Abstract
In the realm of remote sensing image analysis, the task of road extraction poses significant complexities, especially in the context of intricate scenes and diminutive targets. In response to these challenges, we have developed a novel deep learning network, christened CDAU-Net, designed to discern and delineate these features with enhanced precision. This network takes its structural inspiration from the fundamental architecture of U-Net while introducing innovative enhancements: we have integrated CoordConv convolutions into both the initial layer of the U-Net encoder and the terminal layer of the decoder, thereby facilitating a more efficacious processing of spatial information inherent in remote sensing images. Moreover, we have devised a unique mechanism termed the Deep Dual Cross Attention (DDCA), purposed to capture long-range dependencies within images—a critical factor in remote sensing image analysis. Our network replaces the skip-connection component of the U-Net with this newly designed mechanism, dealing with feature maps of the first four scales in the encoder and generating four corresponding outputs. These outputs are subsequently linked with the decoder stage to further capture the remote dependencies present within the remote sensing imagery. We have subjected CDAU-Net to extensive empirical validation, including testing on the Massachusetts Road Dataset and DeepGlobe Road Dataset. Both datasets encompass a diverse range of complex road scenes, making them ideal for evaluating the performance of road extraction algorithms. The experimental results showcase that whether in terms of accuracy, recall rate, or Intersection over Union (IoU) metrics, the CDAU-Net outperforms existing state-of-the-art methods in the task of road extraction. These findings substantiate the effectiveness and superiority of our approach in handling complex scenes and small targets, as well as in capturing long-range dependencies in remote sensing imagery. In sum, the design of CDAU-Net not only enhances the accuracy of road extraction but also presents new perspectives and possibilities for deep learning analysis of remote sensing imagery.
1. Introduction
Roads, as key constituents of modern transportation infrastructure, hold indispensable practical significance in areas such as traffic navigation [1], autonomous driving [2], route planning [3], traffic management [4], and updating geographic information systems [5]. The rapid progression of remote sensing technology has led to constant enhancements in the quality of high-resolution remote sensing image data [6], thereby providing ample resources for the study of terrain information extraction [7]. However, the precision and efficiency of extracting road information from remote sensing images pose formidable challenges. These are due, in part, to the phenomena of spectral diversity for identical objects [8] and spectral similarity for different objects [9], both of which notably complicate image processing. Additionally, the variability in the scale, shape, and color of roads necessitates the development of advanced algorithms for their identification and extraction [10]. To overcome these challenges, we introduce a model based on convolutional neural networks and a deep dual cross-attention mechanism, termed CDAU-Net, which has demonstrated superior precision and stability compared to existing methods in comparative experiments for road extraction tasks involving remote sensing images.
Several advanced algorithms have been proposed for tasks like road network extraction or road area segmentation [11,12,13], yet their performance may falter when dealing with specific road types or image resolutions. This instability or identification failure becomes especially evident when confronted with intricate image scenes or challenging road conditions. From a machine-learning perspective, road extraction tasks can be viewed as binary classification problems, separating roads from the background [14]. The recent stellar performance of deep learning in computer vision tasks has led researchers to favor deep learning methods for tackling road extraction tasks. However, these works often simplify road extraction as a semantic segmentation issue, disregarding the intrinsic structure of roads [15]. In traditional computer vision tasks such as image classification, the spatial resolution is often high, ranging from hundreds to thousands of pixels per dimension. In contrast, remote sensing images, even those termed ‘High Spatial Resolution’ (HSR), may have a relatively lower spatial resolution, where each pixel could represent a much larger ground area, often spanning several meters. This disparity in spatial resolution suggests that road segmentation networks need larger receptive fields to effectively capture adequate contextual information. Additionally, the intricate and narrow road structures in these remote-sensing images necessitate the preservation of fine-grained image features for precise segmentation. However, conventional Convolutional Neural Networks (CNNs) are limited in this aspect, as their receptive fields are generally defined by the dimensions of their convolutional kernels [16]. Fortunately, recent studies suggest that the Transformer architecture holds significant potential for tackling these issues [17]. Its self-attention mechanism can better establish long-distance dependencies, facilitating the utilization of global information at different layers [18]. Consequently, our motivation is to introduce the Attention mechanism into road extraction tasks, which may further enhance segmentation performance.
Based on these discussions, we developed a unique CDAU-Net architecture for extracting road networks from high-resolution remote sensing images. This architecture amalgamates a deep dual cross-attention mechanism with CoordConv, employing standard convolutional operations, CoordConv operations, depth-wise convolutions, point-wise convolutions, and hybrid operations for the dual cross-attention mechanism. This mechanism examines the relative position relationships and long-distance dependencies of pixels in remote-sensing images. The resultant multiscale feature maps are sensibly combined to form high-quality feature maps for predicting precise road networks. Key contributions of the proposed architecture include:
- (1)
- Substituting the first layer of convolution in the U-Net network encoder and the last layer of the decoder with CoordConv convolution: This facilitates the introduction of spatial coordinate information of pixels, enabling a better understanding of spatial structures and relationships in image processing, which subsequently enhances road extraction accuracy [19];
- (2)
- Innovative Integration of Deep Dual Cross-Attention and Skip Connections: We deploy a state-of-the-art DDCA mechanism, in amalgamation with depth-wise separable convolutions, to dramatically minimize the computational overhead while concurrently preserving channel-wise and spatial features. Additionally, this mechanism substitutes certain skip connections in the architecture, aiding the model in learning intricate interactions among features across scales and enabling their weighted fusion for enhanced task performance.
Our research employs the CDAU-Net network for experimentation on the Massachusetts road and DeepGlobe datasets. Both datasets encompass a variety of complex road scenes, making them ideal choices for assessing road extraction algorithm performance. Overall, the main contribution of this paper lies in proposing a novel road extraction model, CDAU-Net, which not only preserves the advantages of CNN and Transformer but also successfully addresses multiscale and long-distance dependency issues by incorporating CoordConv convolution and a deep dual cross-attention mechanism. Experimental validation shows that CDAU-Net surpasses existing methods in terms of road extraction accuracy and stability, providing an important contribution to progress in this field.
The rest of this paper is structured as follows. Section 2 provides an overview of previous work related to road extraction and delineates the differences between our method and related techniques. Section 3 presents a detailed description of the CDAU-Net network architecture and design. Section 4 introduces the datasets used in the experiments and the experimental details, followed by an analysis. Section 5 thoroughly assesses our model’s performance in various test scenarios and compares it with current leading methods. We delve into the model’s strengths and potential limitations, including the influence of various factors on the results, such as the resolution of remote sensing images and image complexity. The conclusion (Section 6) summarizes our research findings and key contributions. Specifically, we discuss how our novel approach, which combines Deep Separable Convolution with Dual Cross-Attention Mechanism, advances the state of road extraction techniques. This architecture addresses the limitations commonly encountered in traditional CNN-based and Transformer-based models, thereby improving both efficiency and accuracy in road extraction tasks.
2. Related Work
In recent years, a substantial body of research has been conducted internationally on high-resolution remote sensing image road extraction, with a variety of methodologies proposed for different application domains of road information [20]. Traditional road extraction methods, such as spectral analysis [21], threshold segmentation [10], regional methods [22], and knowledge model methods [23], are effective yet typically require extensive manual intervention. This labor-intensive process is time-consuming and unable to meet the demands of modern, large-scale automated processing.
The rapid development of deep learning has seen the emergence of Convolutional Neural Networks (CNNs) and Transformer-based methods, significantly advancing the field of road extraction [20]. These deep learning-based methods exhibit superior adaptability and feature-fitting capabilities compared to traditional methods, greatly enhancing both the accuracy and degree of automation in road extraction. CNNs, with their powerful learning and representation abilities, can automatically extract abstract semantic features from raw data. Liu and others proposed a method based on CNNs to learn structural features from raw data [24]. Long and colleagues introduced the Fully Convolutional Network (FCN), an adaptation of the CNN model that dispenses with the fully connected layer, enabling end-to-end semantic feature expression and enhancing processing speed [25]. Wang and associates proposed a Conjoined FCN approach for learning more about road boundary features. However, the continuous down-sampling in the FCN led to the loss of substantial detail in smaller feature maps, making it difficult to restore the original resolution and causing issues such as blurred boundaries, unclear contours, and insufficiently detailed feature expression in the segmentation results. To mitigate this, Ronneberger and others proposed the U-Net network in 2015, adding more skip-connections to link the bottom and top feature maps of the network, further improving the network’s ability to handle detail [26]. Thus, much of the current research focuses on utilizing the unique encoder-decoder structure of the U-Net network to improve the network model and enhance performance and stability. For instance, Ren and colleagues proposed a DA-CapsUNet that utilizes road extraction multiscale information from various angles to generate rich feature encoding and improve the precision of road extraction [27]. Oktay and colleagues introduced an attention mechanism into the U-Net, culminating in the Attention U-Net model [28]. This enhanced model accentuates the segmentation targets by suppressing the feature response of irrelevant background areas, thereby augmenting the precision and robustness of the segmentation. However, as the depth of the U-Net increases, issues such as vanishing and exploding gradients could potentially occur within the network. Addressing the challenge of deep network degradation, He and collaborators proposed the Residual Neural Network (ResNet) model that effectively utilizes residual blocks [29]. By harnessing the advantages of both U-Net and ResNet networks, Zhang et al. developed the ResUNet network [30]. This model, with its abundant skip connections, not only promotes information propagation but also leverages residual connections to maintain gradient propagation stability. Furthermore, Zhou and associates introduced the D-LinkNet model, which expands the receptive field in the U-Net model by employing dilated convolution modules [12]. This approach enhances recognition capabilities for large-scale targets in input images via scaling and cropping at different dimensions. However, the model still lacks sufficient multiscale target recognition capabilities, leading to potential road detail loss, false negatives, and false positives, which in turn affect the road segmentation outcome. Recently, the DeepLab series of neural networks has been proposed [31,32,33]. These networks employ dilated convolutions and develop pyramid pooling layers to retain spatial structure, marking an innovative step forward in this field. Zhu et al. address the limitations of traditional road extraction methods under complex environmental conditions by introducing a globally context-aware network [34]. Their model not only adapts to varying geographical conditions but also ingeniously mitigates batch effects through a batch-independent mechanism. Although the approach makes considerable strides in adapting to complex scenes, it falls short in the precise extraction of localized details. In contrast, Lu et al. adopt a multifaceted strategy aimed at the holistic extraction of road surfaces, centerlines, and edges [35]. They deploy a cascaded multi-tasking network capable of learning these three sub-tasks concurrently. This multi-task approach substantially outperforms single-task-focused networks in comprehensive road extraction. However, the method remains suboptimal in terms of road surface identification. While CNN-based methods have improved road extraction, these networks primarily rely on a local receptive field, limiting their ability to capture long-distance dependencies in images and necessitating complex network designs to tackle multiscale problems [36].
To address these issues, Transformer-based models, which enhance feature representation quality and generate higher-quality road region predictions, have been gradually applied and achieved significant results. The core component of Transformers, the self-attention mechanism, captures global information and achieves a larger receptive field and more context information. However, the self-attention mechanism emphasizes global context semantic information while neglecting local information [37]. When handling remote sensing images, which often have highly similar and strongly dependent neighboring pixels in spatial scale, this can result in dispersed attention weights that impact model performance. Yang and others proposed TransRoadNet, a method for road extraction from remote sensing images that combines semantic features and context, benefiting road extraction in occluded areas [38]. In a notable contribution, Zhang et al. engineered the encoder for the DCS-TransUperNet, utilizing twin subnetwork encoders of different scales [39]. This approach ensures the effective acquisition of both coarse and fine-grained feature representations, thereby tackling the issue of road discontinuity. In a bid to guarantee the correctness of road topology, Xu and colleagues proposed the RNGDet based on transformer and imitation learning methodologies [40]. This innovative model stands as a significant stride towards maintaining road topology accuracy. Meanwhile, in the quest for superior rendering of distant scenes and prevention of information loss, Sun and associates introduced a multi-resolution transformer extraction network [17]. This network embodies an important advancement in addressing potential information loss in remote imaging scenarios.
Furthering the efforts to enhance feature encoding uniqueness, several studies have combined different attention mechanisms. For instance, channel and space attention modules in some architectures are parallel or cascaded to highlight important feature semantics in the channel and spatial domains [41,42]. Despite these advancements, there is still room for further development and application of deep learning methods in the domain of road extraction from high-resolution remote sensing images.
In the realm of high-resolution remote sensing image road extraction, substantial advancements have been achieved through existing deep-learning methodologies. From the progenitor U-Net and its derivative models to Transformer-based solutions, an array of strategies have endeavored to address the multifaceted challenges of multiscale processing and gradient vanishing or exploding. Despite these successes, lingering unsolved issues and limitations persist, especially concerning road extraction in complex terrains and varying environmental conditions. This manuscript presents a novel deep learning model, the CDAU-Net, which amalgamates CoordConv and the Deep Dual Cross Attention (DDCA) mechanism, aimed at surmounting these challenges. Through innovative enhancements to existing methodologies, the CDAU-Net aspires to elevate the accuracy and efficiency of road extraction, thereby charting new territories for future research in this field. The ensuing section will provide a detailed exposition of the CDAU-Net’s architecture and implementation and its optimization strategy for road extraction in high-resolution remote sensing imagery.
3. Methodology
In our study, we introduce a novel deep learning model, named CDAU-Net, optimized for the task of road extraction from remote sensing imagery. The architecture of CDAU-Net is based on the U-Net model but with modifications: the initial convolution layer of the encoder and the terminal convolution layer of the decoder are replaced by CoordConv. Further, we have devised a mechanism named DDCA (Deep Dual-head Cross Attention), designed to substitute the skip-connection component of U-Net. The DDCA module utilizes depthwise separable convolutions for projection and addresses the semantic disparity between encoder and decoder features by capturing the channel and spatial dependencies of multiscale encoder features.
3.1. U-Net Architecture
The U-Net architecture, renowned for its distinctive ‘U’ shape, represents an advancement from the Fully Convolutional Network (FCN) paradigm. U-Net has gained prominence in deep learning, particularly for its efficacy in image segmentation, even with a limited number of training samples. This efficiency is primarily due to its meticulously structured “U” design.
The architecture comprises two main components: the encoder and the decoder. The encoder, which constitutes the left segment of the ‘U’, employs a series of convolutional and pooling layers to downsample the input image, capturing global and abstract contextual features in the process. This downsampling process is instrumental in abstracting high-level semantic information. Conversely, the decoder, representing the right segment, uses upsampling procedures to transform these coarse features into refined, localized representations, essential for precise image segmentation. A vital element of the U-Net design is the incorporation of skip-connections. These connections transmit feature maps from the encoder directly to corresponding layers in the decoder, enhancing the network’s capability to extract robust features across different scales.
3.2. CoordConv Implementation
We have implemented CoordConv within the CDAU-Net model, a technique designed to enhance the spatial perception of the network. In conventional convolutional neural networks, pixel location information in the image is often overlooked. In contrast, CoordConv, by introducing a coordinate matrix of equal size into the input data, endows the model with spatial perception [43]. The coordinate matrix is then added to the input features and subjected to a convolution layer for processing, as described by Equation (1).
where denotes the input features, represent the coordinates of each pixel, signifies concatenation along the dimension direction, indicates convolution layer processing, and denotes the output features.
In the first layer of our model’s encoder, we have replaced standard convolution with CoordConv, enabling the model to acquire spatial information at the onset of feature extraction; this proves crucial for comprehending complex road layouts, especially in remote sensing imagery. In the final layer of the decoder, the application of CoordConv ensures the model fully utilizes location information to yield more accurate road extraction results. Therefore, by applying CoordConv at key locations, the CDAU-Net can perform more accurate road extraction, addressing the challenges faced by traditional U-Net models in this respect. The structure of CoordConv is illustrated in Figure 1.
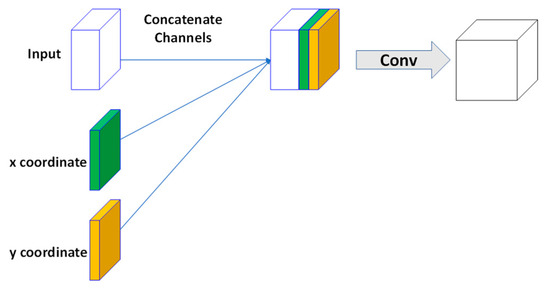
Figure 1.
Schematic diagram of the CoordConv structure: input is the input feature map, x y are the added coordinate channels, the straight arrow points to the concatenate operation, and Conv represents the convolution operation.
3.3. Depthwise Separable Convolution
In this study, we have implemented depthwise separable convolution, an extremely efficient convolution operation that maintains superior performance [44]. Its schematic diagram is illustrated in Figure 2. Depthwise separable convolution breaks down the conventional convolution operation into depth-wise convolution and point-wise convolution. The calculation of depthwise convolution is shown in Equation (2):
where represents the input data, represents the channel index, indicates convolution operation, and denotes the convolution kernel of the m-th input channel.
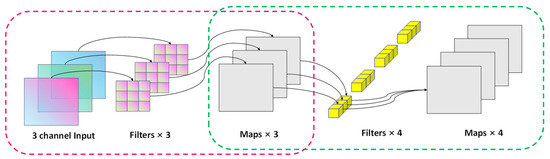
Figure 2.
Schematic diagram of a depthwise separable convolution structure, with three-channel feature maps as input and four-channel output as an example. The red dotted box shows the depthwise convolutional structure. Input 3-channel feature maps, each channel is independently convolved in parallel to obtain three feature maps; the green dashed box is a stepwise point convolution structure, input three feature maps obtained by deep convolution, and 4 × 1 × 3 After the convolution kernel performs convolution calculation, the four-channel feature map is output.
The calculation of point-wise convolution is demonstrated in Equation (3):
where denotes the n-th output channel, is the channel index, and represents the 1 × 1 convolution kernel used for the n-th output channel.
Compared with ordinary convolution operations, depthwise separable convolution reduces the amount of computation and the number of parameters; this is because each convolution kernel only processes one input channel during the depthwise convolution phase, and each convolution kernel is only 1 × 1 in size during the point-wise convolution phase. These factors significantly decrease computational complexity. The cost ratio of computation for standard convolution and depthwise separable convolution when handling an input size of D × D, with M input channels, N output channels, and a convolution kernel size of K × K, is shown in Equation (4):
where represents the computational cost of standard convolution and represents the computational cost of depthwise separable convolution.
Depthwise separable convolution aims to handle each input channel separately, maximizing feature extraction capabilities while maintaining computational efficiency; this is particularly crucial in remote sensing road extraction tasks, as these tasks require precise and efficient feature extraction from complex road layouts and various environmental backgrounds. To achieve this, we have applied depthwise separable convolution to the embedding layer of the model as a novel embedding approach, effectively extracting and utilizing various pieces of information from the input data. Additionally, in our proposed DDCA module, depthwise separable convolution serves as a feature extractor that helps the module more effectively capture and understand encoder features across multiple scales, from channel to spatial dependencies. Therefore, with the introduction and application of depthwise separable convolution, the CDAU-Net model has achieved significant performance improvements in remote sensing road extraction tasks.
3.4. Deep Dual Cross Attention (DDCA)
In the present study, we propose an innovative module titled Deep Dual Cross Attention (DDCA) specifically for road extraction tasks in remote sensing imagery. This module is principally composed of three central components: the Multiscale Feature Embedding (MFE), Deep Multi-head Channel Cross Attention (DCCA), and Deep Multi-head Spatial Cross Attention (DSCA).
The DDCA module is meticulously designed to replace and enhance the skip connections in the U-Net architecture, bridging the semantic gap between the features from the encoder and the decoder. This goal is accomplished by sequentially capturing channel and spatial dependencies across multiscale encoder features. For the five encoder levels present in the U-Net architecture, the DDCA module takes the multiscale features (i.e., the output from the last convolutional layer at each level) from the first four levels, generating enhanced feature representations and connecting them with the corresponding four decoder levels. The realization of this module can be divided into two phases: the first phase involves the MFE module responsible for obtaining encoder tokens; the second phase leverages the DCCA and DSCA modules to capture long-range dependencies by executing our custom-designed DCCA mechanism on these encoder tokens. Finally, we apply layer normalization and GeLU activation functions, followed by upsampling of the tokens to allow for their connection with the corresponding decoder. The specific structure of the DCCA module is shown in Figure 3:
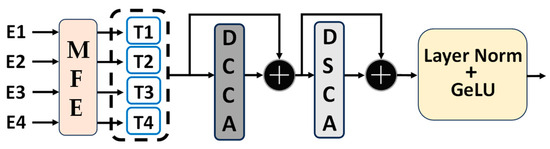
Figure 3.
Schematic diagram of the DDCA module structure. E1, E2, E3, and E4 represent the output of the corresponding layers of the encoder. After being processed by the multiscale feature embedding module (MFE module), T1, T2, T3, and T4 are obtained. DCCA stands for depth channel cross attention mechanism module, DSCA stands for depth space cross attention mechanism module, the black plus symbol represents addition operation, and GeLU is the activation function we use, which is the abbreviation of Gaussian Error Linear Unit.
3.4.1. The Multiscale Feature Embedding (MFE) Module
The Multiscale Feature Embedding (MFE) module proposed in this research focuses on extracting and processing features of various scales from different encoder stages. Deep separable convolution is specifically integrated into this module, enhancing the capture and processing of multiscale and context-dependent features. Firstly, by employing deep separable convolution, we can reduce model parameters and computational complexity without sacrificing performance, thus enhancing computational efficiency. Secondly, the deep separable convolution facilitates a more accurate extraction and description of features across different scales and orientations and contextual relationships with the surrounding environment; this is pivotal in addressing tasks involving road extraction from remote sensing imagery where the morphology, direction, and surrounding environment of roads may vary significantly. The MFE module sets a solid foundation for the subsequent Deep Dual Cross Attention (DDCA) module, which consists of Deep Multi-head Channel Cross Attention (DCCA) and Multi-head Spatial Cross Attention (DSCA) parts. These can take advantage of the multiscale features provided by the MFE module from both spatial and channel perspectives, further enhancing the accuracy of road extraction. The specific structure is shown in Figure 4, and the Projection layer structure is shown in Figure 5:
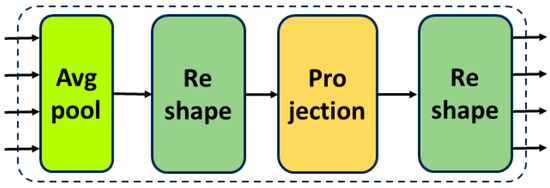
Figure 4.
Schematic diagram of the MFE module: Avg Pool is an adaptive mean pooling module, the Reshape module reshapes the tensor to meet the calculation requirements, and the Projection module is an embedded projection feature extraction module.
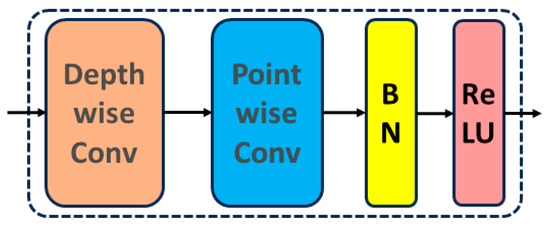
Figure 5.
Schematic diagram of the Projection module: BN stands for batch normalization, and ReLU is the activation function used in this module. Depth convolution is performed on the input data for projection, and then point-by-point convolution batch normalization and ReLU activation function are performed for feature processing.
3.4.2. DCCA
Compared to traditional channel attention mechanisms, our custom-designed Deep Multi-head Channel Cross Attention module utilizes deep convolution instead of linear projection in the projection methodology for each attention head; this significantly reduces computational cost and captures local detail information. We execute cross-attention strategies on the features at each location, allowing the module to learn richer context information in the channel dimension.
First, layer normalization is performed on all input (Represents the i-th token input, i = 1, 2, 3, 4) of size P × Ci and the list nesting operation is performed to obtain the values of , , and after being connected along the channel dimension by Concat. The size is P × (2Cc + Ci), where Cc is the cumulative result of all channel dimensions, and is used for queries.
The core of cross-attention is shown in Equation (8):
where represents the queries, represents the keys, and represents the values, respectively, and is the scaling factor.
The similarity between and determines the value of the weight, which is then applied to through a Softmax function. The weighted sum is inputted into the projection module, producing the output of the DCCA module, which is then inputted into the DSCA module. The structure of the DCCA module is depicted in Figure 6.
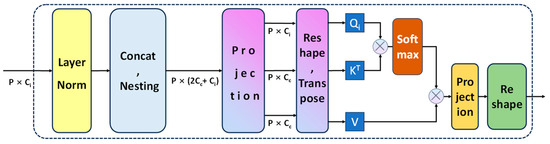
Figure 6.
Schematic diagram of the DCCA module. The multiplication formula below the horizontal direction represents the size of the feature map. The nesting operation of the feature map represented by Nesting is normalized by using the Softmax activation function.
3.4.3. DSCA
The structure of the DSCA module, as illustrated in Figure 7, normalizes the result processed by the DCCA module along the channel, performs concatenation, and lists nesting operations to obtain the values , , and V as . A subsequent decomposition of Q, K, and V is carried out, followed by a nonlinear projection using depthwise separable convolution. This type of convolution includes a depth-wise convolution and a point-wise convolution, effectively extracting local and cross-channel features from the input information. With the use of depthwise separable convolution, the DSCA module is capable of extracting more complex and rich features from input data. A key differentiation from the DCCA module is the use of the concatenated as Q and K, and as V for a depthwise separable projection, with the result presented per the given formula.
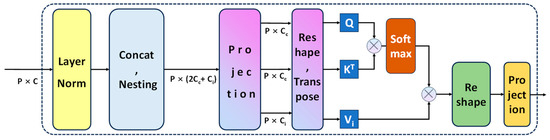
Figure 7.
Schematic diagram of the DSCA module. The multiplication formula below the horizontal direction represents the size of the feature map. The nesting operation of the feature map represented by Nesting is normalized by using the Softmax activation function.
In conclusion, the spatial cross-attention computation is carried out. This process involves a dot product operation between the query and key, producing a matrix that is passed through a Softmax function to generate a weight indicating the similarity between the query and key. This weight is then applied to the value in another dot product operation to yield the final output. The DSCA can be expressed in Equation (12):
where Q represents the queries, K represents the keys, and represents the values, respectively, and 1/ is the scaling factor.
In the output section, the cross-attention output is subjected to a depthwise convolutional projection, enhancing its integration with subsequent modules and augmenting the model’s expressive power.
Overall, by introducing depthwise separable convolution in the spatial cross-attention, the DSCA module effectively improves the balance between the model’s feature extraction capability and computational complexity. It achieves this without adding any additional computational burden while providing subsequent modules with abundant feature information.
3.5. CDAU-Net
The present study introduces a novel deep-learning network architecture specifically designed to tackle the task of road extraction from remote sensing imagery. This network incorporates a Coordination Convolution (CoordConv) layer and integrates a Multiscale Feature Embedding (MFE) module, Depthwise Channel Cross Attention (DCCA) module, and Depthwise Spatial Cross Attention (DSCA) module, with an emphasis on addressing the complexity of remote sensing imagery, which includes multiscale information, spatial dependencies, and anisotropy, among others.
The CoordConv layer represents a unique component within our network, which enhances the model’s ability to handle positional information in remote sensing imagery. By incorporating coordinate information on top of the traditional convolution, CoordConv allows the model to exhibit a heightened perceptual capacity for inputs from different positions. The MFE module in the network employs depthwise separable convolution and adaptive average pooling aimed at effectively capturing and processing multiscale features and contextual information within the remote sensing imagery. This enhancement optimizes the model’s performance in managing road information with substantial variations in scale, direction, and environment. Subsequently, the DCCA and DSCA modules perform cross-attention operations across the channel and space, respectively, on the features extracted by the MFE module. In particular, the DCCA module utilizes depthwise convolution for projection, further refining the functionality of the channel cross-attention mechanism, whereas the DSCA module, through depthwise separable convolution, effectively enhances the performance of the spatial cross-attention mechanism, allowing the network to fully exploit the contextual and multiscale information in remote sensing imagery. The network structure is depicted in Figure 8.
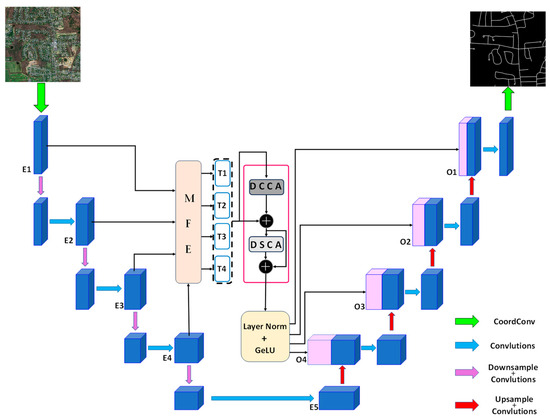
Figure 8.
Schematic diagram of the CDAU-Net network architecture, where the MFE module is combined with the DCCA and DSCA modules to replace the skip connection layer. First, the MFE module receives the feature maps (E1, E2, E3, E4) output by the first four layers of the encoder and generates four Tokens. Then, they are sent to the DCCA and DSCA modules for processing and after corresponding connection operations, and finally, the enhanced representation (O1, O2, O3, O4) of the feature map is generated by layer normalization and GeLU function activation and sent to the corresponding decoder layer for connection.
In general, the network architecture we have designed demonstrates superior performance in the task of road extraction from remote sensing imagery. Its notable features include the incorporation of CoordConv, the usage of depthwise separable convolution, and the integration of multi-head channel and spatial cross-attention mechanisms. These design elements imbue the model with efficient computational performance while ensuring that it can adequately extract and process the complex features inherent in remote sensing imagery.
4. Experiments
4.1. Datasets
4.1.1. Massachusetts Road Dataset
The Massachusetts road dataset, constructed by MiHn and Hinton, is reputed as one of the largest road datasets currently accessible to the public [45]. The dataset spans a broad geographic spectrum from urban to rural areas, covering a territory of about 500 square kilometers. Furthermore, it encapsulates diverse types of roads, including highways, rural dirt roads, and asphalt roads. Additionally, it incorporates elements with characteristics similar to roads, such as rivers and railways, which could potentially cause interference.
This dataset comprises 1171 images, each with a resolution of 1.2 m per pixel and a dimension of 1500 × 1500 pixels. To enhance its scientific value, we segmented it into 1108 training images, 14 validation images, and 49 test images. The 1108 training images and their respective label images were subdivided into 27,700 sub-images of 256 × 256 pixels, which were then allocated in a 9:1 ratio for training and validation. Consequently, the expanded training set comprised 20,776 images of 256 × 256 pixels, while the validation set contained 6924 images of the same size. The original dataset test set was retained for testing.
4.1.2. DeepGlobe Road Dataset
The DeepGlobe Road Dataset is supplied by the DeepGlobe Earth Vision Challenge and is a large-scale geospatial dataset with wide geographic coverage [46]. It incorporates high-precision, pixel-level annotated data from various locations, including Thailand, India, and Indonesia, with a total of 6226 images, each having dimensions of 1024 × 1024 pixels and a spatial resolution of 50 cm per pixel. The dataset’s strength lies in its extensive geographic coverage and varied terrain environments, including mountains, deserts, farmlands, and urban areas, rendering it an ideal data source for high-precision road detection and segmentation tasks. To augment the training dataset and increase its diversity, we created image cuts of 256 × 256 pixels and divided them in an 8:1:1 ratio into training, validation, and test sets.
In the datasets, the labels of the training and validation sets are presented in a binary form, with the pixel value for roads set to 1 and the background set to 0. To prevent model overfitting, this study applied standard data augmentation techniques to both the Massachusetts road dataset and the DeepGlobe dataset. All cropped images underwent cropping, scaling, random rotation, horizontal and vertical flipping, as well as image color transformation operations, enhancing the diversity of the datasets and improving the model’s generalizability.
4.2. Experiment Settings
4.2.1. Training Environment Description
To appraise the capabilities of the newly introduced CDAU-Net model in the domain of road extraction from remote sensing imagery, a comprehensive set of train-validation-test cycles was undertaken using the benchmark Massachusetts Road Dataset. This investigative endeavor was framed within the robust computational environment of the Pytorch platform, specifically leveraging version 1.11.0. The development of this experimental setup was facilitated by the JetBrains PyCharm 2021 integrated development environment, reflecting its versatility and compatibility with high-dimensional data manipulation tasks. Python, with its profound libraries and versatile coding paradigms, was the language of choice for programming. The computational backbone for this endeavor comprised an Intel(R) Core (TM) i7-@2.50 GHz processor. Furthermore, to enhance the processing speed and manage the intensive graphical requirements, an Nvidia GeForce RTX 3060 graphics card was deployed. The system was bolstered by a 12 GB memory configuration, ensuring smooth data flow and processing. Lastly, all operations and model evaluations were conducted on the Windows 10.3.2.3 operating system, which provided a stable and responsive computational environment.
4.2.2. Hyperparameter Settings
The hyperparameters of the model presented in this research were determined through a rigorous sequence of preliminary trials, which were subsequently refined via iterative experimentation. To bolster the robustness of our model and minimize overfitting, we employed cross-validation techniques during the training phase. Both the training and validation sets were supplied to the model, ensuring an adaptable and realistic evaluation metric. Following each training iteration on the training set, a subset of the validation set was strategically chosen to assess the model’s evolving performance metrics. This evaluation encompassed both loss measurements and accuracy determinants, thereby guiding the model’s optimization trajectory. Given the computational constraints posed by our GPU capabilities, we standardized the input image dimensions to 256 × 256 pixels. We adopted the Adam optimizer for its renowned efficiency in updating network parameters, which complements the computational intensity of high-resolution imagery. Batch processing was set to accommodate eight images simultaneously. Our learning rate was initialized at 0.0001, with a floor value of 0.000001, and the training was structured to encompass 100 iterative cycles.
In the context of this study, our model addresses a binary classification conundrum: executing pixel-level categorization to ascertain if a given pixel corresponds to a road feature or the surrounding background. Taking into account that roads roughly constitute 10% of the total area in remote sensing imagery, we integrated the commonly employed cross-entropy loss function tailored for road extraction. Additionally, we considered the Dice coefficient loss function—predominantly recognized in medical image segmentation applications—to alleviate issues stemming from imbalanced sample distributions.
In binary classification contexts, one often resorts to the cross-entropy loss function as a robust measure of classification efficacy. As depicted in Equation (13):
where y represents the true pixel label value, represents the predicted label pixel value by the model, and N represents the number of pixels [47].
Meanwhile, the Dice loss function emerges as a compelling metric for set resemblance. This function typically harnessed for delineating similarity across sample pairs, prefers a value spectrum between 0 and 1. Within the niche of image segmentation, the Dice coefficient gains prominence, offering insights into the harmony between the predicted segmentation expanse and the genuine segment. The defining equation for this coefficient, when perceived as a loss function, finds its illustration in Equation (14):
Within this mathematical representation, signifies the model’s predictive image output, whereas stands for the authentic label of the input imagery. While enumerates the pixel volume of the predicted image, provides a count of the true label’s pixel constituents. Crucially, encapsulates the overlap or intersection of the predicted image with its true label. Given its resilience against issues stemming from sample imbalance, the Dice loss function is particularly pivotal in road extraction assignments. Such tasks often grapple with conspicuous asymmetries between positive and negative samples. A singular reliance on pixel-centric cross-entropy loss might inadvertently skew the model towards over-represented class predictions. However, introducing the Dice loss function alleviates this skewed tendency, establishing a more balanced prediction spectrum.
Conclusively, this investigation amalgamates the virtues of cross-entropy loss with the Dice coefficient loss. By fusing these losses, as illustrated in Equation (15), a comprehensive loss function tailored for this experiment is sculpted.
The interplay between Binary Cross-Entropy (BCE) loss and Dice loss is inherently synergetic. Within the realm of road extraction, such a composite loss function astutely optimizes the pronounced volume of background pixels, courtesy of the BCE loss. Concurrently, it respects the spatial interplay between positive and negative samples, as underscored by the Dice loss. This confluence ensures meticulous management of imbalanced sample scenarios. During nascent prediction phases, where a stark divergence between predictive outputs and true labels is observed, BCE loss introduces substantial gradients, expediting model convergence. As predictive fidelity inches closer to actual labels, the BCE gradient attenuates. Here, the Dice loss ascends to prominence, offering consistent gradients that finely tune the model’s optimization. This intricate balance facilitates both global and local model refinement.
4.2.3. Hyperparameter Settings
To rigorously evaluate the road extraction capabilities of our model, we utilized a comprehensive confusion matrix. This matrix is a pivotal tool for scrutinizing the performance of models in the realm of binary classification. Table 1 delineates this categorization, where the labels are systematically demarcated into positive and negative samples. The predictive outcomes, meanwhile, are parsed into true positives (TPs) and true negatives (TNs) to symbolize accurate predictions. Conversely, false positives (FPs) and false negatives (FNs) encapsulate instances where the model’s predictions deviate from the ground truth. For a nuanced understanding of our model’s prowess, we harnessed three salient evaluation metrics: precision (P), recall (R), and the intersection over union (IoU). Each metric offers a distinct lens to appraise the model’s proficiency in road extraction tasks.

Table 1.
Differences between positive and negative samples.
Precision (P): Precision serves as a measure of the model’s reliability when flagging instances as the positive class. It quantitatively gauges the veracity of the model’s predictions by comparing the instances accurately identified as roads to the total instances the model declared as roads. This metric is instrumental in understanding the false alarms or over-predictions made by the model.
Recall (R): Recall provides insights into the model’s sensitivity, capturing its ability to identify genuine road instances within the dataset. It articulates the model’s efficiency in correctly identifying road instances, ensuring minimal misses.
Intersection over Union (IoU): Often invoked in the spheres of semantic segmentation and object detection, IoU stands as an exemplary metric to assess prediction accuracy. It quantifies the harmony between the model’s extracted results and the reference labels or the ground truth. A more substantial IoU value signifies a heightened congruence between the model’s extraction and the actual road infrastructure.
Embarking on this investigative journey, our primary objective was to elucidate the road extraction competencies of the DCAU-Net model. We meticulously computed the precision, recall, and IoU metrics. By juxtaposing our model’s performance against contemporary state-of-the-art methodologies for road extraction from remote sensing imagery, we aimed to showcase its relative advantages and potential areas for enhancement.
4.3. Comparative Experiment Results and Analysis
In this section, a meticulous comparative evaluation of the CDAU-Net architecture is conducted, benchmarking against five contemporaneous state-of-the-art road extraction networks: U-Net [26], ResUNet [30], HRNetV2 [48], DeepLabV3+ [49], and DDUNet [50].
U-Net, celebrated for its pioneering encoder-decoder structure and seminal introduction of skip connections, masterfully integrates high-level and low-level features from the initial input for nuanced image segmentation. This architecture, characterized by a 3 × 3 convolutional kernel size and employing ReLU activation functions, has been ubiquitously leveraged in road extraction, setting a foundational standard in the field. ResUNet amalgamates the robustness of U-Net and ResNet, enhancing the original U-Net framework with residual modules that deploy skip connections across entire blocks of convolutional layers. This union, aside from deepening the network without sacrificing training stability, ensures that the backpropagation of gradients is safeguarded, thereby ameliorating road extraction outcomes by mitigating the degradation problem. HRNetV2, distinguished by its ability to preserve high-resolution features throughout the network, adeptly manages multiscale information retention. Employing parallel multi-resolution convolutions and deploying a unique, iterative fusion strategy, HRNetV2 demonstrates exceptional proficiency in synthesizing features at varying scales, which is quintessential for road extraction tasks that necessitate nuanced, scale-variant feature management. DeepLabV3+ strategically incorporates atrous convolutions and employs atrous spatial pyramid pooling (ASPP) to adeptly capture multiscale contextual information. By manipulating the dilation rates of its convolutional kernels and utilizing spatial pyramid pooling at several grid scales, it enhances road extraction accuracy and efficiency without surmounting additional computational exigencies. DDUNet, emerging as a novel architecture within road extraction, introduces innovative mechanisms for optimizing feature extraction and contextual understanding. Notably, it features dual-dilated convolutions, which allow it to efficiently manage different receptive field sizes and thus enhance its adaptability to varied road widths and scenarios.
A rigorously devised suite of both qualitative and quantitative analyses will be undertaken to meticulously evaluate and compare the performance, parameter specifications, and efficacy of these six methodologies, shedding light on their respective merits and limitations in the context of road extraction. For optimal visual distinction, the road regions are illustrated in white, with non-road areas rendered in black. To emphasize specific differences, areas of interest are demarcated using red bounding boxes.
4.3.1. Massachusetts Road Dataset Experimental Results
In this section, we undertake an exhaustive evaluation of various algorithmic performances on the Massachusetts road dataset, with an emphasis on distinct region types. For this analysis, six representative images have been judiciously chosen, each exhibiting challenges such as spectral similarities amongst differing objects, varying spectral responses for the same object, and shadow occlusions. The first column, labeled “Image,” displays the original captures. This is followed by a representation of the results from five state-of-the-art algorithms: U-Net, ResUNet, HRNetV2, DeepLabV3+, and DDUNet. The final column delineates the achievements of our proposed CDAU-Net architecture. The extraction results are shown in Figure 9.

Figure 9.
Experimental results on the Massachusetts road dataset. We used red-framed areas to select eight representative areas for display. Image in the figure represents the original image, Label represents the real road label, (a) represents the U-Net extraction result, (b) represents the ResUNet extraction result, (c) represents the HRNetv2 extraction result, (d) represents DeepLabv3+, (e) represents DDUNet Extraction results, (f) represents the extraction results of CDAU-Net, the method in this article. Numbers 1-8 represent the 8 representative areas we selected.
- Spectral Ambiguity Among Different Objects:
Models can encounter difficulties in discerning objects when their reflective properties mirror those of roads.
U-Net: Given its simplistic contextual framework, U-Net may grapple with distinguishing lakes, rivers, and roads. ResUNet: Although residual connections bolster the model’s efficacy, it remains vulnerable to spectral ambiguities. HRNetV2: Its proclivity for high resolution might lead to over-identification of areas bearing similarities to roads. DeepLabV3+: The inclusion of multiscale context endows it with a potential advantage in differentiating roads from other objects. DDUNet: Likely faces challenges akin to U-Net in this realm. CDAU-Net: The incorporation of the deep dual-cross attention mechanism and CoordConv markedly amplifies the model’s resilience against this issue.
- 2.
- Spectral Discrepancies for the Same Object:
Diverse lighting, humidity, and other factors can yield disparate spectral manifestations for roads across images.
U-Net: Its inherent structural constraints possibly hinder the full capture of these nuances. ResUNet: Despite its relative sophistication, it may still grapple with this complexity. HRNetV2: While optimized for detail capture, it may remain vulnerable to broad spectral disparities. DeepLabV3+: Its multiscale attributes render it aptly suited for addressing such challenges. DDUNet: It may align with U-Net’s performance in this context. CDAU-Net: The deep dual-cross attention mechanism potentially fortifies the model’s capacity to discern and adapt to these discrepancies.
- 3.
- Shadow Occlusion:
Shadowing from buildings or other structures remains a predominant obstacle for road detection.
U-Net: It might falter in accurately detecting road sections under the shadow. ResUNet: Notwithstanding certain enhancements, it could remain susceptible to shadow-induced distortions. HRNetV2: Its high-resolution bias might pose difficulties in shadow mitigation. DeepLabV3+: Its multiscale prowess offers promise in alleviating shadow effects. DDUNet: Its performance might closely resonate with that of U-Net and ResUNet in this aspect. CDAU-Net: Through the deep dual-cross attention mechanism combined with CoordConv, it seemingly exhibits superior proficiency in comprehending and addressing shadow issues.
In summary, our CDAU-Net exhibits outstanding performance on the Massachusetts road dataset, proficiently handling a multitude of complex scenarios. This underlines its significant potential for road extraction tasks.
In the quantitative evaluation segment, we subjected various network models to rigorous testing on the Massachusetts road dataset. Precision, recall, and intersection over union (IoU) were selected as performance metrics for each model. The specific results are detailed in Table 2:
Table 2.
Quantitative analysis results of the six models on the Massachusetts road dataset. For easy understanding, we mark the serial numbers with the corresponding letters in Figure 9.
In a comprehensive evaluation across three critical performance metrics—Precision, Recall, and Intersection over Union (IoU)—our proposed CDAU-Net model exhibits unequivocal superiority. With a Precision score of 83.84%, CDAU-Net outperforms its closest competitor, DDUNet, by a significant margin of 2.71 percentage points, thereby demonstrating a marked capability in minimizing false positive extractions. Although CDAU-Net’s Recall score of 84.42% is marginally eclipsed by DDUNet’s 84.65%, the trivial difference reaffirms our model’s proficiency in identifying genuine road pixels. Furthermore, in the overarching IoU metric, which is paramount for semantic segmentation tasks, CDAU-Net again leads the field with a score of 78.56%, marginally exceeding DDUNet’s performance by 0.32 percentage points.
In summary, our proposed CDAU-Net exhibits superior performance on the Massachusetts road dataset compared to other existing deep-learning network models. Both in qualitative and quantitative extraction results, CDAU-Net demonstrates significant superiority. This convincingly indicates the efficacy and efficiency of CDAU-Net in road extraction tasks while also suggesting the model’s high feasibility and potential for practical applications.
4.3.2. DeepGlobe Road Dataset Experimental Results
In this section of our study, we undertook an exhaustive analysis, assessing the extraction abilities of various algorithms within the DeepGlobe road dataset. We curated a selection of eight distinct regions, each encapsulating unique challenges. Figure 10 delineates the segmentation results: the initial column showcases the original image, succeeded by outcomes from U-Net (a), ResUNet (b), HRNetV2 (c), DeepLabV3+ (d), DDUNet (e), and, notably, our novel CDAU-Net (f).
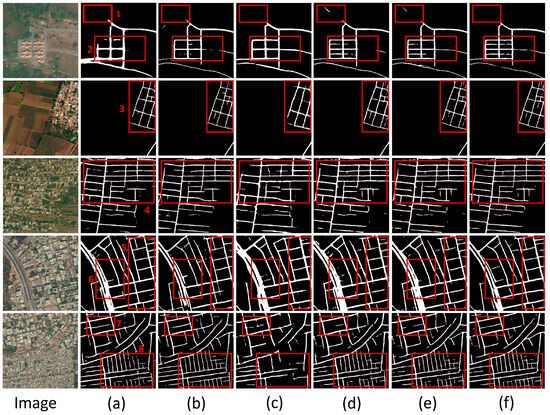
Figure 10.
Display of experimental results of DeepGlobe road dataset. Image in the figure represents the original image, (a) represents the U-Net extraction result, (b) represents the ResUNet extraction result, (c) represents the HRNetv2 extraction result, (d) represents DeepLabv3+, (e) represents DDUNet Extraction results, (f) represents the extraction results of CDAU-Net, the method in this article. Numbers 1-8 represent the 8 representative areas we selected.
Region 1 is characterized by a densely forested environment, making road discernibility a challenge. Both HRNetV2 (c) and DeepLabV3+ (d) display marked road discontinuities coupled with instances of inaccurate extraction. In Region 2, representing a dense housing cluster, internal roads exhibit a pronounced same-spectrum-different-object issue. U-Net (a) captures only the main thoroughfares partially, and ResUNet (b) overlooks the internal roads. While HRNetV2 (c) and DeepLabV3+ (d) manage to detect some road segments, these are compromised by significant discontinuities. However, our CDAU-Net (f) provides superior road coverage, indicating exceptional extraction proficiency. Region 3 encapsulates a rural setting with a dense population. Most conventional methods exhibit significant errors in this context. Conversely, CDAU-Net (f) adeptly delineates the majority of roads with a commendably reduced level of discontinuities. Region 4, a suburban setting interspersed with built structures and green patches, proves challenging for all algorithms. All methods, to varying degrees, show discontinuities, particularly in the most heavily obstructed sectors of Region 4. Notably, U-Net (a) and ResUNet (b) manage to delineate the horizontal road in the top-right quadrant, while HRNetV2 (c), DeepLabV3+ (d), and CDAU-Net (f) capture the two vertical pathways in the bottom-right, albeit with some fragmentation. Regions 5 and 7 are urban road networks, with Region 5 being particularly densely populated. CDAU-Net’s (f) extraction abilities shine in these scenarios, especially in terms of road continuity and overall completeness. Region 6 presents urban roads with substantial tree coverage. Here, while most networks exhibit varying road discontinuities, with HRNetV2 (c) showing the most pronounced, CDAU-Net (f) remarkably achieves near-total extraction. Region 8, with its primary dual carriageway bisected by greenery, is an interesting challenge. Both U-Net (a) and ResUNet (b) can detect the bifurcation, but only CDAU-Net (f) maintains the holistic continuity of the roadway.
In summation, our pioneering CDAU-Net consistently exhibits superior road extraction capabilities across a diverse range of terrains and challenges. While there are areas primed for refinement, on the whole, CDAU-Net outstrips existing network models in a majority of the tested scenarios, underscoring its considerable practical utility in complex road environments.
In our quantitative analysis of the DeepGlobe road dataset, a comprehensive evaluation was performed on various models using three key metrics: Precision, Recall, and Intersection over Union (IoU). These well-established indicators effectively mirror the accuracy and robustness of a model for road extraction tasks. Table 3 presents the specific results:
Table 3.
Quantitative analysis results of the six models on the DeepGlobe road dataset. For easy understanding, we mark the serial numbers with the corresponding letters in Figure 10.
The table presents the performance metrics of six contemporary deep learning models when trained and evaluated on the DeepGlobe road dataset. U-Net, which can be thought of as a seminal model reflecting the foundational properties of the Fully Convolutional Network (FCN), demonstrates Precision, Recall, and IoU scores of 83.43%, 84.45%, and 75.36%, respectively. Although it is a crucial architecture in the semantic segmentation realm, its metrics on this dataset are somewhat overshadowed by the newer, more sophisticated models. ResUNet, an amalgamation of the residual learning and U-Net structure, slightly improves upon U-Net, registering metrics of 84.09%, 84.08%, and 76.81%. Its marginal gains suggest that the addition of residual connections aids, albeit modestly, in road extraction tasks for this specific dataset. HRNetV2, with its unique hierarchical design, which maintains high-resolution representations through the network, posts values of 85.09%, 84.08%, and 77.41%. Its design offers a noticeable leap in Precision and IoU, showcasing the model’s efficacy in capturing intricate details of roads. DeepLabV3+, a state-of-the-art model integrating atrous convolution and spatial pyramid pooling, notches 85.48%, 85.65%, and 77.15%. Despite its advanced architecture, the model performs comparably with HRNetV2, with a slight edge in Recall. DDUNet, a relatively newer contender in the segmentation arena, brings about scores of 85.92%, 86.74%, and 77.85%. It is evident that the model’s design, which might encapsulate more advanced features and learning strategies, nudges ahead of its predecessors, especially in terms of Recall. Lastly, the CDAU-Net, the model proposed in this study, outstrips the competition with scores of 86.69%, 86.59%, and 78.52%. This is a testament to the novel architectural choices and optimization strategies employed by the authors, thereby affirming its superior capability in road extraction from satellite imagery.
4.4. Ablation Study Results and Analysis
During the evaluation of our CDAU-Net model, we designed a series of ablation studies to determine the individual contribution of each component to performance. The ablation study comprised of the following configurations:
- (a)
- Base U-Net: Our baseline model, a standard U-Net network, is devoid of any enhancements we proposed. This experiment aims to display baseline performance as a reference for comparison with other studies.
- (b)
- U-Net + CoordConv: This model variant adds CoordConv convolution to the first layer of the encoder and the last layer of the decoder in the base U-Net. CoordConv convolution is thought to augment model representation and location capabilities; this experiment evaluates the performance impact of this improvement;
- (c)
- U-Net + Cross Attention without Depthwise Separable Convolution: This setup adds a cross-attention mechanism to the U-Net base but does not utilize depthwise separable convolution. We expect this improvement to enhance model performance, but we also aim to investigate the contribution of depthwise separable convolution to performance;
- (d)
- U-Net + Cross Attention with Depthwise Separable Convolution: This experiment builds on the previous setup by further incorporating depthwise separable convolution. We expect this improvement to further enhance model performance;
- (e)
- CDAU-Net (Cross Attention Module with CoordConv and Depthwise Separable Convolution): Our proposed complete model, which combines the cross-attention module with CoordConv and depthwise separable convolution. We anticipate this model to outperform all the ablation experiments.
Each successive version integrates a new enhancement, which allows us to clearly identify the impact of each improvement on model performance. We will test each version on every metric to precisely analyze the contribution of each component to model performance.
To validate the effectiveness of the proposed method in this experiment setup, we performed a quantitative analysis on both the Massachusetts road dataset and the DeepGlobe road dataset. The results are displayed in Table 4:
Table 4.
Accuracy results of five designed ablation experiments on Massachusetts road dataset and DeepGlobe road dataset. Among them, BL stands for Baseline (U-Net), Cc stands for Coordconv operation, CA stands for DCA module without depthwise separable convolution, and DW stands for depthwise separable convolution. P stands for precision, R stands for recall, and IoU stands for Intersection over Union.
Firstly, the experiment results showed that the network introducing CoordConv convolution (b) outperforms the base U-Net network (a). This performance uplift is evident across both datasets, confirming that CoordConv convolution enhances the network’s feature learning capability. Then, comparing the network with the cross-attention mechanism without depthwise separable convolution (c) with the base U-Net network (a), the former demonstrated improvement in all measures, validating the enhancement of feature differentiation ability via the cross-attention mechanism. Further, by integrating depthwise separable convolution into the cross-attention mechanism, network performance was improved (d). This configuration outperformed all measures on both datasets, suggesting that depthwise separable convolution can effectively augment the performance of the cross-attention mechanism. Lastly, our complete model, CDAU-Net (e), which combines the cross-attention module with CoordConv and depthwise separable convolution, surpassed all other configurations on both datasets. This robustly confirms the efficacy of our design choices and illustrates that when used in conjunction, CoordConv and depthwise separable convolution cross-attention modules can be exploited to their full potential. The qualitative performance of the ablation experiment results on the Massachusetts road dataset and the DeepGlobe road dataset is shown in Figure 11.

Figure 11.
The performance results of the five schemes in the ablation experiment on the Massachusetts road dataset and the DeepGlobe road dataset. Where the image represents the original image, (a–e) represents the results of the corresponding experimental plan, 1, 2, and 3 represent images from the Massachusetts road dataset, and 4, 5, and 6 represent images from the DeepGlobe road dataset.
In conclusion, our ablation study clearly demonstrates the contribution of each design choice towards network performance improvement. Moreover, our CDAU-Net outperforms in all comparisons, further validating the effectiveness of our approach in road extraction tasks.
4.5. Computational Efficiency
The implementation of deep learning models in the domain of road extraction entails meticulous consideration of both the model’s performance and computational efficiency to ensure seamless deployment in practical applications. This section elucidates a comparative analysis of the proposed CDAU-Net with several state-of-the-art models, namely U-Net, ResUNet, HRNetV2, DeepLabV3+, and DDUNet, focusing on two pivotal metrics: the number of parameters and Floating Point Operations Per Second (FLOPs). The results are shown in Table 5.
Table 5.
Computational efficiency index results of each network model.
A conspicuous observation from the table unveils that the CDAU-Net, while boasting a moderate number of parameters (16.88 M), performs efficiently with 41.15 GFLOPs, rendering it computationally more efficient than the contrasted models like DeepLabV3+ and DDUNet, which have FLOPs of 90.71 and 62.33, respectively, despite having more parameters. The strategic incorporation of depth-wise separable convolutions in CDAU-Net allows a tangible reduction in computational overhead without impairing the network’s capacity to learn intricate patterns for road extraction.
In the context of real-world applicability, models like ResUNet and DeepLabV3+, while demonstrating compelling performance in various applications, pose a significant computational burden owing to their high FLOPs. This particularly resonates in scenarios demanding rapid inferencing and limited computational resources, where a balance between computational efficiency and performance is imperative.
Conclusively, CDAU-Net emerges as a potent candidate, ensuring a balanced trade-off between computational efficiency and robust performance, thus potentiating its practicality in diverse real-world scenarios and embedded systems where computational resources are often constrained. Future implementations and modifications of the model can explore further optimization techniques to enhance its applicability in more extensive and computationally demanding tasks in road extraction from remotely sensed images.
5. Discussion
In this section, we undertake a comprehensive assessment of the performance of our CDAU-Net for the task of road extraction, drawing comparisons with state-of-the-art methods, evaluating the model’s limitations, and suggesting potential areas for future refinement.
Initially, we conducted experiments on two datasets, the Massachusetts Roads Dataset and the DeepGlobe Road Dataset, which encapsulate complex road scenarios. Across key performance indicators such as precision, recall, and Intersection over Union (IoU), the CDAU-Net displayed notable superiority. This was particularly evident in its handling of small targets and complex scenes within the imagery, underscoring the model’s robust adaptability in these contexts.
The exceptional performance of our CDAU-Net network is largely attributable to the integration of the CoordConv convolution and our bespoke Deep Double Multi-Head Cross Attention mechanism (DDCA). CoordConv convolution enhances the model’s capacity to process spatial information, while the DDCA allows it to capture long-range dependencies within the images. The combination of these technologies exhibits significant potential, specifically within the task of remote sensing image road extraction. Nevertheless, despite the model’s excellent performance in most instances, it encounters limitations in deeply shadowed areas of the images. Roads in such areas are nearly invisible, presenting fresh challenges for the model’s road detection capabilities and hinting at possible avenues for future research.
Additionally, we performed a series of ablation studies that further substantiate the critical role of CoordConv convolution and DDCA within our model, effectively corroborating our design rationale.
In conclusion, although the CDAU-Net exhibits certain limitations under specific conditions, it has demonstrated superior performance in the task of road extraction. This offers fresh perspectives and potential for deep learning in remote sensing image analysis. Looking ahead, we plan to further refine the CDAU-Net to better handle complex scenes and small targets, thereby enhancing its performance in road extraction tasks. Simultaneously, we believe that the design philosophy and structure of the CDAU-Net can be generalized to other tasks in remote sensing image analysis, thereby broadening the impact of deep learning within the field of remote sensing applications.
6. Conclusions
In this study, we introduce and implement a novel deep learning model—CDAU-Net—designed specifically for the task of road extraction in remote sensing imagery. The model ingeniously amalgamates the CoordConv convolution and our crafted Deep Double Multi-Head Cross Attention mechanism (DDCA), thereby demonstrating outstanding capabilities in processing spatial information and managing long-range dependencies. The CDAU-Net is particularly effective in handling small targets and complex scenes.
We conducted extensive experiments on the Massachusetts Roads Dataset and the DeepGlobe Road Dataset, both encompassing a variety of intricate road scenarios. Experimental results unambiguously indicate that the CDAU-Net outperforms current state-of-the-art methods across all assessment metrics, including precision, recall, and Intersection over Union (IoU). However, we also acknowledge certain limitations within our model, even in circumstances where it excels. In particular, the performance can be compromised under extreme conditions, such as in regions with deep shadows where road information is severely lacking. Ablation studies further authenticate the crucial roles of the CoordConv convolution and DDCA in our model, furnishing robust evidence for our design rationale.
On balance, the CDAU-Net achieves not only notable success in the task of road extraction from remote sensing imagery, thereby advancing the field, but also poses new challenges for research and practice. We anticipate that future improvements and optimization will allow the CDAU-Net to attain superior performance in remote sensing image analysis, especially within the vital task of road extraction. Concurrently, we posit that this work paves the way for new possibilities for the application of deep learning technologies in the field of remote sensing, carrying significant theoretical research and practical application value.
Author Contributions
Conceptualization, C.R.; Methodology, A.Y.; Validation, H.S. and X.X.; Investigation, W.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (Grant No. 42064003). The author is located at the Guilin University of Technology.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Huang, H.; Savkin, A.V.; Huang, C. Decentralized Autonomous Navigation of a UAV Network for Road Traffic Monitoring. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 2558–2564. [Google Scholar] [CrossRef]
- Baltodano, S.; Sibi, S.; Martelaro, N.; Gowda, N.; Ju, W. The RRADS Platform: A Real Road Autonomous Driving Simulator. In Proceedings of the 7th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Nottingham, UK, 1–3 September 2015; pp. 281–288. [Google Scholar]
- Sadeghi-Niaraki, A.; Varshosaz, M.; Kim, K.; Jung, J.J. Real World Representation of a Road Network for Route Planning in GIS. Expert Syst. Appl. 2011, 38, 11999–12008. [Google Scholar] [CrossRef]
- Salama, A.S.; Saleh, B.K.; Eassa, M.M. Intelligent Cross Road Traffic Management System (ICRTMS). In Proceedings of the 2010 2nd International Conference on Computer Technology and Development, Cairo, Egypt, 2–4 November 2010; pp. 27–31. [Google Scholar]
- Singh, N.; Katiyar, S.K. Application of Geographical Information System (GIS) in Reducing Accident Blackspots and in Planning of a Safer Urban Road Network: A Review. Ecol. Inform. 2021, 66, 101436. [Google Scholar] [CrossRef]
- Rogan, J.; Chen, D. Remote Sensing Technology for Mapping and Monitoring Land-Cover and Land-Use Change. Prog. Plan. 2004, 61, 301–325. [Google Scholar] [CrossRef]
- Zhang, B.; Wu, Y.; Zhao, B.; Chanussot, J.; Hong, D.; Yao, J.; Gao, L. Progress and Challenges in Intelligent Remote Sensing Satellite Systems. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1814–1822. [Google Scholar] [CrossRef]
- Lu, J.; Liu, H.; Yao, Y.; Tao, S.; Tang, Z.; Lu, J. Hsi Road: A Hyper Spectral Image Dataset for Road Segmentation. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Sebari, I.; He, D.-C. Automatic Fuzzy Object-Based Analysis of VHSR Images for Urban Objects Extraction. ISPRS J. Photogramm. Remote Sens. 2013, 79, 171–184. [Google Scholar] [CrossRef]
- Saeedimoghaddam, M.; Stepinski, T.F. Automatic Extraction of Road Intersection Points from USGS Historical Map Series Using Deep Convolutional Neural Networks. Int. J. Geogr. Inf. Sci. 2020, 34, 947–968. [Google Scholar] [CrossRef]
- Hou, Y.; Liu, Z.; Zhang, T.; Li, Y. C-UNet: Complement UNet for Remote Sensing Road Extraction. Sensors 2021, 21, 2153. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 182–186. [Google Scholar]
- Dai, L.; Zhang, G.; Zhang, R. RADANet: Road Augmented Deformable Attention Network for Road Extraction From Complex High-Resolution Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5602213. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-of-the-Art Review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Lan, M.; Zhang, Y.; Zhang, L.; Du, B. Global Context Based Automatic Road Segmentation via Dilated Convolutional Neural Network. Inf. Sci. 2020, 535, 156–171. [Google Scholar] [CrossRef]
- Wei, Y.; Zhang, K.; Ji, S. Simultaneous Road Surface and Centerline Extraction from Large-Scale Remote Sensing Images Using CNN-Based Segmentation and Tracing. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8919–8931. [Google Scholar] [CrossRef]
- Sun, Z.; Zhou, W.; Ding, C.; Xia, M. Multi-Resolution Transformer Network for Building and Road Segmentation of Remote Sensing Image. ISPRS Int. J. Geo-Inf. 2022, 11, 165. [Google Scholar] [CrossRef]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in Transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Liu, R.; Lehman, J.; Molino, P.; Petroski Such, F.; Frank, E.; Sergeev, A.; Yosinski, J. An Intriguing Failing of Convolutional Neural Networks and the Coordconv Solution. arXiv 2018, arXiv:1807.03247. [Google Scholar]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road Extraction from High-Resolution Remote Sensing Imagery Using Deep Learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef]
- Jonsson, P.; Casselgren, J.; Thörnberg, B. Road Surface Status Classification Using Spectral Analysis of NIR Camera Images. IEEE Sens. J. 2014, 15, 1641–1656. [Google Scholar] [CrossRef]
- Taylor, M.A. Remoteness and Accessibility in the Vulnerability Analysis of Regional Road Networks. Transp. Res. Part A Policy Pract. 2012, 46, 761–771. [Google Scholar] [CrossRef]
- Trinder, J.C.; Wang, Y. Knowledge-Based Road Interpretation in Aerial Images. Int. Arch. Photogramm. Remote Sens. 1998, 32, 635–640. [Google Scholar]
- Xu, G.; Liu, M.; Jiang, Z.; Shen, W.; Huang, C. Online Fault Diagnosis Method Based on Transfer Convolutional Neural Networks. IEEE Trans. Instrum. Meas. 2019, 69, 509–520. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Ren, Y.; Yu, Y.; Guan, H. DA-CapsUNet: A Dual-Attention Capsule U-Net for Road Extraction from Remote Sensing Imagery. Remote Sens. 2020, 12, 2866. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected Crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected Crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhu, Q.; Zhang, Y.; Wang, L.; Zhong, Y.; Guan, Q.; Lu, X.; Zhang, L.; Li, D. A Global Context-Aware and Batch-Independent Network for Road Extraction from VHR Satellite Imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 353–365. [Google Scholar] [CrossRef]
- Lu, X.; Zhong, Y.; Zheng, Z.; Chen, D.; Su, Y.; Ma, A.; Zhang, L. Cascaded Multi-Task Road Extraction Network for Road Surface, Centerline, and Edge Extraction. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5621414. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-Attention with Relative Position Representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Yang, Z.; Zhou, D.; Yang, Y.; Zhang, J.; Chen, Z. TransRoadNet: A Novel Road Extraction Method for Remote Sensing Images via Combining High-Level Semantic Feature and Context. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6509505. [Google Scholar] [CrossRef]
- Zhang, Z.; Miao, C.; Liu, C.; Tian, Q. DCS-TransUperNet: Road Segmentation Network Based on CSwin Transformer with Dual Resolution. Appl. Sci. 2022, 12, 3511. [Google Scholar] [CrossRef]
- Xu, Z.; Liu, Y.; Gan, L.; Sun, Y.; Wu, X.; Liu, M.; Wang, L. Rngdet: Road Network Graph Detection by Transformer in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single Image Super-Resolution via a Holistic Attention Network. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 191–207. [Google Scholar]
- Pan, X.; Yang, F.; Gao, L.; Chen, Z.; Zhang, B.; Fan, H.; Ren, J. Building Extraction from High-Resolution Aerial Imagery Using a Generative Adversarial Network with Spatial and Channel Attention Mechanisms. Remote Sens. 2019, 11, 917. [Google Scholar] [CrossRef]
- Wu, Y.; Wu, Y.; Wang, B.; Yang, H. A Remote Sensing Method for Crop Mapping Based on Multiscale Neighborhood Feature Extraction. Remote Sens. 2022, 15, 47. [Google Scholar] [CrossRef]
- Zhang, R.; Zhu, F.; Liu, J.; Liu, G. Depth-Wise Separable Convolutions and Multi-Level Pooling for an Efficient Spatial CNN-Based Steganalysis. IEEE Trans. Inf. Forensics Secur. 2019, 15, 1138–1150. [Google Scholar] [CrossRef]
- Mnih, V. Machine Learning for Aerial Image Labeling; University of Toronto: Toronto, ON, Canada, 2013. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R.D. A Challenge to Parse the Earth through Satellite Images. arXiv 2018, arXiv:1805.06561. [Google Scholar]
- De Boer, P.-T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A Tutorial on the Cross-Entropy Method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-Resolution Representations for Labeling Pixels and Regions. Available online: https://arxiv.org/abs/1904.04514v1 (accessed on 9 October 2023).
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation; Springer: Berlin/Heidelberg, Germany, 2018; pp. 801–818. [Google Scholar]
- Wang, Y.; Peng, Y.; Li, W.; Alexandropoulos, G.C.; Yu, J.; Ge, D.; Xiang, W. DDU-Net: Dual-Decoder-U-Net for Road Extraction Using High-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4412612. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).