1. Introduction
Deep learning (DL) for automatic modulation classification (AMC) is gaining increasing attention in cognitive radio and spectrum sensing technologies. This approach can support the refarming of spectrum resources with low utilization, which is crucial for developing 5G/6G wireless communications. AMC [
1] refers to the identification of the modulation schemes of an unknown signal received with limited prior knowledge for use in scenarios such as electromagnetic situational awareness [
2], cognitive radio [
3], dynamic spectrum access [
4], and interference identification [
5]. Classical AMC methods can be divided into maximum-likelihood hypothesis testing based on decision theory and pattern recognition based on feature extraction [
6]. The likelihood ratio test methods are optimal in terms of Bayesian estimation for their classification results. However, the identification process requires higher prior knowledge and has stringent hypothesis constraints. Moreover, a suitable likelihood ratio function for different modulation schemes is required [
7,
8], and the calculation complexity of the likelihood ratio function is high. Therefore, pattern recognition based on feature extraction methods [
9,
10] is widely used in practice. However, owing to ever-emerging complex signals and increasingly crowded electromagnetic environments, feature extraction methods face several challenges, including difficulty setting manual feature thresholds and achieving optimal combinations subjectively, resulting in poor adaptability to complex environments, complex modulation schemes, and similar modulation schemes. Furthermore, these methods have low classification accuracy under low signal-to-noise ratio (SNR) conditions.
To address these challenges, recently, deep learning (DL) has been applied to AMC. DL methods do not require manual design or the extraction of signal features. Neural networks can adaptively extract and infer modulation signal features that are more robust and generalizable. The mainstream DL technologies include convolutional neural networks (CNN), recurrent neural networks (RNN) [
11], and some hybrid models, which show superior performance over classical methods in AMC.
Currently, most AMC approaches obtain experimental datasets through three main methods: MATLAB/GNU radio simulation, data collection in a single real scenario, and direct use of publicly available datasets, such as RML 2016 and 2018 [
12]. A part of the generated/sampled/publicly obtained sample data is used to train neural networks, and another part is used to test and verify the method’s effectiveness. In the research process, optimization is primarily conducted on the data or the neural network model to enhance classification performance. Appropriate data preprocessing can maximize the differences between different modulation schemes, thus ensuring improved classification by the neural network. The network model and hyperparameters can also be fine-tuned to AMC tasks.
However, existing DL-based AMC algorithms often encounter specific problems and challenges in practical applications. First, many studies predominantly rely on monomodal information from a single depicting dimension, disregarding the complementarities that multimodal information can generate to better adapt to complex scenarios with different SNR and channel variations. Based on signal representation and preprocessing [
13], the existing DL-based AMC algorithms are divided into four categories: feature representation (such as higher-order cumulants (HOCs) [
9] and spectral features [
10]), image representation (such as constellation diagram [
14], feature point image [
15], eye diagram [
16], and spectral correlation function image [
17]), sequence representation (such as in-phase and quadrature (IQ) sequences [
18], amplitude and phase (AP) sequences [
19], fast Fourier transformation sequences [
20]), and combined representation [
21,
22,
23]. Increased modal space has been theoretically proved to provide more comprehensive knowledge to improve network performance [
24]. Therefore, the use of multimodal information, such as features, images, and sequences, is inevitable in future AMC algorithms. Second, training and test data used currently in DL-based AMC algorithms are generated from the same datasets, assuming they come from the same feature space and follow the same feature distribution. However, time, space, transmitter and receiver performance differences, and channel multipath delay inevitably give rise to notable distinctions in feature distributions between the source and target domain data (defined as the unsupervised non-partial domain adaptation (NPDA) problem for AMC). When the trained model is directly used to test new data, it performs poorly. In practical scenarios, the difficulty in acquiring accurate labels for data in the target domain data hinders the direct utilization of the data for training the network. This is the primary reason for the observed degradation in the performance of trained models. Employing unlabeled data in the target domain for training is a feasible approach to the above problem. Finally, existing research assumes the same modulation classes without considering that the modulation classes of the target domain are often less than those of the source domain (i.e., the target domain class is a proper subset of the source domain class, defined as the unsupervised PDA problem for AMC). Hence, applying nonpartial domain-adaptive AMC algorithms directly to such scenarios can result in negative transfer owing to their global alignment strategies, thereby reducing the method’s performance.
Several studies have attempted to resolve these issues. Insufficient monomodal information representation capability was addressed by converting signals into a two-dimensional image through time-frequency transformation and combined with handcrafted features to form joint features [
23]. The simulation result revealed that CNN models using a fusion strategy achieve favorable classification performance under low SNR conditions. However, after conversion of the raw I-Q sequences into images, the data increase exponentially, and the computation complexity of extracting higher-order cumulants and circular features also increase significantly, affecting classification efficiency. To address the problem of deep neural network model mismatch caused by feature distribution differences between the source and target domains, sharp deterioration in classification performance, and numerous unutilized and unlabeled target domain data samples, adversarial-based domain adaptation (DA) methods [
25,
26] have been proposed [
27,
28,
29]. Discrepancy-based DA methods have been used in [
30] for cross-domain AMC on self-built and public datasets [
31]. These methods achieved better performance improvements than no transfer learning (TL). However, the above studies did not consider cross-domain AMC issues under multiple parameter changes, such as sampling rate, SNR, and channel, or conduct in-depth research on unsupervised PDA problems using multimodal information.
We propose a novel multimodal information and TL framework for cross-domain AMC to address the aforementioned issues. The contributions of this study are summarized as follows.
- (1)
We adopted a multimodal information fusion strategy based on signal time-domain and frequency-domain features, which enables the leverage of the complementary benefits of different modalities to improve the network’s understanding of the input. With the same network structure, our approach achieves improved classification performance.
- (2)
We introduced TL to transfer knowledge from the source domain to the target domain. By leveraging a large amount of unlabeled data in the target domain and aligning the distribution of modulation signal data between the source and target domains using a domain adversarial neural network (DANN), we proposed an unsupervised DANN method that addresses the problem of unsupervised NPDA when multiple parameters vary between the source and target domains.
- (3)
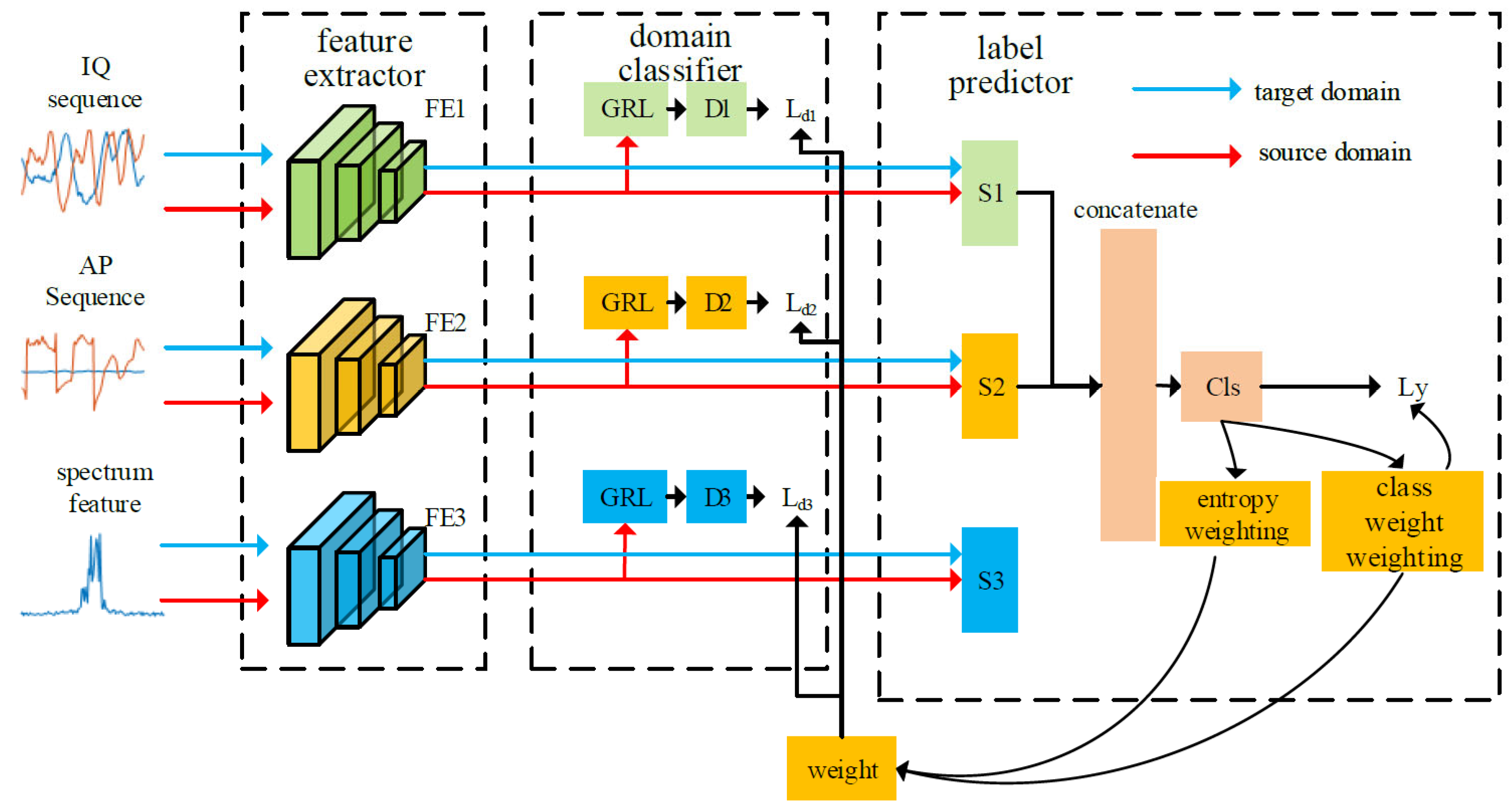
We designed a class weight weighting and entropy weighting mechanism to improve the weight of shared class data samples and effectively address the PDA problem, particularly in scenarios where the number of modulation signal classes in the target domain is smaller than that in the source domain.
- (4)
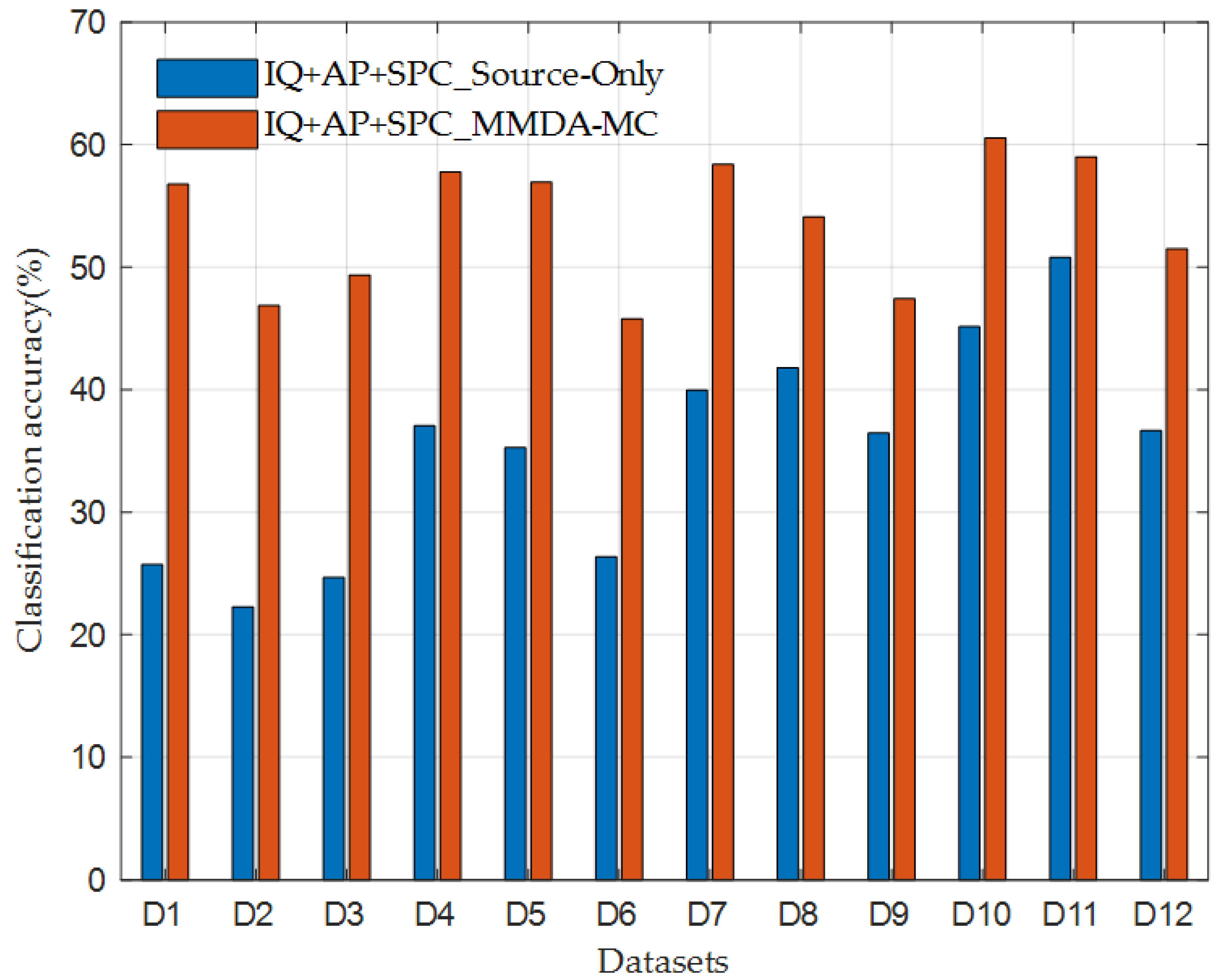
We conducted extensive experiments on two datasets explicitly designed to validate the effectiveness of our approach. The results demonstrated that our method achieves higher classification accuracy in different DA tasks compared with the baseline methods.
The remainder of this study is organized as follows.
Section 2 introduces the system model, including the cross-domain learning model, cross-domain AMC model, and calculation computation of multi-modal feature inputs.
Section 3 details the proposed classification approach, including multimodal information fusion, architecture, and training steps.
Section 4 presents the experimental results and their detailed analysis. Finally,
Section 5 concludes this study. The list of abbreviations and notations used in the article are presented in
Table 1 and
Table 2, respectively.
2. System Model
We will first introduce the cross-domain learning model, then define the cross-domain AMC problem, and finally describe the computation method of multi-feature input adopted in this study.
2.1. Cross-Domain Learning Model
The research methodology employed in this study to resolve the cross-domain AMC problem is based on transfer learning principles. Particularly, we adopt the DANN to align the training and testing data domains.
2.1.1. Transfer Learning
The major task of TL is to transfer learned knowledge from the source to the target domain to improve the learning process of the target task [
25]. Thus, we first define “domain” and “task”. A domain
comprises a feature space
and marginal probability distribution
in which
where
is the
-th feature vectors in
. Hence,
. A task
T in
comprises a label space
and a predictive function
in which
, where
is the
-th label in
. The predictive (or decision) function is learned from the feature vector and label pairs
. Additionally, the predictive function represents the prediction of the corresponding label
given instance
. In this case, the predictive function can be defined as
. Hence,
.
Now, we can formally define TL as follows. Given a source domain with a corresponding source task , and a target domain with a corresponding source task , TL aims to learn the target predictive function by leveraging the knowledge gained from and , where or . Note that implies that and/or . When , the feature space of the source and target domains differ. Similarly, when the marginal distributions of the source and target domain differ. Another scenario of TL is , where and/or . When , the label space of the source and target domains are different. When , the conditional probability distributions of the source and target domains are different.
2.1.2. DANN
In this study, we treat the source and target domains as a whole and train a domain classifier to achieve feature alignment between the two domains. The objective of the domain classifier is to ensure that the deep features extracted from the source and target domains are aligned in the same feature space. This addresses the parameter sensitivity issue that can cause deep-learning-based modulation recognition methods to fail.
Our method utilizes DANN to align the distribution of the source and target domains, thus avoiding the manual designing of the distance losses between the source and target domains. During training, the network spontaneously learns what should be aligned between the two domains and to what extent. This approach typically yields improved results.
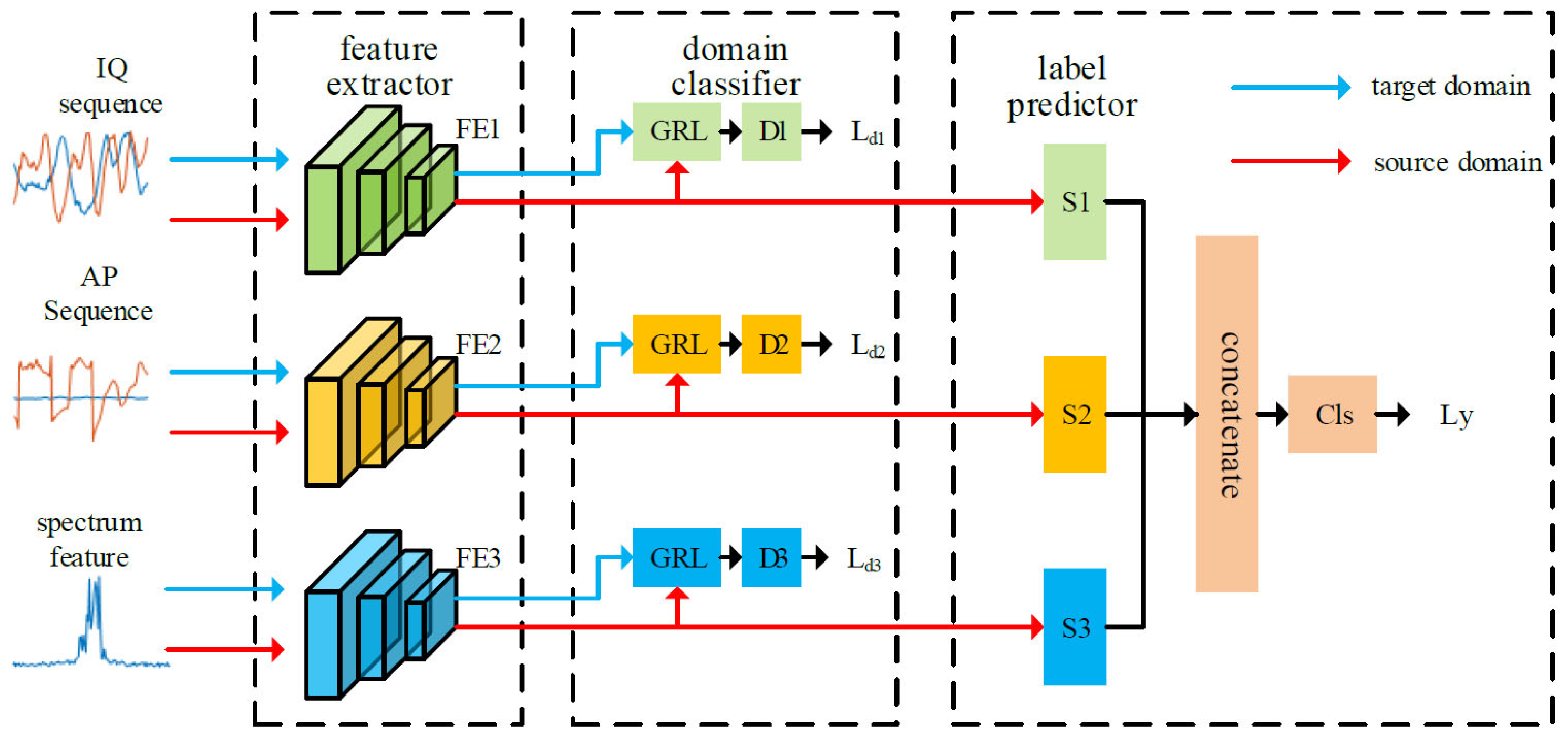
DANN [
25] is a representation learning approach for DA in which the training and test data come from similar but different distributions. The advantage of the DA approaches is the ability to learn a mapping between domains when the target domain data are either fully unlabeled or have few labeled samples. DANN’s architecture consists primarily of a feature extractor, label predictor, and domain classifier (
Figure 1). The learning feature is required to be domain-invariant except for discriminativeness. Therefore, the domain classifier is designed to discriminate whether the underlying features is from the source or target domain during training. The gradient reversal layer (GRL) [
25] propagates the domain classification loss back to the feature extractor, with the weight of the loss function controlled by a hyperparameter λ. Through gradient reversal, the domain adversarial network maximizes the loss of domain classifier while minimizing the loss of the label predictor.
The loss function consists of the source and domain classification loss. The source domain classification loss is used to ensure that the neural network performs well on the source domain data. The domain classification loss aims to align the data distributions of the source and target domains so that the neural network trained on the source domain can also exhibit good classification performance on the unlabeled target domain. By jointly optimizing the source and domain classification loss, we can train a neural network with good generalization performance, enabling it to perform effectively in the target domain.
The core idea of this approach is to use the domain classifier to guide the feature extractor in learning feature representations that have discriminative performance for both the source and target domains. By aligning the source and target domain data features, we can resolve the issue of ineffective deep-learning-based modulation recognition methods caused by parameter sensitivity and improve the model’s generalization performance on unlabeled data.
Therefore, DANN must accomplish the following two core tasks during training. The first task is to accurately classify the source domain data to minimize the loss of the label classifier. The second task is to confuse the source and target domain data to maximize the loss of the domain classifier. The objective function of DANN can be represented as follows.
where
is the feature extractor with parameters
;
is the label predictor in the source domain with parameter
;
is the domain classifier with parameter
; and the number of samples in the source and target domain is denoted as
and
, respectively. Further,
and
are the source domain category label (only the data in the source domain has the category label) and the domain label (both the source and target domain data have the domain label), respectively;
is the weight coefficient; and
and
represent the cross-entropy loss function obtained by finding the saddle point
,
,
such that
A saddle point can be found as a stationary point of the following gradient updates.
where
is the learning rate.
Ref. [
25] added GRL to achieve true end-to-end training and avoid the two-stage training process where the generator and discriminator parameters are fixed separately, as in generative adversarial networks (GANs). Mathematically, we can formally treat the GRL as a “pseudo-function”
defined by two (incompatible) equations describing its forward and backpropagation behavior:
where
is an identity matrix. It is worth noting that Equations (7) and (8) define a trainable network layer that does not require parameter updates. It can be easily implemented using existing deep learning tools, specifically by defining the procedures for forward propagation (identity transformation) and backpropagation (multiplication by −1).
Then, we can define the objective “pseudo-function” of
that is being optimized by the stochastic gradient descent as follows:
2.2. Cross-Domain AMC
The cross-domain AMC problem based on unsupervised DA comprises the source domain with labeled samples and target domain with unlabeled samples. Here, represents a single source-domain-modulated signal sample, with a corresponding label ; and represents a single-target domain-modulated signal sample without a label. Let us assume that the label space of the source domain contains types of radio signal and is denoted as . Similarly, the label space of the target domain contains types of radio signal and is denoted as .
2.2.1. Unsupervised NPDA Problem
For the problem of unsupervised NPDA, we assume that the source and target domains have the same number of labels and label types for radio signals, thus indicating that the domains have the same label space. Let
and
denote the marginal probability distribution of the two domains, where
. The primary objective is to transfer knowledge from the source to the target domain and align the distribution between the target and source domains.
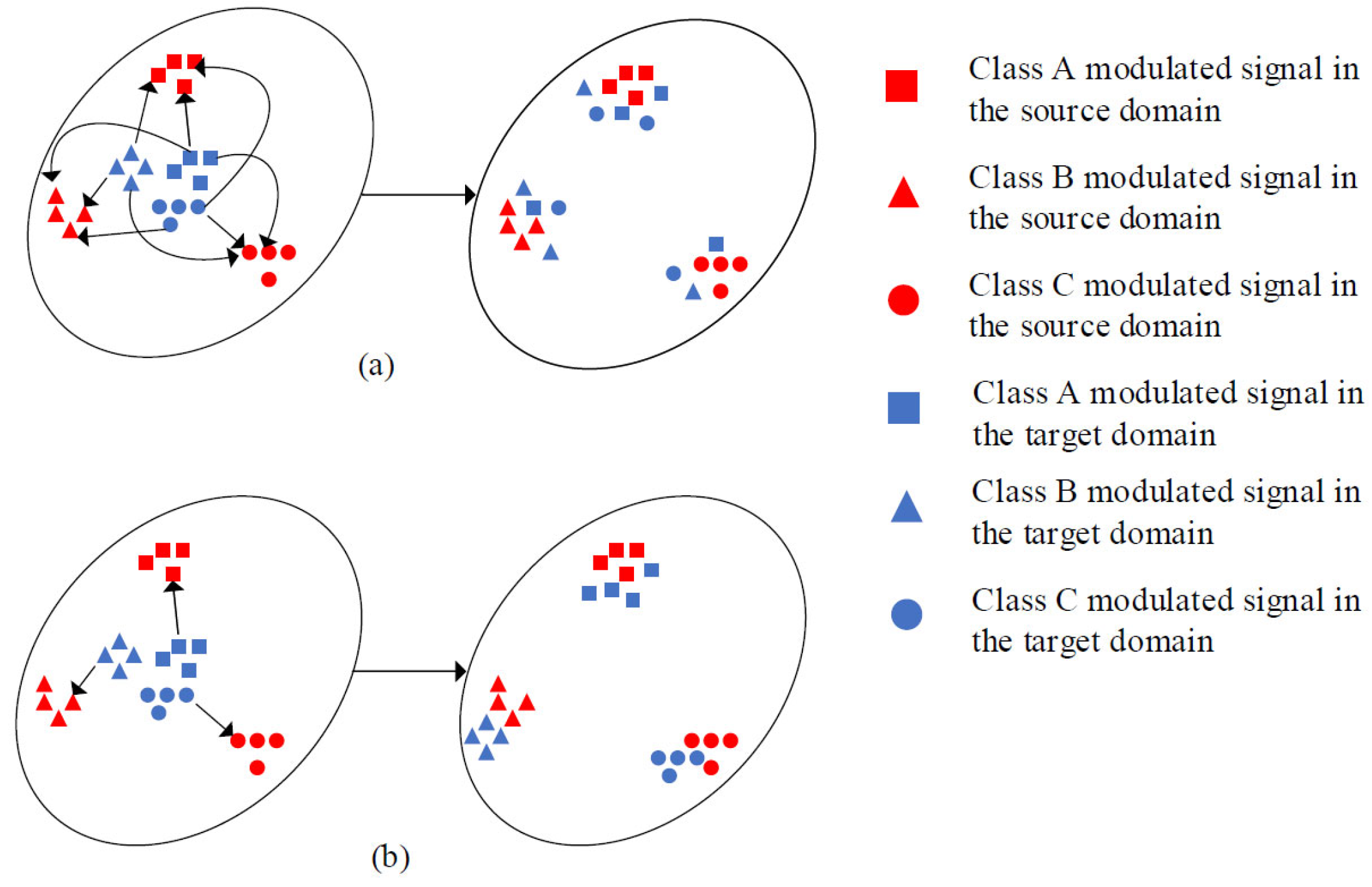
Figure 2 is the schematic of the DL-based AMC method directly applied to the unsupervised NPDA problem of AMC and the expected effect to be achieved using the unsupervised NPDA method.
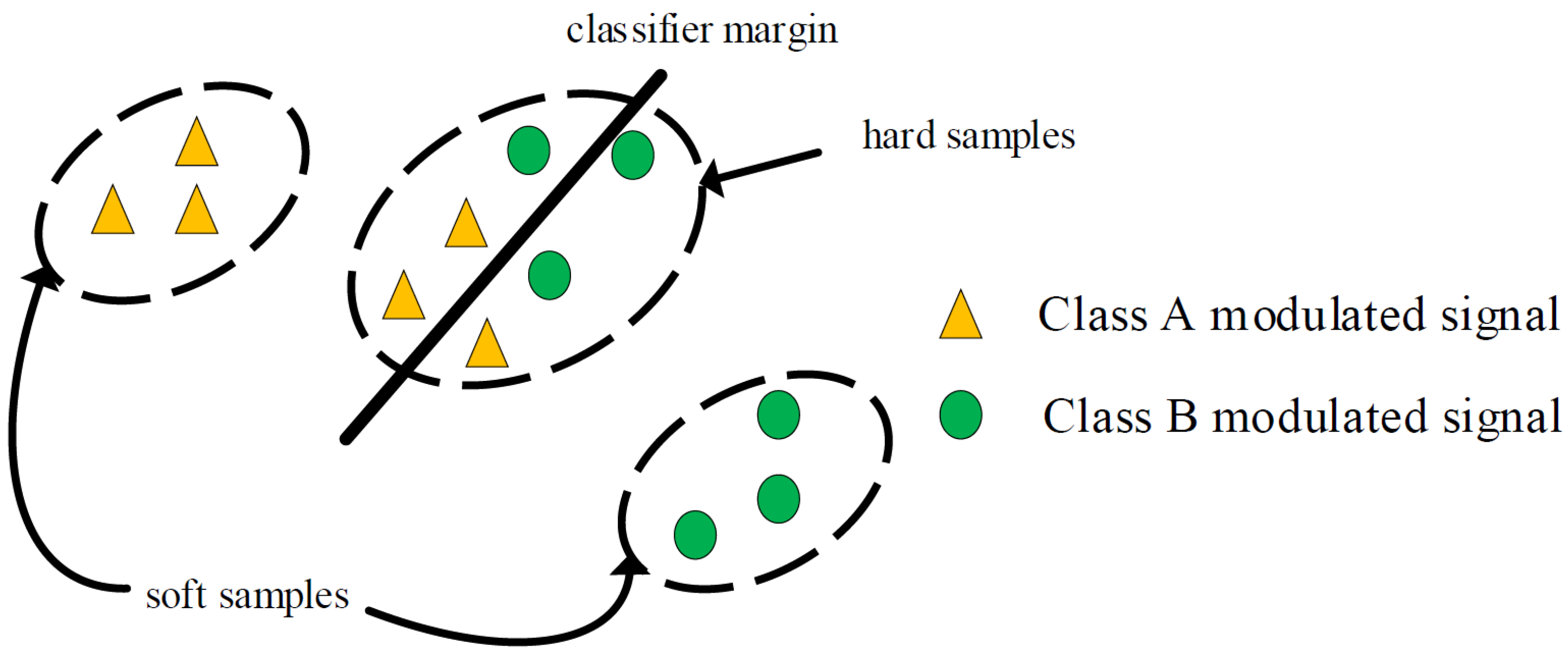
2.2.2. Unsupervised PDA Problem
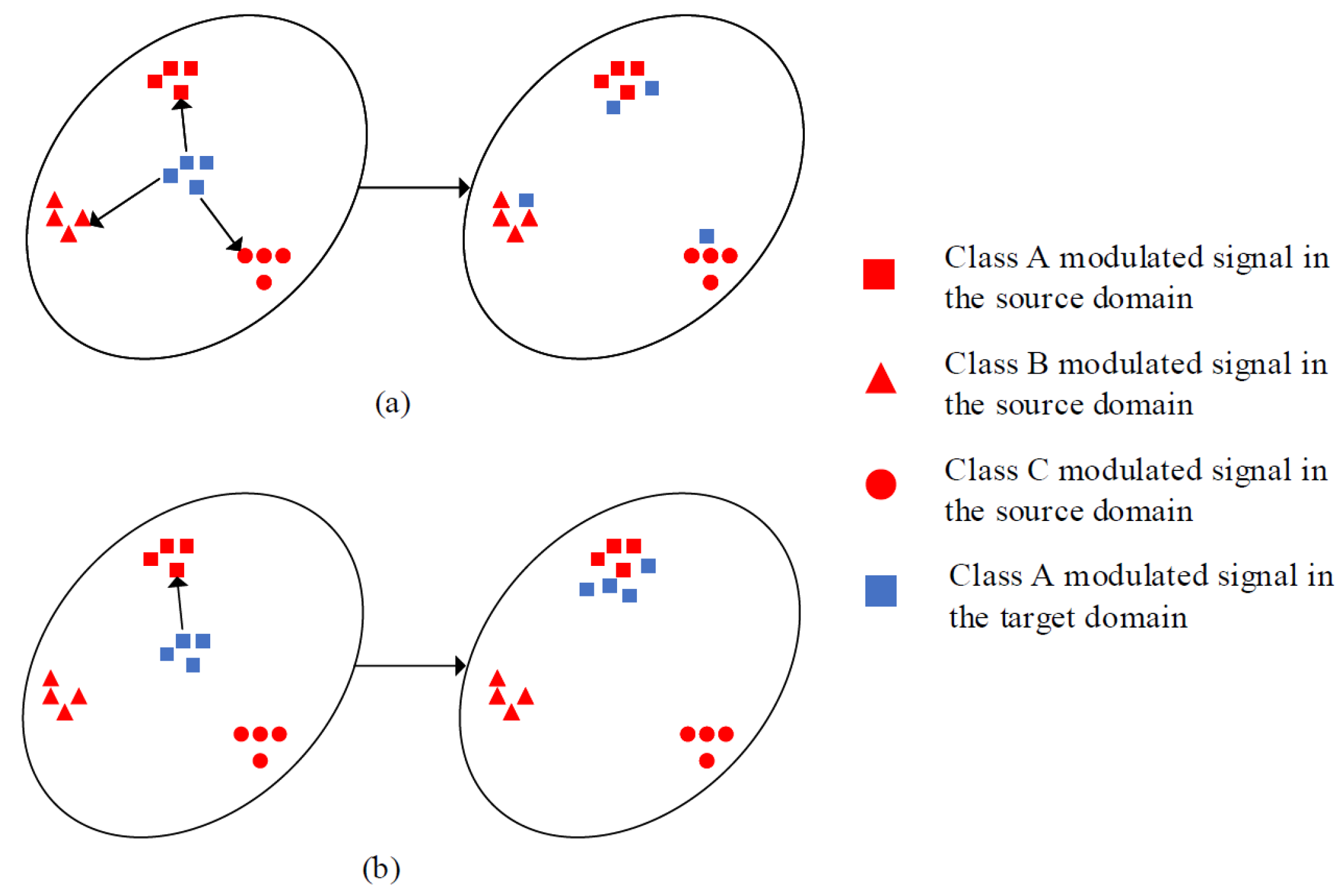
For unsupervised PDA problem, we assume that the label space of the target domain is a proper subset of the source domain, i.e., . Here, and denote the marginal probability distribution of the two domains, where , and denotes the marginal probability distribution of source domain samples with labels shared by the two domains, which differs from that of the target domain. The main objective of unsupervised PDA is to align the fine-grained shared label distributions.
In addition to the challenges of different distributions between the source and target domains of the modulated signal and the lack of labels in the target domain, adaptation also involves the difficulty of not knowing the shared label space for the source and target domain modulation signals during training as the label space of target domain
is unknown at that time [
32]. This poses two technical challenges.
First, directly applying unsupervised NPDA AMC algorithms aligns the global distributions of both domains, thus causing negative transfer due to the existence of outlier classes denoted as
(i.e., signal categories only included in the source domain modulation dataset). Therefore, the matching of outlier classes should be avoided. Second, aligning the distributions of
and
to promote positive transfer is goal of this study. Thus, eliminating or reducing the impact of outlier classes in the source domain and promoting the transfer of shared classes (i.e., signal categories included in the source and target domain modulation datasets) from the source domain to the target domain is critical.
Figure 3 illustrates this problem, considering a simple case with three modulation signal categories in the source domain and only one in the target domain.
2.3. Multimodal Feature Input Calculation
The AMC method based on image representations (such as eye and constellation diagrams) depends on the accurate estimation of signal modulation parameters; thus, it cannot to classify noncooperative received signals. The length of the sampled data considerably influences the accuracy of estimating higher-order cumulant features is computationally complex.
Therefore, under the noncooperative reception condition, we aimed to reduce computational complexity and data volume while fully using the signal’s multimodal features. We used IQ and AP sequences from the signal’s sequential representation and spectral amplitude and squared signal’s spectral amplitude from the feature representation as inputs to the network. Assuming that the baseband complex signal obtained after the received signal is , the detailed calculation methods are as follows.
IQ sequence (I): The in-phase and quadrature components of the signal are the real and imaginary parts of the signal, as follows:
The first modality
is the imaginary part and real part of the received signal, which is expressed as:
Spectral amplitude and squared signal’s spectral amplitude (S): Calculate the spectral amplitude of the signal, as follows:
where | • | denotes the modulus operation.
Calculate the squared signal’s spectral amplitude, as follows:
The second modality
consists of the spectral amplitude and the squared signal’s spectral amplitude, which is expressed as
where
represents spectral features of the received signals in the frequency domain for DL models to recognize frequency and phase modulated signals.
AP sequence (A): Calculate the normalized instantaneous amplitude of the signal, as follows.
This feature can reflect the amplitude variation of different modulated signals, which is helpful for DL models to recognize amplitude-modulated signals.
Calculate the instantaneous phase of the signal, as follows.
where the value of
is
.
The third modality,
, comprises instantaneous amplitude and instantaneous frequency, which is expressed as:
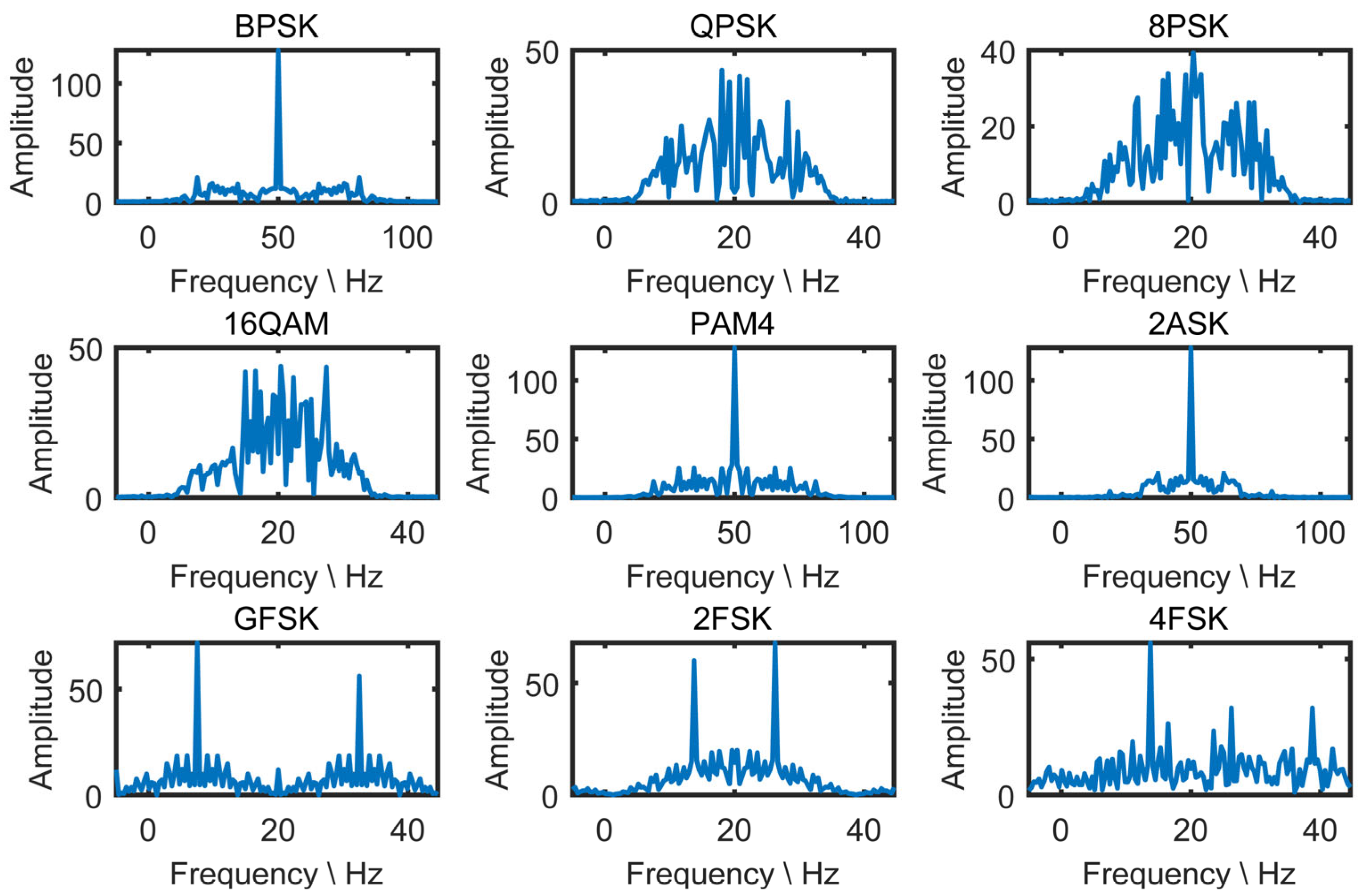
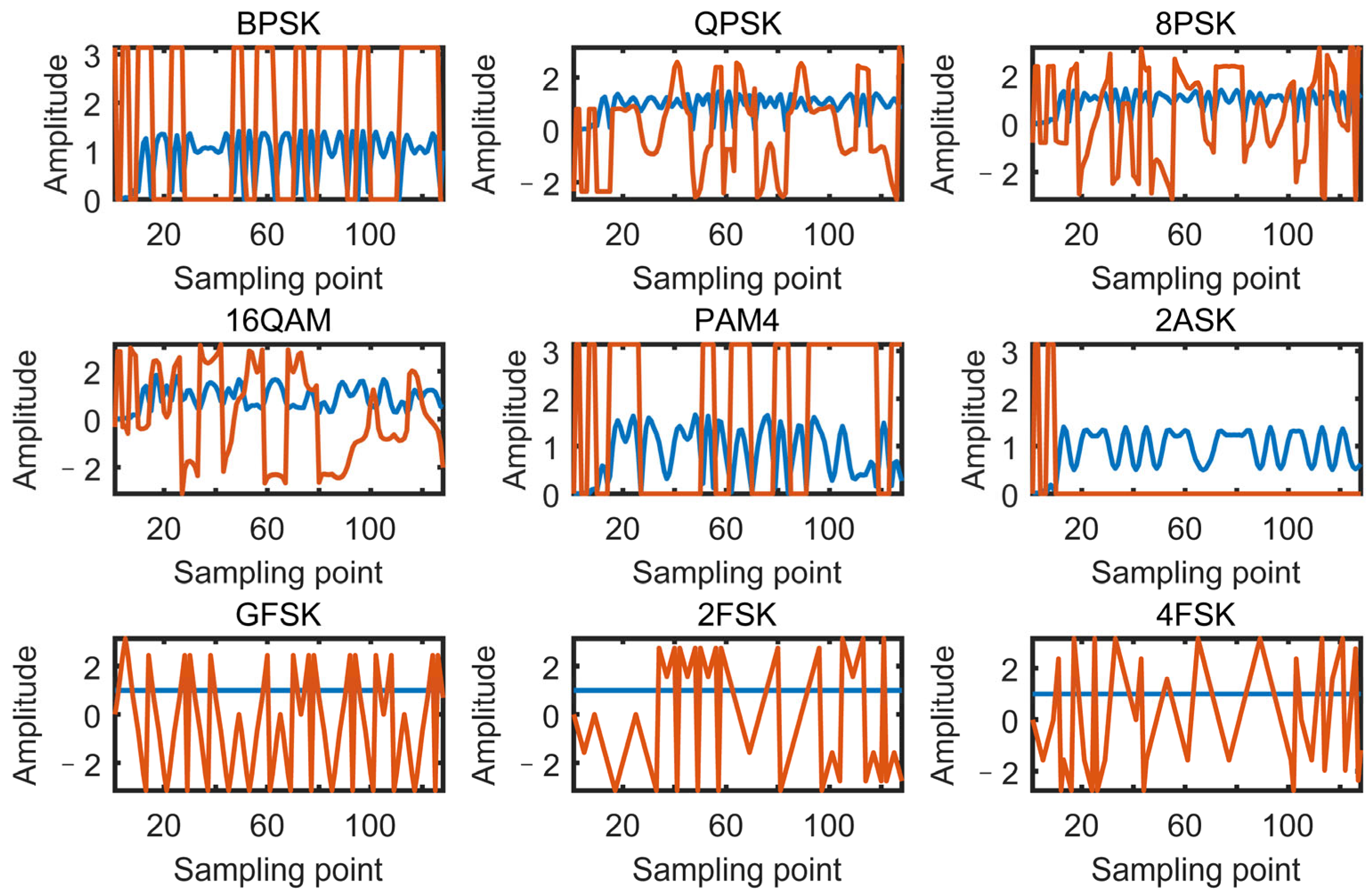
Figure 4,
Figure 5,
Figure 6 and
Figure 7 present the schematic of features extracted from nine modulation schemes, namely 8PSK, BPSK, 2FSK, 4FSK, 2ASK, GFSK, PAM4, QAM16, and QPSK.
The complementarity between the first and third modalities (IQ and AP) has been proven in previous research [
33,
34]. It has been shown that (1) algorithms that utilize AP as input data outperform IQ algorithms at high SNR but show opposite results at low SNR; (2) the features extracted from IQ and AP exhibit complementary characteristics.
Furthermore, selecting features with stronger representational power can enhance the performance of existing deep-learning-based AMC. For instance, when ASK has to be distinguished from other signals, choosing instantaneous amplitude features may yield more effective results. Similarly, when differentiating PSK from other signals, selecting instantaneous phase features may be preferred. When the task is to distinguish FSK from other signals, instantaneous frequency features can be a suitable choice. Lastly, constellation mapping can represent a feature of differentiating higher-order modulation schemes.
Therefore, the utilization of modal information should be determined based on the specific signal categories and their corresponding feature selection. The multi-modal feature input that we have chosen here is provided as an example.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}