Dai D, Wang Z, Chen D, Wang S. Embedded Yolo-Fastest V2-Based 3D Reconstruction and Size Prediction of Grain Silo-Bag. Remote Sensing. 2023; 15(19):4846. https://doi.org/10.3390/rs15194846
Chicago/Turabian StyleGuo, Shujin, Xu Mao, Dong Dai, Zhenyu Wang, Du Chen, and Shumao Wang. 2023. "Embedded Yolo-Fastest V2-Based 3D Reconstruction and Size Prediction of Grain Silo-Bag" Remote Sensing 15, no. 19: 4846. https://doi.org/10.3390/rs15194846
APA StyleGuo, S., Mao, X., Dai, D., Wang, Z., Chen, D., & Wang, S. (2023). Embedded Yolo-Fastest V2-Based 3D Reconstruction and Size Prediction of Grain Silo-Bag. Remote Sensing, 15(19), 4846. https://doi.org/10.3390/rs15194846