
An Enhanced Target Detection Algorithm for Maritime Search and Rescue Based on Aerial Images


Abstract
:1. Introduction
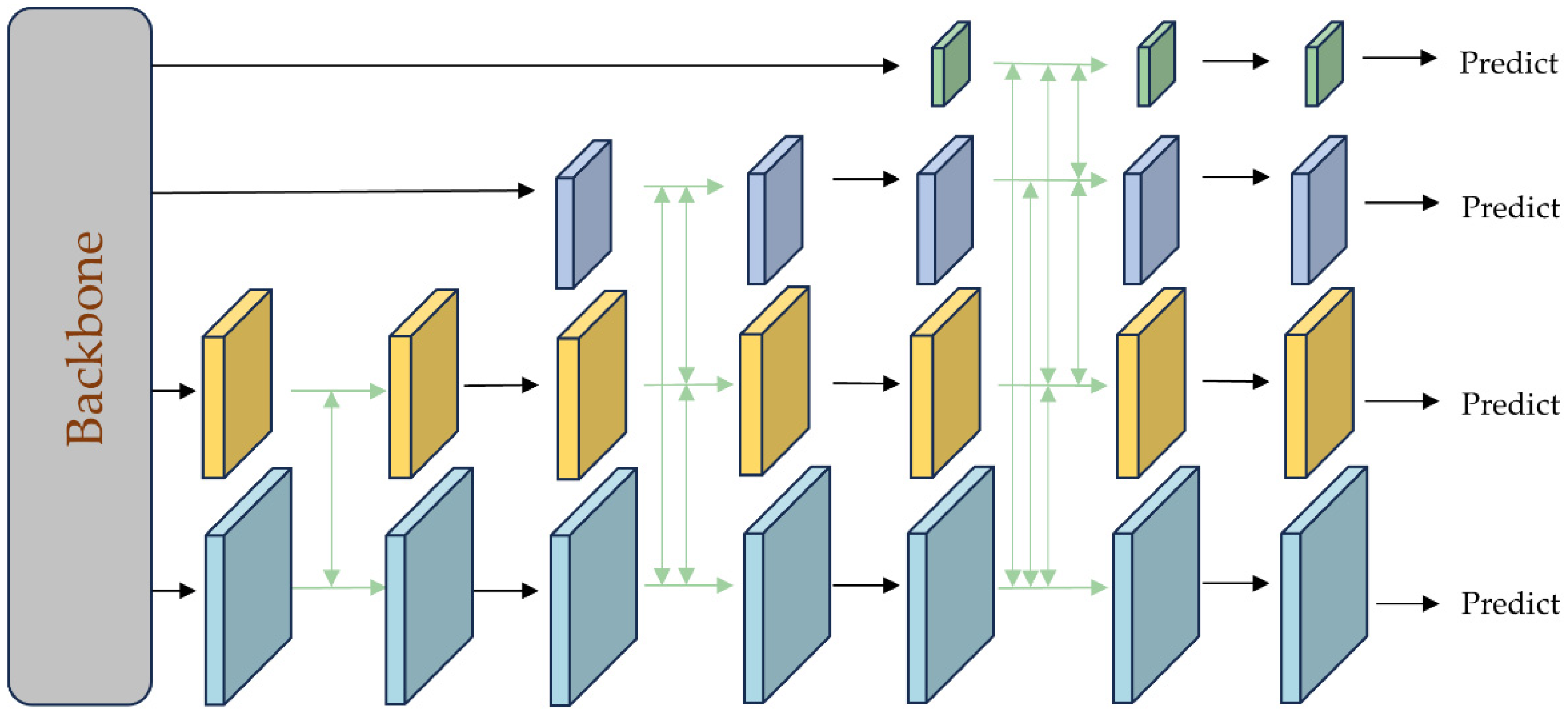
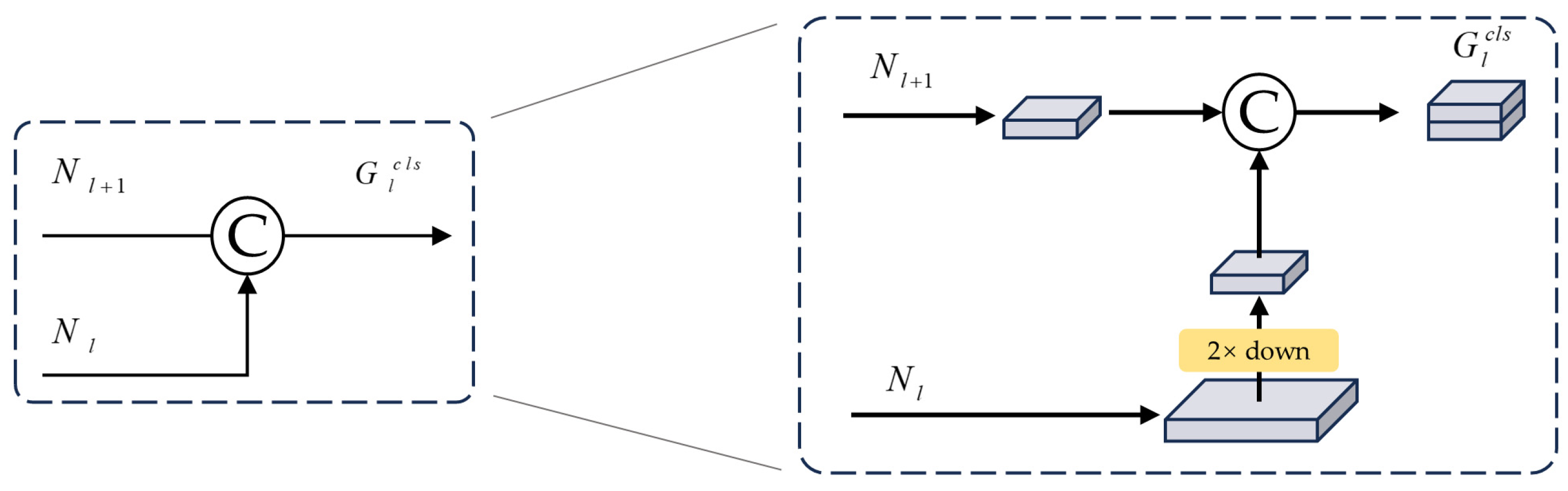
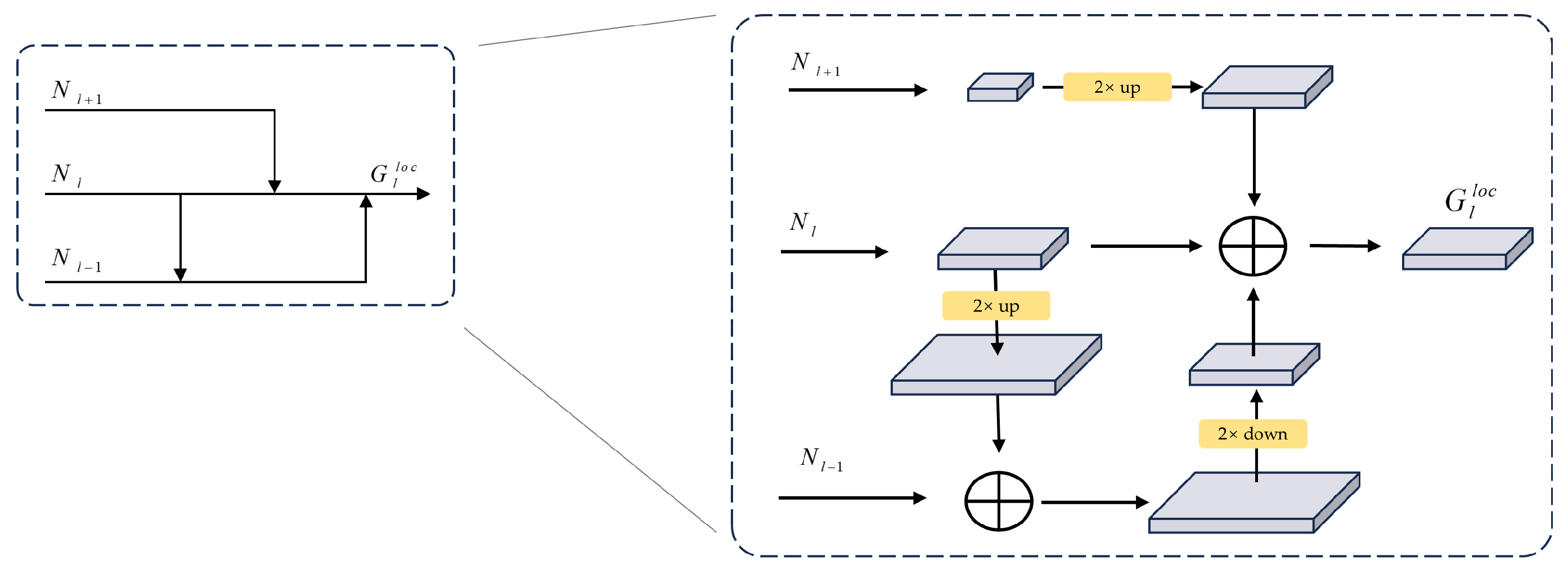
- The model’s feature extraction capability is via integrating an asymptotic feature pyramid network (AFPN). This architectural structure facilitates direct interaction between adjacent hierarchical levels, addresses semantic gaps, and mitigates information loss in the target features. The model retained detailed feature information even in low-light and high-contrast environments.
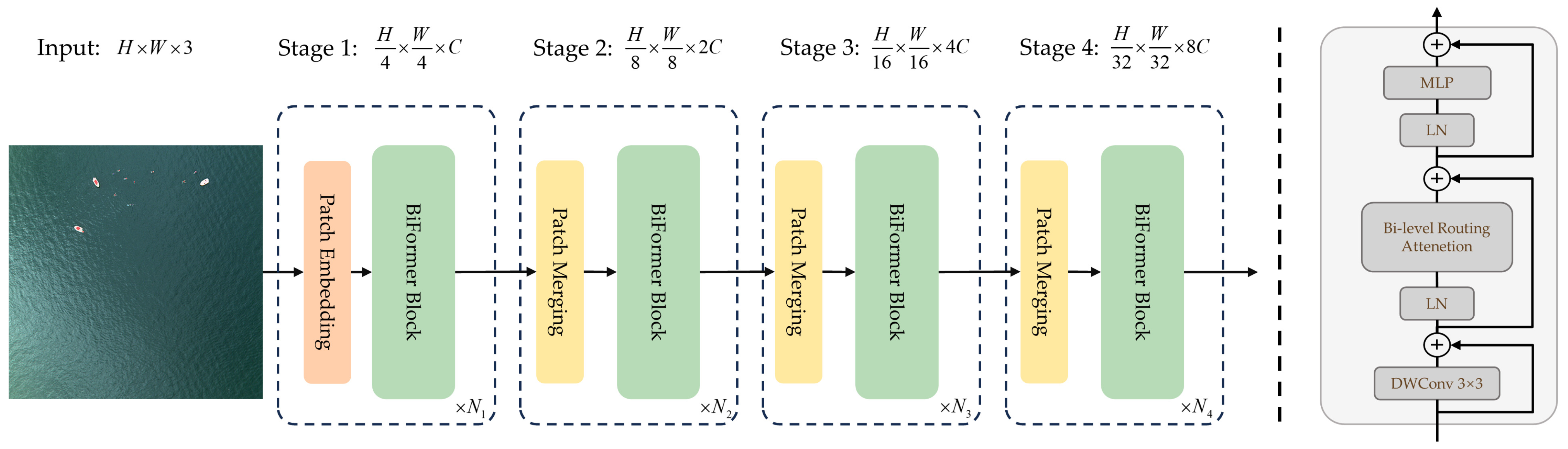
- To enhance the perception of small-scale targets in UAV image data, we introduced an attention module called BiFormer. This module leverages the mechanisms of adaptive computation allocation and content awareness, allowing it to prioritize image regions relevant to the targets, thus enhancing the ability of the model to perceive the characteristics of individuals in maritime distress within the UAV image data.
- To optimize the execution of the localization and classification tasks and to resolve the conflicts between them, we employed a decoupled detection head known as task-specific context decoupling (TSCODE). This approach replaces coupled detection heads, enabling separate execution of localization and classification tasks. Consequently, the accuracy and performance of the model in object detection were significantly enhanced.
2. Related Works
2.1. Object Detection
2.2. Object Detection Based on UAV Images
3. Materials and Methods
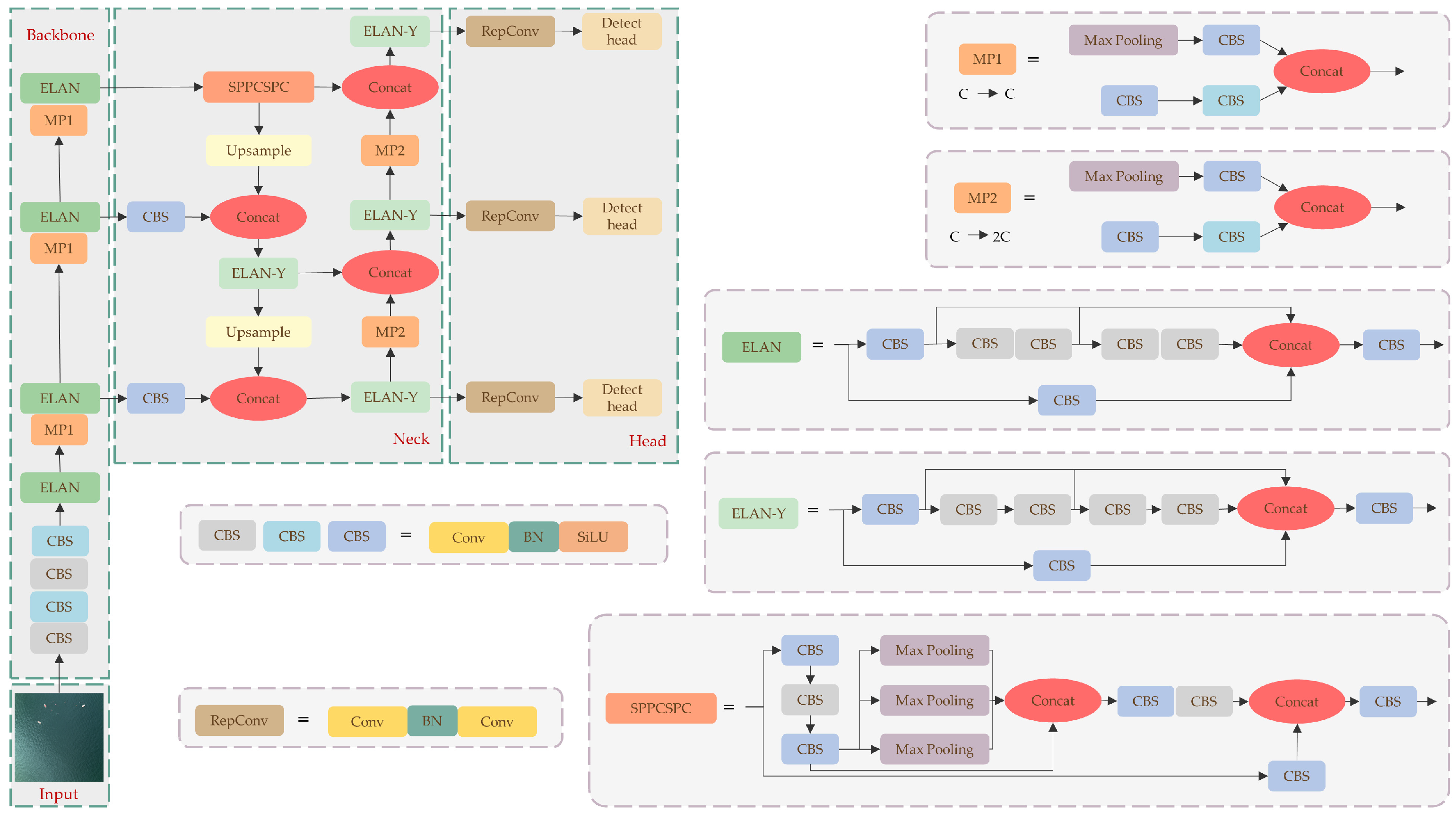
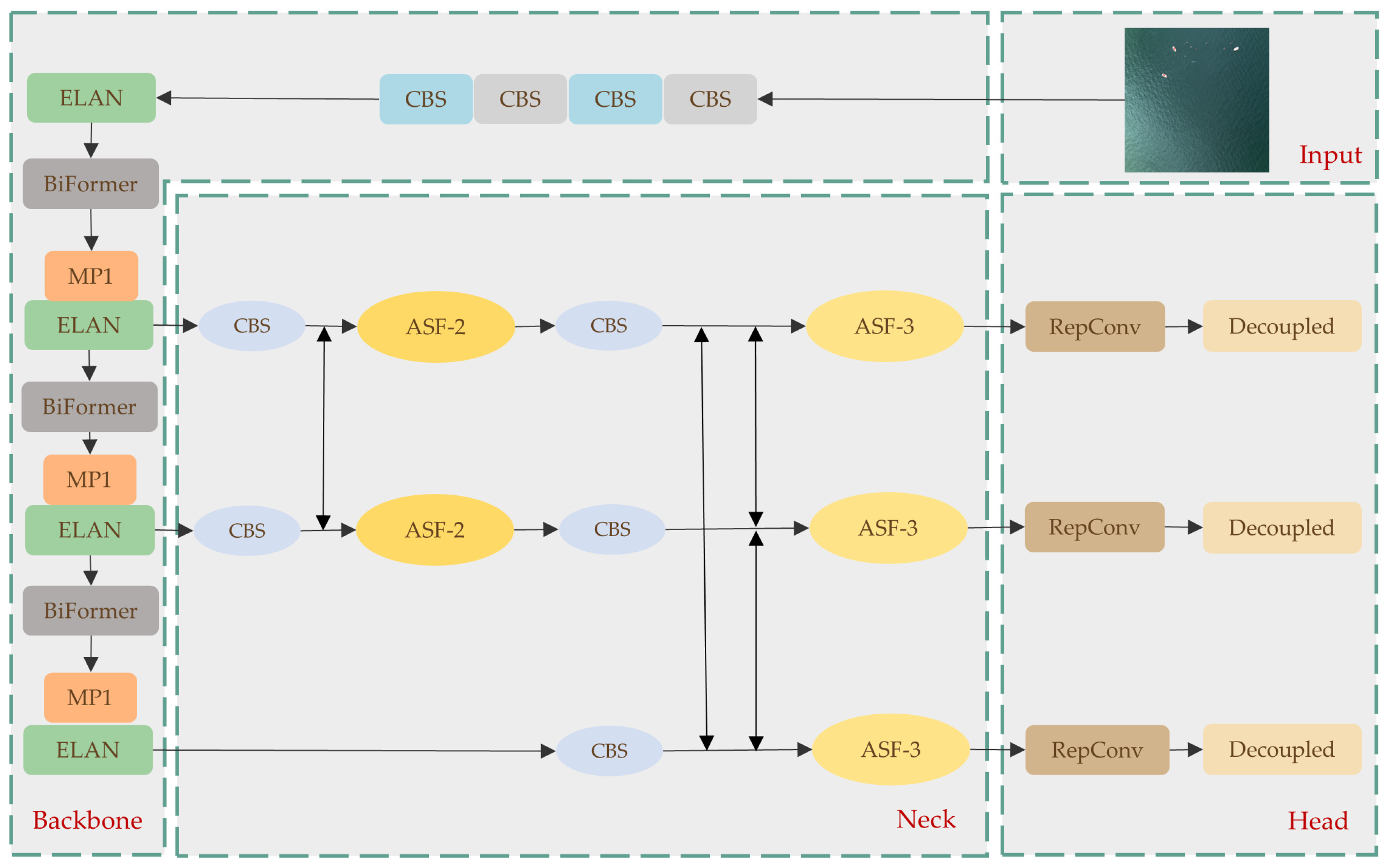
3.1. YOLOv7
3.2. Improvement
3.2.1. Improvement Based on AFPN
3.2.2. Improvement Based on BiFormer
3.2.3. Improvement Based on Decoupled Detection Head
4. Experiments
4.1. Dataset
4.2. Experimental Setup
4.3. Evaluation Metrics
4.4. Results Discussion
4.4.1. Fusion Attention Mechanism Comparison Test
4.4.2. Decoupled Detection Head Comparison Test
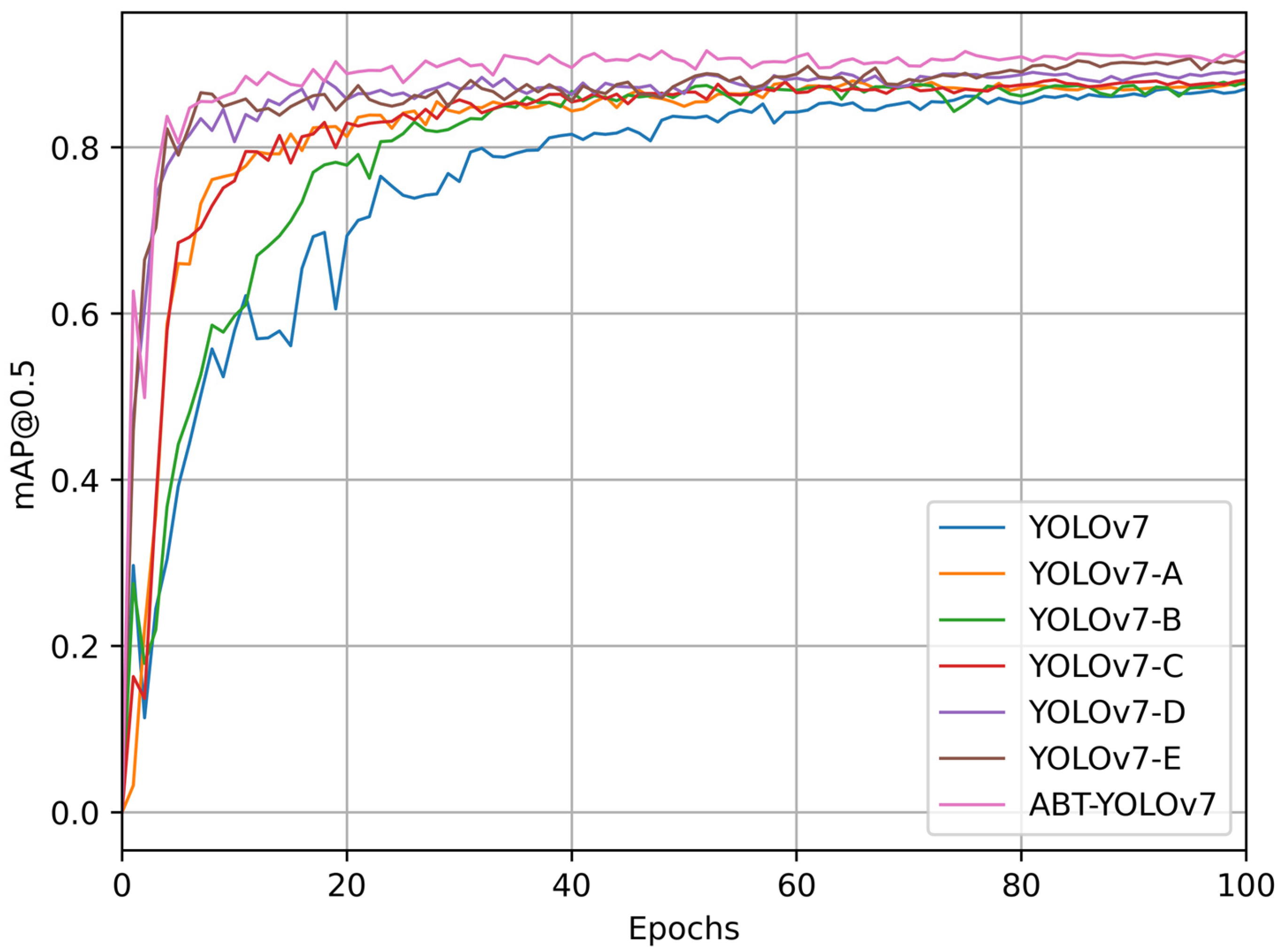
4.4.3. Ablation Test Comparison
- Analysis of experiments 1-3 revealed that the addition of each method improved model performance compared to YOLOv7. Among them, the inclusion of AFPN better preserved features of small-scale objects, resulting in a 0.5% improvement. The introduction of BiFormer enhanced the model’s ability to capture global information, leading to a 0.8% enhancement. The incorporation of TSCODE strengthened both classification and localization capabilities, contributing to a 1% performance boost.
- Experiments 4-5 demonstrated that combining AFPN with BiFormer and TSCODE resulted in 2% and 3.1% improvements, respectively, compared to YOLOv7, highlighting the highly effective detection enhancement brought by the introduction of decoupled heads.
- Building upon the summarized optimization methods, we developed an enhanced search and rescue algorithm tailored for man-overboard scenarios. This algorithm incorporates AFPN for neck feature fusion, integrates the attention mechanism from BiFormer, and leverages TSCODE’s decoupled detection head to generate the final output. In comparison to the original YOLOv7 model, our approach achieved a notable increase in mean average precision (mAP) by 4.5%.
4.4.4. Comparative of Different Object Detection Models
4.4.5. Results and Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Boursianis, A.D.; Papadopoulou, M.S.; Diamantoulakis, P.; Liopa-Tsakalidi, A.; Barouchas, P.; Salahas, G.; Karagiannidis, G.; Wan, S.; Goudos, S.K. Internet of Things (IoT) and Agricultural Unmanned Aerial Vehicles (UAVs) in Smart Farming: A Comprehensive Review. Internet Things 2022, 18, 100187. [Google Scholar] [CrossRef]
- Osco, L.P.; Marcato Junior, J.; Marques Ramos, A.P.; De Castro Jorge, L.A.; Fatholahi, S.N.; De Andrade Silva, J.; Matsubara, E.T.; Pistori, H.; Gonçalves, W.N.; Li, J. A Review on Deep Learning in UAV Remote Sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102456. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid Object Detection Using a Boosted Cascade of Simple Features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, pp. 511–518. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A Discriminatively Trained, Multiscale, Deformable Part Model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Abughalieh, K.M.; Sababha, B.H.; Rawashdeh, N.A. A Video-Based Object Detection and Tracking System for Weight Sensitive UAVs. Multimed. Tools Appl. 2019, 78, 9149–9167. [Google Scholar] [CrossRef]
- Baykara, H.C.; Biyik, E.; Gul, G.; Onural, D.; Ozturk, A.S.; Yildiz, I. Real-Time Detection, Tracking and Classification of Multiple Moving Objects in UAV Videos. In Proceedings of the 2017 IEEE 29th International Conference on Tools with Artificial Intelligence (ICTAI), Boston, MA, USA, 6–8 November 2017; pp. 945–950. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Gilroy, S.; Jones, E.; Glavin, M. Overcoming Occlusion in the Automotive Environment—A Review. IEEE Trans. Intell. Transport. Syst. 2021, 22, 23–35. [Google Scholar] [CrossRef]
- Song, Q.; Li, S.; Bai, Q.; Yang, J.; Zhang, X.; Li, Z.; Duan, Z. Object Detection Method for Grasping Robot Based on Improved YOLOv5. Micromachines 2021, 12, 1273. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.-J.; Lin, T.-N. DET: Depth-Enhanced Tracker to Mitigate Severe Occlusion and Homogeneous Appearance Problems for Indoor Multiple-Object Tracking. IEEE Access 2022, 10, 8287–8304. [Google Scholar] [CrossRef]
- Pu, H.; Chen, X.; Yang, Y.; Tang, R.; Luo, J.; Wang, Y.; Mu, J. Tassel-YOLO: A New High-Precision and Real-Time Method for Maize Tassel Detection and Counting Based on UAV Aerial Images. Drones 2023, 7, 492. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 18–23 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. ISBN 978-3-319-46447-3. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-Style ConvNets Great Again. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13728–13737. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detector. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Zhang, X.; Izquierdo, E.; Chandramouli, K. Dense and Small Object Detection in UAV Vision Based on Cascade Network. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 118–126. [Google Scholar]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. UAV-YOLO: Small Object Detection on Unmanned Aerial Vehicle Perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef] [PubMed]
- Ye, T.; Qin, W.; Li, Y.; Wang, S.; Zhang, J.; Zhao, Z. Dense and Small Object Detection in UAV-Vision Based on a Global-Local Feature Enhanced Network. IEEE Trans. Instrum. Meas. 2022, 71, 1–13. [Google Scholar] [CrossRef]
- Akshatha, K.R.; Karunakar, A.K.; Satish Shenoy, B.; Phani Pavan, K.; Dhareshwar, C.V.; Johnson, D.G. Manipal-UAV Person Detection Dataset: A Step towards Benchmarking Dataset and Algorithms for Small Object Detection. ISPRS J. Photogramm. Remote Sens. 2023, 195, 77–89. [Google Scholar] [CrossRef]
- Wu, W.; Fan, X.; Qu, H.; Yang, X.; Tjahjadi, T. TCDNet: Tree Crown Detection From UAV Optical Images Using Uncertainty-Aware One-Stage Network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Qiu, Q.; Lau, D. Real-Time Detection of Cracks in Tiled Sidewalks Using YOLO-Based Method Applied to Unmanned Aerial Vehicle (UAV) Images. Autom. Constr. 2023, 147, 104745. [Google Scholar] [CrossRef]
- Shao, Y.; Zhang, X.; Chu, H.; Zhang, X.; Zhang, D.; Rao, Y. AIR-YOLOv3: Aerial Infrared Pedestrian Detection via an Improved YOLOv3 with Network Pruning. Appl. Sci. 2022, 12, 3627. [Google Scholar] [CrossRef]
- Qin, Z.; Wang, W.; Dammer, K.-H.; Guo, L.; Cao, Z. Ag-YOLO: A Real-Time Low-Cost Detector for Precise Spraying With Case Study of Palms. Front. Plant Sci. 2021, 12, 753603. [Google Scholar] [CrossRef] [PubMed]
- Safonova, A.; Hamad, Y.; Alekhina, A.; Kaplun, D. Detection of Norway Spruce Trees (Picea Abies) Infested by Bark Beetle in UAV Images Using YOLOs Architectures. IEEE Access 2022, 10, 10384–10392. [Google Scholar] [CrossRef]
- Kainz, O.; Dopiriak, M.; Michalko, M.; Jakab, F.; Nováková, I. Traffic Monitoring from the Perspective of an Unmanned Aerial Vehicle. Appl. Sci. 2022, 12, 7966. [Google Scholar] [CrossRef]
- Souza, B.J.; Stefenon, S.F.; Singh, G.; Freire, R.Z. Hybrid-YOLO for Classification of Insulators Defects in Transmission Lines Based on UAV. Int. J. Electr. Power Energy Syst. 2023, 148, 108982. [Google Scholar] [CrossRef]
- Tran, T.L.C.; Huang, Z.-C.; Tseng, K.-H.; Chou, P.-H. Detection of Bottle Marine Debris Using Unmanned Aerial Vehicles and Machine Learning Techniques. Drones 2022, 6, 401. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, X.; Li, J.; Luan, K. A YOLO-Based Target Detection Model for Offshore Unmanned Aerial Vehicle Data. Sustainability 2021, 13, 12980. [Google Scholar] [CrossRef]
- Lu, Y.; Guo, J.; Guo, S.; Fu, Q.; Xu, J. Study on Marine Fishery Law Enforcement Inspection System Based on Improved YOLO V5 with UAV. In Proceedings of the 2022 IEEE International Conference on Mechatronics and Automation (ICMA), Guilin, Guangxi, China, 7–10 August 2022; pp. 253–258. [Google Scholar]
- Zhao, J.; Chen, Y.; Zhou, Z.; Zhao, J.; Wang, S.; Chen, X. Multiship Speed Measurement Method Based on Machine Vision and Drone Images. IEEE Trans. Instrum. Meas. 2023, 72, 1–12. [Google Scholar] [CrossRef]
- Bai, J.; Dai, J.; Wang, Z.; Yang, S. A Detection Method of the Rescue Targets in the Marine Casualty Based on Improved YOLOv5s. Front. Neurorobot. 2022, 16, 1053124. [Google Scholar] [CrossRef]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic Feature Pyramid Network for Object Detection. arXiv 2023, arXiv:2306.15988. [Google Scholar]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R. BiFormer: Vision Transformer with Bi-Level Routing Attentio. arXiv 2023, arXiv:2303.08810. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Zhuang, J.; Qin, Z.; Yu, H.; Chen, X. Task-Specific Context Decoupling for Object Detection. arXiv 2023, arXiv:2303.01047. [Google Scholar]
- Cafarelli, D.; Ciampi, L.; Vadicamo, L.; Gennaro, C.; Berton, A.; Paterni, M.; Benvenuti, C.; Passera, M.; Falchi, F. MOBDrone: A Drone Video Dataset for Man OverBoard Rescue. In Image Analysis and Processing—ICIAP 2022; Sclaroff, S., Distante, C., Leo, M., Farinella, G.M., Tombari, F., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2022; Volume 13232, pp. 633–644. ISBN 978-3-031-06429-6. [Google Scholar]
- Varga, L.A.; Kiefer, B.; Messmer, M.; Zell, A. SeaDronesSee: A Maritime Benchmark for Detecting Humans in Open Water. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 3686–3696. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Name | Type |
|---|---|---|
| Hardware | CPU | Intel(R) Xeon(R) Bronze 3204 |
| GPU | NVIDIA A100-PCIE-40GB | |
| Memory | 64GB | |
| Software | CUDA | 11.7 |
| Python | 3.8.16 | |
| Anaconda | 2.3.1.0. | |
| PyTorch | 2.0.1. | |
| Hyperparameters | Image Size | 1280 × 1280 |
| Learning Rate | 0.01 | |
| Learning Rate Decay Frequency | 0.1 | |
| Batch Size | 16 | |
| Workers | 8 | |
| Maximum Training Epochs | 100 |
| Detector | Precision (%) | Recall (%) | mAP (%) |
|---|---|---|---|
| YOLOv7 | 87.5 | 84.9 | 87.1 |
| YOLOv7_Head | 87.9 | 85.1 | 87.3 |
| YOLOv7_Neck | 89.1 | 87.6 | 87.7 |
| YOLOv7_Backbone | 89.5 | 88.5 | 87.9 |
| Detector | Precision (%) | Recall (%) | mAP (%) |
|---|---|---|---|
| YOLOv7 | 87.5 | 84.9 | 87.1 |
| YOLOv7_YOLOX | 88.2 | 86.4 | 87.5 |
| YOLOv7_TSCODE | 89.8 | 89.0 | 88.1 |
| Detector | AFPN | BiFormer | TSCODE | Precision (%) | Recall (%) | mAP (%) |
|---|---|---|---|---|---|---|
| YOLOv7 | 87.5 | 84.9 | 87.1 | |||
| YOLOv7_A | ✓ | 88.9 | 86.1 | 87.6 | ||
| YOLOv7_B | ✓ | 89.5 | 88.5 | 87.9 | ||
| YOLOv7_C | ✓ | 89.8 | 89.0 | 88.1 | ||
| YOLOv7_D | ✓ | ✓ | 89.7 | 89.3 | 89.1 | |
| YOLOv7_E | ✓ | ✓ | 92.5 | 89.2 | 90.2 | |
| ABT-YOLOv7 | ✓ | ✓ | ✓ | 92.3 | 91.7 | 91.6 |
| Detector | Precision (%) | Recall (%) | mAP (%) | Parameters/M | FPS |
|---|---|---|---|---|---|
| Faster RCNN | 56.8 | 43.4 | 48.5 | 108 | 4.3 |
| Cascade R-CNN | 87.9 | 86.3 | 86.4 | 68.2 | 3.7 |
| FCOS | 87.4 | 80.2 | 85.7 | 32.1 | 4.8 |
| YOLOv3 | 86.1 | 82.5 | 85.1 | 61.5 | 9.6 |
| YOLOv4 | 87.6 | 79.7 | 84.6 | 52.5 | 18.8 |
| YOLOv5 | 88.7 | 85.6 | 86.1 | 46.2 | 10.6 |
| YOLOv8 | 87.0 | 80.1 | 84.4 | 87.6 | 3.3 |
| ABT-YOLOv7 | 92.3 | 91.7 | 91.6 | 52.4 | 7.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Yin, Y.; Shao, Z. An Enhanced Target Detection Algorithm for Maritime Search and Rescue Based on Aerial Images. Remote Sens. 2023, 15, 4818. https://doi.org/10.3390/rs15194818
Zhang Y, Yin Y, Shao Z. An Enhanced Target Detection Algorithm for Maritime Search and Rescue Based on Aerial Images. Remote Sensing. 2023; 15(19):4818. https://doi.org/10.3390/rs15194818
Chicago/Turabian StyleZhang, Yijian, Yong Yin, and Zeyuan Shao. 2023. "An Enhanced Target Detection Algorithm for Maritime Search and Rescue Based on Aerial Images" Remote Sensing 15, no. 19: 4818. https://doi.org/10.3390/rs15194818
APA StyleZhang, Y., Yin, Y., & Shao, Z. (2023). An Enhanced Target Detection Algorithm for Maritime Search and Rescue Based on Aerial Images. Remote Sensing, 15(19), 4818. https://doi.org/10.3390/rs15194818