
A Network Combining a Transformer and a Convolutional Neural Network for Remote Sensing Image Change Detection



Abstract
:
1. Introduction
2. Materials and Methods
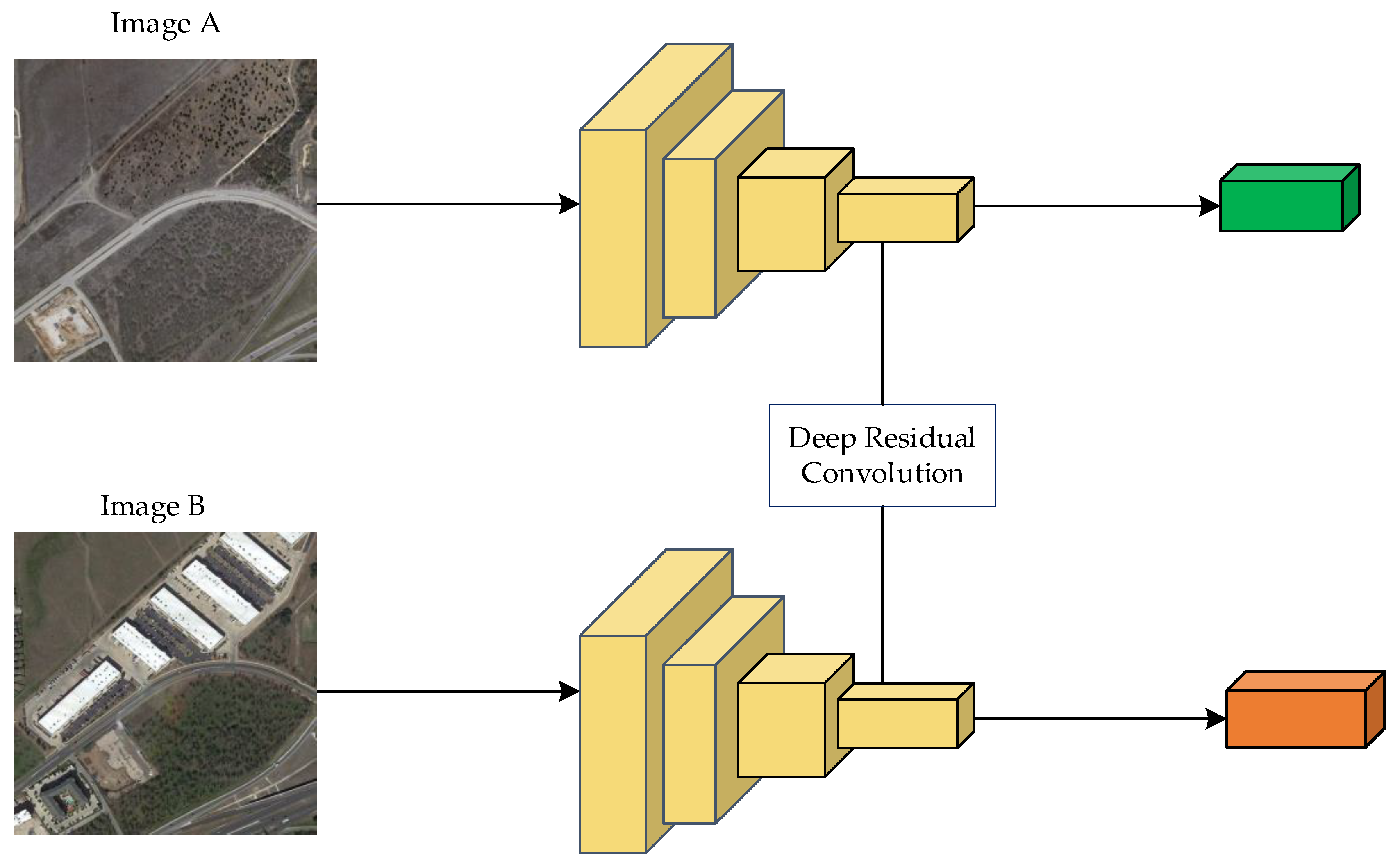
2.1. Basic Siamese Network with a Conv3d-Based Differential Module
2.1.1. Siamese Backbone
2.1.2. Difference Information Extraction
2.1.3. Classification Head
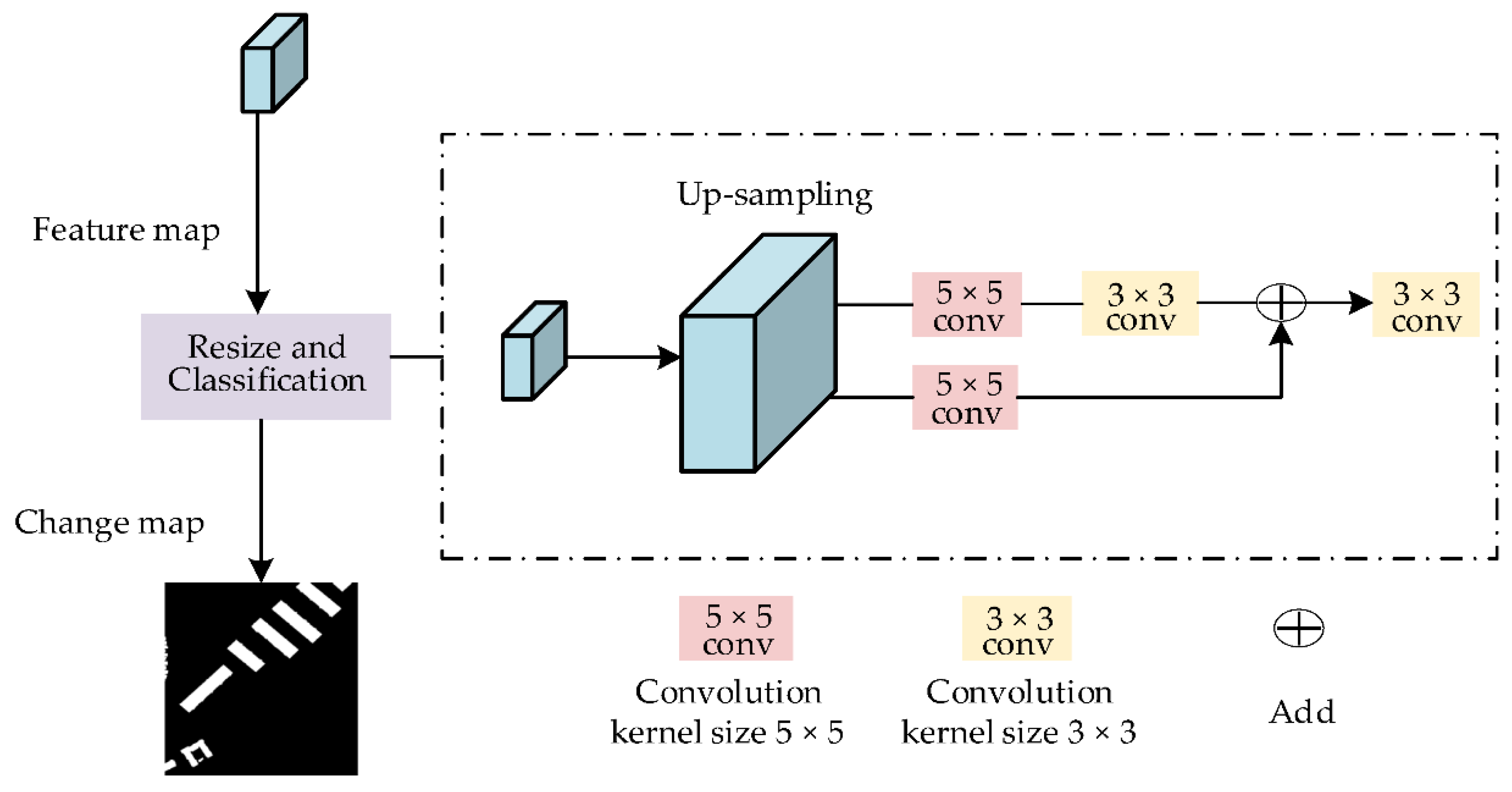
2.1.4. Construction of Extra Predictions
2.1.5. Loss Function
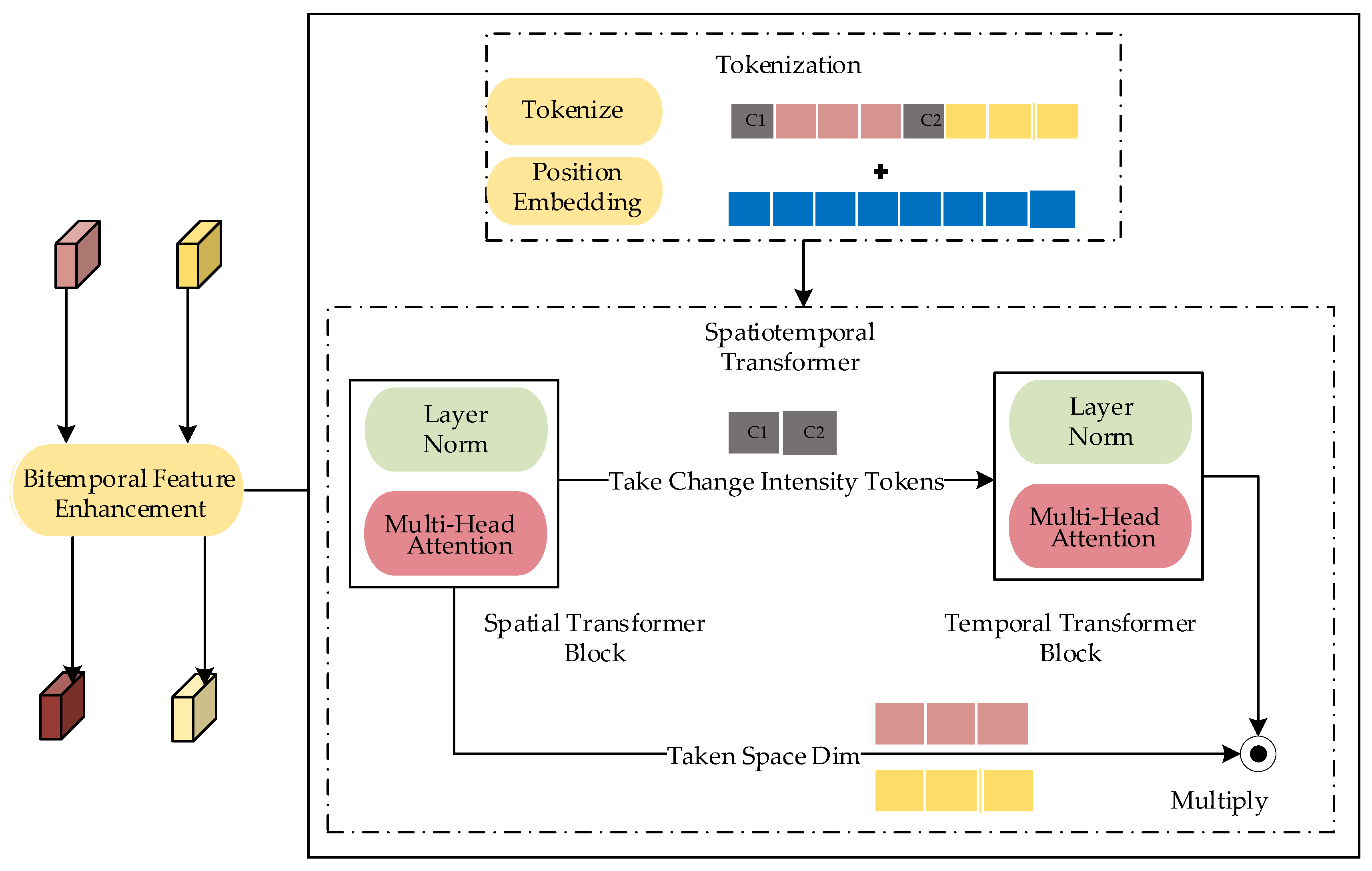
2.2. Bitemporal Feature Enhancement
2.2.1. Tokenization
2.2.2. Spatiotemporal Transformer
3. Experiment
3.1. Dataset Settings
3.2. Training Details
3.3. Evaluation Metrics
3.4. Comparison with Other Methods
- FC-EF [37]: This method concatenates original bitemporal images and processes them through ConvNet to detect changes.
- FC-Siam-D [37]: This is a feature-level difference method that extracts the multilevel features of bitemporal images from a Siamese ConvNet and uses feature differences in algebraic operations to detect changes.
- FC-Siam-Conc [37]: This is a feature-level concatenation method that extracts the multilevel features of bitemporal images from a Siamese ConvNet, and feature concatenation in the channel dimension is used to detect changes.
- DTCDSCN [19]: This is an attention-based, feature-level method that utilizes a dual attention module (DAM) to exploit the interdependencies between the channels and spatial positions of ConvNet features to detect changes.
- STANet [36]: This is another attention-based, feature-level network for CD that integrates a spatial–temporal attention mechanism to detect changes.
- IFNet [14]: This is a multiscale feature-level method that applies channel attention and spatial attention to the concatenated bitemporal features at each level of the decoder. A supervised loss is computed at each level of the decoder. We use multi-loss training strategies inspired by this technique.
- SNUNet [38]: This is a multiscale feature-level concatenation method in which a densely connected (NestedUNet) Siamese network is used for change detection.
- BIT [31]: This is a transformer-based, feature-level method that uses a transformer decoder network to enhance the context information of ConvNet features via semantic tokens; this is followed by feature differencing to obtain the change map.
- ChangeFormer [30]: This is a pure transformer feature-level method that uses a transformer encoder–decoder network to obtain the change map directly.
3.4.1. Experimental Results Obtained on the WHU Dataset
3.4.2. Experimental Results Obtained on the LEVIR-CD Dataset
4. Discussion
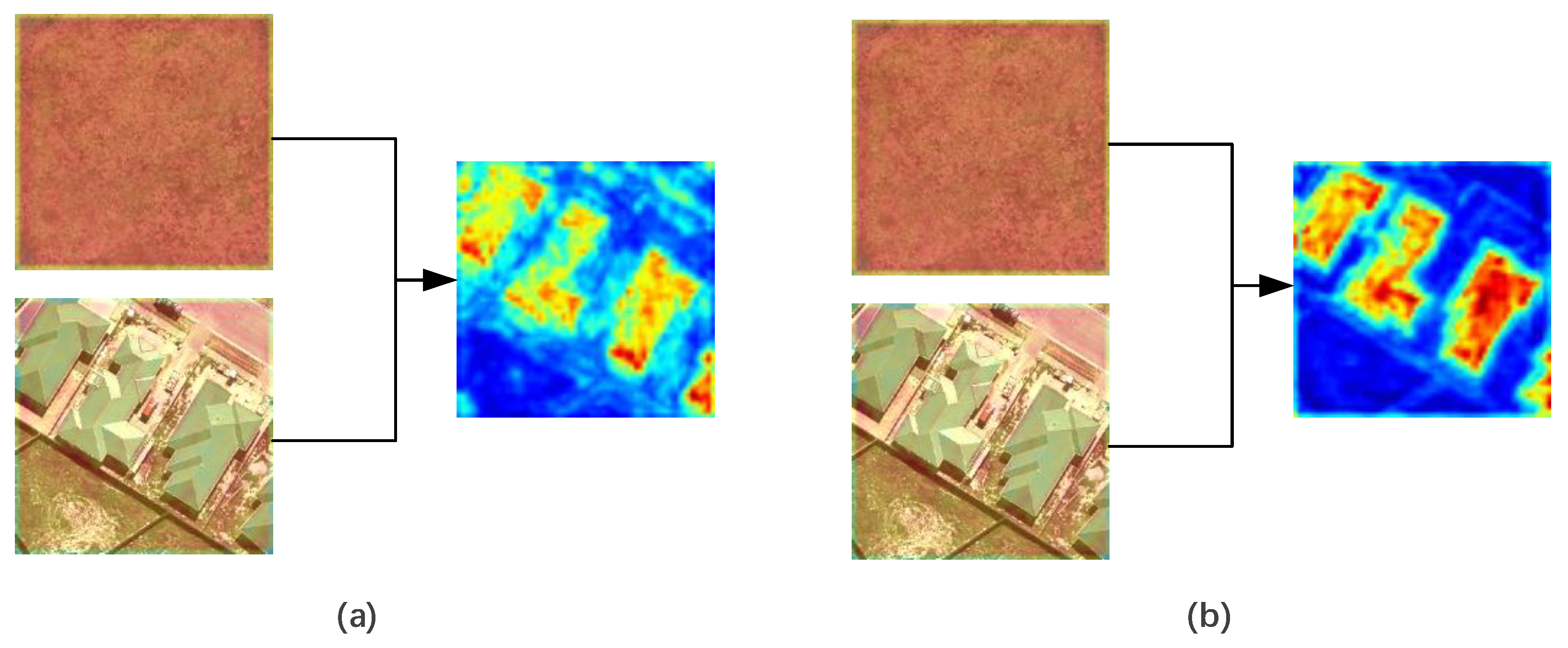
4.1. Effects of Transformers on the Network Structure
- Base_Single: Only the ASPP3d convolution fusion module proposed in this paper is used (without extra classification).
- Base_Muti: The Aspp3d convolution fusion module proposed in this paper is used for extra classification.
- UVA_Single: The proposed ASPP3d convolution fusion module is combined with bitemporal feature enhancement without extra classification.
- UVA_Muti: The proposed ASPP3d convolution fusion module is combined with bitemporal feature enhancement for extra classification.
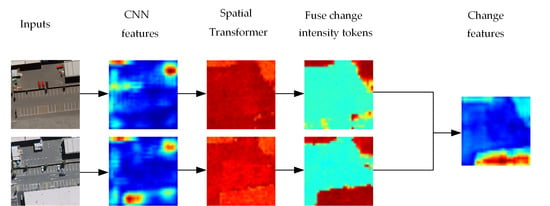
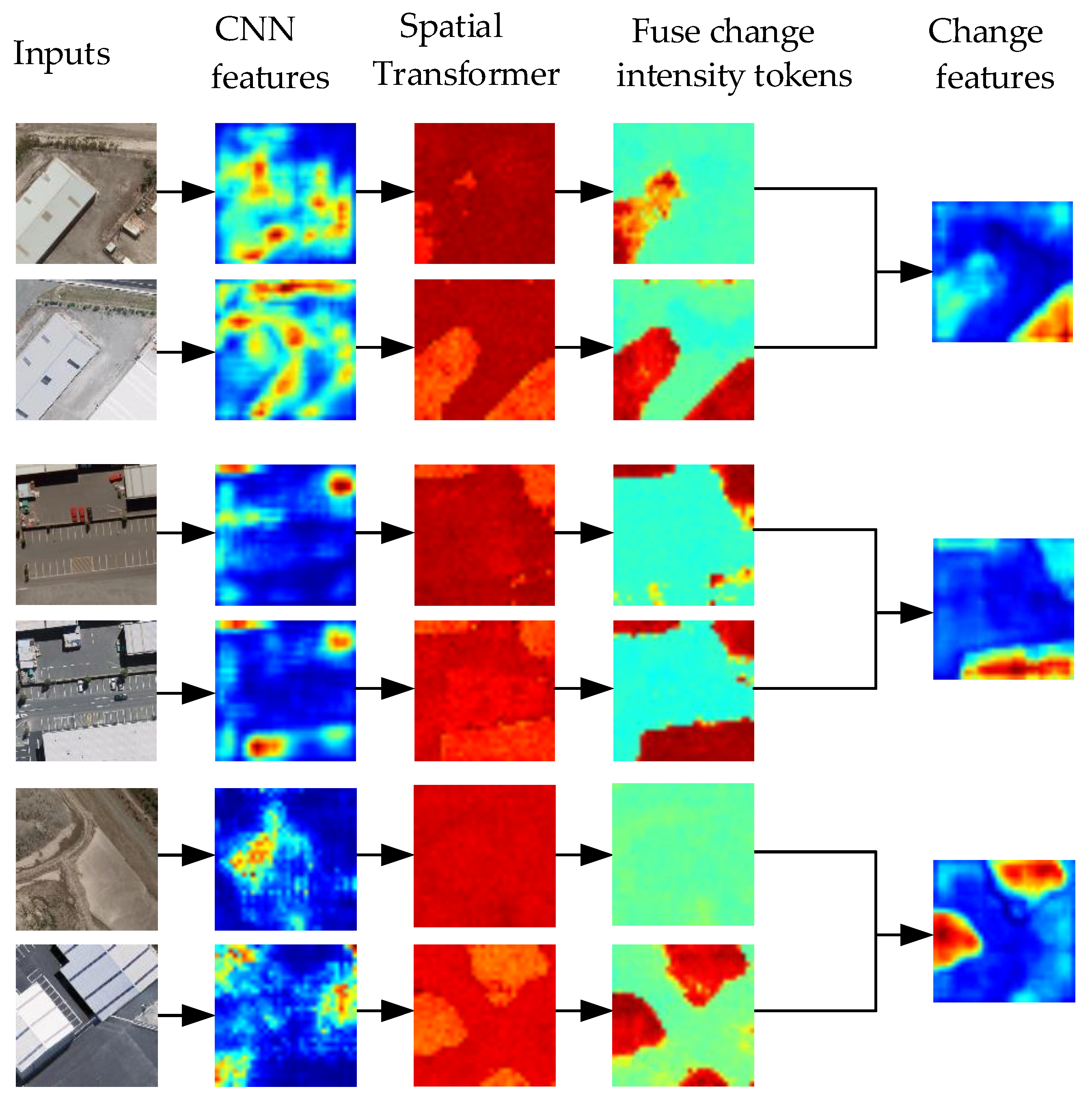
4.2. Visualization of Change Intensity Tokens
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Singh, A. Review article digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef] [Green Version]
- Sandric, I.; Mihai, B.; Savulescu, I.; Suditu, B.; Chitu, Z. Change detection analysis for urban development in Bucharest-Romania, using high resolution satellite imagery. In Proceedings of the 2007 Urban Remote Sensing Joint Event, Paris, France, 11–13 April 2007; pp. 1–8. [Google Scholar]
- Wang, M.; Tan, K.; Jia, X.; Wang, X.; Chen, Y. A deep siamese network with hybrid convolutional feature extraction module for change detection based on multi-sensor remote sensing images. Remote Sens. 2020, 12, 205. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Wang, C.; Zhang, H.; Zhang, B.; Wu, F. Urban building change detection in SAR images using combined differential image and residual u-net network. Remote Sens. 2019, 11, 1091. [Google Scholar] [CrossRef] [Green Version]
- Clement, M.A.; Kilsby, C.; Moore, P. Multi-temporal synthetic aperture radar flood mapping using change detection. J. Flood Risk Manag. 2018, 11, 152–168. [Google Scholar] [CrossRef]
- Sarp, G.; Ozcelik, M. Water body extraction and change detection using time series: A case study of Lake Burdur, Turkey. J. Taibah Univ. Sci. 2017, 11, 381–391. [Google Scholar] [CrossRef] [Green Version]
- Housman, I.W.; Chastain, R.A.; Finco, M.V. An evaluation of forest health insect and disease survey data and satellite-based remote sensing forest change detection methods: Case studies in the United States. Remote Sens. 2018, 10, 1184. [Google Scholar] [CrossRef] [Green Version]
- Washaya, P.; Balz, T.; Mohamadi, B. Coherence change-detection with sentinel-1 for natural and anthropogenic disaster monitoring in urban areas. Remote Sens. 2018, 10, 1026. [Google Scholar] [CrossRef] [Green Version]
- Cheng, H.; Wu, H.; Zheng, J.; Qi, K.; Liu, W. A hierarchical self-attention augmented Laplacian pyramid expanding network for change detection in high-resolution remote sensing images. ISPRS J. Photogramm. Remote Sens. 2021, 182, 52–66. [Google Scholar] [CrossRef]
- Hao, M.; Shi, W.; Zhang, H.; Li, C. Unsupervised change detection with expectation-maximization-based level set. IEEE Geosci. Remote Sens. Lett. 2013, 11, 210–214. [Google Scholar] [CrossRef]
- Chen, J.; Gong, P.; He, C.; Pu, R.; Shi, P. Land-use/land-cover change detection using improved change-vector analysis. Photogramm. Eng. Remote Sens. 2003, 69, 369–379. [Google Scholar] [CrossRef] [Green Version]
- Gong, J.; Hu, X.; Pang, S.; Li, K. Patch matching and dense CRF-based co-refinement for building change detection from Bi-temporal aerial images. Sensors 2019, 19, 1557. [Google Scholar] [CrossRef] [Green Version]
- Gong, M.; Su, L.; Jia, M.; Chen, W. Fuzzy clustering with a modified MRF energy function for change detection in synthetic aperture radar images. IEEE Trans. Fuzzy Syst. 2013, 22, 98–109. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NY, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Du, B.; Ru, L.; Wu, C.; Zhang, L. Unsupervised Deep Slow Feature Analysis for Change Detection in Multi-Temporal Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 9976–9992. [Google Scholar] [CrossRef] [Green Version]
- Mou, L.; Bruzzone, L.; Zhu, X.X. Learning Spectral-Spatial-Temporal Features via a Recurrent Convolutional Neural Network for Change Detection in Multispectral Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 57, 924–935. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Gong, M.; Zhang, P.; Su, L.; Shi, J. Feature-Level Change Detection Using Deep Representation and Feature Change Analysis for Multispectral Imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1666–1670. [Google Scholar] [CrossRef]
- Liu, Y.; Pang, C.; Zhan, Z.; Zhang, X.; Yang, X. Building change detection for remote sensing images using a dual-task constrained deep siamese convolutional network model. IEEE Geosci. Remote Sens. Lett. 2020, 18, 811–815. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual attentive fully convolutional siamese networks for change detection in high-resolution satellite images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1194–1206. [Google Scholar] [CrossRef]
- Peng, X.; Zhong, R.; Li, Z.; Li, Q. Optical remote sensing image change detection based on attention mechanism and image difference. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7296–7307. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Tian, Z.; Yi, J.; Bai, Y.; Tao, J.; Zhang, S.; Wen, Z. Synchronous transformers for end-to-end speech recognition. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtually, 4–8 May 2020; pp. 7884–7888. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. (CSUR) 2021. [Google Scholar] [CrossRef]
- Li, Z.; Chen, G.; Zhang, T. A CNN-transformer hybrid approach for crop classification using multitemporal multisensor images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 847–858. [Google Scholar] [CrossRef]
- Yuan, Y.; Lin, L. Self-supervised pretraining of transformers for satellite image time series classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 474–487. [Google Scholar] [CrossRef]
- He, J.; Zhao, L.; Yang, H.; Zhang, M.; Li, W. HSI-BERT: Hyperspectral image classification using the bidirectional encoder representation from transformers. IEEE Trans. Geosci. Remote Sens. 2019, 58, 165–178. [Google Scholar] [CrossRef]
- Shen, X.; Liu, B.; Zhou, Y.; Zhao, J. Remote sensing image caption generation via transformer and reinforcement learning. Multimed. Tools Appl. 2020, 79, 26661–26682. [Google Scholar] [CrossRef]
- Bandara, W.; Patel, V.M. A Transformer-Based Siamese Network for Change Detection. arXiv 2022, arXiv:2201.01293. [Google Scholar]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 21546965. [Google Scholar] [CrossRef]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 6836–6846. [Google Scholar]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A deeply supervised attention metric-based network and an open aerial image dataset for remote sensing change detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 21518766. [Google Scholar] [CrossRef]
- Zhang, L.; Hu, X.; Zhang, M.; Shu, Z.; Zhou, H. Object-level change detection with a dual correlation attention-guided detector. ISPRS J. Photogramm. Remote Sens. 2021, 177, 147–160. [Google Scholar] [CrossRef]
- Pang, S.; Zhang, A.; Hao, J.; Liu, F.; Chen, J. SCA-CDNet: A robust siamese correlation-and-attention-based change detection network for bitemporal VHR images. Int. J. Remote Sens. 2021, 1–22. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A densely connected siamese network for change detection of VHR images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. Springer Int. Publ. 2015, 9351, 234–241. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction From an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Bands | Image Pairs | Resolution (m) | Image Size | Train/Val/Test Set |
|---|---|---|---|---|---|
| WHU | 3 | 1 | |||
| LEVIR-CD | 3 | 637 |
| Methods | F1 | IoU | Recall | Precision | OA |
|---|---|---|---|---|---|
| FC-EF | 78.75 | 64.94 | 78.64 | 78.86 | 93.03 |
| FC-Siam-diff | 86.00 | 75.44 | 87.31 | 84.73 | 95.33 |
| FC-Siam-conc | 83.47 | 71.62 | 88.80 | 78.73 | 94.22 |
| BiDataNet | 88.63 | 79.59 | 90.60 | 86.75 | 96.19 |
| Unet++_MSOF | 90.66 | 82.92 | 89.40 | 91.96 | 96.98 |
| DASNet | 86.39 | 76.04 | 78.64 | 78.86 | 95.30 |
| DTCDSCN | 89.01 | 79.08 | 89.32 | - | - |
| DDCNN | 91.36 | 84.9 | 89.12 | 93.71 | 97.23 |
| UVACD (ours) | 91.17 | 94.59 |
| Methods | F1 | IoU | Recall | Precision | OA |
|---|---|---|---|---|---|
| FC-EF | 83.40 | 71.53 | 80.17 | 86.91 | 98.39 |
| FC-Siam-diff | 86.31 | 75.92 | 83.31 | 89.53 | 98.67 |
| FC-Siam-conc | 83.69 | 71.96 | 76.77 | 91.99 | 98.49 |
| STANet | 87.26 | 77.40 | 91.00 | 83.81 | 98.66 |
| IFNet | 88.13 | 78.77 | 82.93 | 94.02 | 98.87 |
| SNUNet | 88.16 | 78.83 | 87.17 | 89.18 | 98.82 |
| BIT | 89.31 | 80.68 | 89.37 | 89.24 | 98.92 |
| ChangeFormer | 90.40 | 82.48 | 88.80 | 92.05 | 99.04 |
| UVACD (ours) | 91.30 | 83.98 | 90.70 | 91.90 | 99.12 |
| Ablation Experiments | LEVIR-CD | WHU | ||||||
|---|---|---|---|---|---|---|---|---|
| F1 | IoU | Recall | Precision | F1 | IoU | Recall | Precision | |
| Base_Single | 90.36 | 82.42 | 88.45 | 92.36 | 92.18 | 85.49 | 89.86 | 94.62 |
| UVA_Single | 90.64 | 82.88 | 90.35 | 90.93 | 92.45 | 85.97 | 91.06 | 93.84 |
| Base_Muti | 89.90 | 81.65 | 88.78 | 91.05 | 92.38 | 85.85 | 89.51 | 95.45 |
| UVA_Muti | 91.30 | 83.98 | 90.70 | 91.90 | 92.84 | 86.64 | 91.17 | 94.58 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, G.; Li, B.; Zhang, T.; Zhang, S. A Network Combining a Transformer and a Convolutional Neural Network for Remote Sensing Image Change Detection. Remote Sens. 2022, 14, 2228. https://doi.org/10.3390/rs14092228
Wang G, Li B, Zhang T, Zhang S. A Network Combining a Transformer and a Convolutional Neural Network for Remote Sensing Image Change Detection. Remote Sensing. 2022; 14(9):2228. https://doi.org/10.3390/rs14092228
Chicago/Turabian StyleWang, Guanghui, Bin Li, Tao Zhang, and Shubi Zhang. 2022. "A Network Combining a Transformer and a Convolutional Neural Network for Remote Sensing Image Change Detection" Remote Sensing 14, no. 9: 2228. https://doi.org/10.3390/rs14092228
APA StyleWang, G., Li, B., Zhang, T., & Zhang, S. (2022). A Network Combining a Transformer and a Convolutional Neural Network for Remote Sensing Image Change Detection. Remote Sensing, 14(9), 2228. https://doi.org/10.3390/rs14092228