
Optical Flow and Expansion Based Deep Temporal Up-Sampling of LIDAR Point Clouds


Abstract
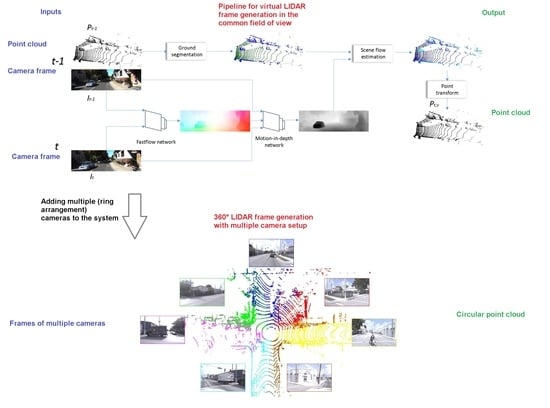
1. Introduction
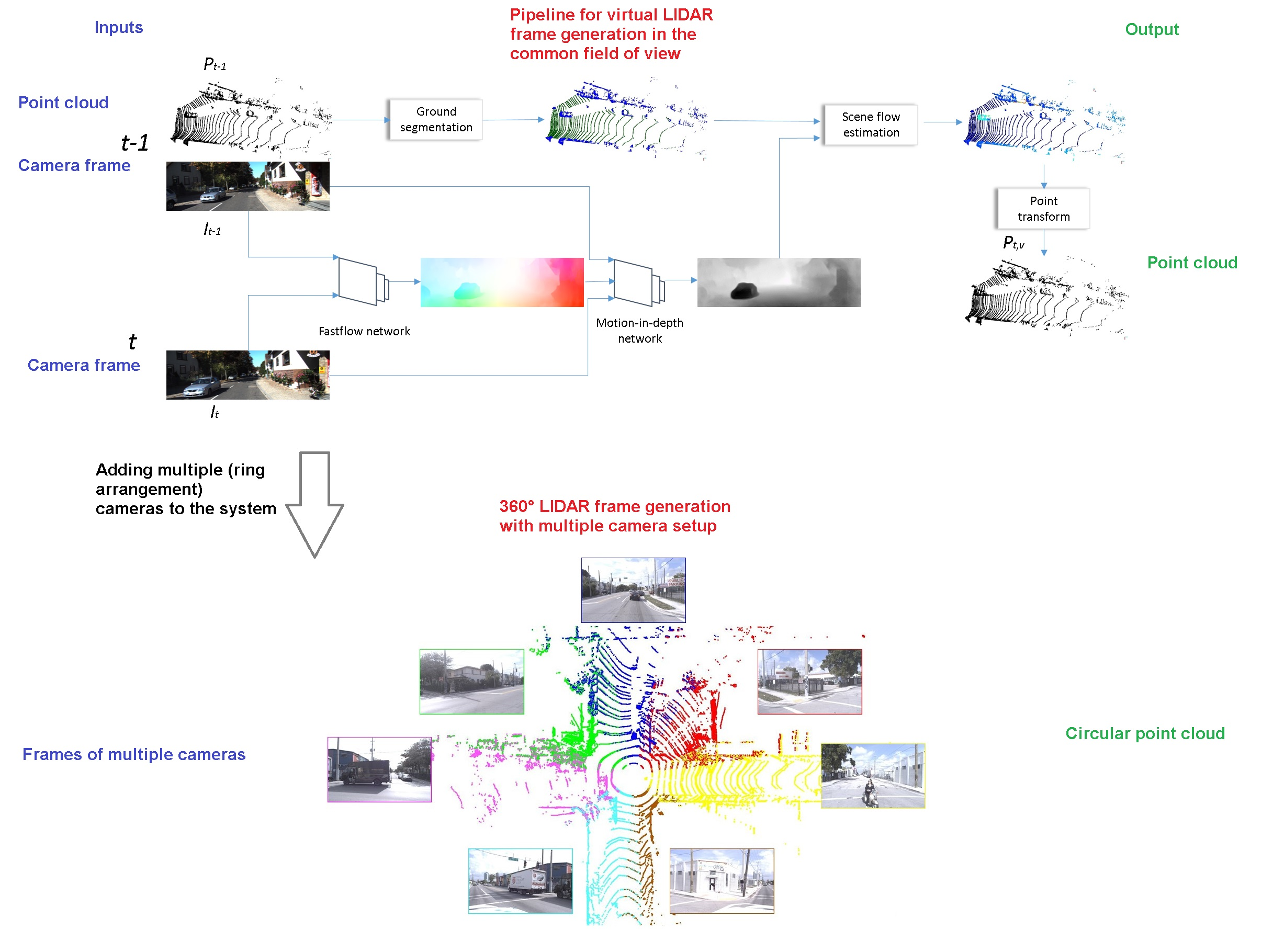
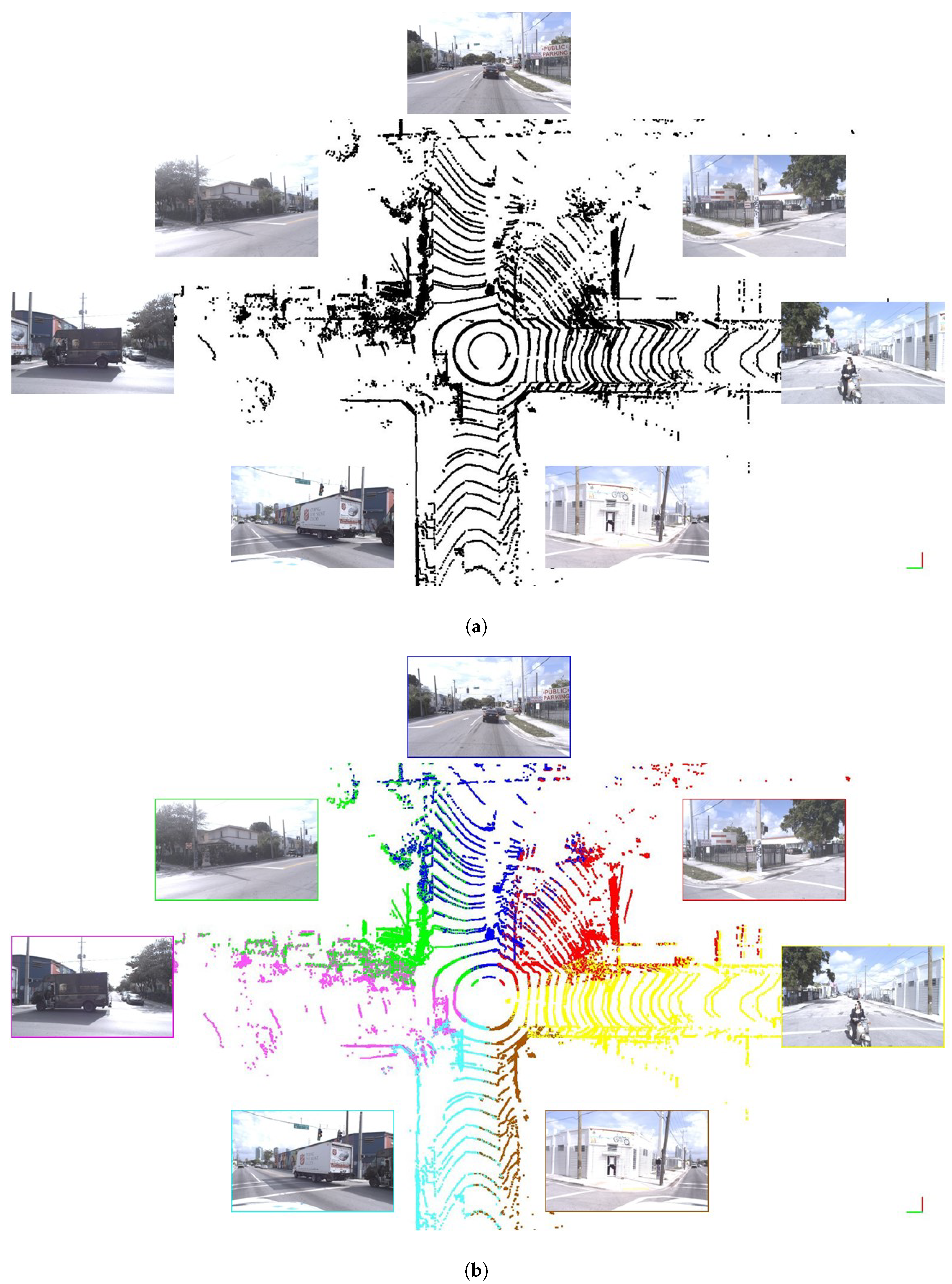
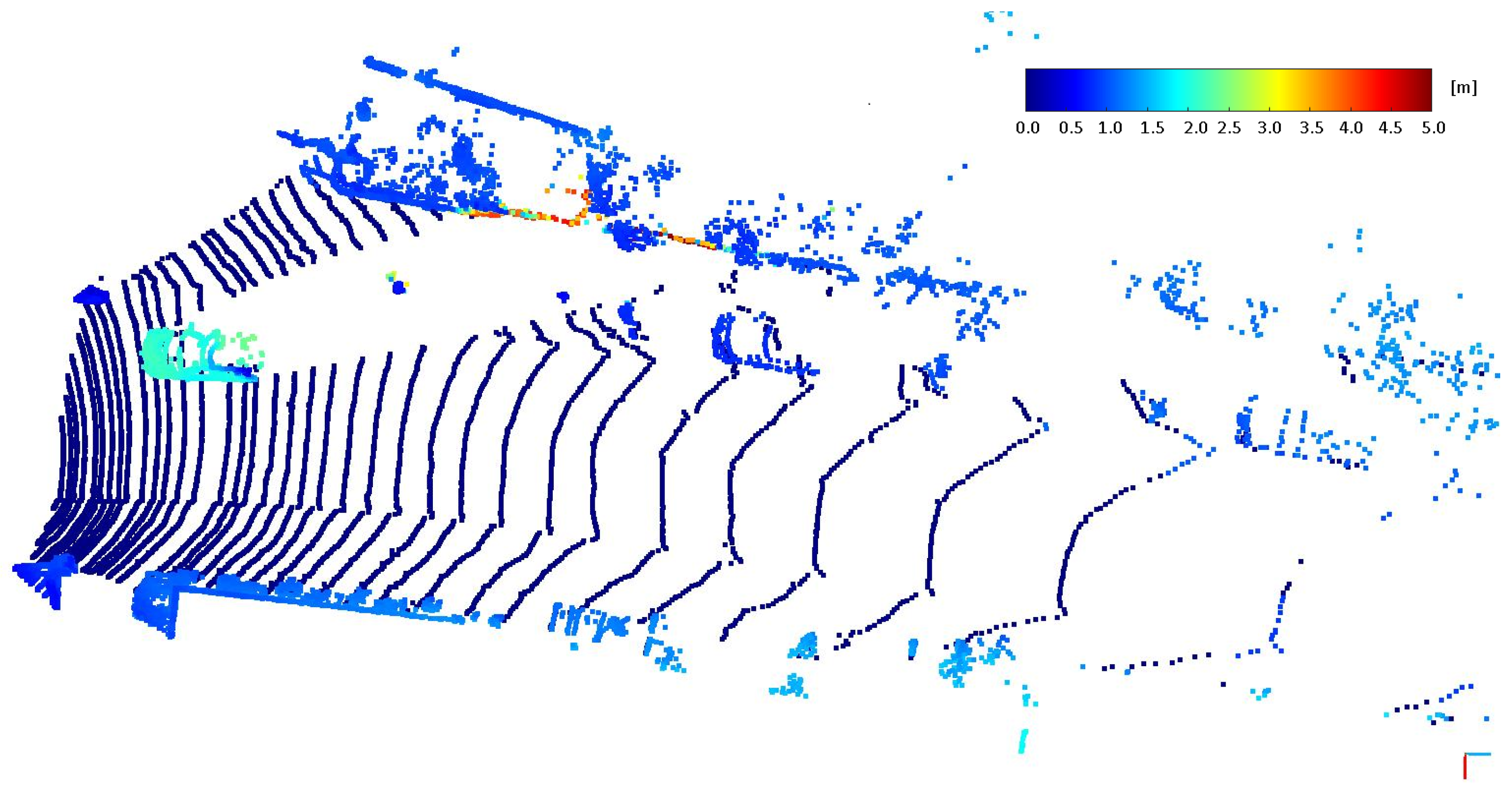
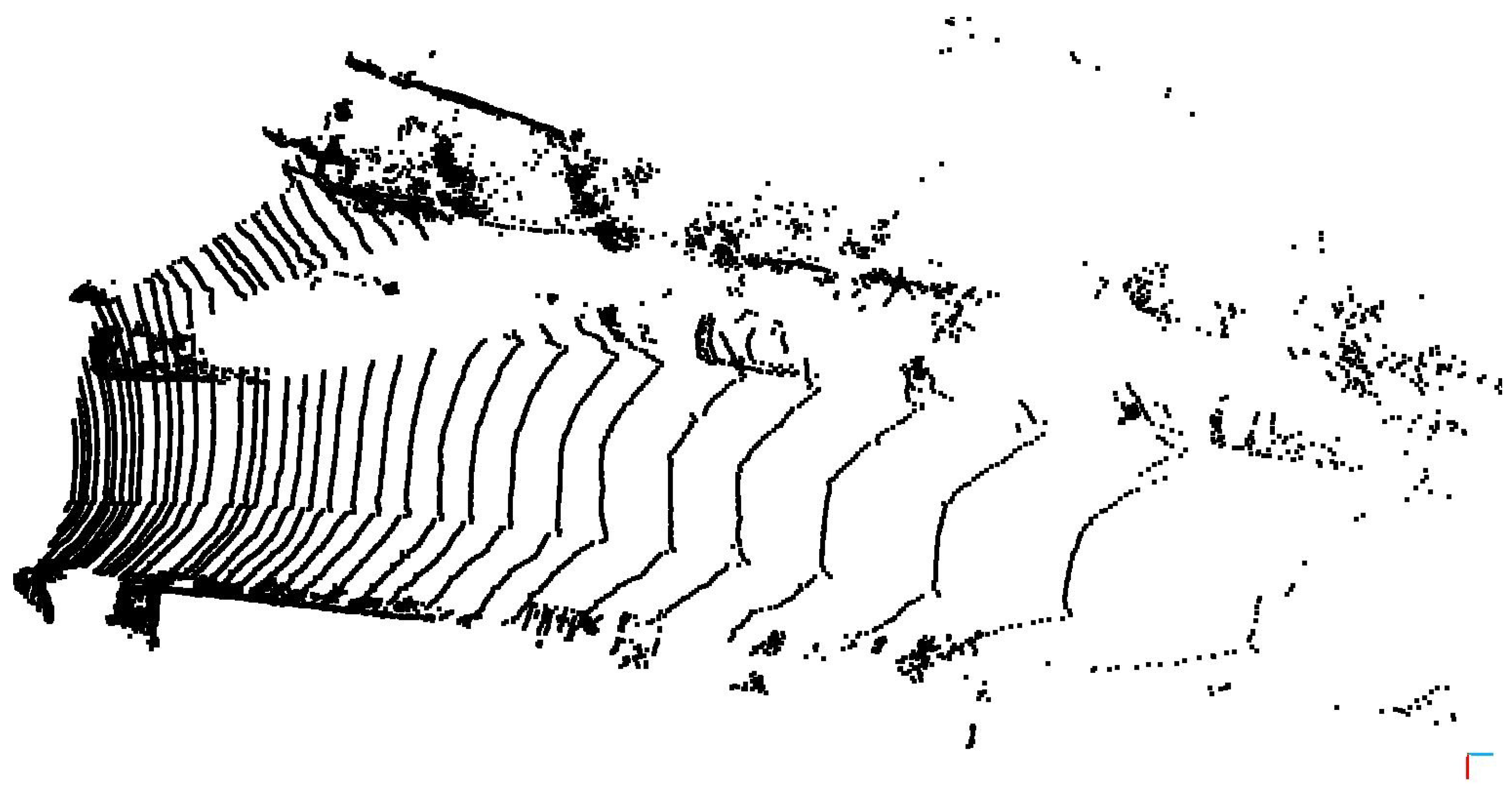
- The pipeline adapts to the point cloud characteristics and generates virtual clouds with similar characteristics to the real measurements. The point-level transformation of the system explains this fact. You can observe that by seeing our result on different LIDAR sensors (e.g., in Figure 2 and Figure in Section 4.2).
1.1. Contribution
- We propose a framework, applying optical principles (flow and expansion) to solve one of the critical problems of autonomous driving researches, namely the balancing between the spatial and temporal resolution of 3D LIDAR measurements.
- We extend the state of the art with a new optical flow calculation method, enabling a real-time run of our system and temporal up-sampling of LIDAR measurements.
- The baseline is enhanced by ground estimation, which ensures higher accuracy of virtual measurement generation.
- Our proposal includes motion vector estimation (point-wise) of surrounding agents (without the requirement of solving the challenging dynamic object segmentation problem [14]). This is a significant advantage compared to alternatives.
1.2. Outline of the Paper


2. Related Works
2.1. Spatial Up-Sampling
2.2. Point Cloud Prediction
- As several previous frames are necessary for the prediction (usually 5), it implies that the motion model is embedded in the system resulting in a loss of generality.
- End-to-end training of point cloud prediction could result in weak robustness against different datasets and point cloud characteristics.
- Most of these methods operate only near real time and in close range.
2.3. Point Cloud Interpolation
2.4. Temporal Up-Sampling
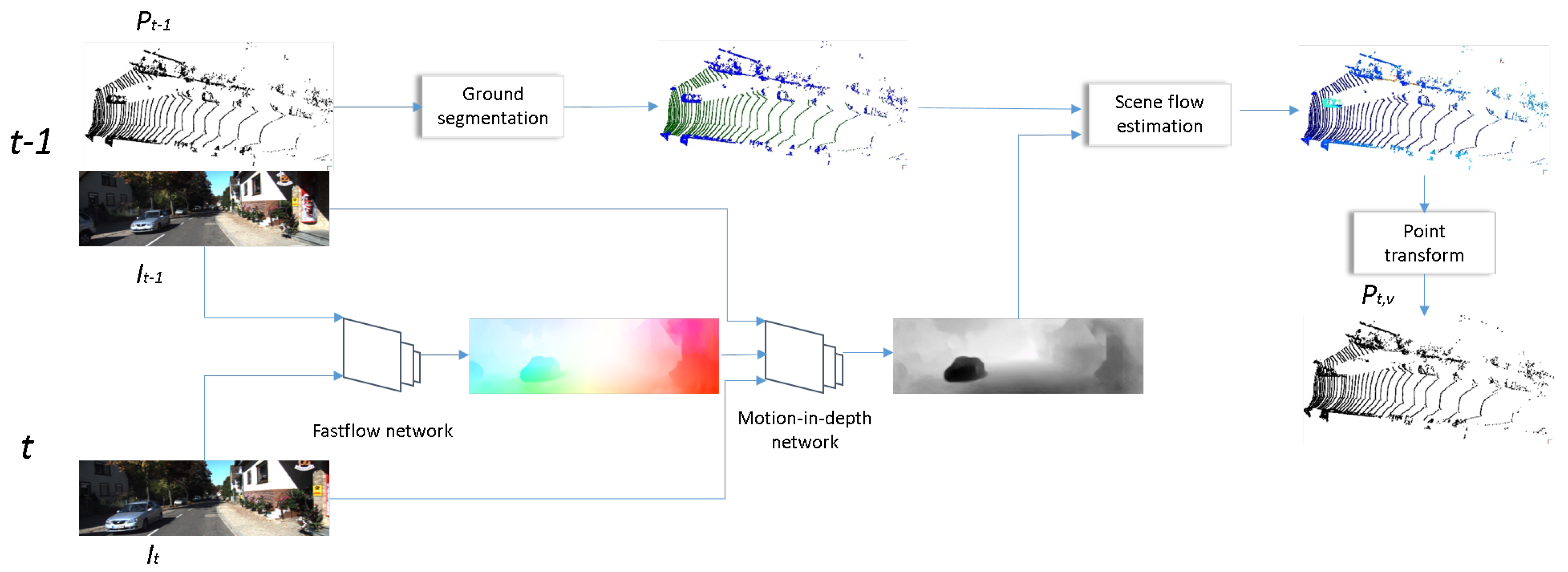
3. The Proposed Method
- Estimate optical flow () between images acquired at and t;
- Estimate optical expansion (s) and motion in depth () from the previously estimated flow;
- Estimate ground model and points on ;
- Calculate scene flow, utilizing the estimations and LIDAR measurements from ;
- Transform the object points with the estimated scene flow to generate the virtual measurement () at t.
3.1. Optical Flow Estimation
3.2. Motion-in-Depth Estimation
3.3. Ground Model Estimation
3.4. Calculate 3D Scene Flow
3.5. Generating Virtual Point Cloud
4. Results
4.1. Data for Comparison
4.2. Odometry Dataset
4.3. Depth Completion Dataset
5. Discussion
5.1. Computation Efficiency
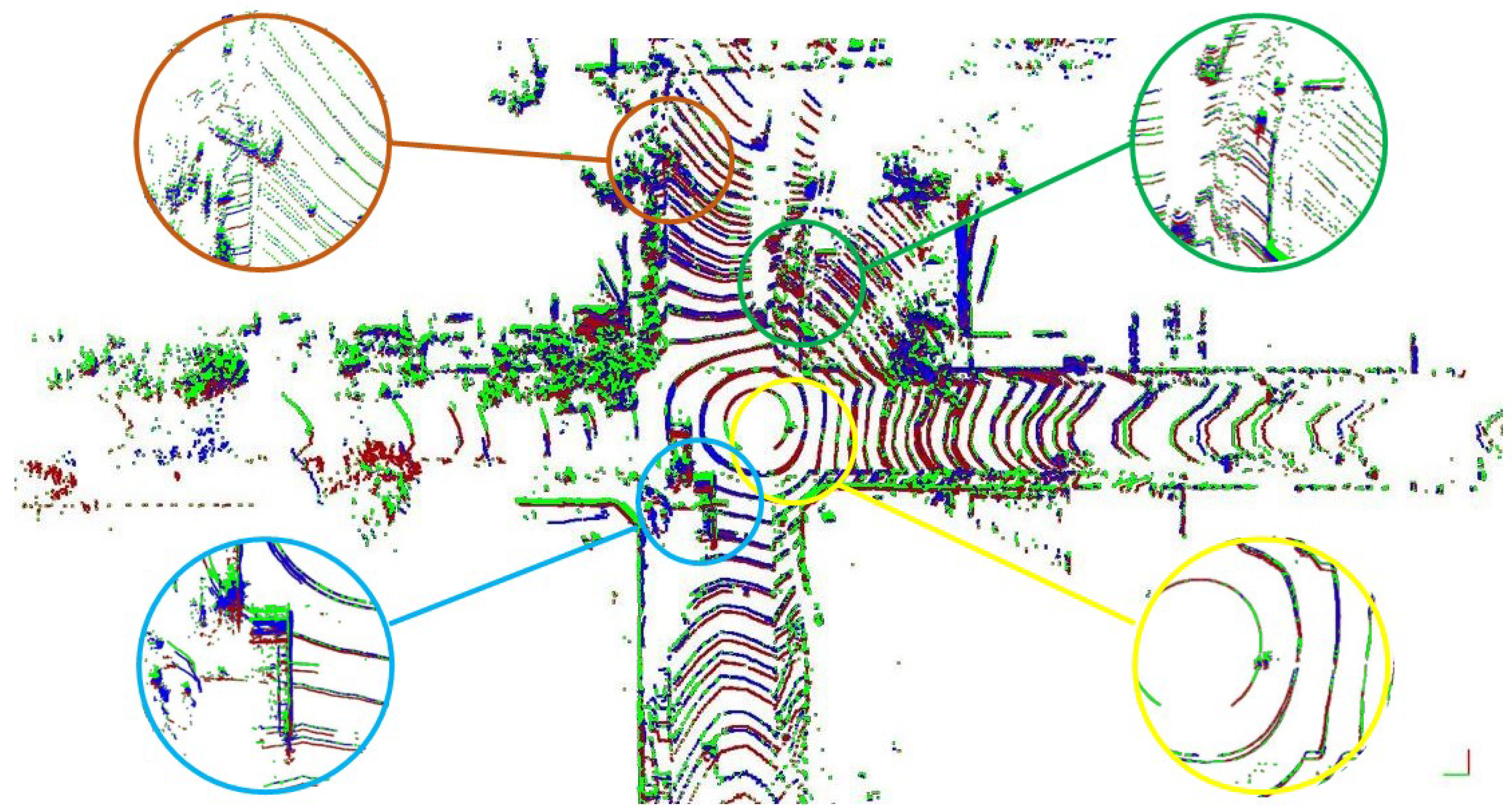
5.2. Dynamic Objects
- Dynamic objects generally pose a greater threat as they change their position and they also can change their state variables (angular and linear velocity, acceleration).
5.3. Ablation Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nagy, B.; Benedek, C. On-the-Fly Camera and Lidar Calibration. Remote Sens. 2020, 12, 1137. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, J.; Tao, D. Progressive LiDAR adaptation for road detection. IEEE/CAA J. Autom. Sin. 2019, 6, 693–702. [Google Scholar] [CrossRef]
- Wu, X.; Peng, L.; Yang, H.; Xie, L.; Huang, C.; Deng, C.; Liu, H.; Cai, D. Sparse Fuse Dense: Towards High Quality 3D Detection with Depth Completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5418–5427. [Google Scholar]
- Liu, Z.; Xiao, X.; Zhong, S.; Wang, W.; Li, Y.; Zhang, L.; Xie, Z. A feature-preserving framework for point cloud denoising. Comput.-Aided Des. 2020, 127, 102857. [Google Scholar] [CrossRef]
- Zhao, S.; Gong, M.; Fu, H.; Tao, D. Adaptive Context-Aware Multi-Modal Network for Depth Completion. IEEE Trans. Image Process. 2021, 30, 5264–5276. [Google Scholar] [CrossRef]
- Hu, M.; Wang, S.; Li, B.; Ning, S.; Fan, L.; Gong, X. PENet: Towards Precise and Efficient Image Guided Depth Completion. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13656–13662. [Google Scholar] [CrossRef]
- Rozsa, Z.; Sziranyi, T. Temporal Up-Sampling of LIDAR Measurements Based on a Mono Camera. In Image Analysis and Processing—ICIAP 2022, Proceedings of the 21st International Conference on Image Analysis and Processing, Lecce, Italy, 23–27 May 2022; Sclaroff, S., Distante, C., Leo, M., Farinella, G.M., Tombari, F., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 51–64. [Google Scholar]
- Rozsa, Z.; Sziranyi, T. Virtually increasing the measurement frequency of LIDAR sensor utilizing a single RGB camera. arXiv 2023, arXiv:2302.05192. [Google Scholar]
- Huang, X.; Lin, C.; Liu, H.; Nie, L.; Zhao, Y. Future Pseudo-LiDAR Frame Prediction for Autonomous Driving. Multimed. Syst. 2022, 28, 1611–1620. [Google Scholar] [CrossRef]
- Lu, F.; Chen, G.; Qu, S.; Li, Z.; Liu, Y.; Knoll, A. PointINet: Point Cloud Frame Interpolation Network. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021. [Google Scholar]
- Xu, J.; Le, X.; Chen, C. SPINet: Self-supervised point cloud frame interpolation network. Neural Comput. Appl. 2022, 35, 9951–9960. [Google Scholar] [CrossRef]
- Weng, X.; Wang, J.; Levine, S.; Kitani, K.; Rhinehart, N. Inverting the Pose Forecasting Pipeline with SPF2: Sequential Pointcloud Forecasting for Sequential Pose Forecasting. In Proceedings of the (CoRL) Conference on Robot Learning, Online, 16–18 November 2020. [Google Scholar]
- Lu, F.; Chen, G.; Li, Z.; Zhang, L.; Liu, Y.; Qu, S.; Knoll, A. MoNet: Motion-Based Point Cloud Prediction Network. IEEE Trans. Intell. Transp. Syst. 2021, 23, 13794–13804. [Google Scholar] [CrossRef]
- Chen, X.; Li, S.; Mersch, B.; Wiesmann, L.; Gall, J.; Behley, J.; Stachniss, C. Moving Object Segmentation in 3D LiDAR Data: A Learning-based Approach Exploiting Sequential Data. IEEE Robot. Autom. Lett. (RA-L) 2021, 6, 6529–6536. [Google Scholar] [CrossRef]
- Chang, M.F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3D Tracking and Forecasting with Rich Maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Uhrig, J.; Schneider, N.; Schneider, L.; Franke, U.; Brox, T.; Geiger, A. Sparsity Invariant CNNs. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017. [Google Scholar] [CrossRef]
- Premebida, C.; Garrote, L.; Asvadi, A.; Ribeiro, A.; Nunes, U. High-resolution LIDAR-based depth mapping using bilateral filter. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 2469–2474. [Google Scholar] [CrossRef]
- Ku, J.; Harakeh, A.; Waslander, S.L. In Defense of Classical Image Processing: Fast Depth Completion on the CPU. In Proceedings of the 2018 15th Conference on Computer and Robot Vision (CRV), Toronto, ON, Canada, 8–10 May 2018; pp. 16–22. [Google Scholar] [CrossRef]
- Zováthi, Ö.; Pálffy, B.; Jankó, Z.; Benedek, C. ST-DepthNet: A spatio-temporal deep network for depth completion using a single non-repetitive circular scanning Lidar. IEEE Robot. Autom. Lett. 2023, 8, 3270–3277. [Google Scholar] [CrossRef]
- Schneider, N.; Schneider, L.; Pinggera, P.; Franke, U.; Pollefeys, M.; Stiller, C. Semantically Guided Depth Upsampling. In Pattern Recognition, Proceedings of the 38th German Conference on Pattern Recognition, Hannover, Germany, 12–15 September 2016; Springer International Publishing: Cham, Switzerland, 2016; Volume 9796, pp. 37–48. [Google Scholar] [CrossRef]
- Wencan, C.; Ko, J.H. Segmentation of Points in the Future: Joint Segmentation and Prediction of a Point Cloud. IEEE Access 2021, 9, 52977–52986. [Google Scholar] [CrossRef]
- Deng, D.; Zakhor, A. Temporal LiDAR Frame Prediction for Autonomous Driving. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020; IEEE Computer Society: Los Alamitos, CA, USA, 2020; pp. 829–837. [Google Scholar]
- He, P.; Emami, P.; Ranka, S.; Rangarajan, A. Learning Scene Dynamics from Point Cloud Sequences. Int. J. Comput. Vis. 2022, 130, 1–27. [Google Scholar] [CrossRef]
- Liu, H.; Liao, K.; Zhao, Y.; Liu, M. PLIN: A Network for Pseudo-LiDAR Point Cloud Interpolation. Sensors 2020, 20, 1573. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Liao, K.; Lin, C.; Zhao, Y.; Guo, Y. Pseudo-LiDAR Point Cloud Interpolation Based on 3D Motion Representation and Spatial Supervision. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6379–6389. [Google Scholar] [CrossRef]
- Beck, H.; Kühn, M. Temporal Up-Sampling of Planar Long-Range Doppler LiDAR Wind Speed Measurements Using Space-Time Conversion. Remote Sens. 2019, 11, 867. [Google Scholar] [CrossRef]
- Yang, G.; Ramanan, D. Upgrading Optical Flow to 3D Scene Flow Through Optical Expansion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Zhou, L.; Li, Z.; Kaess, M. Automatic Extrinsic Calibration of a Camera and a 3D LiDAR Using Line and Plane Correspondences. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 5562–5569. [Google Scholar] [CrossRef]
- Kong, L.; Shen, C.; Yang, J. FastFlowNet: A Lightweight Network for Fast Optical Flow Estimation. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Baker, S.; Scharstein, D.; Lewis, J.; Roth, S.; Black, M.; Szeliski, R. A Database and Evaluation Methodology for Optical Flow. Int. J. Comput. Vis. 2007, 92, 1–31. [Google Scholar] [CrossRef]
- Torr, P.; Zisserman, A. MLESAC: A New Robust Estimator with Application to Estimating Image Geometry. Comput. Vis. Image Underst. 2000, 78, 138–156. [Google Scholar] [CrossRef]
- Vedula, S.; Rander, P.; Collins, R.; Kanade, T. Three-dimensional scene flow. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 475–480. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Bertsekas, D.P. A distributed asynchronous relaxation algorithm for the assignment problem. In Proceedings of the 1985 24th IEEE Conference on Decision and Control, Fort Lauderdale, FL, USA, 11–13 December 1985; pp. 1703–1704. [Google Scholar] [CrossRef]
- Fan, H.; Su, H.; Guibas, L. A Point Set Generation Network for 3D Object Reconstruction from a Single Image. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2463–2471. [Google Scholar] [CrossRef]
- He, L.; Jin, Z.; Gao, Z. De-Skewing LiDAR Scan for Refinement of Local Mapping. Sensors 2020, 20, 1846. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Gomez, J.J.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial and Multi-Map SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Yang, G.; Ramanan, D. Volumetric Correspondence Networks for Optical Flow. In Proceedings of the NeurIPS 2019-Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Application | CD [m] | EMD [m] |
|---|---|---|---|
| MoNet (LSTM) [13] | Forecasting | 0.573 | 91.79 |
| MoNet (GRU) [13] | Forecasting | 0.554 | 91.97 |
| SPINet [11] | Offline Interpolation | 0.465 | 40.69 |
| PointINet [10] | Offline Interpolation | 0.457 | 39.46 |
| Rigid body based up-sampling [8] | Online Interpolation | 0.471 | 33.98 |
| Proposed pipeline | Online Interpolation | 0.486 | 28.51 |
| Methods | Application | CD [m] | EMD [m] |
|---|---|---|---|
| Prediction [22] | Forecasting | 0.202 | 11.498 |
| PLIN [24] | Offline Interpolation | 0.21 | - |
| PLIN+ [25] | Offline Interpolation | 0.12 | - |
| Future pseudo-LIDAR [9] | Online Interpolation | 0.157 | 3.303 |
| Proposed pipeline | Online Interpolation | 0.141 | 0.806 |
| Component | Average Running Time [ms] |
|---|---|
| Optical flow estimation | 14 |
| Motion-in-depth estimation | 29 |
| Ground estimation | 8 |
| Frame generation (scene flow + transformation) | ≈0 |
| Total | 51 |
| Methods | GPU | Average Running Time [ms] |
|---|---|---|
| Future pseudo-LIDAR [9] | Nvidia RTX 2080Ti | 52 |
| Rigid body based up-sampling [8] | Nvidia GTX 1080 | 62 |
| Proposed method | Nvidia GTX 1080 | 51 |
| Methods | CD [m] | EMD [m] |
|---|---|---|
| Point based [12] | 2.37 | 211.47 |
| Range map based [12] | 0.92 | 128.81 |
| Rigid body based up-sampling [8] | 0.63 | 31.03 |
| Proposed pipeline | 0.26 | 17.50 |
| Components | CD [m] | EMD [m] | Runtime [ms] |
|---|---|---|---|
| Proposed pipeline | 0.486 | 28.51 | 51 |
| Without ground estimation | 0.508 | 34.50 | 43 |
| Without FastFlowNet | 0.508 | 34.40 | 95 |
| Baseline (appr.) [27] | 0.547 | 34.39 | 270 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rozsa, Z.; Sziranyi, T. Optical Flow and Expansion Based Deep Temporal Up-Sampling of LIDAR Point Clouds. Remote Sens. 2023, 15, 2487. https://doi.org/10.3390/rs15102487
Rozsa Z, Sziranyi T. Optical Flow and Expansion Based Deep Temporal Up-Sampling of LIDAR Point Clouds. Remote Sensing. 2023; 15(10):2487. https://doi.org/10.3390/rs15102487
Chicago/Turabian StyleRozsa, Zoltan, and Tamas Sziranyi. 2023. "Optical Flow and Expansion Based Deep Temporal Up-Sampling of LIDAR Point Clouds" Remote Sensing 15, no. 10: 2487. https://doi.org/10.3390/rs15102487
APA StyleRozsa, Z., & Sziranyi, T. (2023). Optical Flow and Expansion Based Deep Temporal Up-Sampling of LIDAR Point Clouds. Remote Sensing, 15(10), 2487. https://doi.org/10.3390/rs15102487