






TCUNet: A Lightweight Dual-Branch Parallel Network for Sea–Land Segmentation in Remote Sensing Images




Abstract
:1. Introduction
- In this paper, we propose TCUNet, a parallel two-branch image segmentation network fusing CNN and Transformer, to achieve a fine segmentation of land and sea in multispectral remote sensing images.
- We design a new lightweight feature interaction module (FIM) to achieve feature exchange and information flow in the dual branch, by embedding it between each coding block in the dual branch, to minimize the semantic gap of the dual branch, enhancing the global representation of the CNN branch, while complementing the local details of the Transformer branch.
- We propose a cross-scale, multi-source feature fusion module (CMFFM) to replace the decoder block in UNet, to solve the issue of feature inconsistency between different scales, and achieve the fusion of multi-source features at different scales.
- Based on three Gaofen-6 satellite images produced in February 2023, we constructed a sea–land semantic segmentation dataset, the GF dataset, covering the entire Yellow Sea region of China, which contains 12,600 sheets, each with a size of 512 pixels × 512 pixels. We have made it available for public use.
2. Methods and Materials
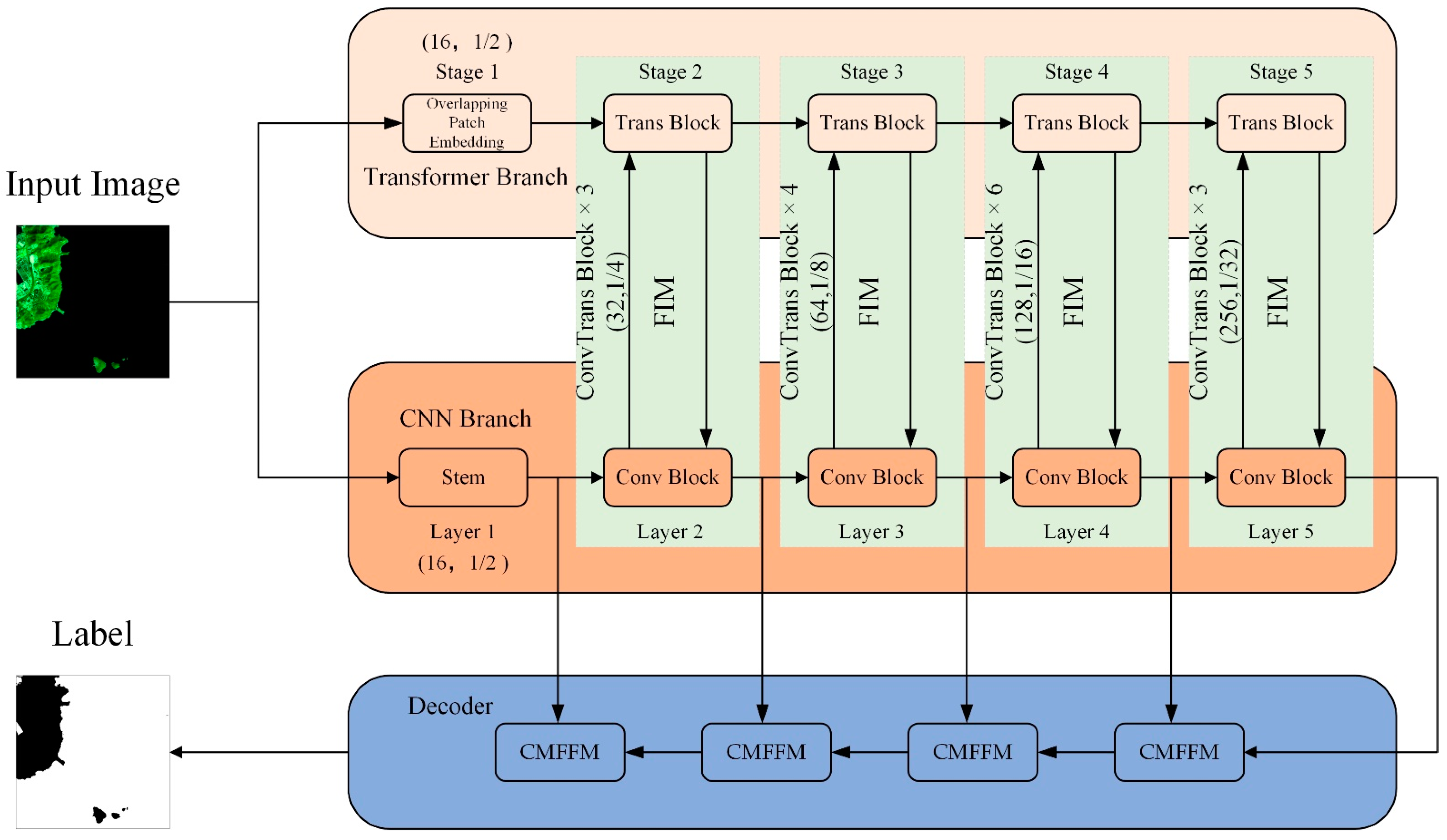
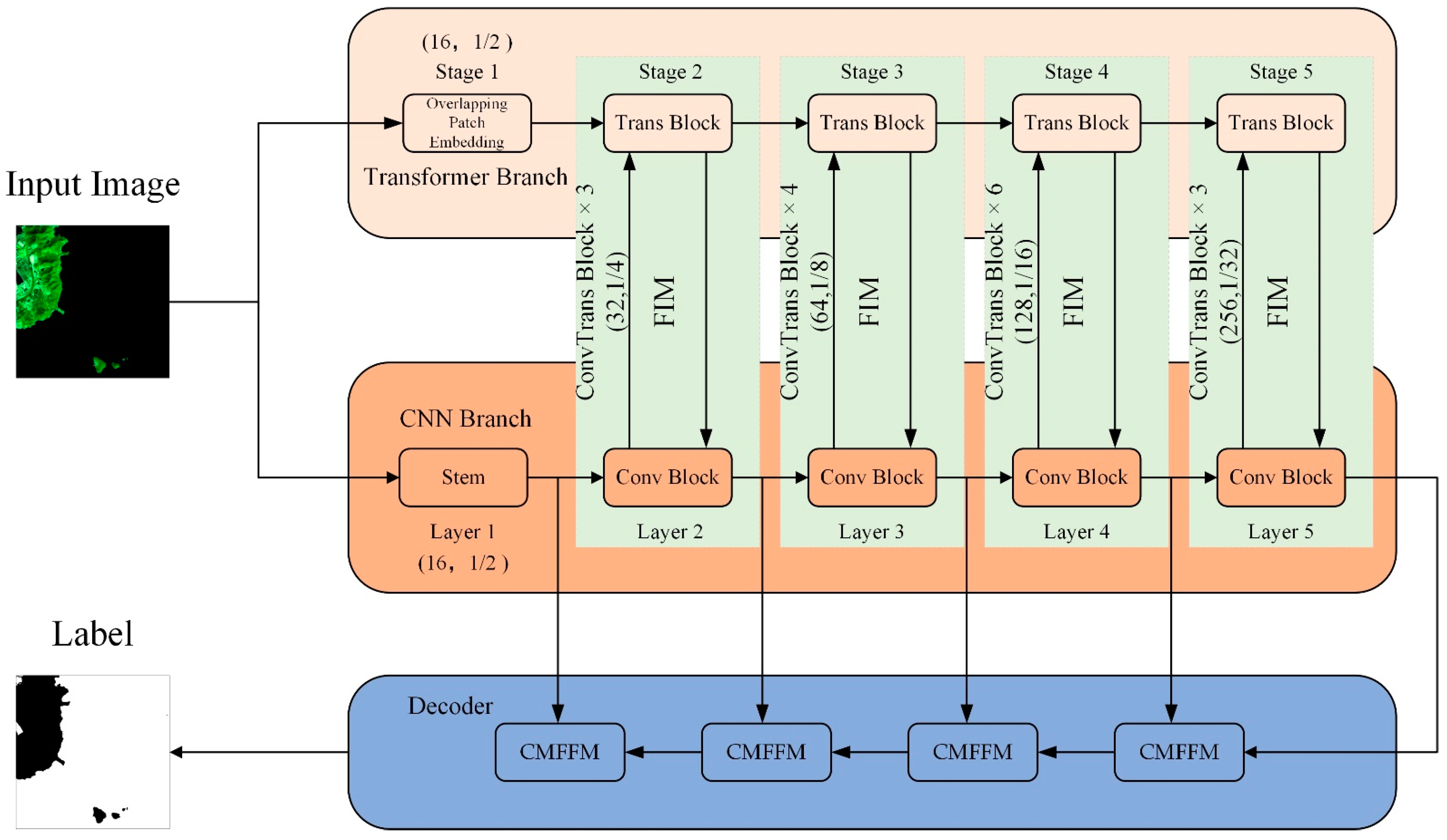
2.1. Overall Network Structure
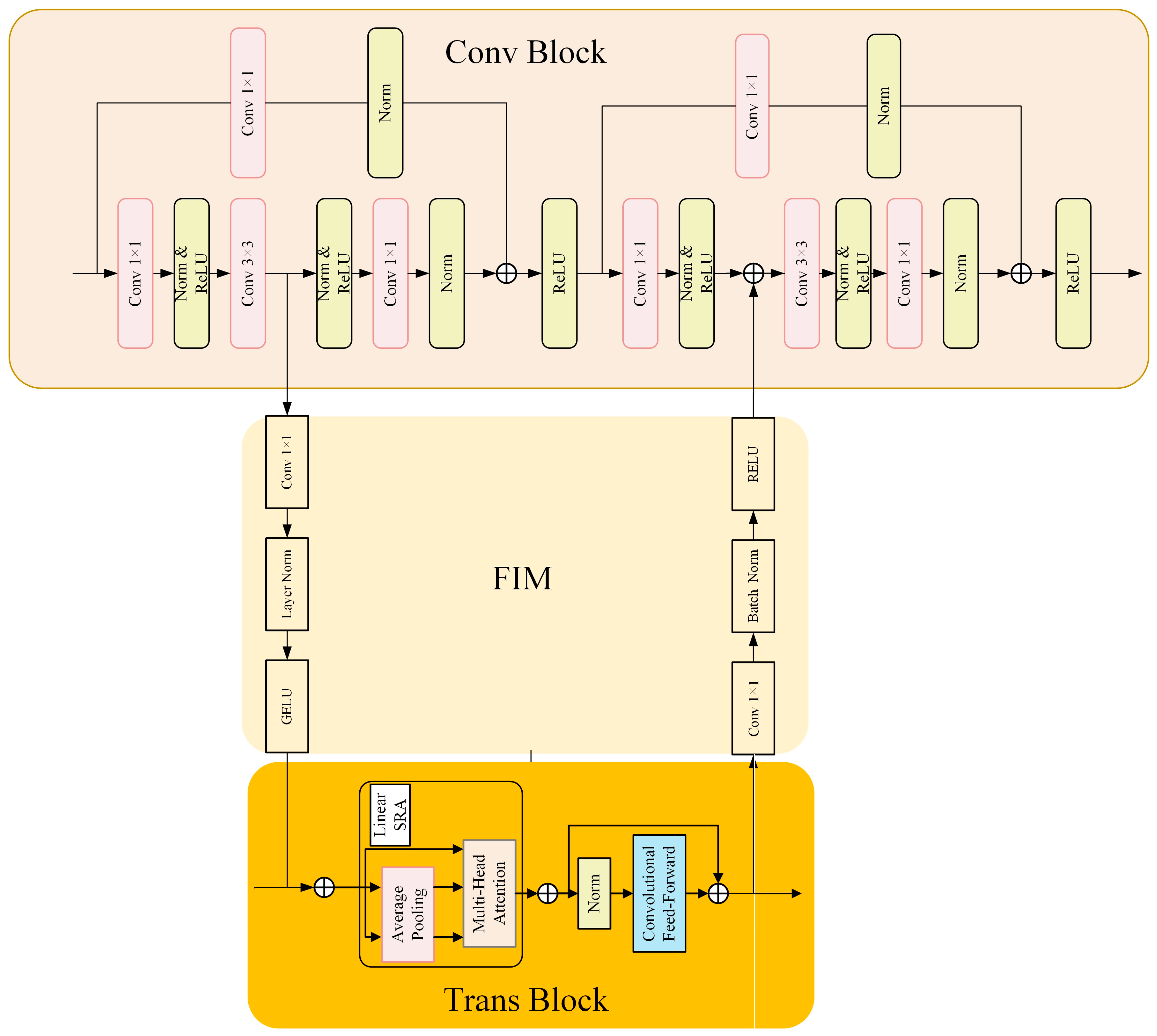
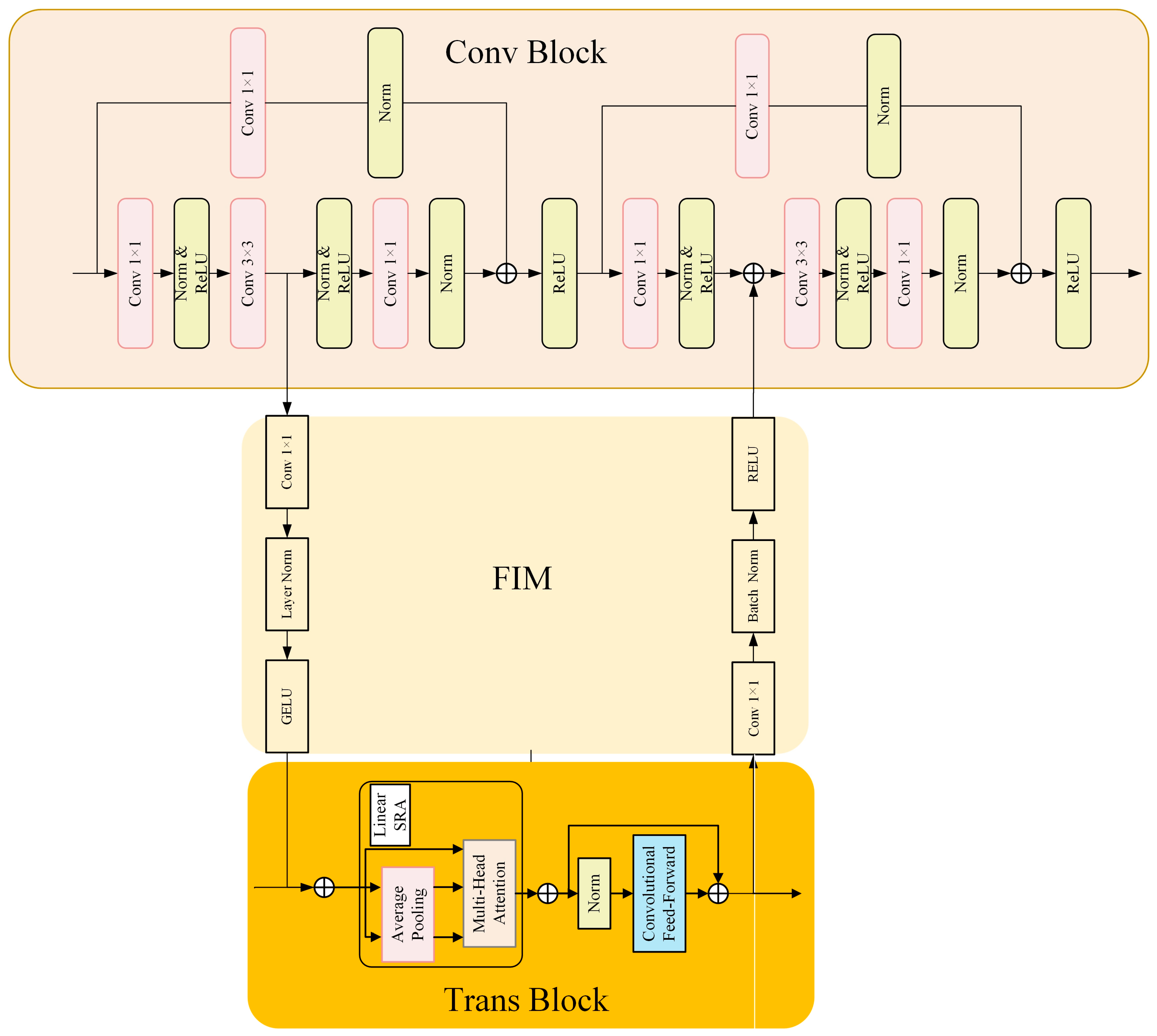
2.2. CNN Branch
2.3. Transformer Branch
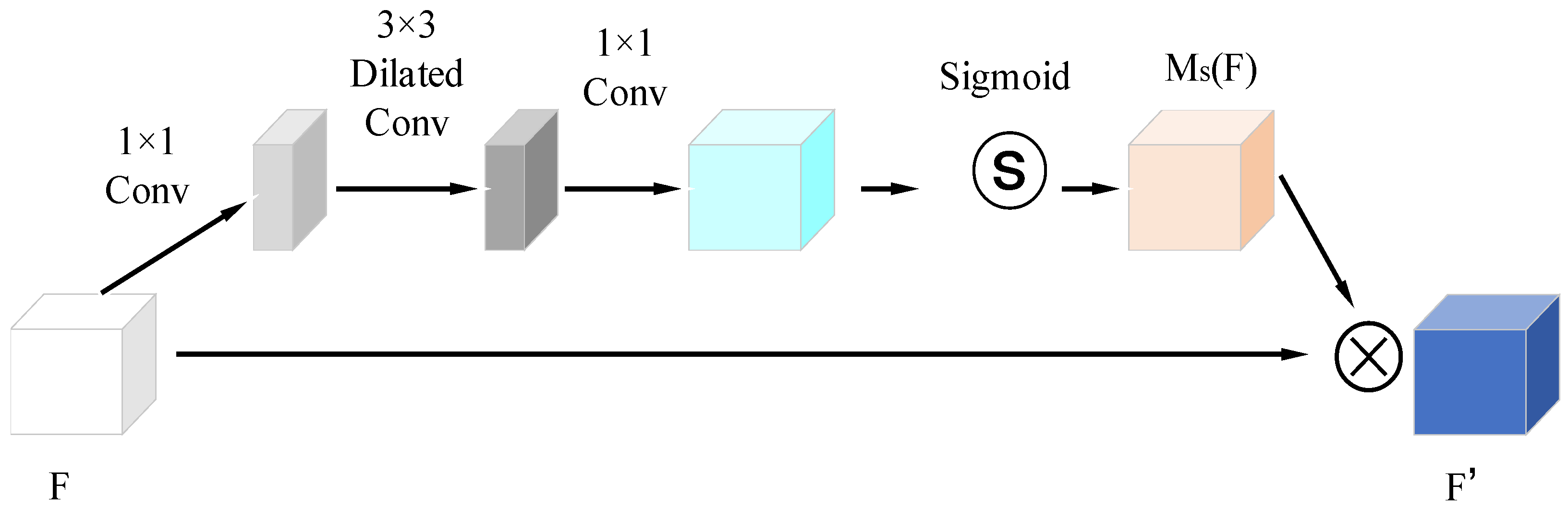
2.4. Feature Interaction Module
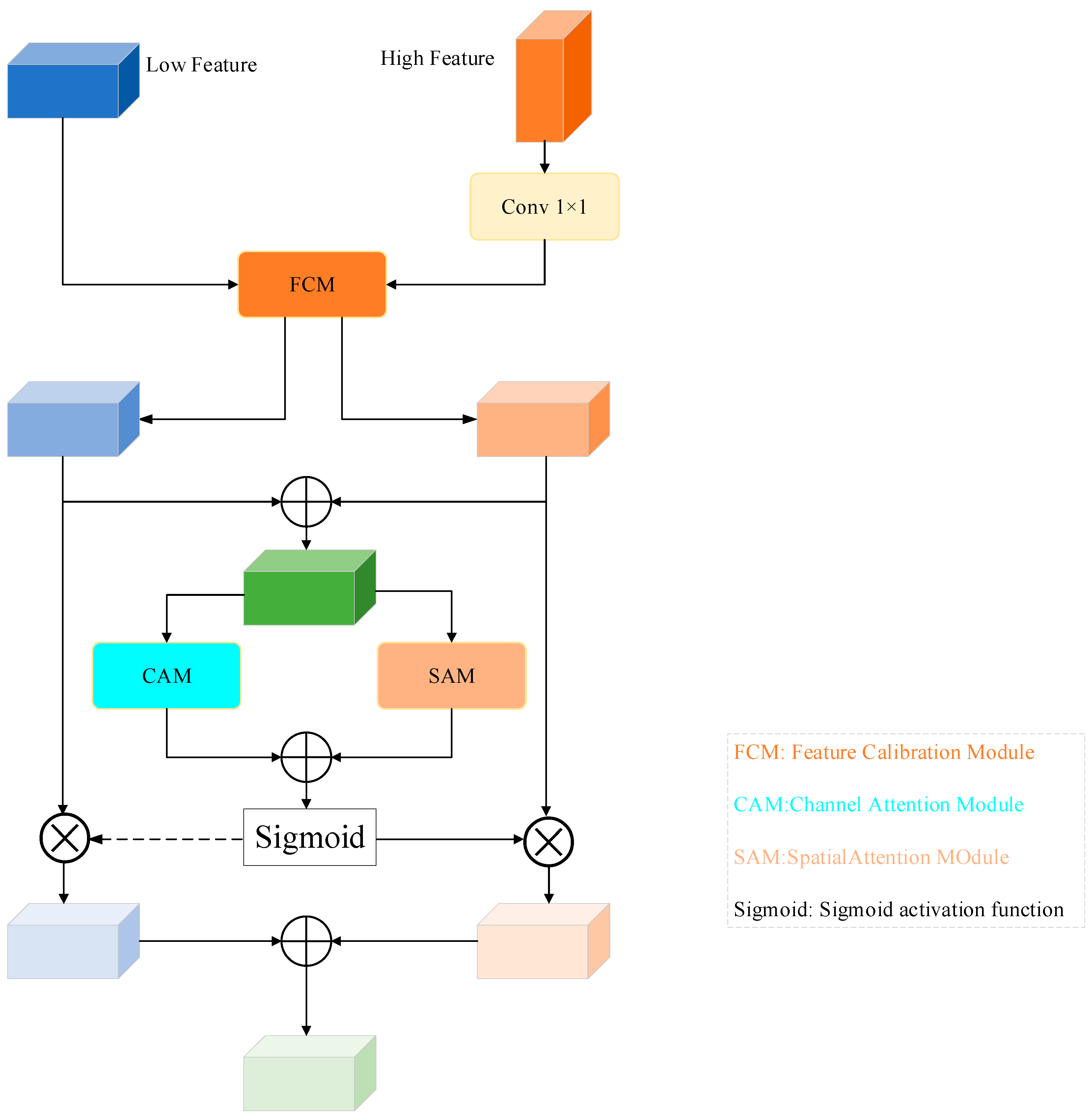
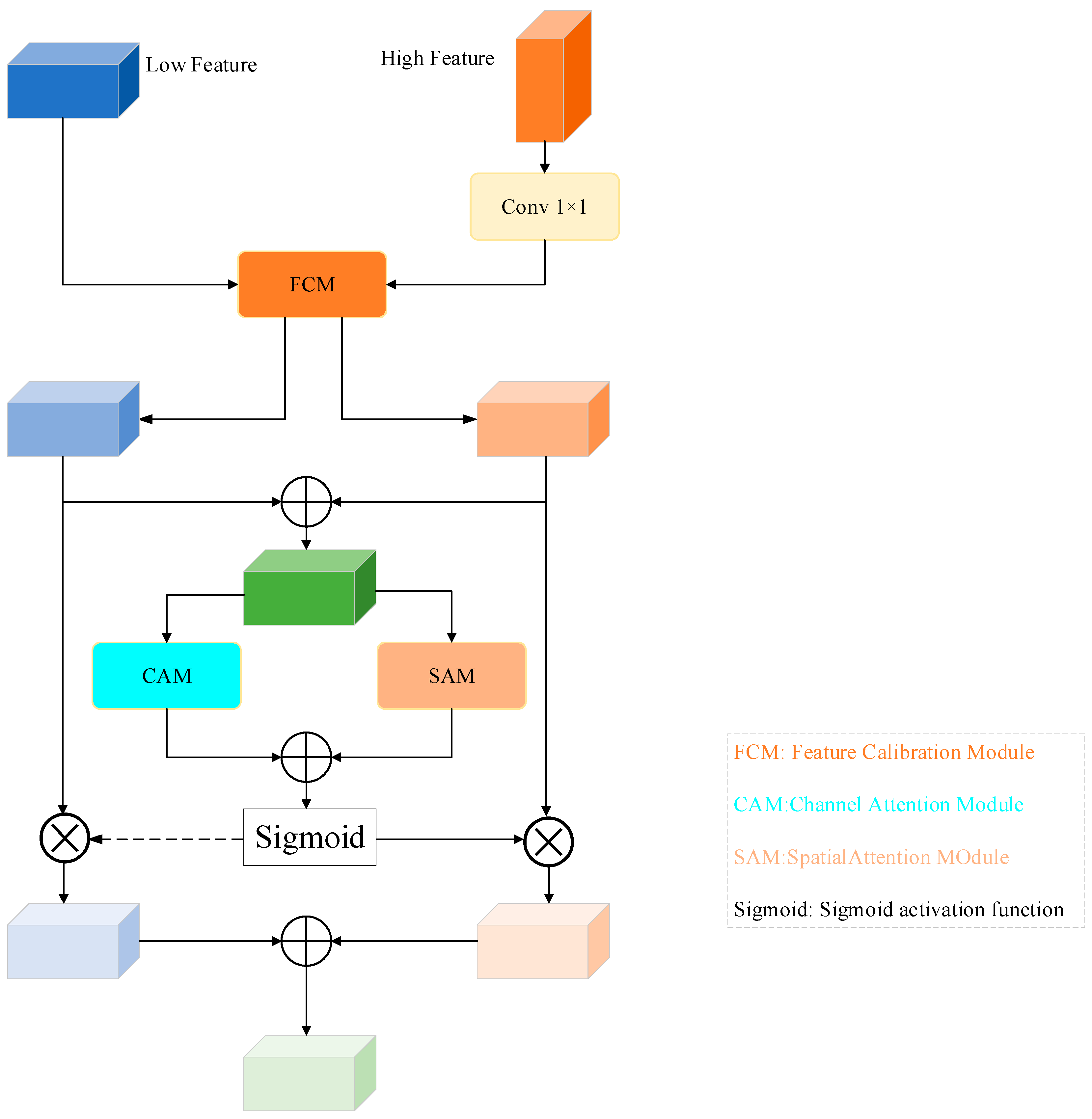
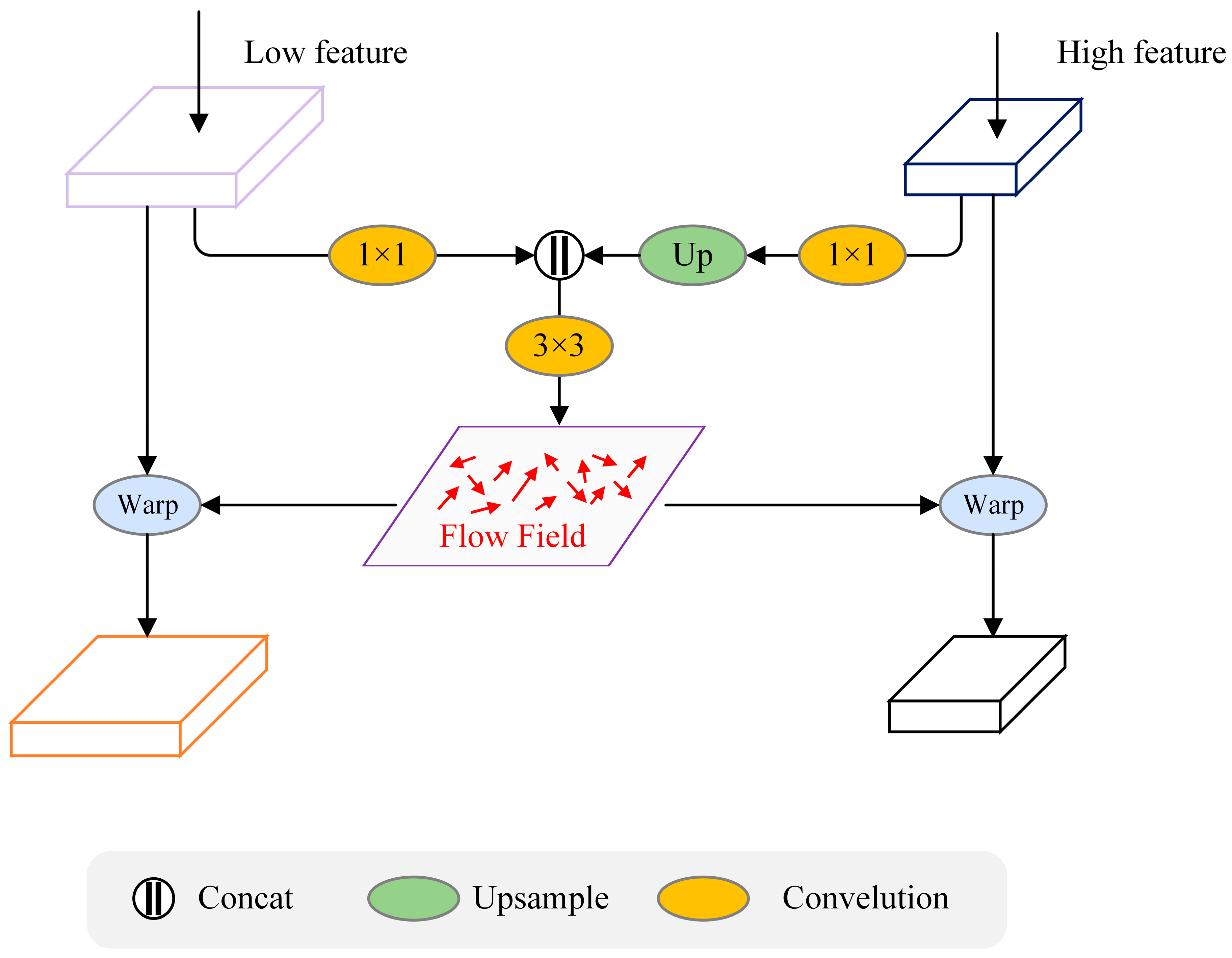
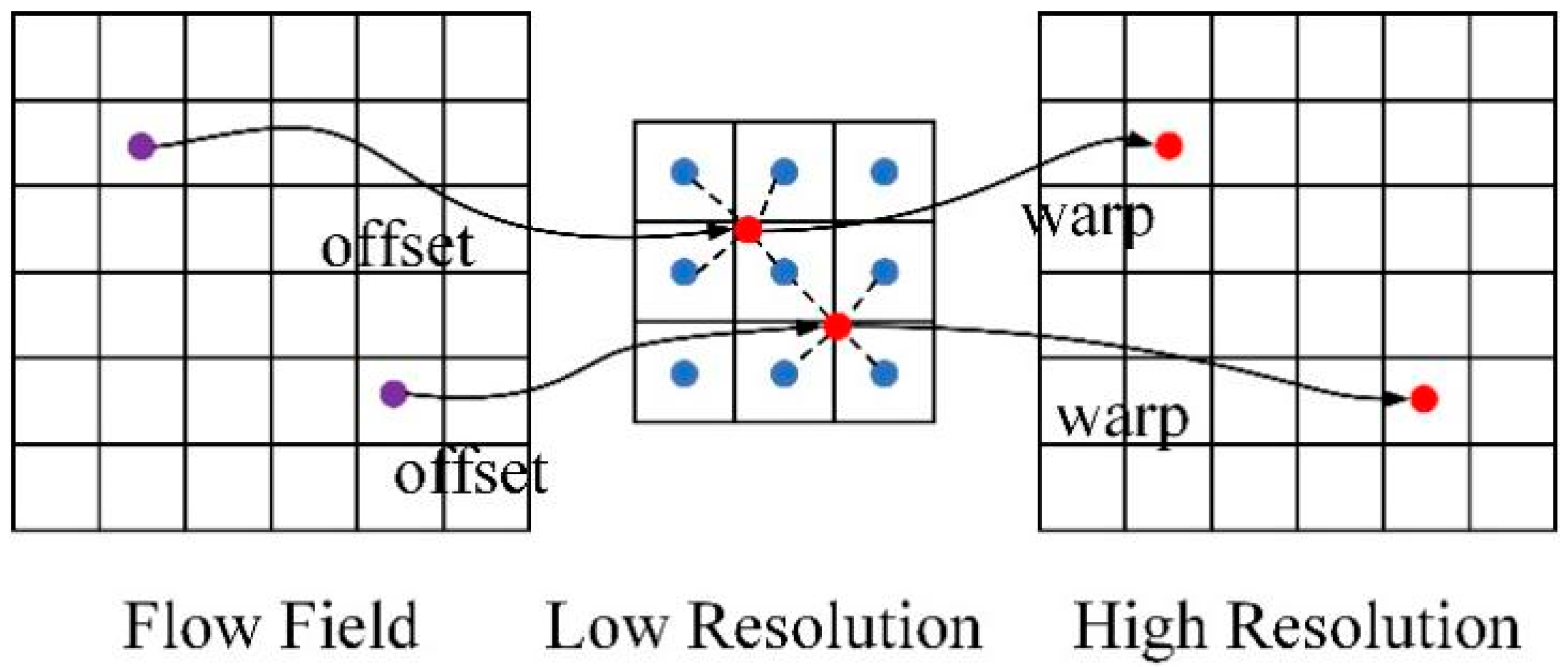
2.5. Cross-Scale Multi-Level Feature Fusion Module
2.5.1. Feature Calibration Module
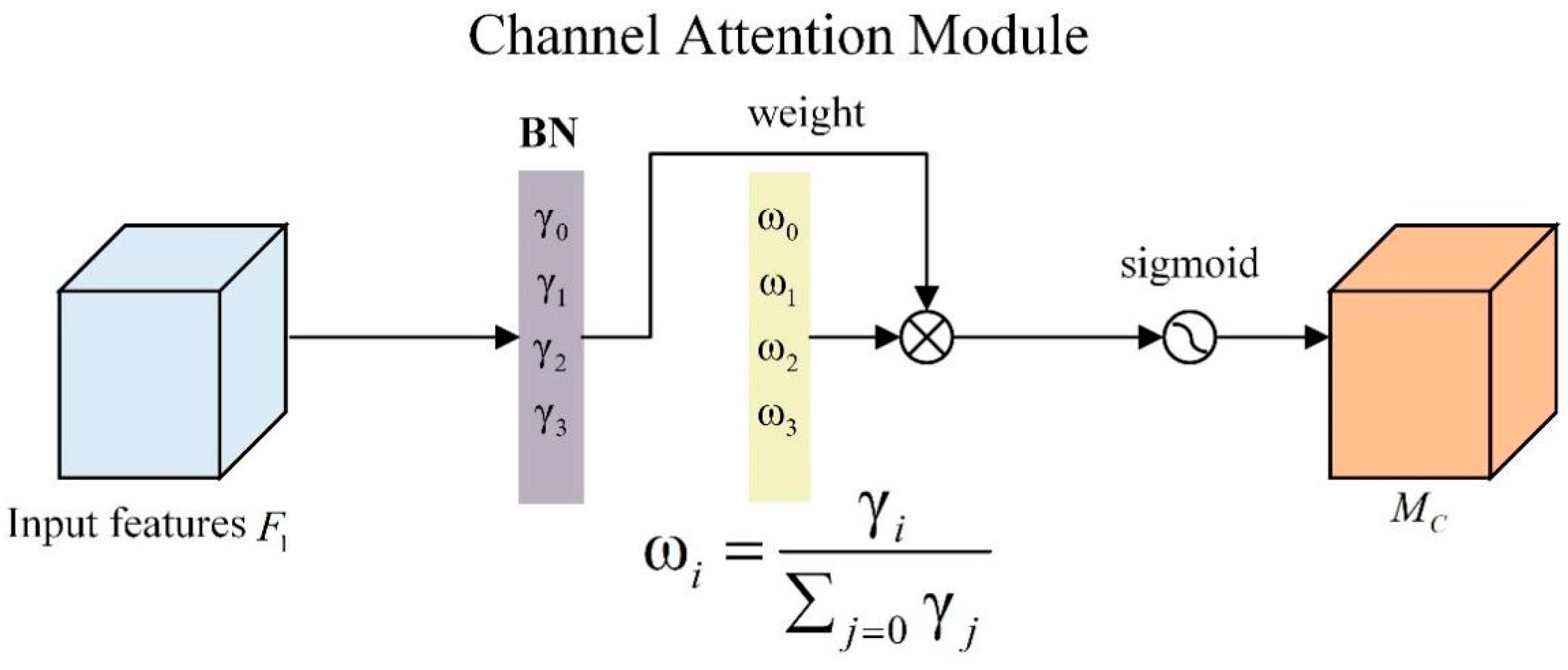
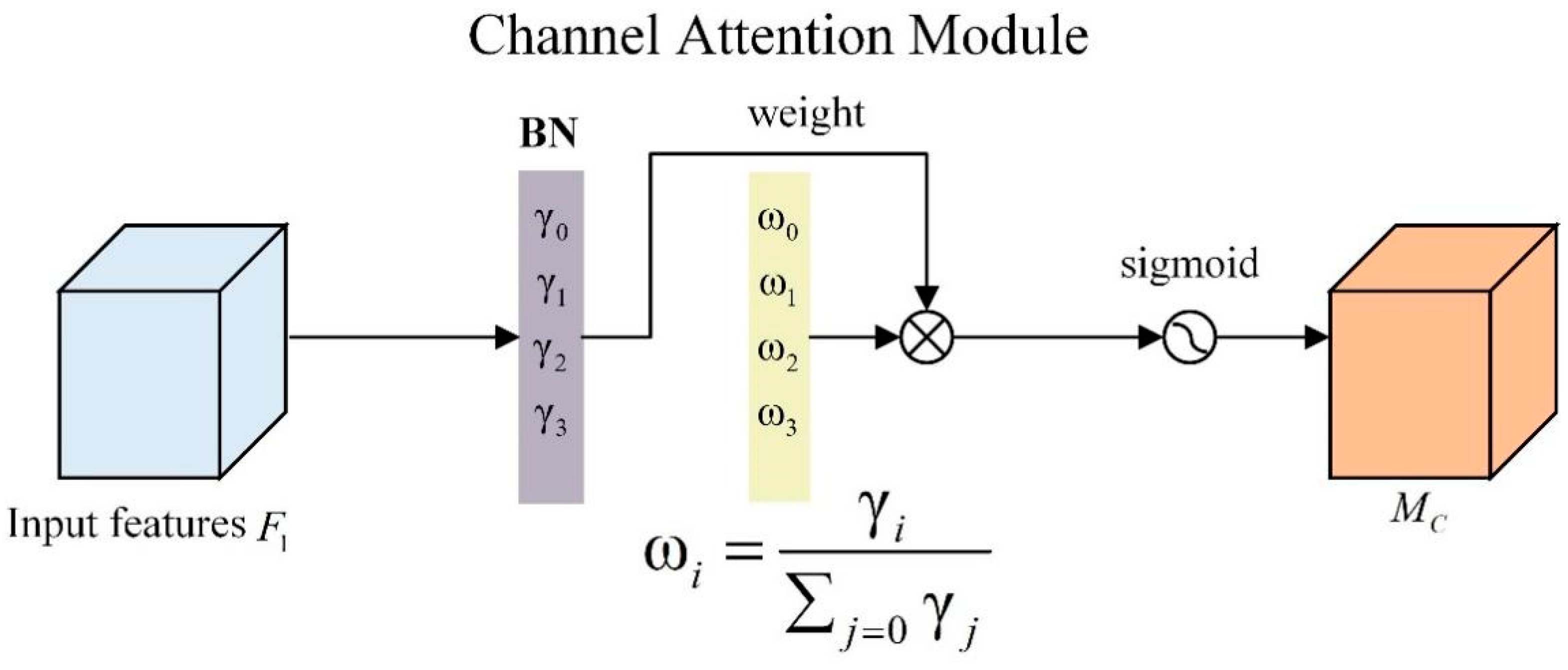
2.5.2. Channel Attention Module
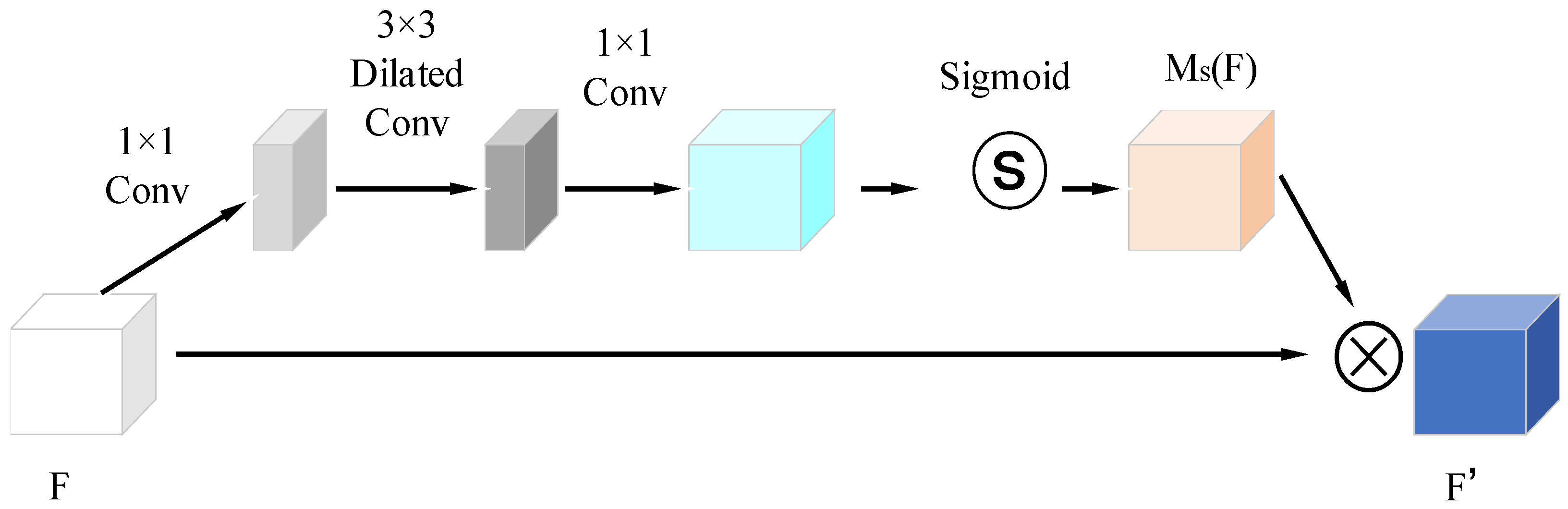
2.5.3. Spatial Attention Module
2.6. Loss Function
3. Results
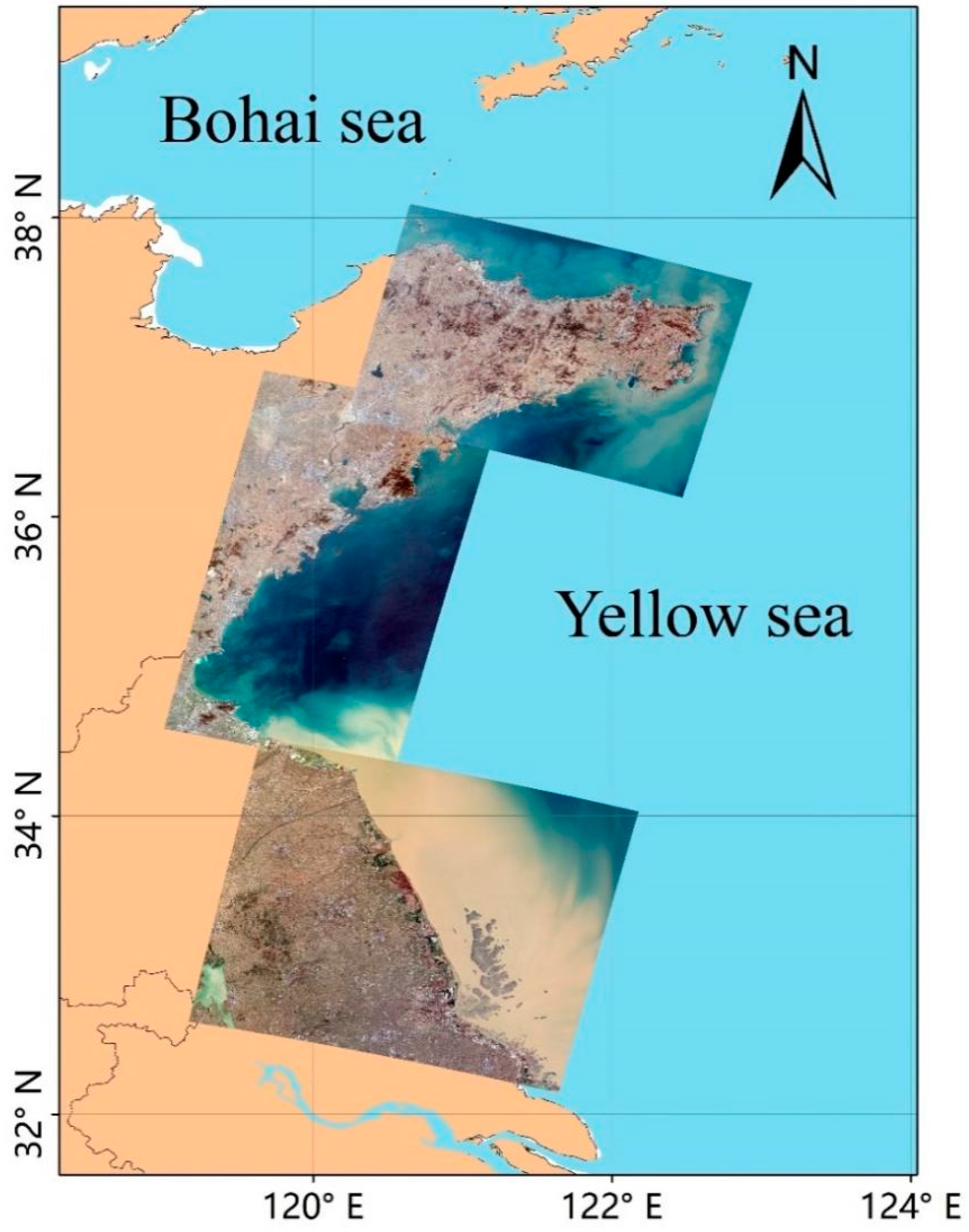
3.1. Study Area and Dataset
3.2. Experimental Details and Evaluation Metrics
3.3. Performance Comparison of Different Band Combinations
3.4. Ablation Study
3.4.1. Performance of Feature Interaction Module
3.4.2. Performance of Cross-Scale, Multi-Level Feature Fusion Module
3.5. Contrast Experiment
4. Discussion
4.1. Comparison of Model Effects on Different Satellite Sensor Images
4.2. Performance under Different Parameter Settings
4.3. Limitations of the Model and Future Prospects
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zollini, S.; Alicandro, M.; Cuevas-González, M.; Baiocchi, V.; Dominici, D.; Buscema, P.M. Shoreline extraction based on an active connection matrix (ACM) image enhancement strategy. J. Mar. Sci. Eng. 2020, 8, 9. [Google Scholar] [CrossRef]
- Boak, E.H.; Turner, I.L. Shoreline Definition and Detection: A Review. J. Coast. Res. 2005, 21, 688–703. [Google Scholar] [CrossRef]
- Soloy, A.; Turki, I.; Lecoq, N.; Gutiérrez Barceló, Á.D.; Costa, S.; Laignel, B.; Bazin, B.; Soufflet, Y.; Le Louargant, L.; Maquaire, O. A fully automated method for monitoring the intertidal topography using Video Monitoring Systems. Coast. Eng. 2021, 167, 103894. [Google Scholar] [CrossRef]
- Yang, L.; Wang, X.; Zhai, J. Waterline Extraction for Artificial Coast With Vision Transformers. Front. Environ. Sci. 2022, 10, 16. [Google Scholar] [CrossRef]
- Bengoufa, S.; Niculescu, S.; Mihoubi, M.K.; Belkessa, R.; Abbad, K. Rocky Shoreline Extraction Using a Deep Learning Model and Object-Based Image Analysis. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. 2021, 43, 23–29. [Google Scholar]
- Bengoufa, S.; Niculescu, S.; Mihoubi, M.K.; Belkessa, R.; Rami, A.; Rabehi, W.; Abbad, K. Machine Learning and Shoreline Monitoring Using Optical Satellite Images: Case Study of the Mostaganem Shoreline, Algeria. J. Appl. Remote Sens. 2021, 15, 026509. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, X.; Zhou, S.; Yu, H.; Guo, J.; Liu, Y. DUPnet: Water Body Segmentation with Dense Block and Multi-Scale Spatial Pyramid Pooling for Remote Sensing Images. Remote Sens. 2022, 14, 5567. [Google Scholar] [CrossRef]
- Pardo-Pascual, J.E.; Almonacid-Caballer, J.; Ruiz, L.A.; Palomar-Vazquez, J. Automatic extraction of shorelines from Landsat TM and ETM+ multi-temporal images with subpixel precision. Remote Sens. Environ. 2012, 123, 1–11. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Yang, C.S.; Park, J.H.; Rashid, H.A. An Improved Method of Land Masking for Synthetic Aperture Radar-based Ship Detection. J. Navig. 2018, 71, 788–804. [Google Scholar] [CrossRef]
- Kanopoulos, N.; Vasanthavada, N.; Baker, R.L. Design of an image edge detection filter using the Sobel operator. IEEE J. Solid-State Circuits 1988, 23, 358–367. [Google Scholar] [CrossRef]
- Liu, H.; Jezek, K.C. Automated extraction of coastline from satellite imagery by integrating Canny edge detection and locally adaptive thresholding methods. Int. J. Remote Sens. 2004, 25, 937–958. [Google Scholar] [CrossRef]
- Toure, S.; Diop, O.; Kpalma, K.; Maiga, A.S. Shoreline detection using optical remote sensing: A review. ISPRS Int. J. Geo-Inf. 2019, 8, 75. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, Z. Research progress on methods of automatic coastline extraction based on remote sensing images. J. Remote Sens. 2019, 23, 582–602. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Suykens, J.A.K.; Vandewalle, J. Least Squares Support Vector Machine Classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Cui, B.; Jing, W.; Huang, L.; Li, Z.; Lu, Y. SANet: A Sea–Land Segmentation Network Via Adaptive Multiscale Feature Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 116–126. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv 2014, arXiv:14042188. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. arXiv 2017, arXiv:1606.00915. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Li, R.; Liu, W.; Yang, L.; Sun, S.; Hu, W.; Zhang, F.; Li, W. Deepunet: A deep fully convolutional network for pixel-level sea-land segmentation. IEEE J. Sel. Top Appl. Earth Obs. Remote Sens. 2018, 11, 3954–3962. [Google Scholar] [CrossRef]
- Shamsolmoali, P.; Zareapoor, M.; Wang, R.; Zhou, H.; Yang, J. A Novel Deep Structure U-Net for Sea-Land Segmentation in Remote Sensing Images. IEEE J. Sel. Top Appl. Earth Obs. Remote Sens. 2019, 12, 3219–3232. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- He, Y.; Yao, S.; Yang, W.; Yan, H.; Zhang, L.; Wen, Z.; Zhang, Y.; Liu, T. An Extraction Method for Glacial Lakes Based on Landsat-8 Imagery Using an Improved U-Net Network. IEEE J. Sel. Top Appl. Earth Obs. Remote Sens. 2021, 14, 6544–6558. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. arXiv 2021, arXiv:2012.15840. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Advances in Neural Information Processing Systems, Proceedings of the Conference on Neural Information Processing Systems, Virtual, 6–14 December 2021; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 12077–12090. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. Cmt: Convolutional neural networks meet vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12175–12185. [Google Scholar]
- Zhang, Y.; Liu, H.; Hu, Q. Transfuse: Fusing transformers and cnns for medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; pp. 14–24. [Google Scholar]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin transformer embedding UNet for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Chen, J.; Xia, M.; Wang, D.; Lin, H. Double Branch Parallel Network for Segmentation of Buildings and Waters in Remote Sensing Images. Remote Sens. 2023, 15, 1536. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvtv2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local features coupling global representations for visual recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 367–376. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Li, X.; You, A.; Zhu, Z.; Zhao, H.; Yang, M.; Yang, K.; Tan, S.; Tong, Y. Semantic flow for fast and accurate scene parsing. In Lecture Notes in Computer Science, Proceedings of the 16th European Conference Computer Vision (ECCV 2020), Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 775–793. [Google Scholar]
- Huang, Z.; Wei, Y.; Wang, X.; Shi, H.; Liu, W.; Huang, T.S. AlignSeg: Feature-Aligned segmentation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 550–557. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference On Computer Vision And Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019; pp. 3141–3149. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Szegedy, S.I.a.C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning ICML, Lile, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Kervadec, H.; Bouchtiba, J.; Desrosiers, C.; Granger, E.; Dolz, J.; Ayed, I.B. Boundary loss for highly unbalanced segmentation. Med. Image Anal. 2021, 67, 101851. [Google Scholar] [CrossRef]
- Yu, Z.; Di, L.; Yang, R.; Tang, J.; Lin, L.; Zhang, C.; Rahman, M.S.; Zhao, H.; Gaigalas, J.; Yu, E.G. Selection of landsat 8 OLI band combinations for land use and land cover classification. In Proceedings of the 2019 8th International Conference on Agro-Geoinformatics, Istanbul, Turkey, 16–19 July 2019; pp. 1–5. [Google Scholar]
- Mou, H.; Li, H.; Zhou, Y.; Dong, R. Response of different band combinations in Gaofen-6 WFV for estimating of regional maize straw resources based on random forest classification. Sustainability 2021, 13, 4603. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Project | GF6/WFV Data |
|---|---|
| Wavelength range/um | B1(Blue): 0.45~0.52 |
| B2(Green): 0.52~0.59 | |
| B3(Red): 0.63~0.69 | |
| B4(NIR): 0.76~0.90 | |
| B5(SWIR1): 0.69~0.73 | |
| B6(SWIR2): 0.73~0.77 | |
| B7(Purple): 0.40~0.45 | |
| B8(Yellow): 0.59~0.63 | |
| Spatial resolution/m | 16 |
| Width/km | 864.2 |
| Band Combination | PA (%) | MIoU (%) | F1 (%) |
|---|---|---|---|
| B1 + B2 + B3 | 96.52 | 91.12 | 95.30 |
| B1 + B4 + B5 | 96.81 | 92.23 | 95.36 |
| B2 + B3 + B4 | 96.95 | 92.64 | 95.58 |
| B2 + B3 + B5 | 96.21 | 91.81 | 94.88 |
| B3 + B4 + B5 | 96.99 | 92.78 | 95.67 |
| B3 + B4 + B8 | 96.64 | 92.07 | 95.27 |
| B3 + B5 + B7 | 95.89 | 89.56 | 94.32 |
| B4 + B5 + B6 | 96.69 | 92.19 | 95.33 |
| B4 + B6 + B7 | 96.31 | 91.28 | 94.82 |
| B5 + B6 + B7 | 96.88 | 92.36 | 95.43 |
| All-bands | 97.52 | 93.53 | 96.63 |
| Method | Encoder | PA (%) | MIoU (%) |
|---|---|---|---|
| TCU-Net | CNN | 96.02 | 92.01 |
| Transformer | 95.89 | 91.95 | |
| CNN + Transformer + FIM | 97.52 | 93.53 |
| Method | Decoder | PA (%) | MIoU (%) | F1 (%) | Params (M) |
|---|---|---|---|---|---|
| TCU-Net | UNet | 96.91 | 93.01 | 96.02 | 2.4 M |
| CSMFF | 97.52 | 93.53 | 96.63 | 1.72 M |
| Method | Backbone | PA (%) | MIoU (%) | F1 (%) | Params (M) | FLOPs (GMac) | Training Time (s) | Inference Time (s) |
|---|---|---|---|---|---|---|---|---|
| UNet [24] | - | 96.95 | 92.15 | 95.96 | 31.04 | 218.9 | 695 | 86.28 |
| Deeplabv3+ [28] | ResNet50 | 96.87 | 91.98 | 95.77 | 40.36 | 70.22 | 385 | 77.28 |
| DANet [51] | ResNet50 | 96.68 | 91.52 | 95.52 | 49.61 | 205.37 | 680 | 85.44 |
| Segformer [40] | MiT-B1 | 97.16 | 92.71 | 96.18 | 13.69 | 13.49 | 375 | 78.48 |
| SwinUNet [57] | Swin-Tiny | 96.88 | 91.95 | 95.92 | 27.18 | 26.56 | 505 | 84.36 |
| TransUNet [41] | ViT-R50 | 97.07 | 92.41 | 96.03 | 100.44 | 25.5 | 810 | 106.26 |
| ST-UNet [44] | - | 97.23 | 92.99 | 96.34 | 160.97 | 95.41 | 915 | 135.54 |
| UNetformer [58] | ResNet18 | 97.15 | 92.67 | 96.15 | 11.72 | 11.73 | 235 | 73.44 |
| TCUNet | - | 97.52 | 93.53 | 96.63 | 1.72 | 3.24 | 445 | 87.78 |
| Project | Landsat 8/OLI |
|---|---|
| Wavelength range/um | B1(Coastal aerosol): 0.43~0.55 |
| B2(Blue): 0.45–0.51 | |
| B3(Green): 0.53–0.59 | |
| B4(Red):0.64–0.67 | |
| B5(NIR): 0.85–0.88 | |
| B6(SWIR1): 1.57–1.65 | |
| B7(SWIR2): 2.11–2.29 | |
| B8(PAN): 0.50–0.68 | |
| Spatial resolution/m | 15 |
| Width/km | 185 |
| Method | PA (%) | MIoU (%) | F1 (%) |
|---|---|---|---|
| UNet | 64.63 | 41.55 | 61.25 |
| Deeplabv3+ | 91.75 | 83.82 | 91.13 |
| DANet | 88.23 | 76.84 | 86.72 |
| Segformer | 80.88 | 67.83 | 80.63 |
| SwinUNet | 81.04 | 68.03 | 80.96 |
| TransUNet | 75.10 | 60.60 | 74.92 |
| ST-UNet | 84.82 | 73.41 | 84.65 |
| UNetformer | 90.17 | 80.20 | 88.89 |
| TCUNet | 95.46 | 90.84 | 95.19 |
| E | C | D | PA (%) | Params |
|---|---|---|---|---|
| 16 | 16 | [2,2,2,2] | 96.92 | 1.04 M |
| [3,4,6,3] | 97.52 | 1.72 M | ||
| 46 | 32 | [2,2,2,2] | 97.06 | 7.07 M |
| [3,4,6,3] | 97.46 | 8.50 M | ||
| 92 | 64 | [2,2,2,2] | 97.42 | 20.43 M |
| [3,4,6,3] | 97.56 | 33.51 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, X.; Wang, X.; Zhang, J.; Huang, B.; Du, R. TCUNet: A Lightweight Dual-Branch Parallel Network for Sea–Land Segmentation in Remote Sensing Images. Remote Sens. 2023, 15, 4413. https://doi.org/10.3390/rs15184413
Xiong X, Wang X, Zhang J, Huang B, Du R. TCUNet: A Lightweight Dual-Branch Parallel Network for Sea–Land Segmentation in Remote Sensing Images. Remote Sensing. 2023; 15(18):4413. https://doi.org/10.3390/rs15184413
Chicago/Turabian StyleXiong, Xuan, Xiaopeng Wang, Jiahua Zhang, Baoxiang Huang, and Runfeng Du. 2023. "TCUNet: A Lightweight Dual-Branch Parallel Network for Sea–Land Segmentation in Remote Sensing Images" Remote Sensing 15, no. 18: 4413. https://doi.org/10.3390/rs15184413
APA StyleXiong, X., Wang, X., Zhang, J., Huang, B., & Du, R. (2023). TCUNet: A Lightweight Dual-Branch Parallel Network for Sea–Land Segmentation in Remote Sensing Images. Remote Sensing, 15(18), 4413. https://doi.org/10.3390/rs15184413