
A Swin Transformer with Dynamic High-Pass Preservation for Remote Sensing Image Pansharpening


Abstract
:1. Introduction
- The detail injection mechanism is further investigated in pansharpening networks. A dynamic high-pass preservation module is developed to enhance the high frequencies present in input shallow features. This module achieves its objective by adaptively acquiring the expertise to generate convolution kernels. Furthermore, it strategically employs distinct kernels for each spatial location, facilitating the effective amplification of high frequencies.
- A subtraction framework with details directly extracted by differentiating the single PAN image with each MS band is proposed. This solution allows us to avoid compromising the spatial information with a preprocessing step using detailed extraction techniques proposed in classical pansharpening approaches, letting the framework spectrally adjust the extracted details through the estimation of the nonlinear and local injection model.
- A full transformer network named SwinPAN is developed for pansharpening based on the Swin Transformer. The proposed network introduces content-based interactions between image content and attention weights, resembling spatially varying convolutions. This is achieved through a shifted-window mechanism, which enables effective long-range dependency modelling. Notably, the Swin Transformer boasts improved performance while utilizing fewer parameters in comparison to the Vision Transformer (ViT).
- Experimental results on three remote sensing datasets, including QuickBird, GaoFen2 and WorldView3, demonstrate that the proposed method achieves superior performance competitiveness compared with other state-of-the-art CNN-based methods.
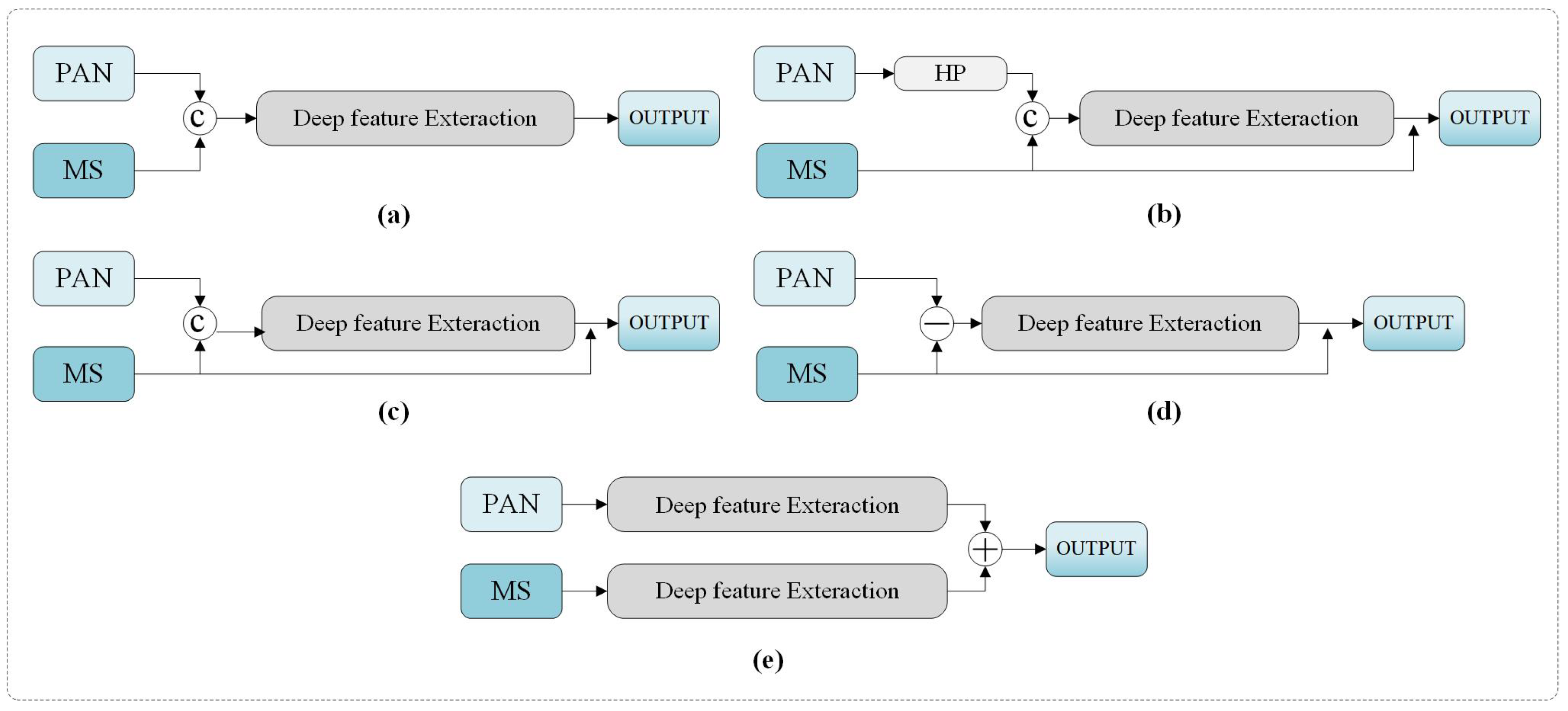
2. Related Works
2.1. CNN-Based Methods
2.2. Transformer-Based Methods
3. Methodology
3.1. Framework
3.2. Detail Reconstruction Block
3.3. Detail Reconstruction Layer
4. Experiments
4.1. Datasets
4.2. Experimental Settings
4.2.1. Data Preparation
4.2.2. Implementation Details
4.2.3. Metrics
4.3. Comparison Analysis
4.3.1. Reduced-Resolution Experiment
4.3.2. Full-Resolution Experiment
5. Discussion
5.1. Ablation Study
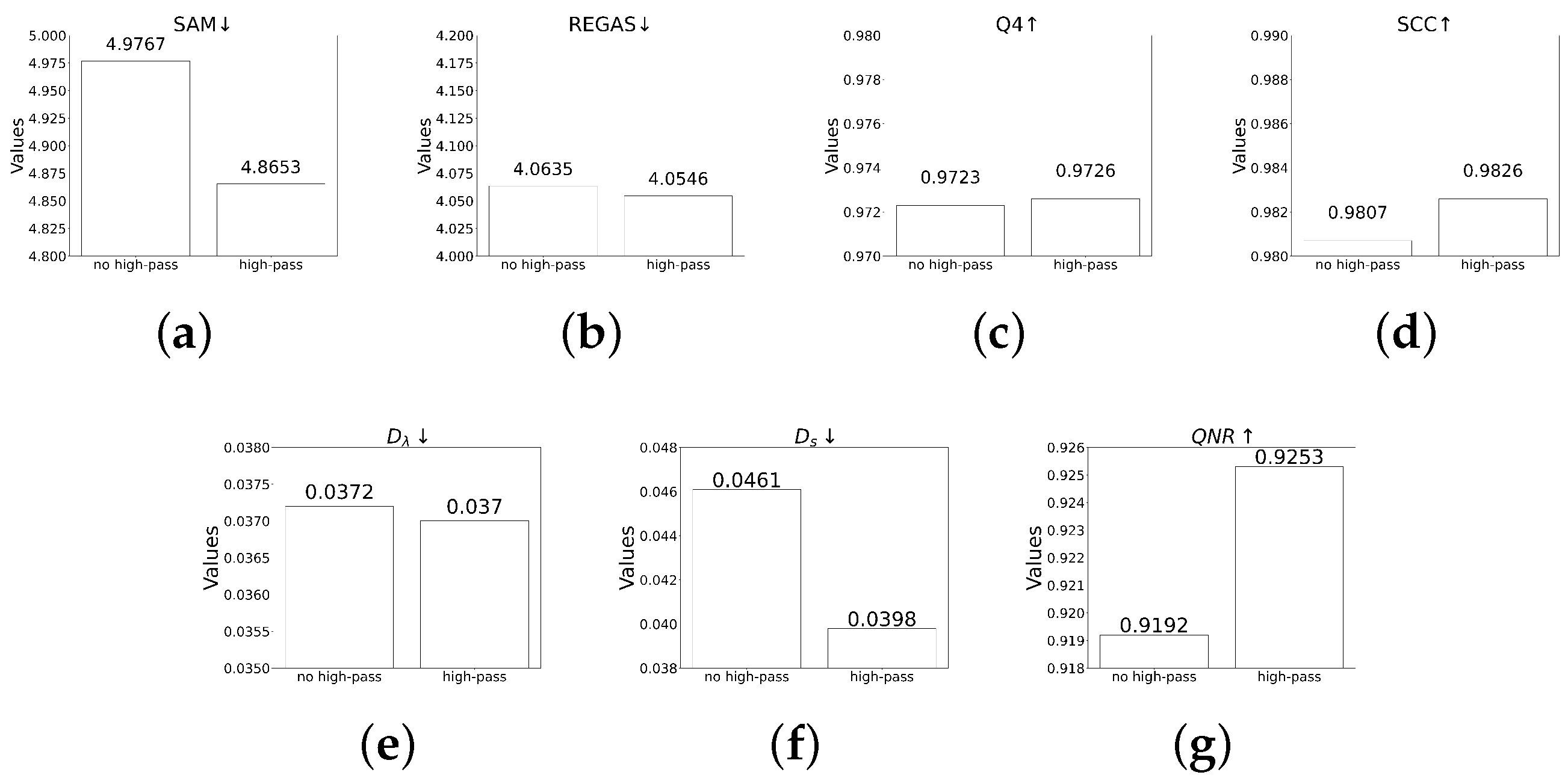
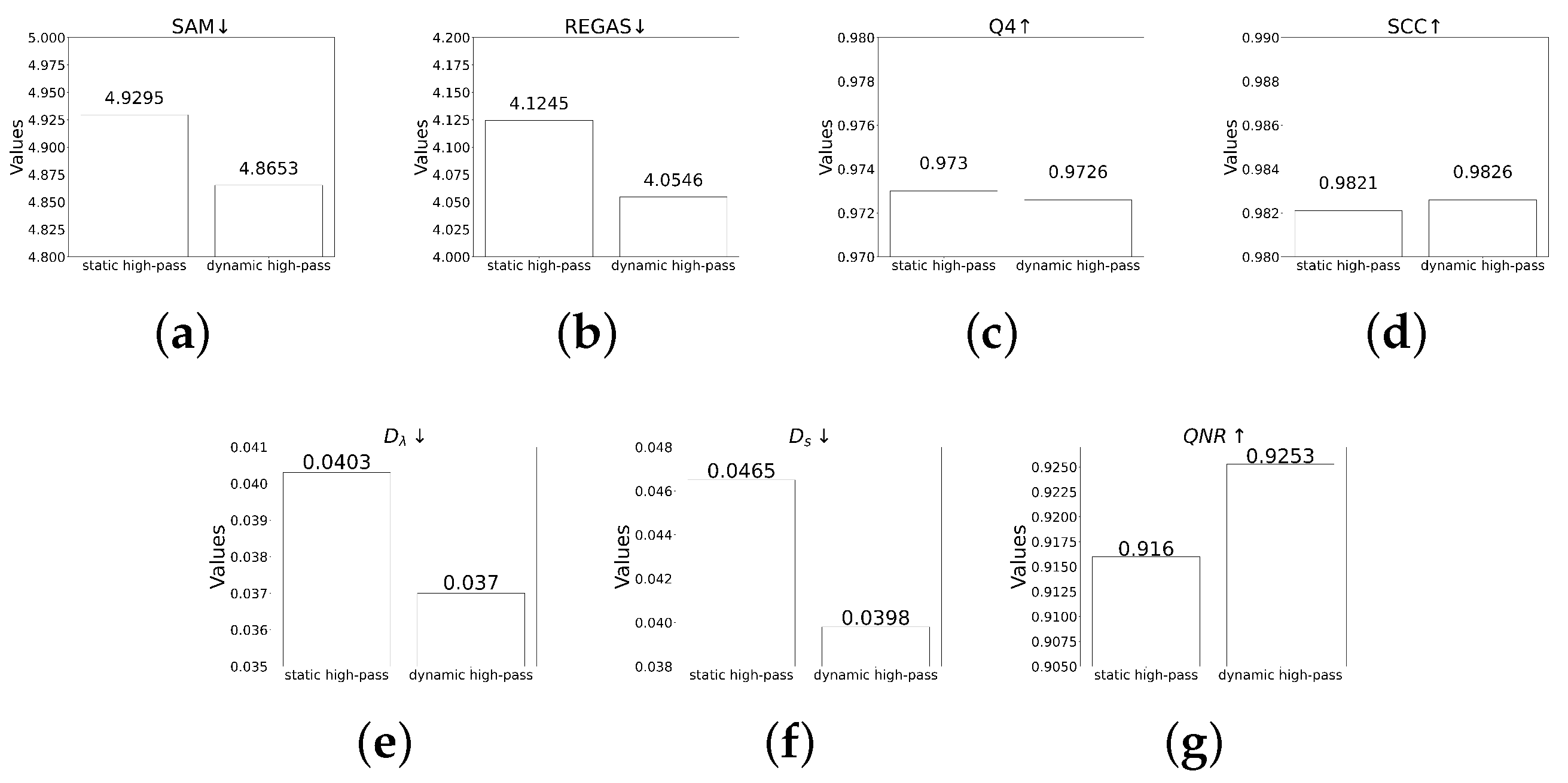
5.1.1. Albation Study of Dynamic High-Pass Preservation Module
5.1.2. Albation Study of Static High-Pass Preservation Module
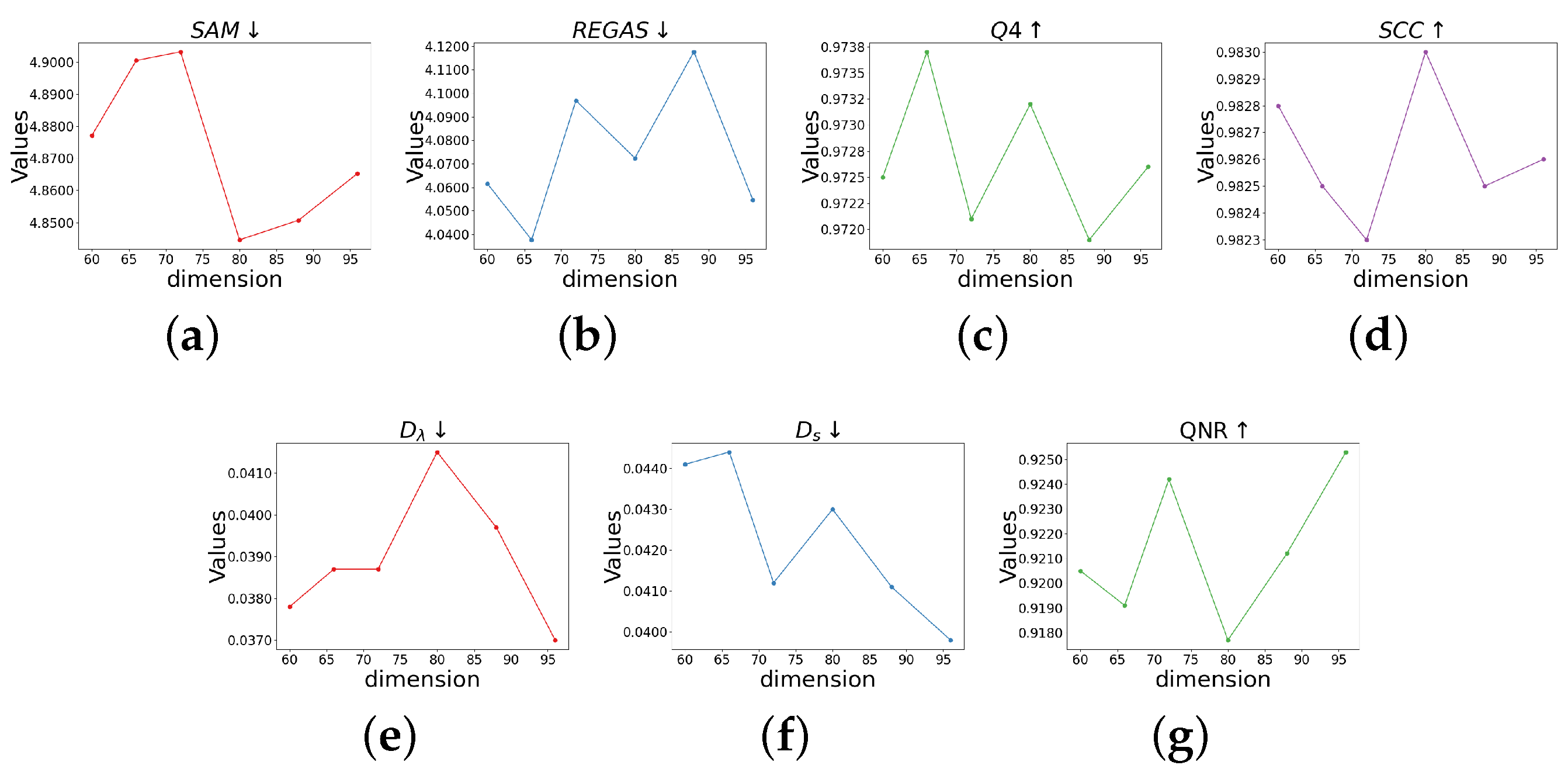
5.2. Parameter Analysis
5.2.1. Feature Dimension
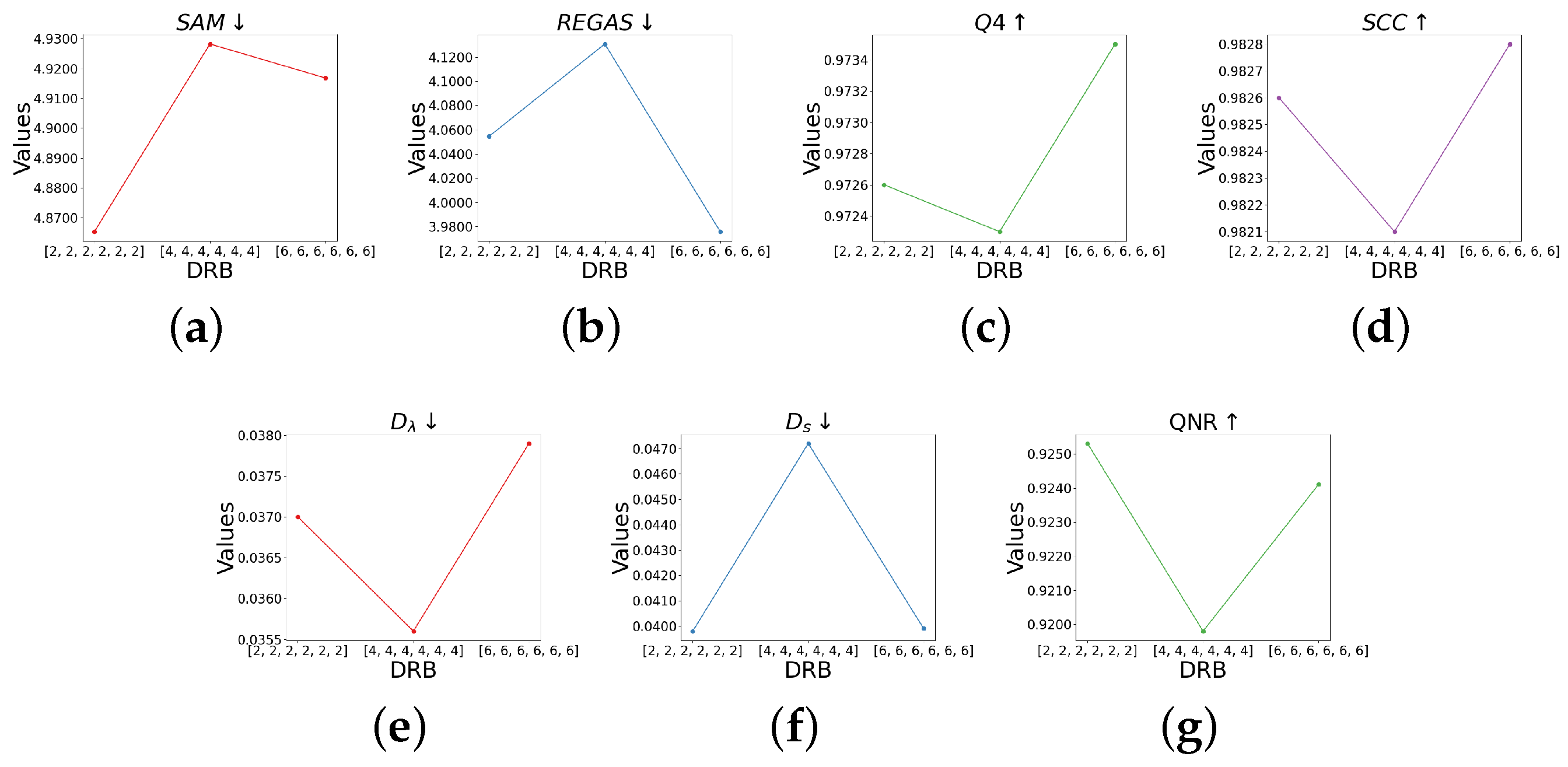
5.2.2. Number of DRLs
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chavez, P.S., Jr.; Kwarteng, A.Y. Extracting spectral contrast in Landsat Thematic Mapper image data using selective principal component analysis. In Proceedings of the 6th Thematic Conference on Remote Sensing for Exploration Geology, Houston, TX, USA, 16–19 May 1988. [Google Scholar]
- Shah, V.P.; Younan, N.H.; King, R.L. An Efficient Pan-Sharpening Method via a Combined Adaptive PCA Approach and Contourlets. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1323–1335. [Google Scholar] [CrossRef]
- Shettigara, V.K. A generalized component substitution technique for spatial enhancement of multispectral images using a higher resolution data set. Photogram. Eng. Remote Sens. 1992, 58, 561–567. [Google Scholar]
- Tu, T.M.; Su, S.C.; Shyu, H.C.; Huang, P.S. A new look at IHS-like image fusion methods. Inf. Fusion 2001, 2, 177–186. [Google Scholar] [CrossRef]
- Choi, J.; Yu, K.; Kim, Y. A New Adaptive Component-Substitution-Based Satellite Image Fusion by Using Partial Replacement. IEEE Trans. Geosci. Remote Sens. 2010, 49, 295–309. [Google Scholar] [CrossRef]
- Burt, P.J. The Laplacian Pyramid as a Compact Image Code. In Readings in Computer Vision; Morgan Kaufmann: Burlington, MA, USA, 1987; pp. 671–679. [Google Scholar]
- Mallat, S.G. A theory for multiresolution signal decomposition: The wavelet representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 674–693. [Google Scholar] [CrossRef]
- Antoniadis, A.; Oppenheim, G. The Stationary Wavelet Transform and some Statistical Applications. In Wavelets and Statistics; [Lecture Notes in Statistics]; Springer Science & Business Media: Berlin, Germany, 1995; Volume 103, pp. 281–299. [Google Scholar] [CrossRef]
- Do, M.N.; Vetterli, M. The contourlet transform: An efficient directional multiresolution image representation. IEEE Trans. Image Process. 2005, 14, 2091–2106. [Google Scholar] [CrossRef]
- Fang, F.; Li, F.; Shen, C.; Zhang, G. A Variational Approach for Pan-Sharpening. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2013, 22, 2822–2834. [Google Scholar] [CrossRef]
- Buades, A.; Coll, B.; Duran, J.; Sbert, C. Implementation of Nonlocal Pansharpening Image Fusion. Image Process. Line 2014, 4, 1–15. [Google Scholar] [CrossRef]
- Deng, L.J.; Feng, M.; Tai, X.C. The fusion of panchromatic and multispectral remote sensing images via tensor-based sparse modeling and hyper-Laplacian prior. Inf. Fusion 2018, 52, 76–89. [Google Scholar] [CrossRef]
- Devi, Y.A.S. Ranking based classification in hyperspectral images. J. Eng. Appl. Sci. 2018, 13, 1606–1612. [Google Scholar]
- Nayak, S.C.; Sanjeev Kumar Dash, C.; Behera, A.K.; Dehuri, S. An elitist artificial-electric-field-algorithm-based artificial neural network for financial time series forecasting. In Biologically Inspired Techniques in Many Criteria Decision Making: Proceedings of BITMDM 2021; Springer: Singapore, 2022; pp. 29–38. [Google Scholar]
- Merugu, S.; Tiwari, A.; Sharma, S.K. Spatial–spectral image classification with edge preserving method. J. Indian Soc. Remote Sens. 2021, 49, 703–711. [Google Scholar] [CrossRef]
- Zhang, X.; Yu, W.; Pun, M.O.; Shi, W. Cross-domain landslide mapping from large-scale remote sensing images using prototype-guided domain-aware progressive representation learning. ISPRS J. Photogramm. Remote Sens. 2023, 197, 1–17. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, B.; Yu, W.; Kang, X. Federated Deep Learning with Prototype Matching for Object Extraction From Very-High-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Dabbu, M.; Karuppusamy, L.; Pulugu, D.; Vootla, S.R.; Reddyvari, V.R. Water atom search algorithm-based deep recurrent neural network for the big data classification based on spark architecture. Int. J. Mach. Learn. Cybern. 2022, 13, 2297–2312. [Google Scholar] [CrossRef]
- Balamurugan, D.; Aravinth, S.; Reddy, P.C.S.; Rupani, A.; Manikandan, A. Multiview objects recognition using deep learning-based wrap-CNN with voting scheme. Neural Process. Lett. 2022, 54, 1495–1521. [Google Scholar] [CrossRef]
- Vitale, S. A cnn-based pansharpening method with perceptual loss. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3105–3108. [Google Scholar]
- Vitale, S.; Scarpa, G. A detail-preserving cross-scale learning strategy for CNN-based pansharpening. Remote Sens. 2020, 12, 348. [Google Scholar] [CrossRef]
- He, L.; Zhu, J.; Li, J.; Plaza, A.; Chanussot, J.; Li, B. HyperPNN: Hyperspectral pansharpening via spectrally predictive convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3092–3100. [Google Scholar] [CrossRef]
- Scarpa, G.; Vitale, S.; Cozzolino, D. Target-adaptive CNN-based pansharpening. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5443–5457. [Google Scholar] [CrossRef]
- Jin, Z.R.; Zhang, T.J.; Jiang, T.X.; Vivone, G.; Deng, L.J. LAGConv: Local-context adaptive convolution kernels with global harmonic bias for pansharpening. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 1113–1121. [Google Scholar]
- Deng, L.J.; Vivone, G.; Jin, C.; Chanussot, J. Detail Injection-Based Deep Convolutional Neural Networks for Pansharpening. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6995–7010. [Google Scholar] [CrossRef]
- Yuan, Q.; Wei, Y.; Meng, X.; Shen, H.; Zhang, L. A Multiscale and Multidepth Convolutional Neural Network for Remote Sensing Imagery Pan-Sharpening. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 978–989. [Google Scholar] [CrossRef]
- Yang, Y.; Tu, W.; Huang, S.; Lu, H.; Wan, W.; Gan, L. Dual-stream convolutional neural network with residual information enhancement for pansharpening. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 13 December 2014; pp. 2672–2680. [Google Scholar]
- Liu, Q.; Zhou, H.; Xu, Q.; Liu, X.; Wang, Y. PSGAN: A generative adversarial network for remote sensing image pan-sharpening. IEEE Trans. Geosci. Remote Sens. 2020, 59, 10227–10242. [Google Scholar] [CrossRef]
- Xu, Q.; Li, Y.; Nie, J.; Liu, Q.; Guo, M. UPanGAN: Unsupervised pansharpening based on the spectral and spatial loss constrained generative adversarial network. Inf. Fusion 2023, 91, 31–46. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhan, J.; Xu, S.; Sun, K.; Huang, L.; Liu, J.; Zhang, C. FGF-GAN: A lightweight generative adversarial network for pansharpening via fast guided filter. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Li, W.; Zhu, M.; Li, C.; Fu, H. PAN-GAN: A Generative Adversarial Network for Pansharpening. Remote Sens. 2020, 12, 1836. [Google Scholar]
- Xu, S.; Zhang, J.; Zhao, Z.; Sun, K.; Liu, J.; Zhang, C. Deep gradient projection networks for pan-sharpening. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1366–1375. [Google Scholar]
- Mifdal, J.; Tomás-Cruz, M.; Sebastianelli, A.; Coll, B.; Duran, J. Deep unfolding for hyper sharpening using a high-frequency injection module. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 17–24 June 2023; pp. 2106–2115. [Google Scholar]
- Zhou, M.; Yan, K.; Pan, J.; Ren, W.; Xie, Q.; Cao, X. Memory-augmented deep unfolding network for guided image super-resolution. Int. J. Comput. Vis. 2023, 131, 215–242. [Google Scholar] [CrossRef]
- Zhang, X.; Yu, W.; Pun, M.O. Multilevel deformable attention-aggregated networks for change detection in bitemporal remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Meng, X.; Wang, N.; Shao, F.; Li, S. Vision Transformer for Pansharpening. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Yin, J.; Qu, J.; Sun, L.; Huang, W.; Chen, Q. A Local and Nonlocal Feature Interaction Network for Pansharpening. Remote Sens. 2022, 14, 3743. [Google Scholar] [CrossRef]
- Li, S.; Guo, Q.; Li, A. Pan-Sharpening Based on CNN+ Pyramid Transformer by Using No-Reference Loss. Remote Sens. 2022, 14, 624. [Google Scholar] [CrossRef]
- Zhang, K.; Li, Z.; Zhang, F.; Wan, W.; Sun, J. Pan-Sharpening Based on Transformer with Redundancy Reduction. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Masi, G.; Cozzolino, D.; Verdoliva, L.; Scarpa, G. Pansharpening by convolutional neural networks. Remote Sens. 2016, 8, 594. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- He, L.; Rao, Y.; Li, J.; Plaza, A.; Zhu, J. Pansharpening via Detail Injection Based Convolutional Neural Networks. arXiv 2018, arXiv:1806.08898. [Google Scholar] [CrossRef]
- Yang, J.; Fu, X.; Hu, Y.; Huang, Y.; Paisley, J. PanNet: A Deep Network Architecture for Pan-Sharpening. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, N.; Meng, X.; Meng, X.; Shao, F. Convolution-Embedded Vision Transformer with Elastic Positional Encoding for Pansharpening. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–9. [Google Scholar] [CrossRef]
- Zhang, F.; Zhang, K.; Sun, J. Multiscale Spatial-Spectral Interaction Transformer for Pan-Sharpening. Remote Sens. 2022, 14, 1736. [Google Scholar] [CrossRef]
- Zhu, W.; Li, J.; An, Z.; Hua, Z. Mutiscale Hybrid Attention Transformer for Remote Sensing Image Pansharpening. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Yuhas, R.H.; Goetz, A.F.; Boardman, J.W. Discrimination among semi-arid landscape endmembers using the spectral angle mapper (SAM) algorithm. In Proceedings of the JPL, Summaries of the Third Annual JPL Airborne Geoscience Workshop. Volume 1: AVIRIS Workshop, Pasadena, CA, USA, 1–5 June 1992. [Google Scholar]
- Liu, X.; Liu, Q.; Wang, Y. Remote sensing image fusion based on two-stream fusion network. Inf. Fusion 2020, 55, 1–15. [Google Scholar] [CrossRef]
- Alparone, L.; Baronti, S.; Garzelli, A.; Nencini, F. A global quality measurement of pan-sharpened multispectral imagery. IEEE Geosci. Remote Sens. Lett. 2004, 1, 313–317. [Google Scholar] [CrossRef]
- Arienzo, A.; Vivone, G.; Garzelli, A.; Alparone, L.; Chanussot, J. Full-resolution quality assessment of pansharpening: Theoretical and hands-on approaches. IEEE Geosci. Remote Sens. Mag. 2022, 10, 168–201. [Google Scholar] [CrossRef]
- Aiazzi, B.; Baronti, S.; Selva, M. Improving Component Substitution Pansharpening Through Multivariate Regression of MS + Pan Data. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3230–3239. [Google Scholar] [CrossRef]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A.; Selva, M. An MTF-based spectral distortion minimizing model for pan-sharpening of very high resolution multispectral images of urban areas. In Proceedings of the 2003 2nd GRSS/ISPRS Joint Workshop on Remote Sensing and Data Fusion over Urban Areas, Berlin, Germany, 22–23 May 2003; pp. 90–94. [Google Scholar]
- Liu, J. Smoothing filter-based intensity modulation: A spectral preserve image fusion technique for improving spatial details. Int. J. Remote Sens. 2000, 21, 3461–3472. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paratmeters | DRB | DRL | Head | Dimension | Learning Rate | Batch Size |
|---|---|---|---|---|---|---|
| QuickBird | 6 | [2, 2, 2, 2, 2, 2] | 2 | 96 | 32 | |
| GaoFen2 | 6 | [2, 2, 2, 2, 2, 2] | 6 | 60 | 32 | |
| WorldView3 | 6 | [2, 2, 2, 2, 2, 2] | 2 | 60 | 32 |
| Methods | SAM↓ | REGAS↓ | Q4↑ | SCC↑ |
|---|---|---|---|---|
| SFIM | 8.1925 ± 1.7282 | 8.8807 ± 2.1295 | 0.8495 ± 0.0788 | 0.9315 ± 0.0150 |
| MTF-GLP-HPM | 8.3063 ± 1.5742 | 10.4731 ± 0.9394 | 0.8411 ± 0.0138 | 0.8796 ± 0.0194 |
| GSA | 8.3497 ± 1.6728 | 9.3289 ± 2.7366 | 0.8289 ± 0.1119 | 0.9284 ± 0.0140 |
| DiCNN | 5.6262 ± 0.9368 | 5.4730 ± 0.3720 | 0.9488 ± 0.0103 | 0.9712 ± 0.0054 |
| MSDCNN | 4.9896 ± 0.8182 | 4.1383 ± 0.2411 | 0.9720 ± 0.0057 | 0.9814 ± 0.0038 |
| DRPNN | 5.0111 ± 0.8288 | 4.1363 ± 0.2487 | 0.9719 ± 0.0057 | 0.9794 ± 0.0040 |
| FusionNet | 5.1158 ± 0.8432 | 4.3962± 0.2662 | 0.9678 ± 0.0071 | 0.9797 ± 0.0039 |
| PNN | 5.4115 ± 0.8705 | 4.7185 ± 0.3218 | 0.9630 ± 0.0087 | 0.9763 ± 0.0044 |
| PanNet | 5.5462 ± 1.0085 | 5.4995 ± 0.8098 | 0.9487 ± 0.0186 | 0.9687 ± 0.0082 |
| HyperTransformer | 4.9931 ± 0.7630 | 4.1189 ± 0.3429 | 0.9715 ± 0.0078 | 0.9813 ± 0.0075 |
| Ours | 4.8653 ± 0.7909 | 4.0546 ± 0.2531 | 0.9726 ± 0.0063 | 0.9826 ± 0.0035 |
| Methods | SAM ↓ | REGAS ↓ | Q4 ↑ | SCC ↑ |
|---|---|---|---|---|
| SFIM | 6.2068 ± 1.1050 | 12.4050 ± 2.1028 | 0.5631 ± 0.1187 | 0.9691 ± 0.0120 |
| MTF-GLP-HPM | 5.1642 ± 1.0338 | 10.5863 ± 3.2607 | 0.6186 ± 0.1613 | 0.9416 ±0.0142 |
| GSA | 6.4668 ± 1.0011 | 12.8536 ±2.1755 | 0.5391 ± 0.1253 | 0.9659 ± 0.0127 |
| DICNN | 1.1003 ± 0.2064 | 1.1222 ± 0.2184 | 0.9840 ± 0.0081 | 0.9862 ± 0.0059 |
| MSDCNN | 0.9889 ± 0.1839 | 0.9679 ± 0.1777 | 0.9886 ± 0.0063 | 0.9901 ± 0.0043 |
| DRPNN | 0.9118 ± 0.1634 | 0.8185 ± 0.1377 | 0.9916 ± 0.0045 | 0.9918 ± 0.0035 |
| FusionNet | 1.0143 ± 0.1959 | 1.0551 ± 0.2079 | 0.9860 ± 0.0071 | 0.9889 ± 0.0048 |
| PNN | 1.0907 ± 0.2105 | 1.1116 ± 0.2259 | 0.9842 ± 0.0085 | 0.9871 ± 0.0058 |
| PanNet | 1.0248 ± 0.1724 | 0.9214 ± 0.1561 | 0.9893 ± 0.0056 | 0.9898 ± 0.0043 |
| HyperTransformer | 0.9538 ± 0.1648 | 0.8506 ± 0.1283 | 0.9908 ± 0.0048 | 0.9905 ± 0.0038 |
| Ours | 0.7996 ± 0.1441 | 0.7790 ± 0.1271 | 0.9922 ± 0.0041 | 0.9936 ± 0.0028 |
| Methods | SAM ↓ | REGAS ↓ | Q8 ↑ | SCC ↑ |
|---|---|---|---|---|
| SFIM | 5.5385 ± 1.4737 | 5.7839 ± 1.7049 | 0.8704 ± 0.4548 | 0.9531 ± 0.0142 |
| MTF-GLP-HPM | 5.7246 ± 1.5042 | 6.5285 ± 1.3622 | 0.8716 ± 0.3886 | 0.9237 ± 0.0211 |
| GSA | 5.6828 ± 1.5025 | 6.6567 ± 1.8083 | 0.8732 ± 0.3973 | 0.9496 ± 0.0137 |
| DICNN | 4.4534 ± 0.8643 | 3.2739 ± 0.8627 | 0.9228 ± 0.5535 | 0.9765 ± 0.0125 |
| MSDCNN | 3.7875 ± 0.6942 | 2.7558 ± 0.6105 | 0.9373 ± 0.3181 | 0.9748 ± 0.0114 |
| DRPNN | 3.5703 ± 0.6365 | 2.5916 ± 0.5484 | 0.8479 ± 0.4550 | 0.9778 ± 0.0119 |
| FusionNet | 3.4672 ± 0.6286 | 2.5718 ± 0.5937 | 0.8516 ± 0.4376 | 0.9825 ± 0.0077 |
| PNN | 3.9548 ± 0.7266 | 2.8655 ± 0.6668 | 0.8968 ± 0.4820 | 0.9750 ± 0.0109 |
| PanNet | 3.7322 ± 0.6609 | 2.7974 ± 0.6270 | 0.8760 ± 0.4258 | 0.9729 ± 0.0128 |
| HyperTransformer | 3.1275 ± 0.5250 | 2.6405 ± 0.5122 | 0.9210 ± 0.3970 | 0.9843 ± 0.1240 |
| Ours | 2.9542 ± 0.5253 | 2.1558 ± 0.4439 | 0.9539 ± 0.4722 | 0.9890 ± 0.0046 |
| Methods | QNR↑ | ||
|---|---|---|---|
| SFIM | 0.0512 ± 0.0113 | 0.1296 ± 0.0996 | 0.8243 ± 0.0974 |
| MTF-GLP-HPM | 0.0506 ± 0.0234 | 0.1341 ± 0.1146 | 0.8217 ± 0.1095 |
| GSA | 0.0465 ± 0.0207 | 0.2007 ± 0.1098 | 0.7614 ± 0.1033 |
| DICNN | 0.0416 ± 0.0300 | 0.0910 ± 0.0514 | 0.8723 ± 0.0711 |
| MSDCNN | 0.0604 ± 0.0390 | 0.0524 ± 0.0137 | 0.8903 ± 0.0391 |
| DRPNN | 0.0394 ± 0.0327 | 0.0409 ± 0.0241 | 0.9219 ± 0.0513 |
| FusionNet | 0.0402 ± 0.0341 | 0.0543 ± 0.0410 | 0.9088 ± 0.0676 |
| PNN | 0.0399 ± 0.0342 | 0.0500 ± 0.0393 | 0.9133 ± 0.0665 |
| PanNet | 0.0409 ± 0.0347 | 0.0418 ± 0.0334 | 0.9200 ± 0.0618 |
| HyperTransformer | 0.0424 ± 0.0376 | 0.0412 ± 0.0195 | 0.9210 ± 0.0499 |
| Ours | 0.0370 ± 0.0333 | 0.0398 ± 0.0257 | 0.9253 ± 0.0536 |
| Methods | QNR↑ | ||
|---|---|---|---|
| SFIM | 0.0371 ± 0.0160 | 0.0647 ± 0.0460 | 0.9010 ± 0.0518 |
| MTF-GLP-HPM | 0.0925 ± 0.0386 | 0.0805 ± 0.0531 | 0.8351 ± 0.0676 |
| GSA | 0.0596 ± 0.0227 | 0.1027 ± 0.0542 | 0.8445 ± 0.0620 |
| DICNN | 0.0179 ± 0.0145 | 0.0590 ± 0.0262 | 0.9244 ± 0.0371 |
| MSDCNN | 0.0121 ± 0.0144 | 0.0387 ± 0.0198 | 0.9499 ± 0.0317 |
| DRPNN | 0.0158 ± 0.0152 | 0.0319 ± 0.0168 | 0.9530 ± 0.0298 |
| FusionNet | 0.0215 ± 0.0191 | 0.0546 ± 0.0262 | 0.9255 ± 0.0419 |
| PNN | 0.0113 ± 0.0130 | 0.0333 ± 0.0175 | 0.9560 ± 0.0285 |
| PanNet | 0.0115 ± 0.0118 | 0.0412 ± 0.0191 | 0.9486 ± 0.0285 |
| HyperTransformer | 0.0174 ± 0.0170 | 0.0414 ± 0.0218 | 0.9422 ± 0.0355 |
| Ours | 0.0110 ± 0.0099 | 0.0309 ± 0.0135 | 0.9585 ± 0.0210 |
| Methods | QNR↑ | ||
|---|---|---|---|
| SFIM | 0.0353 ± 0.0106 | 0.0565 ± 0.0288 | 0.9075 ± 0.0351 |
| MTF-GLP-HPM | 0.0389 ± 0.0229 | 0.0523 ± 0.0332 | 0.9113 ± 0.0482 |
| GSA | 0.0325 ± 0.0131 | 0.0603 ± 0.0293 | 0.9062 ± 0.0381 |
| DICNN | 0.0239 ± 0.0174 | 0.0575 ± 0.0339 | 0.9202 ± 0.0410 |
| MSDCNN | 0.0267 ± 0.0146 | 0.0473 ± 0.0254 | 0.9275 ± 0.0351 |
| DRPNN | 0.0266 ± 0.0168 | 0.0476 ± 0.0234 | 0.9274 ± 0.0369 |
| FusionNet | 0.0320 ± 0.0253 | 0.0490 ± 0.0213 | 0.9207 ± 0.0354 |
| PNN | 0.0249 ± 0.0139 | 0.0451 ± 0.0220 | 0.9313 ± 0.0312 |
| PanNet | 0.0277 ± 0.0142 | 0.0603 ± 0.0237 | 0.9140 ± 0.0342 |
| HyperTransformer | 0.0276 ± 0.0137 | 0.0487 ± 0.0212 | 0.9347 ± 0.0312 |
| Ours | 0.0216 ± 0.0105 | 0.0326 ± 0.0194 | 0.9467 ± 0.0275 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Hu, Y.; Peng, Y.; He, M. A Swin Transformer with Dynamic High-Pass Preservation for Remote Sensing Image Pansharpening. Remote Sens. 2023, 15, 4816. https://doi.org/10.3390/rs15194816
Li W, Hu Y, Peng Y, He M. A Swin Transformer with Dynamic High-Pass Preservation for Remote Sensing Image Pansharpening. Remote Sensing. 2023; 15(19):4816. https://doi.org/10.3390/rs15194816
Chicago/Turabian StyleLi, Weisheng, Yijian Hu, Yidong Peng, and Maolin He. 2023. "A Swin Transformer with Dynamic High-Pass Preservation for Remote Sensing Image Pansharpening" Remote Sensing 15, no. 19: 4816. https://doi.org/10.3390/rs15194816
APA StyleLi, W., Hu, Y., Peng, Y., & He, M. (2023). A Swin Transformer with Dynamic High-Pass Preservation for Remote Sensing Image Pansharpening. Remote Sensing, 15(19), 4816. https://doi.org/10.3390/rs15194816