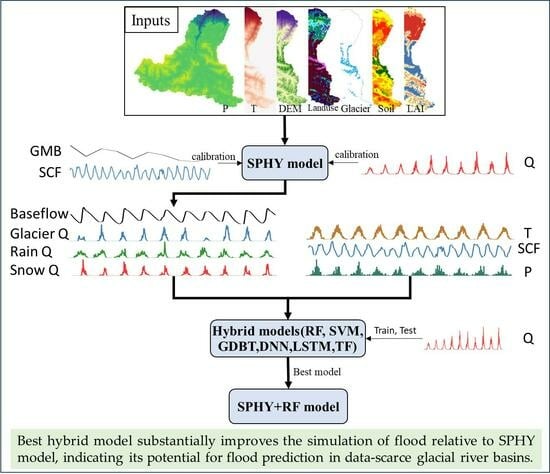
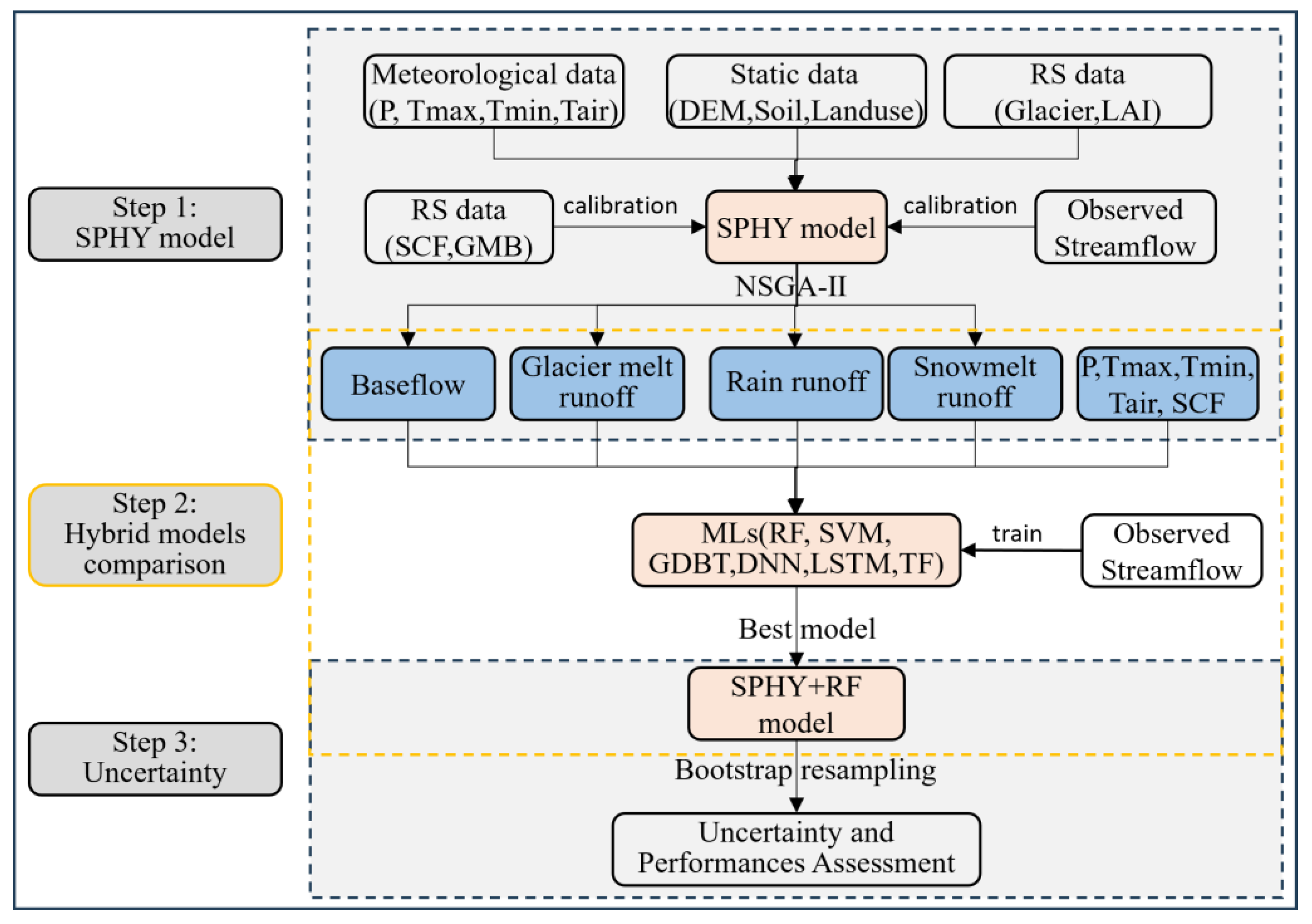
4.1. Streamflow Simulated by SPHY Model
Effective model inputs are crucial for enhancing simulation capabilities, demanding thorough attention. Prior investigations underscore the significance of glacier runoff and snowmelt runoff within the hybrid model [
20], substantiating their pivotal role in enhancing runoff simulation accuracy. In line with these insights, the present study employs a multi-objective calibration approach to meticulously calibrate model parameters across various components.
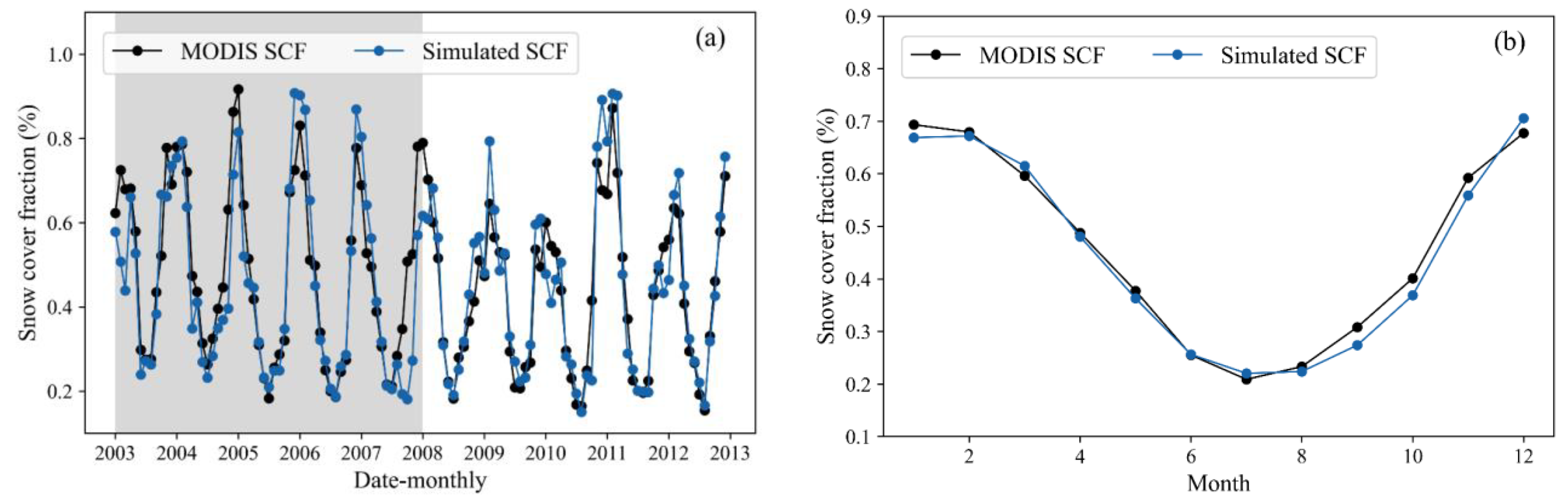
The snow module parameters are systematically optimized to minimize discrepancies between mean monthly simulated snow cover fractions within the SPHY model and those observed through MODIS snow cover data [
31].
Figure 3a displays the time series of simulated snow cover fractions for the Manas basin, while
Table 3 presents the corresponding performance metrics. Utilizing the parameter set calibrated via the NSGA-II algorithm, the SPHY model exhibits robust performance, closely aligning its simulated snow cover fractions with those derived from Muhammad, S. and Thapa, A. [
31]. During the training period, the modeled and observed outcomes exhibit remarkable proximity, evidenced by an NSE value of 0.76, a CC value reaching 0.88, an RMSE value of merely 0.1, and a Bias value of 6.46%. The model’s performance showcases even greater consistency to some extent during the testing period, reflecting an RMSE value of approximately 0.07, an NSE value of 0.87, a CC value of 0.93, and a Bias value hovering around −3.47. The performance during the testing period exhibited improvement, potentially attributed to the SPHY model’s ability to capture a higher snow cover fraction within that timeframe, aided by the parameters calibrated based on the MODIS SCF data.
Figure 2b displays the multi-year monthly mean of simulated and observed snow cover fractions for the Manas basin. SPHY underestimates snow cover fractions for the autumn, while the other months simulate very well. Given the influence of cloud shading on the MODIS snow area product, the snow simulation is considered as notably satisfactory.
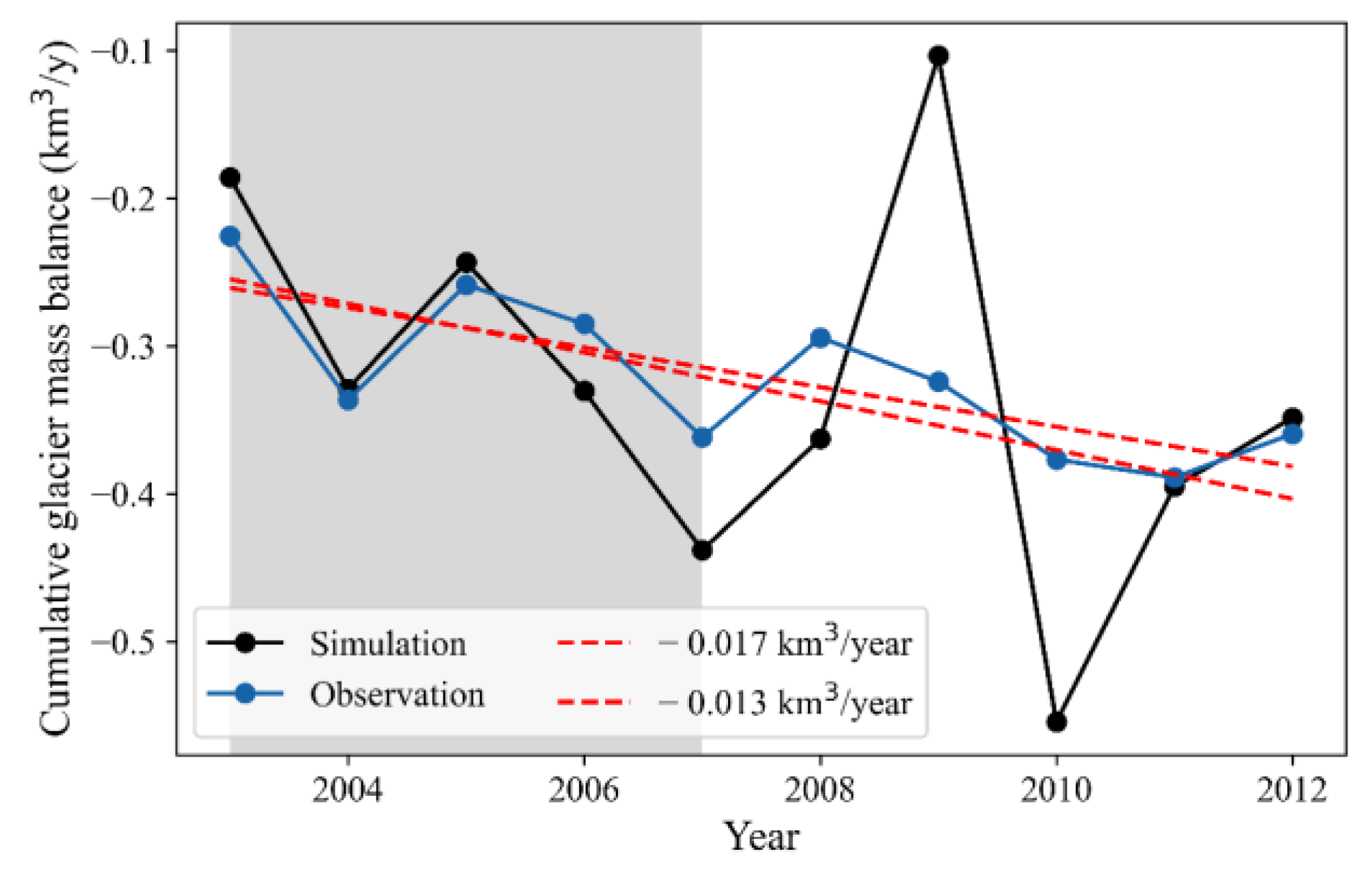
The time series of simulated glacier mass balance for the Manas basin is shown in
Figure 4, and
Table 3 shows corresponding performance metrics. With the calibrated optimal parameter, the SPHY model performs well and simulated glacier mass balances are consistent with observations [
1]. Throughout the training period, the modeled and measured glacier mass balance for the Manas Basin Glacier exhibited remarkable proximity, reflected in an impressive correlation coefficient (CC) value of up to 0.94, a remarkably low root mean square error (RMSE) value of merely 0.04 km
3, and a bias value of 4.05%. Although the model’s performance undergoes a slight decline during the testing period, it remains acceptable across the entirety of the study duration, as evidenced by relatively favorable performance metrics—approximately 0.13 km
3 for RMSE, 0.51 for the CC value, and about 1.18% for Bias. The observed performance dip during the testing period is primarily attributed to the suboptimal accuracy displayed in 2009 and 2010, manifesting as substantial overestimations and underestimations. Despite NSE values of 0.21 during training and −12.9 during testing, indicating subpar performance, the simulation remains relatively satisfactory. This is primarily due to the inherent discontinuities in both the temporal and spatial dimensions of the glacier mass balance data sourced from Hugonnet et al. [
1], necessitating interpolation. Consequently, the temporal alterations in glacier mass balance data are comparatively modest. In actuality, the melt of the Manas River glacier is significantly influenced by temperature and precipitation. A glance at
Figure 3 reveals that in 2009 and 2010, there was a conspicuous reduction in snow cover area in contrast to other years, resulting in a significantly elevated glacier melt volume in 2010. Conversely, the diminished snow cover in 2009 contributed to a reduced glacier melt volume, primarily attributable to lower temperatures. This, in turn, resulted in noticeably diminished runoff for the same year, which can be found in
Figure 5a. Furthermore, the multi-year average glacier melt volume from the simulation closely converges with observation at 0.329 km
3 and 0.321 km
3, respectively. Additionally, the trends of annual glacier melt volumes, −0.017 km
3/year for simulation and −0.013 km
3/year for observation, are remarkably consistent. These simulated values adeptly capture the glacier’s melting trend. Hence, the results of the glacier simulation presented in this study are deemed reasonable.
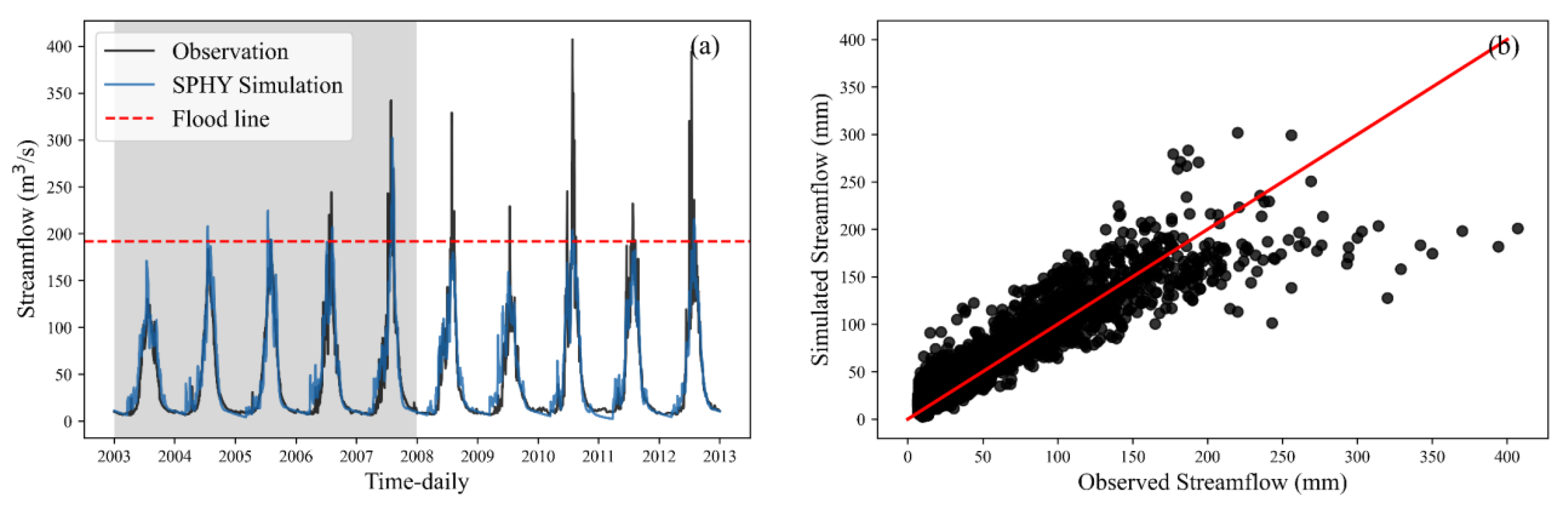
The time series simulated daily streamflow within the Manas basin, which is presented in
Figure 5, while
Table 3 provides an exposition of the corresponding performance metrics. Notably, the SPHY model exhibits commendable performance, with the simulated daily streamflow closely aligned with observational data. Specifically, for the Manas basin, the concurrence between modeled and observed streamflow is particularly pronounced during the calibration period. With a notable NSE value of 0.85, an impressive correlation coefficient (CC) value of up to 0.93, an RMSE value of only 19.09 m
3/s, and a Bias value of 7.10%, the model’s fidelity is evident. Evaluation indicators presented in
Table 3 substantiate the model’s robustness during the testing period, with an RMSE value approximating 20.88 m
3/s, an NSE value of 0.86, a CC value of 0.93, and a Bias value of around 1.6%. Comparing the NSE, CC, and RMSE values between the training and validation periods underscores their close alignment, affirming the model’s adeptness and strong generalization capabilities.
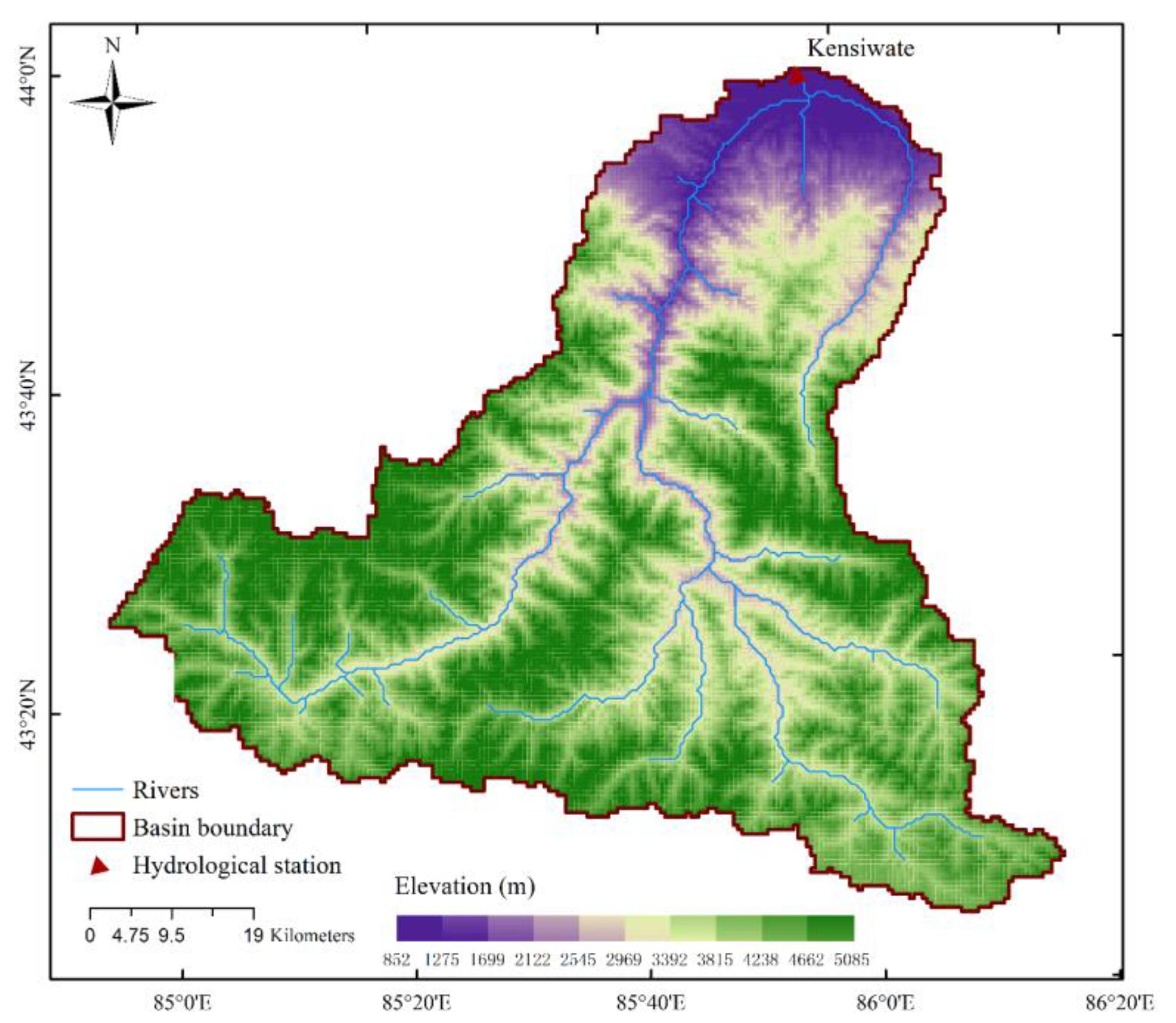
In this study, flood is defined as the minimum flood record value of the Kensiwate hydrological station which is 192 m
3/s. From
Figure 5a, it can be found that the uneven distribution of flood occurrences across various years is notable. Over the ten years from 2003 to 2012, 81 flood events were recorded. Remarkably, during the training period, merely 29 floods were observed, while the testing period accounted for 52 floods. The average magnitude of simulated flood events during the training interval registered at 189.67 m
3/s. In contrast, the corresponding observed average flood magnitude was 228.60 m
3/s, denoting an underestimation of 17.02%. A similar pattern was observed during the testing period, where the average observed flood magnitude reached 244.80 m
3/s, in contrast to the simulated average flood magnitude of 172.11 m
3/s, translating to an underestimation of 29.69%. As can be seen from
Figure 5b, the SPHY model significantly underestimates flooding but is very good for other runoff simulations. These findings distinctly underscore the limitations of the SPHY hydrological model in encapsulating flood events.
In fact, it is common for runoff simulations to underestimate flood events in high mountain areas [
50], in particular the physical-based hydrological model. The root of this limitation can be traced to the paucity of high-quality observed temperature and precipitation data within the Manas River basin. Moreover, the utilization of remote sensing precipitation products, characterized by the averaging of precipitation over a 0.1° × 0.1° grid, while the spatial resolution of the SPHY model is set as 1 km × 1 km, results in the attenuation of precipitation peaks. As an integral factor influencing flood simulations, temperature similarly contributes to this limitation. Despite downscaling through bilinear interpolation, the lower resolution of temperature products impedes accurate reconstruction of temperature peaks, subsequently hampering precise flood simulation. This issue resonates as a universal challenge across data-scarce regions.
4.2. Streamflow Simulated by Hybrid Models
Table 4 displays the statistical metrics of NSE, CC, RMSE and PBIAS for both the training and testing periods for six hybrid models (namely SPHY-RF, SPHY-GDBT, SPHY-SVM, SPHY-DNN, SPHY-LSTM, and SPHY-TF) utilized for simulating streamflow in the Manas River basin. The optimal outcomes among the six models are highlighted in bold. Notably, the NSEs indicate “very good” ratings (i.e., NSE > 0.70) for six hybrid models. Furthermore, compared with the results in
Table 3, it becomes evident that the performance of all hybrid models notably surpasses that of the physical-based SPHY model. This aligns with the common observation that statistical models tend to outperform physical-based models in streamflow simulation [
51]. This highlights the capacity enhancement of streamflow modeling by combining physical models with ML. Assessing CC, NSE, and RMSE among the six hybrid models, the SPHY-GDBT model excels during the training period, while SPHY-RF performs best during the testing period. In terms of generalization, SPHY-RF is better suited for streamflow simulation. Additionally, a comparison among the hybrid models reveals that ensemble-learning-based hybrid models (SPHY-GDBT and SPHY-RF) significantly outperform the simple Support-Vector-Machine (SPHY-SVM)- and deep-learning-based hybrid models (SPHY-DNN, SPHY-LSTM, and SPHY-TF). It is also noticeable that the performance of the simple SVM is comparatively poorer. Thirdly, deep-learning-based hybrid models (SPHY-DNN, SPHY-LSTM) demonstrate remarkable stability, exhibiting minimal deviation between the training and testing periods, consistent with prior research [
21].
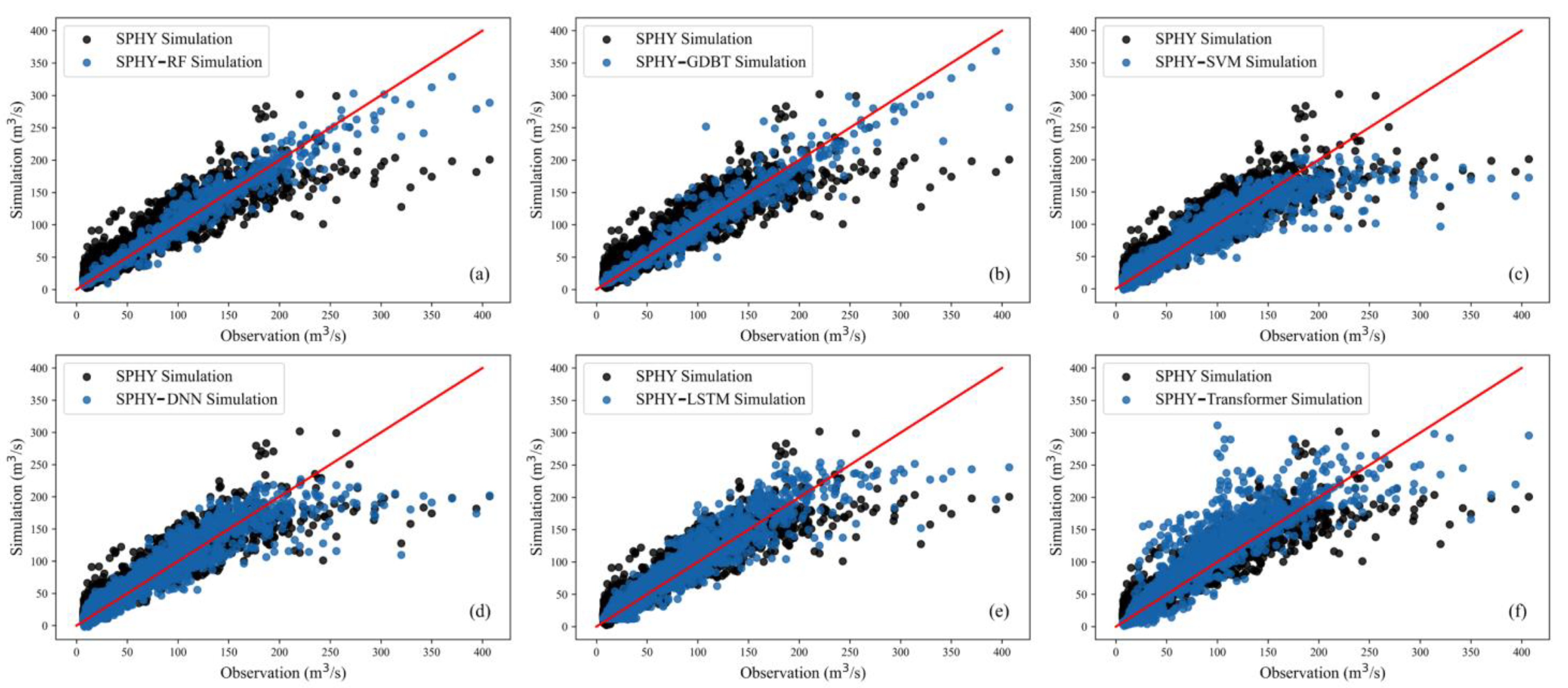
To evaluate the performance of hybrid models in streamflow simulation, the simulated streamflow of the hybrid models was compared against the physical-based model SPHY, as shown in
Figure 6, since the training and testing datasets for hybrid models are divided based on the same distribution principle. In contrast, the physical model divides them based on chronological order; for a fair comparison, all simulated data were juxtaposed. From
Figure 6, it is evident that all hybrid models outperform the SPHY model. Among them, SPHY-SVM performs the poorest (
Figure 6c), with only partial simulated results outperforming the physical model. The advantage is insignificant for most points, and even some high flows are noticeably underestimated. Although SPHY-DNN beats SPHY-SVM regarding evaluation metrics in
Table 4, the comparison between
Figure 6c,d reveals a similar high-flow simulation performance that some high flows are noticeably underestimated. The SPHY-TF model (
Figure 6f) exhibits a slight advantage over the physical model in a flood simulation. However, within 50~150 m
3/s of streamflow, it tends to overestimate, and this phenomenon does not occur in other models. Moreover, all the other five hybrid models can significantly reduce the overestimations of the SPHY model around 200 m
3/s. Comparing the well-performing models SPHY-RF, SPHY-GDBT, and SPHY-LSTM, it is observed that relative to SPHY-LSTM, both SPHY-RF and SPHY-GDBT can simulate high-flow effectively. Among them, SPHY-GDBT performs better, possibly due to better performance during the training period and some degree of overfitting, leading to its inferior performance compared to SPHY-RF during validation. Through the above results, it is found that the hybrid model, namely SPHY-RF, is more suitable for streamflow simulation and prediction.
4.3. Flood Simulated by Hybrid Models
Accurate prediction of high flows is paramount for informed decision-making to prevent water resource wastage during flood events. This study defines the minimum flood value as the lowest recorded flood value of the Kensiwate hydrological station, amounting to 192 m
3/s [
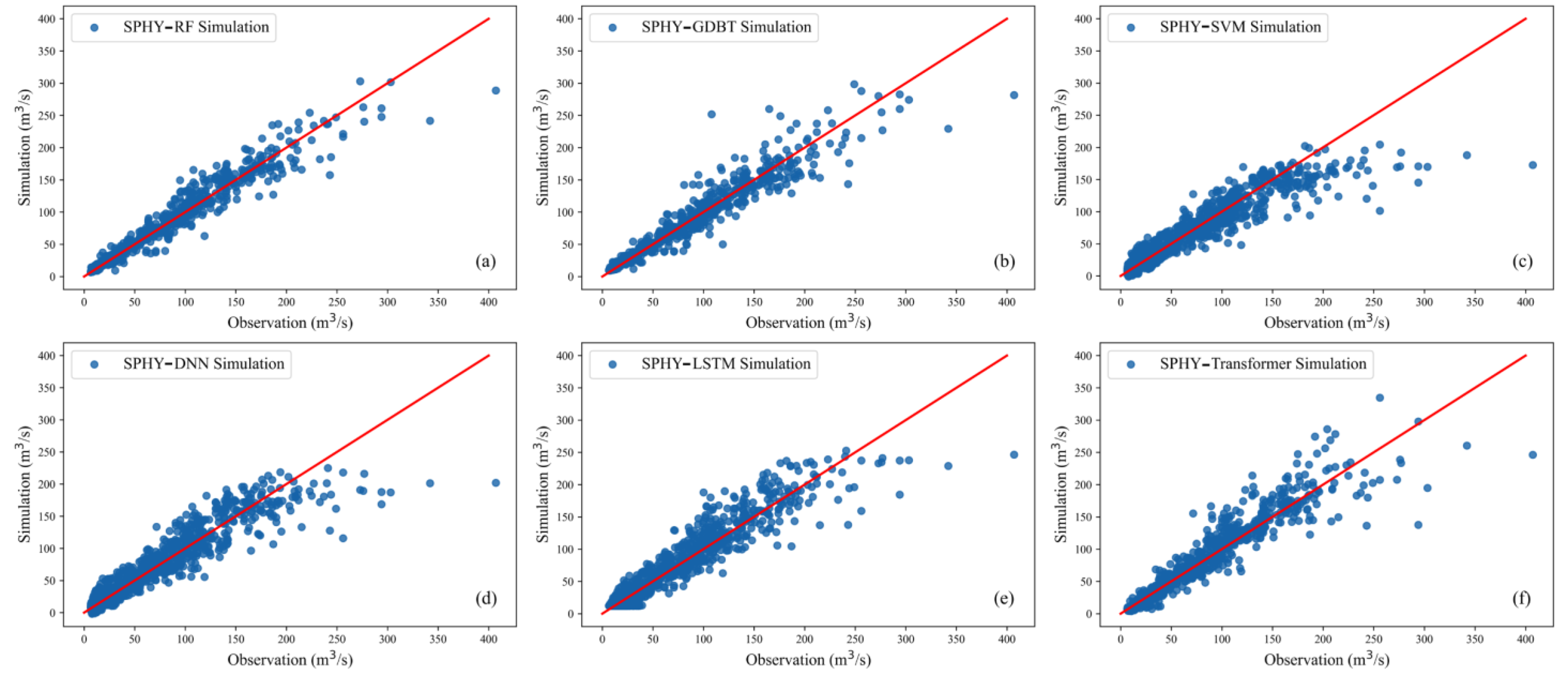
24]. To evaluate the flood simulation performance of various hybrid models during the testing period, the results of each model are compared to observed values, as depicted in
Figure 7. The graphical representation distinctly showcases the superior flood simulation performance of the SPHY-RF hybrid model over the other five counterparts. Specifically, SPHY-SVM (
Figure 7c), SPHY-DNN (
Figure 7d) and SPHY-LSTM (
Figure 7e) exhibit substantial underestimation of flood values, with their scatter plots exhibiting high similarity. This suggests their unsuitability for flood prediction. Moreover, despite SPHY-TF’s comparatively lower performance when juxtaposed with SPHY-RF and SPHY-GDBT, it still demonstrates notable potential in flood prediction. Contrary to the prevalent belief in the pronounced advantages of deep learning algorithms in diverse studies, this research asserts that for straightforward, small-scale size problems, RF outperforms them. Deep learning algorithms such as LSTM and TF might require a larger quantity of samples to effectively train model parameters and attain a heightened level of model stability.
Table 5 presents the evaluation metrics for flood simulations by hybrid models and the SPHY hydrological model to assess the flood modeling capability of hybrid models. Although the training and testing period divisions differ between the SPHY and the hybrid models, the simulation results of the SPHY model still hold certain reference values. From
Table 5, it is evident that during the training period, almost all hybrid models outperform the SPHY model, except for SPHY-SVM, which performs better in terms of NSE but worse in other metrics than the SPHY model, suggesting that SPHY-SVM may not be suitable for flood simulation. Among the hybrid models, SPHY-GDBT exhibits the best performance during the training period, but its testing results deteriorate rapidly, possibly due to overfitting. Regarding the testing period, SPHY-RF achieves the best results, with the highest NSE, CC, and lowest RMSE, PBIAS. Although NSE and CC decreased more than the training period, the consistent performance of RMSE and PBIAS indicates the reliability of SPHY-RF’s training outcomes. The hybrid models based on deep learning demonstrate noticeable improvements over the physical SPHY model, yet they still lag behind SPHY-RF, suggesting that deep learning models still have room for enhancement in flood simulation. All models in
Table 5 exhibit negative PBIAS values in both training and testing periods, indicating an underestimation of flood values. Like other ML streamflow forecasting models, discrepancies with observed peaks could be attributed to various factors: (1) IMERG remote sensing’s inability to capture extreme precipitation; (2) the absence of consideration for glacial lake bursts during summer; (3) inaccurate outputs generated by SPHY due to limited climate data, and (4) challenges inherent to ML in predicting extreme values. Typically, extreme values reside in the tail of the data distribution, while most training data cluster around the distribution’s center. Models might lack sufficient examples of extreme values to predict such scenarios accurately. In conclusion, all the analysis above highlights that the SPHY-RF model excels not only in curve fitting ability during the training period but also in its capacity for generalization.
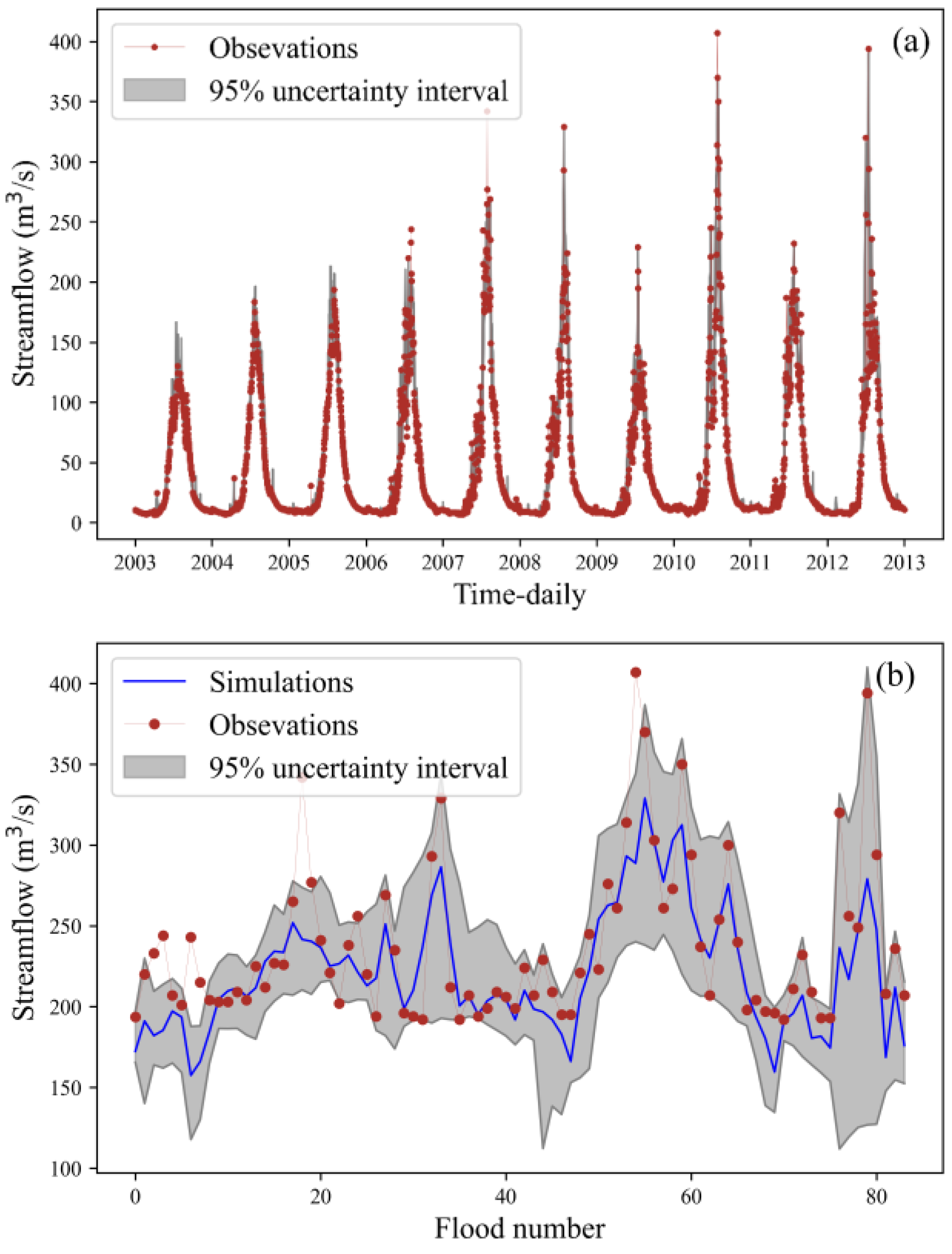
To enhance flood simulation and provide more informative flood forecasting, this study employed the Bootstrap resampling technique to sample the inputs of the SPHY-RF model 10,000 times. The resulting 95% confidence interval was utilized to quantify uncertainty. As depicted in
Figure 8a, the uncertainty interval width for all data was 12.20 m
3/s, with a Percentage of Coverage (POC) of 92.03%. Notably, the majority of observed values were encompassed within the 95% confidence interval, except for certain extreme flood events.
Figure 8b displays the uncertainty intervals for 84 flood values from 2003 to 2012. The uncertainty interval width was 91.66 m
3/s, with a POC of 87.65%. Although certain flood events lie outside the realm of the uncertainty interval, this interval still offers valuable insights. According to statistical analysis, the average value of points exceeding the upper boundary of the uncertainty interval is 30.51 m
3/s. In contrast, the average value of these flood events is 263.4 m
3/s. This indicates that the upper boundary of the uncertainty interval underestimates floods by 11.5%. However, in practical application, this discrepancy can be rectified through real-time corrections. Certainly, the hybrid model failed to capture certain flood events due to the absence of flood-related information among the inputs, such as exceptional heavy rainfall and abrupt events like glacier lake outbursts. Consequently, regardless of the sampling approach, consistently underestimated points will remain so. Furthermore, the figure indicates that flood predictions above approximately 220 m
3/s generally tend to underestimate actual values. This discrepancy might arise from the scarcity of samples representing such extreme floods in the hybrid models dataset, leading to larger deviations and consequently increased uncertainty intervals in predictions.





 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}