
Frequency Spectrum Intensity Attention Network for Building Detection from High-Resolution Imagery


Abstract
1. Introduction
- (a)
- A large number of fine ground targets can be depicted by very-high-resolution aerial imagery, e.g., trees, roads, vehicles, and swimming pools, etc. However, these targets often easily interfere with the identification of buildings due to their similar features (e.g., spectrum, shape, size, structure, etc.).
- (b)
- In urban areas, tall buildings often have severe geometric distortions caused by fixed sensor imaging angles. This may lead to accurate building detection becoming challenging.
- (c)
- With the rapid development of urbanization, many cities and rural areas are interspersed with tall buildings and short buildings. Tall buildings often exhibit large shadows when imaged by the sun. This phenomenon may not only make it difficult to accurately detect tall buildings themselves, but may also obscure other features (especially short buildings), thus limiting the effective detection of buildings.
- (1)
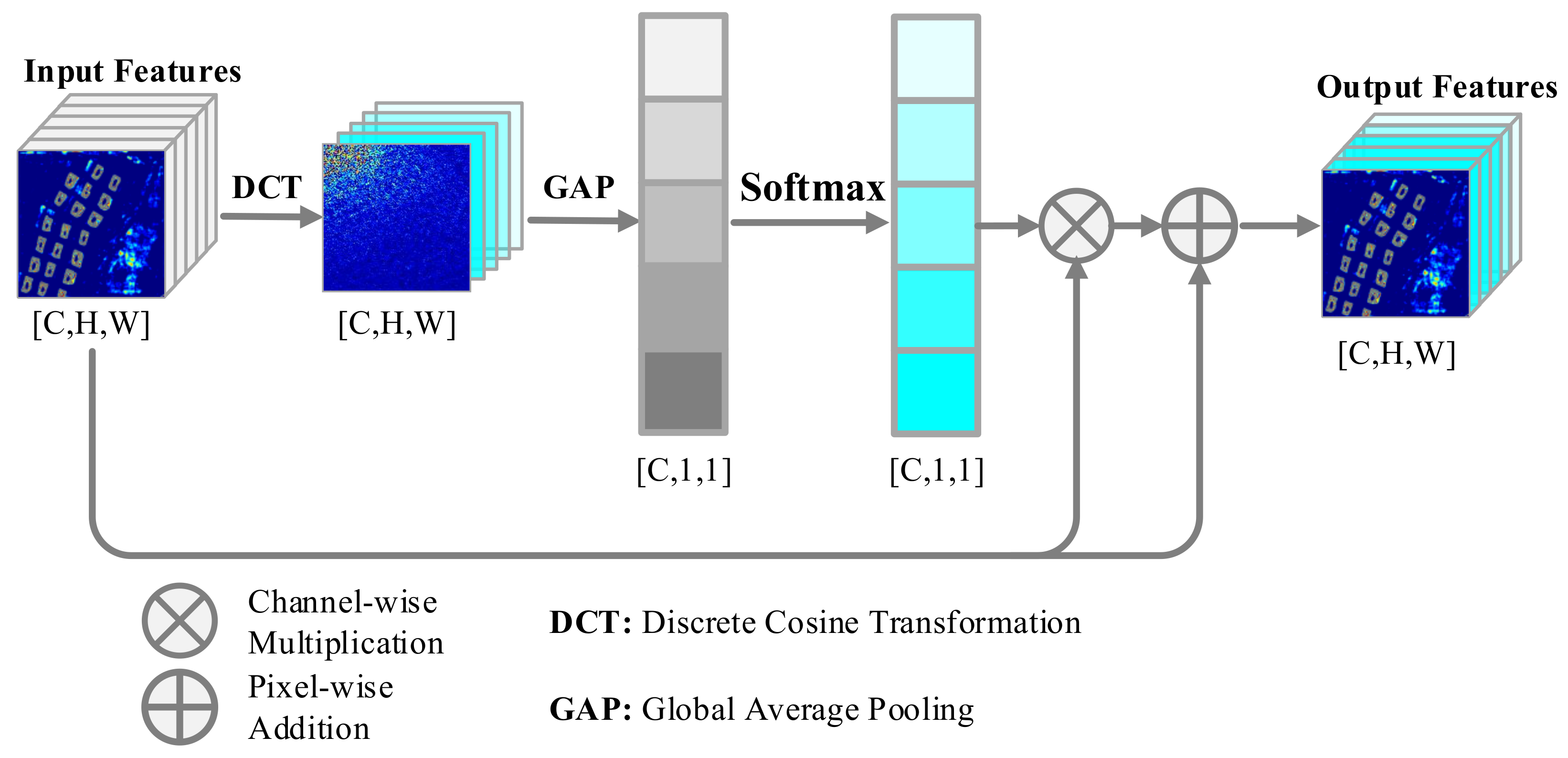
- This paper proposes a novel computational intelligence approach for automatic building detection, named FSIANet. In the proposed FSIANet, we devised a plug-and-play FSIA without the requirement of learnable parameters. The FSIA mechanism based on frequency–domain information can effectively evaluate the informative abundance of the feature maps and enhance feature representation by emphasizing more informative feature maps. To this end, The FSIANet can significantly improve the building detection performance.
- (2)
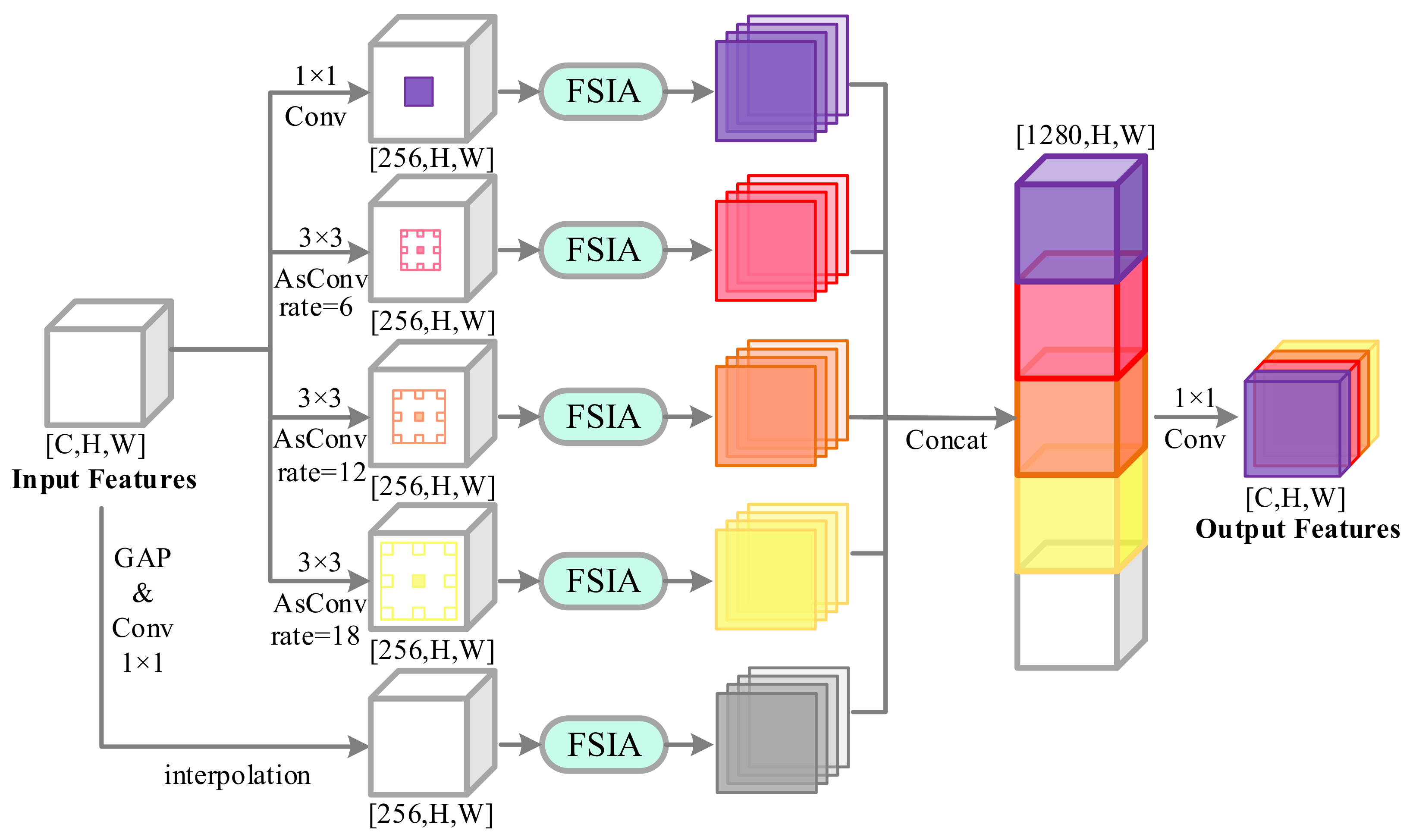
- An atrous frequency spectrum attention pyramid (AFSAP) is devised in the proposed FSIANet. It is able to mine multi-scale features. At the same time, by introducing FSIA in ASPP, it can emphasize the features with high response to building semantic features at each scale and weaken the features with low response, which will enhance the building feature representation.
- (3)
2. Related Work
3. Methodology
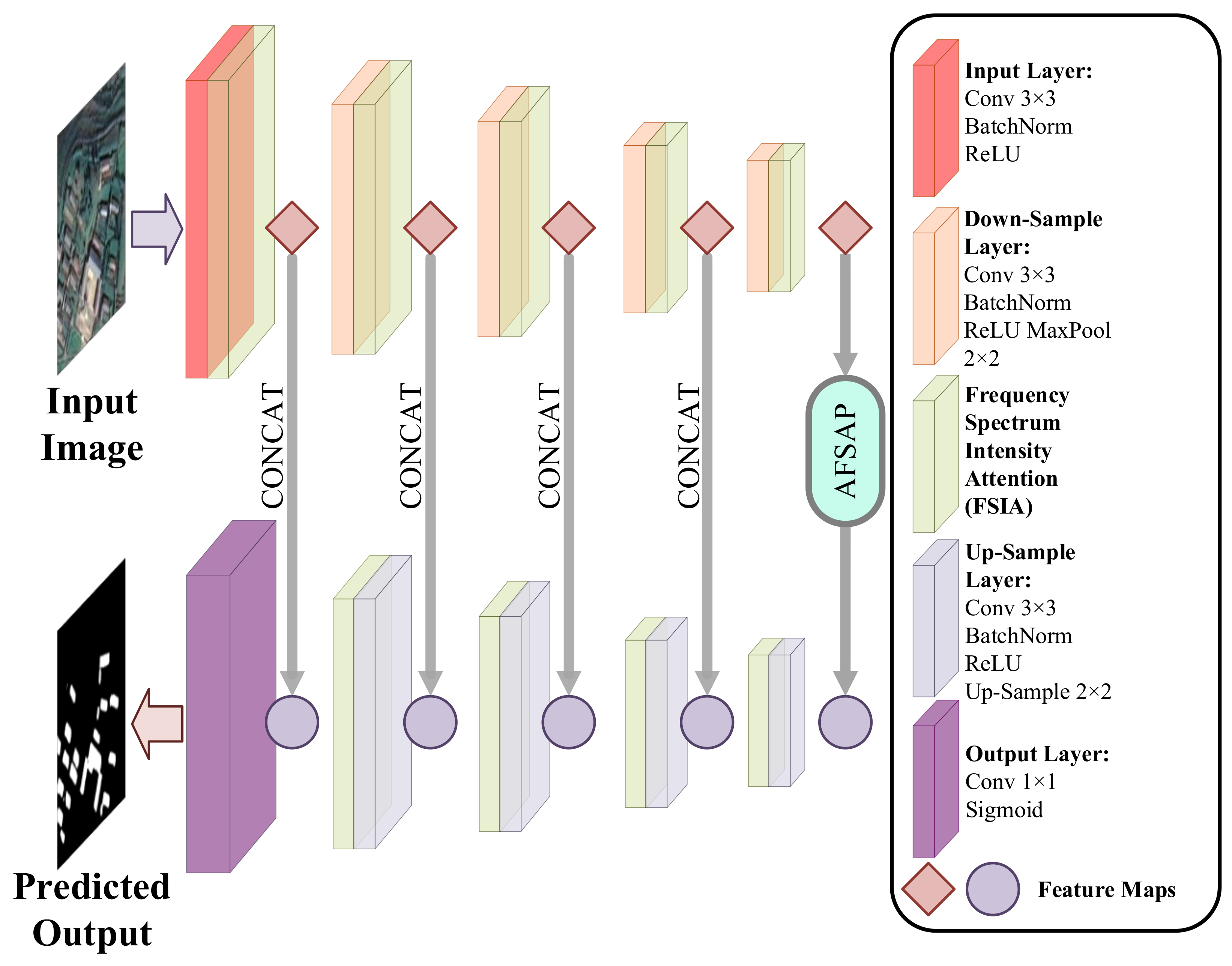
3.1. Overview of FSIANet
3.2. Frequency Spectrum Intensity Attention
3.3. Atrous Frequency Spectrum Attention Pyramid
4. Experimental Results and Analysis
4.1. Dataset Descriptions and Evaluation Metrics
4.2. Implementation Details
4.3. Comparison with Other Methods
4.3.1. Comparative Algorithms
- (1)
- FCN8s [37] (2015): This work includes three classic convolutional neural network characteristics, i.e., a fully convolutional network that discards the fully connected layer to adapt to the input of any size image; deconvolution layers that increase the size of the data enable it to output refined results; and a skip-level structure that combines results from different depth layers while ensuring robustness and accuracy.
- (2)
- (3)
- PSPNet [41] (2017): PSPNet mainly extracts multi-scale information through pyramid pooling, which can better extract global context information and utilize both local and global information to make scene recognition more reliable.
- (4)
- PANet [60] (2018): PANet proposed a pyramid attention network to exploit the influence of global contextual information in semantic segmentation, combining an attention mechanism and a spatial pyramid to extract precise pixel-annotated dense features instead of using complex diffuse convolution and hand-designed decoder networks.
- (5)
- (6)
- BRRNet [27] (2020): The prediction module and residual refinement module are the main innovations of BRRNet. The prediction module obtains a larger receptive field by introducing atrous convolutions with different dilation rates. The residual refinement module takes the output of the prediction module as input.
- (7)
- AGPNet [25] (2021): This is a SOTA ResNet50-based network, which combines grid-based attention gate and ASPP for building detection. This method is similar to ours and is valuable for comparing methods.
- (8)
- Res2-Unet [65] (2022): Res2-Unet employed granular-level multi-scale learning to expand the receptive field size of each bottleneck layer, focusing on pixels in the border region of complex backgrounds.
4.3.2. Results on the East Asia Dataset
4.3.3. Results on the Inria Aerial Image Dataset
4.4. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AFSAP | Atrous Frequency Spectrum Attention Pyramid |
| ASPP | Atrous Spatial Pyramid Pooling |
| BRRNet | Building Residual Refine Network |
| CNN | Convolutional Neural Network |
| DCT | Discrete Cosine Transformation |
| FCN | Fully Convolutional Network |
| FSIANet | Frequency Spectrum Intensity Attention Network |
| HR | High-Resolution |
| SOTA | State-of-the-Art |
| AFSI | Average Frequency Spectrum Intensity |
References
- Wu, Y.; Ma, W.; Gong, M.; Su, L.; Jiao, L. A novel point-matching algorithm based on fast sample consensus for image registration. IEEE Geosci. Remote Sens. Lett. 2014, 12, 43–47. [Google Scholar] [CrossRef]
- Wu, Y.; Li, J.; Yuan, Y.; Qin, A.; Miao, Q.G.; Gong, M.G. Commonality autoencoder: Learning common features for change detection from heterogeneous images. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Li, H.; Liu, Y.; Gong, M. Multi-fidelity evolutionary multitasking optimization for hyperspectral endmember extraction. Appl. Soft Comput. 2021, 111, 107713. [Google Scholar] [CrossRef]
- Lv, Z.; Li, G.; Jin, Z.; Benediktsson, J.A.; Foody, G.M. Iterative training sample expansion to increase and balance the accuracy of land classification from VHR imagery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 139–150. [Google Scholar] [CrossRef]
- Zhang, M.; Gong, M.; Mao, Y.; Li, J.; Wu, Y. Unsupervised feature extraction in hyperspectral images based on wasserstein generative adversarial network. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2669–2688. [Google Scholar] [CrossRef]
- Zhang, M.; Gong, M.; He, H.; Zhu, S. Symmetric all convolutional neural-network-based unsupervised feature extraction for hyperspectral images classification. IEEE Trans. Cybern. 2020. [Google Scholar] [CrossRef]
- Lv, Z.; Wang, F.; Cui, G.; Benediktsson, J.A.; Lei, T.; Sun, W. Spatial–Spectral Attention Network Guided With Change Magnitude Image for Land Cover Change Detection Using Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Gong, M.; Jiang, F.; Qin, A.K.; Liu, T.; Zhan, T.; Lu, D.; Zheng, H.; Zhang, M. A Spectral and Spatial Attention Network for Change Detection in Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Wang, Z.; Jiang, F.; Liu, T.; Xie, F.; Li, P. Attention-Based Spatial and Spectral Network with PCA-Guided Self-Supervised Feature Extraction for Change Detection in Hyperspectral Images. Remote Sens. 2021, 13, 4927. [Google Scholar] [CrossRef]
- Shivappriya, S.; Priyadarsini, M.J.P.; Stateczny, A.; Puttamadappa, C.; Parameshachari, B. Cascade object detection and remote sensing object detection method based on trainable activation function. Remote Sens. 2021, 13, 200. [Google Scholar] [CrossRef]
- Ghanea, M.; Moallem, P.; Momeni, M. Building extraction from high-resolution satellite images in urban areas: Recent methods and strategies against significant challenges. Int. J. Remote Sens. 2016, 37, 5234–5248. [Google Scholar] [CrossRef]
- Singh, D.; Kaur, M.; Jabarulla, M.Y.; Kumar, V.; Lee, H.N. Evolving fusion-based visibility restoration model for hazy remote sensing images using dynamic differential evolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, Y.; Fan, X.; Gong, M.; Miao, Q.; Ma, W. INENet: Inliers Estimation Network with Similarity Learning for Partial Overlapping Registration. IEEE Trans. Circuits Syst. Video Technol. 2022. [Google Scholar] [CrossRef]
- Liu, T.; Gong, M.; Jiang, F.; Zhang, Y.; Li, H. Landslide Inventory Mapping Method Based on Adaptive Histogram-Mean Distance with Bitemporal VHR Aerial Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, Y.; Gong, M.; Gong, P.; Li, H.; Tang, Z.; Miao, Q.; Ma, W. Multi-View Point Cloud Registration Based on Evolutionary Multitasking With Bi-Channel Knowledge Sharing Mechanism. IEEE Trans. Emerg. Top. Comput. Intell. 2022. [Google Scholar] [CrossRef]
- Awrangjeb, M.; Lu, G.; Fraser, C. Automatic building extraction from LiDAR data covering complex urban scenes. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 40, 25. [Google Scholar] [CrossRef]
- Lv, Z.; Liu, T.; Benediktsson, J.A.; Falco, N. Land cover change detection techniques: Very-high-resolution optical images: A review. IEEE Geosci. Remote Sens. Mag. 2021, 10, 44–63. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? The inria aerial image labeling benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction From an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Liu, T.; Gong, M.; Lu, D.; Zhang, Q.; Zheng, H.; Jiang, F.; Zhang, M. Building Change Detection for VHR Remote Sensing Images via Local–Global Pyramid Network and Cross-Task Transfer Learning Strategy. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–17. [Google Scholar] [CrossRef]
- Bi, Q.; Qin, K.; Zhang, H.; Zhang, Y.; Li, Z.; Xu, K. A multi-scale filtering building index for building extraction in very high-resolution satellite imagery. Remote Sens. 2019, 11, 482. [Google Scholar] [CrossRef]
- Ma, J.; Wu, L.; Tang, X.; Liu, F.; Zhang, X.; Jiao, L. Building extraction of aerial images by a global and multi-scale encoder-decoder network. Remote Sens. 2020, 12, 2350. [Google Scholar] [CrossRef]
- Xia, L.; Zhang, X.; Zhang, J.; Yang, H.; Chen, T. Building extraction from very-high-resolution remote sensing images using semi-supervised semantic edge detection. Remote Sens. 2021, 13, 2187. [Google Scholar] [CrossRef]
- Liao, C.; Hu, H.; Li, H.; Ge, X.; Chen, M.; Li, C.; Zhu, Q. Joint learning of contour and structure for boundary-preserved building extraction. Remote Sens. 2021, 13, 1049. [Google Scholar] [CrossRef]
- Deng, W.; Shi, Q.; Li, J. Attention-gate-based encoder–decoder network for automatical building extraction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2611–2620. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, H.; Zheng, X. A Multiscale Attention-Guided UNet++ with Edge Constraint for Building Extraction from High Spatial Resolution Imagery. Applied Sci. 2022, 12, 5960. [Google Scholar] [CrossRef]
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. BRRNet: A fully convolutional neural network for automatic building extraction from high-resolution remote sensing images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef]
- Yang, G.; Zhang, Q.; Zhang, G. EANet: Edge-aware network for the extraction of buildings from aerial images. Remote Sens. 2020, 12, 2161. [Google Scholar] [CrossRef]
- Zheng, H.; Gong, M.; Liu, T.; Jiang, F.; Zhan, T.; Lu, D.; Zhang, M. HFA-Net: High frequency attention siamese network for building change detection in VHR remote sensing images. Pattern Recognit. 2022, 129, 108717. [Google Scholar] [CrossRef]
- He, H.; Yang, D.; Wang, S.; Wang, S.; Li, Y. Road extraction by using atrous spatial pyramid pooling integrated encoder-decoder network and structural similarity loss. Remote Sens. 2019, 11, 1015. [Google Scholar] [CrossRef]
- Yu, M.; Zhang, W.; Chen, X.; Liu, Y.; Niu, J. An End-to-End Atrous Spatial Pyramid Pooling and Skip-Connections Generative Adversarial Segmentation Network for Building Extraction from High-Resolution Aerial Images. Appl. Sci. 2022, 12, 5151. [Google Scholar] [CrossRef]
- Zhang, L.; Huang, X.; Huang, B.; Li, P. A pixel shape index coupled with spectral information for classification of high spatial resolution remotely sensed imagery. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2950–2961. [Google Scholar] [CrossRef]
- Mongus, D.; Lukač, N.; Žalik, B. Ground and building extraction from LiDAR data based on differential morphological profiles and locally fitted surfaces. ISPRS J. Photogramm. Remote Sens. 2014, 93, 145–156. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. A multidirectional and multiscale morphological index for automatic building extraction from multispectral GeoEye-1 imagery. Photogramm. Eng. Remote Sens. 2011, 77, 721–732. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L.; Zhu, T. Building change detection from multitemporal high-resolution remotely sensed images based on a morphological building index. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 7, 105–115. [Google Scholar] [CrossRef]
- You, Y.; Wang, S.; Ma, Y.; Chen, G.; Wang, B.; Shen, M.; Liu, W. Building detection from VHR remote sensing imagery based on the morphological building index. Remote Sens. 2018, 10, 1287. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440.
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin, Germany, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhang, Y.; Gong, M.; Li, J.; Zhang, M.; Jiang, F.; Zhao, H. Self-Supervised Monocular Depth Estimation with Multiscale Perception. IEEE Trans. Image Process. 2022, 31, 3251–3266. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Luo, L.; Li, P.; Yan, X. Deep learning-based building extraction from remote sensing images: A comprehensive review. Energies 2021, 14, 7982. [Google Scholar] [CrossRef]
- Wang, L.; Fang, S.; Meng, X.; Li, R. Building extraction with vision transformer. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Wang, Y.; Liang, B.; Ding, M.; Li, J. Dense semantic labeling with atrous spatial pyramid pooling and decoder for high-resolution remote sensing imagery. Remote Sens. 2018, 11, 20. [Google Scholar] [CrossRef]
- Weihong, C.; Baoyu, X.; Liyao, Z. Multi-scale fully convolutional neural network for building extraction. Acta Geodaetica et Cartogr. Sinica 2019, 48, 597. [Google Scholar]
- Yuan, W.; Xu, W. MSST-Net: A Multi-Scale Adaptive Network for Building Extraction from Remote Sensing Images Based on Swin Transformer. Remote Sens. 2021, 13, 4743. [Google Scholar] [CrossRef]
- Qiu, Y.; Wu, F.; Yin, J.; Liu, C.; Gong, X.; Wang, A. MSL-Net: An Efficient Network for Building Extraction from Aerial Imagery. Remote Sens. 2022, 14, 3914. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Gong, M.; Li, J.; Zhang, Y.; Wu, Y.; Zhang, M. Two-Path Aggregation Attention Network with Quad-Patch Data Augmentation for Few-shot Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022. [Google Scholar] [CrossRef]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 1–38. [Google Scholar] [CrossRef]
- Ghaffarian, S.; Valente, J.; Van Der Voort, M.; Tekinerdogan, B. Effect of attention mechanism in deep learning-based remote sensing image processing: A systematic literature review. Remote Sens. 2021, 13, 2965. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13–19. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Pan, X.; Yang, F.; Gao, L.; Chen, Z.; Zhang, B.; Fan, H.; Ren, J. Building extraction from high-resolution aerial imagery using a generative adversarial network with spatial and channel attention mechanisms. Remote Sens. 2019, 11, 917. [Google Scholar] [CrossRef]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Guo, H.; Shi, Q.; Du, B.; Zhang, L.; Wang, D.; Ding, H. Scene-driven multitask parallel attention network for building extraction in high-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4287–4306. [Google Scholar] [CrossRef]
- Ye, Z.; Fu, Y.; Gan, M.; Deng, J.; Comber, A.; Wang, K. Building extraction from very high resolution aerial imagery using joint attention deep neural network. Remote Sens. 2019, 11, 2970. [Google Scholar] [CrossRef]
- Guo, M.; Liu, H.; Xu, Y.; Huang, Y. Building extraction based on U-Net with an attention block and multiple losses. Remote Sens. 2020, 12, 1400. [Google Scholar] [CrossRef]
- Chen, X.; Qiu, C.; Guo, W.; Yu, A.; Tong, X.; Schmitt, M. Multiscale feature learning by transformer for building extraction from satellite images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Chen, F.; Wang, N.; Yu, B.; Wang, L. Res2-Unet, a New Deep Architecture for Building Detection from High Spatial Resolution Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1494–1501. [Google Scholar] [CrossRef]
- Guo, H.; Du, B.; Zhang, L.; Su, X. A coarse-to-fine boundary refinement network for building footprint extraction from remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2022, 183, 240–252. [Google Scholar] [CrossRef]
- Foody, G.M. Thematic map comparison. Photogramm. Eng. Remote Sens. 2004, 70, 627–633. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | East Asia Dataset | Inria Aerial Image Dataset |
|---|---|---|
| Year | 2019 | 2017 |
| Coverage | 550 km2 | 810 km2 |
| Size | 512 × 512 pixels | 5000 × 5000 pixels |
| Spatial Resolution | 2.7 m | 0.3 m |
| Methods | - | |||
|---|---|---|---|---|
| FCN8s [37] | 87.30 | 70.32 | 77.90 | 63.79 |
| U-Net [38] | 88.41 | 71.22 | 78.89 | 65.14 |
| PSPNet [41] | 83.66 | 69.97 | 76.20 | 61.56 |
| PANet [60] | 87.69 | 64.09 | 74.05 | 58.80 |
| SiU-Net [19] | 89.09 | 69.76 | 78.25 | 64.27 |
| BRRNet [27] | 83.06 | 78.11 | 80.51 | 67.37 |
| AGPNet [25] | 86.37 | 76.59 | 81.19 | 68.34 |
| Res2-Unet [65] | 84.07 | 69.14 | 75.88 | 61.14 |
| FSIANet (Ours) | 84.11 | 80.75 | 82.39 | 70.06 |
| Metrics | Methods | Austin | Chicago | Kitsap | Tyrol | Vienna | Average |
|---|---|---|---|---|---|---|---|
| FCN8s [37] | 88.28 | 81.37 | 85.21 | 88.25 | 89.81 | 86.64 | |
| U-Net [38] | 89.92 | 87.61 | 84.03 | 87.62 | 89.65 | 87.77 | |
| PSPNet [41] | 84.58 | 80.57 | 81.01 | 85.57 | 87.47 | 83.84 | |
| PANet [60] | 87.72 | 77.13 | 80.68 | 86.26 | 84.89 | 83.34 | |
| SiU-Net [19] | 90.94 | 81.39 | 84.42 | 87.67 | 89.02 | 86.69 | |
| BRRNet [27] | 89.30 | 87.20 | 80.09 | 83.13 | 88.04 | 85.55 | |
| AGPNet [25] | 91.72 | 86.37 | 85.91 | 90.30 | 91.45 | 89.15 | |
| Res2-Unet [65] | 86.86 | 79.20 | 77.74 | 85.61 | 86.06 | 83.09 | |
| FSIANet (Ours) | 90.04 | 86.25 | 83.23 | 85.80 | 89.59 | 86.98 | |
| FCN8s [37] | 87.32 | 79.29 | 70.41 | 80.89 | 83.39 | 80.26 | |
| U-Net [38] | 87.03 | 73.49 | 73.16 | 83.37 | 85.33 | 80.48 | |
| PSPNet [41] | 74.33 | 75.19 | 69.73 | 79.99 | 81.99 | 76.25 | |
| PANet [60] | 74.26 | 66.19 | 65.50 | 75.23 | 79.39 | 72.11 | |
| SiU-Net [19] | 86.39 | 78.27 | 73.55 | 82.27 | 84.60 | 81.02 | |
| BRRNet [27] | 89.07 | 75.78 | 77.57 | 85.85 | 85.44 | 82.74 | |
| AGPNet [25] | 86.81 | 78.69 | 76.24 | 82.71 | 85.11 | 81.91 | |
| Res2-Unet [65] | 84.70 | 78.06 | 72.40 | 83.09 | 84.90 | 80.63 | |
| FSIANet (Ours) | 90.30 | 78.75 | 79.39 | 88.35 | 87.01 | 84.76 | |
| - | FCN8s [37] | 87.80 | 80.47 | 77.11 | 84.40 | 86.48 | 83.25 |
| U-Net [38] | 88.45 | 79.94 | 78.22 | 85.44 | 87.43 | 83.90 | |
| PSPNet [41] | 79.12 | 77.79 | 74.95 | 82.69 | 84.64 | 79.84 | |
| PANet [60] | 80.43 | 71.24 | 72.30 | 80.37 | 82.04 | 77.28 | |
| SiU-Net [19] | 88.61 | 79.81 | 78.61 | 84.89 | 86.75 | 83.73 | |
| BRRNet [27] | 89.19 | 81.09 | 79.20 | 84.47 | 86.72 | 84.13 | |
| AGPNet [25] | 89.20 | 82.35 | 80.79 | 86.34 | 88.17 | 85.37 | |
| Res2-Unet [65] | 85.77 | 78.63 | 74.97 | 84.33 | 85.48 | 81.84 | |
| FSIANet (Ours) | 90.17 | 82.33 | 81.26 | 87.06 | 88.28 | 85.82 | |
| FCN8s [37] | 78.25 | 67.32 | 62.74 | 73.02 | 76.18 | 71.50 | |
| U-Net [38] | 79.30 | 66.58 | 64.23 | 74.58 | 77.67 | 72.47 | |
| PSPNet [41] | 65.46 | 63.65 | 59.94 | 70.48 | 73.37 | 66.58 | |
| PANet [60] | 67.24 | 55.33 | 56.62 | 67.18 | 69.55 | 63.18 | |
| SiU-Net [19] | 79.54 | 66.39 | 64.76 | 73.74 | 76.61 | 72.21 | |
| BRRNet [27] | 80.48 | 68.19 | 65.57 | 73.11 | 76.58 | 72.79 | |
| AGPNet [25] | 80.50 | 69.99 | 67.77 | 75.96 | 78.84 | 74.61 | |
| Res2-Unet [65] | 75.09 | 64.78 | 59.96 | 72.90 | 74.64 | 69.47 | |
| FSIANet (Ours) | 82.10 | 69.97 | 68.44 | 77.08 | 79.02 | 75.32 |
| Methods | - | |||
|---|---|---|---|---|
| backbone | 83.52 | 79.04 | 81.22 | 68.38 |
| backbone+FSIA | 84.27 | 79.29 | 81.71 | 69.07 |
| backbone+FSIA+ASPP | 85.39 | 78.62 | 81.86 | 69.30 |
| backbone+FSIA+AFSAP (Full) | 84.11 | 80.75 | 82.39 | 70.06 |
| FSIANet | vs. Backbone | vs. Backbone+FSIA | vs. Backbone+FSIA+ASPP |
|---|---|---|---|
| z value | 154.26 | 80.27 | 28.58 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, D.; Chu, H.; Zheng, L. Frequency Spectrum Intensity Attention Network for Building Detection from High-Resolution Imagery. Remote Sens. 2022, 14, 5457. https://doi.org/10.3390/rs14215457
Feng D, Chu H, Zheng L. Frequency Spectrum Intensity Attention Network for Building Detection from High-Resolution Imagery. Remote Sensing. 2022; 14(21):5457. https://doi.org/10.3390/rs14215457
Chicago/Turabian StyleFeng, Dan, Hongyun Chu, and Ling Zheng. 2022. "Frequency Spectrum Intensity Attention Network for Building Detection from High-Resolution Imagery" Remote Sensing 14, no. 21: 5457. https://doi.org/10.3390/rs14215457
APA StyleFeng, D., Chu, H., & Zheng, L. (2022). Frequency Spectrum Intensity Attention Network for Building Detection from High-Resolution Imagery. Remote Sensing, 14(21), 5457. https://doi.org/10.3390/rs14215457