1. Introduction
With the exception of Earth, impact craters are used as common geomorphic units for terrestrial planets and the moon. These craters are the most direct entry points for studying the evolution of planetary geomorphology. Impact craters are tracers for surface processes, and they record the resurfacing process on Mars. Furthermore, impact craters provide information on the age of surface geological units in addition to being informative for studying subsurface minerals [
1,
2,
3]. Due to distance constraints, the crater size-frequency distribution (CSFD) is a well-recognized and widely used method of dating planetary surfaces in the planetary geology community [
4,
5,
6,
7]. Planetary surface dating utilizes the overlap of surface features with impact craters [
8,
9].
Although the shapes of impact craters on Mars and the Moon are similar, there are differences in the background terrain. In contrast to the moon, Mars has a more complex topography that includes glacial, volcanic, aeolian, and fluvial landforms. Impact crater shapes are heavily modified due to the endogenic and exogenic dynamics on Mars, leading to more complex shapes than on the Moon. In addition, rampart craters are the characteristic terrain of Mars. The sputter of rampart craters is often circular, which influences the identification of boundaries. Therefore, in Martian crater detection studies it is important to understand how to train and optimize the detection algorithms and to provide better and more meaningful results.
Crater detection algorithms (CDAs) have yielded remarkable results thus far [
10]. Many representative catalogs of Martian impact craters, including Barlow [
11], MA132843GT [
12], and Robbins et al. [
13,
14,
15], have been completed based on CDAs. Generally, CDAs are classified into manual and automatic types. The manual method is a visual interpretation technique using images, DEM, and other derived data. Manual CDAs produce accurate results, but they take considerable time and effort. Time and energy could be saved by using automatic CDAs, and the detection standard is uniform in this case. Automatic CDAs are divided into four types based on various detection theories: traditional edge detection and circle fitting, digital terrain analysis methods, traditional machine learning, and deep learning, as shown in
Table 1.
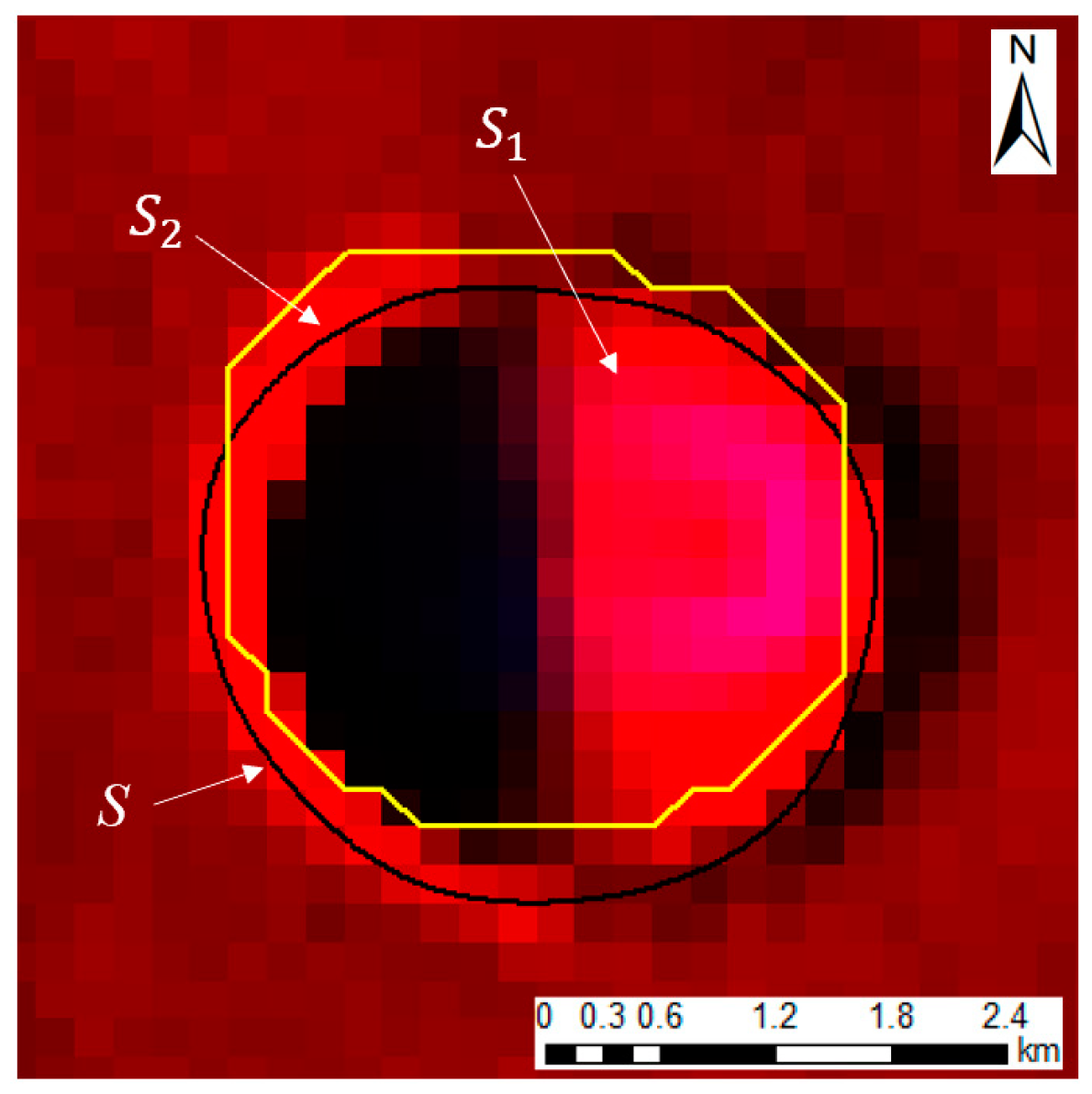
The above CDAs have made impressive strides. However, on the one hand, the existing CDAs based on deep learning only consider the morphological features of impact craters, often ignoring the geographic information involved. On the other hand, in quantity-oriented detection, the boundaries of impact craters are usually assumed to be circles. First, indeed, most researchers have focused on the quantity and radii/diameters of impact craters rather than their accurate boundaries. However, the morphological parameters, such as accurate diameters, accurate volumes, and boundary crushability, depend on accurate boundaries [
39]. Accurate boundaries record the resurfacing caused by impacts, volcanic activity, hydrological effects, wind, and glacial erosion. Thus, accurate boundaries are important for the quantitative calculation of topographic parameters and for reflecting the degree of erosion. Furthermore, accurate boundaries can be used to deduce the history of surface degradation [
26,
27]. Second, obtaining accurate boundaries is essential for planetary geological and geomorphological mapping [
40,
41]. Notably, the identification of impact craters is time- and energy-intensive when mapping the global Moon. Third, accurate boundaries can be used to deduce the impact angle, impact direction, and impact crater formation mechanisms on slopes [
42,
43]. Fourth, the diameters of some impact craters are modified by linear tectonics. By calculating these diameters from accurate boundaries, the causal mechanisms of linear tectonics can be determined [
44,
45].
This study aimed to identify the accurate boundaries of impact craters, which is fundamental work. An impact crater dataset with large geographic coverage is useful for calculating morphological and topographic parameters, creating geological maps, and deducing the history of surface degradation and the causal mechanisms of linear tectonics. Therefore, it is crucial to study an automated algorithm for accurately identifying the boundaries of impact craters. To reduce the gap between circles and accurate boundaries, this article proposes a framework that combines geographic information and deep learning.
The main contributions of our work may be described as follows:
For the first time, a benchmark dataset with annotations for identifying accurate boundaries of impact craters has been completed and made publicly available, and the sampling method considered the geographical distribution.
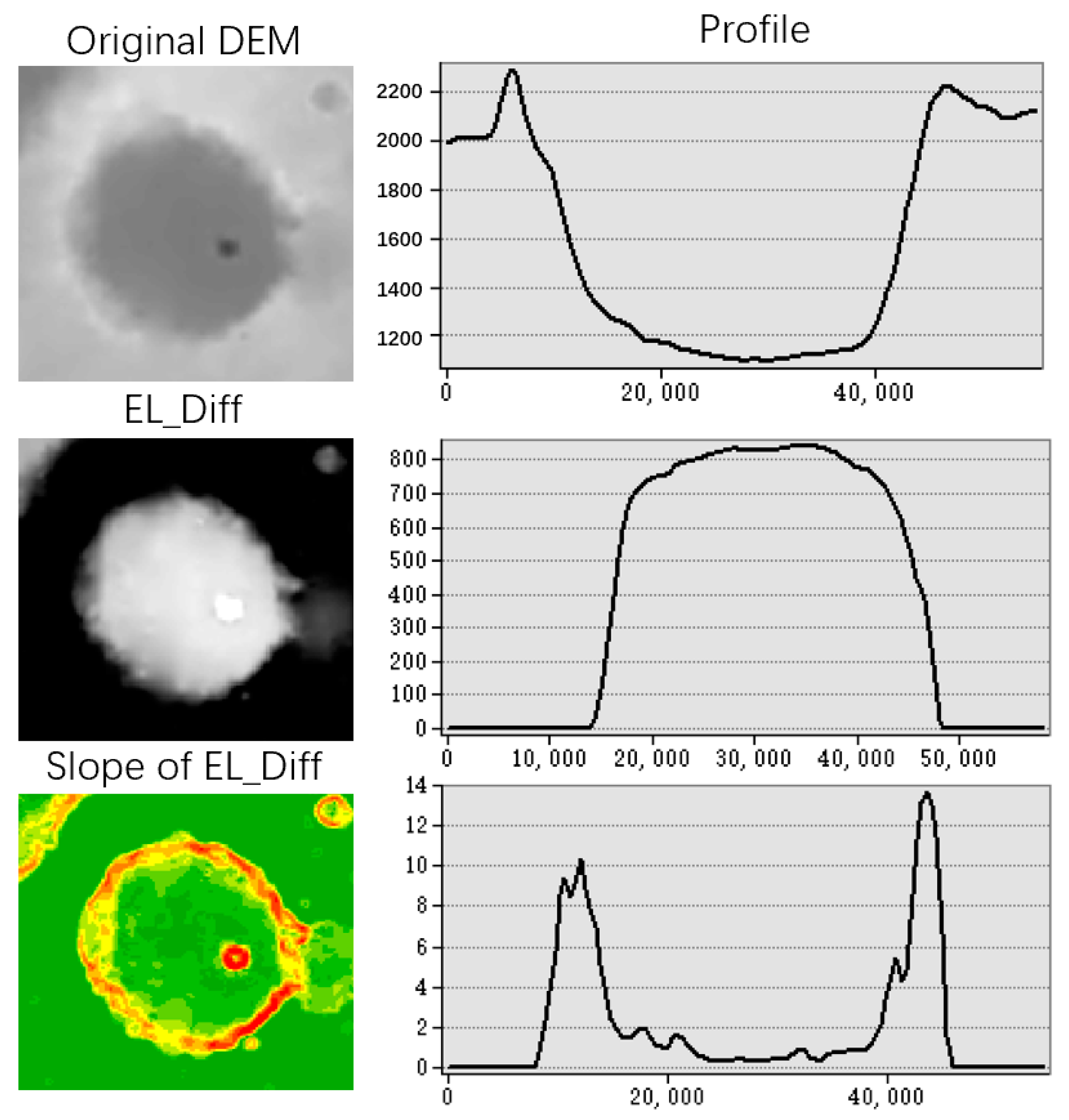
Geographic information called the “slope of EL_Diff” was integrated into fusion data as model input. “Slope of EL_Diff” refers to the slope of elevation difference after filling the DEM in order to highlight the boundaries of impact craters.
A framework called BDMCI was developed to accurately detect the boundaries of impact craters with a large geographic extent.
In this article, a system combining geographic information and deep learning is proposed to accurately detect the boundaries of Martian impact craters. The remaining sections of this article are as follows: The benchmark dataset with annotations and sample regions for the BDMCI framework is introduced in
Section 2. The proposed BDMCI framework is presented in
Section 3, which includes the model input, the introduction of two deep learning models, and postprocessing. In the experiment described in
Section 4, the system was tested using fusion data from the Mars Orbiter Laser Altimeter (MOLA) and the Thermal Emission Imaging System (THEMIS), and a comparison was performed.
3. Methods
According to Liu et al. [
26] and Chen et al. [
27], impact craters include dispersal craters, connective craters, and con-craters (con-craters refer to nested craters containing dispersal craters and connective craters). To detect the above impact craters, the idea of object orientation should be introduced. The outputs of object detection are the boundary box and category, and the output of semantic segmentation is the category of each pixel. Object detection and semantic segmentation may ignore the boundaries of connective craters and con-craters. The outputs of instance segmentation are pixel-level classification results, and this approach is more suitable for detecting impact craters. In this study, Mask2former, Mask R-CNN, SOLOv2, Cascade Mask R-CNN, and SCNet were selected to be trained on detecting impact craters.
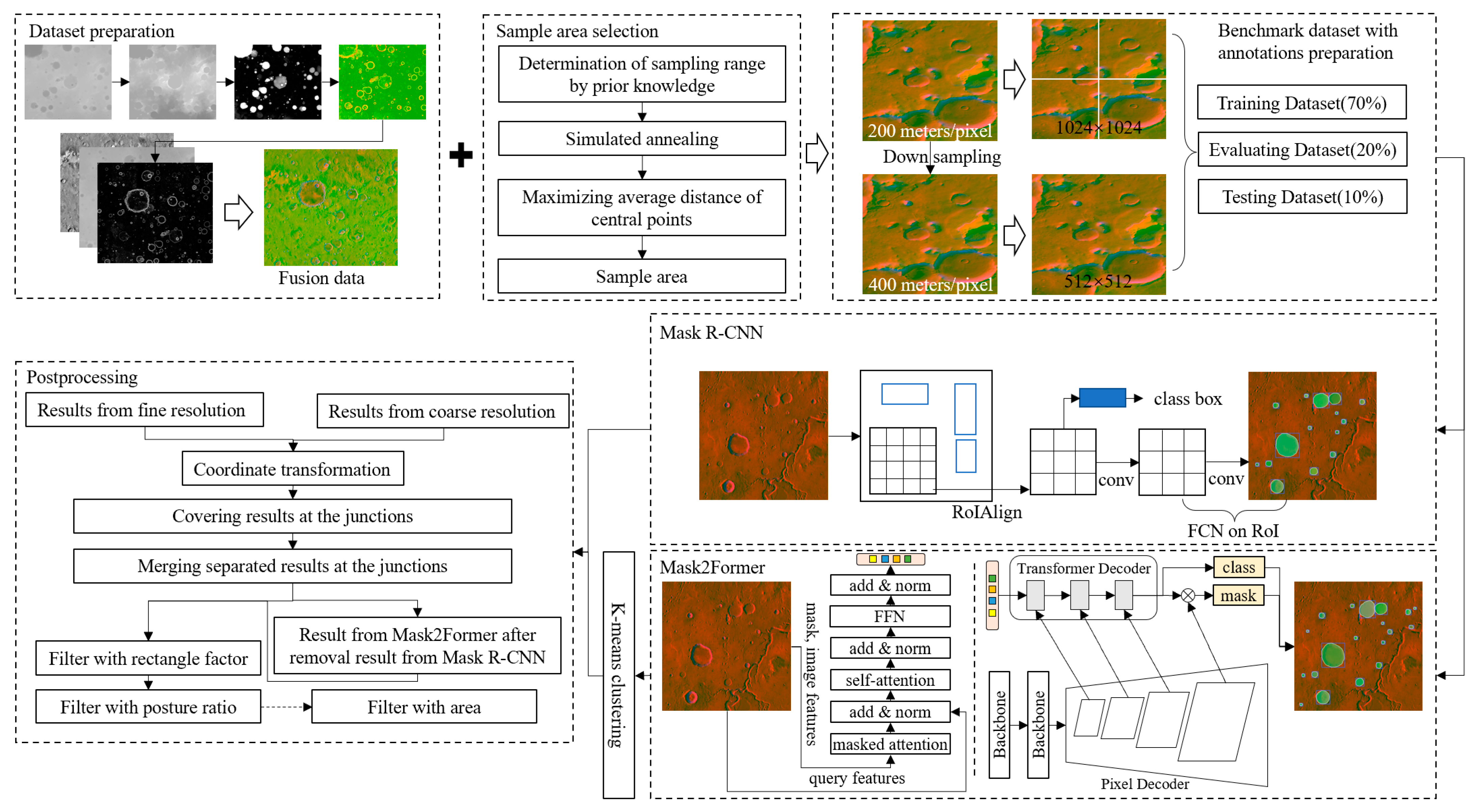
An overview of the proposed BDMCI framework is shown in
Figure 6. In the dataset preparation stage, the DEM, optical image, and slope of EL_Diff (as stated in
Section 2.2) were integrated into the fusion data. The fusion data contain elevation, grayscale information, and the highlighted boundaries of terrain. In the sample area selection stage (
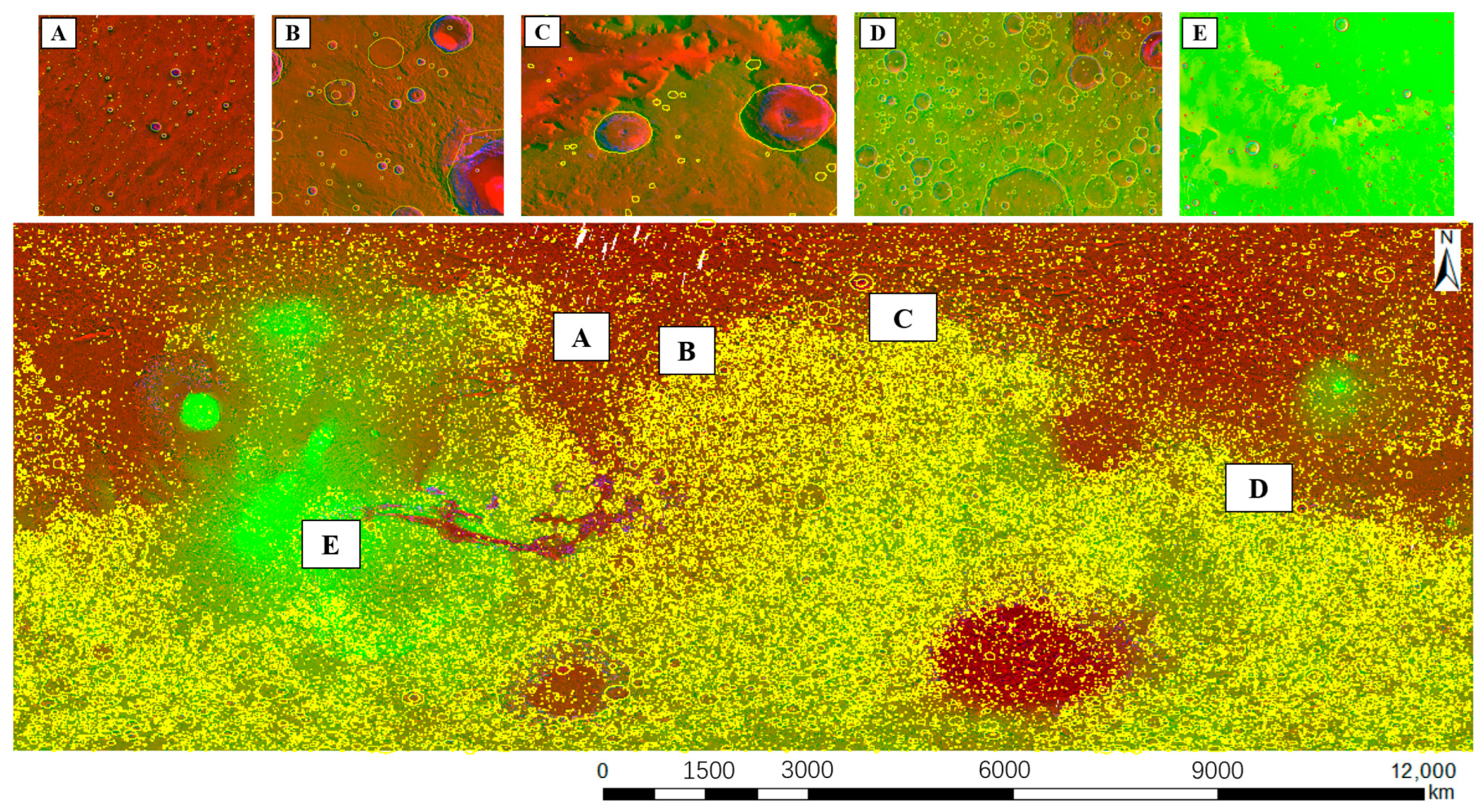
Section 2.3), the sampling range was determined based on prior knowledge. The sample area was selected using simulated annealing and maximizing the average distance from central points. After data preparation and sample area selection, the benchmark dataset with multiscale images and annotations was input into Mask R-CNN and Mask2Former. The results from Mask2Former were processed by K-means clustering and then merged with the results from Mask R-CNN. Finally, the merged results were postprocessed to identify the fractures at junctions and filter out the false results. This framework can be used to identify accurate boundaries of Martian impact craters with geographic information and deep learning. The impact craters between 65°S–65°N, 0°E–360°E were identified using this framework, as discussed in
Section 4.6.
3.1. Model Input
The input data of the model are the fusion data mentioned in
Section 2.1. The first channel is the optical image. The second and third channels are the DEM and the slope of EL_Diff, respectively. The proportion of training to validation to testing is 7:2:1, which ensures that the number of training sets needed to enhance the model is sufficient. There were 451 patches in the six sample areas. The size of the patches was 1024 pixels, with a spatial resolution of 200 m/px. These patches were randomly proportionally divided into a training set, a validation set, and a test set. The training set had 316 patches, the validation set had 90 patches, and the test set had 45 patches. In addition, these three sets did not overlap. The fusion data and benchmark dataset with annotations were clipped based on the divided grids. Images and annotations were input into the models in the format of the Microsoft Common Objects in Context (MS COCO) dataset. Finally, the geographical coordinates were converted into image coordinates.
Impact craters vary in size, which makes identification quite difficult. The diameter of a small impact crater might be 200 m, while the diameter of a large impact crater might be 200 km. Thus, a multiscale dataset was input into the model. Additionally, upsampling might generate some potential artifacts, so the spatial resolution of the fusion data was changed from 200 m/px to 400 m/px through downsampling. Images with pixel sizes of 512 × 512 and 1024 × 1024 were created in MS COCO before being input into the model to potentially improve the identification of multiscale impact craters.
3.2. Fusing Multiple Models
3.2.1. Mask2Former
The masked-attention mask transformer (Mask2Former) [
53] uses mask classification for segmentation and detection. Masked attention, which is used to extract local features by restricting cross-attention to the anticipated mask area, is a crucial part of Mask2Former. To help the model segment small items or regions, Mask2Former uses multiscale, high-resolution features, as shown in
Figure 5. Local features were extracted by limiting cross-attention to the foreground area of the prediction mask in each query rather than focusing on the complete feature map. Compared to the traditional CNNs, the transformer introduces a self-attention mechanism to focus on local information and identify more small impact craters. Thus, Mask2Former was considered the basic model.
However, transformers lack some of the inductive biases inherent to CNNs, such as translation equivariance and locality, and therefore do not generalize well when trained on insufficient amounts of data [
54,
55]. Thus, Mask2Former requires a large benchmark dataset with annotations. In the case of an insufficient benchmark dataset, the boundaries of impact craters would be disturbed by local information. Nevertheless, if a large benchmark dataset with annotations of Martian impact craters were produced, the advantage of automated identification would disappear. To balance the performance and efficiency of identification, it is necessary to combine another model to solve the problem of false positive boundaries.
3.2.2. Mask R-CNN
Mask R-CNN [
56] can not only output bounding boxes but also masks with labels. It extends Faster R-CNN [
57] by adding a small fully convolutional network (FCN) in parallel with the existing branch. Faster R-CNN is designed for classification and bounding box regression. The FCN is designed to predict segmentation masks. With the accurate pixel mask of the FCN, the result is highly accurate. In addition, the use of RoIAlign instead of RoIPooling solves the misalignment problem caused by direct sampling through pooling, which has a large error in the pixel-level mask. RoIAlign makes the pixels in the original image and the pixels in the feature map perfectly aligned, which not only improves the detection accuracy but also facilitates instance segmentation.
Mask R-CNN requires two stages to perform classification, namely, regression and segmentation, as shown in
Figure 5. The first stage is at the same level as the RPN in Faster R-CNN, and it involves scanning images and generating area proposals. In the second stage, a branch of a fully convolutional network is added, as well as category prediction and bounding box regression. Every region of interest (RoI) could be predicted by the corresponding binary mask to mark whether the pixel is part of an object.
3.2.3. Model Selection
This method is a strategy of fusing multiple models, which is a simple method in the ensemble learning field. On the one hand, the transformer has a self-attention mechanism that can better focus on local information, while Mask R-CNN has better scale invariance features. Integrating the models of these two modes can leverage their common advantages. On the other hand, while the benchmark dataset was already sufficient for Mask R-CNN, the transformer requires a large amount of data for training. To prevent inadequate training of the transformer, Mask R-CNN can be used to supplement it. The ability of Mask R-CNN to identify all crater instances is insufficient and can be made up through a transformer.
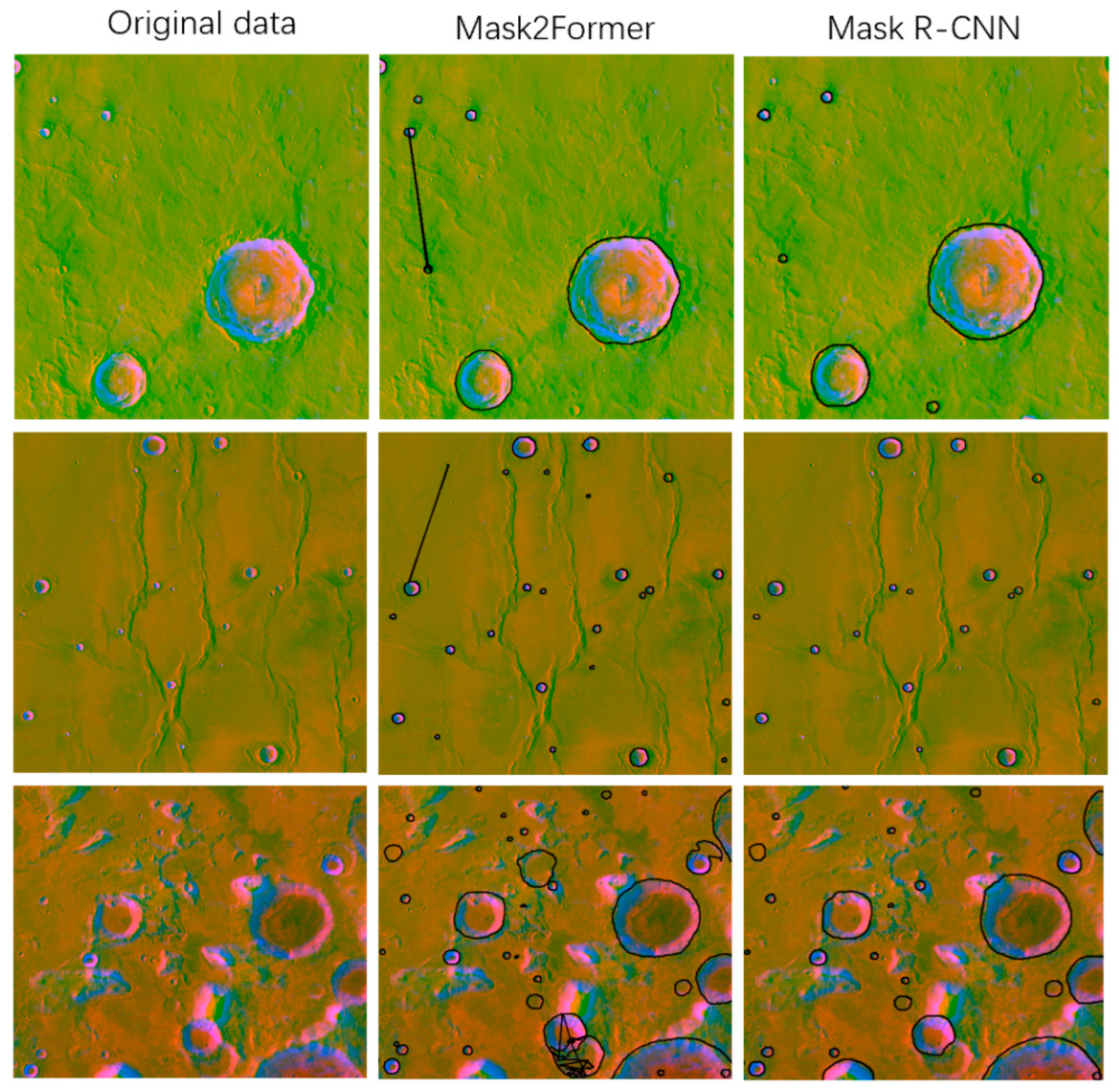
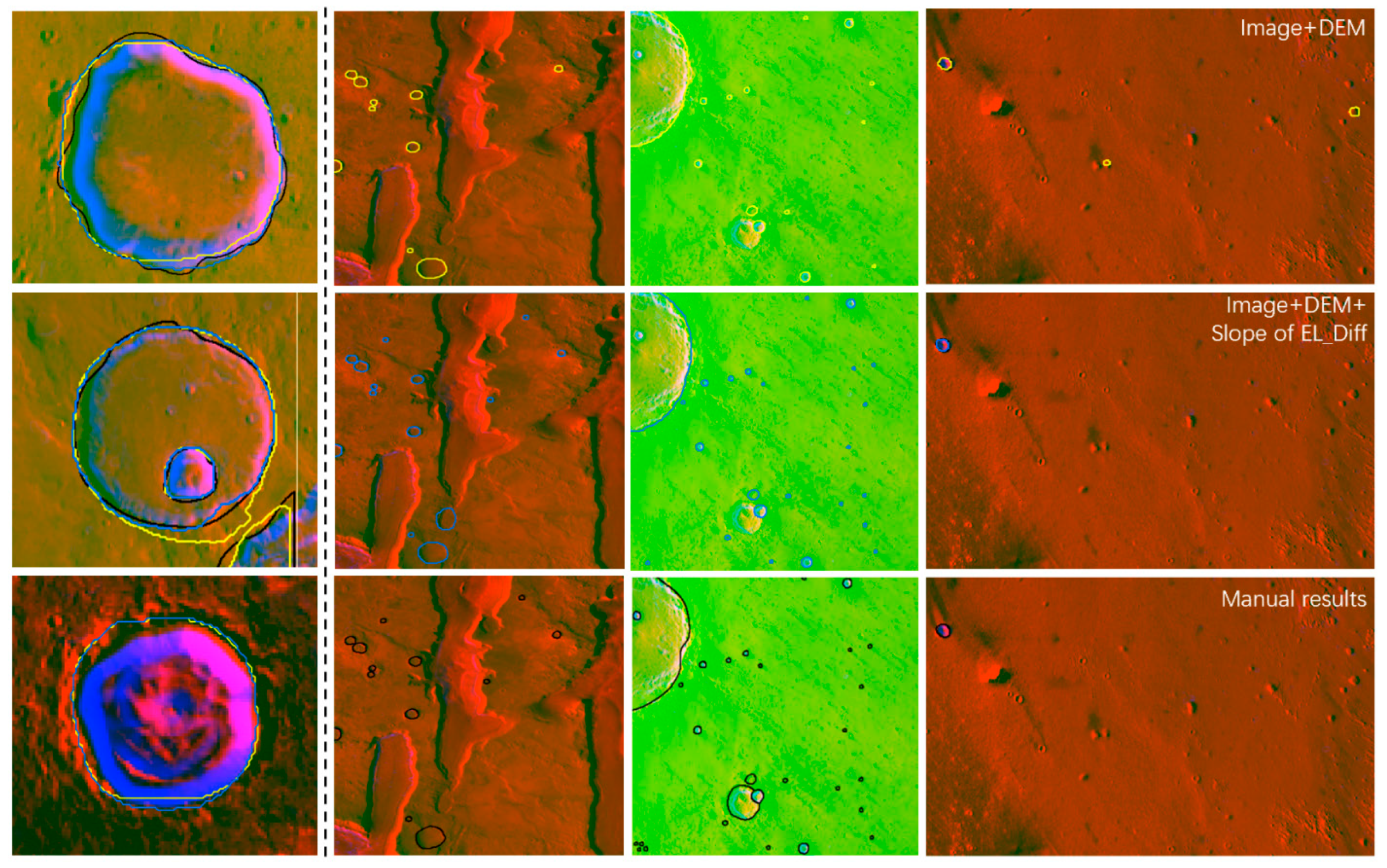
Figure 7 depicts the detection results obtained with Mask2Former and Mask R-CNN. In the second column of
Figure 7, while detecting more small craters than Mask R-CNN, Mask2Former also brings many negative effects (the results that were associated with the same crater) due to an insufficient benchmark dataset. In the third column of
Figure 7, while Mask-RCNN missed some small craters, it could avoid the excessive influence of tiny terrain compared with Mask2Former. After the experiments in
Section 4, we found that the method “Mask R-CNN + Mask2former” performed the best. Finally, “Mask R-CNN + Mask2former” was constructed to identify impact craters with a large geographic extent.
3.3. Postprocessing
The results detected by Mask R-CNN and Mask2Former were both image coordinates. The coordinates were within the range of (0~511). To build Martian impact crater catalogs, it was necessary to transform the image coordinates into geographical coordinates.
In this study, the inputs of the deep learning model were scaled to 512 × 512 pixels in Mask R-CNN, as noted in
Section 3.1. Fractures existed at the junctions of patches. Because the input images were nonoverlapping, the craters at the junctions could not be detected. Multiscale results were integrated to solve this problem.
3.3.1. Coordinate Transformation
This process is called affine transformation. Six parameters were needed for the affine transformation: the geographical coordinates of the upper left corner of the image, the horizontal and vertical spatial resolution of the image, and the image rotation coefficient. Image coordinates (
,
) were transformed into geographic coordinates (
,
) with Equations (1) and (2).
where trans[0] and trans[3] are the
x and
y coordinates of the upper left corner of the image, respectively; trans[1] and trans[5] are the horizontal and vertical spatial resolution of the image, respectively; and trans[2] and trans[4] are the image rotation coefficients. For the north-up images, trans[2] and trans[4] are equal to zero, and col and row are the row and column numbers of pixels in the image, respectively.
3.3.2. Covering the Results at Junctions
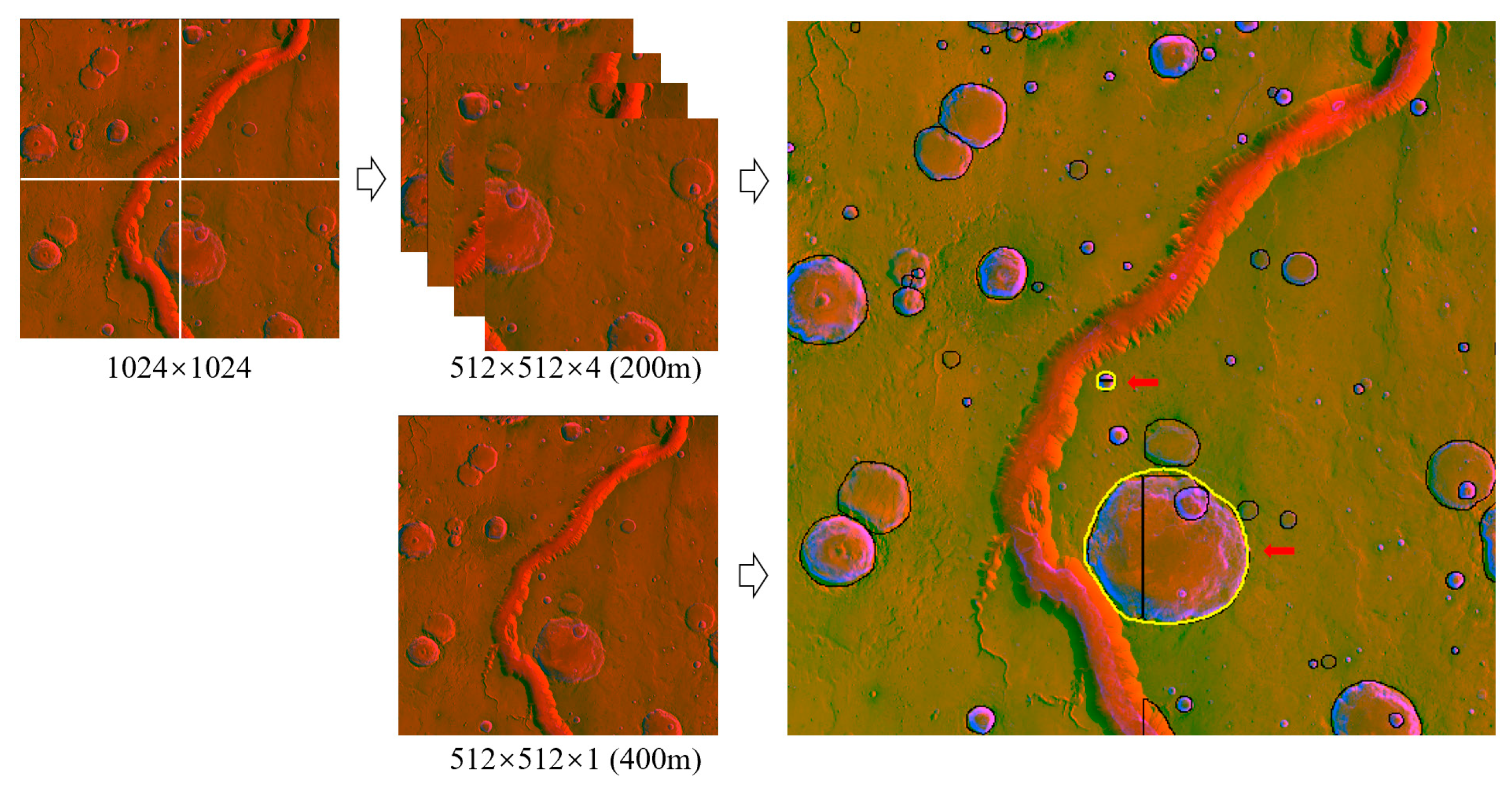
The above models could detect the craters at the junctions of images. However, obvious fractures were shown in the results. A total of 1024 × 1024 pixel patches with a spatial resolution of 200 m/px were clipped directly from the fusion data and then clipped again into 512 × 512 pixels, called fine-scale data. The 512 × 512 pixel patches with a spatial resolution of 400 m were clipped directly from fusion data, called coarse-scale data. The domains of the two datasets were different, while the number of grids was the same, as shown in
Figure 8. The domain of coarse-scale data was four times larger than the domain of fine-scale data. Fine-scale and coarse-scale patches were input into the models. The results based on fine-scale and coarse-scale data were obtained after running the above models. In the test regions, the split lines (white lines in
Figure 8) were calculated. Then, the results from the fine-scale data and the split lines were intersected to obtain the yellow lines in
Figure 8. The fine-scale results at the junctions are covered by yellow lines (from the coarse-scale data).
3.3.3. Merging Separate Results at the Patch Junctions
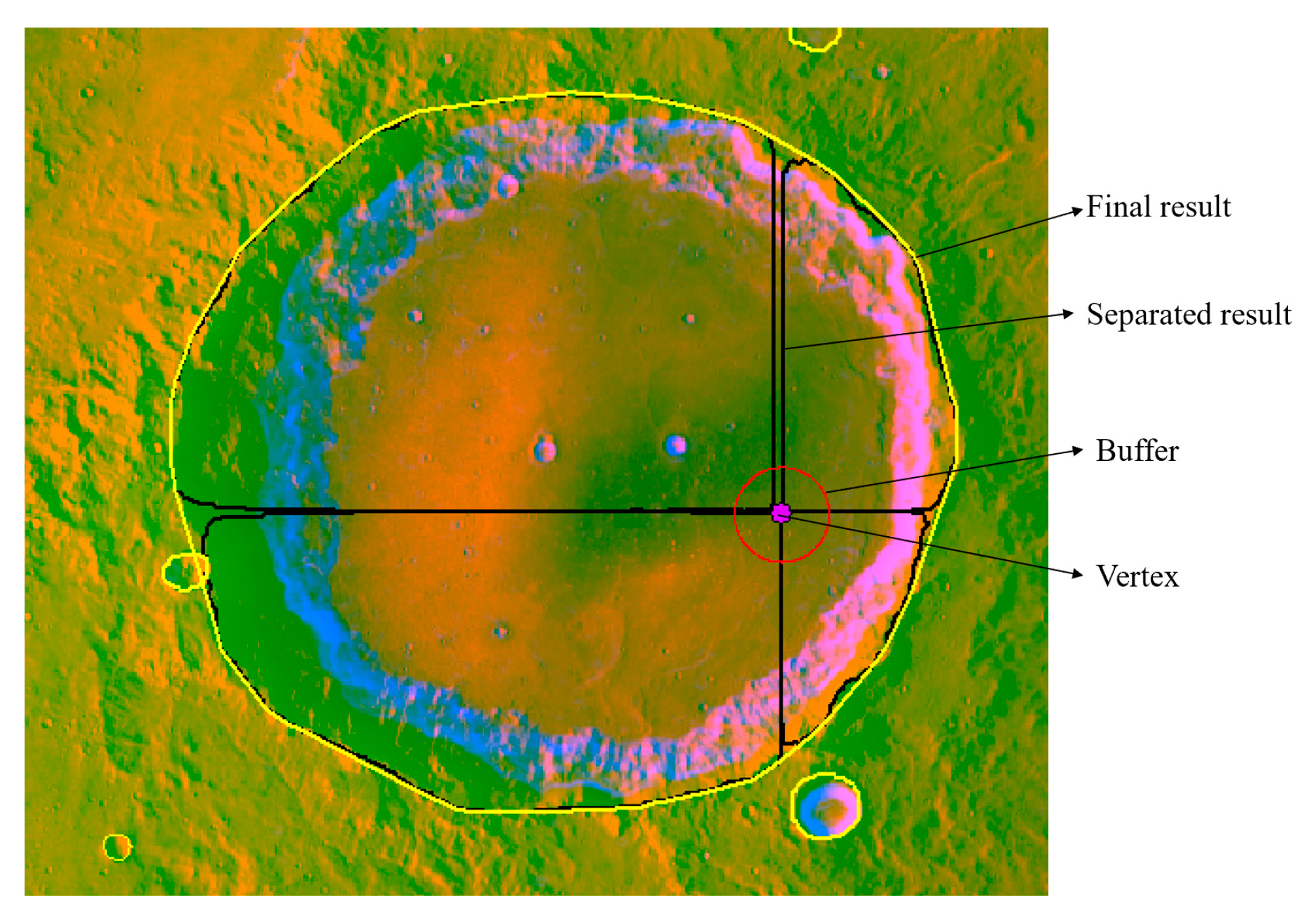
After covering the separate results at the junctions by calculating split lines, several separate results remained. For the results near the vertices of the patches, the associated identifiers were modified by obtaining the buffers of vertices, as shown in
Figure 9. Thus, the identifiers of the same impact crater were set to the same number. For the results on the edges of patches, the associated identifiers were modified manually, as shown in
Figure 10. Then, the corresponding convex hull was calculated to merge the separate results into a complete crater.
3.3.4. K-Means Clustering for the Detection Results of Mask2Former
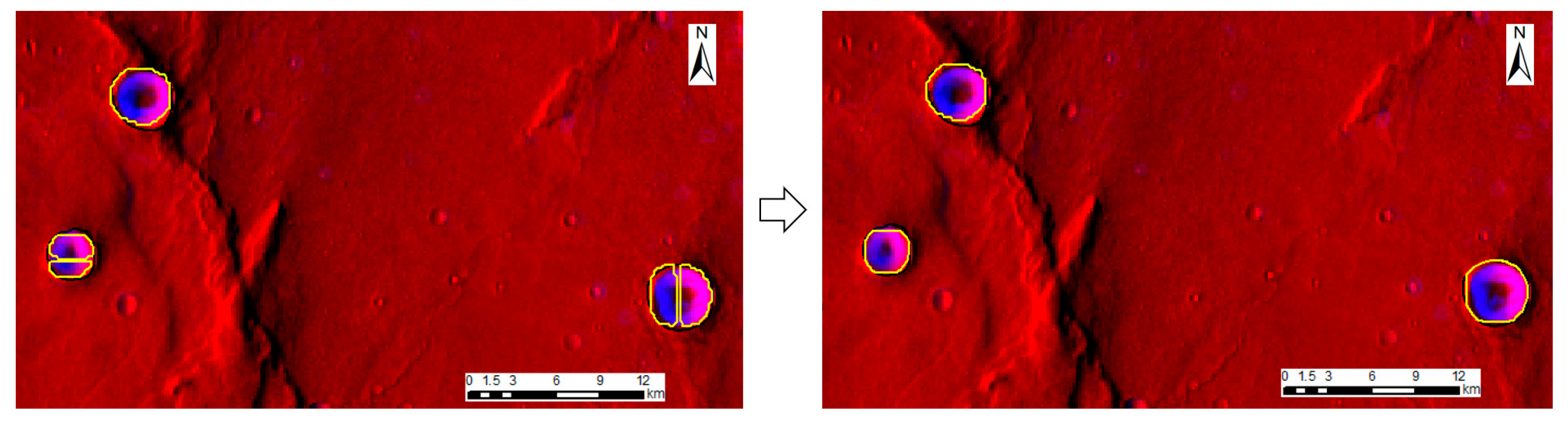
As shown in
Figure 11, two or three craters detected by Mask2Former might be connected, and the points belonging to different impact craters were mixed. To separate the mixed points, k-means clustering [
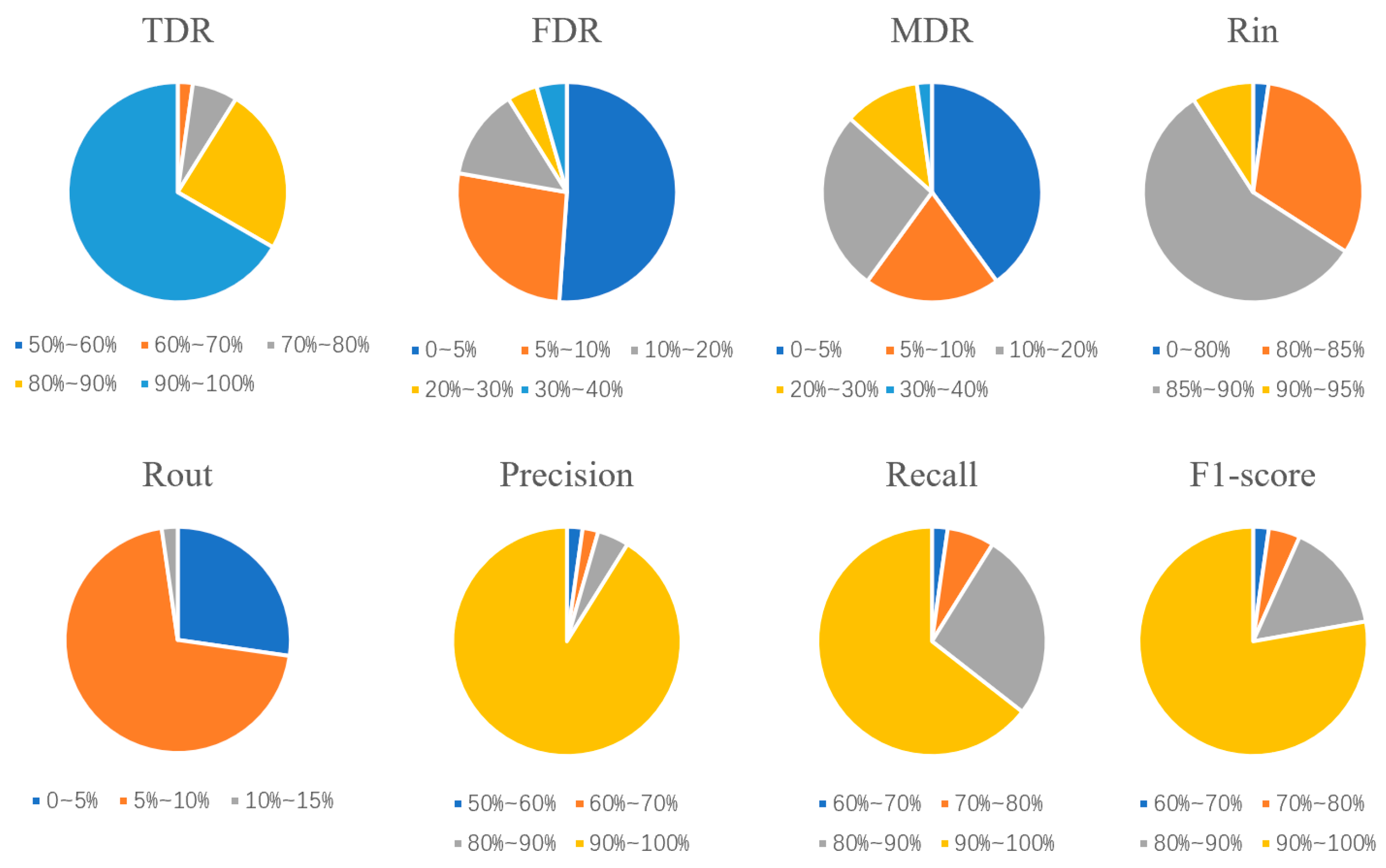
58] was used for classification. It is very important to determine the k value, which is the number of clusters. Based on the elbow method, with the increased cluster number k, the sample division becomes increasingly refined. Thus, the degree of aggregation of each cluster gradually increases, and therefore, the sum of the squared errors (SSE) naturally decreases. The k value was set to 0.6 after comparing the performance of several k values.
3.3.5. Filter with Morphological Parameters
To filter the false results from Mask R-CNN and Mask2Former, morphological parameters, such as the posture ratio, rectangle factor, and area, were used for postprocessing. Their definitions are given as follows:
- (A)
Posture ratio
The posture ratio refers to the ratio between the long side and the short side of the minimum bounding rectangle (MBR). The posture ratio was used to filter the results that were associated with the same crater (the negative effects in the second column of
Figure 7). In general, the MBR of these results was a rectangle with a high posture ratio. The posture ratio was calculated as follows using Equation (3):
where
L is the length of the MBR,
W is the width of the MBR, and
is the posture ratio of the impact crater.
- (B)
Rectangle factor
The rectangle factor refers to the ratio between the area of the impact crater and the area of the corresponding MBR. The rectangle factor reflects the fullness in the MBR, which can be calculated using Equation (4):
where
is the area of the impact crater,
is the area of the MBR, and
is the rectangle factor of the impact crater.
After filtering with the posture ratio and rectangle factor, the results from Mask2Former were filtered based on the area because many small craters with diameters smaller than 2 km were identified.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















