1. Introduction
Compared to traditional two-dimensional RGB images, hyperspectral images (HSIs) have many continuous spectral bands. Therefore, they also contain more information that allows us to better perform tasks, such as object detection, change detection, and geological exploration. Land cover classification is one of the most important issues within these fields, as it aims to apply specific semantic labels to the pixels of the entire HSI on the basis of the unique spatial-spectral features of the HSI. In recent years, there has been increasing interest in Deep Learning (DL) methods for solving the problem of HSI classification. Depending on the shape of the training data, we can divide these methods into the following two categories: the single-pixel-based methods and the patch-data-based methods.
Existing DL models often ignore the inherent relationship between pixels in patch data because they are designed for Euclidean data. In recent years, Graph Convolutional Networks (GCNs) have received increasing attention as a representative of the single-pixel-based methods due to their ability to perform convolutions on arbitrarily structured graphs. By encoding HSI into a graph, the correlation between adjacent land cover can be explicitly exploited, and the spatial context structure of HSI can be better modeled by GCNs [
1]. Shahraki et al. [
2] proposed a model combining 1-D Convolutional Neural Networks and GCNs for HSI classification. However, due to the large number of pixels in HSIs, using each pixel as a node of a graph has been shown to incur huge computational costs and limit its applicability. To solve this issue, Hong et al. [
3] developed a new model named mini-GCN, which can be used to train large GCNs in a mini-batch process. Liu et al. [
1] proposed a heterogeneous model called CEGCN, in which CNN and GCN sub-networks generate complementary feature information at pixel and super-pixel levels. To explore Non-Euclidean structures and reduce high computational costs, Bai et al. [
4] developed a graph attention model with an adaptive graph structure mining approach (GAT-AGSM). Liu et al. [
5] designed a multi-level network based on U-Net operating on a superpixel structured graph, named MSSGU, to learn multi-level features on multi-level graphs and overcome the limitation of specific superpixel segmentation in modeling.
Generally, the methods mentioned above mainly belong to single-pixel-based methods. Recently, researchers still pay more attention to the patch-data-based methods, which can extract more discriminative information and deeper features in model training. In particular, Convolutional Neural Network (CNN) is very popular among patch-data-based methods. Since the feature information contained in a single pixel is limited, CNN cannot extract local context information from the data. To solve this problem, researchers changed the shape of the input data. Specifically, the pixel is placed in the center of the patch data. The pixels around the classified pixel are also included in the patch data. This allows the model to extract more local contextual information from the patch data to enhance the classification accuracy in the central pixel.
In the early days of 2016, researchers mainly focused on HSI classification based on 1D-CNNs and 2D-CNNs [
6]. Chen et al. [
7] proposed a model that uses Stacked Autoencoders (SAE) for high-level information extraction and 1D-CNN for low-level information extraction. In addition to methods based on 1D-CNNs, 2D-CNN-based methods are often introduced into the HSI network to extract spatial feature information. Shen et al. [
8] proposed a model called ENL-FCN to incorporate the long-range context information, which is constructed by a deep fully convolutional network and an efficient non-local module. Since residual blocks have been extensively adopted in the HSI network, Zhong et al. [
9] developed a model to improve the accuracy of HIS classification, which is named the Spectral-Spatial Residual Network (SSRN), and greatly enhanced the feature utilization rate by using front-layer feature information to complement back-layer features. Furthermore, Paoletti et al. [
10] proposed a model named DPRN that also adopted the residual module. Inspired by the 3D convolution, 3D convolution blocks have been widely applied to HSI networks, which utilize spectral-spatial information to achieve more satisfactory classification results. In [
11], Zhong et al. developed 3D Deep-Residual Networks (3D-ResNets) to reduce the influence of model size. To mine deeper spectral-spatial feature information from HSIs, Zhang et al. [
12] also used 3D-CNNs to construct a 3D-DenseNet model.
In recent years, combining 2D and 3D convolutions and optimizing the structure of CNN-based models have gradually become a hotspot. Combining the advantage of 2D-CNN and 3D-CNN, some researchers designed a dual-branche structure to enhance the classification accuracy of HSI. For instance, Zheng et al. [
13] proposed a mixed CNN with covariance pooling, named MCNN-CP, where covariance pooling is used to mine second-order information from the spectral-spatial feature. Roy et al. [
14] developed a model that is a 3D convolution block combined with a 2D convolution block, which is called a hybrid spectral CNN (HybridSN). By introducing an efficient residual structure, the network parameters can be optimized, and a lightweight design can reduce the computational complexity of the model. Wu et al. [
15] designed a re-parametrized network, abbreviated as RepSSRN, which reparametrizes the Spectral-Spatial Residual Network (SSRN). Inspired by the Dense Convolutional Network, Wang et al. [
16] proposed a fast dense spectral-spatial convolution (FDSSC) algorithm. In another work [
17], a network named CMR-CNN adopted the 3D residual blocks followed by the 2D residual blocks together to capture the spatial-spectral feature information of the HSI. To reduce the network parameters and computational complexity, Meng et al. [
18] proposed a lightweight spectral-spatial convolution HSI classification module (LS2CM), and Li et al. [
19] designed a lightweight network architecture (LiteDenseNet). The computational complexity and network parameters in their work are much lower than counter-intuitive deep learning methods. Although these methods mentioned above are effective in improving the classification performance of HSI, it is difficult to overcome the issue caused by the limited training samples and increasing network layers. So, much work has been done to introduce the attention mechanism and transformer models into the HSI network. Sun et al. [
20] constructed a model called the spectral-spatial attention network (SSAN) to acquire important spectral-spatial information in the attention regions of patch data. Li et al. [
21] proposed a model called DBDA to capture a variety of spectral-spatial information, which is a dual-branch network with two attention mechanisms. He et al. [
22] designed a model called the Spatial-Spectral Transformer (SST), which extracted spatial features via the VGGNet network and established the relationship between adjacent spectra by using the dense transformer blocks. Similarly, Sun et al. [
23] designed a network that adopts a Gaussian weighted feature tokenizer to capture high-level semantic features, which is called SSFTT. By improving the traditional transformer model, Hong et al. [
24] designed a novel method that is widely used in HSI classification tasks, which is called SpectralFormer (SF). Although these networks are excellent at capturing spectral signatures, these models cannot capture the local contextual information of patch data well, and they make insufficient use of the spatial features in HSI.
Besides the above limitations, the patch-data-based methods also tend to rely on the local neighborhood information of the patch data in the training process, and sometimes, overfitting is caused by improper setting of the training proportion. To verify whether the patch-data-based CNN methods depend on the homogeneity of patch data during the training process and evaluate the ability of the HSI method to extract spatial location information, we rethink the HSI classification process from the data perspective in the patch-data-based method and design a novel strategy to reconstruct the original dataset. Based on this strategy, we also propose a new model based on the Siamese and Knowledge Distillation Network (SKDN) to complete the classification task. The most important contributions of this work can be summarized in the following way.
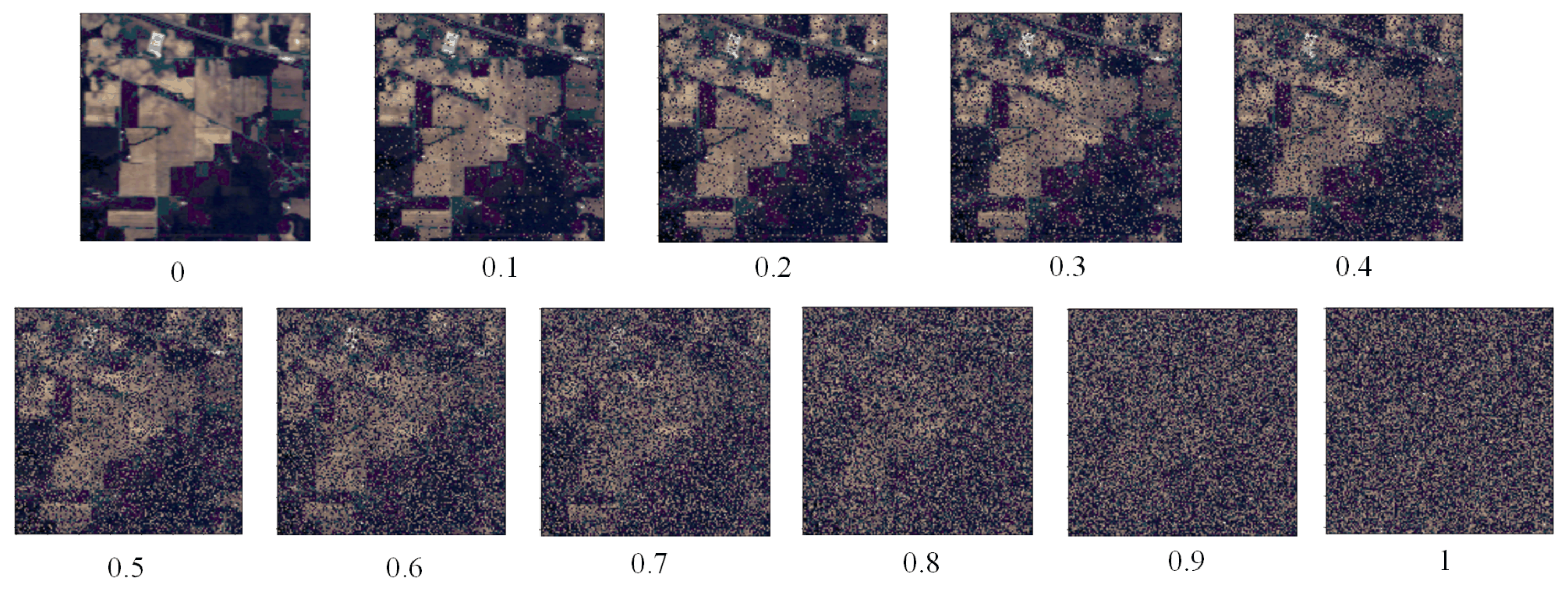
We use the proposed strategy of randomly shuffling data to explore the influence of patch data homogeneity features in HSI classification networks. Specifically, this strategy involves randomly assigning the pixels in the original dataset to other locations to construct a new dataset. Therefore, the new patch data after the random strategy contains richer information about species categories;
We propose a sub-branch to extract features from the reconstructed dataset and fuse the loss values (RFL), which uses a designed loss function in RFL to compute and fuse loss values from two sub-branches. The novelty of this loss function is that the loss rate computed by RFL in the new data is cross combined with the loss rate calculated in the original data from another sub-branch to further optimize the network. Thus, the proposed network can not only enhance the recognition ability of the model, but also increase the classification accuracy on randomly shuffled data, which is based on the Siamese and Knowledge Distillation Network (SKDN) and is constructed from two sub-branches;
We also introduce the proposed sub-branch RFL into the original network to further explore the effectiveness of the RFL, and we let the original model and its improved model achieve HSI classification on the original dataset. The experiments show that the classification performance of the improved model is better than that of the original model, so it can also prove that the proposed sub-branch is effective and feasible;
Experiments conducted on several typical datasets show that, as the proportion of randomly shuffled data increases, the latest patch-data-based CNN methods are unable to extract more abundant local contextual information for HSI classification, while the proposed sub-branch can alleviate this problem.
The rest of this paper consists of the following sections:
Section 2 presents the methodology,
Section 3 presents and analyzes the experiments,
Section 4 discusses the usefulness of the proposed methods, and
Section 5 is the work’s conclusion.
3. Experiments
To test the feasibility of the strategy, four real-world datasets from HSI were selected for the experiment in this paper. They are Indian Pines, Pavia University, Salinas, and Kennedy Space Center. We can see more details of these public datasets in
Table 1.
Indian Pines (IP) is taken by the AVIRIS sensors. The size of this HSI dataset is 145 × 145, including 200 spectral bands and 24 noisy bands that cannot be reflected by water. It has 10,249 pixels that can be divided into 16 land categories for HSI classification. The False Color image and Ground Truth map are shown in
Figure 4.
Pavia University (PU) is taken by the ROSIS sensors. The size of this image data is 615 × 345, which includes 9 categories. This PU dataset only leaves 103 bands and removes 12 bands. The False Color image and Ground Truth map are shown in
Figure 5.
Salinas (SA) is taken by the AVIRIS sensors. It remains 204 bands after removing the noisy bands in HSI. The dataset size of SA is 512 × 217, which holds 54,129 pixels that can be divided into 16 land categories with true labels. The False Color image and Ground Truth map are shown in
Figure 6.
Kennedy Space Center (KSC) is taken by the AVIRIS sensors. The size of KSC data is 512 × 614, which contains 13 land categories with true labels in total. This dataset only leaves 176 bands and removes 48 bands that cannot be reflected by water. The False Color image and Ground Truth map are shown in
Figure 7.
In addition to reducing the spectral bands of the PU by PCA to 90, the spectral bands of the KSC by PCA to 120, and the spectral bands of the IP and SA dataset by PCA to 110, we also set some other parameters. During the training process, we set the learning rate, training epochs, and patch size to 0.001, 200, and 13, respectively. Note that due to the reconstruction of the HSI dataset during training, we still chose the usual training ratio in these four datasets, which is set to 0.05, 0.1, 0.005, and 0.2, respectively. In the reconstructed datasets experiments, we additionally select some training samples from the original dataset to compute the knowledge loss that is used in the SKDN training. In the original datasets experiments, we additionally choose some training samples from the reconstructed dataset to compute the knowledge loss. In addition, three well-known numerical indicators, namely overall accuracy (OA), average accuracy (AA), and kappa coefficient (kappa), are used to evaluate the performance of different classification methods. OA is the ratio of the number of correctly classified samples to the total number of test samples, AA is the average accuracy across the accuracy of all classes, and Kappa is an available measure of agreement between ground truth and classification maps. All experiments were performed using four patch-data-based CNN methods in HSI classification, which are DPRN [
10], CEGCN [
1], SSTFF [
23] and MRViT [
26]. All results of these experiments in four real-world datasets are shown in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10 and
Table 11 and
Figure 8,
Figure 9,
Figure 10 and
Figure 11.
3.1. The Experimental Results of the SKDN on Reconstructed Data Based Four Real-World Datasets
Since our random shuffling strategy disrupts the data homogeneity of the original patch data, we introduce the designed sub-branch into all original networks to form it improved network SKDN, and we complete these experiments on four reconstructed datasets. Note that we additionally chose some training samples from the original datasets for the improved model (SKDN)’s training, where the proportions of these original datasets in the model’s training are the same as the ratio in reconstructed datasets. In these experiments, we set the initial values of
and
to 0.5 in the weighted cross-entropy loss function when the random shuffling ratio was 0%.
Table 2,
Table 3 and
Table 4 report the experimental results of the networks on these four datasets, and the visual results of these networks can be seen in
Figure 8 through
Figure 11.
(1) The analysis of the experiments on the reconstructed dataset based on Indian Pines:
the second row in
Table 2 lists the quantitative results of the different methods, and
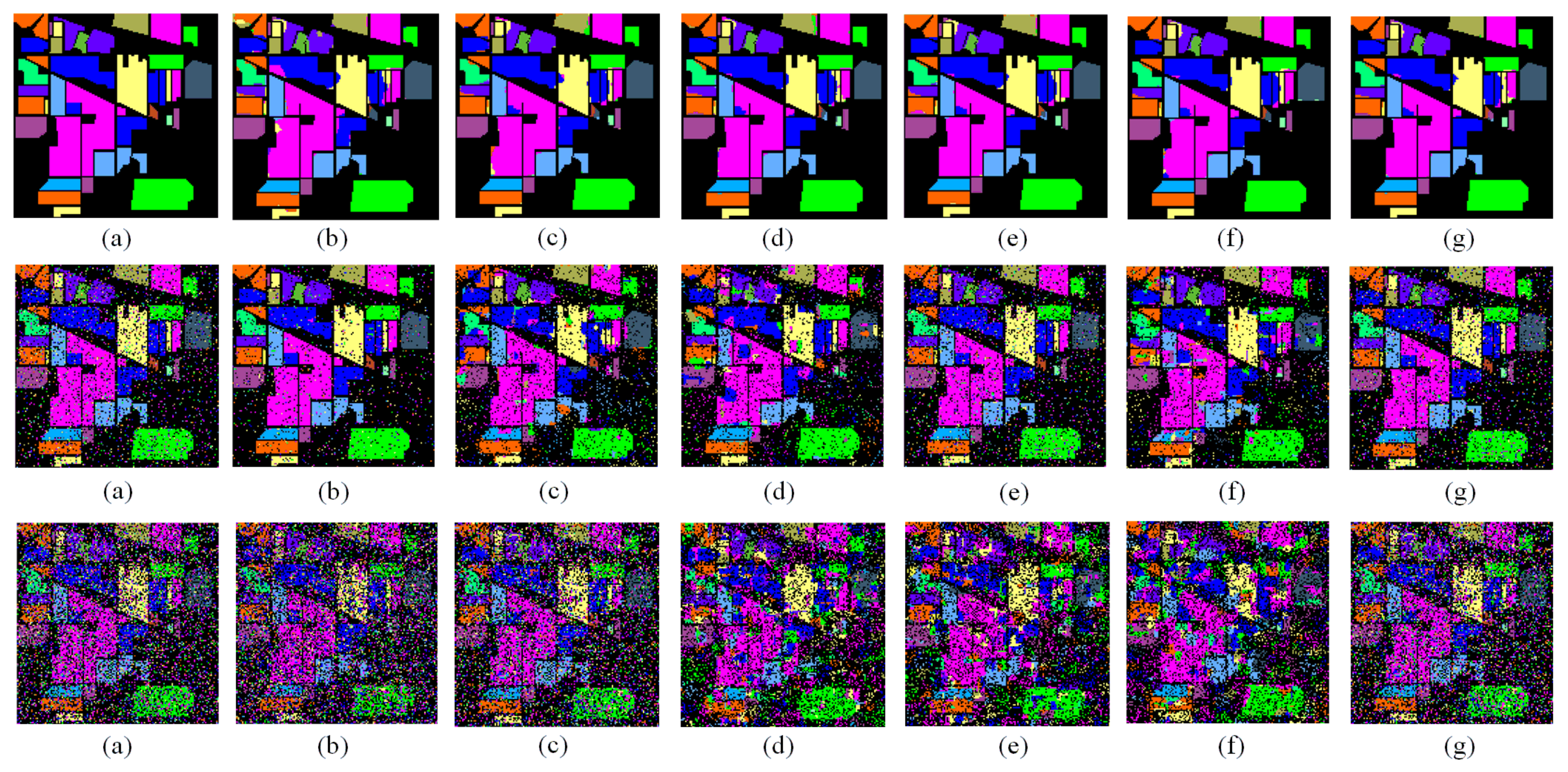
Figure 8 shows the prediction maps corresponding to these methods for the reconstructed IP dataset. Compared to the network DPRN, the SKDN(DPRN) model improves the OA by 11.45% and achieves a better visual result (
Figure 8c) when the random ratio is 20%. It is 12.88% higher than DPRN when the random mixture ratio is 50%. This shows that the result of the improved model is better than that of the original model, which proves the effectiveness of RFL in the network. Obviously, SKDN(SSTFF) also has a better classification performance compared to SSTFF. The value of OA is 5.11% higher than that of SSTFF when the random shuffling ratio is 20%. It is 2.85% higher than that of SSTFF when the ratio of the random mixture is 50%. From
Figure 8f, it is easy to see that the improved model can extract more discriminative local context information and category information in the patch data. The corresponding values of the SKDN(MRViT) model in
Table 2 also show that the improved network performs better than MRViT. The value of OA is 5.5% higher than MRViT when the random mixture proportion is 20%. It is 7.09% higher than MRViT when the proportion of the random mixture is 50%. This also proves that the designed sub-branch RFL is more effective in the reconstructed dataset.
(2) The analysis of the experiments on the reconstructed Pavia University dataset:
the third row in
Table 2 illustrates the quantitative results of the different methods, and
Figure 8 shows the prediction maps corresponding to these methods on for reconstructed PU dataset. It is clear that our improved-method SKDN(DPRN) performs better than the original method DPRN. The value of the OA is 5.37% higher than that of DPRN when the random mixture proportion is 20%. It is 7.36% higher than that of DPRN when the proportion of random mixture is 50%. By analyzing these visual maps, it is easy to find that SKDN(DPRN) in
Figure 9c has a lower prediction error range than DPRN in
Figure 9b. In contrast to SSTFF, the improved SKDN(SSTFF) model in
Figure 9e also has fewer misclassifications. This can be confirmed by the improved OA value (0.55% and 1.19%) in
Table 2.
Figure 9g also shows that the improved SKDN(MRViT) method has better performance, which is also confirmed by its OA value (85.19% and 66.79%) in
Table 2. This is direct evidence that the sub-branching used to construct the SKDN is effective.
(3) The analysis of the experiments on the reconstructed Salinas dataset:
the fourth row in
Table 2 shows the classification results of the different methods. The corresponding prediction graphs for the reconstructed SA dataset are shown in
Figure 10. Compared with the first network, the improved-network SKDN(DPRN) improves the OA by 17.9% when the random shuffling ratio is 20% and achieves a better classification result with fewer misclassified regions in the second row in
Figure 10c. It is 11.7% higher than DPRN when the proportion of random shuffling is 50%. These results show that RFL is useful for the model. It is clear that the experimental results of SKDN(SSTFF) are superior to those of SSTFF, which can also be seen in
Figure 10e and is confirmed by the better OA value (5.49% and 12.91%) in
Table 2. In
Figure 10f,g, the experimental results of SKDN(MRViT) are superior to those of MRViT with fewer training samples. The SKDN(MRViT) model improves OA by 4.01% when the random ratio is 20%. It is 10.72% higher than MRViT when the proportion of random shuffling is 50%. These results can prove that RFL can extract more discriminative local context information in the new dataset.
(4) The analysis of the experiments on the reconstructed dataset Kennedy Space Center: the fifth row in
Table 2 shows the quantitative results of different methods, and
Figure 11 is the prediction maps corresponding to these methods on the reconstructed KSC dataset. It is noticeable that the OA value in the experimental results of the improved model is better than that of the original model. In the following, the results of these methods are only briefly analyzed. Compared with the network DPRN, the model SKDN(DPRN) improves OA by 25.68% and achieves a better result, as shown in
Figure 11c, where the proportion of random shuffling is 20%. It is 28.67% higher than the DPRN when the proportion of random mixture is 50%. Moreover, the classification capability of SKDN(SSTFF) is better than that of SSTFF, which is also evidenced by the better OA value (5.8% and 4.45%). Compared to the MRViT, SKDN(MRViT) also achieves better classification performance (82.38% and 50.91%) in
Table 2. SKDN(MRViT) has less misclassification than MRViT in its domain, which can be seen in
Figure 11g. All the results of these experiments proved that our model SKDN can indeed extract more local context information and category information from random shuffling patch data for HSI classification. Our proposed sub-branch RFL, which fuses the loss rates of two sub-branches in its loss function, can effectively improve the classification accuracy in random shuffling data. All results of these experiments have proven that our model SKDN can really extract more local context information and category information from random shuffling patch data for HSI classification. Our proposed sub-branch RFL, which fuses the loss rates of two sub-branches in its loss function, can effectively improve the classification accuracy in random shuffling data.
3.2. The Experimental Results of the SKDN on Four Real-World Datasets
To further validate the usefulness of the proposed sub-branch RFL, we introduce RFL into the original network to form its improved network SKDN and let the improved model and the original model achieve the HSI classification task on the four original datasets. Note that we additionally chose some training samples from the reconstructed datasets for the improved model (SKDN) training, where the proportions of these reconstructed datasets in model training are the same as the ratio in the original datasets.
Table 5 lists the quantitative results of the original methods and the improved methods on four original datasets. We also set the initial values of
and
to 0.5 in the weighted cross-entropy loss function when the random shuffling ratio was 0%. Hereinafter, we just briefly analyze the results of these methods on four original datasets.
The second row in
Table 5 lists the experimental results of the original networks and the improved models for the IP dataset. The classification result of SKDN(DPRN) is 2.43% higher than the result of DPRN for OA when the proportion of random mixture is 20%; the value of the OA also improves by 7.76% when the random shuffling ratio is 50%. Compared with the network SSTFF, the improved model SKDN(SSTFF) has a better classification performance, which can be verified by its improved OA value (11.35% and 41.6%) in
Table 5. We also find that the improved network SKDN(MRViT) (97.24% and 96.48%) performs better than MRViT. This proves that the proposed RFL is effective in the original dataset.
The third row in
Table 5 shows the experimental results of the original networks and the improved models for the PU dataset. Compared with the original method DPRN, the improved-method SKDN(DPRN) improves OA by 4.15% when the random shuffling ratio is 20%. It is 4.12% higher than DPRN when the proportion of random shuffling is 50%. We also can see that the improved-method SKDN(SSTFF) also performs better than SSTFF, which can also be verified by its OA value (99.61% and 98.61%). Compared to the MRViT, SKDN(MRViT) also achieves a better classification performance, which can be verified by its improved OA value (2.82% and 4.78%). These results demonstrate that the RFL is useful in our model.
The fourth row in
Table 5 shows the experimental results of the original networks and the improved networks for the SA dataset. Compared with DPRN, the improved method SKDN(DPRN) improves OA by 2.77% when the random shuffling ratio is 20%. It is 4.94% higher than DPRN when the proportion of random shuffling is 50%. It is shown that the improved-method SKDN(SSTFF) also performs better than SSTFF, which can be verified by its improved OA value (6.35% and 35.6%). Compared to the MRViT, SKDN(MRViT) also achieves a better classification performance, which can also be seen in its OA value (96.24% and 94.07%) in
Table 5. These results also prove that the RFL can capture the discriminative feature in the original dataset.
The fifth row in
Table 5 lists the experimental results of the original networks and the improved networks for the KSC dataset. Compared with DPRN, the OA of SKDN(DPRN) improves by 4.31% and 5.86% when the random shuffling ratios are 20% and 50%, respectively. Moreover, the OA of SKDN(SSTFF) is 31.08% higher than that of SSTFF when the proportion of random shuffling is 20%. It is 39.59% higher than SSTFF when the random shuffling ratio is 50%. Compared to the MRViT, FSKDN(MRViT) also achieves a better classification performance, which can be verified by its improved OA value (2.74% and 8.6%). All results of these experiments show that the classification capacity of the improved model SKDN is superior to that of the original model, which in turn proves that the proposed RFL sub-branch is effective and feasible.
3.3. The Experimental Results of Single Pixel-Based Methods on Reconstructed Data Based on Four Real-World Datasets
We set the value of the patch-size parameter to 1 in the patch-data-based CNN methods in the HSI classification so that they become the single-pixel-based methods in this experiment.
Table 8,
Table 9,
Table 10 and
Table 11 show the results of each network with different random shuffling ratios and training ratios in the HSI classification. We see that the accuracy of these models improves slightly when the training fraction is increased and the random mixture ratio is kept constant. However, when the same training fraction is kept and the random mixture ratio is increased, the classification results of the CNN-based method and the Transformer-based method, such as the DPRN and the SSTFF, vary only within a certain value interval, and the OA value does not change significantly, but the classification results of the GCN-based network show a downward trend. Using the experiments of the reconstructed dataset based on IP as an analysis case and setting the proportion of each method to 5% in the model’s training, we find that the results of the DPRN are in the range of 64% to 69% when the proportion of random shuffling increases, the results of the SSTFF are in the range of 62% to 65%, the results of the MRViT are in the range of 65% to 68%, and the results of the SKDN(MRViT) are in the range of 72% to 75%. However, the results of the CEGCN decreased from 97% to 19%. These experiments show that no matter how the proportion of random shuffling increases, the classification accuracy results of the single pixel-based models for HSI classification do not change significantly. This may indicate that the single pixel-based methods do not use the local context relationship between pixels for the classification of HSIs, which also proves that the strategy of reconstructing the dataset has no major effect on the experimental classification results of the single pixel-based networks for the classification of HSIs.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}