





Multi-Stage Multi-Scale Local Feature Fusion for Infrared Small Target Detection

Abstract
:
1. Introduction
2. Materials and Methods
2.1. Related Work
2.1.1. Generic Object Detection
2.1.2. Infrared Small Target Detection
2.2. Method
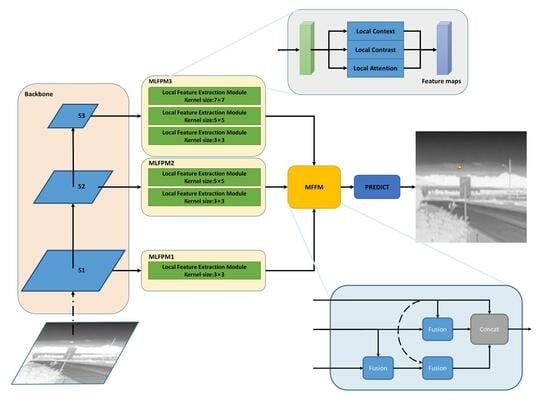
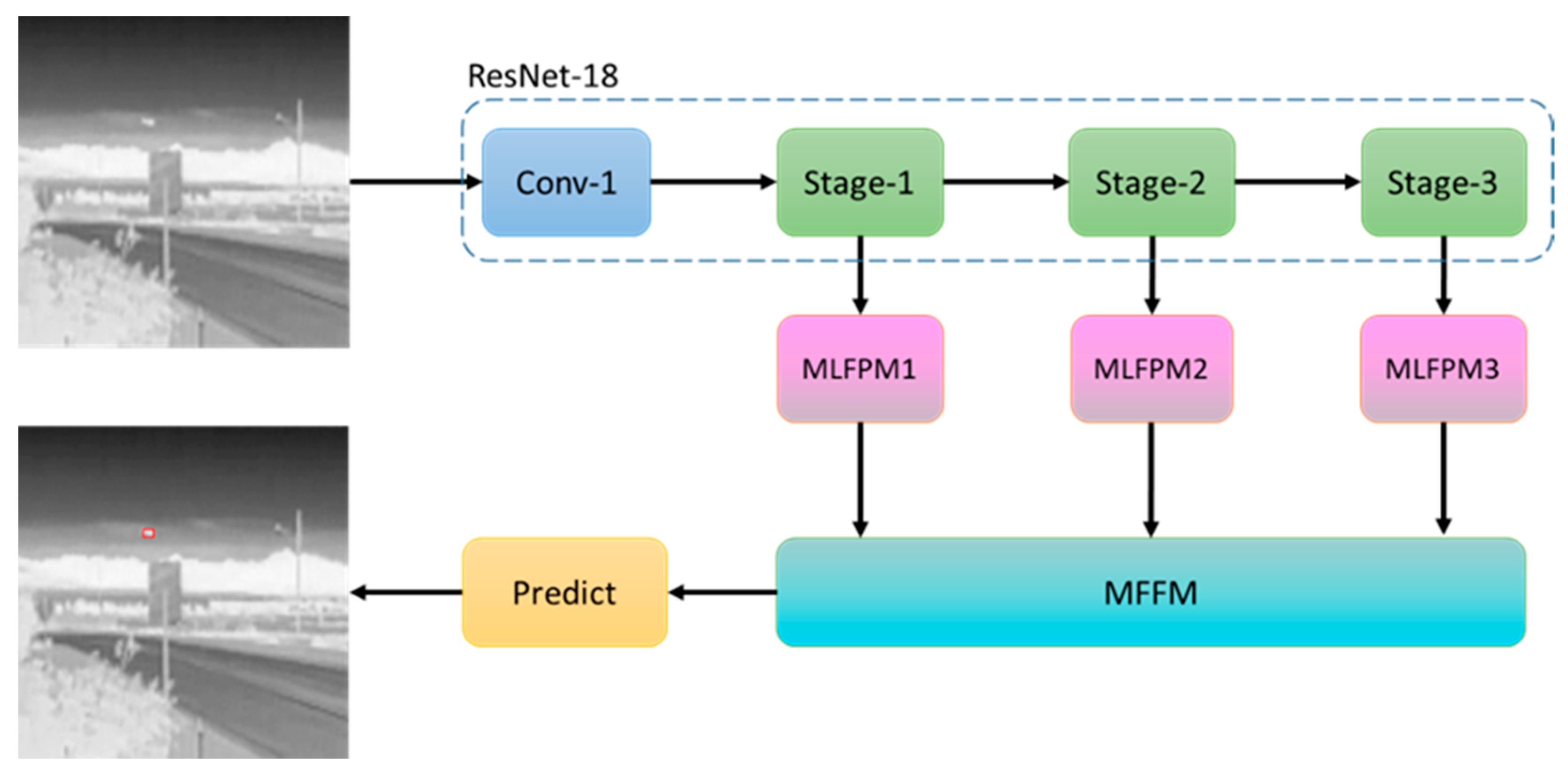
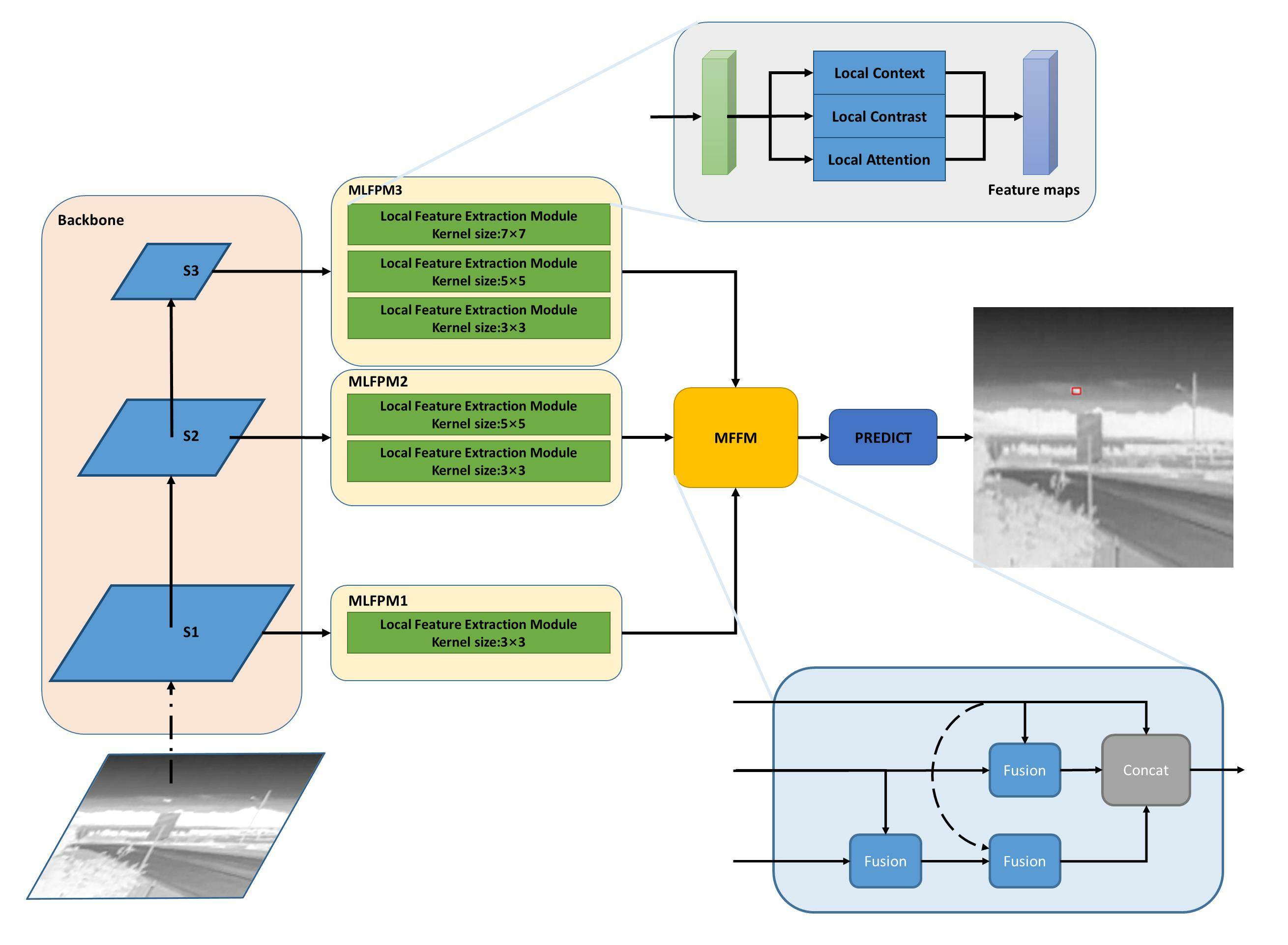
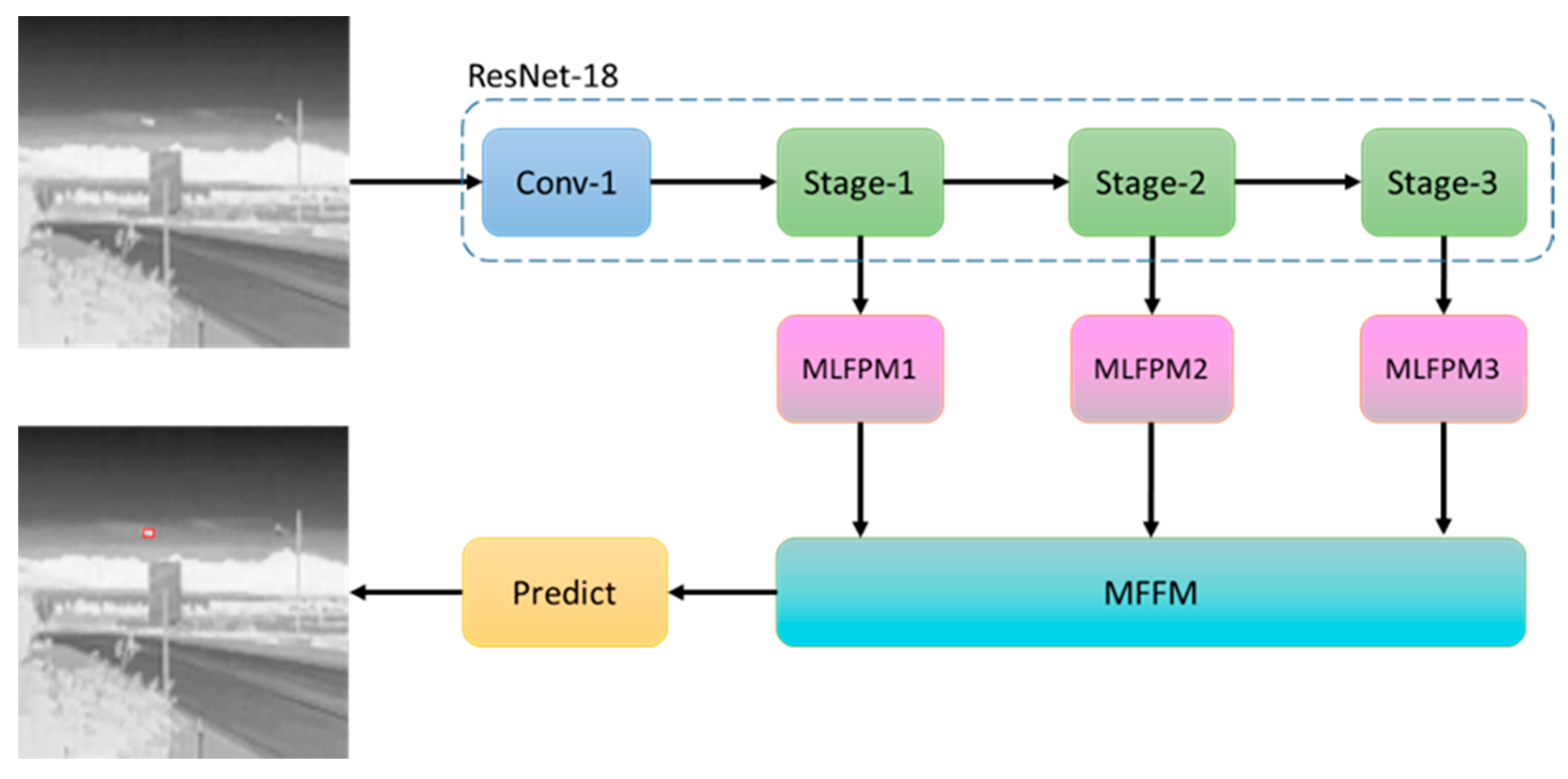
2.2.1. Overall Architecture
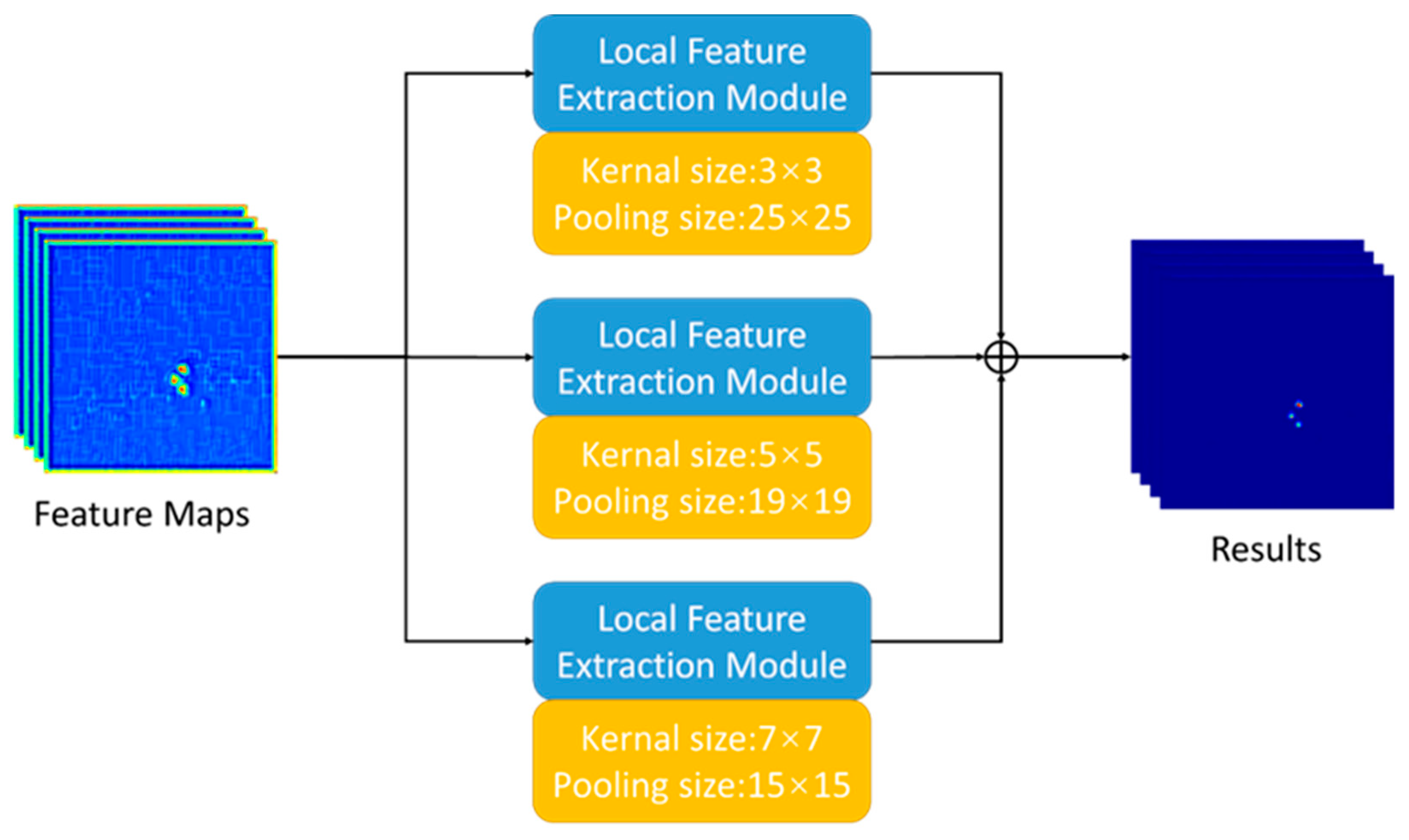
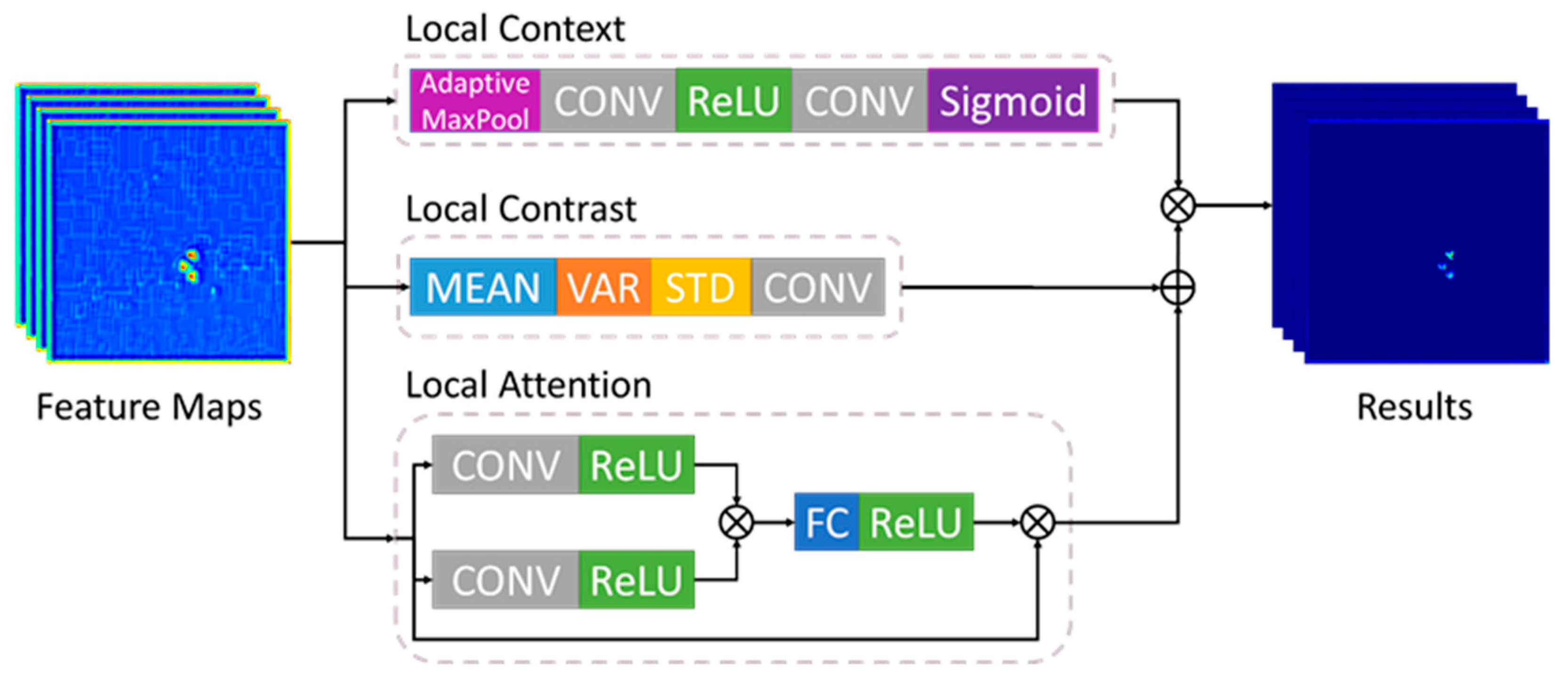
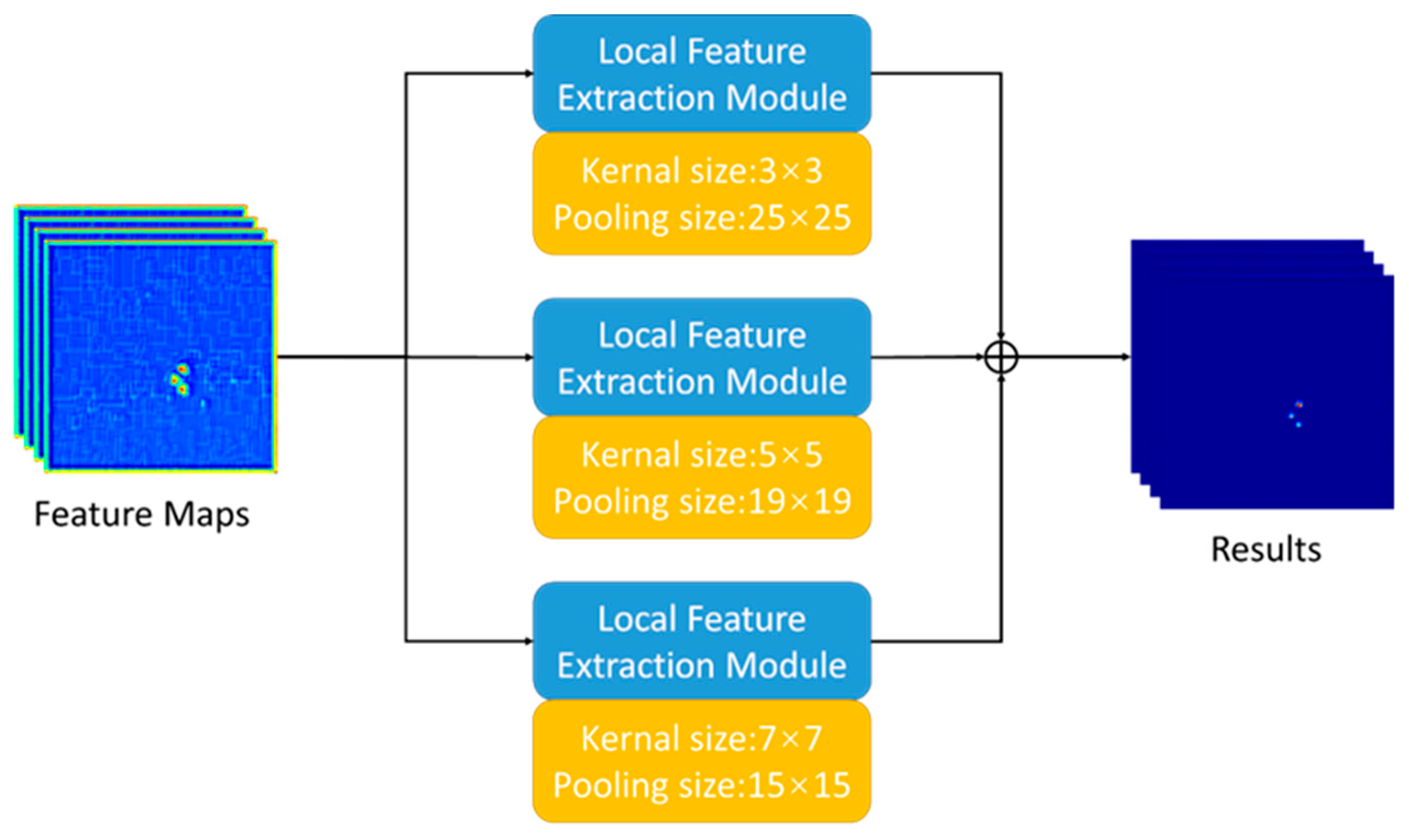
2.2.2. Multi-Scale Local Feature Pyramid Module
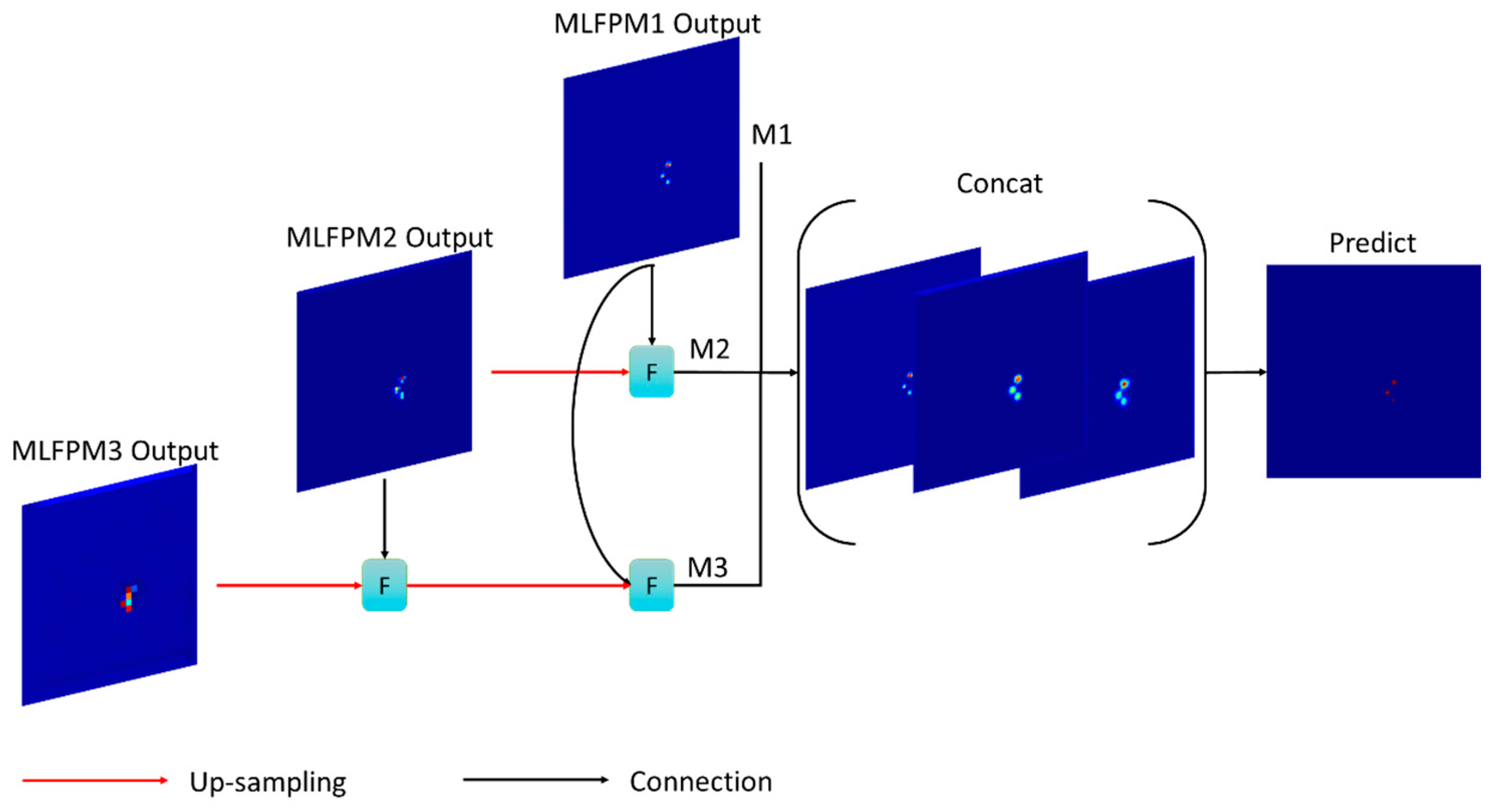
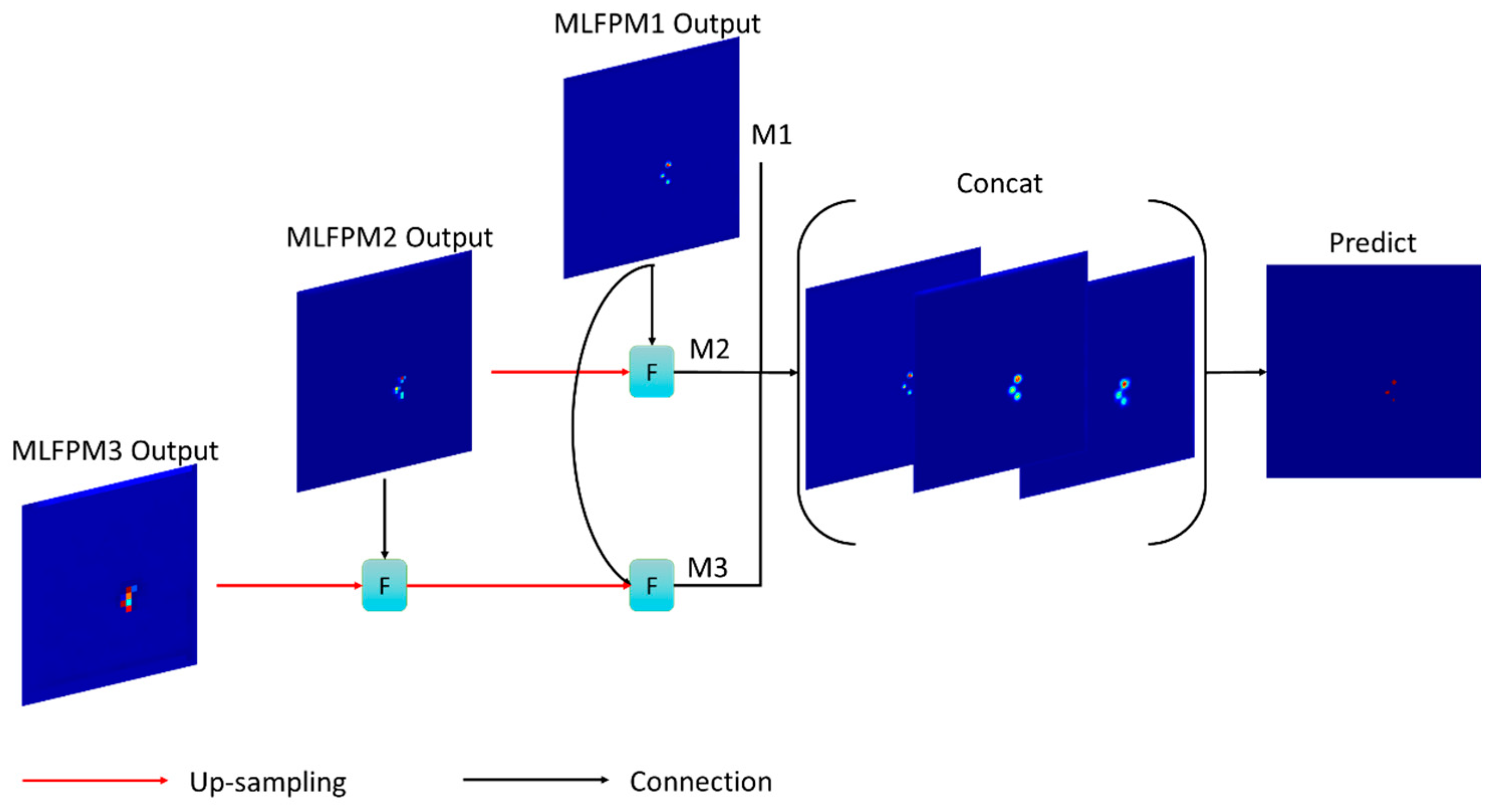
2.2.3. Multi-Scale Feature Fusion Module
3. Results
3.1. Datasets
3.1.1. SIRST
3.1.2. MDFA
3.2. Evaluation Metric
3.3. Implementation Details
3.4. Comparisons with State-of-the-Art Methods
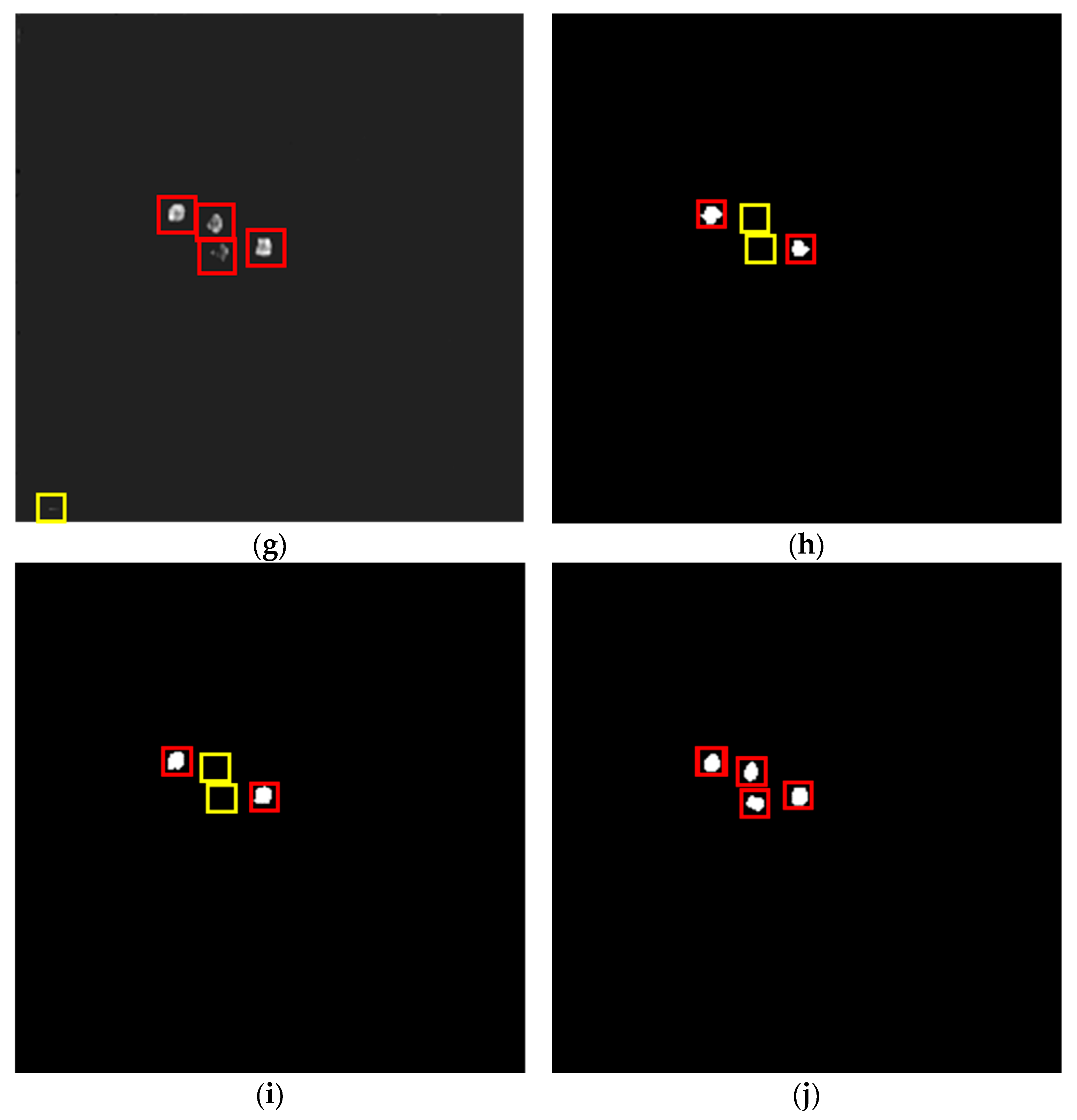
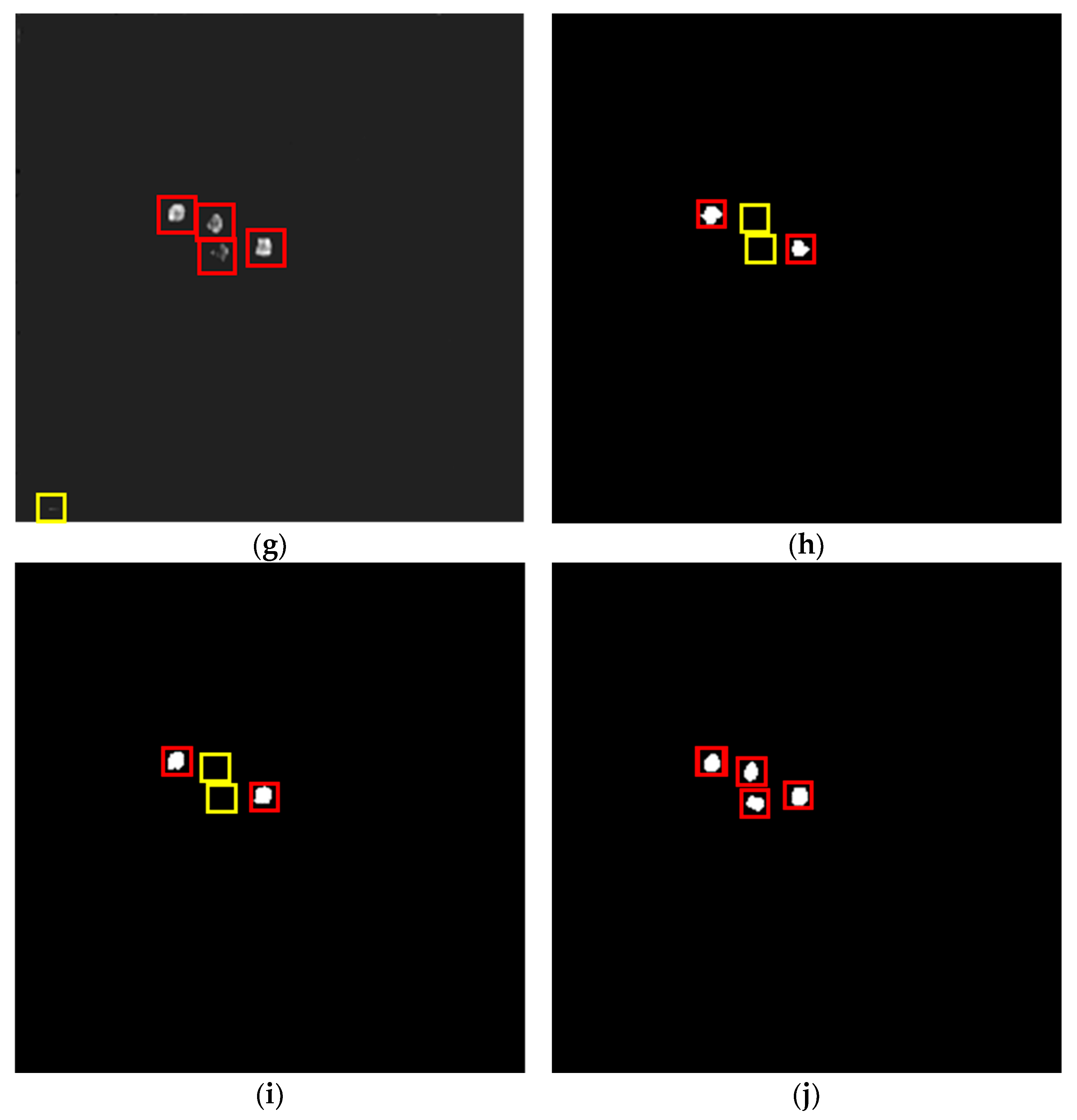
3.4.1. Results on SIRST
3.4.2. Results on MDFA
3.4.3. Running Time
4. Discussion
4.1. Ablation Study
4.1.1. Effect of the Proposed MLFPM
4.1.2. Effect of the Proposed MFFM
4.1.3. Effect of the Three Components in the MLFPM
4.2. Advantages and Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AUC | Area under the curve |
| FPN | Feature pyramid network |
| mIoU | mean intersection over union |
| MLFPM | Multi-scale local feature pyramid module |
| MFFM | Multi-scale feature fusion module |
| RoI | Region of interest |
References
- Voulodimos, A.; Doulamos, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A survey of autonomous driving: Common practices and emerging technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Kortli, Y.; Jridi, M.; Al Falou, A.; Atri, M. Face recognition systems: A survey. Sensors 2020, 20, 342. [Google Scholar] [CrossRef]
- Hearst, M.A.; Dumais, S.T.; Osuna, E. Support vector machines. IEEE Intell. Syst. App. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Hu, W.; Maybank, S. Adaboost-based algorithm for network intrusion detection. IEEE Trans. Syst. Man Cybern. 2008, 38, 577–583. [Google Scholar]
- Zhang, J.; Zulkernine, M.; Haque, A. Random-forests-based network intrusion detection systems. IEEE Trans. Syst. Man Cybern. 2008, 38, 649–659. [Google Scholar] [CrossRef]
- Wen, M.; Wei, L.; Zhuang, X.; He, D.; Wang, S.; Wang, Y. High-sensitivity short-wave infrared technology for thermal imaging. Infrared Phys. Technol. 2018, 95, 93–99. [Google Scholar] [CrossRef]
- Zhou, F.; Wu, Y.; Dai, Y.; Wang, P.; Ni, K. Graph-regularized laplace approximation for detecting small infrared target against complex backgrounds. IEEE Access 2019, 7, 85354–85371. [Google Scholar] [CrossRef]
- Deng, H.; Sun, X.; Liu, M.; Ye, C.; Zhou, X. Small infrared target detection based on weighted local difference measure. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4204–4214. [Google Scholar] [CrossRef]
- Bai, X.; Bi, Y. Derivative entropy-based contrast measure for infrared small-target detection. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2452–2466. [Google Scholar] [CrossRef]
- Hariharan, B.; Arbelaez, P.; Girshick, R. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Rahman, M.A.; Wang, Y. Optimizing intersection-over-union in deep neural networks for image segmentation. In Proceedings of the International Symposium on Visual Computing (ISVC), Las Vegas, NV, USA, 12–14 December 2016. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Singh, B.; Davis, L.S. An analysis of scale invariance in object detection snip. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, H.; Zhou, L.; Wang, L. Miss detection vs. false alarm: Adversarial learning for small object segmentation in infrared images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–1 November 2019. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric contextual modulation for infrared small target detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Deshpande, S.D.; Er, M.H.; Venkateswarlu, R.; Chan, P. Max-mean and max-median filters for detection of small targets. In Proceedings of the Signal and Data Processing of Small Targets 1999 (SPIE), Orlando, FL, USA, 20–22 July 1999. [Google Scholar]
- Bai, X.; Zhou, F. Analysis of new top-hat transformation and the application for infrared dim small target detection. Pattern Recognit. 2010, 43, 2145–2156. [Google Scholar] [CrossRef]
- Chen, C.P.; Li, H.; Wei, Y.; Xia, T.; Tang, Y.Y. A local contrast method for small infrared target detection. IEEE Trans. Geosci. Remote Sens. 2013, 52, 574–581. [Google Scholar] [CrossRef]
- Han, J.; Liang, K.; Zhou, B.; Zhu, X.; Zhao, J.; Zhao, L. Infrared small target detection utilizing the multiscale relative local contrast measure. IEEE Geosci. Remote Sens. Lett. 2018, 15, 612–616. [Google Scholar] [CrossRef]
- Shao, X.; Fan, H.; Lu, G.; Xu, J. An improved infrared dim and small target detection algorithm based on the contrast mechanism of human visual system. Infrared Phys. Technol. 2012, 55, 403–408. [Google Scholar] [CrossRef]
- Qin, Y.; Li, B. Effective infrared small target detection utilizing a novel local contrast method. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1890–1894. [Google Scholar] [CrossRef]
- Yang, L.; Yang, J.; Yang, K. Adaptive detection for infrared small target under sea-sky complex background. Electron. Lett. 2004, 40, 1. [Google Scholar] [CrossRef]
- Shi, Y.; Wei, Y.; Yao, H.; Pan, D.; Xiao, G. High-boost-based multiscale local contrast measure for infrared small target detection. IEEE Geosci. Remote Sens. Lett. 2017, 15, 33–37. [Google Scholar] [CrossRef]
- He, Y.; Li, M.; Zhang, J.; An, Q. Small infrared target detection based on low-rank and sparse representation. Infrared Phys. Technol. 2015, 68, 98–109. [Google Scholar] [CrossRef]
- Liu, D.; Li, Z.; Liu, B.; Chen, W.; Liu, T.; Cao, L. Infrared small target detection in heavy sky scene clutter based on sparse representation. Infrared Phys. Technol. 2017, 85, 13–31. [Google Scholar] [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared patch-image model for small target detection in a single image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Peng, Z.; Kong, D.; Zhang, P.; He, Y. Infrared dim target detection based on total variation regularization and principal component pursuit. Image Vis. Comput. 2017, 63, 1–9. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wu, X.; Hong, D.; Chanussot, J. UIU-Net: U-Net in U-Net for infrared small object detection. IEEE Trans. Image Process. 2022, 32, 364–376. [Google Scholar] [CrossRef] [PubMed]
- Tong, X.; Sun, B.; Wei, J.; Zuo, Z.; Su, S. EAAU-Net: Enhanced asymmetric attention U-Net for infrared small target detection. Remote Sens. 2021, 13, 3200. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Attentional local contrast networks for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9813–9824. [Google Scholar] [CrossRef]
- Hou, Q.; Wang, Z.; Tan, F.; Zhao, Y.; Zheng, H.; Zhang, W. RISTDnet: Robust infrared small target detection network. IEEE Geosci. Remote Sens. Lett. 2021, 19, 7000805. [Google Scholar] [CrossRef]
- Li, B.; Xiao, C.; Wang, L.; Wang, Y.; Lin, Z.; Li, M.; Guo, Y. Dense nested attention network for infrared small target detection. IEEE Transac. Image Process. 2022, 32, 1745–1758. [Google Scholar] [CrossRef]
- Zhang, T.; Li, L.; Cao, S.; Pu, T.; Peng, Z. Attention-Guided Pyramid Context Networks for Detecting Infrared Small Target Under Complex Background. IEEE Transac. Aerosp. Electron. Syst. 2023, 59, 4250–4261. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Fang, H.; Xia, M.; Zhou, G.; Chang, Y.; Yan, L. Infrared small UAV target detection based on residual image prediction via global and local dilated residual networks. IEEE Geosci. Remote Sens. Lett. 2021, 19, 7002305. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Y.; Wu, S.; Hu, Z.; Xia, X.; Lan, D.; Liu, X. Infrared small target detection based on multiscale local contrast learning networks. Infrared Phys. Technol. 2022, 123, 104107. [Google Scholar] [CrossRef]
- Lim, J.S.; Astrid, M.; Yoon, H.J.; Lee, S.I. Small object detection using context and attention. In Proceedings of the 2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Republic of Korea, 20–23 April 2021. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2017. [Google Scholar]
- Zhang, L.; Peng, Z. Infrared small target detection based on partial sum of the tensor nuclear norm. Remote Sens. 2019, 11, 382. [Google Scholar] [CrossRef]
- Wei, Y.; You, X.; Li, H. Multiscale patch-based contrast measure for small infrared target detection. Pattern Recognit. 2016, 58, 216–226. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Hyper-Parameters Settings |
|---|---|
| LCM | Filter radius: 1, 2, 3, 4 |
| RLCM | Filter radius: 1, 2, 3, 4 |
| PSTNN | Patch size: 40 × 40, Slide step: 40, |
| MPCM | Filter radius: 1, 2, 3, 4 |
| IPI | Patch size: 50 × 50, Slide step: 10, |
| Methods | Precision | Recall | mIoU | F-Measure | AUC |
|---|---|---|---|---|---|
| LCM | 0.0241 | 0.9087 | 0.2015 | 0.0469 | 0.7208 |
| RLCM | 0.0111 | 0.9164 | 0.0094 | 0.0219 | 0.9509 |
| PSTNN | 0.7893 | 0.5198 | 0.4262 | 0.6268 | 0.7131 |
| MPCM | 0.0052 | 0.8550 | 0.0046 | 0.0102 | 0.8986 |
| IPI | 0.7541 | 0.5749 | 0.6216 | 0.6524 | 0.8485 |
| MDvsFA | — | — | — | — | — |
| ACM | 0.6262 | 0.7531 | 0.5196 | 0.6838 | 0.9053 |
| AGPCNet | 0.6858 | 0.8424 | 0.6078 | 0.7561 | 0.9321 |
| Ours | 0.6757 | 0.9118 | 0.6343 | 0.7762 | 0.9577 |
| Methods | Precision | Recall | mIoU | F-Measure | AUC |
|---|---|---|---|---|---|
| LCM | 0.0192 | 0.7538 | 0.4085 | 0.0375 | 0.9979 |
| RLCM | 0.0047 | 0.9359 | 0.0276 | 0.0094 | 0.9360 |
| PSTNN | 0.4369 | 0.4996 | 0.3304 | 0.4661 | 0.7752 |
| MPCM | 0.0023 | 0.8859 | 0.0086 | 0.0046 | 0.7850 |
| IPI | 0.4674 | 0.5471 | 0.2836 | 0.5041 | 0.6418 |
| MDvsFA | 0.6600 | 0.5400 | — | 0.6000 | 0.9100 |
| ACM | 0.4615 | 0.7177 | 0.3906 | 0.5617 | 0.9029 |
| AGPCNet | 0.5490 | 0.7231 | 0.4537 | 0.6242 | 0.8814 |
| Ours | 0.5992 | 0.6705 | 0.4629 | 0.6328 | 0.8382 |
| Methods | Running Time on GPU/s |
|---|---|
| LCM | 0.163 |
| RLCM | 8.987 |
| PSTNN | 0.272 |
| MPCM | 0.093 |
| IPI | 23.913 |
| ACM | 0.077 |
| AGPCNet | 0.423 |
| Ours | 0.947 |
| Dataset | Backbone | MLFPM | MFFM | Precision | Recall | mIoU | F-Measure | AUC |
|---|---|---|---|---|---|---|---|---|
| SIRST | ResNet-18 | 0.6437 | 0.8729 | 0.5886 | 0.7410 | 0.9252 | ||
| √ | 0.6777 | 0.8818 | 0.6213 | 0.7664 | 0.9526 | |||
| √ | 0.6658 | 0.8504 | 0.5960 | 0.7469 | 0.9319 | |||
| √ | √ | 0.6757 | 0.9118 | 0.6343 | 0.7762 | 0.9577 | ||
| MDFA | 0.5674 | 0.6574 | 0.4379 | 0.6091 | 0.8454 | |||
| √ | 0.5439 | 0.7231 | 0.4502 | 0.6208 | 0.8529 | |||
| √ | 0.5630 | 0.7185 | 0.4613 | 0.6313 | 0.8833 | |||
| √ | √ | 0.5992 | 0.6705 | 0.4629 | 0.6328 | 0.8382 |
| Dataset | Local Context | Local Contract Extraction | Local Attention | Precision | Recall | mIoU | F-Measure | AUC |
|---|---|---|---|---|---|---|---|---|
| SIRST | √ | √ | 0.6609 | 0.9067 | 0.6188 | 0.7645 | 0.9574 | |
| √ | √ | 0.6597 | 0.8649 | 0.5981 | 0.7485 | 0.9283 | ||
| √ | √ | 0.6554 | 0.8752 | 0.5994 | 0.7495 | 0.9437 | ||
| √ | √ | √ | 0.6757 | 0.9118 | 0.6343 | 0.7762 | 0.9577 | |
| MDFA | √ | √ | 0.6391 | 0.6164 | 0.4573 | 0.6276 | 0.7762 | |
| √ | √ | 0.5915 | 0.5599 | 0.4038 | 0.5753 | 0.4902 | ||
| √ | √ | 0.5997 | 0.6466 | 0.4516 | 0.6223 | 0.7640 | ||
| √ | √ | √ | 0.5992 | 0.6705 | 0.4629 | 0.6328 | 0.8382 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Tian, Y.; Liu, J.; Xu, Y. Multi-Stage Multi-Scale Local Feature Fusion for Infrared Small Target Detection. Remote Sens. 2023, 15, 4506. https://doi.org/10.3390/rs15184506
Wang Y, Tian Y, Liu J, Xu Y. Multi-Stage Multi-Scale Local Feature Fusion for Infrared Small Target Detection. Remote Sensing. 2023; 15(18):4506. https://doi.org/10.3390/rs15184506
Chicago/Turabian StyleWang, Yahui, Yan Tian, Jijun Liu, and Yiping Xu. 2023. "Multi-Stage Multi-Scale Local Feature Fusion for Infrared Small Target Detection" Remote Sensing 15, no. 18: 4506. https://doi.org/10.3390/rs15184506
APA StyleWang, Y., Tian, Y., Liu, J., & Xu, Y. (2023). Multi-Stage Multi-Scale Local Feature Fusion for Infrared Small Target Detection. Remote Sensing, 15(18), 4506. https://doi.org/10.3390/rs15184506