2.3.2. Extraction Methods of Avalanche Infrasound Features
- (1)
Extraction of time domain features
In this study, kurtosis and skewness of the signal are extracted to characterize the waveform characteristics of the signal in the time domain. Kurtosis reflects the gentle degree of the waveform: the higher the kurtosis, the steeper the waveform. Skewness reflects the deflection degree of the waveform: positive skewness indicates right skewness, negative skewness indicates left skewness.
Kurtosis is expressed as:
Skewness is expressed as:
In the equations above, represents the input signal, represents the mean value of the input signals, represents the standard deviation of the input signal, and represents the expected value of the input signal.
- (2)
Extraction of features in frequency domain
In this study, the frequency spectrum and power spectrum of the signal are obtained by Fast Fourier Transform (
FFT), and the center of gravity frequency [
28] and frequency standard deviation [
29] of the signal are extracted. The center of gravity frequency represents the frequency distribution of the signal on the frequency spectrum. The frequency standard deviation characterizes the dispersion of the power spectrum energy of the signal.
represents the Fourier transform of the signal,
is the frequency, and
represents the input signal [
30].
is the power spectrum,
represents the fast Fourier transform of the signal, and
represents the length of the signal.
is the center of gravity frequency.
is the standard deviation of the frequency.
- (3)
Joint extraction of features in time and frequency domains
The time domain analysis and frequency domain analysis of the signal can only characterize the characteristics of the signal from one aspect. In this paper, wavelet and Hilbert–Huang transform analyses were selected to obtain wavelet coefficients and the Hilbert marginal spectrum distribution, respectively, which were used to characterize the features of the signal in both the time domain and the frequency domain.
① Wavelet transform
The discrete wavelet transform depends on the selection of the wavelet function, which is mainly divided into the following five steps [
31]:
Step 1: suppose that the function
satisfies
, and its Fourier transform
satisfies the following conditions, then
is a mother wavelet:
Step 2: by stretching and translating the mother wavelet, a set of wavelet basis functions
are obtained, such as the following formula, where
,
is the scale factor, and
is the translation factor, all of which are continuously changing values:
Step 3: the scale parameter a and the shift parameter b are discretized, that is,
,
,
, and the discrete wavelet basis function,
, is obtained, which is the wavelet coefficient
:
Step 4: discrete wavelet transform of signal
:
Step 5: calculate the energy
and energy proportion
on different scales:
The main eigenvalue extracted based on the wavelet transform is the distribution value of wavelet coefficients, and the extraction includes four main steps:
Step 1: wavelet packet decomposition: the pre-processed signal is decomposed by three layers of wavelet packets, and the waveforms of 8 nodes can be obtained, and each node waveform corresponds to a set of wavelet packet coefficients .
Step 2: take the absolute values of the wavelet coefficients
of the waveform at each node and sum them.
where
is a natural number of finite length of
.
Step 3: the ratio of the sum of wavelet packet coefficients of each node to the sum of all node coefficients is calculated:
where
is the number of nodes corresponding to the number of decomposition layers, and in this study, the decomposition layers are three, that is,
.
Step 4: finally, the ratio of the ratio calculated in the above step and the ratio of the adjacent node is determined, and that is the eigenvalue of the wavelet coefficient distribution.
Through the above steps, the eigenvalues of the wavelet coefficient distribution corresponding to the signal can be extracted. In this study, the signal was decomposed by three layers of wavelet packets, and the corresponding eigenvalue dimension was the dimension.
② Hilbert–Huang transform
The main eigenvalues extracted based on the Hilbert–Huang transform are the Hilbert spectrum and Hilbert marginal spectrum. The marginal spectrum can reflect the distribution of signals at different frequencies, especially local characteristics of signals at lower frequencies. In this study, the proportions of different frequency segments corresponding to the Hilbert marginal spectrum were taken as the characteristics of different sample signals, that is, the frequency distribution value of the marginal spectrum [
32,
33].
The Hilbert–Huang transform is mainly divided into the following nine steps:
Step 1: find all the maximum points, minimum points, and endpoints of signal .
Step 2: the extreme points of all the marks in step 1 are interpolated, and then the upper and lower envelope sequences
and
of the signal
are obtained, and the mean value of the upper and lower envelope of signal
is calculated:
Step 3: calculate the
signal
of signal
:
Step 4: to judge whether satisfies the two conditions of , (1) the difference between the total number of cross-zero points of the signal waveform and the number of all extreme points is less than or equal to 1, (2) and the local mean of the upper and downer envelope of the signal is zero. If the above two conditions are satisfied, then , and the first component is obtained; if the condition is not satisfied, then steps 2 to 4 of the above are repeated as the signal until the two conditions of are met, and the is obtained.
Step 5: the
component is removed to obtain the residual component
:
Step 6: to judge whether conforms to the three conditions of EMD (Empirical Mode Decomposition), (1) if the number of extreme points of the signal is greater than or equal to 2, it means that there is at least one maximum and one minimum point; (2) the time scale of the extreme point can only determine the local time domain characteristics of the original signal; and (3) if a signal has no extreme point, there must be a singularity or inflection point that can be obtained by several differentials. If the above three conditions are satisfied, the EMD decomposition ends. If not, steps 2 to 5 above are repeated with as the new original signal to obtain other components.
Step 7: when
satisfies the termination condition, the
EMD decomposition ends, and the signal
can be expressed in the form of the sum of multiple
components:
Step 8: the Hilbert–Huang transform is performed on each
component to obtain the Hilbert spectrum
, where
represents the real part of the
component:
Step 9: the Hilbert spectrum
is integrated, and the marginal spectrum
is obtained:
In this study, the proportion of different frequency segments corresponding to the Hilbert marginal spectrum is taken as the characteristic of different sample signals, that is, the marginal spectrum frequency distribution value. The extraction process mainly has the following four steps:
Step 1: the marginal spectrum of the signal is obtained by the Hilbert–Huang transform, and the marginal spectrum is divided according to 1 Hz. In this study, after resampling the original data, the corresponding sampling frequency is 25 Hz, so it can be divided into 25 frequency bands, each band corresponding to 1 Hz.
is the marginal spectrum, and is the sampling frequency.
Step 2: the sum of the marginal spectrums of each frequency band, that is, the sum of the amplitudes corresponding to the marginal spectrum, is determined as follows:
In the equation, is a finite natural number of , and is the amplitude corresponding to the marginal spectrum.
Step 3: the ratio of the sum of the marginal spectrums to the sum of the marginal spectrums corresponding to each frequency band is determined as follows:
Step 4: finally, the ratio calculated in step 3 and the ratio of the adjacent frequency bands are calculated again, that is, the eigenvalue of the marginal spectral frequency distribution.
Through the above steps, the eigenvalues of the marginal spectrum frequency distribution corresponding to the signal can be extracted. In this study, 25 frequency segments are obtained after the marginal spectrum is segmented, and the corresponding eigenvalue dimension is 24 dimensions.
- (4)
Extraction of information entropy feature
Information entropy is used to measure the uncertainty of random variables [
34] (Zhu Xuenong, 2001), which is expressed as
where
represents the probability of occurrence of N values of the random variable.
In this study, eigenvalues extracted based on information entropy included singular spectrum entropy based on time domain analysis, power spectrum entropy based on frequency domain analysis, wavelet energy entropy based on the wavelet transform, wavelet packet energy entropy, wavelet packet scale entropy and wavelet packet singular entropy based on the wavelet packet transform, and energy entropy based on EMD(Empirical Mode Decomposition) decomposition.
① Singular spectral entropy based on time domain analysis
The singular spectrum of signals needs to be decomposed before solving the singular spectrum entropy, which includes decomposing and reconstructing signals according to the time series of the signals to extract different components of the signals [
35].
where
denotes the
matrix of signals to be decomposed.
is the unitary matrix of
;
is the unitary matrix of
, that is,
,
; and
is the matrix of
.
It can be obtained from Equation (29).
where
is the eigenvector of
,
is the eigenvector of
,
are singular values.
The corresponding singular spectrum
can be obtained by singular value decomposition of
. By calculating the proportion of every singular value in the singular spectrum, a set of probability density functions can be obtained. By substituting the probability density function into the classical entropy formula, the singular spectrum entropy of the input signal can be obtained.
② Power spectral entropy based on frequency domain analysis
In the part of the extraction of features in the frequency domain, the power spectrum of the input signal,
, has been obtained, and the power spectrum,
contains
band values. By calculating the proportion of every band value of the power spectrum
in the power spectrum, a set of probability density functions
can be obtained. The power spectrum entropy of the input signal can be obtained by substituting the probability density function into the classical entropy formula.
③ Wavelet energy entropy and wavelet packet energy entropy based on the wavelet and wavelet packet transforms
In the part of the extraction of features through the wavelet and wavelet packet transforms, the energy
and energy proportion
of each layer after wavelet decomposition have been calculated, and then the energy entropy can be determined.
④ Wavelet packet scale entropy and wavelet packet singular entropy based on the wavelet packet transform
Similarly, the wavelet scale entropy is the Shannon entropy of the probability density of the wavelet coefficients
of all nodes in the wavelet packet decomposition.
The calculation method of singular entropy of the wavelet packet is consistent with that of singular spectral entropy of the input signal, that is, the singular value of each node is obtained by singular spectral decomposition of the wavelet packet coefficients of each node, and then the singular entropy of wavelet packet is obtained by the same method.
⑤ Energy entropy based on EMD decomposition
In the part of the extraction of features through the Hilbert–Huang transform, a set of
IMF (Intrinsic Mode Function) components of the input signal
can be obtained by
EMD decomposition, and the energy entropy of the probability density function
corresponding to each group of
can be obtained.
The eigenvalues of ice avalanche events, flood events, and wind-and-rain events extracted by using the above feature extraction methods constitute feature vectors of different features.
2.3.3. Class Recognition Method
In this study, supervised pattern recognition was used to classify infrasound signals. Support vector machine (
SVM), K-nearest neighbor (
KNN), classification tree, and BP neural network (
BPNN) were used. After preprocessing of the original infrasound signals, based on feature vectors extracted by time and frequency domain analysis, the wavelet transform and the Hilbert–Huang transform, classification models were constructed, and the model parameters were improved through continuous training to achieve the best classification effect. The trained classification models have been applied to the recognition of unknown signals to judge classes of the signals, with the classification results output [
36,
37].
In order to characterize the recognition effect of the models more accurately, five indexes—recall ratio, precision, accuracy, F1 score, and area under the curve (AUC) were used to evaluate the classification results of the models.
The recall ratio, also known as recall, refers to the ratio of samples of a class identified in the process of class recognition to the actual total samples of this class. It is generally considered that the higher the value, the better the performance of the classifier is, but the higher recall rate also means a greater possibility of misjudgment.
refers to the number of samples of the class concerned that are true in the actual situation and prediction, while is the number of samples that are true, but predicted as false.
Precision refers to the ratio of the actual samples to the predicted samples of the concerned class in the process of class recognition. The higher the value, the better the performance of the classifier is.
represents the number of samples of the class in concern that are actually false, but predicted as true.
Accuracy refers to the ratio of the correctly predicted events to the total events, which characterizes the performance of the classifier. And, the higher the value, the better the classifier is.
indicates the number of samples that are false in the actual situation and prediction.
The
score can characterize the recall rate and accuracy rate at the same time, and it is the harmonic average that can maintain the two indexes as high at the same time.
The area under the, AUC, refers to the area under the Receiver Operating Characteristic Curve (ROC). Its abscissa is the false positive rate; its vertical coordinate is the true positive rate, in which the true positive rate is equal to the recall rate; and the closer the curve is to the upper left corner, the better the recognition effect is. In order to quantitatively characterize the performance of the classifier, AUC, that is, the area under the ROC, values ranging from 0 to 1 are introduced. The closer the AUC value is to 1, the better the performance of the model.
As the main purpose of class identification is to identify disaster events, and this study focuses on ice avalanche disasters, the three types of events were given different weights, ice avalanche events 0.5, flood events 0.4, wind-and-rain events 0.1, and the comprehensive index of each classification model was calculated.









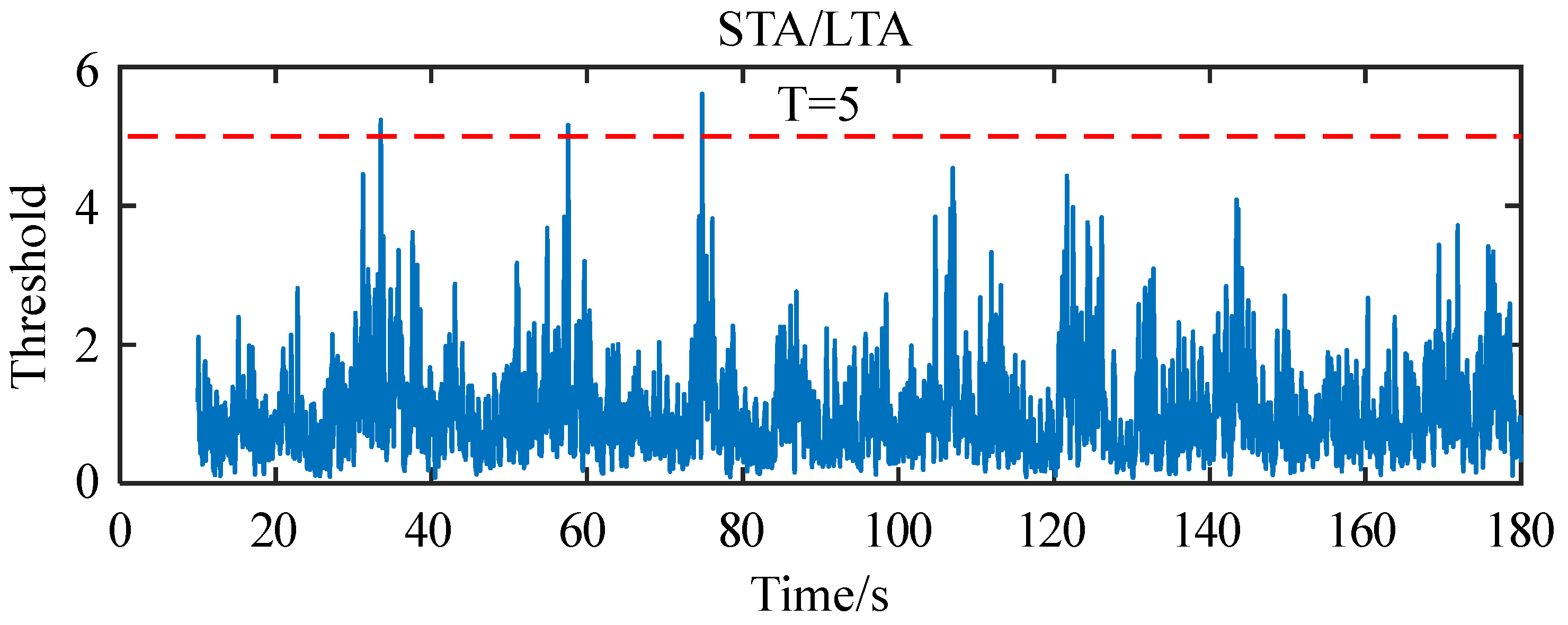
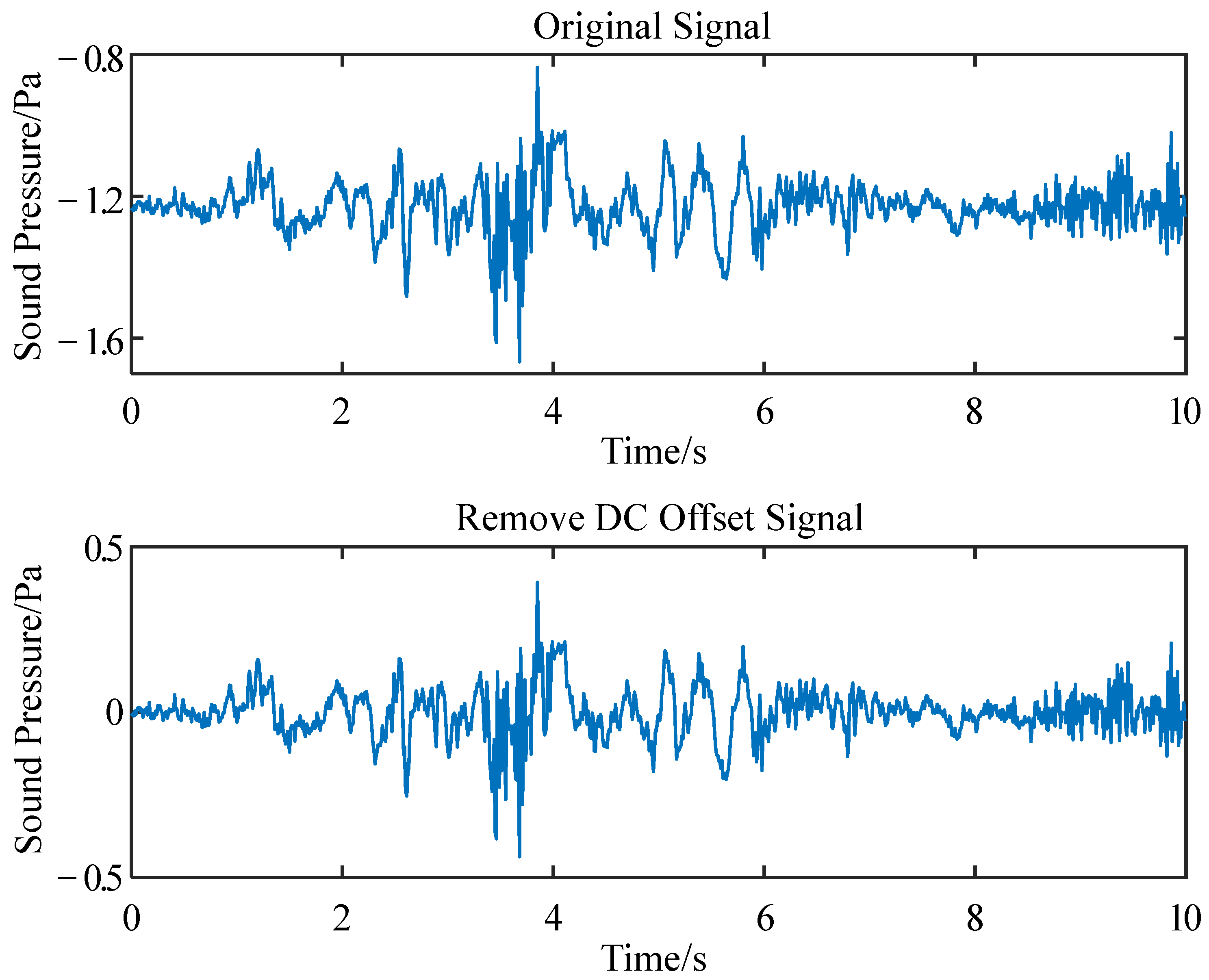

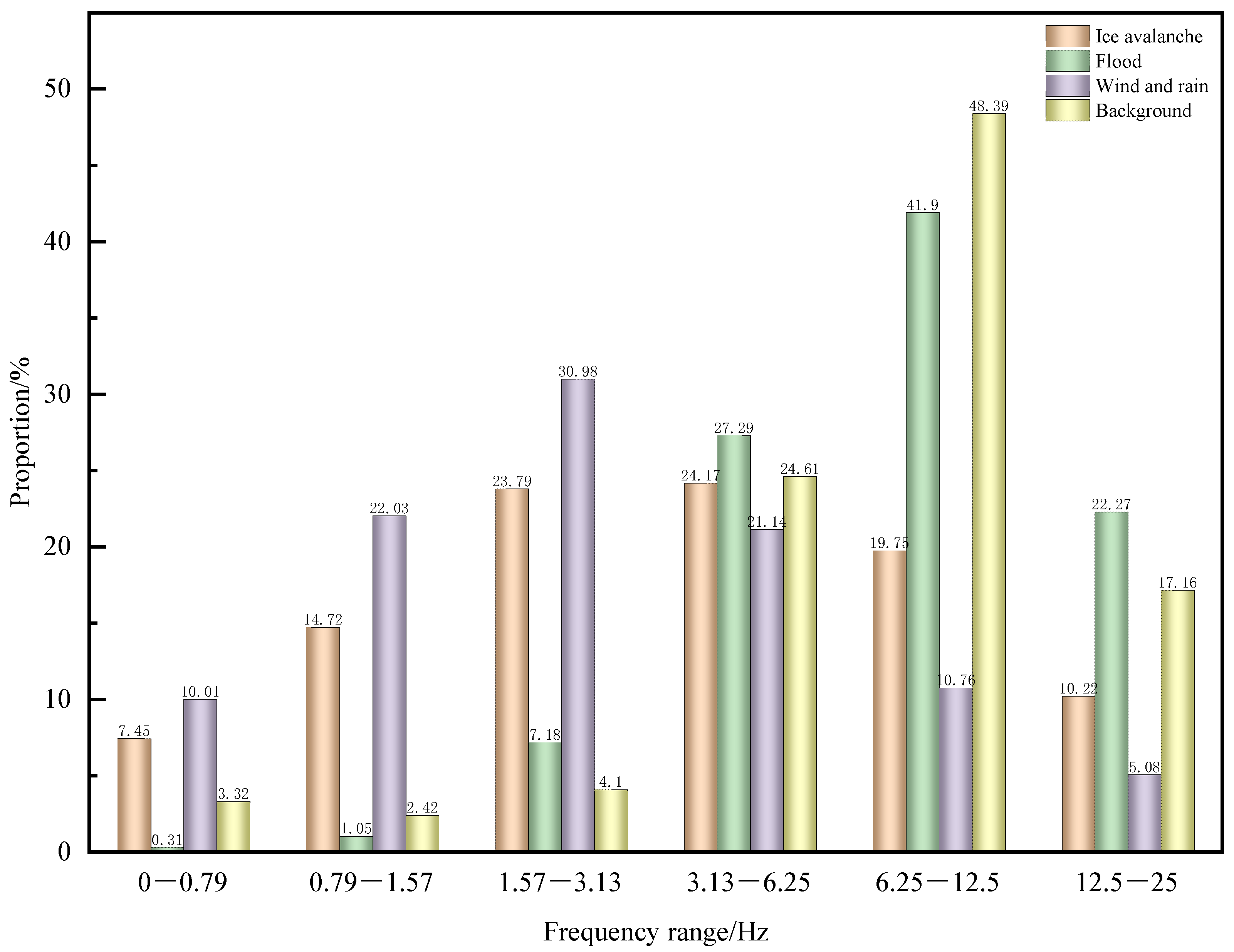

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}