


The Classification of Hyperspectral Images: A Double-Branch Multi-Scale Residual Network



Abstract
:
1. Introduction
- (1)
- The authors propose a DBMSRN, a double-branch architecture that realizes the independent extraction of spectral and spatial features without interfering with each other by utilizing spectral multi-scale residuals and spatial multi-scale residuals on each respective branch.
- (2)
- Due to learning more representative features from limited training samples, we design spectral multi-scale residuals and spatial multi-scale residuals in double branches, respectively. The multi-scale structure based on dilated convolution reduces computational parameters and expands the network width to extract richer multi-scale features. Additionally, the inclusion of residual structure increases the depth of the network and enhances its non-linear expression ability.
- (3)
- We conducted comparative experiments on three distinct datasets and compared the proposed method with other advanced network frameworks. The results demonstrate that our approach achieves superior classification accuracy, highlighting its universality and effectiveness in data analysis.
2. Materials and Method
2.1. HSI Pixel Block Construction
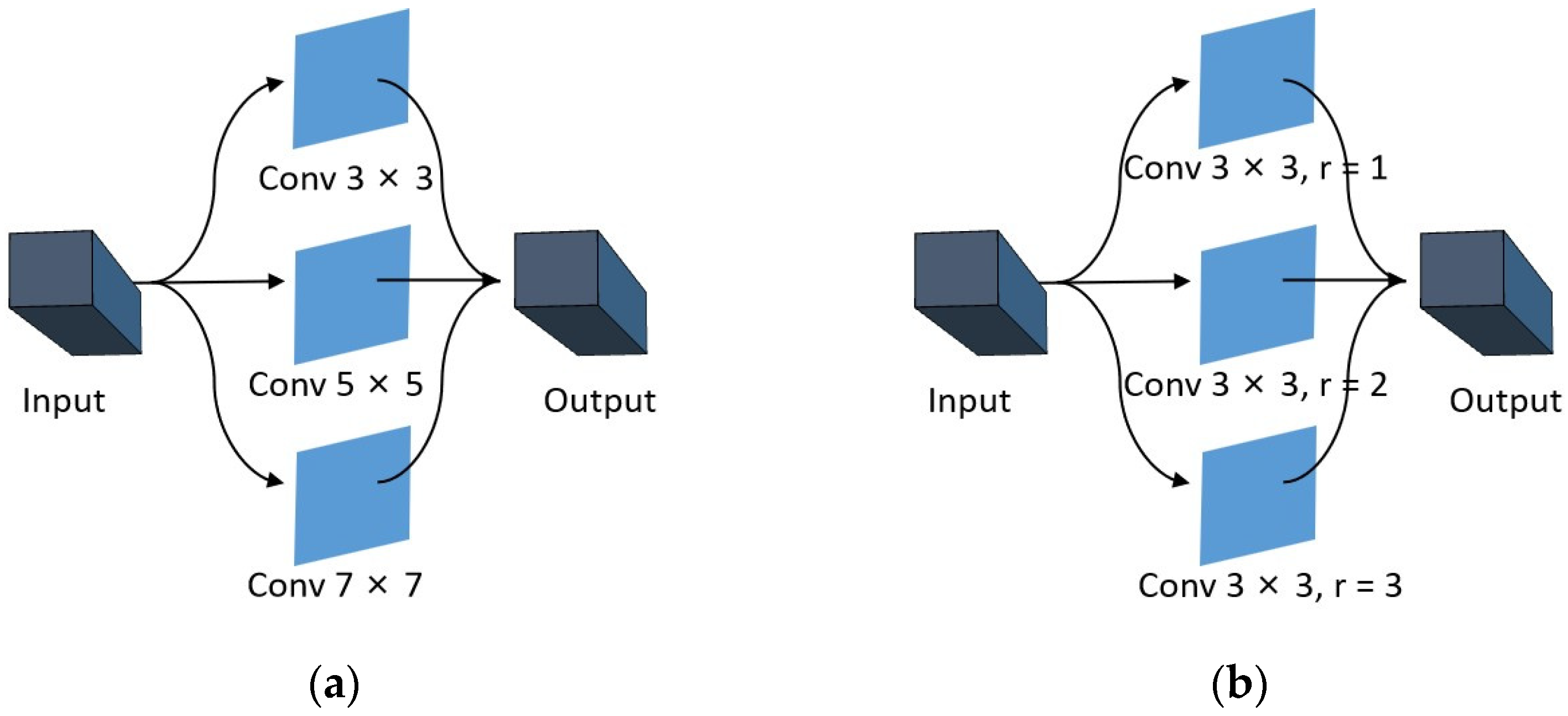
2.2. Construction of the Multi-Scale Dilated Convolution Framework
2.3. Construction of the Residual Block Framework
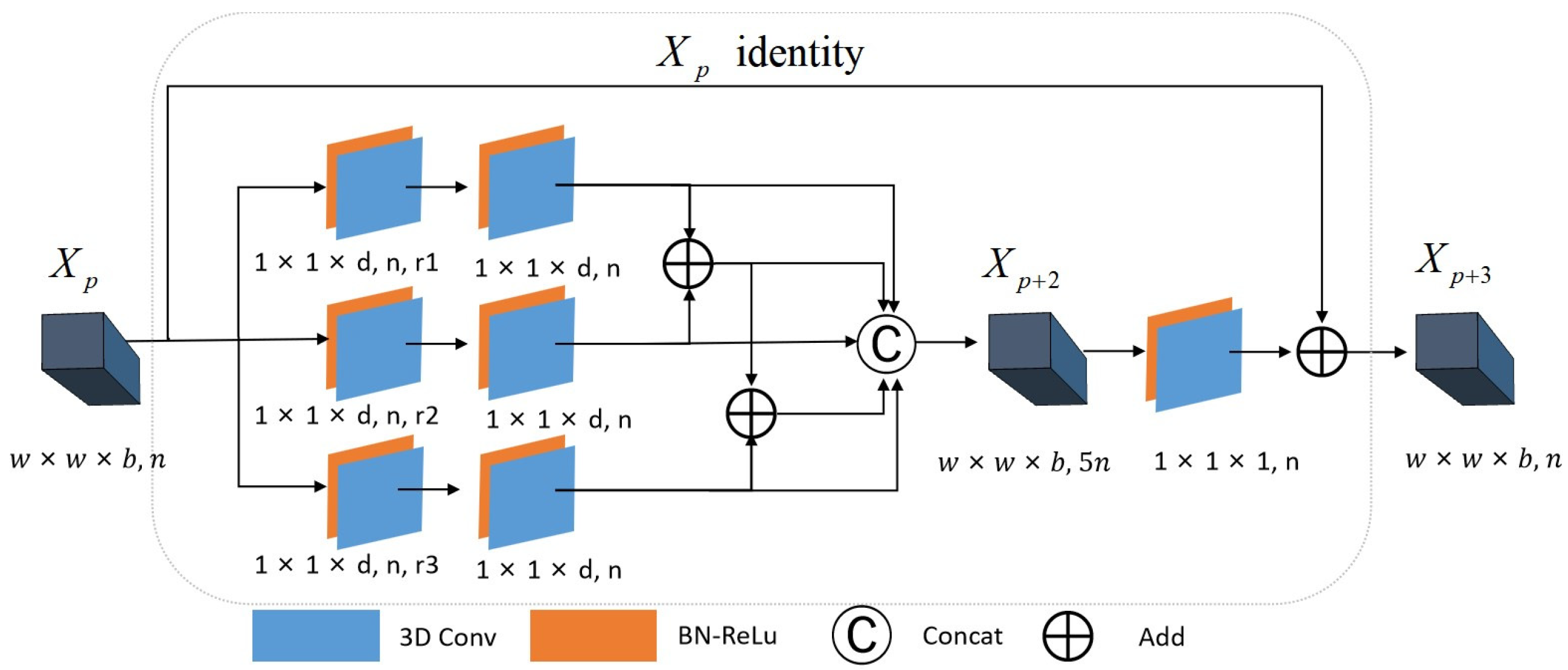
2.3.1. Construction of Multi-Scale Spectral Residual Blocks
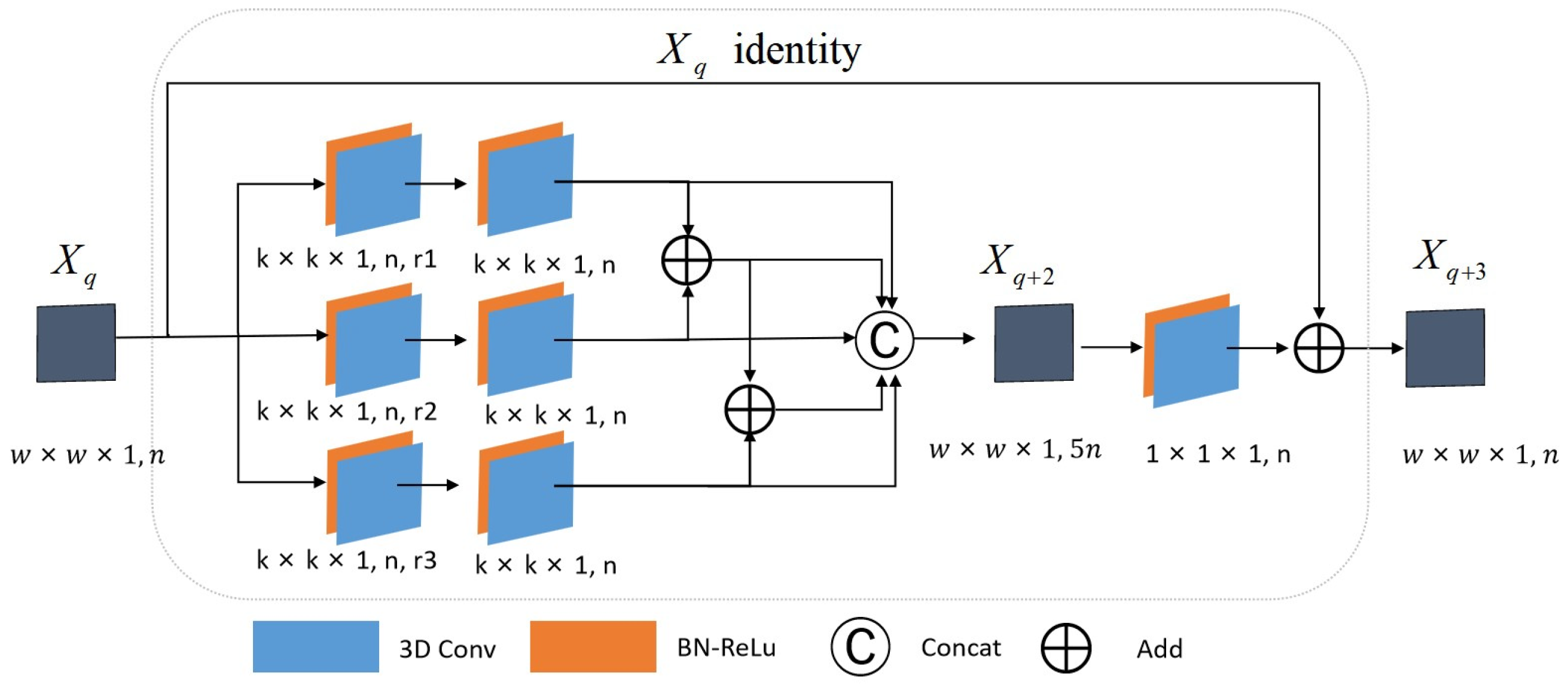
2.3.2. Multi-Scale Spatial Residual Block Construction
2.4. Proposed Framework
2.4.1. Spectral Multi-Scale Residual Block Branch
2.4.2. Spatial Multi-Scale Residual Block Branch
2.4.3. Feature Fusion and Classification
3. Results
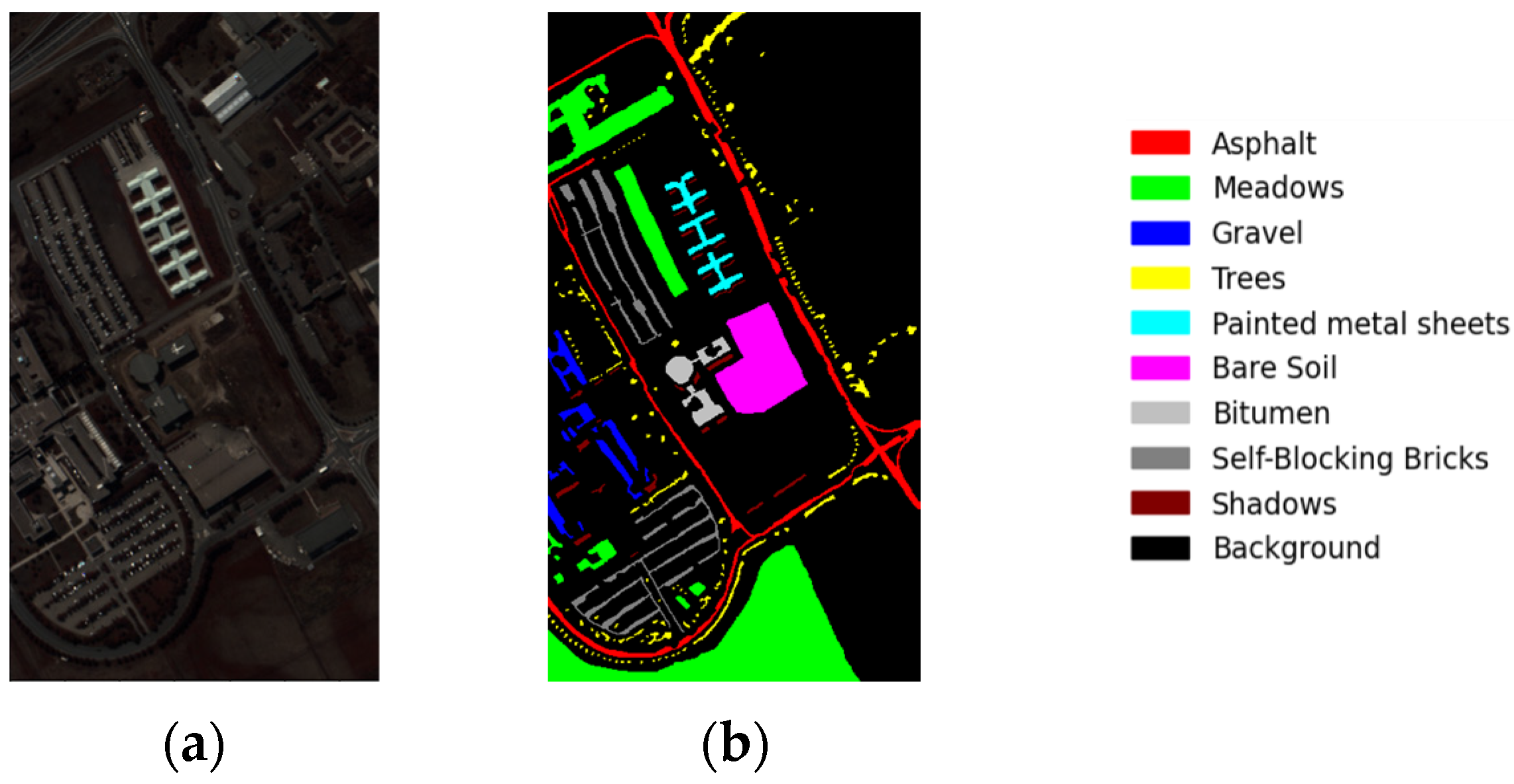
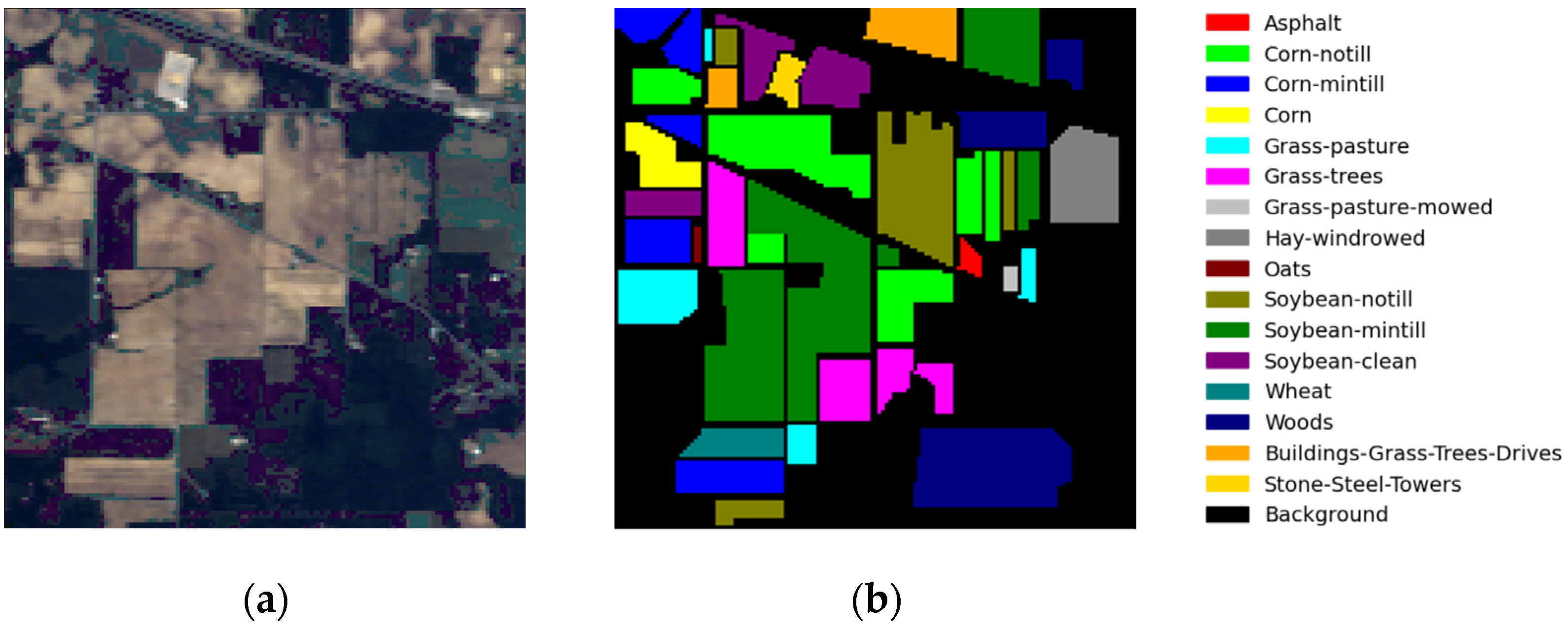
3.1. Experimental Dataset
3.2. Experimental Setting
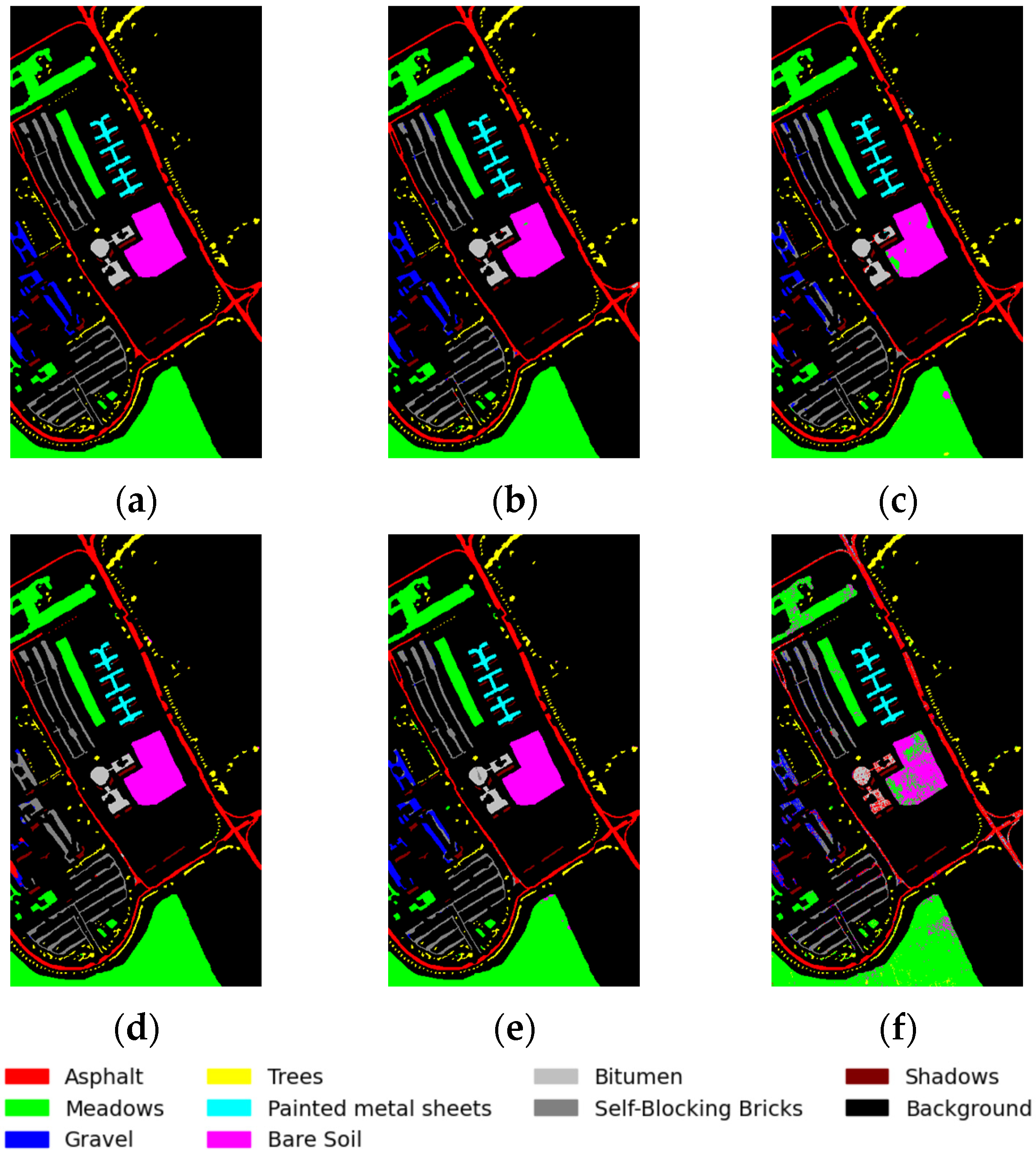
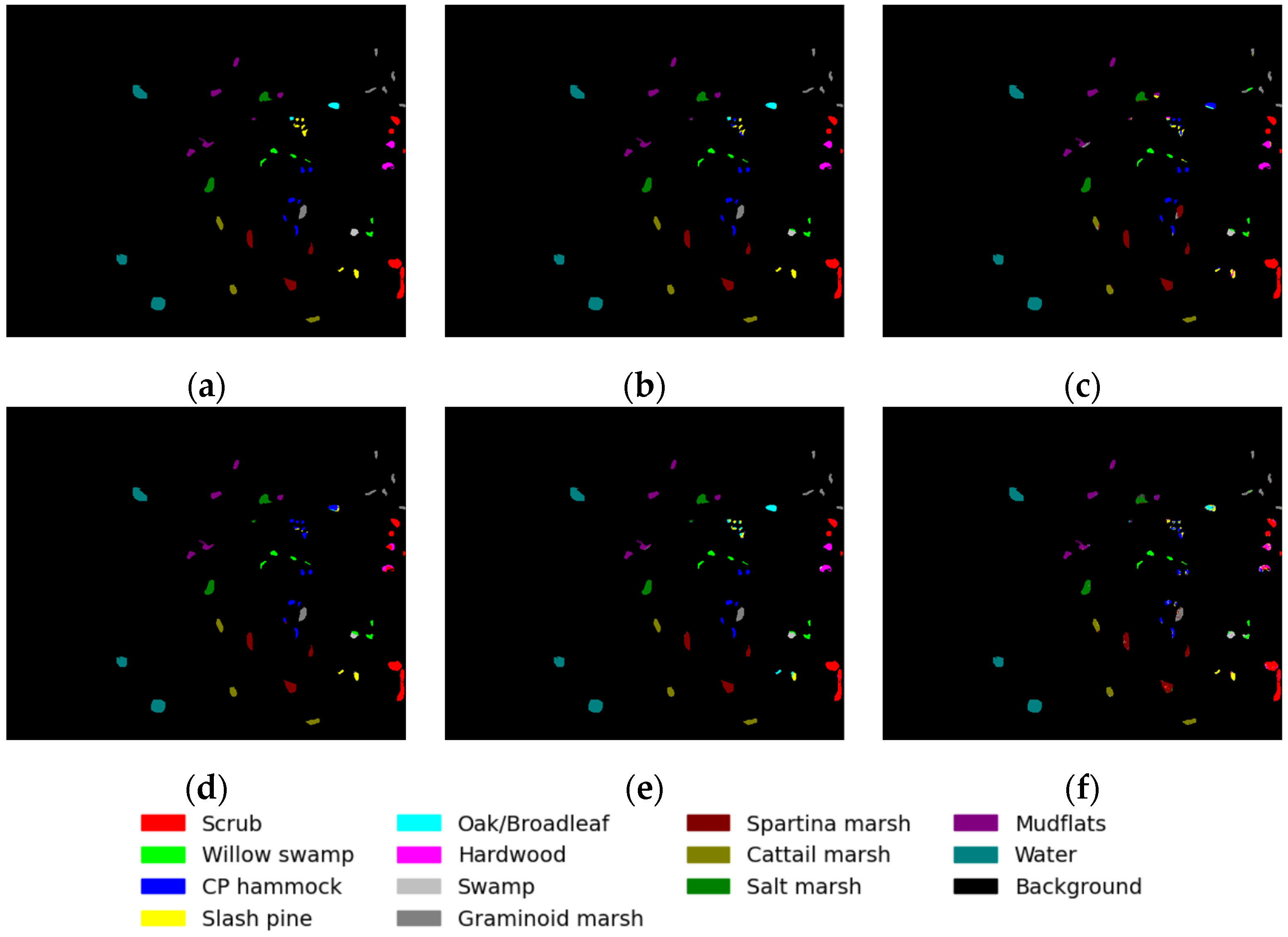
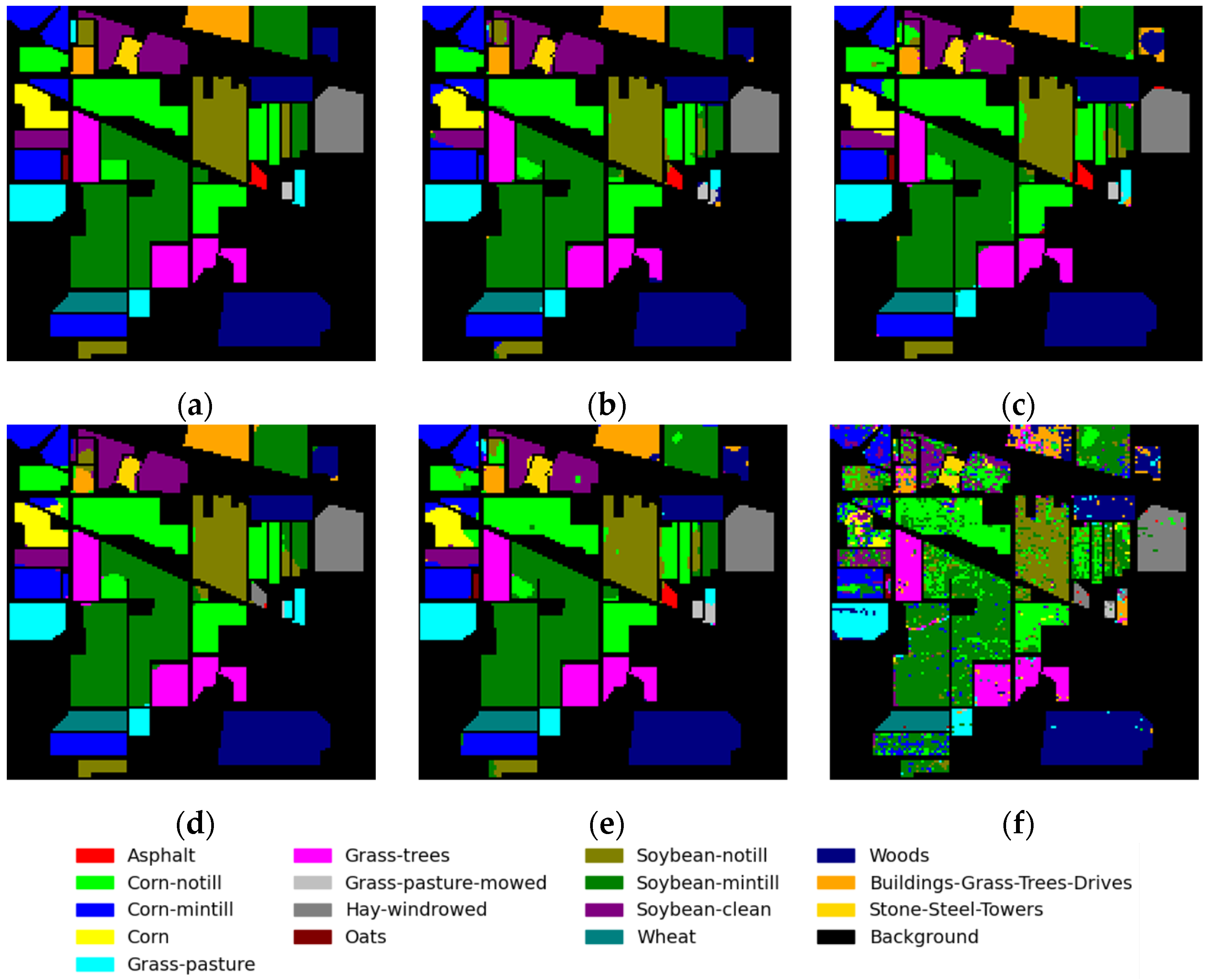
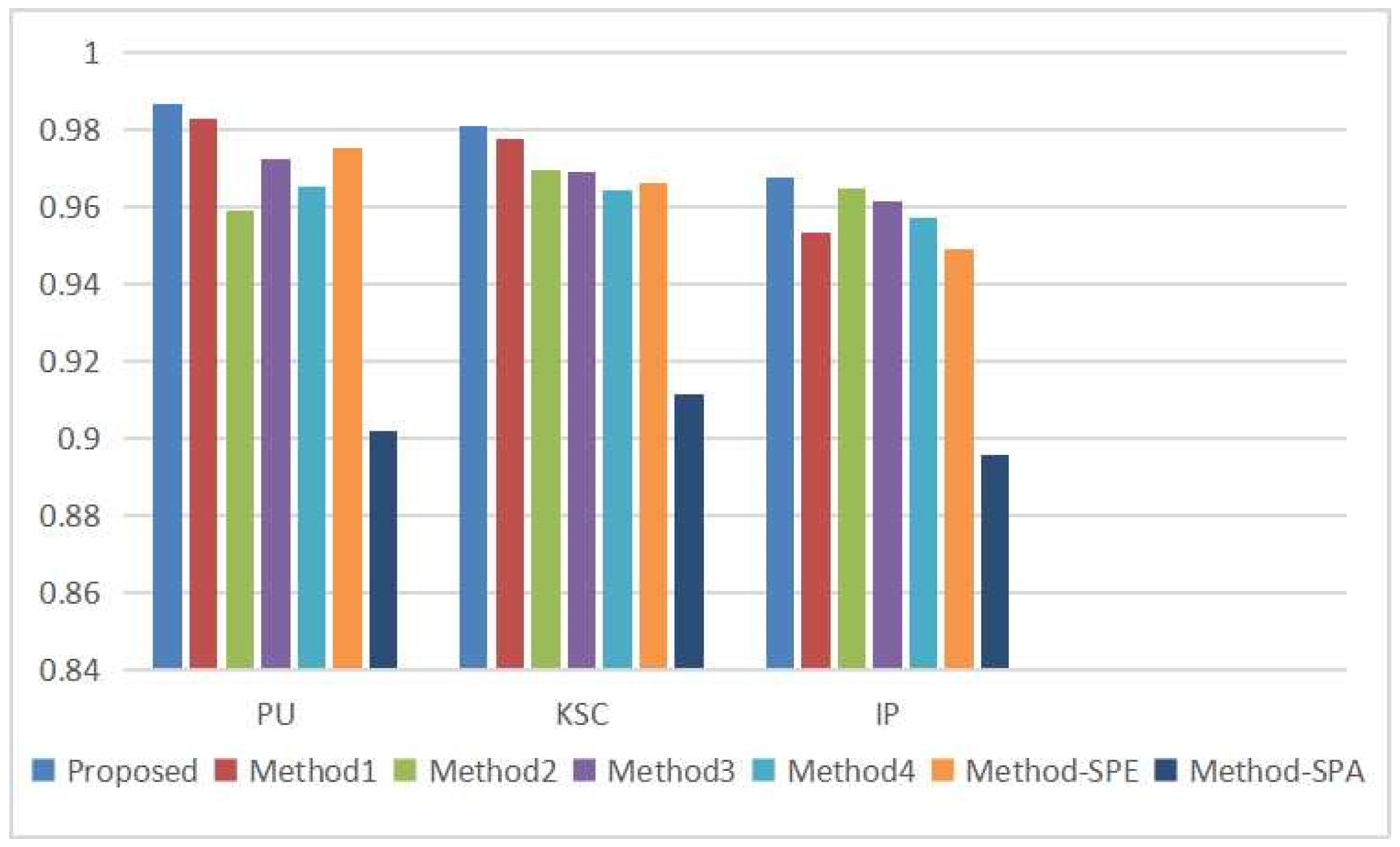
3.3. Experimental Results
4. Discussion
4.1. Classification Results of Training Sets with Varying Proportions
4.2. Ablation Experiment
4.3. Categorization Results with Different Combinations of Dilation Rates
4.4. Effect of Dilated Convolution on Model Complexity
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- David, L. Hyperspectral image data analysis as a high dimensional signal processing problem. IEEE Signal Process. Mag. 2002, 19, 17–28. [Google Scholar]
- Wang, H.; Li, W.; Huang, W.; Niu, J.; Nie, K. Research on land use classification of hyperspectral images based on multiscale superpixels. Math. Biosci. Eng. 2020, 17, 5099–5119. [Google Scholar] [CrossRef]
- Yan, W.Y.; Shaker, A.; El-Ashmawy, N. Urban land cover classification using airborne LiDAR data: A review. Remote Sens. Environ. 2015, 158, 295–310. [Google Scholar] [CrossRef]
- Pirasteh, S.; Mollaee, S.; Fatholahi, S.N.; Li, J. Estimation of phytoplankton chlorophyll-a concentrations in the Western Basin of Lake Erie using Sentinel-2 and Sentinel-3 data. Can. J. Remote Sens. 2020, 46, 585–602. [Google Scholar] [CrossRef]
- Eslami, M.; Mohammadzadeh, A. Developing a spectral-based strategy for urban object detection from airborne hyperspectral TIR and visible data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 9, 1808–1816. [Google Scholar] [CrossRef]
- Gevaert, C.M.; Suomalainen, J.; Tang, J.; Kooistra, L. Generation of spectral–temporal response surfaces by combining multispectral satellite and hyperspectral UAV imagery for precision agriculture applications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3140–3146. [Google Scholar] [CrossRef]
- Ye, C.; Cui, P.; Li, J.; Pirasteh, S. A method for recognising building materials based on hyperspectral remote sensing. Mater. Res. Innov. 2015, 19, S10-90–S10-94. [Google Scholar] [CrossRef]
- dos Anjos, C.E.; Avila, M.R.; Vasconcelos, A.G.; Pereira Neta, A.M.; Medeiros, L.C.; Evsukoff, A.G.; Surmas, R.; Landau, L. Deep learning for lithological classification of carbonate rock micro-CT images. Comput. Geosci. 2021, 25, 971–983. [Google Scholar] [CrossRef]
- Wan, Y.-q.; Fan, Y.-h.; Jin, M.-s. Application of hyperspectral remote sensing for supplementary investigation of polymetallic deposits in Huaniushan ore region, northwestern China. Sci. Rep. 2021, 11, 440. [Google Scholar] [CrossRef]
- Krupnik, D.; Khan, S. Close-range, ground-based hyperspectral imaging for mining applications at various scales: Review and case studies. Earth-Sci. Rev. 2019, 198, 102952. [Google Scholar] [CrossRef]
- Lorenz, S.; Ghamisi, P.; Kirsch, M.; Jackisch, R.; Rasti, B.; Gloaguen, R. Feature extraction for hyperspectral mineral domain mapping: A test of conventional and innovative methods. Remote Sens. Environ. 2021, 252, 112129. [Google Scholar] [CrossRef]
- Haridas, N.; Sowmya, V.; Soman, K. Comparative analysis of scattering and random features in hyperspectral image classification. Procedia Comput. Sci. 2015, 58, 307–314. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Wang, W.-Y.; Li, H.-C.; Pan, L.; Yang, G.; Du, Q. Hyperspectral image classification based on capsule network. In Proceedings of the IGARSS 2018–2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 3571–3574. [Google Scholar]
- Yedidia, J.S.; Freeman, W.T.; Weiss, Y. Understanding belief propagation and its generalizations. Explor. Artif. Intell. New Millenn. 2003, 8, 0018–9448. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Ma, L.; Jiang, H.; Zhao, H. Deep residual networks for hyperspectral image classification. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 1824–1827. [Google Scholar]
- Yu, S.; Jia, S.; Xu, C. Convolutional neural networks for hyperspectral image classification. Neurocomputing 2017, 219, 88–98. [Google Scholar] [CrossRef]
- Zhang, M.; Li, W.; Du, Q. Diverse region-based CNN for hyperspectral image classification. IEEE Trans. Image Process. 2018, 27, 2623–2634. [Google Scholar] [CrossRef]
- Yu, C.; Han, R.; Song, M.; Liu, C.; Chang, C.-I. Feedback attention-based dense CNN for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- He, X.; Chen, Y. Transferring CNN ensemble for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2020, 18, 876–880. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep convolutional neural networks for hyperspectral image classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef]
- Ruiz, D.; Bacca, B.; Caicedo, E. Hyperspectral Images Classification based on Inception Network and Kernel PCA. IEEE Lat. Am. Trans. 2019, 17, 1995–2004. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Shen, Q. Spectral–spatial classification of hyperspectral imagery with 3D convolutional neural network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Ma, W.; Yang, Q.; Wu, Y.; Zhao, W.; Zhang, X. Double-branch multi-attention mechanism network for hyperspectral image classification. Remote Sens. 2019, 11, 1307. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Yang, Y.; Wang, X. Classification of hyperspectral image based on double-branch dual-attention mechanism network. Remote Sens. 2020, 12, 582. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, W.; Dou, S.; Jiang, Z.; Sun, L. A fast dense spectral–spatial convolution network framework for hyperspectral images classification. Remote Sens. 2018, 10, 1068. [Google Scholar] [CrossRef]
- Duan, P.; Kang, X.; Li, S.; Ghamisi, P. Noise-robust hyperspectral image classification via multi-scale total variation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1948–1962. [Google Scholar] [CrossRef]
- Lu, Z.; Xu, B.; Sun, L.; Zhan, T.; Tang, S. 3-D channel and spatial attention based multiscale spatial–spectral residual network for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4311–4324. [Google Scholar] [CrossRef]
- Wu, S.; Zhang, J.; Zhong, C. Multiscale spectral-spatial unified networks for hyperspectral image classification. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July 2019–2 August 2019; pp. 2706–2709. [Google Scholar]
- Pooja, K.; Nidamanuri, R.R.; Mishra, D. Multi-scale dilated residual convolutional neural network for hyperspectral image classification. In Proceedings of the 2019 10th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Amsterdam, The Netherlands, 24–26 September 2019; pp. 1–5. [Google Scholar]
- Cao, F.; Guo, W. Deep hybrid dilated residual networks for hyperspectral image classification. Neurocomputing 2020, 384, 170–181. [Google Scholar] [CrossRef]
- Ali, S.; Pirasteh, S. Geological application of Landsat ETM for mapping structural geology and interpretation: Aided by remote sensing and GIS. Int. J. Remote Sens. 2004, 25, 4715–4727. [Google Scholar] [CrossRef]
- Lu, W.; Song, Z.; Chu, J. A novel 3D medical image super-resolution method based on densely connected network. Biomed. Signal Process. Control 2020, 62, 102120. [Google Scholar] [CrossRef]
- Huang, L.; Chen, Y. Dual-path siamese CNN for hyperspectral image classification with limited training samples. IEEE Geosci. Remote Sens. Lett. 2020, 18, 518–522. [Google Scholar] [CrossRef]
- Yu, C.; Han, R.; Song, M.; Liu, C.; Chang, C.-I. A simplified 2D-3D CNN architecture for hyperspectral image classification based on spatial–spectral fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2485–2501. [Google Scholar] [CrossRef]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lile, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Order | Class | Total Number | Train | Val | Test |
|---|---|---|---|---|---|
| 1 | Asphalt | 6631 | 66 | 66 | 6499 |
| 2 | Meadows | 18,649 | 186 | 186 | 18,277 |
| 3 | Gravel | 2099 | 20 | 20 | 2059 |
| 4 | Trees | 3064 | 30 | 30 | 3004 |
| 5 | Painted Metal Sheets | 1345 | 13 | 13 | 1319 |
| 6 | Bare Soil | 5029 | 50 | 50 | 4929 |
| 7 | Bitumen | 1330 | 13 | 13 | 1304 |
| 8 | Self-Blocking Bricks | 3682 | 36 | 36 | 3610 |
| 9 | Shadows | 947 | 9 | 9 | 929 |
| Total | 42,776 | 423 | 423 | 41,930 | |
| Order | Class | Total Number | Train | Val | Test |
|---|---|---|---|---|---|
| 1 | Scrub | 761 | 38 | 38 | 685 |
| 2 | Willow Swamp | 243 | 12 | 12 | 219 |
| 3 | CP Hammock | 256 | 12 | 12 | 232 |
| 4 | Slash Pine | 252 | 12 | 12 | 228 |
| 5 | Oak/Broadleaf | 161 | 8 | 8 | 145 |
| 6 | Hardwood | 229 | 11 | 11 | 207 |
| 7 | Swamp | 105 | 5 | 5 | 95 |
| 8 | Graminoid Marsh | 431 | 21 | 21 | 389 |
| 9 | Spartina Marsh | 520 | 26 | 26 | 468 |
| 10 | Cattail Marsh | 404 | 20 | 20 | 364 |
| 11 | Salt Marsh | 419 | 20 | 20 | 379 |
| 12 | Mudflats | 503 | 25 | 25 | 453 |
| 13 | Water | 927 | 46 | 46 | 835 |
| Total | 5211 | 256 | 256 | 4699 | |
| Order | Class | Total Number | Train | Val | Test |
|---|---|---|---|---|---|
| 1 | Asphalt | 46 | 3 | 3 | 40 |
| 2 | Corn-Notill | 1428 | 71 | 71 | 1286 |
| 3 | Corn-Mintill | 830 | 41 | 41 | 748 |
| 4 | Corn | 237 | 11 | 11 | 215 |
| 5 | Grass-Pasture | 483 | 24 | 24 | 435 |
| 6 | Grass-Trees | 730 | 36 | 36 | 658 |
| 7 | Grass-Pasture-Mowed | 28 | 3 | 3 | 22 |
| 8 | Hay-Windrowed | 478 | 23 | 23 | 432 |
| 9 | Oats | 20 | 3 | 3 | 14 |
| 10 | Soybean-Notill | 972 | 48 | 48 | 876 |
| 11 | Soybean-Mintill | 2455 | 122 | 122 | 2211 |
| 12 | Soybean-Clean | 593 | 29 | 29 | 535 |
| 13 | Wheat | 205 | 10 | 10 | 185 |
| 14 | Woods | 1265 | 63 | 63 | 1139 |
| 15 | Building-Grass-Trees-Drives | 386 | 19 | 19 | 348 |
| 16 | Stone-Steel-Towers | 93 | 4 | 4 | 85 |
| Total | 10,249 | 510 | 510 | 9229 | |
| Class | Proposed | DBDA | FDSSC | SSRN | SVM |
|---|---|---|---|---|---|
| 1 | 98.71 ± 1.09 | 97.16 ± 1.69 | 97.78 ± 4.45 | 96.24 ± 2.55 | 88.63 ± 2.13 |
| 2 | 99.96 ± 0.04 | 99.33 ± 0.57 | 99.59 ± 0.38 | 99.71 ± 0.24 | 92.07 ± 1.59 |
| 3 | 90.10 ± 6.05 | 77.32 ± 15.89 | 59.33 ± 26.15 | 67.66 ± 33.99 | 73.64 ± 3.51 |
| 4 | 97.66 ± 0.57 | 93.13 ± 2.53 | 94.95 ± 2.58 | 93.29 ± 2.06 | 93.96 ± 2.24 |
| 5 | 99.64 ± 0.38 | 99.52 ± 0.61 | 99.84 ± 0.48 | 99.82 ± 0.17 | 96.45 ± 2.28 |
| 6 | 98.81 ± 0.96 | 94.51 ± 6.31 | 99.97 ± 0.07 | 97.22 ± 3.16 | 84.91 ± 4.44 |
| 7 | 97.22 ± 2.35 | 88.58 ± 7.34 | 76.89 ± 30.34 | 78.29 ± 29.22 | 73.66 ± 9.94 |
| 8 | 97.60 ± 1.67 | 90.20 ± 10.95 | 97.03 ± 2.77 | 96.99 ± 3.01 | 81.72 ± 2.69 |
| 9 | 99.12 ± 0.73 | 93.75 ± 8.54 | 95.70 ± 2.45 | 99.96 ± 0.05 | 99.94 ± 0.05 |
| OA (%) | 98.67 ± 0.30 | 95.67 ± 1.96 | 96.04 ± 1.91 | 95.95 ± 2.61 | 88.70 ± 0.77 |
| AA (%) | 97.65 ± 0.70 | 92.61 ± 3.47 | 91.23 ± 4.51 | 92.13 ± 6.78 | 87.22 ± 1.34 |
| Kappa × 100 | 98.23 ± 0.40 | 94.22 ± 2.64 | 94.74 ± 2.54 | 94.61 ± 3.49 | 84.90 ± 1.07 |
| Class | Proposed | DBDA | FDSSC | SSRN | SVM |
|---|---|---|---|---|---|
| 1 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 99.51 ± 0.35 | 92.43 ± 0.62 |
| 2 | 96.87 ± 4.52 | 88.96 ± 6.90 | 98.56 ± 2.23 | 97.05 ± 3.92 | 86.08 ± 3.32 |
| 3 | 99.48 ± 0.84 | 93.80 ± 5.44 | 97.52 ± 2.40 | 99.05 ± 1.04 | 77.08 ± 8.32 |
| 4 | 86.62 ± 9.59 | 59.55 ± 8.97 | 84.89 ± 12.34 | 65.55 ± 21.54 | 59.00 ± 7.62 |
| 5 | 76.13 ± 35.23 | 56.77 ± 27.45 | 30.01 ± 30.75 | 73.42 ± 36.79 | 64.62 ± 8.78 |
| 6 | 99.23 ± 1.55 | 91.87 ± 4.82 | 96.20 ± 5.86 | 93.72 ± 6.98 | 70.20 ± 5.70 |
| 7 | 93.03 ± 8.57 | 76.65 ± 18.95 | 47.18 ± 38.54 | 91.34 ± 9.47 | 77.25 ± 4.31 |
| 8 | 99.64 ± 0.72 | 87.34 ± 15.92 | 99.85 ± 0.31 | 99.69 ± 0.61 | 89.70 ± 3.79 |
| 9 | 100.00 ± 0.00 | 95.83 ± 5.44 | 100.00 ± 0.00 | 99.87 ± 0.17 | 88.55 ± 3.11 |
| 10 | 100.00 ± 0.00 | 94.94 ± 3.39 | 100.00 ± 0.00 | 99.78 ± 0.32 | 96.82 ± 4.35 |
| 11 | 99.79 ± 0.42 | 97.69 ± 1.84 | 99.42 ± 0.51 | 99.79 ± 0.42 | 95.52 ± 1.13 |
| 12 | 98.68 ± 2.22 | 91.66 ± 3.34 | 98.90 ± 1.35 | 96.51 ± 2.14 | 94.96 ± 1.98 |
| 13 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 99.56 ± 0.83 |
| OA (%) | 98.09 ± 1.36 | 92.22 ± 2.25 | 95.54 ± 2.43 | 96.40 ± 1.42 | 88.90 ± 0.77 |
| AA (%) | 96.11 ± 3.36 | 87.31 ± 3.71 | 88.66 ± 6.41 | 93.48 ± 3.08 | 83.98 ± 0.73 |
| Kappa × 100 | 97.88 ± 1.52 | 91.34 ± 2.51 | 95.03 ± 2.71 | 95.99 ± 1.59 | 87.64 ± 0.86 |
| Class | Proposed | DBDA | FDSSC | SSRN | SVM |
|---|---|---|---|---|---|
| 1 | 97.04 ± 2.38 | 92.63 ± 8.85 | 13.97 ± 24.20 | 72.10 ± 27.84 | 18.04 ± 11.43 |
| 2 | 97.28 ± 0.78 | 92.29 ± 3.49 | 97.60 ± 1.32 | 96.56 ± 1.68 | 61.95 ± 3.48 |
| 3 | 97.34 ± 1.57 | 93.18 ± 4.44 | 98.03 ± 2.03 | 96.40 ± 1.40 | 67.82 ± 2.89 |
| 4 | 86.91 ± 15.33 | 93.11 ± 6.34 | 78.50 ± 20.84 | 85.20 ± 12.04 | 49.03 ± 8.01 |
| 5 | 91.50 ± 2.01 | 90.36 ± 3.83 | 94.14 ± 1.85 | 92.52 ± 2.86 | 86.49 ± 2.37 |
| 6 | 97.93 ± 1.30 | 96.15 ± 2.09 | 98.70 ± 1.01 | 99.79 ± 0.12 | 83.43 ± 2.67 |
| 7 | 92.38 ± 15.24 | 94.00 ± 8.01 | 16.17 ± 25.45 | 61.49 ± 40.18 | 82.20 ± 5.59 |
| 8 | 100.00 ± 0.00 | 99.72 ± 0.31 | 99.95 ± 0.14 | 100.00 ± 0.00 | 88.44 ± 2.49 |
| 9 | 68.57 ± 35.74 | 81.23±14.69 | 1.88 ± 5.63 | 41.25 ± 39.05 | 66.56 ± 25.00 |
| 10 | 93.50 ± 4.17 | 89.61 ± 3.98 | 94.57 ± 2.15 | 93.19 ± 2.00 | 68.35 ± 4.19 |
| 11 | 97.51 ± 1.36 | 95.08 ± 1.60 | 97.53 ± 1.10 | 96.50 ± 1.99 | 69.19 ± 2.00 |
| 12 | 97.87 ± 1.38 | 92.70 ± 4.13 | 97.01 ± 3.25 | 96.72 ± 1.30 | 60.61 ± 5.09 |
| 13 | 99.13 ± 1.75 | 99.03 ± 1.55 | 95.45 ± 5.01 | 98.81 ± 1.31 | 86.83 ± 3.45 |
| 14 | 99.42 ± 0.59 | 98.48 ± 1.07 | 99.82 ± 0.20 | 99.03 ± 1.05 | 89.54 ± 0.96 |
| 15 | 93.55 ± 4.26 | 93.79 ± 3.50 | 95.34 ± 3.09 | 91.78 ± 4.61 | 68.91 ± 4.07 |
| 16 | 95.35 ± 4.05 | 91.51 ± 7.91 | 64.26 ± 27.24 | 82.91 ± 31.87 | 97.85 ± 2.90 |
| OA (%) | 96.76 ± 0.78 | 94.29 ± 1.24 | 95.97 ± 1.08 | 95.91 ± 0.84 | 73.08 ± 1.23 |
| AA (%) | 94.08 ± 3.87 | 93.30 ± 1.53 | 77.68 ± 5.06 | 87.77 ± 7.51 | 71.58 ± 2.44 |
| Kappa × 100 | 96.31 ± 0.89 | 93.49 ± 1.42 | 95.40 ± 1.24 | 95.34 ± 0.96 | 69.02 ± 1.36 |
| Combinations of Dilation Rates | Spectral Branch | ||||||
|---|---|---|---|---|---|---|---|
| Spatial branch | 98.10% | 97.50% | 96.88% | 98.45% | 98.43% | 97.98% | |
| 98.67% | 97.91% | 97.80% | 98.12% | 98.17% | 98.06% | ||
| 96.20% | 97.36% | 98.01% | 98.30% | 97.64% | 98.09% | ||
| Combinations of Dilation Rates | Spectral Branch | ||||||
|---|---|---|---|---|---|---|---|
| Spatial branch | 96.79% | 96.58% | 98.09% | 96.84% | 97.19% | 97.59% | |
| 96.26% | 96.21% | 97.31% | 96.25% | 95.08% | 95.97% | ||
| 95.66% | 97.37% | 96.52% | 97.17% | 96.29% | 97.72% | ||
| Combinations of Dilation Rates | Spectral Branch | ||||||
|---|---|---|---|---|---|---|---|
| Spatial branch | 96.64% | 96.76% | 96.22% | 95.12% | 96.14% | 95.95% | |
| 95.70% | 96.05% | 95.39% | 95.43% | 96.58% | 96.19% | ||
| 95.74% | 96.01% | 95.94% | 96.63% | 95.53% | 96.68% | ||
| Number of Parameters | Number of Parameters | ||
|---|---|---|---|
| 1,2,3 − 1,2,3 | 727,257 | 812,505 | |
| 1,2,4 − 1,2,3 | 819,417 | ||
| 1,2,5 − 1,2,3 | 826,329 | ||
| 1,2,3 − 1,2,4 | 849,369 | ||
| 1,2,3 − 1,3,4 | 877,017 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, L.; Chen, X.; Pirasteh, S.; Xu, Y. The Classification of Hyperspectral Images: A Double-Branch Multi-Scale Residual Network. Remote Sens. 2023, 15, 4471. https://doi.org/10.3390/rs15184471
Fu L, Chen X, Pirasteh S, Xu Y. The Classification of Hyperspectral Images: A Double-Branch Multi-Scale Residual Network. Remote Sensing. 2023; 15(18):4471. https://doi.org/10.3390/rs15184471
Chicago/Turabian StyleFu, Laiying, Xiaoyong Chen, Saied Pirasteh, and Yanan Xu. 2023. "The Classification of Hyperspectral Images: A Double-Branch Multi-Scale Residual Network" Remote Sensing 15, no. 18: 4471. https://doi.org/10.3390/rs15184471
APA StyleFu, L., Chen, X., Pirasteh, S., & Xu, Y. (2023). The Classification of Hyperspectral Images: A Double-Branch Multi-Scale Residual Network. Remote Sensing, 15(18), 4471. https://doi.org/10.3390/rs15184471