
Supervised Classifications of Optical Water Types in Spanish Inland Waters

 , , and
, , and 
Abstract
1. Introduction
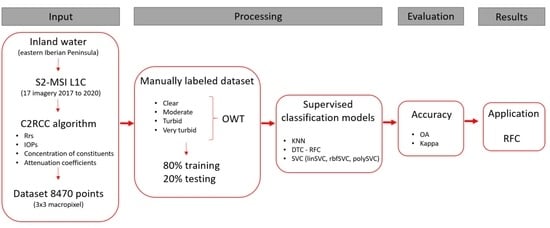
2. Materials and Methods
2.1. Study Area
2.2. Processing Sentinel-2 MSI Imagery
2.3. Definition of Optical Water Types
- Clear: The () signal is weak, with a small peak between 490 and 560 nm. These are waters with low optically active constituent concentrations and high transparency. The higher absorption is in the red and infrared (600–700 nm), and the water appears with very dark or black colors. The content of substances, such as phytoplankton, is possible but in very low quantities. For this class, the Chl-a C2RCC range found is between 0.01 and 14.0 mg m, with an average of 2.15 mg m, and the TSM values are below 22.2 mg L, with an average of 4.3 mg L.
- Moderate: The maximum reflectance is located between 560 and 700 nm. Unlike the “Clear” category, the peak is wider due to a higher presence of substances with optical properties, although there is no one particular matter that dominates. If the signal peak is present at wavelengths 600 nm or longer, it can be linked to the presence of Chl-a, though suspended sediments and other Non-Algal Particles (NAP) in small quantities might also be present. For this class, the Chl-a range calculated with C2RCC is between 1.5 and 38 mg m, with an average of 19 mg m; and the TSM values are between 1.3 and 123 mg L, with an average of 65 mg L. In our study area, this class has the greatest number of measurements.
- Turbid: The () peak can be found closer to green and red wavelengths (500–665 nm), with a secondary peak around 700 nm. In general, reflectances are higher in magnitude than they are in the other classes. The main in-water components of this type of water are related to phytoplankton, such as chlorophyll-a pigments. For this class, the C2RCC Chl-a range is between 1.0 and 280 mg m, with an average of 17.11 mg m; the TSM values can reach 150 mg L, with an average of 43 mg L. In this case, only 8 measurements have Chl-a values > 200 mg m, and they are in correspondence with low TSM values.
- Very Turbid: The highest () values can be found in longer wavelengths, reaching 740 nm and with a clear signal beyond 800 nm. This large spectral amplitude is due to the high concentrations of suspended sediments, mainly (but not only) to non-organic mineral particles. Waters with large amounts of phytoplankton, such as those caused by massive blooms of cyanobacteria, also cause great turbidity in the water, so this type of case could include two types of water with concentrations from different sources. For this class, the C2RCC Chl-a range can reach 364 mg m, with an average of 27 mg m, and the TSM values 150 mg L, with an average of 114 mg L. Only 7 points have Chl-a values > 200 mg m, and they are in correspondence with same high TSM values.
2.4. The Sampling Procedure
2.5. Classification Algorithms
- The K-nearest neighbor (KNN) is very easy to implement and does not require training prior to making the predictions, thus reducing computing times. It calculates the distance of a new data point to all other data points using selected approaches (Euclidean, Manhattan, etc.). K is the number of points with the least distance to the new point. These new data are assigned to the class to which the majority of the K-nearest points belong. The main disadvantage of this classifier is that it can fail if there are too many dimensions (large dataset). K is selected after testing and evaluation, with K = 5 being quite common in the literature, though some testing can be performed to determine which value is recommended for a specific dataset.
- Among decision trees, we selected the basic expression (DTC here) and the random forest classifier (RFC) [38]: RFCs are classical algorithms based on the ensemble of hundreds or thousands of classification trees. The main idea of RFC is that the results obtained by averaging simple classifiers (trees in this case) can obtain better results than the ones obtained by single, more sophisticated, and powerful classifiers. Important and relevant features of DTC and RFC are that they are fast to train and in making predictions; that they are easily parallelizable, making them especially suitable for new hardware composed of multi-core systems; and that they provide a feature ranking (or variable importance) which indicates the most influential features. They are known for obtaining quite good results for remote sensing classification problems.
- The support vector machine for classification, SVC [39], is a well-established, state-of-the-art algorithm for nonlinear binary and multiclass classification. It works by mapping the input (training) samples into a high-dimensional Hilbert space using a (in principle unknown) nonlinear function where a linear classification is performed by defining a hyperplane that separates the different classes with maximum margin. The most relevant characteristics of this type of classifiers are that (i) they obtain a sparse solution where only the most relevant training samples are used, which are called support vectors; (ii) they are able to deal with noisy input samples; (iii) they generalize well, i.e., they are able to make good predictions on new, unseen samples; and (iv) they are relatively fast to train, and once a model is obtained, very fast for making predictions on new input samples.
3. Results
3.1. Comparison of Classifiers
3.2. Feature Importance
3.3. Application of Classifiers: Performance in Contreras Reservoir
3.4. Time-Series Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted | |||||||
|---|---|---|---|---|---|---|---|
| Real | Clear | Moderate | Turbid | Very Turbid | Total | EC | PrAc |
| clear | 196 | 8 | 7 | 0 | 211 | 0.07 | 0.93 |
| moderate | 11 | 1069 | 2 | 0 | 1082 | 0.01 | 0.99 |
| turbid | 4 | 2 | 350 | 4 | 360 | 0.03 | 0.97 |
| very turbid | 5 | 3 | 7 | 26 | 41 | 0.37 | 0.63 |
| Total | 223 | 1080 | 354 | 36 | |||
| EO | 0.08 | 0.01 | 0.04 | 0.13 | |||
| UsAc | 0.91 | 0.99 | 0.96 | 0.87 | |||
| Total accuracy | 1694 | 0.97 | |||||

Appendix B

References
- European Parliament 2000. Available online: https://ec.europa.eu/environment/water/water-framework/index_en.html (accessed on 8 May 2022).
- Soomets, T.; Uudeberg, K.; Jakovels, D.; Zagars, M.; Reinart, A.; Brauns, A.; Kutser, T. Comparison of Lake Optical Water Types Derived from Sentinel-2 and Sentinel-3. Remote Sens. 2019, 11, 2883. [Google Scholar] [CrossRef]
- Copernicus Global Land Service. Available online: https://land.copernicus.eu/global/products/lwq (accessed on 8 May 2022).
- Odermatt, D.; Danne, O.; Philippson, P.; Brockmann, C. Diversity II water quality parameters for 300 lakes worldwide from ENVISAT (2002–2012): A new global information source for lakes. Earth Syst. Sci. Data 2018, 10, 1527–1549. Available online: https://essd.copernicus.org/articles/10/1527/2018/ (accessed on 8 May 2022). [CrossRef]
- Reinart, A.; Paavel, B.; Tuvikene, L. Effect of coloured dissolved organic matter on the attenuation of photosynthetically active radiation in Lake Peipsi. Proc. Est. Acad. Sci. Biol./Ecol. 2004, 53, 88–105. [Google Scholar]
- Mañosa, S.; Mateo, R.; Guitart, R. A review of the effects of agricultural and industrial contamination on the Ebro Delta biota and wildfire. Environ. Monit. Assess. 2001, 71, 187–205. [Google Scholar] [CrossRef]
- Soria, J.M. Past, present and future of la Albufera of Valencia Natural Park. Limnetica 2006, 25, 135–142. [Google Scholar] [CrossRef]
- Serrano, L.; Reina, M.; Martín, I.; Reyes, A.; Arechederra, D.L.; Toja, J. The aquatic systems of Doñana (SW Spain): Watersheds and frontiers. Limnetica 2006, 25, 11–32. [Google Scholar] [CrossRef]
- Soria, J.M.; Caniego, G.; Hernández-Sáez, N.; Dominguez-Gomez, J.A.; Erena, M. Phytoplankton Distribution in Mar Menor Coastal Lagoon (SE Spain) during 2017. J. Mar. Sci. Eng. 2020, 8, 600. [Google Scholar] [CrossRef]
- Sòria-Perpinyà, X.; Vicente, E.; Urrego, P.E.; Pereira-Sandoval, M.; Tenjo, C.; Ruiz-Verdú, A.; Delegido, J.; Soria, J.M.; Peña, R.; Moreno, J. Validation of Water Quality Monitoring Algorithms for Sentinel-2 and Sentinel-3 in Mediterranean Inland Waters with In Situ Reflectance Data. Water 2021, 13, 686. [Google Scholar] [CrossRef]
- Romo, S.; García-Murcia, A.; Villena, M.J.; Sánchez, V.; Ballester, A. Tendencias del fitoplancton en el lago de la Albufera de Valencia e implicaciones para su ecología, gestión y recuperación. Limnetica 2008, 27, 11–28. [Google Scholar] [CrossRef]
- Romo, S.; Soria, J.; Fernández, F.; Ouahid, Y.; Barón-Solá, A. Water residence time and the dynamics of toxic cyanobacteria. Freshw. Biol. 2013, 58, 513–522. [Google Scholar] [CrossRef]
- Global Lakes Sentinel Services. Available online: https://un-spider.org/es/links-and-resources/gis-rs-software/glass-global-lakes-sentinel-services (accessed on 8 May 2022).
- Diversity II. Available online: http://www.diversity2.info/ (accessed on 8 May 2022).
- CyanoAlert. Available online: https://www.cyanoalert.com/ (accessed on 8 May 2022).
- Sentinel Application Platform. Available online: https://step.esa.int/main/download/snap-download/ (accessed on 8 May 2022).
- Moore, T.S.; Campbell, J.W.; Feng, H. A fuzzy logic classification scheme for selecting and blending ocean color algorithms. IEEE Trans. Geosci. Remote Sens. 2001, 39, 1764–1776. [Google Scholar] [CrossRef]
- Moore, T.S.; Dowell, M.; Bradt, S.; Ruiz-Verdú, A. An optical water type framework for selecting and blending retrievals from bio-optical algorithms in lakes and coastal waters. Remote Sens. Environ. 2014, 143, 97–111. [Google Scholar] [CrossRef] [PubMed]
- Le, C.; Li, Y.; Zha, Y.; Sun, D.; Huang, C.; Zhang, H. Remote estimation of chlorophyll a in optically complex waters based on optical classification. Remote Sens. Environ. 2011, 115, 725–737. [Google Scholar] [CrossRef]
- Elveld, M.A.; Ruescas, A.B.; Hommersonm, A.; Moore, T.S.; Peters, S.W.M.; Brockmann, C. An optical classification tool for Global Lake Waters. Remote Sens. 2017, 9, 420. [Google Scholar] [CrossRef]
- Pereira-Sandoval, M.; Urrego, P.E.; Ruiz-Verdú, A.; Tenjo, C.; Delegido, J.; Sorià-Perpinyà, X.; Vicente, E.; Soria, J.M.; Moreno, J. Calibration and validation of algorithms for the estimation of chlorophyll-a concentration and Secchi depth in inland water with Sentinel-2. Limnetica 2019, 38, 471–487. [Google Scholar] [CrossRef]
- Pereira-Sandoval, M.; Ruescas, A.; Urrego, P.E.; Ruiz-Verdú, A.; Delegido, J.; Tenjo, C.; Sorià-Perpinyà, X.; Vicente, E.; Soria, J.M.; Moreno, J. Evaluation of atmospheric correction algorithms over Spanish inland waters for Sentinel-2 Multispectral Imagery Data. Remote Sens. 2019, 11, 1469. [Google Scholar] [CrossRef]
- Sentinel-2. Sentinel Online. Available online: https://sentinel.esa.int/web/sentinel/missions/sentinel-2 (accessed on 8 May 2022).
- Brockmann, C.; Doerffer, R.; Peters, M.; Stelzer, K.; Embacher, S.; Ruescas, A. Evolution of C2RCC neural network for Sentinel 2 and 3 for the retrieval of ocean colour products in normal and extreme optically complex waters. In Proceedings of the Living Planet Symposium 2016, Prague, Czech Republic, 9–13 May 2016; Available online: http://step.esa.int/docs/extra/Evolution%20of%20the%20C2RCC_LPS16.pdf (accessed on 8 May 2022).
- Uudeberg, K.; Ansko, I.; Poru, G.; Ansper, A.; Reinart, A. Using optical water types to monitor changes in optically complex inland and coastal waters. Remote Sens. 2019, 11, 2297. [Google Scholar] [CrossRef]
- Warren, M.A.; Simis, S.G.H.; Martinez-Vicente, V.; Poser, K.; Bresciani, M.; Alikas, K.; Spyrakos, E.; Giardino, C.; Ansper, A. Assessment of atmospheric correction algorithms for the Sentinel-2A MultiSpectral Imager over coastal and inland waters. Remote Sens. Environ. 2019, 225, 267–289. [Google Scholar] [CrossRef]
- Urrego, E.P.; Delegido, J.; Tenjo, C.; Ruiz-Verdú, A.; Soriano-Gonzalez, J.; Pereira-Sandoval, M.; Sorià-Perpinyà, X.; Vicente, E.; Soria, J.M.; Moreno, J. Validation of chlorophyll-a and total suspended matter products generated by C2RCC processor using Sentinel-2 and Sentinel-3 satellites in inland waters. In Proceedings of the XX Congress of the Iberian Association of Limnology, Murcia, Spain, 26–29 October 2020. [Google Scholar]
- Uudeberg, K.; Aavaste, A.; Köks, K.L.; Ansper, A.; Uusöe, M.; Kangro, K.; Ansko, I.; Ligi, M.; Toming, K.; Reinart, A. Optical Water Type Guided Approach to Estimate Optical Water Quality Parameters. Remote Sens. 2020, 12, 931. [Google Scholar] [CrossRef]
- Bailey, S.W.; Werdell, P.J. A multi-sensor approach for the on-orbit validation of ocean color satellite data products. Remote Sens. Environ. 2006, 102, 12–23. [Google Scholar] [CrossRef]
- Shi, K.; Li, Y.; Li, L.; Lu, H.; Song, K.; Liu, Z.; Xu, Y.; Li, Z. Remote chlorophyll-a estimates for inland waters based on a cluster-based classification. Sci. Total. Environ. 2013, 444, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Bi, S.; Li, Y.; Xu, J.; Liu, G.; Song, K.; Mu, M.; Liu, H.; Miao, S.; Xu, J. Optical classification of inland waters based on an improved Fuzzy C-Means method. Opt. Express 2019, 27, 34838–34856. [Google Scholar] [CrossRef] [PubMed]
- Botha, E.J.; Anstee, J.M.; Sagar, S.; Lehmann, E.; Medeiros, T.A.G. Classification of Australian Water bodies across a Wide Range of Optical Water Types. Remote Sens. 2020, 12, 3018. [Google Scholar] [CrossRef]
- Du, Y.; Song, K.; Liu, G. Monitoring Optical Variability in Complex Inland Waters Using Satellite Remote Sensing Data. Remote Sens. 2022, 14, 1910. [Google Scholar] [CrossRef]
- Bourel, M.; Crisci, C.; Martinez, A. Consensus methods based on machine learning techniques for marine phytoplankton presence-absence prediction. Ecol. Inform. 2017, 42, 46–54. [Google Scholar] [CrossRef]
- Chou, J.-S.; Ho, C.-C.; Hoang, H.-S. Determining quality of water in reservoir using machine learning. Ecol. Inform. 2018, 44, 57–75. [Google Scholar] [CrossRef]
- Watanabe, F.S.Y.; Miyoshi, G.T.; Rodrigues, T.W.P.; Bernardo, N.M.R.; Rotta, L.H.S.; Alcântara, E.; Imai, N.N. Inland water’s trophic status classification based on machine learning and remote sensing data. Remote Sens. Appl. Soc. Environ. 2020, 19, 100326. [Google Scholar] [CrossRef]
- Grendaite, D.; Stonevicius, E. Machine Learning Algorithms for Biophysical Classification of Lithuanian Lakes Based on Remote Sensing Data. Water 2022, 14, 1732. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef]
- Pontius, R.G., Jr.; Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy assessment. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Fernandez-Delgado, M.; Cernadas, E.; Barro, S. Do we need hundreds of classifiers to solve real world classification problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Park, J.W.; Korosov, A.A.; Babiker, M.; Won, J.S.; Hansen, M.W.; Kim, H.C. Classification of sea ice types in Sentinel-1 synthetic aperture radar images. Cryosphere 2020, 14, 2629–2645. [Google Scholar] [CrossRef]
- Confederación Hidrográfica del Ebro. Diagnóstico y Gestión Ambiental de Embalses en el ámbito de la Cuenca Hidrográfica del Ebro; Ministerio de Medio Ambiente: Embalse de la Sotonera, Spain, 1996; Available online: https://www.chebro.es/documents/20121/48992/Informe_Final_Embalse_de_la_Sotonera_1996.pdf/b4844842-a49b-209b-96a6-7bb799d125af (accessed on 8 May 2022).
- Dourte, D.R.; Fraisse, C.W.; Bartels, W.L. Exploring changes in rainfall variability in the Southeastern U.S.: Stakeholder engagement, observations, and adaptation. Clim. Risk Manag. 2015, 7, 11–19. [Google Scholar] [CrossRef]
- Yilmaz, A.; Hossain, I.; Perera, B. Effect of climate change and variability on extreme rainfall intensity-frequence-duration relationship: A case study of Melbourne. Hydrol. Earth Syst. Sci. 2014, 18, 4065–4076. [Google Scholar] [CrossRef]
- Sorià-Perpinyà, X.; Vicente, E.; Urrego, P.; Pereira-Sandoval, M.; Ruiz-Verdú, A.; Delegido, J.; Soria, J.M.; Moreno, J. Remote sensing of cyanobacterial blooms in a hyoertrophic lagoon (Albufera of València, Eastern Iberian Peninsula) using multitemporal Sentinel-2 images. Sci. Total. Environ. 2020, 698, 134305. [Google Scholar] [CrossRef]
- Stelzer, K.; Simis, S.; Selmes, N.; Muller, D. Copernicus Global Land Operations “Cryosphere and Water CGLOPS-2”. Product User Manual. Framework Service Contract N° 199496 (JRC). 2020. Available online: https://land.copernicus.eu/global/sites/cgls.vito.be/files/products/CGLOPS2_PUM_LWQ100_S2_v1.2.0_I1.03.pdf (accessed on 8 May 2022).
- Geng, X.; Smith-Miles, K. Incremental Learning. In Encyclopedia of Biometrics; Springer: Boston, MA, USA, 2009. [Google Scholar] [CrossRef]









| Classifier Tests | |||||
|---|---|---|---|---|---|
| Specifications | All Bands | Only Rrs | |||
| OA | Kappa | OA | Kappa | ||
| KNN | 2 neighbors | 0.98 | 0.96 | 0.96 | 0.94 |
| DTC | 0.96 | 0.93 | 0.95 | 0.91 | |
| RFC | max_depth:70; max_leaf:34; min_split:2; n_estimators:430; min_samples_leaf:4 | 0.96 | 0.92 | 0.94 | 0.90 |
| linSVC | lin (gamma:0.01; C:1000) | 0.94 | 0.89 | 0.92 | 0.85 |
| rbfSVC | rbf (gamma:0.1; C:10000) | 0.98 | 0.96 | 0.96 | 0.93 |
| polySVC | poly (degree:9) | 0.93 | 0.86 | 0.91 | 0.81 |
| Predicted | |||||||
|---|---|---|---|---|---|---|---|
| Real | Clear | Moderate | Turbid | Very Turbid | Total | EC | PA |
| clear | 206 | 2 | 3 | 0 | 211 | 0.02 | 0.98 |
| moderate | 21 | 1044 | 17 | 0 | 1082 | 0.04 | 0.96 |
| turbid | 10 | 3 | 333 | 14 | 360 | 0.07 | 0.93 |
| very turbid | 3 | 0 | 3 | 35 | 41 | 0.15 | 0.85 |
| Total | 240 | 1049 | 353 | 49 | |||
| EO | 0.14 | 0.0 | 0.06 | 0.29 | |||
| UA | 0.86 | 1.0 | 0.94 | 0.71 | |||
| Overall accuracy | 1694 | 0.96 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pereira-Sandoval, M.; Ruescas, A.B.; García-Jimenez, J.; Blix, K.; Delegido, J.; Moreno, J. Supervised Classifications of Optical Water Types in Spanish Inland Waters. Remote Sens. 2022, 14, 5568. https://doi.org/10.3390/rs14215568
Pereira-Sandoval M, Ruescas AB, García-Jimenez J, Blix K, Delegido J, Moreno J. Supervised Classifications of Optical Water Types in Spanish Inland Waters. Remote Sensing. 2022; 14(21):5568. https://doi.org/10.3390/rs14215568
Chicago/Turabian StylePereira-Sandoval, Marcela, Ana B. Ruescas, Jorge García-Jimenez, Katalin Blix, Jesús Delegido, and José Moreno. 2022. "Supervised Classifications of Optical Water Types in Spanish Inland Waters" Remote Sensing 14, no. 21: 5568. https://doi.org/10.3390/rs14215568
APA StylePereira-Sandoval, M., Ruescas, A. B., García-Jimenez, J., Blix, K., Delegido, J., & Moreno, J. (2022). Supervised Classifications of Optical Water Types in Spanish Inland Waters. Remote Sensing, 14(21), 5568. https://doi.org/10.3390/rs14215568