1. Introduction
Food security mainly refers to the problem of food supply security [
1]. However, the phenomenon of non-grain-oriented land refers to a change in the cultivation of land from its original use to grow wheat (
Triticum aestivum L.), rice (
Oryza sativa L.), and other grain crops to other purposes, resulting in a reduction in the actual area of grain production and a decline in grain yield. At present, the non-grain-oriented land phenomenon is already the dominant trend in land circulation and, if things continue in this way, it will become a major hidden danger to the national food security strategy [
2].
For this reason, to control the non-grain-oriented use of agricultural land and to guarantee national food security, monitoring of the area of agricultural crop planting is of utmost importance [
3]. Moreover, remote-sensing technology has unique advantages in terms of agricultural crop monitoring due to its large range of observation and short cycles [
4], and many studies have utilized remote-sensing technology to quickly extract the spatial distributions of agricultural crops [
5]. At present, the commonly used methods for crop mapping by remote sensing are pixel-based classification and object-oriented classification; of these, the latter has been gradually adopted in more studies compared to the former [
6,
7] because it can avoid misclassification caused by certain pixels of the same object having different spectra or different objects having the same spectra [
8], and can effectively prevent salt-and-pepper noise [
9]. It can obtain a classification accuracy better than 85% by combing the spectral features, texture features, terrain features, and other factors extracted from remote-sensing images [
10].
However, both pixel-based and object-oriented machine-learning classifiers have gradually replaced the conventional maximum-likelihood classifiers due to their better performance [
11]. The common machine-learning classifiers include the random forest (RF), classification and regression trees (CART), support vector machine (SVM), and so on [
12]. Among them, SVM and RF are regarded as unaffected by data noise, so their application is broader than that of other classifiers [
13]. For example, Adriaan et al. used remote-sensing datasets in combination with 10 types of machine-learning methods to extract the spatial distributions of crops, analyzed the various accuracy indicators of the classification results, and found that RF provided the highest accuracy [
14]. Based on RF, Schulz et al. proposed a new classification method to carry out large-scale agricultural monitoring of fishing crops and obtained an average prediction accuracy of 84% [
15]. The introduction of machine learning has made the launching of remote-sensing research much more convenient. However, if a local computer uses machine learning, the computer performance undoubtedly must reach a certain standard [
16]; at present, the Google Earth Engine (GEE) solves this problem as it can perform the functions of common algorithms, including machine learning, online [
17]. GEE is a cloud computing platform developed by Google for satellite imagery and earth observation data [
18], which provides Landsat, Sentinel, Moderate Resolution Imaging Spectroradiometer (MODIS), and other satellite images as well as data products for free [
19]. The rich resources and powerful computing capabilities of GEE have made the online processing of geographic data the main trend in current remote-sensing research [
20].
Since GEE has greatly reduced the complexity of data calling and calculation, it is easier to carry out remote-sensing research with data fusion, which refers to integration of the information obtained by sensors on satellites, aircraft, and ground platforms with different spatial and spectral resolutions to generate fused data containing more detailed information than any single data source [
21]. Some commonly used methods of image fusion are as follows: (1) pixel-level fusion (data fusion), which combines the original image pixels; (2) feature fusion, which involves extracting features from individual datasets for combination; and (3) decision fusion, which combines the results of multiple algorithms to obtain the final fusion [
21,
22]. Currently, data fusion is widely used in remote-sensing research. In terms of crop classification, some early studies chose to fuse the images during the growth periods of crops [
23]; later, the time-series data obtained during crop growth were found to be able to fully reflect the phenological features of different crops and their changes in different physical and chemical parameters and indicators [
24], and also to contribute greatly to improving accuracy in crop classification [
25]. It is therefore popular for research [
26,
27,
28] to use the data fusion method of calculating the median reflectance or index median of time-series images [
29].
In large-scale remote-sensing research, methods that fuse the images of crops in the growth period and then extract the spectral features to carry out classification [
30] do not combine this with information relating to the growth stages of the crops, so the variation features of the crop spectra in different periods cannot be fully utilized. Moreover, the data volume in the time-series method is relatively large, and the data fusion of the entire area and the subsequent computational flow cannot be completed at the same time, and may even exceed the GEE calculation limit. Therefore, ensuring full utilization of the crop growth variation features [
31] while reducing data redundancy and decreasing the data volume has become a problem to be solved.
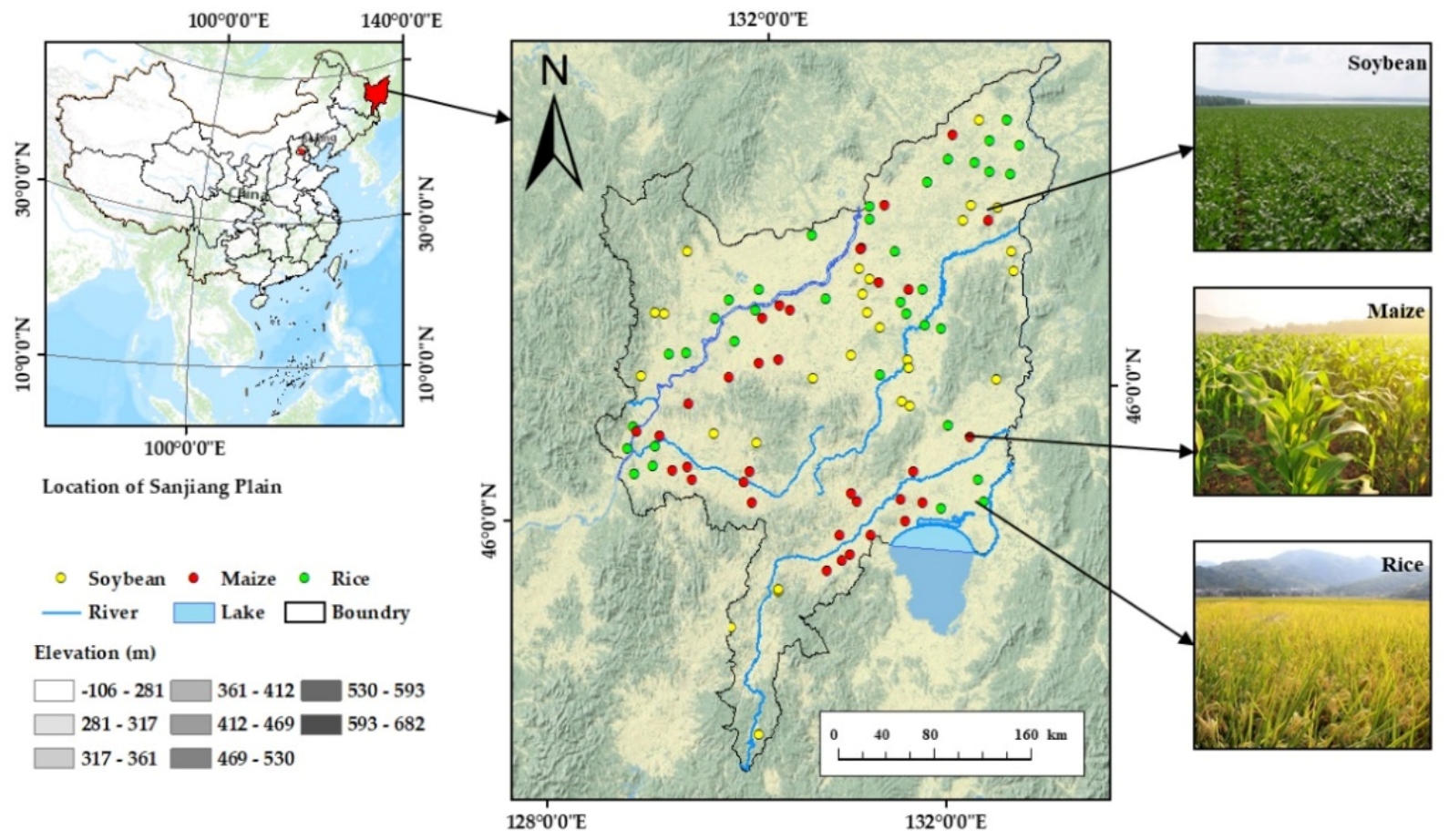
Based on the above analysis and object-oriented classification in combination with the RF classifier, the IO-Growth method for extracting the spatial distribution of crops was proposed, in which each growth stage of the crops is regarded as an independent attribute and is combined with the spectral features to jointly optimize the selection; this method can not only obtain the advantages of time-series data—that is, make full use of the characteristics of the growth stages with high contributions to the classification accuracy of crops—but also filter out the data of the growth stages with low contributions in order to reduce the amount of data, so as to simplify the time-series data. The aims of this study was mainly structured as follows: (1) to explore the characteristics of the extensive extraction of crops online based on the GEE platform; (2) to identify the advantages and disadvantages of the IO-Growth method by comparing it with an object-oriented classification that does not combine the growth stages with the time-series method, which currently has the advantage in accuracy; (3) to obtain the spatial distributions of rice, maize (Zea mays L.), and soybean (Glycine max L. Merr.) in the study area, i.e., the Sanjiang Plain in 2019.
3. Results
3.1. Feature Optimization
3.1.1. JM Distance Screening among Features
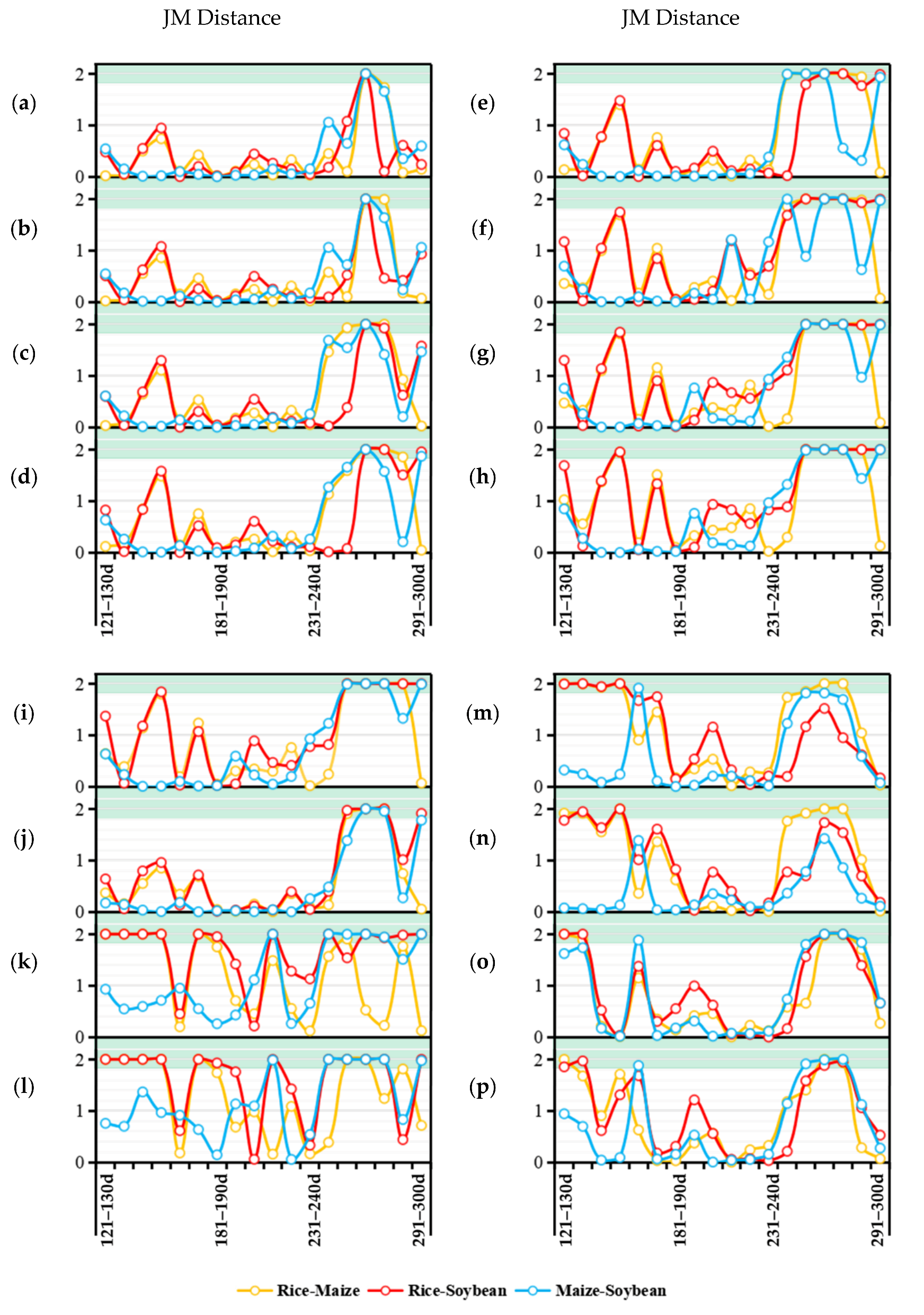
The JM distance was used to select the feature wavebands that conformed to the separability requirements from the feature set; we calculated the original feature set, which contained 288 features, and obtained the JM distances between all spectral features in the set. The computational results are shown in
Figure 4; the features with JM distances between the three crops greater than 1.90 were concentrated between the 251st and 280th days, i.e., between mid- and late September and early October; moreover, between May and August, the JM distances between maize and soybean were low; the features with the JM distances greater than 1.90 between all surface feature categories included only B7, B8, B8A, and B12 from the 251st to 260th days (251–260d); B1, B2, B3, B4, B5, B6, B7, B8, B8A, B9, B12, and NDVI from the 261st to 270th days (261–270d); and B6, B7, B8, B8A, B9, NDVI, and NDWI from the 271st to 280th days (271–280d); that is, of the 288 features in the feature set, only 23 conformed to the separability requirements.
3.1.2. Feature Importance Assessment
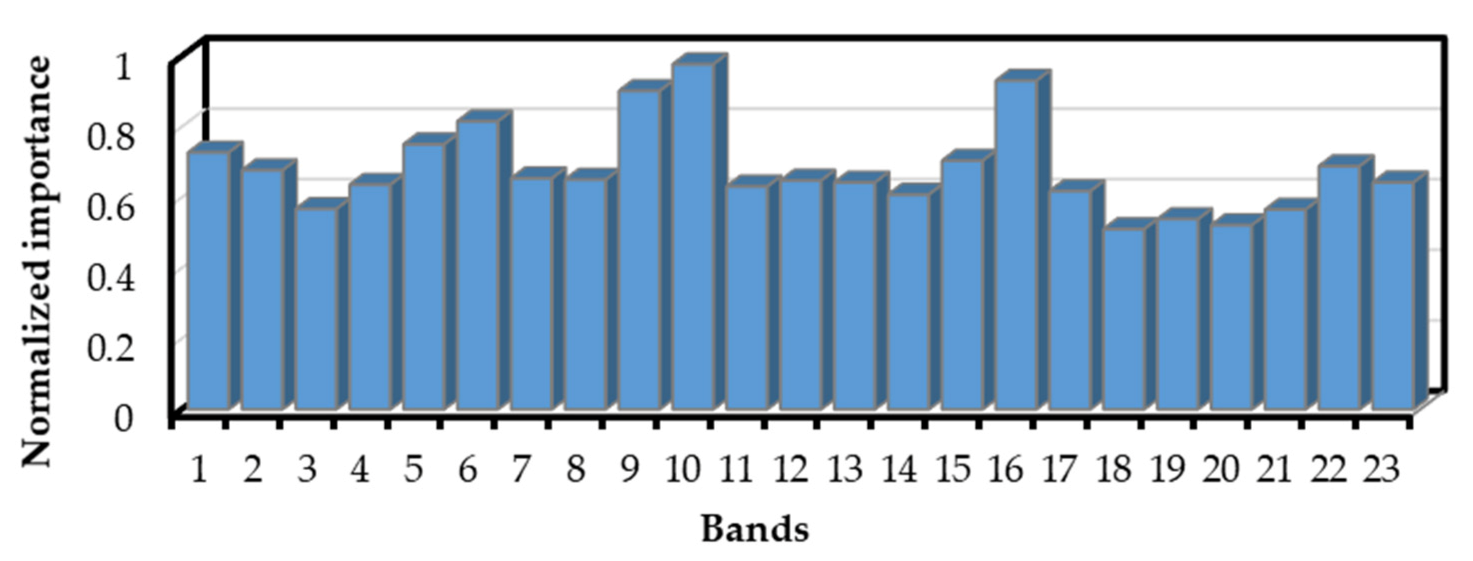
Features with higher importance contributed more to the accuracy of the classification results; to further optimize fewer features from the 23 features that satisfied the separability requirements in order to improve the computational efficiency, the normalized importance was used as the evaluation indicator, and the top five features in importance were selected as the classification features used in the present study. Through computation, the five features were determined to be B5, NDVI, B4, B12, and B1 of 261–270d, i.e., RE1, NDVI, Red, SWIR2, and Aerosols from September 17 to September 28, as shown in
Figure 5.
3.2. Assessment of the Optimal Segmentation Scale
The range of the segmentation scale in the SNIC algorithm was set to 2–100. The LV of the segmentation results of the study area under each segmentation scale was calculated to obtain its ROC, and the main peak values were 52, 55, 61, 68, 77, 87, and 93, which were regarded as the collection of the optimal segmentation scale.
The above peaks were set as segmentation scales, and the segmentation results of each scale in the study area were obtained. However, it was difficult to use the visual analysis method to evaluate the overall segmentation effect since the research area was too large. Therefore, we took a small part of the whole study area for local amplification to compare the segmentation effect at different scales. As shown in
Figure 6, oversegmentation occurred when the scale was smaller than 68, and undersegmentation appeared when the scale was greater than 68. Therefore, 68 was considered the global optimal segmentation scale.
3.3. Object-Oriented Mapping of Crops in the Sanjiang Plain
The optimized feature set, i.e., B1, B4, B5, B12, and NDVI extracted from 261–270d, was used to carry out object-oriented classification based on the SNIC algorithm, thereby obtaining the range of spatial distribution for rice, maize, and soybean in the Sanjiang Plain in 2019.
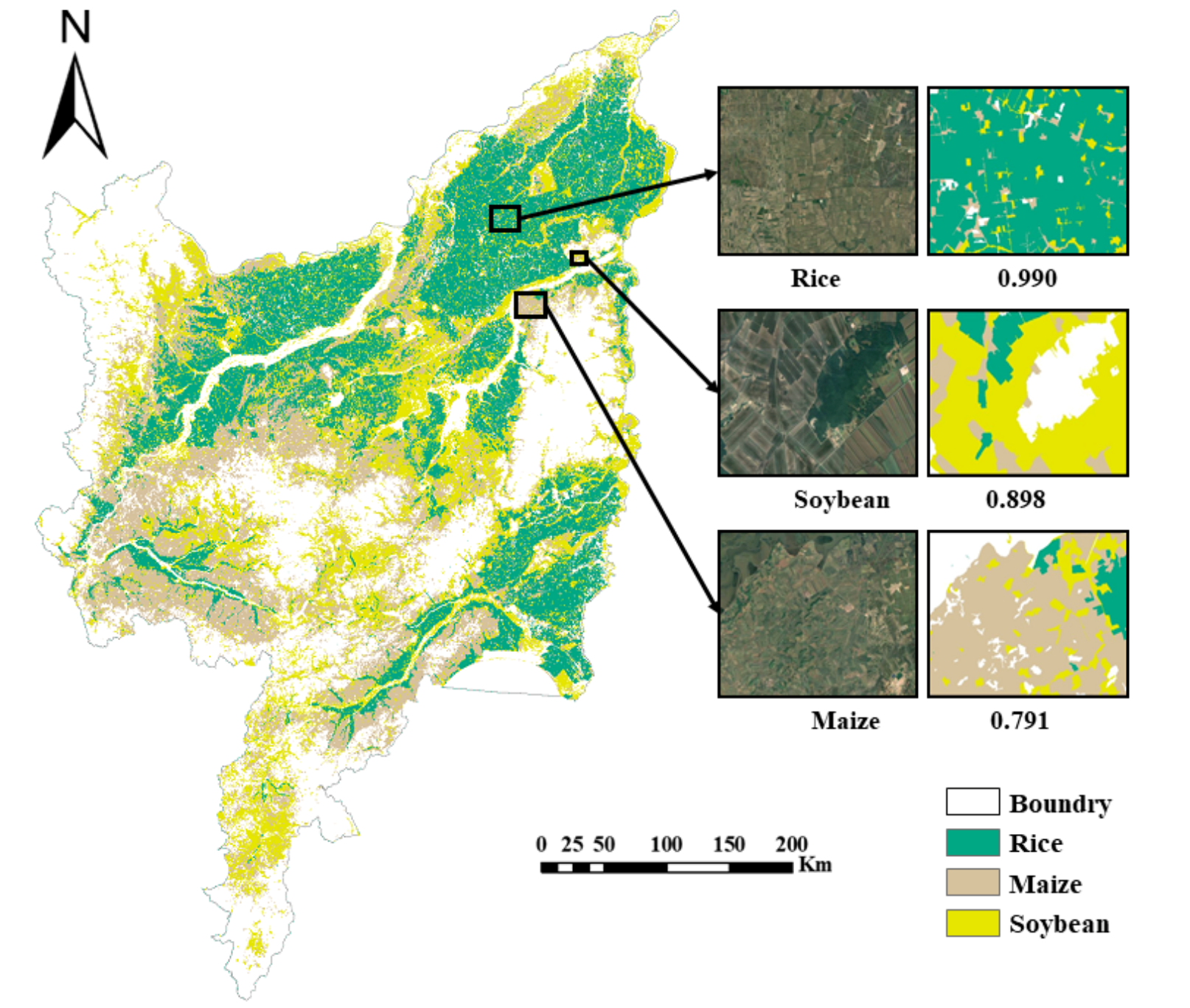
As shown in
Figure 7, maize, soybean, and rice were widely planted in the Sanjiang Plain, and the spatial distributions of the three crops were different. The range of rice planting was the broadest, and the distribution formed patches that were more concentrated, occurring mainly in the northern and eastern parts of the Sanjiang Plain; the range of maize planting appeared mostly strip-shaped and was mainly distributed in the area south of the central part of the Sanjiang Plain. Meanwhile, the range of soybean planting mostly appeared block-shaped and was distributed more evenly in the Sanjiang Plain.
3.4. Comparison of the Accuracy Assessment
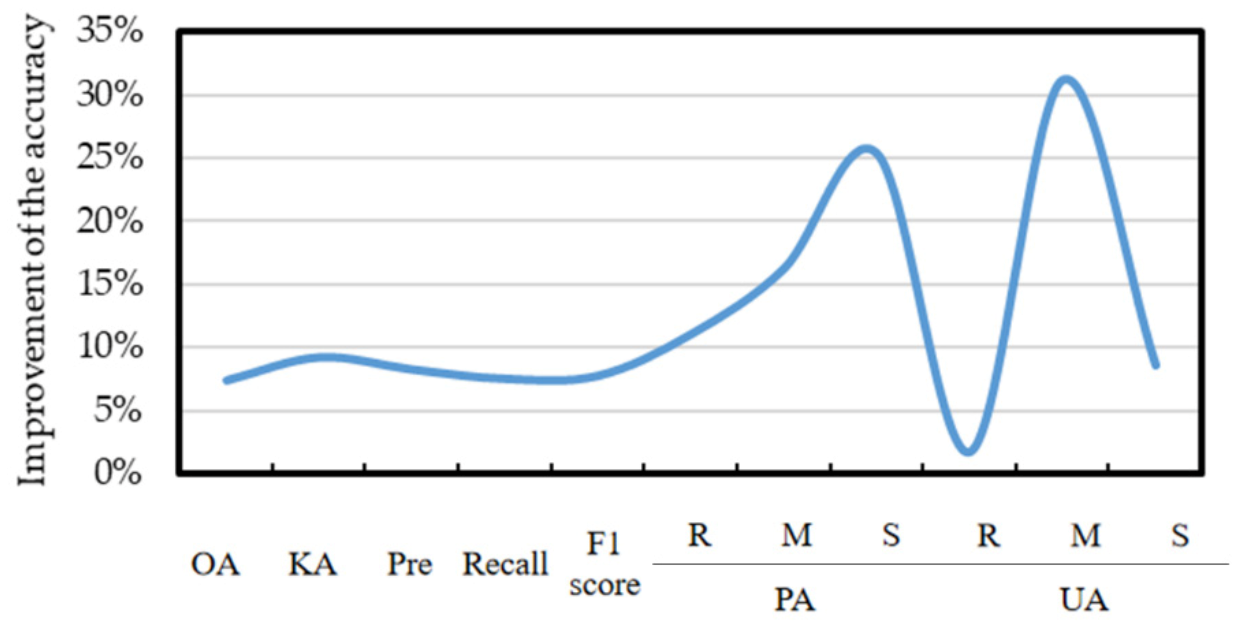
To explore whether IO-Growth method had a better extraction effect than the object-oriented classification that did not combine the growth stages into terms, 30% of the testing sample points were used to evaluate the accuracy of the classification results obtained by the two methods. Since the distribution and selection of the testing points affects accuracy measurement, a random seed was set up to randomly select the testing sample points for the computation of the global confusion matrix and the OA, KA, precision, recall, and F1 scores, as well as the PA and UA of the three crops—rice, maize, and soybean.
As shown in
Table 5, in the classification results obtained by the method that did not combine the growth stages, the PA values of rice, maize, and soybean were 0.89, 0.68, and 0.72, respectively, and the UA values were 0.90, 0.71, and 0.76, respectively, while in the classification results obtained by the IO-Growth method, the PA values of the three crops were 0.99, 0.79, and 0.90, respectively, and the UA values were 0.92, 0.93, and 0.83, respectively.
For rice, the extraction effects obtained by the two methods were equivalent; for maize and soybean, the PA and UA values from the IO-Growth method were higher. Moreover, the OA of the IO-Growth method was 0.92 and the KA was 0.91, which were higher. In addition, the precision, Recall, and F1 scores were far higher than those of the method that did not combine the growth stages.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}