1. Introduction
Due to the advantages of large coverage, low cost, and short data acquisition period, remote sensing has been widely used in water body segmentation [
1,
2,
3]. Water body segmentation is important for water resource management, ecological evaluation, and environmental protection [
4,
5]. The key to water body segmentation is to highlight the features of water bodies from complex backgrounds.
Traditional water body segmentation algorithms are used to extract water bodies directly by calculating a certain water body index, such as Normalized Difference Water Index (NDWI) [
6] and Modified Normalized Difference Water Index (MNDWI) [
7], and then by setting the corresponding thresholds. The water body index segmentation algorithm relies on thresholds that are set manually. The main aim of these indexes is to exploit the differences in the reflectance of water bodies at different wavelengths and to enhance the information about water bodies [
8]. However, due to the diversity and complexity of the background, the different thresholds need to be adjusted for different scenarios. Machine learning-based water body segmentation algorithms build a relationship between water body samples and masks, which reduces the reliance on segmentation thresholds. Many popular algorithms such as Support Vector Machine (SVM) [
9], Random Forests (RF) [
10], Decision Tree (DT), and Deep Learning (DL) have been developed in remote sensing image segmentation [
11,
12]. DL has attracted more attention in image segmentation mainly due to its strong ability to extract variables to express feature information [
13], which boosts the intelligent and automatic interpretation of remote sensing images.
With the rapid development of deep learning, Ronneberger et al. [
14] proposed the U-Net model for medical image segmentation in 2015. U-Net is a symmetric structure and one of the first techniques to use encoder–decoder networks for semantic segmentation. U-Net achieves relatively high accuracy using only a small amount of training data. The encoder module is used to categorize and analyze the low-level local pixel values of the image and obtain higher-order semantic information, while the decoder module is to collect the semantic information and gradually recovers the spatial information of the features.
The encoder–decoder network employs an organized recurrent neural network to deal with the sequence-to-sequence prediction problem, which has been successfully applied to a wide variety of computer vision tasks [
14,
15], and remote sensing image semantic segmentation [
16]. In 2020, He et al. [
17] proposed an improved U-Net network model to extract water bodies on Gaofen-2 remote sensing images and made the feature map as the input of conditional random field (CRF) to improve the fineness of target object edge segmentation. Although the model has a good effect, there is still a need to improve the extraction effect in areas where surrounding conditions differ greatly from the study area. Other networks for image segmentation have also been proposed, such as FCN [
18], SegNet [
19], RefineNet [
20], PSPNet [
21], Deeplab series [
15,
22,
23], etc. The Deeplab series and PSPNet use inflated convolutions, which increase the input size without pooling layers, resulting in a wider range of information in the output for each convolution [
24]. Other semantic segmentation networks are also proposed in water body segmentation research. These networks include HRNet V2 [
25], which is utilized to enhance the high-resolution representation by pooling all parallel convolutional representations; the WatNet [
16], which is used for surface water mapping; and PSPNet, which is applied to detect the water shoreline [
26].
Although these DL methods greatly improved the accuracy and efficiency of water body extraction, there are still challenges in the water body extraction: (1) in the deep learning forward propagation, the resolution of feature maps is reduced due to the repeated max-pooling layers, which leads to the loss of detailed water body information; (2) as the receptive fields of pixels vary, the feature maps produced by convolutional layers at varying depths contain feature information at varying sizes. The integration of gathered features at different scales deserves further research to improve the accuracy of water body extraction.
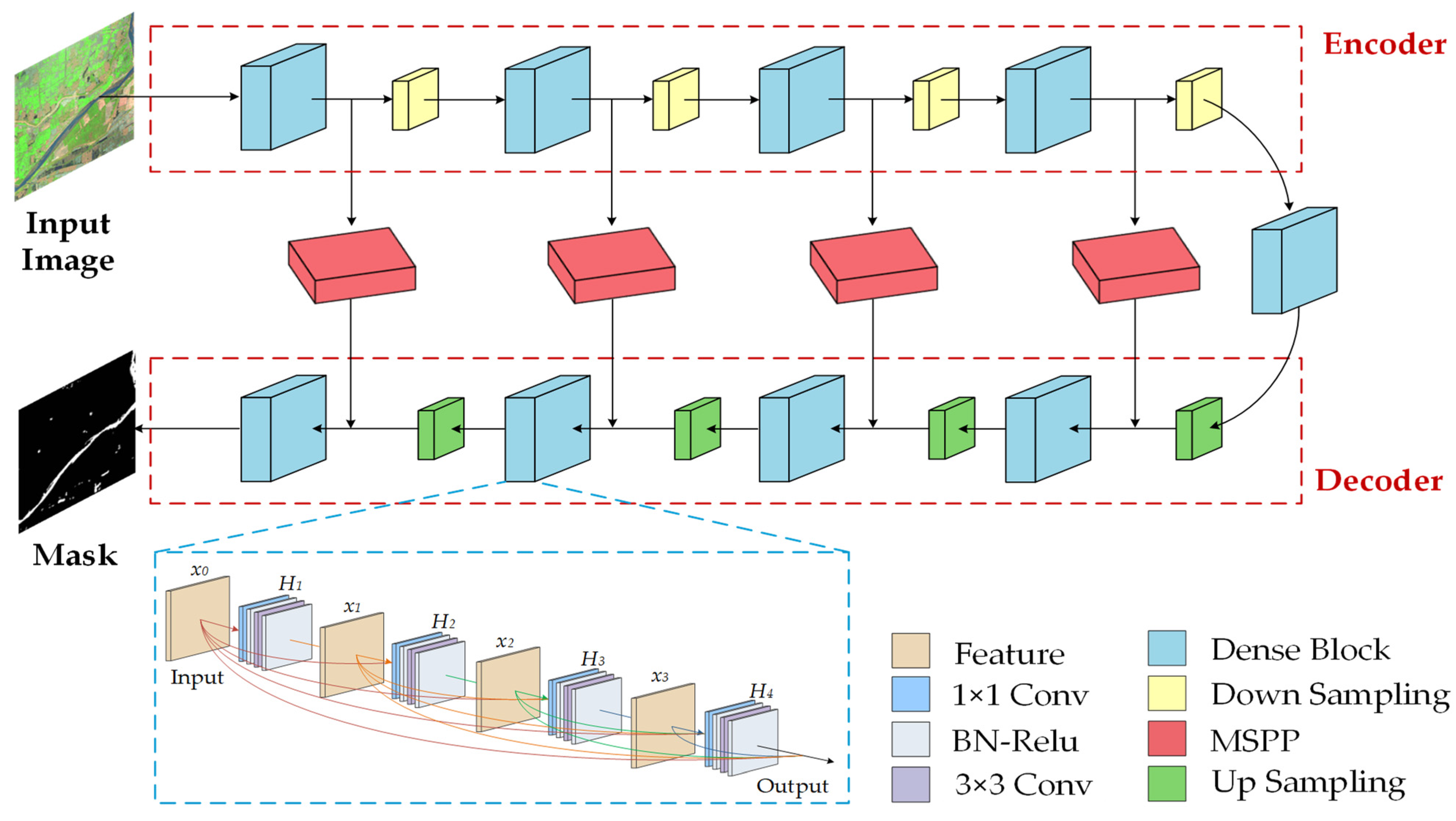
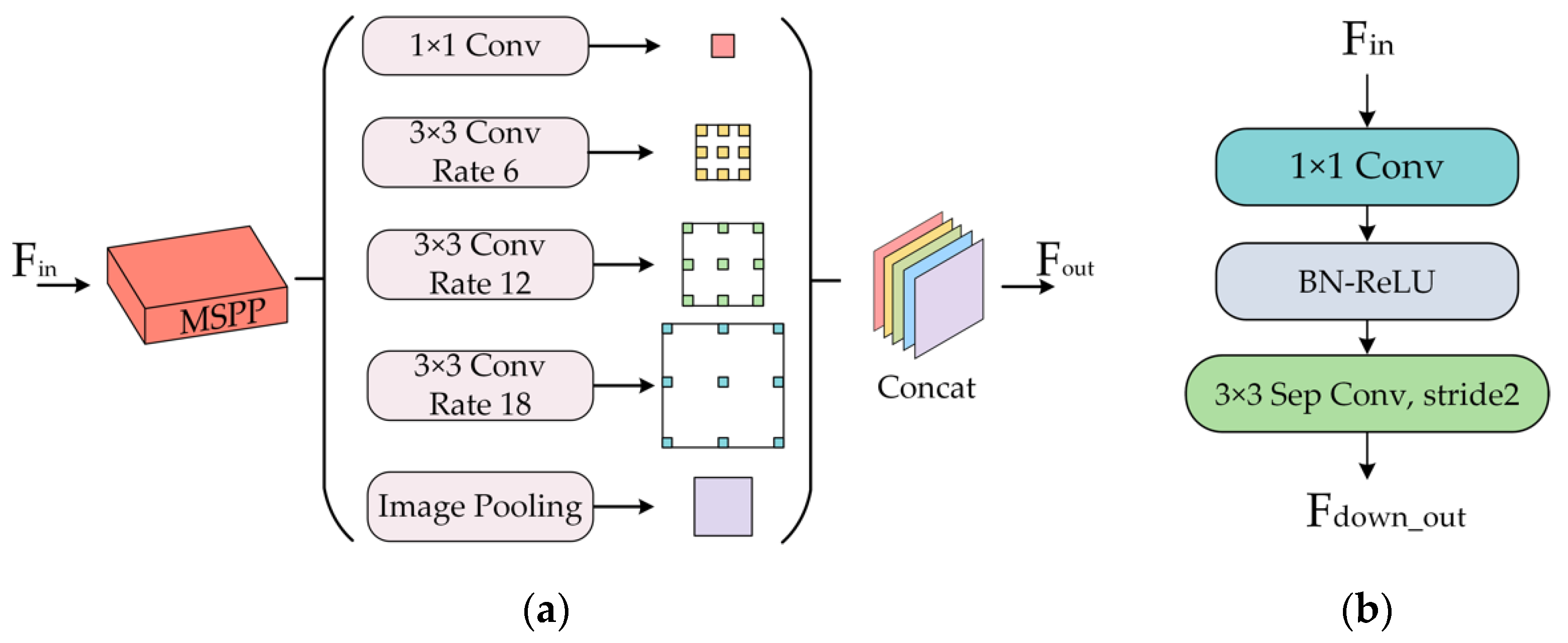
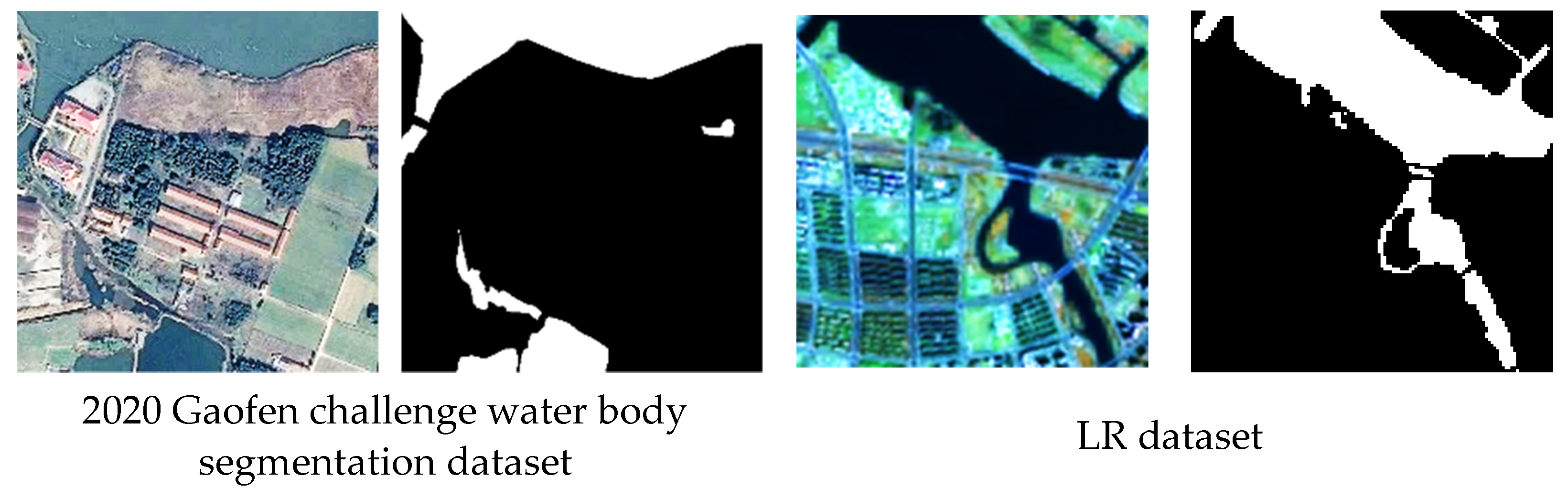
To address the challenges, we created a Landsat 8 water body dataset: Landsat River dataset (LR dataset), and proposed a new semantic segmentation network, namely Dense U-Net+ network (DUPnet), for water bodies in remote sensing images. This model takes global contextual information, multi-scale information, and feature information into account in order to (1) extract multi-scale information for skip connections and alleviate the gradient vanishing problem, we build the multi-scale spatial pyramid pooling module (MSPP); (2) to extract features at different levels, e.g., low-level features and highly abstract features, we introduce Dense Block [
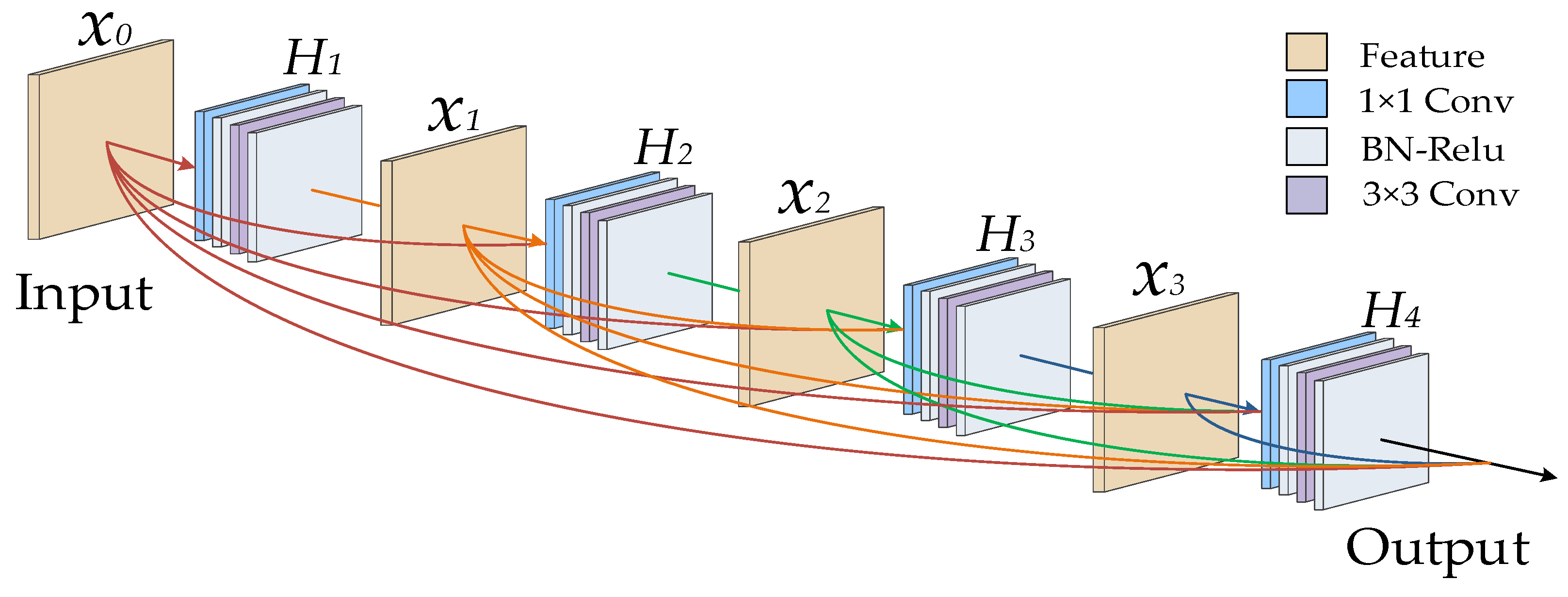
27] to enhance feature propagation and encourage feature reuse; (3) to obtain a better segmentation performance, we use multiple levels of features for pixel-level image semantic segmentation.
When designing a complex deep learning model, the choice of loss functions is also important as they stimulate the learning process. Since 2012, researchers have experimented with loss functions in various fields to improve the results of their datasets. Jadon [
28] summarized 15 loss functions based on image segmentation that have been shown to provide excellent results in different fields. These functions can be classified into four categories: distribution-based [
29,
30], region-based [
31,
32], boundary-based [
33,
34], and compounded [
35,
36]. We finally used a regression loss function with a mixture of distribution-based cross-entropy loss and region-based Tversky loss for training. Cross-entropy [
37] is defined as a measure of the difference between two probability distributions for a random variable or event set and has been frequently used for pixel-level classification segmentation. However, cross-entropy has an obvious drawback when the image segmentation task requires only two cases to be segmented: foreground and background. When there are fewer foreground pixels, the background component of the loss function dominates, resulting in low segmentation accuracy. Furthermore, the Tversky index [
38] can increase the weighting of false positives and false negatives, which effectively address the problem of data imbalance.
The main contributions of this study include the following:
- (a)
A network framework (DUPnet) is proposed by combining the MSPP and dense block to segment water bodies from remote sensing images. The DUPnet uses multi-scale spatial features and multiple levels of spectral features. The experimental results on the 2020 Gaofen challenge water body segmentation dataset and the LR dataset show that the DUPnet model outperforms the majority of state-of-the-art segmentation methods, and the FWIoU for these two datasets are 93.52% and 91.77%, respectively.
- (b)
A water body classification dataset is proposed based on Landsat 8 OLI images, namely the LR dataset, which contains 7154 images with 128 × 128 pixels and covers an area of ~ 34,225 km2 of the Yellow River in the Henan region, China. The LR dataset can provide the research community with high-quality datasets when conducting the water body classification for Landsat imagery.
- (c)
A regression loss function (Log-Cosh Tversky Loss, all for short LCTLoss) was developed based on the Tversky index to address the imbalance of positive and negative samples. By modifying hyperparameters, our method is able to distinguish the water bodies with substantial edge changes. The experimental results on the LR dataset show that our proposed loss function outperforms Cross-Entropy (CE) Loss, Binary Cross-Entropy (BCE) Loss, Focal Loss, Dice Loss, and Tversky Loss, demonstrating the effectiveness of the proposed loss function.
3. Results and Discussion
3.1. Ablation Study
3.1.1. Quantitative Comparison of Ablation Study
Using U-Net as a baseline, an ablation experiment analysis is performed in this work to test the efficiency of MSPP and Dense Block (DB). Where MSPP is introduced into U-Net as a skip connection and DB replaces the original convolutional layer of the U-Net structure. Firstly, to investigate the effect of different dilation rates on MSPP, three distinct dilation rates were chosen: {1, 6, 9, 12}, {1, 6, 12, 18}, and {1, 12, 24, 36}. As shown in
Table 3, with the increase in dilation rate, F1 and MIoU increase first and then decrease. A dilution rate of {1,6,12,18} resulted in the highest F1, MIou, and FWIoU (
Table 3). When the dilation rate is low, the model is less accurate in predicting difficult-to-classify pixels but more accurate in predicting easy-to-classify pixels. The prediction of hard-to-classify pixels may improve, but the prediction of easy-to-classify pixels may degrade. Therefore, we chose a dilation rate of {1, 6, 12, 18} in this study, which can make the MSPP more effective.
To ensure that the MSPP and DB approaches contribute to the results of water segmentation. As shown in
Table 4, adding the MSPP module to U-Net can enhance F1, MIoU, and FWIoU by 1.2%, 2.69%, and 2.79%, respectively, indicating that the MSPP is efficient in water segmentation. The addition of the DB module to U-Net only increases the MIoU by 0.17%, but the addition of the DB module makes the network extract more water body pixels, as shown in
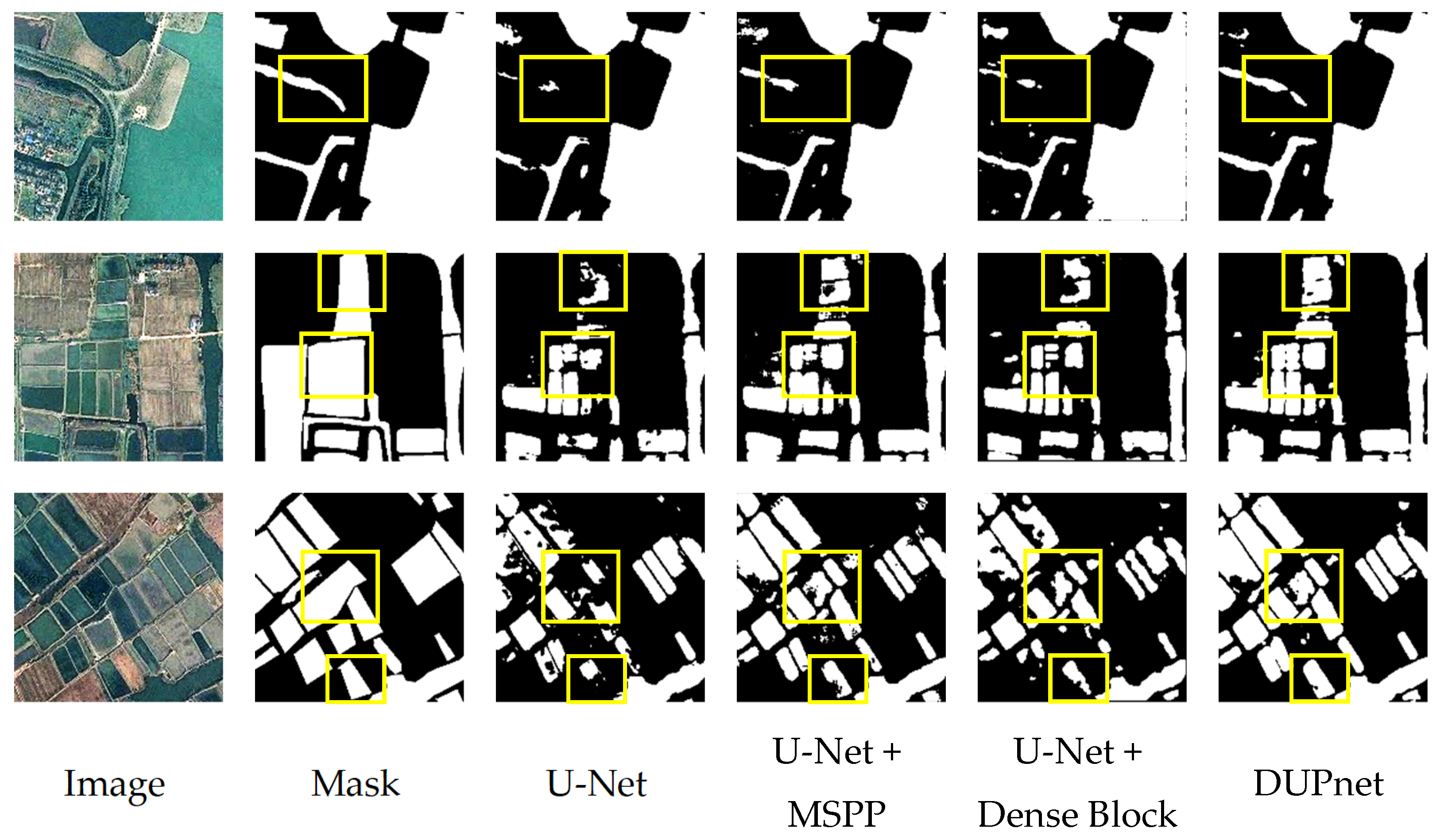
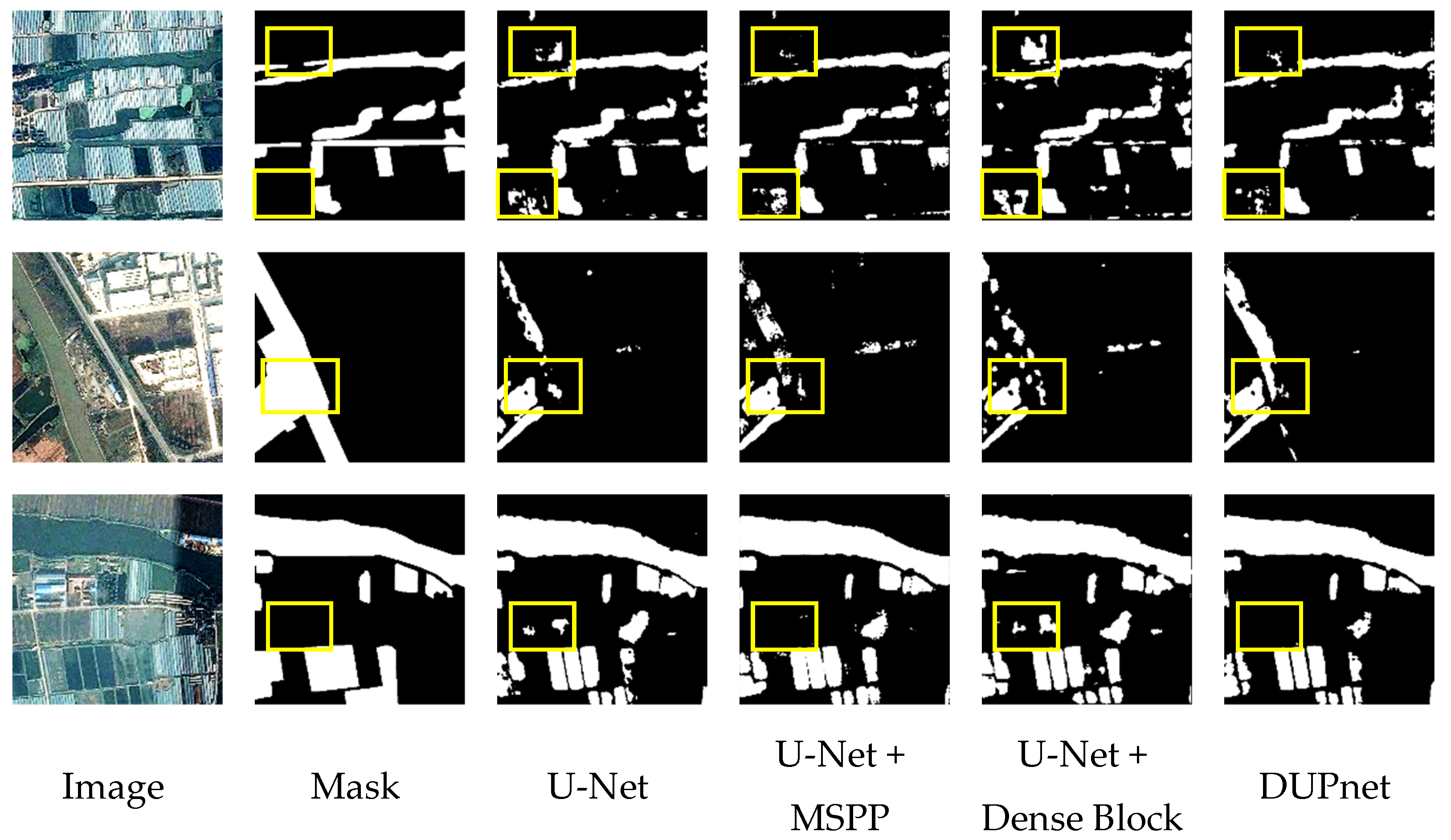
Figure 7 and
Figure 8. The DUPnet uses MSPP for skip connections and DB modules; its F1, MIoU, and FWIoU increase by 1.84%, 4.96%, and 4.47%, respectively, compared to U-Net.
3.1.2. Qualitative Comparison of Ablation Study
This study analyzes the segmentation features created independently before and after using the MSPP and DB to visually confirm the effectiveness of the proposed module. The study uses yellow boxes to highlight the locations where there are discrepancies in identification.
Figure 7 and
Figure 8 depict the effect of the original U-Net, the U-Net with MSPP as skip connections, and the U-Net with DB as a convolutional layer for segmenting water bodies.
As shown in
Figure 7, the U-Net with the MSPP and DB module recognizes more water from the input image, extracts more features, and improves recognition of difficult-to-extract regions such as shadows than the original U-Net.
As shown in
Figure 8, comparison images monitor small water bodies, the original U-Net can only track a tiny percentage of narrow streams on the input image. The addition of MSPP and DB modules can improve the model’s ability to locate water bodies, extract small water bodies, and reduce water body misclassification and omission.
3.2. Quantitative and Qualitative Comparison with State-of-the-Art Methods
3.2.1. Quantitative Comparison with State-of-the-Art Methods
To comprehensively evaluate the segmentation performance of the improved DUPnet model, eight segmentation networks, FCN, SegNet, U-Net, ENVINet5 [
56], PSPNet, DeepLabV3+, HRNet V2, and Maximum Likelihood Classification (MLC) [
57], were chosen for comparison in this study, and the performance of the trained models was tested using the test set. The FCN, SegNet, U-Net, PSPNet, DeepLabV3+, HRNet V2, and DUPnet networks were trained using the network parameter settings in
Section 2.1.3, with the same backbone network Resnet50 used for FCN, PSPNet, and DeepLabV3+. In addition, the best hyper-parameters of the segmentation algorithms were used in the comparison approach.
As shown in
Table 5 and
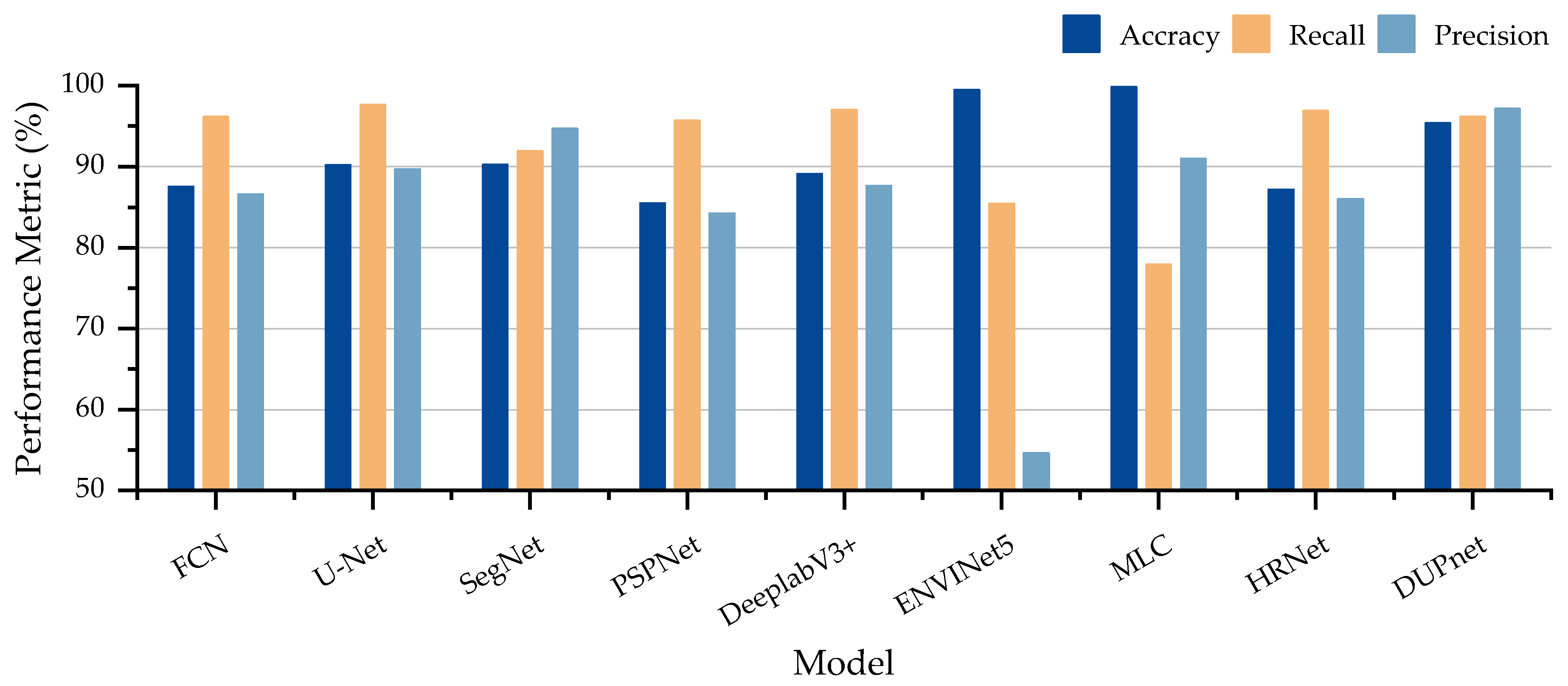
Figure 9, the results of the competence evaluation comparison between DUPnet and other network segmentation results on the LR dataset. The probabilistic discriminatory rules-based MLC has the highest Accuracy of 99.82%; the U-Net performs the best in Recall with 97.62%; the proposed DUPnet has the highest Precision of 97.15%.
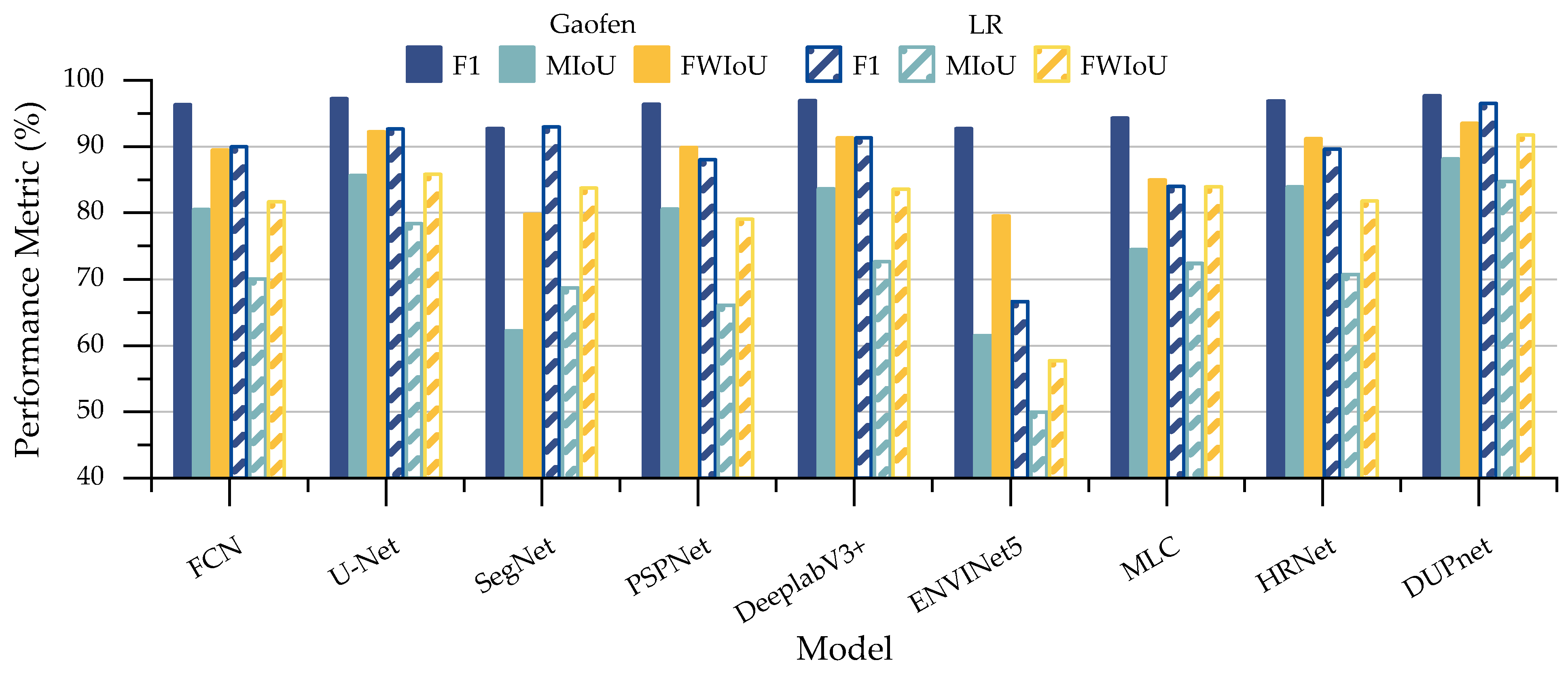
Table 6 and
Figure 10 provide the comparison of our method with state-of-the-art methods on the 2020 Gaofen challenge water body segmentation dataset and the LR dataset in F1, MIoU, and FWIoU. In the case of both datasets, DUPnet achieves the most superior performance for each of the three metrics because DUPnet uses both dense blocks, contextual aggregation, and multi-scale skip connection, which gives it an advantage over the other methods.
As shown in
Table 7, to evaluate the complexity of the compared models, the size of the memory occupied by the model files and the average time used to predict one image (model input is 1 × 3 × 128 × 128) in the test dataset after training by FCN, U-Net, SegNet, PSPNet, DeepLabV3+, HRNet V2, and DUPnet. The U-Net used the maximum pooling layer in 4 down-sampling operations, and the feature layer 4 compressions are performed, U-Net’s model file has the smallest file size (153 M) and average prediction time (0.2500 s) when compared to the remaining five methods. As PSPNet uses ASPP to enlarge the receptive fields, it has the longest model file size (534 M) and average prediction time (0.5556 s) when using the same backbone network Resnet50 as FCN and DeeplabV3+. The DUPnet proposed in this work does not use a backbone network, but dense blocks in the feature propagation process replace maximum pooling with Atrous Separable Convolution in the down-sampling process, which has a higher feature utilization. The DUPnet has a relatively small model size (296 M) and average prediction time (0.4444 s).
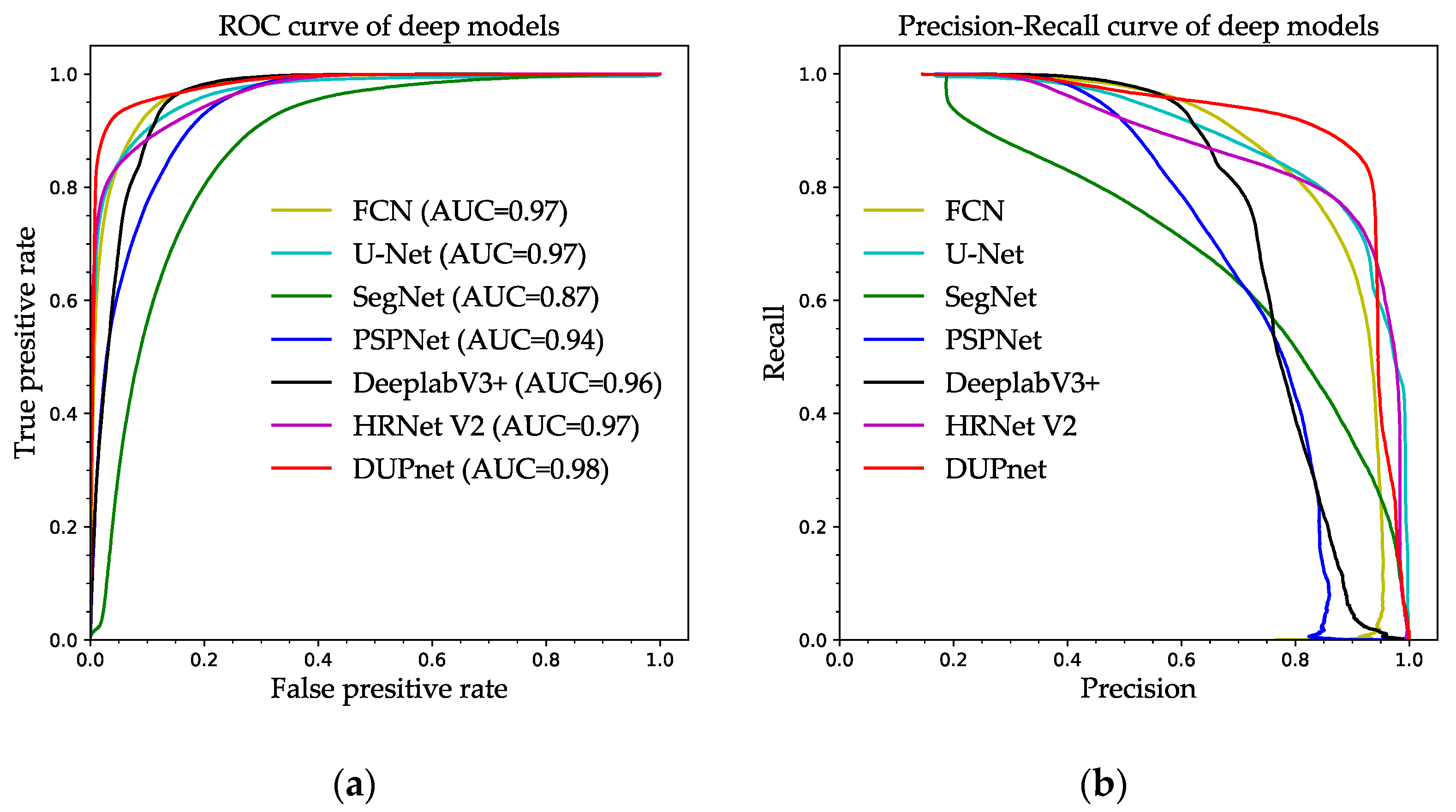
To evaluate the segmentation ability of the compared models, the evaluation of the water segmentation ability of the models of FCN, SegNet, U-Net, PSPNet, DeepLabV3+, and DUPnet in the LR dataset after the completion of training using ROC (Receiver Operating Characteristic) curves and P–R curves are shown in
Figure 11a,b. AUC (Area under Curve), the area under the Roc curve, is between 0.1 and 1. AUC is a value that can visually evaluate the goodness of the classifier. A larger value of AUC represents a better result. In the P–R curve diagram, if the curve bend towards the upper right corner, i.e., (1, 1), the segmentation performance of the corresponding model is better. SegNet has an AUC of 0.87 and has the smallest area under the ROC curve and the P–R curve. Therefore, it had the worst performance for segmentation. The proposed DUPnet has an AUC of 0.98 and contains the largest area under the ROC curve. The P–R curve of DUPnet is closer to the upper right corner compared to the other methods. Therefore, the ROC and P–R curve plots indicate that the proposed DUPnet has better model segmentation ability when compared to other methods.
3.2.2. Qualitative Comparison with State-of-the-Art Methods
A qualitative comparison of the performance of the proposed method and comparable methods on the LR dataset and the 2020 Gaofen challenge water body segmentation dataset was also conducted.
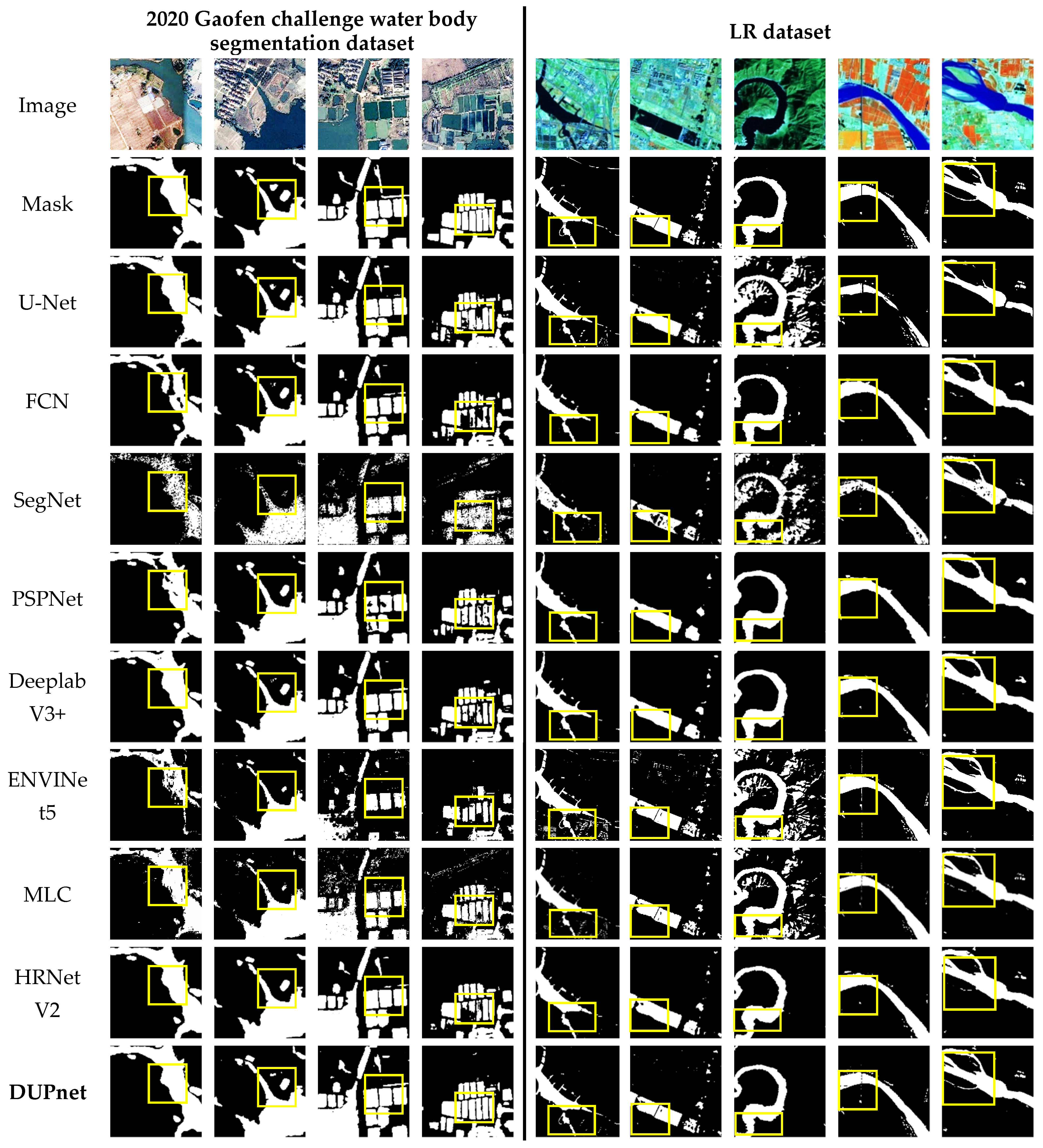
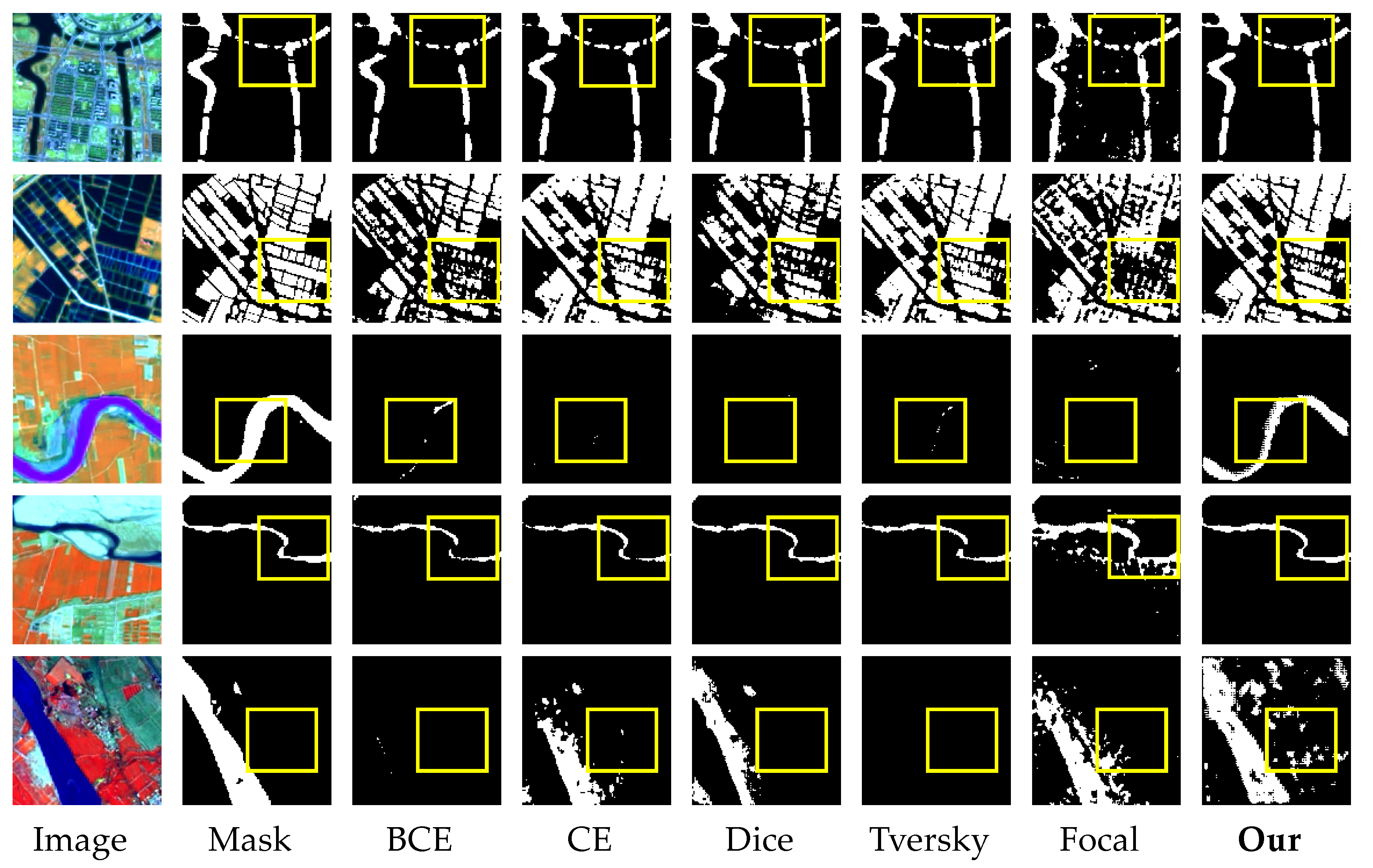
Figure 12 depicts the qualitative evaluation in comparison to several methodologies.
Figure 12 presents examples of water bodies extraction results from the Gaofen dataset in the first through fourth columns. From the results, our proposed deep segmentation network DUPnet can integrate the properties of three networks, including codec structure, dense connection, and Atrous Convolution, to increase the extraction accuracy of water bodies of various types (rivers, water fields, and water channels).
The images in columns 5 and 6 of
Figure 12 show urban waters of various sizes and shapes of our created LR dataset. FCN, PSPNet, and DeeplabV3+ have unclear boundary segmentation of urban waters, and small water bodies in the city are not detected, but the discrimination ability of error-prone sub-pixels such as urban building shadows is good. SegNet has poor discrimination ability for the central region of water bodies. U-Net, ENVINet5, and MLC are effective in extracting urban water bodies of various sizes, but hard-to-identify regions such as urban building shadows are misclassified as water bodies.
As shown in column 7 of
Figure 12, the image background is a mountain of the LR dataset, FCN, PSPNet, and DeeplabV3+ have high accuracy and less error for pixel segmentation of water bodies in the mountains. U-Net, SegNet, ENVINet5, and MLC are easy to confuse hill shadows and water bodies, and the segmentation accuracy is not very high. The proposed DUPnet retains a lot of spatial details for the segmentation of water bodies in the mountains, the edges are clearer and more accurate, and these easily mis-segmented pixels of the hill shadows can be well distinguished.
The images in columns 8 and 9 of
Figure 12 show rivers of varying widths of the LR dataset, and the river water bodies segmented by U-Net are discontinuous, whereas the other approaches find continuous water bodies. SegNet segments river water bodies with gaps, while the ENVINet5 misclassifies roads with a similar color to water bodies as water bodies. FCN, PSPNet, DeeplabV3+, and MLC have a poor resolution for river tributaries. The proposed DUPnet is continuous and can discriminate the hard-to-identify river tributaries. This model produces water-body segmentation images on the LR dataset with more clear and more accurate segmentation edges and retains more water-body details.
In addition, as shown in
Figure 13, FCN, SegNet, PSPNet, and DeeplabV3+ distinguish building shadows with the best result, but the recognition of small waters is less evident; U-Net, ENVINet5, and MLC identify more building shadows as water bodies; our proposed method has a complete and clear boundary, and identifies more water pixels, which has the best segmentation performance on narrow streams and point water.
3.3. Comparative Analysis of Different Loss Functions
Additionally, on the LR dataset, we conduct a comparative experiment for the Cross-Entropy (CE) Loss, Binary Cross-Entropy (BCE) Loss, Focal Loss, Dice Loss, Tversky Loss, and our proposed LCTLoss to evaluate the effects of different loss functions on model performance.
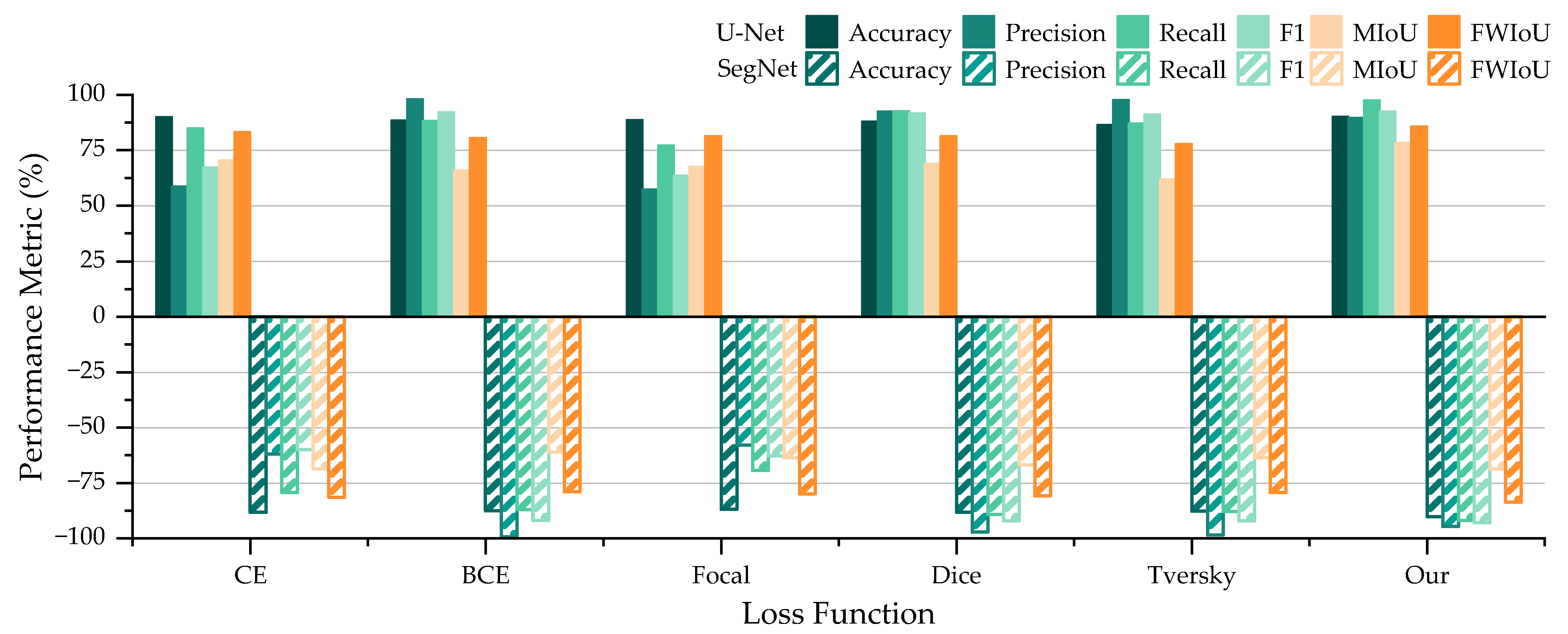
We evaluated the performance of U-Net and SegNet under six different loss functions (
Table 8 and
Figure 14). U-Net achieved the optimal results using our proposed LCTLoss where Accuracy, Recall, F1, MIoU, and FWIoU proposed in this work are 90.23%, 97.62%, 92.67%, 78.37%, and 85.85%, respectively. SegNet achieved the optimal results using our proposed LCTLoss in this paper, where the Accuracy, Recall, F1, and FWIoU are 90.30%, 91.96%, 93.00%, and 83.74%, respectively.
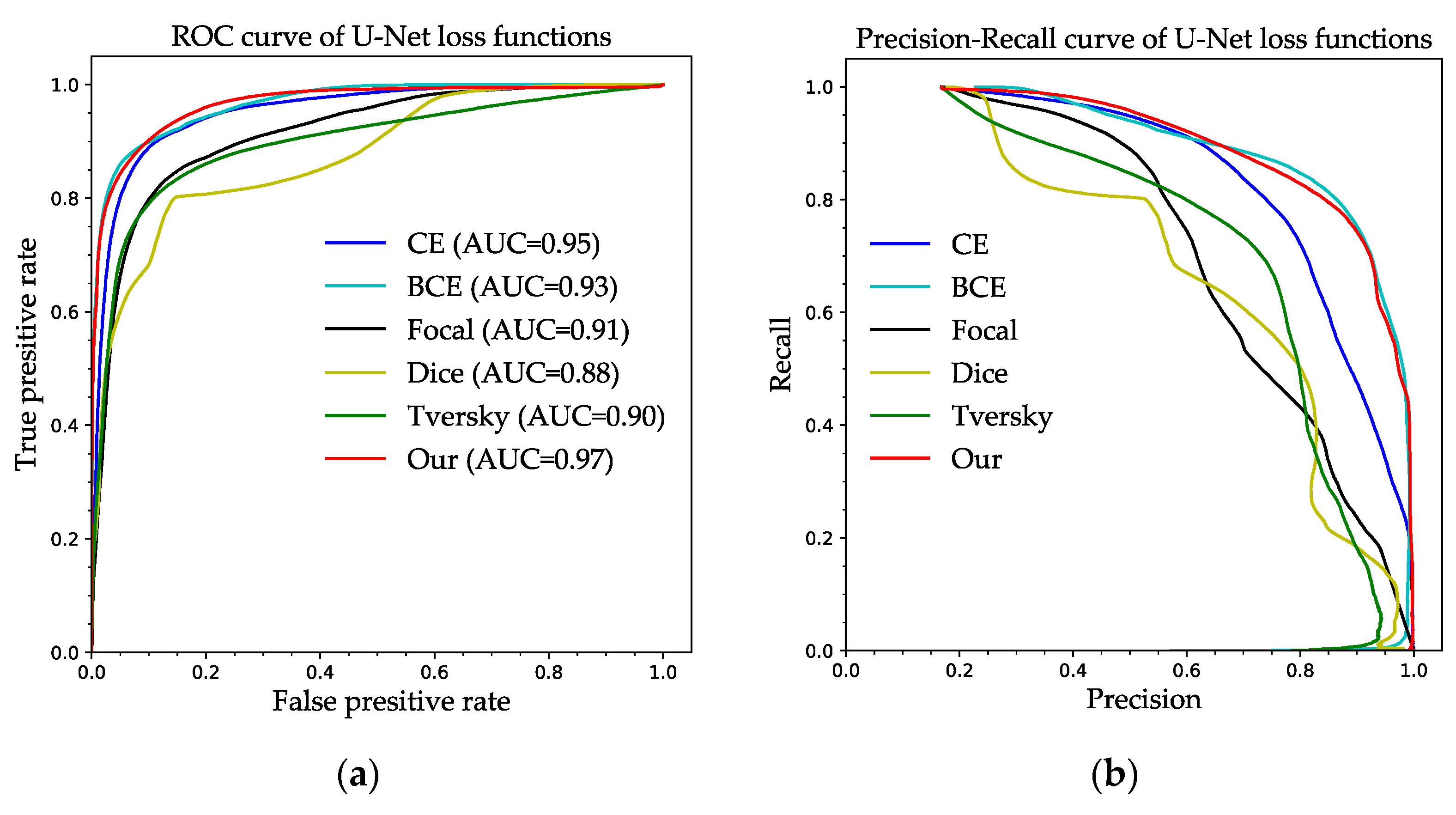
We evaluated the impact of six loss functions on the segmentation ability of U-Net and SegNet by using ROC curves and P–R curves (
Figure 15). It can be seen from
Figure 15a that the U-Net model performed the best using our loss function with an AUC of 0.97 on the ROC curve and the worst using Dice loss with an AUC of 0.88. According to
Figure 15b, U-Net has the closest curve to our loss function and the BCE loss on the P–R curve, but the curve representing the red curve of our loss function contains a large area under the curve, so our loss function is better, while the curve of dice loss contains the smallest area under the curve, so the segmentation ability is inadequate.
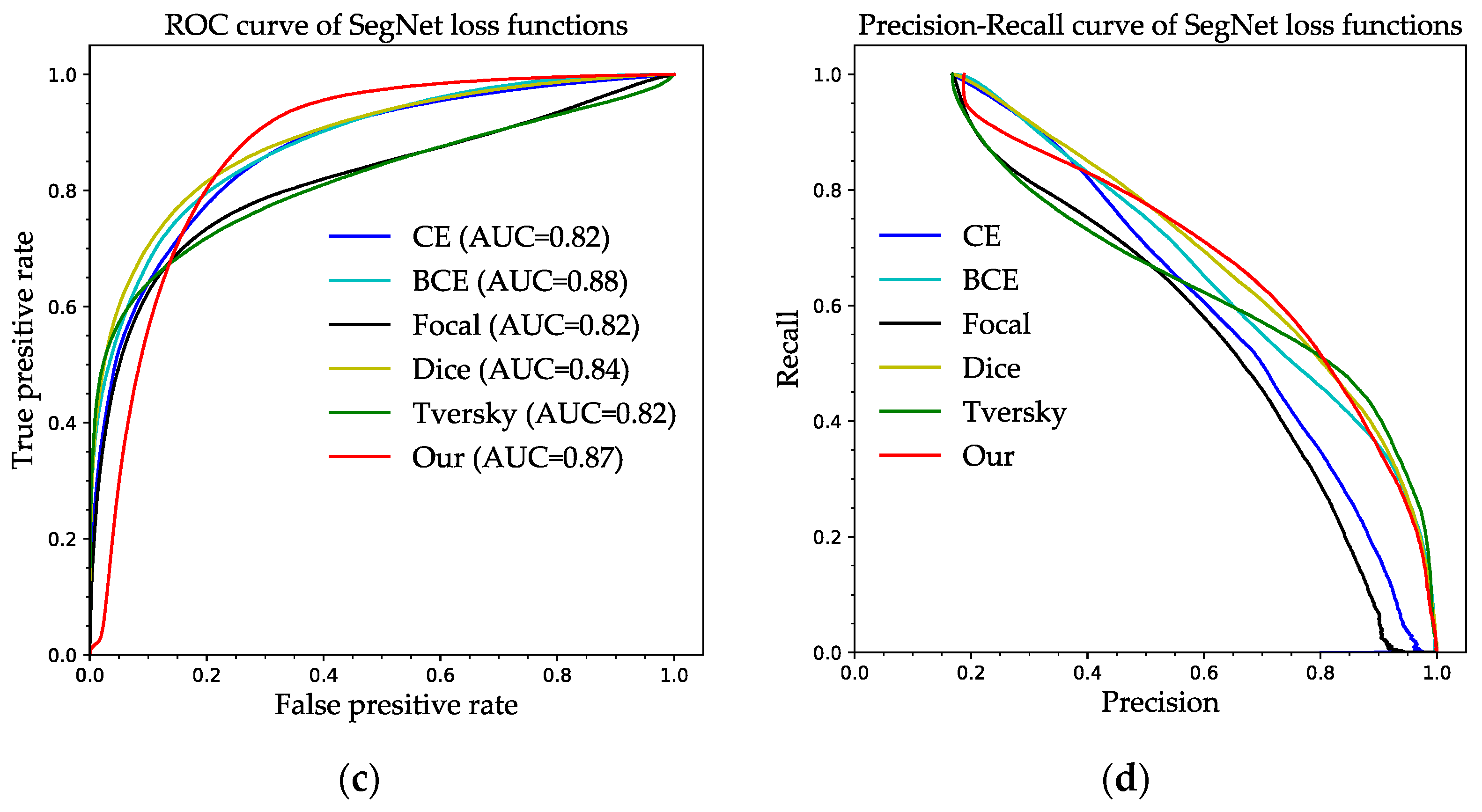
As shown in
Figure 15c,d, the SegNet evaluates the effect of six loss functions on the segmentation ability of the model using the ROC curve and P–R curve. According to
Figure 15c, the BCE loss performs best on the ROC curve for the SegNet model, with an AUC of 0.88, while the Tversky Loss and Focal Loss both perform poorly, and both have equal AUC of 0.82. From
Figure 15d, on the P–R curve, the SegNet has the best segmentation ability, with the curve of our loss function closest to the top-right vertex and the curve of Focal Loss closest to the coordinate origin, indicating that the segmentation effect is undesirable.
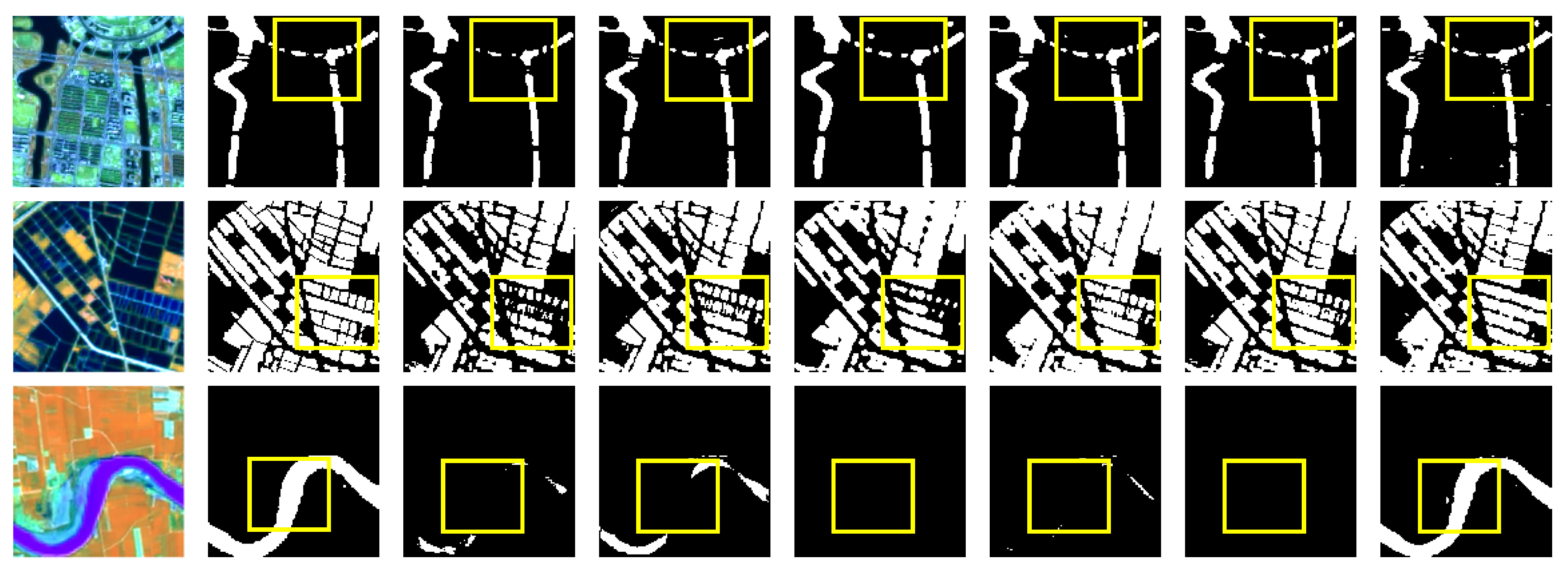
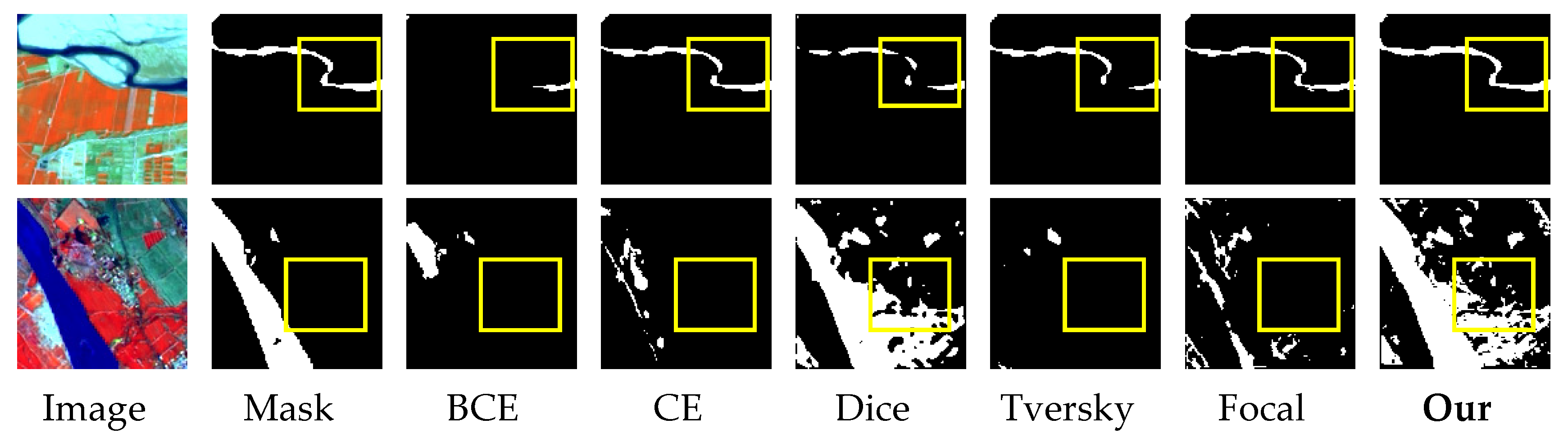
Some representative images for analyzing and observing the performance of the six loss functions are shown in
Figure 16 and
Figure 17, which represent a qualitative comparison of U-Net and SegNet for water body segmentation using these six loss functions, respectively. It can be seen from lines 1 and 2 of
Figure 16 that U-Net identifies more pixels of the water bodies using our loss function. Lines 3 and 4 of
Figure 16 show that U-Net only uses our loss function to segment the complete water bodies with clear boundaries. Line 5 of
Figure 16 shows that U-Net makes Dice loss, and our loss function to identify more water bodies, but the water-body boundaries are not clear. As our proposed loss function set a fixed hyperparameter
β, which does not reach the optimal positive and negative sample balance, it may have an effect on some water body pixels that are hard to distinguish. In this regard, we will continue to investigate the adaptive hyperparameter of the loss function in the future.
As shown in
Figure 17, lines 1 and 2 show that SegNet employs Focal Loss to missegment shadows into bodies of water, but SegNet uses our loss function to segment the water bodies more effectively. As shown in lines 3 and 4 of
Figure 17, SegNet captures more pixels of the water bodies using only our loss function. As shown in line 5 of
Figure 17, SegNet did not identify the water bodies in the image using BCE Loss and Tversky Loss, and the other methods identified water body pixels with missed scores, but SegNet identified more details of water bodies using our loss function.
3.4. Discussion
In this study, from the experimental results in
Section 3.1, the remote sensing water segmentation provided by our proposed approach is the most effective and makes full use of multi-scale features. Dense blocks can improve the use of features, and the MSPP gives the decoder additional spatial information on shallow features so that the relationship between pixels and masks may be precisely described, resulting in the best water-body segmentation. We also analyzed the water segmentation performance of DUPnet on two datasets: the LR dataset and the 2020 Gaofen challenge water body segmentation dataset. We found 16 mislabeled images in the LR dataset, which are shown on our publicly available website (
https://github.com/xuemeichen99/DUPnet-Pytorch, accessed on 3 November 2022). These mislabeled data represent 0.22% of the total dataset. Most of the mislabeling images are located at the mixing area of water bodies and land, which makes it difficult for the human eyes to distinguish. This problem also exists for the Gaofen Challenge 2020 water body segmentation dataset with masks. Furthermore, the compute gradients are normalized at each iteration with RMSprop of the optimization algorithm, which helps reduce the impact of mis-masked samples. From the experimental results in
Section 3.2, some representative cases demonstrate the capability of the proposed DUPnet method and other methods in identifying tributaries and watersheds at different scales. We used the MSPP as skip connections in the DUP network to collect multi-scale spatial domain information from remote sensing images. The MSPP can extract multi-scale features from the encoder layer’s down-sampling output, which has shallow layers and excellent feature resolution. The network can maintain more high-resolution detail information embedded in the high-level feature maps by fusing the multi-scale features with the decoder’s high-level features, thus improving image segmentation accuracy. The proposed DUPnet has the highest F1, MIoU, and FWIoU on the LR dataset and the 2020 Gaofen challenge water body segmentation dataset. From the results in
Figure 12 and
Figure 13, DUPnet provides a superior segmentation effect and retains the most water body information, particularly when extraction water fields narrow rivers. In addition, we proposed a loss function called LCTLoss and conducted a comparative analysis of different loss functions based on the experimental results in
Section 3.3. As shown in
Table 8 and
Figure 14,
Figure 15,
Figure 16 and
Figure 17, the result with LCTLoss is better than those with other loss function methods.
To summarize, the DUPnet network created and designed in this study has the following advantages:
- (1)
Strong capacity for feature extraction: The encoder and decoder rely heavily on DB modules, which improve the network’s ability to extract semantic picture characteristics and provide highly abstracted feature images.
- (2)
Minor loss of feature specifics: The skip connection employs a multi-scale spatial pyramidal pooling MSPP based on Atrous Convolution to enhance the use of features and compensate for the loss of information.
- (3)
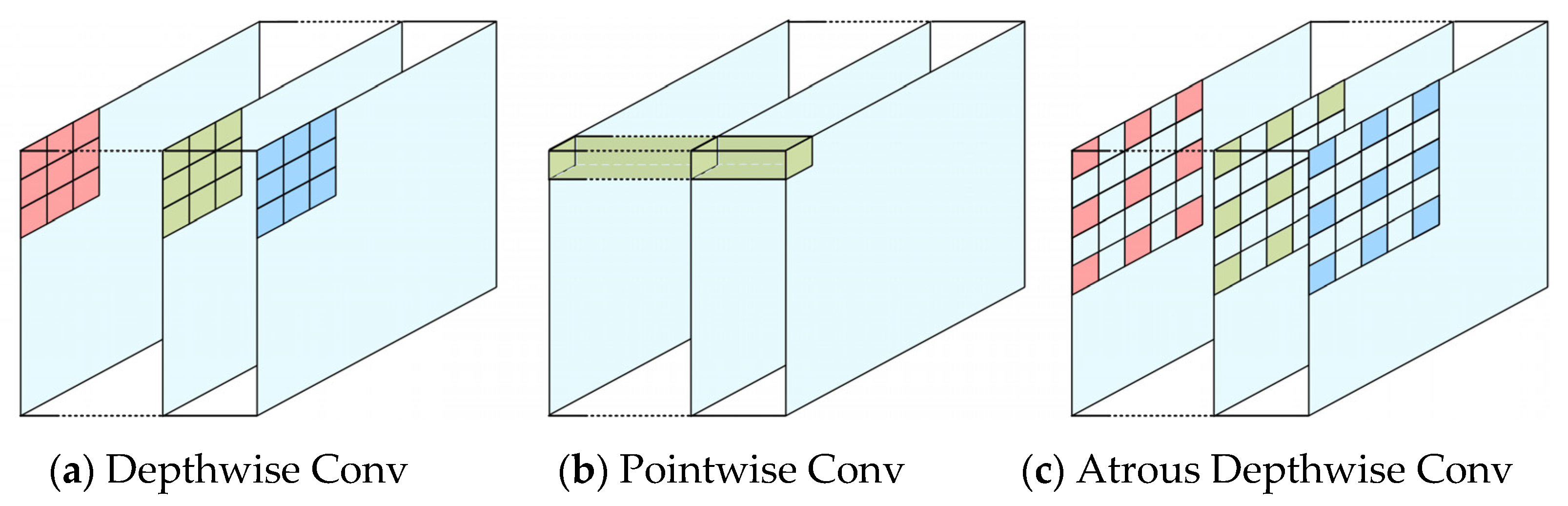
Large feature image perceptual field: Down-sampling module employs depth-separate convolution in replace of maximum pooling layer to enlarge the perceptual field of the feature map and enhance the robustness of the image features.
3.5. Limitations
Due to the limited spectral range of optical remote sensing images, the variety in water body shape and size, and the cloud coverage, water body masks for datasets may show a difference from the ground truth. Our proposed model also needs a high-quality dataset for training. However, there is a dearth of suitable datasets for supervised training in practice. Although incorporating a deep learning neural network model into the training and learning phase of remote sensing image recognition and extraction has the potential to better utilize image feature information, eliminate interference noise, and automate recognition and extraction, its accuracy is limited by the size and breadth of the training set. Future optimization of the model is also needed for training on more datasets.
To address some of the limitations, band combination could be used to reduce the background interference and help to more closely match the ground truth values. Other classifiers could also be used for dataset annotation to improve the accuracy and efficiency of dataset production. A dehaze model may also be developed to address the problem of cloud coverage on remote sensing images. Better model pruning and compressing mechanisms could also be investigated to further improving the performance of the proposed DUPnet model.
4. Conclusions
To improve the existing semantic segmentation algorithm of water bodies on remote sensing images and the limitations, a water body segmentation method based on dense blocks and the multi-scale pyramid pooling module (DUPnet) is proposed. We determined that the DUPnet can use the dense blocks to learn and propagate features, and the encoder part applies Atrous Separable Convolution (Sep Conv) down-sampling to increase the perceptual field of shallow feature maps and improve the robustness of image features. The skip connections can use the MSPP to extract multi-scale features of the encoder part layer to obtain multi-scale features. The up-sampling features are merged with multi-scale features in the decoder component, complementing the semantic and spatial information and boosting the decoder module’s images recovery capacity. A regression loss function based on Tversky coefficients and Log-Cosh regression is proposed in the deep learning model training, which can effectively improve the serious imbalance of positive and negative samples. In addition, we provide a fast method to generate datasets that can be used to train deep learning models. We selected the 5-6-4 bands combination of Landsat 8 OLI images to reduce the background interference. Then, we introduced ENVI SVM classifier for dataset annotation and two rounds of manual correction to improve the accuracy and efficiency of dataset production. This proved to provide good data support for extracting different types of water bodies in Landsat 8. This study efficiently resolves the technical problems of the inefficiency of water body sample masking, the difficulty of extracting small water bodies, the poor flexibility of extraction methods, and the lack of precision. The superiority of the proposed method for water segmentation on the 2020 Gaofen challenge water body segmentation dataset and the LR dataset is demonstrated in this study through ablation experiments and comparisons with comparable methods. DUPnet has the highest Precision, F1, MIoU, and FWIoU with values of 97.15%, 96.52%, 84.72%, and 91.77% on the LR dataset, respectively. On the 2020 Gaofen challenge water body segmentation dataset, DUPnet also has the highest F1, MIoU, and FWIoU with 97.67%, 88.17%, and 93.52%, respectively. To communicate with the researcher, the LR dataset has been provided online at
https://github.com/xuemeichen99/DUPnet-Pytorch (accessed on 3 November 2022).
SVM classifiers can decrease the time and labor of annotation; however, they are generally very sensitive to the selection of appropriate kernel functions and parameter settings in remote sensing segmentation [
49]. The superb fitting ability and portability of deep learning special have made the field of deep learning image algorithms highly popular. The combination of deep learning and machine learning methods will continue to be actively explored. For the dataset, we will continue to create larger, high-resolution multi-source datasets and find simpler and faster ways to improve the quality of the annotations. We will explore the weight assignment of the hybrid loss function in an adaptive manner. In addition, we will prune and compress the network to reduce the number of parameters as well as the processing time of the network while ensuring the performance of the model.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}