Since the article “Traffic Anomaly Prediction System Using Predictive Network” by Riaz et al. [
1] was published, the authors found a few mistakes that need to be corrected. The authors were not aware of the mistakes made in the proofreading phase, and, hence, wish to make some corrections to this paper. The main mistakes come from three aspects: (1) Confusion of references order caused by typesetting problems. (2) Typos caused by editing problems. (3) Unclear Image display caused by image resolution. The authors apologize for any inconvenience caused and state that the scientific conclusions are unaffected. The original article has been updated. The authors wish to make the following corrections to this paper:
1. Figure Legend
The authors apologize for any inconvenience caused and state that the scientific conclusions are unaffected. The original article has been updated.
1.1. Correction Has Been Made to Legend for Figure 1
In the original article, there was a mistake in the legend for Figure 1, which was used to illustrate some state-of-the-art techniques. However, we forgot to cite one reference. The correct legend appears below:
Figure 1. Snapshots of certain specialized strategies for identifying anomalies in a summarized manner. The images are taken from [43]. (a) Motion Interaction Field (MIF) [38] accident detection. (b) The topic-based model anomaly detection [44]. A car that has crossed the stop line appears on top of the row, a middle row is a hybrid, and a vehicle taking an odd turn is on the bottom of the row. (c) Multi-instance learning (MIL) anomaly detection in the real-time example [45]. The use of an anomaly ranking determines the detection of anomalies. (d) A vehicle on a walkway is identified with the STAN method [46]: as the top row is generator anomaly visualization, and the lower row represents the discriminator’s anomaly visualization [47].
1.2. Corrections Have Been Made to Legend for Figure 4
In the original article, there was a mistake in the legend for Figure 4. The author accidentally wrote character instead of character . Meanwhile, there are “five” important components instead of “four”. The correct legend appears below:
Figure 4. Left: FWPredNet architecture for our proposed model, in which each time step consists of five important components— the input unit, the prediction unit, the representation unit, and the error unit. Right: architecture of classification unit .
1.3. Correction Has Been Made to Legend for Figure 5
In the original article, there was a mistake in the legend for Figure 5. It should be read as “weighting” instead of “weighing”. The correct legend appears below:
Figure 5. Weighting of label prediction over time step.
1.4. Correction Has Been Made to Legend for Figure 6
In the original article, there was a mistake in the legend for Figure 6. The author mistakenly failed to cite the reference. The correct legend appears below:
Figure 6. Some real video frames examples of three different large-scale datasets we are using in our experiments. These images are taken from [8–10,59].
3. Incorrect Reference
The authors apologize for any inconvenience caused and state that the scientific conclusions are unaffected. The original article has been updated.
3.1. Correction Has Been Made to Reference [4]
In the original article, reference [4] was incorrectly written as “[4]. Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Li, F.-F Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1725–1732.” It should be “[4]. Zhao, M.; Chen, J. A Review of Methods for Detecting Point Anomalies on Numerical Dataset. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; pp. 559–565.”
3.2. Correction Has Been Made to Reference [8]
In the original article, reference [8] was incorrectly written as “[8]. Singh, H.; Hand, E.M.; Alexis, K. Anomalous Motion Detection On Highway Using Deep Learning. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020: pp. 1901–1905.” It should be “[8]. Yu, F.; Xian. W.; Chen, Y.; Liu, F.; Liao, M.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving video database with scalable annotation tooling. arXiv 2018, arXiv:1805.04687.”
The Original reference [8] has been moved to reference [59] in the current version: “[59] Singh, H.; Hand, E.M.; Alexis, K. Anomalous Motion Detection on Highway Using Deep Learning. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 1901–1905.”
3.3. Correction Has Been Made to Reference [25]
In the original article, reference [25] was incorrectly written as “[25]. Zeng, N.; Crisman, J.D. Vehicle matching using color. In Proceedings of the Conference on Intelligent Transportation Systems, Boston, MA, USA, 12 November 1997.” It should be “[26]. Leibe, B.; Schindler, K.; Cornelis, N.; Van Gool, L. Coupled object detection and tracking from static cameras and moving vehicles. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1683–1698.”
3.4. Correction Has Been Made to Reference [50]
In the original article, reference [50] was incorrectly written as “[50]. Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems 28; Curran Associates, Inc.: Red Hook, NY, USA, 2015.” It should be “[51]. Scharwächter, T.; Enzweiler, M.; Franke, U.; Roth, S. Stixmantics: A medium-level model for real-time semantic scene understanding. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014”.
3.5. Correction Has Been Made to Reference [51]
In the original article, reference [51] was incorrectly written as “[51]. Chan, F.-H.; Chen, Y.-T.; Xiang, Y.; Sun, M. Anticipating Accidents in Dashcam Videos. In Proceedings of the 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Cham, Switzerland, 2017; pp. 136–153,
https://doi.org/10.1007/978-3-319-54190-7_9.” It should be “[52]. Leibe, B.; Cornelis, N.; Cornelis, K.; Van Gool, L. Dynamic 3D Scene Analysis from a Moving Vehicle. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8.”
3.6. Correction Has Been Made to Reference [55]
In the original article, reference [55] was incorrectly written as “[55]. Roshan, R.; Vageesh, S.; Edit, S. Video Action Classification Using Deep Predictive Coding Networks. arXiv 2019, arXiv:1906.11902.” It should be “[58]. Rane, R.P.; Szügyi, E.; Saxena, V.; Ofner, A.; Stober, S. Prednet and Predictive Coding: A Critical Review. In Proceedings of the 2020 International Conference on Multimedia Retrieval, Dublin, Ireland, 8–11 June 2020; pp. 233–241”.
4. Missing Citation
The authors apologize for any inconvenience caused and state that the scientific conclusions are unaffected. The original article has been updated.
4.1. Missing Citation Has Been Inserted in Section, 1 Introduction, Paragraph 5, Lines 8–9
In the original article, ref. [22] was not cited. The citation has now been inserted in Section 1 Introduction, Paragraph 5, Lines 8–9, and should read:
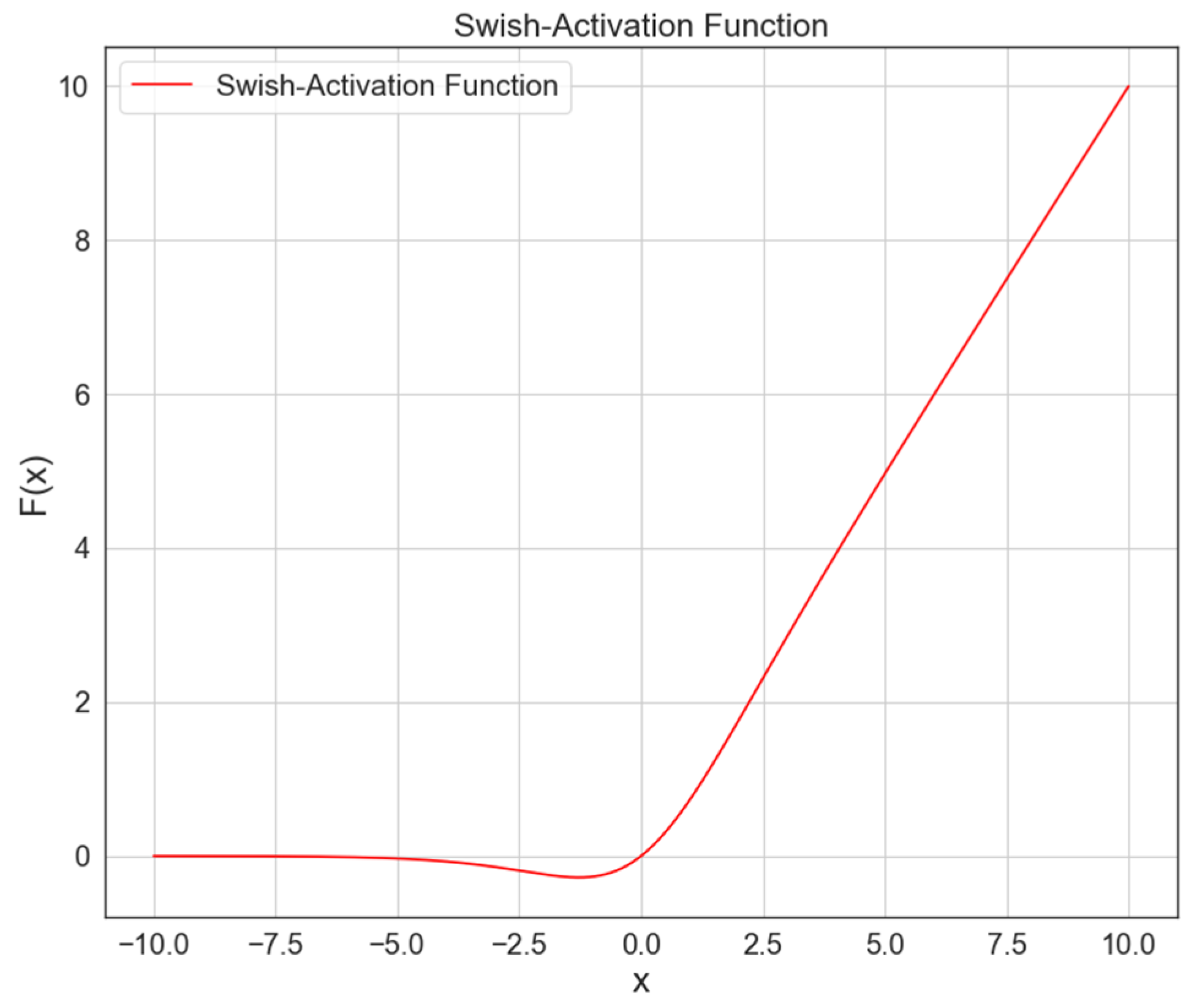
Our model proposed (FWPredNet) which is a combination of CNN model GoogleNet [22] with swish [23] and PredNet [7], to perform action recognition tasks without directly using optical flow.
4.2. Missing Citation Has Been Inserted in Section 1, Introduction, Figure 1
In the original article, ref. [43] was not cited. The citation has now been inserted in Section 1 Introduction, Figure 1, and should read:
Figure 1. Snapshots of certain specialized strategies for identifying anomalies in a summarized manner. The images are taken from [43]. (a) Motion Interaction Field (MIF) [38] accident detection. (b) The topic-based model anomaly detection [44]. A car that has crossed the stop line appears on top of the row, a middle row is a hybrid, and a vehicle taking an odd turn is on the bottom of the row. (c) Multi-instance learning (MIL) anomaly detection in the real-time example [45]. The use of an anomaly ranking determines the detection of anomalies. (d) A vehicle on a walkway is identified with the STAN method [46]: as the top row is generator anomaly visualization, and the lower row represents the discriminator’s anomaly visualization [47].
4.3. Missing Citation Has Been Inserted in Section 2, Related Work, Section 2.2, Related Datasets, Paragraph 1, Line 13
In the original article, ref. [55] was not cited. The citation has now been inserted in Section 2, Related Work, Section 2.2, Related Datasets, Paragraph 1, Line 13, and should read:
The photographs were captured in 50 different cities. Among them, 5k frames and 30k frames are labelled with detailed and with coarse semantic marks [55].
4.4. Missing Citation Has Been Inserted in Section 3, Materials and Methods, Section 3.2, Proposed Method, Paragraph 1, Lines 1–2
In the original article, ref. [57] was not cited. The citation has now been inserted in Section 3, Materials and Methods, Section 3.2, Proposed Method, Paragraph 1, Lines 1–2, and should read:
Inspired by [57], we use a pre-trained CNN model [22] to extract the features at frame level.
5. Text Correction
The authors apologize for any inconvenience caused and state that the scientific conclusions are unaffected. The original article has been updated.
5.1. Corrections Have Been Made to Section 1, Introduction, Paragraph 1, Lines 7–8
There was an error in the original article. Authors wish to combine references [2–4]. A correction has been made to Section 1, Introduction, Paragraph 1, Lines 7–8:
Anomalies are typically categorized as point anomalies, contextual anomalies, and collective anomalies [2–4].
5.2. Corrections Have Been Made to Section 1, Introduction, Paragraph 3, Lines 3–6
There was an error in the original article. Authors wish to combine reference [14–16] and [17–20]. A correction has been made to Section 1 Introduction, Paragraph 3, Lines 3–6:
For this reason, most current advanced models extract the optical flow from contiguous video frames, and then use LSTM (Long Short-Term Memory networks), RNN (Recurrent Neural Networks) or feedforward networks to ingest sequences [14–20].
5.3. Corrections Have Been Made to Section 2, Related Work, Section 2.2, Related Datasets, Paragraph 1, Line 3 and Line 11:
There was an error in the original article. Authors wish to correct [50], [51], [52], and [53] with [51], [52], [53], and [54] with the addition of citation [55]. A correction has been made to Section 2, Related Work, Section 2.2, Related Datasets, Paragraph 1, Line 3 and Line 11:
urban scenes, the Daimler Urban Segmentation [51], Leuven [52], and CamVid [53]… A broad dashcam dataset [54] was published to test semantic segmentation.
5.4. Correction Has Been Made to Section 3, Materials and Methods, Section 3.2.2, FW-PredNet Architecture, Paragraph 3, Line 1
There was an error in the original article. Authors wish to correct citation order as [53] with [50]. A correction has been made to Section 3, Materials and Methods, Section 3.2.2, FW-PredNet Architecture, Paragraph 3, Line 1:
As referred to by Wen et al. [50], in FWPrednet…
5.5. Correction Has Been Made to Section 3, Materials and Methods, Section 3.2.2, FW-PredNet Architecture, Paragraph 2, Line 12
There was an error in the original article. The author accidentally wrote character instead of character . A correction has been made to Section 3, Materials and Methods, Section 3.2.2, FW-PredNet Architecture, Paragraph 2, Line 12:
…in which, , ,, and C units denote representation unit, prediction, input, error and classification unit, respectively.
5.6. Correction Has Been Made to Section 3, Materials and Methods, Section 3.2.2, FW-PredNet Architecture, Equations (5)–(9)
There was an error in the original article. Equations (5)–(9) have minor typos, and have been changed from lowercase to uppercase. A correction has been made to Section 3, Materials and Methods, Section 3.2.,2 FW-PredNet Architecture, Equations (5)–(9):
5.7. Correction Has Been Made to Section 5, Discussion, Paragraph 2, Lines 7–8
There was an error in the original article. The authors wish to correct citation order as [53] with [50]. A correction has been made to Section 5, Discussion, Paragraph 2, Lines 7–8:
Several of the presented techniques for extracting moving items are adopted in order to retrieve cues efficiently [50] and then represent these features as observations in our FWPredNet model by learning deep features.

 ,
, {kind=link}
{kind=link}
{kind=link}