
A Scalable Computing Resources System for Remote Sensing Big Data Processing Using GeoPySpark Based on Spark on K8s




Abstract
:
1. Introduction
2. Methodology and Data Sources
2.1. The Tile-Oriented Programing Model
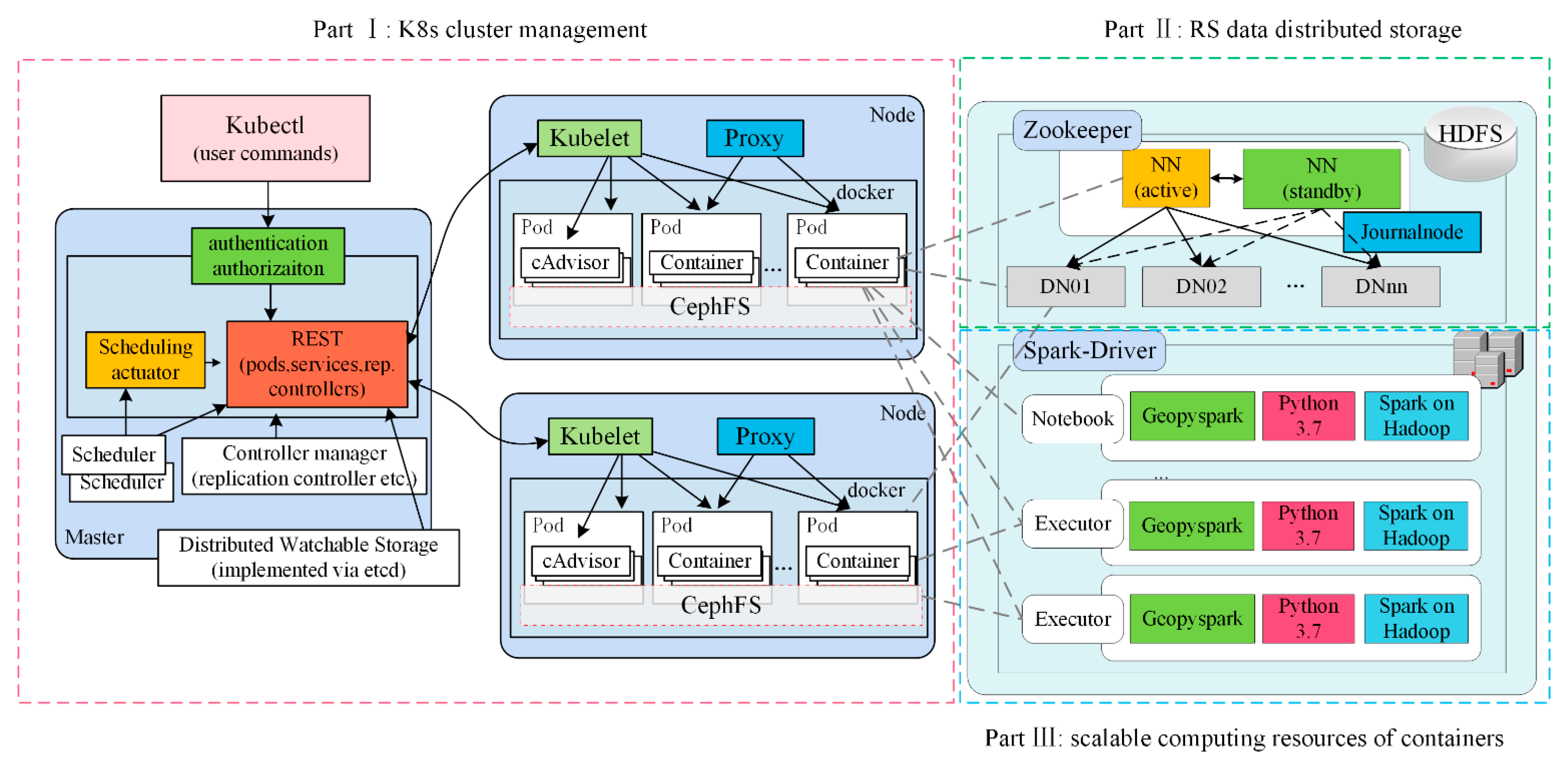
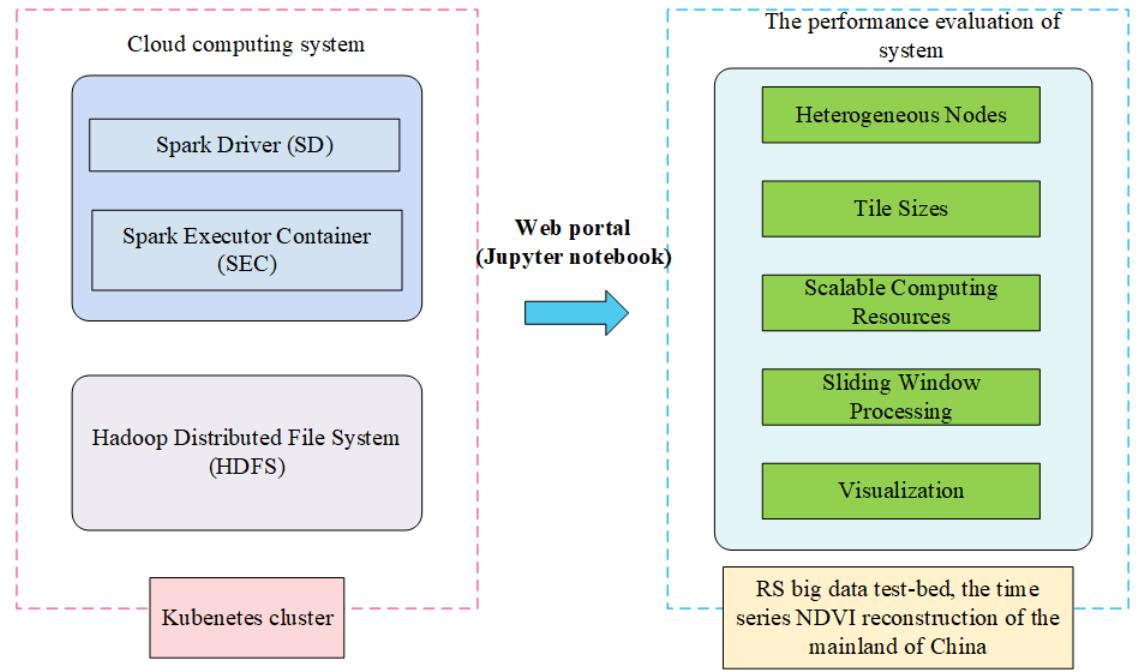
2.2. The Ditributed Parallel Architecture of System
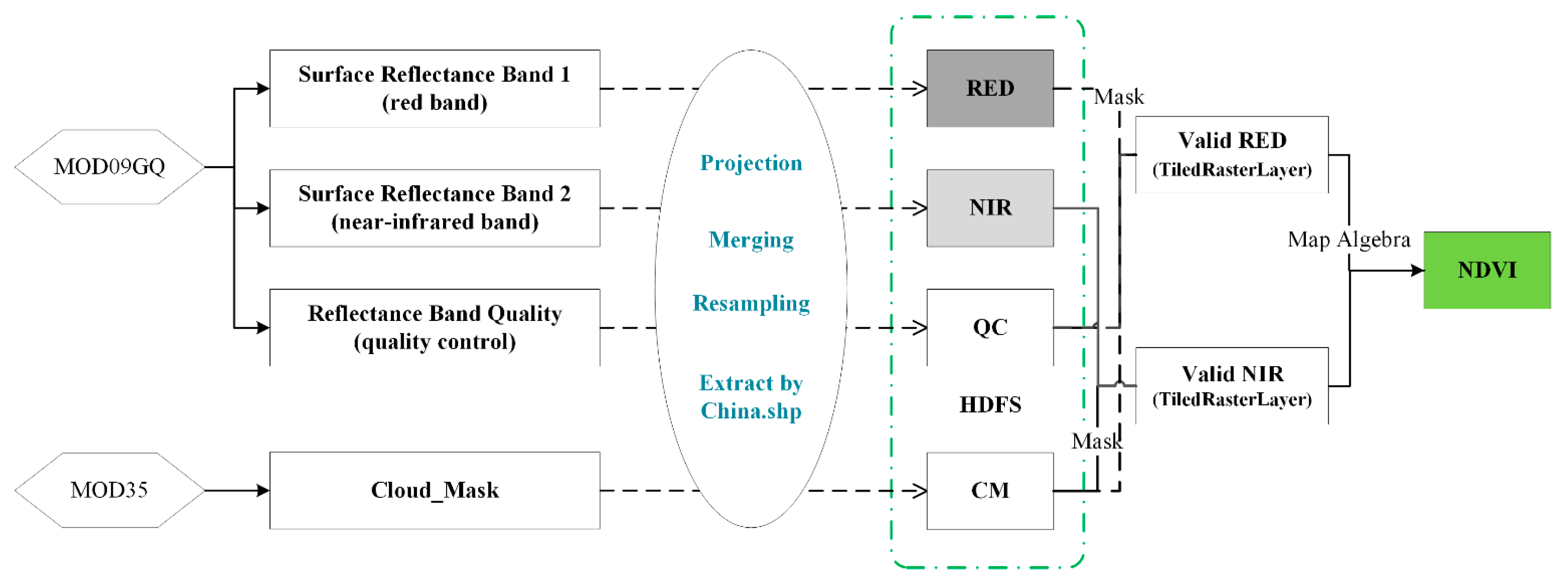
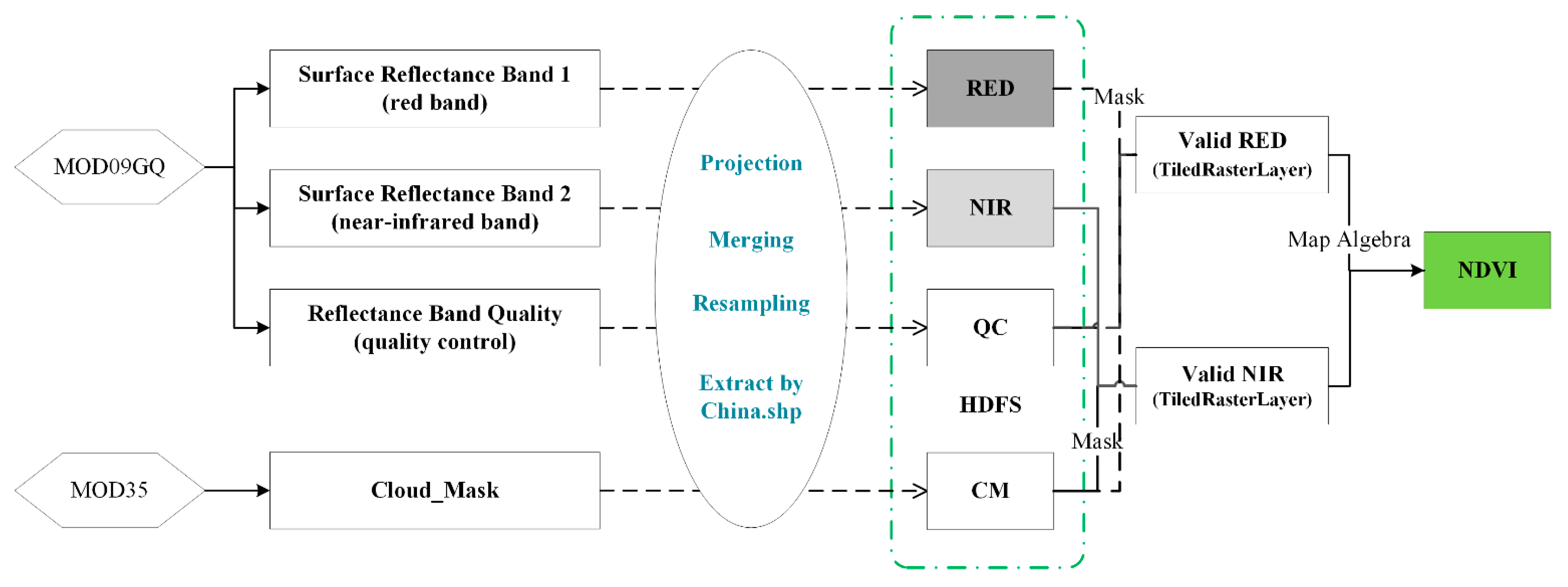
2.3. The Design of Experiments
2.4. The Data Sources of Experiments
2.5. Time Cost of Compurting Mechanism
3. System Environment
4. Results
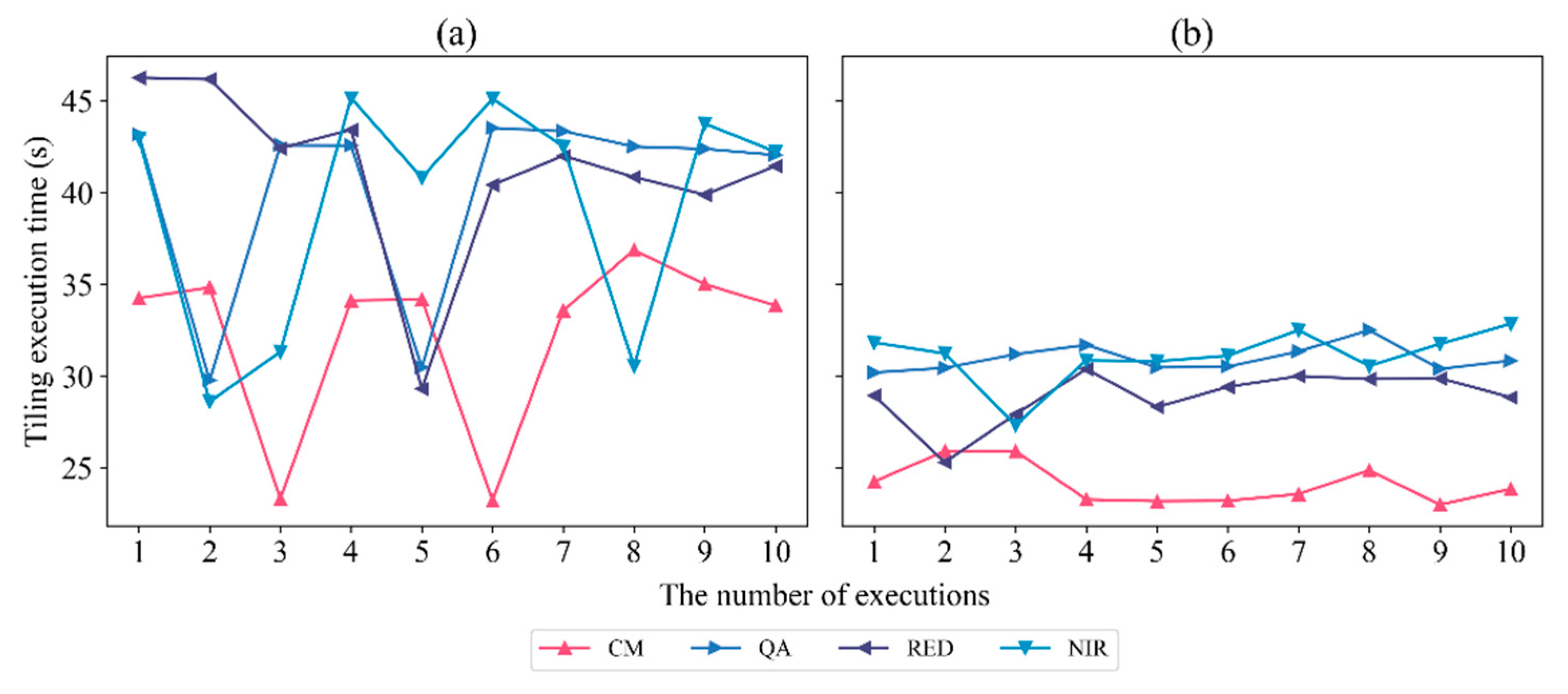
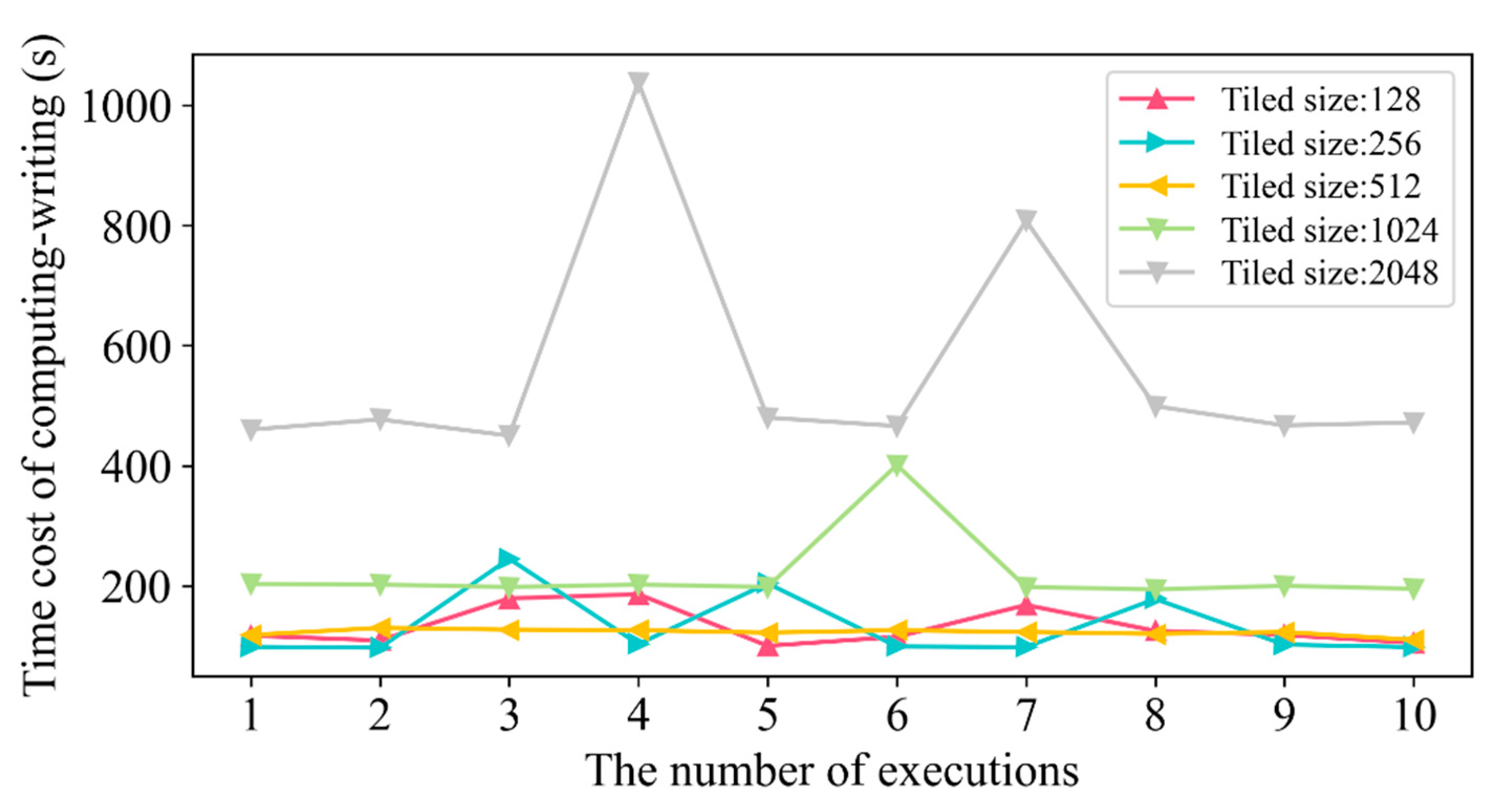
4.1. Time Cost of Heterogeneous Nodes
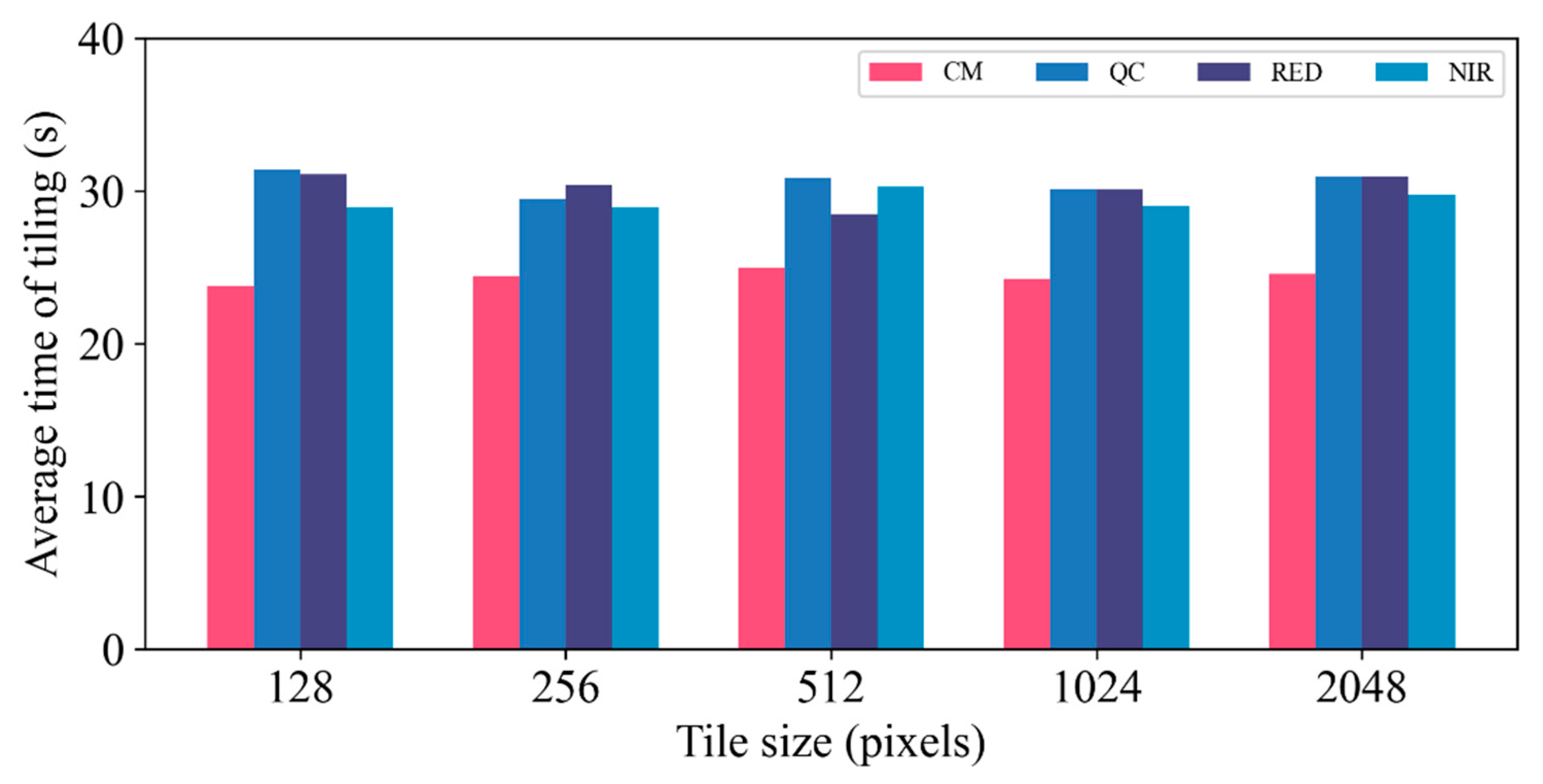
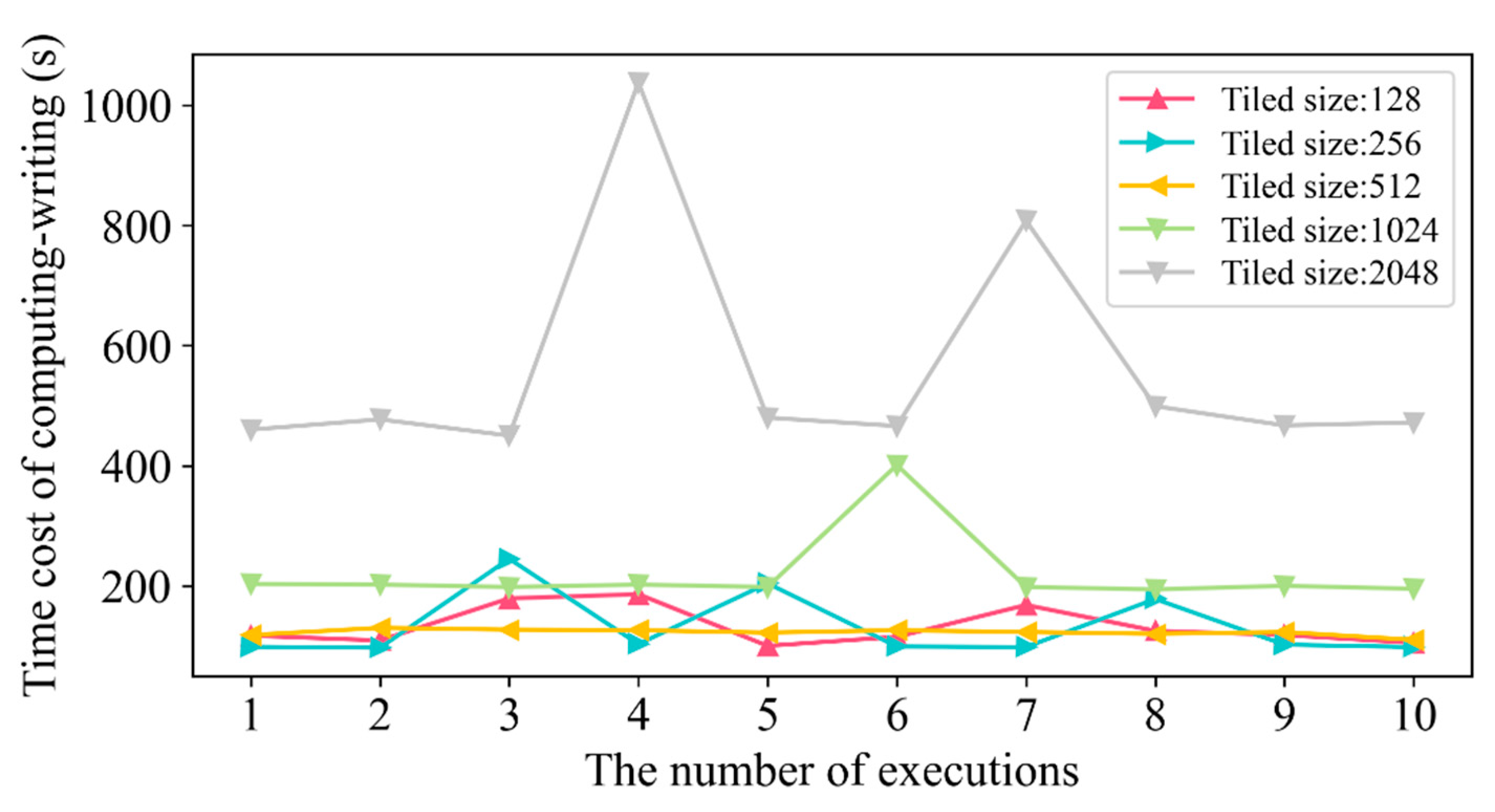
4.2. Time Cost in Different Tile Sizes
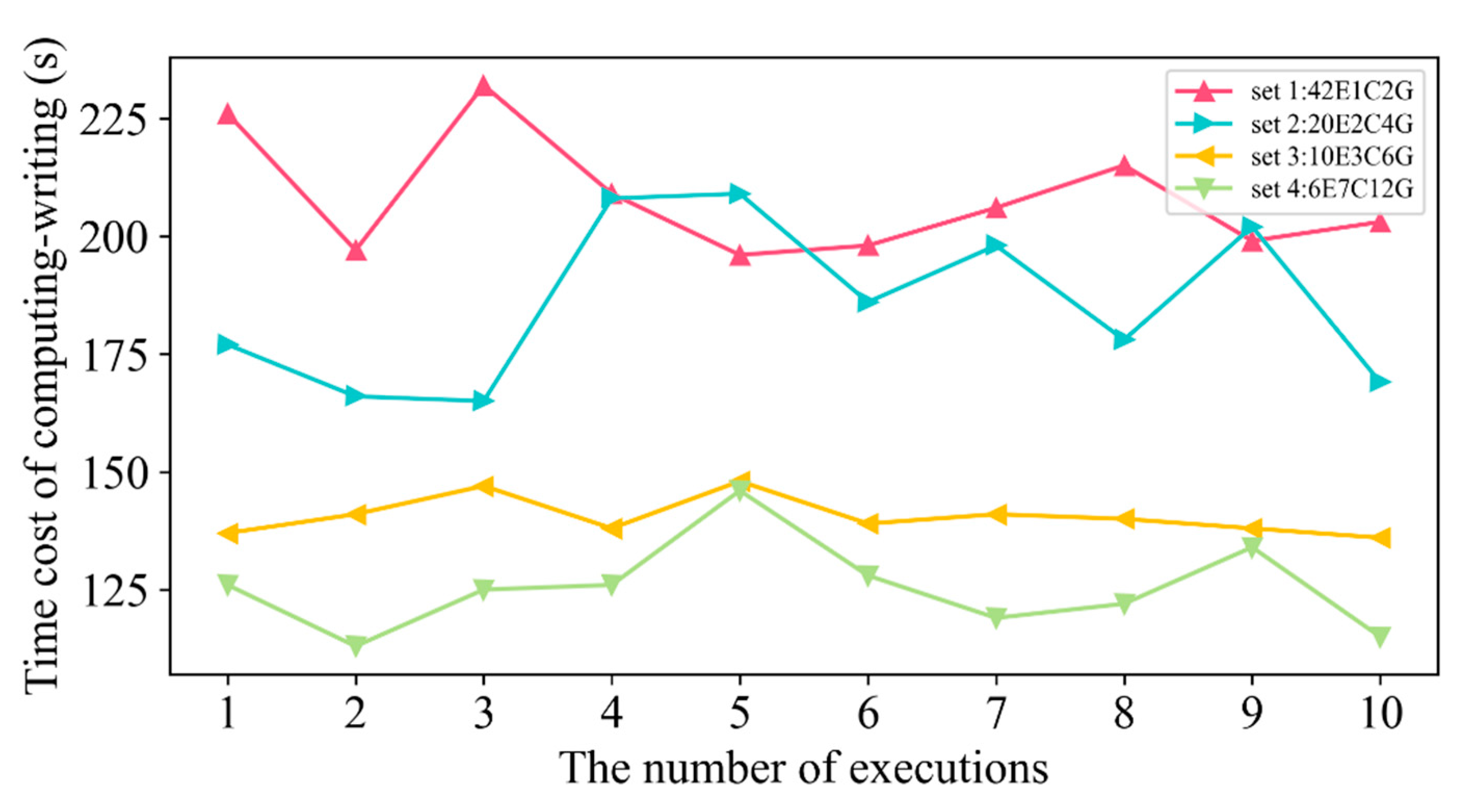
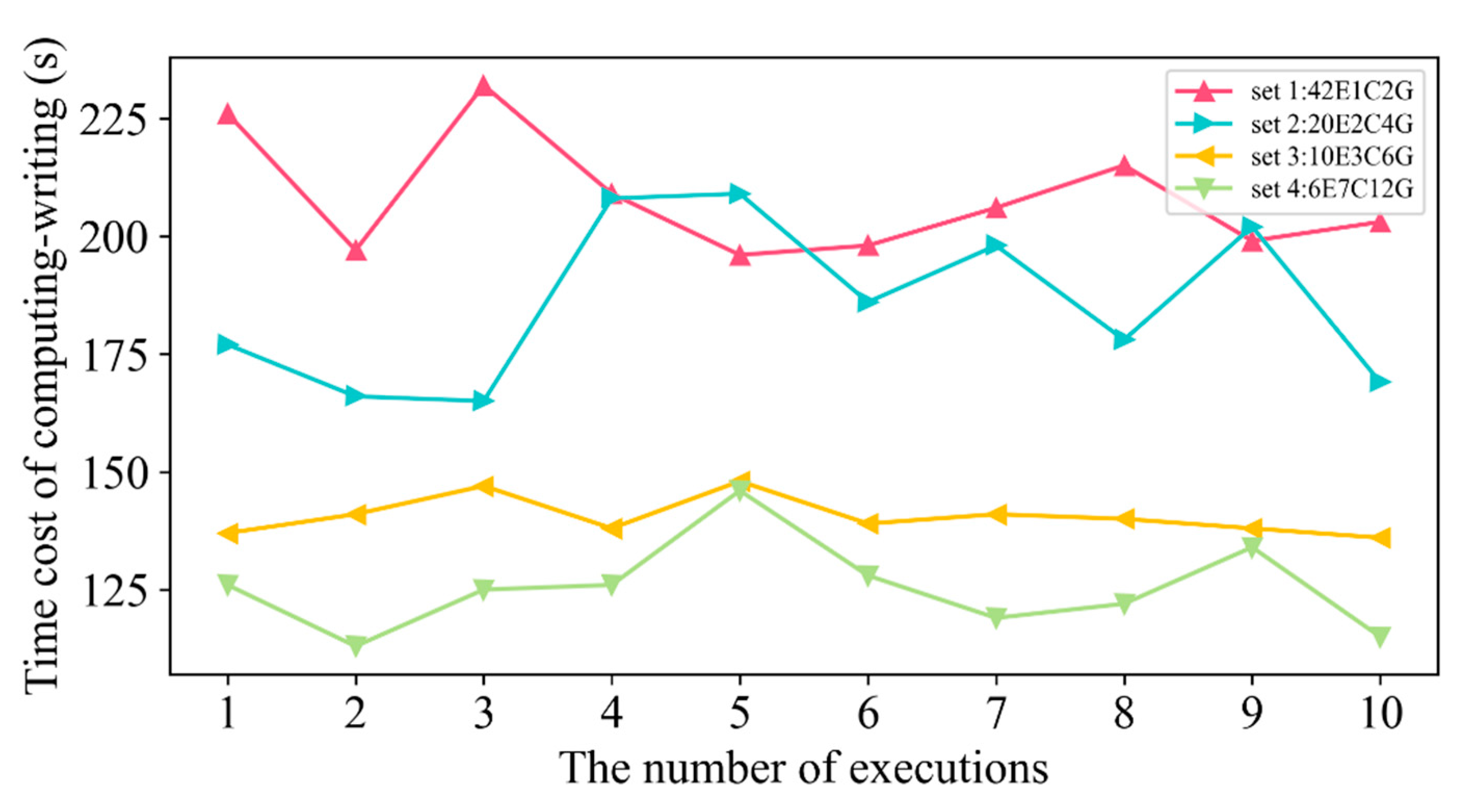
4.3. Time Cost of Scalable Computing Resources
4.4. Time Cost of Sliding Window Processing
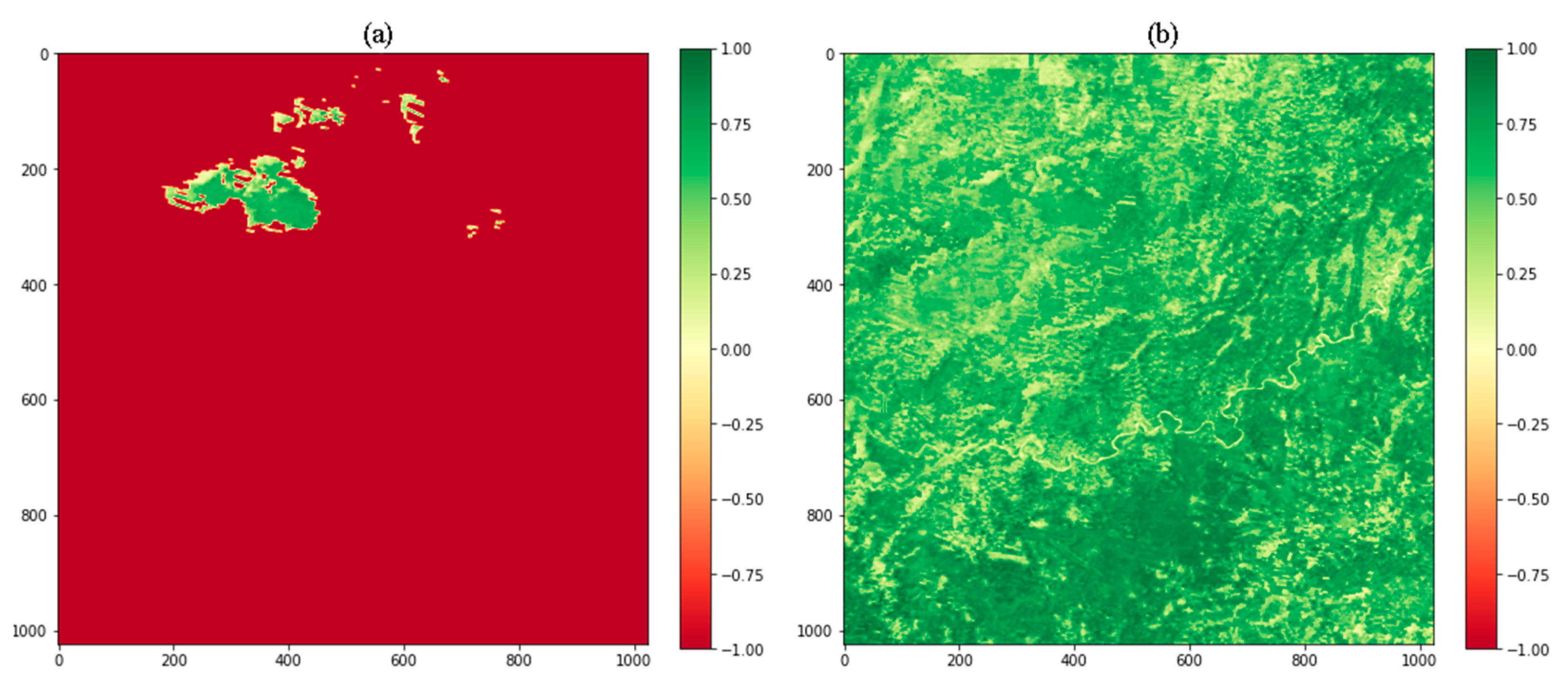
4.5. Multi-Scale Visualization
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CM | Cloud Mask |
| DN | DataNode of HDFS |
| DPC | Distributed Parallel Computing |
| EO | Earth Observation |
| EOS | Earth Observing System |
| FOSS | Free and Open-Source Software |
| GDAL | Geospatial Data Abstraction Library |
| GEE | Google Earth Engine |
| HDFS | Hadoop Distributed File System |
| HPC | High-Performance Computing |
| JEODPP | JRC Earth Observation Data and Processing Platform |
| JRC | Joint Research Center |
| LXC | Linux Container |
| MODIS | Moderate Resolution Imaging Spectroradiometer |
| NDVI | Normalized Difference Vegetation Index |
| NN | NameNode of HDFS |
| ODC | Open Data Cube |
| QC | Quality Control |
| RDD | Resilient Distributed Datasets |
| SD | Spark Driver |
| SEC | Spark Executor Containers |
| SEPAL | System for Earth Observation Data Access, Processing and Analysis for Land Monitoring |
| SH | Sentinel Hub |
| VMN | Virtual Machine Node |
| VMs | Virtual Machines |
| YARN | Yet Another Resource Negotiator |
References
- Deren, L.; Liangpei, Z.; Guisong, X. Automatic analysis and mining of remote sensing big data. Acta Geod. Cartogr. Sin. 2014, 43, 1211. [Google Scholar]
- Ma, Y.; Wu, H.; Wang, L.; Huang, B.; Ranjan, R.; Zomaya, A.; Jie, W. Remote sensing big data computing: Challenges and opportunities. Future Gener. Comput. Syst. 2015, 51, 47–60. [Google Scholar] [CrossRef] [Green Version]
- Skytland, N. Big data: What is nasa doing with big data today. Open. Gov. Open Access Artic. 2012. Available online: https://www.opennasa.org/what-is-nasa-doing-with-big-data-today.html (accessed on 28 November 2021).
- Gamba, P.; Du, P.; Juergens, C.; Maktav, D. Foreword to the special issue on “human settlements: A global remote sensing challenge”. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 5–7. [Google Scholar] [CrossRef]
- Stromann, O.; Nascetti, A.; Yousif, O.; Ban, Y. Dimensionality Reduction and Feature Selection for Object-Based Land Cover Classification based on Sentinel-1 and Sentinel-2 Time Series Using Google Earth Engine. Remote Sens. 2020, 12, 76. [Google Scholar] [CrossRef] [Green Version]
- Müller, M.; Bernard, L.; Brauner, J. Moving code in spatial data infrastructures–web service based deployment of geoprocessing algorithms. Trans. GIS 2010, 14, 101–118. [Google Scholar] [CrossRef]
- Camara, G.; Assis, L.F.; Ribeiro, G.; Ferreira, K.R.; Llapa, E.; Vinhas, L. Big earth observation data analytics: Matching requirements to system architectures. In Proceedings of the 5th ACM SIGSPATIAL International Workshop on Analytics for Big Geospatial Data, Burlingame, CA, USA, 31 October 2016; pp. 1–6. [Google Scholar]
- Gomes, V.C.F.; Queiroz, G.R.; Ferreira, K.R. An Overview of Platforms for Big Earth Observation Data Management and Analysis. Remote Sens. 2020, 12, 1253. [Google Scholar] [CrossRef] [Green Version]
- Mell, P.; Grance, T. The NIST Definition of Cloud Computing; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2011.
- Mutanga, O.; Kumar, L. Google Earth Engine Applications. Remote Sens. 2019, 11, 591. [Google Scholar] [CrossRef] [Green Version]
- White, T. Hadoop: The Definitive Guide; O’Reilly Media, Inc.: Newton, MD, USA, 2012. [Google Scholar]
- Jo, J.; Lee, K.-W. High-performance geospatial big data processing system based on MapReduce. ISPRS Int. J. Geo-Inf. 2018, 7, 399. [Google Scholar] [CrossRef] [Green Version]
- Cary, A.; Sun, Z.; Hristidis, V.; Rishe, N. Experiences on processing spatial data with mapreduce. In Proceedings of the International Conference on Scientific and Statistical Database Management, New Orleans, LA, USA, 2–4 June 2009; pp. 302–319. [Google Scholar]
- Eldawy, A.; Mokbel, M.F. A demonstration of spatialhadoop: An efficient mapreduce framework for spatial data. Proc. VLDB Endow. 2013, 6, 1230–1233. [Google Scholar] [CrossRef] [Green Version]
- Giachetta, R. A framework for processing large scale geospatial and remote sensing data in MapReduce environment. Comput. Graph. 2015, 49, 37–46. [Google Scholar] [CrossRef]
- Aji, A.; Wang, F.; Vo, H.; Lee, R.; Liu, Q.; Zhang, X.; Saltz, J. Hadoop-GIS: A high performance spatial data warehousing system over MapReduce. In Proceedings of the VLDB Endowment International Conference on Very Large Data Bases, Trento, Italy, 26–30 August 2013. [Google Scholar]
- Quirita, V.A.A.; da Costa, G.A.O.P.; Happ, P.N.; Feitosa, R.Q.; da Silva Ferreira, R.; Oliveira, D.A.B.; Plaza, A. A new cloud computing architecture for the classification of remote sensing data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 409–416. [Google Scholar] [CrossRef]
- Huang, W.; Meng, L.; Zhang, D.; Zhang, W. In-memory parallel processing of massive remotely sensed data using an apache spark on hadoop yarn model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 3–19. [Google Scholar] [CrossRef]
- Wang, L.; Ma, Y.; Yan, J.; Chang, V.; Zomaya, A.Y. pipsCloud: High performance cloud computing for remote sensing big data management and processing. Future Gener. Comput. Syst. 2018, 78, 353–368. [Google Scholar] [CrossRef] [Green Version]
- Warmerdam, F. The geospatial data abstraction library. In Open Source Approaches in Spatial Data Handling; Springer: Berlin/Heidelberg, Germany, 2008; pp. 87–104. [Google Scholar]
- Lan, H.; Zheng, X.; Torrens, P.M. Spark Sensing: A Cloud Computing Framework to Unfold Processing Efficiencies for Large and Multiscale Remotely Sensed Data, with Examples on Landsat 8 and MODIS Data. J. Sens. 2018, 2018, 2075057. [Google Scholar] [CrossRef]
- Jonnalagadda, V.S.; Srikanth, P.; Thumati, K.; Nallamala, S.H.; Dist, K. A review study of apache spark in big data processing. Int. J. Comput. Sci. Trends Technol. IJCST 2016, 4, 93–98. [Google Scholar]
- Ghatge, D. Apache spark and big data analytics for solving real world problems. Int. J. Comput. Sci. Trends Technol. 2016, 4, 301–304. [Google Scholar]
- Rathore, M.M.; Son, H.; Ahmad, A.; Paul, A.; Jeon, G. Real-time big data stream processing using GPU with spark over hadoop ecosystem. Int. J. Parallel Program. 2018, 46, 630–646. [Google Scholar] [CrossRef]
- Tian, F.; Wu, B.; Zeng, H.; Zhang, X.; Xu, J. Efficient identification of corn cultivation area with multitemporal synthetic aperture radar and optical images in the google earth engine cloud platform. Remote Sens. 2019, 11, 629. [Google Scholar] [CrossRef] [Green Version]
- Sun, Z.; Chen, F.; Chi, M.; Zhu, Y. A spark-based big data platform for massive remote sensing data processing. In Proceedings of the International Conference on Data Science, Sydney, Australia, 8–9 August 2015; pp. 120–126. [Google Scholar]
- Docker. Docker Overview. Available online: https://docs.docker.com/get-started/overview (accessed on 19 November 2021).
- Bhimani, J.; Yang, Z.; Leeser, M.; Mi, N. Accelerating big data applications using lightweight virtualization framework on enterprise cloud. In Proceedings of the 2017 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 12–14 September 2017; pp. 1–7. [Google Scholar]
- Sollfrank, M.; Loch, F.; Denteneer, S.; Vogel-Heuser, B. Evaluating docker for lightweight virtualization of distributed and time-sensitive applications in industrial automation. IEEE Trans. Ind. Inform. 2020, 17, 3566–3576. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, L.; Pu, C.; Dou, Q.; Wu, L.; Zhou, W. A comparative study of containers and virtual machines in big data environment. In Proceedings of the 2018 IEEE 11th International Conference on Cloud Computing (CLOUD), San Francisco, CA, USA, 2–7 July 2018; pp. 178–185. [Google Scholar]
- Cloud Native Computing Foundation. Overview. Available online: https://kubernetes.io (accessed on 19 November 2021).
- Thurgood, B.; Lennon, R.G. Cloud computing with Kubernetes cluster elastic scaling. In Proceedings of the 3rd International Conference on Future Networks and Distributed Systems, Paris, France, 1–2 July 2019; pp. 1–7. [Google Scholar]
- Vithlani, H.N.; Dogotari, M.; Lam, O.H.Y.; Prüm, M.; Melville, B.; Zimmer, F.; Becker, R. Scale Drone Mapping on K8S: Auto-scale Drone Imagery Processing on Kubernetes-orchestrated On-premise Cloud-computing Platform. In Proceedings of the GISTAM, Prague, Czech Republic, 7–9 May 2020; pp. 318–325. [Google Scholar]
- Jacob, A.; Vicente-Guijalba, F.; Kristen, H.; Costa, A.; Ventura, B.; Monsorno, R.; Notarnicola, C. Organizing Access to Complex Multi-Dimensional Data: An Example From The Esa Seom Sincohmap Project. In Proceedings of the 2017 Conference on Big Data from Space, Toulouse, France, 28–30 November 2017; pp. 205–208. [Google Scholar]
- Huang, W.; Zhou, J.; Zhang, D. On-the-Fly Fusion of Remotely-Sensed Big Data Using an Elastic Computing Paradigm with a Containerized Spark Engine on Kubernetes. Sensors 2021, 21, 2971. [Google Scholar] [CrossRef]
- Guo, Z.; Fox, G.; Zhou, M. Investigation of data locality in mapreduce. In Proceedings of the 2012 12th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (ccgrid 2012), Washington, DC, USA, 13–16 May 2012; pp. 419–426. [Google Scholar]
- Hoyer, S.; Hamman, J. xarray: ND labeled arrays and datasets in Python. J. Open Res. Softw. 2017, 5, 10. [Google Scholar] [CrossRef] [Green Version]
- Soille, P.; Burger, A.; De Marchi, D.; Kempeneers, P.; Rodriguez, D.; Syrris, V.; Vasilev, V. A versatile data-intensive computing platform for information retrieval from big geospatial data. Future Gener. Comput. Syst. 2018, 81, 30–40. [Google Scholar] [CrossRef]
- Open Data Cube. Available online: https://www.sentinel-hub.com/ (accessed on 2 January 2022).
- Eldawy, A. SpatialHadoop: Towards flexible and scalable spatial processing using mapreduce. In Proceedings of the 2014 SIGMOD PhD Symposium, Snowbird, UT, USA, 22–27 June 2014; pp. 46–50. [Google Scholar]
- AS Foundation. Running Spark on Kubernetes. Available online: http://spark.apache.org/docs/latest/running-on-kubernetes.html (accessed on 10 September 2020).
- Bouffard, J.; McClean, J. What Is GeoPySpark? Available online: https://geopyspark.readthedocs.io/en/latest/ (accessed on 19 November 2021).
- Zaharia, M.; Chowdhury, M.; Das, T.; Dave, A.; Ma, J.; McCauly, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In Proceedings of the 9th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 12), San Jose, CA, USA, 25–27 April 2012; pp. 15–28. [Google Scholar]
- Stefanakis, E. Web Mercator and raster tile maps: Two cornerstones of online map service providers. Geomatica 2017, 71, 100–109. [Google Scholar] [CrossRef]
- Dungan, W., Jr.; Stenger, A.; Sutty, G. Texture tile considerations for raster graphics. In Proceedings of the 5th Annual Conference on Computer Graphics and Interactive Techniques, New York, NY, USA, 23–25 August 1978; pp. 130–134. [Google Scholar]
- C Foundation. Intro to Ceph. Available online: https://docs.ceph.com/en/latest/cephfs/index.html (accessed on 29 November 2021).
- TL Foundation. Storage Classes. Available online: https://kubernetes.io/docs/concepts/storage/storage-classes/ (accessed on 29 November 2021).
- TL Foundation. Persistent Volumes. Available online: https://kubernetes.io/docs/concepts/storage/persistent-volumes/ (accessed on 29 November 2021).
- AS Foundation. HDFS Architecture Guide. Available online: https://hadoop.apache.org/docs/r1.2.1/-hdfs_design.pdf (accessed on 16 September 2021).
- Chen, C.P.; Zhang, C.-Y. Data-intensive applications, challenges, techniques and technologies: A survey on Big Data. Inf. Sci. 2014, 275, 314–347. [Google Scholar] [CrossRef]
- Azavea Inc. What Is GeoTrellis? Available online: https://geotrellis.io/documentation (accessed on 20 December 2019).
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- TL Foundation. What Is Helm? Available online: https://helm.sh/docs (accessed on 29 November 2021).
- Pete, L. Haproxy Ingress. Available online: https://haproxy-ingress.github.io/ (accessed on 28 November 2021).
- Ghaderpour, E.; Ben Abbes, A.; Rhif, M.; Pagiatakis, S.D.; Farah, I.R. Non-stationary and unequally spaced NDVI time series analyses by the LSWAVE software. Int. J. Remote Sens. 2020, 41, 2374–2390. [Google Scholar] [CrossRef]
- Zhao, Y. Principles and Methods of Remote Sensing Application Analysis; Science Press: Beijing, China, 2003; pp. 413–416. [Google Scholar]
- Vermote, E.F.; Roger, J.C.; Ray, J.P. MODIS Surface Reflectance User’s Guide. Available online: https://lpdaac.usgs.gov/documents/306/MOD09_User_Guide_V6.pdf (accessed on 29 November 2021).
- Ackerman, S.; Frey, R. MODIS atmosphere L2 cloud mask product. In NASA MODIS Adaptive Processing System; Goddard Space Flight Center: Greenbelt, MD, USA, 2015. [Google Scholar]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring vegetation systems in the Great Plains with ERTS. NASA Spec. Publ. 1974, 351, 309. [Google Scholar]
- Gazul, S.; Kiyaev, V.; Anantchenko, I.; Shepeleva, O.; Lobanov, O. The conceptual model of the hybrid geographic information system based on kubernetes containers and cloud computing. Int. Multidiscip. Sci. GeoConference SGEM 2020, 20, 357–363. [Google Scholar]
- Aliyun. Container repository service. Available online: https://cn.aliyun.com (accessed on 28 November 2021).
- Foundation, A.S. Tuning Spark. Available online: http://spark.apache.org/docs/latest/tuning.html#tuning-spark (accessed on 15 September 2021).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Nodes | Machines | Specification | Actor |
|---|---|---|---|
| Node 1 | VMN (Hosed on FusionServer R006) | 8 vcores CPUs, 32GB memory, and 500G disk | Node of K8s; NameNode (NN) of HDFS; Kuboard |
| Node 2 | VMN (Hosted on FusionServer R006) | 8 vcores CPUs, 32GB memory, and 500G disk | Master of K8s, DataNode (DN) of HDFS |
| Node 3 | VMN (Hosed on FusionServer R006) | 8 vcores CPUs, 16GB memory, and 1074G disk | Node of K8s; NN of HDFS; OSD of CephFS |
| Node 4 | VMN (Hosed on FusionServer R006) | 8 vcores CPUs, 16GB memory, and 1074G disk | Node of K8s; DN of HDFS; OSD of CephFS |
| Node 5 | VMN (Hosted on FusionServer R005) | 8 vcores CPUs, 16GB memory, and 1050G disk | Node of K8s; DN of HDFS; OSD of CephFS |
| Node 6 | VMN (Hosted on FusionServer R005) | 8 vcores CPUs, 32GB memory, and 2.9T disk | Node of K8s; DN of HDFS; OSD of CephFS |
| Object | Software | Version |
|---|---|---|
| Virtual machine node | Docker | 19.03.13 |
| Ceph | 15.2.6 | |
| K8s | 1.19.2 | |
| Kuboard | 2.0.5.5 | |
| Docker image | Hadoop | 2.7.3 |
| Python | 3.7.3 | |
| spark-bin-hadoop | 2.4.6 | |
| GDAL | 3.1.4 | |
| Proj | 6.3.2 |
| Docker Image | Package | Version |
|---|---|---|
| spark-notebook | Jupyter Notebook | 6.2.0 |
| pyspark | 2.4.5 | |
| geopyspark | 0.4.3 | |
| shapely | 1.7.1 | |
| py4j | 0.10.7 | |
| matplotlib | 3.3.4 | |
| pandas | 0.25.3 | |
| numpy | 1.19.5 | |
| snuggs | 1.4.7 | |
| spark-py | pyspark | 2.4.5 |
| geopyspark | 0.4.3 | |
| shapely | 1.7.1 | |
| numpy | 1.19.5 | |
| py4j | 0.10.9.1 | |
| pyproj | 2.2.2 | |
| six | 1.15.0 | |
| snuggs | 1.4.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, J.; Huang, C.; Hou, J. A Scalable Computing Resources System for Remote Sensing Big Data Processing Using GeoPySpark Based on Spark on K8s. Remote Sens. 2022, 14, 521. https://doi.org/10.3390/rs14030521
Guo J, Huang C, Hou J. A Scalable Computing Resources System for Remote Sensing Big Data Processing Using GeoPySpark Based on Spark on K8s. Remote Sensing. 2022; 14(3):521. https://doi.org/10.3390/rs14030521
Chicago/Turabian StyleGuo, Jifu, Chunlin Huang, and Jinliang Hou. 2022. "A Scalable Computing Resources System for Remote Sensing Big Data Processing Using GeoPySpark Based on Spark on K8s" Remote Sensing 14, no. 3: 521. https://doi.org/10.3390/rs14030521
APA StyleGuo, J., Huang, C., & Hou, J. (2022). A Scalable Computing Resources System for Remote Sensing Big Data Processing Using GeoPySpark Based on Spark on K8s. Remote Sensing, 14(3), 521. https://doi.org/10.3390/rs14030521