



Rethinking Representation Learning-Based Hyperspectral Target Detection: A Hierarchical Representation Residual Feature-Based Method

Abstract
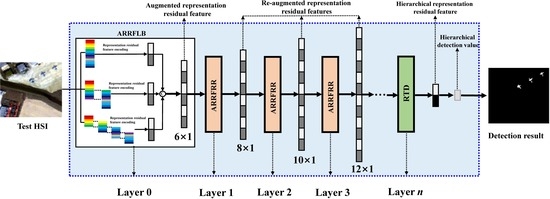
1. Introduction
- (1)
- A Level-wise band-partition-based hierarchical representation residual feature (LBHRF) learning method for HTD is devised in a stepwise training manner without the need for back-propagation optimization. The SoftMax transformation, pooling operation, and augmented representation residual feature reuse and relearning among different layers are incorporated with cycle accumulation to enhance the nonlinear and discriminate feature learning capability of the method;
- (2)
- To flexibly integrate the global spectral integrity as well as the local contextual information of adjacent sub-bands, the original full spectral bands are partitioned into different levels with bands overlapping, and the augmented representation residual feature is then obtained by concatenating different levels of representation residual features;
- (3)
- Due to computational efficiency, the collaborative representation with the minimization of the l2-norm regularized representation coefficient is used in the experiments, and the results on several HSI target detection tasks show that the proposed method can yield overall superior detection performance.
2. Related Work
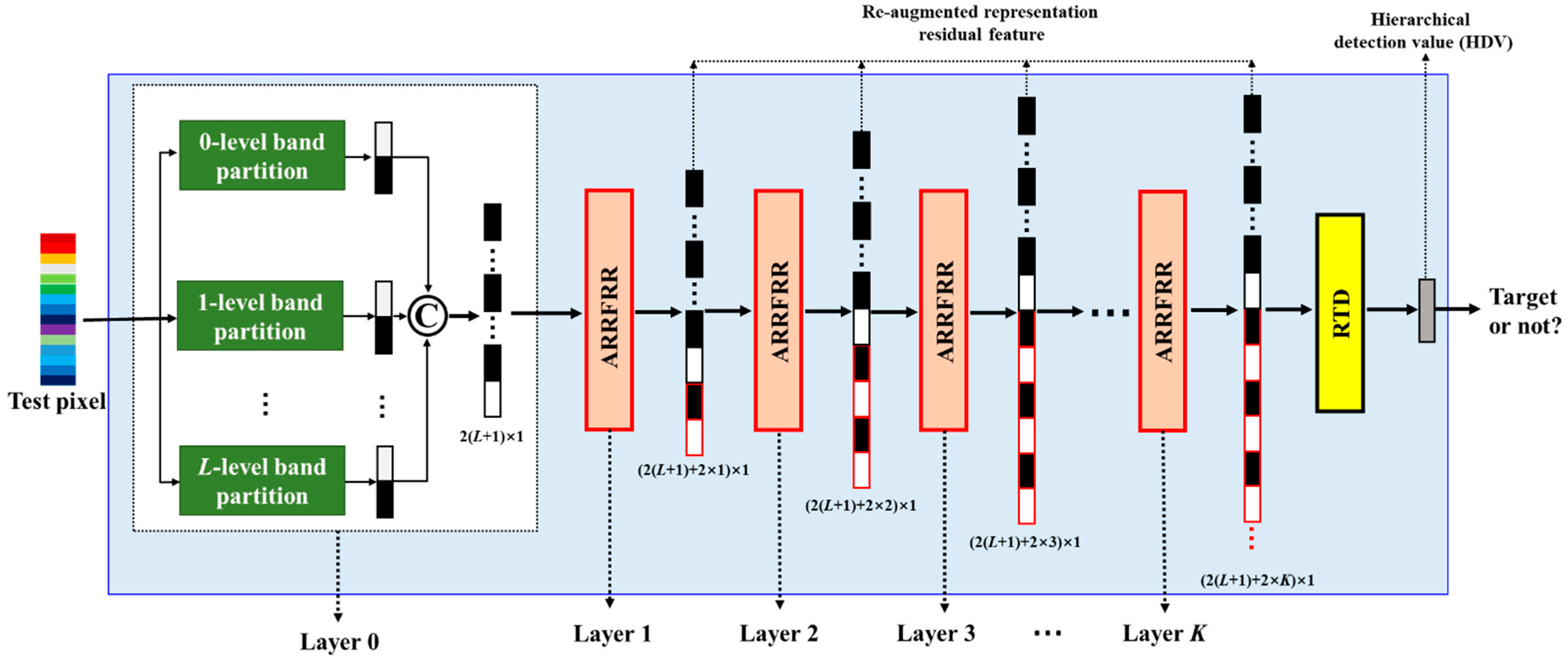
3. Level-Wise Band-Partition-Based Hierarchical Representation Residual Feature Learning for HTD
3.1. Parallel Level-Wise Band-Partition
3.2. Augmented Representation Residual Feature Based on Level-Wise Band-Partition (ARRFLB)
3.3. Augmented Representation Residual Feature Reuse and Relearning (ARRFRR)
| Algorithm 1: The proposed LBHRF learning method for hyperspectral target detection. |
| Input: Test pixel . Target prior spectra and background dictionaries . The band-partition level L. The layer K. 1: Learn the L levels augmented representation residual feature for all the target and background pixels and test pixel via ARRFLB presented in Equations (8)–(14); 2: Initialize k = 1; 3: Repeat; 4: Learn the k-th layer re-augmented representation residual features and for the target and background dictionary pixels and the test pixel based on the augmented representation residual feature and by ARRFRR presented in Equations (17)–(22); 5: k = k + 1; 6: Until k > K; 7: Calculate the hierarchical detection value by RTD as presented in Equations (23) and (24). Output: The hierarchical detection value for target detection. |
4. Experimental Results and Analysis
4.1. Hyperspectral Data Set
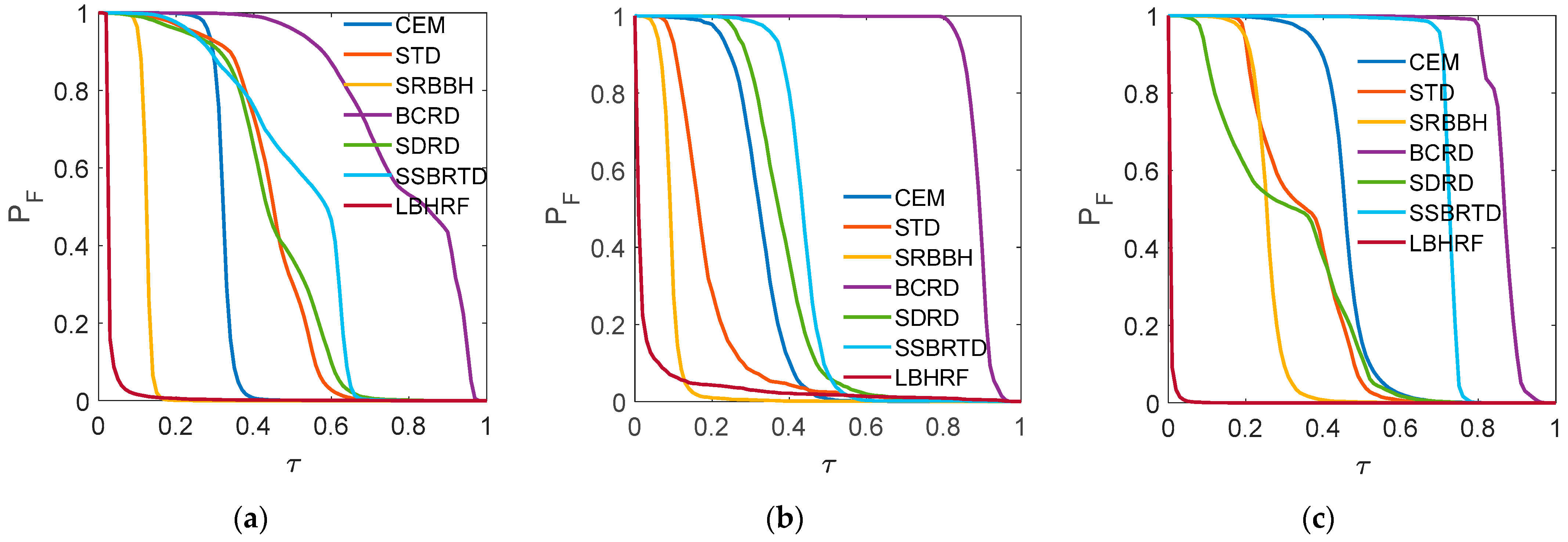
4.2. Experimental Results
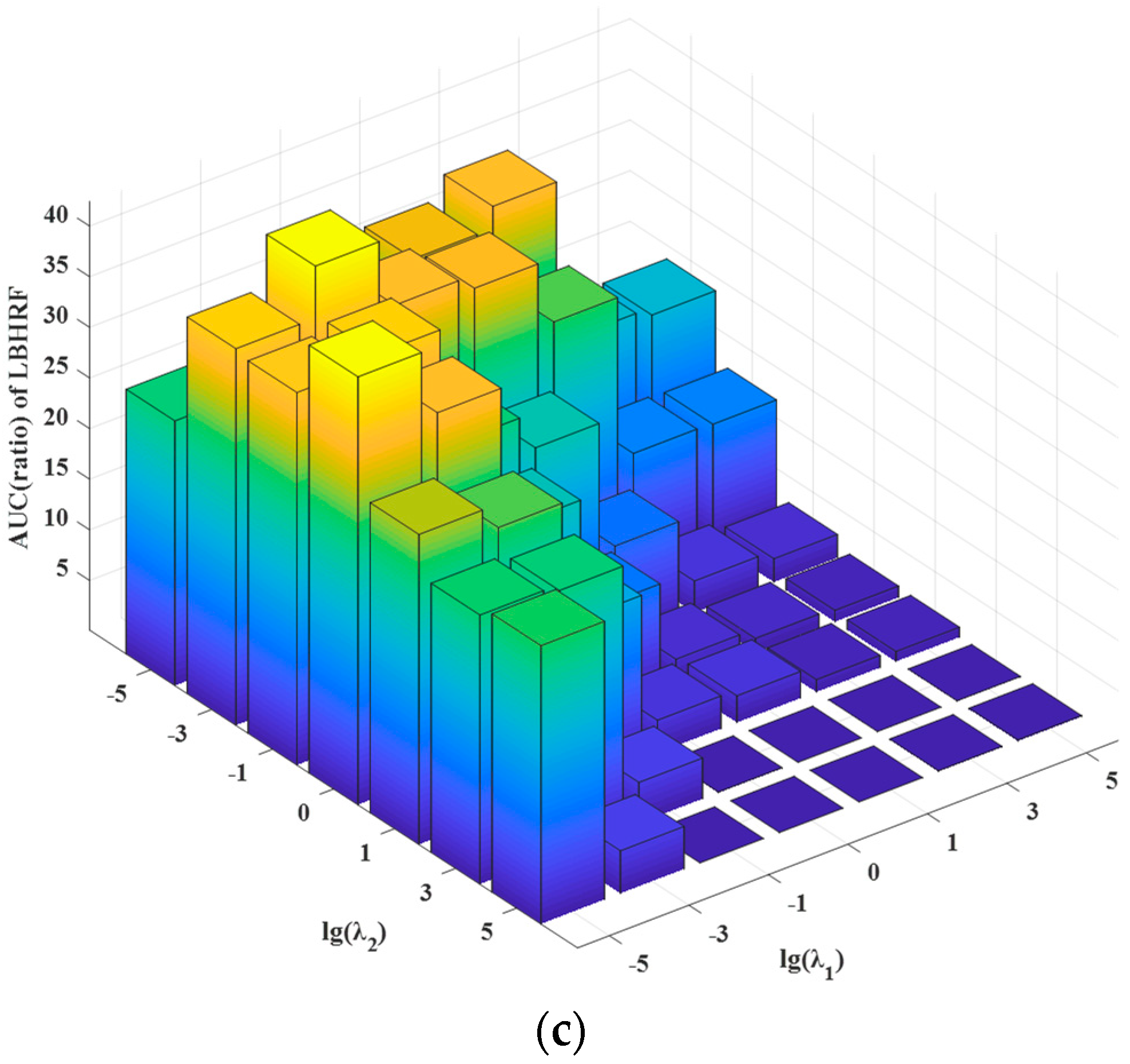
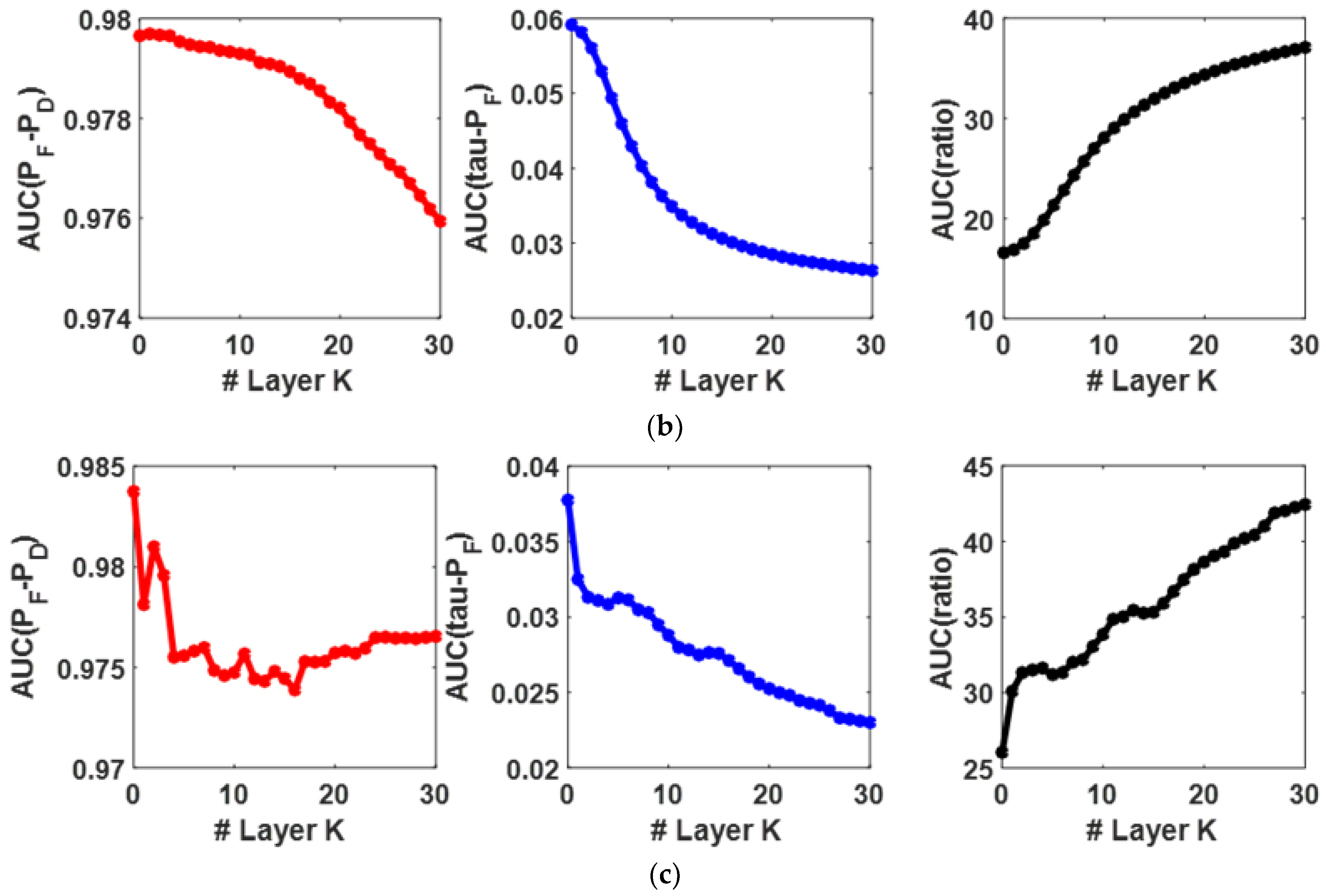
4.3. Parameters Sensitivity Analysis
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gao, L.; Han, Z.; Hong, B.; Zhang, B.; Chanussot, J. CyCU-Net: Cycle-consistency unmixing network by learning cascaded autoencoders. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5503914. [Google Scholar] [CrossRef]
- Guo, T.; Wang, R.; Luo, F.; Gong, X.; Zhang, L.; Gao, X. Dual-View Spectral and Global Spatial Feature Fusion Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5512913. [Google Scholar] [CrossRef]
- Luo, F.; Zou, Z.; Liu, J.; Lin, Z. Dimensionality reduction and classification of hyperspectral image via multi-structure unified discriminative embedding. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5517916. [Google Scholar] [CrossRef]
- Luo, F.; Zhou, T.; Liu, J.; Guo, T.; Gong, X.; Ren, J. Multi-Scale Diff-changed Feature Fusion Network for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5502713. [Google Scholar] [CrossRef]
- Duan, Y.; Luo, F.; Fu, M.; Niu, Y.; Gong, X. Classification via Structure Preserved Hypergraph Convolution Network for Hyperspectral Image. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5507113. [Google Scholar] [CrossRef]
- Guo, T.; Luo, F.; Zhang, L.; Zhang, B.; Tan, X.; Zhou, X. Learning Structurally Incoherent Background and Target Dictionaries for Hyperspectral Target Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3521–3533. [Google Scholar] [CrossRef]
- Zeng, J.; Wang, Q. Sparse Tensor Model-Based Spectral Angle Detector for Hyperspectral Target Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5539315. [Google Scholar] [CrossRef]
- Guo, T.; He, L.; Luo, F.; Gong, X.; Li, Y.; Zhang, L. Anomaly Detection of Hyperspectral Image with Hierarchical Anti-Noise Mutual-Incoherence-Induced Low-Rank Representation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5510213. [Google Scholar] [CrossRef]
- Zhou, H.; Luo, F.; Zhuang, H.; Weng, Z.; Gong, X.; Lin, Z. Attention Multi-Hop Graph and Multi-Scale Convolutional Fusion Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5508614. [Google Scholar] [CrossRef]
- Luo, F.; Huang, H.; Ma, Z.; Liu, J. Semi-supervised sparse manifold discriminative analysis for feature extraction of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6197–6221. [Google Scholar] [CrossRef]
- Guo, T.; Luo, F.; Fang, L.; Zhang, B. Meta-Pixel-Driven Embeddable Discriminative Target and Background Dictionary Pair Learning for Hyperspectral Target Detection. Remote Sens. 2022, 14, 481. [Google Scholar] [CrossRef]
- Gao, L.; Wang, D.; Zhuang, L.; Sun, X.; Huang, M.; Plaza, A. BS3LNet: A new blind-spot self-supervised learning network for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5504218. [Google Scholar] [CrossRef]
- Theiler, J.; Ziemann, A.; Matteoli, S.; Diani, M. Spectral Variability of Remotely Sensed Target Materials: Causes, Models, and Strategies for Mitigation and Robust Exploitation. IEEE Geosci. Remote Sens. Mag. 2019, 7, 8–30. [Google Scholar] [CrossRef]
- Liu, L.; Zou, Z.; Shi, Z. Hyperspectral Remote Sensing Image Synthesis Based on Implicit Neural Spectral Mixing Models. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5500514. [Google Scholar] [CrossRef]
- Du, Q.; Ren, H.; Chang, C.-I. A comparative study for orthogonal subspace projection and constrained energy minimization. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1525–1529. [Google Scholar]
- Guo, T.; Lu, X.-P.; Yu, K.; Zhang, Y.-X.; Wei, W. Integration of Light Curve Brightness Information and Layered Discriminative Constrained Energy Minimization for Automatic Binary Asteroid Detection. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 4984–4999. [Google Scholar] [CrossRef]
- Vincent, F.; Besson, O. One-Step Generalized Likelihood Ratio Test for Subpixel Target Detection in Hyperspectral Imaging. IEEE Trans. Geosci. Remote Sens. 2020, 8, 4479–4489. [Google Scholar] [CrossRef]
- Yang, S.; Shi, Z. SparseCEM and SparseACE for Hyperspectral Image Target Detection. IEEE Geosci. Remote Sens. Lett. 2014, 11, 2135–2139. [Google Scholar] [CrossRef]
- Liu, J.; Li, H.; Himed, B. Threshold Setting for Adaptive Matched Filter and Adaptive Coherence Estimator. IEEE Signal Process. Lett. 2015, 22, 11–15. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Sparse Representation for Target Detection in Hyperspectral Imagery. IEEE J. Sel. Top. Signal Process. 2011, 5, 629–640. [Google Scholar] [CrossRef]
- Zhu, D.; Du, B.; Zhang, L. Binary-Class Collaborative Representation for Target Detection in Hyperspectral Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1100–1104. [Google Scholar] [CrossRef]
- Guo, T.; Luo, F.; Zhang, L.; Tan, X.; Liu, J.; Zhou, X. Target Detection in Hyperspectral Imagery via Sparse and Dense Hybrid Representation. IEEE Geosci. Remote Sens. Lett. 2020, 17, 716–720. [Google Scholar] [CrossRef]
- Zhang, Y.; Du, B.; Zhang, L. A Sparse Representation-Based Binary Hypothesis Model for Target Detection in Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2014, 53, 1346–1354. [Google Scholar] [CrossRef]
- Zhu, D.; Du, B.; Zhang, L. Target Dictionary Construction-Based Sparse Representation Hyperspectral Target Detection Methods. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1254–1264. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, J.; Zhang, B.; Zhang, D.; Zhu, C. Deep Cascade Model Based Face Recognition: When Deep-Layered Learning Meets Small Data. IEEE Trans. Image Process. 2020, 29, 1016–1029. [Google Scholar] [CrossRef]
- Tong, F.; Zhang, Y. Exploiting Spectral-Spatial Information Using Deep Random Forest for Hyperspectral Imagery Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5509505. [Google Scholar] [CrossRef]
- Tang, J.; Deng, C.; Huang, G.-B. Extreme Learning Machine for Multilayer Perceptron. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 809–821. [Google Scholar] [CrossRef]
- Zhu, D.; Du, B.; Zhang, L. Single-spectrum-driven binary-class sparse representation target detector for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1487–1500. [Google Scholar] [CrossRef]
- Chang, C.-I. Comprehensive analysis of receiver operating characteristic (ROC) curves for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5541124. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Sets | The Comparing HSI Detectors | |||||||
|---|---|---|---|---|---|---|---|---|
| CEM [15] | SRD [20] | SRBBH [23] | BCRD [21] | SDRD [22] | SSBRTD [29] | LBHRF | Ground-Truth | |
| HYDICE |  |  |  |  |  |  |  |  |
| AVIRIS I |  |  |  |  |  |  |  |  |
| AVIRIS II |  |  |  |  |  |  |  |  |
| Methods | Data Sets | ||
|---|---|---|---|
| HYDICE | AVIRIS I | AVIRIS II | |
| CEM [15] | 0.9139 | 0.6549 | 0.6983 |
| SRD [20] | 0.9840 | 0.9561 | 0.9331 |
| SRBBH [23] | 0.8909 | 0.8913 | 0.7224 |
| BCRD [21] | 0.9175 | 0.9805 | 0.9899 |
| SDRD [22] | 0.9973 | 0.9583 | 0.9921 |
| SSBRTD [29] | 0.9597 | 0.9051 | 0.9689 |
| LBHRF | 0.9978 | 0.9844 | 0.9987 |
| Methods | Data Sets | ||
|---|---|---|---|
| HYDICE | AVIRIS I | AVIRIS II | |
| CEM [15] | 0.3218 | 0.3236 | 0.4573 |
| SRD [20] | 0.4459 | 0.1876 | 0.3421 |
| SRBBH [23] | 0.1234 | 0.0936 | 0.2558 |
| BCRD [21] | 0.7926 | 0.8888 | 0.8635 |
| SDRD [22] | 0.4488 | 0.3812 | 0.3028 |
| SSBRTD [29] | 0.5106 | 0.4287 | 0.7326 |
| LBHRF | 0.0310 | 0.0388 | 0.0037 |
| Methods | Data Sets | ||
|---|---|---|---|
| HYDICE | AVIRIS I | AVIRIS II | |
| CEM [15] | 2.8400 | 2.0238 | 1.5270 |
| SRD [20] | 2.2068 | 5.0965 | 2.7276 |
| SRBBH [23] | 7.2196 | 9.5224 | 2.8241 |
| BCRD [21] | 1.1576 | 1.1032 | 1.1464 |
| SDRD [22] | 2.2221 | 2.5139 | 3.2764 |
| SSBRTD [29] | 1.8796 | 2.1113 | 1.3225 |
| LBHRF | 32.1871 | 25.3711 | 269.9189 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, T.; Luo, F.; Duan, Y.; Huang, X.; Shi, G. Rethinking Representation Learning-Based Hyperspectral Target Detection: A Hierarchical Representation Residual Feature-Based Method. Remote Sens. 2023, 15, 3608. https://doi.org/10.3390/rs15143608
Guo T, Luo F, Duan Y, Huang X, Shi G. Rethinking Representation Learning-Based Hyperspectral Target Detection: A Hierarchical Representation Residual Feature-Based Method. Remote Sensing. 2023; 15(14):3608. https://doi.org/10.3390/rs15143608
Chicago/Turabian StyleGuo, Tan, Fulin Luo, Yule Duan, Xinjian Huang, and Guangyao Shi. 2023. "Rethinking Representation Learning-Based Hyperspectral Target Detection: A Hierarchical Representation Residual Feature-Based Method" Remote Sensing 15, no. 14: 3608. https://doi.org/10.3390/rs15143608
APA StyleGuo, T., Luo, F., Duan, Y., Huang, X., & Shi, G. (2023). Rethinking Representation Learning-Based Hyperspectral Target Detection: A Hierarchical Representation Residual Feature-Based Method. Remote Sensing, 15(14), 3608. https://doi.org/10.3390/rs15143608