This research demonstrates how low-density scans can be used in a dual parallel computing framework with a GA to optimize urban ALS missions to maximize vertical façade data capture, as needed for many 3D reconstruction and modeling workflows. While building upon the vertical coverage priorities of Hinks et al. [
23], this paper transforms the potential for more complete data coverage by employing a metaheuristic approach. This is performed by substituting the idealized mathematical forms used by Hinks et al. [
23] for actual geometric representations of the real natural and built environment based on previously collected, low-density ALS data from publicly accessible sources. In addition, this research focuses on the underlying parallel computing strategy that ensures the efficiency of the proposed GA method.
The structure of the optimization problem lends itself to a reinforcement learning solution as the combinatoric space is too big for brute force enumeration. Reinforcement learning is a stochastic optimization approach that is regularly used in this area. While there are many optimization approaches suitable for such a problem, such as simulated annealing, particle swarm, and q-learning, as shown by Wolpert and Macready [
41] there has yet to be established an optimal approach for stochastic solvers. The research presented in this paper does not aim to investigate every optimization approach. Instead, GAs were selected because the types of flight paths an aircraft could take were highly constrained. The selection was also based on the success of GAs in solving difficult optimization problems with large combinatoric search spaces for over 30 years [
42]. Herein, a typical GA was implemented to demonstrate how this could be achieved.
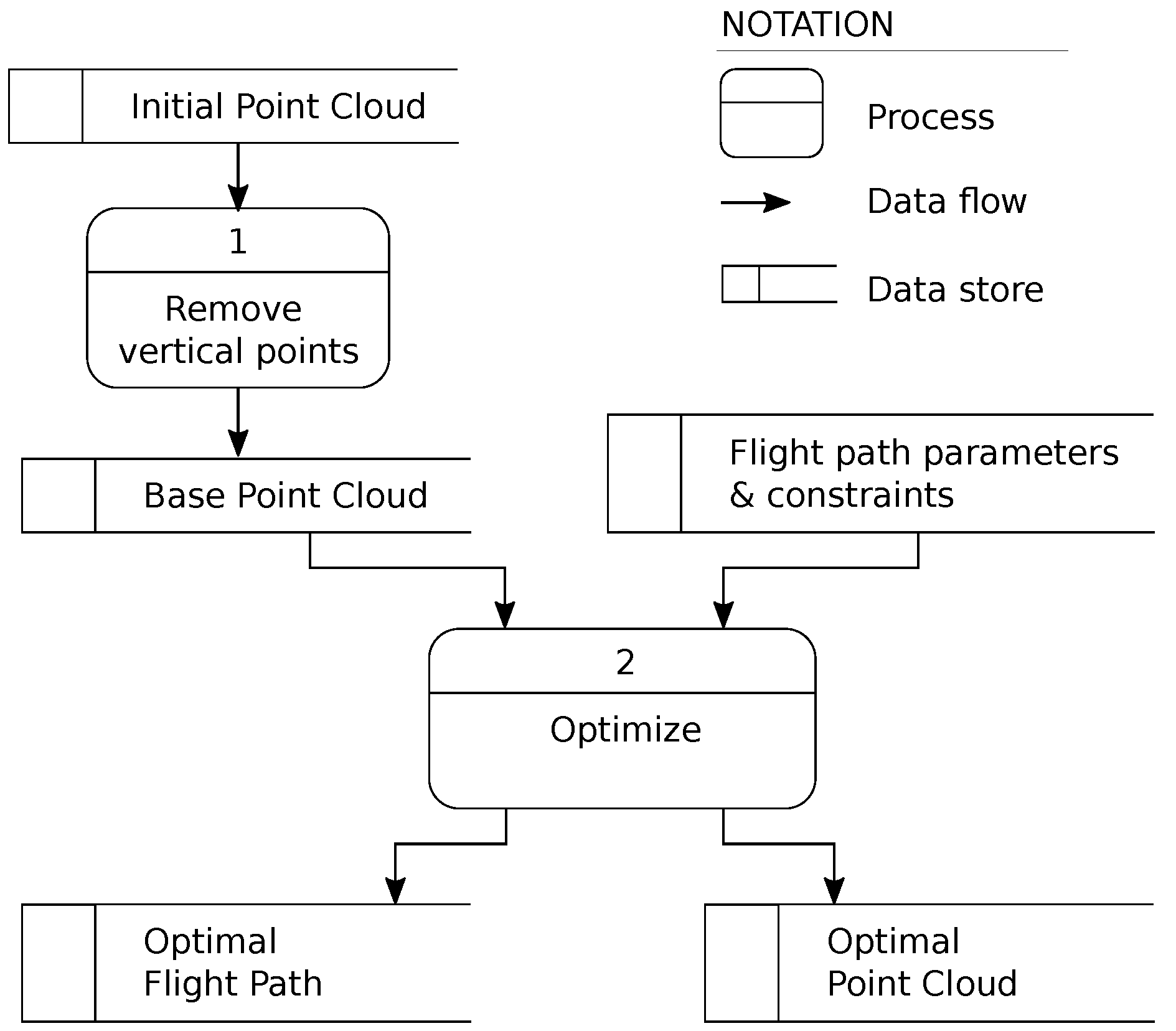
An overview of the data flow and processes employed in the research are presented in
Figure 2. In addition to the flight path parameters and constraints, the optimization (Process 2 in
Figure 2) requires some knowledge of the target urban environment including at least a rough representation of the street topography and building geometries. In this research, the urban environment is represented as a special kind of point cloud, called a base point cloud. A base point cloud represents the data captured in a manner that is likely to be sub-optimal for vertical surface documentation. To avoid introducing bias into the baseline data through the existence of some vertical data, the proposed approach advocates its wholesale removal. A base point cloud can be obtained by removing points on vertical surfaces from a pre-existing point cloud of the area of interest (Process 1 in
Figure 2). Where a pre-existing point cloud is unavailable, a base point cloud can be generated by rasterizing any 3D model of the city [
43]. The optimization described in the remainder of this section aims to search for the most optimal flight path in the form of one that yields the largest number of vertical points. The point cloud derived from the optimal flight path is referred to as the optimal point cloud.
3.1. A Genetic Algorithm for LiDAR Flight Path Optimization
The genetic algorithm was devised to maximize vertical surface point generation. Algorithm 1 presents the pseudo-code of a typical GA. Given an initial set of randomly generated flight grids (
), new generations of flight grids are iteratively created by biologically inspired processes, including selection, mutation, and crossover. The selection is based on a fitness function that provides a metric to evaluate the quality of an individual (i.e., flight grid) [lines 2 & 8 in Algorithm 1]. In the context of urban LiDAR flight path optimization, the fitness function evaluates a flight grid based on the quantity of vertical points the flight grid generates (further explained in
Section 3.2).
Based on the fitness scores (i.e., outputs of the fitness function), two subsets are selected from an original generation () using operations SelectS and SelectO on lines 4 and 5. The first subset (called survivors, ) derived from function SelectS contains high-performing individuals that are passed unchanged onto the next population (line 4 in Algorithm 1). The second subset derived from function SelectO contains other high-performing individuals that are combined pairwise via a process called crossover to create offspring, (line 5 in Algorithm 1). The offspring are supposed to inherit good characteristics from the high-performing individuals in the previous population. Subsequently, a small fraction of the offspring, , is randomly mutated (line 6 in Algorithm 1). The mutation process is supposed to create random characteristics absent in the previous population. The survivors, , and the offspring, , are combined to form the next population, (line 6 of Algorithm 1). New generations of flight grids are iteratively generated, until the results converge. Namely, the fitness scores are not further improved after (1) a certain number of iterations is reached, (2) the best fitness score exceeds a certain value, or (3) the number of iterations reaches a predefined value. The GA returns the best individual of all flight paths generated.
| Algorithm 1 Typical structure of a genetic algorithm |
![Remotesensing 13 04437 i001]() |
There are many GA implementations that differ slightly. In this research, Jenetics, a Java GA library by Wilhelmstötter [
44] was used. Jenetics provides base, domain classes (e.g., Population, Phenotype, Chromosome, and Gene), operation classes (e.g., Alterer and Selector), and Engine classes to connect all components into a GA. A Population is a set of Phenotypes, each of which is a Genotype (i.e., genetic constitution of an individual) with a fitness score. A Genotype is composed of multiple Chromosomes. Each chromosome consists of a set of Genes. A key step in the application of GA to LiDAR flight path optimization is to translate the problem domain into GA concepts.
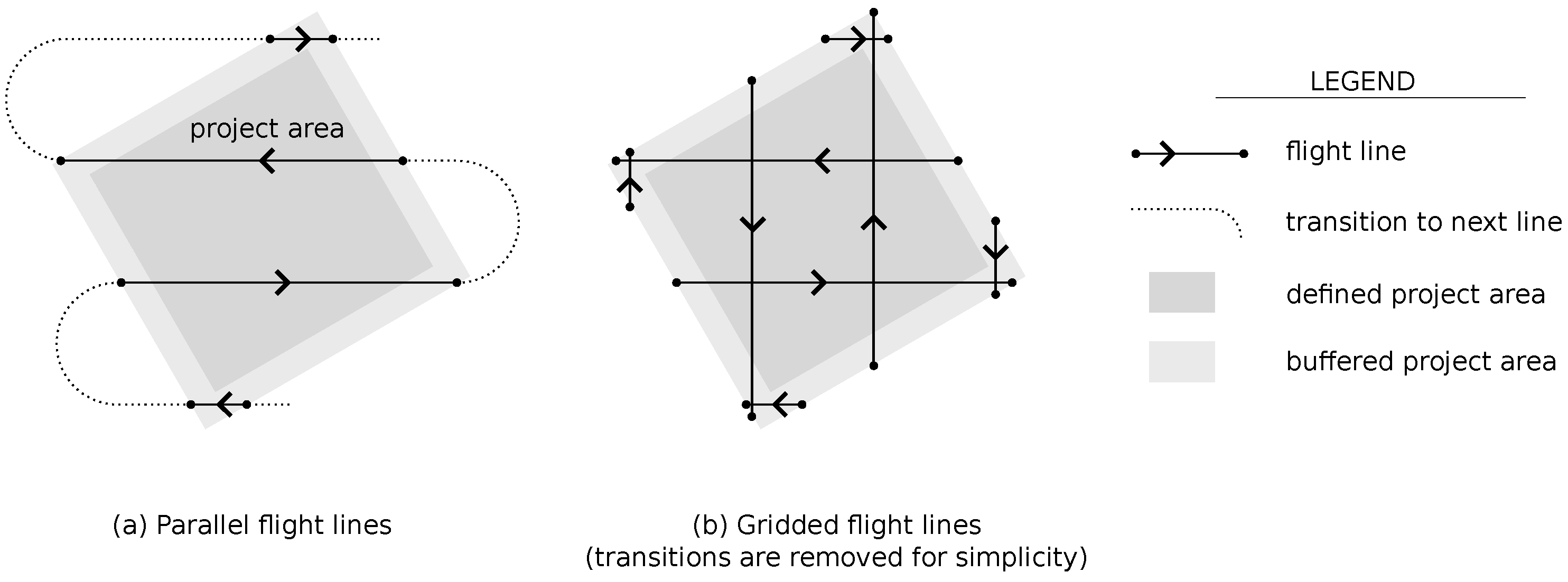
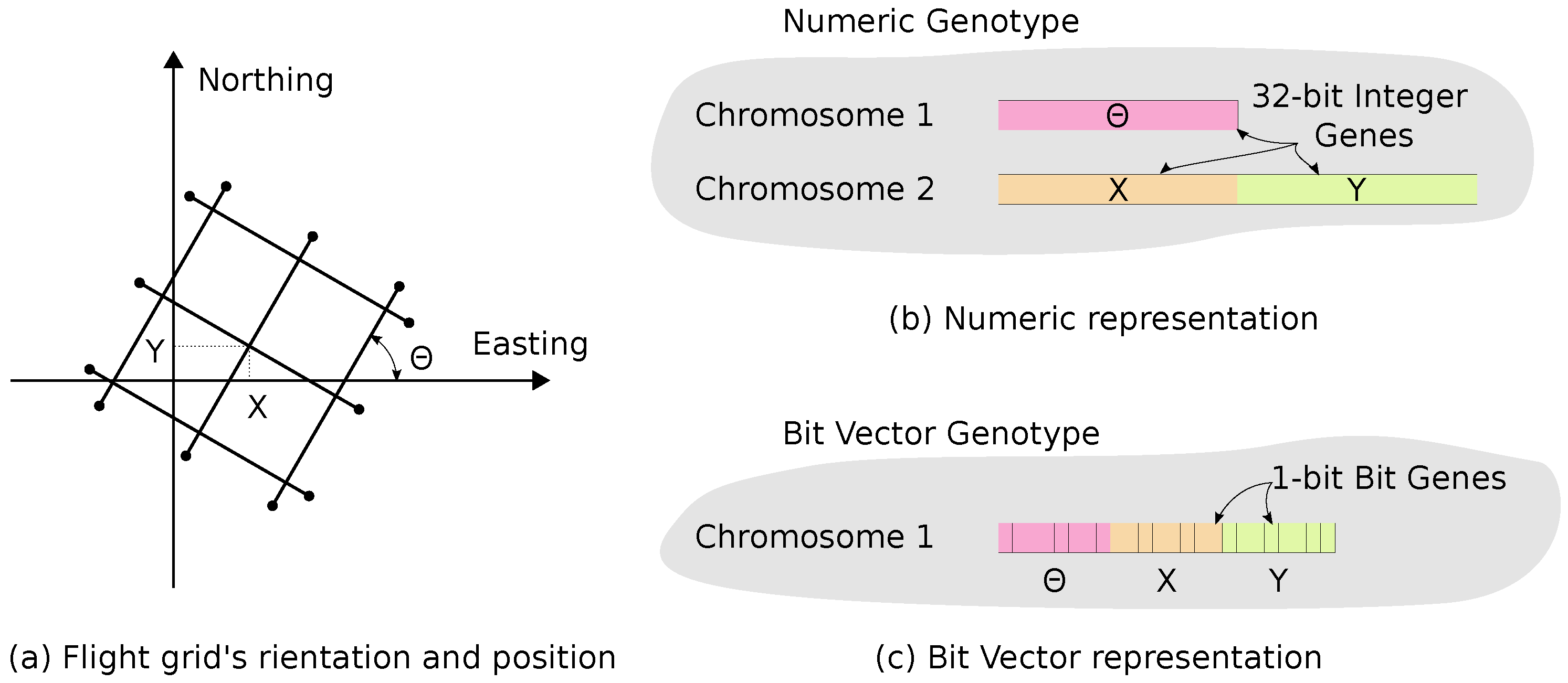
Building upon the work of Hinks et al. [
23], a flight grid pattern (
Figure 1b) is defined. A flight grid is represented by three numeric parameters
that define the orientation and position of the flight grid (
Figure 3a). All three parameters are bounded,
,
,
; where
s is the flight line spacing (
Figure 3a). Two different GA representations of flight grids are considered. The first representation (called Numeric) is based on the Integer Chromosome built-in Jenetics. A Genotype (i.e., a flight grid) is composed of two Integer Chromosome (
Figure 3b). The first Chromosome consists of a single (32-bit) Integer Gene that represents
. The second Chromosome is comprised of two (32-bit) Integer Genes that represent
X and
Y. In the second representation (called Bit Vector), each value of
,
X, and
Y is encoded as a binary string (8-bit integer) and represented as a BitVector Chromosome. A Genotype in this second representation contains only a single Bit Vector Chromosome, which is composed of 32 Bit Genes (
Figure 3c). While a Numeric representation is more straightforward, it appears to be less effective, based on some preliminary testing by the authors. Specifically, the BitVector representation allows faster convergence.
In addition to the representations described in this section, the GA implementation requires a definition of a fitness function, which is explained in
Section 3.2. Apart from these, all other elements of the GA algorithm (e.g., operation classes and evolution engine) were adopted directly from Jenetics.
3.2. A Beam Tracing Algorithm to Simulate Vertical Points Captured by a LiDAR Flight Path
Given that a significant sidelap (>67%) is allowed between every pair of adjacent flight swaths (i.e., stripes of point data captured by a flight line), sufficient capture of the geometry of horizontal surfaces such as ground and building roofs is trivial [
20]. Instead, the main challenge is to capture vertical surfaces such as building façades [
23]. As such, the number of points on vertical surfaces that a flight grid generates is a straightforward indicator by which measure how good or bad a flight grid is, in terms of documenting an urban area. This is used as the basis of the fitness score. While the output is simple to understand, computing it is complex, as the simulation requires knowledge of the flight geometry (i.e., altitude, position and orientation of the flight grid), the urban geometry (i.e., buildings and other urban objects), and certain scanner settings (e.g., scan angle, angular resolution).
Figure 4 illustrates the spatial model underlying the estimation of the number of vertical points that a flight grid can generate (i.e., the fitness score). The flight geometry is in all cases assumed to be composed of a set of straight flight lines separated by a predetermined, uniform flight line spacing,
. Each flight line is discretized into a set of way points, spaced
apart (
Figure 4a). By discretizing the flight lines, the real, continuous movement of the aircraft is modeled as a discrete stepwise traverse across the way points. As previously noted, the urban geometry is represented using a base point cloud, which eliminates the need to model the complex urban environment manually or via a simplified mathematical model, which avoids any inaccuracies that could be introduced through such approaches. A scanner’s settings are usually available in equipment specification sheets and can be input directly into the simulation. Given the spatial model (
Figure 4), which encapsulates the flight geometry, urban geometry, and scanner settings, laser beams can be simulated from every way point toward the portion of the base point cloud that intersects the field of view (FOV) corresponding to each way point (
Figure 4c). Because the base point cloud only consists of non-vertical points, if a laser beam arrives in the vicinity a point in the base point cloud (beams
−
and
−
in
Figure 4c), the laser beam is assumed to be incident on a non-vertical surface. If a laser beam does not approach any point in the base point cloud (e.g., beam
in
Figure 4c), then further computation (detailed in the remainder of this section) is performed to confirm whether the beam strikes a vertical surface.
Figure 4c presents a subset
of the base point cloud
P within the FOV of a way point,
, and the laser beams
B cast from this way point. The beam tracing from each way point is performed in the 2D vertical plane containing the way point using Algorithm 2. The laser beams are sorted counter-clockwise based on the beams’ angles to nadir (
to
in
Figure 4c, Algorithm 2 line 1). Each point in subset
is mapped to its nearest laser beam (Algorithm 2, line 3). If multiple points are mapped to the same beam (e.g.,
,
and
are mapped to
in
Figure 4b), the point closest to the way point is kept (e.g.,
). All further points are discarded, as the first point is assumed to obstruct all laser energy. The discarded points are colored in grey in
Figure 4c. The logic is represented on lines 4–6 in Algorithm 2.
In the next step (lines 10–23 in Algorithm 2), the laser beams and their corresponding base points are evaluated in their sorting order (i.e.,
to
, beam set
B on line 10 in Algorithm 2). During the evaluation, when a non-empty beam (i.e., a beam that associates to a base point) is encountered (Algorithm 2 line 12), its corresponding base point is recorded (i.e.,
). As previously mentioned, such a beam is assumed to be incident on a non-vertical surface. When the encountered beam is empty (i.e., the beam does not associate with any base point, Algorithm 2 line 14), the algorithm traces back to the latest recorded base point,
. In the example in
Figure 4c, the first empty beam is
, and the latest recorded point is
. The algorithm searches the neighborhood of
for structures that resemble building façades (
Figure 4d). The search domain differs depending on the relative position of
, with respect to nadir. If
is in the left flank of the FOV (Algorithm 2 line 15), then the algorithm searches the lower part of the neighborhood of
(Algorithm 2 line 16). Otherwise, the upper part of the neighborhood is searched (Algorithm 2 line 18). If the search returns another point (
), which together with
forms a vertical structure, the number of laser beams striking on the vertical segment
is interpolated (line 21 in Algorithm 2). The total number of such vertical laser beams is the output of the beam casting from
is calculated (Algorithm 2 line 21). The fitness score of a flight grid is the total number of such beams derived from all way points of the flight grid. Notably, the number of beams is assumed to be equal to the number of points yielded by a flight grid since a beam striking on a façade surface usually results in a single point return. The beam tracing algorithm accounts for both self-shadow and street-shadow based occlusions as defined by Hinks et al. [
23]. The use of a base point cloud is designed explicitly to allow a more accurate representation of the complex urban environment and, thus, a more robust measure of the algorithm’s output. The beam casting algorithm in Algorithm 2 and its use in computing the fitness scores for the optimization clearly reflect the objective of the optimization.
| Algorithm 2 Beam casting from a specific way point |
![Remotesensing 13 04437 i002]() |
3.3. A Distributed Computing Strategy for Fitness Function Evaluation
The beam tracing introduced in
Section 3.2 is not particularly computationally complex, nor does it involve big data. In contrast, the actual computational challenge is in the fitness computation, which comes from two sources. First is that the number of way points can be large. Thus, the beam tracing must be performed thousands or millions of times. Second, the selection of base points inside the FOV of a way point is an expensive process. Matching base points to their corresponding way points is essentially a spatial join between two potentially large datasets,
. The point dataset,
P, can contain millions or even billions of points depending on the spatial extent and the point density. The number of way points in
W can be several thousands or more depending on the flight geometry and the discretization resolution. A base point
is joined with way point
, if the FOV of a
contains
. The join is many-to-many, where a way point is joined with multiple base points, and a base point is joined with multiple way points. Algorithm 3 presents a complete strategy for the fitness score computation that addresses both challenges.
| Algorithm 3 Parallel algorithm for computing the fitness score (i.e., the total number of laser beams incident on vertical surfaces) of a flight grid |
![Remotesensing 13 04437 i003]() |
Algorithm 3 computes the fitness score,
n, of a candidate flight grid using the base point cloud,
P, and the flight parameters,
. The algorithm is composed of two stages. Stage 1 (the for loop on lines 2–5 in Algorithm 3) performs
(i.e., base points and way points joint). Stage 2 (the for loop on lines 9–11 in Algorithm 3) performs beam casting for each way point as described in
Section 3.2. Between the two stages is the data shuffling operation (i.e.,
AggregateByKey, line 8 in Algorithm 3), which aggregates base points by their corresponding way points. Both for loops are straightforwardly parallelizable. Each execution of the first for loop takes an individual base point
, calculates coordinates of the way points
corresponding to the given base point and add the way point – base point pairs to
. The calculation of way point coordinates starts with transforming the coordinate system (lines 3 in Algorithm 3) so that the flight lines are parallel to the coordinate axes.
Consider a set of flight lines parallel to the
Y axis as in
Figure 5, the algorithm calculates the index of the flight line closest to
using Equation (1a). The squared brackets denote rounding to the nearest integer. In the example in
Figure 5, the closest flight line to
is
because
. On the given flight line, the way point closest to
is calculated using Equation (1b). In
Figure 5,
. Hence,
is closest to way point
on flight line
. In addition to the closest way point,
is mapped to way points on other flight lines nearby the closest flight line, as long as the Euclidean distance from
to the line calculated in the XY plane is shorter than the expected half swath width. The half swath width (
) is calculated as in Equation (1c) and is constant for the entire flight mission. Function
WayPoint on line 4 of Algorithm 2 encapsulates the way point calculation expressed in Equation (1a–1c). Thanks to the coordinate transformation, the spatial mapping of base points to way points becomes the simple arithmetic formulae in Equation (1). More importantly, both of the transformations (i.e.,
CoordTransform and
WayPoint) are performed independently for each base point. As
is a distributed dataset, adding the newly computed way point — base point pairs do not require any synchronization among elements of the dataset. Every step in the first for loop is parallel. In the second for loop (lines 9–11 of Algorithm 3), each execution takes an individual way point,
, and the corresponding base point subset
to perform the beam casting algorithm described in Algorithm 2 and
Section 3.2. Similar to the first for loop, the second for loop is straightforwardly parallelizable since each individual execution is independent.
Figure 6 shows the data lineage corresponding to Algorithm 3. All datasets in Algorithm 3 are distributed datasets, called Resilient Distributed Datasets (RDD) in Spark, the distributed computing framework selected to implement the algorithm. Each dataset (e.g., the base point cloud,
P) is divided into multiple partitions distributed across multiple executors for parallel transformation and computation. Executors are distributed software processes that can reside on different nodes of a computing cluster. In
Figure 6, each rounded box represents a data partition, and each stack of partitions represents an RDD.
Notably, the transformations within Stage 1 and Stage 2 do not require data to be exchanged between partitions, and their data flows are confined to be within the partition boundaries. Thus, no communication between executors or nodes is needed. The CoordTransform and WayPoint transformations in Stage 1 are applied for each base point . Similarly, the BeamCasting transformation in Stage 2 is applied on each way point and a limited subset of base points () corresponding to the way point. All of those transformations are easily parallelizable, because manipulation of one record is totally independent of other manipulations and side effects. In addition, the amount of data involved in each transformation is limited. Thus, each transformation is performed in memory.
The operation that is not straightforwardly parallelizable is the aggregation of base points by way point that occurs between the two stages. That operation requires physical movement of data between partitions that potentially reside on different nodes. Multiple partitions need to be combined to build partitions for a new RDD. The complex operation is implemented based on the parallel AggregateByKey function in Spark. The AggregateByKey function aggregates data within each partition before shuffling the data between nodes, thereby minimizing data transfer across the cluster. Another operation that needs data transfer across nodes is the final function that gathers the numbers of vertical points from all partitions and computes the final sum. That operation is straightforward and is implemented using the Collect function in Spark.
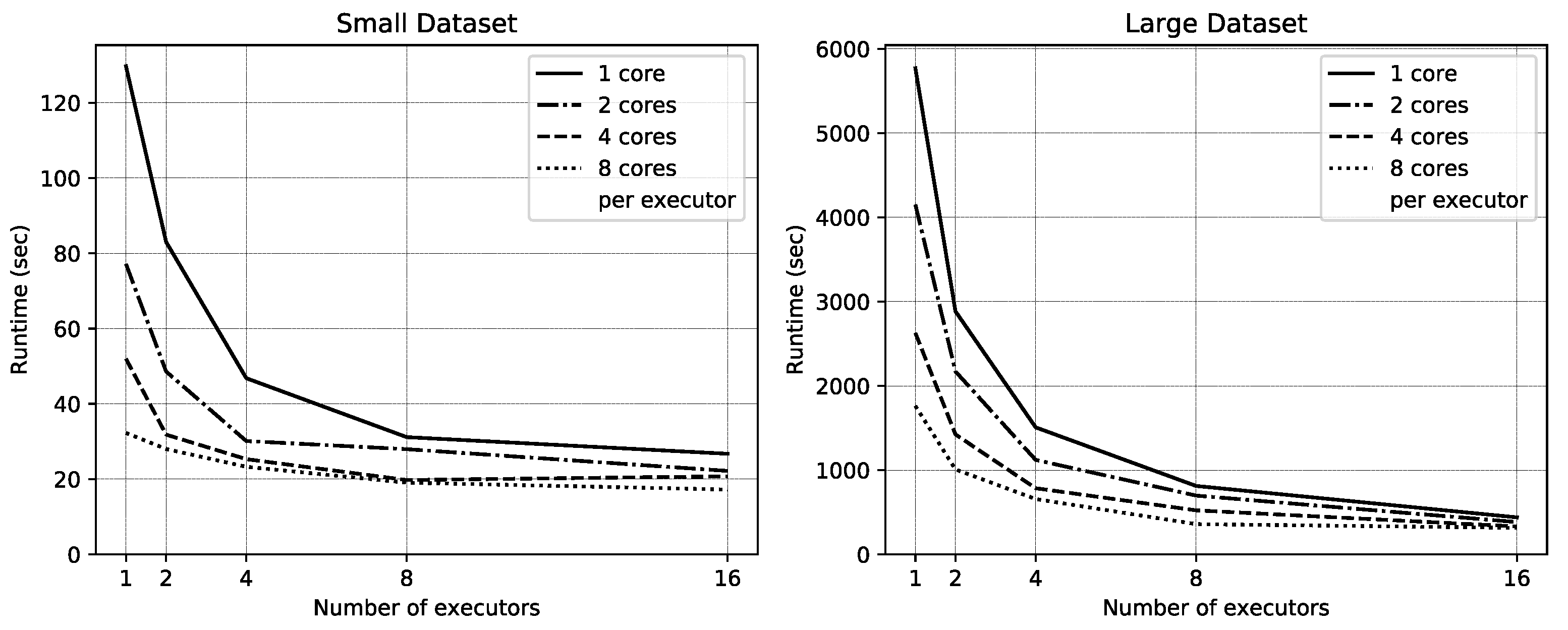
In summary, the principal strategy behind the fitness score computation is data parallelism. The algorithm is composed of two map transformations and one data shuffling transformation. The datasets are divided into small partitions distributed across multiple executors. During each map transformation, multiple executors work in parallel to apply the same transformation to their data partitions. The data partitions are kept sufficiently small so that every transformation can be performed within the memory space allocated to each executor. The shuffling transformation that occurs between the two map transformations is the most complex part of the algorithm. That shuffling transformation is implemented based on a highly optimized function in Spark (i.e., AggregateByKey). Throughout that algorithm, the computation is decomposed into loosely coupled transformations that are conducted by different executors in a highly independent manner. Expensive communication across executors and nodes is restricted. As such, the algorithm is suitable for being deployed on a distributed-memory cluster in which the computing nodes that host executors do not share a memory space and use an interconnect for their limited communication.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}