
Identifying Grassland Distribution in a Mountainous Region in Southwest China Using Multi-Source Remote Sensing Images

Abstract
:1. Introduction
2. Study Area and Data Sources
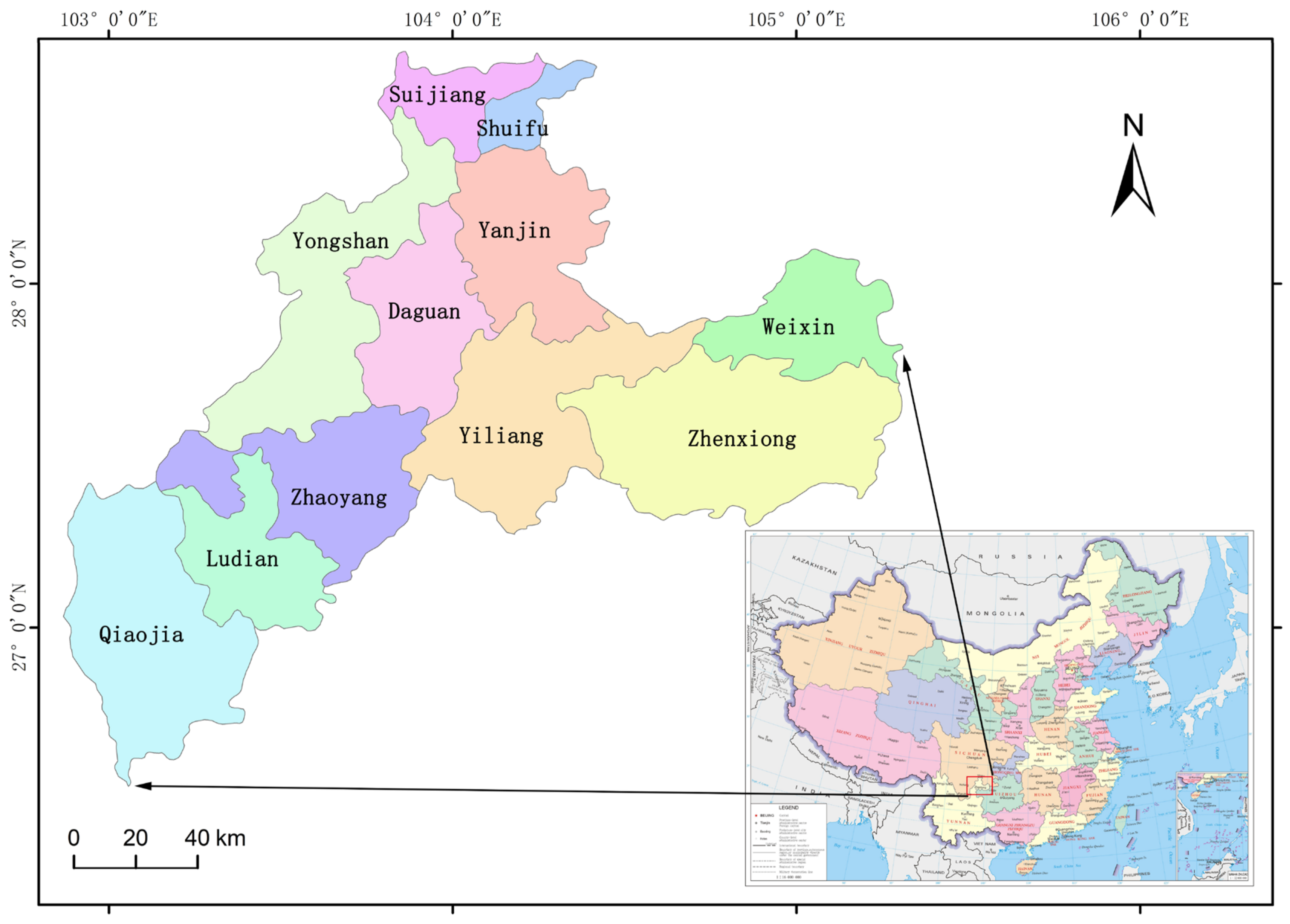
2.1. Study Area
2.2. Data Sources
2.2.1. Remote Sensing Data
2.2.2. Terrain Data
2.2.3. Use of Existing Thematic Databases
2.2.4. Verification Data
3. Methods
3.1. Sample Selection
- (1)
- Determine the sample range using a non-homologous data-voting method:
- (2)
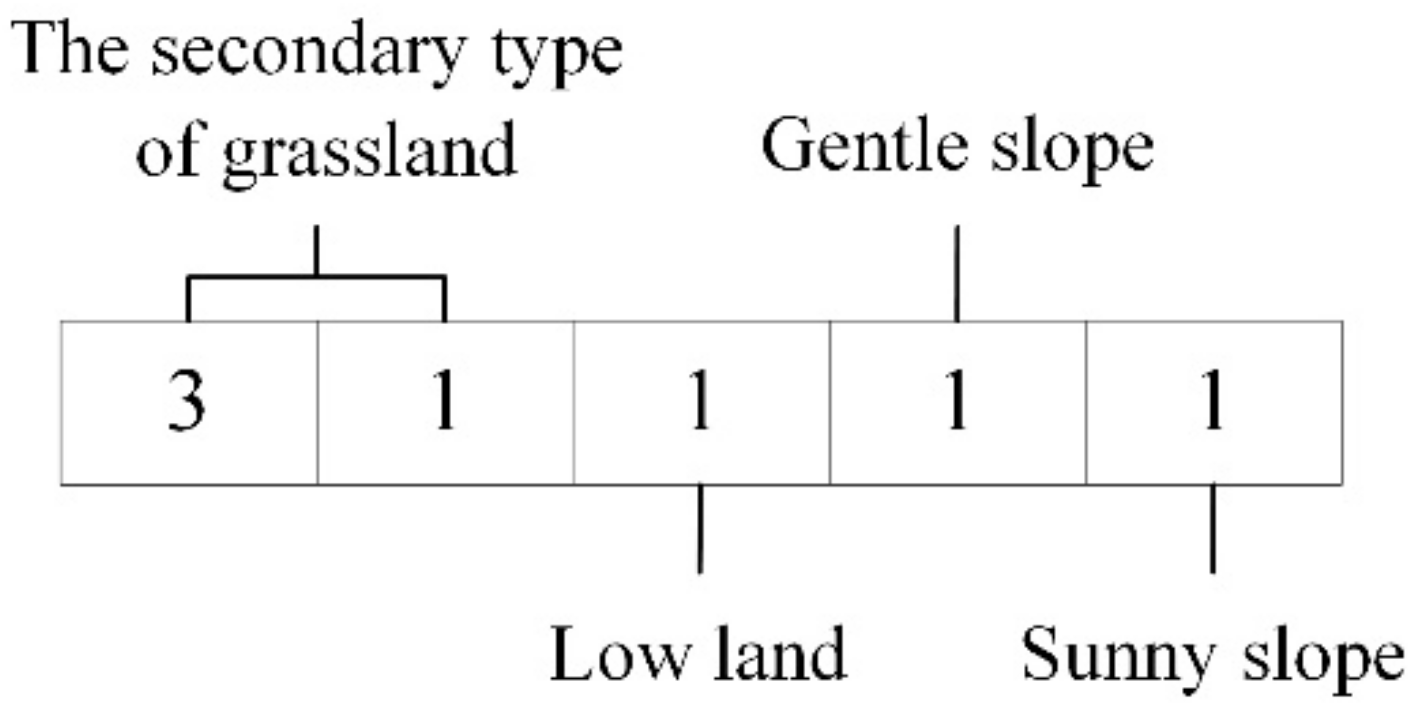
- Divide and recode the sample selection range according to the secondary land use types and terrain multi-factor data:
- (3)
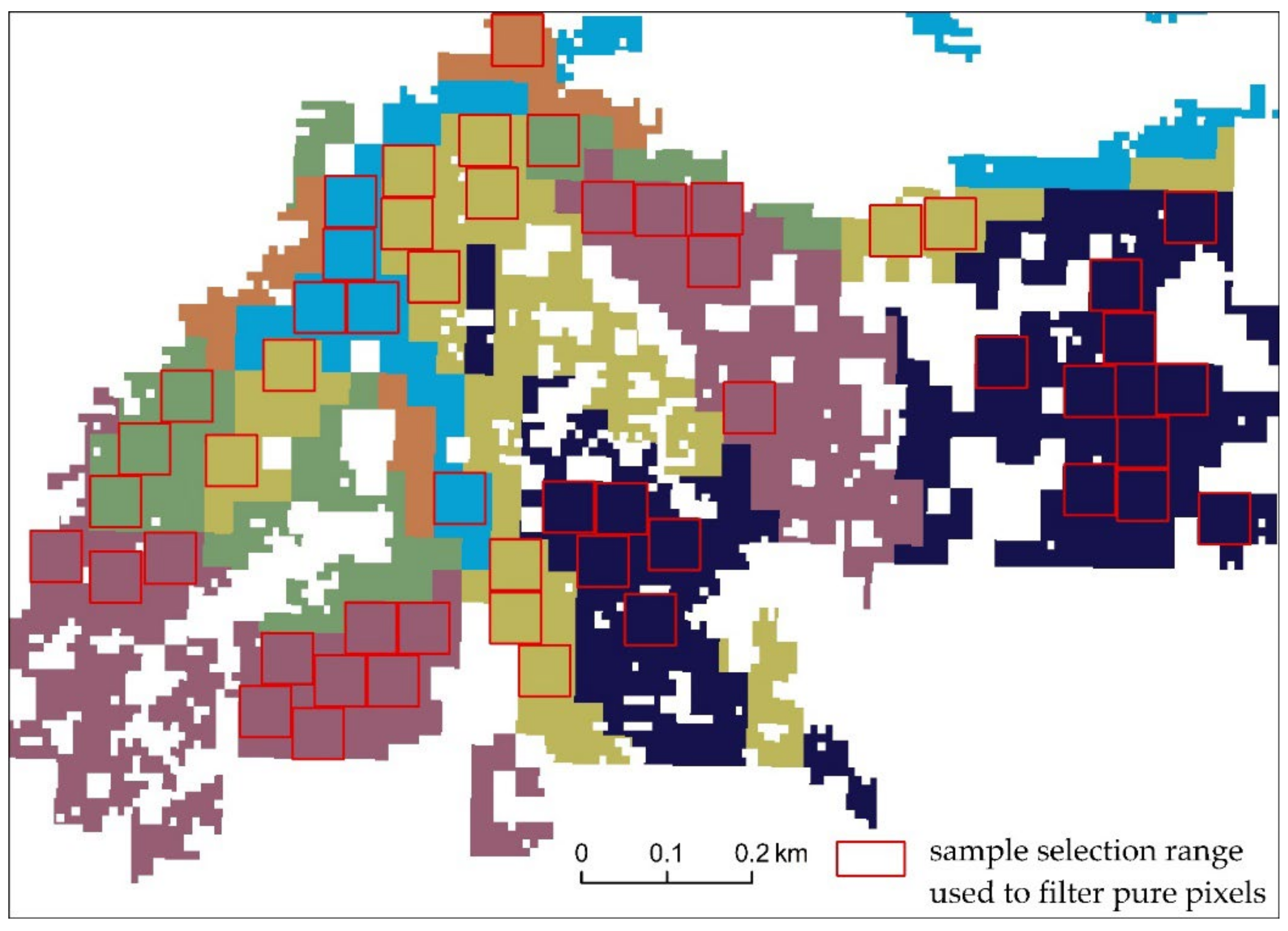
- Determine the final sample selection range by filtering pure pixels and then generate random samples:
- (4)
- Delete and supplement samples manually on the basis of (3):
3.2. Input Feature Selection
3.3. Random Forest Classification on the GEE Platform
3.4. Verification of Grassland Extraction Results
4. Results and Analysis
4.1. Results and Analysis of Sample Selection
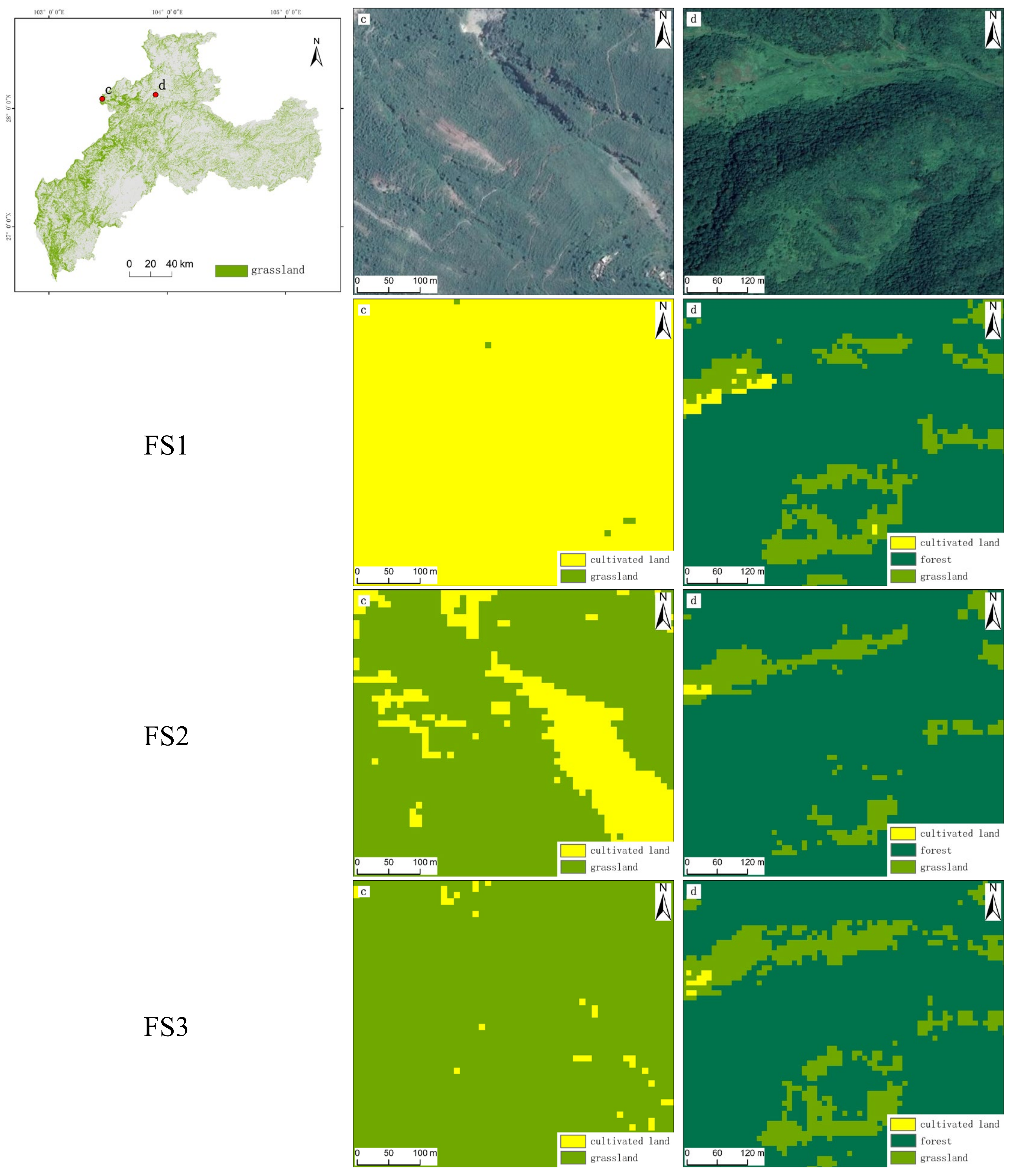
4.2. Results and Analysis of Input Feature Selection
4.3. Results and Analysis for the Grassland Distribution Identification
5. Discussion
6. Conclusions
- (1)
- Sample selection should follow the principles of completeness and randomness. If the sample selection range is not divided according to the secondary land use types and terrain multi-factor data, the results of random sample selection in the study area will not be fully representative. This can cause poorer classification results in areas lacking samples that conform to the realistic representation of primary land use types. In this study, complete sample selection mainly reduced the omission errors of grassland and effectively solved the problem of the grassland distribution being difficult to accurately identify due to the complex topography of southwest China.
- (2)
- The combined use of all available multispectral and radar data has the potential to identify the grassland distribution in mountainous fragmented terrain, and terrain characteristics are vital to mountainous grassland identification. This study used multispectral and radar time series data as input features, which effectively solved the problem of the grassland distribution being difficult to accurately extract due to cloud cover and heavy rain in southwest China. The input features applied in this study enabled the model to learn the time spectrum characteristics of radar and optical images, and the topographic features of southwest grassland, which improved the separability of ground objects.
- (3)
- The random forest model is suitable for dealing with the classification problem of multiple input features, which can be efficiently calculated and classified by the GEE cloud computing platform. In this study, there were 2527 sample points (including training and test samples) and 67 bands of input features. Experiments have shown that the random forest model can effectively learn multiple input features, and that the GEE platform only takes approximately 2–3 min to identify the optimal parameters (number of decision trees) for the model. Therefore, with a small time cost, a remote sensing thematic map of the grassland distribution in Zhaotong City in 2020 was obtained using the GEE platform.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, X.Y.; Wang, J.T. China Grass Industry Statistics (2017); China Agriculture Press: Beijing, China, 2018. [Google Scholar]
- Su, D.X. Analysis on the Development and Production Potential of Grassland in Southern China. Grassl. Turf 1998, 15–19. [Google Scholar] [CrossRef]
- Shi, Y.L. Encyclopedia of Chinese Resources Science; China University of Petroleum Press: Shandong, China, 2000. [Google Scholar]
- Xie, L.; Zhang, H.; Li, H.Z.; Wang, C. A Unified Framework for Crop Classification in Southern China Using Fully Polarimetric, Dual Polarimetric, and Compact Polarimetric SAR Data. Int. J. Remote Sens. 2015, 36, 3798–3818. [Google Scholar] [CrossRef]
- Li, Y.C.; Ge, J.; Hou, M.J.; Gao, H.Y.; Liu, J.; Bao, X.Y.; Yin, J.P.; Gao, J.L.; Feng, Q.S.; Liang, T.G. A Study of the SpatiotemPoral Dynamic of Land Cover Types and the Driving Forces of Grassland Area Change in Gannan Prefecture and Northwest Sichuan Based on CCI-LC Data. Acta Pratacult. Sin. 2020, 29, 1–15. [Google Scholar]
- Pan, H.T.; Wang, X. Study on the Effect of Training Samples on the Accuracy of Crop Remote Sensing Classification. Infrared Laser Eng. 2017, 46, 143–150. [Google Scholar]
- Li, J.C. Research on Remote Sensing Image Classification Based on Feature Selection. Mod. Inf. Technol. 2020, 4, 61–63. [Google Scholar]
- Zhang, H.; Shi, W.Z.; Wang, Y.J. Study on Relicble Classification Methods Based on Remotely Sensed Imagery; Surveying and Mapping Press: Beijing, China, 2016. [Google Scholar]
- Zhang, M.; Qian, Y.R.; Du, J.; Fan, Y.Y. The Application of the Convolution Neural Network to Grassland Classification in Remote Sensing Images. J. Northeast Norm. Univ. (Nat. Sci. Ed.) 2019, 51, 53–58. [Google Scholar]
- Senf, C.; Leitão, P.J.; Pflugmacher, D.; Linden, S.V.D.; Hostert, P. Mapping Land Cover in Complex Mediterranean Landscapes Using Landsat: Improved Classification Accuracies from Integrating Multi-seasonal and Synthetic Imagery. Remote Sens. Environ. 2015, 156, 527–536. [Google Scholar] [CrossRef]
- Gebhardt, S.; Wehrmann, T.; Ruiz, M.A.M.; Maeda, P.; Bishop, J.; Schramm, M.; Kopeinig, R.; Cartus, O.; Kellndorfer, J.; Ressl, R.; et al. MAD-MEX: Automatic Wall-to-Wall Land Cover Monitoring for the Mexican REDD-MRV Program Using All Landsat Data. Remote Sens. 2014, 6, 3923–3943. [Google Scholar] [CrossRef] [Green Version]
- Li, J.H.; Xu, J.D. Tree Species Classification of Time Series Remote Sensing Images by Dynamic Time Warping. J. Northeast For. Univ. 2017, 45, 56–61. [Google Scholar]
- Maus, V.; Câmara, G.; Appel, M.; Kuschnig, N.; Giorgino, T. dtwSat: Time-Weighted Dynamic Time Warping for Satellite Image Time Series Analysis in R. J. Stat. Softw. 2017, 90, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Belgiu, M.; Csillik, O. Sentinel-2 Cropland Mapping Using Pixel-based and Object-based Time-weighted Dynamic Time Warping Analysis. Remote Sens. Environ. 2018, 204, 509–523. [Google Scholar] [CrossRef]
- Cheng, K.; Wang, J. Forest-Type Classification Using Time-Weighted Dynamic Time Warping Analysis in Mountain Areas: A Case Study in Southern China. Forests 2019, 10, 1040. [Google Scholar] [CrossRef] [Green Version]
- Viana, C.M.; Girão, I.; Rocha, J. Long-Term Satellite Image Time-Series for Land Use/Land Cover Change Detection Using Refined Open Source Data in a Rural Region. Remote Sens. 2019, 11, 1104. [Google Scholar] [CrossRef] [Green Version]
- Qiu, P.X.; Wang, X.Q.; Cha, M.X.; Li, Y.L. Crop Identification Based on TWDTW Method and Time Series GF-1 WFV. Sci. Agric. Sin. 2019, 52, 2951–2961. [Google Scholar]
- Wang, X.Q.; Qiu, P.X.; Li, Y.L.; Cha, M.X. Crops Identification in Kaikong River Basin of Xinjiang Based on Time Series Landsat Remote Sensing Images. Trans. Chin. Soc. Agric. Eng. 2019, 35, 180–188. [Google Scholar]
- He, Y.; Dong, J.; Liao, X.; Sun, L.; Wang, Z.P.; Nan, S.Y.; Li, Z.C.; Fu, P. Examining Rice Distribution and Cropping Intensity in a Mixed Single- and Double-cropping Region in South China Using All Available Sentinel 1/2 Images. Int. J. Appl. Earth Obs. Geoinf. 2021, 101, 102351. [Google Scholar] [CrossRef]
- Zhao, L.C.; Liu, R.T.; Yang, Y.H.; Li, Y.J.; Zhang, X.Q.; Sun, X.L. Study on the Remote Sensing Classification of Grasslands Based on the Topographic Factors. Pratacult. Sci. 2006, 23, 26–30. [Google Scholar]
- Zhou, W.; Yang, F.; Qian, Y.R.; Li, J.L. Typical Grassland Classification and Precision Evaluation Based on Remote Sensing Data in the Northern Slope of Tianshan Mountain. Pratacult. Sci. 2012, 29, 1526–1532. [Google Scholar]
- Qian, Y.R.; Yu, J.; Jia, Z.H.; Sun, H.; Guligeina, D. The Classification Strategy of Desert Grassland Based on Decision Tree Using Remote Sensing Image. J. Northwest AF Univ. (Nat. Sci. Ed.) 2013, 41, 159–166. [Google Scholar]
- Sun, M.; Shen, W.S.; Xie, M.; Li, H.D.; Gao, F. The Identification of Grassland Types in the Source Region of the Yarlung Zangbo River Based on Spectral Features. Remote Sens. Land Resour. 2012, 15, 83–89. [Google Scholar]
- Gorelick, N.; Hancher, M.; Dixon, M.; IIyushchenko, S.; Moore, R. Google Earth Engine: Planetary-scale Geospatial Analysis for Everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Kumar, L.; Mutanga, O. Google Earth Engine Applications Since Inception: Usage, Trends, and Potential. Remote Sens. 2018, 10, 1509. [Google Scholar] [CrossRef] [Green Version]
- Luo, C.; Qi, B.S.; Liu, H.J.; Guo, D.; Lu, L.P.; Fu, Q.; Shao, Y.Q. Using Time Series Sentinel-1 Images for Object-Oriented Crop Classification in Google Earth Engine. Remote Sens. 2021, 13, 561. [Google Scholar] [CrossRef]
- Inoue, S.; Ito, A.; Yonezawa, C. Mapping Paddy Fields in Japan by Using a Sentinel-1 SAR Time Series Supplemented by Sentinel-2 Images on Google Earth Engine. Remote Sens. 2020, 12, 1622. [Google Scholar] [CrossRef]
- Xie, S.; Liu, L.Y.; Zhang, X.; Yang, J.N.; Chen, X.D.; Gao, Y. Automatic Land-Cover Mapping Using Landsat Time-Series Data based on Google Earth Engine. Remote Sens. 2019, 11, 3023. [Google Scholar] [CrossRef] [Green Version]
- Li, P.; Xiao, H.M.; Zhao, X.Y.; Guo, Y.; Qin, Y.C. Mapping Winter Crops Using a Phenology Algorithm, Time-Series Sentinel-2 and Landsat-7/8 Images, and Google Earth Engine. Remote Sens. 2021, 13, 2510. [Google Scholar]
- Ren, J.Z.; Zhang, Y.J. Grassland Resources in the South of China and Its Development Strategy. J. China Inst. Metrol. 2002, 13, 174–180. [Google Scholar]
- Cheng, X.B.; Yang, Z.S. Temporal and Spatial Variation Characteristics and Driving Forces of Land Use in Zhaotong City of Yunnan Province. Bull. Soil Water Conserv. 2018, 38, 166–170. [Google Scholar]
- Rao, J.; Li, X.C. Discussion on the Status Quo and Countermeasures of the Industrialization of Animal Husbandry in Zhaotong City. Contemp. Anim. Husb. 2016, 78–79, CNKI:SUN:DDXM.0.2016-18-041. [Google Scholar]
- Liu, J.Y.; Zhang, Z.X.; Li, X.B.; Zhuang, D.F.; Zhang, S.W. Research on Remote Sensing Spatio-Temporal Information of Landuse Change in China in the 1990s; Science Press: Beijing, China, 2005. [Google Scholar]
- Chen, J.; Liao, A.P.; Chen, J.; Peng, S.; Chen, L.J.; Zhang, H.W. 30-Meter Global Land Cover Data Product-GlobeLand30. Geomat. World 2017, 24, 1–8. [Google Scholar]
- Buchhorn, M.; Smets, B.; Bertels, L.; De Roo, B.; Lesiv, M.; Tsendbazar, N.E.; Linlin, L.; Tarko, A. Copernicus Global Land Service: Land Cover 100 m: Version 3 Globe 2015–2019: Validation Report; Zenodo: Geneva, Switzerland, 2020. [Google Scholar]
- Zhang, X.; Liu, L.Y.; Chen, X.D.; Gao, Y.; Xie, S.; Mi, J. GLC_FCS30: Global Land-cover Product with Fine Classification System at 30m Using Time-series Landsat Imagery. Earth Syst. Sci. Data 2021, 13, 2753–2776. [Google Scholar] [CrossRef]
- Gong, P.; Liu, H.; Zhang, M.N.; Li, C.C.; Wang, J.; Huang, H.B.; Clinton, N.; Ji, L.Y.; Li, W.Y.; Bai, Y.Q.; et al. Stable Classification with Limited Sample: Transferring a 30-m Resolution Sample Set Collected in 2015 to Mapping 10-m Resolution Global Land Cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar] [CrossRef] [Green Version]
- Su, Y.; Guo, Q.; Hu, T.; Guan, H.C.; Jin, S.C.; An, S.Z.; Chen, X.L.; Guo, K.; Hao, Z.Q.; Hu, Y.M. An Updated Vegetation Map of China (1: 1,000,000). Sci. Bull. 2020, 65, 1125–1136. [Google Scholar] [CrossRef]
- Zhu, X.F.; Pan, Y.Z.; Zhang, J.S.; Wang, S.; Gu, X.H.; Xu, C. The Effects of Training Samples on the Wheat Planting Area Measure Accuracy in TM Scale(I): The Accuracy Response of Different Classifiers to Training Samples. J. Remote Sens. 2006, 11, 826–837. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Li, C.C.; Xian, G.; Zhou, Q.; Pengra, B.W. A Novel Automatic Phenology Learning (APL) Method of Training Sample Selection Using Multiple Datasets for Time-series Land Cover Mapping. Remote Sens. Environ. 2021, 266, 112670. [Google Scholar] [CrossRef]
- Jing, X.; Wang, J.D.; Wang, J.H.; Huang, W.J.; Liu, L.Y. Classifying Forest Vegetation Using Sub-region ClassificationBbased on Multi-temporal Remote Sensing Images. Remote Sens. Technol. Appl. 2008, 23, 394–397. [Google Scholar]
- Jing, X.U.; An, Y.L.; Liu, S.H.; Han, K.X. Discussion on classification for Sentinel-1A SAR data in mountainous plateau based on backscatter features—A case study in Anshun city. J. Guizhou Norm. Univ. (Nat. Sci.) 2016. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor Used | Bands | Descriptions | Resolution | Input Features |
|---|---|---|---|---|
| Sentinel-1 | VV | 5.405 GHz | 10 m | Radar time series data |
| VH | 5.405 GHz | 10 m | ||
| Landsat 8 OLI | Blue | 452–512 nm | 30 m | Multispectral time series data |
| Green | 533–590 nm | 30 m | ||
| Red | 636–673 nm | 30 m | ||
| NIR | 851–879 nm | 30 m | ||
| SWIR1 | 1566–1651 nm | 30 m | ||
| SWIR2 | 2107–2294 nm | 30 m | ||
| Sentinel-2A/B | Blue | 496.6 nm (S2A)/492.1 nm (S2B) | 10 m | |
| Green | 560 nm (S2A)/559 nm (S2B) | 10 m | ||
| Red | 664.5 nm (S2A)/665 nm (S2B) | 10 m | ||
| NIR | 835.1 nm (S2A)/833 nm (S2B) | 10 m | ||
| SWIR1 | 1613.7 nm (S2A)/1610.4 nm (S2B) | 20 m | ||
| SWIR2 | 2202.4 nm (S2A)/2185.7 nm (S2B) | 20 m | ||
| GF-1 | Blue | 450–520 nm | 16 m | |
| Green | 520–590 nm | 16 m | ||
| Red | 630–690 nm | 16 m | ||
| NIR | 770–890 nm | 16 m |
| Name | Resolution | Mapping Accuracy |
|---|---|---|
| 1:100,000 land use data [33] | 30 m | 85% |
| GlobeLand30 data [34] | 30 m | 83.50% |
| CGLOPS-1 data [35] | 100 m | 80% |
| GLC_FCS30 data [36] | 30 m | 82.50% |
| FROMLC data [37] | 10 m | 72.76% |
| China 1:1,000,000 vegetation map [38] | — | 64.8% |
| Primary Land Use Types | Secondary Land Use Types |
|---|---|
| Cultivated land | Mountain paddy; hilly paddy; plain paddy; paddy with slopes above 25°; mountain dryland; hilly dryland; plain dryland; dryland with slopes above 25° |
| Grassland | High coverage grassland; medium coverage grassland; low coverage grassland |
| Impervious surfaces | Urban land; rural residential land; industrial and construction land |
| Forest | Closed forest, evergreen needle leaf; closed forest, deciduous needle leaf; closed forest, evergreen, broad leaf; closed forest, deciduous, broad leaf; closed forest, mixed; closed forest, unknown; open forest, evergreen needle leaf; open forest, deciduous needle leaf; open forest, evergreen broad leaf; open forest, deciduous broad leaf; open forest, mixed; open forest, unknown |
| FS1 | FS2 | FS3 | |
|---|---|---|---|
| Multispectral time series data | √ | √ | √ |
| Radar time series data | √ | √ | |
| The terrain multi-factor data | √ |
| Actual Value | Grassland | Other Lands | |
|---|---|---|---|
| Predicted Value | |||
| Grassland | True Positive (TP) | False Positive (FP) | |
| Other lands | False Negative (FN) | True Negative (TN) | |
| Precision | Recall | Overall Accuracy | F1 Score | |
|---|---|---|---|---|
| EXP1 | 0.9375 | 0.3846 | 0.6725 | 0.5455 |
| EXP2 | 0.9296 | 0.5641 | 0.7555 | 0.7021 |
| EXP3 | 0.9730 | 0.6154 | 0.7948 | 0.7539 |
| Precision | Recall | Overall Accuracy | F1 Score | |
|---|---|---|---|---|
| FS1 | 0.9398 | 0.6667 | 0.8079 | 0.7800 |
| FS2 | 0.9873 | 0.6667 | 0.8253 | 0.7959 |
| FS3 | 0.9891 | 0.7778 | 0.8821 | 0.8708 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, Y.; Wen, Q.; Zhao, X.; Liu, S.; Zhu, K.; Hu, B. Identifying Grassland Distribution in a Mountainous Region in Southwest China Using Multi-Source Remote Sensing Images. Remote Sens. 2022, 14, 1472. https://doi.org/10.3390/rs14061472
Yuan Y, Wen Q, Zhao X, Liu S, Zhu K, Hu B. Identifying Grassland Distribution in a Mountainous Region in Southwest China Using Multi-Source Remote Sensing Images. Remote Sensing. 2022; 14(6):1472. https://doi.org/10.3390/rs14061472
Chicago/Turabian StyleYuan, Yixin, Qingke Wen, Xiaoli Zhao, Shuo Liu, Kunpeng Zhu, and Bo Hu. 2022. "Identifying Grassland Distribution in a Mountainous Region in Southwest China Using Multi-Source Remote Sensing Images" Remote Sensing 14, no. 6: 1472. https://doi.org/10.3390/rs14061472
APA StyleYuan, Y., Wen, Q., Zhao, X., Liu, S., Zhu, K., & Hu, B. (2022). Identifying Grassland Distribution in a Mountainous Region in Southwest China Using Multi-Source Remote Sensing Images. Remote Sensing, 14(6), 1472. https://doi.org/10.3390/rs14061472