
Tree Species Classification Using Ground-Based LiDAR Data by Various Point Cloud Deep Learning Methods

 ,
,  ,
,  ,
, 

Abstract
1. Introduction
2. Materials and Methods
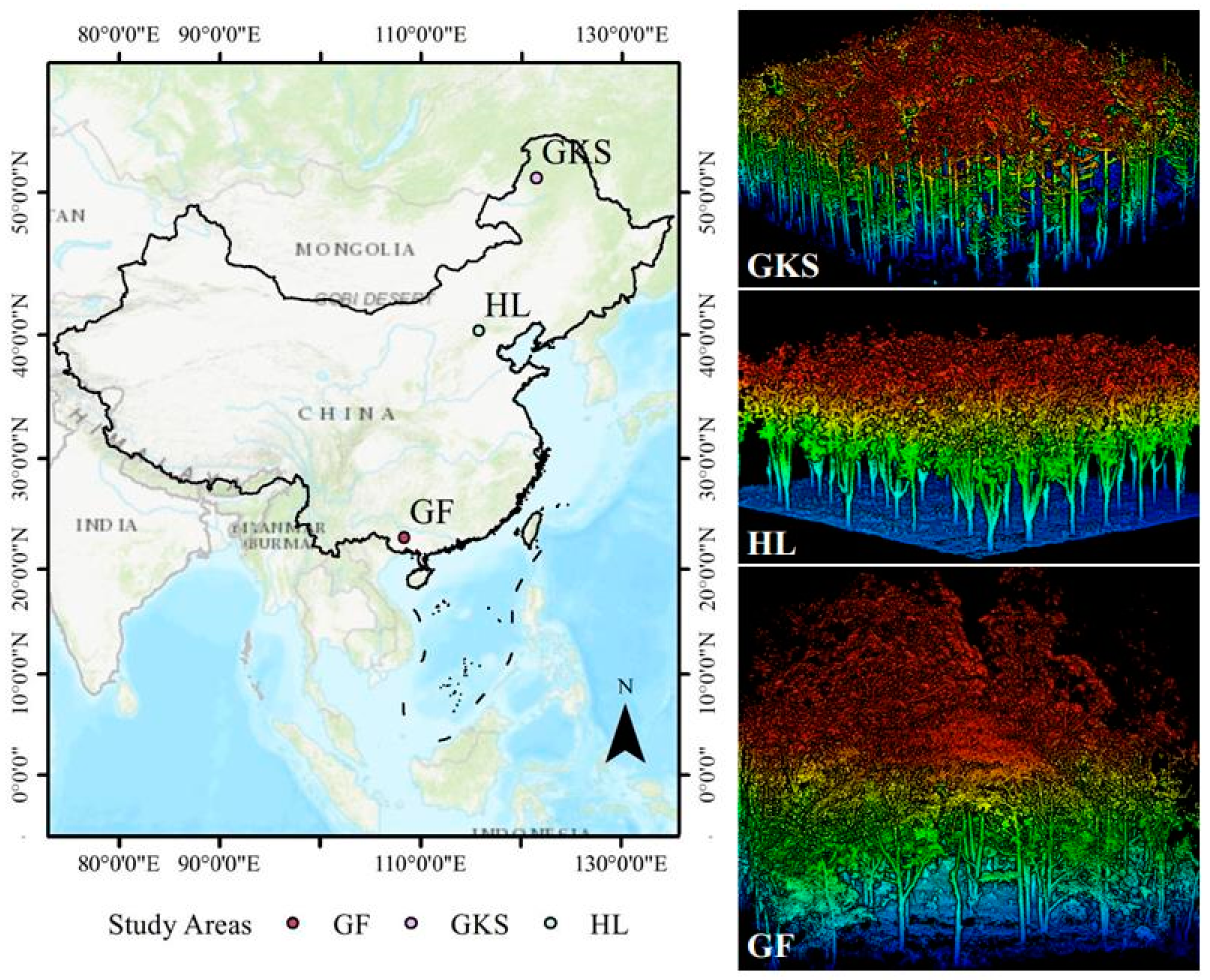
2.1. Study Area and Data Collection
2.2. Data Pre-Processing
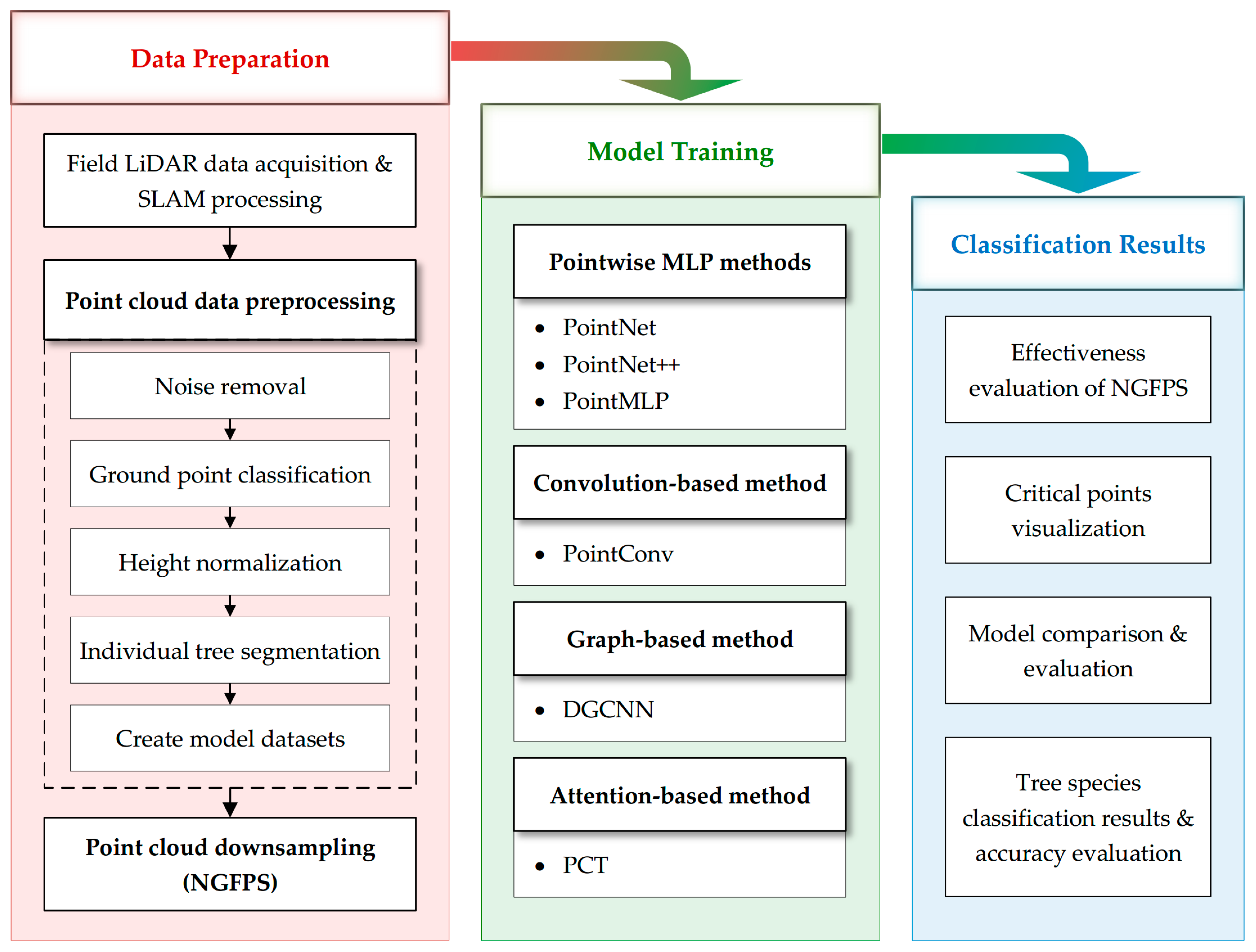
2.3. Research Workflow
3. Methods
3.1. Methods Combined with Non-Uniform Grid and Farthest Point Sampling
- The objects are downsampled using the NGS algorithm, and k is iterate as an input parameter. The minimum value of k is set to 6, and the value of k is increased by 1 at each iteration;
- When the number of points satisfies N(k) < N after downsampling the object, the iteration is stopped, and the experimental results of N(k−1) are retained;
- We use the FPS algorithm to downsample the N(k−1) points to the specified number of points N.
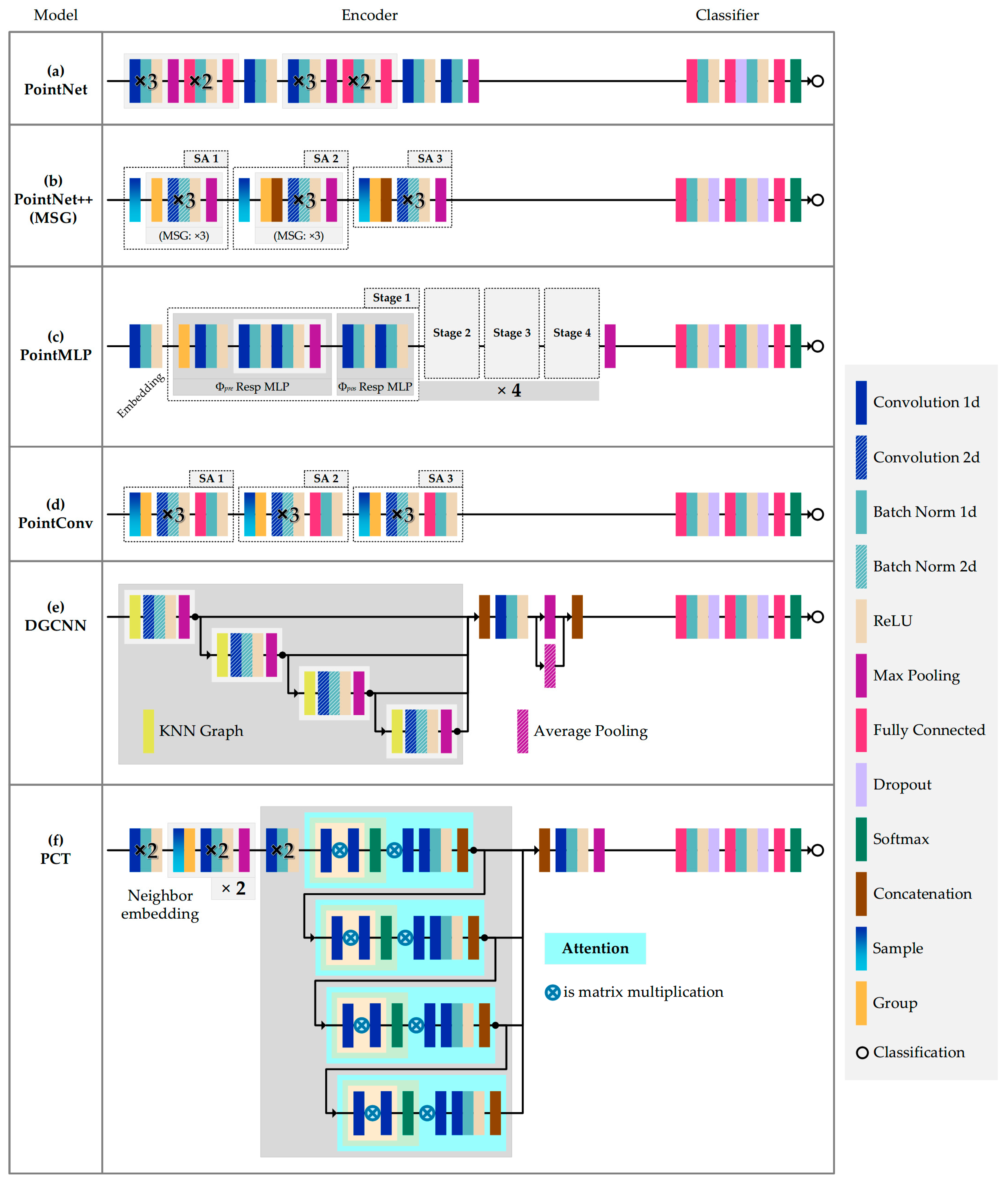
3.2. Point Cloud Deep Learning Methods
3.2.1. Pointwise MLP Methods
3.2.2. Convolution-Based Method
3.2.3. Graph-Based Method
3.2.4. Attention-Based Method
3.3. Critical Points Visualization
3.4. Model Accuracy Evaluation Metrics
4. Results
4.1. Analysis of the Effect of NGFPS Downsampling Method
4.2. Evaluation of Tree Species Classification Accuracy Using Six Deep Learning Methods
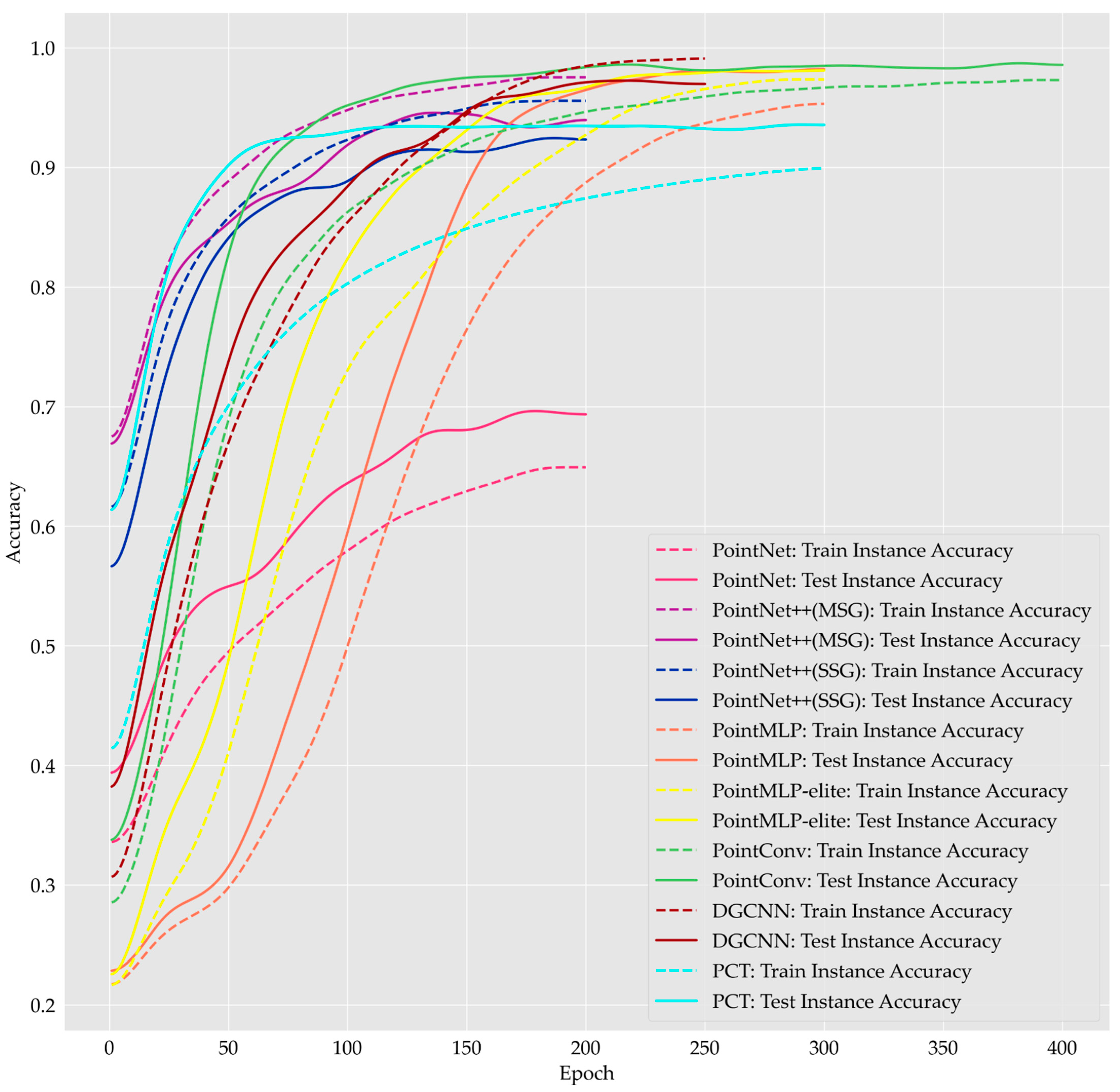
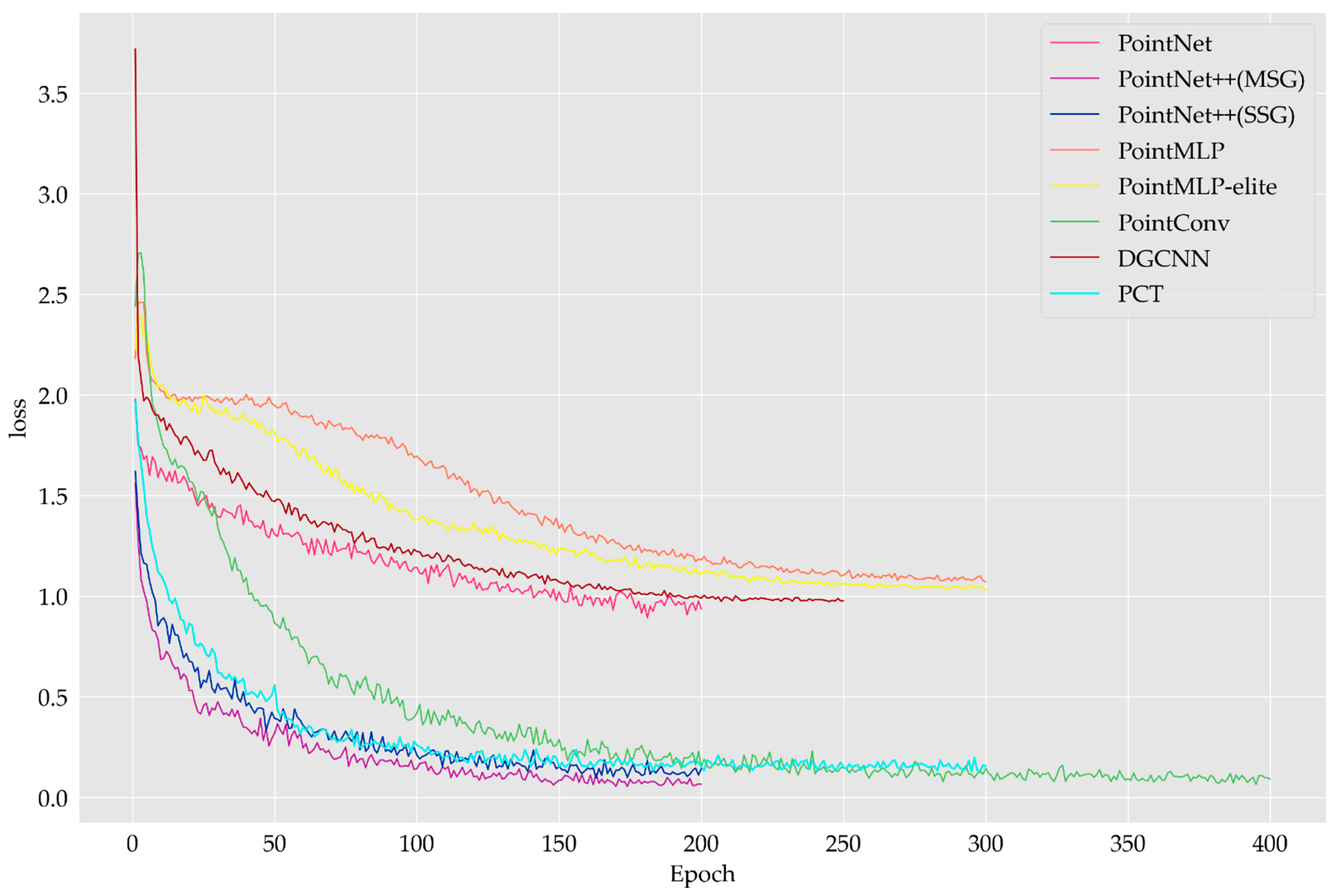
4.2.1. Training Process of Deep Learning Models
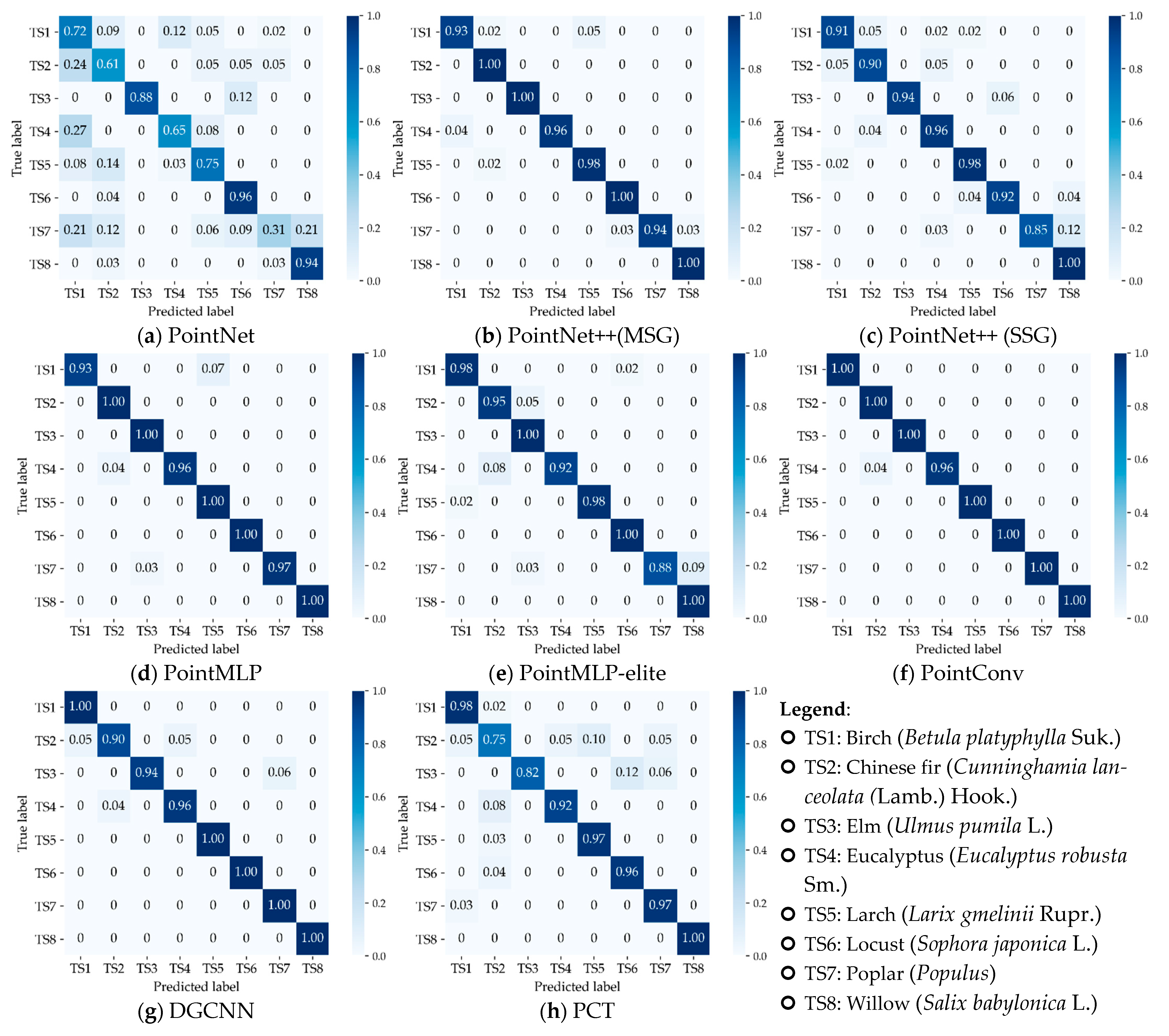
4.2.2. Accuracy of Tree Species Classification
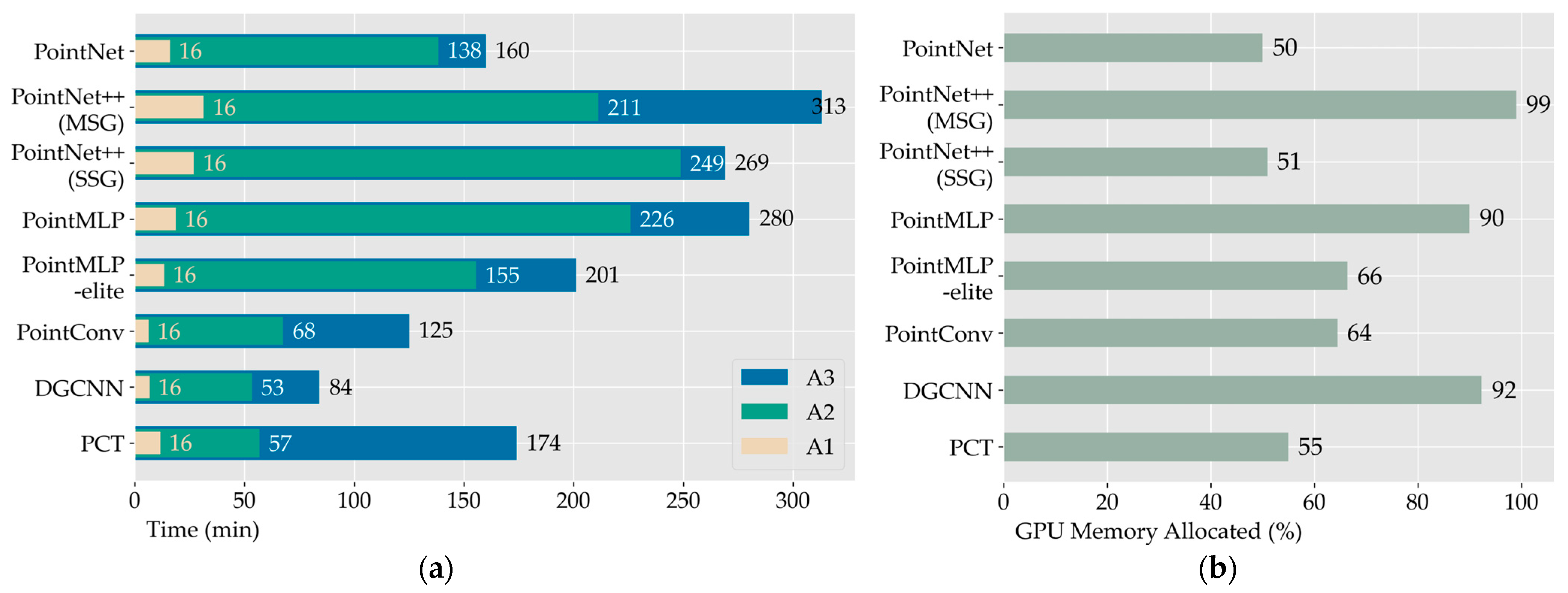
4.2.3. Model Comparison and Analysis
4.3. Visualization of Critical Points
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Schiefer, F.; Kattenborn, T.; Frick, A.; Frey, J.; Schall, P.; Koch, B.; Schmidtlein, S. Mapping forest tree species in high resolution UAV-based RGB-imagery by means of convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2020, 170, 205–215. [Google Scholar] [CrossRef]
- Crabbe, R.A.; Lamb, D.; Edwards, C. Discrimination of species composition types of a grazed pasture landscape using Sentinel-1 and Sentinel-2 data. Int. J. Appl. Earth Obs. Geoinf. 2020, 84, 101978. [Google Scholar] [CrossRef]
- Torabzadeh, H.; Leiterer, R.; Hueni, A.; Schaepman, M.E.; Morsdorf, F. Tree species classification in a temperate mixed forest using a combination of imaging spectroscopy and airborne laser scanning. Agric. For. Meteorol. 2019, 279, 107744. [Google Scholar] [CrossRef]
- Liu, J.; Wang, X.; Wang, T. Classification of tree species and stock volume estimation in ground forest images using Deep Learning. Comput. Electron. Agric. 2019, 166, 105012. [Google Scholar] [CrossRef]
- Pu, R. Mapping Tree Species Using Advanced Remote Sensing Technologies: A State-of-the-Art Review and Perspective. J. Remote Sens. 2021, 2021, 812624. [Google Scholar] [CrossRef]
- Briechle, S.; Krzystek, P.; Vosselman, G. Semantic Labeling of Als Point Clouds for Tree Species Mapping Using the Deep Neural Network Pointnet++. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W13, 951–955. [Google Scholar] [CrossRef]
- Briechle, S.; Krzystek, P.; Vosselman, G. Classification of Tree Species and Standing Dead Trees by Fusing Uav-Based Lidar Data and Multispectral Imagery in the 3d Deep Neural Network Pointnet++. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, V-2-2020, 203–210. [Google Scholar] [CrossRef]
- Liu, M.; Han, Z.; Chen, Y.; Liu, Z.; Han, Y. Tree species classification of LiDAR data based on 3D deep learning. Measurement 2021, 177, 109301. [Google Scholar] [CrossRef]
- Lv, Y.; Zhang, Y.; Dong, S.; Yang, L.; Zhang, Z.; Li, Z.; Hu, S. A Convex Hull-Based Feature Descriptor for Learning Tree Species Classification from ALS Point Clouds. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Seidel, D.; Annighofer, P.; Thielman, A.; Seifert, Q.E.; Thauer, J.H.; Glatthorn, J.; Ehbrecht, M.; Kneib, T.; Ammer, C. Predicting Tree Species From 3D Laser Scanning Point Clouds Using Deep Learning. Front. Plant Sci. 2021, 12, 635440. [Google Scholar] [CrossRef]
- Xi, Z.; Hopkinson, C.; Rood, S.B.; Peddle, D.R. See the forest and the trees: Effective machine and deep learning algorithms for wood filtering and tree species classification from terrestrial laser scanning. ISPRS J. Photogramm. Remote Sens. 2020, 168, 1–16. [Google Scholar] [CrossRef]
- Su, Y.; Guo, Q.; Jin, S.; Guan, H.; Sun, X.; Ma, Q.; Hu, T.; Wang, R.; Li, Y. The Development and Evaluation of a Backpack LiDAR System for Accurate and Efficient Forest Inventory. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1660–1664. [Google Scholar] [CrossRef]
- Guan, H.; Yu, Y.; Ji, Z.; Li, J.; Zhang, Q. Deep learning-based tree classification using mobile LiDAR data. Remote Sens. Lett. 2015, 6, 864–873. [Google Scholar] [CrossRef]
- Liu, B.; Chen, S.; Huang, H.; Tian, X. Tree Species Classification of Backpack Laser Scanning Data Using the PointNet++ Point Cloud Deep Learning Method. Remote Sens. 2022, 14, 3809. [Google Scholar] [CrossRef]
- Zou, X.; Cheng, M.; Wang, C.; Xia, Y.; Li, J. Tree Classification in Complex Forest Point Clouds Based on Deep Learning. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2360–2364. [Google Scholar] [CrossRef]
- Wan, H.; Tang, Y.; Jing, L.; Li, H.; Qiu, F.; Wu, W. Tree Species Classification of Forest Stands Using Multisource Remote Sensing Data. Remote Sens. 2021, 13, 144. [Google Scholar] [CrossRef]
- Åkerblom, M.; Raumonen, P.; Mäkipää, R.; Kaasalainen, M. Automatic tree species recognition with quantitative structure models. Remote Sens. Environ. 2017, 191, 1–12. [Google Scholar] [CrossRef]
- Ba, A.; Laslier, M.; Dufour, S.; Hubert-Moy, L. Riparian trees genera identification based on leaf-on/leaf-off airborne laser scanner data and machine learning classifiers in northern France. Int. J. Remote Sens. 2019, 41, 1645–1667. [Google Scholar] [CrossRef]
- Lin, Y.; Herold, M. Tree species classification based on explicit tree structure feature parameters derived from static terrestrial laser scanning data. Agric. For. Meteorol. 2016, 216, 105–114. [Google Scholar] [CrossRef]
- Yang, G.; Zhao, Y.; Li, B.; Ma, Y.; Li, R.; Jing, J.; Dian, Y. Tree Species Classification by Employing Multiple Features Acquired from Integrated Sensors. J. Sens. 2019, 2019, 3247946. [Google Scholar] [CrossRef]
- Budei, B.C.; St-Onge, B.; Hopkinson, C.; Audet, F.-A. Identifying the genus or species of individual trees using a three-wavelength airborne lidar system. Remote Sens. Environ. 2018, 204, 632–647. [Google Scholar] [CrossRef]
- Liu, L.; Coops, N.C.; Aven, N.W.; Pang, Y. Mapping urban tree species using integrated airborne hyperspectral and LiDAR remote sensing data. Remote Sens. Environ. 2017, 200, 170–182. [Google Scholar] [CrossRef]
- Yu, X.; Hyyppä, J.; Litkey, P.; Kaartinen, H.; Vastaranta, M.; Holopainen, M. Single-Sensor Solution to Tree Species Classification Using Multispectral Airborne Laser Scanning. Remote Sens. 2017, 9, 108. [Google Scholar] [CrossRef]
- Ma, X.; Qin, C.; You, H.; Ran, H.; Fu, Y. Rethinking Network Design and Local Geometry in Point Cloud: A Simple Residual MLP Framework. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, 25–29 April 2022. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 30th Annual Conference on Neural Information Processing Systems Conference (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4338–4364. [Google Scholar] [CrossRef]
- Wang, W.; Li, L. Review of Deep Learning in Point Cloud Classification. Comput. Eng. Appl. 2022, 58, 26–40. [Google Scholar] [CrossRef]
- Ge, L.; Yang, Z.; Sun, Z.; Zhang, G.; Zhang, M.; Zhang, K.; Zhang, C.; Tan, Y.; Li, W. A Method for Broccoli Seedling Recognition in Natural Environment Based on Binocular Stereo Vision and Gaussian Mixture Model. Sensors 2019, 19, 1132. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Angelov, P.P.; Soares, E.A.; Jiang, R.; Arnold, N.I.; Atkinson, P.M. Explainable artificial intelligence: An analytical review. WIREs Data Min. Knowl. Discov. 2021, 11, e1424. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, B.; Shen, W.; Wei, Z. A claim approach to understanding the pointnet. In Proceedings of the International Conference on Algorithms, Computing and Artificial Intelligence, Sanya, China, 20–22 December 2019; pp. 97–103. [Google Scholar]
- Wu, W.; Qi, Z.; Fuxin, L. PointConv: Deep Convolutional Networks on 3D Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9621–9630. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Guo, M.; Cai, J.; Liu, Z.; Mu, T.; Martin, R.R.; Hu, S. PCT: Point cloud transformer. Comput. Vis. Media 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Zhang, W.; Qi, J.; Wan, P.; Wang, H.; Xie, D.; Wang, X.; Yan, G. An Easy-to-Use Airborne LiDAR Data Filtering Method Based on Cloth Simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Tao, S.; Wu, F.; Guo, Q.; Wang, Y.; Li, W.; Xue, B.; Hu, X.; Li, P.; Tian, D.; Li, C.; et al. Segmenting tree crowns from terrestrial and mobile LiDAR data by exploring ecological theories. ISPRS J. Photogramm. Remote Sens. 2015, 110, 66–76. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Pomerleau, F.; Colas, F.; Siegwart, R.; Magnenat, S. Comparing ICP variants on real-world data sets. Auton. Robot. 2013, 34, 133–148. [Google Scholar] [CrossRef]
- Lee, K.H.; Woo, H.; Suk, T. Point Data Reduction Using 3D Grids. Int. J. Adv. Manuf. Technol. 2001, 18, 201–210. [Google Scholar] [CrossRef]
- Mo, K.; Yin, Z. Surface Reconstruction of Defective Point Clouds Based on Dual Off-Set Gradient Functions. In Advances in Mechatronics; IntechOpen: Rijeka, Croatia, 2011. [Google Scholar]
- Zhao, S.; Li, F.; Liu, Y.; Rao, Y. A New Method for Cloud Data Reduction Using Uniform Grids. In Proceedings of the 2013 International Conference on Advanced Computer Science and Electronics Information (ICACSEI 2013), Beijing, China, 25–26 July 2013; pp. 64–67. [Google Scholar]
- Fan, S.; Dong, Q.; Zhu, F.; Lv, Y.; Ye, P.; Wang, F. SCF-Net: Learning Spatial Contextual Features for Large-Scale Point Cloud Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14504–14513. [Google Scholar]
- Xu, M.; Ding, R.; Zhao, H.; Qi, X. PAConv: Position Adaptive Convolution With Dynamic Kernel Assembling on Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3173–3182. [Google Scholar]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.S.; Koltun, V. Point Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16259–16268. [Google Scholar]
- Engel, N.; Belagiannis, V.; Dietmayer, K. Point Transformer. IEEE Access 2021, 9, 134826–134840. [Google Scholar] [CrossRef]
- Cheng, X.; Doosthosseini, A.; Kunkel, J. Improve the Deep Learning Models in Forestry Based on Explanations and Expertise. Front. Plant Sci. 2022, 13, 902105. [Google Scholar] [CrossRef]
- Liu, Y.; Sangineto, E.; Bi, W.; Sebe, N.; Lepri, B.; Nadai, M.D. Efficient Training of Visual Transformers with Small Datasets. In Proceedings of the 35th Conference on Neural Information Processing Systems, Virtual Conference, 7–10 December 2021. [Google Scholar]
- Wen, J.; Wu, X.; Wang, J.; Tang, R.; Ma, D.; Zeng, Q.; Gong, B.; Xiao, Q. Characterizing the Effect of Spatial Heterogeneity and the Deployment of Sampled Plots on the Uncertainty of Ground “Truth” on a Coarse Grid Scale: Case Study for Near-Infrared (NIR) Surface Reflectance. J. Geophys. Res. Atmos. 2022, 127, e2022JD036779. [Google Scholar] [CrossRef]
- Wen, J.; You, D.; Han, Y.; Lin, X.; Wu, S.; Tang, Y.; Xiao, Q.; Liu, Q. Estimating Surface BRDF/Albedo Over Rugged Terrain Using an Extended Multisensor Combined BRDF Inversion (EMCBI) Model. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Wu, X.; Wen, J.; Xiao, Q.; Bao, Y.; You, D.; Wang, J.; Ma, D.; Lin, X.; Gong, B. Quantification of the Uncertainty Caused by Geometric Registration Errors in Multiscale Validation of Satellite Products. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study Area | Location | Plot Size | Tree Species | Genus | Tree Height (m) | Number |
|---|---|---|---|---|---|---|
| GKS | 120°12′ to 122°55′ E, 50°20′ to 52°30′ N | 25 m × 25 m | Birch (Betula platyphylla Suk.) | Betula | 6.58–20.87 | 215 |
| Larch (Larix gmelinii Rupr.) | Larix | 6.23–19.30 | 295 | |||
| HL | 115°47′ E, 40°20′ N | 20 m × 20 m | Locust (Styphnolobium japonicum L.) | Styphnolobium | 4.91–9.79 | 142 |
| Willow (Salix babylonica L.) | Salix | 6.33–12.55 | 174 | |||
| Poplar (Populus L.) | Populus | 14.39–25.04 | 165 | |||
| Elm (Ulmus pumila L.) | Ulmus | 4.37–13.48 | 85 | |||
| GF | 108°20′ to 108°32′ E, 22°56′ to 23°4′ N | 20 m × 20 m | Eucalyptus (Eucalyptus robusta Sm.) | Eucalyptus | 20.34–34.66 | 131 |
| Chinese fir (Cunninghamia lanceolata (Lamb.) Hook.) | Cunninghamia | 7.51–22.64 | 105 |
| Category | Pointwise MLP | Convolution | Graph | Attention | ||
|---|---|---|---|---|---|---|
| Model | PointNet | PointNet++ | PointMLP | PointConv | DGCNN | PCT |
| Batch Size | 12 | 12 | 12 | 12 | 8 | 12 |
| Number of Points | 2048 | 2048 | 2048 | 2048 | 2048 | 2048 |
| Number of Categories | 8 | 8 | 8 | 8 | 8 | 8 |
| Epochs | 200 | 200 | 300 | 400 | 250 | 300 |
| Optimizer | Adam | Adam | SGD | SGD | SGD | Adam |
| Learning Rate | 0.001 | 0.001 | 0.1 | 0.01 | 0.1 | 0.0001 |
| Weight Decay | 0.0001 | 0.0001 | 0.0002 | — | 0.0001 | 0.0001 |
| Momentum | — | — | 0.9 | 0.9 | 0.9 | — |
| Learning Rate Scheduler 1 | StepLR | StepLR | CosineAnnealingLR | StepLR | CosineAnnealingLR | StepLR |
| Loss Function 2 | NLLLOSS | NLLLOSS | CrossEntropyLoss | NLLLOSS | CrossEntropyLoss | CrossEntropyLoss |
| Activation Function | ReLU and LogSoftmax | ReLU and LogSoftmax | ReLU and AdaptiveMaxPool1d | ReLU and LogSoftmax | LeakyReLU and AdaptiveMaxPool1d + AdaptiveAvgPool1d | ReLU and Max |
| Model | BAcc | Pr | Re | F | kappa | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | Train | Test | Train | Test | |
| PointNet | 0.6251 | 0.7288 | 0.6277 | 0.7492 | 0.6351 | 0.7241 | 0.6288 | 0.7183 | 0.5726 | 0.679 |
| PointNet++(MSG) | 0.9642 | 0.9768 | 0.9648 | 0.974 | 0.9646 | 0.9732 | 0.9645 | 0.9731 | 0.9587 | 0.9687 |
| PointNet++(SSG) | 0.9579 | 0.9343 | 0.9579 | 0.9421 | 0.9579 | 0.9387 | 0.9578 | 0.9387 | 0.9508 | 0.9284 |
| PointMLP | 0.9097 | 0.9827 | 0.931 | 0.9818 | 0.9301 | 0.9808 | 0.9294 | 0.9808 | 0.9181 | 0.9776 |
| PointMLP-elite | 0.9467 | 0.9643 | 0.9562 | 0.9677 | 0.955 | 0.9655 | 0.955 | 0.9655 | 0.9473 | 0.9598 |
| PointConv | 0.9432 | 0.9952 | 0.9507 | 0.9963 | 0.9505 | 0.9962 | 0.9505 | 0.9962 | 0.9423 | 0.9955 |
| DGCNN | 0.9759 | 0.9614 | 0.9847 | 0.9648 | 0.9847 | 0.9647 | 0.9845 | 0.9647 | 0.9821 | 0.9588 |
| PCT | 0.9321 | 0.9232 | 0.9343 | 0.9441 | 0.9343 | 0.9425 | 0.9342 | 0.9426 | 0.9234 | 0.9329 |
| Model | Year | mAcc | OA | #Params | #FLOPs | Ref. |
|---|---|---|---|---|---|---|
| PointNet | 2017 | 0.860 | 0.892 | 3.47 M | 0.45 G | [25] |
| PointNet++(MSG) | 2017 | — | 0.919 | 1.74 M | 4.09 G | [26] |
| PointNet++(SSG) | 2017 | — | 0.907 | 1.48 M | 1.68 G | [26] |
| PointMLP | 2022 | 0.914 | 0.945 | 12.6 M | — | [24] |
| PointMLP-elite | 2022 | 0.907 | 0.940 | 0.68 M | — | [24] |
| PointConv | 2018 | — | 0.925 | — | — | [33] |
| DGCNN | 2019 | 0.902 | 0.929 | 1.81 M | 2.43 G | [34] |
| PCT | 2021 | — | 0.932 | 2.88 M | 2.32 G | [35] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Huang, H.; Su, Y.; Chen, S.; Li, Z.; Chen, E.; Tian, X. Tree Species Classification Using Ground-Based LiDAR Data by Various Point Cloud Deep Learning Methods. Remote Sens. 2022, 14, 5733. https://doi.org/10.3390/rs14225733
Liu B, Huang H, Su Y, Chen S, Li Z, Chen E, Tian X. Tree Species Classification Using Ground-Based LiDAR Data by Various Point Cloud Deep Learning Methods. Remote Sensing. 2022; 14(22):5733. https://doi.org/10.3390/rs14225733
Chicago/Turabian StyleLiu, Bingjie, Huaguo Huang, Yong Su, Shuxin Chen, Zengyuan Li, Erxue Chen, and Xin Tian. 2022. "Tree Species Classification Using Ground-Based LiDAR Data by Various Point Cloud Deep Learning Methods" Remote Sensing 14, no. 22: 5733. https://doi.org/10.3390/rs14225733
APA StyleLiu, B., Huang, H., Su, Y., Chen, S., Li, Z., Chen, E., & Tian, X. (2022). Tree Species Classification Using Ground-Based LiDAR Data by Various Point Cloud Deep Learning Methods. Remote Sensing, 14(22), 5733. https://doi.org/10.3390/rs14225733