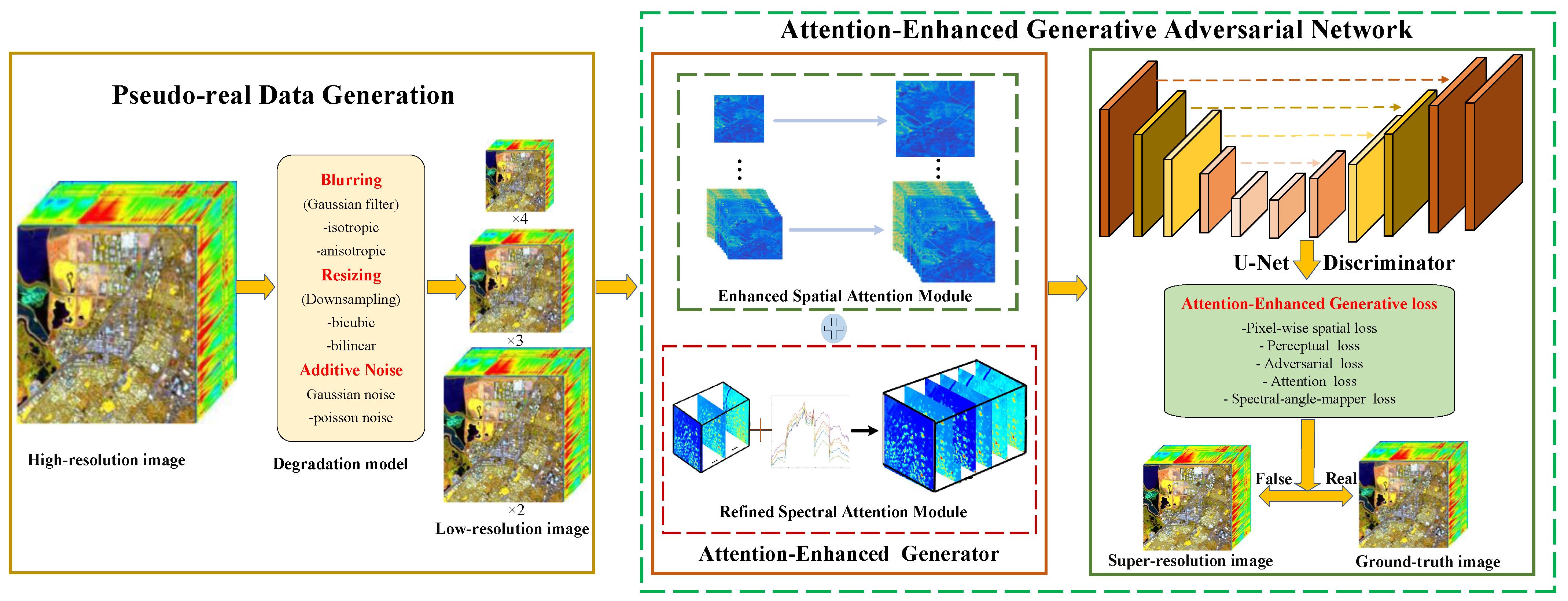
In this section, numerous experiments are performed to evaluate the performance of the proposed AEGAN method. First, the experimental hyperspectral remote sensing datasets, implementation details, and quantitative evaluation criteria are introduced. Then, several relevant ablation studies, as well as comparative experiments with existing state-of-the-art, are conducted on both pseudo-real datasets and benchmark datasets.
4.1. Experimental Datasets and Implementation Details
In the experiment, three publicly available real datasets of hyperspectral remote sensing scenes (available online at
http://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes, accessed on 9 January 2022) (Pavia University dataset, Pavia Center dataset and Cuprite dataset) are employed as original HSIs for validation. The Pavia University dataset covers 103 bands of the spectrum from 430 nm to 860 nm after discarding the noisy band and bad-band, containing 610 × 340 pixels in each spectral band with a geometric resolution of 1.3 m. The Pavia Center dataset collects 102 spectral bands after discarding bad-bands, comprising a total of 1096 × 1096 pixels in each spectral band. While in the Pavia Center scene, information on partial areas is not available, and only 1096 × 715 valid pixels remained in each spectral band. The cuprite dataset captures 202 valid spectral bands in the spectrum from 370 nm to 2480 nm after the corrupted bands’ removal, and each band consists of 512 × 614 pixels.
The input LR samples (the pseudo real data) are generated from original HSI samples by the high-order degeneration model with scaling factors of 2 and 4. The original HSI serves as the reference authentic image . For the employed three data sets, to testify to the effectiveness of the proposed AEGAN approach, some patches in size of 150 × 150 × L pixels with the richest texture details are cropped as testing images, and the remaining parts are utilized as training samples. To cope with the issue of inadequate training images, the training samples are augmented by flipping horizontally and rotating for , , . Therefore, the size of the LR HSI samples could be 36 × 36 × L or 72 × 72 × L, and the corresponding output HR HSIs are 144 × 144 × L.
The adaptive moment estimation (Adam) optimizer [
58] with default exponential decay rates
and
is adopted for network training. All of the network training and testing is implemented on four NVIDIA GeForce GTX 1080Ti GPU adopting Pytorch (available online at
https://pytorch.org, accessed on 9 January 2022) frameworks. Due to the constraint of GPU memory, following [
55], the batch size is assigned to 16 and the initial learning rate is allocated to 0.0001, while the learning process is terminated in 2500 epochs. Coefficients of attention-enhanced generative loss function are empirically allocated as
,
,
, and
, respectively. Moreover, during training, to retain the spatial size of feature map after convolution, zero-padding operation is applied in all convolutional layers.
4.2. Evaluation Metrics
To comprehensively evaluate the performance of the developed HSI SR approach, several commonly used evaluation metrics are adopted, including the mean peak signal-to-noise ratio (MPSNR), the mean structural similarity index (MSSIM), the erreur relative global adimensionnelle de synthese (ERGAS), and the spectral angle mapper (SAM). MPSNR describes the similarity match based on the mean-square-error, and the MSSIM represents the structural consistency between the recovered HSI and the ground-truth one. In this work, both MPSNR and MSSIM are measured by the mean values in all spectral bands. ERGAS is a global image quality indicator measuring the band-wise normalized root of MSE between the super-resolved image and the authentic one. For spectral fidelity, and SAM investigates the spectral recovery quality by estimating the average angle between spectral vectors of the recovered HSI and the actual HSI. MPSNR close to and MSSIM close to 1, and SAM and ERGAS close to 0, denote a better reconstructed HR HSI.
Given a super-resolved HR HSI
and an authentic HSI
, the above-mentioned evaluation metrics can be respectively formulated as follows:
in which
indicates the maximum intensity of the
k-th band of HSI.
,
and
,
denote the average values and variances of
and
, respectively.
stands for the covariance between
and
.
and
are two constants to improve stability, which are set to 0.01 and 0.03, respectively.
stands for the dot product of two spectra vectors,
denotes the
-norm, and
s represents the scaling factor.
4.3. Ablation Studies
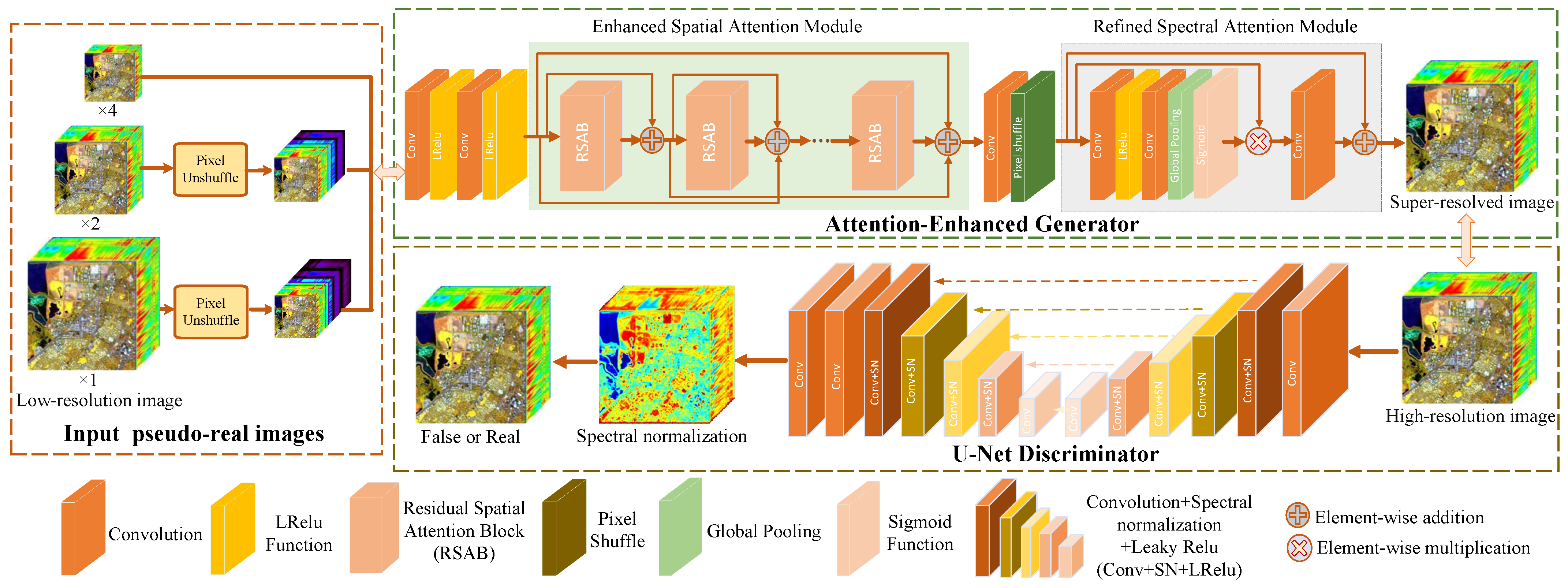
In this work, ablation studies are conducted on the Pavia Center, Pavia University, and Cuprite datasets to illustrate the effectiveness of several specific designs in the proposed approach, including ESAM or RSAM in the attention-enhanced generator structure, the U-Net discriminator, the pseudo-real data generation, the pre-training and fine-tuning model, and the attention-enhanced generative loss function. The effectiveness of one component is testified and validated by removing it from the proposed method, while other components remain unchanged. Specifically, the baseline is set as employing bicubic downsampled HR HSI as LR HSI, replacing ESAM, RSAM, and the U-Net discriminator with ordinary convolutional layers.
(1) Ablation study on ESAM or RSAM: To demonstrate the positive effect of ESAM and RSAM in the proposed method, ESAM or RSAM are removed from the attention-enhanced generator structure, denoted as w/o ESAM and w/o RSAM, respectively. It can be observed from
Table 1 that both of them contribute to the performance improvement of the proposed approach. Particularly, without ESAM or RSAM in the attention-enhanced generator, the super-resolution performance severely deteriorates, i.e., MPSNR and MSSIM decrease by 0.3413dB and 0.0345, 0.1812dB and 0.0164, and 0.9498dB and 0.0553 on three HSI datasets, respectively. Moreover, the visual results of w/o ESAM and w/o RSAM are exhibited in
Figure 6, as well as the reference ground truth. The result of w/o ESAM appears to be a little blurry, while the result of w/o RSAM seems too sharp, leading to a loss of detailed texture. The experimental results illustrate that ESAM is effective at improving and enhancing the feature representation ability of both low-frequency and high-frequency information, and RSAM is dedicated to finer texture detail reconstruction.
(2) Ablation study on U-Net discriminator: The U-Net discriminator (w/o U-Net) component is substituted with the simple convolutional layer. As shown in
Table 1, it can be obviously seen that the performance of the proposed AEGAN approach is slightly better than that without the U-Net discriminator.
(3) Ablation study on Pseudo-real data generation: The pseudo-real data generation employs a high-order degradation model to better mimic the complicated authentic degradation procedure. To testify to its effectiveness, LR inputs obtained by bicubic interpolation are employed rather than the generated pseudo-real data (the corresponding method is denoted as w/o pseudo-real). From the results represented in
Table 1, it can be observed with pseudo-real data generation that MPSNR and MSSIM are improved by 0.1397 dB and 0.0214, 0.1205 dB and 0.0095, and 0.0220 dB and 0.0217 for the three datasets, respectively.
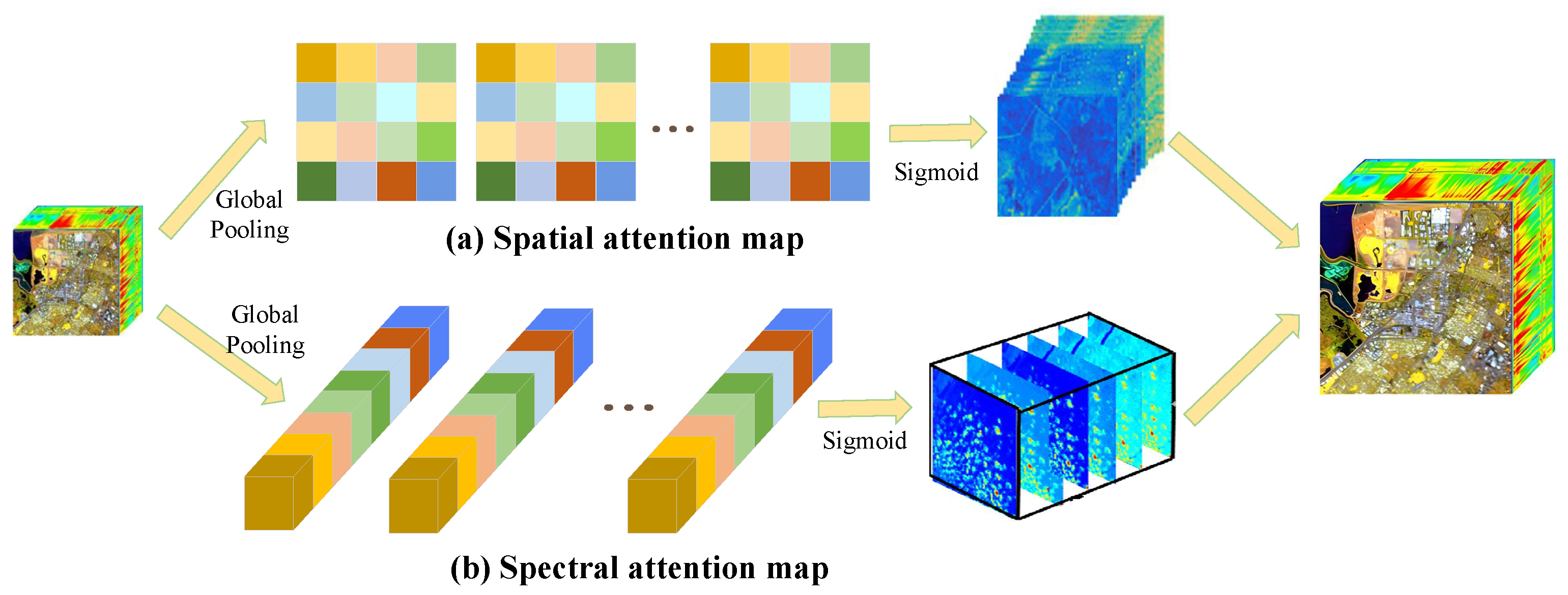
(4) Ablation study on spatial attention and spectral attention: The core structures of ESAM and RSAM are the spatial attention block and spectral attention block in the residual connection of AEGAN. The influence of spatial attention and spectral attention of the proposed AEGAN model is also explored by removing spatial attention in ESAM (denoted as w/o SpaA) and removing spectral attention in RSAM (denoted as w/o SpeA), respectively. The corresponding experimental results on the Pavia Centre dataset at scale factor 4 are reported in
Table 2. It can be observed that both spatial attention and spectral attention are conducive to improving the performance of ESAM and RSAM, in which MPSNR boosts 1.0282 dB and 1.1610 dB, MSSIM increases 0.0367 and 0.0439, SAM decreases 0.1474 and 0.1919, and ERGAS decreases 1.3486 and 1.4408 compared to the baseline model. Simultaneously, w/o ESAM differs from w/o SpaA with only 0.0015 in MPSNR, and w/o RSAM differs w/o SpeA with only 0.0032. Consequently, the construction and development of ESAM and RSAM in the proposed method exhibits a positive effect on the spatial-spectral characterization and improvement in HR HSI reconstruction.
(5) Ablation study on pre-training and fine-tuning: To demonstrate the effect of the pre-trained network model and fine-tuned network model, the pre-training and fine-tuning strategies are removed from the proposed network, respectively (denoted as w/o pre-training and w/o fine-tuning). The experimental results are tabulated in
Table 3. It can be easily observed that the proposed AEGAN approach with the pre-training and fine-tuning strategies attains the superior results, avoiding the deterioration in both spatial and spectral evaluation. Concretely, with fine-tuning and pre-training strategies, the performance of the proposed AEGAN method is boosted by 0.7585 dB and 0.1874 dB in MPSNR and 0.0581 and 0.0294 in MSSIM, respectively. This reveals the fact that the pre-training and fine-tuning strategies are more beneficial for HSI SR and can remarkably improve the performance of the proposed approach.
(6) Ablation study on attention-enhanced generative loss function: To explore the effectiveness of different combination-based loss terms on the proposed network, ablation studies are carried out on the pixel-wise spatial-based loss term (
), the perceptual-based loss term (
), the adversarial-based loss term (
), the attention-based loss term (
), and the SAM-based loss term (
). For HSI, the pixel-wise spatial-based loss term and SAM-based loss term can guarantee the fidelity and consistency of spatial-spectral structure information; therefore, the combination of
and
is regarded as the base in this paper. The quantitative experiment results using different combination-based loss terms on the Pavia Centre dataset at scale factor 4 are evaluated in
Table 4. Clearly, combining the base with the adversarial-based loss function can promote the super-resolved performance of HSI by increasing 0.1457 dB and 0.0052 in MPSNR and MSSIM, respectively. The addition of perceptual loss term slightly improves the reconstruction performance of the network by boosting MPSNR with 0.0322 dB, making the reconstructed HSI perceptually approximate to the actual HR HSI. As shown in
Table 4, coupled with attention-based loss term, the proposed method can acquire high-quality HR HSI estimation. This can be attributed to the accurate reconstruction of spectral information for each pixel and the finer expression of high-frequency spatial texture details spatially.
4.4. Comparison Experimental Results and Analysis
To illustrate the advancement of the proposed SR network, it is compared with different SR scenarios. The compared SR methods include the bicubic interpolation-based method [
13], several representative CNN-based methods (SRCNN [
26], 3D-FCNN [
36], SSJSR [
40], ERCSR [
38], and HLNACNN [
25]), and the GAN-based method (ESRGAN [
16]).
Table 5 and
Table 6 list the evaluation metrics of different SR approaches for the three benchmark hyperspectral datasets with a spatial upsampling factor of 2 and 4, respectively. It can be observed that the proposed AEGAN method outperforms all the other compared spatial SR approaches, producing SR results with the highest MPSNR and MSSIM and the lowest SAM and ERGAS. These demonstrate that the proposed AEGAN approach can well reconstruct the spatial texture and structural detail information of HSI.
In order to better distinguish the reconstructed differences between the super-resolved HSI perceptually, parts of the super-resolved HSI generated by different methods are depicted in
Figure 7 and
Figure 8. It can be clearly observed that the proposed approach is capable of producing visually better HR HSI with finer textures and less blurring artifacts as well as distortion. Compared with the ground truth, the results generated by Bicubic, SRCNN, and 3DFCN suffer from severe blurring artifacts. SSJSR, ERCSR, and HLNACNN produce results lacking detailed information in some locations and introduce undesired noise. The results of ESRGAN are extreme and exhibit obvious distortion. By contrast, the proposed AEGAN approach can not only preserve the central structural information but also mitigate this distortion.
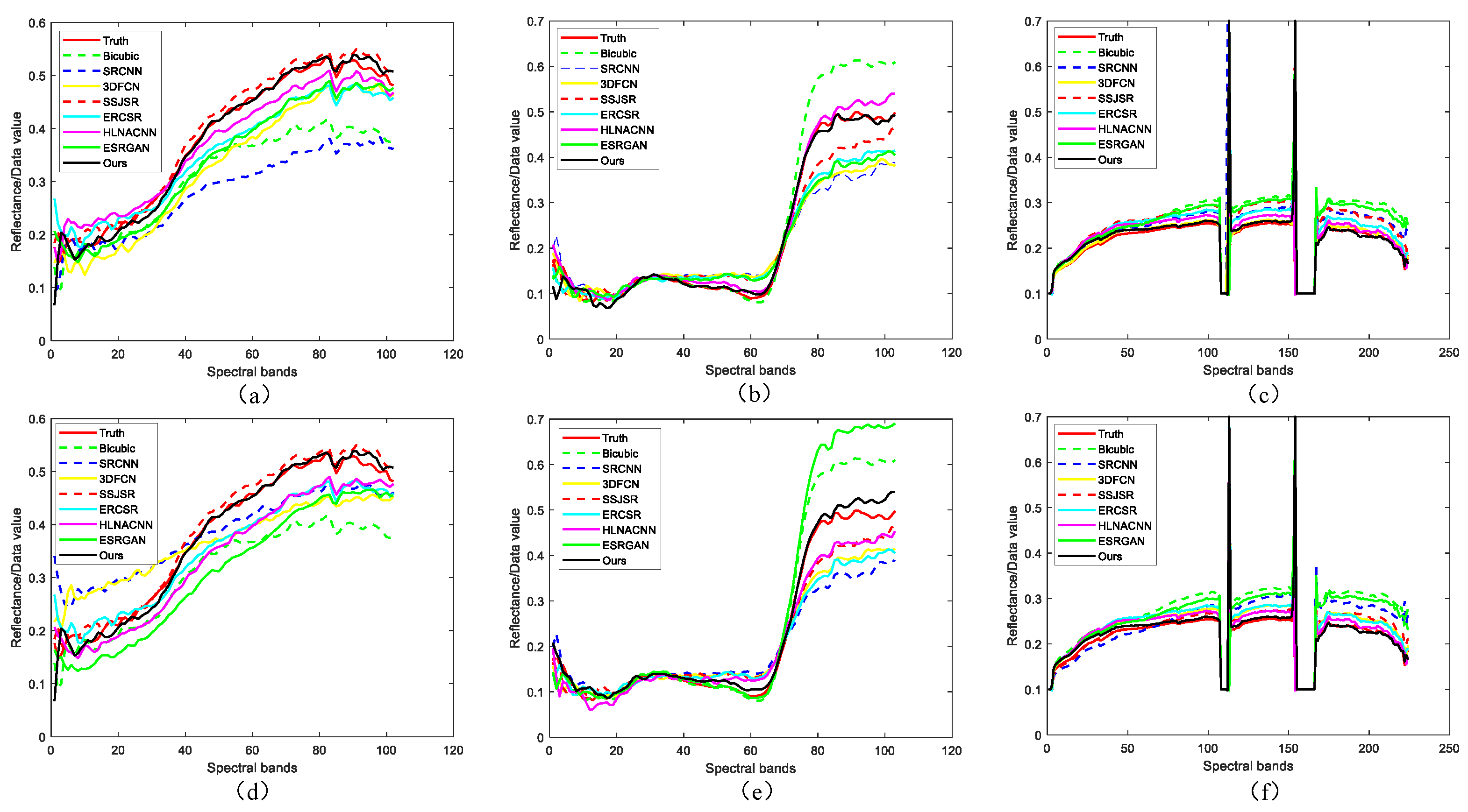
In addition, some reconstructed spectral curve graphs of different SR approaches are depicted in
Figure 9. One pixel position is randomly selected for each dataset for spectral distortion analysis and discussion. It can be easily observed that all of the reconstructed spectral curves are consistent with the shape of ground-truth. In a few cases, the SRCNN approach and the ESRGAN approach have a certain degree of deviation, i.e., small spectral distortion, while the proposed AEGAN approach is the closest to the ground-truth, indicating its excellent performance in spectral information preservation.
We utilize the original codes of compared methods to calculate the parameter and complexity.
Table 7 comprehensively shows the parameters, FLOPs, and inference time for different SR methods. We can see that our proposed method has the smallest computation burden.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}