1. Introduction
SAR (Synthetic Aperture Radar) images are widely used in many environment monitor applications because they offer some advantages over optical remote sensing images, such as its acquisition capability being independent of sun light or the weather. In SAR imagery, the interference of waves reflected during the acquisition process gives rise to a multiplicative and non-Gaussian noise known as speckle [
1], which produces a visual degradation of the image and hinders its interpretation. The purpose of image noise removal is to enhance its automatic understanding without blurring edges and obliterating small details. Reducing speckle is beneficial for SAR image visual interpretation, region-based detection, segmentation and classification, among other applications [
2]. However, classical methods for noise reduction are not adequate for SAR denoising since this type of data are heavy-tailed and outlier-prone [
3,
4]. These features of SAR images make the modeling of the images with suitable statistical distributions essential. In the literature, there exists several probability distribution models to describe SAR data, in [
5] a summary of this topic is presented.
The classic Lee filter for SAR image denoising was widespread since it was presented in [
6,
7]. It is based on performing operations on the value of the pixels, by sliding a window over the image, taking into account the coefficient of variation inside the window. Later it was improved by incorporating the data asymmetry [
8].
A similar type of filter is the Maximum a Posteriori (MAP) based filter, which has been used to reduce the noise of single-look SAR images, modeling the a priori distribution of the backscatter with a Gaussian law [
9]. Other distributions, such as
and
, were utilized in subsequent works [
10,
11] with relative success because they are applicable only in homogeneous areas [
12]. Moschetti et al. [
13] compared MAP filters, modeling the data with the
,
, and
K distributions.
Perona and Malik [
14] proposed the anisotropic diffusion filter. Such an approach had a huge impact on the imaging community because it uses the scale-space and is efficient at edge-preserving but it was developed for Gaussian noise elimination. Thus, this model is not proper for multiplicative speckle noise. Based in this idea, Yu and Acton [
15] proposed SRAD (Speckled Reducing Anisotropic Diffusion), a specialized anisotropic diffusion filter for speckled data. It is based on a mathematical modeling of speckle noise that is removed through solving a differential equation in partial derivatives.
Cozzolino et al. [
16] proposed the FANS (Fast Adaptive Non-local SAR Despeckling) filter. It is based on wavelets, and it is widely used by the SAR image processing community for its speed and good performance.
Buades et al. [
17] introduced the Non-local Means (NLM) approach. These filters use the information of a group of pixels surrounding a target pixel to smooth the image by using a large convolution mask. It takes an average of all pixels in the mask, weighted by a similarity measure between these pixels and the center of the mask. The NLM approach has been utilized in many developments of image filtering. For example, Duval et al. [
18] enhanced this idea, highlighting the importance of choosing local parameters in image filtering to balance the bias and the variance of the filter. In addition, Delon and Desolneux [
19] addressed the problem of recovering an image contaminated with a mixture of Gaussian and impulse noise, employing an image patch-based method, which relies on the NLM idea. Lebrun et al. [
20] proposed a Bayesian version of this approach and Torres et al. [
21] built non-local means filters for polarimetric SAR data by comparing samples with stochastic distances between Wishart models. More recently, Refs. [
22,
23] have approached the comparison of samples using the properties of ratios between observations, and have enhanced the filter performance with anisotropic diffusion despeckling.
Argenti et al. [
24] made an extensive review of despeckling methods. The authors compared various algorithms, including non-local, Bayesian, non-Bayesian, total variation, and wavelet-based filters.
Non-local means filters rely on two types of transformations to compare the samples, namely: (i) Pointwise comparisons, e.g., the
norm or the ratio of the observations [
22] (which requires samples of the same size); and (ii) parameter estimation. In this article, we propose a technique in line with parameter estimation.
This diversity of proposals generates the need of defining criteria to evaluate the quality of speckle filters quantitatively. With this objective, Gómez Déniz et al. [
25] proposed the
index. It is a good choice because it does not require a reference image and is tailored to SAR data.
Due to speckle noise’s stochastic nature, SAR data’s statistical modeling is strategic for image analysis and speckle noise reduction. The multiplicative model is one of the most widely used descriptions. It states that the observed data can be modeled by a random variable
Z, which is the product of two independent random variables:
X, which describes the backscatter, and
Y that models the speckle noise. Yue et al. [
26], Yue et al. [
27] provide a comprehensive account of the models that arise from this assumption. Following the multiplicative model, Frery et al. [
28] introduced the
distribution which has been widely used for SAR data analysis. It is referred to as a universal model because of its flexibility and tractability [
29]. It provides a suitable way for modeling areas with different degrees of texture, reflectivity, and signal-to-noise ratio.
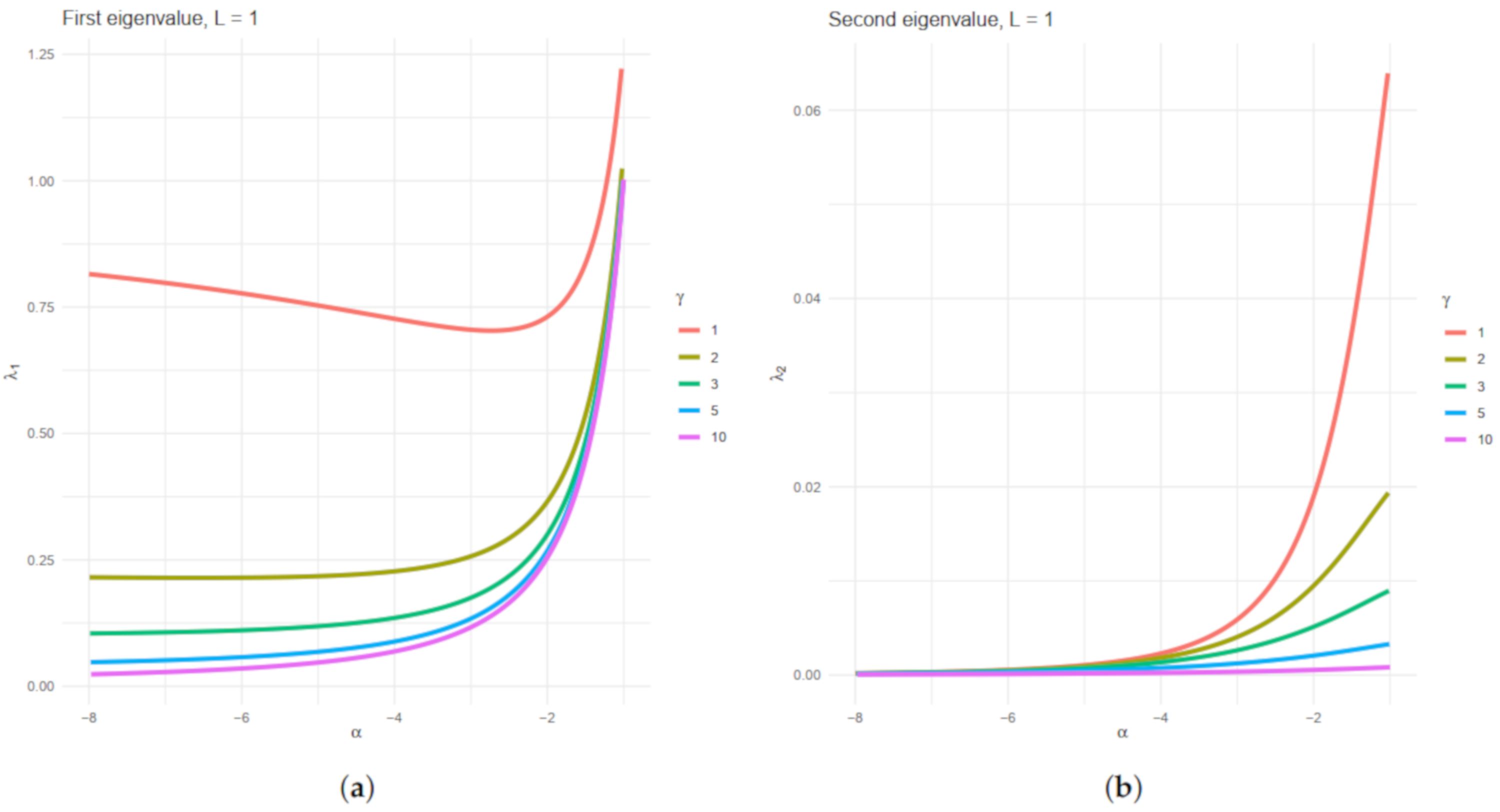
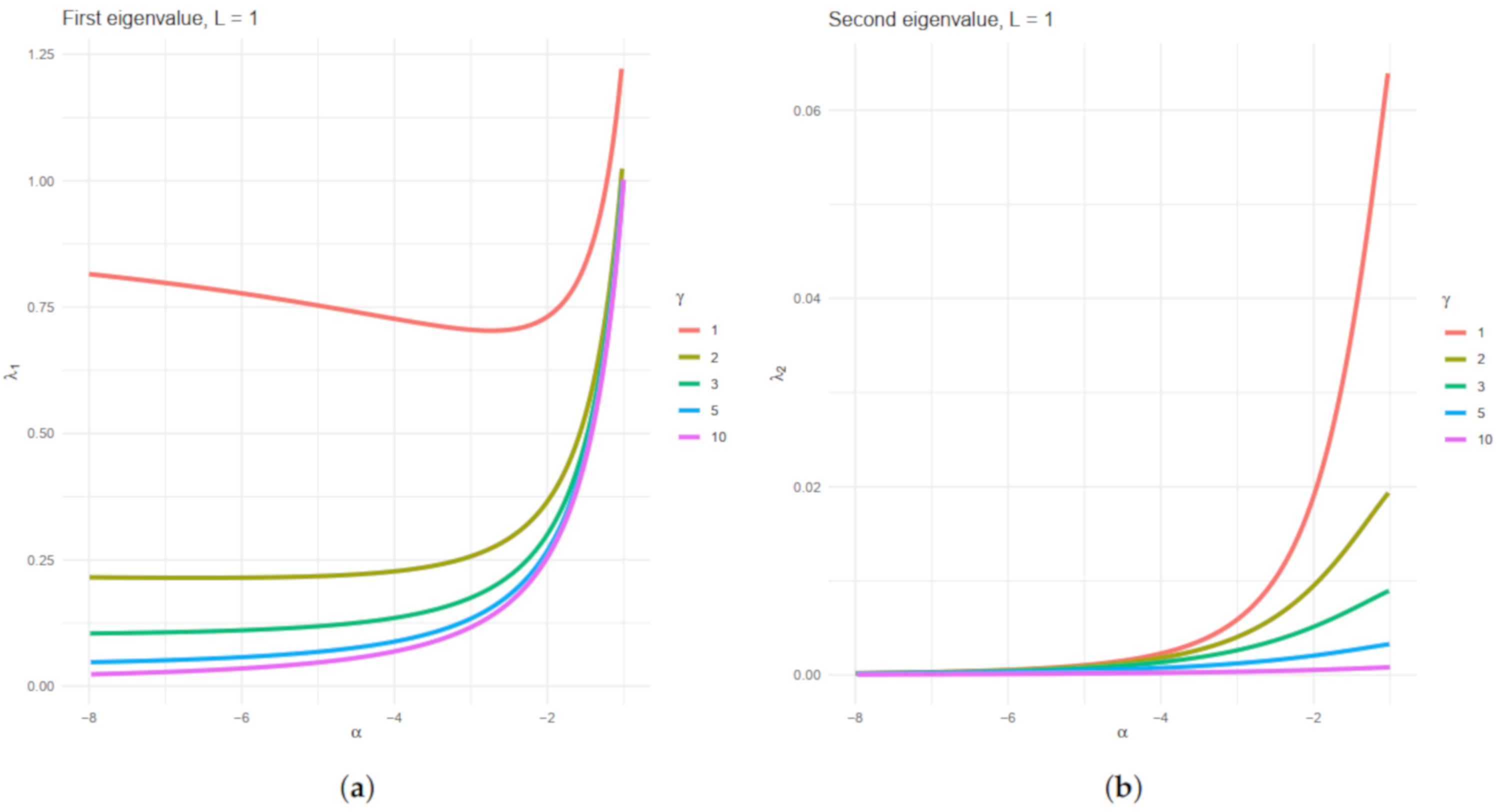
Three parameters index the distribution: , related to the target texture, , related to the brightness and called scale parameter, and L, the number of looks, which describes the signal-to-noise ratio. The two first may vary among positions, while the latter can be considered the same on the whole image and can be known or estimated.
The entropy, which is a measure of a system’s disorder, is a central concept to information theory [
30]. The Shannon entropy has been widely applied in statistics, image processing, and even SAR image analysis [
31]. Kullback and Leibler [
32] and Rényi [
33], among others, studied in depth the properties of several forms of entropy. Two or more random samples may be compared with test statistics based on several forms of entropy, and this is the approach we will follow.
Chan et al. [
34] presented the first attempt at using the entropy as the driving measure in a non-local means approach for speckle reduction. In this work we advance this idea by:
Assessing and solving numerical errors that may appear when inverting the Fisher information matrix;
Using a smooth transformation between p-values and weights that improves the results;
Evaluating the filter performance with a metric that takes into account first- and second-order statistics;
Applications to actual SAR images;
Comparisons with state-of-the-art filters.
In this work, following the results by Salicrú et al. [
35], we develop two statistical tests to evaluate if two random samples have the same entropy. These tests are based on the Shannon and Rényi entropies under the
distribution. With this information, we propose a non-local means filter for speckled images noise reduction. We obtain the necessary mathematical apparatus for defining such filters, e.g., the Fisher information matrix of the
law, and the asymptotic variance of its maximum likelihood estimators.
We evaluate these entropy-based non-local means filters’ performance using simulated data and an actual single-look SAR image. The new algorithm results are competitive with Lee, SRAD (Speckle Reducing Anisotropic Diffusion), and FANS (Fast Adaptive Nonlocal SAR Despeckling), and in some cases, they are better. Moreover, we show that building a non-local means filter with a proxy, as the entropy, is a feasible approach.
This article unfolds as follows. In
Section 2, some properties of the
distribution for intensity format SAR data are recalled, which results in the
distribution.
Section 3 introduces the formulae of Shannon and Rényi entropies under the
model, the asymptotic entropies distribution, and the hypothesis tests with entropies. In
Section 4, the details of the proposal of entropy-based non-local means filters are explained.
Section 5 presents measures for assessing the performance of speckle filters. In
Section 6, the results of applying the proposed despeckling algorithm to synthetic and actual data along with the results of applying FANS (Fast Adaptive Nonlocal SAR Despeckling), Lee, and SRAD (Speckle Reducing Anisotropic Diffusion) methods are shown. We also assess their relative performance. Finally, in
Section 7 some conclusions are drawn. We also assess their relative performance. Finally, in
Section 7 some conclusions are drawn.
Appendix A provides information about the computational platform and points at the provided code and data.
2. The Distribution
Speckle noise follows a Gamma distribution, with density:
denoted by
. The physics of image formation imposes
.
The model for the backscatter
X may be any distribution with positive support. Frery et al. [
28] proposed using the reciprocal gamma law, a particular case of the generalized inverse Gaussian distribution, which is characterized by the density:
where
and
are the texture and the scale parameters, respectively. Under the multiplicative model, the return
follows a
distribution, whose density is:
where
and
. The
r-order moments of the
distribution are:
provided
, and infinite otherwise. The
distribution also arises when the observation is described as a sum of a random number of returns [
26,
36].
We will study the noisiest case which occurs when
; it is called single-look and expression (
1) becomes:
The expected value is given by:
Chan et al. [
37], using a connection between this distribution and certain Pareto laws, studied alternatives for obtaining quality samples.
We employed the maximum likelihood approach for parameter estimation. Given the sample
of independent and identically distributed random variables with common distribution
with
, a maximum likelihood estimator of
satisfies:
where
is the likelihood function given by:
This leads to
and
such that:
where
is the digamma function. We solved this system with numerical routines, using as an initial solution the moments estimators that stem from Equation (
2) with
.
4. Speckle Reduction by Comparing Entropies
The proposed method for despeckling images is based on testing whether two random samples and have the same diversity. We then compare the Shannon and Rényi entropies, which are scalars that depend on the parameters.
Non-local means filters use a large convolution mask of size with , taking an average of all pixels in the mask, weighted by a similarity measure between these pixels and the center of the mask.
Let
Z be the noisy image of size
, then the filtered image
in position
is given by:
where
estimates the noiseless image
X, and
are the weights.
In our proposal, we build an image filter by computing the mask
w in each step of the algorithm, using the test statistic from Equation (
27) with significance level
. For simplicity, we will describe the implementation using square windows, but the user may consider any shape. We defined two sets: The search and the estimation windows. The search window
has fixed size
and is centered on every pixel
. At every location of this search window, we define estimation patches around each pixel. These windows may vary in size, e.g., in an adaptive scheme.
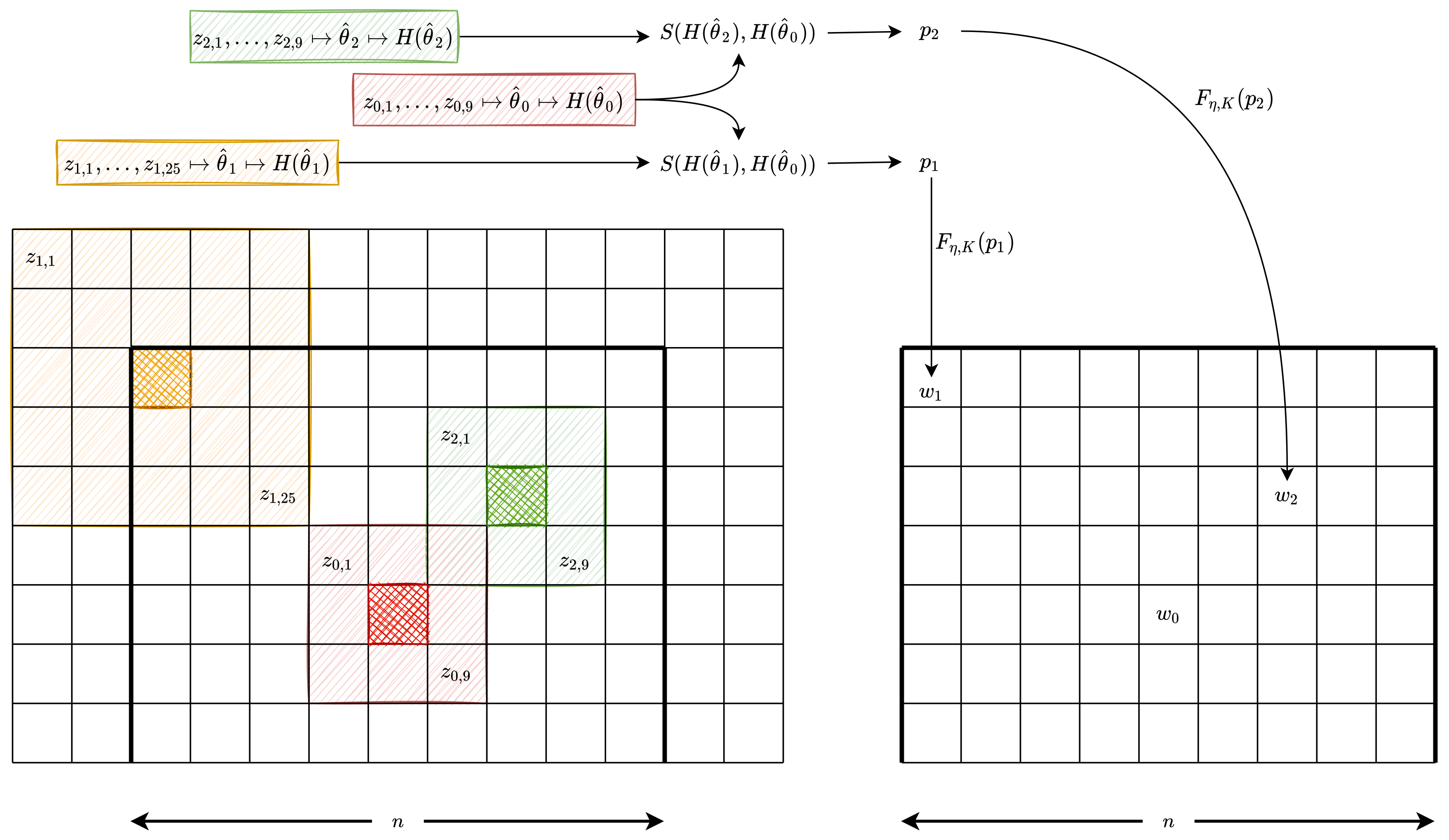
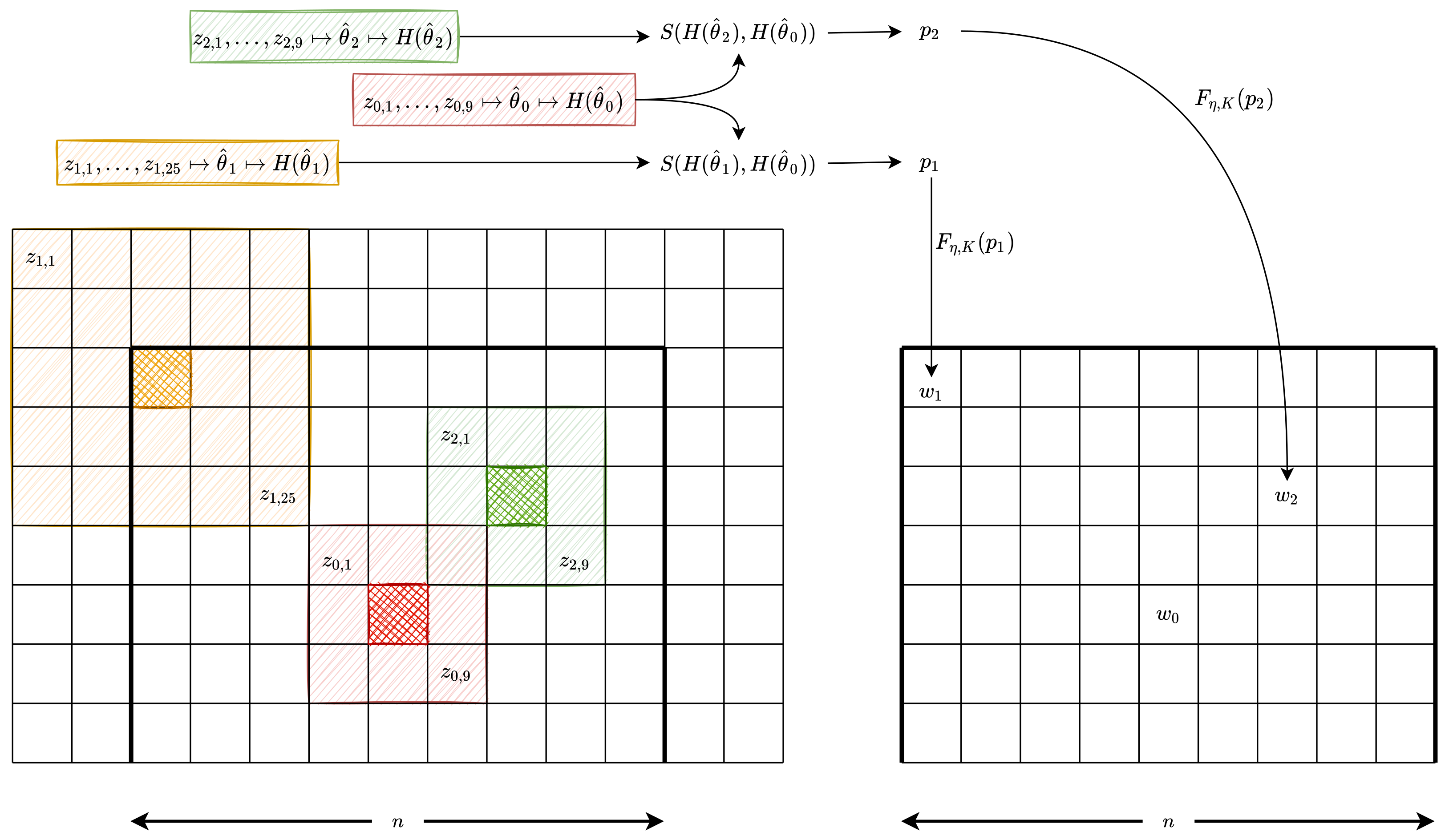
Figure 2 illustrates an instance of such implementation with
. The left grid represents the image, while the right grid shows the mask that will be applied to the central pixel (identified in red cross-hatch).
The central pixel is identified with red cross-hatch, and its estimation window has size ; denote these observations as . We also show two estimations windows; those corresponding to the pixels identified with orange and green cross-hatches and have, respectively, dimensions and , and their observations are and , respectively.
We compare the pairwise diversities of the samples
,
, summarized as
in
Figure 2, with respect to
estimating by maximum likelihood the parameters
from the
distribution. We obtain
from
,
from
, and
from
; this step is summarized as
in
Figure 2. Then, both the Shannon and Rényi entropies are estimated (summarized as
) and the test statistic is obtained. The weight
(
respectively) stems from comparing the samples
(
respectively) and
. Finally, we transform the observed
p-values in the weights
and
by using a smoothing function.
Each
p-value may be used directly as a weight
w but, as discussed by Torres et al. [
21], such a choice introduces a conceptual distortion. Consider, for instance, the samples
and
. Assume that, when contrasted with the central sample
, they produce the
p-values
and
. In this case, the first weight will be significantly smaller than the second one, whereas there is no evidence to reject any of the samples at level
. Torres et al. [
21] proposed using a piece-wise linear function that maps all values above
to 1, a linear transformation of values between
and
, and zero below
. In this work, we propose a smooth activating function with zero first- and second-order derivatives at the inflexion points. The “smoother step function” defined by Ebert [
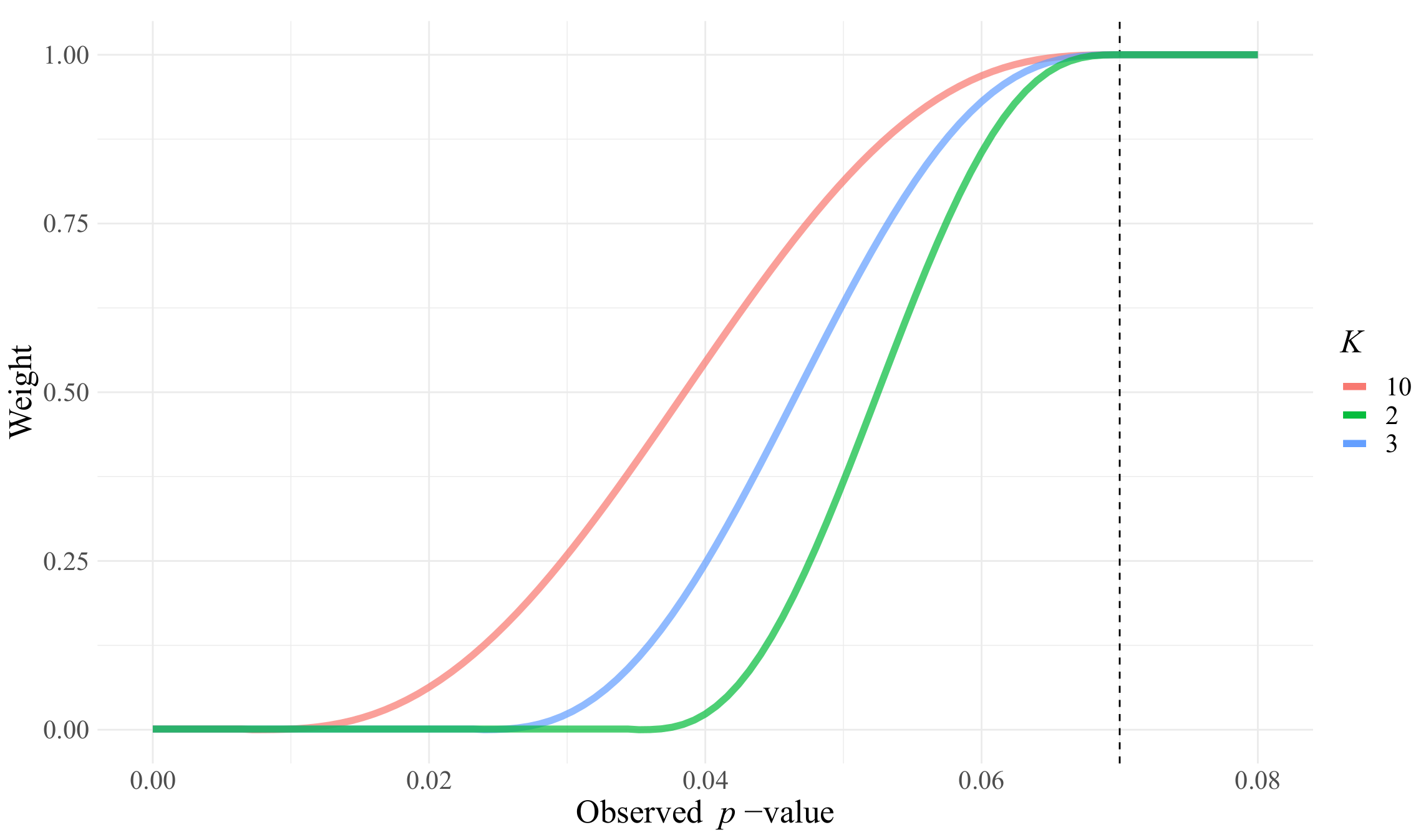
45] is given as:
This function connects in a smooth manner the points
and
. We modify
in order to connect
and
, for every
, and define the weight
w as a function of the observed
p-value as the result of the following activating function:
This function is zero for
, and is one above
. The parameter
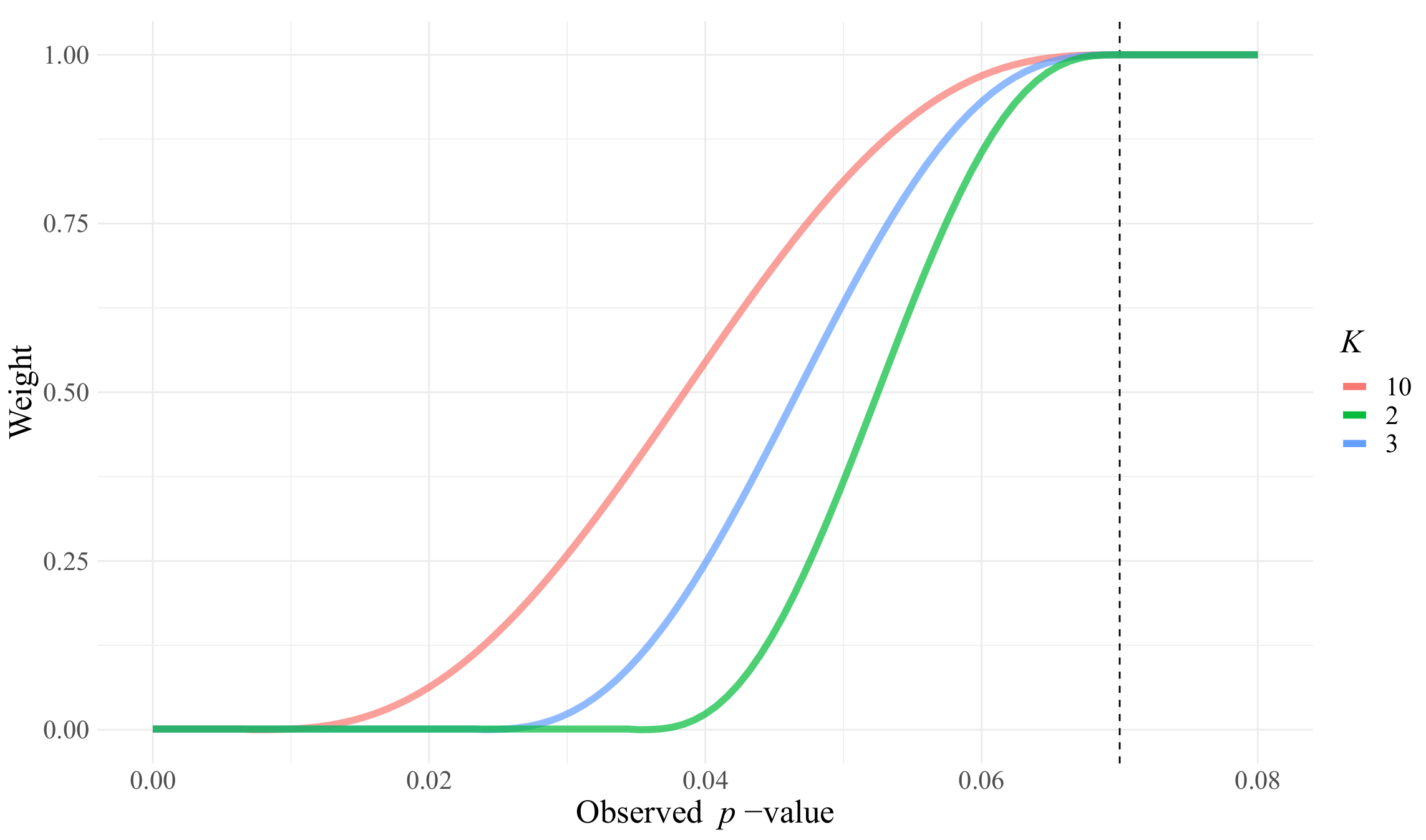
K controls the transformation’s steepness, as shown in
Figure 3. From our experiments, we recommend
.
Algorithm 1 shows the steps of the method.
| Algorithm 1 Despeckling by similarity of entropies. |
- 1:
Input: Original noisy image Z of size , d, k, sizes of the large and small sliding windows, respectively - 2:
fordo - 3:
Consider a sliding window of size around pixel i - 4:
Let be the central pixel of - 5:
Consider a neighborhood of , named - 6:
Compute the maximum likelihood parameter estimates of the parameters, , the entropy and the asymptotic variance for the sample - 7:
for do - 8:
Consider , patches of size inside the large window , corresponding to the neighborhoods of each pixel , as Figure 2 shows - 9:
Compute the estimates , the entropy, and its asymptotic variance of the sample - 10:
Compute the statistic , using Equation ( 33), and , its p-value using its asymptotic distribution - 11:
Compute the (yet to be normalized) weight - 12:
end for - 13:
Divide all the weights by - 14:
Compute the estimated noiseless observation - 15:
end for - 16:
return ,
|
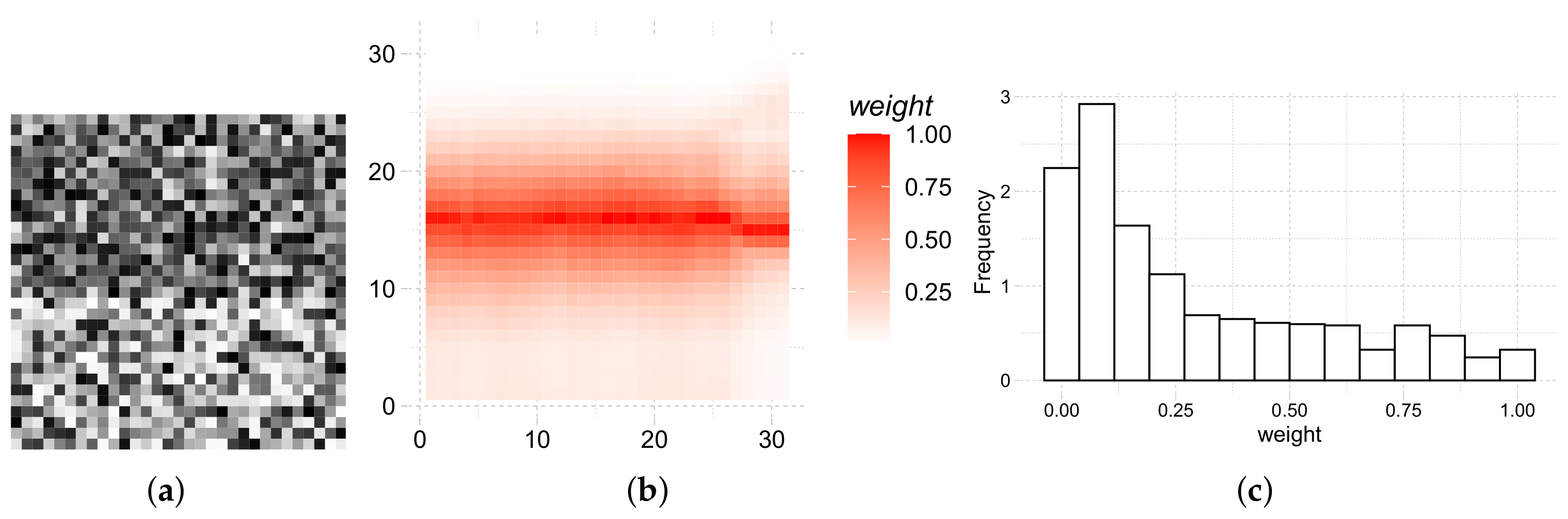
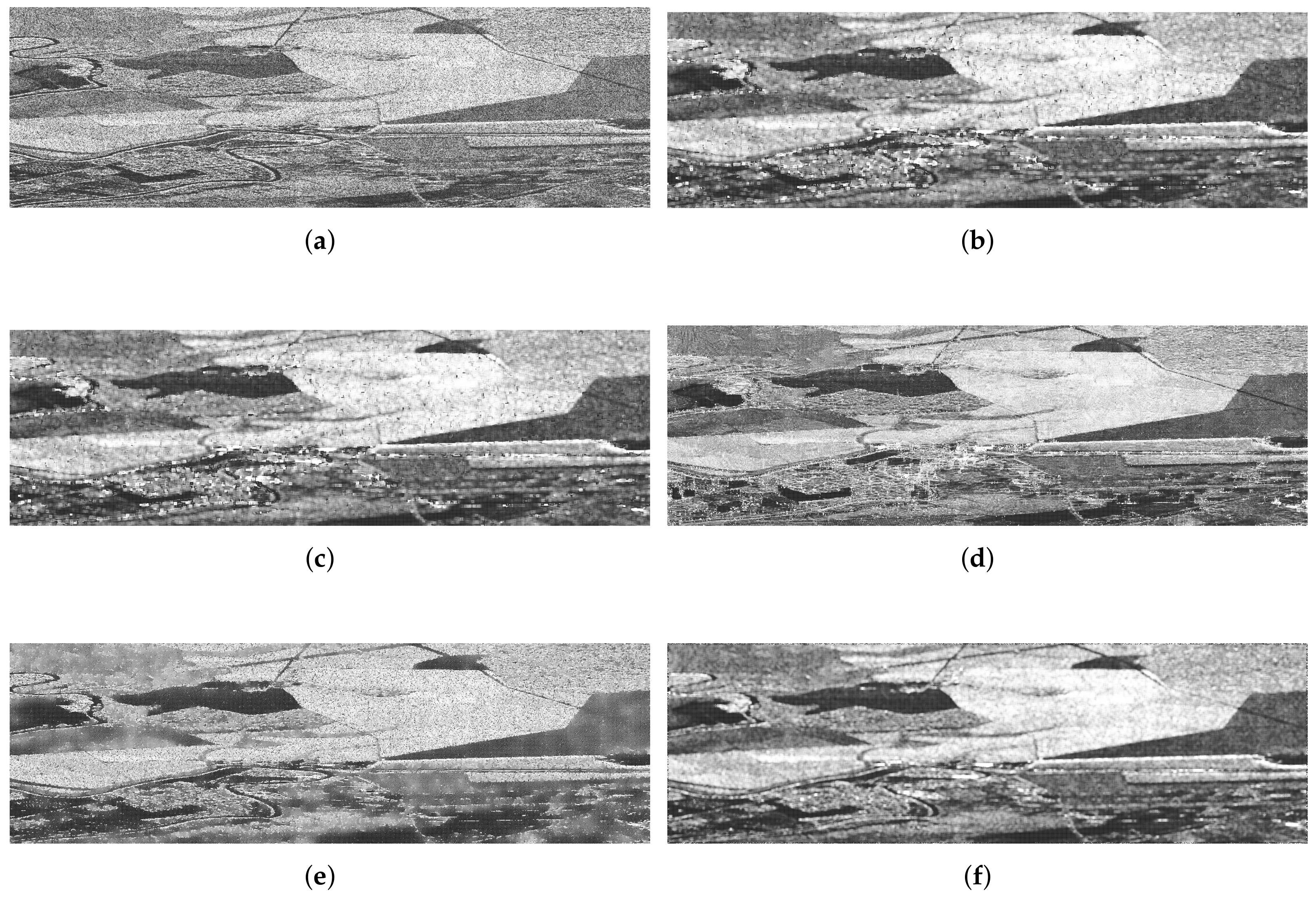
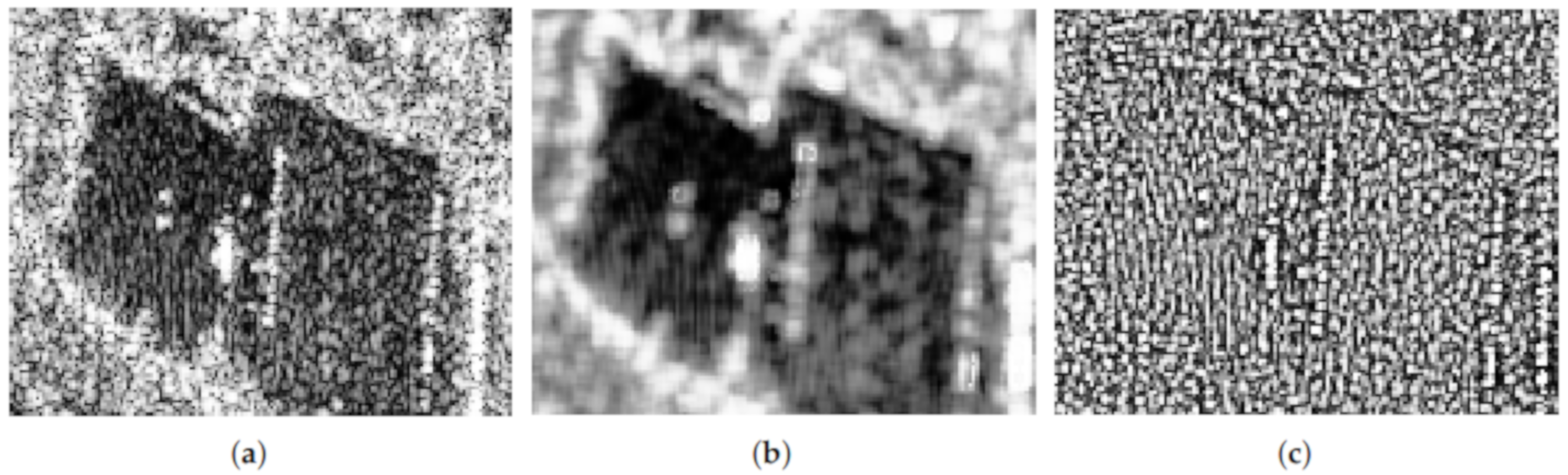
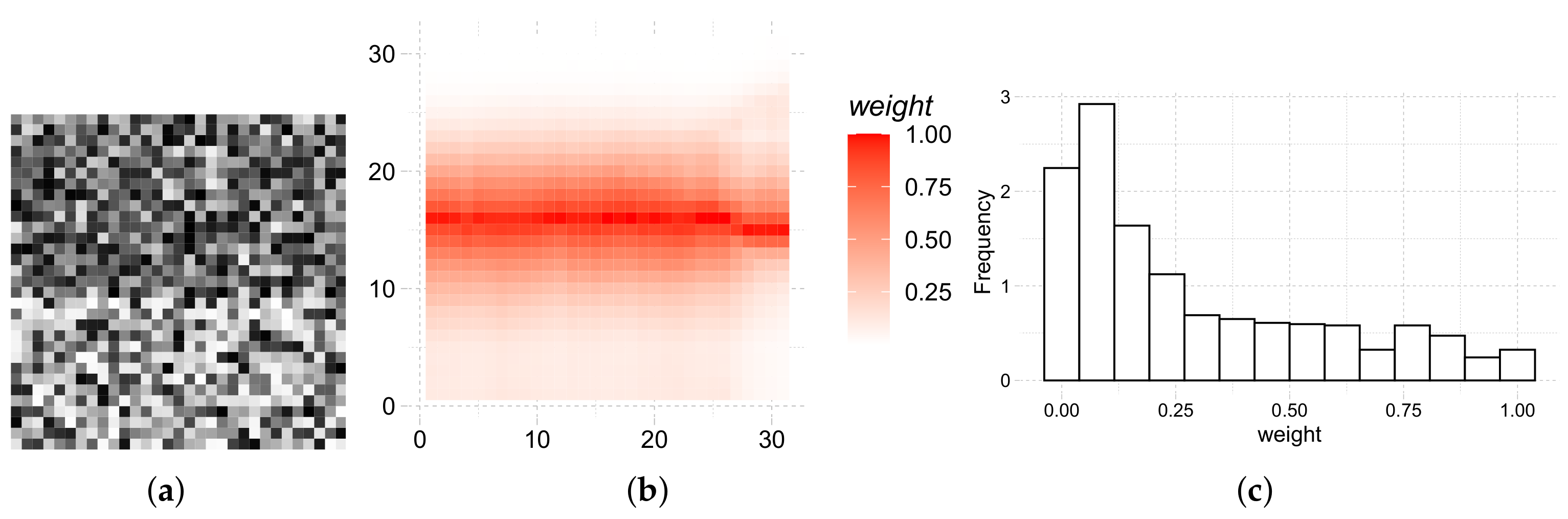
Figure 4 shows the heatmap and histogram of the weights of a sliding window over an edge of the original image.
Figure 4a shows the cropping of the image where the weights were computed. Observations on the edge, and close to it have a strong influence on the filtered data, while those far or with a different underlying distribution weigh less.
7. Conclusions and Future Work
We proposed a new non-local means filter for single-look speckled data based on the asymptotic distribution of the Shannon and Rényi entropies for the distribution.
The similarity between the diversities of the central window and the patches is based on a statistical test that measures the difference between the entropies of two random samples. If two samples have the same distribution in a neighborhood, then there are no image edges, the diversity is lower, and the zone can be blurred to reduce speckle. This approach does not require using patches of equal sizes, and they can even vary along the image. The mask for speckle noise reduction is built with a smoothing function depending on the computed p-value.
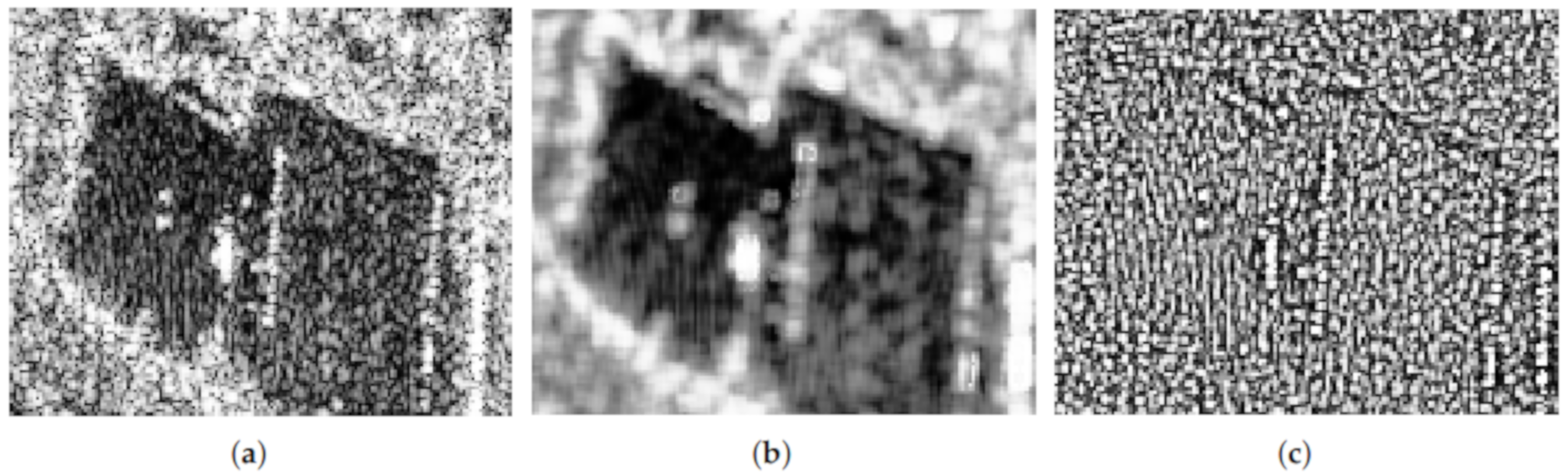
We tested our proposal in simulated data and an actual single-look image, and we compared it with three other successful filters. The results are encouraging, as the filtered image has a better signal-to-noise ratio, it preserves the mean, and the edges are not severely blurred. Although the filter based on the Rényi entropy is attractive due to its improved flexibility (the parameter can be tuned), it produces very similar results to those provided by the use of the Shannon entropy that is simpler to implement.
In future works, we will assess this filter’s performance with several criteria in cases of contaminated data, and we will consider other measures, as the Kullback–Leibler distance.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}