




A Super-Resolution Network for High-Resolution Reconstruction of Landslide Main Bodies in Remote Sensing Imagery Using Coordinated Attention Mechanisms and Deep Residual Blocks
Abstract
:1. Introduction
2. Materials
3. Methods
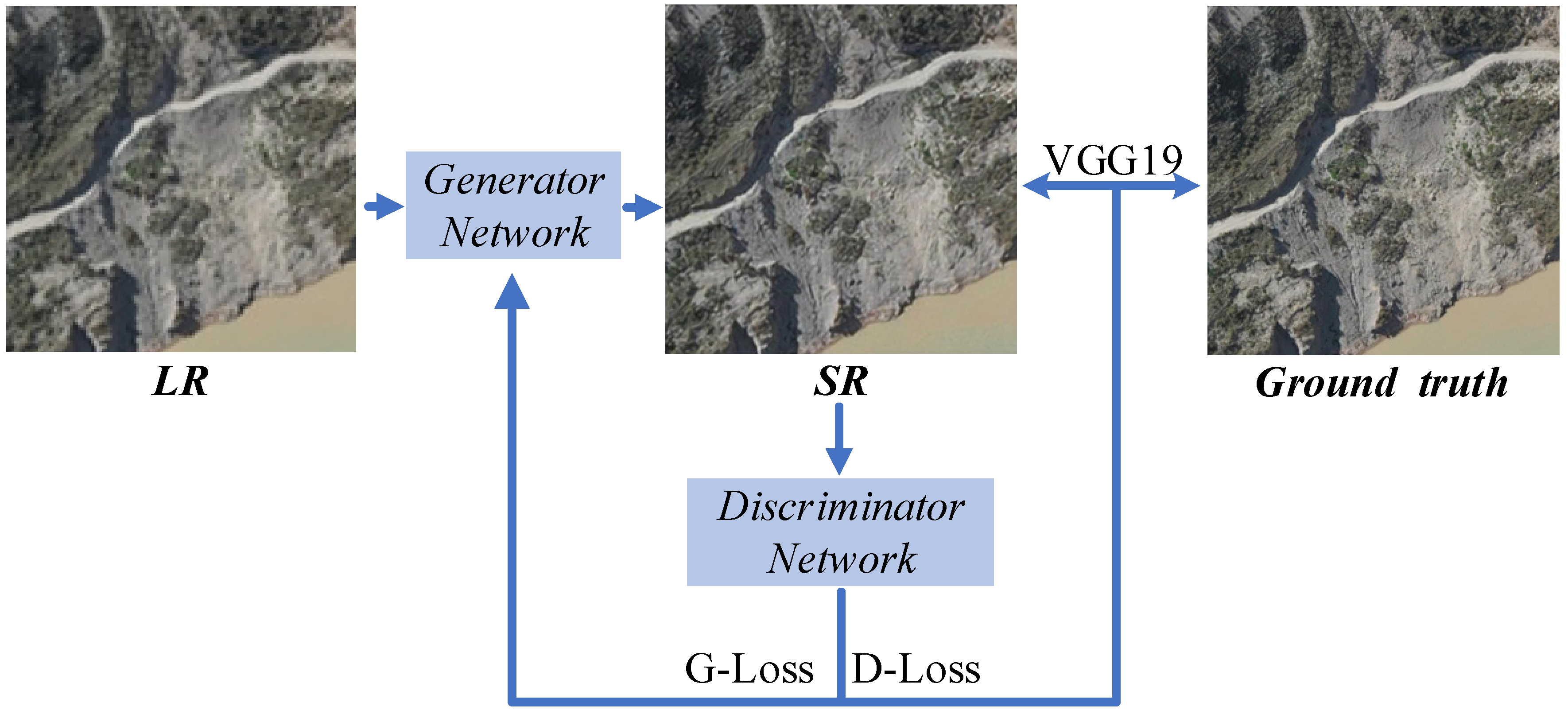
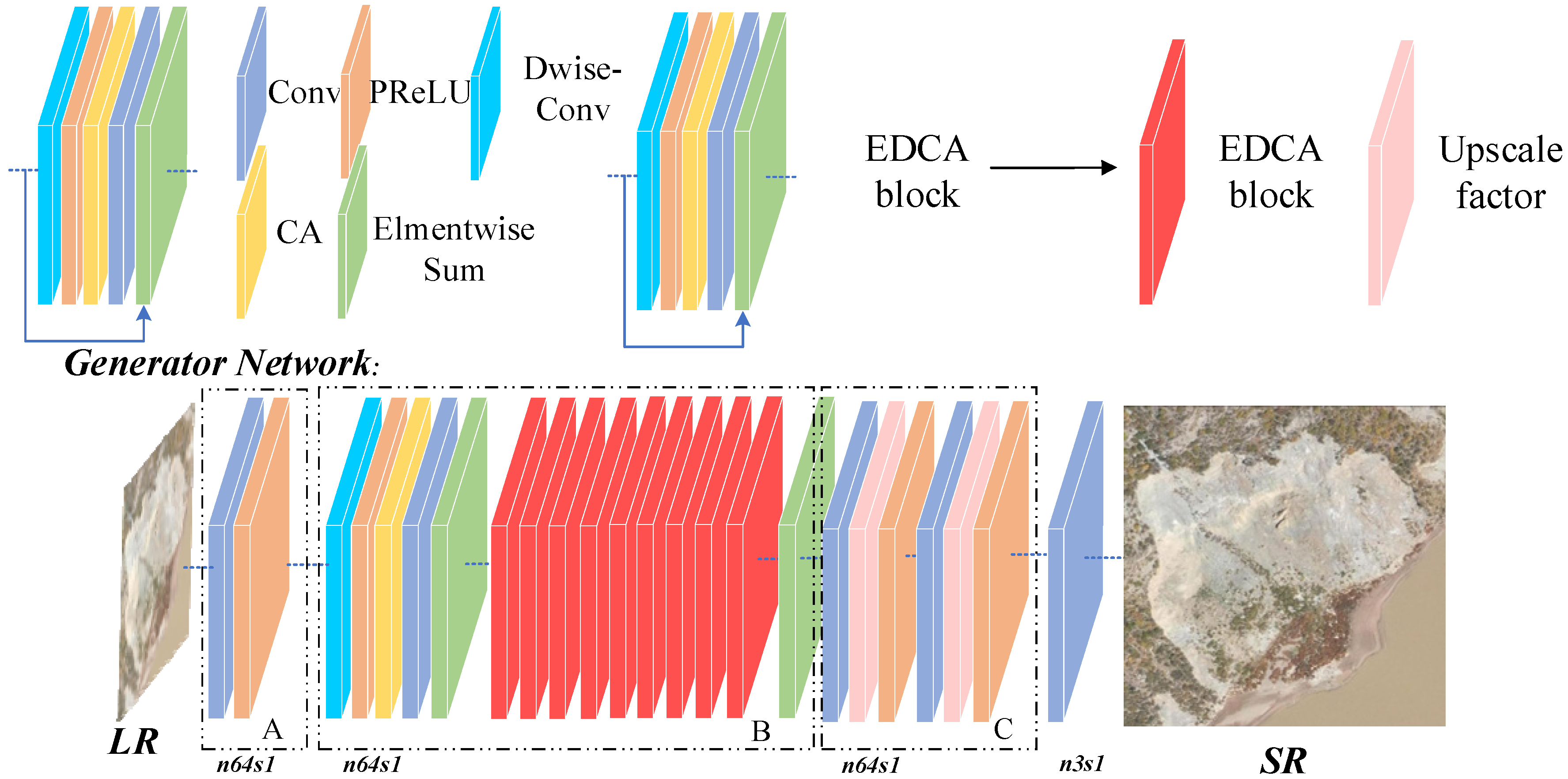
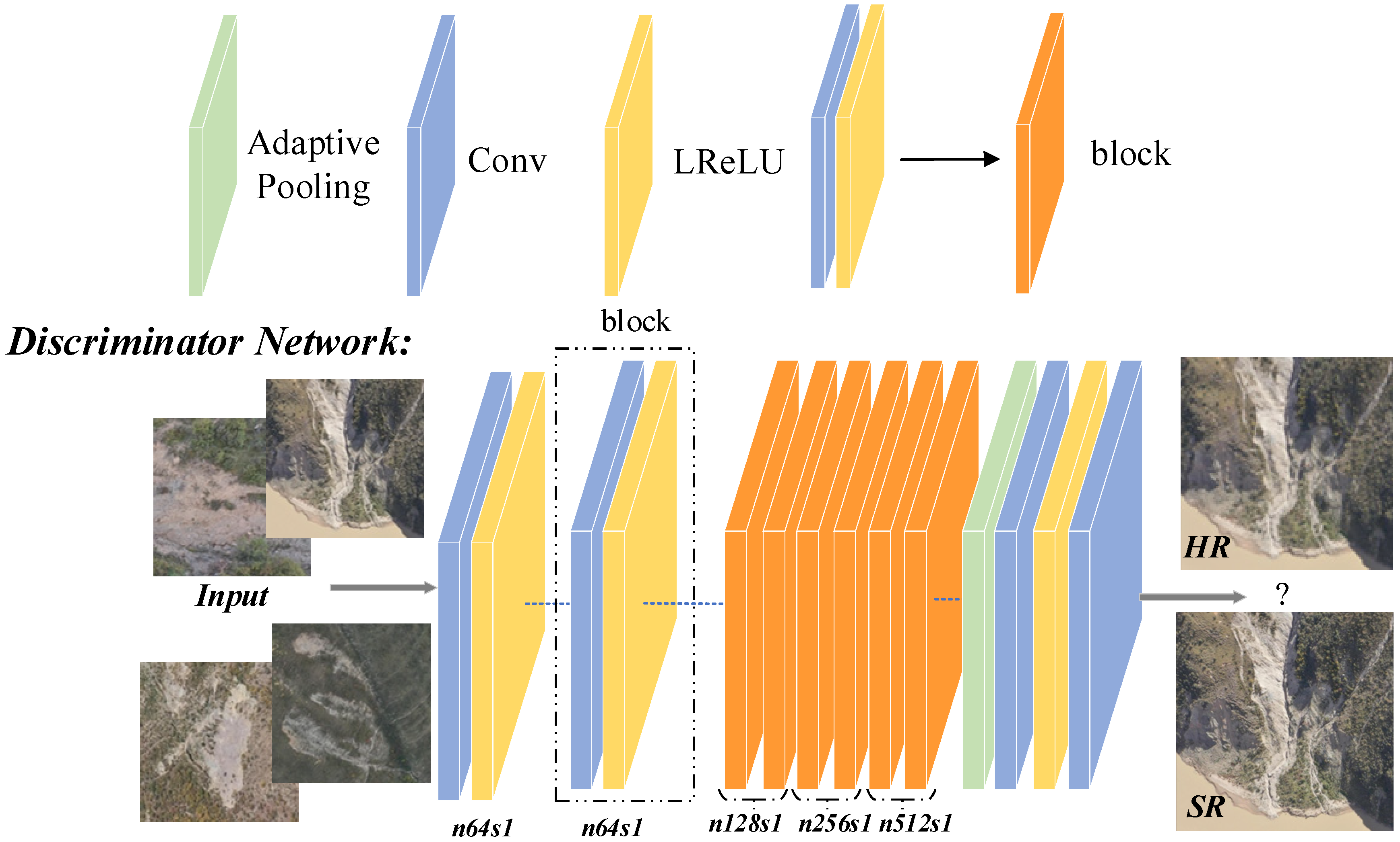
3.1. Network Architecture
- (1)
- The first module in the EDCA-SRGAN generator is the feature extraction module A, comprising the initial convolution layer of the network architecture. Small convolution kernels excel at extracting high-frequency edge details, while larger kernels perform better at capturing rougher structural content information. Therefore, to retain the edge detail information found in landslide images and minimize computational complexity, we leverage a small 3 × 3 convolution kernel. Furthermore, the generator takes in low-resolution landslide images through LR;
- (2)
- Comprising 10 EDCA (Enhanced Deep Residual Network with Coordinated Attention) residual blocks and a convolution layer using a 3 × 3 kernel size, module B enhances the features extracted in the previous module. The stacking of residual blocks facilitates deep feature extraction by allowing for the inclusion of additional layers and connections, leading to better network performance. Notably, residual connections are crucial in mitigating the problem of “gradient disappearance,” which arises in networks with numerous layers;
- (3)
- Module C, responsible for upsampling reconstruction, comprises an upsampling layer and a convolution layer. Instead of the common, general pooling technique, our paper utilizes adaptive pooling (Adaptive-Pooling) to upscale images. The benefits of Adaptive-Pooling are numerous; for instance, the function automatically determines the convolution kernel and step size, negating the need for arbitrary input. Besides, the convolution kernel is variable, and the step size is dynamic, providing overlap between adjacent pooling windows.
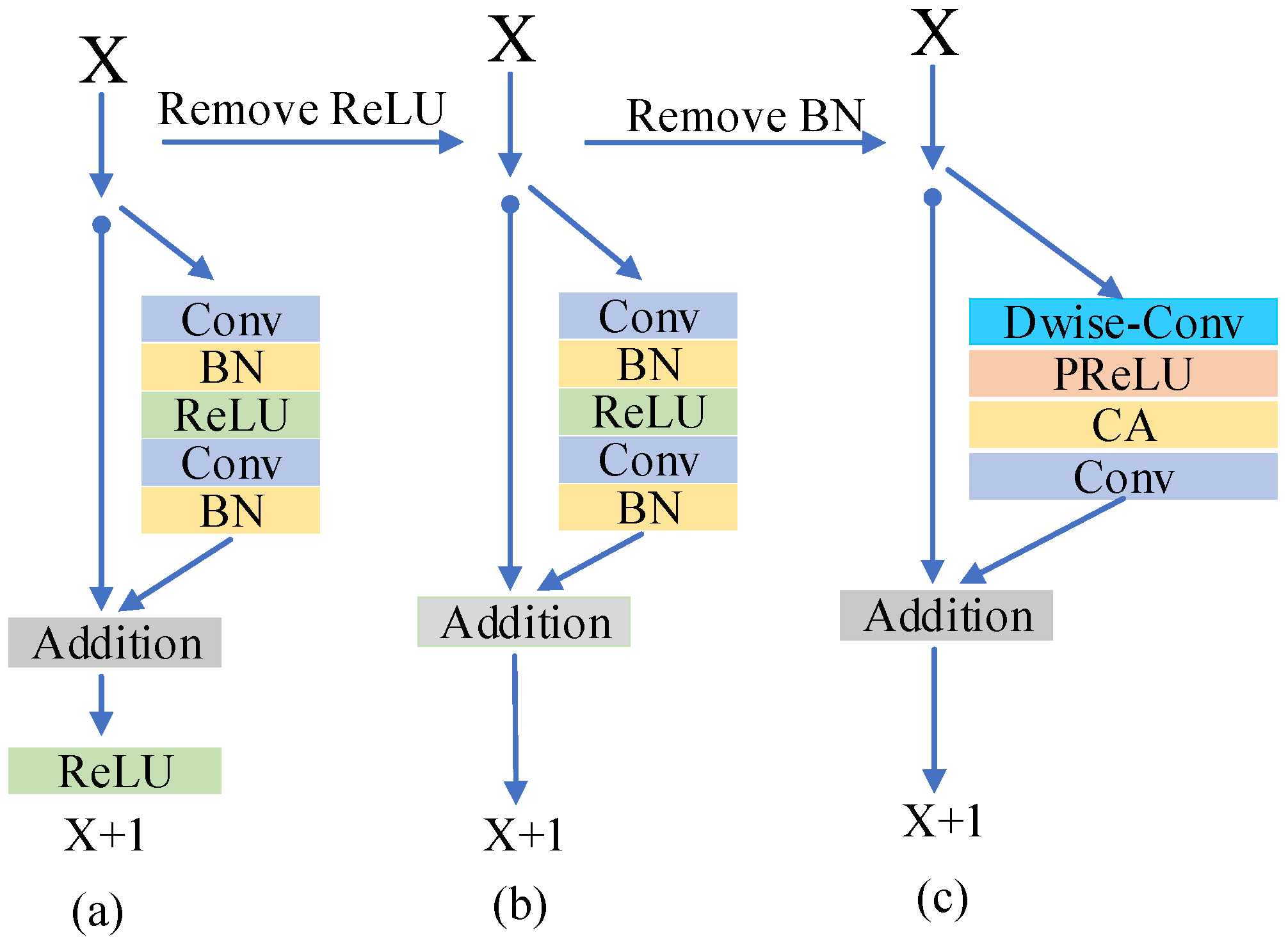
3.2. EDCA Structure
3.3. Coordinate Attention
3.4. Loss Function
3.5. Image Quality Evaluation Index
4. Experimental Results
4.1. Implement Details
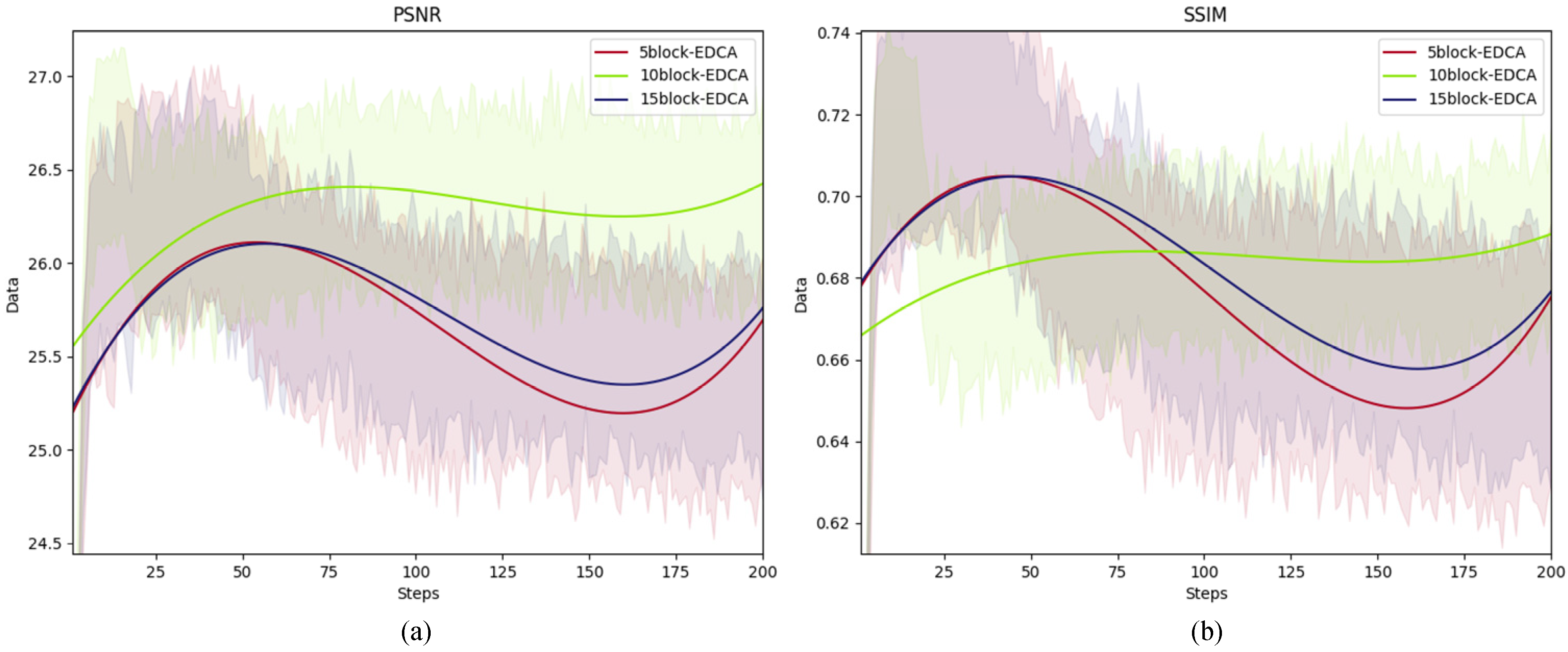
4.2. Evaluation Using Different Number of EDCA Blocks
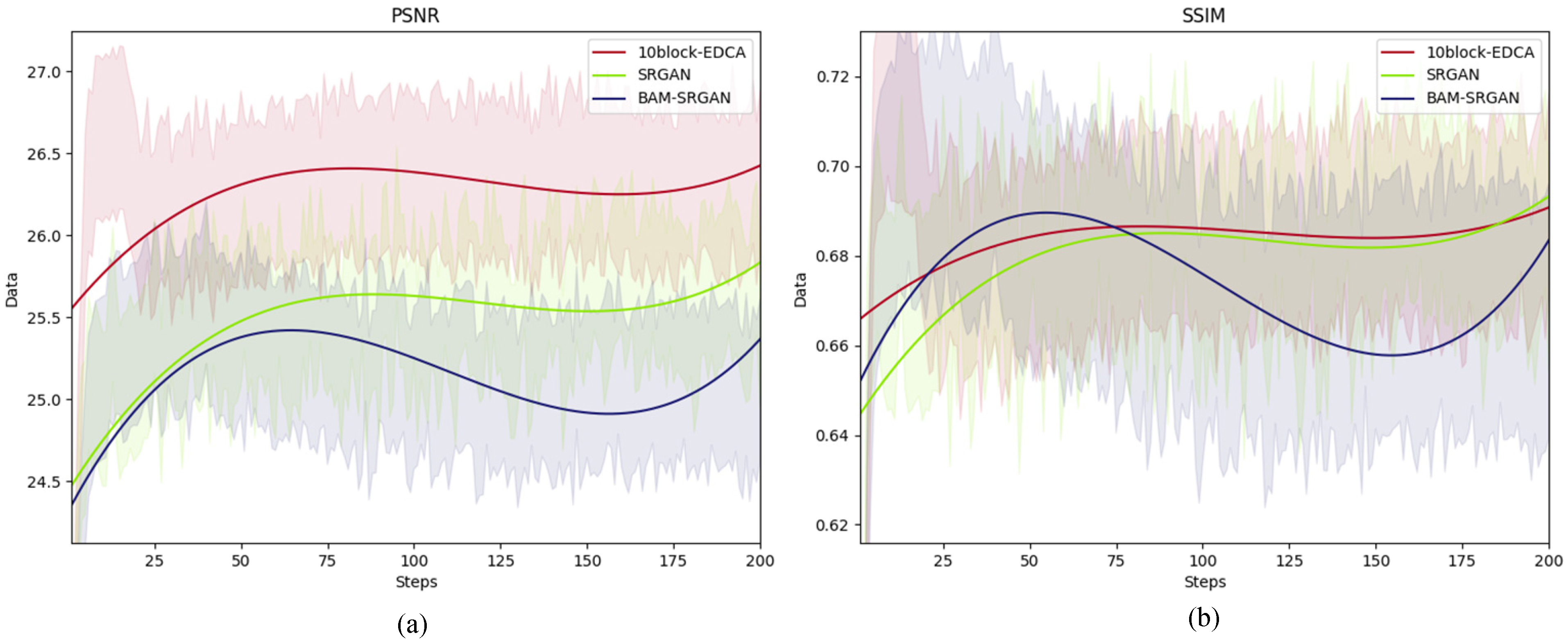
4.3. Evaluation Result
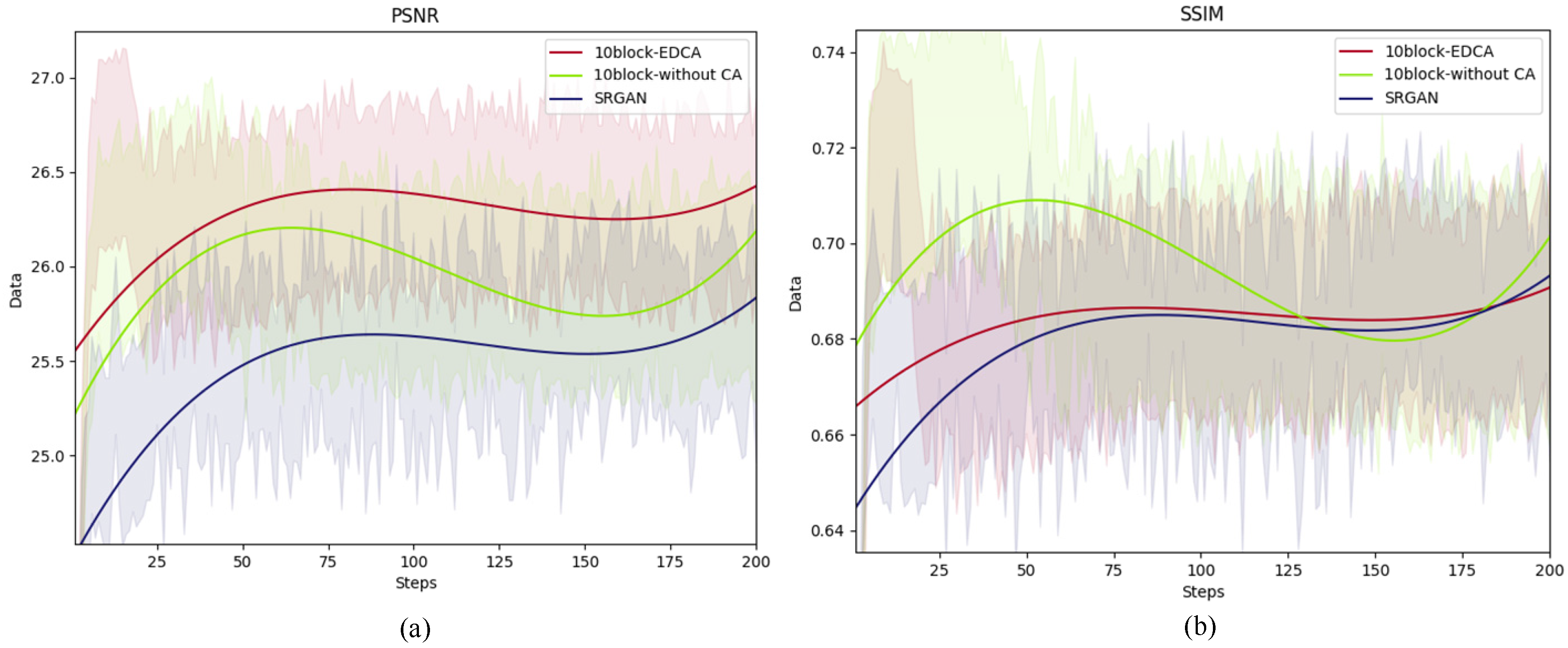
4.4. Ablation Experiment
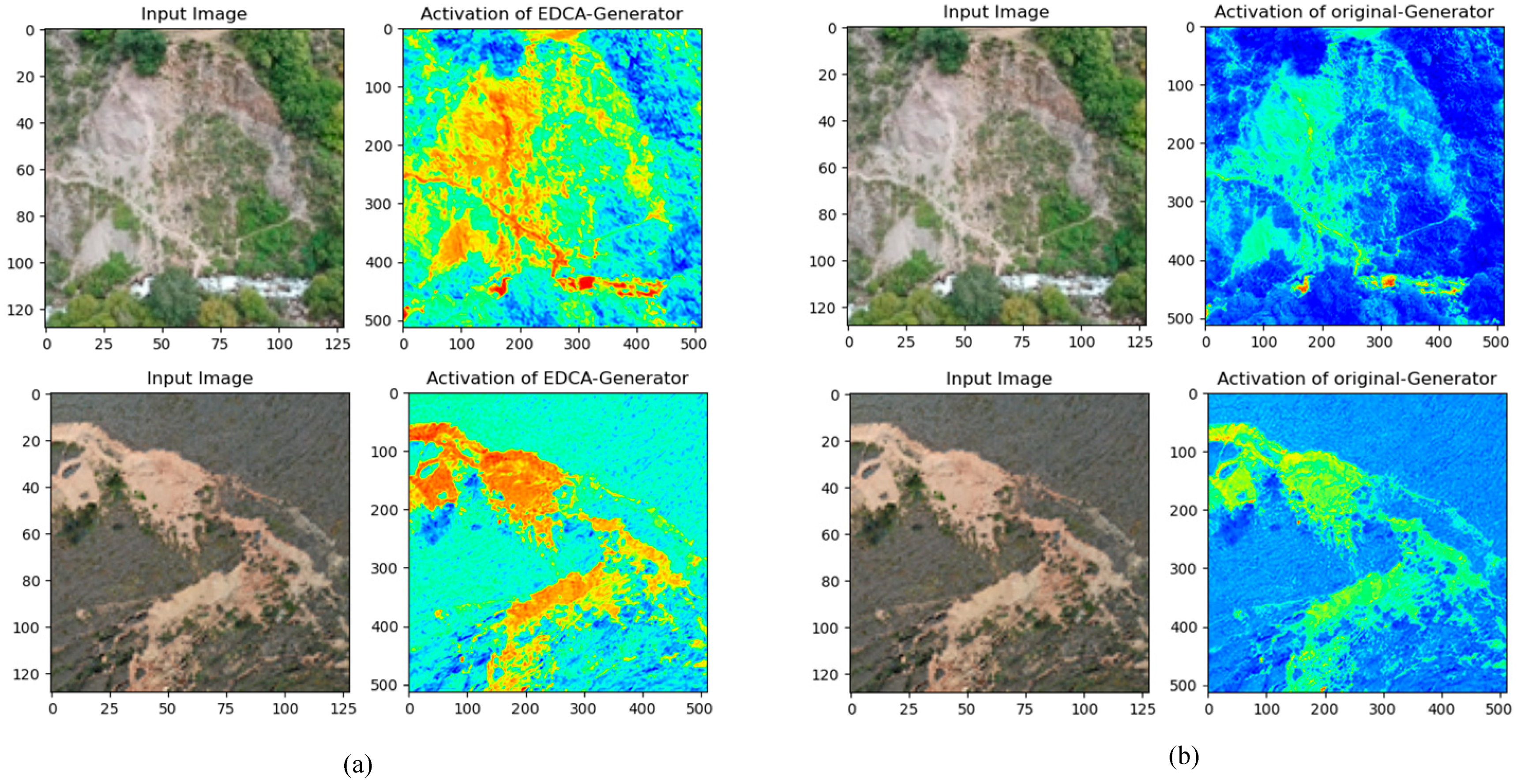
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hungr, O.; Leroueil, S.; Picarelli, L. The Varnes Classification of Landslide Types, an Update. Landslides 2014, 11, 167–194. [Google Scholar] [CrossRef]
- Leynaud, D.; Mulder, T.; Hanquiez, V.; Gonthier, E.; Regert, A. Sediment Failure Types, Preconditions and Triggering Factors in the Gulf of Cadiz. Landslides 2017, 14, 233–248. [Google Scholar] [CrossRef]
- Wang, L.; Qiu, H.; Zhou, W.; Zhu, Y.; Liu, Z.; Ma, S.; Yang, D.; Tang, B. The Post-Failure Spatiotemporal Deformation of Certain Translational Landslides May Follow the Pre-Failure Pattern. Remote Sens. 2022, 14, 2333. [Google Scholar] [CrossRef]
- Ji, S.; Yu, D.; Shen, C.; Li, W.; Xu, Q. Landslide Detection from an Open Satellite Imagery and Digital Elevation Model Dataset Using Attention Boosted Convolutional Neural Networks. Landslides 2020, 17, 1337–1352. [Google Scholar] [CrossRef]
- Li, D.; Huang, F.; Yan, L.; Cao, Z.; Chen, J.; Ye, Z. Landslide Susceptibility Prediction Using Particle-Swarm-Optimized Multilayer Perceptron: Comparisons with Multilayer-Perceptron-Only, BP Neural Network, and Information Value Models. Appl. Sci. 2019, 9, 3664. [Google Scholar] [CrossRef]
- Varnes, D.J.; Bufe, C.G. The Cyclic and Fractal Seismic Series Preceding an m(b) 4.8 Earthquake on 1980 February 14 near the Virgin Islands. Geophys. J. Int. 1996, 124, 149–158. [Google Scholar] [CrossRef]
- Dao, D.V.; Jaafari, A.; Bayat, M.; Mafi-Gholami, D.; Qi, C.; Moayedi, H.; Phong, T.V.; Ly, H.-B.; Le, T.-T.; Trinh, P.T.; et al. A Spatially Explicit Deep Learning Neural Network Model for the Prediction of Landslide Susceptibility. Catena 2020, 188, 104451. [Google Scholar] [CrossRef]
- Wang, H.; Cui, P.; Liu, D.; Liu, W.; Bazai, N.A.; Wang, J.; Zhang, G.; Lei, Y. Evolution of a Landslide-Dammed Lake on the Southeastern Tibetan Plateau and Its Influence on River Longitudinal Profiles. Geomorphology 2019, 343, 15–32. [Google Scholar] [CrossRef]
- Pei, Y.; Qiu, H.; Yang, D.; Liu, Z.; Ma, S.; Li, J.; Cao, M.; Wufuer, W. Increasing Landslide Activity in the Taxkorgan River Basin (Eastern Pamirs Plateau, China) Driven by Climate Change. Catena 2023, 223, 106911. [Google Scholar] [CrossRef]
- Wei, K.; Ouyang, C.; Duan, H.; Li, Y.; Chen, M.; Ma, J.; An, H.; Zhou, S. Reflections on the Catastrophic 2020 Yangtze River Basin Flooding in Southern China. Innovation 2020, 1, 100038. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, X.; Cao, X.; Huang, C.; Liu, E.; Qian, S.; Liu, X.; Wu, Y.; Dong, F.; Qiu, C.-W.; et al. Artificial Intelligence: A Powerful Paradigm for Scientific Research. Innovation 2021, 2, 100179. [Google Scholar] [CrossRef] [PubMed]
- Cui, P.; Peng, J.; Shi, P.; Tang, H.; Ouyang, C.; Zou, Q.; Liu, L.; Li, C.; Lei, Y. Scientific Challenges of Research on Natural Hazards and Disaster Risk. Geogr. Sustain. 2021, 2, 216–223. [Google Scholar] [CrossRef]
- Xu, Q.; Ouyang, C.; Jiang, T.; Yuan, X.; Fan, X.; Cheng, D. MFFENet and ADANet: A Robust Deep Transfer Learning Method and Its Application in High Precision and Fast Cross-Scene Recognition of Earthquake-Induced Landslides. Landslides 2022, 19, 1617–1647. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Shahabi, H.; Crivellari, A.; Homayouni, S.; Blaschke, T.; Ghamisi, P. Landslide Detection Using Deep Learning and Object-Based Image Analysis. Landslides 2022, 19, 929–939. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, L.; Yin, K.; Luo, H.; Li, J. Landslide Identification Using Machine Learning. Geosci. Front. 2021, 12, 351–364. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, L.; Luo, H.; He, J.; Cheung, R.W.M. AI-Powered Landslide Susceptibility Assessment in Hong Kong. Eng. Geol. 2021, 288, 106103. [Google Scholar] [CrossRef]
- Jia, S.; Wang, Z.; Li, Q.; Jia, X.; Xu, M. Multiattention Generative Adversarial Network for Remote Sensing Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, P.; Jiang, Z. Nonpairwise-Trained Cycle Convolutional Neural Network for Single Remote Sensing Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4250–4261. [Google Scholar] [CrossRef]
- Dong, R.; Zhang, L.; Fu, H. RRSGAN: Reference-Based Super-Resolution for Remote Sensing Image. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5601117. [Google Scholar] [CrossRef]
- Qiu, H.; Zhu, Y.; Zhou, W.; Sun, H.; He, J.; Liu, Z. Influence of DEM Resolution on Landslide Simulation Performance Based on the Scoops 3D Model. Geomat. Nat. Hazards Risk 2022, 13, 1663–1681. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, H.; Liu, L.; Tao, J.; Zhang, Q.; Yang, K.; Xia, R.; Xie, J. Research on Image Inpainting Algorithm of Improved Total Variation Minimization Method. J. Ambient Intell. Humaniz. Comput. 2023, 14, 5555–5564. [Google Scholar] [CrossRef]
- Liu, K.; Yu, H.; Zhang, M.; Zhao, L.; Wang, X.; Liu, S.; Li, H.; Yang, K. A Lightweight Low-Dose PET Image Super-Resolution Reconstruction Method Based on Convolutional Neural Network. Curr. Med. Imaging 2023, 19, 1427–1435. [Google Scholar] [CrossRef] [PubMed]
- Shi, J.; Ye, Y.; Liu, H.; Zhu, D.; Su, L.; Chen, Y.; Huang, Y.; Huang, J. Super-Resolution Reconstruction of Pneumocystis Carinii Pneumonia Images Based on Generative Confrontation Network. Comput. Methods Programs Biomed. 2022, 215, 106578. [Google Scholar] [CrossRef] [PubMed]
- Keys, R. Cubic Convolution Interpolation for Digital Image Processing. IEEE Trans. Acoust. Speech Signal Process. 1981, 29, 1153–1160. [Google Scholar] [CrossRef]
- Zhang, L.; Chen, D. A Novel Saliency-Oriented Superresolution Method for Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1922–1926. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Computer Vision—ECCV 2014; Lecture Notes in Computer Science; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Germany, 2014; Volume 8692, pp. 184–199. ISBN 978-3-319-10592-5. [Google Scholar]
- Lei, S.; Shi, Z.; Zou, Z. Super-Resolution for Remote Sensing Images via Local-Global Combined Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar] [CrossRef]
- Ma, W.; Pan, Z.; Guo, J.; Lei, B. Achieving Super-Resolution Remote Sensing Images via the Wavelet Transform Combined With the Recursive Res-Net. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3512–3527. [Google Scholar] [CrossRef]
- Liu, Q.; Zhou, H.; Xu, Q.; Liu, X.; Wang, Y. PSGAN: A Generative Adversarial Network for Remote Sensing Image Pan-Sharpening. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10227–10242. [Google Scholar] [CrossRef]
- Liu, B.; Zhao, L.; Li, J.; Zhao, H.; Liu, W.; Li, Y.; Wang, Y.; Chen, H.; Cao, W. Saliency-Guided Remote Sensing Image Super-Resolution. Remote Sens. 2021, 13, 5144. [Google Scholar] [CrossRef]
- Ma, J.; Yu, J.; Liu, S.; Chen, L.; Li, X.; Feng, J.; Chen, Z.; Zeng, S.; Liu, X.; Cheng, S. PathSRGAN: Multi-Supervised Super-Resolution for Cytopathological Images Using Generative Adversarial Network. IEEE Trans. Med. Imaging 2020, 39, 2920–2930. [Google Scholar] [CrossRef] [PubMed]
- Lei, J.; Xue, H.; Yang, S.; Shi, W.; Zhang, S.; Wu, Y. HFF-SRGAN: Super-Resolution Generative Adversarial Network Based on High-Frequency Feature Fusion. J. Electron. Imaging 2022, 31, 033011. [Google Scholar] [CrossRef]
- Yan, Y.; Liu, C.; Chen, C.; Sun, X.; Jin, L.; Peng, X.; Zhou, X. Fine-Grained Attention and Feature-Sharing Generative Adversarial Networks for Single Image Super-Resolution. IEEE Trans. Multimed. 2022, 24, 1473–1487. [Google Scholar] [CrossRef]
- Altini, N.; Marvulli, T.M.; Zito, F.A.; Caputo, M.; Tommasi, S.; Azzariti, A.; Brunetti, A.; Prencipe, B.; Mattioli, E.; De Summa, S.; et al. The Role of Unpaired Image-to-Image Translation for Stain Color Normalization in Colorectal Cancer Histology Classification. Comput. Meth. Programs Biomed. 2023, 234, 107511. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, W.; Chen, S.; Yang, F.; Jingchang, P. Boundary Equilibrium SR: Effective Loss Functions for Single Image Super-Resolution. Appl. Intell. 2023, 53, 17128–17138. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.-Y.; Kweon, I.S. BAM: Bottleneck Attention Module. arXiv 2018, arXiv:1807.06514. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PSNR (dB) | SSIM | Block Number | Params Number |
|---|---|---|---|---|
| Ground truth | ∞ | 1.00000 | 0 | 0 |
| SRGAN | 25.46945 | 0.67910 | 10 | 1,103,377 |
| BAM-SRGAN | 25.11715 | 0.67298 | 10 | 1,118,177 |
| EDCA-SRGAN | 26.25111 | 0.68343 | 10 | 1,156,497 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Ye, C.; Zhou, Y.; Tang, R.; Wei, R. A Super-Resolution Network for High-Resolution Reconstruction of Landslide Main Bodies in Remote Sensing Imagery Using Coordinated Attention Mechanisms and Deep Residual Blocks. Remote Sens. 2023, 15, 4498. https://doi.org/10.3390/rs15184498
Zhang H, Ye C, Zhou Y, Tang R, Wei R. A Super-Resolution Network for High-Resolution Reconstruction of Landslide Main Bodies in Remote Sensing Imagery Using Coordinated Attention Mechanisms and Deep Residual Blocks. Remote Sensing. 2023; 15(18):4498. https://doi.org/10.3390/rs15184498
Chicago/Turabian StyleZhang, Huajun, Chengming Ye, Yuzhan Zhou, Rong Tang, and Ruilong Wei. 2023. "A Super-Resolution Network for High-Resolution Reconstruction of Landslide Main Bodies in Remote Sensing Imagery Using Coordinated Attention Mechanisms and Deep Residual Blocks" Remote Sensing 15, no. 18: 4498. https://doi.org/10.3390/rs15184498
APA StyleZhang, H., Ye, C., Zhou, Y., Tang, R., & Wei, R. (2023). A Super-Resolution Network for High-Resolution Reconstruction of Landslide Main Bodies in Remote Sensing Imagery Using Coordinated Attention Mechanisms and Deep Residual Blocks. Remote Sensing, 15(18), 4498. https://doi.org/10.3390/rs15184498